
Subjective Trusts for the Control of Mobile Robots under Uncertainty



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Algebra of Control Variables
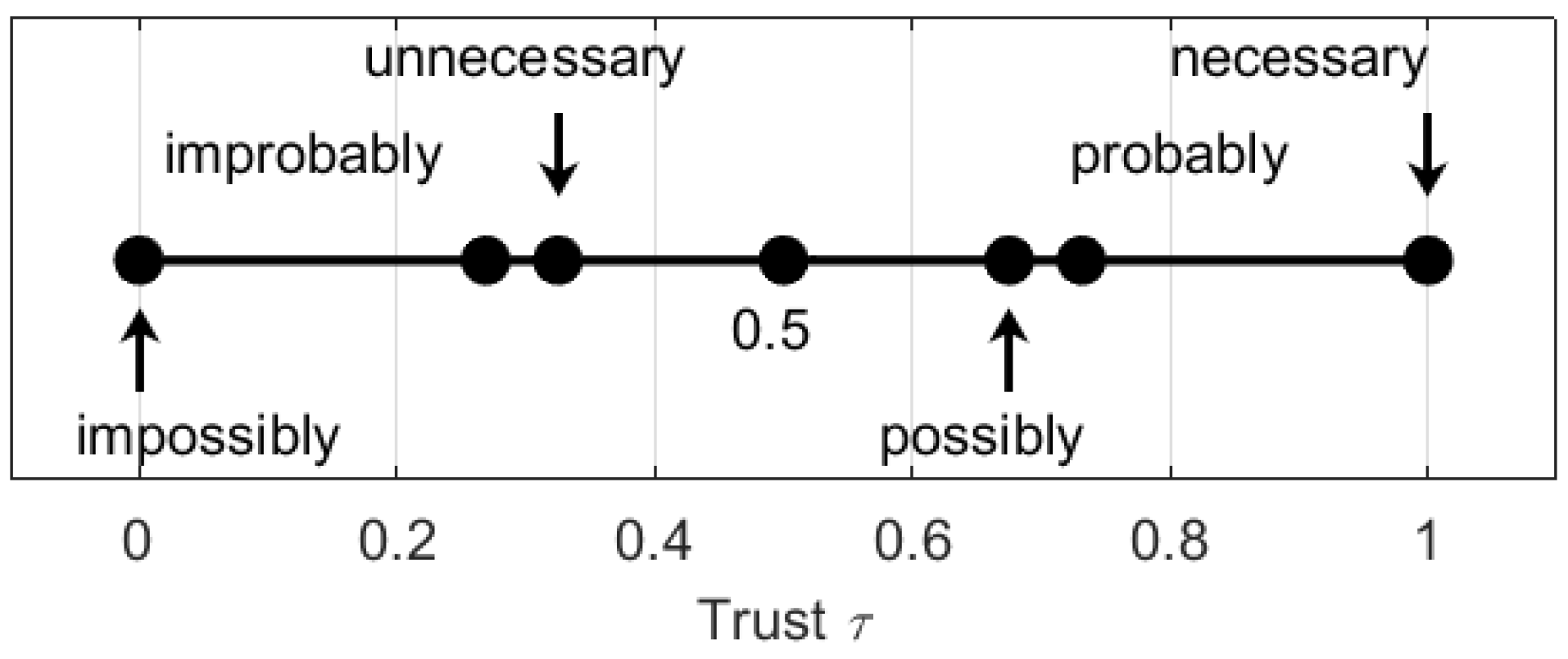
2.1. Algebraic Structure for Multivalued Logic
- means that is necessary and means that is impossible;
