
Performance Analysis and Architecture of a Clustering Hybrid Algorithm Called FA+GA-DBSCAN Using Artificial Datasets

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Data Preprocessing
2.1. Data Collection Method
2.2. Data Normalization
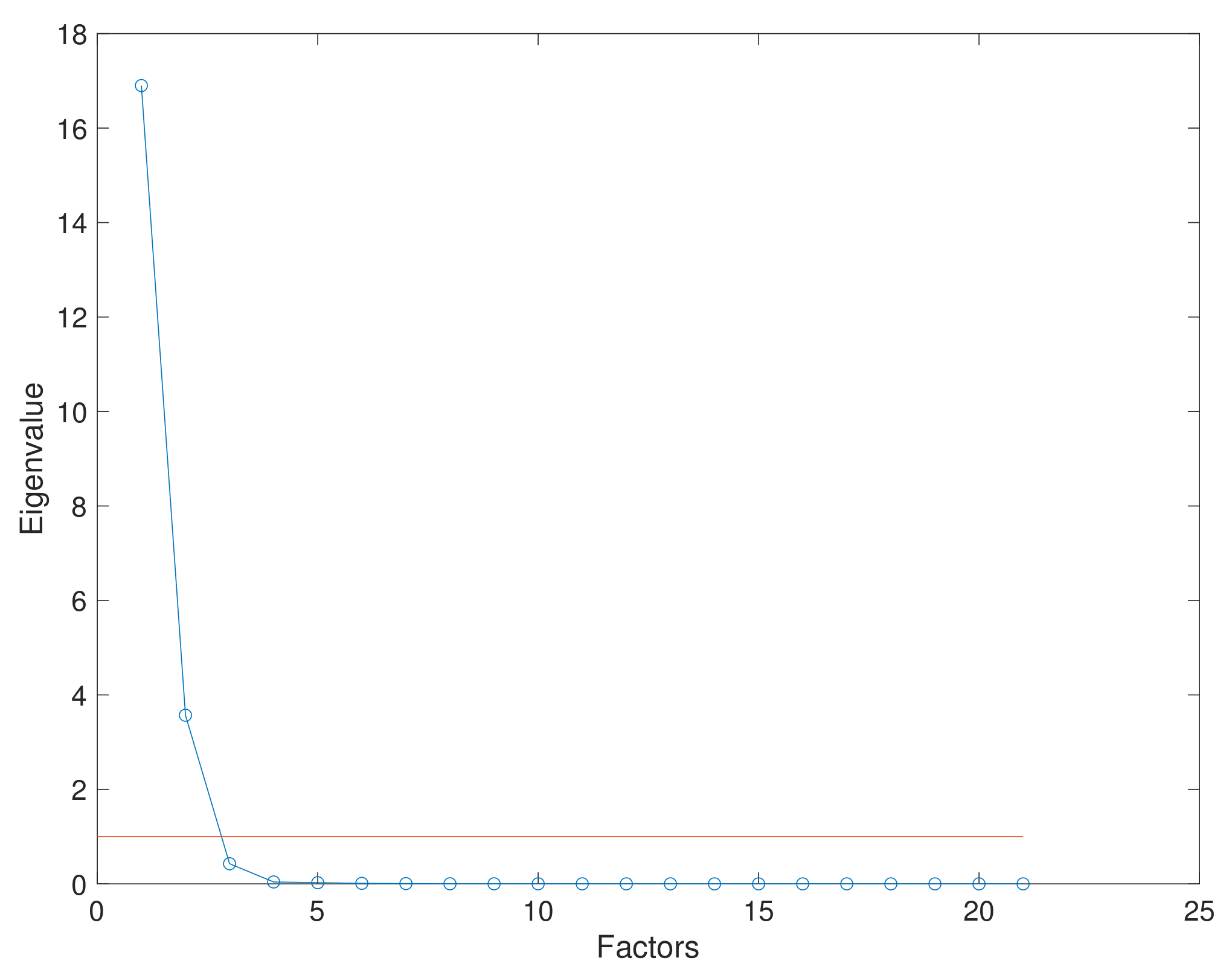
2.3. Dimensionality Reduction Technique
| Algorithm 1: Dimensionality reduction using Factor Analysis. |
 |
3. Dbscan Algorithm
- Eps-neighborhood of point: The Eps-neighborhood of a point p, denoted by , is defined by .
- Directly density-reachable: A point p is directly density-reachable from a point q if:
- –
- .
- –
- The core point condition is reached, i.e., .
- Density-reachable: A point p is density-reachable from a point q if there is a set of points , with and , such that is directly density-reachable from .
