
Lexicons of Key Terms in Scholarly Texts and Their Disciplinary Differences: From Quantum Semantics Construction to Relative-Entropy-Based Comparisons


Abstract
:1. Introduction
2. Materials and Methods
- Quantum semantics is used to construct the lexicons corresponding a given text.
- The relevant connectivities of lexicons are found through network analysis.
- The comparison of lexicons is performed based on a quantum information theoretic version of Jensen–Shannon divergence.
2.1. Text Samples
2.2. Generalizing Word Co-Occurrence: Concurrence
2.3. Constructing Lexicons from Concurrences
2.4. Characterizing Lexicons: Density Matrix
2.5. Comparing Lexicons: Divergence and Similarity
3. Results
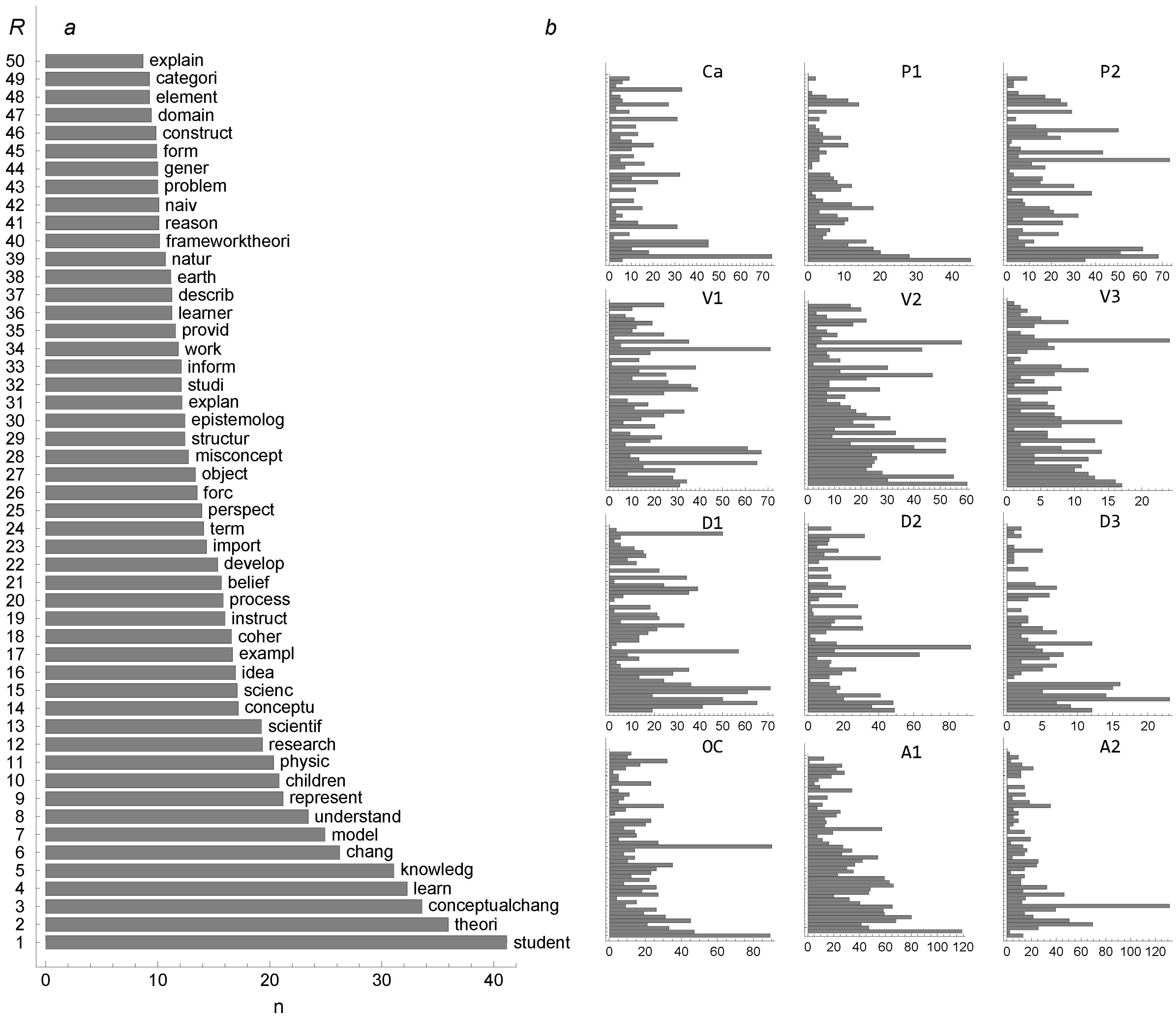
3.1. Word Frequency Statistics
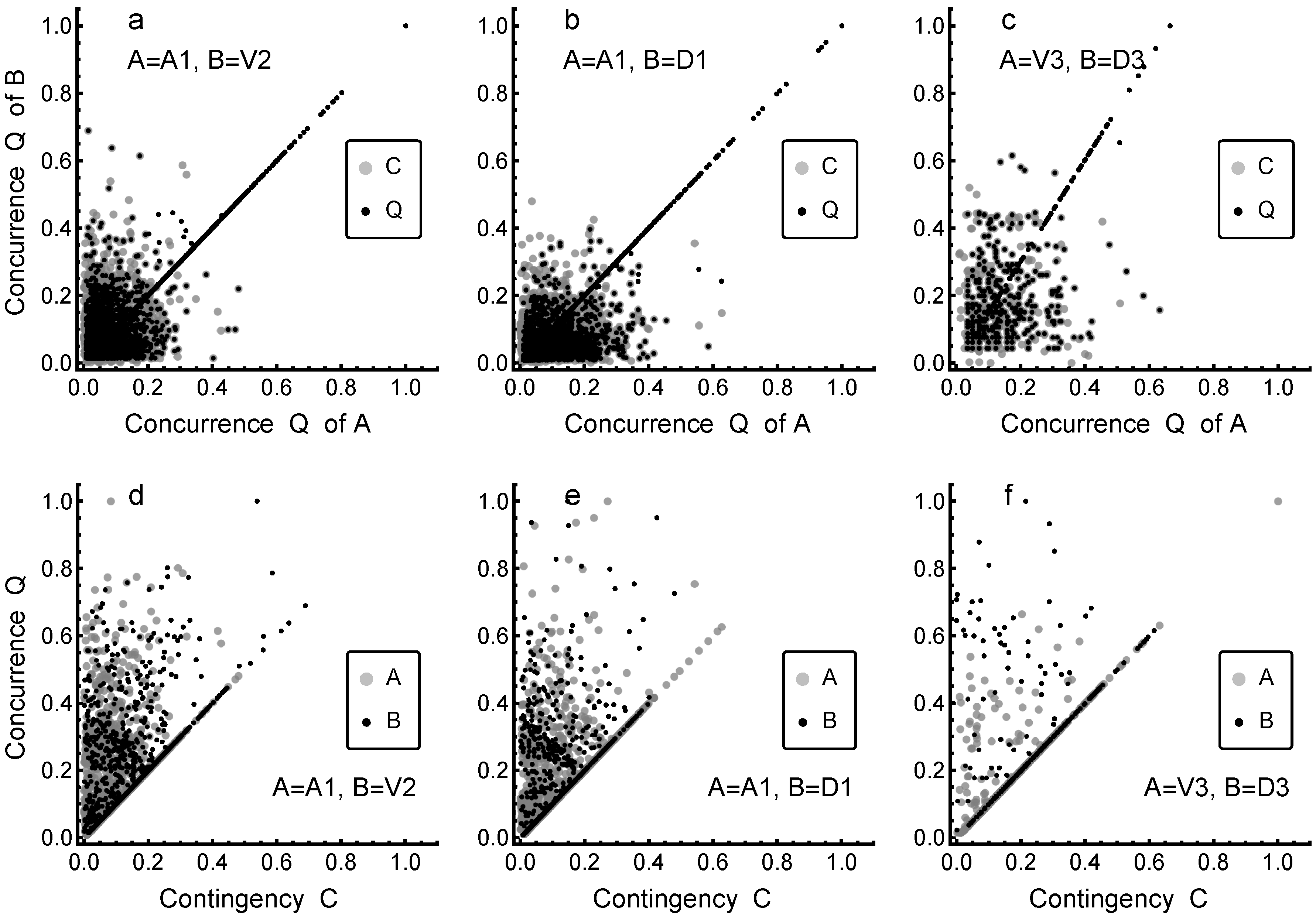
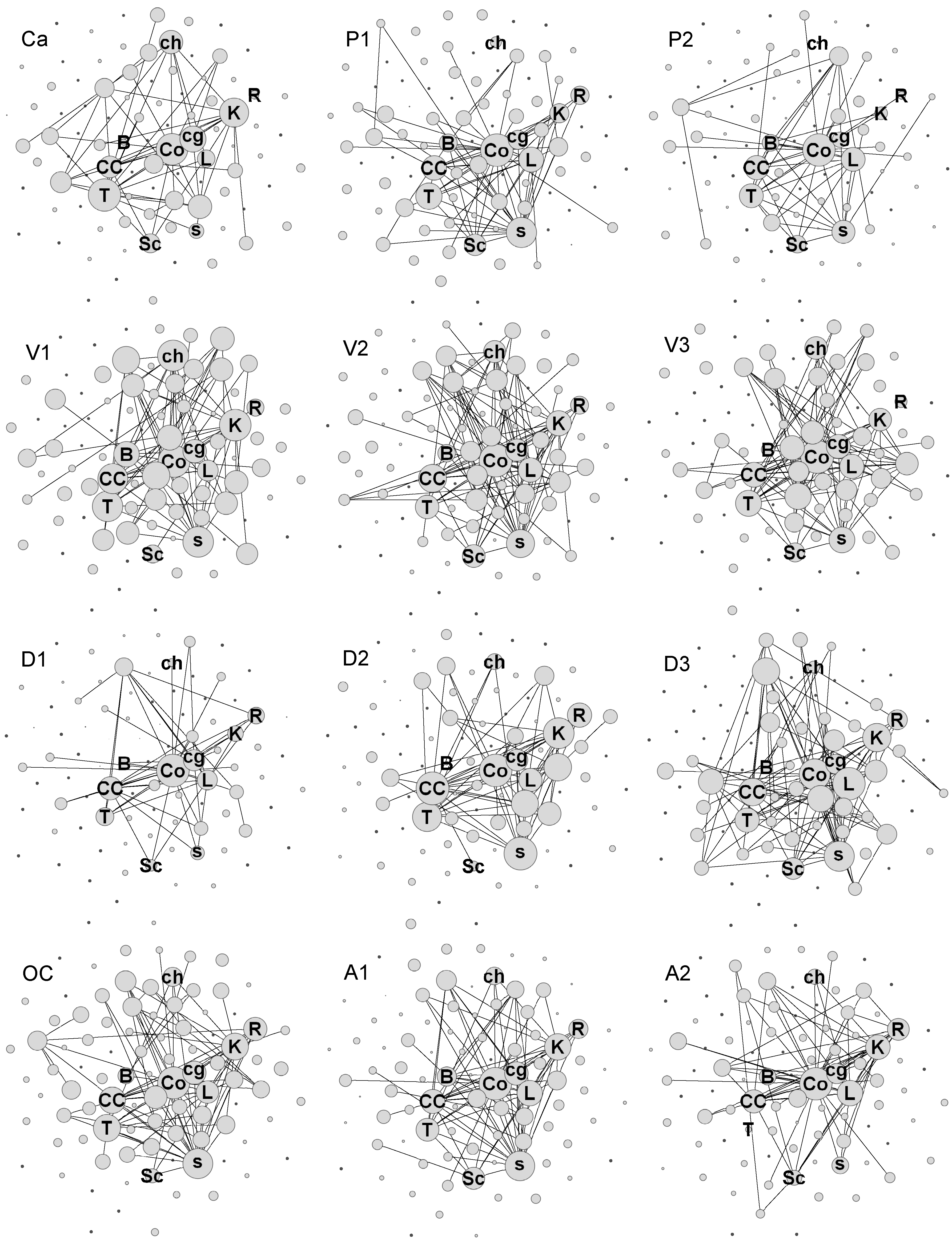
3.2. Lexicons: Concurrence and Construction
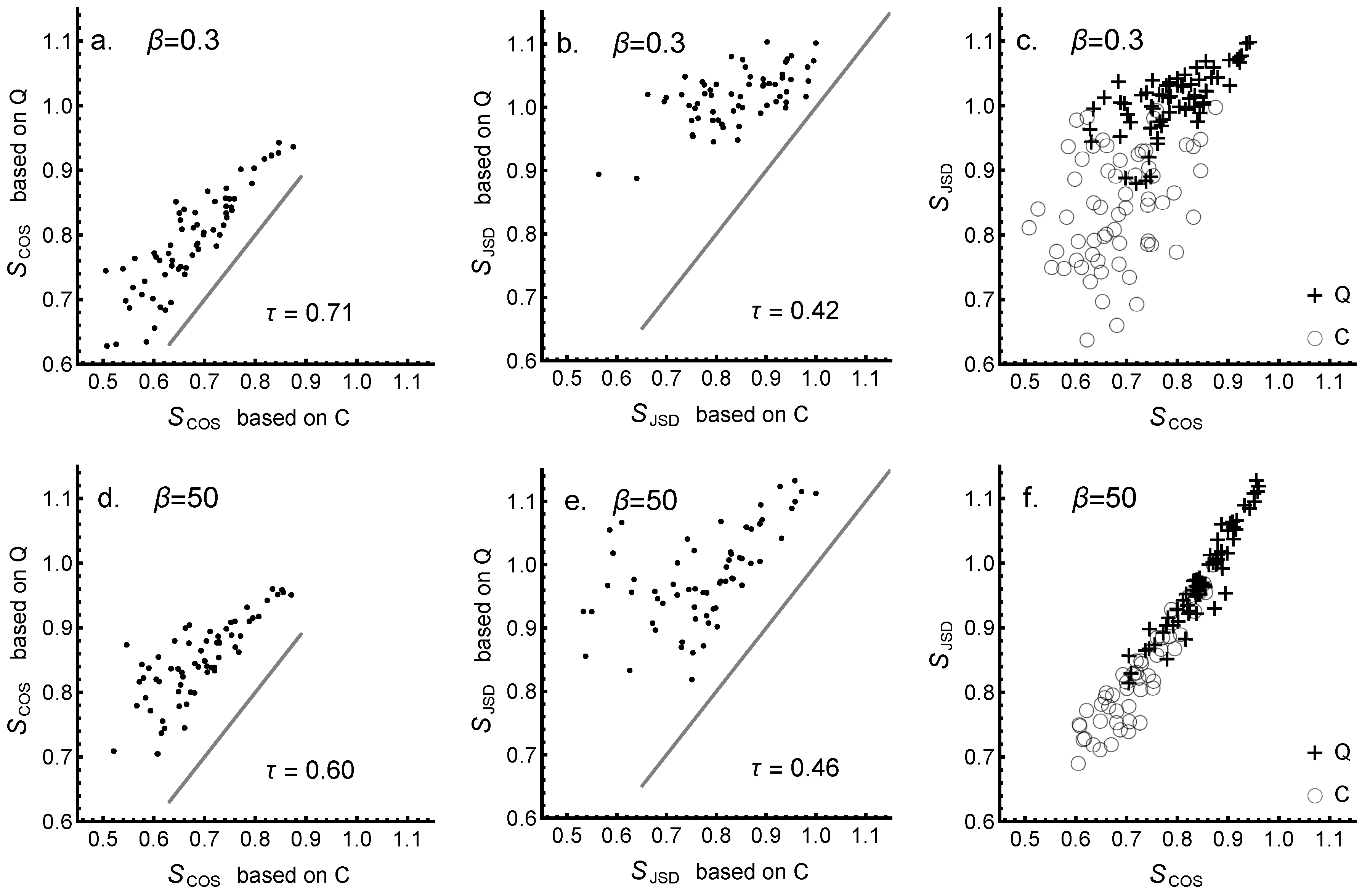
3.3. Divergence and Similarity of Lexicons
3.4. Key Terms and Shared Key Terms
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Concurrence
Appendix B. Density Matrix and Correlation Matrix
References
- Fanelli, D.; Glänzel, W. Bibliometric evidence for a hierarchy of the sciences. PLoS ONE 2013, 8, e66938. [Google Scholar] [CrossRef] [PubMed]
- Fanelli, D. “Positive” results increase down the hierarchy of the sciences. PLoS ONE 2010, 5, e10068. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, T.S. The Structure of Scientific Revolutions, 1st ed.; University of Chicago Press: Chicago, IL, USA, 1962. [Google Scholar]
- De Solla Price, D.J. The Science of Science. Bull. At. Sci. 1965, 21, 2–8. [Google Scholar] [CrossRef]
- Garfield, E. Citation indexes for science: A new dimension in documentation through association of ideas. Science 1955, 122, 108–111. [Google Scholar] [CrossRef]
- Klavans, R.; Boyack, K.W. Toward a consensus map of science. J. Am. Soc. Inf. Sci. Tech. 2009, 60, 455–476. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Rafols, I. Interactive overlays: A new method for generating global journal maps from Web-of-Science data. J. Informetr. 2012, 6, 318–332. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Carley, S.; Rafols, I. Global maps of science based on the new Web-of-Science categories. Scientometrics 2013, 94, 589–593. [Google Scholar] [CrossRef]
