
FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification

Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Related Work
1.2.1. Detection and Classification Method of Android Malware Based on ML
1.2.2. Malware Classification Method Based on Federated Learning
1.3. Contribution
2. System Model and Problem Description
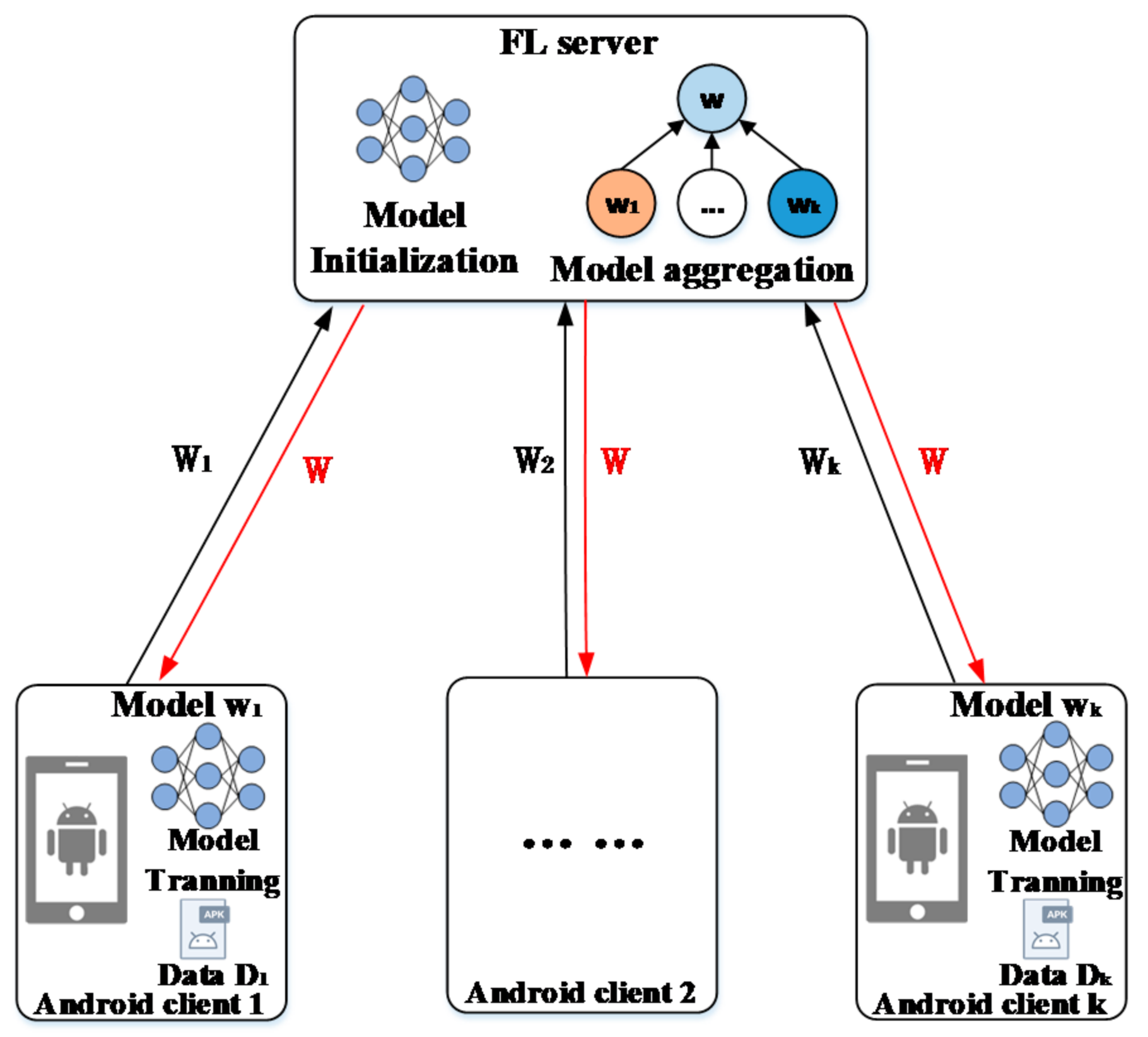
2.1. System Model
2.2. Problem Description
2.3. Abbreviations and Mathematical Symbols
3. Proposed Methods
3.1. FedHGCdroid Framework Overview
3.1.1. Framework of Proposed FedHGCDroid
3.1.2. Threat Model
3.1.3. Privacy Analysis
3.2. Multi-Dimensional Android Malware Classification Model: HGCdroid
3.2.1. Sample Decompiling and Feature Preprocessing
3.2.2. Multi-Attribute Coding Method for APIs
3.2.3. Network Architecture of HGCDroid
3.3. Adaptive Training Mechanism of Classification Model Based on Contribution Degree: FedAdapt
3.3.1. Meta-Learning-Based Local Model Training Method
3.3.2. Contribution Degree-Based Model Aggregation Method
3.3.3. The Training Process of FedAdapt
| Algorithm 1: Training mechanism of adaptive classification model based on contribution degree. | |
| Input | Number of iterations , number of clients , number of iterations of client dataset , batch of client data , weight of client in round is , client learning rate , |
| Output | Vector representation of a node |
| 1: | function |
| 2: | for do |
| 3: | Send global model to each client |
| 4: | for do |
| 5: | |
| 6: | |
| 7: | end for |
| 8: | |
| 9: | |
| 10: | |
| 11: | |
| 12: | end for |
| 13: | end function |
| 14: | function : |
| 15: | Initialize local model weights |
| 16: | for do |
| 17: | for do |
| 18: | |
| 19: | end for |
| 20: | |
| 21: | end for |
| 22: | return |
| 23: | end function |
4. Results
4.1. Simulation Setup
4.1.1. Dataset
4.1.2. Experimental Environment
4.1.3. Performance Metrics
