
Efficiency of the Moscow Stock Exchange before 2022


Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Apparent Inefficiencies
2.2.1. EWMA
2.2.2. Estimation of Price Staleness
2.2.3. Modification of EWMA
2.3. Calculating a Degree of Market Inefficiency
2.3.1. The Shannon Entropy
2.3.2. Discretization
2.3.3. The Estimation Of Entropy
2.3.4. Detection of Inefficiency
2.4. Kullback–Leibler Distance
3. Results
3.1. Simulations
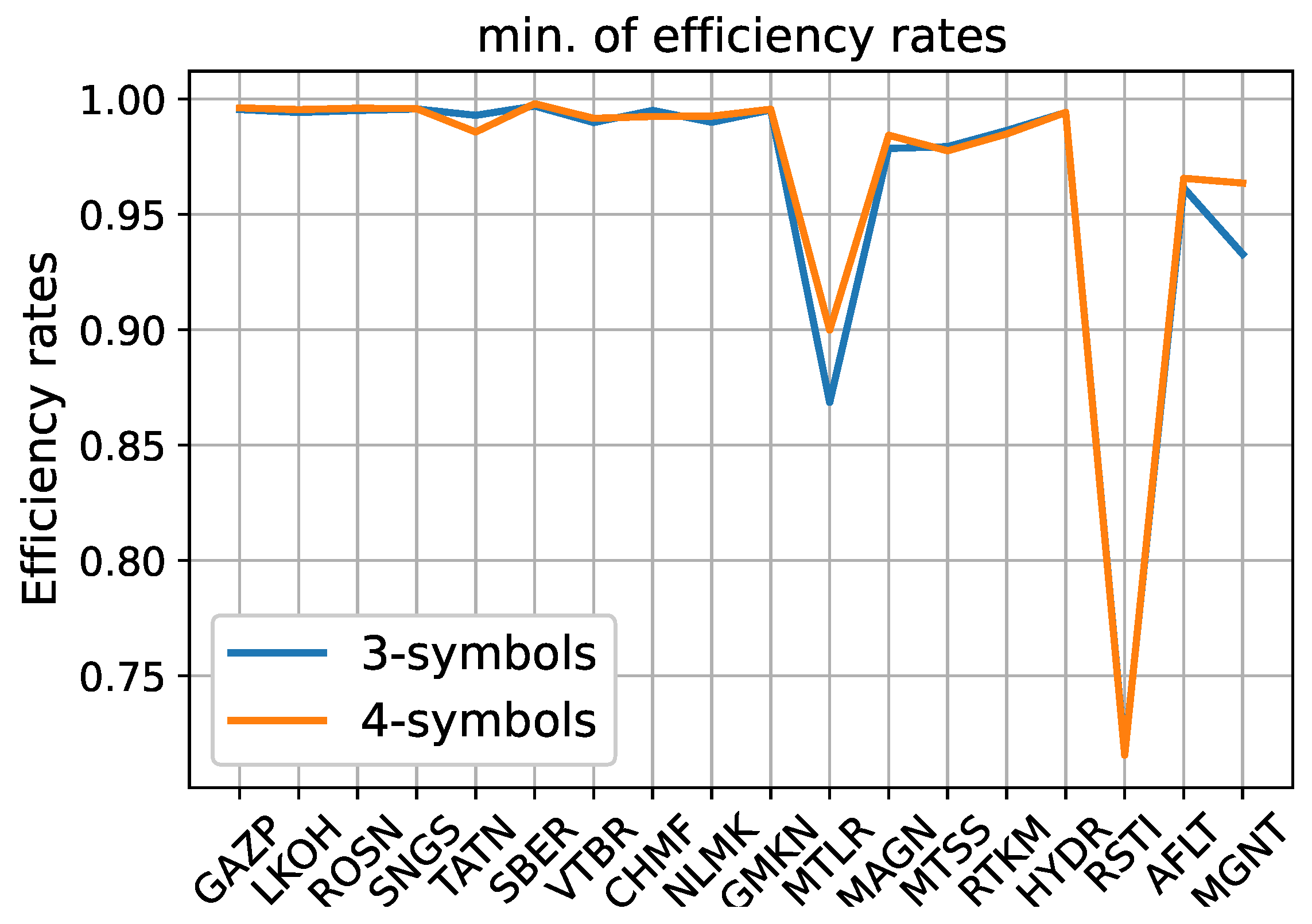
3.2. Moscow Stock Exchange
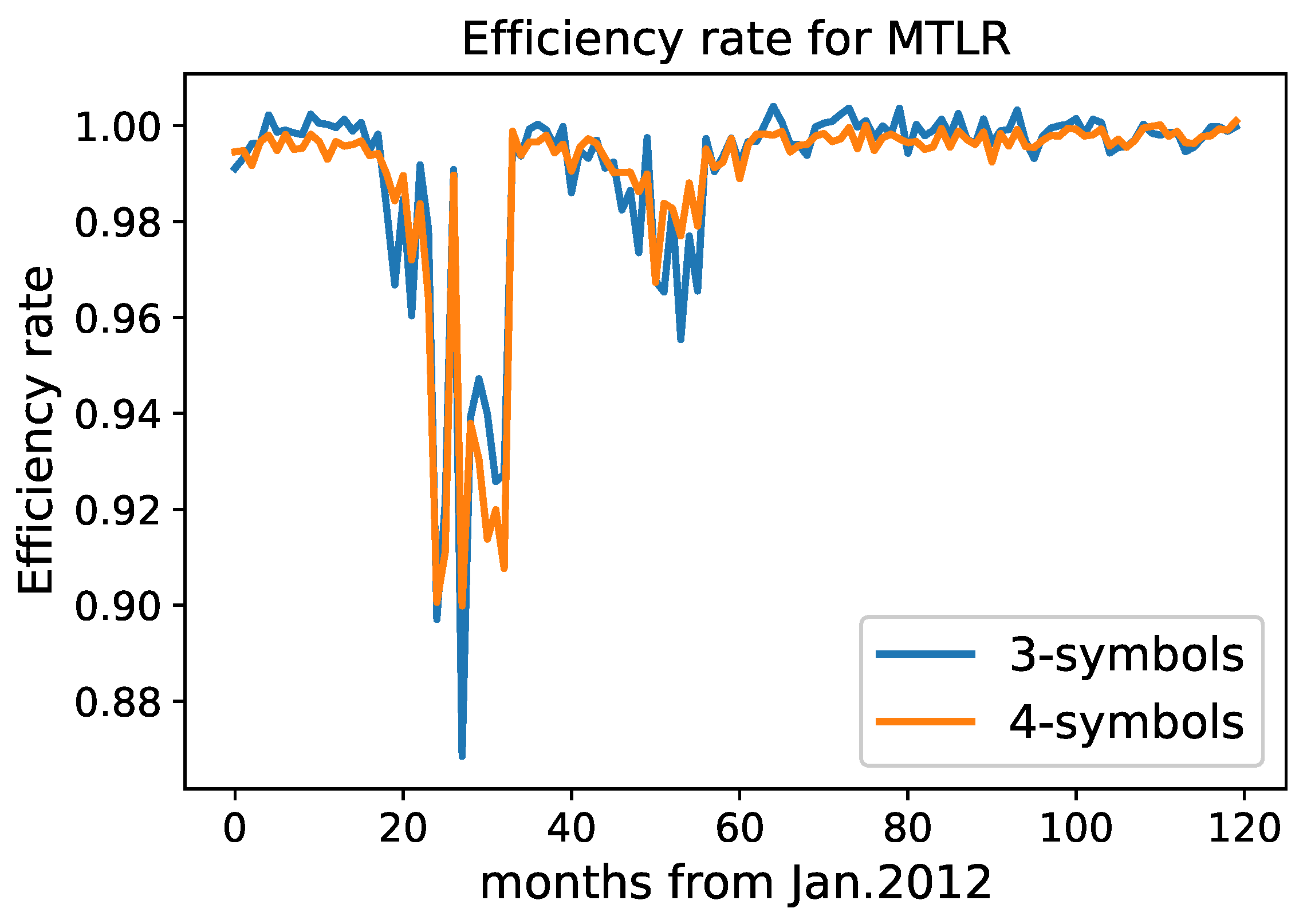
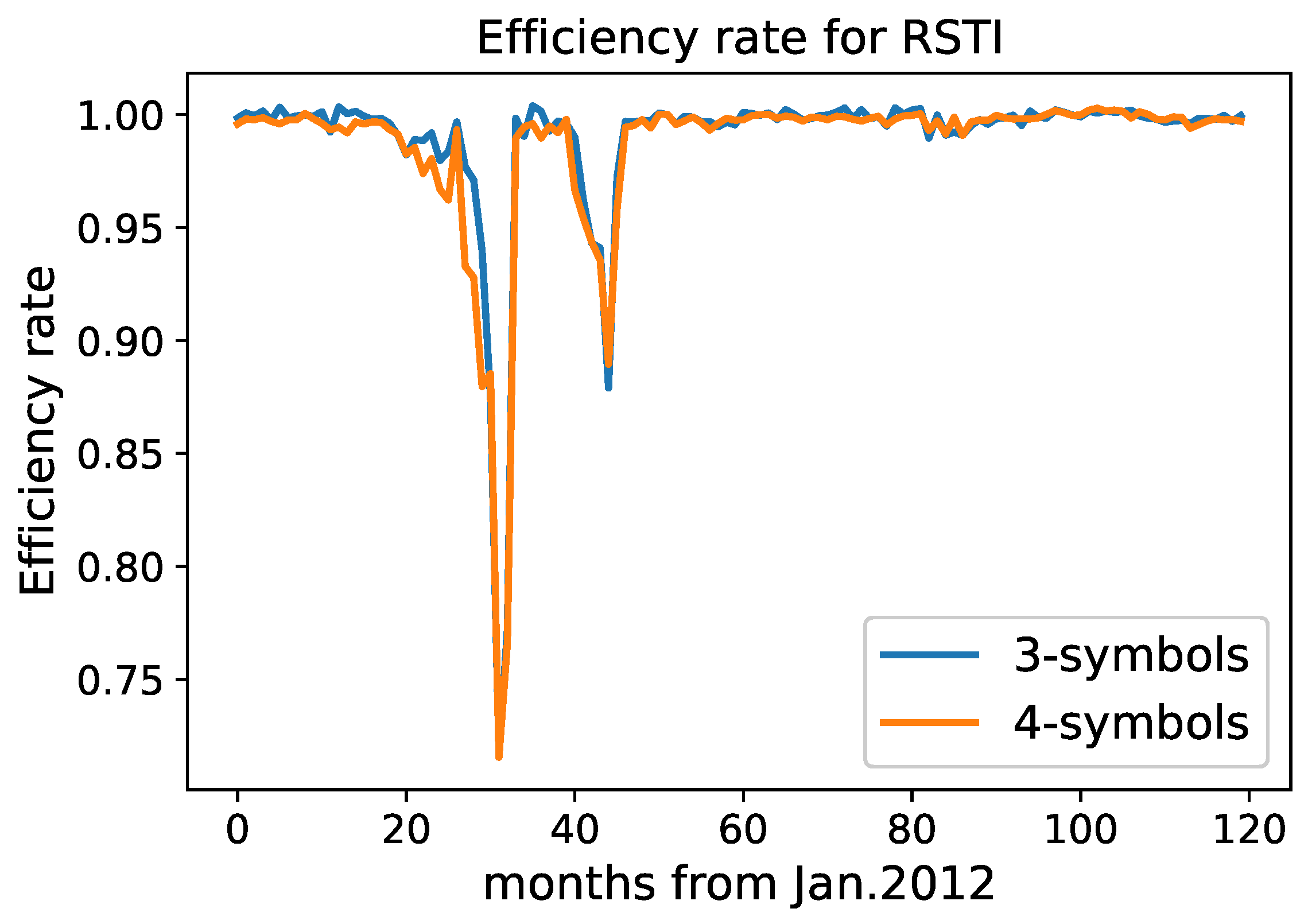
Analysis of MLTR and RSTI
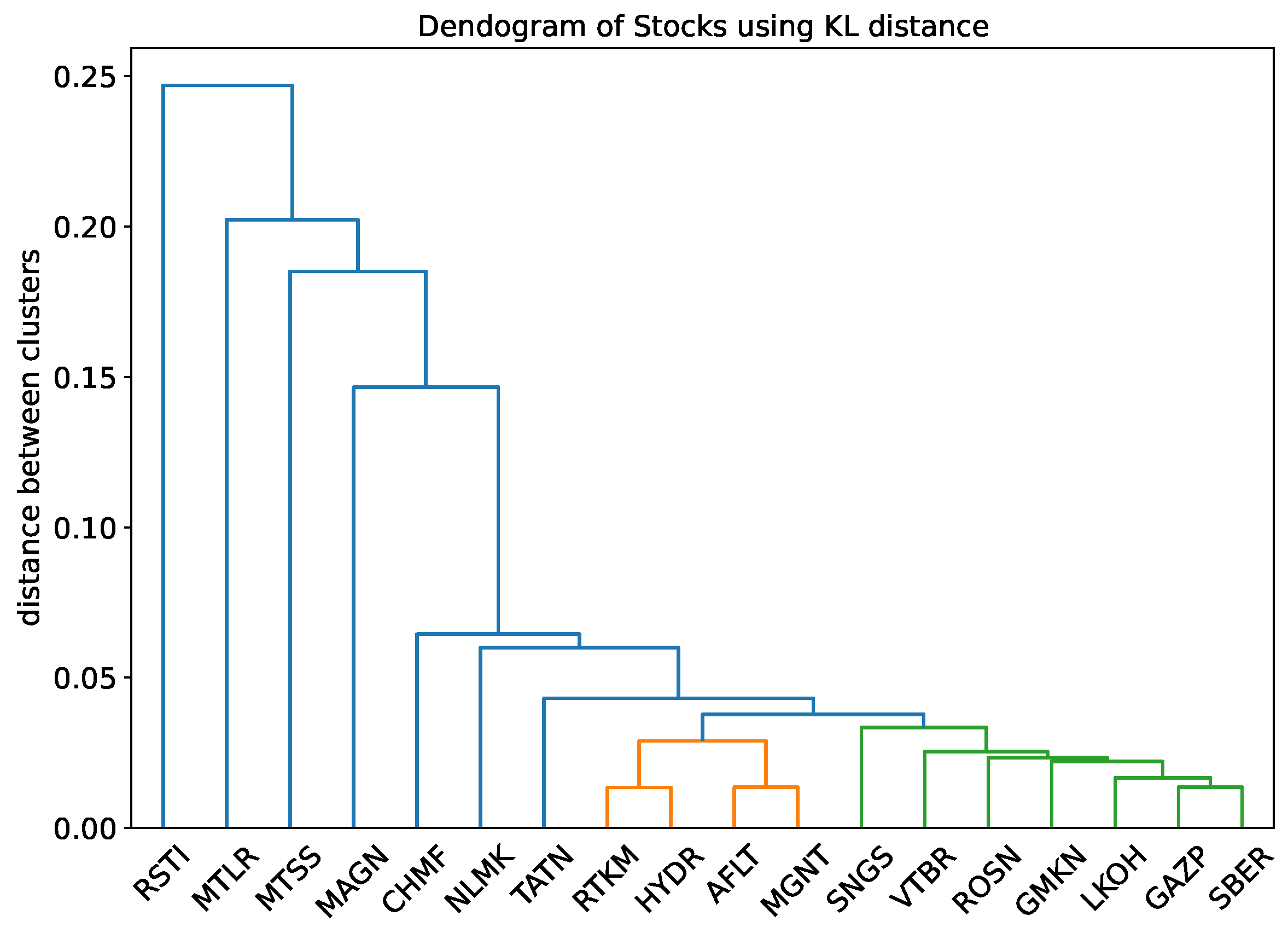
3.3. Stock Market Clustering
3.3.1. Kullback–Leibler Distance
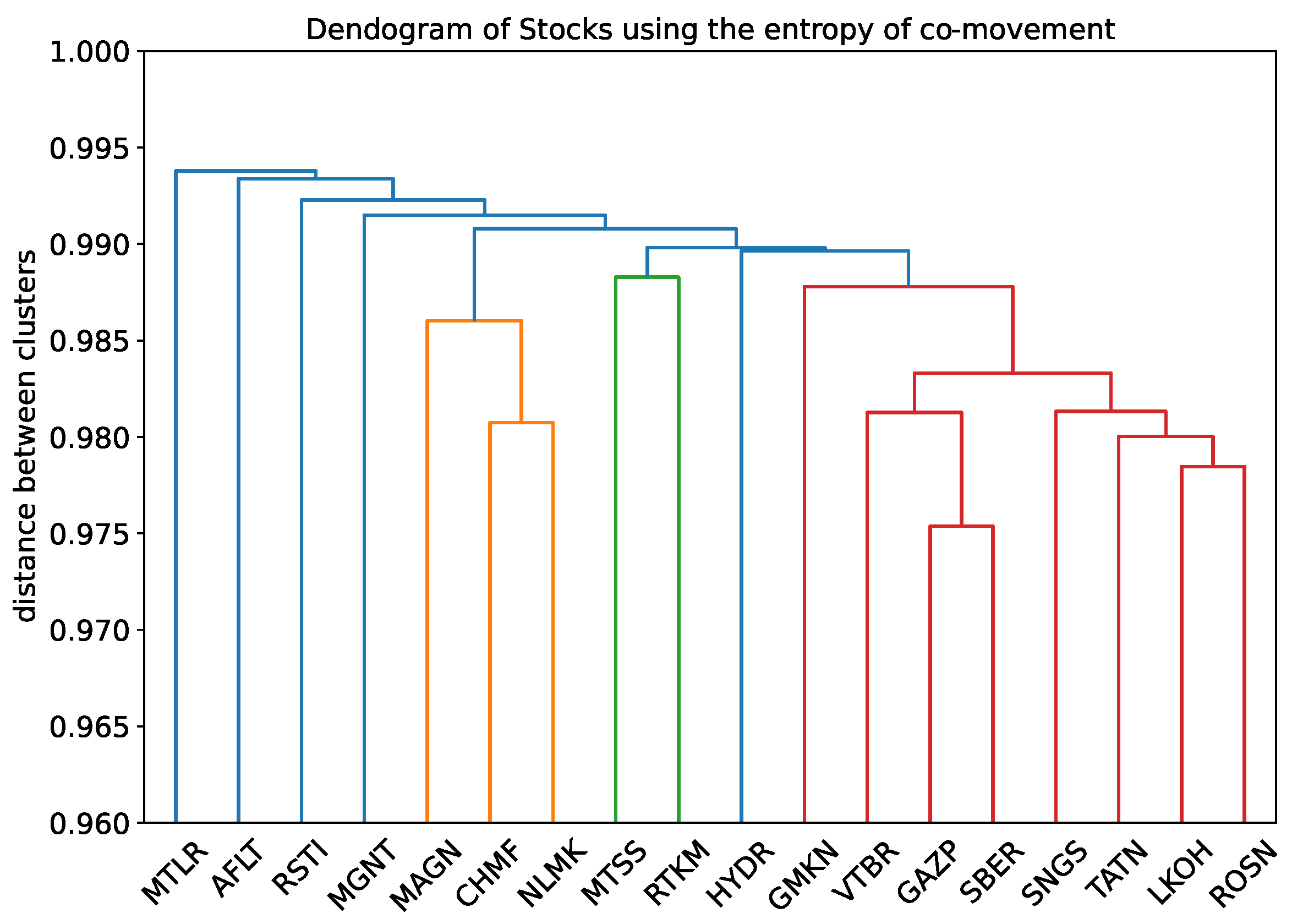
3.3.2. Entropy of Co-Movement
4. Discussion and Conclusions
- Even after filtering out all known sources of regularity, most months contain signals of market inefficiency.
- The most inefficient months are grouped together for two stocks exhibiting the lowest efficiency rates.
- For such months, discretized price returns before and after filtering out apparent inefficiencies are predictable.
- We introduced the entropy of co-movement. Stock prices display common patterns that have an interpretation in terms of the sector that the stock belong to.
