
State-of-the-Art Statistical Approaches for Estimating Flood Events




Abstract
:1. Introduction
2. Methods
2.1. Linear Higher Order-Moments (LH-Moments)
2.2. Estimation of the Parameters of the Selected PDFs Based on LH-Moments
2.2.1. Generalized Logistics (GLO) Distribution
2.2.2. Generalized Extreme Value (GEV) Distribution
2.2.3. Generalized Pareto (GPA) Distribution
2.3. Goodness-of-Fit (GOF) Tests
2.4. Quantile Estimates for Different Return Periods of Floods Based on LH-Moments
2.5. Quantile Estimates for Different Return Periods of Floods Based on Nonparametric Kernel Function
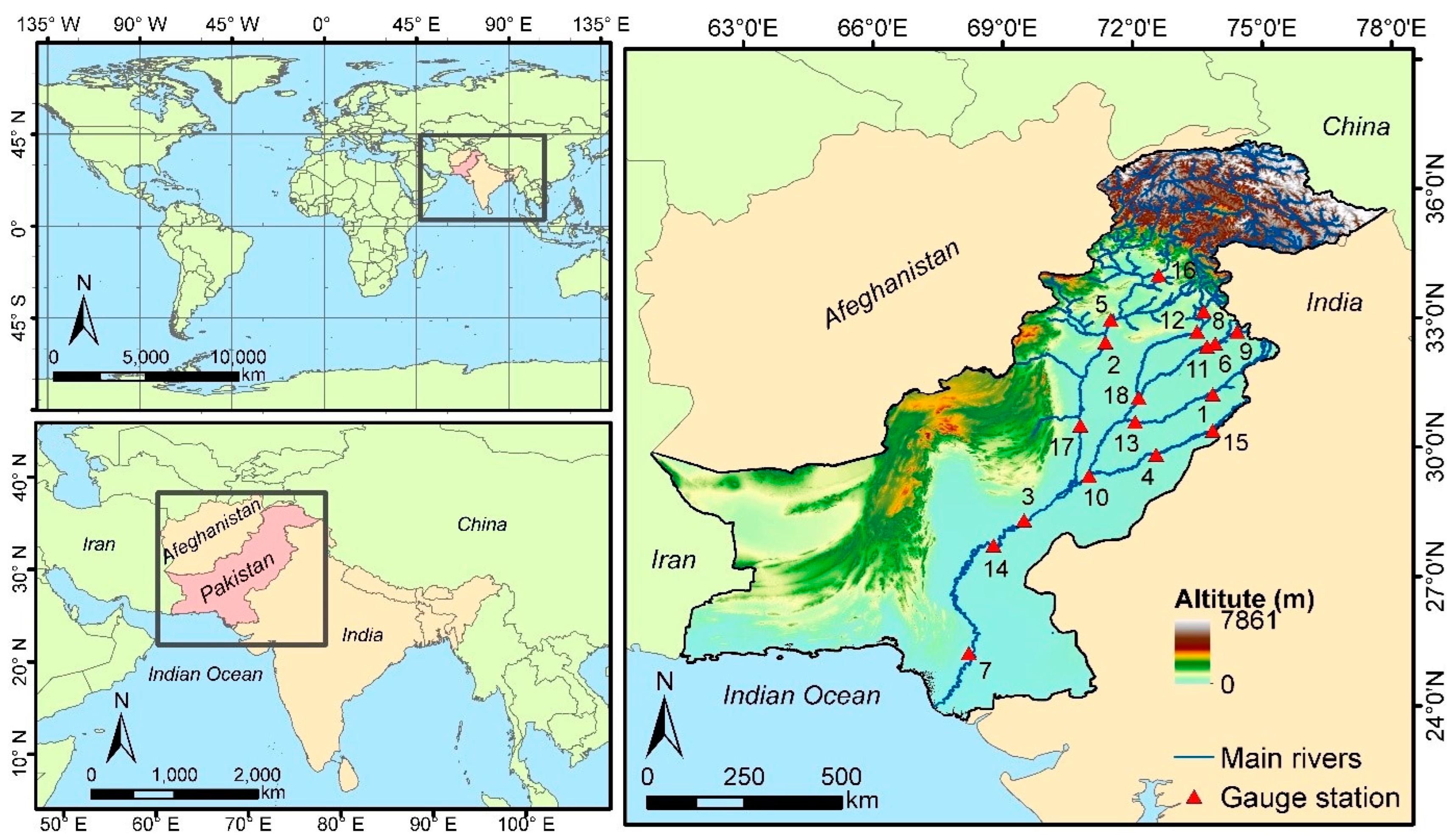
3. Study Area and Data
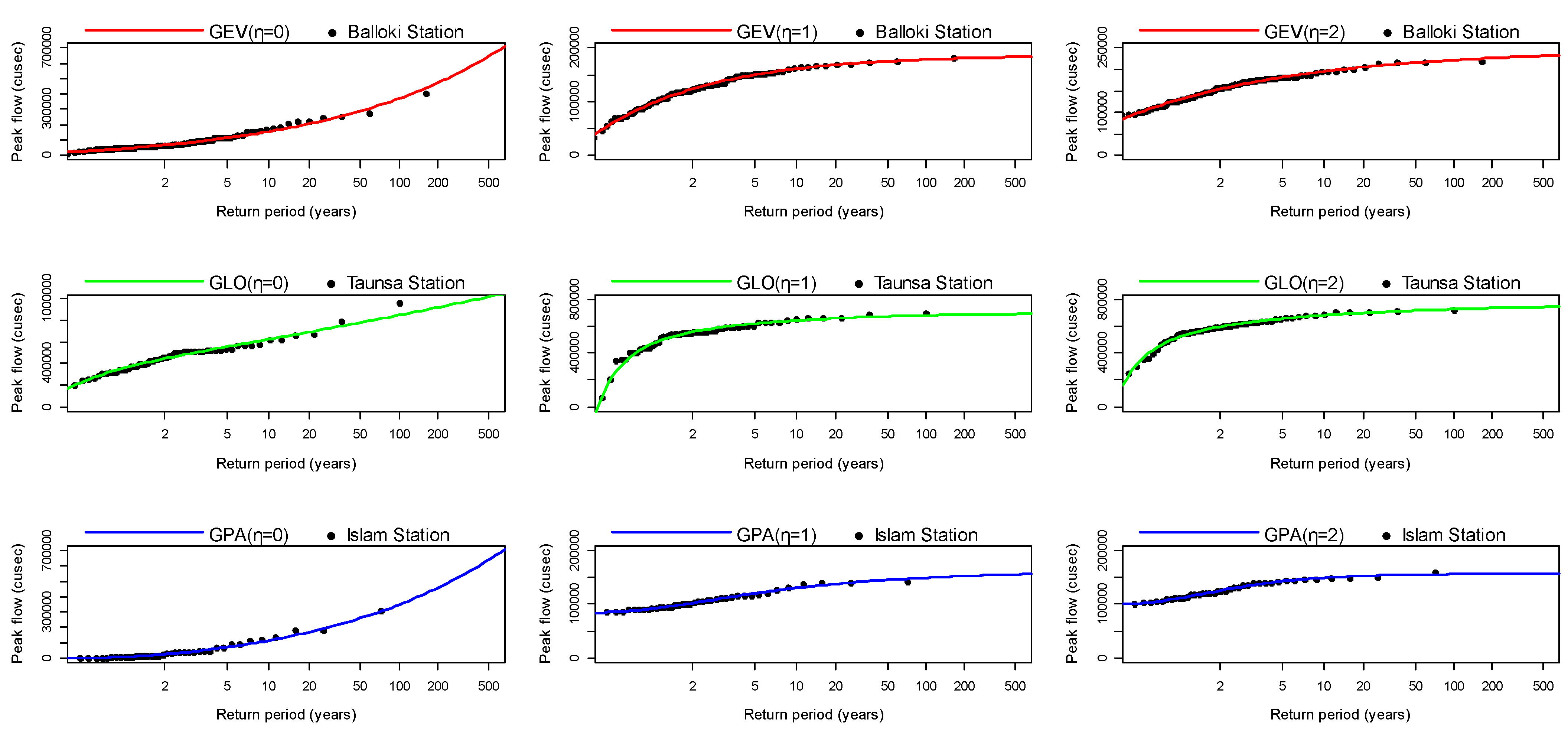
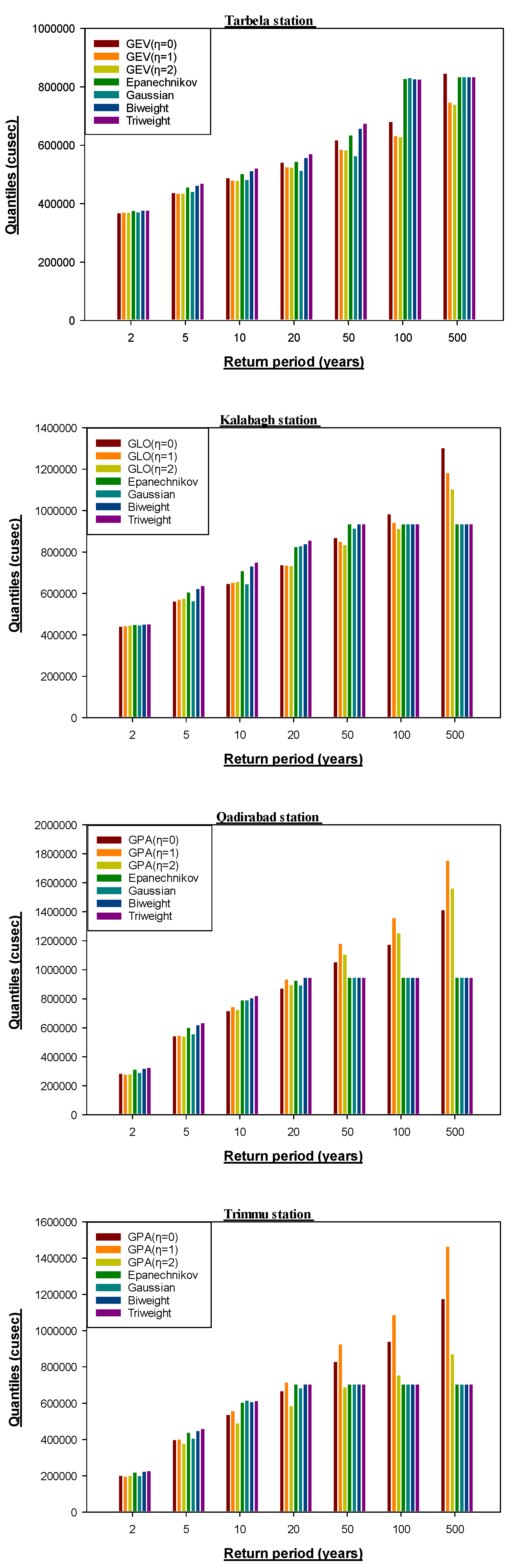
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stedinger, J.R.; Griffis, V.W. Flood frequency analysis in the United States: Time to update. J. Hydrol. Eng. 2008, 13, 199–204. [Google Scholar] [CrossRef] [Green Version]
- De Michele, C.; Salvadori, G.; Canossi, M.; Petaccia, A.; Rosso, R. Bivariate statistical approach to check adequacy of dam spillway. J. Hydrol. Eng. 2005, 10, 50–57. [Google Scholar] [CrossRef]
- Haddad, K.; Rahman, A. Regional flood frequency analysis in eastern Australia: Bayesian GLS regression-based methods within fixed region and ROI framework—Quantile regression vs. parameter regression technique. J. Hydrol. 2012, 430, 142–161. [Google Scholar] [CrossRef]
- Cunnane, C. Statistical distributions for flood frequency analysis. In Operational Hydrology Report; WMO: Geneva, Switzerland, 1989. [Google Scholar]
- Bobée, B.; Cavadias, G.; Ashkar, F.; Bernier, J.; Rasmussen, P. Towards a systematic approach to comparing distributions used in flood frequency analysis. J. Hydrol. 1993, 142, 121–136. [Google Scholar] [CrossRef]
- Haddad, K.; Rahman, A. Selection of the best fit flood frequency distribution and parameter estimation procedure: A case study for Tasmania in Australia. Stoch. Hydrol. Hydraul. 2010, 25, 415–428. [Google Scholar] [CrossRef]
- Hamed, K.; Rao, A.R. Flood Frequency Analysis; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Ahmad, I.; Fawad, M.; Mahmood, I. At-site flood frequency analysis of annual maximum stream flows in Pakistan using robust estimation methods. Pol. J. Environ. Stud. 2015, 24, 2345–2353. [Google Scholar] [CrossRef]
- Ahmad, I.; Fawad, M.; Akbar, M.; Abbass, A.; Zafar, H. Regional frequency analysis of annual peak flows in Pakistan using linear combination of order statistics. Pol. J. Environ. Stud. 2016, 25, 2255–2264. [Google Scholar] [CrossRef]
- Hosking, J.R.M. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B Stat. Methodol. 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Wang, Q.J. LH moments for statistical analysis of extreme events. Water Resour. Res. 1997, 33, 2841–2848. [Google Scholar] [CrossRef]
- Hussain, Z.; Pasha, G.R. Regional flood frequency analysis of the seven sites of Punjab, Pakistan, using L-moments. Water Resour. Manag. 2008, 23, 1917–1933. [Google Scholar] [CrossRef]
- Hussain, Z. Application of the regional flood frequency analysis to the upper and lower basins of the Indus River, Pakistan. Water Resour. Manag. 2011, 25, 2797–2822. [Google Scholar] [CrossRef]
- Afreen, S.; Muhammad, F. Flood frequency analysis of various dams and barrages in Pakistan. Irrig. Drain. 2011, 61, 116–128. [Google Scholar] [CrossRef]
