1. Introduction
Rotary kilns are widely used in cement, metallurgy, chemical and environmental protection fields. The firing zone temperature in the kilns is adjusted by controlling the amount of coal feeding, the damper opening and the kiln rotational speed according to the current kiln conditions during the production process. They are the most important factors in determining the clinker quality and are usually used as the controlled variables in the rotary kiln control strategies [
1,
2]. However, due to the influence of interfering factors, such as smoke and dust in the kilns, the traditional method is difficult to measure the temperature of the sintering zone accurately.
There is a close relationship between flame image and temperature, and the flame image of the firing zone contains a wealth of information about the operating conditions. In order to achieve intelligent control of rotary kilns, many intelligent methods, such as singular value decomposition (SVD) [
3], support vector machine (SVM) and K-means [
4] are applied to the feature extraction and classification of such flame images to recognize working conditions of rotary kilns.
However, machine learning and neural network approaches alone are not satisfactory in terms of recognition accuracy. As a result, most of the subsequent studies chose to pre-process the flame images by combining filters or image segmentation to highlight the regions of interest before using neural networks for working condition recognition, which improved recognition accuracy to a certain extent [
5,
6]. However, due to the limitation of the number of network layers and performance, these methods using neural networks are difficult to distinguish important features when extracting features from flame images with high similarity, and it is also difficult to select classifiers.
In recent years, the application of deep learning in the field of image recognition has made breakthrough progress [
7]. However, it is difficult to obtain images of rotary kiln flames: the lack of sample data makes it difficult to meet the demand for image feature extraction in deep learning networks, and the training is prone to overfitting. To reduce the dependence of deep learning models on the number of training samples, transfer learning can be applied to classification recognition tasks for speeding up training efficiency [
8]. Therefore, a combination of deep learning and transfer learning is applied to the recognition of rotary kiln working conditions. In [
9], a convolutional neural network was used for feature migration, and the network was trained and tested for automatic recognition of combustion states. There are also methods based on deep transfer learning to obtain the feature space of the dynamic convolutional neural network and input the feature vector into stochastic configuration networks (SCN) to realize the recognition of the burning state of the flame image [
10]. These methods have alleviated the problem of a lack of sample data for flame images to some extent, but due to the high similarity between different classes of flame images of rotary kilns, the existing deep learning models do not pay special attention to the important image features, resulting in difficulties in extracting key features during the training process.
In order to improve the ability of deep learning networks to extract key features, an attention mechanism [
11,
12] is added to the computer vision research to complement and improve existing deep learning networks, which is popular in natural language processing. The attention mechanism was first used on the RNN model, and a visual processing framework based on it was proposed [
13]. In [
14], in order to find the most relevant regions in the input images, a deep learning network Deep RNN and attention mechanism were combined to recognize images and reduce the image classification errors.
The method of combining attention mechanism and deep learning network has begun to be widely used in the field of computer vision [
15], such as the classification and recognition of medical images [
16], the classification of remote sensing images [
17], and the detection of industrial casting defects [
18]. Inspired by the above research, a rotary kiln condition recognition method based on transfer learning and attention mechanism is proposed. The main contributions of this work are as follows:
Transfer learning is used to solve the problem of data acquisition difficulty of rotary kiln flame images and avoid overfitting during model training.
A deep residual network is used to directly perform feature extraction, classification and recognition on the flame images without segmenting them.
An attention mechanism is added during feature extraction to improve the weight of the key flame image features, solving the problem of insufficiently extracting key features with traditional methods.
It is the first time a combination of transfer learning and attention mechanism is used to identify rotary kiln working conditions from flame images, which accelerates the model convergence speed, and improves the model recognition accuracy and generalization ability.
The other parts of the paper are organized as follows: related work is given in
Section 2.
Section 3 presents a method for recognition working conditions of rotary kilns based on transfer learning and attention mechanism. The results of the experiments are reported in
Section 4 and discussed in
Section 5. Finally, the conclusions are given in
Section 6.
2. Related Work
Recognition of a sintering state by flame image is helpful to determine a sintering state. In [
3], the authors proposed a method of rotary-kiln combustion-state identification based on singular value decomposition (SVD) and support vector machine (SVM). The flame image features between the two libraries were extracted and used as input to train the SVM classifier offline to realize the recognition of rotary kiln. In [
5], the author gradually optimized the feature space of the flame image by evaluating the uncertain cognitive results of different cognitive demand values and realized the simulated feedback cognitive mode from global to local. In this study, the authors combined the coupling operation of training layer and cognitive decision layer and established a simulation feedback mechanism based on bag of words model, latent semantic analysis method and entropy theory. The average recognition accuracy of the proposed rotary-kiln combustion-state cognition method reached 92.32%. In [
4], the author proposed a combustion state recognition method for cement rotary kiln based on Otsu–K-means flame image segmentation and SVM. The Otsu–K-means image segmentation method is used to achieve the effective segmentation of the flame image target region. On this basis, 10 feature parameters of the target region are extracted as the state recognition features. Then, the one minute statistical average of the extracted feature parameters was used as the input type to classify and identify the flame image, and 28 groups of samples could be correctly identified. In [
19], the authors proposed an effective quality sensing feature of texture intensity (TI) to model texture, structure and naturalness of images. Using the video quality score statistics calculated by TI-NIQE as input features, the automatic visual recognition model of rotary kiln status recognition was trained. It has high prediction accuracy for rotary kiln state recognition on the benchmark data set. However, it is challenging to extract the key features of flame image efficiently.
There are also methods of feature extraction using flame video directly. In [
1], the author proposed an effective model based on the spatiotemporal feature extraction of flame video. The dynamic texture descriptor 3DBLBP is used to extract the dynamic texture and flame motion from three adjacent frames of a video block. Then, the dynamic structure descriptor HOPC-TOP is used to extract the three-dimensional phase consistency information from three orthogonal planes to capture the structure and motion characteristics of the flame. Combining these two descriptors, the spatiotemporal characteristics of flame fragments are extracted to identify the burning state. In [
20], the author designed a set of trajectory evolution characteristics and morphological distribution characteristics of chaotic attractors. After the chaotic attractors were reconstructed from the intensity sequence of the flame video through phase-space reconstruction, quantitative features were extracted from the recursive graph and morphological distribution, and then put into the decision tree to identify the burning conditions. The authors claim that the method is more than 5% more accurate than other methods.
