1. Introduction
Speech is one of the most natural behaviors through which emotional information is communicated in the daily life of human beings [
1,
2]. Hence, research into speech emotion recognition (SER), which seeks to enable machines to learn how to automatically understand emotional states, e.g.,
,
, and
, from speech signals, has attracted attention among affective computing, pattern recognition, and speech signal processing research communities. Over recent decades, many well-performing SER methods have been proposed and have achieved promising levels of performance for widely-used speech emotion corpora [
3,
4,
5,
6,
7,
8]. However, the existing SER methods are far from being practically applicable. One of the major reasons is that such methods do not consider real-world scenarios, in which the training and testing speech signals may be recorded by different acoustic sensors. For example, the audio data of EmoDB [
9], a widely-used speech emotion corpus, were recorded using a Sennheiser MKH40-P48 microphone and a Tascam DA-P1 portable DAT recorder. However, as for another popular speech emotion corpus, CASIA [
10], its samples were recorded using a RODE K2 (a large membrane microphone) and Fireface 800 (sound card). When using these two speech emotion corpora to alternatively serve training and testing purposes, an evident feature distribution mismatch inevitably exists between their corresponding feature sets due to the acoustic sensor difference. Hence, the performance of an initially well-performing SER method will drop significantly.
The above example highlights a challenging, but interesting, task in SER, i.e., cross-corpus SER. Formally, in the task of cross-corpus SER, the training and testing speech sample sets belong to different corpora. The emotion label information of the training sample sets is provided, while the target sample sets’ labels are not entirely given. We need to enable a classifier guided by the source emotion label information to accurately predict the emotions of the unlabeled testing speech samples. Note that, in what follows, we follow the custom in the research concerning transfer learning and domain adaptation [
11,
12,
13], which are closely related to cross-corpus SER, and refer to the training and testing speech samples/signals/corpora/feature sets as the source and target sets, respectively, such that readers can better understand this paper.
In this paper, we try to deal with cross-corpus SER tasks from the perspective of transfer learning and domain adaptation and propose a straightforward transfer subspace learning method called multiple distribution-adapted regression (MDAR). As with most existing transfer subspace learning methods [
14,
15,
16,
17,
18], MDAR aims to learn a projection matrix to find a common subspace bridging the source and target speech samples from different corpora. However, we pay more attention to designing an emotion wheel knowledge-guided regularization term to help MDAR better eliminate the feature distribution difference between the source and target speech samples. Specifically, instead of directly measuring and improving both corpora’s marginal feature distribution gaps, our MDAR incorporates the idea of joint distribution adaption (JDA) [
17] and joint alleviation of marginal distribution mismatch and fine emotion class-aware conditions. More importantly, unlike existing JDA-based methods [
16,
17,
19,
20], MDAR extends the JDA operation to a multiple distribution adaption (MDA) method by additionally introducing a well-designed rough emotion class-aware conditional distribution adaption to improve the feature distribution difference alleviation between the speech samples from different corpora. By resorting to MDA, MDAR can learn both corpus invariant and emotion discriminative feature representations for cross-corpus SER.
To evaluate the proposed MDAR, we carried out extensive cross-corpus SER experiments on three widely used speech emotion corpora, including EmoDB [
9], eNTERFACE [
21], and CASIA [
10]. The experimental results showed that, compared with existing state-of-the-art transfer subspace learning, and several well-performing deep transfer learning methods, our MDAR achieved more promising performance when dealing with cross-corpus SER tasks. In summary, the main contributions of this paper are three-fold:
We propose a novel transfer subspace learning method called MDAR to deal with cross-corpus SER tasks. The basic idea of MDAR is very straightforward, i.e., learning corpus invariant and emotion discriminative representations for both source and target speech samples belonging to different corpora such that the classifier learning based on the labeled source speech samples is also applicable to predicting the emotions of target speech signals.
We present a new distribution difference alleviation regularization term called MDA for MDAR to guide the corpus invariant feature learning for the recognition of the emotions of speech signals. MDA collaboratively aligns marginal, fine emotion class-aware conditional, and rough emotion class-aware feature distributions between source and target speech samples.