- Lee, S.H.; Maeng, S.J. Comparison and analysis of design floods by the change in the order of LH-moment methods. Irrig. Drain. J. Int. Comm. Irrig. Drain. 2003, 52, 231–245. [Google Scholar] [CrossRef]
- Hewa, G.A.; Wang, Q.J.; McMahon, T.; Nathan, R.J.; Peel, M.C. Generalized extreme value distribution fitted by LH moments for low-flow frequency analysis. Water Resour. Res. 2007, 43, W06301. [Google Scholar] [CrossRef] [Green Version]
- Meshgi, A.; Khalili, D. Comprehensive evaluation of regional flood frequency analysis by L- and LH-moments. I. A revisit to regional homogeneity. Stoch. Environ. Res. Risk Assess. 2009, 23, 119–135. [Google Scholar] [CrossRef]
- Meshgi, A.; Khalili, D. Comprehensive evaluation of regional flood frequency analysis by L- and LH-moments. II. Development of LH-moments parameters for the generalized Pareto and generalized logistic distributions. Stoch. Hydrol. Hydraul. 2008, 23, 137–152. [Google Scholar] [CrossRef]
- Bhuyan, A.; Borah, M.; Kumar, R. Regional flood frequency analysis of North-Bank of the River Brahmaputra by using LH-moments. Water Resour. Manag. 2009, 24, 1779–1790. [Google Scholar] [CrossRef]
- Gheidari, M.H.N. Comparisons of the L- and LH-moments in the selection of the best distribution for regional flood frequency analysis in Lake Urmia Basin. Civ. Eng. Environ. Syst. 2013, 30, 72–84. [Google Scholar] [CrossRef]
- Ahmad, I.; Abbass, A.; Saghir, A.; Fawad, M. Finding probability distributions for annual daily maximum rainfall in Pakistan using linear moments and variants. Pol. J. Environ. Stud. 2016, 25, 925–937. [Google Scholar] [CrossRef]
- Shabri, A. Comparisons of the LH moments and the L moments. Matematika 2002, 18, 33–43. [Google Scholar]
- Deka, S.C.; Borah, M.; Kakaty, S.C. Statistical analysis of annual maximum rainfall in North-East India: An application of LH-moments. Theor. Appl. Climatol. 2010, 104, 111–122. [Google Scholar] [CrossRef]
- Adamowski, K. Nonparametric kernel estimation of flood frequencies. Water Resour. Res. 1985, 21, 1585–1590. [Google Scholar] [CrossRef]
- Adamowski, K. A Monte Carlo comparison of parametric and nonparametric estimation of flood frequencies. J. Hydrol. 1989, 108, 295–308. [Google Scholar] [CrossRef]
- Adamowski, K.; Feluch, W. Nonparametric flood-frequency analysis with historical information. J. Hydraul. Eng. 1990, 116, 1035–1047. [Google Scholar] [CrossRef]
- Schuster, E.; Yakowitz, S. Parametric/nonparametric mixture density estimation with application to flood-frequency analysis. (JAWRA) J. Am. Water Resour. Assoc. 1985, 21, 797–804. [Google Scholar] [CrossRef]
- Adamowski, K.; Labatiuk, C. Estimation of flood frequencies by a nonparametric density procedure. In Hydrologic Frequency Modeling; Springer: Berlin/Heidelberg, Germany, 1987; pp. 97–106. [Google Scholar] [CrossRef]
- Bardsley, W. Using historical data in nonparametric flood estimation. J. Hydrol. 1989, 108, 249–255. [Google Scholar] [CrossRef]
- Guo, S.L. Nonparametric variable kernel estimation with historical floods and paleoflood information. Water Resour. Res. 1991, 27, 91–98. [Google Scholar] [CrossRef]
- Moon, Y.-I.; Lall, U.; Bosworth, K. A comparison of tail probability estimators for flood frequency analysis. J. Hydrol. 1993, 151, 343–363. [Google Scholar] [CrossRef]
- Moon, Y.-I.; Lall, U. Kernel quantite function estimator for flood frequency analysis. Water Resour. Res. 1994, 30, 3095–3103. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; CRC Press: Boca Raton, FL, USA, 1986. [Google Scholar]
