1. Introduction
Motivated by applications in tamper-resilient hardware, Dziembowski, Pietrzak, and Wichs [
1] introduced non-malleable codes as a natural generalization of error correction and error detection codes.
The error correction and the error detection codes are the most basic objects in the codes theory. They do, however, have significant drawbacks, which makes them unsuitable for the applications to tamper-resilient cryptography. In the case of error correction codes, the message can be retrieved as long as only a limited number of positions of the codeword have been flipped; however, it is hard to find a scenario where an adversary would limit himself to flipping only a few positions when given access to the whole codeword. The error detection codes face a different interesting challenge, namely whatever tampering limitations we impose on the adversary (be it polynomial time, bounded memory or some structure limitations like split-state), the adversary can not be allowed to overwrite the codeword. Overwriting a codeword with another valid pre-computed codeword makes the detection of tampering clearly impossible. However, overwrites are quite simple attacks, and the adversary wipes the memory of the device, and uploads some new data. While this attack seems irrational, there are scenarios when partial overwrites are realistic attacks on the scheme (Those attacks often allow the adversary to gradually learn the underlying secret key. They are especially prevalent in the natural scenarios where the adversary gets to tamper with the device multiple times.). Naturally, we would like to allow for a wide spectrum of attacks including overwrite attacks.
Motivated by this, Dziembowski, Pietrzak, and Wichs [
1] considered a notion of non-malleable codes (NMC). It was a weakening of detection/correction codes based on the concept of
non-malleability introduced by [
2].
The model is very natural and clean. We start with the message m, we encode it , and then we store the encoding on the device; the adversary picks any adversarial function (where is a class of tampering channels), a codeword is tampered to , and, after decoding, we obtain . In the error-correction codes, we would like ; in the error-detection codes, we would like or (where ⊥ is a special symbol denoting detection of tampering). As we already discussed, if the family of channels contains constant functions, then neither correction nor detection is possible. There is, however, a meaningful definition that can be considered here. Non-malleable code against the family of channels guarantees that, after the tampering above, or is completely independent of m; for instance, is not possible.
Dziembowski, Pietrzak, and Wichs formalized this notion using the simulation paradigm: the output of the experiment can be simulated by a simulator that depends only on the adversarial channel t (and not the message m), and is allowed to output a special symbol which is replaced by the encoded message m.
Definition 1 (Non-malleable codes [
1]).
A pair of randomized (Ref. [1] defined to be deterministic; however, here we allow decoding to be randomized; it is not clear if randomized and deterministic decoding are equivalent; in particular, no strong separations are known.) algorithms, , is an ε-non-malleable code with respect to a family of channels , if the following properties hold:- 1.
(Correctness)
For every message ,, where the probability is over the randomness of the encoding and decoding procedures. - 2.
(Security)
For every , there is a random variable supported on that is independent of the randomness in , such that, for every message where denotes statistical distance (total variation distance) at most ε, and the function is defined as
A few years later, Aggarwal, Dodis, Kazana, and Obremski [
3] introduced an alternative perspective on non-malleable codes by introducing the notion of non-malleable reductions. To intuitively describe a non-malleable reduction, imagine the scenario discussed earlier, where the message
m is encoded as a codeword
c, and
c is tampered using
into
. The tampered codeword
decodes to
. A non-malleable reduction from
to
guarantees that
, where
g is a possibly randomized tampering function sampled from
. In particular, if the family of functions
contains only the identity function and all constant functions, then the corresponding non-malleable reduction is a non-malleable code for
.
The relaxed guarantees of a non-malleable code may seem a bit arbitrary at first glance; however, the object has natural applications in tamper resilient hardware. In the 1990s, high profile side-channel attacks on a number of cryptographic schemes were published that broke security by evaluating the schemes on a sequences of algebraically-related keys [
4,
5]. A number of ad-hoc solutions for these “related-key attacks” were suggested, and eventually theoretical solutions were proposed by Gennaro, Lysyanskaya, Malkin, Micali, and Rabin [
6] as well as Ishai, Prabhakaran, Sahai, and Wagner [
7].
In [
6], the authors addressed tampering attacks with a solution that assumes a (public) tamper and leakage resilient circuit in conjunction with leakage resilient memory. The justification for using tamper and leakage resilient-hardware was two-fold: (1) leakage-resilience had been addressed far more systematically in the literature and existing approaches could be applied off-the-shelf, (2) because the tamper and leakage resilient circuit was public (in particular, contained no secret keys), it was safer to assume appropriately hardened hardware could be responsibly manufactured; their approach was to sign the contents of memory with a strong signature scheme. Unfortunately, this also makes it infeasible to update the memory without a secret key (which would again need to be protected). In [
7], it was shown how to compile a circuit into a tamper-resilient one, building on ideas from secure computation. Unfortunately, the tampering attacks handled by this approach are quite limited, and it has proven difficult to extend their results to more general tampering attacks.
Dziembowski, Pietrzak, and Wichs motivated non-malleable codes as a means of extending the approach of [
6]. They considered the same model of a tamper and leakage resilient (public) circuit with leakage-resilient memory, but instead of signing the memory (using a secret key), the memory is encoded with a (public) non-malleable code. This allows the tamper and leakage resilient circuit to update any state in the memory itself by decoding, computing, and re-encoding. In contrast with [
6], where a trusted third party holding the secret signing key is needed to sign new memory contents, this achieves non-malleability for stateful functionalities. The downside is that, while a strong signature scheme is resilient to arbitrary polynomial time tampering attacks, efficient non-malleable codes (because they are public) have no hope of handling such attacks (See Feasibility below, as well as
Section 7 for more details).
It is not difficult to see that non-malleable codes only exist for restricted classes of channels : otherwise, one can always consider the channel that decodes the message, flips a bit, and re-encodes the resulting message. Thus, the natural question to ask is against which classes of tampering channels is it possible to build non-malleable codes. As a first result, Dziembowski, Pietrzak, and Wichs gave an efficient, explicit construction of a non-malleable code against channels that can tamper each codeword bit independently (so-called “bitwise tampering”). They additionally provided a non-constructive argument that -non-malleable codes exist for any class of channels that is not too big, i.e., . They left constructing explicit codes for larger, richer classes of channels as an open problem.
A well-studied class of tampering functions is the 2-split-state model where the codeword consists of two states
L and
R, and the adversary tampers with each of these states independently. This is a very large class of tampering channels that, in particular, includes the bitwise tampering family of channels mentioned above. We now sketch the landscape of this area and particularly summarize the results on 2-split-state NMCs in
Table 1. In [
1], in addition to introducing non-malleable codes, the authors also introduced a model of tampering called the
t-split-state model, where the codeword consists of
t independently tamperable states. They give the first NMC constructions in the
n-split-state model (We already mentioned this result above as a non-malleable code against bitwise tampering. We mention it again just to emphasize that bitwise tampering is a special case of split-state tampering) (where
n is the codeword length) and the 2-split-state model (using random oracles). Dziembowski, Kazana, and Obremski [
8] provided the first construction of 2-split-state NMCs without any assumptions. Their construction enabled encoding of 1-bit messages and used two-source extractors. The first NMC in the 2-split-state model for
k-bit messages was given by Aggarwal, Dodis, and Lovett [
9], which used inner product extractors with tools from additive combinatorics. In [
10], Cheraghchi and Guruswami studied the optimal rate of the non-malleable codes for various tampering families, where the rate of a code is defined as
. In particular, they showed that the optimal achievable rate for the
t-split-state family is
. Note that, in the split-state tampering model, having as few states as possible is most desirable, with two states being the best achievable. By the above result, the best possible rate for the 2-split-state model is therefore
. A long series of works (Other works have considered non-malleable codes in models other than the 2-split-state model or under computational assumptions [
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26]). Refs. [
3,
24,
27,
28,
29,
30,
31,
32,
33,
34,
35] have made significant progress towards achieving this rate. We now discuss some of these results. The work of Cheraghchi and Guruswami [
27] gave the first optimal rate non-malleable code in the
n-split-state model (where
n is the codeword length). More importantly, this work introduced non-malleable two-source extractors and demonstrated that these special extractors can be used to generically build 2-split-state NMCs. This connection has led to several fascinating works [
28,
29,
30,
31] striving to improve the rate and number of states of non-malleable codes. Most notably, Chattopadhyay and Zuckerman [
28] built a 10-state NMC with a constant rate, making this the first constant rate construction with a constant number of states. They achieve their result by first building a non-malleable extractor with 10 sources and then using the connection due to [
10] to obtain the corresponding non-malleable code. The work of Kanukurthi, Obbattu, and Sekar [
32] used seeded extractors to build a compiler that transforms a low rate non-malleable code into one with high rate and, in particular, obtained a rate
,
state non-malleable code. This was subsequently improved to three states in the works of Kanukurthi, Obbattu, and Sekar [
33] as well as Gupta, Maji, and Wang [
24]. Li [
31] obtained 2-split-state NMC with rate
(where
is the error). Particularly, this gave a rate of
, for negligible error
, and a constant rate for constant error, making this the first constant rate scheme in the
split-state model. The concept of non-malleable reductions due to [
3] was used to build the first constant rate NMC with negligible error in the 2-split-state model [
34]. In a recent work, Ref. [
35], it was shown that the construction from [
32] (with rate
) is actually non-malleable even against two split-state tampering (and hence is nearly an optimal rate construction for two split-state tampering).
