
Learning from Knowledge Graphs: Neural Fine-Grained Entity Typing with Copy-Generation Networks


Abstract
:1. Introduction
2. Related Work
2.1. Fine-Grained Entity Typing
2.2. Copy Mechanism
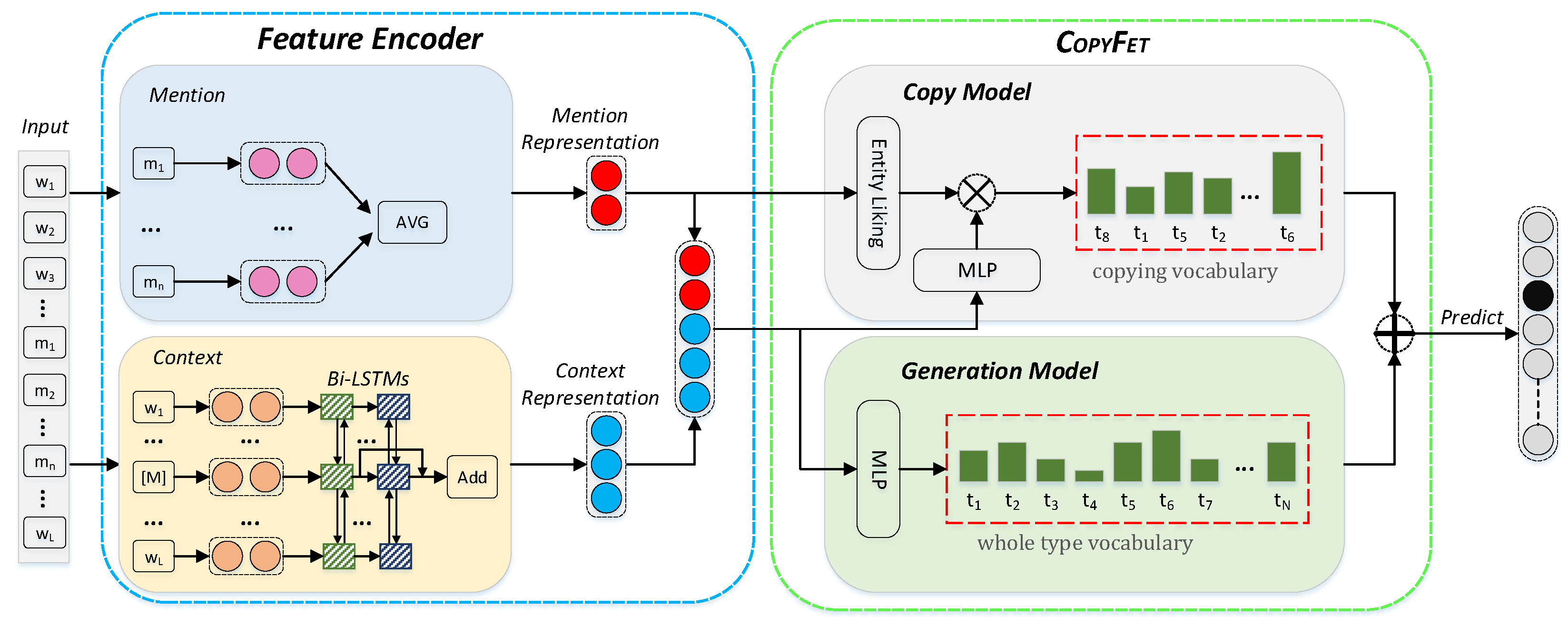
3. Methodology
3.1. Copy Model
3.2. Generation Model
3.3. Incorporating Copy Model with Generation Model for FET
4. Cross-Entropy Loss Function for Optimization
5. Experiments
5.1. Datasets
5.2. Baselines
- AFET [44]: one of the most widely used FET model. AFET models the samples with only one label and samples with multiple labels separately with a partial label loss to handle noisy labels.
- Attentive [63]: a popular attention-based neural network model which uses attention mechanism to focus on relevant information.
- AAA [45]: an extension of AFET which jointly encodes entity mentions and their context representation.
- NFETC [38]: a very popular model which formulates FET as a single-label classification problem with hierarchy-aware loss.
- NFETC-CLSC [48]: an influential extension of NFETC which utilizes imperfect annotation as model regularization via compact latent space clustering to address the confirmation bias problem.
