
Optimal Control of Background-Based Uncertain Systems with Applications in DC Pension Plan

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminary
2.1. Uncertainty Space
- (i)
- ,
- (ii)
- for any event ,
- (iii)
- for every countable sequence of events .
- (iv)
- Let be uncertainty spaces for The product uncertain measure is
2.2. Optimistic Value and Pessimistic Value
- (i)
- if , then , and ;
- (ii)
- , then , and ;
- (iii)
- , .
- (i)
- and almost all sample paths are Lipschitz continuous,
- (ii)
- has stationary and independent increments,
- (iii)
- every increment is a normal distributed uncertain variable with expected value 0 and variance , whose uncertainty distribution is
- (i)
- ,
- (ii)
- has stationary and independent increments,
- (iii)
- every increment is a Z jump uncertain variable , whose uncertainty distribution is
3. Optimistic Value Model under Background-State of Uncertain Optimal Control with Jump
4. Optimality Condition
- (1)
- when , (i) if , then , (ii) if , then , (iii) if , then ;
- (2)
- when , (i) if , then , (ii) if , then , (iii) if , then .
- (1)
- if , then
- (2)
- if , then
- (1)
- if , then
- (2)
- if , then
5. An Optimal Control Problem of DC Pension Fund
5.1. Finance Market
5.2. Wealth Process
5.3. Optimization Model
5.4. The Solution to the Model
- (1)
- If , we differentiate the expression in brackets with respect to and to find thatSubstituting them into (44) implieswhere , , .Multiplying both sides of equation byNext we solve the partial differential Equation (48).Supposing , then differentiating both sides with respect to t, x, and l, then , , . Substituting them into (48) yieldsAssuming , then , . Substituting them into (49) yieldsDecomposing Equation (50) obtainsBy solving Equation (51), we getThus,Then,So the optimal investment rate and the payment rate are determined, respectively, by
- (2)
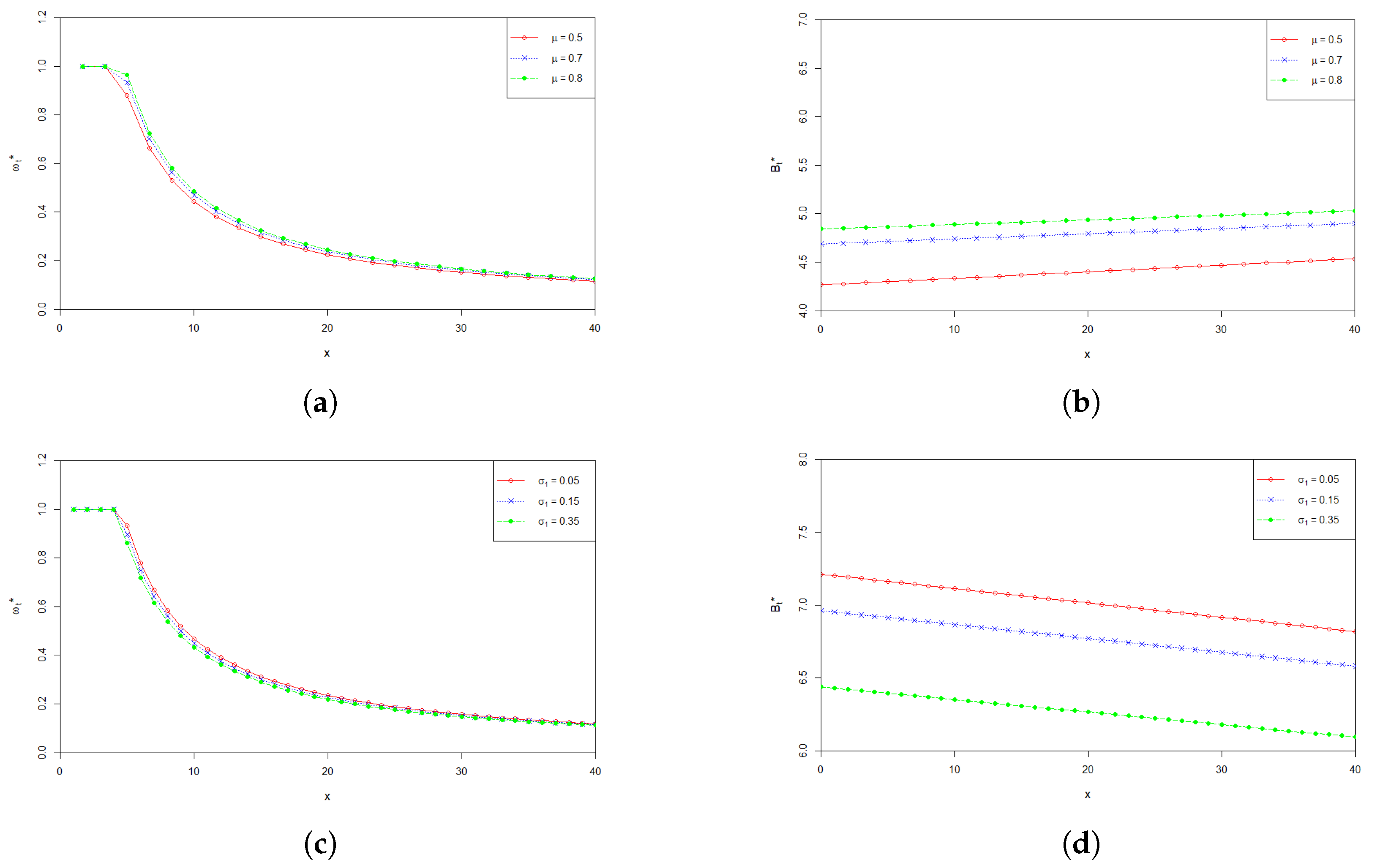
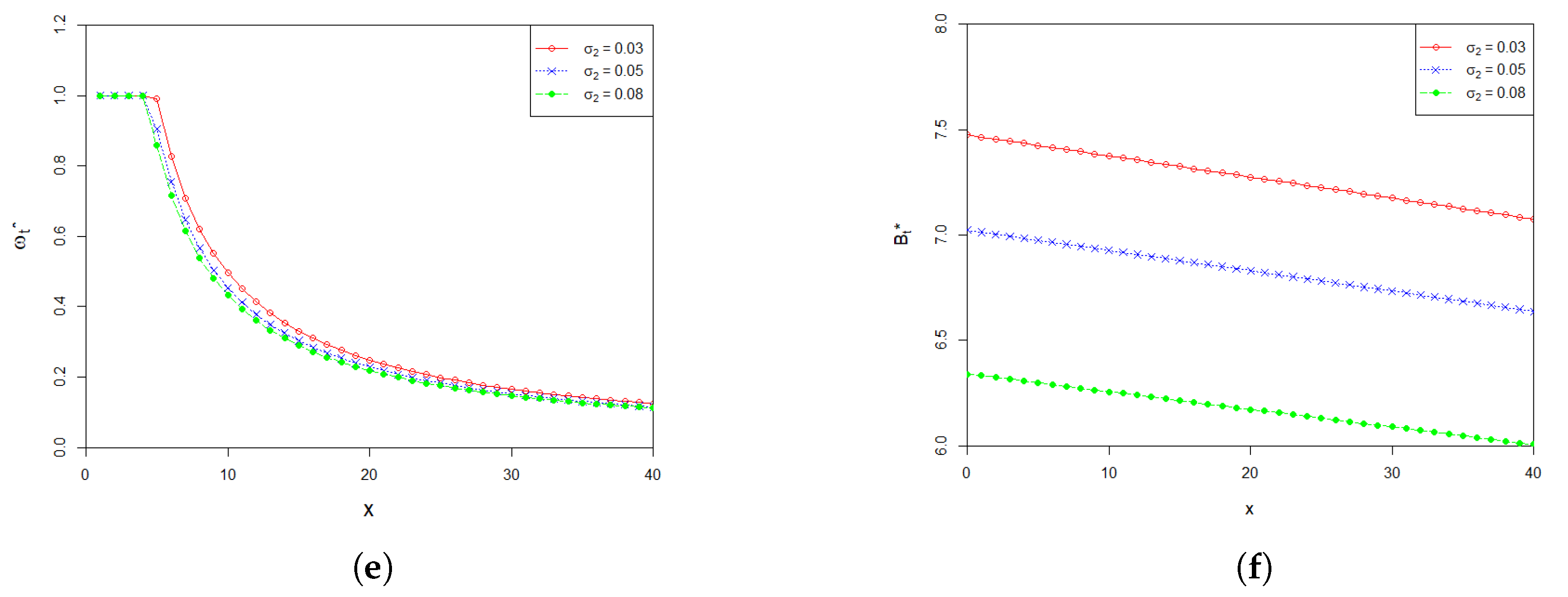
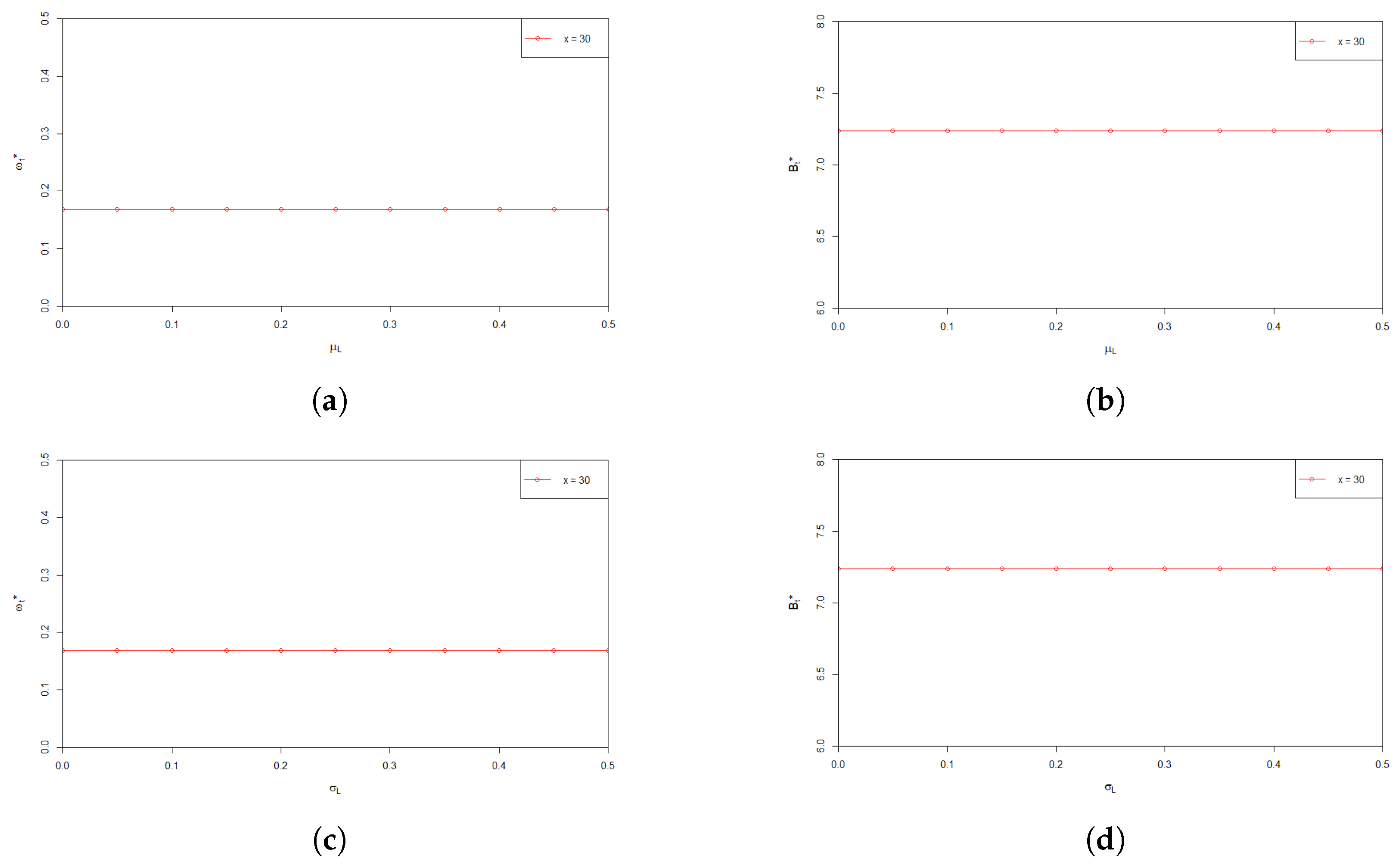
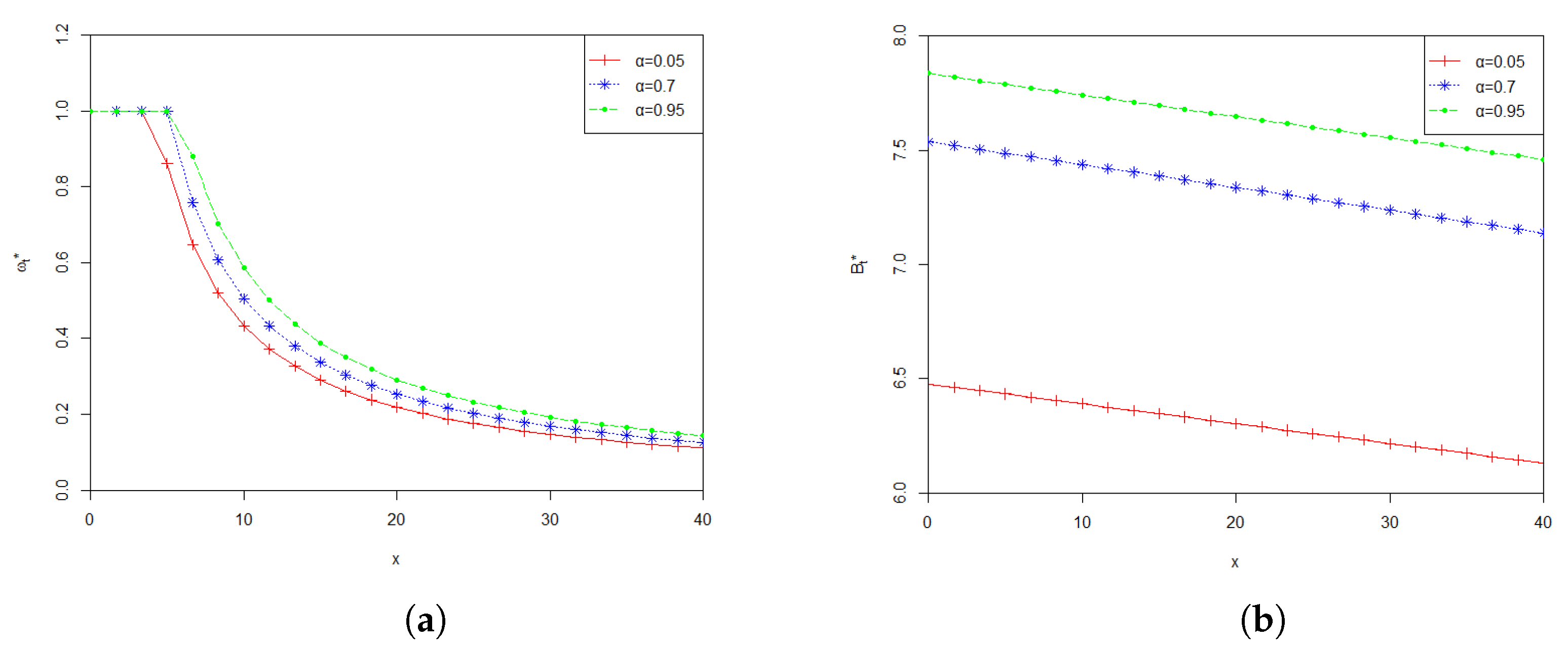
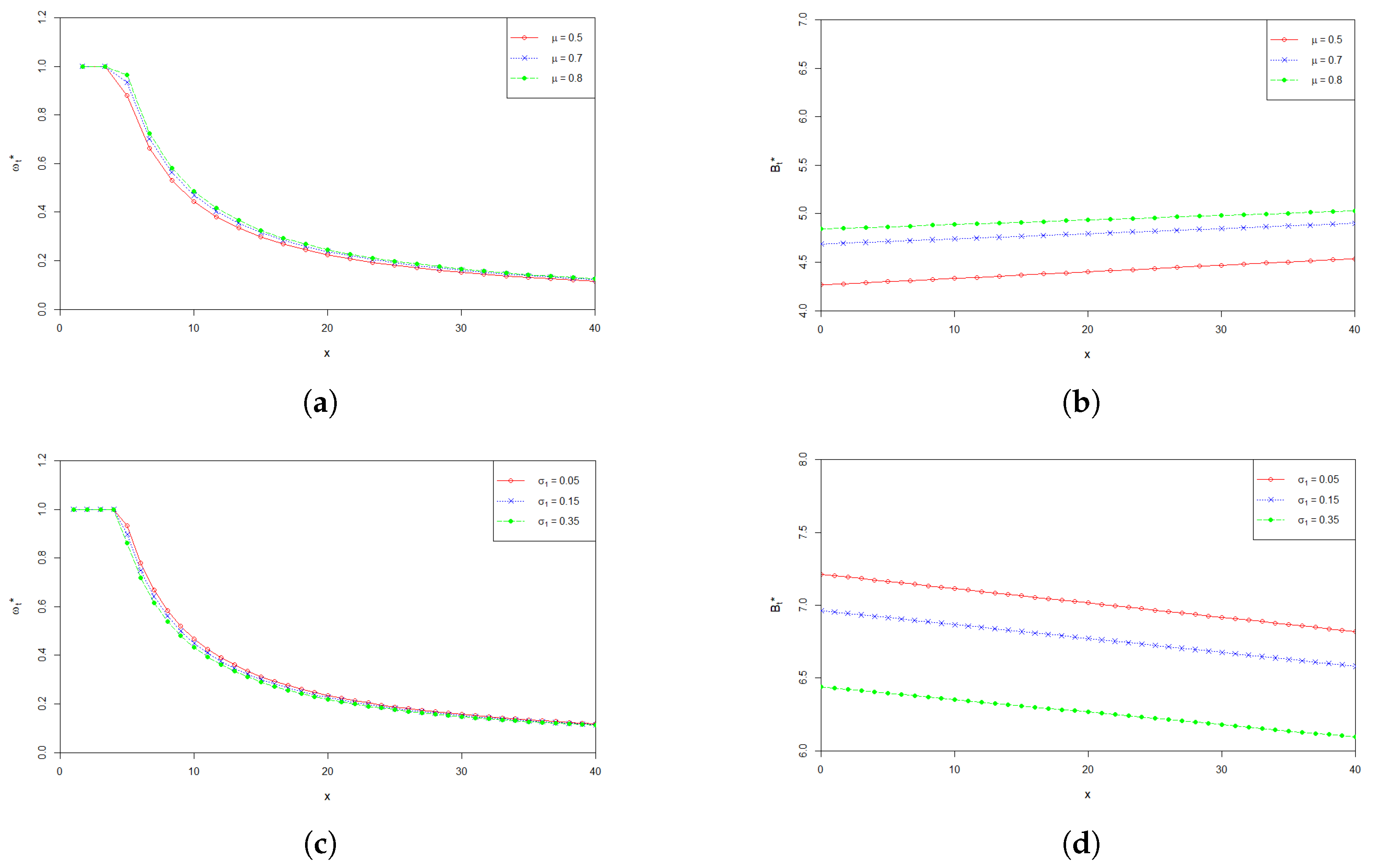
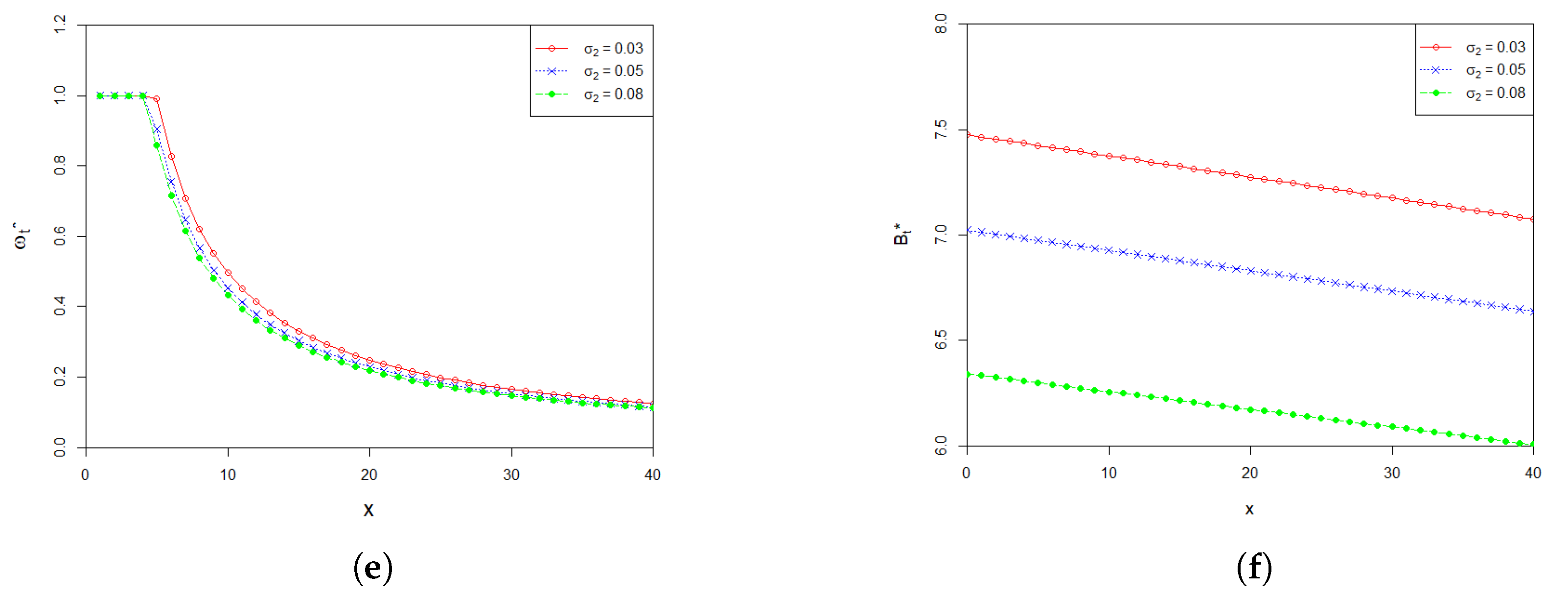
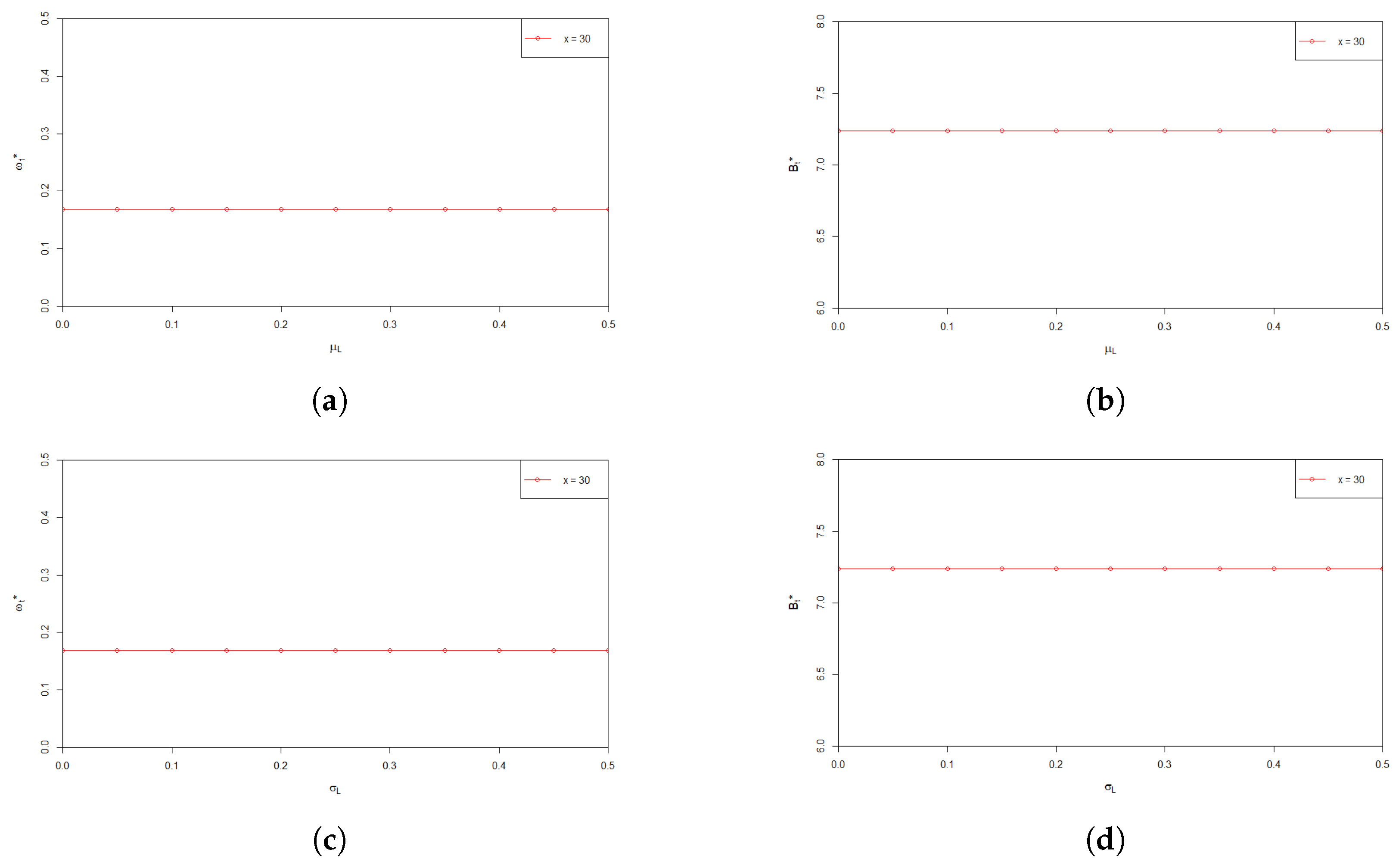
6. Numerical Analysis
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Merton, R. Optimum consumption and portfolio rules in a continuous-time model. J. Econ. Theory 1971, 3, 373–413. [Google Scholar] [CrossRef] [Green Version]
