We present the results of the experiments using the synthesized weights based on the logical operators AND, OR and XOR (henceforth collectively referred to as
logical groups). First, for the same logical operator, we compare the performance of each of the methods in each dataset (
Section 7.2.1). Then, we compare the prediction accuracy over the original weights versus the synthesized weights (
Section 7.2.2). Finally, we compare the performance between logical operators, highlighting how different relationships between weight and node metadata can affect prediction performance (
Section 7.2.3).
To make comparisons of the prediction accuracy obtained in different scenarions, we performed two-sided t-tests with a significance level of 5%, where the mean of the PCC and RSE for each of the weights generated using a logical operator (AND, OR and XOR) was compared to the mean of the PCC and RSE obtained for the original weights. We also performed a pairwise comparison of the logical groups AND, OR and XOR with respect to their mean PCC and RSE using two-sided t-tests with the same significance level. The null hypothesis in all cases was that the mean over any two given groups was equal.
7.2.1. Comparison between Methods on Synthesized Weights
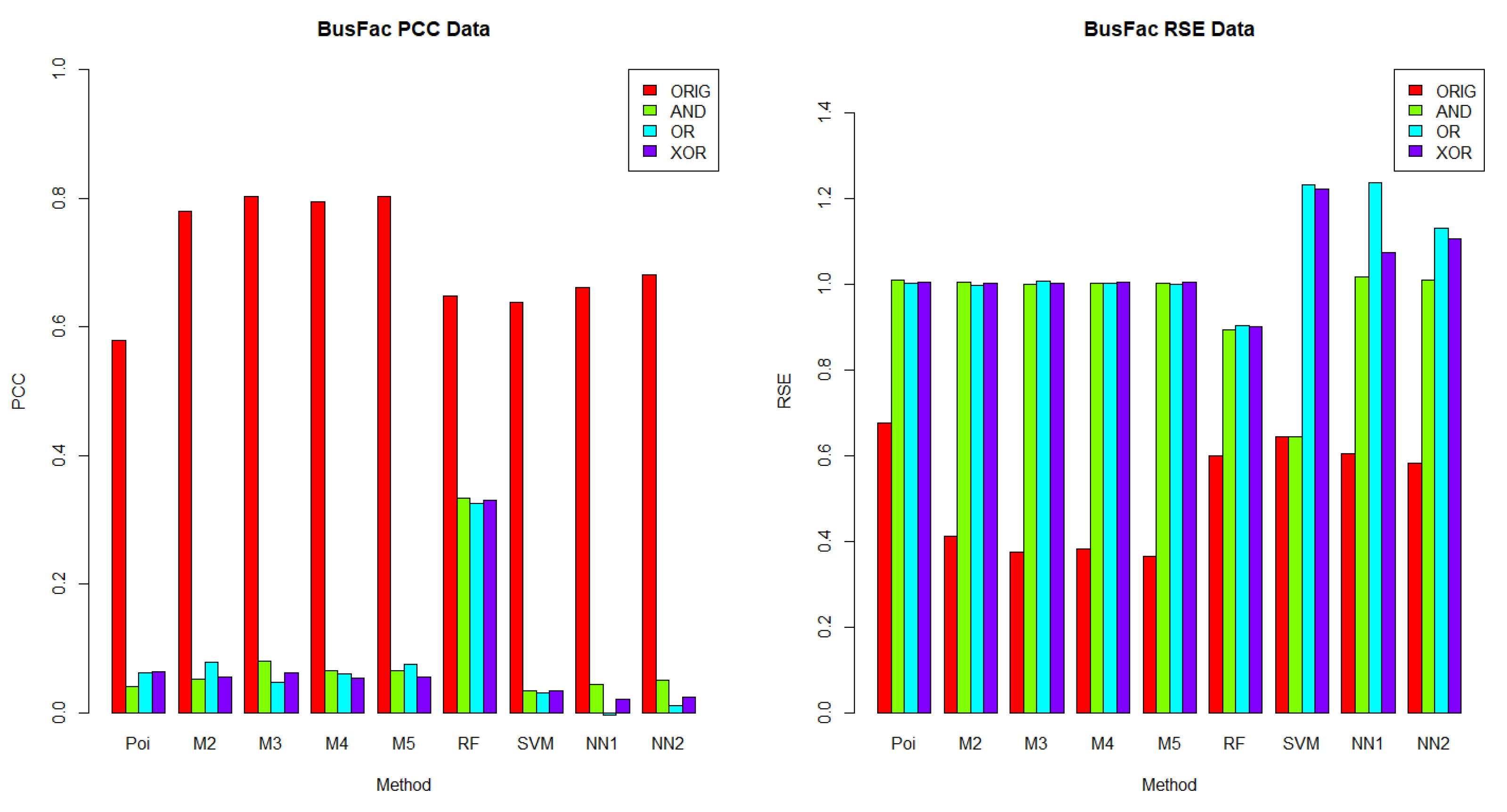
In this section, we aimed to understand which methods performed best in each dataset, given a logical operator (AND, OR and XOR). The results for
BusFac,
CompSciFac,
HistFac and
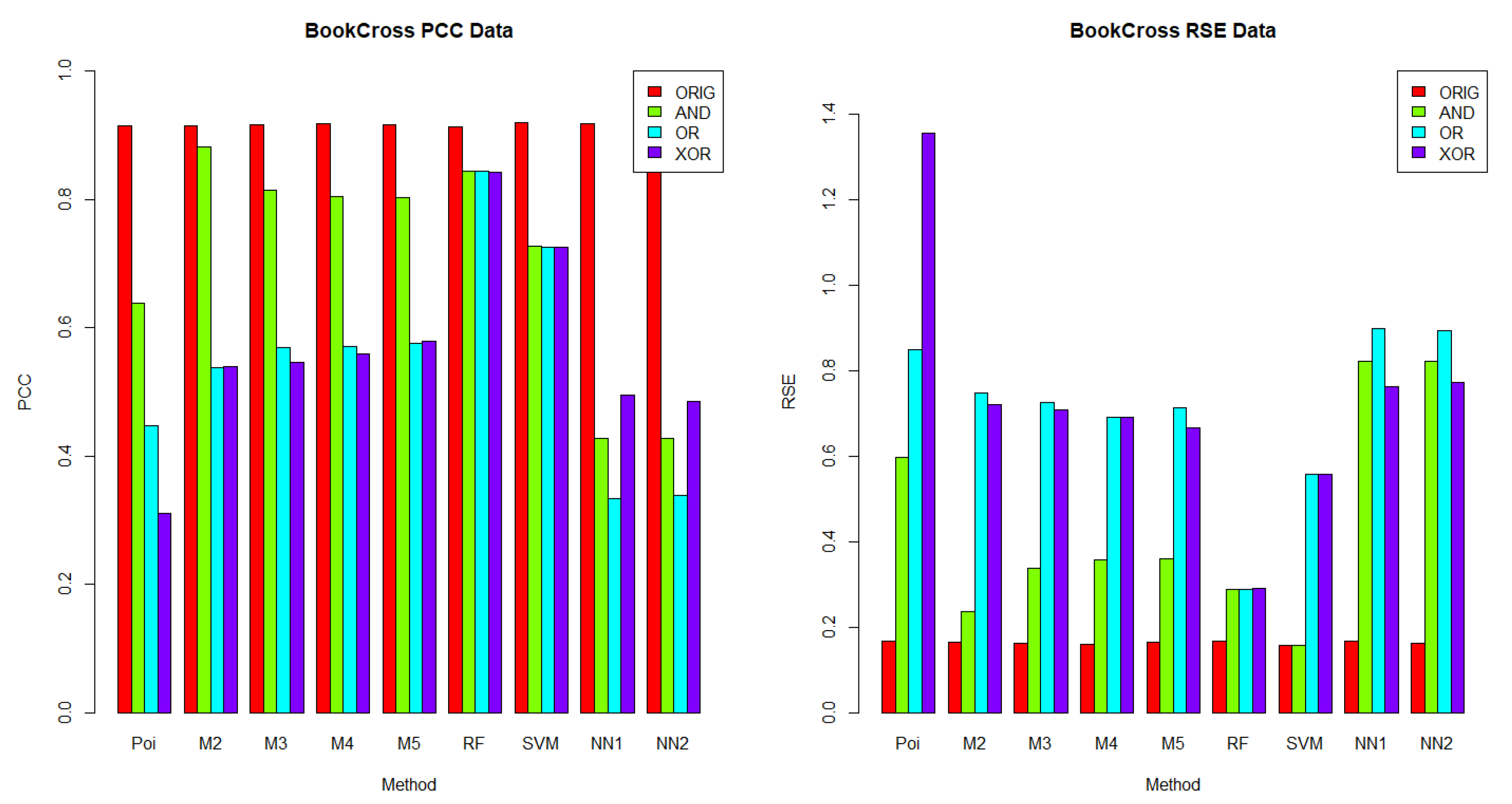
BookCross are displayed in
Figure 2,
Figure 3,
Figure 4 and
Figure 5, respectively, using the PCC and RSE metrics. Furthermore, we analyzed whether there was any dataset in which a method exhibited a better performance across all logical operators. Notably, for each logical operator, we were able to identify the best and worst performing methods across all datasets, with very few exceptions. Moreover, those methods tended to be the same for all logical operators, as we detail below.