- Zeng, A.; Shen, Z.; Zhou, J.; Wu, J.; Fan, Y.; Wang, Y.; Stanley, H.E. The science of science: From the perspective of complex systems. Phys. Rep. 2017, 714–715, 1–73. [Google Scholar]
- Fortunato, S.; Bergstrom, C.T.; Börner, K.; Evans, J.A.; Helbing, D.; Milojević, S.; Petersen, A.M.; Radicchi, F.; Sinatra, R.; Uzzi, B.; et al. Science of science. Science 2018, 359, e0185. [Google Scholar] [CrossRef]
- De Domenico, M.; Omodei, E.; Arenas, A. Quantifying the diaspora of knowledge in the last century. Appl. Netw. Sci. 2016, 1, 15. [Google Scholar] [CrossRef]
- Ding, J.; Ahlgren, P.; Yang, L.; Yue, T. Disciplinary structures in Nature, Science and PNAS: Journal and country levels. Scientometrics 2018, 116, 1817–1852. [Google Scholar] [CrossRef]
- Herrera, M.; Roberts, D.C.; Gulbahce, N. Mapping the Evolution of Scientific Fields. PLoS ONE 2010, 5, e10355. [Google Scholar] [CrossRef]
- Milojevic, S. Quantifying the cognitive extent of science. J. Informetr. 2015, 9, 962–973. [Google Scholar] [CrossRef]
- Leydesdorff, L.; Adina Nerghes, A. Co-word Maps and Topic Modeling: A Comparison Using Small and Medium-Sized Corpora. J. Assoc. Inform. Sci. Tech. 2017, 68, 1024–1035. [Google Scholar] [CrossRef]
- Kuhn, T.S. The Road since Structure; University of Chicago Press: Chicago, IL, USA, 2000. [Google Scholar]
- Hoyningen-Huene, P. Reconstructing Scientific Revolutions; University of Chicago Press: Chicago, IL, USA, 1993. [Google Scholar]
- Gattei, S. Thomas Kuhn’s Linguistic Turn and the Legacy of Logical Empiricism; Routledge: Oxon, UK, 2016. [Google Scholar]
- Callon, M.; Courtial, J.-P.; Turner, W.A.; Bauin, S. From translations to problematic networks: An introduction to co-word analysis. Soc. Sci. Inform. 1983, 22, 191–235. [Google Scholar] [CrossRef]
- Leydesdorff, L. Words and co-words as indicators of intellectual organization. Res. Policy 1989, 18, 209–223. [Google Scholar] [CrossRef]
- Tijssen, R.; Van Raan, A. Mapping co-word structures: A comparison of multidimensional scaling and LEXIMAPPE. Scientometrics 1989, 15, 283–295. [Google Scholar] [CrossRef]
- Lehmann, F. Semantic networks. Comp. Math. Apll. 1992, 23, 1–50. [Google Scholar] [CrossRef]
