
Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism




Abstract
:1. Introduction
- A dynamic semi-supervised federated learning fault diagnosis method based on an attention mechanism is proposed to solve the problem of negative transfer due to unreliable information hidden in a local model. This guarantees the performance of the federation model and enhances the classification ability of clients without labeled data.
- A federation strategy driven by an attention mechanism is designed to filter out unreliable information so that the federation model can incorporate useful information from an unreliable local model. A new loss function related to supervised classification, unsupervised feature reconstruction, and the reliability of the local model is designed to train the federation model. According to the reliability of the federation model, the local model can be optimized by dynamically adjusting how the unlabeled data are utilized and the extent to which they can contribute.
- In cases where there are certain clients without labeled data, the method proposed in this study can still ensure the performance of the federation model and render it capable of fault classification for local clients without labeled data.
2. Related Work
2.1. Semi-Supervised Deep-Learning-Based Fault Diagnosis Method
2.2. Semi-Supervised Federated Learning Fault Diagnosis Method
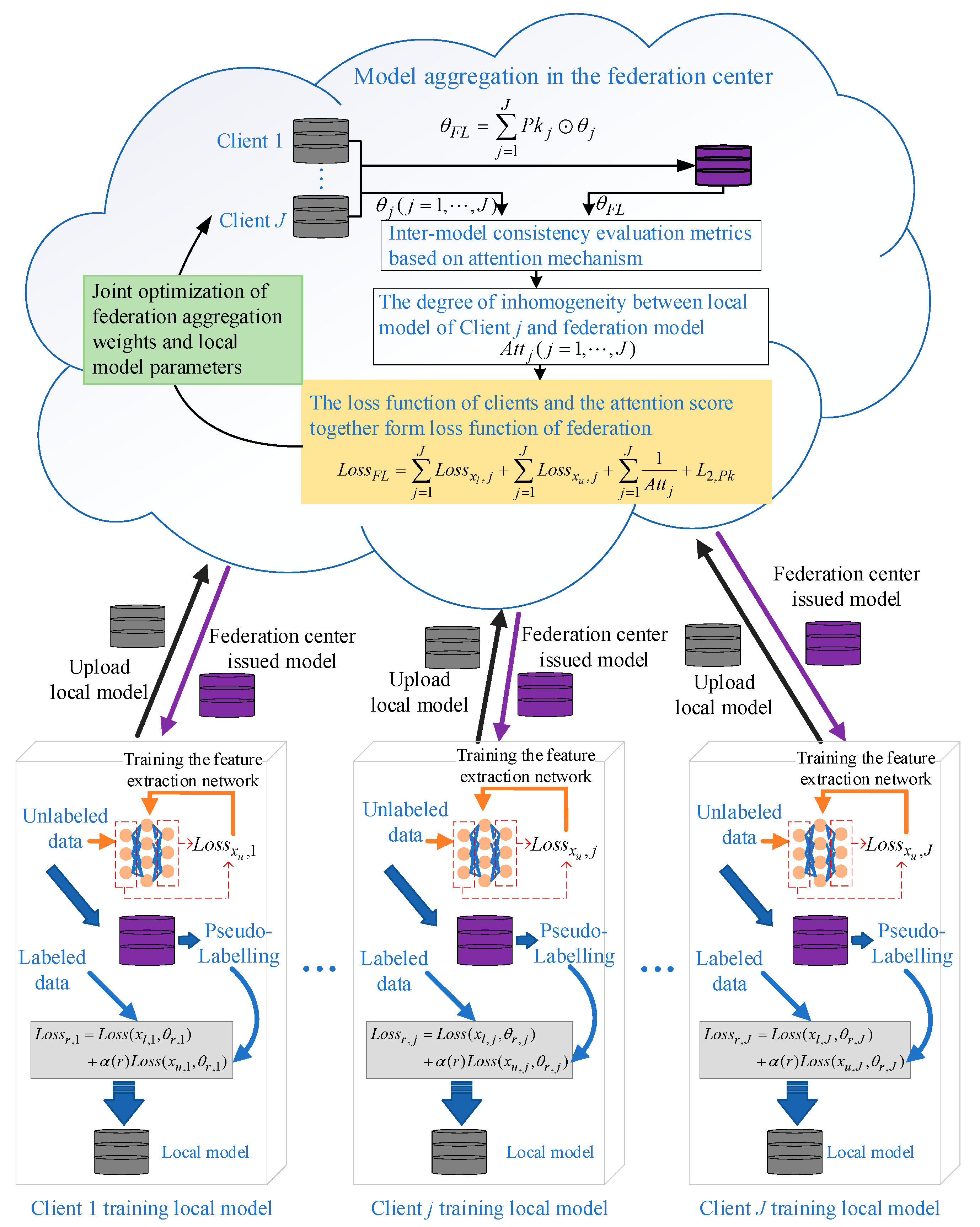
3. Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism
3.1. Dynamic Local Optimization Mechanism Based on Federation Performance
- Step 1: When the federation model is unreliable, the recursive optimization of the local model is achieved using unlabeled data.
