1. Introduction
The concept of memory is ubiquitous both in everyday conversations and in scientific investigations. Our identities, personal, familial, and national, are molded from memories rooted in interpersonal interactions, top-down discourses (e.g., if a nation decides to celebrate one political holiday but not another), and self-reflection. In terms of cultural objects, their popularity at the time when they are made public and in the following years can be seen as a proxy to gauge long-term permanence in collective memory. Thus, one could assume that if a new cultural object was met with a significant and positive reception, it is plausible that such an object will remain longer in collective memory.
This work is dedicated to investigating video game popularity via lognormal distributions and their deformations by Box–Cox transformations. This study is inserted in the broad context of collective and, more specifically, cultural memory. The latter can be characterized, as completed by Assmann [
1], as “[…] a form of collective memory in that a number of people share cultural memory and in that it conveys to them a collective (i.e., cultural) identity”. Usually, studies on memory and forgetting of products analyze data stemming from the consumption of books, movies, etc. [
2]. This work presents two novelties in this debate. The first is the focus on the popularity of video games over time as indicative of their permanence in collective memory. Multiplicative processes (lognormal distributions) are associated with a memoryless player distribution and deformations of such processes (Box–Cox transformations) with memory effects. The main metrics employed here to quantify how popular video games are is the average number of players of each game per month from July 2012 to December 2020. Other metrics employed as well are the release date and categories of each video game.
The second novelty is associated with the choice of memory studies as a framework for interpreting our quantitative model. While memory studies were already employed in the investigation of the forgetting process for cultural objects [
3], this article is the first, to the best of our knowledge, in the context of video game popularity. A valid consideration is in regard to the time frame studied, since cultural memory is usually concerned with intergenerational continuity and longer time intervals. However, in this digital age, new cultural trends are created, appropriated, resignified, and discarded in an almost continuous manner, processes influenced by interpersonal interactions, social networks, and the presence (even pervasiveness) of online advertisement. Thus, in an ever-accelerating society, it seems plausible to discuss cultural objects and memories over shorter time frames and this discussion becomes more relevant in a cultural context dominated by younger people [
4,
5].
At this point, an objection may be raised: why study video game popularity? To respond to this objection, it should be noted that the socioeconomic role of digital games has been growing, which is reflected in the increased scientific interest from diverse research areas such as education/training [
6,
7,
8,
9,
10,
11], computer/network science [
12,
13,
14,
15,
16], psychology [
17,
18,
19], and human health/neurology [
20,
21,
22,
23]. Of particular interest for the present work, it is worth mentioning that studies are investigating the popularity of video game categories [
24,
25] and which factors are responsible for keeping players invested in this hobby, the main ones being online play with friends (social factor), intrinsic fun of the game (immersive factor), and achievements (individual factor) [
26,
27,
28,
29]. In addition to the increased scientific interest, video games have a value of their own as a cultural object since, unlike most other objects, they are an interactive media, which means that the players are active contributors to the overall experience. In other words, only by understanding user preferences can one fully comprehend video games as cultural phenomena.
The article starts with a data analysis to better understand the dataset, where the growth of the players and games over time was characterized. A model for the relative popularity of video games is proposed, with the simplistic assumption of no prior knowledge of the video game before its release. Afterward, a model that refines this initial assumption is advanced, one that depends on the Box–Cox transformation. Given the natural classification of video games into categories and the existent interest in the literature, the investigation proceeds to consider the relative popularity in the most popular categories using the same models, with the underlying assumption that a model that accurately describes the global layer will be able to reasonably describe its parts. Finally, this work examines the temporal evolution of the number of distinct categories and the probability distribution of all categories according to the number of games in each of them. This examination was guided by the two conjectures. The first is that, while a new video game may grow and decline in popularity over months, it is reasonable to assume that categories are more resilient since they represent the preferences and sensibilities of a fraction of the population. The second is whether the more popular categories are the ones with more options to choose from, i.e., the ones with more games.
From the above discussion, the following conjectures will be explored and investigated in this work:
The number of video games and of players are growing either linearly or exponentially over time;
The relative popularity among games is described by a distribution that resembles the lognormal one, a hypothesis which was driven by the fact that this distribution has been employed and studied in the context of econophysics [
30], quantitative linguistics [
31], and in the popularity analysis of other cultural products, such as patent citation, scientific citation, Wikipedia entries, and memes in social networks [
32,
33,
34,
35];
The distributions are stable over time;
The popularity distributions for the major categories will be similar to each other and to the global one;
The number of categories will grow more slowly compared to the number of games and players.
2. Materials and Methods
In our investigation about video game popularity, we employed data from a digital platform,
Steam. This platform is a digital media distribution developed by Valve Corporation and an online game store responsible for managing the copyrights of the games in its database [
36].
Steam currently has more than ninety million users [
37], reaching more than twenty million users simultaneously online [
38]. Unfortunately, due to user anonymity, we cannot determine users’ countries and, therefore, we are unable to provide player population by country. Nevertheless, the data is a representative sample of the global player population because network usage data by country is made available and one can see that there is network usage in all five continents, with China and the United States having the largest shares. It should also be noted that
Steam was already the largest digital distribution platform for PC gaming in 2013 [
39] in terms of users. Today, in
Steam, there are more than fifty thousand video games [
40].
Regarding user data, they are anonymous and unidentifiable. For example, we do not know who is playing, we only have information on how many users are playing each game in each hour. Eventually, the same user can play more than one game at a time. For example, if a user is playing two games simultaneously, he or she will be counted as a separate user in each of the two games. From the number of users per game per hour, one can obtain derived data such as the average number of users per hour in each month, as presented in the
steamcharts website [
41]. Because our analysis is limited to games indexed in
steamcharts, we considered approximately twenty-two thousand games. Since the
Steam data used here are not reported by the users, a reduction in subjective aspects of the analysis can be expected. Another type of data employed in our analysis is the meta information of each game (its release date, categories, etc.) on
Steam [
36]. From these data, we obtained the number of games released each month and the number of distinct games per category over time.