Because the flame image is difficult to obtain, it is sometimes necessary to solve the problem of uneven data sets. The authors in [
2] proposed a comprehensive framework considering class disequilibrium for sintering condition recognition. The characteristics of heat signal were analyzed by the Lipschitz method, and four discriminative features were extracted to comprehensively describe different sintering conditions. A new recognition model, kernel modified ODM (KMODM), was proposed for the identification of a sintering state, which alleviated the decrease in the accuracy of minority detection. For a sintering state identification under class imbalance, a cascade stack autoencoder (SAE) model [
21] was proposed to integrate prior knowledge and hidden information, extract hidden information from thermal signals, and extract discriminant features of unbalanced data. At the same time, the kernel modified Optimal Margin distribution machine (ddKMODM) is used as the sintering state recognition model, and the overall sintering state recognition accuracy of the scheme is more than 92%.
In order to meet the requirements of deep learning on the number of training samples, a rotary kiln recognition method combining transfer learning has emerged. In [
10], the author proposed an intelligent sensing model of flame image combustion condition based on deep transfer learning. On the one hand, the adaptive structure convolutional neural networks (ASCNN) were constructed by a self-optimizing adjustment mechanism. On the other hand, stochastic configuration networks (SCN) with stochastic approximation ability are constructed. Experimental results demonstrate the feasibility of the recognition model. In [
9], the author adopted the convolutional neural network VGG-16 model for feature transfer, and trained and tested the flame images of different combustion states in the rotary kiln through the network so as to achieve the purpose of automatic identification of combustion states. However, the application of deep learning in rotary kiln working condition recognition still has great development potential.
3. Rotary Kiln Working Condition Recognition Based on Transfer Learning and Attention Mechanism
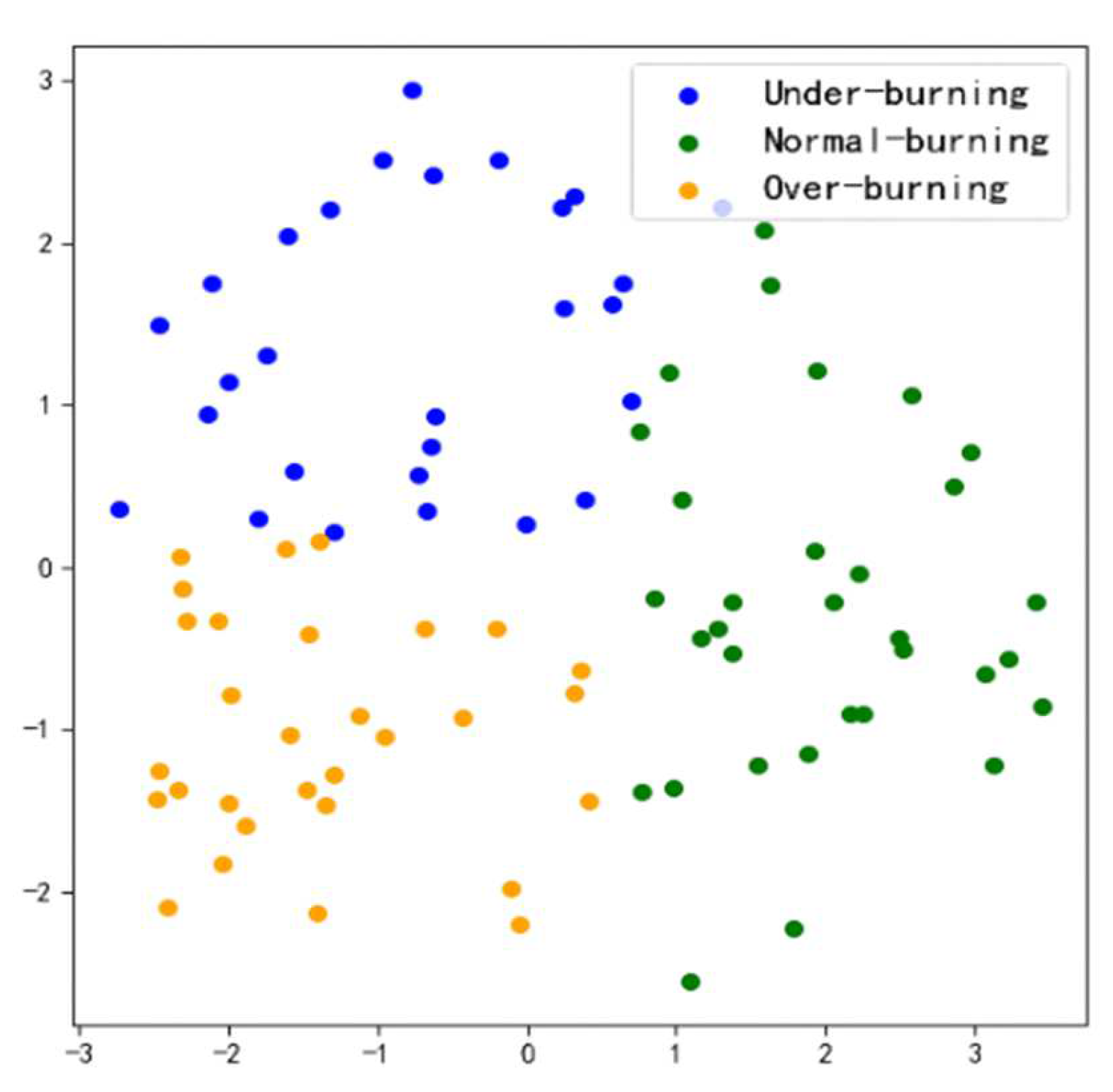
The working conditions in rotary kilns are generally divided into three types: under-burning state, normal-burning state and over-burning state. The flame brightness is low, and the shiny area is small when it is under the “under-burning state”; the flame area has uniform brightness when it is under the “normal-burning state”; the flame has a high brightness and a large shiny area, and even exposure occurs, when it is under the “over-burning state”. In order to extract useful information features and improve the recognition accuracy of the working conditions, a method for identifying the working conditions of the rotary kiln based on transfer learning and attention mechanism is proposed in the paper.
