1. Introduction
Location-based service (LBS) has become increasingly popular in people’s daily lives due to the proliferation of mobile devices [
1]. At present, LBS has covered all aspects of national economy and social life, such as navigation, query and recommendation of interest points, takeout, check-in, social networking [
2], etc. Moreover, the implementation of LBS depends on published trajectory data [
3]. However, when releasing trajectory data, there is a probability of being attacked by attackers, resulting in the disclosure of users’ trajectory information. The disclosure of trajectory information may lead to the exposure of more personal privacy information, so trajectory privacy has become one of the most important privacies of people.
Traditional trajectory privacy protection technologies include K-anonymity, encryption and differential privacy [
4]. The K-anonymity model and its derivative model provide a means of quantitative evaluation, which makes different types of schemes comparable, but cannot provide strict mathematical proof [
5]. Meanwhile, the security depends on the background knowledge grasped by the attacker. In addition, cryptography-based privacy protection methods can provide strict protection on data confidentiality, but their disadvantages and challenges lie in weak scalability and low implementation efficiency [
6]. This is mainly because the current homomorphic encryption mechanisms inevitably have large computational complexity overhead. The emergence of differential privacy technology makes up for the above problems effectively. It hides sensitive raw data by attaching a noise value that obeys a certain distribution to the raw data. On the one hand, the differential privacy model makes the maximum assumption about the attacker’s ability, and does not depend on the background knowledge the attacker has mastered [
7]. On the other hand, the differential privacy model is built on a solid mathematical basis, and gives a quantitative model of the degree of privacy leakage, which is simple to implement and efficient to calculate. However, existing studies on trajectory differential privacy protection still have problems in the following three aspects:
- (1)
The existing trajectory privacy protection mechanism does not take into account the problem of excessive overhead of real-time sensitivity calculation. It is difficult to obtain accurate sensitivity of each position in the trajectory, although the amount of calculation is reduced offline.
- (2)
The impact of semantic location on trajectory is not considered in the previous scheme. Semantic location is likely to increase the risk of user privacy information disclosure. For example, users’ preferences and economic level can be inferred according to the frequency of users’ access to certain semantic location points.
- (3)
In the publishing process of the differential privacy trajectory data set, the allocation of the privacy budget is one of the key factors determining the final amount of noise added. If the privacy budget is not allocated properly, it can cause serious waste and add too much overall noise. However, the current method of privacy budget allocation still stays at average allocation or simple balance allocation, and there is still a certain degree of waste. How to design a more reasonable way of privacy budget allocation according to the characteristics of trajectory data sets is still lacking in relevant research.
If the sensitivity can only be calculated in real time, the calculation cost is too large, which will increase the time cost of the scheme and reduce the operation efficiency. In this paper, a sensitivity map is defined so that the sensitivity of each position point of trajectory can be queried offline. If the impact of semantic location is not taken into account, it is likely to increase the risk of privacy leakage. For example, a user’s trajectory is between home and school every day. School is a special semantic location. After acquiring the user’s trajectory, the attacker can infer his occupation or even economic status easily. This paper takes into account the impact of semantic location on user location sensitivity to improve the privacy protection effect. In addition, if the allocation of privacy budget is not reasonable, the added noise will be too large or too small. This can result in reduced data availability or insufficient privacy. Therefore, the allocation method of privacy budget is improved in this paper. A semantics- and prediction-based differential privacy protection scheme for trajectory data (SPDP) is proposed in this paper. The contributions are summarized as follows:
- (1)
A sensitivity map is defined so that the sensitivity of the current position can be accurately confirmed even offline. Thus, the computational overhead is reduced and the operating efficiency of this scheme is improved. The differentiation protection mechanism of location privacy based on a sensitivity map is designed. By allowing users to customize the sensitivity of semantic locations, the privacy budget can be tailored to further improve its utilization.
- (2)
The differentiation protection mechanism of location privacy based on semantic location is designed. Considering the influence of semantic location sensitivity, sensitivity is determined by the number of trajectories containing the node prefix and semantic sensitivity. The privacy levels are divided according to the location sensitivity. Then the sensitivity ratio and privacy levels are used to allocate the privacy budget of each location to further improve its utilization.
- (3)
A privacy budget adjustment algorithm based on a Markov chain is proposed. After the privacy budget is allocated based on sensitivity and privacy level, the attack probability of the nodes in the prefix tree is calculated by using the property of the Markov process. Then, the sensitivity and privacy level are adjusted by attack probability, so as to adjust the allocation of privacy budget and make the allocation of privacy budget more reasonable.