- Carley, K.M. Network text analysis: The network position of concepts. In Text Analysis for the Social Sciences: Methods for Drawing Statistical Inferences from Texts and Transcripts; Roberts, C.W., Ed.; Lawrence Erlbaum: Mahwah, NJ, USA, 1997; pp. 79–102. [Google Scholar]
- Leydesdorff, L.; Welbers, K. The semantic mapping of words and co-words in context. J. Informetr. 2011, 5, 469–475. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. Topic models. In Text Mining: Classification, Clustering, and Applications; Srivastava, A.N., Sahami, A., Eds.; Taylor and Francis: London, UK, 2009; pp. 71–94. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Amancio, D.R.; Oliveira, O.N., Jr.; da Fontoura Costa, L. Structure–semantics interplay in complex networks and its effects on the predictability of similarity in texts. Physica A 2012, 391, 4406–4419. [Google Scholar] [CrossRef]
- Kulig, A.; Drozdz, S.; Kwapien, J.; Oswiecimka, P. Modeling the average shortest-path length in growth of word-adjacency networks. Phys. Rev. E 2015, 91, 032810. [Google Scholar] [CrossRef] [PubMed]
- Yin, X.; Wang, H.; Yin, P.; Zhu, H.; Zhang, Z. A co-occurrence based approach of automatic keyword expansion using mass diffusion. Scientometrics 2020, 124, 1885–1905. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, Y. Co-word analysis method based on metapath of subject knowledge network. Scientometrics 2020, 123, 753–766. [Google Scholar] [CrossRef]
- Teixeira, A.S.; Talaga, S.; Swanson, T.J.; Stella, M. Revealing semantic and emotional structure of suicide notes with cognitive network science. Sci. Rep. 2021, 11, 19423. [Google Scholar] [CrossRef] [PubMed]
- Christianson, N.H.; Sizemore, B.A.; Bassett, D.S. Architecture and evolution of semantic networks in mathematics texts. Proc. R. Soc. A 2020, 476, 20190741. [Google Scholar] [CrossRef]
- Chai, L.R.; Zhou, D.; Bassett, D.S. Evolution of semantic networks in biomedical texts. J. Complex Netw. 2020, 8, cnz023. [Google Scholar] [CrossRef]
- Ribeiro, E.; Teixeira, A.S.; Ribeiro, R.; de Matos, D.M. Semantic frame induction through the detection of communities of verbs and their arguments. Appl. Netw. Sci. 2020, 5, 69. [Google Scholar] [CrossRef]
- Medeuov, D.; Roth, C.; Puzyreva, K.; Basov, N. Appraising discrepancies and similarities in semantic networks using concept-centered subnetworks. Appl. Netw. Sci. 2021, 6, 66. [Google Scholar] [CrossRef]
