Abstract
Deep-learning techniques have significantly improved object detection performance, especially with binocular images in 3D scenarios. To supervise the depth information in stereo 3D object detection, reconstructing the 3D dense depth of LiDAR point clouds causes higher computational costs and lower inference speed. After exploring the intrinsic relationship between the implicit depth information and semantic texture features of the binocular images, we propose an efficient and accurate 3D object detection algorithm, FCNet, in stereo images. First, we construct a multi-scale cost–volume containing implicit depth information using the normalized dot-product by generating multi-scale feature maps from the input stereo images. Secondly, the variant attention model enhances its global and local description, and the sparse region monitors the depth loss deep regression. Thirdly, for balancing the channel information preservation of the re-fused left–right feature maps and computational burden, a reweighting strategy is employed to enhance the feature correlation in merging the last-layer features of binocular images. Extensive experiment results on the challenging KITTI benchmark demonstrate that the proposed algorithm achieves better performance, including a lower computational cost and higher inference speed in 3D object detection.
1. Introduction
Object detection is one of the fundamental tasks in computer vision. Three-dimensional object detection in RGB-D images aims to predict the 3D bounding boxes and class labels for each object in applications, such as autonomous driving, mobile robots, and virtual reality augmentation [1,2]. The methods include three categories, i.e., LiDAR-based [3,4,5,6,7,8,9], Monocular-based [10,11,12,13,14,15], and Stereo-based [16,17,18,19]. In the LiDAR-based method, the point clouds generated by expensive LiDAR sensors provide accurate depth information of the 3D space. However, the short operating distance of the LiDAR devices and the sparse point clouds limit its deployment in real scenarios.
In monocular-based methods, predicting objects in 3D space is difficult due to an inherent lack of precise depth cues [10,15,20]. Nonetheless, the fluctuation of inferred depth information influences the suboptimal performance [21]. Thus, stereo cameras offer a reasonable alternative solution, providing denser depth information through left–right photometric alignment and enabling more real-time 3D object detection with considerable accuracy, which provides more data support for controlling the robot, such as cooperative control of manipulators [22] and kinematic control of redundant manipulators [23].
These are the potential applications in low-cost scenarios, such as mobile robots and autonomous driving. The main challenge of stereo-based approaches is the effective acquisition of the implicit depth information, textures, and semantic features in binocular images. Pseudo-LiDAR [20], a commonly used image-based 3D object detection method, converts the depth information into pseudo-LiDAR point clouds and then completes detection using LiDAR-based detection.
The downside to this method is losing accurate semantic information and adding noise when transforming the background. Although designing subsequent point-cloud detection frameworks meet the higher requirements, it requires a vast GPU memory to train the network, which hinders the stereo systems deployment in low-cost applications. Some researchers directly introduced point clouds to improve the detection performance [16,24], while others utilized instance segmentation to focus on the foreground [25,26]. These methods described above essentially transform images into other feature representations; however, they do not thoroughly infer the intrinsic relationship between the implicit depth information, textures, and semantic features. Motivated by the above inspirations, we use the stereo image-based method for 3D object detection with higher accuracy and speed.
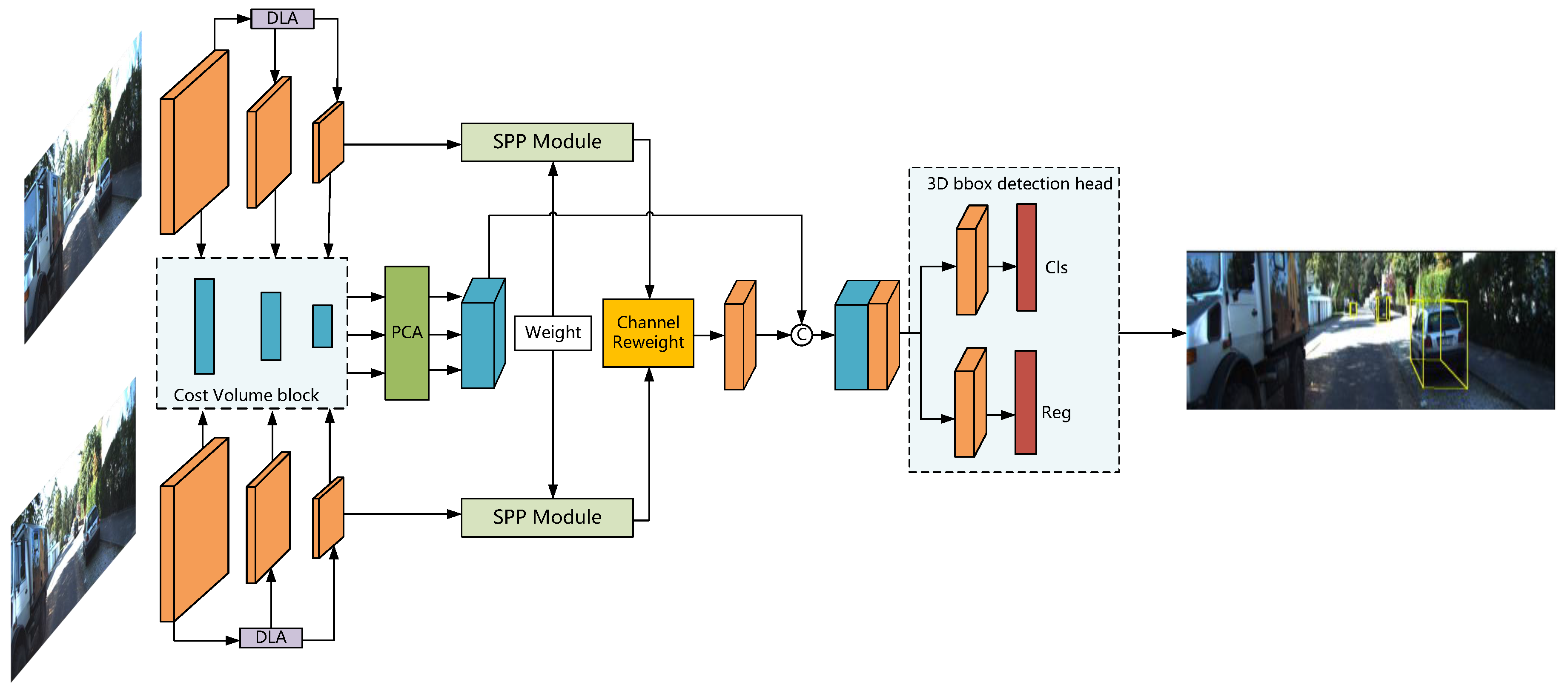
The proposed framework FCNet, as depicted in Figure 1, is trained end-to-end by using stereo image data only. To efficiently correlate sparse depth features in binocular images with semantic and texture features, we introduce the deep-layer aggregation structure for extracting more contextual information. Based on the multi-scale cost–volume with a normalized dot-product, we develop parallel convolutional attention modules to enhance the feature representation and fuse them in top-down processing. Moreover, we formulate the channel similarity reweighting strategy for reducing the redundant features in merging the last-layer features of binocular images. Finally, the combined features generate the base feature of detection heads.
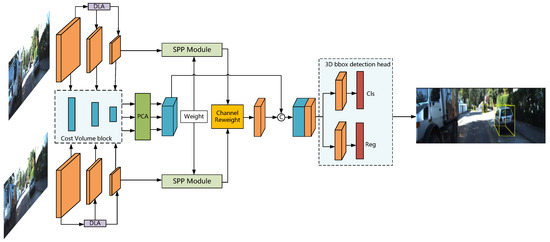
Figure 1.
Network inference structure of FCNet. Stereo images are first passed through a simple Siamese network to generate the multi-scale features and then apply a normalized dot-product to construct a multi-scale cost–volume. Finally, we use the parallel attention model and channel similarity reweighting strategy to fuse multi-path features for building the features-based detection heads effectively.