- The stocks of banks and oil companies cluster together in terms of co-inefficiency for the case of the Moscow stock exchange.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Data Cleaning And Whitening
Appendix A.1. Outliers
Appendix A.2. Stock Splits
Appendix A.3. Intraday Volatility Pattern
Appendix A.4. Heteroskedasticity
Appendix A.5. Price Staleness
Appendix A.6. Microstructure Noise
Appendix B. Algorithm
Pseudocode
- If is missing: ; Increase by the amount of consecutive missing prices
- Else if :
- –
- If and : ,
- –
- Else: , ,
- Else: ,
- Calculate (Equation (3))
- If is not missing,
- If ,
Appendix C. A Predictable Time Series with Entropy at Maximum

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| First Symbol | |||
|---|---|---|---|
References
- Samuelson, P.A. Proof that properly anticipated prices fluctuate randomly. Ind. Manag. Rev. 1965, 6, 41–49. [Google Scholar]
- Fama, E.F. Efficient Capital Markets: A Review of Theory and Empirical Work. J. Financ. 1970, 25, 383–417. [Google Scholar] [CrossRef]
- Fama, E.F. Efficient Capital Markets: II. J. Financ. 1991, 46, 1575. [Google Scholar] [CrossRef]
- Kim, J.H.; Shamsuddin, A. Are Asian stock markets efficient? Evidence from new multiple variance ratio tests. J. Empir. Financ. 2008, 15, 518–532. [Google Scholar] [CrossRef]