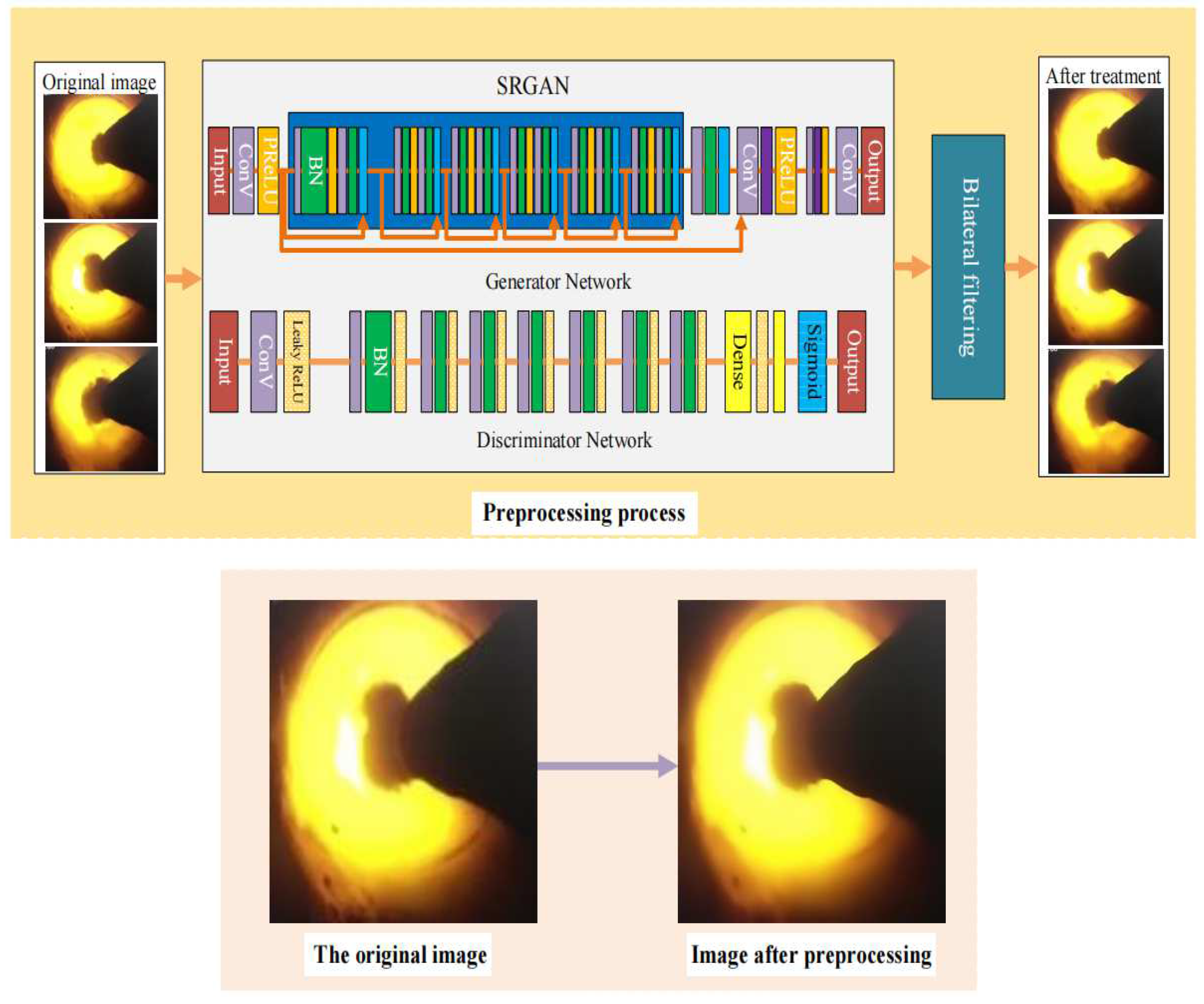
Figure 1 shows the workflow and methodology of our proposed work. It includes five parts: A: Rotary kiln flame image dataset is prepared for inputs. B: The flame images are preprocessed using bilateral filtering [
22] and their resolution are improved through super resolution generative adversarial network (SRGAN) [
23]. C: The pre-trained model of ResNet50 [
24] is loaded for feature migration, and the coordinate attention module is embedded in the fully connected layer of the network model to improve the weight of key features in the network; its activation function Mish [
25] is optimized to reduce the loss of effective information. D: The optimal model is saved. E: The corresponding rotary kiln working condition category is outputted.
3.1. Image Preprocessing
The original rotary kiln flame image data is collected by the kiln head camera. In order to make the image dataset better adapt to the recognition model, the flame images need to be preprocessed. The comparison before and after image preprocessing is shown in
Figure 2. Firstly, the resolution of the flame images is improved to 224 × 224 by super resolution generative adversarial network (SRGAN). The bilateral filtering is then used to refine the edge features of flame images due to the large similarity of flame features under the three working conditions.
SRGAN consists of a generator network and a discriminant network. The real images, fake images and their corresponding labels are inputs to the discriminant network. The fake images are generated by sending low-resolution images into the generator network, and the authenticity of the input images is judged by the discriminant network through training. The images are further trained by the generator network according to the discriminator’s results. At the same time, the real high-resolution images and the fake high-resolution images are sent to the VGG network by the generator to obtain the features of the two kinds of images, and the loss is obtained by comparing them. The perceptual loss
is used to improve the realism of the recovered images and their resolution, and retain high-frequency details, which is beneficial to the identification of working conditions. The perceptual loss
consists of the content loss
and the adversarial loss
.
where
is the amplification factor.
are the width and height of the images, respectively.
is the high-resolution image and
and
represent the generator network and network parameters.
where
represents low resolution image,
represents discriminant network and
is discriminant network parameter.