In summary, the main contributions of our work are below:
- A simple and efficient stereo 3D object detection method, FCNet, is proposed. Compared with SOTA approaches, it achieves better performance without LiDAR point clouds and other additional supervision while maintaining an inference time of about 0.1 s per frame.
- After building a multi-scale cost–volume containing implicit depth information, we develop a variant attention module to enhance the global structure representation and local detail description of the multi-scale cost–volume. A region depth loss supervises depth regression.
- A channel reweighting strategy is used to strengthen the feature correlation while integrating the binocular images’ last-layer features by removing the redundant and robust correlation features while retaining the weak correlation features with significant differences. This facilitates the balance between channel information preservation and the computational burden.
2. Related Works
2.1. Image Depth Estimation
As mentioned previously, 3D object detection using image data is inherently challenging due to the scarcity of reliable depth information. Chen et al. [27] proposed Multi-View 3D Object Detection networks encoded LiDAR point clouds into multi-view feature maps fused with binocular images and predict 3D bounding boxes. Xu et al. [28] applied different sub-networks to process LiDAR point clouds and image data and fused them at the feature level.
Lam et al. [29] adopted a fully convolutional framework. After inputting an RGB image and sparse 3D point clouds to form a sparse depth map and taking the 3D point clouds as depth constraints onto the images, they created an RGB-D image. In addition, some researchers also performed stereo matching to estimate the depth of information. Refs. [30,31] applied the dot-product between binocular feature maps to estimate the disparity distribution.
In PSMNet [32], a spatial pyramid pooling module improves the concatenation-based cost–volumes, and multiple 3D CNN obtains the corresponding depth estimation from rich context information. Unlike the methods of constructing pixel-level cost–volume, TLNet [33] employs 3D anchors to explicitly produce object-level correspondences of the RoI in stereo images, which significantly reduces the depth estimation computational workload. EDNet [34] performs fast stereo estimation using residual attention to aggregate 3D correlation features and 4D concatenation volume on multiple scales and constructs a fast 2D CNN instead of 3D CNN.
In this paper, we take an approach similar to many other stereo 3D object detection algorithms to construct reliable depth features in binocular images, rather than introducing LiDAR point clouds to match the depth information.
2.2. 3D Object Detection
LiDAR-based 3D Object Detection: In most state-of-the-art 3D object detection methods [3,4,6,8,9,35,36], 3D LiDAR point clouds provide accurate 3D information. In terms of procedures of point clouds, there are two types of streams, i.e., directly operating on the unordered point clouds in 3D [6,8,35,36] and discretizing the locations of point clouds into some voxel grids with a fixed voxel size [3,4,9]. The LiDAR-based methods have high performance, but because of the high-cost LiDAR and huge GPU memory, they are unsuitable for camera-only applications, such as mobile robots and autonomous vehicles.
Monocular-based 3D Object Detection: It is challenging to detect 3D objects with a single image for loss of depth information. Mono3D [11] generates 3D bounding boxes from monocular images by utilizing the geometric constraints between 2D and 3D cues, such as semantic and instance segmentation masks. Deep3DBox [21] finishes depth estimation and 3D detection by using angle and scale information. After predicting nine keypoints of a 3D bounding box in image space, RTM3D [12] recovers the location, dimension, and orientation in 3D space by designing a multi-task detection head. Due to the constraints of the target geometric relationship, AutoShape [37] develops more 3D keypoints to improve detection performance.
M3DSSD [13] proposes a two-step feature alignment method to resolve feature mismatching in the context of 2D and 3D Box regression. Unlike the geometric constraint-based methods mentioned above, MonoFENet [14] and DDMP [38] adopted depth estimation to enhance the features of 2D and 3D for accurate 3D localization. MonoGRNet [39] decouples the 3D object detection task into four progressive subtasks, enabling flexible adaptation to fully and weakly supervised learning. Detecting objects in the 3D space with monocular-based methods is difficult due to the shortage of accurate depth information.
Stereo-Based 3D Object Detection: Compared with monocular images, stereo images are more appropriate for 3D detection since the disparities between left and right images are conducive to providing more reliable depth information. Despite this, few researchers are concerned about 3D object detection. Pseudo-LiDAR [20] converts the disparity map into 3D point clouds.
Pseudo-LIDAR++ [16] directly obtains a depth map by relying on the depth cost–volume instead of the depth estimation network, effectively reducing computational workload. Disp RCNN [25] predicts disparity only for pixels on objects of interest and generates dense disparity without needing LiDAR point clouds. Similarly, OC-Stereo [26] proposes an object-centric stereo matching method to match differences between foreground and background. By building 4D feature-consistent embedding (FCE) space as the intermediate representation of 3D space, RTS3D [40] improves the detection accuracy without dense supervision information.
Moreover, Stereo-RCNN [17], as a classic image-only 3D detection network, directly applies the existing 2D object detection network to recover a coarse 3D bounding box using left and right RoIs. YOLOStereo3D [18] takes a stereo 3D detection task as a monocular one to enhance stereo features with faster inference speed. The motivations for our work are PSMNet [32] and Stereo-RCNN [17].
3. Methods
In this section, we elaborate on the proposed FCNet network structure and the applied methods in this paper. After introducing the anchors’ preprocessing procedures, we present a parallel convolutional attention (PCA) module to produce a more powerful and robust sparse depth feature from binocular images using global context information. We devise a channel similarity reweighting (CSR) strategy to enhance the left and right association feature. Finally, we deliver the multi-task loss function of FCNet.
3.1. Anchors Preprocessing
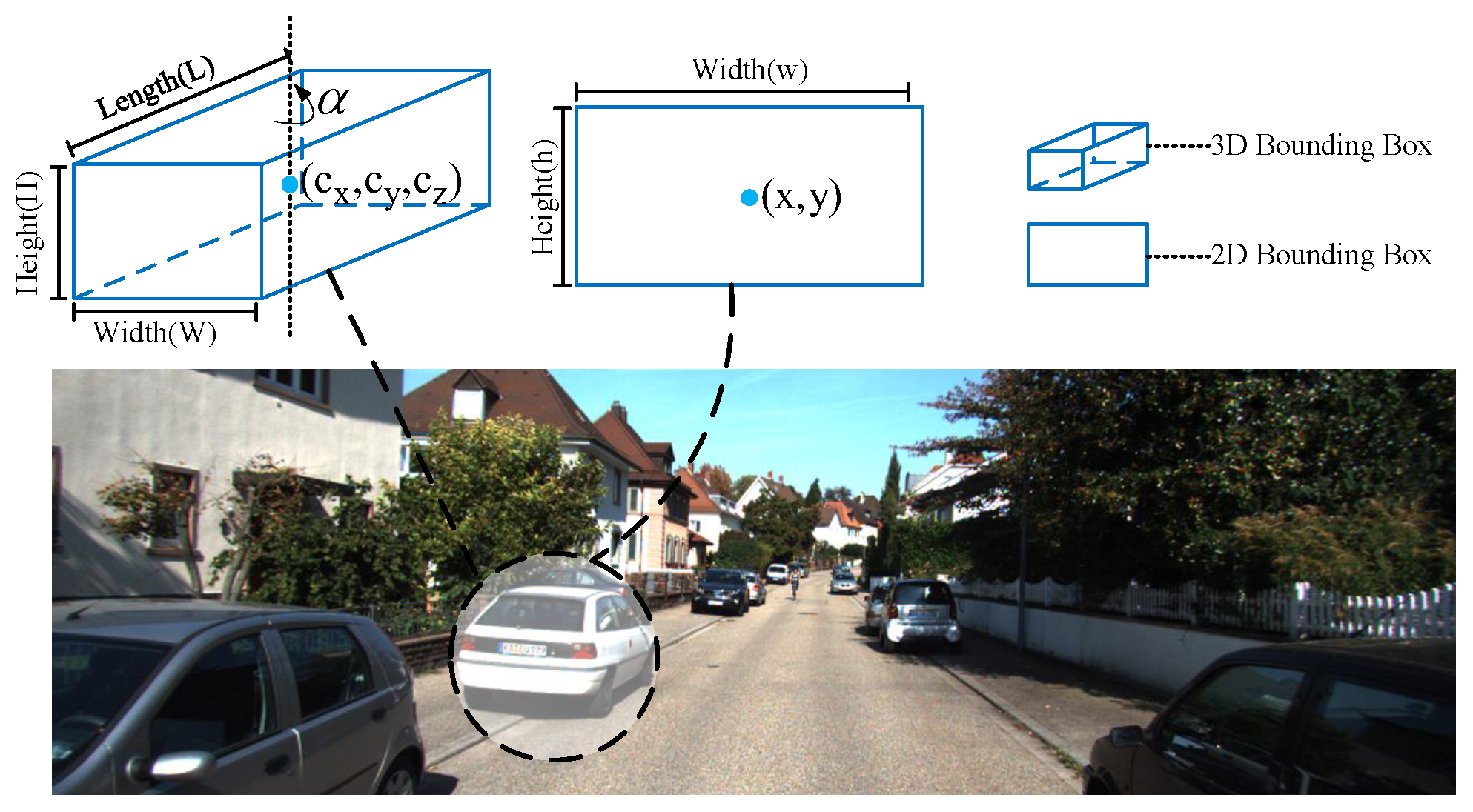
(1) Anchors Definition: The states of a 3D anchor can be represented by , as shown in Figure 2, where is the center of the left 2D box and is the width and height; is the 3D centers of objects, where is the center of the object projected on the image plane and z is the depth; corresponds to the width, height and length of the 3D bounding box, and estimates the observation angle of objects.
