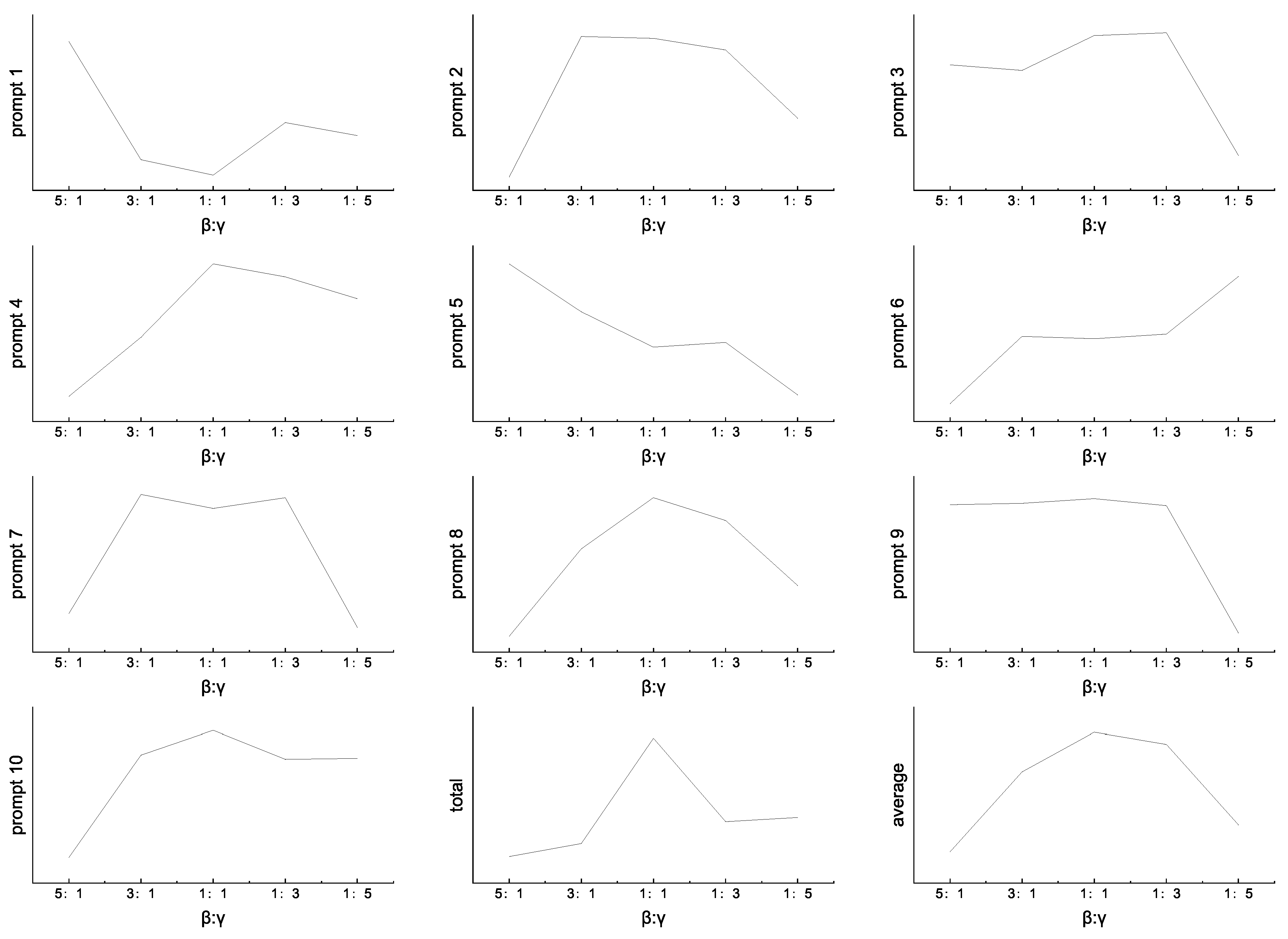1. Introduction
Automated essay scoring (AES), which aims to automatically evaluate and score essays, is one typical application of natural language processing (NLP) technique in the field of education [
1]. In earlier studies, a combination of handcrafted design features and statistical machine learning is used [
2,
3], and with the development of deep learning, neural network-based approaches gradually become mainstream [
4,
5,
6,
7,
8]. Recently, pre-trained language models have gradually become the foundation module of NLP, and the paradigm of pre-training, then fine-tuning, is also widely adopted.