- Step 2: Dynamic local semi-supervised training based on the degree of pseudo-label utilization.
3.2. Federation Strategy Driven by Screening of Reliable Information
- Step 1: Semi-supervised federation model aggregation.
- Step 2: Establish model reliability metrics based on the degree of consistency.
- Step 3: The federation aggregation process is driven by the performance of the federation model and the reliability of the local model.
- Step 4: Joint optimization of local model parameters and federation aggregation weights.
3.3. Fault Diagnosis Based on SSFL-ATT
| Algorithm 1: Fault diagnosis based on SSFL-ATT |
| Require: local data Server executes: Initializing federation model Step1: Model training for semi-supervised federated learning Dynamic local training mechanism based on federation model performance Clients dynamically adjust how to use local unlabeled data based on federation model performance. Federation aggregation strategy driven by reliable information screening Reliable information can be screened from local models based on attention mechanisms The loss function can be designed by combining performance of federation model and reliability of local model Joint optimization of local model parameters and federation aggregation weights. Joint optimization of local model parameters and coalition aggregation weights can be achieved based on loss function of federation center , Step2: Fault diagnosis for each client Each client uses well-trained federation model to achieve fault diagnosis |
4. Experiment and Analysis
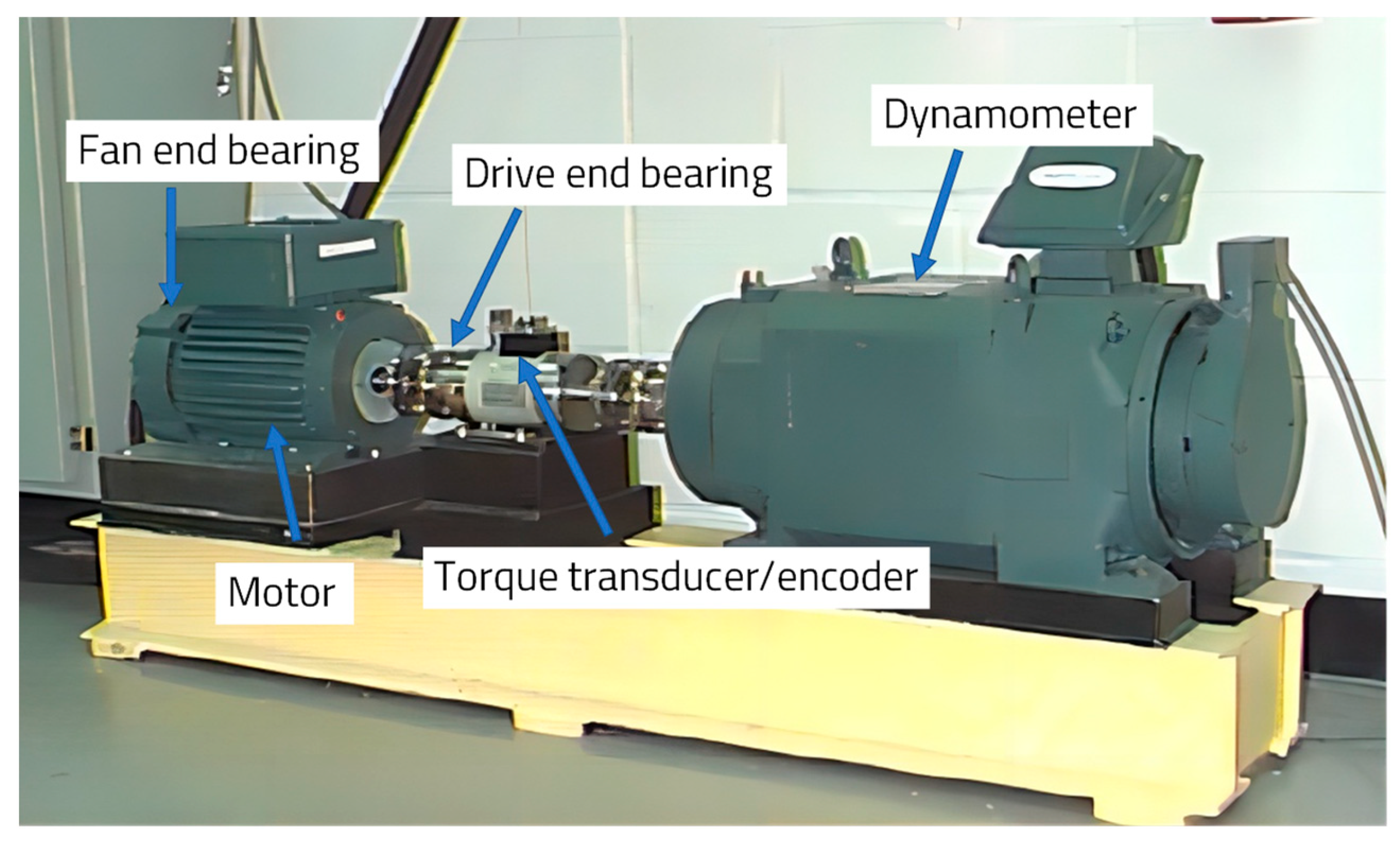
4.1. Experimental Analysis of the Bearing Fault Simulation Platform at Case Western Reserve University
4.1.1. Bearing Data Description
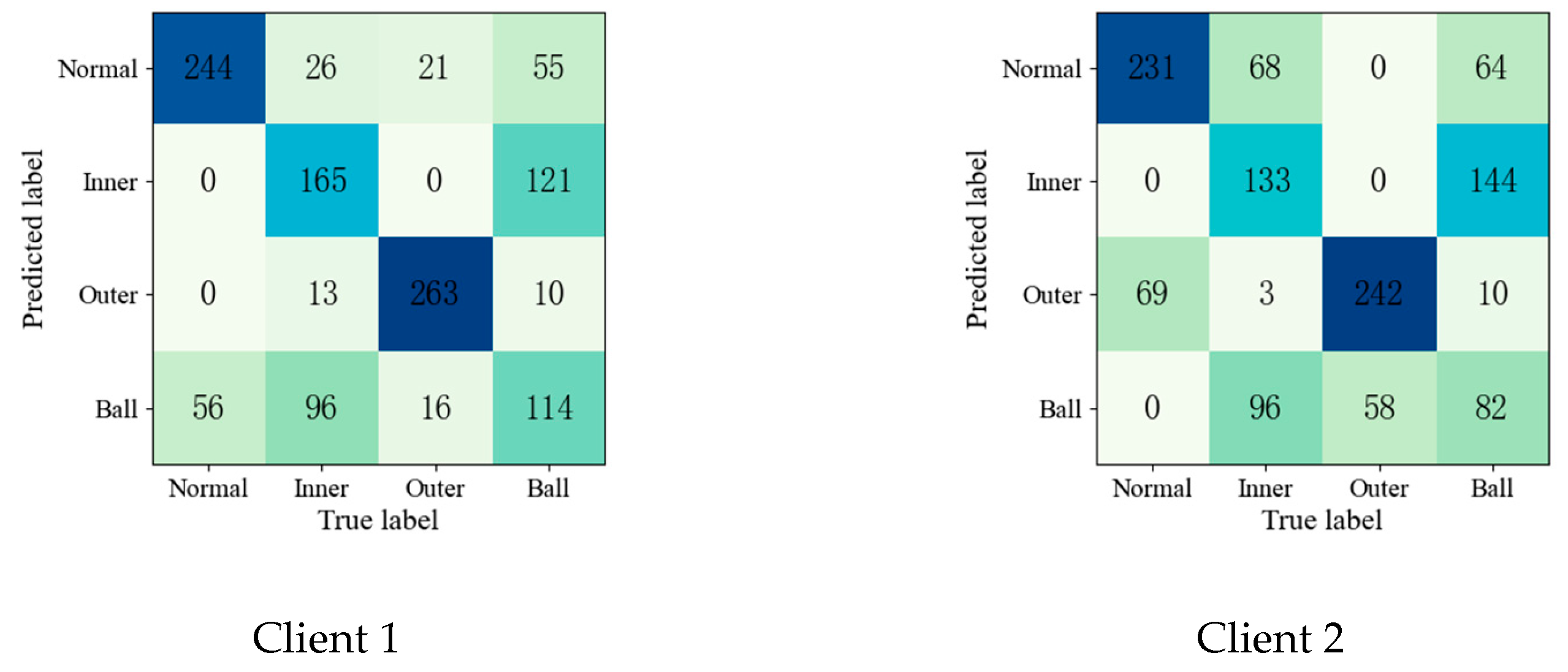
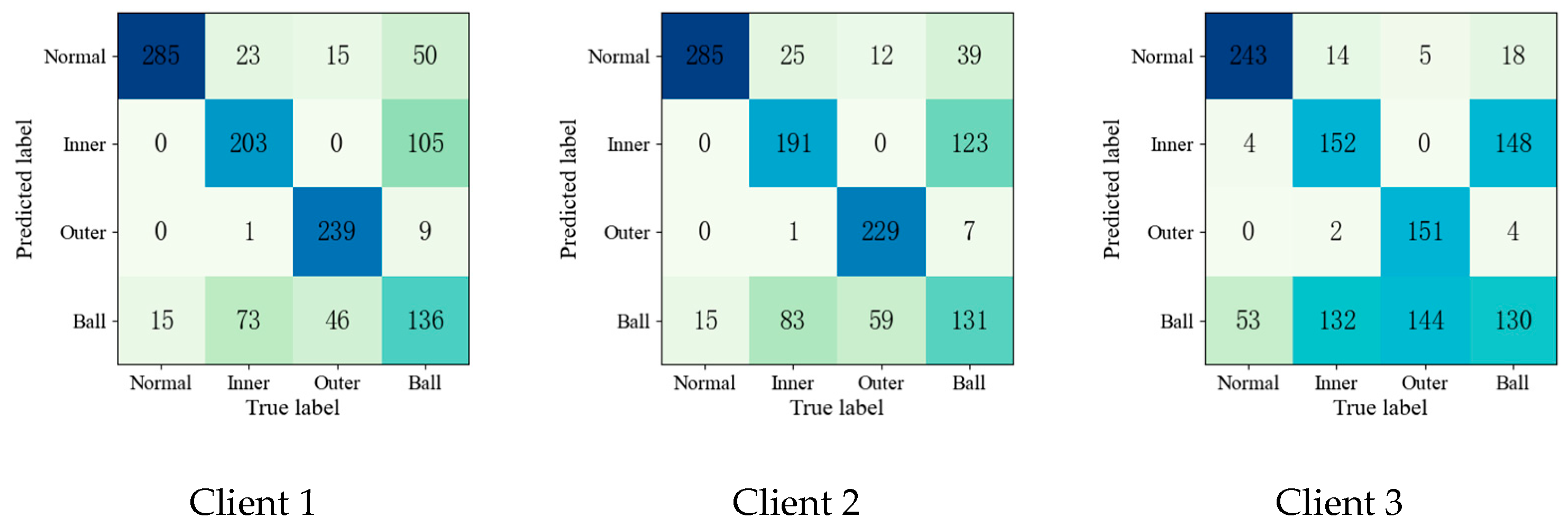
4.1.2. Bearing Experiment Results and Analysis
4.2. Experimental Analysis of Motor Fault Simulation Platform at Shanghai Maritime University
4.2.1. Motor Dataset Description
4.2.2. Motor Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yao, X.; Wang, J.; Cao, L.; Yang, L.; Shen, Y.; Wu, Y. Fault Diagnosis of Rolling Bearing based on VMD Feature Energy Reconstruction and ADE-ELM. In Proceedings of the 2022 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Chongqing, China, 5–7 August 2022; pp. 81–86. [Google Scholar]