- Lall, U.; Moon, Y.-I.; Bosworth, K. Kernel flood frequency estimators: Bandwidth selection and kernel choice. Water Resour. Res. 1993, 29, 1003–1015. [Google Scholar] [CrossRef]
- Cassalho, F.; Beskow, S.; de Mello, C.; de Moura, M.M.; Kerstner, L.; Ávila, L.F. At-site flood frequency analysis coupled with multiparameter probability distributions. Water Resour. Manag. 2017, 32, 285–300. [Google Scholar] [CrossRef]
- Lall, U. Recent advances in nonparametric function estimation: Hydrologic applications. Rev. Geophys. 1995, 33, 1093–1102. [Google Scholar] [CrossRef]
- Ahmad, I.; Almanjahie, I.M.; Hameedullah; Chikr-Elmezouar, Z.; Laksaci, A. Artificial neural network modeling for annual peak flows: A case study. Appl. Ecol. Environ. Res. 2019, 17, 6917–6935. [Google Scholar] [CrossRef]
- Khan, M.; Hussain, Z.; Ahmad, I. A comparison of quadratic regression and artificial neural networks for the estimation of quantiles at ungauged sites in regional frequency analysis. Appl. Ecol. Environ. Res. 2019, 17, 6937–6959. [Google Scholar] [CrossRef]
- Khan, M.; Hussain, Z.; Ahmad, I. Regional flood frequency analysis, using L-moments, artificial neural networks and OLS regression, of various sites of Khyber-Pakhtunkhwa, Pakistan. Appl. Ecol. Environ. Res. 2021, 19, 471–489. [Google Scholar] [CrossRef]
- Zelterman, D. Parameter estimation in the generalized logistic distribution. Comput. Stat. Data Anal. 1987, 5, 177–184. [Google Scholar] [CrossRef]
- Zelterman, D. Order statistics of the generalized logistic distribution. Comput. Stat. Data Anal. 1988, 7, 69–77. [Google Scholar] [CrossRef]
- Reed, D. Flood Estimation Handbook: Overview; Institute of Hydrology Wallingford: Wallingford, UK, 1999. [Google Scholar]
- Ashkar, F.; Mahdi, S. Fitting the log-logistic distribution by generalized moments. J. Hydrol. 2006, 328, 694–703. [Google Scholar] [CrossRef]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Q. J. R. Meteorol. Soc. 1955, 81, 158–171. [Google Scholar] [CrossRef]
- Pickands, J., III. Statistical inference using extreme order statistics. Ann. Stat. 1975, 3, 119–131. [Google Scholar]
- Hosking, J.; Wallis, J. An index flood procedure for regional rainfall frequency analysis. EOS Trans. Am. Geophys. Union 1987, 68, 312. [Google Scholar]
- Singh, V.P.; Guo, H. Parameter estimation for 3-parameter generalized pareto distribution by the principle of maximum entropy (POME). Hydrol. Sci. J. 1995, 40, 165–181. [Google Scholar] [CrossRef] [Green Version]
- Beskow, S.; Caldeira, T.L.; de Mello, C.R.; Faria, L.C.; Guedes, H.A.S. Multiparameter probability distributions for heavy rainfall modeling in extreme southern Brazil. J. Hydrol. Reg. Stud. 2015, 4, 123–133. [Google Scholar] [CrossRef] [Green Version]
- Heo, J.-H.; Shin, H.; Nam, W.; Om, J.; Jeong, C. Approximation of modified Anderson–Darling test statistics for extreme value distributions with unknown shape parameter. J. Hydrol. 2013, 499, 41–49. [Google Scholar] [CrossRef]
- Csörgő, S.; Faraway, J.J. The exact and asymptotic distributions of Cramér-von Mises statistics. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 221–234. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Adamowski, K.; Liang, G.-C.; Patry, G.G. Annual maxima and partial duration flood series analysis by parametric and non-parametric methods. Hydrol. Process. 1998, 12, 1685–1699. [Google Scholar] [CrossRef]