All data described above correspond to the period from July 2012 to December 2020, where games released prior to 2012 and games without time series were excluded. For user data per game per hour,
Steam freely provides only from the current hour. Therefore, for creating a larger database, there needs to be a systematic accumulation of data over a given period. Although the
Steam platform started in September 2003, this data storage process has only been freely made available by
steamcharts from 2012 to the present day, justifying the starting date for the data used in our study. In turn, the data were downloaded and analyzed using Python scripts and the
Steam API. These data are provided in .csv format as a dataset and can also be obtained in
https://gitlab.com/tdfb/steam-data-2020/ (accessed on 16 June 2022). We note that the data collection method complied with the terms and conditions of the website. In addition, the sharing of the data also complies with the terms and conditions. To summarize, an outline of the data employed in this work is given in
Table 1, where
is the sum of the average concurrent players for all games and all months, while
is the same sum but only for games in the largest category,
Indie.
3. Results
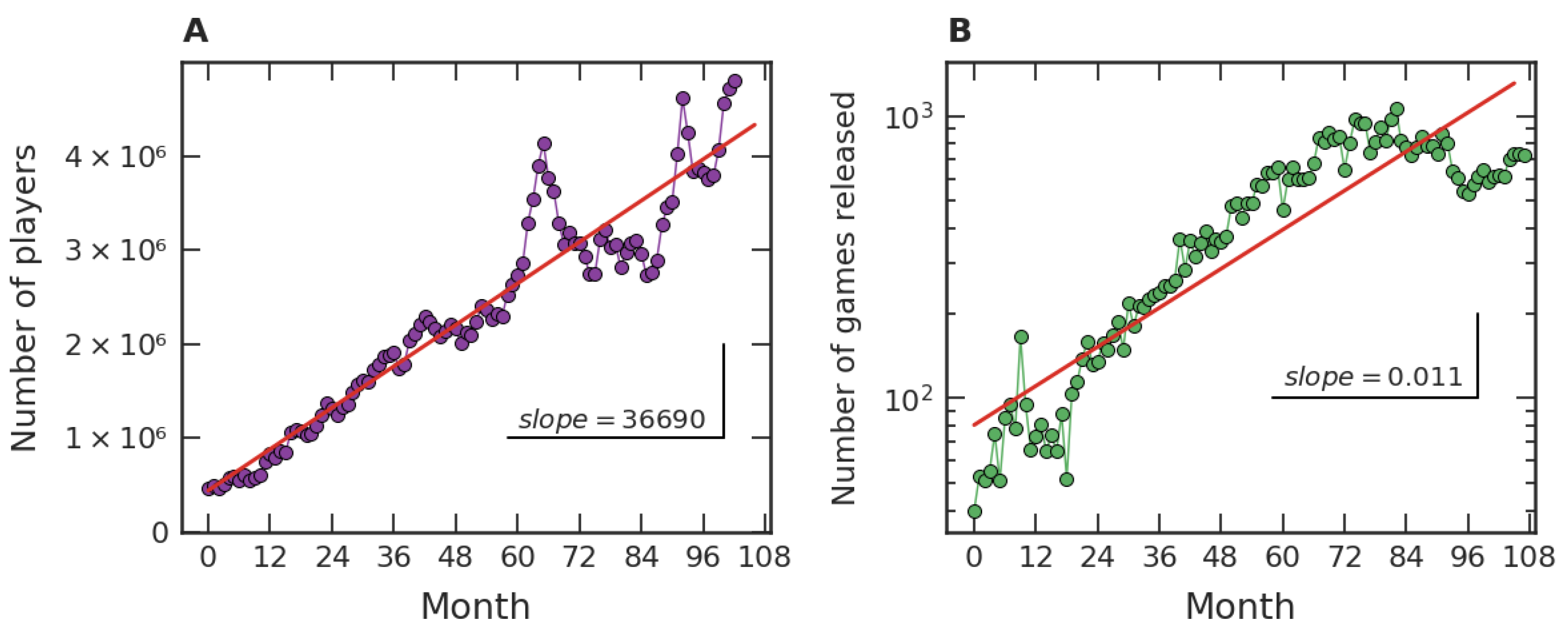
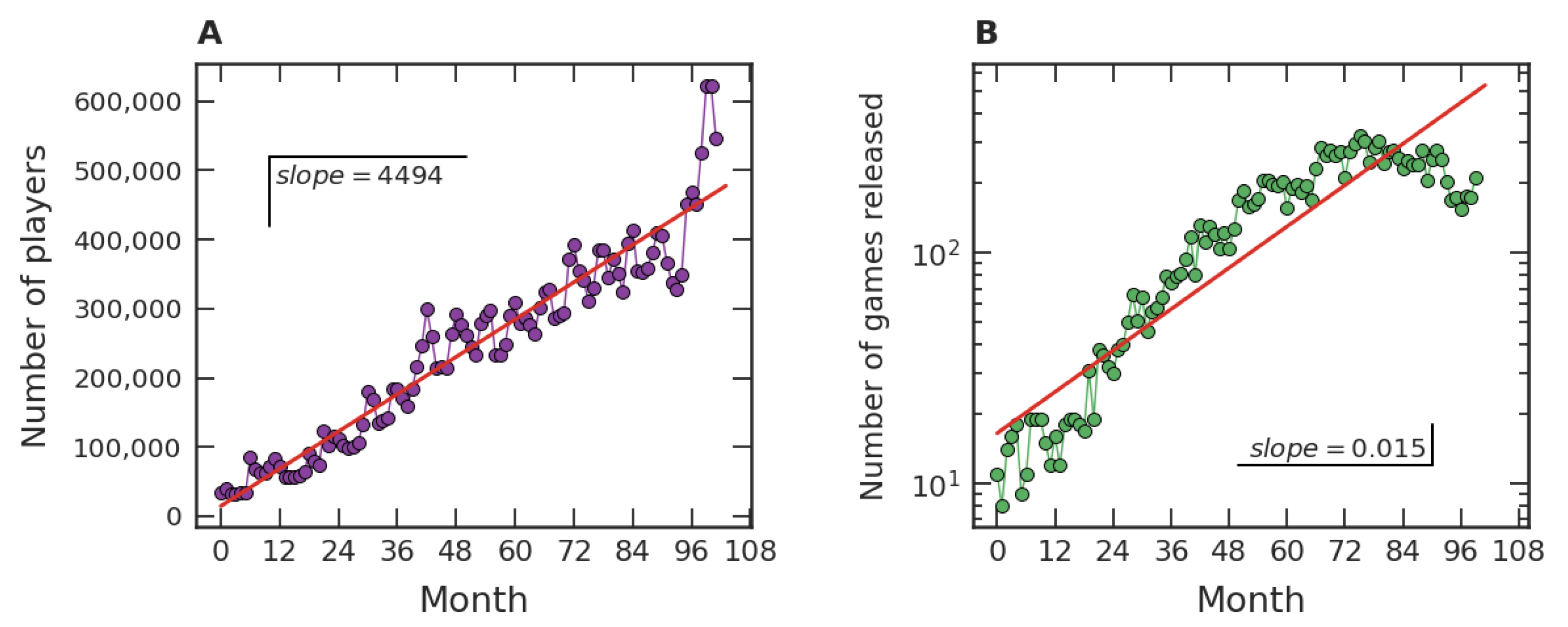
Our investigation on the popularity of video games initially focused on fairly general features of the dataset, which are exhibited in
Figure 1.
Figure 1A represents the time evolution of the average number of players per hour in each month in
Steam. In an hour of December 2019, for instance, a few million users connected to
Steam were in-game.
Figure 1B presents the number of games released monthly in