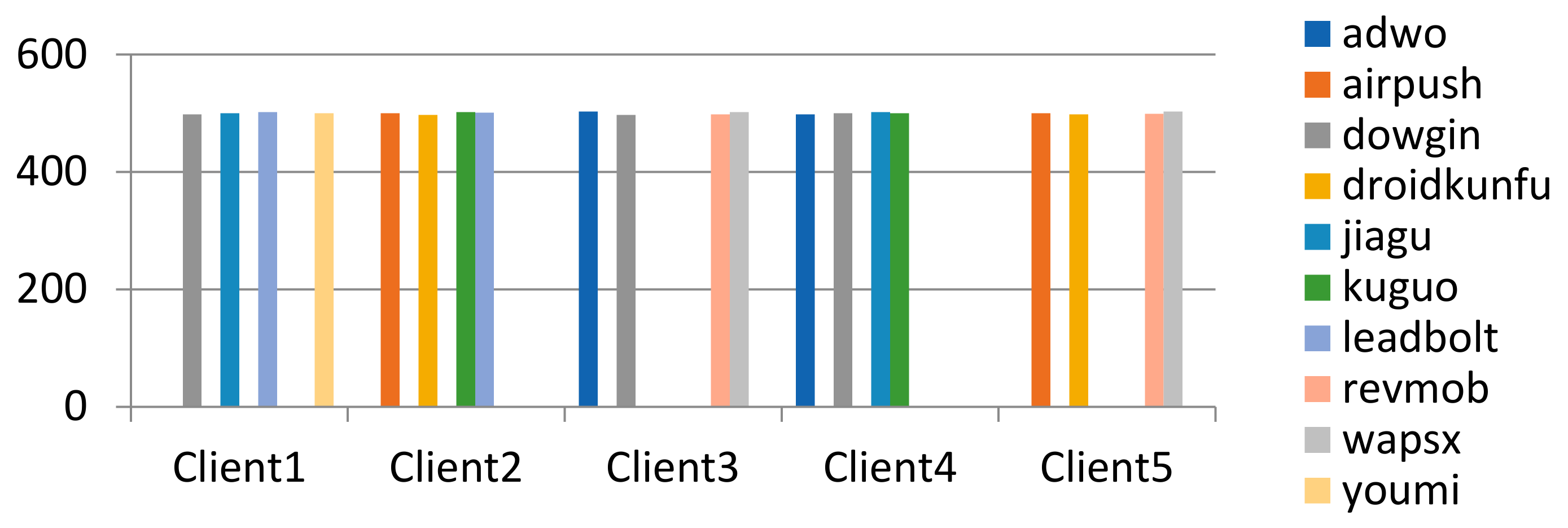
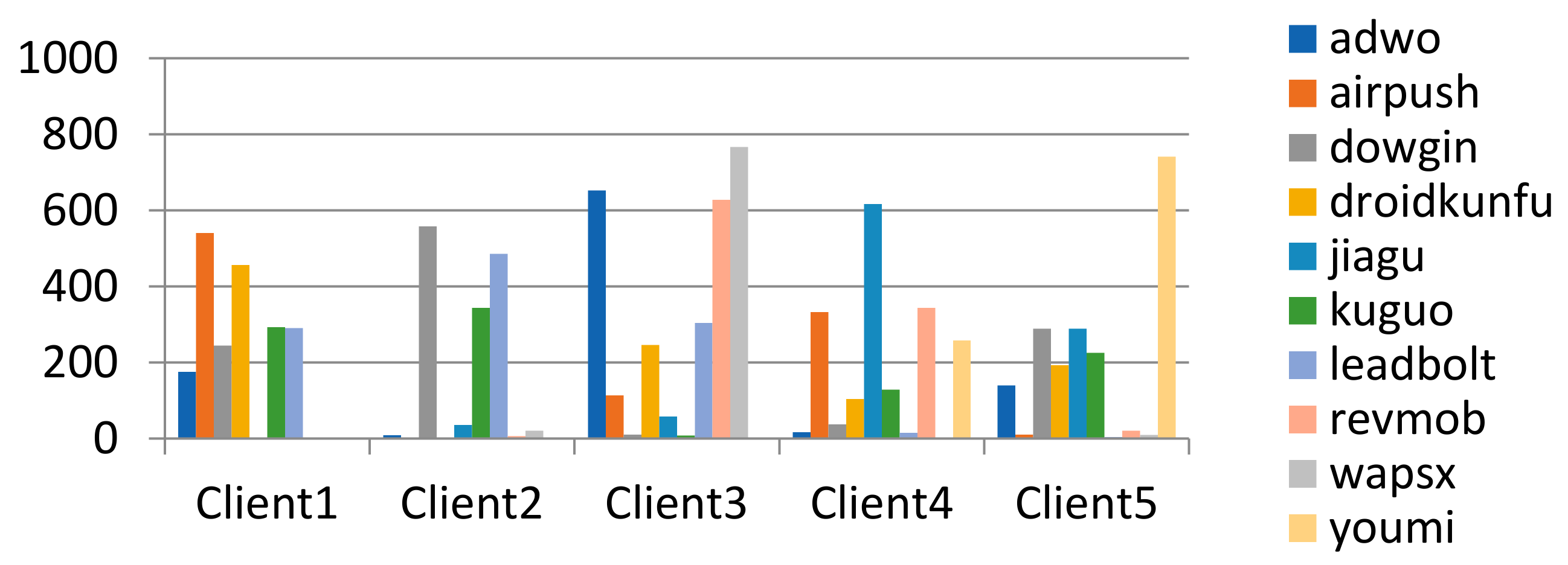
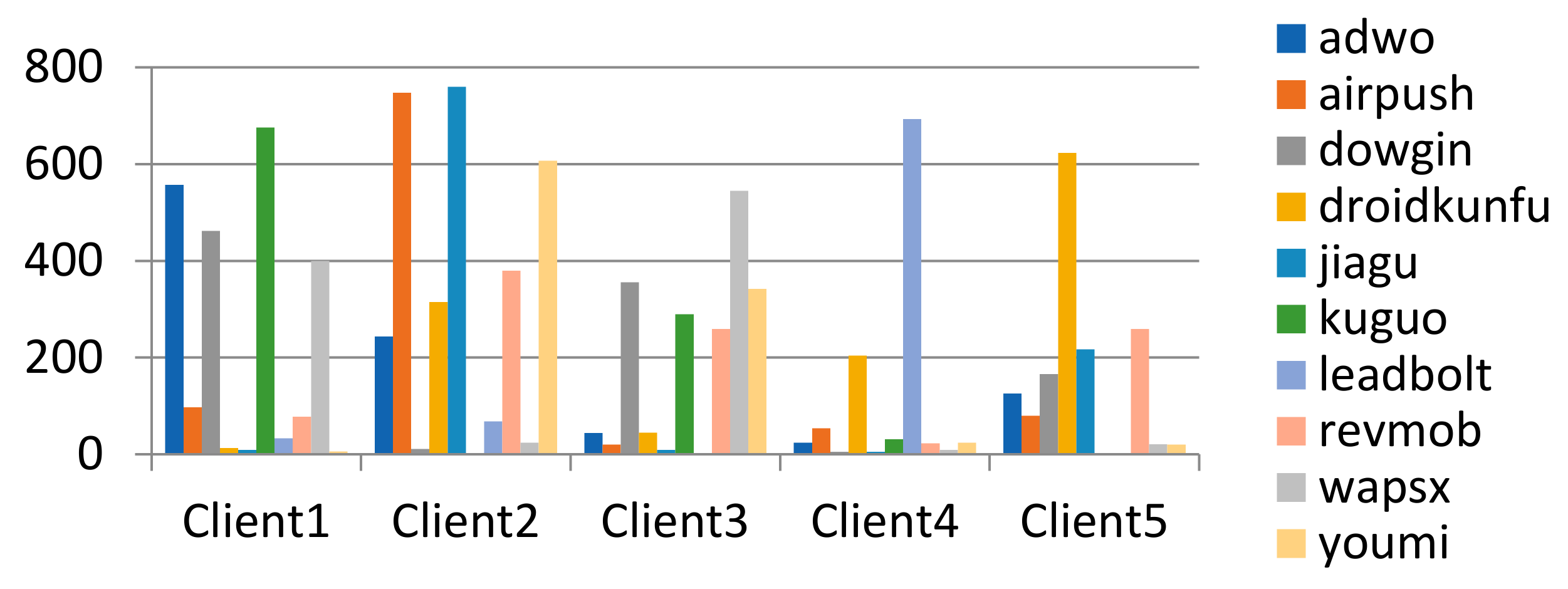
4.1.4. Non-IID Data Partitioning and Non-IID Degree Measurement Methods
- Setting method of malware’s distribution on the client;
- The method of quantifying the degree of non-IID in the distribution of malware on clients;
- Client’s malware distribution setting and effect verification of distribution difference quantification method
4.2. Comparison and Analysis of the Results of Experimental Tasks
4.2.1. Test Classification Performance of HGCDroid and Other Malware Classification Model
4.2.2. Test the Performance of the FedHGCDroid and Other FL-Based Malware Classification Schemes under Different non-IID Data Settings
- Comparison of classification performance between FedHGCDroid and other state-of-the-art studies on FL-based malware classification schemes
- Comparison of adaptive performance between FedHGCDroid and other state-of-the-art studies on FL-based malware classification schemes
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S. A Survey of Android Malware Detection with Deep Neural Models. ACM Comput. Surv. 2021, 53, 126. [Google Scholar] [CrossRef]
- Li, J.; Sun, L.; Yan, Q.; Li, Z.; Srisa-an, W.; Ye, H. Significant permission identification for machine-learning-based Android malware detection. IEEE Trans. Ind. Inform. 2018, 14, 3216–3225. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, C.; Bo, B.; Feng, Y. MalDeep: A deep learning classification framework against malware variants based on texture visualization. Secur. Commun. Netw. 2019, 2019, 4895984. [Google Scholar] [CrossRef]
- Tu, Z.; Li, R.; Li, Y.; Wang, G.; Wu, D.; Hui, P.; Su, L.; Jin, D. Your Apps Give You Away: Distinguishing Mobile Users by Their App Usage Fingerprints. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 138. [Google Scholar] [CrossRef]