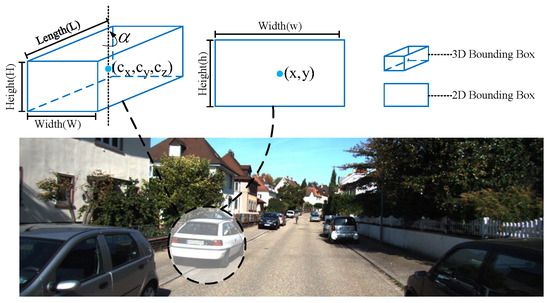
Figure 2.
Illustration of the 3D anchor.
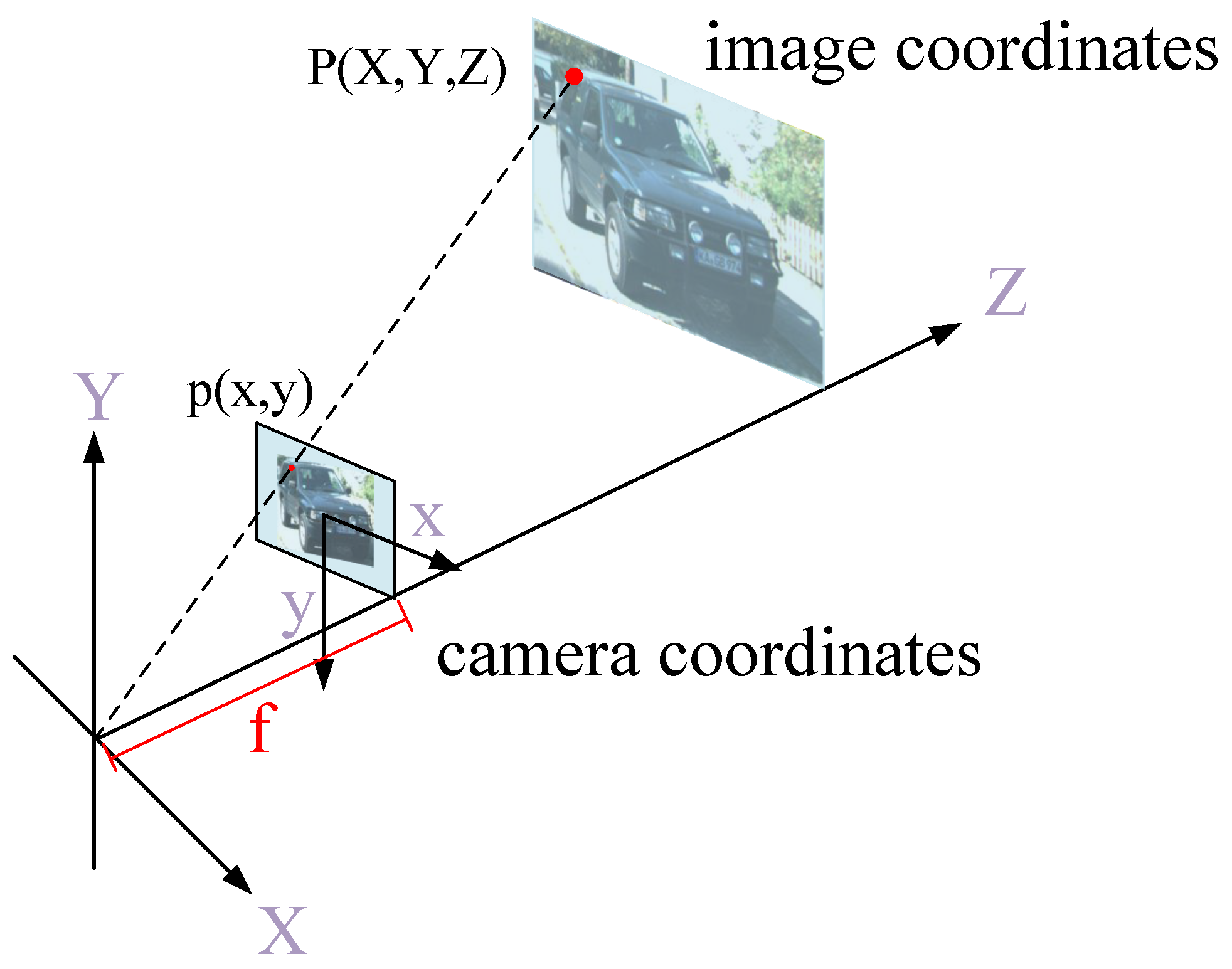
(2) Priors Extraction from label: As shown in Figure 3, given a 3D point in camera coordinates, its corresponding point in image coordinates is given as:
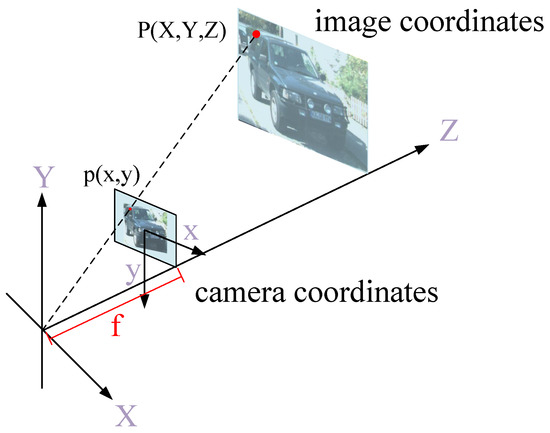
Figure 3.
Principles of perspectivegeometry.
Suppose the average depth of the object in the 3D space is , then we can infer the intrinsic relationship between 2D space and 3D space according to Equation (1).
where refers to the size of the 2D box, is the volume of the object and f is the focal length of the camera.
Since the volume of an object in three-dimensional space is relatively constant, we can assume that the anchor depth Z is inversely proportional to the object’s size in the image, and we can infer the rough object depth information based on the size of the 2D or 3D bounding box. Thus, we consider each anchor as a distribution with the individual mean and variance of the object proposal in 3D space. After iterating through the training set for utilizing the prior statistical knowledge from the anchor boxes, we estimate the mean Z and variance value S of the 2D bounding box. In the training period, we convert 2D dense anchor boxes into 3D ones and filter out the anchor boxes with abnormal depth information according to the depth value retrieved from the average area S. The schematic diagram illustrates in Figure 4.