- Hou, Q.; Liu, Y.; Guo, P.; Shao, C.; Cao, L.; Huang, L. Rolling bearing fault diagnosis utilizing pearson’s correlation coefficient optimizing variational mode decomposition based deep learning model. In Proceedings of the 2022 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Chongqing, China, 5–7 August 2022; pp. 206–213. [Google Scholar]
- Le, Y.; Liang, C.; Jinglin, W.; Xiaohan, Y.; Yong, S.; Yingjian, W. Bearing fault feature extraction measure using multi-layer noise reduction technology. In Proceedings of the 2022 IEEE International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Chongqing, China, 5–7 August 2022; pp. 53–56. [Google Scholar]
- Zhang, Y.; Zhou, T.; Huang, X.; Cao, L.; Zhou, Q. Fault diagnosis of rotating machinery based on recurrent neural networks. Measurement 2021, 171, 108774. [Google Scholar] [CrossRef]
- Liang, G.; Gumabay, M.V.N.; Zhang, Q.; Zhu, G. Smart Fault Diagnosis of Rotating Machinery with Analytics Using Deep Learning Algorithm. In Proceedings of the 2022 5th International Conference on Advanced Electronic Materials, Computers and Software Engineering (AEMCSE), Wuhan, China, 22–24 April 2022; pp. 660–665. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; She, Z.; Zhang, A. A Semi-Supervision Fault Diagnosis Method Based on Attitude Information for a Satellite. IEEE Access 2017, 5, 20303–20312. [Google Scholar] [CrossRef]
- Yetiştiren, Z.; Özbey, C.; Arkangil, H.E. Different Scenarios and Query Strategies in Active Learning for Document Classification. In Proceedings of the 2021 6th International Conference on Computer Science and Engineering (UBMK), Ankara, Turkey, 15–17 September 2021; pp. 332–335. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Károly, A.I.; Fullér, R.; Galambos, P. Unsupervised clustering for deep learning: A tutorial survey. Acta Polytech. Hung. 2018, 15, 29–53. [Google Scholar] [CrossRef]
- Vale, K.M.O.; Gorgônio, A.C.; Gorgônio, F.D.L.E.; Canuto, A.M.D.P. An Efficient Approach to Select Instances in Self-Training and Co-Training Semi-Supervised Methods. IEEE Access 2022, 10, 7254–7276. [Google Scholar] [CrossRef]