- Linton, O.; Smetanina, E. Testing the martingale hypothesis for gross returns. J. Empir. Financ. 2016, 38, 664–689. [Google Scholar] [CrossRef]
- Mandes, A. Algorithmic and High-Frequency Trading Strategies: A Literature Review; MAGKS Papers on Economics 201625; Philipps-Universität Marburg, Faculty of Business Administration and Economics, Department of Economics (Volkswirtschaftliche Abteilung): Marburg, Germany, 2016. [Google Scholar]
- Huang, B.; Huan, Y.; Xu, L.D.; Zheng, L.; Zou, Z. Automated trading systems statistical and machine learning methods and hardware implementation: A survey. Enterp. Inf. Syst. 2019, 13, 132–144. [Google Scholar] [CrossRef]
- Grossman, S.J.; Stiglitz, J.E. On the Impossibility of Informationally Efficient Markets. Am. Econ. Rev. 1980, 70, 393–408. [Google Scholar]
- Cont, R. Empirical properties of asset returns: Stylized facts and statistical issues. Quant. Financ. 2001, 1, 223–236. [Google Scholar] [CrossRef]
- Cajueiro, D.O.; Tabak, B.M. Ranking efficiency for emerging markets. Chaos Solitons Fractals 2004, 22, 349–352. [Google Scholar] [CrossRef]
- Cajueiro, D.; Tabak, B. Ranking efficiency for emerging markets II. Chaos Solitons Fractals 2005, 23, 671–675. [Google Scholar] [CrossRef]
