
Improving Automated Essay Scoring by Prompt Prediction and Matching


Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Motivation
3.2. Input and Feature Extraction Layer
3.3. Essay Scoring Layer
3.4. Subtask 1: Prompt Prediction
3.5. Subtask 2: Prompt Matching
3.6. Multi-Task Loss Function
4. Experiment
4.1. Dataset
4.2. Evaluation Metrics
4.3. Comparisons
4.4. Parameter Settings
5. Results and Discussions
5.1. Main Results and Analysis
5.2. Result and Effect of Auxiliary Tasks
5.3. Effect of Loss Weight
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AES | Automated Essay Scoring |
| NLP | Natural Language Processing |
| QWK | Quadratic Weighted Kappa |
| PCC | Pearson’s Correlation Coefficient |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | QWK | PCC | QWK | PCC | QWK | PCC | QWK | PCC | QWK | PCC |
|---|---|---|---|---|---|---|---|---|---|---|
| Method | Prompt 1 | Prompt 2 | Prompt 3 | Prompt 4 | Prompt 5 | |||||
| CNN-LSTM † | 0.721 | 0.742 | 0.634 | 0.644 | 0.646 | 0.669 | 0.644 | 0.661 | 0.666 | 0.702 |
| CNN-LSTM-att † | 0.759 | 0.767 | 0.639 | 0.650 | 0.662 | 0.683 | 0.649 | 0.671 | 0.654 | 0.695 |
| CNN-LSTM ‡ | 0.730 | 0.749 | 0.638 | 0.657 | 0.613 | 0.663 | 0.673 | 0.696 | 0.671 | 0.709 |
| CNN-LSTM-att ‡ | 0.767 | 0.773 | 0.622 | 0.634 | 0.679 | 0.701 | 0.680 | 0.694 | 0.668 | 0.705 |
| EModel (Pro.) ‡ | 0.752 | 0.769 | 0.664 | 0.681 | 0.672 | 0.687 | 0.693 | 0.710 | 0.676 | 0.704 |
| BERT-FT | 0.725 | 0.765 | 0.701 | 0.748 | 0.678 | 0.720 | 0.726 | 0.763 | 0.667 | 0.699 |
| BERT-concat | 0.746 | 0.772 | 0.718 | 0.756 | 0.681 | 0.726 | 0.713 | 0.751 | 0.686 | 0.709 |
| BERT-PP | 0.735 | 0.773 | 0.718 | 0.758 | 0.680 | 0.724 | 0.715 | 0.743 | 0.658 | 0.681 |
| BERT-PM | 0.749 | 0.774 | 0.739 | 0.771 | 0.708 | 0.744 | 0.729 | 0.753 | 0.687 | 0.704 |
| BERT-PP&PM | 0.716 | 0.780 | 0.728 | 0.766 | 0.708 | 0.734 | 0.741 | 0.753 | 0.687 | 0.707 |
| NEZHA-FT | 0.719 | 0.769 | 0.706 | 0.763 | 0.671 | 0.715 | 0.706 | 0.744 | 0.661 | 0.689 |
| NEZHA-concat | 0.703 | 0.751 | 0.696 | 0.761 | 0.665 | 0.715 | 0.715 | 0.754 | 0.712 | 0.737 |
| NEZHA-PP | 0.750 | 0.791 | 0.700 | 0.764 | 0.692 | 0.747 | 0.731 | 0.763 | 0.692 | 0.728 |
| NEZHA-PM | 0.756 | 0.787 | 0.735 | 0.774 | 0.697 | 0.741 | 0.714 | 0.760 | 0.684 | 0.717 |
| NEZHA-PP&PM | 0.687 | 0.781 | 0.740 | 0.765 | 0.715 | 0.745 | 0.742 | 0.761 | 0.697 | 0.710 |