The rest of the article is organized as follows: the related work is given in
Section 2; the preliminaries are given in
Section 3; the privacy protection method is designed in
Section 4; the simulation analysis is discussed in
Section 5; and finally, the conclusion is given in
Section 6.
2. Related Work
The relevant technologies involved in this paper include trajectory differential privacy protection [
8,
9,
10] and location recommendation mechanism [
11,
12,
13]. Therefore, the typical methods of trajectory differential privacy protection and location recommendation mechanism are analyzed, respectively.
Due to the gradual increase of location service applications, the research on privacy protection of location trajectory data has become a hot research topic. In recent years, the differential privacy model based on false data technology has been rapidly applied to protect the privacy of data release after being proposed. This model realizes privacy protection by adding noise to real data sets [
14]. In data release, differential privacy realizes different privacy protection degrees and data release accuracy by adjusting privacy parameter ε. Generally speaking, the higher the value of
is, the lower the degree of privacy protection is, and the higher the accuracy of published data sets is. Differential privacy is mainly realized through a noise mechanism. The first universal differential privacy mechanism is the Laplace mechanism proposed in [
15], which is mainly aimed at numerical query. For non-numerical queries, the exponent mechanism is proposed in [
16], which is the second universal mechanism to realize differential privacy.
In the privacy protection of trajectory data set release, the prefix method based on the differential privacy model is proposed for the first time in [
17]. This method uses a hierarchical framework to construct a prefix tree, divides the trajectories with the same prefix into the same branch of the tree, and realizes differential privacy by adding noise to the node count. However, as the tree grows, the prefix will form a large number of leaf nodes, resulting in too much noise and reducing the accuracy of the published data set. Later, on the basis of prefix method, location trajectory and check-in frequency are used to set thresholds in [
18], so as to classify the level of location sensitivity. Then, the corresponding privacy budget is allocated according to the sensitivity, which makes the allocation of privacy budget more reasonable and reduces the amount of noise data.
The work [
19] proposes the method of merging similar trajectories. By dividing the trajectory coverage area into grids, the trajectory position points falling into the same grid are represented by the center points of the grid, thus improving the counting value of position points greatly. In [
20], the regional division is improved by adopting a multi-level grid model to divide position points at different speeds in the trajectory according to different granularity, so as to maintain the original sequence information of the trajectory to the maximum extent. However, these methods have the problem of low data availability due to excessive information loss rate, and fail to fully consider the semantic location information of users, resulting in semantic inference attacks [
21], which leads to the disclosure of users’ sensitive privacy.
Published trajectory data can be used in various location services. Location recommendation service in LBS is frequently used. For example, Nur [
22] presents a new problem of user identification of top-K social space co-participation location selection (SSLS) in social graphs. Two exact solutions and two approximate solutions are developed to solve this NP-hard problem. Thus, the best set of K positions can be selected for the user from a large number of candidate positions. Location recommendation methods can be divided into three categories generally: content-based recommendation system, collaborative filtering recommendation and mixed recommendation [
23]. A content-based recommendation system mainly selects items with high similarity to them as recommendations according to the items users like. Collaborative filtering technology determines a group of recommender users with similar behaviors according to the evaluation behavior of the target users, and takes the evaluation of the recommender users on the project as the recommendation value of the target users. Mixed recommendation is mainly to solve the deficiency of single recommendation technology. Different recommendation technologies can be combined according to different mixing strategies to complete the recommendation.
Lian first proposes a collaborative filtering algorithm based on implicit feedback and content perception [
24], which gives a lower preference value to the locations that users have not visited, and a higher preference value to the locations that users have visited according to their historical access frequency. Then, Lian combines the matrix factor decomposition method and puts forward the improved schemes Geo MF [
25] and Geo MF++ [
26], which improve the accuracy of the recommendation system effectively. In recent years, with the development of deep learning theory, neural network technology has also been used to solve the problem of location recommendation [
27,
28,
29]. Shyamali [
30] proposes the fault tolerance technology of the relevant sensitive random logic circuit to reduce the system error. Lalli [
31] reduces operational risk by training four neural networks to detect and handle errors before they cause harm. However, the technology needs a lot of data support. In addition, the above recommendation schemes only focus on the recommendation effect and ignore the user’s privacy and security issues. The lack of protection of trajectory data may cause the disclosure of user’s privacy information easily.
