
Jaynes-Gibbs Entropic Convex Duals and Orthogonal Polynomials


Faculté de Médecine et des Sciences de la Santé, Université de Sherbrooke 1, 3001, 12 ème Avenue Nord, Sherbrooke, QC J1H 5N4, Canada
Entropy 2022, 24(5), 709; https://doi.org/10.3390/e24050709
Submission received: 8 March 2022
/
Revised: 8 May 2022
/
Accepted: 10 May 2022
/
Published: 16 May 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:The univariate noncentral distributions can be derived by multiplying their central distributions with translation factors. When constructed in terms of translated uniform distributions on unit radius hyperspheres, these translation factors become generating functions for classical families of orthogonal polynomials. The ultraspherical noncentral t, normal N, F, and distributions are thus found to be associated with the Gegenbauer, Hermite, Jacobi, and Laguerre polynomial families, respectively, with the corresponding central distributions standing for the polynomial family-defining weights. Obtained through an unconstrained minimization of the Gibbs potential, Jaynes’ maximal entropy priors are formally expressed in terms of the empirical densities’ entropic convex duals. Expanding these duals on orthogonal polynomial bases allows for the expedient determination of the Jaynes–Gibbs priors. Invoking the moment problem and the duality principle, modelization can be reduced to the direct determination of the prior moments in parametric space in terms of the Bayes factor’s orthogonal polynomial expansion coefficients in random variable space. Genomics and geophysics examples are provided.
1. Introduction
We shall argue that the four noncentral univariates t, F, the normal N, and distributions with r being the one-dimensional random space variable, and the one-dimensional noncentrality parameter of the respective distributions, can all be constructed in a modular fashion by multiplying their central counterparts with a factor effecting a central distribution translation, that is,
In statistical parlance, the noncentral distributions are needed to estimate or modelize effect sizes [1]. With the exception of the normal distribution, these translations are non-shape-preserving. The derivation of the translation factors can be carried out in two manners, depending on whether primacy is put upon translated uniform density distributions on unit radius hyperspheres, as is done in this manuscript, or on translated normal distributions, as done classically. We shall review both derivations herein, with emphasis on the hyperspherical distributions.
We choose to place primacy upon the simple uniform density distribution on the unit radius hypersphere , where stands for either the dimension of the hypersphere surface , or, equivalently, the degrees of freedom (dof) of the specified distribution. It is known that the projection of a unit radius uniform density hyperspherical distribution on on any given polar axis readily provides us with the central t distribution [2], and that such a projection converges with the central normal distribution with null mean when tends to infinity [3] (p. 59). This observation provides us with the needed building principle used throughout this manuscript: use the uniform density distribution on the unit radius hypersphere to derive modular expressions for the central and noncentral t, F, N, and distributions. In order to proceed, one needs to master some very simple notions concerning the hypersphere geometry. The projection of a random unit vector on the unit radius hypersphere on any given unit polar axis naturally defines a polar angle through the scalar product . As such, the central t distribution with degrees of freedom can be drawn on the compact support , on which it acquires a simple expression in trigonometric terms: it is simply proportional to after integration of the azimuthal coordinates. See Saville and Wood [2] for a very extensive digression on the subject. On the familiar sphere , the latter provides us with the well-known spherical surface element after the integration of the azimuthal coordinate. Similarly, the central distribution becomes proportional to on the compact domain , where is the angle between a random vector on the hypersphere and a secant hyperplane defining the subspace . In statistical parlance, the and subspaces refer to the between-class and within-class variance spaces in an analysis variance (ANOVA), as reflected by the F-statistic redefinition in trigonometric terms, found in Section 2. As it turns out, these two central uniform hyperspherical distributions are all that is needed to proceed with the derivation of all the univariate noncentral t, F, N, and distributions where, for uniformity of designation, a normal distribution with non-vanishing mean and unit variance will be simply referred to as the noncentral normal distribution. Finally, in the theory of orthogonal polynomials, the designation ultraspherical polynomials—also known as Gegenbauer polynomials [4]—has prevailed over that of hyperspherical polynomials, and we shall abide by this nomenclature. In order to distinguish the ultraspherical t and F distributions from the ones derived classically from the normal N and distributions, we shall designate the former densities by the Greek letter (upsilon), as in υπερσφαίρα (ypersfaíra or hypersphere in English), and the latter densities by the Greek letter .
In Bayesian inference, the determination of the Bayes prior is referred to as an inverse problem, and Jaynes’ data-constrained maximal entropy priors provide a principled solution to this inverse problem [5,6,7]. The maximal entropy is reached by minimizing the Gibbs potential, and the solution to this optimization problem requires the determination of the empirical density entropic convex dual. See Le Blanc [8] for an extensive review on the subject, with references. As derived from translated normal distributions, the classical noncentral distributions all have a submodular decomposition for their translation factor of the form
with being a generalized hypergeometric function, a decomposition which does not readily provide regrouping of terms of similar order in the noncentrality parameter . Conversely, the translation factors for the noncentral t, the normal N, F, and distributions, as derived from translated uniform distributions on unit radius hyperspheres, are found to be generating functions for the Gegenbauer, Hermite, Laguerre, and Jacobi orthogonal polynomial families , respectively, and intrinsic properties of the orthogonal polynomials [9] allow for regrouping all terms of similar order in the noncentrality parameter that is,
with the constants provided hereafter. To the best of our knowledge, the derivation of these translation factors and their identification as orthogonal polynomial family-generating functions has not been carried out before. As a consequence, one can expand the entropic convex duals on a generally small number of low-order orthogonal polynomials, an approach which greatly curtails the computational cost of determining the duals and, thus, the Jaynes–Gibbs priors. To the best of our knowledge, the expansion and discretization of the convex duals over orthogonal polynomial bases has not been proposed before. We adopt in this manuscript the convention that the polynomial family-defining weight functions should be provided by the corresponding normalized central distributions, a convention which results in much simplified expressions for the norm of the orthogonal polynomials.
In parametric Bayesian modeling, the translation factor can be weighted by a Bayesian prior to obtain the Bayes factor
for the generic superposition density
We will, in this manuscript, identify the normalized central distribution with the orthogonal polynomial family-defining weight [9], with, as a result, the rewriting of any generic density as
that is, the Bayes factor can stand as a substitute to the generic density With standing for the cumulative density function of the respective central distributions , or, equivalently, the p-value of the null hypothesis statistical testing (NHST) procedure, we have that . That is, the Bayes factor stands for the generally nonuniform p-value distribution of the above generic superposition density (see Le Blanc [10] for details of a proof), to be contrasted with the NHST framework which only considers the central distribution with its uninformative uniform p-value distribution. Now, if one’s goal is only to model the density or to compute the associated local false discovery rate [11], one then only needs prior moments to carry on with the modelization. Invoking the moment problem [12] and the duality principle [13], prior moments in parametric space will be shown to be readily provided by Bayes factor orthogonal polynomial expansion coefficients in random variable space—that is,
The paper is organized as follows. In Section 2, we review, for the sake of completeness, the derivation of the classical univariate noncentral distributions as derived from translated normal distributions. In Section 3, the univariate ultraspherical noncentral t, the normal N, F, and distributions are derived from translated uniform density distributions on unit radius hyperspheres, and are shown to be expressible as products of their central distribution times specific generating functions for the Gegenbauer, Hermite, Jacobi, and Laguerre orthogonal polynomial families, respectively. We argue, in Section 4, that the determination of the Gibbs priors in terms of empirical densities’ entropic convex duals is much simplified when these duals are expanded on a small number of low-order orthogonal polynomials. We also discuss how prior moments in parametric space are directly provided by the Bayes factor orthogonal polynomial expansion coefficients in random variable space. Section 5 and Section 6 are devoted to applications in genomics and geophysics, respectively.