- Fleming, W.; Rishel, R. Deterministic and Stochastic Optimal Control; Springer: New York, NY, USA, 1975. [Google Scholar]
- Whittle, P. Optimization over Time: Dynamic Programming and Stochastic Control; Wiley: New York, NY, USA, 1983. [Google Scholar]
- Boulier, J.; Trussant, E.; Florens, D. A dynamic model for pension funds management. In Proceedings of the Fifth AFIR International Colloquium, Brussels, Belgium, 7–8 September 1995; pp. 361–384. [Google Scholar]
- Yong, J.; Zhou, X. Stochastic Controls: Hamiltonian Systems and HJB Equations; Springer: New York, NY, USA, 1999. [Google Scholar]
- Taksar, M. Optimal risk and dividend distribution control models for an insurance company. Math. Methods Oper. Res. 2000, 51, 1–42. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, L. Optimal investment for insurer with jump-diffusion risk process. Insur. Math. Econ. 2005, 37, 615–634. [Google Scholar] [CrossRef]
- Schmidli, H. Stochastic Control in Discrete Time. In Stochastic Control in Insurance; Springer: London, UK, 2008. [Google Scholar]
- Bjork, T.; Murgoci, A. A general theory of markovian time inconsistent stochastic control problems. SSRN Electron. J. 2010, 336, 1694759. [Google Scholar] [CrossRef] [Green Version]
- Fleming, W.H.; Soner, H.M. Controlled Markov Process and Viscosity Solutions; Springer: New York, NY, USA, 2010. [Google Scholar]
- Josa-Fombellida, R.; Rinco-Zapatero, J. Stochastic pension funding when the benefit and the risky asset follow jump diffusion processes. Eur. J. Oper. Res. 2012, 220, 404–413. [Google Scholar] [CrossRef]
- He, L.; Liang, Z. Optimal investment strategy for the DC plan with the return of premiums clauses in a mean variance framework. Insur. Math. Econ. 2013, 53, 643–649. [Google Scholar] [CrossRef]
- Guan, G.; Liang, Z. Optimal management of DC pension plan in a stochastic interest rate and stochastic volatility framework. Insur. Math. Econ. 2014, 57, 58–66. [Google Scholar] [CrossRef]
- Sun, J.; Li, Z.; Zeng, Y. Precommitment and equilibrium investment strategies for defined contribution pension plans under a jump-diffusion model. Insur. Math. Econ. 2016, 67, 158–172. [Google Scholar] [CrossRef]
