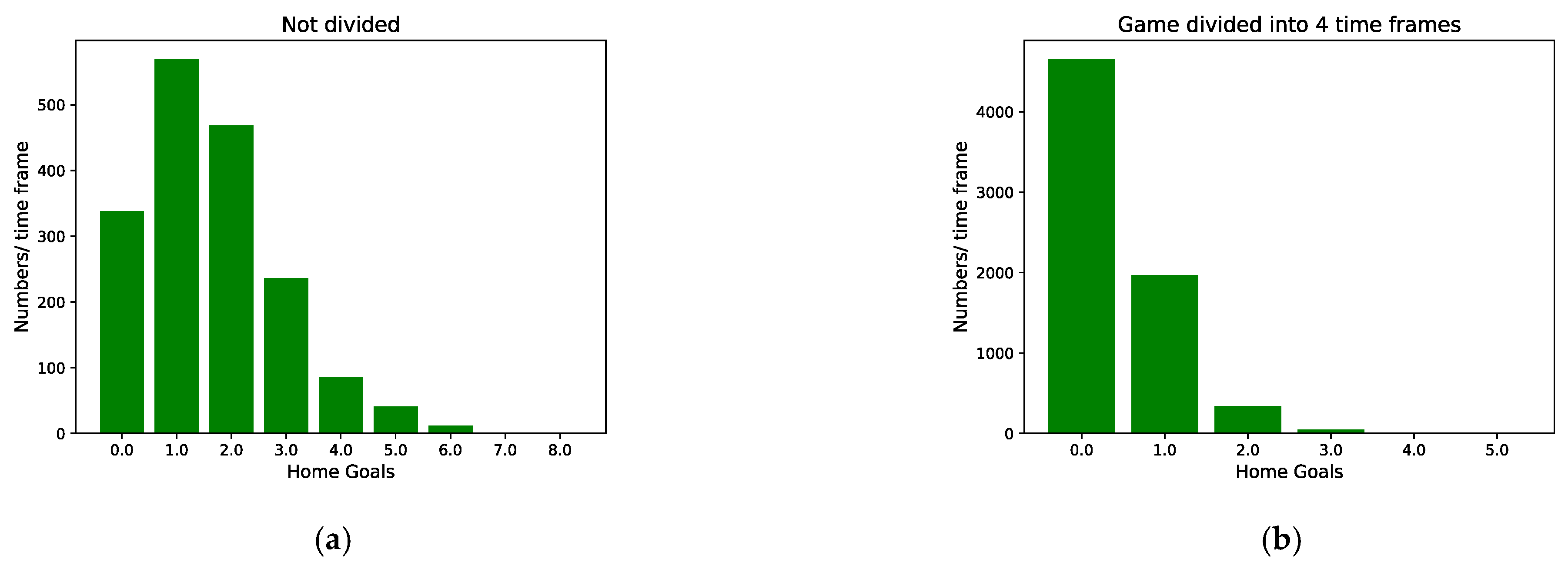
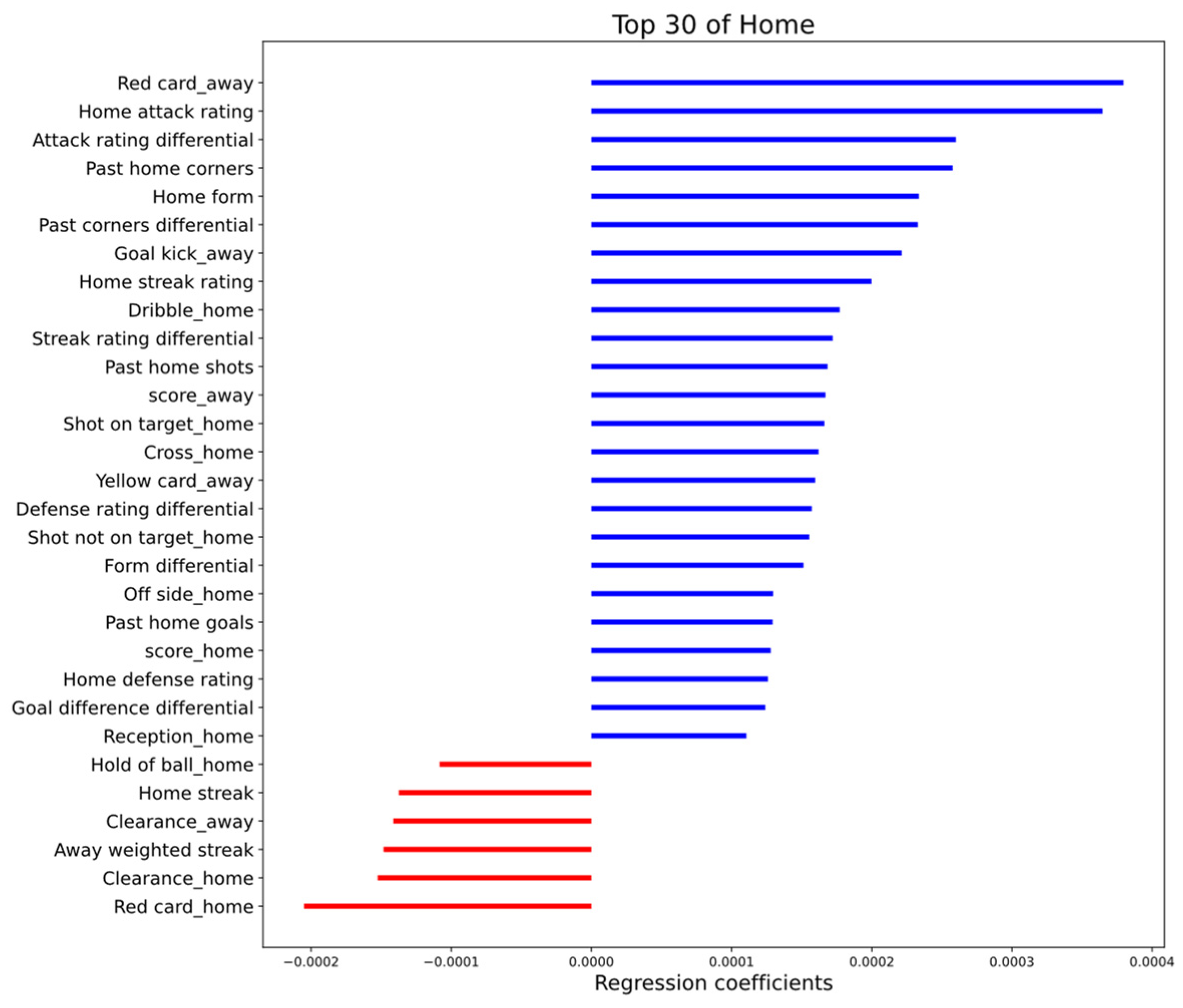
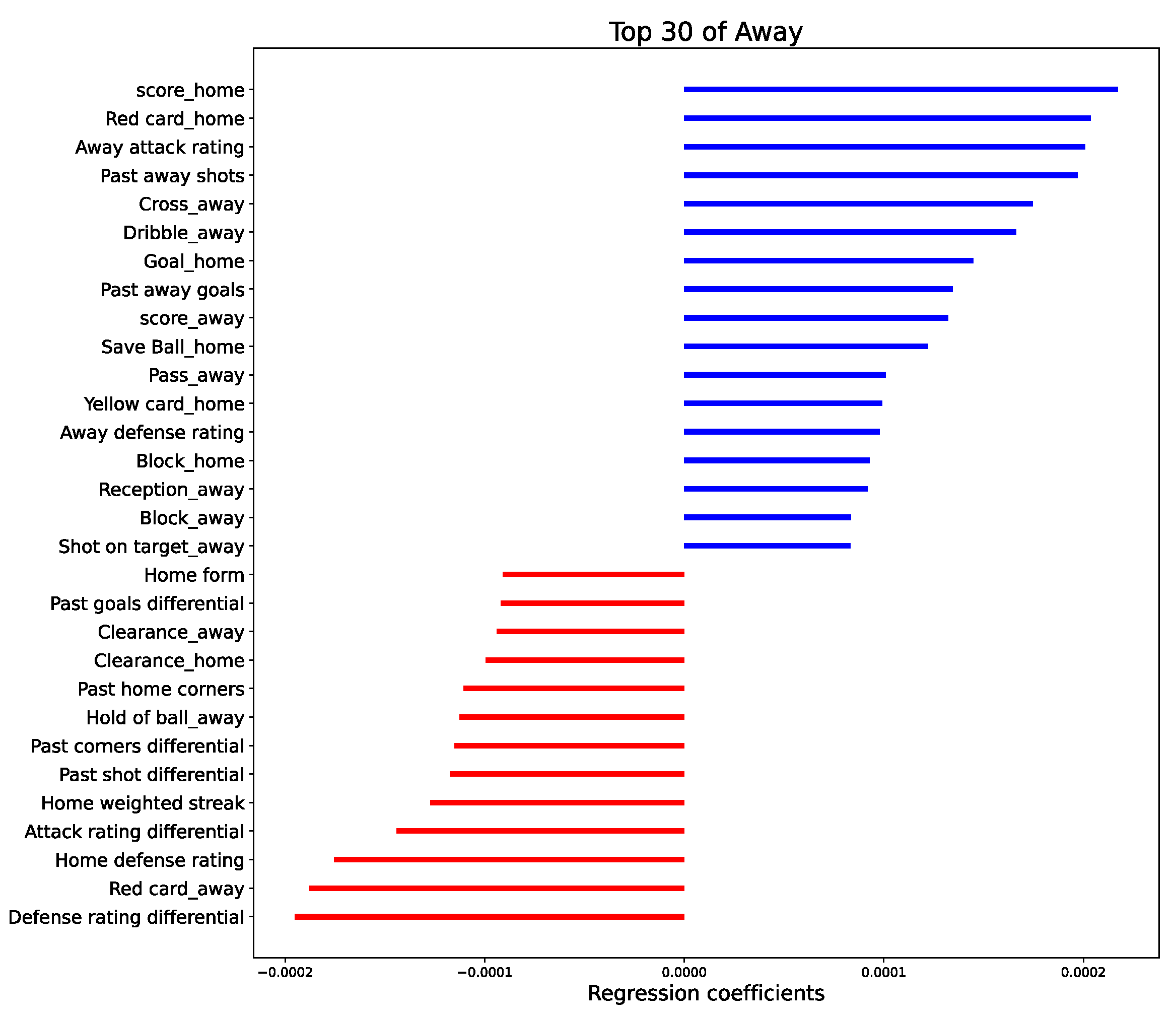
3.2. Method Evaluation
For evaluation purposes, this article compares IGSOP with two other methods. In other sports [
23,
24,
25], result-based methods employ machine learning models for classification to directly predict the probability distribution of the outcome. The result-based method treats the predictions as a classification problem. This paper chooses this multiclass classification (MC) method [
23,
24,
25] as a baseline method. MC is a general method but it will be hampered by the problems associated with the nature of low-scoring games and frequent draws in soccer, as to be discussed in the later experiments. In this paper, MC employs Logistic Regression Classifier [
25] to predict final outcomes of games. The target variables of MC are the classification of game outcomes.
The other method is the one proposed by Robberechts et al. [