- Quintela-Del-Rio, A. On bandwidth selection for nonparametric estimation in flood frequency analysis. Hydrol. Process. 2011, 25, 671–678. [Google Scholar] [CrossRef]
- Francisco-Fernández, M.; Quintela-Del-Río, A. Comparing simultaneous and pointwise confidence intervals for hydrological processes. PLoS ONE 2016, 11, e0147505. [Google Scholar] [CrossRef]
- Vittal, H.; Singh, J.; Kumar, P.; Karmakar, S. A framework for multivariate data-based at-site flood frequency analysis: Essentiality of the conjugal application of parametric and nonparametric approaches. J. Hydrol. 2015, 525, 658–675. [Google Scholar] [CrossRef]
- Rajagopalan, B.; Lall, U.; Tarboton, D.G. Evaluation of kernel density estimation methods for daily precipitation resampling. Stoch. Hydrol. Hydraul. 1997, 11, 523–547. [Google Scholar] [CrossRef]
- Adamowski, K. Regional analysis of annual maximum and partial duration flood data by nonparametric and L-moment methods. J. Hydrol. 2000, 229, 219–231. [Google Scholar] [CrossRef]
- Altman, N.; Léger, C. Bandwidth selection for kernel distribution function estimation. J. Stat. Plan. Inference 1995, 46, 195–214. [Google Scholar] [CrossRef] [Green Version]
- Quintela-del-Río, A.; Estévez-Pérez, G. Nonparametric kernel distribution function estimation with kerdiest: An R package for bandwidth choice and applications. J. Stat. Softw. 2012, 50, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Polansky, A.M.; Baker, E.R. Multistage plug—in bandwidth selection for kernel distribution function estimates. J. Stat. Comput. Simul. 2000, 65, 63–80. [Google Scholar] [CrossRef]
- Bowman, A.; Hall, P.; Prvan, T. Bandwidth selection for the smoothing of distribution functions. Biometrika 1998, 85, 799–808. [Google Scholar] [CrossRef]
- Quintela-del-Rı, A.; Francisco-Fernández, M. Nonparametric functional data estimation applied to ozone data: Prediction and extreme value analysis. Chemosphere 2011, 82, 800–808. [Google Scholar] [CrossRef]
- Sarfaraz, S.; Arsalan, M.H.; Fatima, H. Regionalizing the climate of Pakistan using Köppen classification system. Pak. Geogr. Rev. 2014, 69, 111–132. [Google Scholar]
- Fawad, M.; Yan, T.; Chen, L.; Huang, K.; Singh, V.P. Multiparameter probability distributions for at-site frequency analysis of annual maximum wind speed with L-moments for parameter estimation. Energy 2019, 181, 724–737. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Stations | River | Latitude (North) | Longitude (East) | Period (Years) | Mean | Standard Deviation | Skewness | Kurtosis | Minimum Peak Flow | Maximum Peak Flow |
|---|---|---|---|---|---|---|---|---|---|---|
| Tarbela | Indus | 33.99 | 72.61 | 1960–2013 | 386,962.963 | 87,785.537 | 2.626 | 11.806 | 273,000 | 835,000 |
| Kalabagh | Indus | 32.95 | 71.50 | 1968–2013 | 464,719.956 | 151,843.363 | 1.186 | 2.102 | 237,297 | 936,453 |
| Chashma | Indus | 32.43 | 71.38 | 1971–2013 | 475,333.046 | 149,635.274 | 1.22 | 3.727 | 214,045 | 1,038,873 |
| Taunsa | Indus | 30.50 | 70.80 | 1958–2013 | 452,791.554 | 140,793.102 | 0.804 | 2.144 | 182,372 | 959,991 |
| Guddu | Indus | 28.30 | 69.50 | 1962–2013 | 609,909.423 | 284,534.413 | 0.552 | −0.557 | 170,831 | 1,176,150 |
| Sukkur | Indus | 27.72 | 68.79 | 1982–2013 | 546,609.594 | 309,470.519 | 0.629 | −0.645 | 126,130 | 1,172,000 |
| Kotri | Indus | 25.22 | 68.22 | 1970–2013 | 395,262.068 | 379,599.333 | 3.705 | 18.290 | 47,100 | 2,409,000 |
| Mangla | Jhelum | 33.15 | 73.65 | 1960–2013 | 132,481.778 | 136,385.297 | 4.240 | 22.770 | 20,460 | 932,700 |