Three widely used speech emotion corpora, i.e., EmoDB, eNTERFACE, and CASIA, were used to design the cross-corpus SER tasks to evaluate the proposed MDAR. Extensive experiments were conducted to demonstrate the effectiveness and superior performance of MDAR in coping with cross-corpus SER tasks.
The remainder of this paper is organized as follows:
Section 2 reviews progress in cross-corpus SER.
Section 3 provides details of the proposed MDAR method. In
Section 4, extensive cross-corpus SER experiments, conducted to evaluate the proposed MDAR method, are described. Finally, we conclude this paper in
Section 5.
3. Proposed Method
3.1. Notations
In this section, we address the proposed MDAR method in detail and describe how to use MDAR to deal with cross-corpus SER tasks. To begin with, we give several notations which are needed in formulating MDAR. Suppose we have a set of labeled source speech samples from one corpus whose feature matrix is denoted by , where d is the dimension of the speech feature vectors and is the source speech sample number. Their corresponding emotion ground truth information is denoted by a label matrix , where c is the emotion class number and its ith column describes its corresponding speech sample’s emotion information. As for , only the jth entry is set as 1 while the others are set as 0 if this speech sample’s label is the jth emotion.
Simliarly, let the target speech feature matrix corresponding to the other corpus and its corresponding unknown label matrix be and , where is the target sample number. According to the emotion class, we divide the source and target speech feature matrices and into and , where and denote the source and target speech feature matrices corresponding to the ith emotion among the fine emotion class set . Accordingly, several fine emotion class feature matrix sets can further merge to obtain the rough emotion class feature matrix set for source and target speech samples, which can be expressed as and , where and represent the feature matrices corresponding to the ith rough emotion class and is the rough emotion class number.
3.2. Formulation of MDAR
As described previously, the basic idea of MDAR is to build a subspace learning model to learn emotion discriminative and corpus invariant representations for both source and target speech samples belonging to different corpora. To achieve this goal, we propose to use the label-information-guided feature space to serve as the subspace and then learn a projection matrix to build the relationship between this subspace and the original feature space, which can be formulated as a simple linear regression optimization problem:
where
is such a satisfactory projection matrix and
denotes the Frobenius norm of a matrix. Using
, we can easily transform the speech samples from the original feature space to the emotion label space. In other words, this learned projection matrix is endowed with emotion discriminative ability.
Subsequently, we need to further enable the projection matrix
to be robust to the variance of speech corpora such that it is applicable to the problem of cross-corpus SER. To this end, we design a regularization term to help MDAR learn such an expectative projection matrix, whose corresponding optimization problem can be expressed as follows:
where
is a trade-off parameter controlling the balance between different terms, and
,
,
,
,
, and
are all the one-valued vectors, and their dimensions are the numbers of source and target samples denoted by
and
, target and target samples corresponding to
ith fine emotion class denoted by
and
, and source and target samples corresponding to
ith rough emotion class denoted by
and
, respectively.
From Equation (
2), it is clear that the objective function designed for the corpus robustness of the projection matrix consists of a
norm and a combination of marginal, fine emotion class-aware conditional, and rough emotion class-aware conditional distributions aligned functions with respect to
, respectively. These two terms correspond to two aspects of our efforts regarding MDAR:
can be called the feature selection term. Minimizing helps the MDAR learn a row-sparse projection matrix, which suppresses the speech features contributing less to the distinction of different emotions, while highlighting the features contributing most to distinction.
The other aspect is the multiple distribution adaption (MDA), which corresponds to the resting three terms. Among these, the first two terms are so-called joint distribution adaptions (JDA) [
16,
17,
19,
20]. JDA is a combination of the marginal distribution adaption and the fine emotion class-aware conditional adaption and has been demonstrated the effectiveness in coping with domain adaptation and other cross-domain recognition tasks. Our MDA can be viewed as an extension of JDA incorporating an additional rough emotion class-aware conditional distribution-adapted term, which enables further enhancement of the corpus invariant ability of the proposed MDAR.