21]. This paper names this method Poisson distribution (PD). It is a goal-based method that first predicts the distribution of goals and then the game outcomes. PD utilizes machine learning algorithms to estimate scoring intensities (the expected value of the Poisson distribution) and uses Poisson distributions to represent the probability of scoring a goal. Next, PD estimates the final outcome based on the future goal distribution of both the home and away teams. PD can better cope with these changes in momentum that often happen after scoring a goal by modeling the number of future goals. However, since the parameters of the Poisson distribution are time-varying, it is difficult to estimate. Slightly different from the method in [
21], PD does not use the ADVI algorithm [
28] to predict the target variables but the same Ridge Regression algorithm as IGSOP. The target variables of PD are the number of future goals scored by the home and away teams after time
.
Except for the difference in the target variables, all methods are trained with the same set of features. To improve performance, a 5-fold cross-validation grid search is performed for parameter of Logistic Regression Classifier used by MC and parameter of Ridge Regression used by IGSOP and PD.
We measure the accuracy of our forecasting method with the ranked probability score (RPS) [
41,
42]. The RPS proved to be more appropriate in assessing probabilistic soccer game predictions than other more popular metrics [
43]. The RPS is a scoring function suitable for evaluating the predictions expressed as probability distributions. In soccer outcome prediction, RPS reflects that if the observed outcome is a home win, then a prediction of a draw is more accurate than a prediction of an away win. The RPS represents the difference between cumulative predicted and observed distributions, and is calculated as follows:
where
is the number of potential outcomes, and
for home win, draw, and away win in our task. Let
denote the vector of predicted probabilities for a home win (
), draw (
), and away win (
), and let
denote the vector of the real results. For the away win
, if the predicted outcome is
, then the RPS is 0.1. The smaller the RPS, the better the prediction is.