- Zheng, X.; Wang, H.; Chen, J.; Kong, Y.; Zheng, S. A Generic Semi-Supervised Deep Learning-Based Approach for Automated Surface Inspection. IEEE Access 2020, 8, 114088–114099. [Google Scholar] [CrossRef]
- Neto, H.N.C.; Hribar, J.; Dusparic, I.; Mattos, D.M.F.; Fernandes, N.C. A Survey on Securing Federated Learning: Analysis of Applications, Attacks, Challenges, and Trends. IEEE Access 2023, 11, 41928–41953. [Google Scholar] [CrossRef]
- Jeong, W.; Yoon, J.; Yang, E.; Hwang, S.J. Federated semi-supervised learning with inter-client consistency & disjoint learning. arXiv 2020, arXiv:2006.12097. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Nigam, K.; McCallum, A.K.; Thrun, S.; Mitchell, T. Text Classification from Labeled and Unlabeled Documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef]
- Fan, X.H.; Guo, Z.Y.; Ma, H.F. An Improved EM-Based Semi-supervised Learning Method. In Proceeding of the 2009 International Joint Conference on Bioinformatics, Shanghai, China, 3–5 August 2009; pp. 529–532. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceeding of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–13. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Jia, J.T.; Schaub, M.T.; Segarra, S.; Benson, A.R. Graph-based Semi-Supervised & Active Learning for Edge Flows. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 761–771. [Google Scholar]
- Yi, H.; Jiang, Q. Graph-based semi-supervised learning for icing fault detection of wind turbine blade. Meas. Sci. Technol. 2021, 32, 035117. [Google Scholar] [CrossRef]
- Liu, Y.F.; Zheng, Y.F.; Jiang, L.Y.; Li, G.H.; Zhang, W.J. Survey on Pseudo-Labeling Methods in Deep Semi-supervised Learning. J. Front. Comput. Sci. Technol. 2022, 16, 1279–1290. [Google Scholar]
- Yu, K.; Lin, T.R.; Ma, H.; Li, X.; Li, X. A multi-stage semi-supervised learning approach for intelligent fault diagnosis of rolling bearing using data augmentation and metric learning. Mech. Syst. Signal Process. 2021, 146, 107043. [Google Scholar] [CrossRef]
- Liu, T.; Ye, W. A semi-supervised learning method for surface defect classification of magnetic tiles. Mach. Vis. Appl. 2022, 33, 35. [Google Scholar] [CrossRef]
- Ribeiro, F.D.S.; Calivá, F.; Swainson, M.; Gudmundsson, K.; Leontidis, G.; Kollias, S. Deep Bayesian Self-Training. Neural Comput. Appl. 2020, 32, 4275–4291. [Google Scholar] [CrossRef]