The split-state tampering model is a very natural model. In particular, there are cryptographic settings where the separation of states is natural, like in secret sharing or in multiparty computation (MPC) scenarios. Non-malleable codes in the split-state model have found many applications in achieving security against physical (leakage and tampering) attacks [
1,
36], domain extension of encryption schemes [
37,
38], non-malleable commitments [
39], non-malleable secret sharing [
40,
41,
42,
43], non-malleable oblivious transfer [
44], and privacy amplification [
45]. We discuss the application to non-malleable commitments in more detail in
Section 8.
Additionally, non-malleable codes in the split-state model have found many applications in the construction of non-malleable codes against other important and natural tampering families, as mentioned below:
Decision tree tampering ([
46]): each tampered output symbol is a function of a small polynomial number of (adaptively chosen) queries to codeword symbols.
Small-depth circuit tampering ([
46,
47]): the tampered codeword is produced by a boolean circuit of polynomial size and nearly logarithmic depth.
(Bounded) Polynomial-size circuit tampering ([
48]): the tampered codeword is produced by circuit of bounded polynomial size,
for some constant
d, where
n is the codeword length.
Continuous NMCs ( [
16]): the tampering is still split-state, but the adversary is allowed to tamper repeatedly until the tampering is detected.
The applications to decision tree tampering, small-depth circuits, and polynomial size circuit tampering are discussed in
Section 7.
Organization of the Paper
Section 2 contains preliminaries and definition of non-malleable reductions, and the reader may refer to it when required;
Section 3 contains a gentle introduction to different variants of non-malleable codes and their properties such as secret sharing and leakage-resilience.
In
Section 4, we give the first, and arguably the simplest, construction of non-malleable codes in the split-state model [
9]. The simplicity made it a particularly useful tool for several follow-up works that required non-standard properties from the underlying non-malleable code.
In
Section 5, we briefly mention two-source non-malleable extractors, and their connection to non-malleable codes in the split-state model, as well as to other cryptographic primitives.
In
Section 6, we give an overview of the rate amplification technique from [
32,
33,
34,
35] that gives an almost optimal rate non-malleable code in the split-state model.
In
Section 7, we survey some of the applications of split-state non-malleable codes to constructing non-malleable codes against computationally bounded tampering classes. In particular, we give an overview of the techniques in the following works: Ref. [
46] for small-depth decision trees, Ref. [
47] for small-depth circuit tampering, and Ref. [
48] for polynomial size circuit tampering.
In
Section 8, we give a construction of a non-malleable commitment scheme due to [
39] that is one of the most important applications of non-malleable codes in the split-state model.
3. Basic Properties and Variants of Non-Malleable Codes and Continuous Non-Malleable Codes
In this section, we will discuss various basic properties of the 2−split state non-malleable codes, as well as numerous variants of their definitions.
3.1. A Few Examples
As a warm up, we will go through few basic examples of codes that are not non-malleable.
Example 1. To encode , we pick and uniformly random such that .
Above clearly is not a non-malleable code: pick and ; then, ; we have changed the message, but the message is not independent of the original message.
Example 2. To encode , pick uniformly random such that , where stands for the inner product over .
Again, the attack is quite simple: pick and let , , then . Again, the message has changed but remained strongly correlated with the original message. The above attack depends on ; however, over , we will not have any other option. Thus, maybe let us consider the following code:
Example 3. To encode , pick uniformly at random such that , where stands for the inner product over .
Sadly again, there is a simple attack; let
(and
respectively) be equal to
L (and
R respectively) on all positions except the last, we will set the last position to
(and
). Now, with probability
, we have
, and with probability
we have
. This can not be a non-malleable code, as [
8] showed for single bit message (We also assume that
, i.e., there are no invalid codewords): if we can flip the output of the Decoder with probability greater then
(plus some non-negligible factor), then the code can not be non-malleable.
3.2. Secret Sharing
We will show that the split state non-malleable code has to be a 2 out of 2 secret sharing. Let be two messages and let and . If given , we could guess i, and we would be able to tamper the codewords in a way that and , where are two fixed distinct messages (different than ). This clearly breaks non-malleability since the original messages are not preserved, but the messages after tampering are correlated with the original messages: tampered message is if and only if the original message was . This conveys the main intuition: if the message is not preserved, then tampered message should not reveal the original message.
Let us construct the above-mentioned attack: find such that and (we know they must exist else r alone would determine the output of the decoder, and we could carry on the same attack on the right state). Now for the tampering: we will completely overwrite the right state , and, given , if we think , we will tamper with ; if we think that , then we tamper with ; this gives the desired result.
To be more precise, we recall the theorem from [
20].
Lemma 10 (from [
20])
. If is an non-malleable code, then for any two messages , and for and , we obtain: 3.3. Leakage-Resilience
Thus far, we only discussed active adversary that tampers the states. It is natural to consider its weaker version: a passive adversary.
A long time ago, we thought of a cryptographic device as a box that holds a secret key and has a strictly defined interface, and the attacker is only allowed to use that well-defined input/output interface. However, no device is a true blackbox; it consumes electricity, emits electromagnetic radiation, and has a heat signature and a running time; those values were not predicted in the clean blackbox-security model, and thus the first wave of passive attacks was born. Now the adversary could exploit side-channel information like the one mentioned above and with its help break the security of the device. We often refer to such side information as leakage, and the adversary that exploits it as a passive adversary.
We can start with the following theorem:
Theorem 2 (from [
15])
. Let , and let . Let , be an non-malleable code in the split state model. For every set and every message , Before we get to the proof, notice that one can run the above lemma for the following sets: and and (for the set, the statement is trivial); this means that, given the indicators , , we can not distinguish between and (where encode message ). One should remark that, while the above is just a one bit leakage, one can easily leverage it to the arbitrary size t leakage at the price of the multiplicative penalty in the error; we refer to the similar reasoning below Remark 4.
This is only a mild version of leakage resilience, and we will expand it further in this section.
Below we go over the proof of Theorem 2, and we mention that a similar reasoning forms the core of Remark 4 and Theorem 5.
Proof. We claim that there exist such that , , and are all different from . Before proving this claim, we show why this implies the given result. Let , consider the tampering functions such that if , and otherwise, and if , and , otherwise. Thus, for , if and only if . The result then follows from the -non-malleability of .
Now, to prove the claim, we will use the probabilistic method. Let U be uniform in , and let . Furthermore, let be uniform and independent of . We claim that satisfy the required property with non-zero probability.
It is easy to see that the probability that is either of or is at most . In addition, by Lemma 10, we have that, except with probability , X is independent of U. In addition, W is independent of U. Thus, the probability that is at most . Similarly, the probability that is at most . Finally, are independent of U, and so the probability that is at most .
Thus, by union bound, the probability that do not satisfy the condition of the claim is at most .