The existing studies on trajectory differential privacy protection do not take into account the impact of semantic features on trajectory, and the privacy budget allocation is not precise enough. In addition, the existing location recommendation mechanisms ignore the privacy protection of user data. Therefore, a semantics- and prediction-based differential privacy protection scheme for trajectory data is proposed in this paper. The semantic sensitivity and the Markov technology are introduced to improve the utilization rate of the privacy budget. Meanwhile, the location recommendation mechanism is combined with the differential privacy technology to protect the security of the trajectory data while ensuring the location recommendation effect.
3. Preliminaries
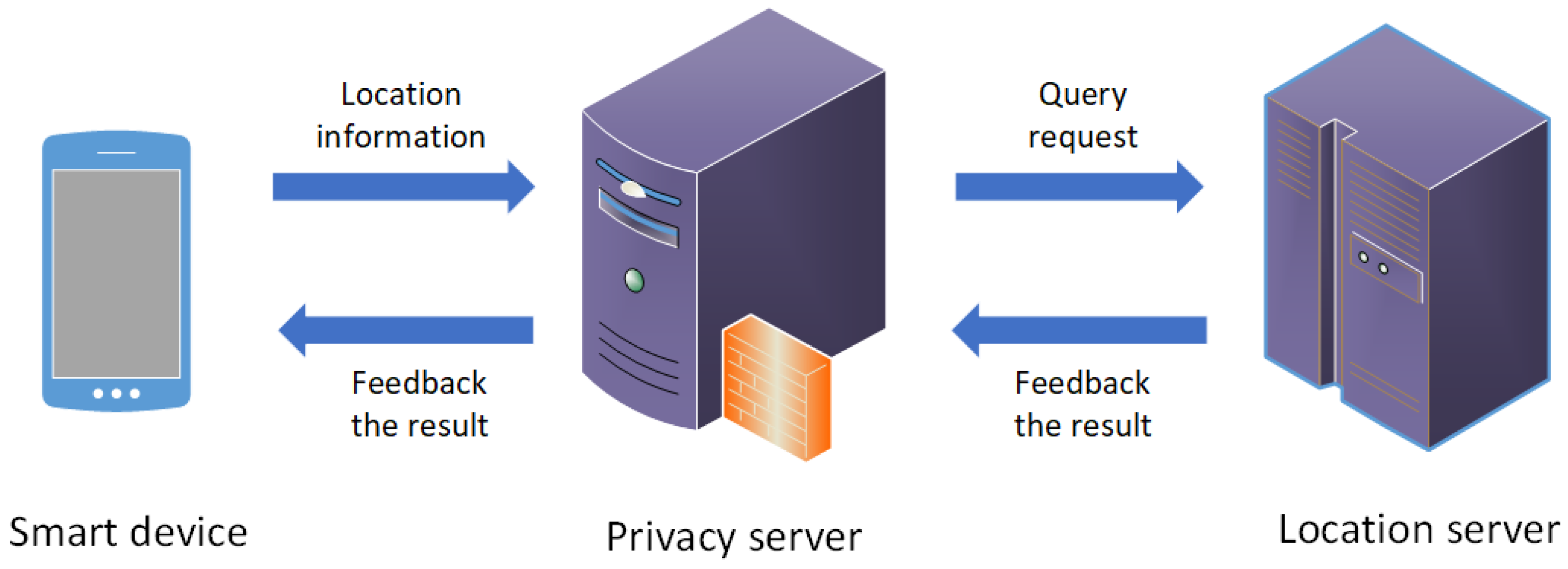
The system model of semantics and prediction based differential privacy protection scheme for trajectory data (SPDP) is presented in
Figure 1. The system model consists of three parts: mobile smart device, privacy server and location server. Among them, privacy server is a trusted third party anonymous server. This paper focuses on the privacy protection of the system, so it ignores the details of the internal network connection. The location information to be protected is the trajectory data published by the mobile smart device, including the user check-in time, location identification (ID), longitude and latitude. These assumptions are used in most previous works, such as [
7,
17,
18]. In addition, the SPDP scheme proposed in this paper uses differential privacy technology, prefix tree structure, Markov chain and so on to protect the trajectory data. Therefore, the definitions of related concepts are quoted and designed. The detailed definitions involved are shown below.
Definition 1. -Differential Privacy[14]. Given a query algorithmthat supports a random mechanism, if for any data setand its adjacent data set, algorithmsatisfies Formula (1) for any output, then the random algorithmsatisfies-differential privacy. There is only one record difference between adjacent data sets, that is,. is the privacy budget, which determines the degree of privacy protection and the accuracy of released data sets. The lower the privacy budget is, the closer the probability ratio of algorithmoutputting the same result onandis to 1, and the higher the degree of privacy protection is, the lower the accuracy of the corresponding published data set is. When= 0,will output the result with the same probability distribution onand, and the degree of privacy protection will reach the highest at this moment, but the published data will not reflect any useful information.