In terms of PCC, random forest was the best performing method over the logical groups, outperforming the Poisson regression, the mixture models with two to five components, SVM and neural networks with one and two hidden layers in 99.07% of combinations of logical groups (AND, OR, XOR) and all of the four datasets. For example, for the weights generated using the AND logical operator on the
CompSciFac dataset, the random forest method had a PCC of 0.4922 and an RSE of 0.7633. Meanwhile, for the AND logical operator and dataset
CompSciFac, Poisson regression had a PCC of 0.3138 and RSE of 0.9054, whereas the mixture model methods with two, three, four and five components had a PCC of 0.3175, 0.3300, 0.3278 and 0.3371, and an RSE of 0.9033, 0.8959, 0.8982 and 0.8911, respectively. SVM had a PCC of 0.3742 and an RSE of 1.0005. Neural Networks with one and two hidden layers had a PCC of 0.3562 and 0.3506 and an RSE of 0.8928 and 0.8938, respectively. The only instance where random forest did not outperform the other methods in the logical groups was for
BookCross with the AND logical operator (see
Figure 5), where the mixture model with two components performed best (0.8811 for PCC, 0.2369 for RSE); random forest had a lower PCC of 0.8443 and a higher RSE of 0.2875.
On the other hand, Poisson regression and the neural network with one hidden layer were the worst performing methods on the logical groups in terms of the PCC metric. Poisson regression was outperformed by the mixture model methods with two to five components, random forest, SVM and neural networks with one to two hidden layers in 74.07% of combinations of logical groups (AND, OR, XOR) and all four datasets. For example, for the weights generated using the XOR logical operator on the BookCross dataset, the Poisson regression method had a PCC of 0.3109. Meanwhile, in the same context, for the weights generated by the operator XOR on the BookCross datset, the mixture models with two, three, four and five components had PCC values of 0.5389, 0.5464, 0.5592, and 0.5781, respectively; the random forest method had a PCC of 0.8429; the SVM method had a PCC of 0.7253 and the neural networks with one to two hidden layers had PCC values of 0.4948 and 0.4850, respectively. Additionally, the neural network with one hidden layer method was outperformed by the Poisson regression, the mixture model methods with two to five components, random forest, SVM and the neural networks with two hidden layers in 79.63% of combinations of logical groups (AND, OR, XOR) and datasets. For instance, for the weights generated using the XOR logical operator on the BusFac dataset, the neural network with one hidden layer had a PCC of 0.0208; the Poisson regression method had a PCC of 0.0642; the mixture models with two, three, four and five components had PCC values of 0.0546, 0.0623, 0.0534 and 0.0561, respectively; the random forest method had a PCC of 0.3303; the SVM method a PCC of 0.0331 and the neural network with two hidden layers had a PCC of 0.0243.
When comparing the performance across datasets, each method on the logical groups performed better on the BookCross dataset, which had the highest PCC and lowest RSE in 100% (in terms of PCC) and 99.07% (in terms of RSE) of combinations of methods and weight generation process (with AND, OR and XOR operators). For example, the mixture model method with two components over the weights generated using the AND logical operator had a PCC of 0.8811 and an RSE of 0.2369 on the BookCross dataset. For the same generation process with the AND operator and the mixture model with two components, the predictions on the other datasets had a lower PCC and a higher RSE. For instance, on the BusFac dataset, this combination had a PCC of 0.0527 and an RSE of 1.0041, on CompSciFac a PCC of 0.3175 and an RSE of 0.9033 and, finally, on HistFac a PCC of 0.3091 and an RSE of 0.9154.
In contrast, the prediction accuracy of the synthesized weights was worse on the BusFac dataset than in other datasets in 100% of methods on the logical groups in terms of the PCC metric and in 96.3% of cases in terms of the RSE metric. For example, for the SVM method, the weights generated with the OR logical operator on the BusFac dataset had a PCC of 0.0310 and an RSE of 1.2303. For the same logical operator OR, the predictions of the SVM had a higher PCC and a lower RSE in all the other datasets. On CompSciFac, the combination had a PCC of 0.3734 and an RSE of 0.9995, on HistFac a PCC of 0.1493 and an RSE of 1.2084, and on BookCross a higher PCC of 0.7253 and a lower RSE of 0.5563.