As we already hinted, the above is only a mild version of leakage resilience; for the full version, we would expect, for example, that the decoded message along with the leakage does not reveal anything about the message.
To formalize the above intuitive notion, we first have to recall the original definition from [
1]:
Definition 7 (Non-Malleable Code from [
1])
. Let be an encoding scheme. For and for any , define the experiment as:The above represents the state of the message after tampering. The claim that the message has either not changed or is completely independent of the original message is expressed in a following way: We say that the encoding scheme is ε-DPW-non-malleable in the split-state model if, for every function , there exists distribution on (without the access to the original message) such that, for every , we have In other words, there exists a simulator that can simulate the tampering experiment; the simulator has no access to the original message: he can only output special symbol that will be replaced with an original message.
Adding Leakage Resilience to Non-Malleable Codes
To add a true leakage resilience, we have few options:
Tampering functions might depend on the leakages (e.g., [
20,
36,
46]):
We can also consider outputting the leakage along with the tampered message (e.g., [
35,
53]):
In addition, of course, we can also consider a combination of the above, where tampering depends on the leakage, and the leakage is also part of the tampering output:
In all of the above, we expect the (modified) simulator to be indistinguishable from the tampering experiment. In the case of the experiment 2 and experiment 3, we slightly modify the simulator: The
simulates not only the message but also the leakage:
Remark 1. Usually, we consider to be bounded output size leakages. In addition, and might be a series of adaptive leakages depending on each other; then, one has to apply Lemma 4 to obtain the independence of X and Y given the leakages. We have to remark here that Lemma 4 states that X and Y are independent given and ; however, one has to remain vigilant since and might not be efficiently sampleable sources; thus, the extension to the adaptive leakage case is straightforward only in the information theoretic world.
Remark 2. The second definition might seem a bit artificial; however, it is quite useful for technical reasons. Sometimes, non-malleable code is merely one of many building blocks of bigger protocol/application, and the leakage is a byproduct of the technical proof—other parts of the protocol might behave differently depending on the non-malleable encoding (which is most conveniently modeled as a leakage), thus non-malleable code is tampered in a usual way while the rest of the protocol leaks extra information.
The first compiler that returns a leakage resilient (with respect to the variant 1) non-malleable code was given by [
20]; it could tolerate up to
leakage rate (i.e., output size of leakage functions can be up to
of the input size), but it required a symmetric decoder (
). Later, Ball, Guo, and Wichs gave a better compiler:
Theorem 3 (from [
46,
48])
. For any , there exists a compiler that takes any split state non-malleable code and outputs a leakage resilient (with respect to definition variants 1, 2, and 3) non-malleable code with leakage rate α. The rate of the new code is and the error stays the same except for an extra factor (where n is the new code’s length). Remark 3 (from [
46])
. Originally, it only showed that their compiler worked for the variant 1. However, Ref. [48] later extended their analysis to the latter variants. In addition, for the variants 2 and 3, we have the following result:
Theorem 4 (from [
53]).
Any split-state non-malleable code is also non-malleable code that tolerates up to t bits of leakage (with respect to Definition 2 or 3). Remark 4. Originally, the above paper considered Definition 2 only, but simple inspection of the proof gives the security with respect to the variant 3 too.
The idea of the proof is quite simple: we guess the leakage functions (thus the penalty ) and tampering function check if the leakage is consistent with their view; if any of the views does not match the guessed leakage, then the tampering aborts (f or g outputs ⊥, and the decoder aborts). Else, if the guessed leakage is consistent with the views of the tampering functions, the tampering happens as intended.; the above expands the power of tampering functions: instead of , we have ; this is without a loss of generality—in a similar fashion as in Theorem 2, we can show that adding ⊥ as a possible output of the tampering functions does not break the definition.
Later, Ref. [
35] expanded the result from Theorem 4 for augmented (see
Section 3.4) non-malleable codes.
Theorem 5 (from [
35])
. Any split-state augmented non-malleable code is also an augmented non-malleable code that tolerates up to t bits of leakage (with respect to Definition 2 or 3). Similarly, the [
46] compiler also preserves the augmented property:
Theorem 6 (from [
48])
. For any , 2-split-state augmented non-malleable code can be compiled into an augmented split-state -non-malleable code with rate and leakage rate α (with respect to any variant above). 3.4. Augmented NMCS
Many applications require an extra property, namely that adversary on top of receiving a tampered message can get one of the states (similar to the leakage resilience discussed above).
Definition 8 (Left-augmented NMC)
. Let be an encoding scheme. For and, for any , define the experiment as:We say that the encoding scheme is left-augmented
-non-malleable in a
split-state model
if, for every function , there exists a distribution on (without the access to the original message) such that, for every , we have Symmetrically, we can consider the right-augmented property, where the right state is revealed.
Most of the known constructions like [
9,
29,
30,
31,
35] are augmented (both left and right augmented). Interestingly [
33], the non-malleable randomness encoder (see
Section 6.1 for details) is right-augmented but not left-augmented.
3.5. Simulation vs. Game
Definition 7 is the most common simulation-based definition. However, in some situations, it is actually more convenient to consider a game based definition, where the adversary picks two messages ; the challenger encodes for uniformly chosen b, and the adversary has to guess b based on the tampering of .
In particular, the following alternative definition of a non-malleable code will give a smoother transition to the subsequent definitions in this section.
The transition from a simulator to a game is not quite trivial: let and imagine the tampering with and ; now, both messages have been completely overwritten and both tampering experiments should output . However, notice that tampering experiment has two options: it can answer or it can answer , while can only answer . In the above example, can not answer else it will be distinguishable. To solve the dilemma, we have to add an extra “helper” sitting inside the tampering experiment that will decide if the tampering experiment should output or .
Definition 9 (Game definition for non-malleable code, from [
15]).
We say that an encoding scheme is-non-malleable in the split-state model
if, for every function , there exists a family of distributions each on such that for every where In [
15] (Appendix A), the authors show the equivalence of Definitions 7 and 9.
Theorem 7 (from [
15]).
If is an non-malleable code according to the game-based definition, then it is also an non-malleable code according to the definition from [1]. Theorem 8 (from [
15]).
If is an -non-malleable code according to the definition from [1], then it is non-malleable code according to the game-based definition. To prove the above, the authors construct explicit “helper” distribution. There was another game-based definition already considered in [
1], but the above definition is easier to generalize to the definition for stronger notions of non-malleable codes.
3.6. Strong, Super, and Super-Strong Variants
Some results in the literature like [
12,
14] have considered a notion of super-strong non-malleable codes. We start with the following intermediate notion of super non-malleable codes introduced in [
15]. In this variant, if the tampering is successful and non-trivial i.e., output is not ⊥ or
, then the tampering experiment outputs the whole tampered codeword. In other words, we require that, for valid tampering, either tampering does not change the message, or even the tampered codeword itself does not carry any information about the original message.
Definition 10 (Super non-malleable code).
We say that an encoding scheme is -super non-malleable in a split-state model
if, for every function, , there exists a family of distributions each on such that for every where Remark 5. This definition is clearly stronger than the standard version, since, given the tampered codeword, we can apply the decoder and obtain the tampered message.
In [
1], the authors considered a strong variant. This is a variant that follows the standard definition closely except it puts a restriction on the use of
—it can only be outputted only if
(Notice that outputting
in that case is unavoidable). This variant is perhaps the closest to the intuition; if the codeword is tampered with, then it is either invalid or it decodes to something independent of the original message.
Definition 11 (Strong non-malleable code).
We say that an encoding scheme is -strong non-malleable in the split-state model
if for every function and for every where Notice that above we do not need a “helper” distribution anymore since the conditions to output are so restrictive.
Finally, one can consider both the super and strong version. Here, we require that can only be outputted if , and, if the codeword is valid and not trivially tampered with, then the whole tampered codeword does not reveal any information about the original message.
Definition 12 (Super strong non-malleable code).
We say that an encoding scheme is ε-super strong non-malleable in the split-state model if for every function and for every where Examples of the codes:
Ref. [
8] is not super and not strong;
Ref. [
9] is super but not strong;
All non-malleable extractors including [
29,
30,
31] are strong but not super;
Ref. [
9] compiled with [
15] is super and strong.
