
Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation




{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- -
- The entropy-argumentative concept (i.e., the mathematical model and methods) of computational phonetic analysis of speech, taking into account dialect and individuality of phonation;
- -
- The entropy-argumentative concept of detection and correction of errors of computational phonetic analysis of speech.
2. Materials and Methods
2.1. Statement of Research
2.2. Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation
2.3. Entropy-Argumentative Concept of Detection and Correction of Errors of Computational Phonetic Analysis of Speech
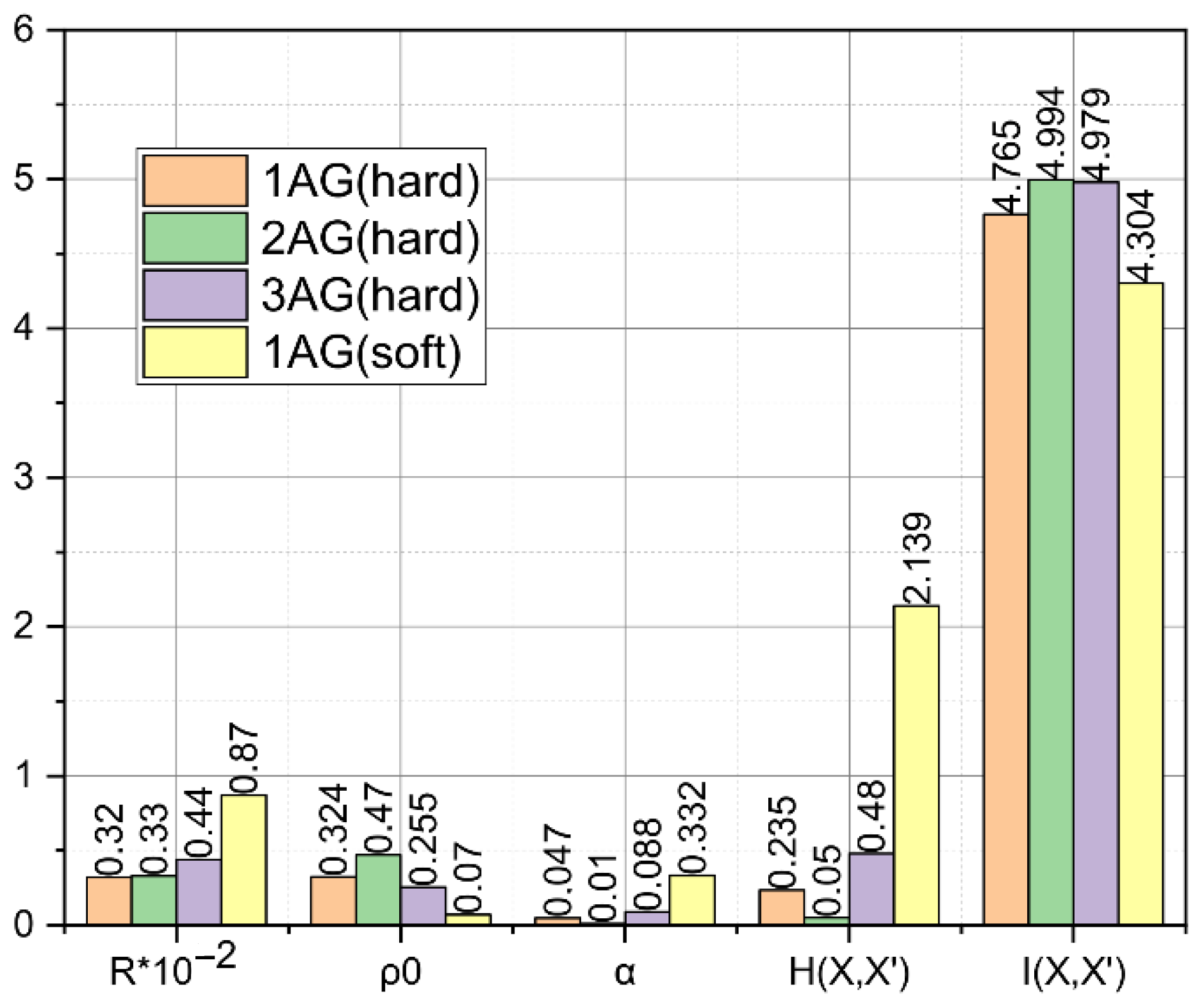
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Almutiri, T.; Nadeem, F. Markov Models Applications in Natural Language Processing: A Survey. Int. J. Inf. Technol. Comput. Sci. 2022, 2, 1–16. [Google Scholar] [CrossRef]
- Bhanja, C.C.; Laskar, M.A.; Laskar, R.H. Modelling multi-level prosody and spectral features using deep neural network for an automatic tonal and non-tonal pre-classification-based Indian language identification system. Lang. Resour. Eval. 2021, 55, 689–730. [Google Scholar] [CrossRef]
- Umasankar, C.D.; Ram, M.S.S. Speech Enhancement through Implementation of Adaptive Noise Canceller Using FHEDS Adaptive Algorithm. Int. J. Image Graph. Signal Process. 2022, 3, 11–22. [Google Scholar] [CrossRef]
- Firooz, S.G.; Reza, S.; Shekofteh, Y. Spoken language recognition using a new conditional cascade method to combine acoustic and phonetic results. Int. J. Speech Technol. 2018, 21, 649–657. [Google Scholar] [CrossRef]
- Sunitha, P.; Prasad, K.S. Speech Enhancement based on Wavelet Thresholding the Multitaper Spectrum Combined with Noise Estimation Algorithm. Int. J. Image Graph. Signal Process. 2019, 11, 44–55. [Google Scholar] [CrossRef]
- Pujar, R.S. Wiener Filter Based Noise Reduction Algorithm with Perceptual Post Filtering for Hearing Aids. Int. J. Image Graph. Signal Process. 2019, 11, 69–81. [Google Scholar] [CrossRef]
- Bender, E.M.; Drellishak, S.; Fokkens, A.; Poulson, L.; Saleem, S. Grammar Customization. Res. Lang. Comput. 2010, 8, 23–72. [Google Scholar] [CrossRef]
- Al-Bakeri, A.A. ASR for Tajweed Rules: Integrated with SelfLearning Environments. Int. J. Inf. Eng. Electron. Bus. 2017, 9, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Moran, S.; Grossman, E.; Verkerk, A. Investigating diachronic trends in phonological inventories using BDPROTO. Lang Resour. Eval. 2020, 55, 79–103. [Google Scholar] [CrossRef] [Green Version]
- Peleshko, D.; Rak, T.; Izonin, I. Image Superresolution via Divergence Matrix and Automatic Detection of Crossover. Int. J. Intell. Syst. Appl. 2016, 8, 1–8. [Google Scholar] [CrossRef]
- Chittaragi, N.B.; Koolagudi, S.G. Automatic dialect identification system for Kannada language using single and ensemble SVM algorithms. Lang. Resour. Eval. 2020, 54, 553–585. [Google Scholar] [CrossRef]
- Izonin, I.; Trostianchyn, A.; Duriagina, Z.; Tkachenko, R.; Tepla, T.; Lotoshynska, N. The Combined Use of the Wiener Polynomial and SVM for Material Classification Task in Medical Implants Production. Int. J. Intell. Syst. Appl. 2018, 10, 40–47. [Google Scholar] [CrossRef] [Green Version]