Table 5 gives the average RPS of the three methods for the first half, the second half, the last 25% of games, the last 10% of games, and the whole game. As shown in
Table 5, IGSOP outperforms MC and PD in terms of RPS values. In particularly in the second half of the game, the improvement is more pronounced. In the last 10% of the game, the RPS value of the comparison PD was 58% lower than that of the MC, and the RPS value of IGSOP was 6.4% lower than PD.
The MC method is a pure machine learning approach, predicting game outcomes based on features extracted from current and past states of the game. Current scores by both teams, being treated as merely one of the features by MC, are not given specific consideration. PD and IGSOP, on the other hand, predict goals to be made by both teams during the remainder of the game and adds them to the current scores to make the final prediction. In other words, these two methods put more emphasis on current scores than MC does as the game approaches its end, and thus make better predictions over MC during late games.
To compare in-game outcome predictions, a pre-game outcome prediction model is trained by the XGBoost algorithm with all the pre-game features used by IGSOP. The RPS value of this model on the same test set is 0.2083. This result demonstrates that the added in-game features significantly improve the outcome prediction.
To further demonstrate how significant those differences are, we perform the 5 × 2 cv paired
t-test [
44] to statistically analyze the performance of these methods. The 5 × 2 cv paired
t-test performs the 2-fold cross-validation 5 times, where, in each repetition, the available data are randomly split into two equal-sized sets. Each of the methods,
A and
B, is trained on each of the sets and is tested on the other, correspondingly. In each of the 5 iterations, the 5 × 2 cv
t-test computes two performance differences:
where
and
represent the performance of methods
A and
B on dataset 1, respectively. Then, the mean and variance of the performance differences are calculated the following way:
The variance is computed for the five iterations and then used to compute the
t-statistic as follows:
where
is the
obtained from the first iteration.
Table 6 shows the calculated
t-statistic and
p-values. Considering these values and significance level
, IGSOP is significantly better compared to MC but not compared to PD. Then, we run a 5 × 2 cv paired
t-test to compare IGSOP and PD during the last 10% games, and we obtain a
t-statistic of −2.593 and a
p-value of 0.048 < 0.05, which means IGSOP does give a better performance than PD during the last 10% games. The final moments of soccer games are often more dramatic, better accuracy leads to greater profitability in both betting and game broadcasting.