Informal Theorem 1 (from [
15])
. There exists a compiler that turns any super non-malleable code (with certain sampling properties which we discuss below) in a 2-split state model into a super-strong non-malleable code in a 2—split state model, at a minimal loss to the rate of the code. The above compiler also turns a non-malleable code into a strong non-malleable code. The idea behind the compiler is to introduce a certain level of circularity: ; in other words, the codeword encodes its own “checks”. Notice that the difference between the strong and not-strong variant is only in the use of output. The checks ensure that, if the code was tampered with and still decodes to the same message, then the checks remain unchanged—this leads to the decoder error since the checks will not match the changed codeword.
This approach has a problem: the circularity introduced above does not necessarily allow for efficient encoding, and thus there are additional requirements on the underlying non-malleable code. The authors show that the extra assumptions are fulfilled by the code from [
9], thereby giving a super-strong non-malleable code.
3.7. Continuous Non-Malleable Codes
We can push the definition further; imagine that the codeword is tampered not once, but multiple times. This is the idea behind continuous non-malleable codes. Meanwhile, in principle, we can take any of the four variants: standard, strong, super, super-strong, and extend the definition to multiple tamperings for various technical reasons (The main problem of non-super variants is that, immediately after the first tampering, are not independent anymore given ; this causes huge technical problems; thus, in practice, it is actually easier to aim for the strongest variant. Intuitively speaking remain “somewhat-independent” given , where by “somewhat-independent”, we mean that still form a valid codeword, but revealing extra information does not add any additional correlations) the super-strong extension is the one that received attention.
There are again four variants that stem from two possible flags: self-destruct (yes/no) and persistence (yes/no).
Self-destruct decides what happens when one of the tamperings outputs ⊥—should we stop the experiment, or should we allow the adversary to continue tampering? We will discuss later that non-self-destruct codes do not exist for the most of the reasonable tampering families.
Persistence (often referred to as resettability) decides how the tampering is applied; say codeword c was tampered into , is the next tampering applied to original c, or should it be applied on top of ? As long as is a bijection, that is not a problem, but, if the tampering function was very lossy given , we can not recreate c, thus this becomes a non-trivial choice. Indeed, later we will discuss impossibility results that strongly separate persistent (not-resettable) and non-persistent (resettable) codes.
Remark 6 (Note on two-source non-malleable extractors). It is important to stress few things: two-source non-malleable extractors do not output ⊥, thus (for the same reason why non-self-destruct codes do not exist for reasonable tampering classes) we can not consider a continuous version of them. However, we can, and usually do, consider a times tampering variants, where a two-source non-malleable extractor is tampered t times for some fixed in advance t.
Definition 13 (Continuous Non-Malleable Code).
Ref. [14] define four types of continuous non-malleable codes based on two flags: (self-destruct)
and (persistent)
. We say that an encoding scheme is-continuous
non-malleable in the split-state model
if, for every Adversary and for every where Remark 7. In the case of persistent tampering, the above definition by [14] assumes that the tampering experiment stops if there is a non-trivial tampering that does not decode to ⊥, since, in this case, the adversary learns the entire tampered codeword and can simulate the remaining tampering experiment himself (since the tampering is persistent). Remark 8. In any model allowing bitwise tampering, in particular the split state model, it is not difficult to conclude that the non-self-destruct property is impossible to achieve even in the case of persistent tampering if the space of messages contains at least three elements. To see this, notice that one can tamper the codeword to obtain . The adversary then obtains the output of the tampering experiment, which is if and only if . Thus, the adversary learns and continues the tampering experiment with (note that this tampering is persistent). Thus, the adversary can continue to learn the codeword one bit at a time, thereby learning the entire codeword in N steps where N is the length of the codeword.
The constructions:
Theorem 9 (from [
15]).
If is an ε-super strong non-malleable code in the split-state model, then is a continuous self-destruct, persistent non-malleable code in the split-state model. This combined with [9] compiled with [15] gives an explicit and efficient continuous self-destruct persistent non-malleable code in the split-state model. Remark 9. The number of tampering rounds T does not have to be specified in advance (unlike with two-source non-malleable extractors). We expect the number of tamperings to be polynomial, and ε to be negligible; one can plug those in and obtain a code with unlimited (but polynomial) number of tamperings and security for any .
The idea behind the theorem is as follows: there are only two output patters that we can observe: either there will be some number of outputs followed by a ⊥ or followed by the tampered codeword . The authors argue that the long chain does not teach us much, thus the only tampering that really matters is the last one (the one that leads to not-). Thus, the continuous tampering is actually reduced to the one non-trivial tampering; we just have to pay a small price in epsilon, since we basically have to guess in which round the non- tampering will happen.
Remark 10. The above technique was extended and generalized by [54] for the other tampering classes. In particular, the authors achieve continuous NMC against persistent decision tree tampering. Informal Theorem 2 (from [
16])
. There exists an explicit and efficient self-destruct, non-persistent (resettable) continuous non-malleable code in the 8-split state model (i.e., where we have eight states instead of 2). Remark 11. Ref. [12] shows that non-persistent continuous non-malleable codes are impossible to construct in a 2-split state model. We know that eight states is enough, and we hypothesize that the idea behind [16] could be extended to give an existential (not efficient or explicit) 6-state construction. The exact number of states required to construct non-persistent code remains an opened question even in the non-explicit case. 6. Rate Amplification Techniques
Another useful technique towards improving the rate of NMC constructions is rate amplification or bootstrapping. It is a recurring theme in cryptography to combine a scheme with a very strong security but bad efficiency with a scheme with bad security but a great efficiency in such a way that the resulting scheme inherits the best of both worlds: good security and efficiency.
In the context of non-malleable codes, it was first used by [
13]. The authors achieved a rate 1 non-malleable code against bitwise tampering and permutations by combining the rate 0 scheme (from [
59]) with an error correcting a secret sharing scheme (that has no non-malleability guarantee). In the context of a 2-split state tampering, it was used by [
32,
33,
34,
35].
The abstract idea is to use an efficient code to encode the message, while the bad rate code will encode tags and checks independent of the message’s size. What is left is to argue that those tags will guarantee the security of the construction.
In the remainder of this section, we will dive deeper into the construction of [
32,
33,
35]. The latter paper achieves a current state-of-the-art rate of
, but it strongly builds on the construction of the former paper; thus, we can not discuss one without the other.
6.1. Technical Overview of “Non-Malleable Randomness Encoders and Their Applications”
This paper ([
33]) does not build non-malleable code, but it forms a crucial building block for the construction of [
35].
Informal Theorem 3 (Main Result of [
33])
. There exists an efficient, information theoretically secure non-malleable randomness encoder with a rate arbitrarily close to , and the negligible error. Kanukurthi, Obbattu, and Sekar [
33] introduced the notion of
non-malleable randomness encoders (NMRE). Similar to a 2-split-state NMC, a 2-split-state NMRE consists of two independently tamperable states
L and
R. Contrary to an NMC, where the encoder encodes arbitrary messages, an NMRE’s encoder outputs
L and
R such that they decode to a random string, and herein lies all the difference: as we have already discussed in the context of non-malleable extractors, it might not be possible to efficiently find the preimage of the specific message, or the security parameter might be too small to allow for fixing the specific message in a blackbox way.
While the problem of building high-rate NMCs has eluded researchers for over a decade, we know how to build NMREs with rate
(see [
33]). At the same time, we emphasize that obtaining a high-rate NMC (instead of an NMRE) is critical for many applications (such as non-malleable commitments.) Informally, the NMRE of [
33] (see
Figure 1) picks the source
w and seed
s to a strong seeded extractor (
) as well as a key
k to a message authentication code (MAC). The code consists of two states, left:
, and right:
r, where
are an encoding of
with any low-rate augmented non-malleable code, and
is a tag evaluated on
w with
k as the key. The codeword, if valid, decodes to
.
To denote the tampering of a variable x, we will use the notation. The security proof can be split into an analysis of the following three cases:
. This partition corresponds to the adversary not tampering with the codeword. In this case, the codeword will decode to the same message.