- de Arruda, H.F.; Silva, F.N.; Marinho, V.Q.; Amancio, D.R.; da Fontoura Costa, L. Representation of texts as complex networks: A mesoscopic approach. J. Complex Netw. 2018, 6, 125–144. [Google Scholar] [CrossRef]
- Amancio, D.R. Probing the Topological Properties of Complex Networks Modeling Short Written Texts. PLoS ONE 2015, 10, e0118394. [Google Scholar] [CrossRef] [PubMed]
- Surov, I.A.; Semenenko, E.; Platonov, A.V.; Bessmertny, I.A.; Galofaro, F.; Toffano, Z.; Khrennikov, A.Y.; Alodjants, A.P. Quantum semantics of text perception. Sci. Rep. 2021, 11, 4193. [Google Scholar] [CrossRef]
- Surov, I.A. Quantum Cognitive Triad: Semantic Geometry of Context Representation. Found. Sci. 2021, 26, 947–975. [Google Scholar] [CrossRef]
- Galofaro, F.; Toffano, Z.; Doan, B.-L. A quantum-based semiotic model for textual semantics. Kybernetes 2018, 47, 307–320. [Google Scholar] [CrossRef]
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Estrada, E. The Structure of Complex Networks: Theory and Applications; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Estrada, E.; Hatano, N.; Benzi, M. The physics of communicability in complex networks. Phys. Rep. 2012, 514, 89–119. [Google Scholar] [CrossRef]
- Benzi, M.; Estrada, E.; Klymko, C. Ranking hubs and authorities using matrix functions. Linear Algebra Appl. 2013, 438, 2447–2474. [Google Scholar] [CrossRef]
- Kunegis, J.; Fay, D.; Bauckhage, C. Spectral evolution in dynamic networks. Knowl. Inf. Syst. 2013, 37, 1–36. [Google Scholar] [CrossRef]
- Dehmer, M. Information processing in complex networks: Graph entropy and information functionals. Appl. Math. Comput. 2008, 201, 82–94. [Google Scholar] [CrossRef]
- Estrada, E. Informational cost and networks navigability. Appl. Math. Comp. 2021, 397, 125914. [Google Scholar] [CrossRef]
- Biamonte, J.; Faccin, M.; De Domenico, M. Complex networks from classic to quantum. Comm. Phys. 2019, 2, 53. [Google Scholar] [CrossRef]
- Faccin, M.; Johnson, T.; Biamonte, J.; Kais, S.; Migdał, P. Degree Distribution in Quantum Walks on Complex Networks. Phys. Rev. X 2013, 3, 041007. [Google Scholar] [CrossRef]
- De Domenico, M.; Biamonte, J. Spectral Entropies as Information-Theoretic Tools for Complex Network Comparison. Phys. Rev. X 2016, 6, 041062. [Google Scholar] [CrossRef]