2. The Classical Noncentral Distributions
The four central F, , t, and normal N distributions can be given by
respectively, where we have redefined the conventional t and F statistics so that
and
so as to re-scale the corresponding t and F distributions on the specified finite compact domains. As discussed in the Introduction, the above central t and F distributions are projections of uniform distributions on the unit radius and hyperspheres, respectively. The reasons for such rescaling will become apparent when we link in Section 3 the ultraspherical noncentral t and F distributions with the Gegenbauer and Jacobi orthogonal polynomial families, respectively, families which both have similar finite compact support domains. It is straightforward to verify that the above central t and F distributions converge with the central normal N and distributions, respectively, in the limit : see the discussions leading to Equations (19) and (36) below. In geometric terms, the limit allows one to restrict the study of the central t and F distributions on a restricted domain around the angle , around which these distributions will concentrate their respective distribution weights in concordance with the notion that a high-dimensional hypersphere concentrates its surface on a narrow equatorial band at its equator [3]. In this limit, with the respective variable substitutions and , the normal N and respective central distributions’ definition domains consequently extend to infinity as , as reflected by the respective distribution domains provided above.
The noncentral t distribution has been classically derived by considering the ratio of a random variable which distributes according to a noncentral normal distribution with non-vanishing mean , over that of a random variable distributed according to a central distribution with degrees of freedom. Similarly, the noncentral F distribution is classically derived by considering the ratio of a noncentral random variable with noncentrality parameter and degrees of freedom over that of a central random variable with degrees of freedom. See, for example, Walck et al. [14] for explicit steps for such derivations. As a result, as discussed in the Introduction, the classical distributions have a submodular decomposition for their translation factor of the form , with being a generalized hypergeometric function [15]. Upon recalling that the F and noncentral parameter stands for the square of the noncentral parameter for the noncentral t and normal distributions, we have that
with the respective factors’ McLaurin expansions — computed following the steps elaborated by Walck et al. [14]—given by
where
stands for the generalized hypergeometric function, and where stands for the normalized modified Bessel function [16]. The respective first expansions for the multiplicative factors E are successively simpler versions of the Maclaurin expansion for the noncentral F distribution multiplicative factor , such that
with the understanding that the respective Maclaurin summations involve either only the even integers for the F and cases, or both odd and even integers for the t and normal cases. It is straightforward to verify that the classical noncentral t and F distributions converge with the noncentral normal and distributions, respectively, in the limit . The expressions for the classical noncentral distributions do not readily regroup terms of similar order in their noncentrality parameter, contrarily to the ultraspherical noncentral distributions, which do so, as is discussed next.
3. The Ultraspherical Noncentral Distributions
Using geometrical arguments, the ultraspherical noncentral t-distribution for the t-statistic (2) on the hypersphere was shown by Le Blanc [10] to be given by
where is identical to the central t-distribution given in Equation (1), where the multiplicative distribution translation factor is given by
and where
in terms of the noncentrality parameter As it turns out, the translation term is a generating function for the ultraspherical or, equivalently, Gegenbauer polynomials: redefining the variables so that , , and , we have that
where are Gegenbauer polynomials with the explicit representation [4]
where the Pochhammer symbol is defined by the equality
where , the floor of y, is given by the lowest integer such that , and where the last equality given in terms of the hypergeometric function can be deduced from Rainville [17] (Equation (144.8)). The Gegenbauer polynomials are orthogonal:
with respect to the weight function
which is identical to the central t distribution (1), except for the change of the variable . With this weight function normalization—which, note, differs from the usual weight function for the Gegenbauer polynomials [4]—the norm of the Gegenbauer polynomials simplifies to
with, in particular, . Note also that Equation (11) could be used to define a generalization for the Chebyshev polynomials of the first kind, , with
which encompasses the defining equation
for the Chebyshev polynomials of the first kind. Setting and , the central t distribution converges with the normal central distribution
in the limit . Applying the same limit to the Gegenbauer polynomials and their generating function (11), we have that
where we have used the limit result [4]
The multiplicative factor imparts a non-vanishing mean to the zero mean normal distribution, since
where one recognizes the generating function for the Hermite polynomials , with the explicit representation [4]
The latter are orthogonal with respect to their defining weight function
with norm
and with in particular.
Using geometrical arguments, the ultraspherical noncentral F-distribution for the F-statistic (3) was shown by Le Blanc [10] to be given by the integral representation
where is identical to the central F distribution given in Equation (1), where the multiplicative distribution translation factor is given by the integral
with integrand
and where
in terms of the noncentral parameter . The special case is given by
Setting , and making use of the Gegenbauer polynomial-generating function expansion (11) together with the corresponding polynomials’ explicit expression (12), the integration in (27) can be carried out: we find
where the polynomials which one related to the Jacobi polynomials [4], through
are provided with the explicit representation
and where the last equality—deduced from Rainville [17] (Equation (132.10))—provides us with a generating function for the polynomials in terms of the hypergeometric function . The polynomials are orthogonal with respect to the weight function
which is identical to the central F distribution (1), except for the change of the variable with norm
and with in particular. Equation (31) can be verified to be valid for the special case (30) with (). In the limit , the central F distribution converges with the central distribution
which, with , can be used as a normalized defining weight function,
for the Laguerre orthogonal polynomial family. The Laguerre polynomials can be given the explicit representation [4]
Since Equation (32) provides the noncentral F distribution translation factor with an expansion in terms of the Jacobi polynomials , and since the limit result
holds [4], one verifies with and that
which is a lesser-known expression for the noncentral distribution translation factor first derived by Tiku [18]. Under normalization (37) for their defining weight factor, the norm of the Laguerre polynomials is given by
with, in particular,
To summarize, the four ultraspherical noncentral F, , t, and the normal N distributions are given by the product of translation factors T, which take the form of generating functions for specific orthogonal polynomial families, times the corresponding normalized central distributions which also stand for the corresponding polynomial family-defining weight functions. Thus, we have that
with the normalized central distributions
providing the polynomial family-defining weights, and with the corresponding generating functions and orthogonal polynomial expansions given by
We conclude this section by stressing the fact that the random variable space for the ultraspherical noncentral distributions are translated hyperspheres rather than translated normal distributions, as is assumed for the classical noncentral distributions. The tide model developed in Section 6 provides a concrete example of such a distribution on a translated sphere. As more extensively argued in [15], the ultraspherical and classical noncentral F and t distributions correspond to projections of translated hyperspheres and translated normal distributions, respectively; are identical in their central distributions when their noncentrality parameters are zero; and converge in high-dimensional spaces, but diverge in low-dimension spaces and for large noncentrality parameters. See Figure 1. These properties ultimately stem from the counterintuitive properties of the solid hypersphere which concentrates its volume on a thin ultraspherical shell in high-dimensional spaces [3], allowing one to use the ultraspherical distributions as surrogates for the classical noncentral t and F distributions in high-dimensional spaces.