- Density-connected: A point p is density-connected to a point q if there is a point o such that p and q are density-reachable from o.
- Cluster: Let D be a specific dataset. A cluster is a non-empty subgroup from dataset D that meets the following criteria:
- –
- Maximality : if and q is density-reachable from p, then .
- –
- Connectivity , then p is density-connected to q.
- Noise: Let be the clusters of dataset D. Noise is defined as the set of points in the dataset D not belonging to any cluster , that is .
| Algorithm 2: Clustering using DBSCAN algorithm. |
 |
3.1. Definition of Parameter MinPts
3.2. Definition of Parameter Eps Using a Fitness Proportionate Selection
| Algorithm 3: Selection of DBSCAN parameters using a genetic algorithm. |
 |
4. Results
4.1. Performance Evaluation Metrics
4.1.1. Precision
4.1.2. Entropy
4.1.3. Calinski–Harabasz Clustering Evaluation Method
4.2. Clustering Performance Analysis
5. Case Studies
5.1. Aircraft Engine Degradation
5.2. Lidar Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kriegel, H.P.; Kröger, P.; Sander, J.; Zimek, A. Density-based clustering. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 231–240. [Google Scholar] [CrossRef]
- Bhattacharjee, P.; Mitra, P. A survey of density based clustering algorithms. Front. Comput. Sci. 2021, 15, 1–27. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Knowledge Discovery and Data Mining KDD, Portland, OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Schubert, E.; Sander, J.; Ester, M.; Kriegel, H.P.; Xu, X. DBSCAN revisited, revisited: Why and how you should (still) use DBSCAN. ACM Trans. Database Syst. (TODS) 2017, 42, 1–21. [Google Scholar] [CrossRef]
- Ng, R.T.; Han, J. CLARANS: A method for clustering objects for spatial data mining. IEEE Trans. Knowl. Data Eng. 2002, 14, 1003–1016. [Google Scholar] [CrossRef] [Green Version]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering points to identify the clustering structure. ACM Sigmod Rec. 1999, 28, 49–60. [Google Scholar] [CrossRef]
- Hinneburg, A.; Gabriel, H.H. Denclue 2.0: Fast clustering based on kernel density estimation. In International Symposium on Intelligent Data Analysis; Springer: Berlin/Heidelberg, Germany, 2007; pp. 70–80. [Google Scholar]
- Pei, T.; Jasra, A.; Hand, D.J.; Zhu, A.X.; Zhou, C. DECODE: A new method for discovering clusters of different densities in spatial data. Data Min. Knowl. Discov. 2009, 18, 337–369. [Google Scholar] [CrossRef]
- De Moura Ventorim, I.; Luchi, D.; Rodrigues, A.L.; Varejão, F.M. BIRCHSCAN: A sampling method for applying DBSCAN to large datasets. Expert Syst. Appl. 2021, 184, 115518. [Google Scholar] [CrossRef]
- Lai, W.; Zhou, M.; Hu, F.; Bian, K.; Song, Q. A new DBSCAN parameters determination method based on improved MVO. IEEE Access 2019, 7, 104085–104095. [Google Scholar] [CrossRef]
- Wang, C.; Ji, M.; Wang, J.; Wen, W.; Li, T.; Sun, Y. An improved DBSCAN method for LiDAR data segmentation with automatic Eps estimation. Sensors 2019, 19, 172. [Google Scholar] [CrossRef] [Green Version]
- Darong, H.; Peng, W. Grid-based DBSCAN algorithm with referential parameters. Phys. Procedia 2012, 24, 1166–1170. [Google Scholar] [CrossRef] [Green Version]
- Ohadi, N.; Kamandi, A.; Shabankhah, M.; Fatemi, S.M.; Hosseini, S.M.; Mahmoudi, A. Sw-dbscan: A grid-based dbscan algorithm for large datasets. In Proceedings of the 2020 6th International Conference on Web Research (ICWR), Tehran, Iran, 22–23 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 139–145. [Google Scholar]
- Shamisa, A.; Majidi, B.; Patra, J.C. Sliding-window-based real-time model order reduction for stability prediction in smart grid. IEEE Trans. Power Syst. 2018, 34, 326–337. [Google Scholar] [CrossRef]
- Karami, A.; Johansson, R. Choosing DBSCAN parameters automatically using differential evolution. Int. J. Comput. Appl. 2014, 91, 1–11. [Google Scholar] [CrossRef]
- Kumar, K.M.; Reddy, A.R.M. A fast DBSCAN clustering algorithm by accelerating neighbor searching using Groups method. Pattern Recognit. 2016, 58, 39–48. [Google Scholar] [CrossRef]
- Zhu, L.; Zhu, J.; Bao, C.; Zhou, L.; Wang, C.; Kong, B. Improvement of DBSCAN Algorithm Based on Adaptive Eps Parameter Estimation. In Proceedings of the 2018 International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 21–23 December 2018; pp. 1–7. [Google Scholar]