- Drożdż, S.; Gȩbarowski, R.; Minati, L.; Oświȩcimka, P.; Watorek, M. Bitcoin market route to maturity? Evidence from return fluctuations, temporal correlations and multiscaling effects. Chaos 2018, 28, 071101. [Google Scholar] [CrossRef] [PubMed]
- Shahzad, S.J.H.; Nor, S.M.; Mensi, W.; Kumar, R.R. Examining the efficiency and interdependence of US credit and stock markets through MF-DFA and MF-DXA approaches. Phys. A 2017, 471, 351–363. [Google Scholar] [CrossRef]
- Giglio, R.; Matsushita, R.; Figueiredo, A.; Gleria, I.; Silva, S.D. Algorithmic complexity theory and the relative efficiency of financial markets. EPL 2008, 84, 48005. [Google Scholar] [CrossRef]
- Shmilovici, A.; Alon-Brimer, Y.; Hauser, S. Using a Stochastic Complexity Measure to Check the Efficient Market Hypothesis. Comput. Econ. 2003, 22, 273–284. [Google Scholar] [CrossRef]
- Molgedey, L.; Ebeling, W. Local order, entropy and predictability of financial time series. Eur. Phys. J. B 2000, 15, 733–737. [Google Scholar] [CrossRef]
- Risso, W.A. The informational efficiency and the financial crashes. J. Int. Bus. Stud. 2008, 22, 396–408. [Google Scholar] [CrossRef]