| Rasul | Jhelum | 32.68 | 73.50 | 1970–2013 | 134,418.386 | 161,219.596 | 3.582 | 15.787 | 19,702 | 952,170 |
| Marala | Chenab | 32.68 | 74.43 | 1960–2013 | 308,572.407 | 196,419.272 | 1.097 | 0.227 | 93,150 | 792,765 |
| Khanki | Chenab | 32.40 | 73.92 | 1925–2013 | 351,963.191 | 242,710.633 | 1.494 | 1.391 | 97,058 | 1,086,460 |
| Qadirabad | Chenab | 32.33 | 73.73 | 1970–2013 | 356,547.704 | 247,771.998 | 1.030 | 0.106 | 76,336 | 948,520 |
| Trimmu | Chenab | 31.14 | 72.15 | 1968–2013 | 261,376.217 | 194,828.961 | 1.099 | 0.1693 | 42,756 | 706,433 |
| Panjnad | Chenab | 29.33 | 71.00 | 1960–2013 | 260,134.722 | 193,661.339 | 0.980 | 0.554 | 17,833 | 802,516 |
| Balloki | Ravi | 31.22 | 73.86 | 1922–2013 | 87,914.728 | 64,039.572 | 2.183 | 6.180 | 14,000 | 399,356 |
| Sidhani | Ravi | 30.58 | 72.07 | 1925–2013 | 64,143.427 | 56,691.878 | 2.159 | 4.916 | 8488 | 296,086 |
| Sulemanki | Sutlej | 30.38 | 73.86 | 1975–2013 | 70,254.923 | 84,914.177 | 2.267 | 5.865 | 1506 | 399,453 |
| Islam | Sutlej | 29.82 | 72.55 | 1974–2013 | 49,089.45 | 63,209.754 | 2.362 | 6.497 | 1231 | 306,425 |
| Stations | L-Moments (η = 0) | L1-Moments (η = 1) | L2-Moments (η = 2) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AD Test | KS Test | CVM Test | AD Test | KS Test | CVM Test | AD Test | KS Test | CVM Test | |
| Tarbela | GEV(0.984) | GEV(0.975) | GEV(0.973) | GEV(0.395) | GEV(0.605) | GEV(0.670) | GEV(0.233) | GEV(0.332) | GLO(0.360) |
| Kalabagh | GLO(0.954) | GLO(0.938) | GLO(0.972) | GLO(0.855) | GLO(0.785) | GLO(0.876) | GLO(0.642) | GLO(0.682) | GLO(0.696) |
| Chashma | GLO(0.983) | GLO(0.965) | GLO(0.970) | GLO(0.943) | GLO(0.895) | GLO(0.951) | GLO(0.801) | GLO(0.836) | GLO(0.853) |
| Taunsa | GLO(0.811) | GEV(0.537) | GLO(0.705) | GLO(0.832) | GEV(0.606) | GLO(0.761) | GLO(0.762) | GLO(0.627) | GLO(0.753) |
| Guddu | GEV(0.740) | GLO(0.878) | GEV(0.769) | GEV(0.765) | GLO(0.889) | GEV(0.781) | GEV(0.742) | GEV(0.923) | GEV(0.790) |
| Sukkur | GPA(0.990) | GPA(0.978) | GPA(0.992) | GPA(0.944) | GPA(0.962) | GPA(0.960) | GPA(0.963) | GPA(0.988) | GPA(0.971) |
| Kotri | GEV(0.974) | GEV(0.837) | GEV(0.924) | GEV(0.947) | GEV(0.821) | GEV(0.916) | GEV(0.859) | GEV(0.831) | GLO(0.887) |
| Mangla | GLO(0.956) | GLO(0.900) | GLO(0.932) | GEV(0.803) | GEV(0.864) | GEV(0.916) | GEV(0.537) | GLO(0.851) | GLO(0.877) |
| Rasul | GEV(0.946) | GEV(0.984) | GLO(0.939) | GEV(0.962) | GEV(0.988) | GEV(0.950) | GPA(0.928) | GEV(0.991) | GPA(0.943) |
| Marala | GPA(0.969) | GPA(0.973) | GPA(0.974) | GPA(0.758) | GPA(0.823) | GPA(0.880) | GPA(0.735) | GPA(0.875) | GPA(0.787) |
| Khanki | GEV(0.693) | GPA(0.868) | GEV(0.744) | GEV(0.612) | GEV(0.713) | GEV(0.712) | GEV(0.465) | GEV(0.741) | GEV(0.655) |
| Qadirabad | GPA(0.995) | GPA(0.996) | GPA(0.999) | GEV(0.930) | GPA(0.983) | GPA(0.988) | GPA(0.943) | GPA(0.985) | GPA(0.968) |
| Trimmu | GPA(0.779) | GPA(0.778) | GPA(0.726) | GEV(0.683) | GPA(0.679) | GPA(0.699) | GEV(0.698) | GPA(0.622) | GPA(0.648) |
| Panjnad | GPA(0.908) | GEV(0.879) | GEV(0.878) | GPA(0.914) | GPA(0.885) | GPA(0.894) | GPA(0.933) | GPA(0.897) | GPA(0.906) |
| Balloki | GEV(0.582) | GEV(0.624) | GEV(0.551) | GEV(0.486) | GEV(0.621) | GEV(0.517) | GEV(0.325) | GEV(0.621) | GEV(0.480) |
| Sidhani | GEV(0.978) | GEV(0.990) | GEV(0.974) | GEV(0.971) | GEV(0.992) | GEV(0.969) | GEV(0.933) | GEV(0.982) | GEV(0.957) |
| Sulemanki | GPA(0.996) | GPA(0.994) | GPA(0.998) | GPA(0.998) | GPA(0.991) | GPA(0.998) | GPA(0.999) | GPA(0.990) | GPA(0.998) |