Finally, for the methods and datasets analyzed, we also noted that the best-performing method on the weights generated based on the logical operators on the metadata were different from the ones generated based on the original weights from the empirical datasets. As described above, when the weights were determined using logical operators on the metadata, then random forest performed better in 99.07% of cases. On the other hand, mixture models or random forest may achieve better performance on the unknown real-world generation process, as discussed in
Section 6.2.1.
7.2.2. Comparison between Original and Synthesized Weights
In this section, we analyzed whether the prediction accuracy of the tested methods based on the original weights was higher than that based on each of the sets of synthesized weights generated by logical operators AND, OR and XOR on node metadata, given the same method and dataset.
The results for the
regression-based methods and
comparison methods (defined in
Section 4) with the PCC metric are displayed in
Table 5 and
Table 6, respectively. For each method
X, we display the average PCC for the original, AND, OR and XOR weight generation processes (denoted as
ORIG-X, AND-X, OR-X and
XOR-X, respectively) side by side. The best-performing weight generation processes according to the metric used are indicated in bold, and in gray we indicate the rows for which we rejected the null hypothesis that the means were equal between the original weight generation process and each of the logical operator weight generation processes, with a statistical significance of 5%.
A side-by-side presentation of the results obtained with the RSE metric regarding the
regression-based methods and the
comparison methods is included in the
Appendix A in
Table A1 and
Table A2, respectively, since the results obtained with the RSE metric were mostly consistent with the PCC metric. As with the PCC results, the average RSE for the original, AND, OR and XOR weight generation processes (denoted as
ORIG-X, AND-X, OR-X and
XOR-X, respectively) are presented side-by-side for each method
X.
For both the regression-based methods (
Table 5) and the comparison methods (
Table 6), we concluded that, for each dataset, method and metric, the prediction accuracy based on the original weights was higher than for each of the logical operator groups (for both PCC and RSE metrics). In all cases, we rejected the null hypothesis at a significance level of 5%.
As an illustration, for the Poisson regression method, the prediction accuracy was worse than for the original weights for each of the generation processes with AND, OR and XOR operators, with the latter having lower PCC values. For example, on the
BusFac dataset, the prediction accuracy over the original weights (ORIG) had a PCC of 0.5784. Meanwhile, for the same
BusFac dataset and the Poisson regression method, the AND, OR and XOR weight generation methods had PCC values of 0.0409, 0.0618 and 0.0642, respectively, as shown in
Table 5.
Additionally, for the mixture model with three components on the HistFac dataset, the prediction accuracy over the original weights (ORIG) had a PCC of 0.7252. Meanwhile, the prediction accuracy was worse for each of the other generation processes with AND, OR and XOR operators, with lower PCC values. More specifically, the AND, OR and XOR weight generation methods had lower PCCs of 0.3486, 0.1462 and 0.1435, respectively.
It is evident that the original weight generation process makes it significantly easier to predict weights than the logical operator weight generation processes for the methods and set of features investigated. This might be related to a higher explanatory power of the topological features in the original weight generation process as compared to the processes that are solely dependent on metadata. Even so, it is worth noting that some PCC values in the logical groups indicated a degree of correlation above 0.8. This was true of the BookCross dataset for the AND logical operator group for the mixture model method with two components (0.8811 for PCC, 0.2369 for RSE), for the AND logical operator group for the mixture model with three components (0.8151 for PCC, 0.3376 for RSE), for the AND logical operator group for the mixture model with four components (0.8047 for PCC, 0.3564 for RSE), for the AND logical operator group for the mixture model with five components (0.8031 for PCC, 0.3596 for RSE), for the AND logical operator group for random forest (0.8443 for PCC, 0.2875 for RSE), for the OR logical operator group for random forest (0.8442 for PCC, 0.2878 for RSE) and for the XOR logical operator group for random forest (0.8429 for PCC, 0.2899 for RSE).
7.2.3. Comparison between Weights Generated from Logical Groups
In this section, we compare the prediction accuracy forthe synthesized weights generated based on logical operators, given the same dataset and method. For the
regression-based methods and
comparison methods, we performed a pairwise comparison between the logical operators AND, OR and XOR with respect to the prediction accuracy of each method, as presented in
Table 7 and
Table 8, respectively. For each method
X, we display its average PCC for each pair of logical operator AND, OR and XOR weight generation processes (denoted as
AND-X, OR-X and
XOR-X, respectively) side by side. For each dataset (row), the best-performing logical operator in each pair is indicated in bold, whereas the comparisons for which we rejected the hypothesis that the means were equal with a statistical significance of 5% are highlighted in gray.