Definition 2. Global Sensitivity[16]. For any query function, the global sensitivity ofis Global sensitivity is the maximum range of output value variation of a particular query functionon all possible adjacent datasetsand, and its measure is thedistance between the two.
Definition 3. Laplacian Mechanism[8]. For any functionon data set, if the output result of functionsatisfies Equation (3), then the random algorithmsatisfies-differential privacy.where,is the sensitivity of the query function. The location parameter of the Laplace distribution is 0, and the scale parameter is.
Definition 4. Trajectory Prefix[17]. A trajectoryis a prefix of a trajectory, denoted by, if and only ifand,.
For example, a trajectory and the corresponding trajectory sequence of user
are shown in
Figure 2 and
Table 1. For trajectory 1:
, it can be seen that
,
and
are their prefixes, but
is not a prefix.
Definition 5. Prefix Tree[17]. A prefix treeof a trajectory databaseis a triplet, whereis the set of nodes labeled with locations, each corresponding to a unique trajectory prefix in;is the set of edges, representing transitions between nodes;is the virtual root of. The unique trajectory prefix represented by a node, denoted by prefix , is an ordered list of locations starting fromto.
Each node
of
keeps a doublet in the form of
, where
is the location sensitivity, and
is the privacy level of the location.
Figure 3 illustrates the prefix tree of the sample database in
Table 1, where each node
is labeled with its location, sensitivity and privacy level.
Definition 6. Semantic location. Semantic location refers to the location that conforms to the characteristics of semantic location type, denoted as. In this paper, semantic location types are divided into 10 categories according to geographic tags, including science, education and culture, catering, leisure and entertainment, medical care and so on. Semantic locations can be obtained from map information. Each semantic location has a certain semantic sensitivity, and will affect the location sensitivity within a certain range. Therefore, each locationhas a certain semantic sensitivity, denoted as.
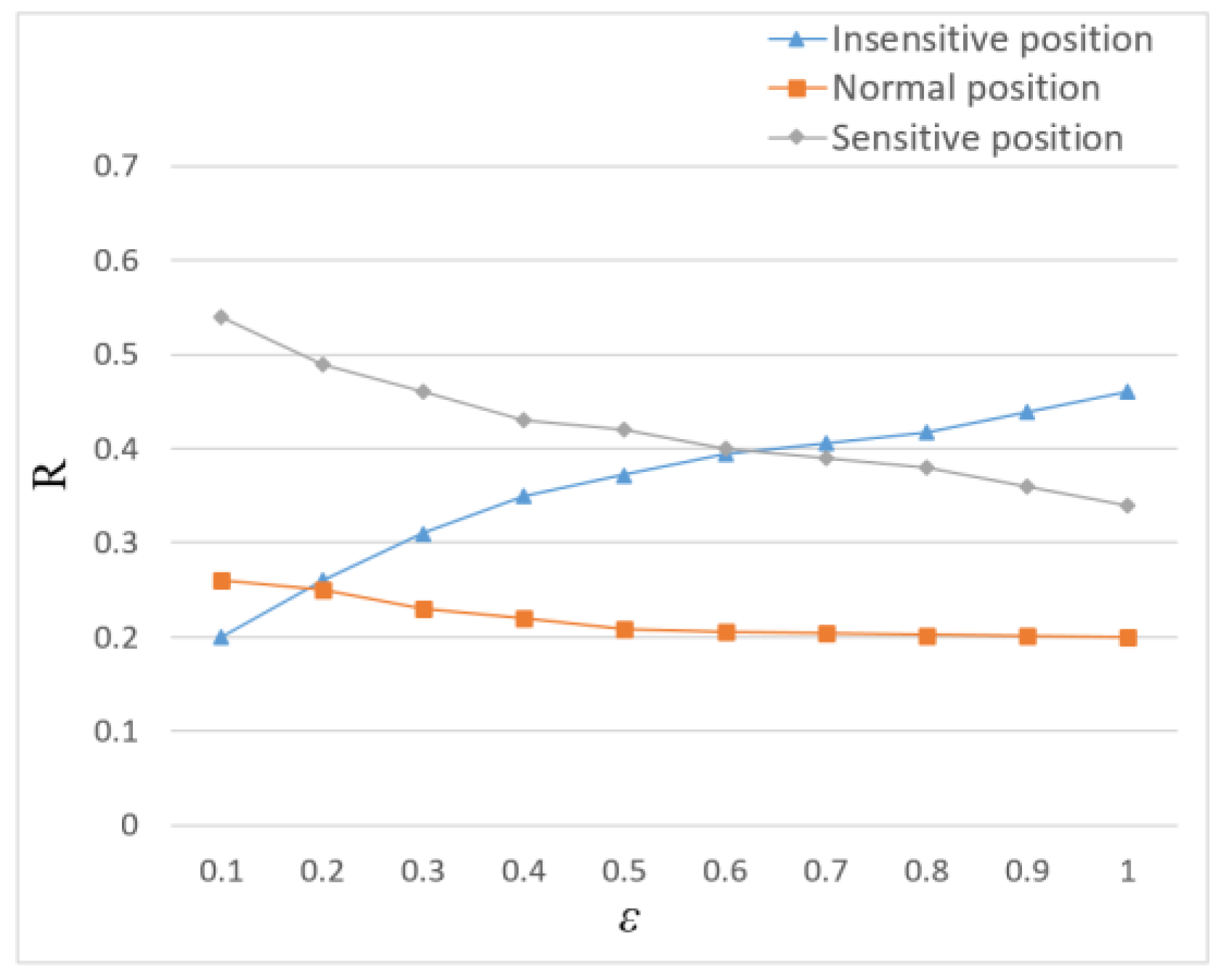