- Gerlach, M.; Font-Clos, F.; Altmann, E.G. Similarity of Symbol Frequency Distributions with Heavy Tails. Phys. Rev. X 2016, 6, 021009. [Google Scholar] [CrossRef]
- Ré, M.A.; Azad, R.K. Generalization of Entropy Based Divergence Measures for Symbolic Sequence Analysis. PLoS ONE 2014, 9, e93532. [Google Scholar] [CrossRef] [PubMed]
- Dias, L.; Gerlach, M.; Scharloth, J.; Altmann, E.G. Using text analysis to quantify the similarity and evolution of scientific disciplines. R. Soc. Open Sci. 2018, 5, 171545. [Google Scholar] [CrossRef]
- Potvin, P.; Nenciovici, L.; Malenfant-Robichaud, G.; Thibault, F.; Sy, O.; Mahhou, M.A.; Bernard, A.; Allaire-Duquette, G.; Sarrasin, J.B.; Brault Foisy, L.-M.; et al. Models of conceptual change in science learning: Establishing an exhaustive inventory based on support given by articles published in major journals. Stud. Sci. Educ. 2020, 56, 157–211. [Google Scholar] [CrossRef]
- Carey, S. Reorganization of knowledge in the course of acquisition. In Ontogeny, Phylogeny, and Historical Development; Strauss, S., Ed.; Ablex: Norwood, NJ, USA, 1983; pp. 1–27. [Google Scholar]
- Posner, G.J.; Strike, K.A.; Hewson, P.W.; Gertzog, W.A. Accommodation of a Scientific Conception: Towards a Theory of Conceptual Change. Sci. Educ. 1982, 66, 211–227. [Google Scholar] [CrossRef]
- Strike, K.A.; Posner, G.J. A revisionist theory of conceptual change. In Philosophy of Science, Cognitive Psychology, and Educational Theory and Practice; Duschl, R.A., Hamilton, R.J., Eds.; Sunny Press: Newark, NJ, USA, 1992; pp. 147–176. [Google Scholar]
- Vosniadou, S. Capturing and modelling the process of conceptual change. Learn. Instr. 1994, 4, 45–69. [Google Scholar] [CrossRef]
- Vosniadou, S.; Skopeliti, I. Conceptual change from the framework theory side of the fence. Sci. & Educ. 2014, 23, 1427–1445. [Google Scholar]
- Vosniadou, S. Initial and scientific understandings and the problem of conceptual change. In Converging Perspectives on Conceptual Change; Amin, T.G., Levrini, O., Eds.; Routledge: London, UK, 2017; pp. 17–25. [Google Scholar]
- diSessa, A.A.; Sherin, B.L. What Changes in Conceptual Change? Int. J. Sci. Educ. 1998, 20, 1155–1191. [Google Scholar] [CrossRef]