. This partition corresponds to the case where and . Since the MAC’s key remains secure and hidden from the adversary, the codeword will decode to ⊥ with high probability via the security of the message authentication codes.
. Finally, this partition represents the case when adversary did apply non-trivial tampering to . By the properties of non-malleable code, if the codeword falls into this partition (and the likelihood of falling into this partition is not too small) is independent of S (even given L).
Now we will proceed with the following trick: we will reveal and L, since is now a function of W only (We can ignore tag as a tiny leakage, alternatively the tag can be moved inside the non-malleable encoding) we obtain that , where penalty comes since might have depended on W and thus might depend on W.
This is a spot where we need augmented property as S remains uniform and independent of W, and L. Thus, as long as , we will obtain that is uniform given . This means that the original message remains uniform given the message after tampering. The only thing to ensure is that . Since the size of S is small, we roughly obtain that , which leads to the rate .
In order to extend this construction to encode an arbitrary message m, one option would be to reverse sample w and s such that . Unfortunately, this will not work because, on the one hand, we require the seed s to be short (as it is encoded using a poor-rate NMC) and, on the other hand, given a source w, there will be at most possible messages that could have been encoded; thus, adversary tampering with w will likely be able to distinguish between two messages of his choice (since, only for one of them, there will exist such that ). In other words, to obtain any meaningful security, s needs to be as long as the message. However, if s is long, the above approach will not yield an improvement in the rate.
6.2. Technical Overview of “Rate One-Third Non-Malleable Codes”
Theorem 14 (Main Result of [
35]).
There exists an efficient, information-theoretically secure ε-right-augmented (The right-augmented property guarantees that the right state of the NMC is simulatable independent of the message, along with the tampered message) non-malleable code in the 2-split-state model with rate 1/3. The authors give two instantiations of the scheme: the first gives a strikingly simple construction and achieves an error of 2; the second instantiation loses out on the simplicity but achieves an error of ε = 2, where κ is the size of the message. As we discussed earlier, fixing a specific message in the scheme of [
33] is not possible. The idea is to add extra information to the right state that will allow for fixing a specific message. The construction described in
Figure 2 goes as follows: as before, we will pick random
; then, we will fix
, and, after that, we will pick two random keys
and encode using a non malleable code:
. Finally, we calculate
an MAC of
w under key
and
a tag of
c under key
. The encoding is left state:
and right state:
.
As a side note, we mention that the encoding scheme is identical to that due to Kanukurthi, Obbattu, and Sekar [
32]. While [
32] gave a four-state construction, Ref. [
35] merged states to obtain a two-state construction.
We now offer an overview of the proof.
This construction uses the following building blocks: a message authentication code, a strong seeded extractor, and a low-rate non-malleable code which we shall use to encode the keys of the message authentication code and the seed for the seeded extractor. In addition, for a variable X, will denote its tampering. We proceed with a slightly simplified sketch of the proof.
The proof proceeds by partitioning the codeword space. We describe the partitions below:
. This partition captures the scenario when, even after tampering, the inner codeword () decodes to the same message, and remain unchanged; in this case, the final codeword must decode to the same message.
. captures the scenario when the decoding of the inner code remains unchanged after tampering, while one of the pairs or are changed; if this event occurs, then, using the security of MACs, the tampering is detected with overwhelming probability.
. captures the scenario that the inner code is non-trivially tampered and does not decode to . The authors show that the tampered codeword is independent of the original message m. This is the most interesting case.
In order to prove non-malleability, we need to demonstrate the existence of a simulator whose outputs are indistinguishable from the output of the tampering experiment. The simulator does not use the message; however, it outputs a special symbol to indicate that the tampered message is unchanged. The simulator’s output is run through a special wrapper function (typically called “” function) that, in this case, outputs the original message.
The simulator generates the codeword of a random message. If this simulated codeword is in , it outputs . Recall that the wrapper function will then output the original message. If the simulated codeword is in , the simulator outputs ⊥, else the simulator outputs . (Note that the code is right-augmented i.e., it satisfies a stronger notion of security where the right state of the codeword can be revealed without breaking non-malleability.)
To prove non-malleability, we need to show that this behavior of the simulator is indistinguishable from that of the tampering experiment. To do this, we first need to argue that the probability of a codeword being in any given partition is independent of the message. The authors do it by showing how to determine a partition given small leakages from the left and right state and then arguing that those small leakages can not leak the encoded message, and thus the probability of falling into each partition can not depend on the encoded message (This proof relies on the secret sharing property of the non-malleable code as well as the security of the strong randomness extractor).
Next, the authors show that the output of the tampering experiment is, in each case, indistinguishable from the simulator’s output.
For the case where the codeword is in partition , it is clear that the simulator output is identical to that of the tampering experiment. We, therefore, focus on the other two cases.
6.2.1. Codeword is in i.e.,
Intuitively, we would like to argue that the tag keys will remain securely hidden from the adversary, and, if he decides to tamper with W or C, he will not be able to fake tags . Thus, either the whole codeword remains untampered (in which case, we are in ) or the new codeword will not be valid.
The standard approach would be to argue that, if
is not too small, then
is negligible. However, we have to be delicate here. For example, if the adversary wants to tamper with
W, he has access to
L and knows that
. This reveals some information about
R and thus the adversary potentially might get hold of some partial information about the encoded data (and
in particular). This is why it is actually easier to directly argue that
is negligible. Notice that the codeword will not be valid in only one of three cases: if
or if one of the MACs on
W or
C does not verify correctly. Since
, we know that the only options left are the failures to verify MACs. Moreover, we know that
, thus Inequality (
3) can be rewritten:
is negligible. Now, we can upper-bound the term in the Inequality (
4) by the following
which by the union bound can be upper-bounded with
Finally, we can argue that each of the elements of the sum is negligible. Notice that when tampering with a W adversary has access to L but that can not reveal any information about since every non-malleable code is a secret sharing scheme. The rest follows from the security of MACs.
6.2.2. Codeword Is in i.e.,
In this case, we will follow the adventures of the seed S; the MACs and keys do not play any role here. In fact, for the purposes of this proof sketch, we will ignore the MAC keys and tags. We will also assume that this case (i.e., codeword ) occurs with substantial probability (else we do not have to worry about it). In such a case, we will argue that the final message is independent of the original message.
We start with replacing
C (see
Figure 2) with
where
is completely uniform and independent of the message (eventually, we would need to replace
back with
).
After technical transformations, the authors obtain that:
The intuition behind the equation above is very similar to the case of
in
Section 6.1; the proof is more involved than the one in [
33], but we omit the technical details behind Equation (
5). In addition, note that, in the equation above, there is no dependence on
m on either side as
is independent of
m. Ultimately, we would like to say that the output of the tampering experiment is indistinguishable from the simulated output. The authors accomplish this in three steps:
In Equation (
5), the only information correlated to
W and
R is
. Since
even given
, we can safely add
R to Equation (
5).
From here, we would ideally like to drop
and somehow bring back the dependence on
m via
C. For now, we drop
The way, we will bring C is to condition on being a “cipher of m”. For that, we first need to prove that is independent of W given appropriate auxiliary information.
- 2.
Capturing ’s correlation with W
In this step, the authors prove that is independent of W given . We first observe that is independent of W given . Now, we would like to add the other random variables in the auxiliary information. The authors use a Lemma due to Dziembowski and Pietrzak which states that independence in the presence of additional auxiliary information is indeed possible, provided it satisfies a few properties:
The auxiliary information may be computed in multiple steps;
Computation in all of the steps can use and the part of the auxiliary information generated in previous steps;
Computation in a given step can either depend on or W but not both.
By computing auxiliary information in the order followed by followed by , one can easily prove that is independent of W given .
- 3.
Conditioning appropriately
Since
W is independent of
given appropriate auxilliary information, in Equation (
6), we can condition
to either be
or
. (Note that the former is identical to
C.) By doing so, Equation (
6) will lead to the following
, where
are appropriately computed.
The desired result follows by observing that the tampered codeword is a function of
Thus far, we have described the simulator and sketched the proof for showing that the simulated output is indistinguishable from the tampered output in each of the cases. To complete the proof, we need to combine all three cases and, in particular, the probability that the codewords (tampered vs. simulated) lie in each of the partitions needs to be analysed.