| Method | Prompt 6 | Prompt 7 | Prompt 8 | Prompt 9 | Prompt 10 | |||||
| CNN-LSTM † | 0.539 | 0.564 | 0.553 | 0.580 | 0.456 | 0.496 | 0.612 | 0.669 | 0.646 | 0.688 |
| CNN-LSTM-att † | 0.552 | 0.581 | 0.552 | 0.604 | 0.454 | 0.507 | 0.598 | 0.660 | 0.630 | 0.661 |
| CNN-LSTM ‡ | 0.479 | 0.519 | 0.542 | 0.565 | 0.396 | 0.446 | 0.596 | 0.652 | 0.627 | 0.674 |
| CNN-LSTM-att ‡ | 0.486 | 0.516 | 0.553 | 0.590 | 0.356 | 0.399 | 0.575 | 0.616 | 0.649 | 0.665 |
| EModel (Pro.) ‡ | 0.503 | 0.528 | 0.560 | 0.602 | 0.413 | 0.457 | 0.597 | 0.661 | 0.667 | 0.693 |
| BERT-FT | 0.582 | 0.625 | 0.673 | 0.705 | 0.558 | 0.625 | 0.683 | 0.746 | 0.677 | 0.733 |
| BERT-concat | 0.580 | 0.630 | 0.651 | 0.698 | 0.571 | 0.619 | 0.672 | 0.720 | 0.690 | 0.738 |
| BERT-PP | 0.562 | 0.615 | 0.664 | 0.700 | 0.553 | 0.611 | 0.694 | 0.739 | 0.696 | 0.740 |
| BERT-PM | 0.579 | 0.620 | 0.682 | 0.711 | 0.578 | 0.619 | 0.688 | 0.736 | 0.700 | 0.752 |
| BERT-PP&PM | 0.617 | 0.627 | 0.696 | 0.705 | 0.568 | 0.601 | 0.718 | 0.739 | 0.695 | 0.741 |
| NEZHA-FT | 0.594 | 0.631 | 0.674 | 0.707 | 0.553 | 0.599 | 0.655 | 0.722 | 0.677 | 0.738 |
| NEZHA-concat | 0.595 | 0.642 | 0.689 | 0.718 | 0.554 | 0.610 | 0.658 | 0.716 | 0.684 | 0.738 |
| NEZHA-PP | 0.588 | 0.639 | 0.688 | 0.723 | 0.579 | 0.633 | 0.672 | 0.745 | 0.706 | 0.751 |
| NEZHA-PM | 0.576 | 0.630 | 0.672 | 0.719 | 0.583 | 0.624 | 0.692 | 0.740 | 0.715 | 0.752 |
| NEZHA-PP&PM | 0.620 | 0.647 | 0.693 | 0.715 | 0.589 | 0.618 | 0.701 | 0.729 | 0.684 | 0.750 |
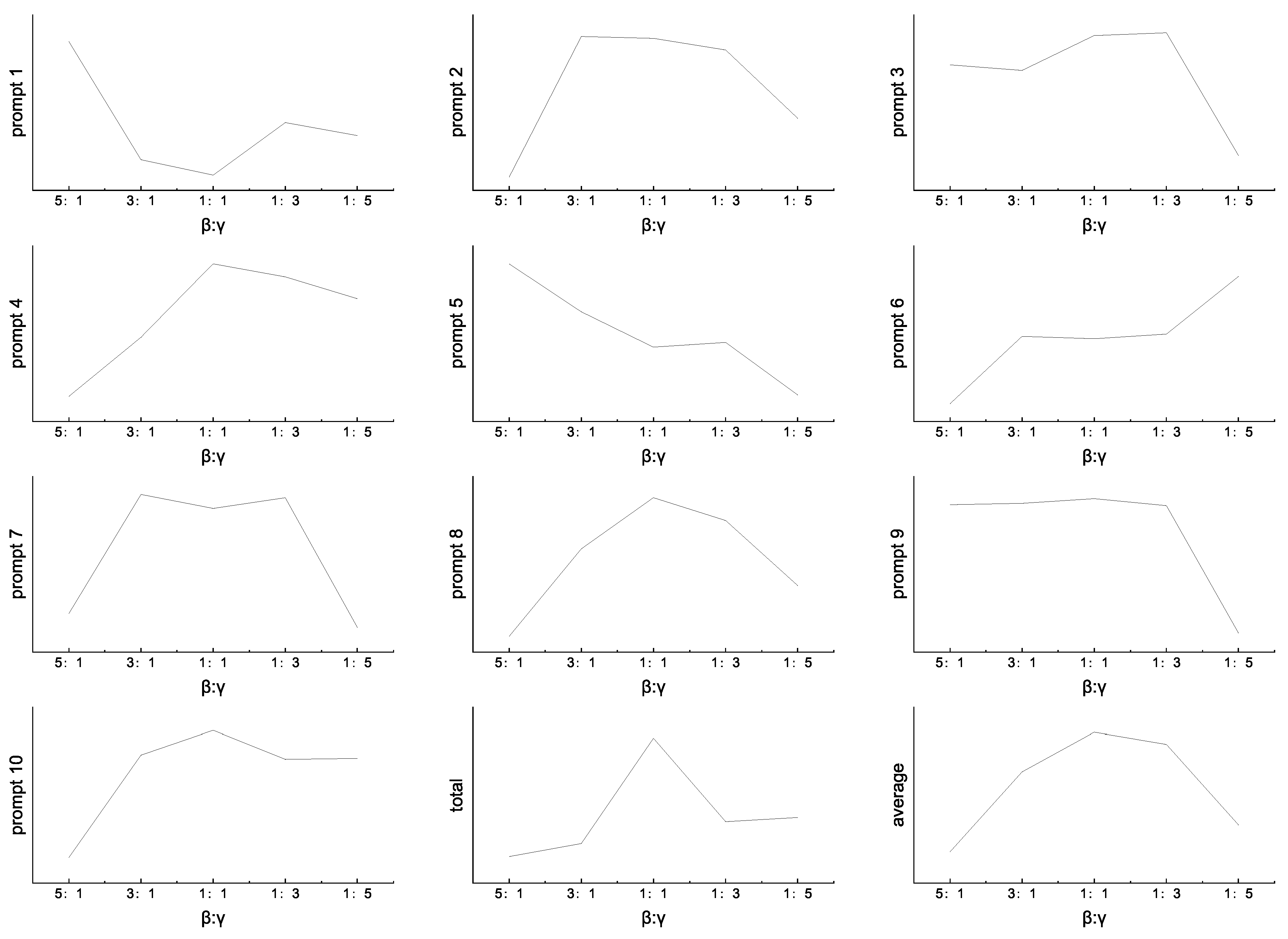
References
- Page, E.B. The imminence of… grading essays by computer. Phi Delta Kappan 1966, 47, 238–243. [Google Scholar]
- Higgins, D.; Burstein, J.; Marcu, D.; Gentile, C. Evaluating multiple aspects of coherence in student essays. In Proceedings of the NAACL-HLT, Boston, MA, USA, 2–7 May 2004; pp. 185–192. [Google Scholar]
- Persing, I.; Ng, V. Modeling prompt adherence in student essays. In Proceedings of the ACL, Baltimore, MD, USA, 22–27 June 2014; pp. 1534–1543. [Google Scholar]
- Taghipour, K.; Ng, H.T. A neural approach to automated essay scoring. In Proceedings of the EMNLP, Austin, TX, USA, 1–5 November 2016; pp. 1882–1891. [Google Scholar]
- Dong, F.; Zhang, Y.; Yang, J. Attention-based recurrent convolutional neural network for automatic essay scoring. In Proceedings of the CoNLL, Vancouver, BC, Canada, 3–4 August 2017; pp. 153–162. [Google Scholar]
