4.2. Datasets and Evaluation
As shown in
Figure 5, the proposed model is examined on four popular public benchmark datasets: 300W-LP [
21], BIWI [
23], AFLW2000 [
22], and UPNA [
24].
300W-LP: The 300W-LP [
21] dataset is an extended version of the 300 W [
51] dataset, which has over 120 k images for face alignment with 68 landmarks.
BIWI: The BIWI dataset [
23] has 24 videos produced from 20 subjects, totaling 15,678 frames, each corresponding to both RGB and depth images. Since face position is not offered in this dataset, in our study, Yolo5-face [
52] is employed to produce the persons’ head borders.
AFLW2000: The AFLW2000 [
22] dataset is derived from the first 2000 images in the AFW [
53] dataset with 68 landmarks. Faces in this dataset have complicated pose variations and backgrounds.
UPNA: The UPNA [
24] dataset has 10 groups, each with 12 videos from one subject. Each video contains only a single direction of head pose variation and uses 54 landmarks, totaling 36,000 images. The face deflection range in this dataset is small and solitary.
For comparison with other the-state-of-the-art approaches, as stated in Hopenet [
15], FSA-Net [
10], and TriNet [
11], the same training and testing setup is used in our study, and the images with Euler angle deflection outside of −99° to 99° are filtered out. In particular, it is discovered that the angle distributions of the UPNA and BIWI datasets are between [−48°, 36°] and [−75°, 85°], respectively.
Figure 5 shows samples of the datasets, and this study is conducted in the following two scenarios:
- (1)
The model is trained and evaluated on the datasets of 300W-LP, BIWI, AFLW2000, and UPNA.
- (2)
In total, of the BIWI and UPNA datasets are employed for training and for testing. The train set is not crossed with the test set. For example, in the BIWI dataset, 16 videos are employed for training and 8 videos for testing.
In all of the above studies, to assess the performance of the proposed model, the MAE is used as the loss function.
4.3. Competing Methods
To show the effectiveness, we compare the proposed approach with other state-of-the-art approaches on public benchmark datasets, with data from either the original article or experimental findings.
The following is a brief description of previous work related to the proposed model, all based on RGB images. Dlib [
1] addresses 2D to 3D fitting challenges by matching face landmark points for head pose estimation. 3DDFA [
21] employed a CNN to develop an approach for fitting 3D face models to 2D images that skips the step of facial landmark detection. There are also more popular methods that do not rely on key points. For example, Hopenet [
15] suggested a concept of head pose estimation without key points based on Resnet-50, considerably enhancing the model’s performance under complex scenes. Thereafter, FSA-Net [
10] introduced the idea of soft stagewise regression and developed a fine-grained structural mapping to capture spatial features. QuatNet [
16] employed a multivariate loss function based on quaternion to address the difficulty of the non-stationary property caused by Euler angle representation. FDN [
13] elaborates a feature decoupling network with cross-category center loss to restrict the distribution of the latent variable subspaces. MFDNet [
12] constructed the triplet module and the matrix’s Fisher distribution module to address the uncertainty of head rotation. TriNet [
11] re-labeled dataset samples using orthogonal constraints on the three vectors and assessed them using MAEV. To enhance the accuracy of head pose estimation for drivers, ref. [
54] proposed a spatial temporal vision transformer (ST-ViT) model, taking a pair of image frames rather than one single frame as the input.
4.4. Experiment Results
We explore the performance variation of the model using different backbone networks. The comparison between three various backbones (including ResNet-50, ResNext-101, and the latest ConvNext) is given in
Table 1. Notably, in this study, all orientations are shown in degrees.
First, we note that “w” denotes with the proposed method (see the odd rows in
Table 1), and “w/o” denotes without the proposed method (see the even rows in
Table 1). The comparison between the odd and even rows shows that the proposed method can improve the model performance for all three backbones. Taking ResNet-50 as an example, by introducing the proposed method, the average MAE value (of yaw, pitch, and roll) on the AFLW 2000 dataset can be improved from 6.16° to 4.40°, and the average MAE value (of yaw, pitch, and roll) on the BIWI 2000 dataset can be improved from 5.18° to 3.56°.
Second, the comparison between the three backbones show that the best performance can be achieved by using ResNet-50. Taking the validation on the AFLW 20,000 dataset, for example, the MAE values on ResNet-50, ResNet101, and ConvNext are 4.40°, 5.62°, and 7.84°, respectively. Since the best results are achieved with the ResNet-50 backbone, the experiments will be conducted on ResNet-50.