- Pedronette, D.; Latecki, L.J. Rank-based self-training for graph convolutional networks. Inf. Process. Manag. 2021, 58, 102443. [Google Scholar] [CrossRef]
- Zhang, S.; Ye, F.; Wang, B.; Habetler, T.G. Semi-Supervised Bearing Fault Diagnosis and Classification Using Variational Autoencoder-Based Deep Generative Models. IEEE Sens. J. 2021, 21, 6476–6486. [Google Scholar] [CrossRef]
- Tang, S.J.; Zhou, F.N.; Liu, W. Semi-supervised bearing fault diagnosis based on Deep neural network joint optimization. In Proceeding of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 6508–6513. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.y. Communication-efficient learning of deep networks from decentralized data. Mach. Learn. 2017, 54, 1273–1282. [Google Scholar]
- Albaseer, A.; Ciftler, B.S.; Abdallah, M.; Al-Fuqaha, A. Exploiting unlabeled data in smart cities using federated edge learning. In Proceeding of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Byblos, Lebanon, 15–19 June 2020; pp. 1666–1671. [Google Scholar]
- Diao, E.; Ding, J.; Tarokh, V. SemiFL: Semi-supervised federated learning for unlabeled clients with alternate training. In Proceeding of Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; pp. 17871–17884. [Google Scholar]
- Presotto, R.; Civitarese, G.; Bettini, C. Semi-supervised and personalized federated activity recognition based on active learning and label propagation. Pers. Ubiquitous Comput. 2022, 26, 1281–1298. [Google Scholar] [CrossRef]
- Hou, K.C.; Wang, N.Z.; Ke, J.; Song, L.; Yuan, Q.; Miao, F.J. Semi-supervised federated learning model based on AutoEncoder neural network. Appl. Res. Comput. 2022, 39, 1071–1104. (In Chinese) [Google Scholar]
- Shi, Y.H.; Chen, S.G.; Zhang, H.J. Uncertainty Minimization for Personalized Federated Semi-Supervised Learning. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1060–1073. [Google Scholar] [CrossRef]
- Itahara, S.; Nishio, T.; Koda, Y.; Morikura, M.; Yamamoto, K. Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-iid private data. IEEE Trans. Mob. Comput. 2021, 22, 191–205. [Google Scholar] [CrossRef]
- Case Western Reserve University Bearing Data Center Website. Available online: https://engineering.case.edu/bearingdatacenter (accessed on 20 July 2023).