- Kurimo, M.; Enarvi, S.; Tilk, O.; Varjokallio, M.; Mansikkaniemi, A.; Alumäe, T. Modeling under-resourced languages for speech recognition. Lang. Resour. Eval. 2017, 51, 961–987. [Google Scholar] [CrossRef] [Green Version]
- Masmoudi, A.; Bougares, F.; Ellouze, M.; Estève, Y.; Belguith, L. Automatic speech recognition system for Tunisian dialect. Lang. Resour. Eval. 2018, 52, 249–267. [Google Scholar] [CrossRef]
- Elvira-García, W.; Roseano, P.; Fernández-Planas, A.M.; Martínez-Celdrán, E. A tool for automatic transcription of intonation: Eti_ToBI a ToBI transcriber for Spanish and Catalan. Lang. Resour. Eval. 2016, 50, 767–792. [Google Scholar] [CrossRef]
- Hu, Z.; Mashtalir, S.V.; Tyshchenko, O.K.; Stolbovyi, M.I. Clustering Matrix Sequences Based on the Iterative Dynamic Time Deformation Procedure. Int. J. Intell. Syst. Appl. 2018, 10, 66–73. [Google Scholar] [CrossRef] [Green Version]
- Aissiou, M. A genetic model for acoustic and phonetic decoding of standard arabic vowels in continuous speech. Int. J. Intell. Syst. Appl. 2020, 23, 425–434. [Google Scholar] [CrossRef]
- Hu, Z.; Tereykovski, I.A.; Tereykovska, L.O.; Pogorelov, V.V. Determination of Structural Parameters of Multilayer Perceptron Designed to Estimate Parameters of Technical Systems. Int. J. Intell. Syst. Appl. 2017, 9, 57–62. [Google Scholar] [CrossRef] [Green Version]
- Chittaragi, N.B.; Koolagudi, S.G. Acoustic-phonetic feature based Kannada dialect identification from vowel sounds. Int. J. Speech Technol. 2019, 22, 1099–1113. [Google Scholar] [CrossRef]
- Kleynhans, N.T.; Barnard, E. Efficient data selection for ASR. Lang. Resour. Eval. 2015, 49, 327–353. [Google Scholar] [CrossRef]
- Hu, Z.; Ivashchenko, M.; Lyushenko, L.; Klyushnyk, D. Artificial Neural Network Training Criterion Formulation Using Error Continuous Domain. Int. J. Mod. Educ. Comput. Sci. 2021, 13, 13–22. [Google Scholar] [CrossRef]
- Vinola, F.A.F.; Padma, G. A probabilistic stochastic model for analysis on the epileptic syndrome using speech synthesis and state space representation. Int. J. Speech Technol. 2020, 23, 355–360. [Google Scholar] [CrossRef]
- Mehrabani, M.; Hansen, J.H.L. Automatic analysis of dialect/language sets. Int. J. Speech Technol. 2015, 18, 277–286. [Google Scholar] [CrossRef] [Green Version]
- Rello, L.; Baeza-Yates, R.; Llisterri, J. A resource of errors written in Spanish by people with dyslexia and its linguistic, phonetic and visual analysis. Lang. Resour. Eval. 2016, 51, 379–408. [Google Scholar] [CrossRef]
- Chaki, J. Pattern analysis based acoustic signal processing: A survey of the state-of-art. Int. J. Speech Technol. 2020, 24, 913–955. [Google Scholar] [CrossRef]
- Bhangale, K.B.; Mohanaprasad, K. A review on speech processing using machine learning paradigm. Int. J. Speech Technol. 2021, 24, 367–388. [Google Scholar] [CrossRef]
- Verma, P.; Das, P.K. i-Vectors in speech processing applications: A survey. Int. J. Speech Technol. 2015, 18, 529–546. [Google Scholar] [CrossRef]