- Tu, Z.; Cao, H.; Lagerspetz, E. Demographics of mobile app usage: Long-term analysis of mobile app usage. CCF Trans. Pervasive Comput. Interact. 2021, 3, 235–252. [Google Scholar] [CrossRef]
- Lin, F.; Zhou, Y.; An, X.; You, I.; Choo, K.-K.R. Fair resource allocation in an intrusion detection system for edge computing: Ensuring the security of internet of Tings devices. IEEE Consum. Electron. Mag. 2018, 7, 45–50. [Google Scholar] [CrossRef]
- Wang, C.; Wang, D.; Xu, G.; He, D. Efficient privacy preserving user authentication scheme with forward secrecy for industry 4.0. Sci. China Inf. Sci. 2022, 65, 112301. [Google Scholar] [CrossRef]
- Yang, M.; Wang, S.; Ling, Z.; Liu, Y.; Ni, Z. Detection of malicious behavior in android apps through API calls and permission uses analysis. Concurr. Comput. Pract. Exp. 2017, 29, e4172. [Google Scholar] [CrossRef]
- Cai, H.; Meng, N.; Ryder, B.; Yao, D. Droidcat: Effective android malware detection and categorization via app-level profiling. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1455–1470. [Google Scholar] [CrossRef]
- Feng, P.; Ma, J.; Sun, C.; Xu, X.; Ma, Y. A Novel Dynamic Android Malware Detection System with Ensemble Learning. IEEE Access. 2018, 6, 30996–31011. [Google Scholar] [CrossRef]
- Lu, R. Malware detection with LSTM using opcode language. arXiv 2019, arXiv:1906.04593. [Google Scholar]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K. DREBIN: Effective and Explainable Detection of Android Malware in Your Pocket. In Proceedings of the NDSS, San Diego, CA, USA, 23–26 February 2014; pp. 1–16. [Google Scholar]
- Jerome, Q.; Allix, K.; State, R.; Engel, T. Using opcode-sequences to detect malicious android applications. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, Australia, 10–14 June 2014; pp. 914–919. [Google Scholar]