- means that is probable and means that is improbable;
- means that is possible and means that is unnecessary.
- means that is objectively true and means that is objectively false;
- means that is subjectively true (true from the observer’s point of view) and means that is subjectively false (false from the observer’s point of view);
- means that seems to be true and means that is seems to be false.
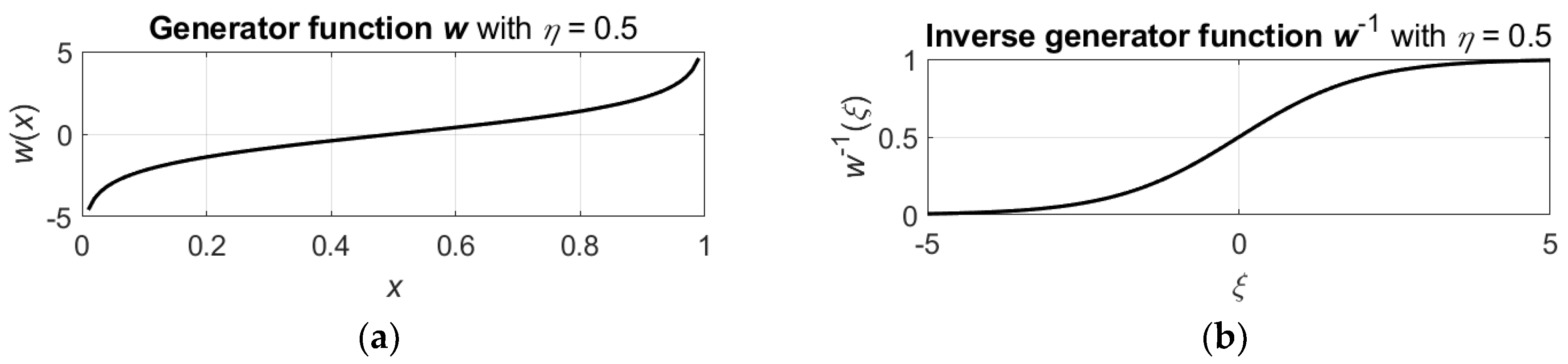
2.2. Algebra of Control Variables
3. Neural Network with Mobile Neurons in Algebra
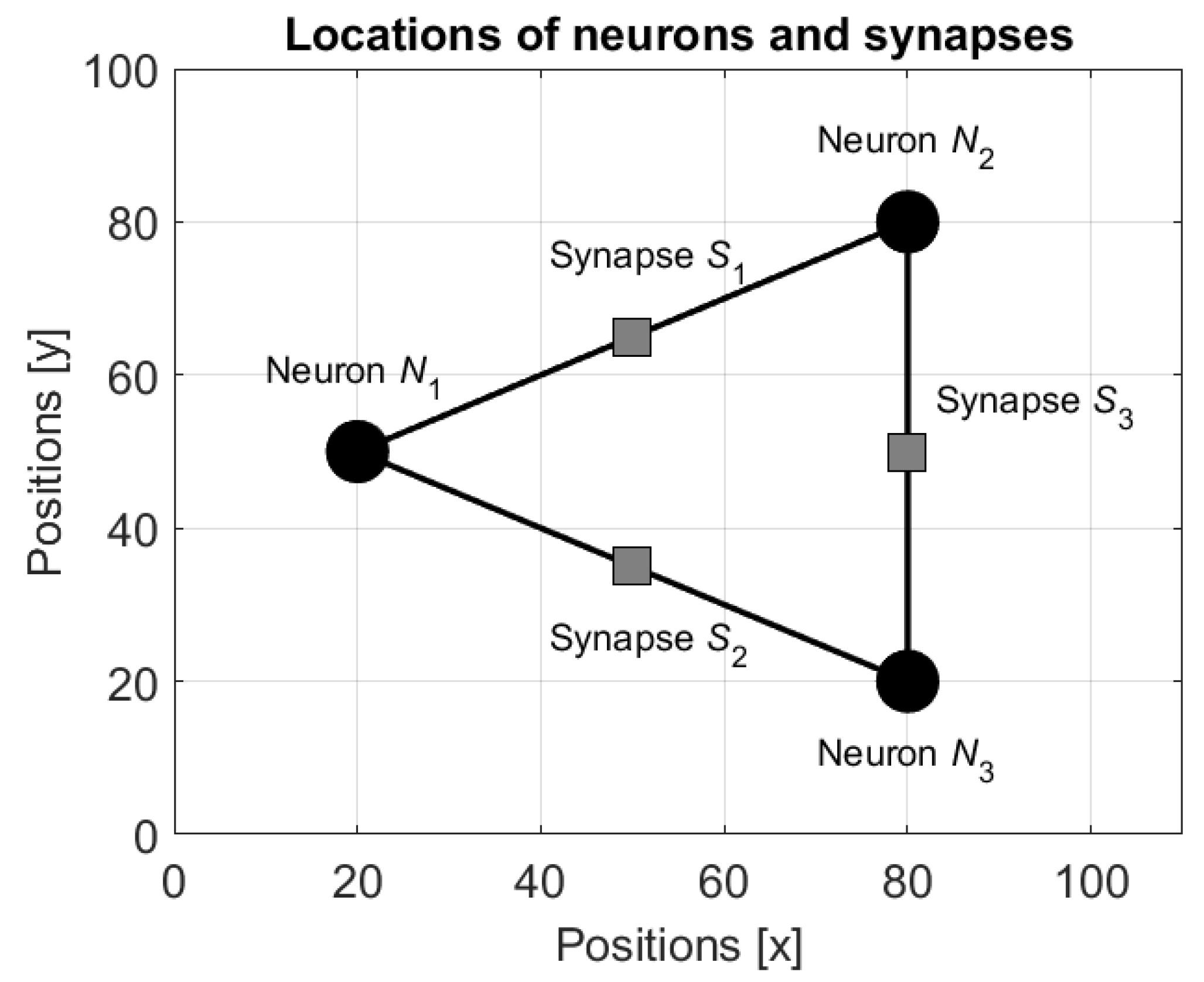
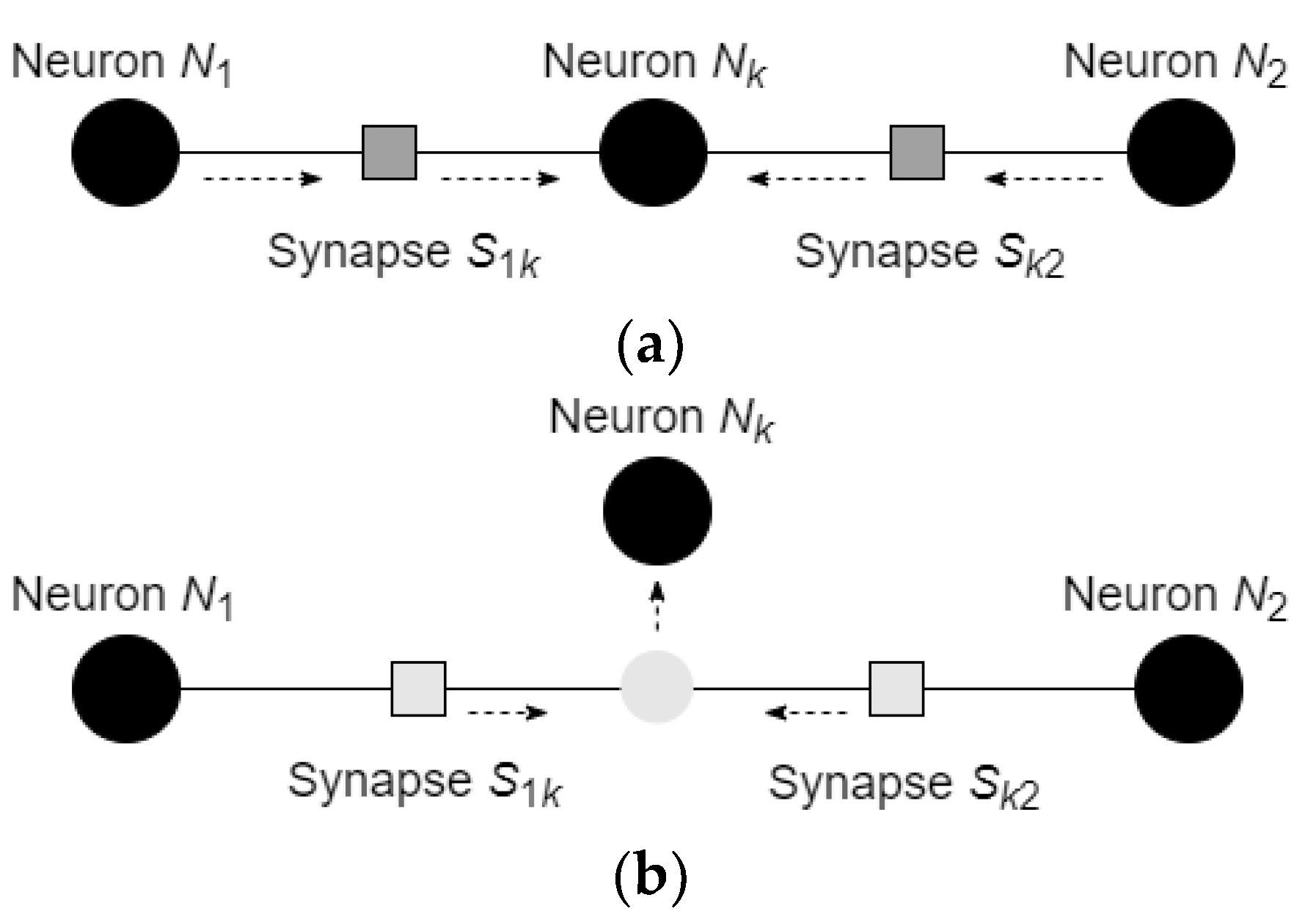
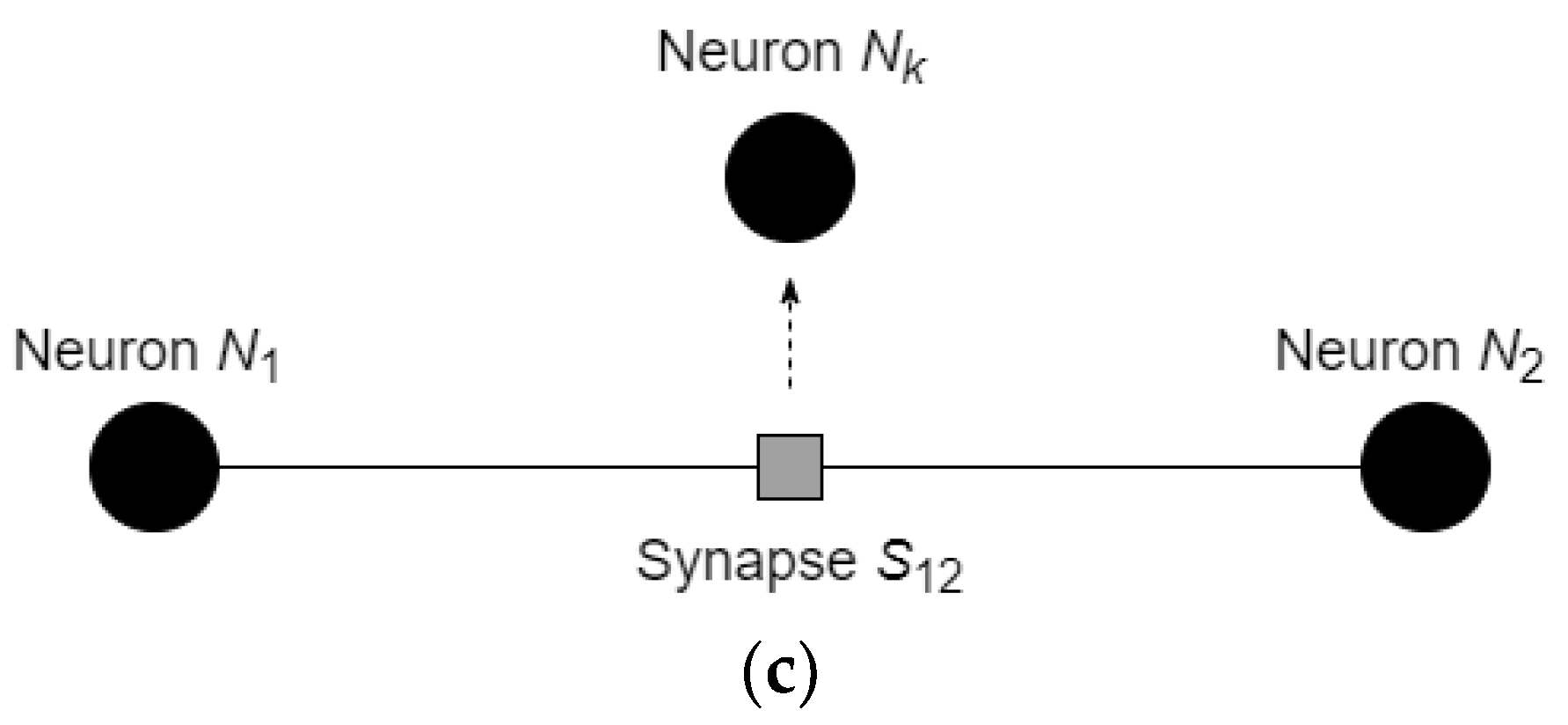