- IFETET [34]: a FET model which utilizes entity type information from a KB obtained through entity linking to form the final feature vector of a mention.
- NDP [7]: a random-walk-based model which weighs out noise with a loss function.
- HFET [41]: a popular ELMo-based pretrained language model which adopts a hybrid type classifier.
- HET [8]: a recent model that takes the hierarchical ontology into account with a multilevel learning-to-rank loss and gains great performance improvement.
- FGET-RR [50]: a recent model that refines the noisy mention representations by attending to corpus-level contextual clues prior to the end classification.
- Box [64]: a recent box-based model for fine-grained entity typing.
5.3. Experimental Settings
5.4. Results and Analysis
5.5. Ablation Study
5.6. Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yogatama, D.; Gillick, D.; Lazic, N. Embedding methods for fine grained entity type classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 291–296. [Google Scholar]
- Corro, D.; Luciano; Abujabal, A.; Gemulla, R.; Weikum, G. Finet: Context-aware fine-grained named entity typing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing; Lisbon, Portugal, 17–21 September 2015, pp. 868–878.
- Collins, M.; Singer, Y. Unsupervised models for named entity classification. In Proceedings of the 1999 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, College Park, MD, USA, 21–22 June 1999. [Google Scholar]
- Ratinov, L.; Roth, D. Design challenges and misconceptions in named entity recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), Boulder, CO, USA, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Choi, E.; Levy, O.; Choi, Y.; Zettlemoyer, L.S. Ultra-fine entity typing. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Hou, F.; Wang, R.; Zhou, Y. Transfer learning for fine-grained entity typing. Nowledge Inf. Syst. 2021, 63, 845–866. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, R.; Mao, Y.; Guo, H.; Huai, J. Modeling Noisy Hierarchical Types in Fine-Grained Entity Typing: A Content-Based Weighting Approach. In Proceedings of the International Joint Conferences on Artificial Intelligence Organization, Beijing, China, 10–16 August 2019; pp. 5264–5270. [Google Scholar]
- Chen, T.; Chen, Y.; Durme, B.V. Hierarchical Entity Typing via Multi-level Learning to Rank. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8465–8475. [Google Scholar]
- Ling, X.; Weld, D.S. Fine-grained entity recognition. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, OT, Canada, 22–26 July 2012. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP 2009, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Liu, Y.; Liu, K.; Xu, L.; Zhao, J. Exploring fine-grained entity type constraints for distantly supervised relation extraction. In Proceedings of the InProceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers 2014, Dublin, Ireland, 11 August 2014; pp. 2107–2116. [Google Scholar]
- Toral, A.; Noguera, E.; Llopis, F.; Munoz, R. Improving question answering using named entity recognition. In Proceedings of the International Conference on Application of Natural Language to Information Systems, Alicante, Spain, 15–17 June 2005; pp. 181–191. [Google Scholar]
- Yahya, M.; Berberich, K.; Elbassuoni, S.; Weikum, G. Robust question answering over the web of linked data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management 2013, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1107–1116. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2014, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Li, D.; Liu, H.; Zhang, Z.; Lin, K.; Fang, S.; Li, Z.; Xiong, N.N. CARM: Confidence-aware recommender model via review representation learning and historical rating behavior in the online platforms. Neurocomputing 2021, 455, 283–296. [Google Scholar] [CrossRef]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inform. 2021, 18, 4361–4371. [Google Scholar] [CrossRef]
- Ren, X.; He, W.; Qu, M.; Voss, C.R.; Ji, H.; Han, J. Label Noise Reduction in Entity Typing by Heterogeneous Partial-Label Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2016, San Francisco, CA, USA, 13–17 August 2016; pp. 1825–1834. [Google Scholar]
- Weischedel, R.; Hovy, E.; Marcus, M.; Palmer, M.; Belvin, R.; Pradhan, S.; Ramshaw, L.; Xue, N. Ontonotes: A large training corpus for enhanced processing. In Handbook of Natural Language Processing and Machine Translation: DARPA Global Autonomous Language Exploitation; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data 2008, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web 2007, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia: A largescale, multilingual knowledge base extracted from Wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Weischedel, R.; Palmer, M.; Marcus, M.; Hovy, E.; Pradhan, S.; Ramshaw, L.; Xue, N.; Taylor, A.; Kaufman, J.; Franchini, M.; et al. OntoNotes Release 5.0. Abacus Data Network. 2013.