- Mensi, W.; Aloui, C.; Hamdi, M.; Nguyen, D.K. Crude oil market efficiency: An empirical investigation via the Shannon entropy. Écon. Intern. 2012, 129, 119–137. [Google Scholar] [CrossRef]
- Calcagnile, L.M.; Corsi, F.; Marmi, S. Entropy and Efficiency of the ETF Market. Comput. Econ. 2020, 55, 143–184. [Google Scholar] [CrossRef]
- Bandi, F.M.; Kolokolov, A.; Pirino, D.; Renò, R. Zeros. Manag. Sci. 2020, 66, 3466–3479. [Google Scholar] [CrossRef]
- Sucarrat, G.; Escribano, A. Estimation of log-GARCH models in the presence of zero returns. Eur. J. Financ. 2018, 24, 809–827. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B Stat. Methodol. 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Risso, W.A. The informational efficiency: The emerging markets versus the developed markets. Appl. Econ. Lett. 2009, 16, 485–487. [Google Scholar] [CrossRef]
- Alvarez-Ramirez, J.; Rodriguez, E. A singular value decomposition entropy approach for testing stock market efficiency. Phys. A 2021, 583, 126337. [Google Scholar] [CrossRef]
- Degutis, A.; Novickytė, L. The efficient market hypothesis: A critical review of literature and methodology. Ekonomika 2014, 93, 7–23. [Google Scholar] [CrossRef]
- Ahn, K.; Lee, D.; Sohn, S.; Yang, B. Stock market uncertainty and economic fundamentals: An entropy-based approach. Quant. Financ. 2019, 19, 1151–1163. [Google Scholar] [CrossRef]