3.2. Transfer Learning
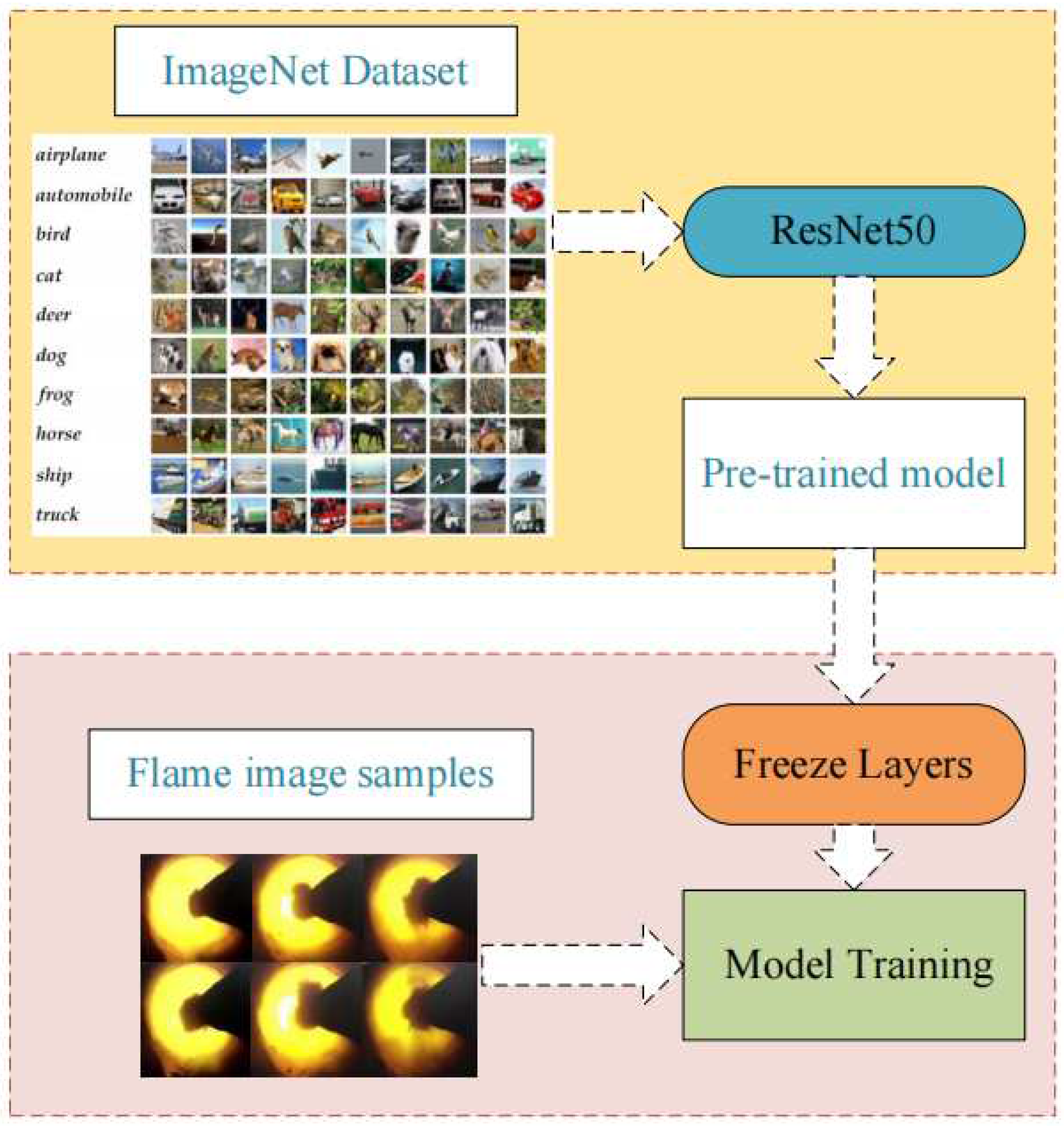
Transfer learning is an effective way to improve model performance when the number of training data is insufficient, especially when small sample data size is used in network models with complex structures and train difficulty [
26].
Figure 3 shows the transfer learning approach. The basic network model is pre-trained using ImageNet dataset, and the pre-trained model is obtained by learning a large number of common underlying image features. However, as the ImageNet data set is not a special flame image data set, on the basis of the training model of the flame image, recognition is not targeted. Consequently, in the process of model training, the first step is to freeze the model of the backbone network, and then the flame image sample is used to fine-tune and train the model.
3.3. Coordinate Attention Module
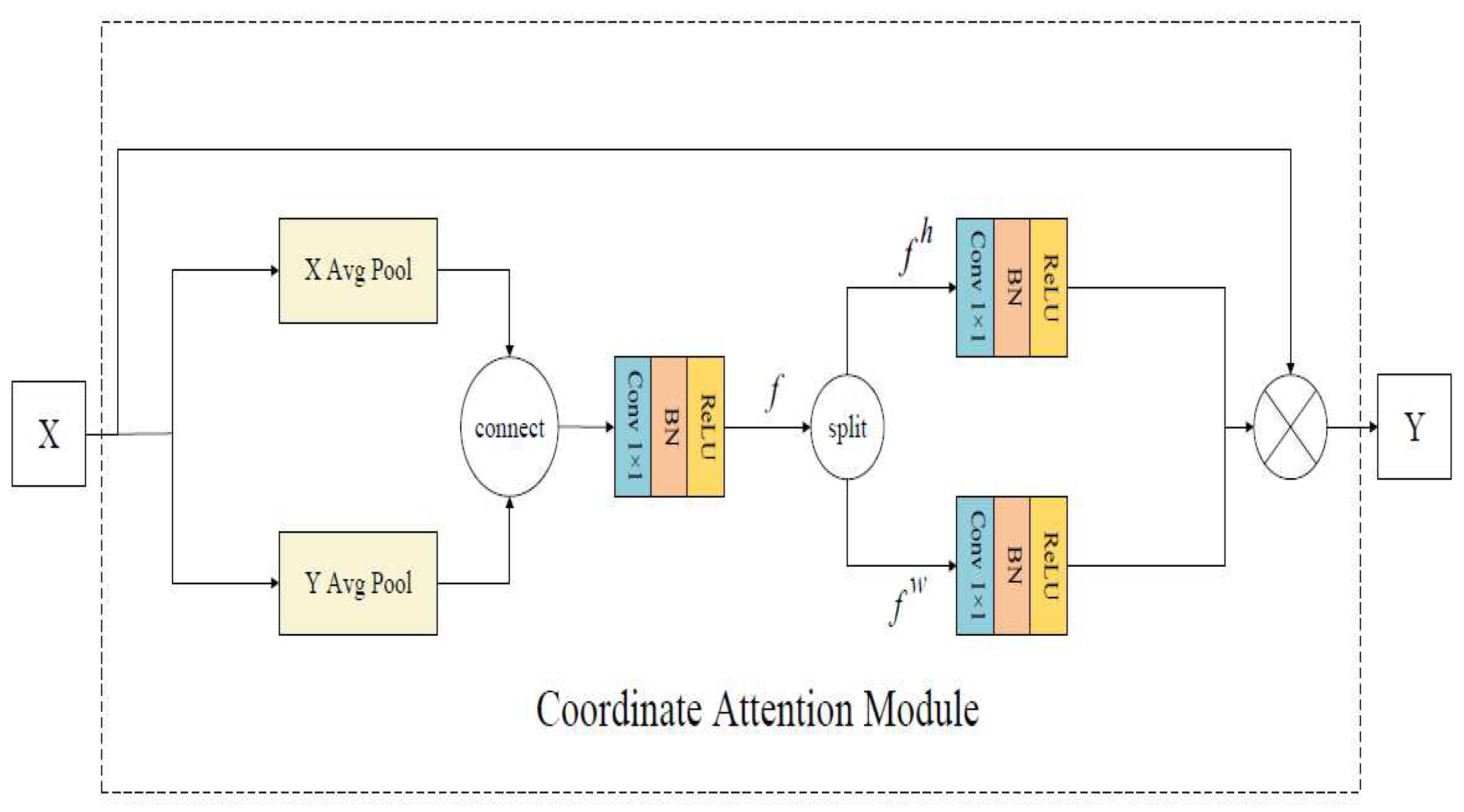
The Coordinate Attention (CA) module [
27] is a lightweight attention mechanism. The location information is embedded into the channel attention to capture accurate location information and areas of interest when it acquires the feature information between channels. The specific structure of the CA module is shown in
Figure 4.