4. Entropic Convex Duals Expansion in Terms of Orthogonal Polynomials
Bayes–Jaynes–Gibbs data-constrained maximal entropy priors—simply designated as Gibbs priors in the following—can be objectively computed for dense datasets. See Le Blanc [8] for an extensive review on the subject, from which we recall that the Bayes–Laplace prior and posterior update rules are rooted in the convex geometry of Shannon’s entropy function, with the Kullback–Leibler relative entropy being a Bregman divergence defined in terms of the former. The Gibbs priors can be formally expressed as
where the partition function is given by
and where is the entropic convex dual of the empirical density . The latter is obtained through the unconstrained minimization of the Gibbs potential
which, by convex duality, corresponds to Jaynes data-constrained maximal entropy. The corresponding Gibbs–Jaynes model for a generic empirical density is given by
As posed, solving for the entropic convex dual function in (47) requires one to compute its value across the entire support domain of the empirical distribution , a task which can be expensive in computing terms. Now, since the ultraspherical noncentral distribution translation factors are generating functions for orthogonal polynomial families, and since the corresponding central distributions are the family-defining weight functions , one can rewrite the unconstrained minimization problem in simpler terms. Indeed, the exponentiated term in the partition function (46) can be rewritten as
where the polynomials , with their respective multiplicative coefficients , are listed in (44), and where the are the entropic convex dual expansion coefficients on family-wise orthogonal polynomials that remain to be determined. Similarly, the additive constraint term in (47) can be rewritten as
where is the empirical density to be modeled, and where
with, in particular, . Within the division by the factor , the latter equality is the Bayes factor expansion on the orthogonal polynomials in random sample space. The unconstrained optimization problem can thus be reformulated as
in terms of orthogonal polynomial expansion coefficient sets for the continuous entropic convex dual function , sets which can be restricted to a small finite number of coefficients, as can be assessed by the Kullback–Leibler divergence between the empirical density and its model in terms of orthogonal polynomials. At the minimum of the Gibbs potential (52), one has the simple condition
which states that the moment of the noncentrality parameter , as weighted by the Gibbs prior
is, within the factor , equal to the coefficient of the Bayes factor expansion (51) on the orthogonal polynomial basis in random sample space. In practical terms, the determination of the Gibbs prior in terms of a small number of polynomial expansion coefficients for the entropic dual convex results in a substantial reduction in the computing time needed to find the Gibbs potential minimum.
Once obtained, the Gibbs prior can be used to modelize the empirical density according to Equation (48), in which the central distribution stands for the weight function for the ultraspherical distributions listed in (42). A generic density can thus be expanded as
where we have invoked the optimality condition (53) in going from the second to the third line. This sequence of equalities provides us with two alternative ways,
to model the Bayes factors and the empirical densities: either one determines the Gibbs prior via the optimization problem (52) and uses it to weigh the analytical orthogonal polynomial-generating functions listed in (44); or, one directly determines the prior moments in parametric space in terms of the Bayes factor expansion coefficients in random variable space, as per the last equality above. The latter strategy amounts to the construction of a probability distribution in terms of its moments [12]. In that respect, recall the Hausdorff moment problem, which stipulates that the collection of all moments of a probability distribution on a bounded interval uniquely determine the distribution [19], and the Hamburger moment problem, which considers the uniqueness of solutions for the same problem on the unbounded real line [20].
Numerical exploration indicates that the convergence of the polynomial expansion for the ultraspherical noncentral t and F distributions’ generating functions is affected by the Gibbs phenomenon at the extremities of their finite noncentrality parameter ranges [21]. For this reason, when considering the noncentral t and F distributions, one can either solve for the Gibbs prior to weigh the corresponding analytic generating functions (44) in constructing the models, or use the large b limit for the distributions which converge with the noncentral normal N and distributions, respectively, together with the associated Hermite and Laguerre orthogonal polynomial families, to directly compute the prior moments in parametric space in terms of the Bayes factor expansion coefficients in random variable space, as according to (56). Both strategies are found to be unaffected by the Gibbs effect, as exemplified in the next section.
5. Genomics Examples
We first revisit, in this section, the NCBI Gene Expression Omnibus head and neck squamous cell carcinoma microarray dataset produced by [22], pertaining to 22 paired samples () of normal versus cancerous tissues, and interrogating 11,302 genes via 2-sample t-tests. In Le Blanc [10], a maximal entropy prior equal to the central ultraspherical t distribution (1) was postulated. In Le Blanc [8], the entropic dual convex was computed on the full random variable range . Here, the Bayes factor is provided with two models. The first model is given in terms of the Gibbs prior (54) and the analytical Gegenbauer polynomial-generating function (11). We assessed the computational gains in our determination of the entropic convex dual via Equation (52): with the empirical distribution binned in 200 bins, and using the ® optimization subroutine fminunc in a 64-bit Windows environment on a PC with an Intel(R) Core(TM) i9-9900K CPU @ 3.60 GHz processor and 64 GB of RAM, the determination times for the entropic convex dual in terms of a small number of Gegenbauer polynomial coefficients were curtailed by a factor ranging from 100 to 1000, compared to previous determination times of on the full random variable range , with elapsed times as short as a few tenths of a second. In the second model, according to (56) and with the Hermite polynomials standing for the Gegenbauer polynomials in the large b limit, the Bayes factor expansion in random variable space on the Hermite polynomials provides us with the Gibbs prior moments in parametric space. As can be seen in Figure 2, the convergence of the two models with the empirical distribution is rapidly achieved with ten coefficients or less.
Next, we study a genome-wide association study (GWAS) dataset. A GWAS is an observational study assessing a genome-wide set of genetic variants in different individuals, and seeking to identify statistically significant variant-trait associations. Such studies commonly focus on associations between single-nucleotide polymorphisms (SNPs) and traits. We retrieved the GenoMICC EUR vs. UK biobank controls dataset from the GenOMICC (Genetics Of Mortality In Critical Care) GWAS, comparing 2244 critically ill patients with COVID-19 from UK intensive care units with European ancestry-matched control individuals selected from the large population-based cohort of the UK Biobank [23]. A logistic regression model was used for each of the 4,380,209 SNPs individually tested for statistical significance. We computed the empirical density of all the statistical test-associated r-statistics, and used it to compute the first eight terms of the direct polynomial expansion (56) on Laguerre polynomials for the Bayes Factor . As illustrated in Figure 3, the accrual of the successive polynomial expansion terms allows for an incrementally better fit of the p-value empirical density, which strongly deviates from the NHST null hypothesis in the low p-value range where associations are detected. In the Bayesian framework, NHST statistical significance is replaced by the strength of Bayesian evidence, as assessed by magnitude of , which, in turn, allows for the computation of a local false discovery rate [11]
as is also illustrated in Figure 3.