- Mahmoud, I.; Sebai, S.; Naoui, K.; Jemmali, H. Market Informational Efficiency of Tunisian Stock Market: The Contribution of Shannon Entropy. J. Econ. Financ. Adm. Sci. 2014, 6, 6–17. [Google Scholar]
- Coronel-Brizio, H.; Hernández-Montoya, A.; Huerta-Quintanilla, R.; Rodríguez-Achach, M. Evidence of increment of efficiency of the Mexican Stock Market through the analysis of its variations. Phys. A 2007, 380, 391–398. [Google Scholar] [CrossRef]
- Dionisio, A.; Menezes, R.; Mendes, D.A. An econophysics approach to analyse uncertainty in financial markets: An application to the Portuguese stock market. Eur. Phys. J. B 2006, 50, 161–164. [Google Scholar] [CrossRef]
- Brownlees, C.; Gallo, G. Financial econometric analysis at ultra-high frequency: Data handling concerns. Comput. Stat. Data Anal. 2006, 51, 2232–2245. [Google Scholar] [CrossRef]
- Hunter, J.S. The Exponentially Weighted Moving Average. J. Qual. Technol. 1986, 18, 203–210. [Google Scholar] [CrossRef]
- Morgan, J.; Longerstaey, J.; Spencer, M. RiskMetrics: Technical Document; J. P. Morgan: New York, NY, USA, 1996; Available online: https://www.msci.com/documents/10199/5915b101-4206-4ba0-aee2-3449d5c7e95a (accessed on 17 August 2022).