The input feature map uses the adaptive average pooling layer in the horizontal and vertical directions to extract features for each feature channel, and the generated feature maps are connected. Then, 1 × 1 convolution is used to generate the intermediate feature map with vertical and horizontal spatial information, and the intermediate feature map is divided into two feature maps along the spatial direction. Then 1 × 1 convolution is used to transform the attention weights in vertical and horizontal spatial directions, which are multiplied with the input feature map to obtain the feature map with the attention weight.
The CA module is introduced to improve ResNet50, and the location information is embedded in the channel attention so that the network can obtain the feature information between each channel, and improve the ability of the model to extract the key features of the flame image.
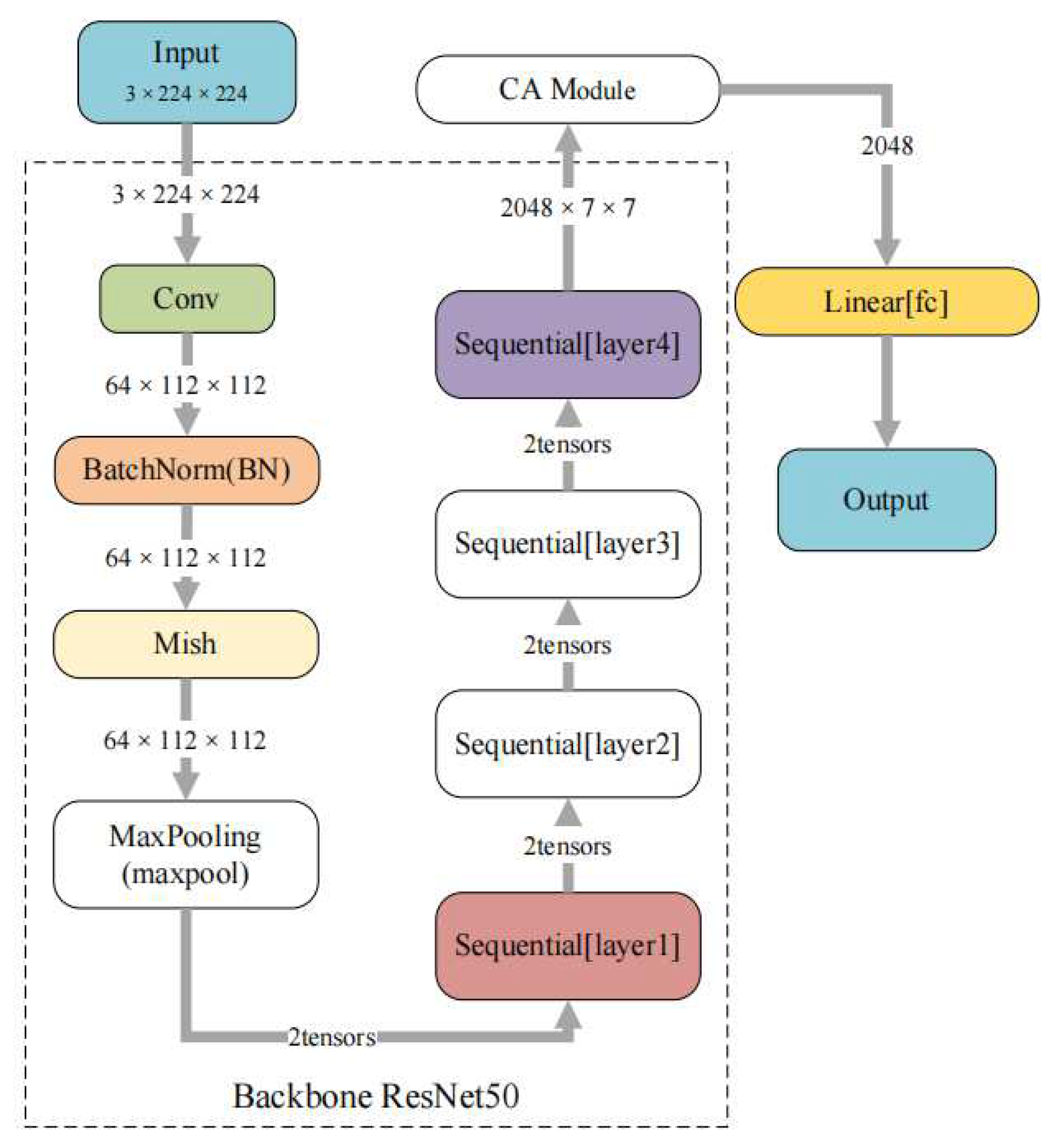
The improved ResNet50 network is shown in
Figure 5. Its input is a 3 × 224 × 224 flame image, which first goes through the convolutional layers (Conv) and batch normalization (BN). Next, is the max pooling after activation with the Mish function and is then passed through the four residual modules of ResNet50 in turn. This process is simplified to Layer1 through Layer4. Then, the CA module is used for processing before the full connection layer (fc), and finally the output, is obtained.