- Zhu, H.J.; You, Z.H.; Zhu, Z.X.; Shi, W.L.; Chen, X.; Cheng, L. DroidDet: Effective and robust detection of android malware using static analysis along with rotation forest model. Neurocomputing 2018, 272, 638–646. [Google Scholar] [CrossRef]
- Nguyen, M.H.; Nguyen, D.L.; Nguyen, X.M.; Quan, T.T. Auto-detection of sophisticated malware using lazy-binding control flow graph and deep learning. Comput. Secur. 2018, 76, 128–155. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2021, arXiv:1812.08434. [Google Scholar] [CrossRef]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Jiang, H.; Turki, T.; Wang, J.T.L. DLGraph: Malware detection using deep learning and graph embedding. In Proceedings of the 2018 17th IEEE international conference on machine learning and applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 1029–1033. [Google Scholar]
- Pektas, A.; Acarman, T. Deep learning for effective android malware detection using api call graph embeddings. Soft Comput. 2020, 24, 1027–1043. [Google Scholar] [CrossRef]
- Singh, N.; Kasyap, H.; Tripathy, S. Collaborative Learning Based Effective Malware Detection System. In PKDD/ECML Workshops; Springer: Berlin/Heidelberg, Germany, 2020; pp. 205–219. [Google Scholar]
- Galvez, R.; Moonsamy, V.; Díaz, C. Less is More: A privacy-respecting Android malware classifier using federated learning. Proc. Priv. Enhancing Technol. 2021, 2021, 96–116. [Google Scholar] [CrossRef]
- Shukla, S.; Manoj, P.D.S.; Kolhe, G.; Rafatirad, S. On-device Malware Detection using Performance-Aware and Robust Collaborative Learning. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 967–972. [Google Scholar]
- Taheri, R.; Shojafar, M.; Alazab, M.; Tafazolli, R. Fed-IIoT: A Robust Federated Malware Detection Architecture in Industrial IoT. IEEE Trans. Ind. Inform. 2021, 17, 8442–8452. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Singh, A.K.; Goyal, N. Android Web Security Solution using Cross-device Federated Learning. In Proceedings of the 2022 14th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; pp. 473–481. [Google Scholar]