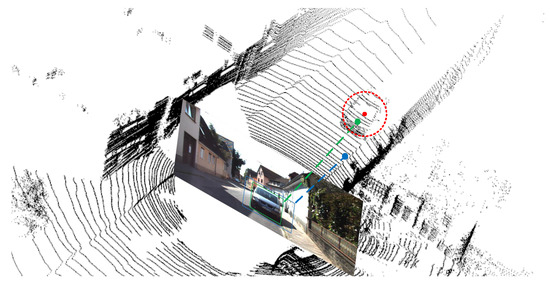
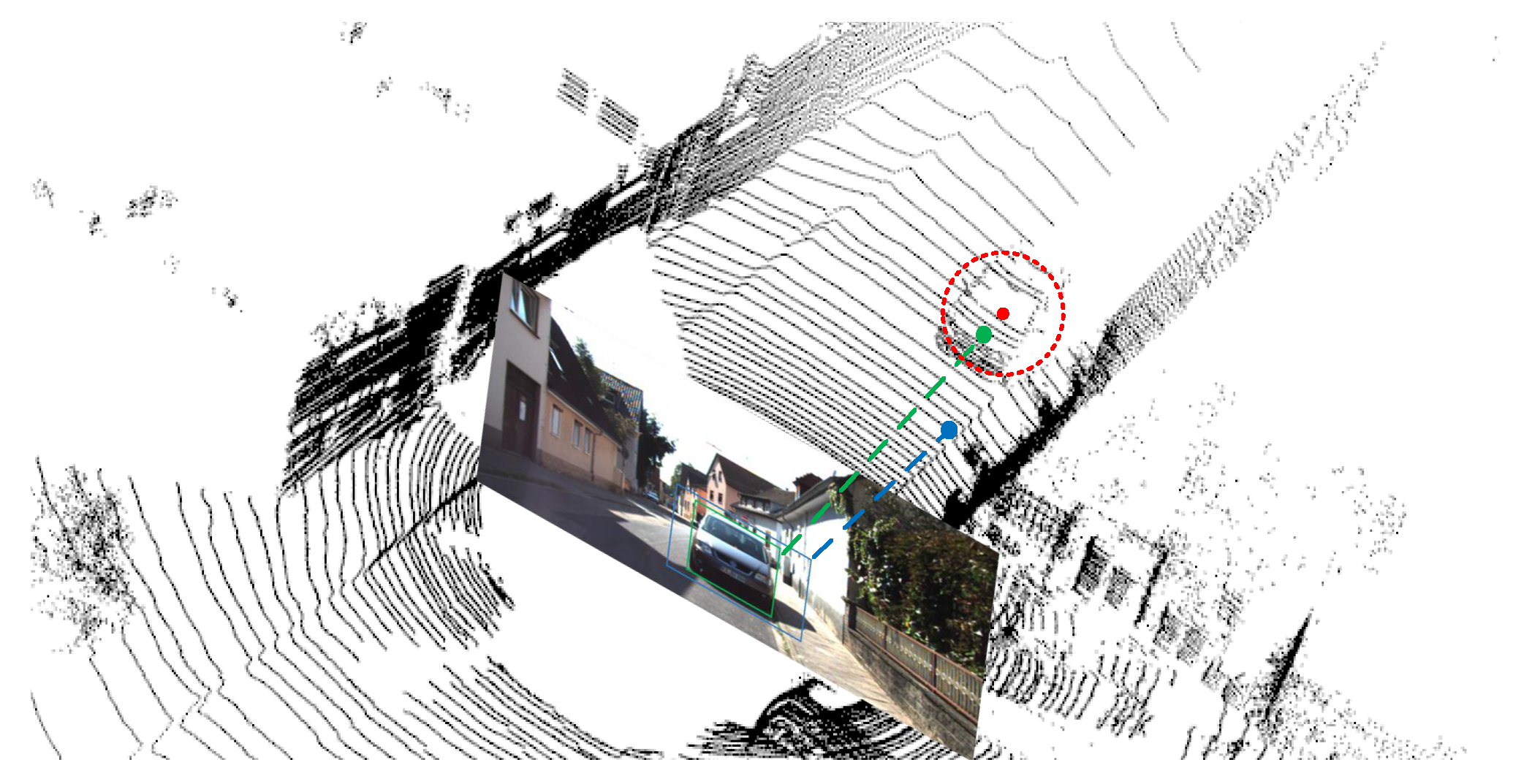
Figure 4.
We project anchor boxes with the mean area value S of the 2D bounding box into 3D. We filter out anchor boxes with abnormal depth based on the depth value retrieved from the average area during training (the anchor corresponding to the blue point in the figure).
3.2. Sparse Depth Feature Extraction
Deepening the number of layers is effectively helpful in extracting stereo features. However, it has negative impacts on growing the exponentially computational overhead, which is unsuitable for rapidly changing scenarios, such as autonomous driving.
As shown in Figure 1, we adopt ResNet-34 as the backbone network and apply a deep-layer aggregation structure to give the network better accuracy and fewer parameters. In addition, after using a normalized dot-product to calculate multi-scale cost–volumes, we propose a parallel convolutional attention mechanism to enhance the sparse depth features.
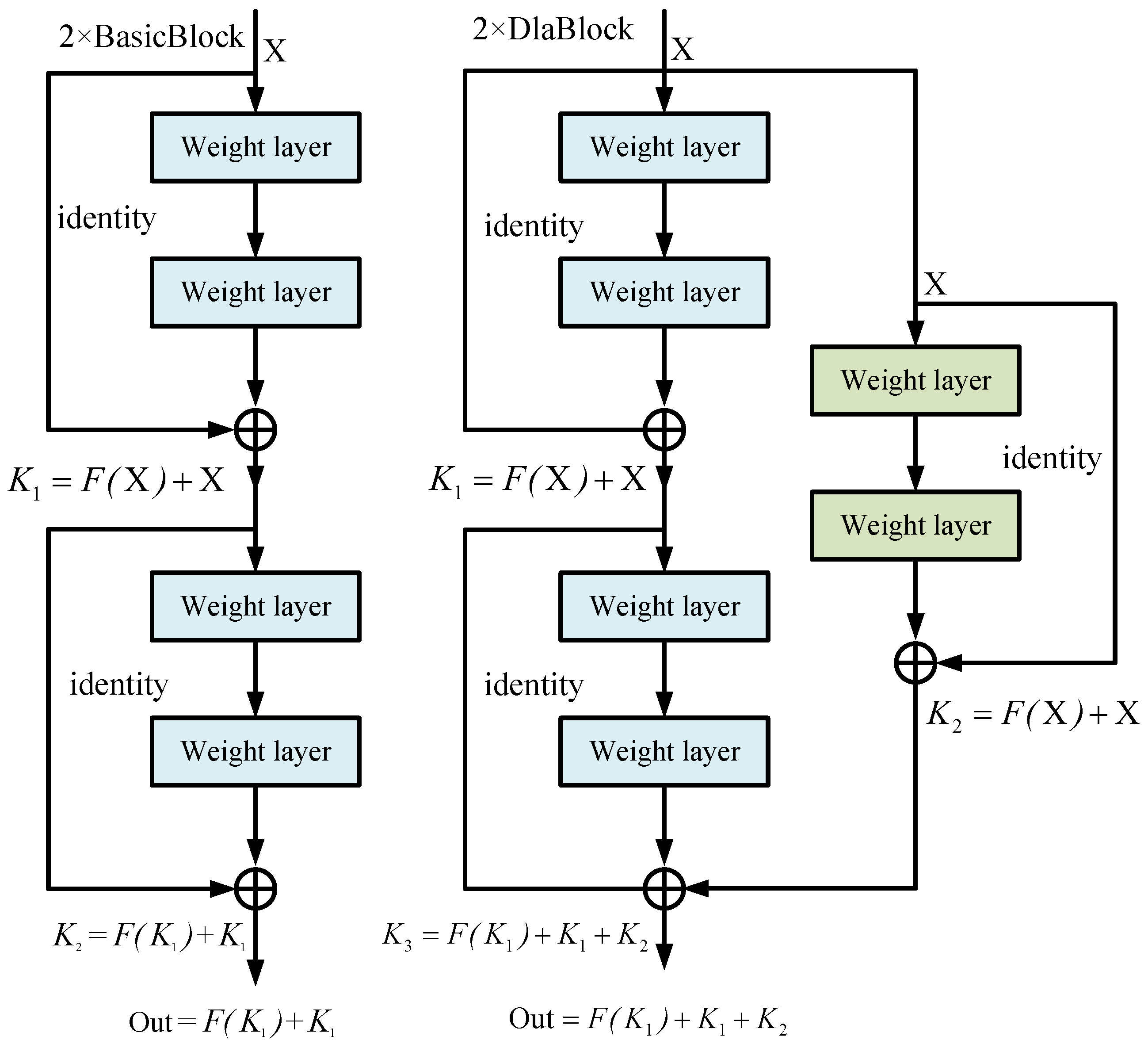
(1) Deep-Layer Aggregation: As mentioned above, we propose a deep-layer aggregation structure to extract the richer features. In contrast to directly increasing the number of neurons in each layer, we assemble a residual branch to aggregate features of different layers as shown in Figure 5.