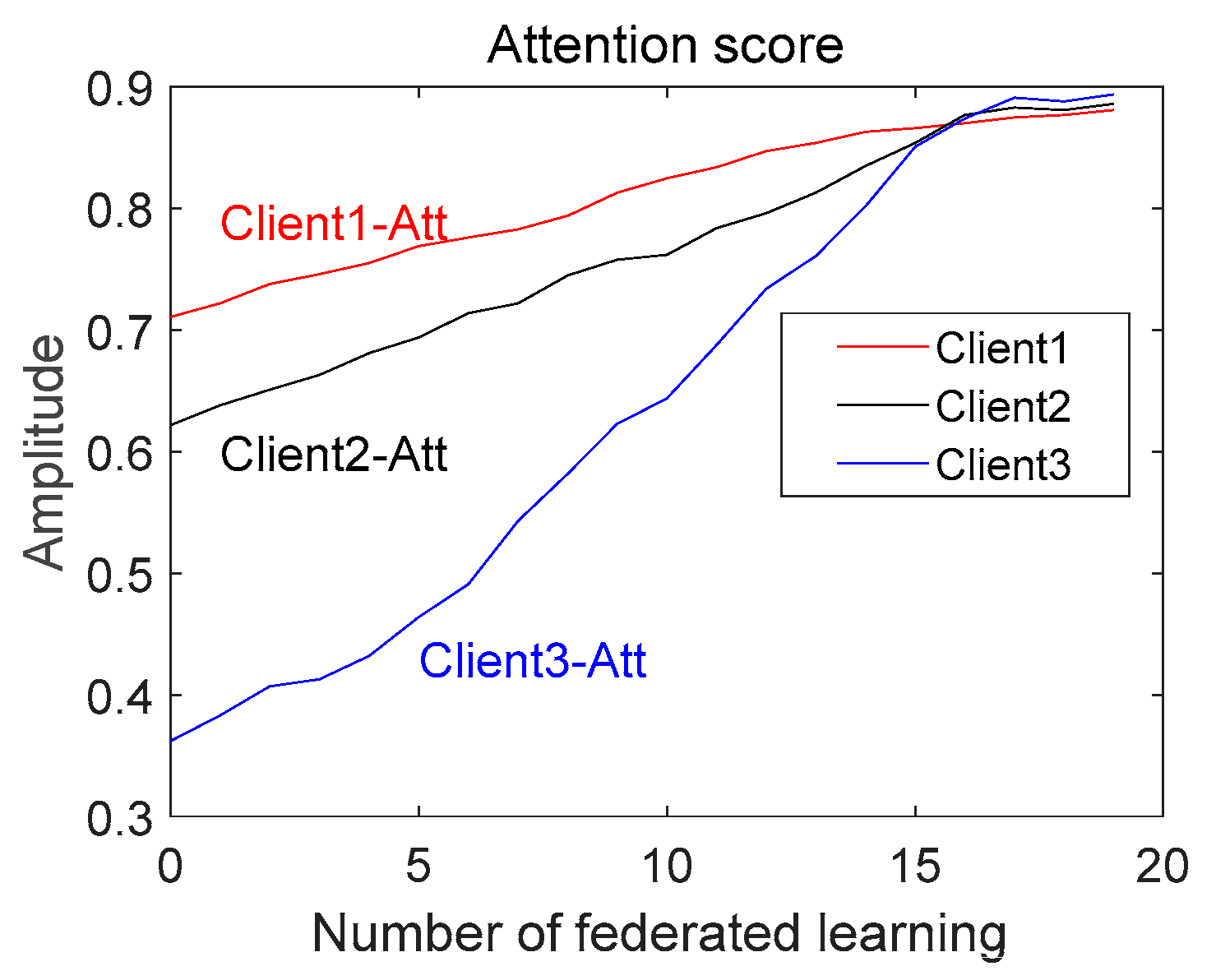
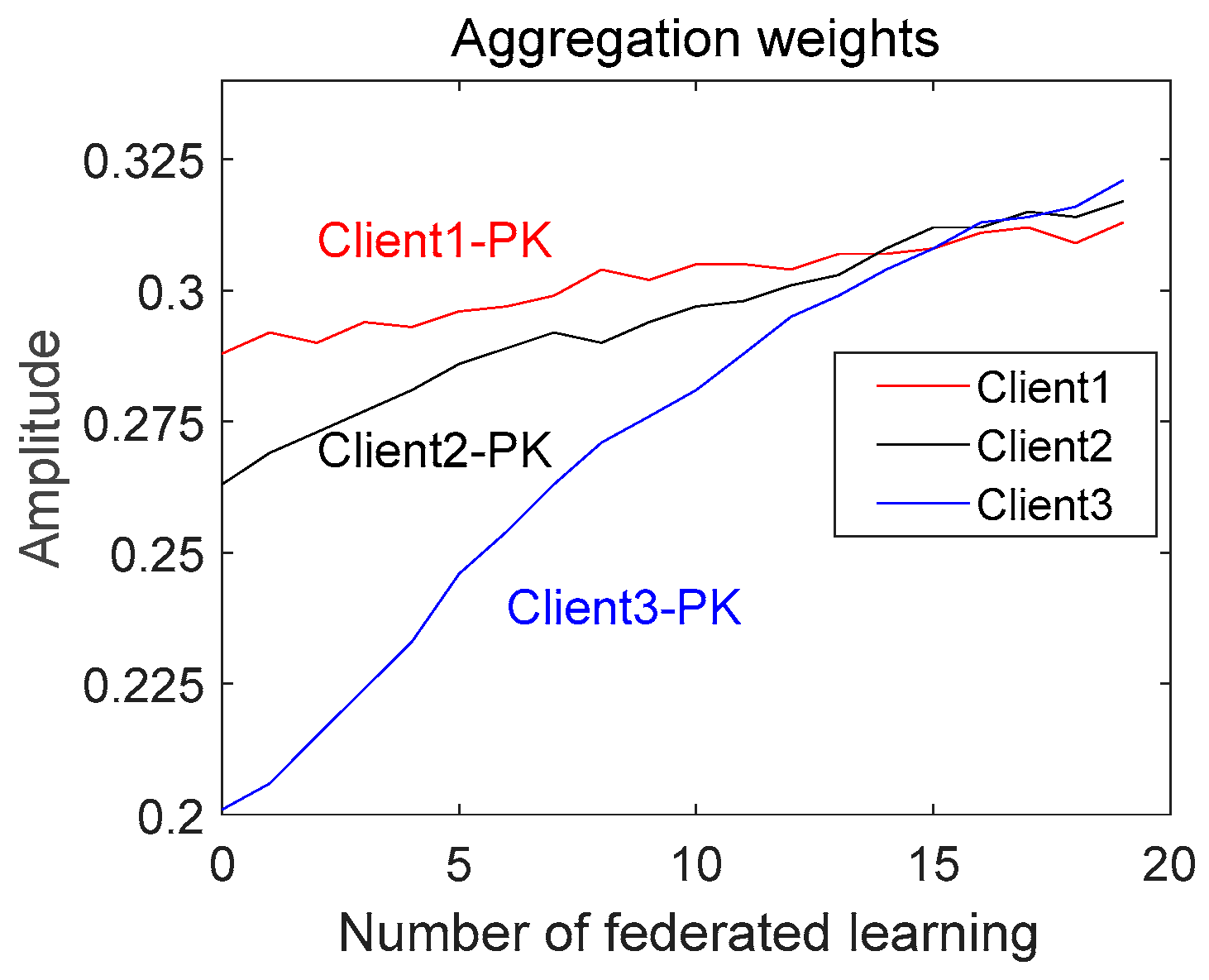



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fault Type | Failure Size (Inch) | Label |
|---|---|---|
| Normal data | 0 | Normal |
| Inner ring failure | 0.021 | Inner |
| Outer ring failure | 0.021 | Outer |
| Ball failure | 0.021 | Ball |
| Model | Brief Description of the Model | Model Parameters | Number of Clients |
|---|---|---|---|
| Feature-Clustering | Fault diagnosis is achieved via clustering after extracting fault features; then, unsupervised learning is used to execute fault diagnosis. | Clustering centers: 4 | 1 |
| DNN | Traditional deep learning fault diagnosis model. | Number of network layers: 5 Number of neurons in each layer: 400/500/100/30/4 Learning rate: 0.005 | 1 |
| FedAvg [29] | The local model is trained using supervised learning. The federated averaging algorithm is used to obtain a federation model, which is downloaded by all clients to achieve fault diagnosis. | 3 | |
| FedSem [30] | The federation model assigns a pseudo-label to unlabeled data and then adds them to the model-retraining process. | 3 | |
| Sem-Fed | The local model is used to assign a pseudo-label to unlabeled data, and then the federated averaging strategy is used to aggregate models. | 3 | |