Pre-training is the most common method for transfer learning, in which a model is trained on a surrogate task and then adapted to the desired downstream task by
fine-tuning [
9]. Some research has attempted to use pre-training modules in AES tasks [
10,
11,
12]. Howard et al. [
10] utilize the pre-trained encoder as a feature extraction module to obtain a representation of the input text and update the pre-trained model parameters based on the downstream text classification task by adding a linear layer. Rodriguez et al. [
11] employ a pre-trained encoder as the essay representation extraction module for the AES task, with inputs at various granularities of the sentence, paragraph, overall, etc., and then use regression as the training target for the downstream task to further optimize the representation. In this paper, we fine-tune the pre-trained encoder as a feature extraction module and convert the essay scoring task into regression as in previous studies [
4,
5,
6,
7].
The existing neural methods obtain a generic representation of the text through a hierarchical model using convolutional neural networks (CNN) for word-level representation and long short-term memory (LSTM) for sentence-level representation [
4], which is not specific to different features. To enhance the representation of the essay, some studies have attempted to incorporate features such as prompt [
3,
13], organization [
14], coherence [
2], and discourse structure [
15,
16,
17] into the neural model. These features are critical for the AES task because they help the model understand the essay while also making the essay scoring more interpretable. In actual scenarios, prompt adherence is an important feature in essay scoring tasks [
3]. The hierarchical model is insensitive to changes in the corresponding prompt for the essay and always assigns the same score for the same essay, regardless of the essay prompt. Persing and Ng [
3] propose a feature-rich approach that integrates the prompt adherence dimension. Ref. [
18] improves document modeling with a topic word. Li et al. [
7] utilizes a hierarchical structure with an attention mechanism to construct prompt information. However, the above feature fusion methods are unsuitable for fine-tuning.
The two challenges in effectively incorporating pre-trained models into AES feature representation are the data dimension and the methodological dimension. For the data dimension, the use of fine-tuning approaches to transfer the pre-trained encoder to downstream tasks frequently necessitates sufficient data, and there has been more research on both training and testing data from the same target prompt [
4,
5], but the data size is relatively small, varying between a few hundred and a few thousand, and pre-trained encoders cannot be fine-tuned well. In order to solve this challenge, we use the whole training set, which includes various prompts. In terms of methodology, we employ the pre-training and multi-task learning (MTL) paradigms, which can learn features that cannot be learned in a single task through joint learning, learning to learn, and learning with auxiliary tasks [
19], etc. MTL methods have been applied to several NLP tasks, such as text classification [
20,
21], semantic analysis [
22] et al. Our method creates two auxiliary tasks that need to be learned alongside the main task. The main task and auxiliary tasks can increase each other’s performance by sharing information and complementing each other.
In this paper, we propose an essay scoring model based on fine-tuning that utilizes multi-task learning to fuse prompt features by designing two auxiliary tasks, prompt prediction, and prompt matching, which is more suitable for fine-tuning. Our approach can effectively incorporate the prompt feature in essays and improve the representation and understanding of the essay. The paper is organized as follows. In
Section 2, we first review related studies. We describe our method and experiment in
Section 3 and
Section 4.
Section 5 presents the findings and discussions. Finally, in
Section 6, we provide a conclusion, future work, and the limitations of the paper.
2. Related Work
Pre-trained language models, such as BERT [
23], BERT-WWM [
24], RoBERTa [
25], and NEZHA [
26], have gradually become a fundamental technique for NLP, with great success on both English and Chinese tasks [
27]. In our approach, we use the BERT and NEZHA feature extraction layers. BERT is the abbreviation of Bidirectional Encoder Representations from Transformers, and it is based on transformer blocks that are built using the attention mechanism [
28] to extract semantic information. It is trained on two unsupervised tasks using large-scale datasets: masked language model (MLM) and next sentence prediction (NSP). NEZHA is a Chinese pre-training model that employs functional relative positional encoding and whole word masking (WWM) rather than BERT. The pre-training then the fine-tuning mechanism is widely used in downstream NLP tasks, including AES [
11,
12,
15]. Mim et al. [
15] propose a pre-training approach for evaluating the organization and argument strength of essays based on modeling coherence. Song et al. [
12] present a multi-stage pre-training method for automated Chinese essay scoring that consists of three components: weakly supervised pre-training, supervised cross-prompt fine-tuning, and supervised target-prompt fine-tuning. Rodriguez et al. [
11] use BERT and XLNET [
29] for representation and fine-tuning of English corpus.