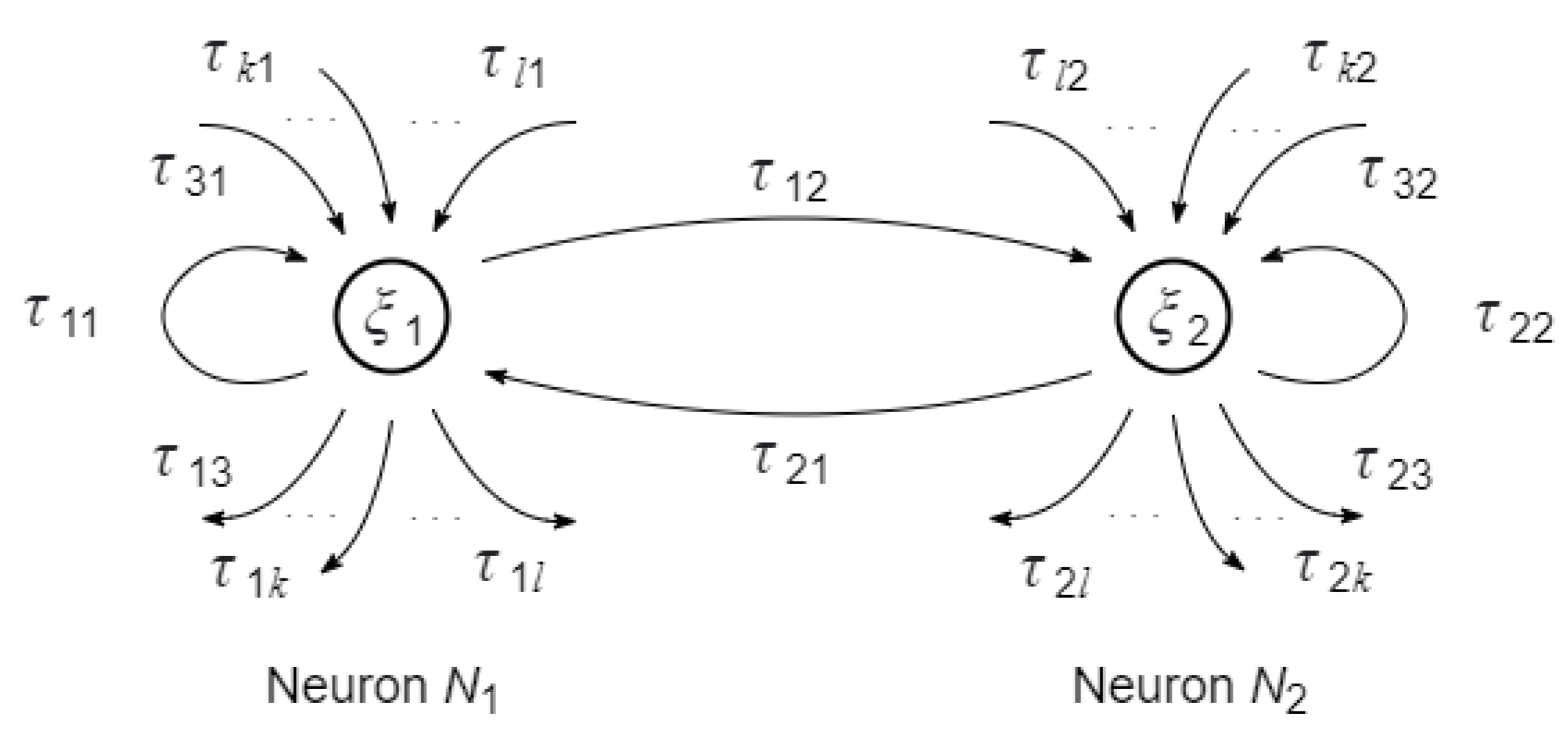
3.1. States of the Neurons and of the Synapses
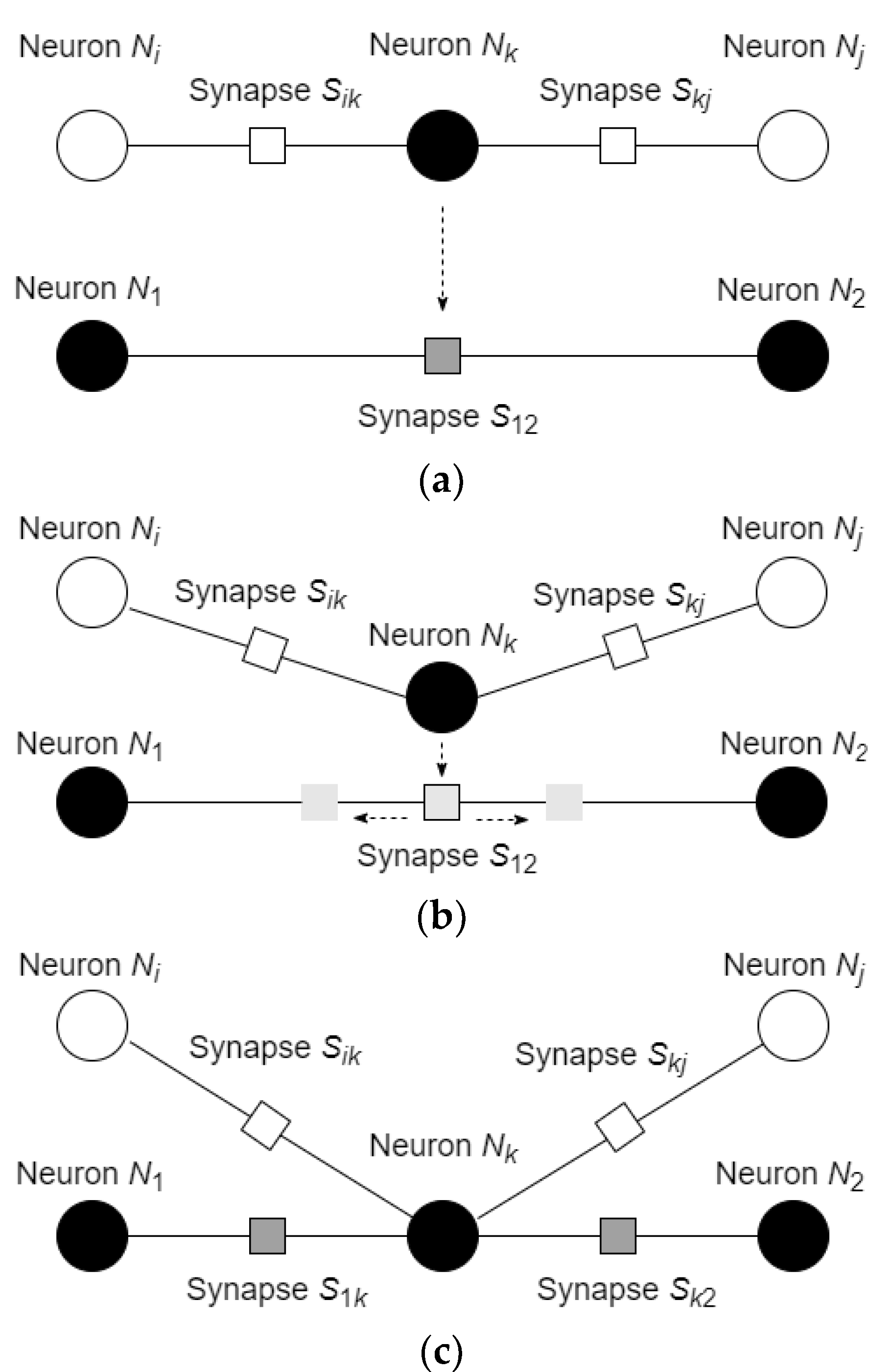
3.2. Reactive Learning and Motion of the Neurons
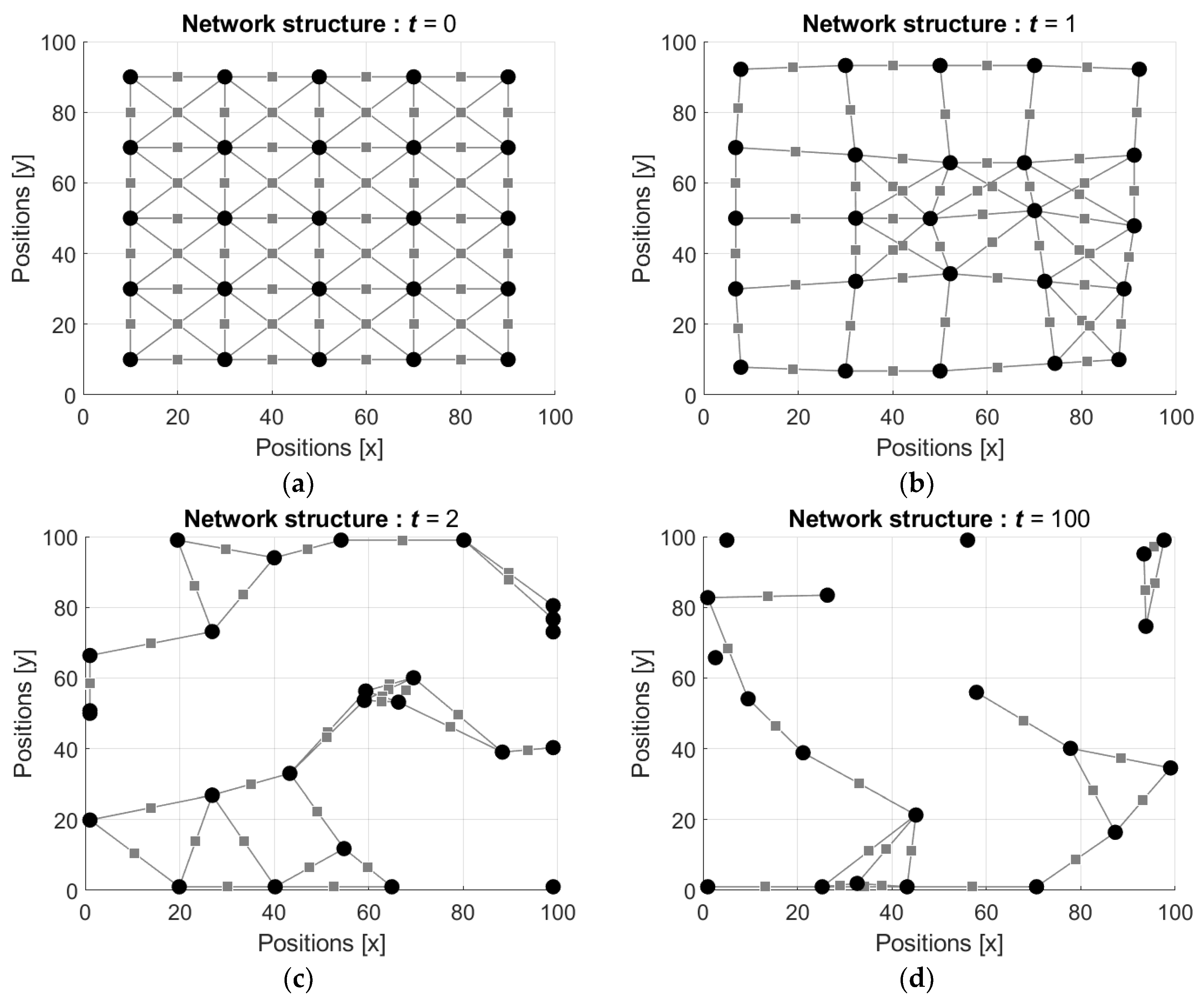
3.3. Simulation of the Network Activity
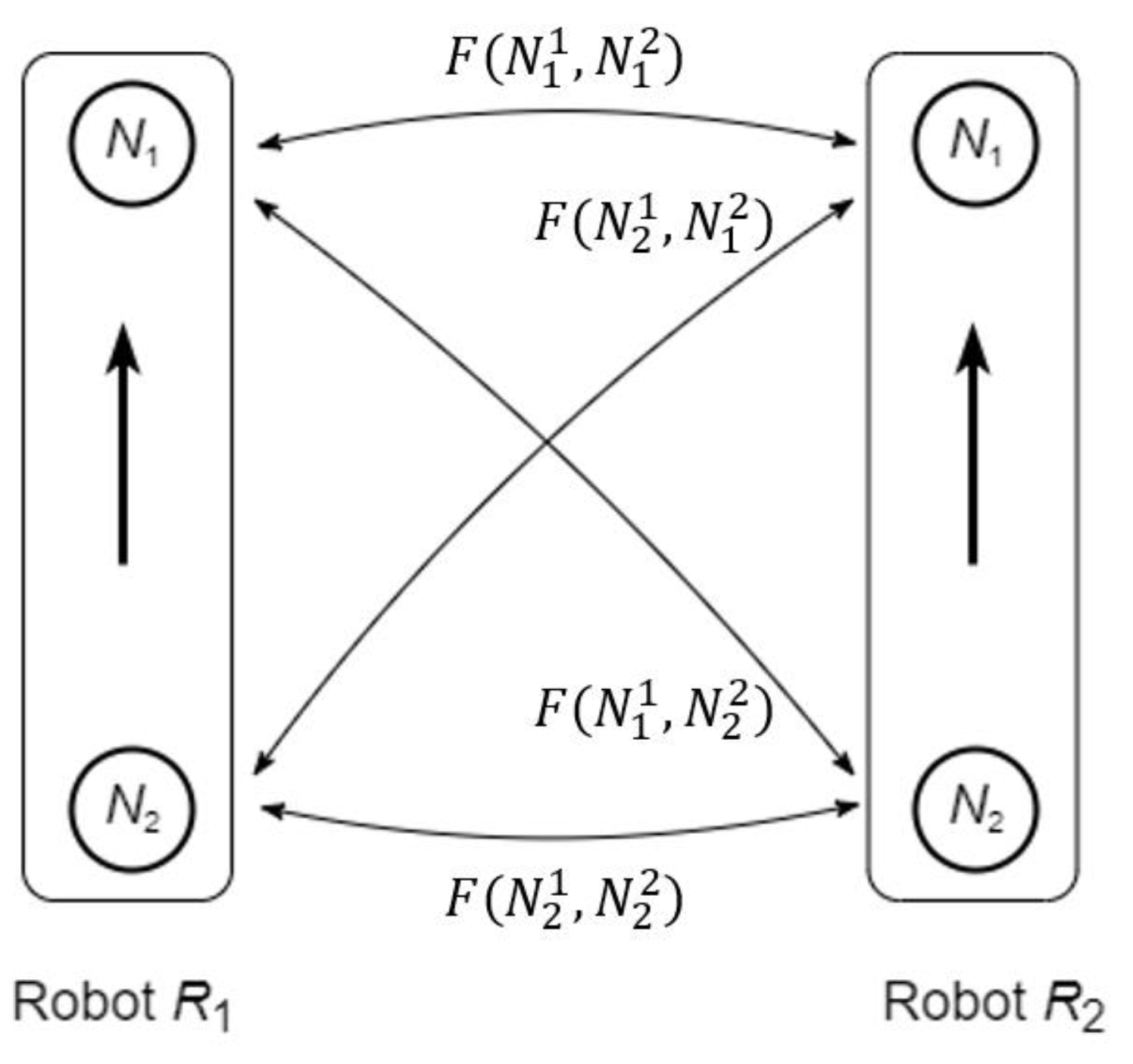
4. Robot States and Movements
4.1. Robot States under Uncertainty
- -
- The trust vector means that the heading of the robot is necessary ;
- -
- The trust vector means that the heading of the robot is necessary ;
- -
- The trust vector means that the heading of the robot is necessary ;
- -
- The trust vector means that the heading of the robot is necessary .