To do this, the authors follow a standard argument: they consider a “skewed” codeword, which, like the tampered codeword, encodes the real message. However, the probability with which the skewed codeword lies in various partitions are the same as for the simulated codewords (in other words, “skewed” codeword behaves like original codeword on each partition, but partitions are “assembled” with slightly modified probabilities). The authors complete the proof by showing that the probability that the tampered codeword lies in a partition is independent of the message and then combines all three cases using the skewed codeword as an intermediate hybrid.
This allows the authors to finish the argument about tampered message not revealing the original message.
While one can turn any augmented non-malleable code (or randomness encoder) into a good rate non-malleable code, a very simple result can be obtained using [
9]. To encode a message
m, all we will need is
an affine evasive functionh. It is a function
such that
is negligible for all
, and
should be efficiently sampleable, the construction of the said function can be found in [
9,
49]. The encoding procedure is described in
Figure 3.
7. Application: Non-Malleable Codes for Computable Tampering
Split-state tampering functions, even when allowed leakage between the states, are subject to strong independence constraints. In this section, we will look at tampering families without any such constraints but instead having limited computational complexity. In fact, we will show, in some sense, how to reduce computational constraints to independence by showing how to construct non-malleable codes for a variety natural computational tampering classes from split state non-malleable codes. We will consider the following tampering classes:
Decision tree tampering (
Section 7.1 [
46]): each tampered output symbol is a function of a small polynomial number of (adaptively chosen) queries to codeword symbols.
Small-depth circuit tampering (
Section 7.2 [
22,
46,
47]): the tampered codeword is produced by a boolean circuit of polynomial size and nearly logarithmic depth.
(Bounded) Polynomial-size circuit tampering (
Section 7.3 [
48]): the tampered codeword is produced by circuit of bounded polynomial size,
for some constant
d where
n is the codeword length.
We begin with some remarks connecting non-malleable codes with more conventional computational complexity. First, we note that non-malleable codes for circuit classes require circuit lower bounds.
Proposition 1 (Informal). For most natural tampering classes, , an explicit non-malleable code resilient to tampering by class implies a circuit lower bound for that class: an explicit function that is hard for to compute.
In particular, if is a non-malleable code resilient to tampering, then cannot be computed by . Suppose not; then, consider the tampering function that computes and outputs a fixed encoding 0 if the first bit of the message is 1 and outputs a fixed encoding of 1, otherwise. Moreover, it is not difficult to observe that gives rise to (efficiently sampleable) input distributions against which is hard-on-average for to compute.
Given our difficulties in proving circuit lower bounds, one interpretation of this observation is that we can only expect to construct unconditionally secure non-malleable codes against very limited circuit classes—or in other words, non-malleable codes for expressive circuit classes, such as polynomial size circuits, require computational assumptions.
Given that (strong) circuit lower bounds are necessary for non-malleable codes, one might wonder if they are sufficient. In general, this is not true.
Theorem 15 (Informal [
60]).
Explicit hard functions for a class do not imply non-malleable codes for . Consider the class of tampering functions, , such that each output bit is an arbitrary function of all but 1 of the input bits, i.e., for each the function computing the jth tampered bit, can be written as for some . It is easy to observe that such functions cannot compute Parity, i.e . (There is a syntactic problem here in that the output length of Parity does not match that of the tampering class, but consider instead a function whose first bit of output is the Parity of its inputs.) In fact, functions in have no advantage over random guessing computing Parity of uniformly random inputs.
One might hope to use the fact that Parity is hard for this class, , directly by encoding a single bit b as uniformly bits such that . However, note that this code, while providing some form of leakage-resilience, is trivially malleable by the class: consider the function that flips the first bit.
This straw man argument intuitively leads us to believe that non-malleability requires much more than (average-case) circuit lower bounds. Ref. [
60] justified this intuition, proving that non-malleable codes for
tampering
do not exist.
We saw that the straw man approach of encoding directly using a hard function for a computational tampering class will not succeed; instead, we show how to leverage split-state non-malleable codes to construct non-malleable codes against computational tampering classes. The high level intuition for all of these constructions is to induce and exploit communication bottlenecks in the tampering computation.
What do we mean by communication bottlenecks? Imagine that the (random) inputs to a computation can be partitioned into two subsets X and Y such that two parties, Alice (holding X) and Bob (holding Y), can simulate the computation by communicating at most t bits. Why is this helpful? This class of computation (independent tampering on X and Y conditioned on small communication between X and Y) precisely corresponds to the tampering class handled by (adaptive) leakage-leakage resilient split-state non-malleable codes (See extensions to Definition 7 and Remark 1). For clarity, we define this tampering class as two-party t-communication tampering (This class is also referred to as “leaky split state tampering” in the literature. ).
Definition 14. Let be a function and , such that .
We say that f is a two-party -communication tampering functionif there is a two-party protocol where two parties Alice and Bob communicate at most bits such that, for any , if Alice is given x and Bob is given y, Alice outputs and Bob outputs .
We denote the class of two-party -communication tampering functions as . Moreover, we say a non-malleable code for this tampering class is augmented if the left half of the codeword, communication transcript, and outcome of the tampering experiment can be jointly simulated.
Our goal, in this section, is to construct coding schemes,
that induce communication bottlenecks when composed with any tampering function in the target class, i.e., for any tampering
f, the function
can be simulated by a two party protocol with at most
t bits of communication (existing leakage-resilient split-state codes can handle
t that is a constant fraction of
and
). More precisely, we want to construct a non-malleable reduction (Definition 4),
, from the computational tampering class,
, to two-party
t-communication tampering, i.e., for every tampering function
there exists some distribution
over two-party
t-communication tampering protocols such that
In
Section 7.1, we will see how [
46] constructs such a non-malleable reduction for the class of decision tree tampering functions: where each tampered output bit is produced by a bounded number of queries to the input bits. Ref. ([
46]’s construction extends an earlier of [
61] for local tampering functions, which corresponds to the case where the queries are static: chosen independently of the input.)
Section 7.2 will not construct a communication bottlenecking non-malleable reduction directly, but implicitly. In particular, this section will present [
47]’s non-malleable reduction from small-depth circuit tampering to decision tree tampering. This reduction, as well as an earlier (but inefficient) construction of [
22], critically uses a technique from the circuit lower bound literature: random restrictions.
Finally, in
Section 7.3, we will see how assumptions in the derandomization literature can be used to induce communication bottlenecks in polynomial size circuit tampering. In particular, how Ref. [
48] uses hardness against
nondeterministic circuits to construct non-malleable codes for polynomial size circuit tampering from augmented leakage-resilient split-state non-malleable codes. The code presented here has only inverse polynomial security. Other constructions for this class are known that do not rely on split-state non-malleable codes. Unfortunately, while these constructions are beautiful and achieve negligible security error, they are not fully explicit: relying either on an untamperable common random strings (CRS model) [
10,
62], or poorly understood heuristic cryptographic assumptions [
63,
64]. (The latter constructions from cryptographic assumptions only achieve computational security: no
efficient distinguisher (polynomial size circuit) can distinguish the real and simulated experiments).
The idea of communication bottlenecks has a fruitful history in pseudorandomness [
65,
66,
67,
68], but our setting presents unique challenges that make it difficult to extend results directly.
Firstly, non-malleable codes are required to meaningfully encode (and decode) information. (In contrast, pseudorandomness is only required to “fool” the computation.) While it is often intuitive how to tweak a pseudorandom generator to encode information, we must also simulate decoding of whatever the computation outputs with low communication, which can be delicate as the adversarial tampering could try to force decoding to behave badly.
Secondly, and perhaps more importantly, non-malleable codes must handle adversarial computations that take n bits of input and output n bits. (Compare with pseudorandomness, where it only necessary (and possible) to consider adversarial computations with short output.) For example, while it is straightforward to fool a single decision-tree (using bounded-inependence), n decision trees can copy X to the Y portion which cannot be simulated with low communication.