6. Geophysics Examples
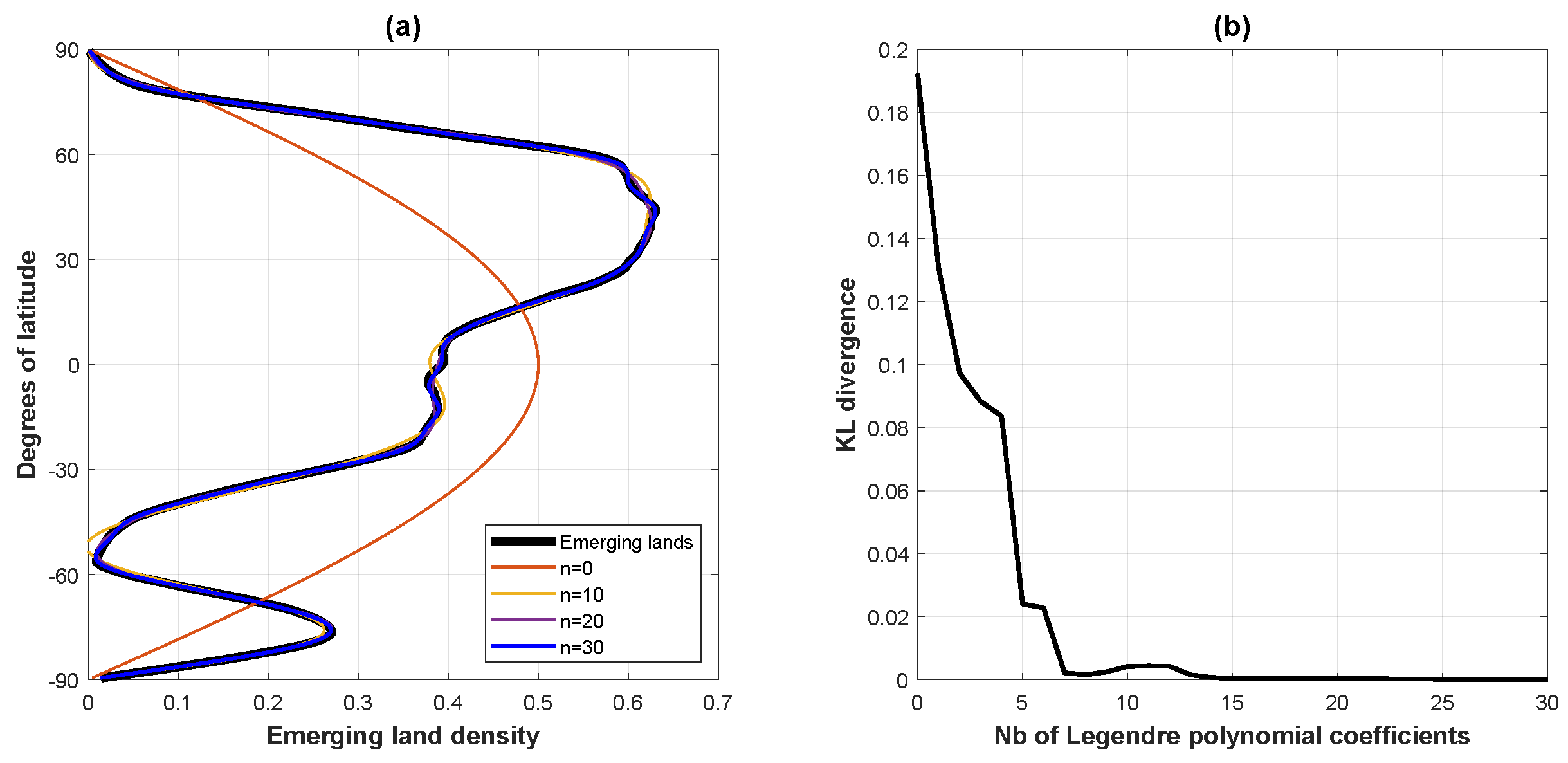
We begin this section by modeling, in Figure 4, Earth’s above-sea-level emerging land/ice latitudinal density [24]. Because an ideal Earth surface can be described by the sphere , we have that the parameter , with the weight factor in (15) reducing to the constant As a consequence, Equation (55) is equivalent to a standard expansion on Legendre polynomials—equivalently, Gegenbauer polynomials—except for the fact that our convention regarding the central distribution normalization (rather than the usual weight ) on the span ensures that expansion (55) defines a normalized density.
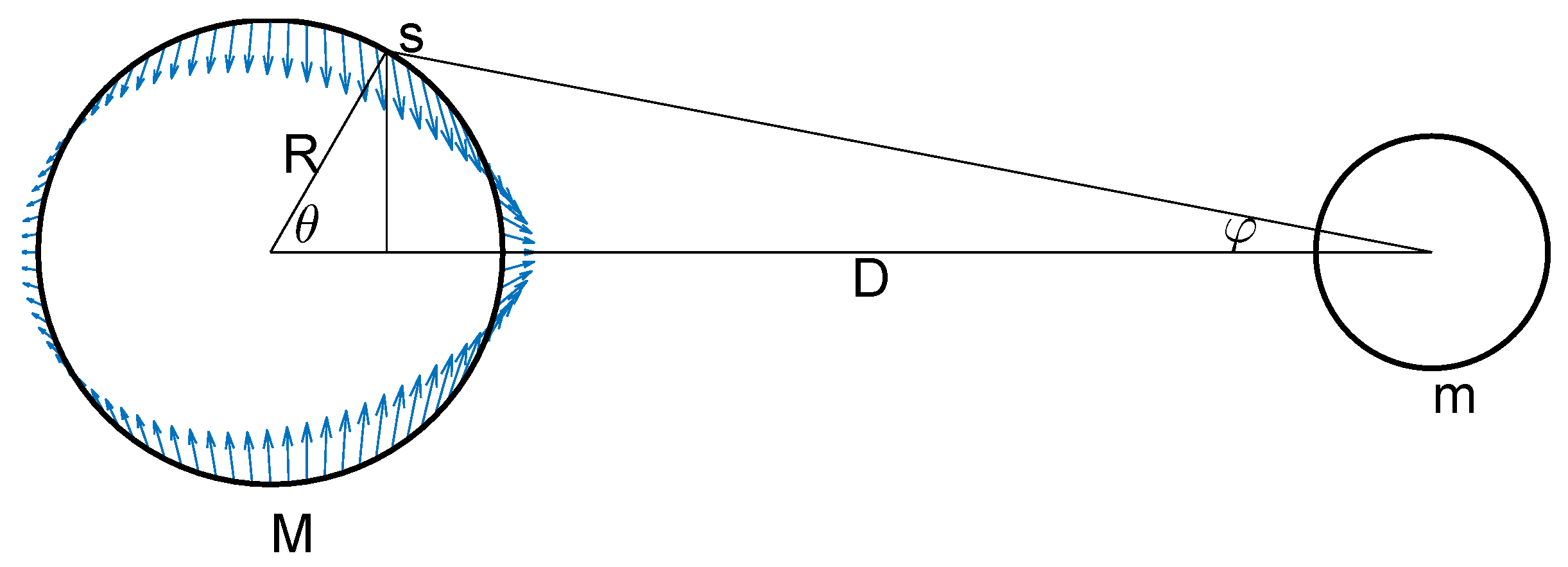
We conclude with an example in which the translating factor (9) for the ultraspherical noncentral t distribution is kept as-is, instead of using its expansion (11) in terms of Gegenbauer polynomials, to argue that the noncentral spherical t distribution (8) on can be used to describe the geometry of the gravity forces of a simple tide model. Consider Figure 5, which describes the gravitational pull of an ideal Moon of mass m on the thin water layer covering an ideal Earth of mass M and radius R at distance D from the Moon. The gravitational tidal force per unit mass on point s on the Earth’s surface is given by
The horizontal and vertical components of that force are given by
respectively. Setting our physical units so that , and defining , we have that
The horizontal tidal force component is thus simply given by the noncentral spherical t distribution translation factor , as provided by Equation (4). One can integrate this horizontal tidal force over the entire spherical shell by weighing it with the central spherical distribution to account for the spherical geometry of the Earth. Since the integrand to this integral corresponds to the noncentral spherical t distribution on , the tidal force integrates to one in our unit system. In order for the system to be stationary, an opposing force must be opposed to this integrated tidal force of one. The inertial centrifugal force originating from the joint rotation of the Moon and Earth around their center of mass plays such a role. It is evaluated to be given by in our unit system [25], which we add to the normalized horizontal tidal force above. We have plotted the resulting force field in Figure 5, with the noncentrality parameter set to an unrealistic value of 0.2 to enhance the visualization of the geometrical distribution of the tidal forces. Unlike most illustrative tide diagrams with symmetrical bulges found in the literature, our tide diagram, together with its unsymmetrical equatorial water bulges, provides a more accurate visual depiction of the expected asymmetry of the tidal forces resulting from purely geometrical considerations.