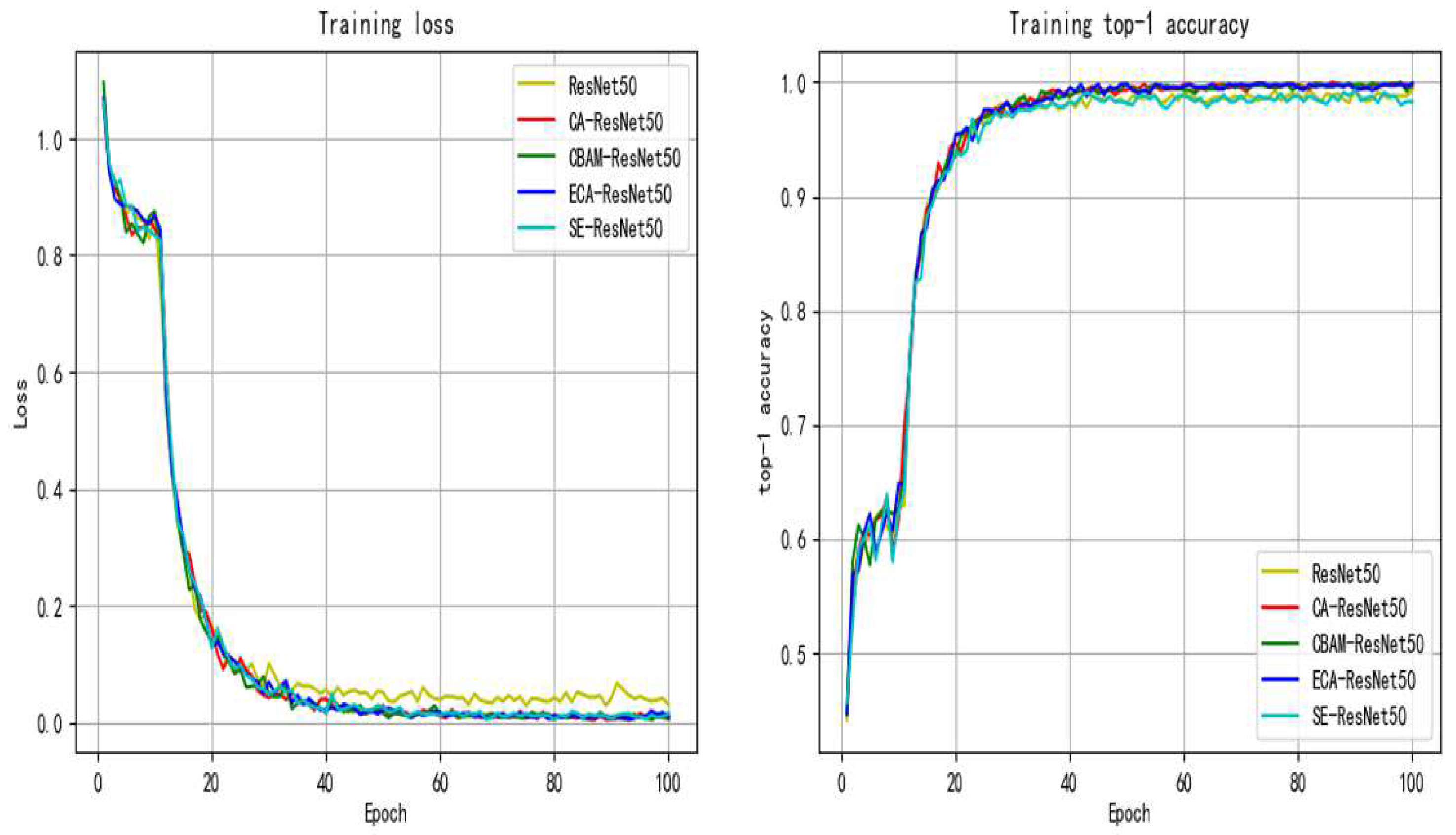
5. Discussion
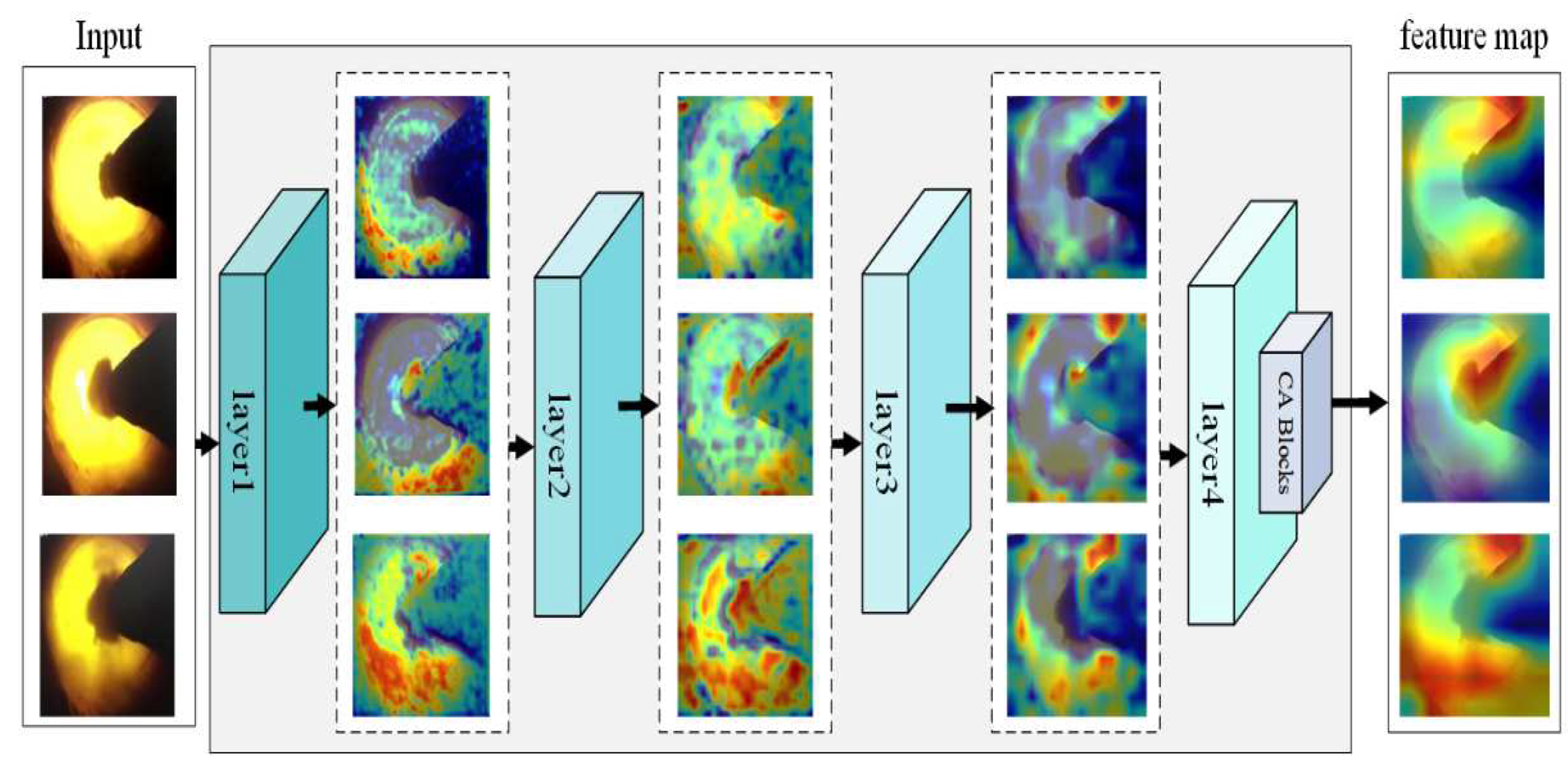
The method proposed in this paper uses a deep learning model combined with transfer learning and CA attention module to help extract key features of flame images while reducing training costs. It can also be seen in
Figure 6 and
Table 3 that the addition of the attention module improves the condition recognition ability of the model, indicating that the addition of the attention module can effectively improve the ability of the network to extract key features of flame images. As can be seen from the number of parameter changes in the table, increasing the attention module will hardly increase the complexity of the model, and improve the performance of the model at a small cost. Combined with the visual analysis in
Figure 7, it can be seen that the recognition model, after adding the CA module, expands the range of feature areas through network learning and gradually finds the important features that are conducive to distinguishing categories on the image. Then, the attention module is used to improve the network’s attention to important features and increase the corresponding feature weights.