- diSessa, A. A Bird’s-Eye View of the “Pieces” vs. “Coherence” Controversy (from the “Pieces” Side of the Fence). In International Handbook of Research on Conceptual Change; Vosniadou, S., Ed.; Routledge: New York, NY, USA, 2013; pp. 35–60. [Google Scholar]
- diSessa, A. Knowledge in pieces: An evolving framework for understanding knowing and learning. In Converging Perspectives on Conceptual Change; Amin, T.G., Levrini, O., Eds.; Routledge: London, UK, 2017; pp. 9–16. [Google Scholar]
- Özdemir, G.; Clark, D.B. An overview of conceptual change theories. Eur. J. Math. Sci. Tech. Educ. 2007, 3, 351–361. [Google Scholar] [CrossRef]
- Amin, T.G.; Smith, C.L.; Wiser, M. Student Conceptions and Conceptual Change. Three overlapping phases of research. In Handbook of Research on Science Education; Lederman, N.G., Abell, S.K., Eds.; Routledge: London, UK, 2014; Volume 2, pp. 57–81. [Google Scholar]
- Amin, T. Representation, concepts, and concept learning. In Converging Perspectives on Conceptual Change; Amin, T.G., Levrini, O., Eds.; Routledge: London, UK, 2017; pp. 129–139. [Google Scholar]
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Wootters, W.K. Entanglement of formation of an arbitrary state of two qubits. Phys. Rev. Lett. 1998, 80, 2245–2248. [Google Scholar] [CrossRef]
- Yule, G.U. On the Methods of Measuring Association Between Two Attributes. J. R Stat. Soc. 1912, 75, 579–652. [Google Scholar] [CrossRef]
- Warrens, M.J. On association coefficients for 2x2 tables and properties that do not depend on the marginal distributions. Psychomterika 2008, 73, 777–789. [Google Scholar] [CrossRef] [PubMed]
- Bonett, D.G.; Price, R.M. Statistical Inference for Generalized Yule Coefficients in 2x2 Contingency Tables. Soc. Meth. Res. 2007, 35, 429–446. [Google Scholar] [CrossRef]
- Zhang, Z.; Shan, T.; Chen, G. Random walks on weighted networks. Phys. Rev. E 2013, 87, 012112. [Google Scholar] [CrossRef]
- Majtey, A.; Lamberti, P.W.; Prato, D.P. Jensen-Shannon divergence as a measure of distinguishability between mixed quantum states. Phys. Rev. A 2005, 72, 052310. [Google Scholar] [CrossRef]
- Briët, J.; Harremoës, P. Properties of classical and quantum Jensen-Shannon divergence. Phys. Rev. A 2009, 79, 052311. [Google Scholar] [CrossRef]
- Lamberti, P.W.; Majtey, A.P.; Borras, A.; Casas, M.; Plastino, A. Metric character of the quantum Jensen-Shannon divergence. Phys. Rev. A 2008, 77, 052311. [Google Scholar] [CrossRef]