As in the previous section, we leave the results regarding the RSE metric for the
Appendix A, which can be found in
Table A3 and
Table A4. For each regression-based method or comparison method
X, these tables display the average RSE for each of the pairs of weight generation processes, as for the PCC metric.
When comparing the performance of the AND and OR logical operators, the weight generation process with the AND logical operator had a significantly higher accuracy (in terms of PCC or RSE) at a significance level of 5% than the weight generation process with the OR logical operator in 61.11% (in terms of PCC and RSE) of all 36 dataset and method combinations, whereas the weight generation with the OR logical operator was significantly easier to predict in 5.56% (in terms of PCC) and 8.33% (in terms of RSE) of all 36 dataset and method combinations. For example, for Poisson regression on BookCross the weights generated using the AND logical operator had a PCC of 0.6381 and an RSE of 0.5977, whereas the weights generated using the OR logical operator had a lower PCC of 0.4476 and a higher RSE of 0.8480. For mixture models with two components on CompSciFac, the weights generated using the AND logical operator had a PCC of 0.3175 and an RSE of 0.9033, whereas the weights generated using the OR logical operator had a lower PCC of 0.2917 and a higher RSE of 0.9181. Moreover, for mixture models with three components on HistFac, the weights generated using the AND logical operator had a PCC of 0.3486 and an RSE of 0.9013, and the weights generated using the OR logical operator had a lower PCC of 0.1462 and a higher RSE of 0.9846.
As for the comparison between the AND and XOR operators, the weight generation process with the AND logical operator had a significantly higher accuracy (in terms of PCC or RSE) at a significance level of 5% than the weight generation process with the XOR logical operator in 47.22% (in terms of PCC) and in 52.78% (in terms of RSE) of combinations between all 36 datasets and methods, whereas the XOR had higher prediction accuracy in in 8.33% (in terms of PCC) and 5.56% (in terms of RSE) of cases. For example, for Poisson regression on BookCross, the weight generation method with the AND logical operator had significantly higher prediction accuracy with a PCC of 0.6381 and an RSE of 0.5977 than the weight generation with the XOR logical operators with a lower PCC of 0.3108 and a higher RSE of 1.3553. Furthermore, for mixture models with two components on HistFac the weights generated using the AND logical operator had a PCC of 0.3091 and an RSE of 0.9154, whereas the weights generated using the XOR logical operator had a lower PCC of 0.1427 and a higher RSE of 0.9853. For mixture models with four components on BookCross the weights generated using the AND logical operator had a PCC of 0.8047 and an RSE of 0.3564 and the weights generated using the XOR logical operator had a lower PCC of 0.5592 and a higher RSE of 0.6903. For mixture models with five components on CompSciFac the weights generated using the AND logical operator had a PCC of 0.3371 and an RSE of 0.8911, and the weights generated using the XOR logical operator had a lower PCC of 0.2819 and a higher RSE of 0.9248.
Finally, when comparing the OR and XOR logical operators, none of the two weight generation process presented higher prediction accuracy for most cases. The OR logical operator had a significantly higher accuracy (in terms of PCC or RSE) at a significance level of 5% than the weight generation process with the XOR logical operator in 11.11% (in terms of PCC) and 5.56% (in terms of RSE) of all three dataset and method combinations, whereas the XOR had significantly higher prediction accuracy in in 11.11% (in terms of PCC) and 22.22% (in terms of RSE) of cases. For example, the weight generation method with the OR logical operator had significantly higher prediction accuracy than the weight generation with the XOR logical operators for mixture model with two components on BusFac, where the prediction of weights generated using the OR logical operator had a PCC of 0.0780 and an RSE of 0.9979 and of the weights generated using the XOR logical operator had a lower PCC of 0.0546 and a higher RSE of 1.0029. On the other hand, for mixture models with five components on HistFac, the weights generated using the XOR logical operator had a PCC of 0.1546 and an RSE of 0.9837, whereas the weights generated using the OR logical operator had a lower PCC of 0.1115 and a higher RSE of 0.9980.
Overall, we noted that the regression-based methods had higher and significant prediction accuracy over the synthesized weights based on the AND logical operator when compared pairwise to the OR and XOR operators, as can be observed from the first two columns in
Table 7. Notably, for all datasets, the neural networks with one and two hidden layers also had significantly higher prediction accuracy for the weights generated by the AND operator in comparison to the OR one, as shown in
Table 8. The same pattern was repeated for the
comparison methods random Forest and SVM but the differences in prediction accuracy were not significant. Given that some of the features used for prediction were based on the metadata similarity of end nodes, the fact that the weights generated by the AND operator were directly related to another measure of similarity between the metadata of the end nodes may have contributed to the better performance of the methods in these cases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