- Valerian Rey, Pedro Miguel Sánchez Sánchez, Alberto Huertas Celdrán, Gérôme Bovet: Federated learning for malware detection in IoT devices. Comput. Netw. 2022, 204, 108693. [CrossRef]
- Lim, W.Y.B.; Luong, C.; Hoang, T.; Jiao, Y.; Liang, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef] [Green Version]
- Makkar, A.; Ghosh, U.; Rawat, D.B.; Abawajy, J.H. FedLearnSP: Preserving Privacy and Security Using Federated Learning and Edge Computing. IEEE Consum. Electron. Mag. 2022, 11, 21–27. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Pereira, F.; Crocker, P.; Leithardt, V.R.Q. PADRES: Tool for Privacy, Data Regulation and Security. SoftwareX 2022, 17, 100895. [Google Scholar] [CrossRef]
- Han, R.; Li, D.; Ouyang, J.; Liu, C.H.; Wang, G.; Wu, D.; Chen, L.Y. Accurate Differentially Private Deep Learning on the Edge. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2231–2247. [Google Scholar] [CrossRef]
- Mikolov, L.T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Vieira, J.C.; Sartori, A.; Stefenon, S.F.; Perez, F.L.; de Jesus, G.S.; Leithardt, V.R.Q. Low-Cost CNN for Automatic Violence Recognition on Embedded System. IEEE Access 2022, 10, 25190–25202. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Allix, K.; Bissyandé, T.F.; Klein, J.; Traon, Y.L. AndroZoo: Collecting millions of Android apps for the research community. In Proceedings of the 13th International Conference on Mining Software Repositories, Austin, TX, USA, 14–15 May 2016; pp. 468–471. [Google Scholar]
- VirusTotal: Free Online Virus, Malware and URL Scanner [EB/OL]. 2021. Available online: https://www.virustotal.com (accessed on 14 March 2019).