Finally, by combining Equations (
1) and (
2), we arrive at the eventual optimization problem of the proposed MDAR method, which can be formulated as follows:
where
and
are the trade-off parameters to balance all the terms.
3.3. Disturbance Strategy for Constructing Rough Emotion Groups in MDA
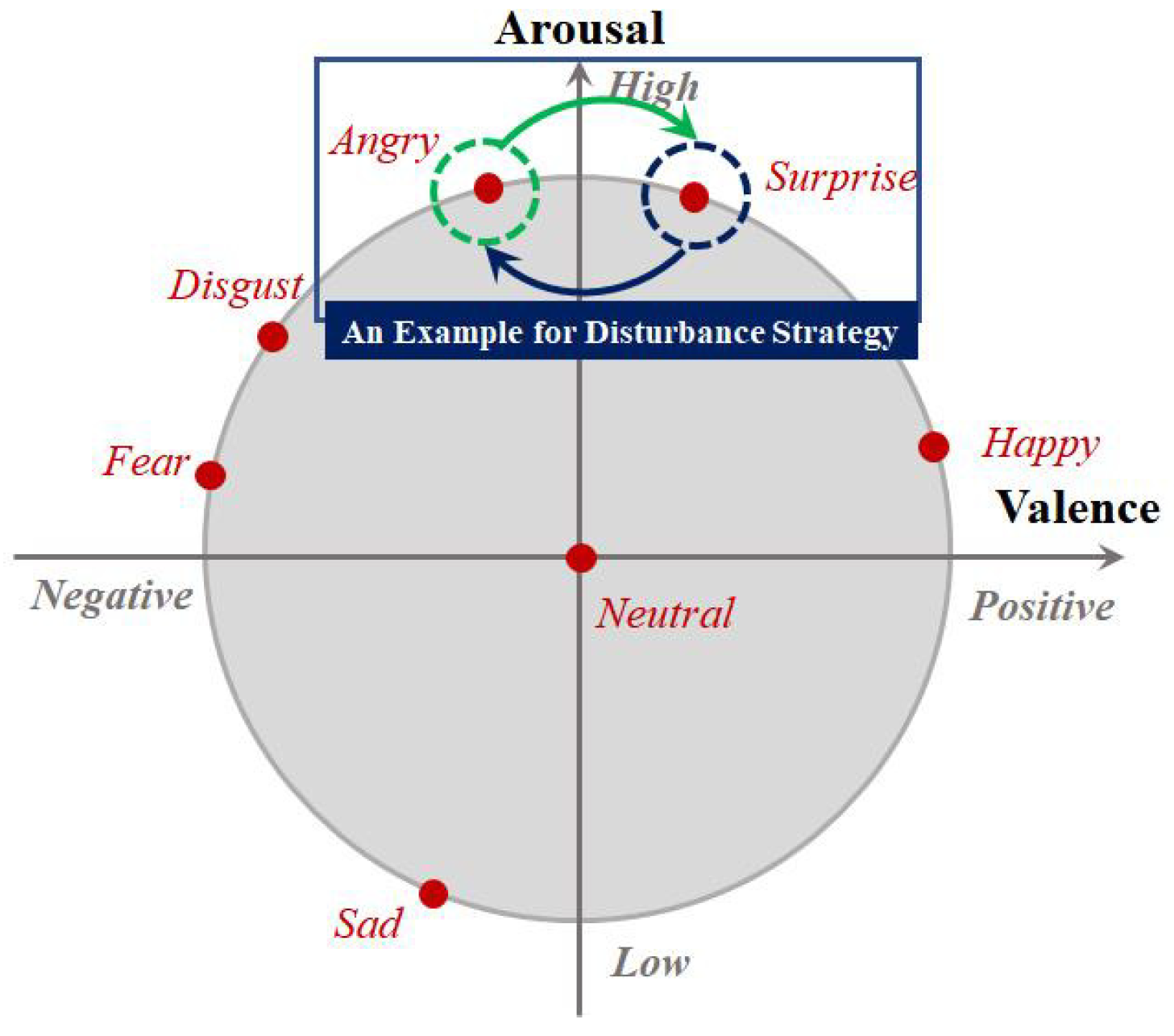
The major inspiration for designing the rough emotion class-aware conditional distribution adapted term to obtain MDA was the recent work of [
32], in which a modified 2D arousal-valence emotion wheel consisting of two dimensions, i.e., valence and arousal, is presented. To better understand our motivation, we repost Yang et al.’s emotion wheel in
Figure 1. From
Figure 1, it is clear that each typical discrete emotion, e.g.,
,
, and
, can be mapped to one point in the emotion wheel based on its corresponding valence and arousal degrees. As the emotion wheel shows, there is an intrinsic distance between two emotions according to their positions on the emotion wheel. Several typical emotions, e.g.,
vs.