7. Discussion
We have seen that the univariate noncentral distributions can be constructed in a modular fashion by multiplying their central distributions with specific translation factors. Using geometrical arguments, we have found that the translation factors for the ultraspherical noncentral t, normal, F, and distributions stand for generating functions for the Gegenbauer, Hermite, Jacobi, and Laguerre polynomial families, respectively, with their central distributions standing for the corresponding polynomial family-defining weights. These developments clearly link four of the most important classical continuous probability distributions with the powerful orthogonal polynomial formalism. To the best of our knowledge, the derivation of these translation factors and their identification as orthogonal polynomial family-generating functions has not been carried out before.
Jaynes’ maximal entropy prior is obtained through the unconstrained minimization of the Gibbs potential. In parametric Bayesian inference, the formal expression for the Gibbs potential comprises an integral of the product of the empirical distribution’s entropic convex dual times the parametric kernel, or, equivalently, the likelihood function In the case of the ultraspherical noncentral distributions, the latter integral yields discretized expansion coefficients of the entropic convex duals on orthogonal polynomial bases. The determination of the entropic convex duals is thus reduced to the much simpler and computationally economical determination of a few low-order orthogonal polynomial coefficients. By invoking the moment problem and the duality principle, prior moments in parametric space are equated with Bayes factors expansion coefficients over orthogonal polynomial bases in random variable space. To the best of our knowledge, the expansion and discretization of convex duals over orthogonal polynomial bases has not been proposed before. In an approach which bears some similarities to our work, Alibrandi and Ricciardi [26] proposed a moment-based approach, the use of a discretized kernel set , and the use of Jaynes’ maximal entropy principle to determine the set’s weighting factors . While their kernel discretization procedure is an ad hoc procedure, our kernel discretization is principled since it is based on the powerful orthogonal polynomial formalism.
The machine learning community has begun to exploit the classical orthogonal polynomial formalism. A non-exhaustive review identifies the use of orthogonal polynomials in optical character recognition [27], in support vector machine kernel construction [28], and in polynomial-based iteration methods for symmetric linear systems [29,30]. In a similar vein, we hope to contribute the present formalism to both the statistical and the machine learning communities.
Funding
This research received no external funding.
Data Availability Statement
For the head and neck cancer microarray dataset, please refer to [31]. The COVID-19 GWAS dataset was accessed at https://genomicc.org/data, accessed on 3 January 2022. For Earth’s emerging land/ice latitudinal density, please refer to [32].
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ANOVA | analysis of variance |
| dof | degrees of freedom |
| FDR | false discovery rate |
| GWAS | genome-wide association study |
| NHST | null-hypothesis statistical testing |
| SNP | single-nucleotide polymorphism |
References
- Wikipedia Contributors. Effect Size—Wikipedia, The Free Encyclopedia. 2022. Available online: https://en.wikipedia.org/wiki/Effect_size (accessed on 7 March 2022).
- Saville, D.J.; Wood, G.R. Statistical Methods: A Geometric Primer; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge University Press: Cambridge, UK, 2018; Volume 47. [Google Scholar]
- Olver, F.W.J.; Olde Daalhuis, A.B.; Lozier, D.W.; Schneider, B.I.; Boisvert, R.F.; Clark, C.W.; Miller, B.R.; Saunders, B.V.; Cohl, H.S.; McClain, M.A. NIST Digital Library of Mathematical Functions. 2021. Available online: http://dlmf.nist.gov/ (accessed on 15 September 2021).
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. Information theory and statistical mechanics. II. Phys. Rev. 1957, 108, 171. [Google Scholar] [CrossRef]
- Pressé, S.; Ghosh, K.; Lee, J.; Dill, K.A. Principles of maximum entropy and maximum caliber in statistical physics. Rev. Mod. Phys. 2013, 85, 1115. [Google Scholar] [CrossRef] [Green Version]
- Le Blanc, R. Entropic convex duality in the determination of data-constrained kernel-based Bayes-Jaynes priors. J. Convex Anal. 2022, 29, 623–647. [Google Scholar]
- Ismail, M.; Ismail, M.E.; van Assche, W. Classical and Quantum Orthogonal Polynomials in One Variable; Cambridge University Press: Cambridge, UK, 2005; Volume 13. [Google Scholar]
- Le Blanc, R. Bayesian Analysis on a Noncentral Fisher–Student’s Hypersphere. Am. Stat. 2019, 73, 126–140. [Google Scholar] [CrossRef] [Green Version]
- Stephens, M. False discovery rates: A new deal. Biostatistics 2017, 18, 275–294. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schmüdgen, K. The Moment Problem; Springer: Berlin/Heidelberg, Germany, 2017; Volume 9. [Google Scholar]
- Rockafellar, R.T. Convex Analysis; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Walck, C. Hand-book on statistical distributions for experimentalists. Univ. Stockh. 2007, 10, 96-01. [Google Scholar]
- Le Blanc, R. Noncentral univariate distributions. 2022; to be submitted. [Google Scholar]
- András, S.; Baricz, Á. Properties of the probability density function of the non-central chi-squared distribution. J. Math. Anal. Appl. 2008, 346, 395–402. [Google Scholar] [CrossRef] [Green Version]
- Rainville, E.D. Special Functions; The Macmillan Company: New York, NY, USA, 1960; Volume 5. [Google Scholar]
- Tiku, M. Laguerre series forms of non-central χ2 and F distributions. Biometrika 1965, 52, 415–427. [Google Scholar] [PubMed]
- Wikipedia Contributors. Hausdorff Moment Problem—Wikipedia, The Free Encyclopedia. 2021. Available online: https://en.wikipedia.org/w/index.php?title=Hausdorff_moment_problem&oldid=1016911791 (accessed on 27 February 2022).
- Wikipedia Contributors. Hamburger Moment Problem—Wikipedia, The Free Encyclopedia. 2021. Available online: https://en.wikipedia.org/w/index.php?title=Hamburger_moment_problem&oldid=1060022764 (accessed on 27 February 2022).