- -
- The trust matrix means preserving current direction of the robot with necessity;
- -
- The trust matrix means turn left with necessity;
- -
- The trust matrix means turn right with necessity.
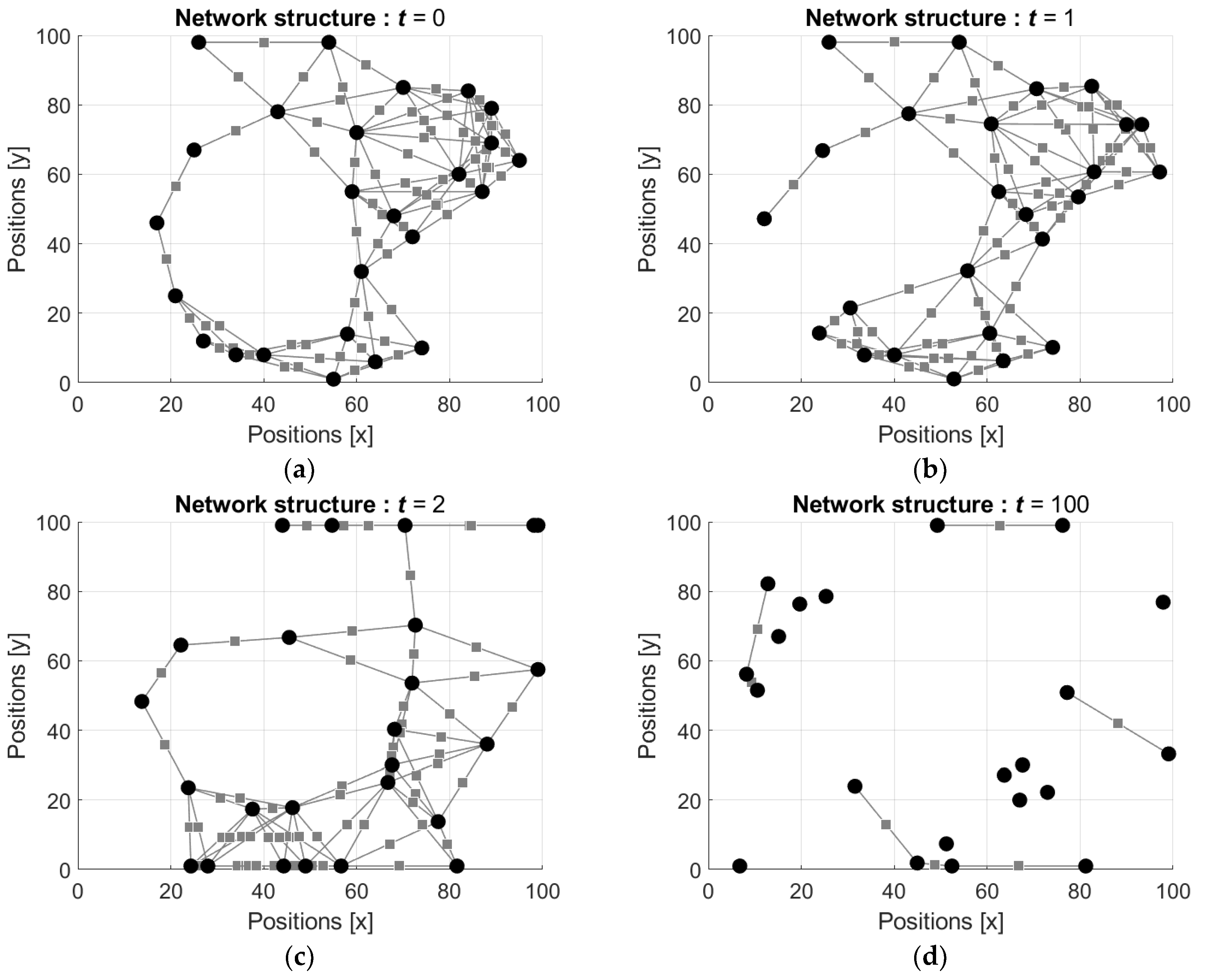
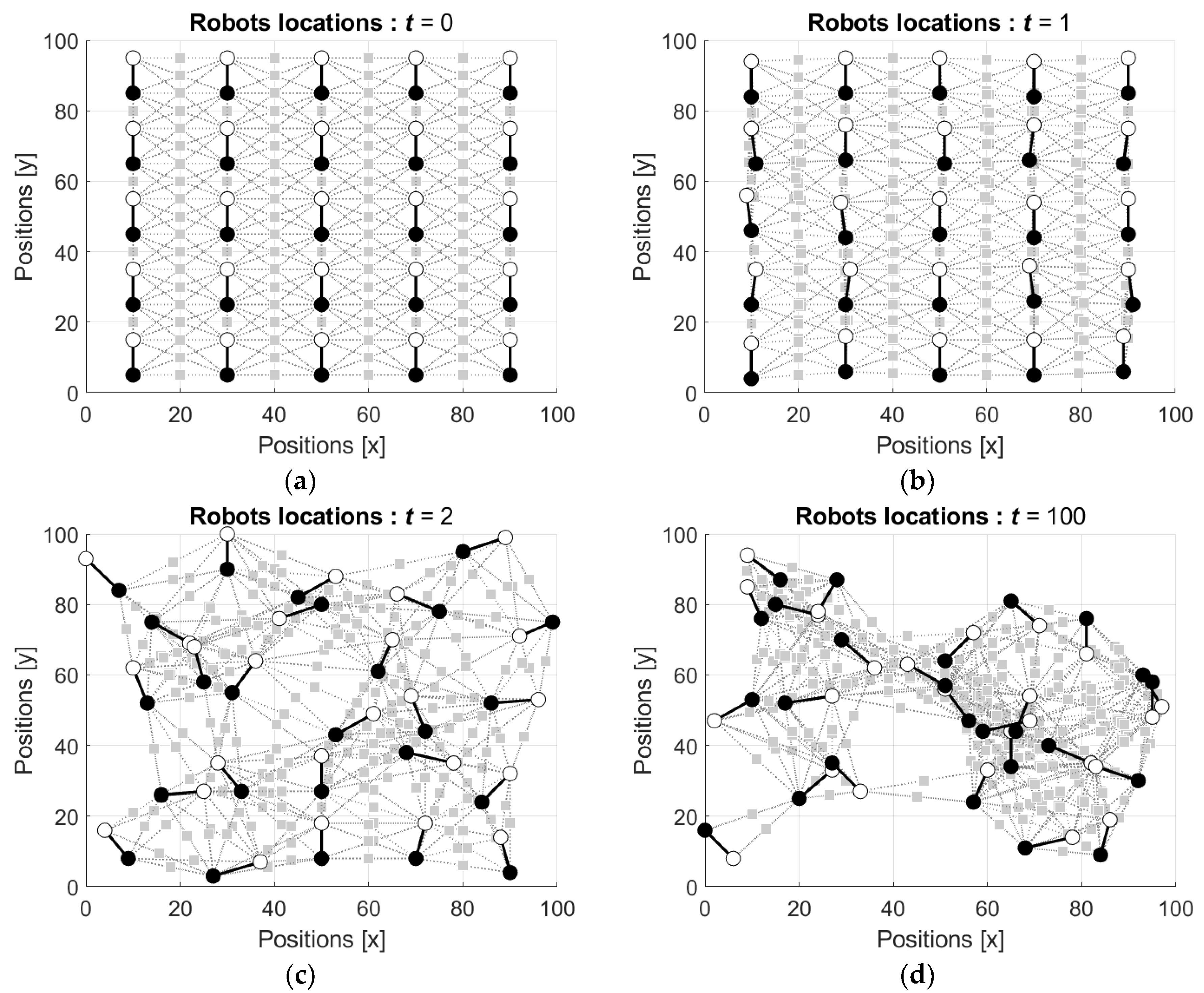
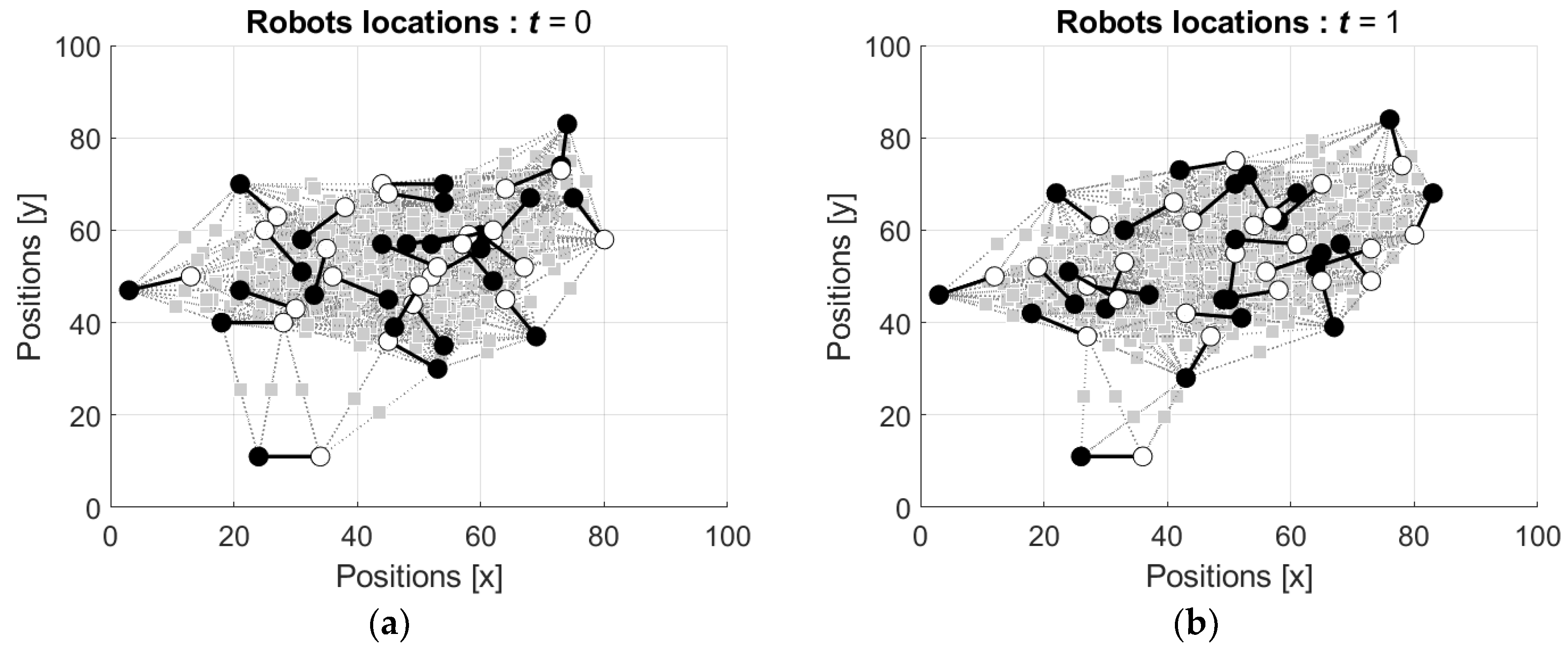
4.2. Simulation of the Robots’ Motion and Swarming
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Maxwell, J.C. On governors. Proc. R. Soc. Lond. 1868, 16, 270–283. [Google Scholar]
- Aliev, R.; Huseynov, O. Decision Theory with Imperfect Information; World Scientific: Singapore, 2014. [Google Scholar]
- Feldbaum, A.A. Theory of Optimal Automated Systems; PhysMatGiz: Moscow, Russia, 1963. [Google Scholar]
- Aoki, M. Optimization of Stochastic Systems; Academic Press: New York, NY, USA; London, UK, 1967. [Google Scholar]
- Åström, K.J. Introduction to Stochastic Control Theory; Academic Press: New York, NY, USA, 1970. [Google Scholar]
- Bertsekas, D.P.; Shreve, S.E. Stochastic Optimal Control: The Discrete Time Case; Academic Press: New York, NY, USA, 1978. [Google Scholar]
- Dubois, D.; Prade, H. Possibility Theory; Plenum: New York, NY, USA, 1988. [Google Scholar]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect theory: An analysis of decision under risk. Econometrica 1979, 47, 263–292. [Google Scholar] [CrossRef] [Green Version]
- Ruggeri, K.; Ali, S.; Berge, M.L.; Bertoldo, G.; Bjørndal, L.D.; Cortijos-Bernabeu, A.; Davison, C.; Demić, E.; Esteban-Serna, C.; Friedemann, M.; et al. Replicating patterns of prospect theory for decision under risk. Nat. Hum. Behav. 2020, 4, 622–633. [Google Scholar] [CrossRef] [PubMed]
- Hassoun, M.; Kagan, E. On the right combination of altruism and randomness in the motion of homogeneous distributed autonomous agents. Nat. Comput. 2021. [Google Scholar] [CrossRef]