- Nkeki, C.; Mcaleer, M. Optimal investment and optimal additional voluntary contribution rate of a DC pension fund in a jump diffusion environment. Ann. Financ. Econ. 2018, 12, 1750017. [Google Scholar] [CrossRef]
- Zhao, P.; Zhou, B.; Wang, J. Non–Gaussian Closed Form Solutions for Geometric Average Asian Options in the Framework of Non-Extensive Statistical Mechanics. Entropy 2018, 20, 71. [Google Scholar] [CrossRef] [Green Version]
- Mwanakatwe, P.; Song, L.; Hagenimana, E.; Wang, X. Management strategies for a defined contribution pension fund under the hybrid stochastic volatility model. Comput. Appl. Math. 2019, 38, 45. [Google Scholar] [CrossRef]
- Lima, L. Nonlinear Stochastic Equation within an It? Prescription for Modelling of Financial Market. Entropy 2019, 21, 530. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lindgren, J. Efficient Markets and Contingent Claims Valuation: An Information Theoretic Approach. Entropy 2020, 22, 1283. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Guo, J. Optimal defined contribution pension management with salary and risky assets following jump diffusion processes. East Asian J. Appl. Math. 2020, 10, 22–39. [Google Scholar]
- Liu, B. Uncertainty Theory, 2nd ed.; Springer: Berlin, Germany, 2007. [Google Scholar]