| Islam | GPA(0.900) | GPA(0.753) | GPA(0.877) | GPA(0.931) | GPA(0.693) | GPA(0.885) | GPA(0.936) | GPA(0.715) | GPA(0.886) |
| Station Name | Best Fitted Distribution | 2 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| Tarbela | (η = 0) | 0.008 | 0.009 | 0.015 | 0.028 | 0.053 | 0.077 | 0.156 |
| GEV (η = 1) | 0.004 | 0.005 | 0.008 | 0.011 | 0.017 | 0.022 | 0.035 | |
| (η = 2) | 0.003 | 0.004 | 0.006 | 0.008 | 0.011 | 0.014 | 0.02 | |
| Kalabagh | (η = 0) | 0.011 | 0.012 | 0.023 | 0.041 | 0.072 | 0.103 | 0.202 |
| GLO (η = 1) | 0.009 | 0.012 | 0.016 | 0.021 | 0.03 | 0.039 | 0.063 | |
| (η = 2) | 0.009 | 0.013 | 0.015 | 0.018 | 0.024 | 0.029 | 0.045 | |
| Chashma | (η = 0) | 0.01 | 0.012 | 0.022 | 0.036 | 0.061 | 0.085 | 0.156 |
| GLO (η = 1) | 0.01 | 0.014 | 0.017 | 0.022 | 0.03 | 0.037 | 0.059 | |
| (η = 2) | 0.011 | 0.014 | 0.016 | 0.019 | 0.025 | 0.031 | 0.048 | |
| Taunsa | (η = 0) | 0.009 | 0.012 | 0.019 | 0.029 | 0.046 | 0.061 | 0.106 |
| GLO (η = 1) | 0.01 | 0.014 | 0.016 | 0.02 | 0.027 | 0.033 | 0.05 | |
| (η = 2) | 0.01 | 0.013 | 0.015 | 0.019 | 0.025 | 0.03 | 0.046 | |
| Guddu | (η = 0) | 0.016 | 0.016 | 0.025 | 0.041 | 0.065 | 0.087 | 0.144 |
| GEV (η = 1) | 0.013 | 0.015 | 0.022 | 0.032 | 0.047 | 0.06 | 0.09 | |
| (η = 2) | 0.012 | 0.015 | 0.02 | 0.028 | 0.039 | 0.047 | 0.067 | |
| Sukkur | (η = 0) | 0.023 | 0.026 | 0.032 | 0.053 | 0.086 | 0.112 | 0.172 |
| GPA (η = 1) | 0.021 | 0.024 | 0.03 | 0.048 | 0.076 | 0.096 | 0.14 | |
| (η = 2) | 0.018 | 0.021 | 0.027 | 0.043 | 0.066 | 0.082 | 0.114 | |
| Kotri | (η = 0) | 0.03 | 0.041 | 0.043 | 0.081 | 0.159 | 0.235 | 0.483 |
| GEV (η = 1) | 0.019 | 0.021 | 0.03 | 0.047 | 0.075 | 0.099 | 0.163 | |
| (η = 2) | 0.017 | 0.021 | 0.028 | 0.039 | 0.054 | 0.067 | 0.096 | |
| Mangla | GLO (η = 0) | 0.042 | 0.046 | 0.073 | 0.079 | 0.159 | 0.235 | 0.47 |
| GEV (η = 1) | 0.016 | 0.018 | 0.026 | 0.042 | 0.068 | 0.09 | 0.148 | |
| GLO (η = 2) | 0.016 | 0.018 | 0.026 | 0.037 | 0.056 | 0.072 | 0.119 | |
| Rasul | GEV (η = 0) | 0.056 | 0.067 | 0.089 | 0.096 | 0.174 | 0.256 | 0.505 |
| GEV (η = 1) | 0.022 | 0.034 | 0.036 | 0.065 | 0.113 | 0.157 | 0.285 | |
| GPA (η = 2) | 0.018 | 0.022 | 0.027 | 0.044 | 0.069 | 0.087 | 0.124 | |
| Marala | (η = 0) | 0.022 | 0.024 | 0.031 | 0.052 | 0.09 | 0.124 | 0.214 |
| GPA (η = 1) | 0.017 | 0.018 | 0.025 | 0.041 | 0.069 | 0.092 | 0.151 | |
| (η = 2) | 0.013 | 0.014 | 0.019 | 0.031 | 0.049 | 0.063 | 0.094 | |
| Khanki | (η = 0) | 0.021 | 0.026 | 0.036 | 0.056 | 0.112 | 0.166 | 0.337 |
| GEV (η = 1) | 0.012 | 0.017 | 0.021 | 0.04 | 0.073 | 0.103 | 0.189 | |
| (η = 2) | 0.009 | 0.01 | 0.016 | 0.025 | 0.04 | 0.053 | 0.087 | |
| Qadirabad | (η = 0) | 0.025 | 0.029 | 0.034 | 0.057 | 0.098 | 0.133 | 0.226 |
| GPA (η = 1) | 0.022 | 0.023 | 0.029 | 0.048 | 0.079 | 0.105 | 0.166 | |
| (η = 2) | 0.018 | 0.019 | 0.025 | 0.041 | 0.065 | 0.082 | 0.119 | |
| Trimmu | (η = 0) | 0.027 | 0.032 | 0.035 | 0.06 | 0.105 | 0.145 | 0.253 |
| GPA (η = 1) | 0.022 | 0.024 | 0.03 | 0.05 | 0.083 | 0.109 | 0.175 | |
| (η = 2) | 0.017 | 0.02 | 0.025 | 0.042 | 0.064 | 0.079 | 0.109 | |
| Panjnad | GEV (η = 0) | 0.02 | 0.031 | 0.035 | 0.058 | 0.099 | 0.135 | 0.235 |
| GPA (η = 1) | 0.018 | 0.026 | 0.03 | 0.048 | 0.071 | 0.086 | 0.112 | |
| GPA (η = 2) | 0.015 | 0.022 | 0.026 | 0.044 | 0.068 | 0.079 | 0.096 | |
| Balloki | (η = 0) | 0.023 | 0.026 | 0.038 | 0.056 | 0.114 | 0.17 | 0.343 |
| GEV (η = 1) | 0.011 | 0.014 | 0.02 | 0.035 | 0.061 | 0.084 | 0.149 | |