- Zhu, Q.; Tang, X.; Elahi, A. Application of the novel harmony search optimization algorithm for DBSCAN clustering. Expert Syst. Appl. 2021, 178, 115054. [Google Scholar] [CrossRef]
- Hou, J.; Gao, H.; Li, X. DSets-DBSCAN: A parameter-free clustering algorithm. IEEE Trans. Image Process. 2016, 25, 3182–3193. [Google Scholar] [CrossRef]
- Starczewski, A.; Goetzen, P.; Er, M.J. A new method for automatic determining of the DBSCAN parameters. J. Artif. Intell. Soft Comput. Res. 2020, 10, 209–221. [Google Scholar] [CrossRef]
- Starczewski, A.; Cader, A. Determining the EPS parameter of the DBSCAN algorithm. In Proceedings of the International Conference on Artificial Intelligence and Soft Computing, Zakopane, Poland, 16–20 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 420–430. [Google Scholar]
- Ozkok, F.O.; Celik, M. A new approach to determine Eps parameter of DBSCAN algorithm. Int. J. Intell. Syst. Appl. Eng. 2017, 5, 247–251. [Google Scholar] [CrossRef] [Green Version]
- Soni, N.; Ganatra, A. Aged (automatic generation of eps for dbscan). Int. J. Comput. Sci. Inf. Secur. 2016, 14, 536. [Google Scholar]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Li, M.; Bi, X.; Wang, L.; Han, X. A method of two-stage clustering learning based on improved DBSCAN and density peak algorithm. Comput. Commun. 2021, 167, 75–84. [Google Scholar] [CrossRef]
- He, Y.; Tan, H.; Luo, W.; Mao, H.; Ma, D.; Feng, S.; Fan, J. Mr-dbscan: An efficient parallel density-based clustering algorithm using mapreduce. In Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems, Tainan, Taiwan, 7–9 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 473–480. [Google Scholar]
- Chen, Y.; Zhou, L.; Bouguila, N.; Wang, C.; Chen, Y.; Du, J. BLOCK-DBSCAN: Fast clustering for large scale data. Pattern Recognit. 2021, 109, 107624. [Google Scholar] [CrossRef]
- Gholizadeh, N.; Saadatfar, H.; Hanafi, N. K-DBSCAN: An improved DBSCAN algorithm for big data. J. Supercomput. 2021, 77, 6214–6235. [Google Scholar] [CrossRef]
- Perafán-López, J.C.; Sierra-Pérez, J. An unsupervised pattern recognition methodology based on factor analysis and a genetic-DBSCAN algorithm to infer operational conditions from strain measurements in structural applications. Chin. J. Aeronaut. 2021, 34, 165–181. [Google Scholar] [CrossRef]
- Lawley, D.N.; Maxwell, A.E. Factor analysis as a statistical method. J. R. Stat. Soc. Ser. Stat. 1962, 12, 209–229. [Google Scholar] [CrossRef]
- Mujica, L.; Rodellar, J.; Fernandez, A.; Güemes, A. Q-statistic and T2-statistic PCA-based measures for damage assessment in structures. Struct. Health Monit. 2011, 10, 539–553. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Kaiser, H.F. The varimax criterion for analytic rotation in factor analysis. Psychometrika 1958, 23, 187–200. [Google Scholar] [CrossRef]
- Neuhaus, J.O.; Wrigley, C. The quartimax method: An analytic approach to orthogonal simple structure 1. Br. J. Stat. Psychol. 1954, 7, 81–91. [Google Scholar] [CrossRef]
- Hendrickson, A.E.; White, P.O. Promax: A quick method for rotation to oblique simple structure. Br. J. Stat. Psychol. 1964, 17, 65–70. [Google Scholar] [CrossRef]
- Khan, K.; Rehman, S.U.; Aziz, K.; Fong, S.; Sarasvady, S. DBSCAN: Past, present and future. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 232–238. [Google Scholar]
- Gaonkar, M.N.; Sawant, K. AutoEpsDBSCAN: DBSCAN with Eps automatic for large dataset. Int. J. Adv. Comput. Theory Eng. 2013, 2, 11–16. [Google Scholar]
- Lin, C.Y.; Chang, C.C.; Lin, C.C. A new density-based scheme for clustering based on genetic algorithm. Fundam. Inform. 2005, 68, 315–331. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Abasi, A.K.; Khader, A.T.; Al-Betar, M.A.; Naim, S.; Alyasseri, Z.A.A.; Makhadmeh, S.N. A novel hybrid multi-verse optimizer with K-means for text documents clustering. Neural Comput. Appl. 2020, 32, 17703–17729. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, H.; Chen, J.; He, E. Detecting unfavorable driving states in electroencephalography based on a PCA sample Entropy feature and multiple classification algorithms. Entropy 2020, 22, 1248. [Google Scholar] [CrossRef] [PubMed]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Heris, M.K. DBSCAN Clustering in MATLAB. 2015. Available online: https://yarpiz.com/255/ypml110-dbscan-clustering (accessed on 8 February 2021).