- Liu, B. Fuzzy process, hybrid process and uncertain process. J. Uncertain Syst. 2008, 2, 3–16. [Google Scholar]
- Liu, B. Some research problems in uncertainty theory. J. Uncertain Syst. 2009, 3, 3–10. [Google Scholar]
- Liu, B. Uncertainty Theory: A Branch of Mathematics for Modeling Human Uncertainty; Springer: Berlin, Germany, 2010. [Google Scholar]
- Liu, B. Uncertainty Theory, 5th ed.; Springer: Berlin, Germany, 2020. [Google Scholar]
- Sheng, L.; Zhu, Y. Optimistic value model of uncertain optimal control. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2013, 21 (Suppl. 01), 75–87. [Google Scholar] [CrossRef]
- Deng, L.; Chen, Y. Optimal control of uncertain systems with jump under optimistic value criterion. Eur. J. Control 2017, 38, 7–15. [Google Scholar] [CrossRef]
- Zhu, Y. Uncertain optimal control with application to a portfolio selection model. Cybern. Syst. Int. J. 2010, 41, 535–547. [Google Scholar] [CrossRef]
- Zhu, Y. Uncertain fractional differential equations and an interest rate model. Math. Methods Appl. Sci. 2015, 38, 3359–3368. [Google Scholar] [CrossRef]