- Jin, C.; He, B.; Hui, K.; Sun, L. TDNN: A two-stage deep neural network for prompt-independent automated essay scoring. In Proceedings of the ACL, Melbourne, Australia, 15–20 July 2018; pp. 1088–1097. [Google Scholar]
- Li, X.; Chen, M.; Nie, J.Y. SEDNN: Shared and enhanced deep neural network model for cross-prompt automated essay scoring. Knowl.-Based Syst. 2020, 210, 106491. [Google Scholar] [CrossRef]
- Park, Y.H.; Choi, Y.S.; Park, C.Y.; Lee, K.J. EssayGAN: Essay Data Augmentation Based on Generative Adversarial Networks for Automated Essay Scoring. Appl. Sci. 2022, 12, 5803. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the ACL, Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Rodriguez, P.U.; Jafari, A.; Ormerod, C.M. Language models and automated essay scoring. arXiv 2019, arXiv:1909.09482. [Google Scholar]
- Song, W.; Zhang, K.; Fu, R.; Liu, L.; Liu, T.; Cheng, M. Multi-stage pre-training for automated Chinese essay scoring. In Proceedings of the EMNLP, Online, 16–20 November 2020; pp. 6723–6733. [Google Scholar]
- Louis, A.; Higgins, D. Off-topic essay detection using short prompt texts. In Proceedings of the NAACL-HLT, Los Angeles, CA, USA, 1–6 June 2010; pp. 92–95. [Google Scholar]
- Persing, I.; Davis, A.; Ng, V. Modeling organization in student essays. In Proceedings of the EMNLP, Cambridge, MA, USA, 9–11 October 2010; pp. 229–239. [Google Scholar]
- Mim, F.S.; Inoue, N.; Reisert, P.; Ouchi, H.; Inui, K. Unsupervised learning of discourse-aware text representation for essay scoring. In Proceedings of the ACL, Florence, Italy, 28 July–2 August 2019; pp. 378–385. [Google Scholar]
- Nadeem, F.; Nguyen, H.; Liu, Y.; Ostendorf, M. Automated essay scoring with discourse-aware neural models. In Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, Florence, Italy, 2 August 2019; pp. 484–493. [Google Scholar]
- Song, W.; Song, Z.; Fu, R.; Liu, L.; Cheng, M.; Liu, T. Discourse Self-Attention for Discourse Element Identification in Argumentative Student Essays. In Proceedings of the EMNLP, Online, 16–20 November 2020; pp. 2820–2830. [Google Scholar]