The essay prompt introduces the topic, offers concepts, and restricts both content and perspective. Some studies have attempted to enhance the AES system by incorporating prompt features in many ways, such as by integrating prompt information to determine if an essay is off-topic [
13,
18] or by considering prompt adherence as a crucial indicator [
3]. Louis and Higgins [
13] improve model performance by expanding prompt information with a list of related words and reducing spelling errors. Persing and Ng [
3] propose a feature-rich method for incorporating the prompt adherence dimension via manual annotation. Klebanov et al. [
18] also improve essay modeling with topic words to quantify the overall relevance of the essay to the prompt, and the relationship between prompt adherence scores and total essay quality is also discussed. The methods described above mostly employ statistical machine learning, prompt information is enriched by annotation and the construction of datasets, as well as the construction of word lists and topic word mining. While all of them are making great progress, the approaches they are employing are more difficult to directly transfer to fine-tuning. Li et al. [
7] propose a shared model and an enhanced model (EModel), and utilize a neural network hierarchical structure with an attention mechanism to construct features of the essay such as discourse, coherence, relevancy, and prompt. For the representation, the paper employs GloVe [
30] rather than a pre-trained model. In the experiment section, we compared our method to the sub-module of EModel (Pro.) which incorporates the prompt feature.
4. Experiment
4.1. Dataset
We use HSK (HSK is the acronym of Hanyu Shuiping Kaoshi, which is Chinese Pinyin for the Chinese Proficiency Test). Dynamic Composition Corpus (
http://hsk.blcu.edu.cn/ (accessed on 6 March 2022)) as our dataset as in existing studies [
31]. HSK is also called “TOEFL in Chinese”, which is a national standardized test designed to test the proficiency of non-native speakers of Chinese. The HSK corpus includes 11,569 essays composed by foreigners from more than thirty different nations or regions in response to more than fifty distinct prompts. We eliminate any prompts with fewer than 500 student writings from the HSK dataset to constitute the experimental data. The statistical results of the final filtered dataset are provided in
Table 1, which comprises 8878 essays across 10 prompts taken from the actual HSK test. Each essay score ranges from 40 to 95 points. We divide the entire dataset at random into the training set, validation set, and test set in the ratio of 6:2:2. To alleviate the problem of insufficient data under a single prompt, we apply the entire training set that consists of different prompts for fine-tuning. We test every prompt individually as well as the entire test set during the testing phase and utilize the same 5-fold cross-validation procedure as [
4,
5]. Finally, we report the average performance.
4.2. Evaluation Metrics
For the main task, we use the Quadratic Weighted Kappa (QWK)approach, which is widely used in AES [
32], to analyze the agreement between prediction scores and the ground truth. QWK can be calculated by Equations (
11) and (
12)
where
i and
j are the golden score of the human rater and the AES system score, and each essay has
N possible ratings. Second, calculate the QWK score using Equation (
12).
where
denotes the number of essays that receive a rating
i by the human rater and a rating
j by the AES system. The expected rating matrix
is histogram vectors of the golden rating and AES system rating and normalized so that the sum of its elements equals the sum of its elements in
. We also utilize Pearson’s Correlation Coefficient (PCC) to measure the association as in previous studies [
3,
32,
33], which quantifies the degree of linear dependency between two variables and describes the level of covariation. In contrast to the QWK metric, which evaluates the agreement between the model output and the gold standard, we use PCC to assess whether the AES system ranks essays similarly to the gold standard, indicating the capacity of the AES system to appropriately rank texts, i.e., high scores ahead of low scores. For auxiliary tasks, we consider prompt prediction and prompt matching as classification problems and use macro-F1 score (F1), and accuracy (Acc.) as evaluation metrics.
4.3. Comparisons
Our model is compared to the baseline models listed below. The former three are existing neural AES methods, and we experiment with both character and word input when training for comparison. The fourth method is to fine-tune the pre-trained model, and the rest are variations of our proposed method.