- Hurier, M.; Suarez-Tangil, G.; Dash, S.K.; Bissyandé, T.F.; Traon, Y.L.; Klein, J.; Cavallaro, L. Euphony: Harmonious unification of cacophonous anti-virus vendor labels for Android malware. In Proceedings of the 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR), Buenos Aires, Argentina, 20–21 May 2017; pp. 425–435. [Google Scholar]
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Don’ts of Machine Learning in Computer Security. arXiv 2020, arXiv:2010.09470v2. [Google Scholar]
- Pendlebury, F.; Pierazzi, F.; Jordaney, R.; Kinder, J.; Cavallaro, L. TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time. In Proceedings of the USENIX Security Symposium 2019, Santa Clara, CA, USA, 14–16 August 2019; pp. 729–746. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated Learning with Personalization Layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Huang, Y.; Chu, L.; Zhou, Z.; Wang, L.; Liu, J.; Pei, J.; Zhang, Y. Personalized cross-silo federated learning on non-iid data. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2 June 2021; pp. 7865–7873. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Model | Features | Training Method | Statistical Feature | Graphical Feature | Privacy -Preserving | Adaptive |
|---|---|---|---|---|---|---|---|
| [12] | SVM | Permissions, Sensitive APIs | Centralized | √ | - | - | - |
| [13] | N-gram | Operation sequences | Centralized | √ | - | - | - |
| [9] | CNN | Method calls, App resources, Inter-Component Communication | Centralized | √ | - | - | - |
| [11] | LSTM | Opcode | Centralized | √ | - | - | - |
| [18] | DNN | Function call graph | Centralized | - | √ | - | - |
| [15] | CNN | Control flow diagram | Centralized | - | √ | - | - |
| [14] | Rotation Forest | API calls, Permission, System events | Centralized | √ | - | - | |
| [19] | GNN | API call graph | Centralized | - | √ | - | - |
| [20] | CNN, AC-GAN | Image transformations, Bytes, Call graph | FL | √ | - | √ | - |
| [21] | DNN | Permissions, APIs, Intents | FL | √ | - | √ | - |
| [22] | CNN | Image transformations | FL | √ | - | √ | - |
| [23] | CNN | Permissions, Intents, and API calls | FL | √ | - | √ | - |
| Proposed FedHGCDroid | GNN, CNN | Function call graph, Permissions, API, Intent | FL | √ | √ | √ | √ |
| Ref | Key Contributions | Limitations |
|---|---|---|
| [12] | A lightweight method that detects malware on smartphones | These schemes only mine the characteristics of malware from a single dimension, and it is difficult to capture the essential behavior of malware comprehensively and effectively. Privacy issues during training are not considered. |
| [9] | Presented a novel classification approach based on dynamic analysis, which is robust to the obfuscation | |
| [11] | Propose a novel and efficient approach which uses LSTM to obtain the feature representations of opcode sequences of malware | |
| [19] | Feature mining of function call graph is carried out by graph embedding technique | |
| [15] | Propose an approach that transforms the control flow diagram into RGB images for the convolutional neural network for malware detection | |
| [14] | Propose a highly efficient method to extract API calls, permission rate, surveillance system events, and permissions as features | |
| [21] | Proposed a semi-supervised federated learning algorithm that works without user supervision | These schemes’ lack of adaptability to the problems that the non-IID distribution of malware on different clients |
| [22] | Introduces a performance-aware FL framework to reduce the communication overhead of device-level computing | |
| [23] | Proposed a robust FL-based framework, namely, Fed-IIoT, for detecting Android malware in the Internet of Things |
| Abbreviation and Symbol | Explanation |
|---|---|
| non-IID | Non-independent and identically distributed |
| FL | Federated learning |
| API | Application Programming Interface |
| DL | Deep learning |
| ML | Machine learning |