- Osán, T.M.; Bussandri, D.G.; Lamberti, P.W. Quantum metrics based upon classical Jensen–Shannon divergence. Physica A 2022, 594, 127001. [Google Scholar] [CrossRef]
- Furuichi, S.; Mitroi-Symeonidis, F.-C.; Symeonidis, E. On Some Properties of Tsallis Hypoentropies and Hypodivergences. Entropy 2014, 16, 5377–5399. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M.; Shi, Y. Fifty years of graph matching, network alignment and network comparison. Inform. Sci. 2016, 346–347, 180–197. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Newman, M. Networks, 2nd ed.; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Surov, I.A. Natural Code of Subjective Experience. Biosemiotics 2022, 15, 109–139. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acr. | Ref. | Description of Position |
|---|---|---|
| Ca | [55] | Developmental psychology and cognition; theories of concepts; cognitive science |
| P1 | [56] | Piaget’s theory of learning; Kuhn’s theory of science; scientific knowledge |
| P2 | [57] | Updated and augmented version of P1 |
| V1 | [58] | Framework theory; Knowledge-as-theory view; synthetic conceptual models |
| V2 | [59] | Updated and extended version on V1; Contrasts to Knowledge-as-elements view |
| V3 | [60] | Review of views in V1 and V2; Contrasts to Knowledge-as-elements view |
| D1 | [61] | P-prims and knowledge-as-elements view; Contrasts to knowledge-as-theory view |
| D2 | [62] | Augments D1 by Coordination classes; Contrasts to knowledge-as-theory view |
| D3 | [63] | Review of views D1 and D2; Contrasts to knowledge-as-theory view |
| OC | [64] | Attempts synthesis between knowledge-as-elements and -theory views |
| A1 | [65] | Discusses views Ca, P1-2, V1-2, D1-2 and attempts to find common viewpoint |
| A2 | [66] | Review, augments A1, with specific emphasis on views as in Ca |
| Symbol/Abbreviation | Symbol/Abbreviation | Symbol/Abbreviation | |||
|---|---|---|---|---|---|
| Q | Concurrence | Concurrence matrix | Time-like parameter | ||
| Prefactor of Q | Element of | Correlation matrix | |||
| R | Ratio of averages in Q | Contingency matrix | Correlation centrality | ||
| Phase factor in Q | Element of | Vector of elements | |||
| Co-occurrence frequency | Normalized | H | von Neumann entropy | ||