- Shizgal, B.D.; Jung, J.H. Towards the resolution of the Gibbs phenomena. J. Comput. Appl. Math. 2003, 161, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Kuriakose, M.; Chen, W.; He, Z.; Sikora, A.; Zhang, P.; Zhang, Z.; Qiu, W.; Hsu, D.; McMunn-Coffran, C.; Brown, S.; et al. Selection and validation of differentially expressed genes in head and neck cancer. Cell. Mol. Life Sci. 2004, 61, 1372–1383. [Google Scholar] [CrossRef]
- Pairo-Castineira, E.; Clohisey, S.; Klaric, L.; Bretherick, A.D.; Rawlik, K.; Pasko, D.; Walker, S.; Parkinson, N.; Fourman, M.H.; Russell, C.D.; et al. Genetic mechanisms of critical illness in COVID-19. Nature 2021, 591, 92–98. [Google Scholar] [CrossRef]
- Amante, C.; Eakins, B.W. ETOPO1 Global Relief Model Converted to PanMap Layer Format; NOAA-National Geophysical Data Center: Boulder CO, USA, 2009. [Google Scholar] [CrossRef]
- Matsuda, T.; Isaka, H.; Boffin, H.M. Confusion around the tidal force and the centrifugal force. arXiv 2015, arXiv:1506.04085. [Google Scholar]
- Alibrandi, U.; Ricciardi, G. Efficient evaluation of the pdf of a random variable through the kernel density maximum entropy approach. Int. J. Numer. Methods Eng. 2008, 75, 1511–1548. [Google Scholar] [CrossRef]
- Abdulhussain, S.H.; Mahmmod, B.M.; Naser, M.A.; Alsabah, M.Q.; Ali, R.; Al-Haddad, S. A robust handwritten numeral recognition using hybrid orthogonal polynomials and moments. Sensors 2021, 21, 1999. [Google Scholar] [CrossRef] [PubMed]
- Padierna, L.C.; Carpio, M.; Rojas-Domínguez, A.; Puga, H.; Fraire, H. A novel formulation of orthogonal polynomial kernel functions for SVM classifiers: The Gegenbauer family. Pattern Recognit. 2018, 84, 211–225. [Google Scholar] [CrossRef]
- Fischer, B. Polynomial Based Iteration Methods for Symmetric Linear Systems; SIAM: Philadelphia, PA, USA, 2011. [Google Scholar]
- Pedregosa, F.; Scieur, D. Acceleration through spectral density estimation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 7553–7562. [Google Scholar]
- Kuriakose, M.; Chen, W.; He, Z.; Sikora, A.; Zhang, P.; Zhang, Z.; Qiu, W.; Hsu, D.; McMunn-Coffran, C.; Brown, S.; et al. Expression Data from Head and Neck Squamous Cell Carcinoma. 2007. Available online: https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE6631 (accessed on 7 March 2022).
- National Geophysical Data Center, NESDIS, NOAA, U.S. Department of Commerce. ETOPO1, Global 1 Arc-minute Ocean Depth and Land Elevation from the US National Geophysical Data Center (NGDC). 2011. Available online: https://rda.ucar.edu/datasets/ds759.4/ (accessed on 7 March 2022).
Figure 1.
Symmetrized Kullback–Leibler divergence (a) between the hyperspherical and the classical noncentral t—distributions in the upper-left-corner plot, and (b–f) between the hyperspherical and the classical noncentral F distributions for , respectively, for all the other plots. The ultraspherical and classical noncentral t and F distributions correspond to projections of translated uniform distributions on unit radius hyperspheres and translated normal distributions, respectively; are identical in their central distributions when their noncentrality parameters or vanish; converge in high-dimensional (large degree-of-freedom ) spaces, but diverge in low-dimension spaces and for large noncentrality or parameters. The ultraspherical noncentral distributions can be used as surrogates for the classical noncentral t and F distributions in high-dimensional spaces. See the text for details.
Figure 1.