| GNN | Graph neural network |
| SVM | Support Vector Machine |
| CNN | Convolutional neural network |
| Local dataset | |
| Size of local dataset | |
| Global mel | |
| Global loss nction | |
| Local loss nction | |
| Feature space of Android malware | |
| Category space of Android malware | |
| Feature of Android malware | |
| Category of Android malware | |
| Initial model parameters | |
| Gradient of initialization parameters | |
| Mathematical expectation | |
| Coding vector of statistical features | |
| Coding function call graph | |
| The node set of function call graph | |
| Edge set of function call graph | |
| The embedded representation of node in the function call graph at the layer. | |
| Neighbor node sampling | |
| Represent the degree of non-IID | |
| Derivative of the loss function of the model to the weight of the model | |
| GDPR | General Data Protection Regulation |
| The scale parameter of the data partitioning method |
| Layer | Input × Output | Conv Kernel Size | Stride | |
|---|---|---|---|---|
| CNN-1 | Conv1D | 1 × 64 | 3 | 1 |
| BatchNorm1D | 64 × 64 | - | - | |
| Relu | 64 × 64 | - | - | |
| CNN-2 | MaxPool1D | 64 × 64 | 3 | 3 |
| Conv1D | 64 × 128 | 3 | 1 | |
| BatchNorm1D | 128 × 128 | - | - | |
| Relu | 128 × 128 | - | - | |
| CNN-3 | MaxPool1D | 128 × 128 | 3 | 3 |
| Conv1D | 128 × 256 | 5 | 1 | |
| BatchNorm1D | 256 × 256 | - | - | |
| Relu | 256 × 256 | - | - | |
| CNN-4 | MaxPool1D | 256 × 256 | 3 | 3 |
| Conv1D | 256 × 256 | 5 | 1 | |
| BatchNorm1D | 256 × 256 | - | - | |
| Relu | 256 × 256 | - | - | |
| Pool | MaxPool1D | 256 × 256 | 3 | 3 |
| Layer | Input × Output | |
|---|---|---|
| GNN-1 | GraphConv | 102 × 256 |
| Relu | 256 × 256 | |
| GNN-2 | GraphConv | 256 × 256 |
| Relu | 256 × 256 | |
| GNN-3 | GraphConv | 256 × 256 |
| Relu | 256 × 256 | |
| Pool | Readout | 1536 |
| Layer | Input × Output | Layer | Input × Output | ||
|---|---|---|---|---|---|
| FC-1 | Linear | 2560 × 2560 | FC-4 | Linear | 1536 × 1024 |
| LayerNorm | 2560 × 2560 | LayerNorm | 1024 × 1024 | ||
| LeakyRelu | 2560 × 2560 | LeakyRelu | 1024 × 1024 | ||
| FC-2 | Linear | 2560 × 2560 | FC-5 | Linear | 1024 × 1024 |
| LayerNorm | 2560 × 2560 | LayerNorm | 1024 × 1024 | ||
| LeakyRelu | 2560 × 2560 | LeakyRelu | 1024 × 1024 | ||
| FC-3 | Linear | 2560 × Output | FC-6 | Linear | 1024 × 1024 |
| FC-7 | Sum | Output × Output | |||
| SF | Softmax | Output × Output | |||
| Task Type | Category | Quantity | Description |
|---|---|---|---|
| Malware detection | Benign | 29,977 | Normal application. |
| Malicious | 28,855 | An application that performs malicious operations that cause losses to the user. | |
| Malware type classification | Adware | 5000 | Flood a user’s device with unwanted ads, enticing them to click incorrectly. |
| Trojan | 3338 | Masquerading software, damaging user devices, collecting sensitive data, deleting important files, and monitoring user activity. | |
| Riskware | 5000 | Collect users’ bank account information and payment records. | |
| Ransom | 4322 | Software that prevents the user from behaving normally and requires the user to pay a ransom to release control. | |
| Exploit | 1225 | Exploit system vulnerabilities to gain permissions by breaking the application sandbox. | |
| Spyware | 2476 | Transfer of personal information and data to places other than the Android device without the user’s consent. | |
| Downloader | 4023 | Remote download malicious code, frequently download and install operations. | |
| Fraudware | 3776 | To charge users in a deliberately deceptive manner. | |
| Malware family classification | Adwo | 1000 | Display intrusive ads and gain privacy from the device. |
| Airpush | 1000 | Trojan, take the initiative to push advertising to equipment notification bar. | |
| Dowgin | 1000 | Advertising module, collect device location, network, telephone sensitive information. | |