- Zhu, Y. Uncertain Optimal Control; Springer Nature: Singapore, 2019. [Google Scholar]
- Deng, L.; Shen, J.; Chen, Y. Hurwicz model of uncertain optimal control with jump. Math. Methods Appl. Sci. 2020, 43, 10054–10069. [Google Scholar] [CrossRef]
- Huang, X.; Di, H. Uncertain portfolio selection with background risk. Appl. Math. Comput. 2016, 276, 284–296. [Google Scholar] [CrossRef]
- Li, B.; Zhu, Y.; Sun, Y.; Aw, G.; Teo, K. Multi-period portfolio selection problem under uncertain environment with bankruptcy constraint. Appl. Math. Model. 2018, 56, 539–550. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Yan, H.; Zhu, Y. European option pricing model based on uncertain fractional differential equation. Fuzzy Optim. Decis. Mak. 2019, 18, 199–217. [Google Scholar] [CrossRef]
- Jin, T.; Sun, Y.; Zhu, Y. Time integral about solution of an uncertain fractional order differential equation and application to zero-coupon bond model. Appl. Math. Comput. 2020, 372, 124991. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, M.; Zhai, J.; Bai, M. Portfolio selection of the defined contribution pension fund with uncertain return and salary: A multi-period mean-variance model. J. Intell. Fuzzy Syst. 2018, 34, 2363–2371. [Google Scholar] [CrossRef]