- Klebanov, B.B.; Flor, M.; Gyawali, B. Topicality-based indices for essay scoring. In Proceedings of the BEA, San Diego, CA, USA, 16 June 2016; pp. 63–72. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. In Proceedings of the ACL, Florence, Italy, 28 July–2 August 2019; pp. 4487–4496. [Google Scholar]
- Yu, J.; Jiang, J. Learning sentence embeddings with auxiliary tasks for cross-domain sentiment classification. In Proceedings of the EMNLP, Austin, TX, USA, 1–5 November 2016; pp. 236–246. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wei, J.; Ren, X.; Li, X.; Huang, W.; Liao, Y.; Wang, Y.; Lin, J.; Jiang, X.; Chen, X.; Liu, Q. Nezha: Neural contextualized representation for chinese language understanding. arXiv 2019, arXiv:1909.00204. [Google Scholar]
- Schomacker, T.; Tropmann-Frick, M. Language Representation Models: An Overview. Entropy 2021, 23, 1422. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the NeurIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Proceedings of the NeurIPS, Vancouver, CA, USA, 8–14 December 2019; pp. 5754–5764. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the EMNLP, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Wang, Y.; Hu, R. A Prompt-Independent and Interpretable Automated Essay Scoring Method for Chinese Second Language Writing. In Proceedings of the CCL, Hohhot, China, 13–15 August 2021; pp. 450–470. [Google Scholar]
- Ke, Z.; Ng, V. Automated Essay Scoring: A Survey of the State of the Art. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 6300–6308. [Google Scholar]
- Yannakoudakis, H.; Cummins, R. Evaluating the performance of automated text scoring systems. In Proceedings of the the Tenth Workshop on Innovative Use of NLP for Building Educational Applications, Denver, CO, USA, 4 June 2015; pp. 213–223. [Google Scholar]




| Set | #Essay | Avg #len | Chinese Prompt (English Translation) |
|---|---|---|---|
| 1 | 522 | 336 | 一封求职信 |
| (A cover letter) | |||
| 2 | 703 | 395 | 记对我影响最大的一个人 |
| (Remember the person who influenced me the most) | |||
| 3 | 707 | 340 | 如何看待“安乐死” |
| (How to view “euthanasia”) | |||
| 4 | 957 | 338 | 由“三个和尚没水喝”想到的 |
| (Thought on “Three monks without water”) | |||
| 5 | 829 | 356 | 如何解决“代沟”问题 |
| (How to solve the “generation gap”) | |||
| 6 | 694 | 387 | 一封写给父母的信 |
| (A letter to parents) | |||
| 7 | 1529 | 350 | 绿色食品与饥饿 |
| (Green food and hunger) | |||
| 8 | 1333 | 330 | 吸烟对个人健康和公众利益的影响 |
| (Effects of smoking on personal health and public interest) | |||