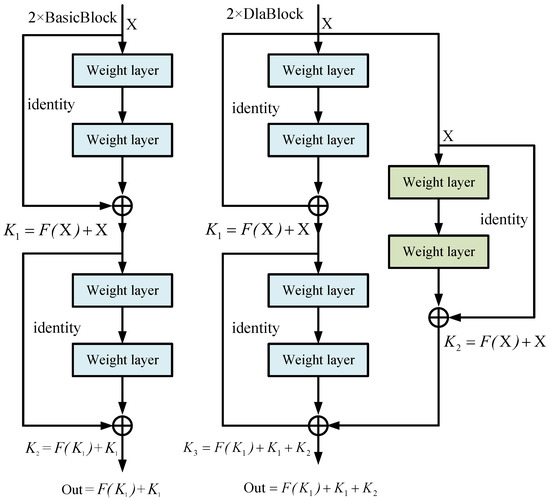
Figure 5.
Deep-layer aggregation structure. We choose the simplest two conv layers with a kernel size of 3 as the aggregation node to aggregate the features of 2 stacked BasicBlock.
Take the ResNet-6 as the sample, which means 2 × BasicBlocks are stacked. Let the BasicBlock be . Suppose is the input of the i-th BasicBlock, and is the output of the i-th BasicBlock. In this case, the output describes as follows:
The output of 2 × BasicBlock is written as follows:
In the same way, the output of 2 × DlaBlock, which has the deep-layer aggregation, lists as follows:
In Equation (5), denotes the output of the previous BasicBlock. The network with a deep-layer aggregation structure efficiently reuses the features of different BasicBlocks, which enhances abundant the extracted abundant features due to integrating multiple BasicBlocks.
(2) Multi-scale Cost Volume: Instead of supervising the depth information with point clouds, we densely concatenate left feature maps with their corresponding right feature maps across each disparity level to construct a cost–volume block that contains the depth information of the object. As illustrated in Figure 1, the backbone network includes three output branches of different scales, each generating a cost–volume block. To extract more reliable stereo features and exploit more contextual information, we apply the parallel convolutional attention module proposed in the following subsection to merge the cost–volume block of shape sizes , and densely. Finally, we use top-down processing to normalize these cost–volume blocks to form a 4D cost–volume with the shape .
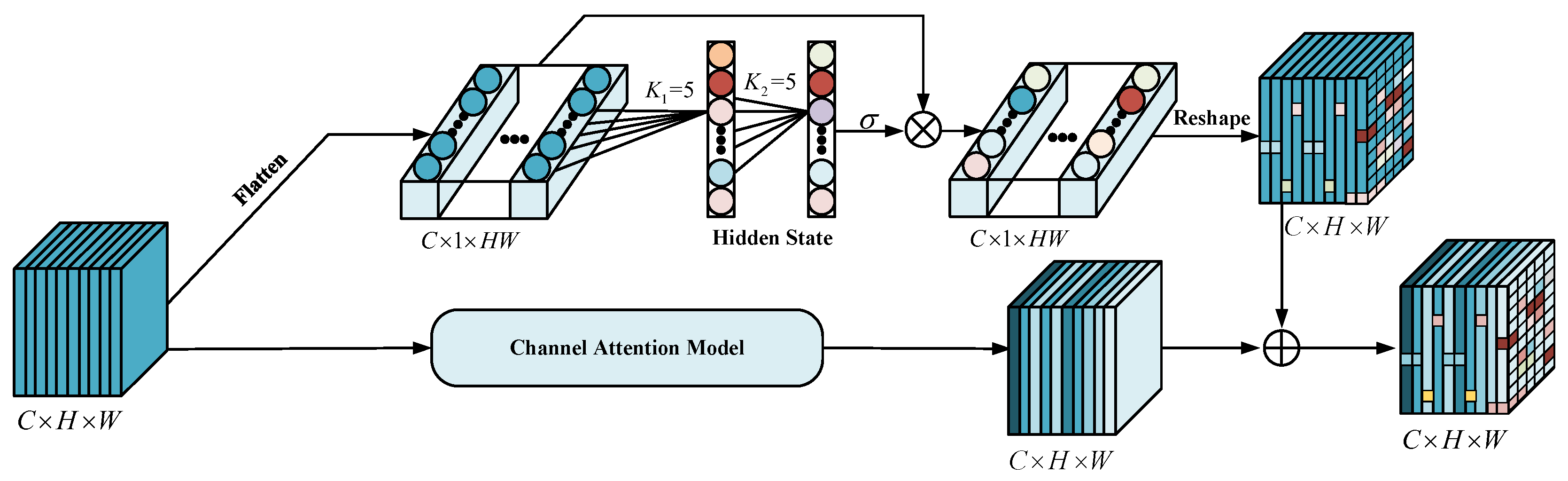
(3) Parallel Convolutional Attention Module: Small objects, such as pedestrians have a small proportion of the image’s foreground. It is still difficult to detect small objects accurately for their complex texture features. Thus, a convolutional module, a combination of pixel-level attention and channel attention, is proposed to detect small objects. As shown in Figure 6, given an intermediate feature map as input, the module infers, in parallel, a 2D pixel-level attention map and a 1D channel attention map . The overall attention process is summarized as follows:
where represents the size of the attention map into , ⊙ is element-wise multiplication, and is the final refined output of channel attention. is the final progressive output of pixel-level attention.
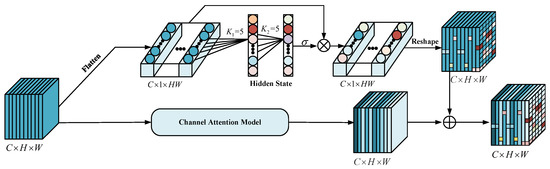
Figure 6.
Architectures of the proposed parallel convolutional attention module.
To generate the final refined output of channel attention mentioned in Equation (6), We first select the scheme proposed in [41] to create a channel attention map and then multiply by F to get the final output. The entire procedure of channel attention is described as follows:
where and denote the Sigmoid function and a multi-layer perceptron with one hidden layer, respectively. and represents average-pooling and max-pooling operation separately. Furthermore, the values of pixels in a specific region inextricably link with the depth information of the target, so we use a pixel-level attention module to extract the correlation for neighboring pixels in different regions. Specifically, we flatten an intermediate feature map to , perform two fast 1D convolutions of size 5 to generate the pixel-level attention map , and multiply by to obtain the final fine output of pixel-level attention . The pixel-level attention is described as follows:
where is the Sigmoid function, and is 1D convolution.