Definition 7. Sensitivity. The check-in times of userat locationcan indicate the user’s preference for this location. It is assumed that the more times users check in, the higher the preference degree of users for this location. Attackers can easily master users’ preferences by calculating check-in statistics of specific locations, so users’ privacy is vulnerable to leakage. To solve this problem, this paper defines the sensitivity of the user’s check-in location:. Where,represents the check-in times of userat position, andrepresents the semantic sensitivity of user at position. As shown in Figure 3 and Table 2. The user’s check-in timesand semantic sensitivityare combined as the location sensitivityof node. The more times a user checks in to a location, the more sensitive that location is. Definition 8. Privacy Level. The location privacy level is defined asin this paper. It is determined by the sensitivity of userto the location. Three privacy levels are set in this paper, namely insensitive, normal and sensitive. Then the thresholds are set for position sensitivity. When sensitivity reaches the thresholds, the privacy level of this location changes.
It is defined as the highest privacy level when in this paper. As sensitivity increases, the privacy level of a location decreases. In other words, the position is most sensitive when , and the position is less sensitive when the value of is larger. If is small, the sensitivity of the position is relatively high, that is, the more sensitive position is, the less weight it will have. Therefore, the privacy budget allocated to location is small. In differential privacy protection, the smaller the privacy budget allocated to position , the greater the added noise and the higher the privacy protection intensity.
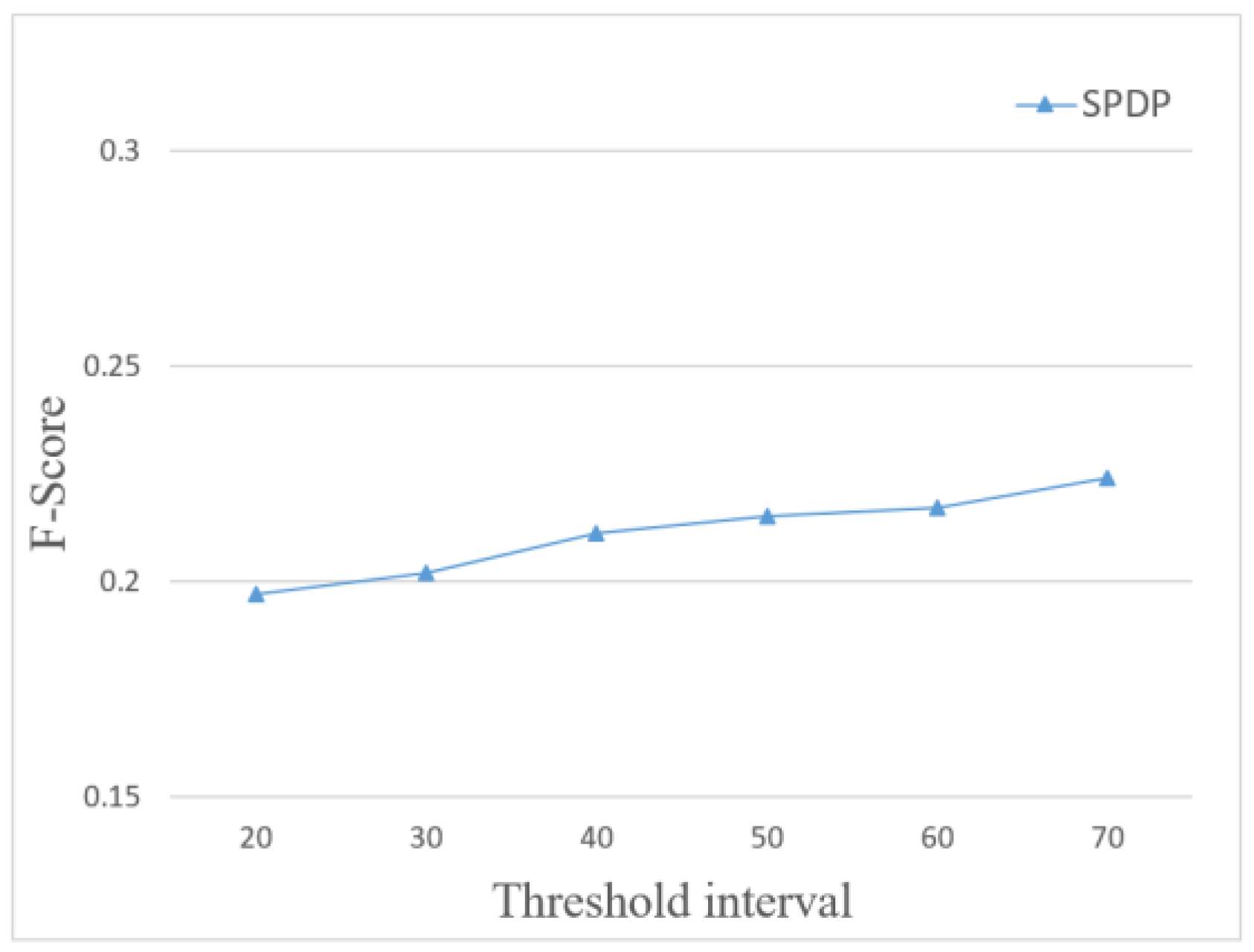
For example, divide the privacy level for the trajectory example of user
shown in
Figure 2 and
Table 1. Suppose the position is least sensitive when the assumed sensitivity is less than 5. Then assume that the threshold interval is 5, and when the sensitivity exceeds the threshold, the privacy level will change. When the sensitivity exceeds 10, the privacy level is the highest and the location is the most sensitive. Accordingly, the privacy level division of the trajectory example is obtained, as shown in
Table 3.
Definition 9. Markov Process[32]. Assume that the time parameter set of random processisand the state spaceis discrete,. For any,, then: If the random processsatisfies Equation (4), the random process is a Markov process. Where,represents the state of random processat timeis. The property of Markov processes is that the future state is only related to the present state, not to the past state.
4. Semantics- and Prediction-Based Differential Privacy Protection Scheme for Trajectory Data (SPDP)