Steam, e.g., seven hundred and twenty-seven games were released in our dataset in December 2020. The data range from July 2012 to December 2020 and are organized in such a way that the first month (Month 1) represents July 2012, the second month (Month 2) represents August 2012, and so on. From
Figure 1A we can note a mean linear growth tendency, with a growth rate of approximately thirty-seven thousand players per hour per month. On the other hand,
Figure 1B shows a crude exponential growth trend of the games released on
Steam, with an intrinsic growth rate close to
/month.
One way of further investigating video game popularity is made possible by dividing the data by release trimester (e.g., games released in January, February, or March of the same year would belong to one set). This data collation criterion coincides with the game releases by seasons. These sampling periods also correspond with quarterly reports to investors and shareholders. If we had chosen a monthly grouping window, we would have few games per window, especially in the first months of our database. For each trimester dataset, we analyzed the temporal evolution of popularity aspects in the subsequent months.
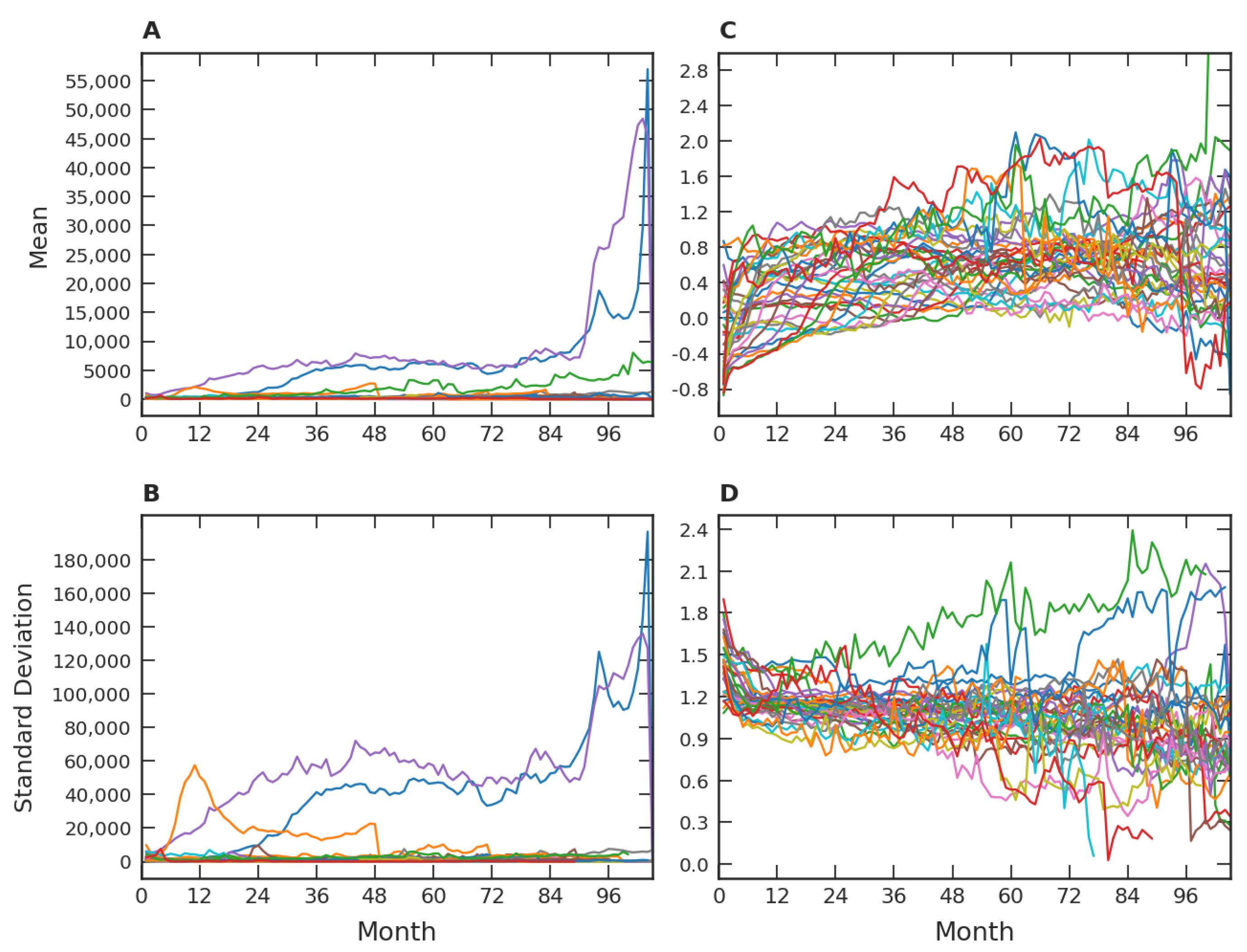
Figure 2A,B show the time evolution of the means and standard deviations, where each color corresponds to a distinct trimester grouping. We used month one as the first month of each group and, consequently, the most recently launched sets of games have shorter time series, with the smallest series having two months. Due to outliers, the average behavior of different groups vary wildly in all ranges, clearly exemplified by the three upper curves in
Figure 1A. A similar pattern is also observed with the standard deviation, only on a different scale. Note that the presence of such outliers makes it difficult to identify a general pattern in a limited range for all means and standard deviations.