Symmetrized Kullback–Leibler divergence (a) between the hyperspherical and the classical noncentral t—distributions in the upper-left-corner plot, and (b–f) between the hyperspherical and the classical noncentral F distributions for , respectively, for all the other plots. The ultraspherical and classical noncentral t and F distributions correspond to projections of translated uniform distributions on unit radius hyperspheres and translated normal distributions, respectively; are identical in their central distributions when their noncentrality parameters or vanish; converge in high-dimensional (large degree-of-freedom ) spaces, but diverge in low-dimension spaces and for large noncentrality or parameters. The ultraspherical noncentral distributions can be used as surrogates for the classical noncentral t and F distributions in high-dimensional spaces. See the text for details.
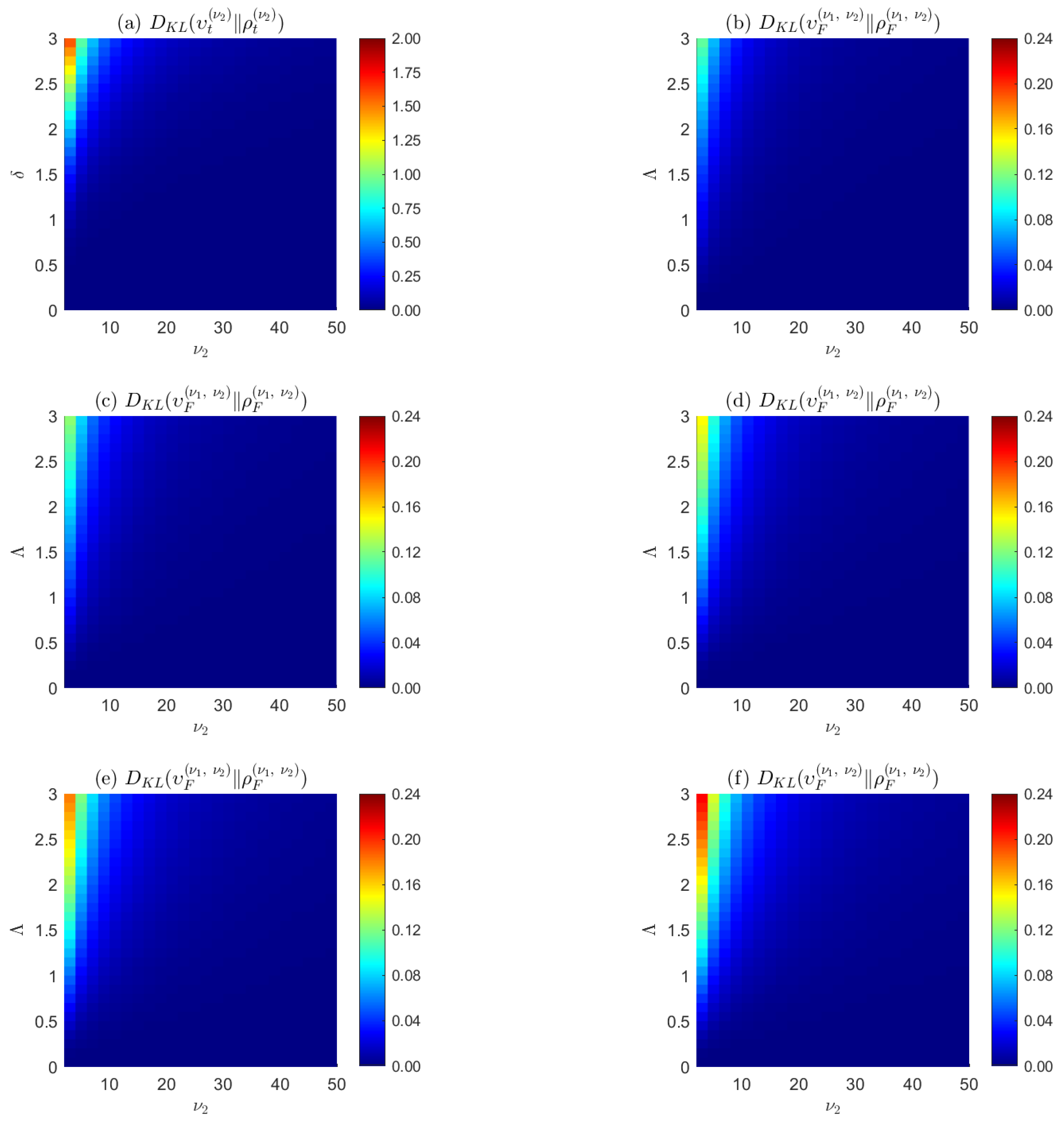
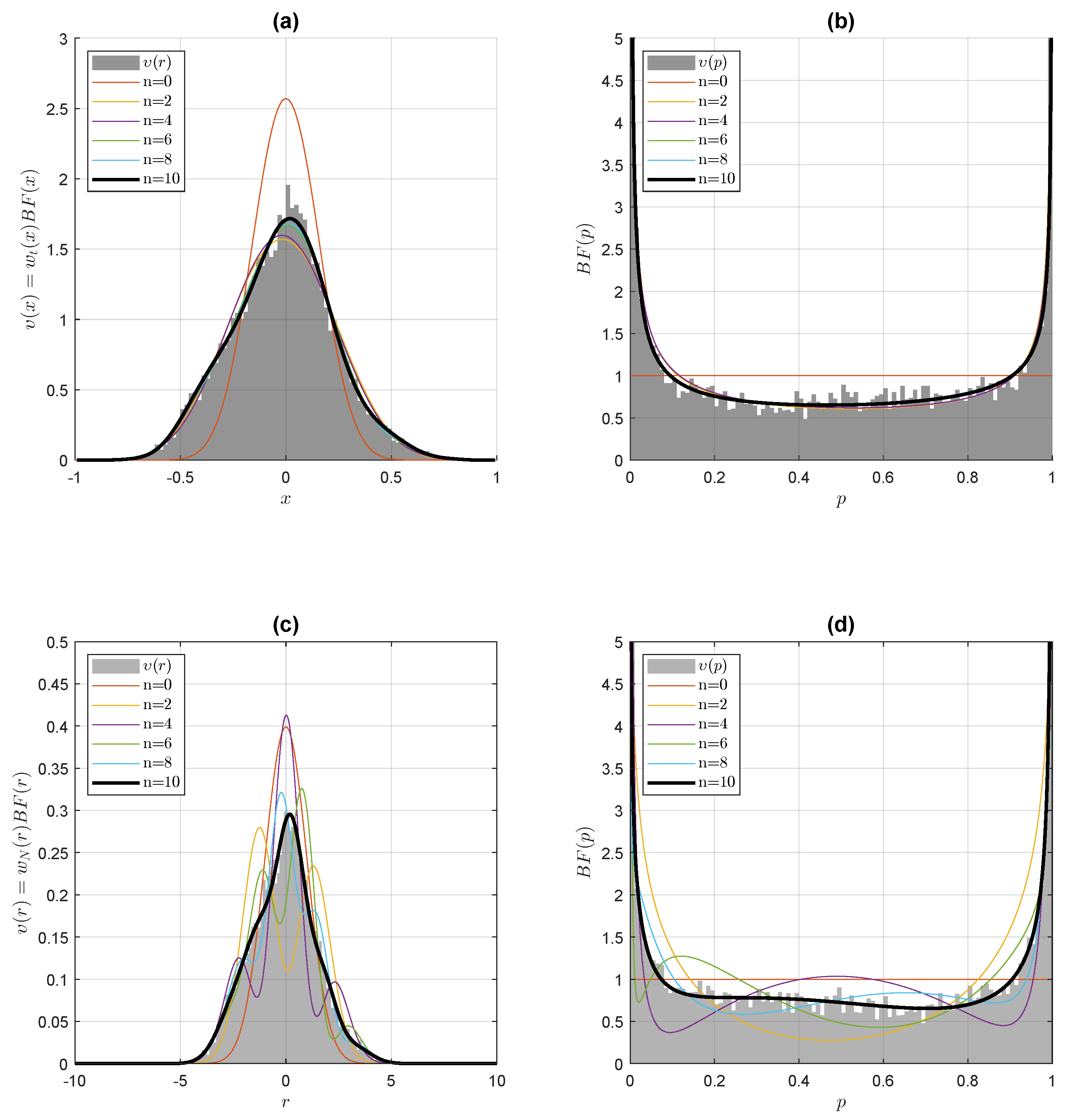
Figure 2.
Empirical random space densities and NHST p-value densities modelization for the head and neck cancer dataset. The upper panels illustrate the Jaynes–Gibbs model , as provided by the Gibbs prior (54) and the analytical generating function (11) for the Gegenbauer polynomials. (a) Upper left-hand panel: convergence of the Jaynes–Gibbs model with the empirical density . (b) Upper right-hand panel: corresponding NHST t-test p-value model densities, as modeled by the Bayes factor . As can be observed, convergence on the empirical densities is rapidly achieved with the expansion of the entropic convex dual on a small number n of Gegenbauer polynomials. In the lower panels, with the Hermite polynomials standing for the Gegenbauer polynomials in the large b limit (21), the Bayes factor expansion coefficients in random variable space directly provides the Gibbs prior moments in parametric space, as according to (56). (c) Lower left-hand panel: cumulative orthogonal polynomial expansion of the Bayes factor in random variable space. (d) Lower right-hand panel: corresponding NHST central normal distribution p-value densities as modeled by the Bayes factor . As can be observed, convergence on the empirical densities is rapidly achieved with a small number n of low-order Hermite polynomials.
Figure 2.
Empirical random space densities and NHST p-value densities modelization for the head and neck cancer dataset. The upper panels illustrate the Jaynes–Gibbs model , as provided by the Gibbs prior (54) and the analytical generating function (11) for the Gegenbauer polynomials. (a) Upper left-hand panel: convergence of the Jaynes–Gibbs model with the empirical density . (b) Upper right-hand panel: corresponding NHST t-test p-value model densities, as modeled by the Bayes factor . As can be observed, convergence on the empirical densities is rapidly achieved with the expansion of the entropic convex dual on a small number n of Gegenbauer polynomials. In the lower panels, with the Hermite polynomials standing for the Gegenbauer polynomials in the large b limit (21), the Bayes factor expansion coefficients in random variable space directly provides the Gibbs prior moments in parametric space, as according to (56). (c) Lower left-hand panel: cumulative orthogonal polynomial expansion of the Bayes factor in random variable space. (d) Lower right-hand panel: corresponding NHST central normal distribution p-value densities as modeled by the Bayes factor . As can be observed, convergence on the empirical densities is rapidly achieved with a small number n of low-order Hermite polynomials.