- Ding, N.; Xu, G.; Chen, Y.; Wang, X.; Han, X.; Xie, P.; Zheng, H.T.; Liu, Z. Few-nerd: A few-shot named entity recognition dataset. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 3198–3213. [Google Scholar]
- Weischedel, R. BBN Pronoun Coreference and Entity Type Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 2005; p. 112. [Google Scholar]
- Meng, R.; Zhao, S.; Han, S.; He, D.; Brusilovsky, P.; Chi, Y. Deep keyphrase generation. In Proceedings of the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 582–592. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Xu, S.; Li, H.; Yuan, P.; Wu, Y.; He, X.; Zhou, B. Self-Attention Guided Copy Mechanism for Abstractive Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1355–1362. [Google Scholar]
- Gillick, D.; Lazic, N.; Ganchev, K.; Kirchner, J.; Huynh, D. Context-dependent fine-grained entity type tagging. arXiv 2014, arXiv:1412.1820. [Google Scholar]
- Yao, L.; Riedel, S.; McCallum, A. Universal schema for entity type prediction. In Proceedings of the 2013 Workshop on Automated Knowledge Base Construction, San Francisco, CA, USA, 27–28 October 2013; pp. 79–84. [Google Scholar]
- Zhang, S.; Duh, K.; Durme, B.V. Fine-grained Entity Typing through Increased Discourse Context and Adaptive Classification Thresholds. In Proceedings of the Seventh Joint Conference on Lexical and Computational Semantics, New Orleans, LA, USA, 5–6 June 2018; pp. 173–179. [Google Scholar]
- Yaghoobzadeh, Y.; Schutze, H. Corpus-level Fine-grained Entity Typing Using Contextual Information. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP2015), Lisbon, Portugal, 17–21 September 2015; pp. 715–725. [Google Scholar]
- Yaghoobzadeh, Y.; Adel, H.; Schütze, H. Corpus-level fine-grained entity typing. J. Artif. Intell. Res. 2018, 61, 835–862. [Google Scholar] [CrossRef]
- Yosef, M.A.; Bauer, S.; Hoffart, J.; Spaniol, M.; Weikum, G. Hyena: Hierarchical type classification for entity names. In Proceedings of the COLING 2012: Posters, Mumbai, India, 8–15 December 2012; pp. 1361–1370. [Google Scholar]
- Dai, H.; Du, D.; Li, X.; Song, Y. Improving Fine-grained Entity Typing with Entity Linking. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6210–6215. [Google Scholar]
- Xiong, W.; Wu, J.; Lei, D.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. Imposing Label-Relational Inductive Bias for Extremely Fine-Grained Entity Typing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 773–784. [Google Scholar]
- Dong, L.; Wei, F.; Sun, H.; Zhou, M.; Xu, K. A hybrid neural model for type classification of entity mentions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2009; pp. 1243–1249. [Google Scholar]
- Xin, J.; Lin, Y.; Liu, Z.; Sun, M. Improving Neural Fine-Grained Entity Typing with Knowledge Attention. In Proceedings of the AAAI Conference on Artificial Intelligence 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 5997–6004. [Google Scholar]
- Xu, P.; Barbosa, D. Neural fine-grained entity type classification with hierarchy-aware loss. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 16–25. [Google Scholar]
- Murty, S.; Verga, P.; Vilnis, L.; Radovanovic, I.; McCallum, A. Hierarchical Losses and New Resources for Fine-grained Entity Typing and Linking. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) 2018, Melbourne, Australia, 15–20 July 2018; pp. 97–1092018. [Google Scholar]
- Yuan, Z.; Downey, D. OTyper: A neural architecture for open named entity typing. In Proceedings of the AAAI Conference on Artificial Intelligence 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lin, Y.; Ji, H. An Attentive Fine-Grained Entity Typing Model with Latent Type Representation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6197–6202. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Ren, X.; He, W.; Qu, M.; Huang, L.; Ji, H.; Han, J. AFET: Automatic fine-grained entity typing by hierarchical partial-label embedding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing 2016, Austin, TX, USA, 1–4 November 2016. [Google Scholar]