Table 2 and
Table 3 show the findings of our proposed model, which is compared with other state-of-the-art approaches. We note that the proposed model is trained on the 300W-LP dataset. In
Table 2, the test results on the AFLW2000 dataset are shown. From this table, we can see that the proposed model THESL-Net attains the minimum error on a roll, and the MAE is somewhat higher than that of MFDNet, but the structure of the proposed approach is much simpler and thus can be readily conducted on other models. Furthermore, in
Table 3, the test results on the BIWI dataset are shown. From this table, we can see that THESL-Net realizes the best performance with an MAE reduction of 0.06° compared to the second-best approach (MFDNet). The proposed approach does not rely on landmark detection, and the loss limitation factors can be adjusted automatically with the evaluation process without additional settings.
Table 4 reveals the findings compared with other approaches on the BIWI dataset, where 70% and 30% of the data were employed for training and testing, respectively, without crossover. All compared methods are based on RGB, and the finding of Hopenet [
15] are derived from re-runs in [
11]. THESL-Net is first fine-tuned, resulting in the best finding on yaw, and the MAE decreases by 0.36° compared to the second place. Other indicators are also in the upper middle position, which indicates the effectiveness of our tiered estimation concept.
The performance of the proposed method on the UPNA dataset is given in
Table 5, where ‘/’ means the corresponding value is not given in the original article. To make a fair comparison, we make up the experiment by using 90% of the UPNA dataset for training and 10% of the UPNA dataset for testing. From this table, it can be seen that the best MAE was achieved by the proposed method when using the same dataset-partitioning method.
To examine the influence of head deflection angle range on the proposed model, we further compare the BIWI dataset with the UPNA dataset and generate the findings as shown in
Figure 6. Both datasets are obtained in an experimental setting with low disturbance, containing three angles of different intervals. We only employ the MAE to evaluate the change in model performance. The experimental findings reveal that the proposed model has good performance in various angle ranges.
Table 6 shows the details. Equation (10) shows further development of a new loss function, which consists of MSE and MAEV. It is compared with the proposed approach to show the extent to which the loss function and labeling affect the angle estimation discontinuity, as shown in
Table 6.
By combining the loss limitation and the rotation matrix, as shown in Equation (11), the overall loss increases instead.
A reasonable explanation is that loss-limiting and labeling approaches have similar influences, and simply adding them together equals , which destroys the loss function’s coordination within 1° of the prediction error again.
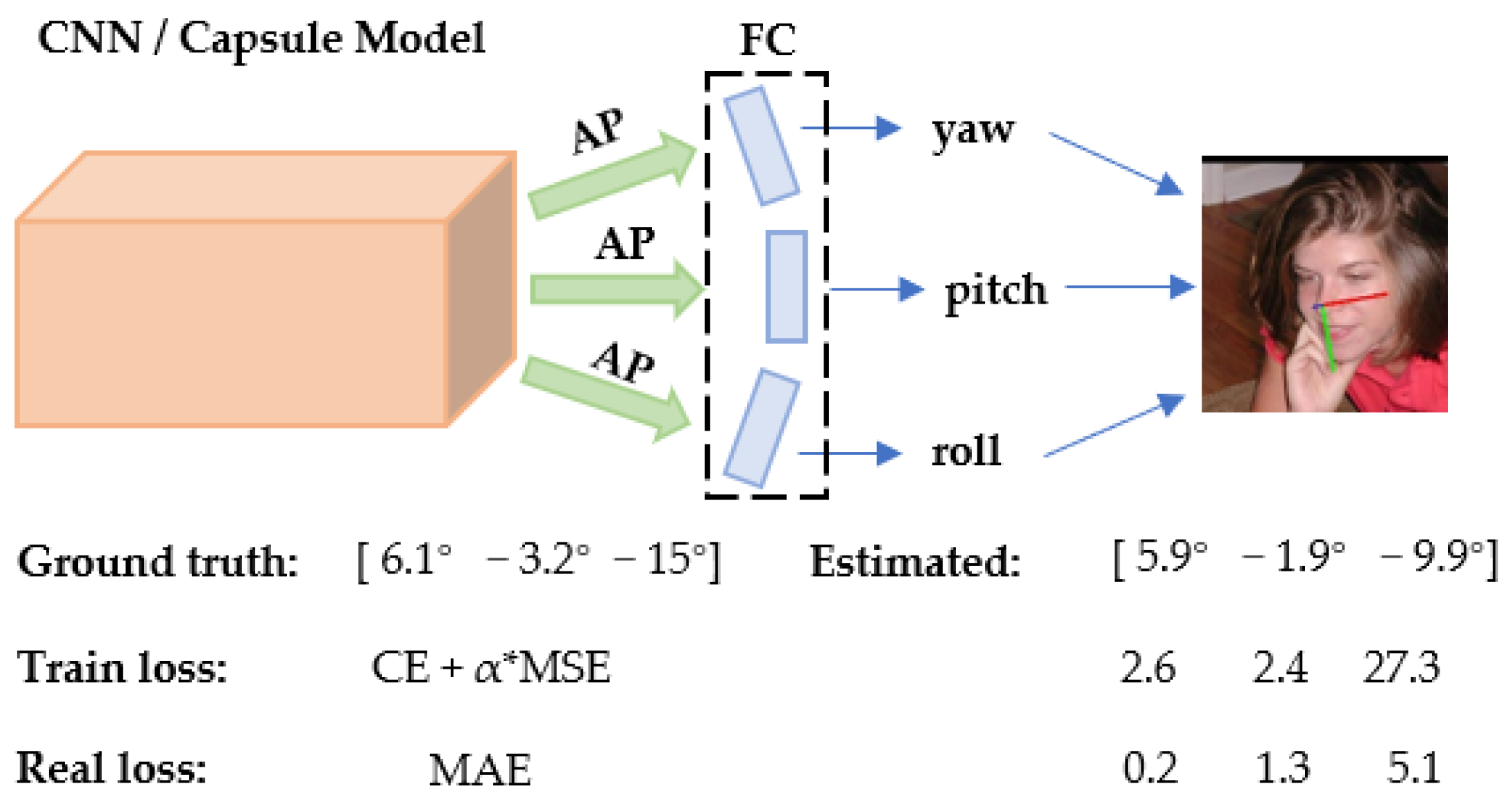
4.5. Visualization
In this section, the process of model training and the comparison between different approaches are visualized. First,
Figure 7 shows the performance of the proposed approach in the case of occlusion and significant angle deflection. We have selected a part of the images with significant angle deflection in the AFLW2000 dataset. Both the Hopenet and THESL-Net models, which have a similar backbone, are employed to forecast the head pose. We plot various colored lines to visualize the head deflection, where the blue, green, and red lines are used to indicate the front, bottom, and side of the face, respectively. Our approach minimizes the MAE by more than 10° in deflection cases and also reduces the MAE by about 4° for the case where the face is obscured.