- Jain, A.K.; Law, M.H. Data clustering: A user’s dilemma. In Proceedings of the International Conference on Pattern Recognition and Machine Intelligence, Kolkata, India, 20–22 December 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–10. [Google Scholar]
- Gionis, A.; Mannila, H.; Tsaparas, P. Clustering aggregation. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 4-es. [Google Scholar] [CrossRef] [Green Version]
- Zahn, C.T. Graph-theoretical methods for detecting and describing gestalt clusters. IEEE Trans. Comput. 1971, 100, 68–86. [Google Scholar] [CrossRef] [Green Version]
- Iglesias, F.; Zseby, T.; Ferreira, D.; Zimek, A. MDCGen: Multidimensional dataset generator for clustering. J. Classif. 2019, 36, 599–618. [Google Scholar] [CrossRef] [Green Version]
- Franti, P.; Virmajoki, O.; Hautamaki, V. Fast agglomerative clustering using a k-nearest neighbor graph. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1875–1881. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. K-means properties on six clustering benchmark datasets. Appl. Intell. 2018, 48, 4743–4759. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–9. [Google Scholar]
- Saxena, A.; Goebel, K. “Turbofan Engine Degradation Simulation Data Set”, NASA Ames Prognostics Data Repository. 2008. Available online: http://ti.arc.nasa.gov/project/prognostic-data-repository (accessed on 20 May 2022).
- The Math Works, Inc. MATLAB and Statistics Toolbox Release R2021b; The Math Works, Inc.: Natick, MA, USA, 2022. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Allele 1 | Allele 2 | |
|---|---|---|
| x | y | Radius r |
| 51.606 | 12.783 | 1.036 |
| Dataset Name | Eps | MinPts |
|---|---|---|
| Aggregation | ||
| Compound | ||
| Jain | ||
| Dim064 | ||
| Wine | ||
| MDCgen |
| Dataset Name | Classes | Calinski–Harabasz Optimal C | C Defined by FA+GA-DBSCAN |
|---|---|---|---|
| Jain | 2 | 9 | 2 |
| Aggregation | 7 | 6 | 7 |
| Compound | 2 | 2 | 3 |
| MDCgen | 3 | 5 | 3 |
| dim064 | 16 | 16 | 16 |
| Wine | 3 | 3 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perafan-Lopez, J.C.; Ferrer-Gregory, V.L.; Nieto-Londoño, C.; Sierra-Pérez, J. Performance Analysis and Architecture of a Clustering Hybrid Algorithm Called FA+GA-DBSCAN Using Artificial Datasets. Entropy 2022, 24, 875. https://doi.org/10.3390/e24070875
Perafan-Lopez JC, Ferrer-Gregory VL, Nieto-Londoño C, Sierra-Pérez J. Performance Analysis and Architecture of a Clustering Hybrid Algorithm Called FA+GA-DBSCAN Using Artificial Datasets. Entropy. 2022; 24(7):875. https://doi.org/10.3390/e24070875
Chicago/Turabian StylePerafan-Lopez, Juan Carlos, Valeria Lucía Ferrer-Gregory, César Nieto-Londoño, and Julián Sierra-Pérez. 2022. "Performance Analysis and Architecture of a Clustering Hybrid Algorithm Called FA+GA-DBSCAN Using Artificial Datasets" Entropy 24, no. 7: 875. https://doi.org/10.3390/e24070875
APA StylePerafan-Lopez, J. C., Ferrer-Gregory, V. L., Nieto-Londoño, C., & Sierra-Pérez, J. (2022). Performance Analysis and Architecture of a Clustering Hybrid Algorithm Called FA+GA-DBSCAN Using Artificial Datasets. Entropy, 24(7), 875. https://doi.org/10.3390/e24070875