| 9 | 865 | 347 | 父母是孩子的第一任老师 |
| (Parents are children’s first teachers) | |||
| 10 | 739 | 337 | 我看流行歌曲 |
| (My opinion on popular songs) |
| Parameters | Baselines Settings | Our Methods Settings |
|---|---|---|
| Embedding size | 100 | 768 |
| Vocab size | 500 | 21,128 |
| Epoch | 50 | 10 |
| Batch size | 64 | 16 |
| Optimizer | RMSprop | Adam |
| Learning rate | 1 × 10−3 | 5 × 10−6 |
| LSTM hidden state | 100 | - |
| CNN filters (kernel size) | 100 (5) | - |
| Word embedding | Tencent (small) https://ai.tencent.com/ailab/nlp/en/download.html (accessed on 17 March 2022) | - |
| Models | Total | Average | ||
|---|---|---|---|---|
| QWK | PCC | QWK | PCC | |
| CNN-LSTM † | 0.632 | 0.672 | 0.612 | 0.642 |
| CNN-LSTM-att † | 0.642 | 0.672 | 0.615 | 0.648 |
| CNN-LSTM ‡ | 0.617 | 0.653 | 0.596 | 0.633 |
| CNN-LSTM-att ‡ | 0.623 | 0.658 | 0.603 | 0.629 |
| EModel (Pro.) ‡ | 0.642 | 0.669 | 0.620 | 0.649 |
| BERT-FT | 0.683 | 0.722 | 0.667 | 0.713 |
| BERT-concat | 0.685 | 0.719 | 0.671 | 0.712 |
| BERT-PP | 0.688 | 0.714 | 0.668 | 0.709 |
| BERT-PM | 0.700 | 0.726 | 0.684 | 0.719 |
| BERT-PP&PM | 0.703 | 0.711 | 0.687 | 0.715 |
| NEZHA-FT | 0.676 | 0.714 | 0.662 | 0.708 |
| NEZHA-concat | 0.681 | 0.717 | 0.667 | 0.714 |
| NEZHA-PP | 0.695 | 0.727 | 0.680 | 0.728 |
| NEZHA-PM | 0.698 | 0.732 | 0.682 | 0.724 |
| NEZHA-PP&PM | 0.704 | 0.714 | 0.687 | 0.722 |
| Models | Prompt Prediction | Prompt Matching | ||
|---|---|---|---|---|
| Acc. (%) | F1 (%) | Acc. (%) | F1 (%) | |
| BERT-PP&PM | 86.6 | 85.6 | 85.5 | 85.6 |
| NEZHA-PP&PM | 91.7 | 98.1 | 90.7 | 91.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Song, T.; Song, J.; Peng, W. Improving Automated Essay Scoring by Prompt Prediction and Matching. Entropy 2022, 24, 1206. https://doi.org/10.3390/e24091206
Sun J, Song T, Song J, Peng W. Improving Automated Essay Scoring by Prompt Prediction and Matching. Entropy. 2022; 24(9):1206. https://doi.org/10.3390/e24091206
Chicago/Turabian StyleSun, Jingbo, Tianbao Song, Jihua Song, and Weiming Peng. 2022. "Improving Automated Essay Scoring by Prompt Prediction and Matching" Entropy 24, no. 9: 1206. https://doi.org/10.3390/e24091206
APA StyleSun, J., Song, T., Song, J., & Peng, W. (2022). Improving Automated Essay Scoring by Prompt Prediction and Matching. Entropy, 24(9), 1206. https://doi.org/10.3390/e24091206