| Weighted adjac. matrix | Element of | J | J-S divergence (JSD) | ||
| Element of | Density matrix | JSD-similarity | |||
| Weighted node degree | Element of | cos-similarity | |||
| Ca | P1 | P2 | V1 | V2 | V3 | D1 | D2 | D3 | OC | A1 | A2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 339 | 160 | 453 | 240 | 245 | 86 | 626 | 392 | 105 | 260 | 410 | 287 | |
| 3801 | 1617 | 3793 | 3299 | 3449 | 1205 | 5692 | 3720 | 1075 | 3092 | 6185 | 3651 | |
| 11.2 | 10.1 | 8.4 | 13.7 | 14.1 | 14.0 | 9.1 | 9.5 | 10.2 | 11.9 | 15.1 | 12.7 |
| Cohort | ||
|---|---|---|
| Q-I | concept, conceptual change, knowledge, student | theory/ies |
| Q-II | change, learn | process |
| Q-III | belief, children, explanation, model, | |
| research, science, term, process | nature, idea | |
| Q-IV | construct, epistemol., experience | naive |
| information, misconception, p-prim, world | ||
| nature, idea, analog, coherence | ||
| C-I | concept, student | |
| C-II | change, learn,conceptual change, knowledge, thery/(ies) | student |
| C-III | belief, children,research, science, term, | |
| process,nature, explanation, idea | ||
| C-IV | construct, epistemol., experience | naive, idea |
| information, misconception, p-prim, world | explanation | |
| analog, coherence, evidence, model |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koponen, I.; Södervik, I. Lexicons of Key Terms in Scholarly Texts and Their Disciplinary Differences: From Quantum Semantics Construction to Relative-Entropy-Based Comparisons. Entropy 2022, 24, 1058. https://doi.org/10.3390/e24081058
Koponen I, Södervik I. Lexicons of Key Terms in Scholarly Texts and Their Disciplinary Differences: From Quantum Semantics Construction to Relative-Entropy-Based Comparisons. Entropy. 2022; 24(8):1058. https://doi.org/10.3390/e24081058
Chicago/Turabian StyleKoponen, Ismo, and Ilona Södervik. 2022. "Lexicons of Key Terms in Scholarly Texts and Their Disciplinary Differences: From Quantum Semantics Construction to Relative-Entropy-Based Comparisons" Entropy 24, no. 8: 1058. https://doi.org/10.3390/e24081058
APA StyleKoponen, I., & Södervik, I. (2022). Lexicons of Key Terms in Scholarly Texts and Their Disciplinary Differences: From Quantum Semantics Construction to Relative-Entropy-Based Comparisons. Entropy, 24(8), 1058. https://doi.org/10.3390/e24081058