A procedure that can favor the identification of a universal pattern related to
Figure 2A,B come from attenuating the effects caused by outliers. In this direction, we will employ a new variable that smoothes outlier contributions. It is defined by:
where
represents the average number of players by the hour in each month in the
i-th game and log refers to the logarithm in base
e. Using this new variable, we in fact verified an improvement in the temporal behavior of the means and the standard deviations, in the sense of revealing a more constant behavior after the first months after the game’s release. This fact is illustrated in
Figure 2C,D.
To go beyond means and standard deviations, we move our study in the direction of probability distributions. This approach enables us to investigate relative popularity among video games, since the relative frequency of occurrences of video games with a different number of players can be put in evidence. With this goal in mind, we firstly determined probability density functions (PDFs) of
. Note that, due to the approximate constancy of each mean and standard deviation previously discussed, PDFs that trend towards stability are expected. Pursuing the investigation of these PDFs, we grouped the games in trimesters by their release date, as employed in the discussion of means and standard deviations. To conduct an exploratory analysis of the data, we initially chose to investigate one of these release date trimesters separately. The group randomly chosen from the thirty-four trimesters in our database was the one with games released in the first trimester of 2015
. Motivated by the approximate constancy of means and standard deviations (
Figure 2C,D), we grouped the monthly average of players per game per hour in each subsequent quarter until December 2020, giving 24 quarters of time evolution. Since there are 420 games in the
trimester, the quantity of
considered is 420 × 24 (=10,080).
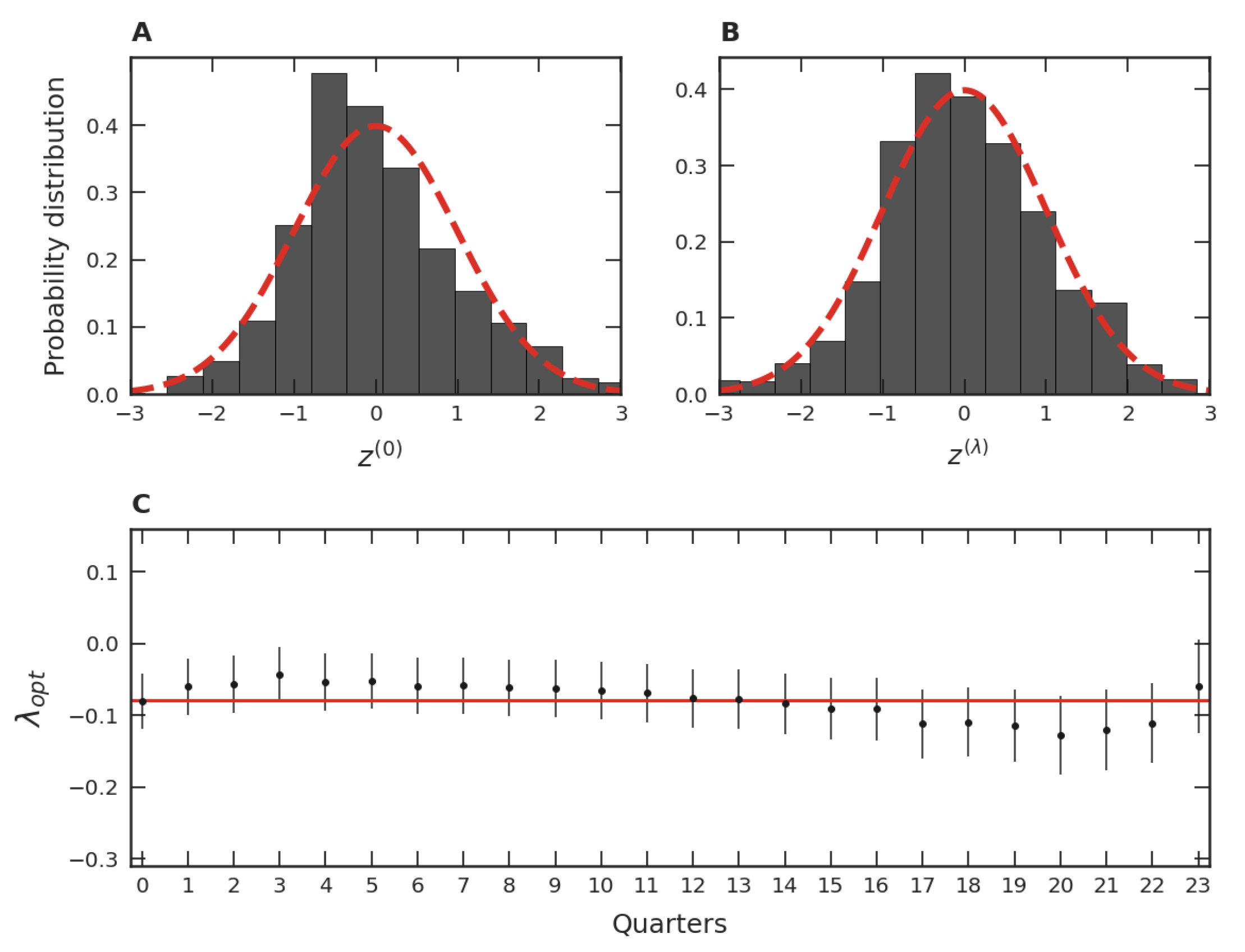
Figure 3A shows the PDF of these 10,080 data, where we used the normalized variable
z, that is,
with
and
being respectively the mean and standard deviation of the quarterly set of
’s. As we can see from this figure, the PDF is somewhat left-skewed. Proceeding similarly, we verified that this slightly asymmetrical pattern occurs in the other remaining thirty-three release date trimesters of our database.