- Kagan, E.; Rybalov, A. Subjective trusts and prospects: Some practical remarks on decision making with imperfect information. Oper. Res. Forum 2022, 3, 19. [Google Scholar] [CrossRef]
- Kagan, E.; Rybalov, A.; Yager, R. Sum of certainties with the product of reasons: Neural network with fuzzy aggregators. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2022, 30, 1–18. [Google Scholar] [CrossRef]
- Yager, R.; Rybalov, A. Uninorm aggregation operators. Fuzzy Sets Syst. 1996, 80, 111–120. [Google Scholar] [CrossRef]
- Batyrshin, I.; Kaynak, O.; Rudas, I. Fuzzy modeling based on generalized conjunction operations. IEEE Trans. Fuzzy Syst. 2002, 10, 678–683. [Google Scholar] [CrossRef]
- Fodor, J.; Rudas, I.; Bede, B. Uninorms and absorbing norms with applications to image processing. In Proceedings of the Information Conference SISY, 4th Serbian-Hungarian Joint Symposium on Intelligent Systems, Subotica, Serbia, 29–30 September 2006; pp. 59–72. [Google Scholar]
- Kagan, E.; Rybalov, A.; Siegelmann, H.; Yager, R. Probability-generated aggregators. Int. J. Intell. Syst. 2013, 28, 709–727. [Google Scholar] [CrossRef]
- Apolloni, B.; Bassis, S.; Valerio, L. Training a network of mobile neurons. In Proceedings of the International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1683–1691. [Google Scholar]
- Gazi, V.; Passino, K.M. Swarm Stability and Optimization; Springer: Berlin, Germany, 2011. [Google Scholar]
- Kagan, E.; Shvalb, N.; Ben-Gal, I. (Eds.) Autonomous Mobile Robots and Multi-Robot Systems: Motion-Planning, Communication, and Swarming; John Wiley & Sons: Chichester, UK, 2019. [Google Scholar]
- Fregnac, Y. Hebbian cell ensembles. In Encyclopedia of Cognitive Science; Nature Publishing Group: Berlin, Germany, 2003; pp. 320–329. [Google Scholar]
- Saeidi, H. Trust-Based Control of (Semi) Autonomous Mobile Robotic Systems. Ph.D. Thesis, Clemson University, Clemson, SC, USA, 2016. [Google Scholar]