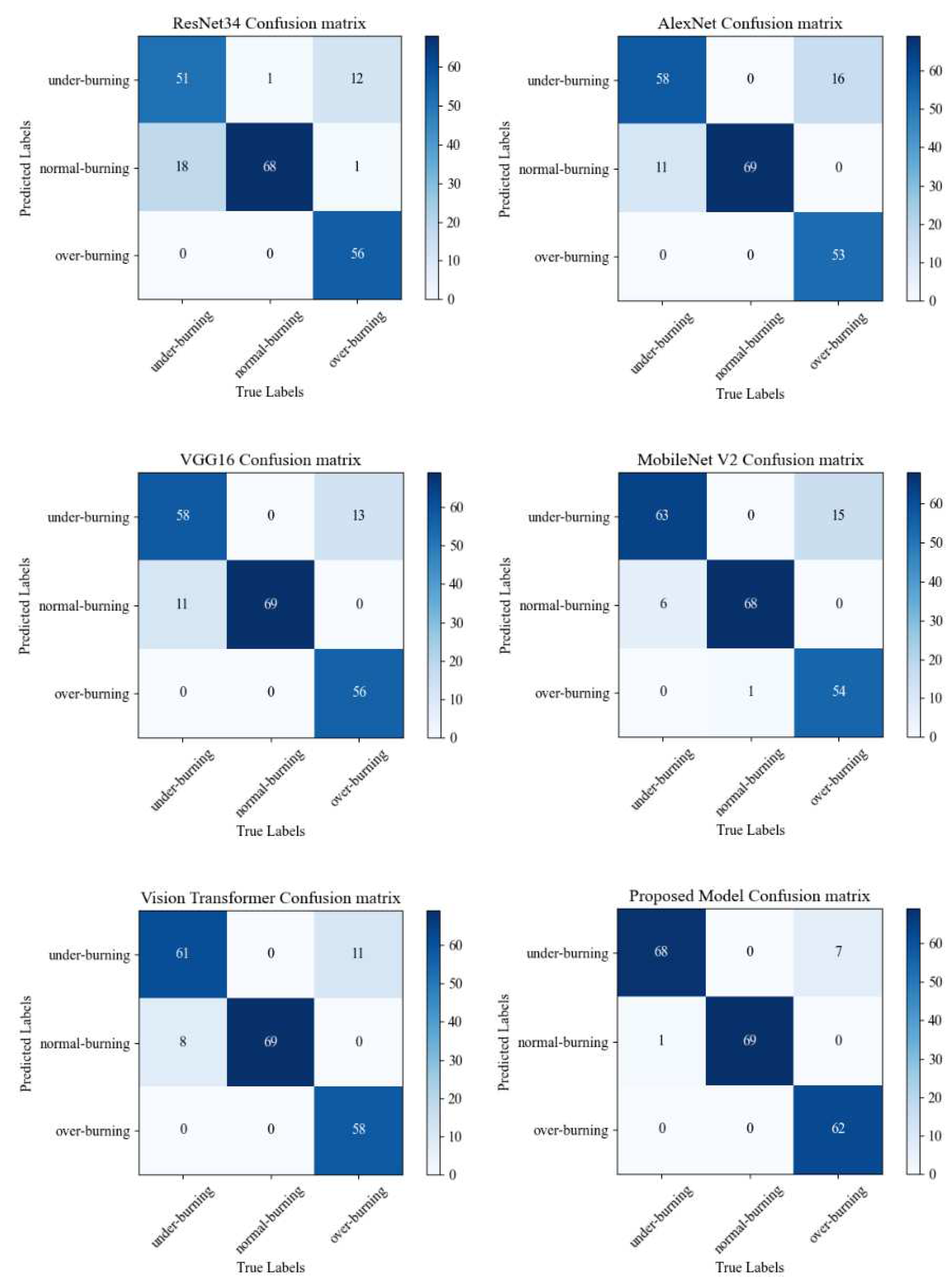
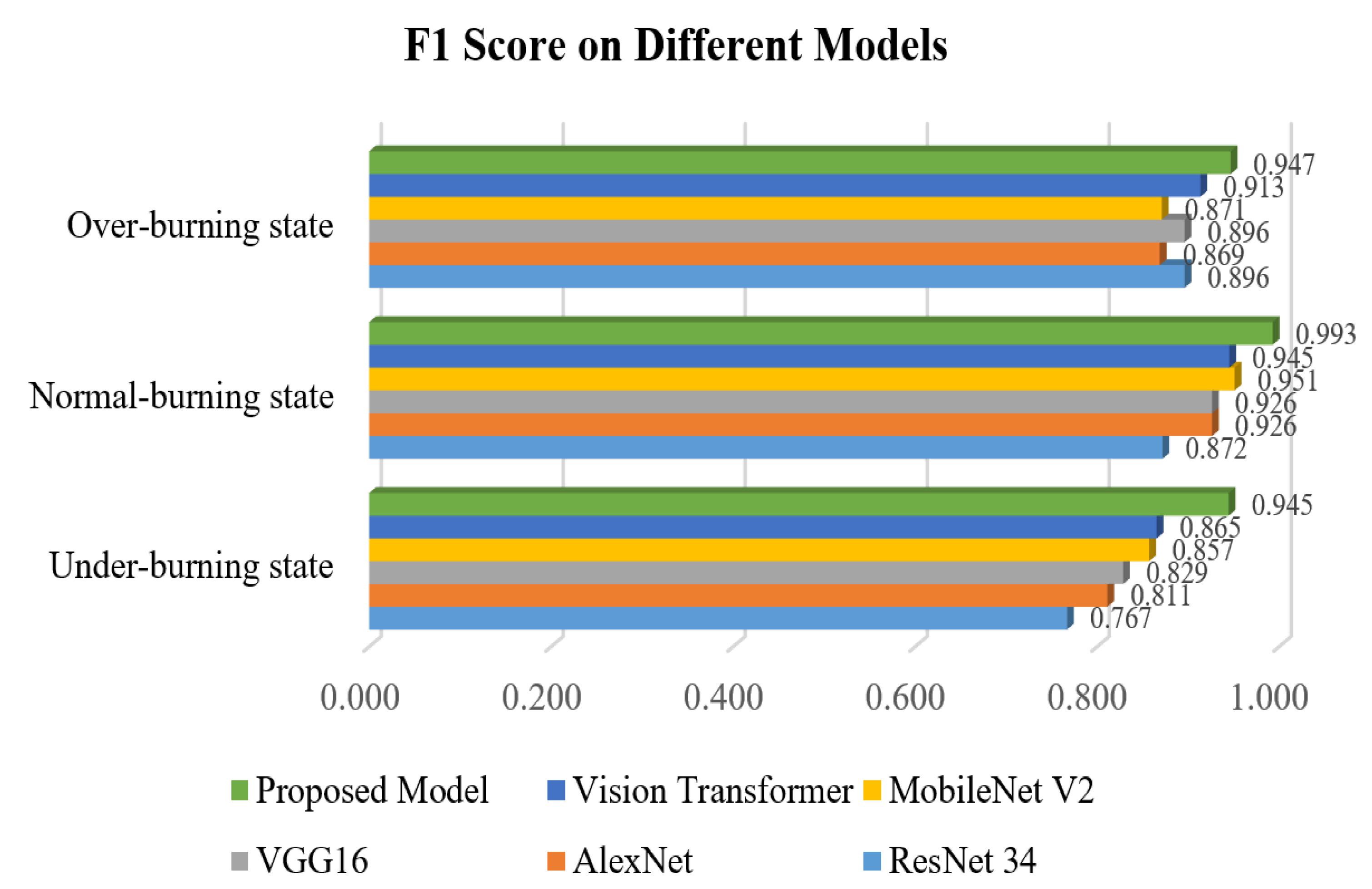
According to the various evaluation indexes of different models in
Figure 9,
Figure 10,
Figure 11 and
Figure 12 and
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9, such as precision, sensitivity, specificity, heatmaps, and F1 score, it can be seen that all networks have more misjudgments on the understanding of under-burning state and over-burning state. This is because the flame of these two conditions is similar, and it is difficult to classify them. However, the model proposed in this paper has a good ability to recognize the three types of working conditions. It can be seen from
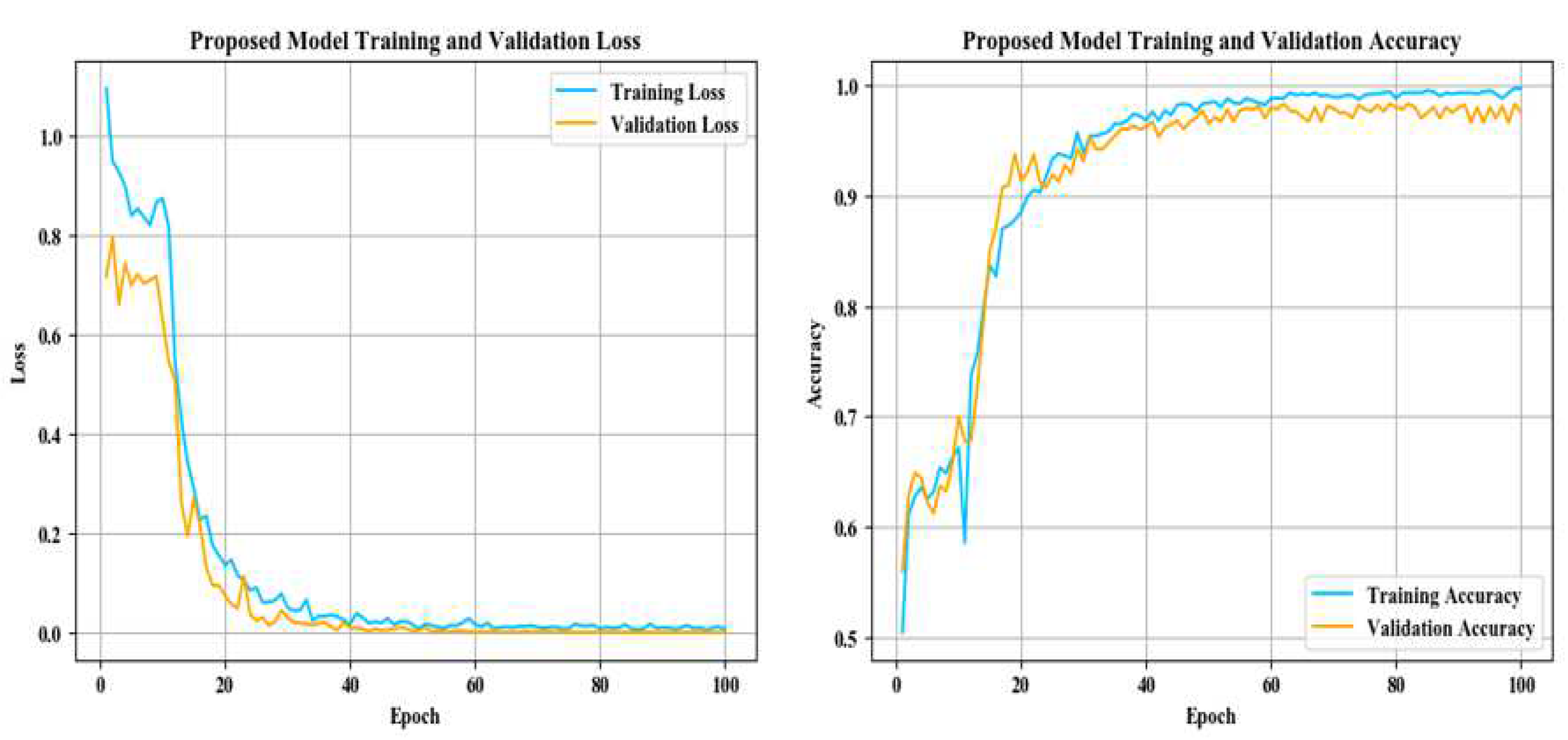
Table 10 that on the flame image dataset: ResNet34 achieves a top-1 accuracy of 84.54%; AlexNet reached 86.47%; The top-1 accuracy of VGG16 and MobileNetV2 in the test set reaches about 90%, but VGG16 has a large number of parameters and spends more time during training process; Vision Transformer reached 94.20%, but the model structure is relatively complex and the training takes up more resources, so it is difficult to converge.
The accuracy of the proposed model is 96.14%, and the recognition accuracy is slightly higher than that of the Vision Transformer. However, the complexity of the model is low, the running time takes up less resources and the training time cost is relatively small, indicating that the proposed model has a better performance in the task of condition recognition.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}