- Brent, R.P. An Algorithm with Guaranteed Convergence for Finding a Zero of a Function. Comput. J. 1971, 14, 422–425. [Google Scholar] [CrossRef]
- Kiefer, J. Sequential Minimax Search for a Maximum. Proc. Am. Math. Soc. 1953, 4, 502. [Google Scholar] [CrossRef]
- Shternshis, A.; Mazzarisi, P.; Marmi, S. Measuring market efficiency: The Shannon entropy of high-frequency financial time series. Chaos Solitons Fractals 2022, 162, 112403. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell. Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Marton, K.; Shields, P.C. Entropy and the Consistent Estimation of Joint Distributions. Ann. Probab. 1994, 22, 960–977. [Google Scholar] [CrossRef]
- Grassberger, P. Entropy Estimates from Insufficient Samplings. arXiv 2003, arXiv:physics/0307138. [Google Scholar] [CrossRef]
- Grassberger, P. On Generalized Schürmann Entropy Estimators. Entropy 2022, 24, 680. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Benedetto, D.; Caglioti, E.; Loreto, V. Language Trees and Zipping. Phys. Rev. Lett. 2002, 88, 048702. [Google Scholar] [CrossRef]
- Kolokolov, A.; Livieri, G.; Pirino, D. Statistical inferences for price staleness. J. Econom. 2020, 218, 32–81. [Google Scholar] [CrossRef]
- Engle, R.F. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Sokal, R.R.; Michener, C.D. A statistical method for evaluating systematic relationships. Univ. Kansas Sci. Bull. 1958, 38, 1409–1438. [Google Scholar]
- Bollen, B. What should the value of lambda be in the exponentially weighted moving average volatility model? Appl. Econ. 2015, 47, 853–860. [Google Scholar] [CrossRef]
- Jones, R.H. Maximum Likelihood Fitting of ARMA Models to Time Series with Missing Observations. Technometrics 1980, 22, 389–395. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the Dimension of a Model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]





| Ticker | Company | Sector | Size | Outliers |
|---|---|---|---|---|
| GAZP | Gazprom | Oil | 1,307,427 | 50 |
| LKOH | Lukoil | Oil | 1,287,582 | 192 |
| ROSN | Rosneft | Oil | 1,270,592 | 130 |
| SNGS | Surgutneftegaz | Oil | 1,211,809 | 11 |
| TATN | Tatneft | Oil | 1,191,390 | 174 |
| SBER | Sberbank | Bank | 1,309,402 | 37 |
| VTBR | VTB Bank | Bank | 1,287,330 | 0 |
| CHMF | Severstal | Metal | 1,214,735 | 157 |
| NLMK | Novolipetsk Steel | Metal | 1,194,324 | 58 |
| GMKN | Nornikel | Metal | 1,272,769 | 197 |
| MTLR | Mechel | Metal | 1,084,990 | 161 |
| MAGN | Magnitogorsk Iron and Steel Works | Metal | 1,106,771 | 13 |
| MTSS | Mobile TeleSystems | Telecommunications | 1,153,527 | 260 |
| RTKM | Rostelecom | Telecommunications | 1,140,798 | 134 |
| HYDR | RusHydro | Electric utility | 1,252,584 | 0 |
| RSTI | Rosseti | Electricity | 1,094,244 | 0 |
| AFLT | Aeroflot | Airline | 1,083,552 | 123 |