Figure 8 shows the function of the tiered estimation module in the training process. A batch of features generated from the backbone network is taken as input, and then a 1 × 1 convolution layer is used to deflate the number of channels. The three colors in the figure denote the respective regions of interest in the estimation task of yaw, pitch, and roll. Finally, the features after weight assignment go through a layer of
convolution to reduction channel numbers before outputting to the linear layer. Notably, we use the external attention mechanism to detect common features among different character samples, although other tasks may require different attention mechanisms. The concept of tiered estimation minimizes the influence of fine-tuning between the three angles.
Furthermore, demonstrating the changes more explicitly in the model during the training process, Grad-CAM [
50] is employed to visualize the areas that the model focuses on before the tiered layer, as shown in
Figure 9: columns (a) and (c) have separate identities, columns (a) and (b) have different postures, and columns (a) and (d) are both different. As the training epochs improve, the external attention makes the model’s area of interest gradually focus on those common features, which leads to good robustness in the head pose estimation model for people with a similar pose, but separate identities. Additionally, for the same person, the regions that the model focuses on are alsso different for different head poses. This indicates that the proposed model is simultaneously identity-robust and pose-robust.
4.6. Ablation Study
In this section, the effect of different blocks (tiered estimation module and various loss limits) on the THESL-Net model performance is investigated. The ablation studies are performed following the enhancement of Resnet-50; the three techniques used are shown in
Figure 4. For this, two sets of studies are developed. The first set is trained on 300W-LP and tested on the AFLW2000 and BIWI datasets. The second set employs 70% of each of the BIWI and UPNA datasets as the training set, and 30% as the test set. Each set of studies examines the influence of with/without the tiered idea and with β/2β/without loss limit on the findings differently. The experimental findings are shown in
Table 7 and
Table 8.
As observed in
Table 7, the MAE of the base model is 5.65° on AFLW2000 and 4.82° on the BIWI dataset when either module is not used. However, the model performance is significantly improved when either of the two modules is added alone. Among them, the performance of THESL-Net is optimal when using the tiered module with loss limit
, which reduces by 1.25° and 1.26° on the AFLW2000 and BIWI datasets, respectively. This shows that both of our strategies are effective.
In
Table 8, we introduce the ablation findings for the BIWI and UPNA datasets, which have different angle distribution ranges, whereas the UPNA dataset alone has a smaller and more concentrated one. The losses using the best combination in the BIWI and UPNA datasets are minimized by 0.94° and 1.39°, respectively, and the final MAE of the two are not considerably different, indicating that our model performs well at various angle ranges.
Figure 10 further reveals the details of the experimental findings for each module of the model at various angles. As seen from the figure, using the combination of the two techniques always attains optimal findings.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}