On the upside, here the adversarial computation does not have the last word: the (standard) non-malleability experiment only outputs after decoding. Additionally, non-malleable codes are not concerned with pseudorandomness, so there is no need to stringently account for the randomness consumed by the encoding.
Despite these differences, some of the constructions here will draw on techniques from the pseudorandomness literature, particularly those of
Section 7.2 and
Section 7.3.
7.1. Decision Tree Tampering
Now we will give an overview of [
46]. As mentioned above, decision trees of depth
d capture tampering where each output bit is set arbitrarily after adaptively reading
d locations of the input, where the choice of which input location to read next at any point in time can depend on the values of all the previous locations read.
Definition 15 (Decision Trees). A decision tree with n input bits is a binary tree whose internal nodes have labels from and whose leaves have labels from . If a node has label , then the test performed at that node is to examine the i-th bit of the input. If the result is 0, one descends into the left subtree, whereas, if the result is 1, one descends into the right subtree. The label of the leaf so reached is the output value on that particular input. The depth of a decision tree is the number of edges in a longest path from the root to a leaf. Let denote decision trees with depth at most t.
Ref. [
46] constructs non-malleable codes resilient to tampering by decision-trees of depth
.
Theorem 16 ([
46]).
For any , there is an explicit and efficient non-malleable code that is unconditionally secure against depth-t decision trees with codeword length and error for a k-bit message. This theorem follows by constructing a non-malleable reduction (Definition 4) from decision-tree tampering to two-party bounded communication tampering. Theorem 16 follows from composing this reduction with a leakage-resilient split-state non-malleable code (i.e., a non-malleable code for two-party bounded communication tampering).
Lemma 13 (NMR from [
46]).
For any constant and , there is a -non-malleable reduction with rate where . We will outline [
46]’s reduction for decision tree tampering. Their reduction builds on a reduction of [
61] for local tampering (where the bounded number queries to codeword are made non-adaptively). In fact, the two reductions are quite similar (though not identical); however, the analysis differs substantially.
The key idea of this construction is to exploit size differences. The encoder and decoder will work independently on the left and right pieces of the message, so we will in turn think of having left and right encoders, decoders, codewords, and tampering functions (corresponding to the respective outputs).
First, suppose that the right piece of the message (corresponding to the right split-state codeword) is much longer than that of the left. Then, suppose both the right and left encoders and decoders are simply the identity function. Then, all the left tampering functions together will make a number of queries to the right codeword that is below the leakage threshold.
However, because the right is much longer than the left, the above analysis will not help in simulating tampering on the right with low leakage from the left. Instead, Ref. [
46] modifies the left encoder/decoder to make it much longer than the right, but while retaining the property that the left can be decoded from just a few decision trees. To do so, sample a random small set, whose size is that of the message, in a much larger array. Then, plant the message in these locations and zero everything else out. Then, the bit-wise secret shares a description of the small set (i.e., its seed) such that the secrecy threshold is relatively large. To decode, simply extract the seed and output what is in the corresponding locations of the array.
Now, note that decoding the left still only requires at most relatively few queries to the right: decision tree depth times both encoded seed length plus message length. However, we can not make the encoded seed too long or we will be dead again. Instead, Ref. [
46] critically uses the fact that tampering is by a
forest of decision trees. In particular, for any small set of tampering functions on the right, the seed remains uniformly chosen regardless of what queries the set makes, so we expect only a small fraction of any queries made to the array to actually hit the message locations. Strong concentrations bounds guarantee that this is more or less what actually happens. Then, simply union bound over all such subsets to guarantee that collectively the right tampering function makes few queries to the left with overwhelming probability.
Finally, apply the same style of encoding used on the left to the right side to fix the syntactic mismatch and reduce to the case where the right and left messages are the same size.
7.2. Small-Depth Circuit Tampering
We will give an overview of [
47]. Small-depth circuit tampering captures the case where each tampered output bit is produced by a size
circuit of depth
over the standard basis with arbitrary fan-in, we denote this class
. (This includes the case where each output is produced by a constant depth polynomial size circuit,
.)
Theorem 17 ([
46,
47]).
For , there exists an explicit, efficient, information theoretic non-malleable code for d-depth circuits (of unbounded fan-in) of size with error and encoding length , where are constants.For the special case of -tampering, there exist efficient non-malleable codes for -depth polynomial size circuits circuits with negligible error and encoding length .
Ref. [
47] showed how to use a tool from circuit lower bounds and derandomization, pseudorandom switching lemmas, to construct a non-malleable reduction from small-depth circuit tampering to decision tree tampering (which, as we have seen, can be reduced to split-state tampering). Prior to this construction, Chattopadhyay and Li had constructed an (invertible)
seedless non-malleable extractor for small-depth circuit tampering [
22]. However, unlike the construction here, the error of their extractor yields inefficient non-malleable codes (
k length messages encode into codewords of length
). We state [
47]’s main technical lemma, a non-malleable reduction from small-depth circuit tampering to small-depth decision tree tampering, before sketching their non-malleable reduction and its analysis here.
Lemma 14 ([
47]).
For , there exists and such that, for any ,where Let us start by considering the simpler case of reducing w-DNFs (each clause contains at most w literals) to low-depth decision tree tampering. The reduction for general small-depth circuits will follow from a recursive composition of this reduction.
A non-malleable reduction
reducing DNF-tampering to small-depth decision tree tampering needs to satisfy two conditions (i)
for any
x and, (ii)
is a distribution over small-depth decision trees for any width-
w DNF
f. A classic result from circuit complexity, the switching lemma [
69,
70,
71,
72] states that DNFs become small-depth decision trees under random restrictions (“killing” input variables by independently fixing them to a random value with some probability). Thus, a natural choice of
for satisfying (ii) is to simply sample from the generating distribution of restrictions and embed the message in the surviving variable locations (fixing the rest according to restriction). However, although
becomes a decision tree, it is not at all clear how to decode and fails even (i). To satisfy (i), a naive idea is to simply append the “survivor” location information to the encoding. However, this is now far from a random restriction (which requires among other things that the surviving variables are chosen independently of the random values used to fix the killed variables) is no longer guaranteed to “switch” the DNFs to decision trees with overwhelming probability.
To circumvent those limitations, we consider
pseudorandom switching lemmas, usually arising in the context of derandomization [
73,
74,
75,
76,
77,
78], to relax the stringent properties of the distribution of random restrictions needed for classical switching lemmas. In particular, we invoke a pseudorandom switching lemma from Trevisan and Xue [
77], which reduces DNFs to decision trees while only requiring that randomness specifying survivors and fixed values be
-wise independent. This allows us to avoid problems with independence arising in the naive solution above. Now, we can append a
-wise independent encoding of the (short) random seed that specifies the surviving variables. This gives us a generating distribution of random restrictions such that (a) DNFs are switched to decision trees, and (b) the seed can be decoded and used to extract the input locations.
At this point, we can satisfy (i) easily: decodes the seed (whose encoding is always in, say, the first m coordinates), then uses the seed to specify the surviving variable locations and extract the original message. In addition to correctness, becomes a distribution over local functions where the distribution only depends on f (not the message). However, composing with induces dependence on underlying message: tampered encoding of the seed may depend on the message in the survivor locations. The encoded seed is comparatively small and thus (assuming the restricted DNF collapses to a low-depth decision tree) requires a comparatively small number of bits to be leaked from the message in order to simulate the tampering of the encoded seed; given a well simulated seed, we can accurately specify the decision trees that will tamper the input (the restricted DNFs whose output locations coincide with the survivors specified by the tampered seed). This intermediate leaky decision tampering class, which can be described via the following adversarial game: (1) the adversary commits to N decision trees, (2) the adversary can select m of the decision trees to get leakage from, and (3) the adversary then selects the actual tampering function to apply from the remaining local functions. However, provided the seed length, m, is short enough, this just amounts to querying a slightly higher depth decision tree.
To deal with depth d circuits, we can recursively apply this restriction-embedding scheme d times. Each recursive application allows us to trade a layer of gates for another (adaptive) round of m bits of leakage in the leaky decision tree game. One can think of the recursively composed simulator as applying the composed random restrictions to collapse the circuit to decision trees and then, working inwardly, sampling all the seeds and the corresponding survivor locations until the final survivor locations can be used to specify ultimate decision tree tampering.