- Abhishek, A.; Anand, A.; Awekar, A. Fine-grained entity type classification by jointly learning representations and label embeddings. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics 2017, Valencia, Spain, 3–7 April 2017; pp. 797–807. [Google Scholar]
- Xin, J.; Zhu, H.; Han, X.; Liu, Z.; Sun, M. Put It Back: Entity Typing with Language Model Enhancement. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 993–998. [Google Scholar]
- Onoe, Y.; Durrett, G. Learning to Denoise Distantly-Labeled Data for Entity Typing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2407–2417. [Google Scholar]
- Chen, B.; Gu, X.; Hu, Y.; Tang, S.; Hu, G.; Zhuang, Y.; Ren, X. Improving Distantly-supervised Entity Typing with Compact Latent Space Clustering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 2862–2872. [Google Scholar]
- Shi, H.; Tang, S.; Gu, X.; Chen, B.; Chen, Z.; Shao, J.; Ren, X. Alleviate Dataset Shift Problem in Fine-grained Entity Typing with Virtual Adversarial Training. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence 2021, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Ali, M.A.; Sun, Y.; Li, B.; Wang, W. Fine-Grained Named Entity Typing over Distantly Supervised Data Based on Refined Representations. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; pp. 7391–7398. [Google Scholar]
- Zhang, H.; Long, D.; Xu, G.; Zhu, M.; Xie, P.; Huang, F.; Wang, J. Learning with Noise: Improving Distantly-Supervised Fine-grained Entity Typing via Automatic Relabeling. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence 2021, Yokohama, Japan, 11–17 July 2020. [Google Scholar]
- Zhao, Y.; Zhang, A.; Xie, R.; Liu, K.; Wang, X. Connecting Embeddings for Knowledge Graph Entity Typing. In Proceedings of the Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6419–6428. [Google Scholar]
- Yaghoobzadeh, Y.; Schütze, H. Multi-Multi-View Learning: Multilingual and Multi-Representation Entity Typing. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, online, 5–10 July 2020; pp. 3060–3066. [Google Scholar]
- Jin, H.; Hou, L.; Li, J.; Dong, T. Fine-Grained Entity Typing via Hierarchical Multi Graph Convolutional Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 4969–4978. [Google Scholar]
- Moon, C.; Jones, P.; Samatova, N.F. Learning Entity Type Embeddings for Knowledge Graph Completion. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 2215–2218. [Google Scholar]
- Zhou, B.; Khashabi, D.; Tsai, C.T.; Roth, D. Zero-Shot Open Entity Typing as Type-Compatible Grounding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2020; pp. 2065–2076. [Google Scholar]
- Obeidat, R.; Fern, X.; Shahbazi, H.; Tadepalli, P. Description-Based Zero-shot Fine-Grained Entity Typing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 807–814. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Montreal, 7–12 December 2015; pp. 2692–2700. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O.K. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1631–1640. [Google Scholar]
- Zhu, C.; Chen, M.; Fan, C.; Cheng, G.; Zhang, Y. Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Zhou, M. Sequential copying networks. In Proceedings of the AAAI Conference on Artificial Intelligence 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Pan, X.; Cassidy, T.; Hermjakob, U.; Ji, H.; Knight, K. Unsupervised entity linking with abstract meaning representation. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 2015, Denver, CO, USA, 31 May–5 June 2015; pp. 1130–1139. [Google Scholar]