- Deng, L.; You, Z.; Chen, Y. Optimistic value model of multidimensional uncertain optimal control with jump. Eur. J. Control 2018, 39, 1–7. [Google Scholar] [CrossRef]
- Deng, L.; Zhu, Y. Uncertain optimal control with jump. ICIC Express Lett. Part B Appl. 2012, 3, 419–424. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Wu, W.; Tang, X.; Hu, Y. Optimal Control of Background-Based Uncertain Systems with Applications in DC Pension Plan. Entropy 2022, 24, 734. https://doi.org/10.3390/e24050734
Liu W, Wu W, Tang X, Hu Y. Optimal Control of Background-Based Uncertain Systems with Applications in DC Pension Plan. Entropy. 2022; 24(5):734. https://doi.org/10.3390/e24050734
Chicago/Turabian StyleLiu, Wei, Wanying Wu, Xiaoyi Tang, and Yijun Hu. 2022. "Optimal Control of Background-Based Uncertain Systems with Applications in DC Pension Plan" Entropy 24, no. 5: 734. https://doi.org/10.3390/e24050734
APA StyleLiu, W., Wu, W., Tang, X., & Hu, Y. (2022). Optimal Control of Background-Based Uncertain Systems with Applications in DC Pension Plan. Entropy, 24(5), 734. https://doi.org/10.3390/e24050734