| ANN-SSFL [33] | The local model is jointly trained by determining unsupervised and supervised loss and then aggregated via the federated averaging algorithm. | 3 | |
| SSFL-ATT | Dynamic semi-supervised federated learning fault diagnosis method based on attention mechanism. | 3 |
| Experiment | Quantity of Data for Client 1 | Quantity of Data for Client 2 | Quantity of Data for Client 3 | |||
|---|---|---|---|---|---|---|
| Labeled | Unlabeled | Labeled | Unlabeled | Labeled | Unlabeled | |
| Experiment 1 | 4 × 100 | 0 | 4 × 50 | 4 × 1000 | 0 | 4 × 5000 |
| Experiment 2 | 4 × 50 | 0 | 4 × 20 | 4 × 1000 | 0 | 4 × 5000 |
| Experiment 3 | 4 × 20 | 0 | 4 × 10 | 4 × 1000 | 0 | 4 × 5000 |
| Experiment 4 | 4 × 20 | 0 | 4 × 10 | 4 × 1000 | 0 | 4 × 3000 |
| Experiment 5 | 4 × 20 | 0 | 4 × 10 | 4 × 1000 | 0 | 4 × 2000 |
| Experiment 6 | 4 × 20 | 0 | 4 × 10 | 4 × 1000 | 0 | 4 × 1500 |
| Experiment | Client | Feature Clustering | DNN | FedAvg | FedSem | Sem-Fed | ANN-SSFL | SSFL-ATT |
|---|---|---|---|---|---|---|---|---|
| Experiment 1 | Client 1 | — | 71.50% | 75.50% | 70.67% | 72.67% | 76.83% | 82.08% |
| Client 2 | 37.17% | 64.50% | 74.08% | 69.17% | 73.41% | 75.00% | 81.50% | |
| Client 3 | 44.25% | — | 61.75% | 67.33% | 68.17% | 70.92% | 79.50% | |