As can be seen, the graph of the data in
Figure 3A resembles a Gaussian in the variable
z, that is, a lognormal distribution in the variable
x. Despite this similarity, the slight asymmetry of the data distribution, when compared to the normal one of mean zero and unit standard deviation, suggests a necessity of a more fine-grained variable transformation than the logarithm. In cases like this, the Box–Cox transformation is usually employed [
42,
43,
44,
45,
46]:
where, at the limit
, the logarithmic behavior is recovered and the value of the parameter
indicates the degree of deviation from this behavior.
A standard procedure to arrive at an optimal
is the maximum likelihood method [
47]. The result of this procedure, applied to the same data of
Figure 3A, can be seen in
Figure 3B. In this figure, we utilized the normalized variable:
where
is the mean value
of the more than ten thousand
’s and
is the corresponding standard deviation
. It is noticeable that the degree of symmetry of the data distribution in
Figure 3B is greater than that in
Figure 3A. This gain in symmetry was verified for all the thirty-four quarterly groups of our database. Note also that, in terms of the original variable and employing the Box–Cox transformation, the popularity distribution is given by:
where
and
is replaced by
when
, reducing
to a lognormal distribution.
Despite our grouping of the twenty-four quarters of the time evolution for the
trimester data, it should be noted that we can apply the Box–Cox transformation separately for each of these quarters. The results of these applications are PDFs comparable to the one presented in
Figure 3B. In addition, the optimal
for each one of these PDFs is close to the
considered in