| (η = 2) | 0.008 | 0.01 | 0.014 | 0.021 | 0.032 | 0.04 | 0.06 | |
| Sidhani | (η = 0) | 0.028 | 0.028 | 0.047 | 0.06 | 0.123 | 0.182 | 0.362 |
| GEV (η = 1) | 0.013 | 0.02 | 0.023 | 0.042 | 0.073 | 0.099 | 0.173 | |
| (η = 2) | 0.012 | 0.012 | 0.019 | 0.03 | 0.046 | 0.059 | 0.093 | |
| Sulemanki | (η = 0) | 0.053 | 0.059 | 0.085 | 0.09 | 0.173 | 0.253 | 0.512 |
| GPA (η = 1) | 0.037 | 0.042 | 0.054 | 0.076 | 0.138 | 0.193 | 0.355 | |
| (η = 2) | 0.029 | 0.039 | 0.044 | 0.069 | 0.118 | 0.158 | 0.263 | |
| Islam | (η = 0) | 0.058 | 0.068 | 0.091 | 0.096 | 0.175 | 0.256 | 0.518 |
| GPA (η = 1) | 0.042 | 0.044 | 0.063 | 0.08 | 0.149 | 0.211 | 0.397 | |
| (η = 2) | 0.031 | 0.039 | 0.046 | 0.07 | 0.121 | 0.164 | 0.278 |
| Station Name | Kernel Function Type | 2 | 5 | 10 | 20 | 50 | 100 | 500 |
|---|---|---|---|---|---|---|---|---|
| Tarbela | Epanechnikov | 0.027 | 0.033 | 0.046 | 0.064 | 0.182 | 0.346 | 0.728 |
| Gaussian | 0.014 | 0.02 | 0.027 | 0.049 | 0.079 | 0.12 | 0.24 | |
| Biweight | 0.029 | 0.047 | 0.064 | 0.087 | 0.211 | 0.39 | 0.74 | |
| Triweight | 0.03 | 0.06 | 0.081 | 0.107 | 0.23 | 0.31 | 0.5 | |
| Kalabagh | Epanechnikov | 0.01 | 0.024 | 0.101 | 0.124 | 0.2 | 0.23 | 0.33 |
| Gaussian | 0.004 | 0.01 | 0.018 | 0.023 | 0.032 | 0.07 | 0.125 | |
| Biweight | 0.006 | 0.013 | 0.125 | 0.127 | 0.14 | 0.19 | 0.21 | |
| Triweight | 0.014 | 0.016 | 0.145 | 0.149 | 0.17 | 0.198 | 0.24 | |
| Chashma | Epanechnikov | 0.004 | 0.078 | 0.081 | 0.12 | 0.183 | 0.263 | 0.58 |
| Gaussian | 0.005 | 0.01 | 0.024 | 0.068 | 0.088 | 0.2 | 0.534 | |
| Biweight | 0.003 | 0.055 | 0.127 | 0.152 | 0.214 | 0.434 | 0.63 | |
| Triweight | 0.002 | 0.029 | 0.128 | 0.178 | 0.239 | 0.488 | 0.678 | |
| Taunsa | Epanechnikov | 0.019 | 0.089 | 0.097 | 0.101 | 0.103 | 0.121 | 0.2 |
| Gaussian | 0.014 | 0.017 | 0.02 | 0.025 | 0.046 | 0.067 | 0.167 | |
| Biweight | 0.019 | 0.115 | 0.116 | 0.122 | 0.129 | 0.222 | 0.29 | |
| Triweight | 0.019 | 0.134 | 0.139 | 0.14 | 0.153 | 0.267 | 0.32 | |
| Guddu | Epanechnikov | 0.013 | 0.014 | 0.023 | 0.091 | 0.182 | 0.311 | 0.671 |
| Gaussian | 0.003 | 0.005 | 0.017 | 0.042 | 0.11 | 0.224 | 0.422 | |
| Biweight | 0.02 | 0.023 | 0.033 | 0.11 | 0.196 | 0.375 | 0.76 | |
| Triweight | 0.025 | 0.023 | 0.054 | 0.127 | 0.215 | 0.46 | 0.845 | |
| Sukkur | Epanechnikov | 0.032 | 0.035 | 0.069 | 0.139 | 0.216 | 0.297 | 0.532 |
| Gaussian | 0.027 | 0.03 | 0.035 | 0.06 | 0.1 | 0.19 | 0.383 | |
| Biweight | 0.035 | 0.041 | 0.089 | 0.171 | 0.342 | 0.441 | 0.72 | |
| Triweight | 0.035 | 0.046 | 0.089 | 0.199 | 0.438 | 0.564 | 0.783 | |
| Kotri | Epanechnikov | 0.095 | 0.131 | 0.162 | 0.191 | 0.257 | 0.501 | 0.732 |
| Gaussian | 0.04 | 0.055 | 0.083 | 0.15 | 0.2 | 0.295 | 0.527 | |
| Biweight | 0.05 | 0.11 | 0.13 | 0.158 | 0.222 | 0.45 | 0.69 | |
| Triweight | 0.073 | 0.124 | 0.15 | 0.181 | 0.245 | 0.489 | 0.705 | |
| Mangla | Epanechnikov | 0.107 | 0.127 | 0.132 | 0.154 | 0.231 | 0.476 | 0.845 |
| Gaussian | 0.051 | 0.068 | 0.099 | 0.134 | 0.198 | 0.345 | 0.695 | |
| Biweight | 0.12 | 0.153 | 0.183 | 0.203 | 0.282 | 0.523 | 0.912 | |
| Triweight | 0.135 | 0.17 | 0.185 | 0.212 | 0.292 | 0.545 | 0.989 | |
| Rasul | Epanechnikov | 0.069 | 0.092 | 0.105 | 0.15 | 0.315 | 0.605 | 1.21 |
| Gaussian | 0.06 | 0.09 | 0.099 | 0.13 | 0.265 | 0.55 | 0.999 | |
| Biweight | 0.083 | 0.101 | 0.163 | 0.193 | 0.386 | 0.71 | 1.421 | |
| Triweight | 0.085 | 0.105 | 0.183 | 0.213 | 0.412 | 0.8 | 1.89 | |