- Saeidi, H.; Wang, Y. Incorporating trust and self-confidence analysis in the guidance and control of (semi) autonomous mobile robotic systems. IEEE Robot. Autom. Lett. 2018, 4, 239–246. [Google Scholar] [CrossRef]
- Tchieu, A.A.; Kanso, E.; Newton, P.K. The finite-dipole dynamical system. Proc. R. Soc. A 2012, 468, 3006–3026. [Google Scholar] [CrossRef]
- Fodor, J.; Yager, R.; Rybalov, A. Structure of uninorms. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1997, 5, 411–427. [Google Scholar] [CrossRef]
- Klement, E.; Mesiar, R.; Pap, E. Triangular Norms; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Hopfield, J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kagan, E.; Ben-Gal, I. Navigation of quantum-controlled mobile robots. In Recent Advances in Mobile Robotics; InTech: Rijeka, Czech Republic, 2011; pp. 311–326. [Google Scholar]
- Jantzen, J. Foundations of Fuzzy Control; John Wiley & Sons: Chichester, UK, 2013. [Google Scholar]
- Passino, K.M.; Yurkovich, S. Fuzzy Control; Addison-Wesley: Menlo Park, CA, USA, 1998. [Google Scholar]
- Benioff, P. Quantum Robots and Environments. Phys. Rev. A 1998, 58, 893–904. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kagan, E.; Rybalov, A. Subjective Trusts for the Control of Mobile Robots under Uncertainty. Entropy 2022, 24, 790. https://doi.org/10.3390/e24060790
Kagan E, Rybalov A. Subjective Trusts for the Control of Mobile Robots under Uncertainty. Entropy. 2022; 24(6):790. https://doi.org/10.3390/e24060790
Chicago/Turabian StyleKagan, Eugene, and Alexander Rybalov. 2022. "Subjective Trusts for the Control of Mobile Robots under Uncertainty" Entropy 24, no. 6: 790. https://doi.org/10.3390/e24060790
APA StyleKagan, E., & Rybalov, A. (2022). Subjective Trusts for the Control of Mobile Robots under Uncertainty. Entropy, 24(6), 790. https://doi.org/10.3390/e24060790