| MGNT | Magnit | Food retailer | 1,184,223 | 544 |
| Model | MAPE, Method | MAPE, | MAPE with , | MAPE with , | MAPE w/o 0-Filtering, | MAPE w/o 0-Filtering, |
|---|---|---|---|---|---|---|
| Model | for | for | , | , | Fraction of Data Deleted, | Fraction of Data Deleted, |
|---|---|---|---|---|---|---|
| Ticker | Degree of Inefficiency | For 3 Symbols Only | For 4 Symbols Only |
|---|---|---|---|
| GAZP | 0.725 | 0.392 | 0.675 |
| LKOH | 0.65 | 0.342 | 0.542 |
| ROSN | 0.742 | 0.392 | 0.708 |
| SNGS | 0.725 | 0.4 | 0.625 |
| TATN | 0.617 | 0.392 | 0.525 |
| SBER | 0.725 | 0.433 | 0.658 |
| VTBR | 0.842 | 0.592 | 0.792 |
| CHMF | 0.858 | 0.55 | 0.692 |
| NLMK | 0.8 | 0.467 | 0.692 |
| GMKN | 0.733 | 0.475 | 0.608 |
| MTLR | 0.992 | 0.783 | 0.975 |
| MAGN | 0.833 | 0.65 | 0.758 |
| MTSS | 0.967 | 0.7 | 0.942 |
| RTKM | 0.942 | 0.683 | 0.908 |
| HYDR | 0.892 | 0.75 | 0.8 |
| RSTI | 0.917 | 0.742 | 0.875 |
| AFLT | 0.983 | 0.775 | 0.95 |
| MGNT | 0.842 | 0.667 | 0.742 |
| Months of 2014 | The Most Frequent Block, 3-s | The Most Frequent Block, 4-s | Prob. of Success, Filtered | Prob. of Success, Original |
|---|---|---|---|---|
| January | 00000 | 1111 | 0.64 | 0.75 |
| February | 00000 | 2222 | 0.64 | 0.74 |
| May | 00000 | 1111 | 0.61 | 0.73 |
| June | 22222 | 1111 | 0.60 | 0.73 |
| July | 11111 | 1111 | 0.62 | 0.74 |
| August | 00000 | 1111 | 0.61 | 0.76 |
| September | 00000 | 1111 | 0.63 | 0.74 |
| October | 120120 | 0303 | 0.55 | 0.6 |
| Months | The Most Frequent Block, 3-s | The Most Frequent Block, 4-s | Prob. of Success, Filtered | Prob. of Success, Original |
|---|---|---|---|---|
| April 2014 | 212121 | 0111 | 0.63 | 0.77 |
| May 2014 | 00000 | 1111 | 0.61 | 0.73 |
| June 2014 | 00000 | 1111 | 0.6 | 0.73 |
| July 2014 | 00000 | 2222 | 0.62 | 0.74 |
| August 2014 | 00000 | 2222 | 0.61 | 0.76 |
| September 2014 | 000000 | 22222 | 0.63 | 0.74 |
| June 2015 | 00000 | 2222 | 0.54 | 0.61 |
| July 2015 | 00000 | 1111 | 0.55 | 0.6 |
| August 2015 | 00000 | 2222 | 0.54 | 0.6 |
| September 2015 | 00000 | 2222 | 0.55 | 0.61 |
| October 2015 | 11111 | 0111 | 0.56 | 0.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shternshis, A.; Mazzarisi, P.; Marmi, S. Efficiency of the Moscow Stock Exchange before 2022. Entropy 2022, 24, 1184. https://doi.org/10.3390/e24091184
Shternshis A, Mazzarisi P, Marmi S. Efficiency of the Moscow Stock Exchange before 2022. Entropy. 2022; 24(9):1184. https://doi.org/10.3390/e24091184
Chicago/Turabian StyleShternshis, Andrey, Piero Mazzarisi, and Stefano Marmi. 2022. "Efficiency of the Moscow Stock Exchange before 2022" Entropy 24, no. 9: 1184. https://doi.org/10.3390/e24091184
APA StyleShternshis, A., Mazzarisi, P., & Marmi, S. (2022). Efficiency of the Moscow Stock Exchange before 2022. Entropy, 24(9), 1184. https://doi.org/10.3390/e24091184