| Droidkunfu | 1000 | Trojans, which exploit vulnerabilities to send confidential information to remote servers. | |
| Jiagu | 1000 | Risk software, malicious packaging program. | |
| Kuguo | 1000 | Advertising module, steal sensitive information. | |
| Leadbolt | 1000 | Changes browser Settings to display ads in the notification bar. | |
| Revmob | 1000 | Get geolocation, download hidden executables. | |
| Wapsx | 1000 | Delivers AD content and displays unwanted ads in the notification bar. | |
| Youmi | 1000 | Steals user privacy, including location, phone, phone id, etc. |
| Component | Parameter | |
|---|---|---|
| Hardware | CPU/GPU | Intel Golden 6240/NVIDIA A100 GPU |
| Memory/Hard disk | 64G/2T | |
| Software | OS | CentOS 7.6, Cuda10.1 |
| Programming language | Python3.8 | |
| Software tools | Vscode, Slrum | |
| Machine learning library | Pytorch1.8.1, Sklearn1.0.2, PyG2.0.1 | |
| Other libraries | Androguard3.3.5, Numpy1.20.3, Matplotlib3.4.2, Gensim4.1.2, Conda4.8.2, Networkx2.6.3, |
| Performance Metrics | Calculation Formula |
|---|---|
| Accuracy | |
| Precision | |
| Recall | |
| F1 score |
| Experiment Task | Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Malware detection | SVM (Arp et al. 2014) [12] | 89.2 | 89.27 | 89.04 | 89.16 |
| DNN (Jiang et al. 2018) [18] | 90.67 | 91.3 | 90.99 | 91.14 | |
| CNN (Taheri et al. 2021) [23] | 88.16 | 87.95 | 88.28 | 87.99 | |
| GNN (Pektas et al. 2020) [19] | 90.55 | 90.21 | 91.06 | 90.63 | |
| HGCDroid | 91.3 | 90.8 | 92.79 | 91.29 | |
| Malware type classification | SVM (Arp et al. 2014) [12] | 72.08 | 72.68 | 73.62 | 73.14 |
| DNN (Jiang et al. 2018) [18] | 78.14 | 76.72 | 77.69 | 77.38 | |
| CNN (Taheri et al. 2021) [23] | 79.13 | 79.71 | 78.61 | 79.07 | |
| GNN (Pektas et al. 2020) [19] | 80.5 | 82.66 | 81.59 | 82.12 | |
| HGCDroid | 83.29 | 83.45 | 83.85 | 83.67 |
| Algorithm | |||||
|---|---|---|---|---|---|
| Fedavg + HGCdroid | 91.37 | 90.12 | 89.77 | 90.06 | 91.91 |
| LiM | 88.58 | 81.02 | 85.11 | 86.71 | 78.57 |
| RAPID | 89.8 | 88.05 | 87.16 | 88.71 | 88.25 |
| Fed-IIoT | 90.51 | 87.47 | 88.62 | 88.96 | 80.54 |
| Fedamp + HGCdroid | 91.80 | 92.46 | 93.28 | 90.57 | 93.43 |
| Fedper + HGCdroid | 90.82 | 91.78 | 93.26 | 90.53 | 93.53 |
| FedHGCdroid | 91.82 | 92.79 | 93.95 | 91.18 | 93.19 |
| Algorithm | |||||
|---|---|---|---|---|---|
| Fedavg + HGCdroid | 82.16 | 76.13 | 77.03 | 80.65 | 82.60 |
| LiM | 79.82 | 72.58 | 73.46 | 76.67 | 77.63 |
| RAPID | 80.04 | 77.33 | 76.94 | 78.5 | 77.48 |
| Fed-IIoT | 80.92 | 76.79 | 76.27 | 78.73 | 78.44 |
| Fedamp + HGCdroid | 81.47 | 83.87 | 85.41 | 83.75 | 83.19 |
| Fedper + HGCdroid | 78.25 | 82.86 | 83.79 | 81.99 | 83.11 |
| FEDHGCdroid | 81.79 | 84.77 | 85.98 | 84.09 | 84.83 |
| Algorithm | |||||
|---|---|---|---|---|---|
| Fedavg + HGCdroid | 81.01 | 76.77 | 78.63 | 76.98 | 74.67 |
| LiM | 76.63 | 73.15 | 72.34 | 75.82 | 72.96 |
| RAPID | 79.65 | 74.95 | 75.95 | 75.29 | 75.11 |
| Fed-IIoT | 79.93 | 74.63 | 77.67 | 78.42 | 74.86 |
| Fedamp + HGCdroid | 80.55 | 83.21 | 84.92 | 86.48 | 85.02 |
| Fedper + HGCdroid | 76.65 | 82.45 | 83.75 | 83.82 | 84.02 |
| FedHGCdroid | 82.25 | 85.74 | 86.36 | 86.27 | 87.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, C.; Yin, K.; Xia, C.; Huang, W. FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification. Entropy 2022, 24, 919. https://doi.org/10.3390/e24070919
Jiang C, Yin K, Xia C, Huang W. FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification. Entropy. 2022; 24(7):919. https://doi.org/10.3390/e24070919
Chicago/Turabian StyleJiang, Changnan, Kanglong Yin, Chunhe Xia, and Weidong Huang. 2022. "FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification" Entropy 24, no. 7: 919. https://doi.org/10.3390/e24070919
APA StyleJiang, C., Yin, K., Xia, C., & Huang, W. (2022). FedHGCDroid: An Adaptive Multi-Dimensional Federated Learning for Privacy-Preserving Android Malware Classification. Entropy, 24(7), 919. https://doi.org/10.3390/e24070919