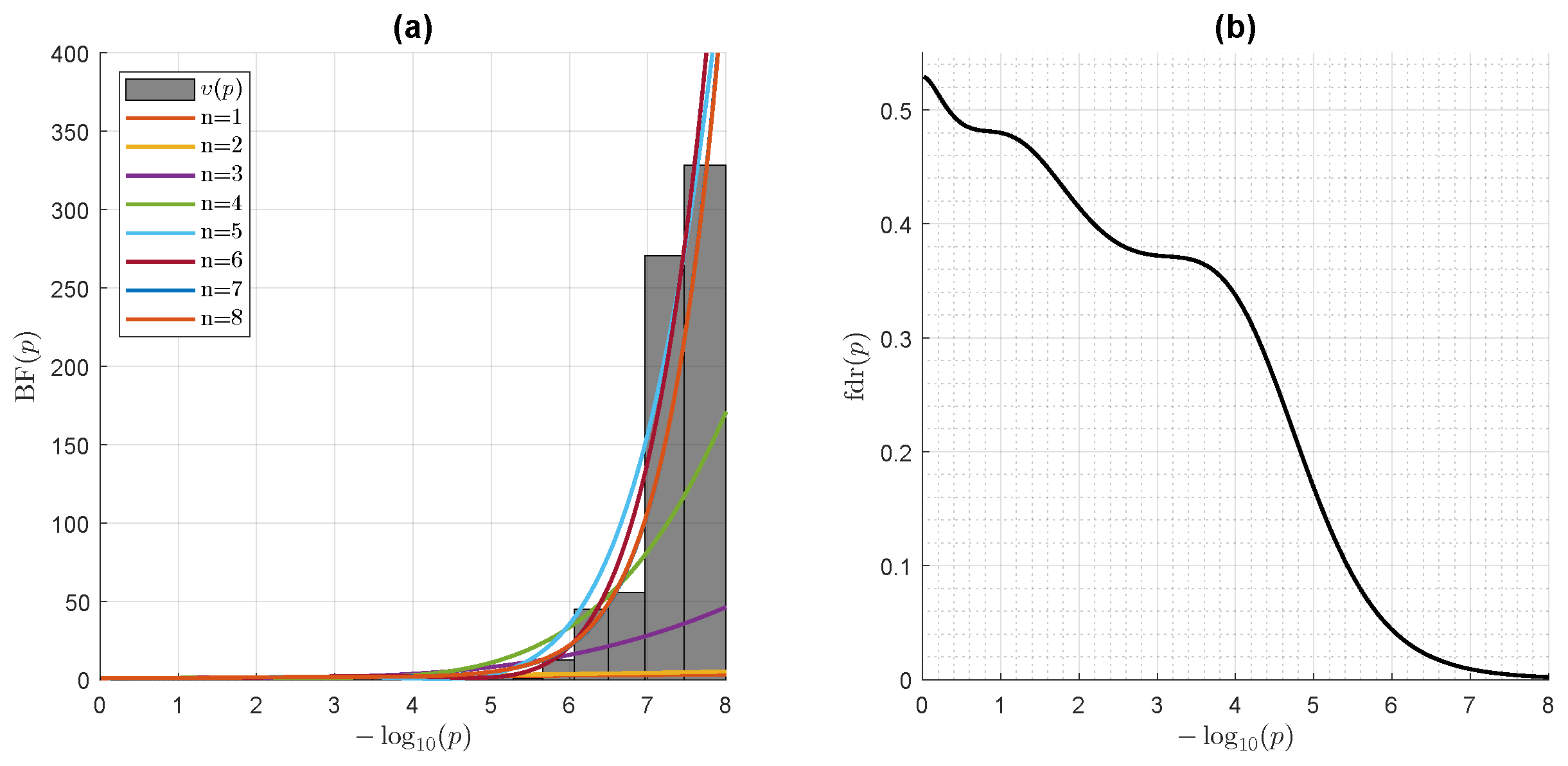
Figure 3.
Bayes Factor modeling a NHST p-value distribution from a genome-wide association study (GWAS) dataset. The GWAS compared 2244 critically ill patients with COVID-19 with 3 times as many ancestry-matched control individuals. The dataset comprises 4,380,209 r-statistics, accounting for all the SNPs in the set, which have been modelized by a logistic regression model and tested for statistical significance. (a) Left panel: Accrual of the successive Laguerre polynomial expansion terms in Equation (56) for the Bayes factor demonstrating an incrementally better fit of the p-value empirical density which strongly deviates from the NHST null hypothesis in the low p-value range. (b) Right panel: Local false discovery rate . The Bayesian-based fdr crosses the 0.01 threshold (i.e., a fdr of 1%) when the NHST p-value reaches about (), in close concordance with the threshold of significance of () chosen by the authors.
Figure 3.
Bayes Factor modeling a NHST p-value distribution from a genome-wide association study (GWAS) dataset. The GWAS compared 2244 critically ill patients with COVID-19 with 3 times as many ancestry-matched control individuals. The dataset comprises 4,380,209 r-statistics, accounting for all the SNPs in the set, which have been modelized by a logistic regression model and tested for statistical significance. (a) Left panel: Accrual of the successive Laguerre polynomial expansion terms in Equation (56) for the Bayes factor demonstrating an incrementally better fit of the p-value empirical density which strongly deviates from the NHST null hypothesis in the low p-value range. (b) Right panel: Local false discovery rate . The Bayesian-based fdr crosses the 0.01 threshold (i.e., a fdr of 1%) when the NHST p-value reaches about (), in close concordance with the threshold of significance of () chosen by the authors.

Figure 4.
Earth’s emerging land/ice latitudinal density. Orthogonal Legendre polynomial (Gegenbaeur polynomial) modeling of Earth’s emerging land/ice masses’ latitudinal density. (a) Left panel: orthogonal Legendre polynomial modeling (55) of Earth’s emerging land/ice latitudinal density as expanded on the first 30 Legendre polynomials. (b) Right panel: Kullback–Leibler divergence between the empirical density and the model as a function of the number of orthogonal Legendre polynomials accrued.
Figure 4.
Earth’s emerging land/ice latitudinal density. Orthogonal Legendre polynomial (Gegenbaeur polynomial) modeling of Earth’s emerging land/ice masses’ latitudinal density. (a) Left panel: orthogonal Legendre polynomial modeling (55) of Earth’s emerging land/ice latitudinal density as expanded on the first 30 Legendre polynomials. (b) Right panel: Kullback–Leibler divergence between the empirical density and the model as a function of the number of orthogonal Legendre polynomials accrued.

Figure 5.
Tide geometry. Idealized model describing the gravitational tidal pull of an ideal Moon of mass m on a thin water layer covering an ideal Earth of mass M and radius R at distance D from the Moon. The horizontal tidal force is given by the modular translation factor (9), defining on the noncentral spherical distribution (8) with , minus a factor of one, accounting for the centrifugal force induced by the Moon–Earth system revolving around its center of gravity. The equatorial bulges are not symmetric in this purely geometrical model. The noncentrality parameter is set to an unrealistic value of 0.2 to enhance the visualization of the geometrical distribution of the tidal forces.
Figure 5.
Tide geometry. Idealized model describing the gravitational tidal pull of an ideal Moon of mass m on a thin water layer covering an ideal Earth of mass M and radius R at distance D from the Moon. The horizontal tidal force is given by the modular translation factor (9), defining on the noncentral spherical distribution (8) with , minus a factor of one, accounting for the centrifugal force induced by the Moon–Earth system revolving around its center of gravity. The equatorial bulges are not symmetric in this purely geometrical model. The noncentrality parameter is set to an unrealistic value of 0.2 to enhance the visualization of the geometrical distribution of the tidal forces.

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Le Blanc, R. Jaynes-Gibbs Entropic Convex Duals and Orthogonal Polynomials. Entropy 2022, 24, 709. https://doi.org/10.3390/e24050709
AMA Style
Le Blanc R. Jaynes-Gibbs Entropic Convex Duals and Orthogonal Polynomials. Entropy. 2022; 24(5):709. https://doi.org/10.3390/e24050709
Chicago/Turabian StyleLe Blanc, Richard. 2022. "Jaynes-Gibbs Entropic Convex Duals and Orthogonal Polynomials" Entropy 24, no. 5: 709. https://doi.org/10.3390/e24050709
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.