The specific process of the semantics- and prediction-based differential privacy protection scheme for trajectory data (SPDP) proposed in this paper is shown in
Figure 4.
Step 1. Sensitivity processing based on semantic location: Allocate different privacy budgets for different semantic locations, determine the semantic sensitivity of the location through the generated semantic sensitivity map, and obtain the location sensitivity and privacy level by combining the check-in times of the location.
Step 2. Privacy budget allocation based on prefix tree: A single location satisfying -differential privacy cannot ensure trajectory privacy security. Therefore, the user trajectory is transformed into a prefix tree structure to ensure that the trajectory meets -differential privacy, and the privacy budget is allocated according to the sensitivity of the location.
Step 3. Privacy budget adjustment based on Markov chain: The attack probability of the location is predicted by a Markov chain, and the allocated privacy budget is adjusted according to the attack probability to further improve its utilization rate.
Step 4. Location recommendation under differential privacy protection: Add corresponding noise to the location, and reflect the validity and availability of trajectory data under differential privacy protection through the recommendation effect of location recommendation service.
4.1. Sensitivity Processing Based on Semantic Location
Not only semantic locations directly connected to sensitive locations are sensitive. From the perspective of random disturbance distribution, those semantic locations close to sensitive locations still have the risk of exposing sensitive locations even if they are not connected to sensitive locations directly. Therefore, certain semantic sensitivity should also be assigned. This paper considers the global connectivity between location points and radiates the semantic sensitivity of semantically sensitive locations to nearby nodes according to the distance and access degree.
As shown in
Figure 5, the semantic location node set
with a privacy level near any location
is first obtained. Then, the map is transformed into an undirected graph. According to the distance and access degree, the equivalent distance between any location
and semantic location
is
. Where,
is the Euclidean distance between
and
, and
is the number of nodes traversed by the shortest path between the two nodes. Finally, the semantic sensitivity of semantic location radiation in
of any location
is obtained, as shown in Equation (5).
where,
represents the semantic sensitivity of location
.