As shown in Figure 7, we apply the pre-trained PCA module to extract features of the camera images. We intuitively notice that the network with the PCA module pays more attention to the pixels at the edge region in images, which highlights by the red ellipse in the in Figure 7.

Figure 7.
Taking the left images of the stereo pairs as input, the output of the parallel convolutional attention module.
In addition, as listed in Table 1 and Table 2, the PCA module has superiority in improving performance, especially for pedestrians detection.

Table 1.
Ablation study results of Car on the KITTI validation set.
Table 2.
Ablation study results of Pedestrian on the KITTI validation set.
3.3. Feature Correlation Model
We engineer a correlation-based fusion scheme to utilize the left and right feature maps obtained through the backbone network while reducing feature redundancy.
In Figure 1, taking a pair of left–right feature maps with C channels and size as input, we subsequently transfer them into a Siamese Spatial Pyramid Pooling Network to initially find their similarities. Then, we re-fuse the left–right feature maps by utilizing the left–right coherence scores concatenated with spare depth feature maps obtained by stereo matching methods. Finally, we transform them into task-specific fully-connected layers to predict the objectiveness confidence and 3D bounding box offsets.
We choose the absolute value of the Pearson correlation coefficient to calculate the coherence score for the ith channel in the left–right features maps, which is defined as follows:
where is the covariance of x and y, and are the ith pair of the left–right feature maps, and are the standard deviations of and , and are the jth element of and , and are the mean value for the ith pair of feature maps.
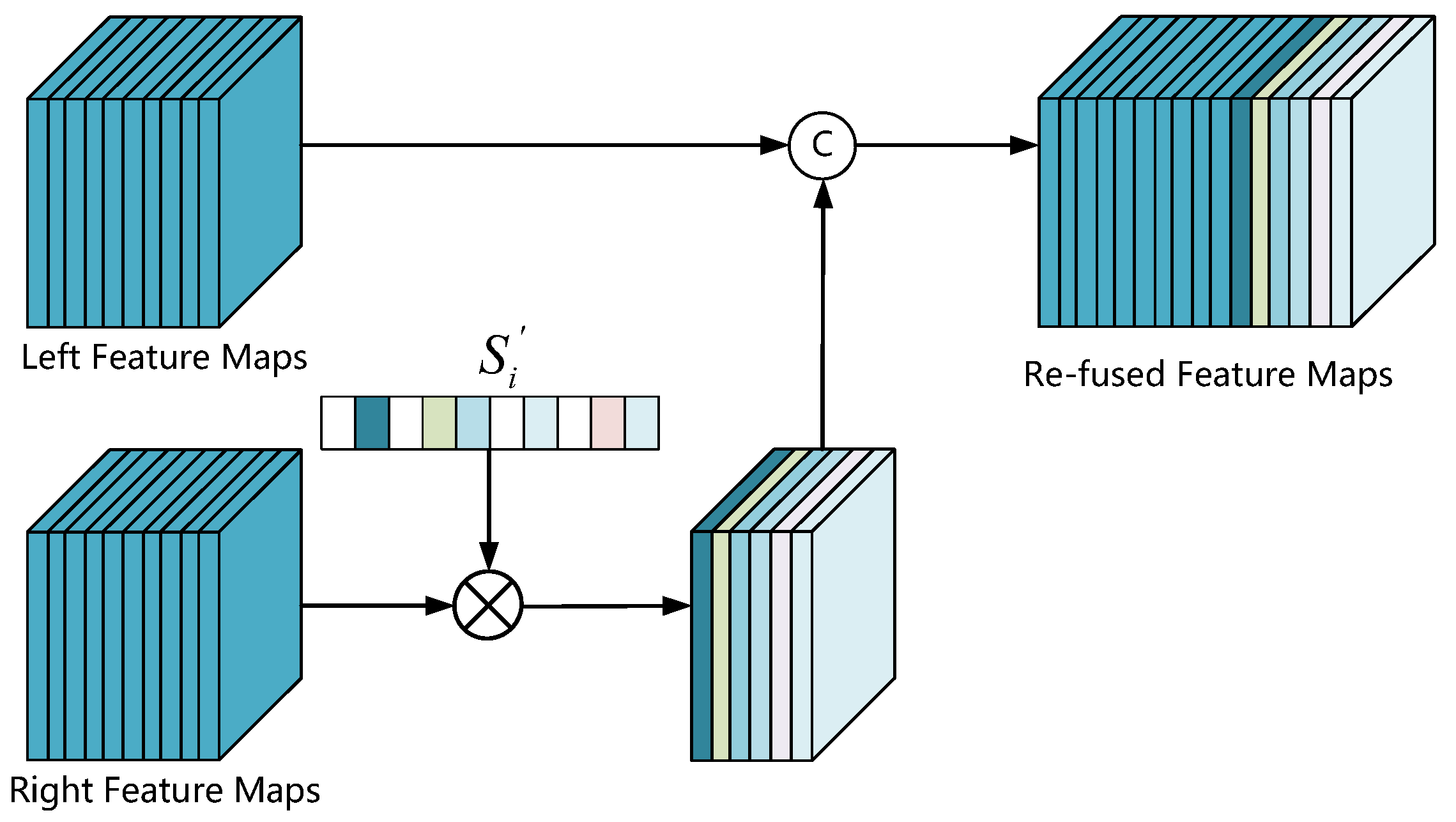
After calculating the coherence scores of all channels in the left and right feature maps, we select channel similarity reweighting (CSR) to enhance the associated representations of the left–right feature maps. Specifically, we still retain the valuable features despite eliminating useless features by setting a threshold to reweight the coherence scores . The reweighting strategy described as follows:
Then, we use the reweighting left–right coherence scores to re-fuse the left–right feature maps, and the re-fuse process illustrates in Figure 8. By multiplying the ith channel of the right feature maps with , we remove the redundant and robust correlation features whose coherence score is greater than the threshold value from the right feature maps. After doing this, we retain weak correlation features with significant differences to compensate for the scarcity of features in the left feature maps.
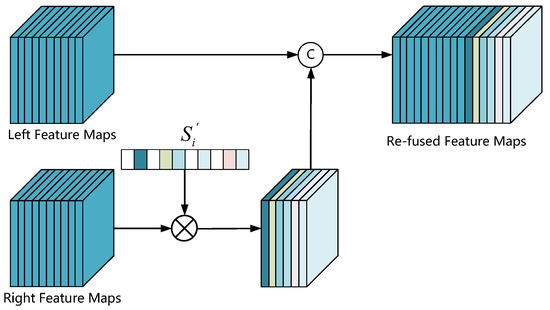
Figure 8.
CSR architecture. We first introduce the absolute value of Pearson correlation coefficient to calculate the coherence score of each pair of channels, then rescale the coherence score based on the reweight threshold, and finally multiply the reweighted coherence scores with the right feature maps and concatenate it with the left feature maps.
The features with weak correlation are strengthened instead of preserving that of strong correlation because the correlation coefficient of features is larger than the threshold value. The network with the proposed method obtains more discriminative features from stereo images. The positive effects of CSR on 3D object detection shows in Table 1 and Table 2. We verify that the reweighting threshold also affects the network performance, and our experiments’ optimal value is 0.59.
3.4. Loss Function
We train the proposed FCNet using a multi-task loss function. This loss function configures four elements, i.e., a classification loss , 2D BBox regression loss , 3D BBox regression loss , and a sparse depth regression loss . The multi-task loss function is defined as follows:
where , , are three hyperparameters for balancing different tasks.
The multi-task loss function describes in more detail.
(1) Focal loss function: For object classification, the focal loss [42] deals with the imbalanced classes:
where is the estimated probability of class c. and are the parameters of the focal loss. We use and in our training process as in the original paper.
(2) GIoU loss function: As mentioned in Section 3.1, learning 2D bounding box parameters is crucial to filter out anchor boxes with abnormal depth. Therefore, The GIoU [43] loss supervises the regression of the 2D bounding box:
where is the predicted 2D BBox, is the ground-truth 2D BBox and is the smallest enclosing BBox of and .