Figure 3B, as presented in
Figure 3C. Similar results were verified for each optimal
value of the other thirty-three trimesters of our data. These results indicate that the PDFs of each one of the thirty-four trimester groups are both stable and similar to each other over time, justifying the use of the grouping process employed in
Figure 3A,B.
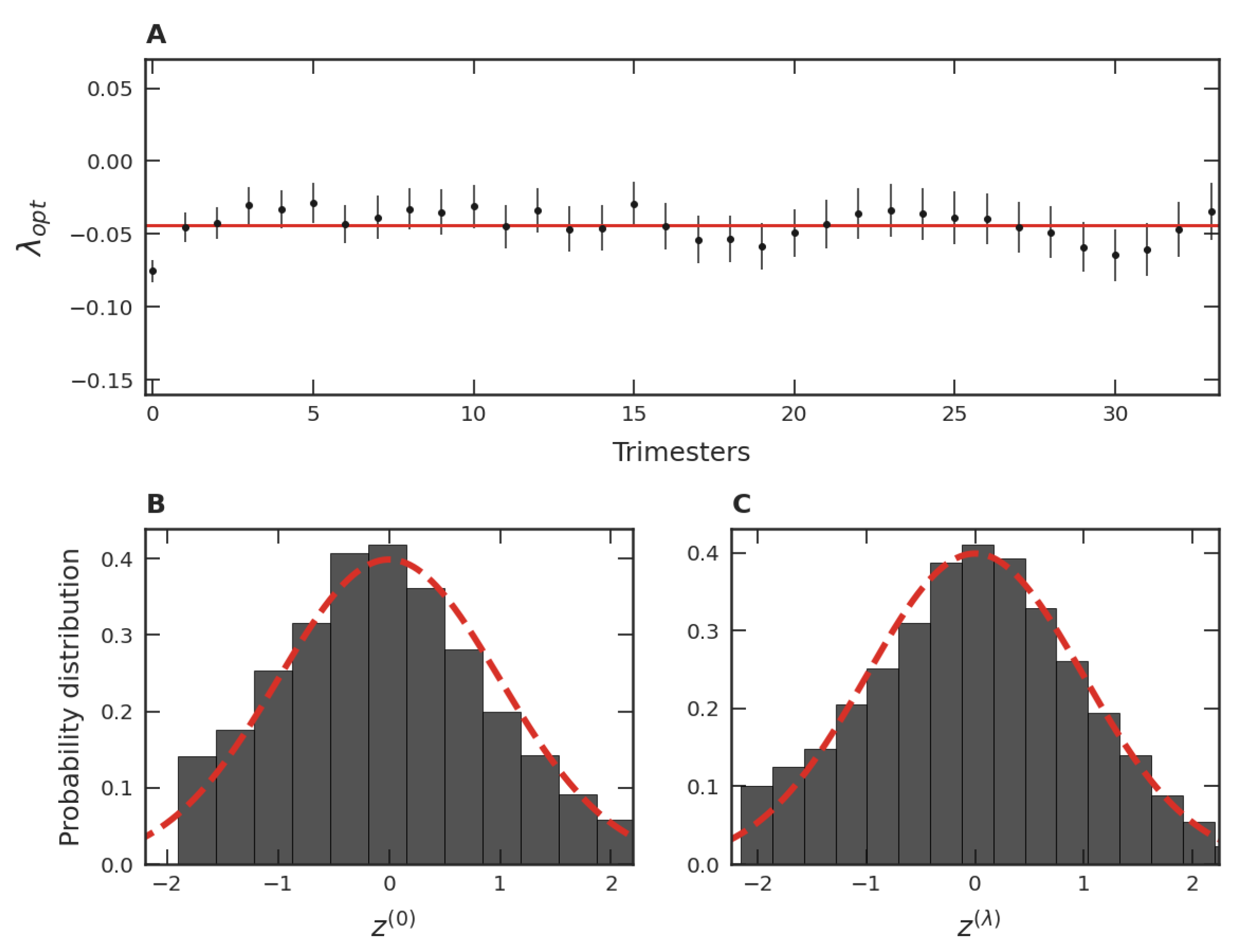
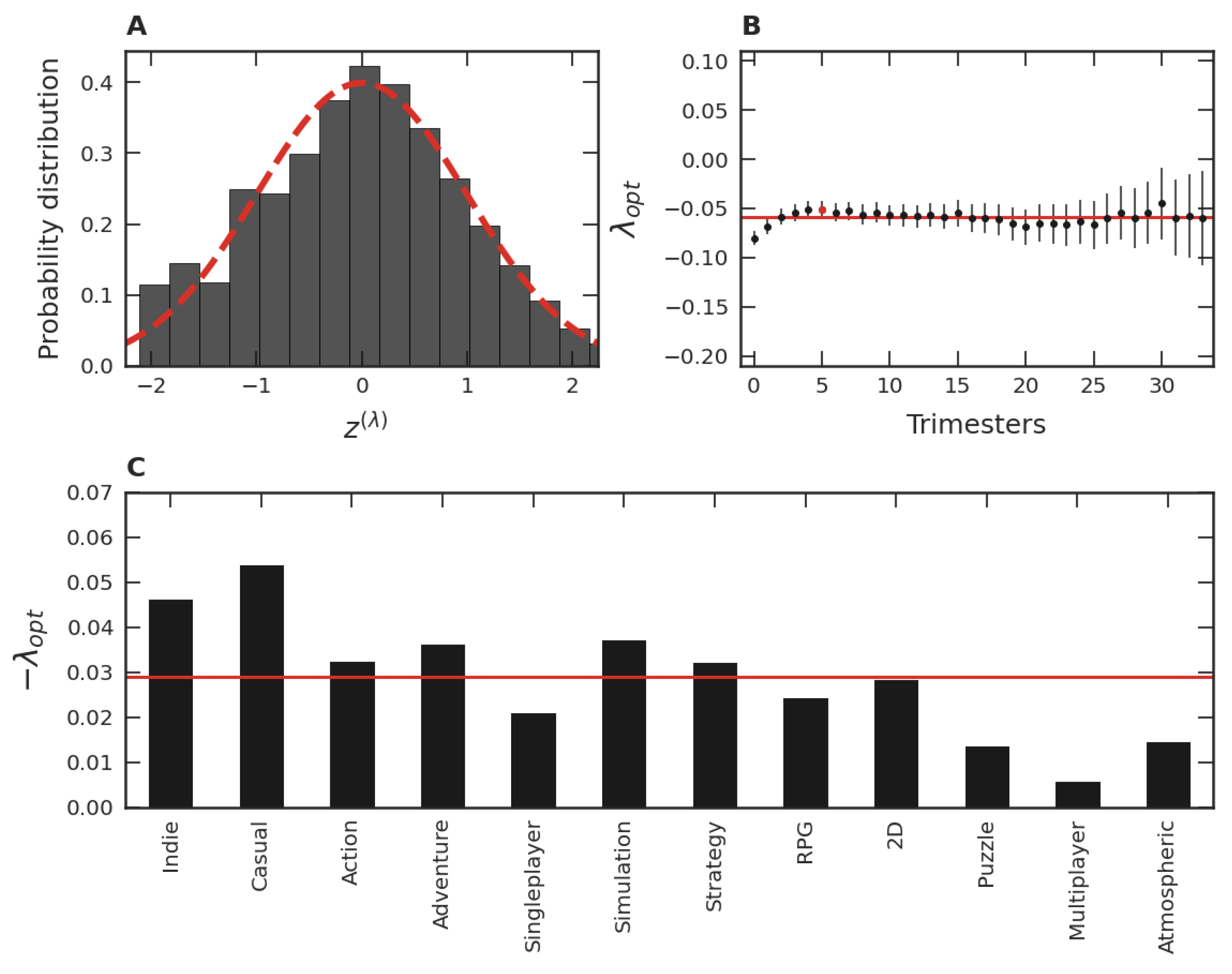
When a procedure analogous to that discussed in connection to
Figure 3B is applied to each one of the thirty-four trimester groups, a mean
,
, is obtained. These values of
are shown in
Figure 4A. Among all
’s, the smallest
is
, the largest is
, and the mean is
. These facts point to a similarity of the PDFs of the trimester data normalized via the transformation given in Equation (
4). This robustness also suggests investigating the behavior of all standardized trimester data as a unique data set via a single PDF. In this case,
Figure 4B illustrates how the distribution in terms of the variable
would be. Note that the slight asymmetry of this data distribution is consistent with that of the dataset presented in
Figure 3A. In turn, when the variable
with the maximum likelihood is employed, we obtain the optimal global parameter equal to
. Note that this value is close to the behavior of the different
’s shown as dots in
Figure 4A and also close to the mean value of all
’s, shown as the continuous line. From
Figure 4B,C, we also verify that the similarity with the Gaussian is accentuated when
is used instead of
, just as it was for the data used in
Figure 3A,B. These facts point to a unifying standard PDF of the normalized variable, including all thirty-four trimesters as well as their time evolution.