7.3. (Bounded) Polynomial Size Circuit Tampering
In this subsection we follow [
48], we show how to construct non-malleable codes for tampering by
-size circuits, where
c is some constant. As mentioned at the outset, non-malleable codes for circuit tampering imply circuit lower bounds. Given that explicit lower bounds against superlinear size circuits are well-beyond our current techniques in complexity, assumptions are needed for such non-malleable codes. Ref. [
48] showed how to use hardness assumptions against
nondeterministic circuits to construct such codes from split-state non-malleable codes. We begin by presenting the hardness assumption before giving a brief overview of [
48]’s construction.
Definition 16 (Nondeterministic circuit). A nondeterministic circuit C is a circuit with “non-deterministic” inputs, in addition to the usual inputs. We say C evaluates to 1 on x if and only if there exists an assignment, w, to the non-deterministic input wires such that the circuit, evaluated deterministically on input outputs 1.
Assumption 1 ( requires exponential size nondeterministic circuits). There is a language and a constant γ such that, for sufficiently large n, non-deterministic circuits of size fail to decide L on inputs of length n.
Informally, the above assumption says that non-uniformity and non-determinism do not always imply significant speed-ups of uniform deterministic computations.
Theorem 18 ([
48]).
If requires exponential size non-deterministic circuits, then, for every constant c, and for sufficiently large k, there is an explicit, efficient, -secure non-malleable code for k-bit messages, with codeword length , resilient to tampering by -size circuits. Ref. [
48] constructs their codes by “fooling” non-malleable codes for
split-state tampering with special properties: augmented, leakage-resilient, and admitting a special form of encoding (given half a codeword can efficiently sample the other half to encode any message).
Split-state tampering functions may manipulate the left and right halves of a codeword arbitrarily, but independently (i.e., functions such that
for some
). Leakage-resilient split-state tampering allows each tampered codeword half to depend on bounded leakage from the opposite codeword half. In addition to split-state NMC, Ref. [
48] also uses a pseudorandom generator (PRG) for nondeterministic circuits, where
is a constant. In particular, they require that the PRG,
G, is secure even when given the seed (seed extending), i.e., no nondeterministic circuit of bounded polynomial size can distinguish
from a uniformly random string
and s is a prefix of
. The existence of such PRGs follows from Assumption A1 [
79,
80,
81,
82,
83,
84].
Given a (leakage-resilient) split-state non-malleable code, with necessary properties and a seed-extending pseudorandom PRG for nondeterministic circuits,
G, we encode a message
x by sampling the following:
The proof proceeds by contradiction starting with the assumption that the construction is not non-malleable. The analysis follows by giving a nondeterministic reduction that uses the (assumed) malleablity of the construction to violate the PRG security.
Assume towards contradiction that is malleable and fix the corresponding poly-size tampering function g, which is not split-state and violates non-malleability.
Transform g into a split-state tampering function on , where (1) is unbounded, relies on bits of leakage from and returns some , (2) is efficient, relies on bits of leakage from and returns . Crucially, a split-state tampering function is guaranteed to break non-malleability when .
Since is a leakage-resilient split-state non-malleable code where is uniform random, then when is random (as opposed to in the construction where codewords are sampled as ), every tampering functon fails to break non-malleability, even when is unbounded and chooses its output in the “optimal” way.
Construct an Arthur–Merlin protocol (with bounded poly-size Arthur), that distinguishes between input
being random or pseudorandom. Such a protocol can then be transformed into a non-deterministic polynomial bounded circuit (this follows from classical results:
[
84,
85,
86,
87]).
Intuitively, Arthur can efficiently compute all the values needed to simulate the tampering experiment except for , which is obtained from Merlin. Specifically, on input , Arthur samples , and computes , as well as the leakage on . Arthur sends and the leakage on to Merlin who responds with . If is pseudorandom, then an honest Merlin will return , and, with Merlin’s help, Arthur can check that non-malleability is violated with this . If is random, then, despite any response from Merlin, non-malleability will not be violated, and a dishonest Merlin cannot convince Arthur otherwise.



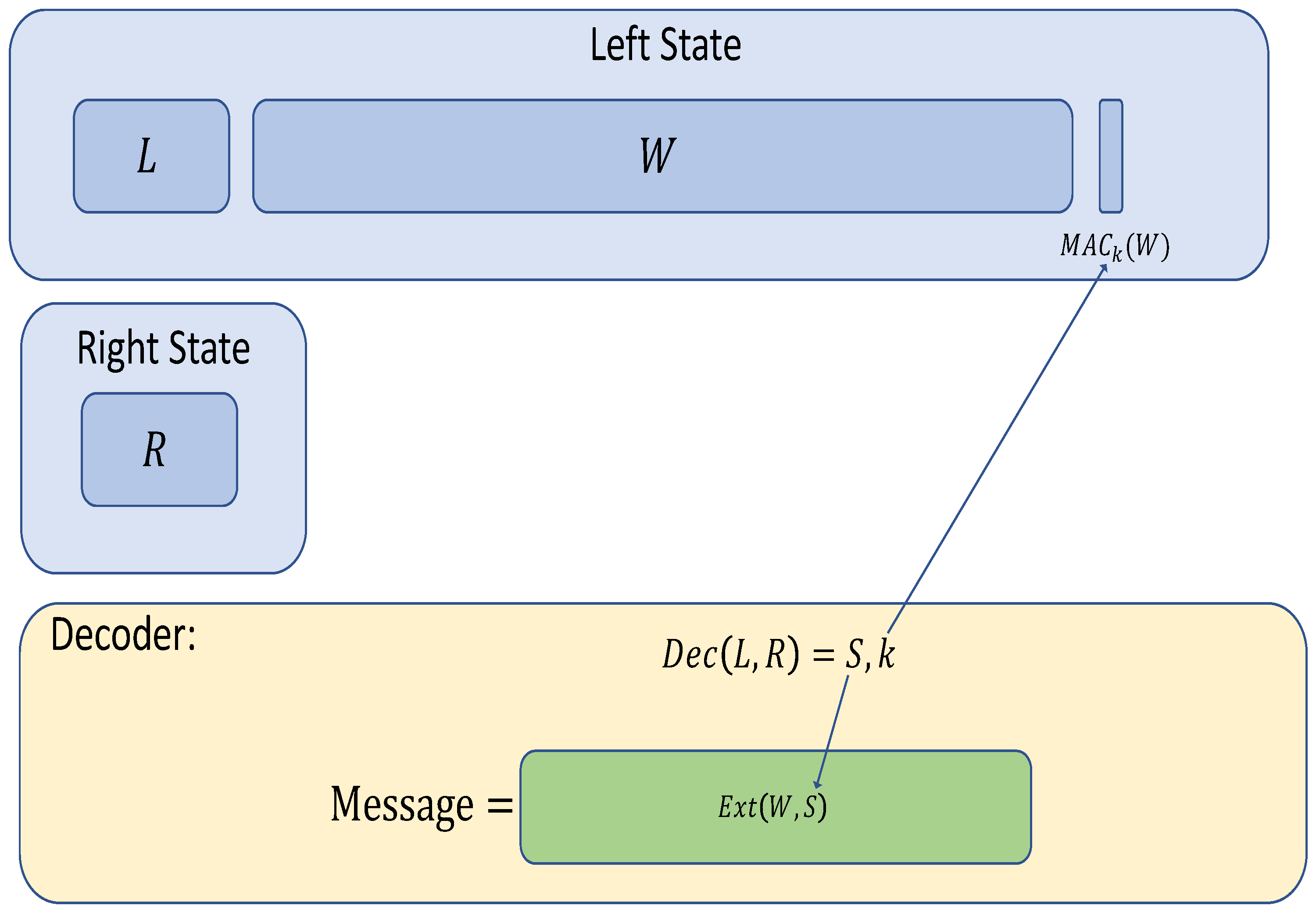




{kind=link}
{kind=link}
{kind=link}
{kind=link}