,
indicates the threshold set by the user.
For the convenience of calculation, we use this paper grid map. Then, the semantic sensitivity of each region in the map is calculated using the above process, and the semantic sensitivity map is generated.
In Algorithm 1, the check-in times
and semantic sensitivity
of each node point in data set T are calculated firstly, and the two are combined as the sensitivity
of node (1–6 lines of Algorithm 1). Lines 7–12 of Algorithm 1 divide privacy levels according to node sensitivity. Based on the experimental data, this paper divides the privacy level into three categories. When
, the position is the most sensitive, when
, it is classified as normal, and when
, it is classified as insensitive. If the sensitivity of the node is less than 10, the privacy level is set to level 3. If the sensitivity is between 10 and 50, the privacy level is set to level 2. If sensitivity is greater than or equal to 50, the privacy level is set to level 1. Finally, a prefix tree is constructed and the sensitivity map
is generated according to the sensitivity and privacy level of nodes (13–15 lines of Algorithm 1).
| Algorithm 1: Sensitivity Processing Algorithm Based on Semantic Location |
Input: User check-in location data set T
Output: Sensitivity map , prefix tree TT
begin
1: ;
2: for every position in T do
3: ;
4: ;
5: ;
6: ;
7: if
8: ;
9: else
10: ;
11: else
12: 1;
13: ;
14: end for
15: return , TT
end |
4.2. Privacy Budget Allocation Based on Prefix Tree
Because the root node in the prefix tree is not the actual check-in location, the root node does not consume the privacy budget. The privacy budget allocation scheme in this paper is mainly divided into two steps: the privacy budget allocation of each trajectory subsequence and the privacy budget allocation of each child node on the trajectory subsequence. Firstly, the average sensitivity of each trajectory subsequence is calculated to calculate the access probability of each subsequence. Then, the privacy budget is assigned to the trajectory subsequence according to the access probability. Since the higher the access probability, the higher the sensitivity, the allocated privacy budget should be inversely proportional to the access probability. Secondly, the privacy budget is allocated to each node according to the proportion of each node’s privacy level in the sum of the privacy level of each trajectory subsequence. Finally, because part of the location points appear in multiple trajectory subsequences, the repeated privacy budget is merged. The privacy budget allocation algorithm based on location sensitivity is shown as follows:
In Algorithm 2, the privacy budget (lines 1–4 of Algorithm 2) is first assigned to the trajectory subsequence. The average sensitivity of each trajectory in dataset T is calculated. Then, the access probability of each trajectory is calculated according to the proportion of sensitivity, and the privacy budget is allocated according to the inverse relationship between the access probability and the privacy budget. In lines 5–7 of Algorithm 2, the privacy budget is allocated to each location in the trajectory according to the location’s privacy level, and finally, the privacy budget of the location in multiple trajectories is combined.
| Algorithm 2: Privacy Budget Allocation Algorithm Based on Sensitivity |
Input: Privacy budget ε, prefix tree TT
Output: Trajectory set TB after allocating privacy budget
Begin
1: for every trajectory in TT do;
2: ;
3: ;
4: ;
5: for every position in do;
6: ;
7: ;
8: end for
9: end for
10: return
end |
4.3. Privacy Budget Adjustment Based on Markov Chain
A trajectory consists of a series of position points that are continuous. The property of the Markov chain corresponds to the trajectory, that the next position depends only on the previous position. The two most important components of the Markov chain are the initial state probability distribution and state transition matrix.
Assume that the possible location set generated by the user at the moment is
, and its probability value is
. That is the initial state probability distribution. Suppose there are
possible positions for a user’s trajectory, namely
. The state transition probability from position
to position
is denoted as
, then matrix
is formed, which is called state transition probability matrix.
Then, the state transition probability matrix is used to calculate the possible position at time as , and its probability value is , where , is the attack probability of the possible position at time .
Assume that an attacker’s attack starts at the initial position of the trajectory and continues in the direction of the trajectory. The property of Markov process is used to calculate the attack probability of nodes in the prefix tree, and the sensitivity is adjusted by calculating the probability, so as to adjust the allocated privacy budget. The privacy budget adjustment algorithm based on Markov is shown in Algorithm 3.