, and
vs.
, are very similar and difficult to distinguish from their distance measured with respect to the valence and arousal. In other words, it may be hard to directly align the fine class-aware conditional distribution associated with these emotions due to the unavailability of target speech sample emotion labels. Although we can predict their pseudo emotion labels to calculate statistics for the fine class-aware conditional distribution, the emotion discriminative ability of MDAR is limited in the initial iterations of optimization.
To relieve this tension, in this paper, we introduce the rough emotion class-aware conditional distribution-adapted term and present a disturbance strategy to construct its rough emotion class groups. Specifically, along the valence dimension, we first divide the emotions into two rough emotion class groups including - (, , and ) and - (, , , and ). Then, regarding the specific cross-corpus SER task, we make several modifications to the original rough emotion groups to break the inseparability of some emotions which have a close distance with respect to the degree of valence and arousal. For example, we can switch and for - and - groups. Finally, following the modified mixed emotion groups, we calculate the rough emotion class-aware conditional distribution-adapted term .
Note that, introducing the above rough emotion class-aware conditional distribution-adapted term under the disturbance strategy for MDAR has two expectative benefits. First, the modification of the mixed emotion groups alleviates the inseparability of the emotion elements in - or - groups and, hence, assists fine emotion class-aware conditional distribution adaption in MDAR. Second, unlike the fine emotion class-aware conditional distribution adaption, performing a rough adaption does not require over-precise target pseudo-labels, which affects the fine emotion class-aware conditional distribution adaption. However, the proposed rough adaption does not have this drawback because it only needs rough emotion labels of target speech samples, the prediction of which is an easier task.
3.4. Predicting the Target Emotion Label Using MDAR
Once the optimal projection matrix of MDAR denoted by
is learned, we are able to predict the emotion label of the target speech samples according to the following criterion:
Note that denotes the target emotion label vector and can be computed by , where is its corresponding feature vector and is its ith entry.
3.5. Optimization of MDAR
The optimization of MDAR can be solved by the alternated direction method (ADM) and inexact augmented Lagrangian multiplier (IALM) [
33]. Specifically, we first initialize the projection matrix
and then repeat the following two major steps until convergence:
Predict the target emotion labels based on the projection matrix
and Equation (
4). Then compute the original marginal and two aware conditional
feature distribution gaps denoted by
,
, and
according to the predicted target emotion labels using the following Equations (
5)–(
7):
where
.
where
.
Solve the following optimization problem:
where
is a zero matrix, and
.
As for Equation (
8), IALM can be used to efficiently optimize it. More specifically, we introduce an auxiliary variable
satisfying
. Thus, we can convert the original optimization problem to a constrained problem as follows:
where
and
.
Subsequently, we can write its corresponding Lagrangian function as follows:
where
denotes the trace of a square matrix,
is the multiplier matrix and
is the trade-off parameter. By alternatively minimizing the Lagrangian function with respect to the variables, we can obtain the optimal
. We summarize the detailed updating rules in Algorithm 1.
| Algorithm 1 Complete updating rule for learning the optimal in Equation (10). |
Repeat the following steps until convergence:Fix , , and , update : , which results in . Fix , , and , update : , whose solution is obtained by , if , where and are the ith row of and , respectively. Otherwise, . Update and : , and . Check convergence: .
|









{kind=link}
{kind=link}