(3) Smooth L1 loss function: For the 3D BBox regression task, the smooth L1 loss function similar to [44] is defined as follows:
where is the center of the left 2D box and is the width and height; is the center of the object projected on the image plane and z is the depth; corresponds to the width, height and length of the 3D bounding box, and is the yaw rotation around the z-axis.
(4) Sparse depth regression loss function: We feed the multi-scale cost–volume obtained by stereo matching into a decoder to generate the corresponding sparse depth map and introduce a regional depth loss as an auxiliary loss to regularize the training process. The sparse depth regression loss is defined as follows:
where w, h are the corresponding width and height of the 2D BBox mapped to the sparse depth map, is the center of the 2D BBox, s is the scaling factor to adjust the size of the selected area, is the depth at position x, y, is the ground truth depth of the 3D centers of objects.
To optimize the multi-task loss function, we use the Adam optimizer with an initial learning rate of and train for 100 epochs.
4. Experiments
4.1. Datasets and Evaluation Metrics
We evaluate our method on the challenging KITTI object-detection benchmark [45] for 3D object detection. The KITTI dataset composes 7481 images with labels and 7518 images for testing. Thus, we split 7481 training images into 3712 for the training set and 3769 for the validation set following [18]. To fully evaluate the performance of the proposed FCNet, we follow the official settings to conduct experiments using the 3D Average Precision and 2D Average Precision as the main metrics by comparing to state-of-the-art and self-ablation.
We adopt the ResNet-34 pre-trained on ImageNet as the backbone network in our proposed FCNet and train the network with a batch size of 4 on a single Nvidia GeForce 3060 GPU. We resize the input images to . The loss weights , and in Equation (11) are , , . Term s in Equation (15) is set to 8. As with [13], We use 12 anchor scales ranging from 24 to 288 pixels following the power function of , and aspect ratios of [0.5, 1.0, 2.0] to define a total of 36 anchors for multi-class detection. As implemented in [17], we use 1024 input channels in the final classification and regression layers.
4.2. Ablation Studies
To validate the effectiveness of enhancing our model performance, we conduct ablation experiments on the validation set of Chen’s splits. We train the model on the “Car” and “Pedestrian” types. As shown in Table 1 and Table 2, we obtain the experimental results after 50 epochs of training. Each ablation experiment describes below.
(1) Deep-Layer Aggregation Structure: The DLA structure essentially expands the width of the network, improving the reuse of feature maps and guiding each layer to extract richer features.
To test the effectiveness of the DLA structure in boosting the network performance, we switch the status of the network structure with the DLA structure branch or not. As shown in Table 1 and Table 2, Compared with the network without DLA structure, the network with DLA structure achieves , , , , , performance improvements for on the “Easy”, “Moderate”, and “Hard” categories of car and pedestrian.
(2) Anchor Preprocessing: The anchor priors merge into the 3D object detection pipeline during training inference. Thanks to the geometric prior knowledge and constraints, the network further enhances the performance of 3D object detection. We conduct two experiments to verify its effectiveness. In the first experiment, we do not use the prior learned knowledge of BBox, such as the average size and mean square error. In the other experiment, we disable prior-based anchor filtering, i.e., anchors with abnormal depth are not filtered out. The results show that anchor priors significantly boost the network performance, and filtering out irrelevant anchors during training is also necessary to accelerate inference and improve the network performance.
(3) Parallel convolutional Attention Module: We also have an ablation study on the importance of parallel attention convolutional modules to improve network performance. The experimental results show that the network with the PCA module achieves practical gains in both car and pedestrian categories, especially for pedestrians with complex textures and edge features. In addition, we visualize the influence of this module on features. As shown in Figure 7, we draw the effect diagrams of the PCA module acting on cars and pedestrians, respectively. We observe from the Figure that the module has apparent effects on the extraction of pedestrian texture features and the division of regional pixels and has a particular impact on the edge calibration and pixel area segmentation of the car.
(4) Channel Similarity Reweighting: Reweighting highly similar channels during the fusion between the left and right features significantly reduces noise interference and compensates for channel information loss. To evaluate the effectiveness of the reweighting strategy, we directly fuse the left and right feature maps instead of reweighting-based fusion. According to the results, the reweighting strategy is critical to improving the accuracy of 3D object detection. Furthermore, the reweighting threshold also affects the network performance, and we seek the optimal threshold. To further emphasize the generalization ability and effectiveness of the reweighting strategy, we construct the left image with occlusion by randomly cropping some regions on the original left image to cover the target region (the red circle in Figure 9), and then feed it. The original right image into the detection network, the result is shown in Figure 9. Our proposed network can still effectively detect the target even if interference information exists in the left image.

Figure 9.
Effectiveness of the reweighting strategy. From left to right: original left images, left images with occlusion, original right images, and detection results.
4.3. Qualitative Comparison
The qualitative validation results estimated by our FCNet provides in Figure 10. In addition, we also visualize the detection results of other stereo-based 3D object detection frameworks, as shown in Figure 11.

Figure 10.
Qualitative results of 3D object detection on KITTI benchmarkt. The RGB images show the detection results on the left images. The LiDAR point clouds are visualized for reference but not used in both training and evaluation.The blue bounding boxes are the 3D prediction from FCNet and the red bounding boxes are the ground truth 3D bounding box.

Figure 11.
Comparison of our results with other state-of-the-art approaches. Our results are shown in the first column. The remaining second and third columns are results obtained by [18,46], respectively. The red arrows in the figure indicate detected objects or objects with large detection errors, and green arrows indicate validly detected objects.
From the results, we observe that, for simple cases of non-occluded objects within a reasonable distance, the most successful predictions of our model are visually consistent with the context. With the proposed model, we correctly detect the pose 3D boxes from other labeled data under incorrectly labeling the original bounding box (e.g., the car pointed by the red arrow in Figure 10). In addition, in some complex cases that seem very challenging in images with lots of nearby or even overlapping 2D boxes, our model can still detect 3D objects correctly. On the other hand, the reasons for several failure detections are that the targets are out of the reachable distance or the presence of severe visual occlusion, which are possible directions for future efforts.
4.4. Quantitative Comparison
To further quantitatively evaluate the prediction results of our model, we use the best-trained model in our experiment to calculate the 3D Average Precision () and 2D Average Precision () on the KITTI test set and compare the performance of our model with other state-of-the-art methods. The results demonstrate in Table 3 and Table 4. In terms of detection speed, the average inference time of the proposed FCNet is about 0.1s per frame, which is much faster than most other 3D detection networks on the KITTI benchmark (e.g., Pseudo-LiDAR [20], Pseudo-LiDAR++ [16], Disp R-CNN [25] and DSGN [47]).
Table 3.
3D detection performance. Comparison of our method to other 3D detection frameworks for Car and Pedestrain categories, evaluted using average precision of 3D bounding boxes () on KITTI test set. The 3D IoU thresholds are set to 0.7 for car and 0.5 for pedestrian as the same as the official settings.
Table 4.
2D detection performance. Comparison of our method to other 3D detection frameworks for Car categories, evaluted using average precision of 2D bounding boxes () on KITTI test set.
Regarding , our proposed network FCNet outperforms the most recently proposed methods in 3D detection, significantly outperforming the LiDAR-based method Complex-YOLO by on pedestrian detection in the complicated regime. For 2D object detection, we achieve comparable accuracy to state-of-the-art methods. Although FCNet does not compete directly with SOTA methods for 2D detection, its performance is suitable to facilitate the 3D detection task. FCNet has a comparable detection speed to prior art but significantly higher overall precision.
5. Conclusions
This paper proposed a novel and practical framework, FCNet, that utilizes the reweighted features and multi-scale cost–volume for 3D object detection. We first applied a deep-layer aggregation structure for widening the backbone to extract richer contextual information and use priors in anchors for depth inference during training to filter out many useless negative samples. Then, we constructed a multi-scale cost–volume and utilized a parallel attention module to enhance the global context information and structural representations in the multi-scale cost–volume fusion stage.