CNN-LSTM [4]: This method builds a document using CNN for word-level representation and LSTM for sentence-level representation, as well as the addition of a pooling layer to obtain the text representation. Finally, the score is obtained by applying the linear layer of the sigmoid function.
CNN-LSTM-att [5]: This method incorporates an attention mechanism into both the word-level and sentence-level representations of CNN-LSTM.
EModel (Pro.): This method concatenates the prompt information in the input layer of CNN-LSTM-att, which is a sub-module of [
7].
BERT/NEZHA-FT: This method is used to fine-tune the pre-trained model. To obtain the essay representation, we directly feed an essay into the pre-trained encoder as the input. We choose the [CLS] embedding as essay representations and feed them into a linear layer of the sigmoid function for scoring.
BERT/NEZHA-concat: The difference between this method and fine-tune is that the input representation concatenates the prompt to the front of the essay in token embedding, as in
Figure 1.
BERT/NEZHA-PP: This model incorporates prompt prediction as an auxiliary task, with the same input as the concat model and the output using [CLS] as the essay representation. A linear layer with the sigmoid function is used for essay scoring, and a linear layer with the softmax function is used for prompt prediction.
BERT/NEZHA-PM: This model includes prompt matching as an auxiliary task. In the input stage of constructing the training data, there is a 50% probability that the prompt and the essay are mismatched. [CLS] embedding is used to represent the essay. A linear layer with the sigmoid function is used for essay scoring, and a linear layer with the softmax function is used for prompt matching.
BERT/NEZHA-PP&PM: This model utilizes two auxiliary tasks, prompt prediction, and prompt matching, with the same inputs and outputs as the PM model. The output layer of the auxiliary tasks is the same as above.
4.4. Parameter Settings
We use BERT (
https://github.com/google-research/bert (accessed on 11 March 2022)) and NEZHA (
https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/NEZHA-TensorFlow (accessed on 11 March 2022)) as pre-trained encoder. To obtain tokens and token embeddings, we employ the tokenizer and vocabulary of the pre-trained encoder. The parameters of the pre-trained encoder are learnable during both the fine-tuning and training phases. The maximum length of the input is set to 512 and
Table 2 includes additional parameters. The baseline models, CNN-LSTM and CNN-LSTM-att, are trained from scratch, and their parameters are shown in
Table 2. Our experiments are carried out on NVIDIA TESLA V100 32 G GPUs.
6. Conclusions and Future Work
This paper presents a pre-training and then fine-tuning model for automated essay scoring. The model incorporates the essay prompts to the model input and obtains better features more applicable to essay scoring by multi-task learning with two auxiliary tasks, prompt prediction, and prompt matching. Experiments demonstrate that the model outperforms baselines in results measured by the QWK and PCC on average across all results on the HSK dataset, indicating that our model is substantially better in terms of agreement and association. The experimental results also show that both auxiliary tasks can effectively improve the model performance, and the combination of the two auxiliary tasks with the NEZHA pre-trained encoder yields the best results, with QWK enhancing 2.5% and PCC improving 2% compared to the strong baseline, the concatenate model, on average across all results on the HSK dataset. When compared to existing neural essay scoring methods, the experimental results show that QWK improves by 7.2% and PCC improves by 8% on average across all results.
Although our work has enhanced the effectiveness of the AES system, there are still limitations. Regarding the data dimension, this research primarily investigates fusing prompt features in Chinese; other languages are not examined extensively. Nevertheless, our method is more convenient for migration than the manual annotation approach, and other languages can be directly migrated. Furthermore, other features in different languages can use our method to create similar auxiliary tasks for information fusion. Moreover, as the number of prompts grows, the difficulty of training for prompt prediction increases, and we will consider combining prompts with genre and other information to design auxiliary tasks suitable for more prompts, as well as attempting to find a balance between the number of essays and the number of prompts to make prompt prediction more efficient. The parameters of the loss function are now defined empirically at the methodological level, which is not conducive to additional auxiliary activities. In future work, we will optimize the parameter selection scheme and build dynamic parameter optimization techniques to accommodate variable numbers of auxiliary tasks. In terms of application, our approaches focus on fusing textual information in prompts, while they do not cover all prompt forms. Our system now requires additional modules for the chart and picture prompt. In future research, we will experiment with multimodal prompt data to improve the application scenarios of the AES system.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}