Another way of focusing on the popularity of video games involves comparing games with others of the same category (also called
tag in
Steam). The category of a video game is indicated by developers or users. In our analysis, we use the user-defined categories (decided by popular vote) as the classification of a game. The twelve categories with the largest number of games are
Indie (15,348), Casual (9201), Action (8705), Adventure (8601), Single Player (6835), Simulation (5514), Strategy (5063), RPG (4027), 2D (3451), Puzzle (2753), Atmospheric (2479), and Early Access (2351), in which the numbers in parentheses indicate the number of games as of December 2020. Note that there is overlap between the categories, e.g., a game could belong to both the
Indie and to the Puzzle category. In
Figure 5A, the time evolution of the average number of players per hour in each month from July 2012 to December 2020 of the largest category,
Indie, is shown. As can be seen, there is a mean linear growth trend similar to the one identified in the general case shown in
Figure 1A. Linear growth trends over time of the average number of players per hour have also been verified for the majority of the twelve largest categories. Other categories, which have less than 150 games, show many statistical fluctuations in their temporal evolution, making it difficult in most cases to identify a pattern. On the other hand, as in the general case (
Figure 1B), the number of games released monthly exhibits an approximate exponential growth trend (at least for the intermediate months) for most of the twelve major categories of games. This behavior is illustrated for the
Indie case in
Figure 5B. For each of the other categories of games, the number of games released per month is smaller and the possible identification of an exponential behavior becomes less clear.
Continuing with the analysis of the popularity of categorized video games,
Figure 6A is analogous to
Figure 4C (all quarters of all trimester groups together) focusing on the distribution of the number of users for
Indie video games. In this case, one has a Box–Cox transformation with
. This value is consistent with the
obtained for each quarterly data of the
Indie category, shown in
Figure 6B (the analogous of
Figure 4A). Similar behaviors to those shown in
Figure 6A,B were also obtained for the other eleven major categories of games, whose
’s are presented in
Figure 6C. In turn, the mean of these twelve average values of
is equal to
, a result close to the global mean shown in
Figure 4B. The calculation of these optimal
’s for the remaining categories is also close to
in most cases, even though the number of games involved in each category is small.
As the last stratum of our analysis, we examine further aspects of the popularity of video game categories. The first concern considered was the growth of the number of distinct video game categories over time. As shown in
Figure 7A, we identified a linear growth trend, whose increase rate is approximately 8 categories/month. In turn, the approach to investigate the relative popularity among categories is similar to the one of
Figure 6A,B. In this investigation, we focus on the relative popularity distribution of categories as a function of their number of video games. By using an optimal Box–Cox transformation, this distribution in December 2020 is displayed in
Figure 7B. In December 2020 there were 1044 categories, encompassing 21,752 games. Despite having many categories with only one game, we did not consider them. This is because the naming of the pertinent category can be quite uncertain since there is a very limited number of votes for these categories, which leads to statistical uncertainties. As we can see from
Figure 7B, the Box–Cox transformed data can be adjusted by a normal distribution of mean zero and unity standard deviation, but in a less precise manner than in our previous studies (
Figure 3B,
Figure 4C and
Figure 6A). However, the optimal
,
, is close to the ones previously found, indicating a unified view for our study of the popularity of video games. This result is reinforced by the stability of
time evolution in recent years, shown in
Figure 7C. In the early years of our database, there were both few categories and few games, worsening the adjustment of the data by a Box–Cox distribution and leading to an unclear
value, evidenced by wider confidence intervals. As in previous analyses, since
is close to zero, the data as in
Figure 7B can be represented by a lognormal distribution in a first approximation.
To summarize our quantitative results about the comparative popularity of video games, we present in
Table 2 typical values of optimal
as well as the corresponding Box–Cox transformed mean (
), standard deviation (
), skewness (
), and kurtosis (
) for the popularity distribution of video games both globally and per-category. If the PDF, considering a convenient variable transformation, was Gaussian, it would be symmetric in relation to
,
, and there would be a balance between the distribution tail and its peak,
[
48]. Therefore, deviations from these values indicate discrepancies from normality. For instance, if a logarithmic variable (
) is used and if
and
are close to zero, these values of
and
indicate, in a first approximation, that the data can be seen as lognormally distributed (usually, this approximation could be improved by employing an optimal
). In terms of the original variables, the optimized popularity distribution for each stratum presented in
Table 2 is obtained using the corresponding values for
,
, and
in the Equation (
5).
4. Discussion
Our empirical results about the popularity of video games, based on one of the major gaming platforms (
Steam), suggest a robust scenario. Firstly, our studies are consistent with the notion of a crescent number of video game players around the world, as well as with an increase in video games released over time. Quantitatively, the average number of players per hour along the months approximately displays a linear growth, which is manifested both from a global point of view (
Figure 1A) and from the perspective of game categories (
Figure 5A), especially for the major ones. For the number of distinct categories, a pattern of growth similar to the ones presented in
Figure 1B and
Figure 5B was also verified in
Figure 7A. As for the evolution of the number of released games, an approximately exponential growth trend was identified at the global level (
Figure 1B). This behavior of linear (arithmetic) resource growth and exponential (geometric) demand has already been well explored by Malthus [
49]. Indeed, players will occupy the role of resources and games and the role of demand in the Malthusian view if we interpret games as competing with each other for players’ attention. In this case, the exponential increase drastically dominates the linear one in the long term. In addition to
Figure 1A,B, a Malthusian pattern of growth is also present when analyzing the data in categories (
Figure 5A,B), but less robust. These studies point to common patterns of growth in the three levels under investigation: global data, major categories, and among categories. The Malthusian behavior is common in population dynamics in biological [
50] and social [
51] systems when there are no limitations, typically occurring in the early stages. On the other hand, restrictions to this initial growth regime commonly manifest over time, indicating some kind of population saturation [
52].