- Drugman, T.; Dutoit, T. The Deterministic Plus Stochastic Model of the Residual Signal and Its Applications. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 968–981. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Bao, C. Phoneme-Unit-Specific Time-Delay Neural Network for Speaker Verification. IEEE ACM Trans. Audio Speech Lang. Process. 2021, 29, 1243–1255. [Google Scholar] [CrossRef]
- Hu, Z.; Tereikovskyi, I.; Chernyshev, D.; Tereikovska, L.; Tereikovskyi, O.; Wang, D. Procedure for Processing Biometric Parameters Based on Wavelet Transformations. Int. J. Mod. Educ. Comput. Sci. 2021, 13, 11–22. [Google Scholar] [CrossRef]
- Omer, A.I.; Zampieri, M.; Oakes, M.M. Phonetic differences for dialect clustering. In Proceedings of the 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 145–150. [Google Scholar] [CrossRef]
- Viacheslav, K.; Kovtun, O. System of methods of automated cognitive linguistic analysis of speech signals with noise. Multimedia Tools Appl. 2022, 1–20. [Google Scholar] [CrossRef]
- Bisikalo, O.; Boivan, O.; Kovtun, O.; Kovtun, V. Research of the Influence of Phonation Variability on The Result of the Process of Recognition of Language Units. CEUR Workshop Proc. 2022, 3156, 82–93. [Google Scholar]
- Kannadaguli, P.; Bhat, V. A comparison of Bayesian multivariate modeling and hidden Markov modeling (HMM) based approaches for automatic phoneme recognition in kannada. Recent Emerg. Trends Comput. Comput. Sci. 2015, 1–5. [Google Scholar] [CrossRef]
- Laleye, F.A.A.; Ezin, E.C.; Motamed, C. Automatic Text-Independent Syllable Segmentation Using Singularity Exponents And Rényi Entropy. J. Signal Process. Syst. 2016, 88, 439–451. [Google Scholar] [CrossRef]
- Kang, J.; Zhang, W.-Q.; Liu, W.-W.; Liu, J.; Johnson, M.T. Lattice Based Transcription Loss for End-to-End Speech Recognition. J. Signal Process. Syst. 2017, 90, 1013–1023. [Google Scholar] [CrossRef]
- Qian, Y.; Ubale, R.; Lange, P.; Evanini, K.; Ramanarayanan, V.; Soong, F.K. Spoken Language Understanding of Human-Machine Conversations for Language Learning Applications. J. Signal Process. Syst. 2019, 92, 805–817. [Google Scholar] [CrossRef]
- Cui, Y.; Sirén, J.; Koski, T.; Corander, J. Simultaneous Predictive Gaussian Classifiers. J. Classif. 2016, 33, 73–102. [Google Scholar] [CrossRef]
- Bisikalo, O.; Boivan, O.; Khairova, N.; Kovtun, O.; Kovtun, V. Precision Automated Phonetic Analysis of Speech Signals for Information Technology of Text-dependent Authentication of a Person by Voice. CEUR Workshop Proc. 2021, 2853, 276–288. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovtun, V.; Kovtun, O.; Semenov, A. Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation. Entropy 2022, 24, 1006. https://doi.org/10.3390/e24071006
Kovtun V, Kovtun O, Semenov A. Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation. Entropy. 2022; 24(7):1006. https://doi.org/10.3390/e24071006
Chicago/Turabian StyleKovtun, Viacheslav, Oksana Kovtun, and Andriy Semenov. 2022. "Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation" Entropy 24, no. 7: 1006. https://doi.org/10.3390/e24071006
APA StyleKovtun, V., Kovtun, O., & Semenov, A. (2022). Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation. Entropy, 24(7), 1006. https://doi.org/10.3390/e24071006