In Algorithm 3, the access probability of each trajectory is firstly calculated, and then the access probability of each position in the trajectory is calculated as the initial probability state distribution (lines 1–8 of Algorithm 3). Then, the state transition matrix is calculated according to the proportion of check-in times in the data set, so as to obtain the attack probability at time
(lines 9–11 of Algorithm 3). Finally, sensitivity and privacy level are adjusted linearly according to the attack probability, so as to adjust the privacy budget (lines 12–15 of Algorithm 3).
| Algorithm 3: Privacy Budget Adjustment Algorithm Based on Markov |
Input: Trajectory set TB after allocating privacy budget
Output: Trajectory set TC after adjusting privacy budget
Begin
1: for every trajectory in TB do;
2: ;
3: ;
4: for every position in do;
5: ;
6: ;
7: end for
8: end for
9: ;
10: ;
11: ;
12: for every position in TB do
13: ;
14: ;
15: ;
16: end for
17: return TC
end |
4.4. Location Recommendation under Differential Privacy Protection
Through the previous three sections, the privacy budget assigned by the user for each location is available. Then, the Laplace mechanism is used to add the corresponding noise to the sensitivity of the position to change the privacy level of the position in this paper. As the location privacy level changes, it is difficult for an attacker to discover a user’s true preference for the location.
After the location privacy level is changed, the interest score of user
on location
is calculated by Equation (7). Where,
and
represent the position sensitivity and position score weight after adding noise, respectively:
Position
is most sensitive when
is minimal. However, when the location score is calculated, the weight of the location will increase as the privacy level of the location increases. Therefore, Equation (8) is used in this paper to calculate the score weight of the position.
Since location sensitivity is used as location score directly, the score difference between locations will be too large, affecting the accuracy of the results. Therefore,
is normalized to obtain the normalized location score
, and then the scoring matrix
of users and locations is constructed,
is shown as follows:
After obtaining score matrix
, the Pearson correlation coefficient is used to calculate users’ similarity
, and user similarity matrix
is constructed, where
represented the similarity between user
and user
.
where,
represents the common check-in location set of user
and user
, and
represents the average location score of user
. Finally, according to the user similarity matrix
,
users with the highest similarity to the target user are regarded as similar users. In addition, the locations of similar users are set and the locations not visited by target users are arranged in descending order of score, and the first
locations are recommended to target users. The location recommendation algorithm is as follows.
Assume that an attacker’s attack starts at the initial position of the trajectory and continues in the direction of the trajectory. The property of the Markov process is used to calculate the attack probability of nodes in the prefix tree, and the sensitivity is adjusted by calculating the probability, so as to adjust the allocated privacy budget. The privacy budget adjustment algorithm based on Markov is shown in Algorithm 4.
| Algorithm 4: Location Recommendation Algorithm |
Input: Trajectory set TC after adjusting privacy budget
Output: Location recommendation set LR
Begin
1: for every position in TC do;
2: ;
3: ;
4: ;
5: ;
6: ;\\
7: for every user in TC do
8: ;
9: Arrange in descending order, take
the top-n users in ;
10: for the in top-n users that are not accessed by
the target user do
11: Arrange in descending order, take
the top-n locations in
12: end for
13: end for
14: end for
15: return top-n
end |
In Algorithm 4, noise is first added to the sensitivity and privacy level of the location (lines 1–3 of Algorithm 4). Then score weight and interest score are calculated and normalized (lines 5–6 of Algorithm 4). Lines 7–9 of Algorithm 4 calculate the similarity between users and take the first n users with the highest similarity. Finally, the position with the highest interest score among the first n locations that are not visited by similar users is selected for recommendation (lines 10–15 of Algorithm 4).
6. Conclusions
In order to protect the trajectory data security of data release, a semantics- and prediction-based differential privacy protection scheme for trajectory data is proposed in this paper. In this scheme, trajectory sequences are stored by a prefix tree structure, and the privacy level of the location is divided by check-in statistics combined with the influence of semantic location. Then, the privacy budget is allocated according to the privacy level, and further adjusted through the Markov chain. The appropriate differential privacy noise is added to the user’s check-in position sensitivity, and the position sensitivity level is changed to achieve the effect of privacy protection. By analyzing the experimental results of real location data sets, the proposed scheme can protect the trajectory privacy of users and reduce the impact of differential privacy noise on the quality of service effectively.
The scheme proposed in this paper is based on the centralized differential privacy, which requires that the third-party service providers are completely trusted and will not actively steal or passively leak users’ private information. However, in practical applications, it is impossible to find an absolutely secure third-party service provider. Therefore, the local differential privacy model will be introduced to better resist attacks on third-party servers in future research work, so as to achieve better privacy protection effects.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}