Finally, we used a novel reweighting strategy that balances the channel information preservation of the re-fused left–right feature maps and the computational burden. Comprehensive experiments on the KITTI 3D object-detection benchmark demonstrated that our method achieved better or comparable performance compared to recent SOTA approaches without using LiDAR point clouds and other additional supervision. FCNet also achieved a competitive inference speed with only one GPU with 8 GB GPU memory, which boosts the deployment of 3D object detection on low-cost devices.
In the future, we plan to utilize network pruning to deploy the model on low-cost mobile robots and extend the proposed method to multi-view 3D object detection or video 3D object detection. In addition, we will explore practical methods to reduce the trial and error time for finding the most suitable hyperparameters by using meta-optimization to further improve the system performance.
Author Contributions
Methodology, Software, Writing, Original Draft, Software, Validation, Y.W.; Conceptualization, Supervision, Methodology, Writing, Review, Editing, Funding Acquisition, Z.L.; Visualization, Y.C.; Formal Analysis, X.Z.; Conceptualization, G.T.; Software, Q.Z. and M.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Guizhou Science and Technology Foundation under Grant No. (2016) 1054, Guizhou Province Joint funding Project under Grant No. LH (2017) 7226, Guizhou University Academic New Seeding training and Innovation and Exploration Project under Grant No. (2017) 5788.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained with in the article.
Acknowledgments
Thanks are given for the computing support of the State Key Laboratory of Public Big Data, Guizhou University.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, Y.; Sun, P.; Zhang, Y.; Anguelov, D.; Gao, J.; Ouyang, T.; Guo, J.; Ngiam, J.; Vasudevan, V. End-to-end multi-view fusion for 3d object detection in lidar point clouds. In Proceedings of the Conference on Robot Learning, Virtual Event, 16–18 November 2020; pp. 923–932. [Google Scholar]
- Liu, Y.; Han, C.; Zhang, L.; Gao, X. Pedestrian detection with multi-view convolution fusion algorithm. Entropy 2022, 24, 165. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. arXiv 2020, arXiv:2012.15712. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1951–1960. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Zhang, Y.; Huang, D.; Wang, Y. PC-RGNN: Point Cloud Completion and Graph Neural Network for 3D Object Detection. arXiv 2020, arXiv:2012.10412. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Peng, L.; Liu, F.; Yan, S.; He, X.; Cai, D. Ocm3d: Object-centric monocular 3d object detection. arXiv 2021, arXiv:2104.06041. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3d object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. Rtm3d: Real-time monocular 3d detection from object keypoints for autonomous driving. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 644–660. [Google Scholar]
- Luo, S.; Dai, H.; Shao, L.; Ding, Y. M3DSSD: Monocular 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 21–25 June 2021; pp. 6145–6154. [Google Scholar]
- Bao, W.; Xu, B.; Chen, Z. Monofenet: Monocular 3d object detection with feature enhancement networks. IEEE Trans. Image Process. 2019, 29, 2753–2765. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Huang, Y.; Tian, W.; Gao, Z.; Xiong, L. Monorun: Monocular 3d object detection by reconstruction and uncertainty propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10379–10388. [Google Scholar]
- You, Y.; Wang, Y.; Chao, W.L.; Garg, D.; Pleiss, G.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar++: Accurate depth for 3d object detection in autonomous driving. arXiv 2019, arXiv:1906.06310. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo r-cnn based 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7644–7652. [Google Scholar]
- Liu, Y.; Wang, L.; Liu, M. Yolostereo3d: A step back to 2d for efficient stereo 3d detection. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 13018–13024. [Google Scholar]
- Shi, Y.; Guo, Y.; Mi, Z.; Li, X. Stereo CenterNet-based 3D object detection for autonomous driving. Neurocomputing 2022, 471, 219–229. [Google Scholar] [CrossRef]
- Wang, Y.; Chao, W.L.; Garg, D.; Hariharan, B.; Campbell, M.; Weinberger, K.Q. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8445–8453. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7074–7082. [Google Scholar]
- Li, S.; He, J.; Li, Y.; Rafique, M.U. Distributed recurrent neural networks for cooperative control of manipulators: A game-theoretic perspective. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 415–426. [Google Scholar] [CrossRef]
- Li, S.; Zhang, Y.; Jin, L. Kinematic control of redundant manipulators using neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2243–2254. [Google Scholar] [CrossRef] [PubMed]
- Qian, R.; Garg, D.; Wang, Y.; You, Y.; Belongie, S.; Hariharan, B.; Campbell, M.; Weinberger, K.Q.; Chao, W.L. End-to-end pseudo-lidar for image-based 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5881–5890. [Google Scholar]
- Sun, J.; Chen, L.; Xie, Y.; Zhang, S.; Jiang, Q.; Zhou, X.; Bao, H. Disp r-cnn: Stereo 3d object detection via shape prior guided instance disparity estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10548–10557. [Google Scholar]
- Pon, A.D.; Ku, J.; Li, C.; Waslander, S.L. Object-centric stereo matching for 3d object detection. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8383–8389. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Huynh, L.; Nguyen, P.; Matas, J.; Rahtu, E.; Heikkilä, J. Boosting monocular depth estimation with lightweight 3d point fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 12767–12776. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient deep learning for stereo matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Zbontar, J.; LeCun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 2287–2318. [Google Scholar]
- Chang, J.R.; Chen, Y.S. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. Triangulation learning network: From monocular to stereo 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 7615–7623. [Google Scholar]
- Zhang, S.; Wang, Z.; Wang, Q.; Zhang, J.; Wei, G.; Chu, X. EDNet: Efficient Disparity Estimation with Cost Volume Combination and Attention-based Spatial Residual. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5433–5442. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Shi, S.; Wang, Z.; Wang, X.; Li, H. Part-A2 net: 3d part-aware and aggregation neural network for object detection from point cloud. arXiv 2019, arXiv:1907.03670. [Google Scholar]
- Liu, Z.; Zhou, D.; Lu, F.; Fang, J.; Zhang, L. Autoshape: Real-time shape-aware monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15641–15650. [Google Scholar]
- Wang, L.; Du, L.; Ye, X.; Fu, Y.; Guo, G.; Xue, X.; Feng, J.; Zhang, L. Depth-conditioned dynamic message propagation for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 454–463. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. Monogrnet: A general framework for monocular 3d object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5170–5184. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Su, S.; Zhao, H. RTS3D: Real-time Stereo 3D Detection from 4D Feature-Consistency Embedding Space for Autonomous Driving. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1930–1939. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Liu, C.; Gu, S.; Van Gool, L.; Timofte, R. Deep Line Encoding for Monocular 3D Object Detection and Depth Prediction. In Proceedings of the 32nd British Machine Vision Conference (BMVC 2021), Online, 22–25 November 2021; p. 354. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. Dsgn: Deep stereo geometry network for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12536–12545. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3289–3298. [Google Scholar]
- Liu, X.; Xue, N.; Wu, T. Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection. arXiv 2021, arXiv:2112.04628. [Google Scholar] [CrossRef]
- Weng, X.; Kitani, K. A baseline for 3d multi-object tracking. arXiv 2019, arXiv:1907.03961. [Google Scholar]
- Gao, A.; Pang, Y.; Nie, J.; Cao, J.; Guo, Y. EGFN: Efficient Geometry Feature Network for Fast Stereo 3D Object Detection. arXiv 2021, arXiv:2111.14055. [Google Scholar]
- Königshof, H.; Salscheider, N.O.; Stiller, C. Realtime 3d object detection for automated driving using stereo vision and semantic information. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1405–1410. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Beltrán, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; Garcia, F.; De La Escalera, A. Birdnet: A 3d object detection framework from lidar information. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).