- Shimaoka, S.; Stenetorp, P.; Inui, K.; Riedel, S. An attentive neural architecture for fine-grained entity type classification. In Proceedings of the 5th Workshop on AKBC, San Diego, CA, USA, 17 June 2016; pp. 69–74. [Google Scholar]
- Onoe, Y.; Boratko, M.; McCallum, A.; Durrett, G. Modeling Fine-Grained Entity Types with Box Embeddings. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 2051–2064. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]


{kind=link}
{kind=link}
| Benchmark FET Datasets | # Type | # Testing Mentions | # Typing Facts Included in KG | KG Coverage |
|---|---|---|---|---|
| Wiki/FIGER (GOLD) [9] | 128 | 563 | 280 | 49.73% |
| BBN [24] | 56 | 13,282 | 8505 | 64.03% |
| Dataset | # Train | # Dev | # Test | # Label | Depth |
|---|---|---|---|---|---|
| FIGER [9] | 4,932,761 | 2000 | 563 | 128 | 2 |
| BBN [24] | 4,695,789 | 2000 | 13,282 | 56 | 2 |
| Parameter | Wiki/FIGER (GOLD) | BBN |
|---|---|---|
| Learning rate | 1 × 10−3 | 1 × 10−3 |
| Batch size | 256 | 256 |
| Word vector size | 300 | 300 |
| LSTM hidden | 250 | 250 |
| dropout | 0.5 | 0.5 |
| 0.5 | 0.7 | |
| 0.5 | 0.5 |
| Model | Wiki/FIGER (GOLD) | BBN | ||||
|---|---|---|---|---|---|---|
| Strict Acc. | Macro F1 | Micro F1 | Strict Acc. | Macro F1 | Micro F1 | |
| AFET [44] | 53.3 | 69.3 | 66.4 | 67.0 | 72.7 | 73.5 |
| Attentive [63] | 59.7 | 80.0 | 75.4 | 48.4 | 73.2 | 72.4 |
| AAA [45] | 65.8 | 81.2 | 77.4 | 73.3 | 79.1 | 79.2 |
| NFETC [38] | 68.9 | 81.9 | 79.0 | 72.1 | 77.1 | 77.5 |
| NFETC-CLSC [48] | - | - | - | 74.7 | 80.7 | 80.5 |
| IFETET [34] | 74.9 | 86.2 | 84.0 | 82.1 | 88.1 | 89.3 |
| NDP [7] | 67.7 | 81.8 | 78.0 | 72.7 | 76.4 | 77.7 |
| HFET [41] | 62.9 | 83.0 | 79.8 | 55.9 | 79.3 | 78.1 |
| HET [8] | 65.5 | 80.5 | 78.1 | 75.2 | 79.7 | 80.5 |
| FGET-RR [50] | 71.0 | 84.7 | 80.5 | 70.3 | 81.9 | 82.3 |
| Box [64] | - | 79.4 | 75.0 | - | 78.7 | 78.0 |
| CopyFet (Ours) | 76.4 | 86.7 | 84.6 | 83.6 | 89.4 | 89.9 |
| Model | Wiki/FIGER (GOLD) | BBN | ||||
|---|---|---|---|---|---|---|
| Strict Acc. | Macro F1 | Micro F1 | Strict Acc. | Macro F1 | Micro F1 | |
| CopyFet-Generation-only | 69.9 | 82.7 | 80.6 | 79.8 | 86.8 | 87.9 |
| CopyFet | 76.4 | 86.7 | 84.6 | 83.6 | 89.4 | 89.9 |
| Data | Mention and Context | Known Facts in KGs | CopyFet-Generation-only | CopyFet |
|---|---|---|---|---|
| Wiki | The study is from the Unitec Institute of Technology, Auckland, New Zealand. | (UNITEC, /organization) (UNITEC, /organ./edu-cational_inst.) | /location | organization/edu-cational_institution |
| BBN | The Fleet Street reaction was captured in the Guardian headline, “ Departure Reveals Thatcher Poison.” | (D. R. T. P., /art) (D. R. T. P., /work_of_art) | /organization | /work_of_art |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Z.; Zhang, A.; Feng, H.; Du, H.; Wei, S.; Zhao, Y. Learning from Knowledge Graphs: Neural Fine-Grained Entity Typing with Copy-Generation Networks. Entropy 2022, 24, 964. https://doi.org/10.3390/e24070964
Yu Z, Zhang A, Feng H, Du H, Wei S, Zhao Y. Learning from Knowledge Graphs: Neural Fine-Grained Entity Typing with Copy-Generation Networks. Entropy. 2022; 24(7):964. https://doi.org/10.3390/e24070964
Chicago/Turabian StyleYu, Zongjian, Anxiang Zhang, Huali Feng, Huaming Du, Shaopeng Wei, and Yu Zhao. 2022. "Learning from Knowledge Graphs: Neural Fine-Grained Entity Typing with Copy-Generation Networks" Entropy 24, no. 7: 964. https://doi.org/10.3390/e24070964
APA StyleYu, Z., Zhang, A., Feng, H., Du, H., Wei, S., & Zhao, Y. (2022). Learning from Knowledge Graphs: Neural Fine-Grained Entity Typing with Copy-Generation Networks. Entropy, 24(7), 964. https://doi.org/10.3390/e24070964