At the core of the PD method stands the scoring intensity, which is defined as the expected value of the Poisson distribution that models the number of goals scored by each team in the remainder of the game. The scoring intensity, and the features derived from state of the game that are used to predict it through a machine learning approach, are both time dependent. This introduces great complexity to the algorithm, which grows even greater as the game evolves towards the end as more time-dependent features are involved, and eventually impact the performance of PD during the final moments of games. Test results back up such concern, as the advantage of IGSOP over PD method grows remarkably as the game matures, in terms of prediction accuracy.
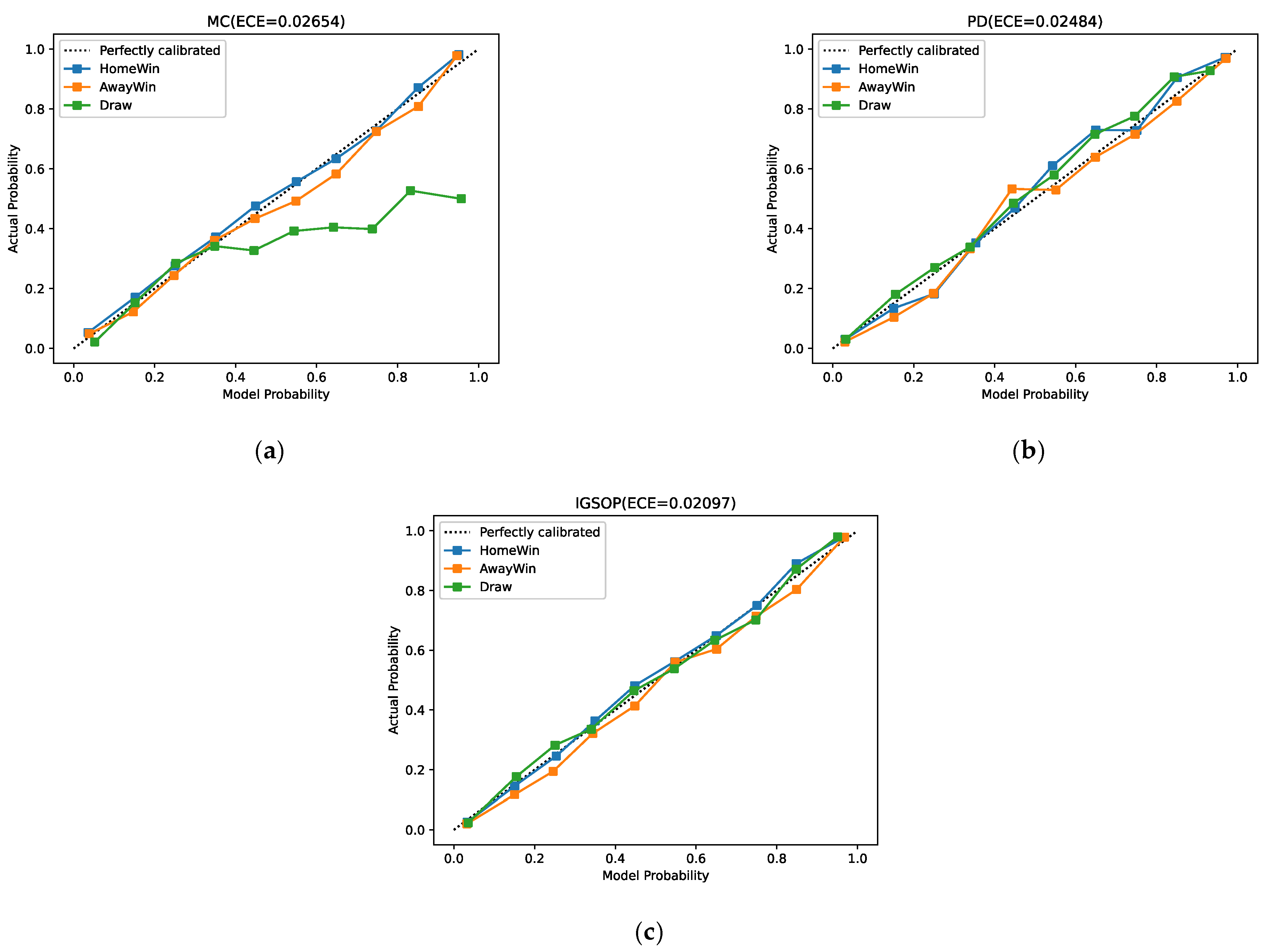
For the outcome prediction model, in addition to the gap between the outcome value and the actual value, the calibration of the model needs to be provided to evaluate the performance of the model. In other words, the probability associated with the predicted class label should reflect its ground truth correctness likelihood. For example, when a perfect calibrated model predicts that a draw will occur with 0.3 probability, this means that if 100 games with the same state are played simultaneously, there will be approximately 30 draw games. Our experiments employ the calibration curves [
45] and expected calibration error (ECE) [
46] as evaluation metrics to assess model calibration. The calibration curve is a visual representation of model calibration. If the model is perfectly calibrated, the calibration curve will be a standard diagonal line. Meanwhile, ECE is a scalar summary statistic of calibration that can compare the difference between two models directly and clearly. To estimate the expected accuracy from limited samples, the predictions are divided into
bins and calculated as a weighted average of the accuracy differences for the bins. The ECE can be computed as:
where
is the number of bins, which is set to 10 in our experiments.
is the number of samples, and
is the number of samples in the bth box.
represents the average value of the actual labels of the samples in the bth box, and
is the average value of the predicted probabilities in the bth box. The smaller the ECE, the better the calibration.
The calibration curves and ECE of IGSOP, MC, and PD are displayed in
Figure 3. From the title of these figures, we can see that the ECE value of IGSOP is 0.02097, which is significantly better than MC and PD. As is shown in these calibration curves, IGSOP curve fits the diagonal excellently in all three cases: home wins, away wins, and draws. The calibration curve of PD also fits the diagonal well but is inferior to IGSOP. Nevertheless, MC fails to perform in predicting draws, as its calibration curve of draws is completely off the diagonal. This is because the machine learning algorithm used by MC directly predicts win/loss of a game instead of actual scores, yet it fails to put extra effort into the draw game situation, which results in a trained model where win/losses are overly represented, and draws are inappropriately under. In contrast, IGSOP calibration curve of draws is the best of these three methods.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}