Another aspect investigated in this work was the relative popularity of the games, in this case, made through probability distributions. In our results, we conducted the lognormal distribution by considering the stability of log-transformed means and standard deviations (
Figure 2). However, for the purposes of this discussion, we emphasize another viewpoint. In this direction and from a qualitative perspective, one could consider that each video game release fragments (partitions) of the player base in a given proportion. In turn, successive releases lead to subsequent fragmentation (partition) of the player base. The simplest hypothesis is that the games are unknown to the players at the time of their release and, as a consequence, one could assume in a first approximation that these successive fragmentations occur entirely at random and independently of each other, that is, this multiplicative process occurs in a memoryless manner. This simple hypothesis is an essential condition for obtaining the lognormal distribution [
53]. An important result of this study was to detect similar approximate lognormal patterns across three different strata. Despite the apparent simplicity of the memoryless (randomness) hypothesis, the lognormal distribution has been successfully employed in the most diverse contexts, such as in the investigation of news and memes [
35,
54], proportional elections [
55], or in the network analysis of seed dispersion [
45].
As discussed above, we found that the lognormal distribution is a first approximation of the empirical distribution. Deviations from this distribution are related to the violation of the simple hypothesis; that is, some factors we assume to drive the lognormal distribution are not fully true. It is unreasonable to assume that games are completely unknown to players at the time of their release, or that ignorance remains over time. For instance, each game has its defining characteristics, its peculiarities, its target audience, and its business model. Moreover, there exists some cultural memory due to advertisements and well-established game franchises. Communicative memory between players, such as social networks, anticipation for a game’s release, and the accumulation of fame, also change the perception of games. Since all these factors disturb the memoryless (randomness) hypothesis, they can contribute to explaining the asymmetry shown by
Figure 3A and
Figure 4B. Quantitatively, the
parameter provides a measure of the departure from the initial hypothesis. Thus, we interpret the magnitude of
as a measure of the presence of cultural and communicative memories in the distribution of popularity, where
corresponds to the memoryless hypothesis. This finding is consistent over time (
Figure 3C), across different game groups (
Figure 4A), and in the game categories (
Figure 6B). Despite small variations around the average (showing that the popularity of some games is more affected by memories than others), the effect of memories is present in all strata investigated.
Some particularities of the game categories can be concretely related to cultural and communicative memories. As
Figure 6C shows, some categories have the
magnitude notably larger than others. Particularly, the popularity of the
Indie and Casual categories are most affected by memories. An explanation consistent with our interpretation is that this is due to the business model adopted by the developers of these game categories. For instance,
Indie games are considered independent, relatively small productions in the gaming market. Frequently, these games are unknown to the public, and the goal of these small developers is to sell as many games as possible at a fair price. In this way, the games that survive and achieve success are through word of mouth among players, characterizing a high communicative memory. In the same vein, Casual games have similar features, that is, they do not usually involve expensive productions, are considered a hobby of a few hours, and their business model is similar to that of
Indie. In contrast, the business model adopted by Multiplayer game developers is quite different. Most of these games are “freemium”, meaning they are free or inexpensive, where the goal is to keep people playing as much as possible and spending money on customization. Since these games are readily available to every user, the decision to play or not is entirely up to the person, favoring the hypothesis of randomness and, consequently, the small magnitude of
. Despite variations, all
’s found were negative. The more negative the
, the more asymmetric is the empirical distribution (see
Figure 3A and
Figure 4B), favoring the presence of outliers. Thus, memory mechanisms seem to contribute to increasing the popularity inequality among video games by promoting the existence of highly popular games. This inequality was further investigated regarding the distribution of video game categories (
Figure 7B) over time (
Figure 7C). Curiously, the patterns discovered were consistent with the ones found in
Figure 3B and
Figure 4C, and in
Figure 3C and
Figure 4A, respectively. A possible reason for this resemblance could be that some video game developers try to develop games belonging to popular categories, since it is difficult to gauge popular reception of an unknown genre and, therefore, there is a greater risk of commercial failure.
For the objectives outlined in this work, the Box–Cox transformation was sufficient to identify memory effects and to describe prominent aspects of the relative popularity distributions. Without doubt, other families of distributions could be employed in the direction of further refining the empirical data description. In particular, a limitation of the present study is that we are unable to clearly separate cultural and communicative memories and, thus, our interpretations of the magnitude of the
parameter rely on domain knowledge. As a next step in improving the model, one could, in a direction similar to the one proposed in Reference [
3], try to untangle the memory phenomena via a model with extra parameters (for instance, a multivariate Box–Cox transformation could potentially be employed, where each of the parameters would be interpreted as a distinct memory mechanism). However, this new hypothetical model would probably require other types of data to correctly quantify the diverse memory mechanisms (e.g., the number of unique user
tweets that refers to a game in the weeks following its release as a way to gauge communicative memory). In addition, it would be worthwhile to re-investigate the linear growth of the number of players and the exponential number of games released to amplify the coverage of our analysis and to confirm if the Malthusian competition remains valid. This latter point would be of special value if it were possible to combine several game databases since, if the growth trends are similar across different bases, this could indicate the existence of a universal video game consumption pattern.
Finally, we believe that the model proposed to describe the relative popularity could potentially contribute to psychological and sociological investigations. For instance, a perennial issue both in academic [
19,
56] and quotidian [
57] discussions is if video game usage contributes to violent behavior. A possible future application of the work presented here would be, first, to correlate the popularity of violent game categories (e.g.,
Steam has games with the Gore and Violent tags) with socioeconomic indicators in the same period. If the relative popularity of these categories is better described by a Box–Cox transformed distribution rather than by a lognormal, this could be suggestive of a communicative memory effect; that is, a collective, user-centered preference for violent games. Such description could then be utilized to better understand this consumption pattern and to serve to support the psychological/social sciences in formulating hypotheses to answer the aforementioned issue.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}