| Marala | Epanechnikov | 0.03 | 0.045 | 0.055 | 0.08 | 0.12 | 0.223 | 0.525 |
| Gaussian | 0.028 | 0.04 | 0.053 | 0.069 | 0.1 | 0.193 | 0.412 | |
| Biweight | 0.055 | 0.075 | 0.097 | 0.13 | 0.274 | 0.498 | 0.875 | |
| Triweight | 0.067 | 0.091 | 0.104 | 0.198 | 0.32 | 0.53 | 0.995 | |
| Khanki | Epanechnikov | 0.081 | 0.09 | 0.124 | 0.175 | 0.243 | 0.475 | 0.822 |
| Gaussian | 0.043 | 0.075 | 0.106 | 0.135 | 0.203 | 0.422 | 0.79 | |
| Biweight | 0.099 | 0.109 | 0.141 | 0.19 | 0.275 | 0.49 | 0.918 | |
| Triweight | 0.103 | 0.116 | 0.142 | 0.203 | 0.303 | 0.503 | 1.116 | |
| Qadirabad | Epanechnikov | 0.046 | 0.061 | 0.076 | 0.122 | 0.17 | 0.328 | 0.631 |
| Gaussian | 0.029 | 0.052 | 0.076 | 0.105 | 0.152 | 0.298 | 0.608 | |
| Biweight | 0.058 | 0.073 | 0.079 | 0.139 | 0.185 | 0.347 | 0.675 | |
| Triweight | 0.063 | 0.079 | 0.096 | 0.151 | 0.196 | 0.365 | 0.692 | |
| Trimmu | Epanechnikov | 0.038 | 0.083 | 0.108 | 0.244 | 0.331 | 0.644 | 1.976 |
| Gaussian | 0.025 | 0.058 | 0.101 | 0.175 | 0.305 | 0.563 | 1.107 | |
| Biweight | 0.033 | 0.063 | 0.106 | 0.261 | 0.36 | 0.682 | 2.19 | |
| Triweight | 0.033 | 0.073 | 0.125 | 0.273 | 0.36 | 0.705 | 2.806 | |
| Panjnad | Epanechnikov | 0.034 | 0.073 | 0.095 | 0.109 | 0.136 | 0.275 | 0.595 |
| Gaussian | 0.047 | 0.057 | 0.083 | 0.105 | 0.126 | 0.234 | 0.498 | |
| Biweight | 0.038 | 0.073 | 0.117 | 0.128 | 0.143 | 0.283 | 0.607 | |
| Triweight | 0.064 | 0.073 | 0.126 | 0.156 | 0.17 | 0.303 | 0.67 | |
| Balloki | Epanechnikov | 0.031 | 0.047 | 0.077 | 0.119 | 0.177 | 0.219 | 0.445 |
| Gaussian | 0.04 | 0.049 | 0.064 | 0.108 | 0.133 | 0.212 | 0.414 | |
| Biweight | 0.028 | 0.043 | 0.092 | 0.124 | 0.192 | 0.324 | 0.59 | |
| Triweight | 0.029 | 0.046 | 0.105 | 0.135 | 0.205 | 0.335 | 0.67 | |
| Sidhani | Epanechnikov | 0.068 | 0.081 | 0.095 | 0.155 | 0.218 | 0.402 | 0.851 |
| Gaussian | 0.041 | 0.051 | 0.075 | 0.131 | 0.197 | 0.359 | 0.738 | |
| Biweight | 0.085 | 0.096 | 0.105 | 0.174 | 0.29 | 0.507 | 0.907 | |
| Triweight | 0.098 | 0.104 | 0.118 | 0.192 | 0.317 | 0.541 | 0.942 | |
| Sulemanki | Epanechnikov | 0.068 | 0.112 | 0.146 | 0.182 | 0.268 | 0.573 | 1.165 |
| Gaussian | 0.063 | 0.078 | 0.112 | 0.148 | 0.233 | 0.438 | 0.91 | |
| Biweight | 0.071 | 0.087 | 0.137 | 0.185 | 0.271 | 0.518 | 1.154 | |
| Triweight | 0.071 | 0.082 | 0.132 | 0.155 | 0.251 | 0.502 | 1.123 | |
| Islam | Epanechnikov | 0.099 | 0.145 | 0.191 | 0.245 | 0.399 | 0.745 | 1.168 |
| Gaussian | 0.067 | 0.11 | 0.154 | 0.21 | 0.367 | 0.61 | 0.929 | |
| Biweight | 0.109 | 0.168 | 0.217 | 0.268 | 0.409 | 0.778 | 1.481 | |
| Triweight | 0.118 | 0.19 | 0.26 | 0.329 | 0.418 | 0.819 | 1.921 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fawad, M.; Cassalho, F.; Ren, J.; Chen, L.; Yan, T. State-of-the-Art Statistical Approaches for Estimating Flood Events. Entropy 2022, 24, 898. https://doi.org/10.3390/e24070898
Fawad M, Cassalho F, Ren J, Chen L, Yan T. State-of-the-Art Statistical Approaches for Estimating Flood Events. Entropy. 2022; 24(7):898. https://doi.org/10.3390/e24070898
Chicago/Turabian StyleFawad, Muhammad, Felício Cassalho, Jingli Ren, Lu Chen, and Ting Yan. 2022. "State-of-the-Art Statistical Approaches for Estimating Flood Events" Entropy 24, no. 7: 898. https://doi.org/10.3390/e24070898
APA StyleFawad, M., Cassalho, F., Ren, J., Chen, L., & Yan, T. (2022). State-of-the-Art Statistical Approaches for Estimating Flood Events. Entropy, 24(7), 898. https://doi.org/10.3390/e24070898