| Mean | — | — | 70.44% | 69.06% | 71.42% | 74.25% | 81.03% | |
| Experiment 2 | Client 1 | — | 65.50% | 71.92% | 66.08% | 68.83% | 72.92% | 77.58% |
| Client 2 | 36.67% | 57.33% | 69.67% | 65.75% | 69.00% | 71.08% | 78.58% | |
| Client 3 | 44.17% | — | 56.33% | 62.50% | 65.58% | 67.50% | 78.75% | |
| Mean | — | — | 65.97% | 64.78% | 67.80% | 70.50% | 78.30% | |
| Experiment 3 | Client 1 | — | 56.92% | 67.83% | 63.41% | 67.58% | 68.25% | 74.83% |
| Client 2 | 35.41% | 51.67% | 66.33% | 62.17% | 66.08% | 68.83% | 75.17% | |
| Client 3 | 44.92% | — | 54.41% | 60.08% | 65.00% | 66.92% | 75.58% | |
| Mean | — | — | 62.86% | 61.89% | 66.22% | 68.00% | 75.19% |
| Experiment | Client | Feature Clustering | DNN | FedAvg | FedSem | Sem-Fed | ANN-SSFL | SSFL-ATT |
|---|---|---|---|---|---|---|---|---|
| Experiment 4 | Client 1 | — | 56.58% | 63.41% | 60.58% | 64.17% | 65.58% | 73.58% |
| Client 2 | 37.50% | 52.08% | 63.33% | 59.92% | 63.41% | 65.41% | 74.83% | |
| Client 3 | 44.50% | — | 54.83% | 58.83% | 62.33% | 63.75% | 73.50% | |
| Mean | — | — | 60.52% | 59.78% | 63.30% | 64.91% | 73.97% | |
| Experiment 5 | Client 1 | — | 56.25% | 62.50% | 58.50% | 63.50% | 64.75% | 71.83% |
| Client 2 | 36.25% | 52.50% | 62.83% | 59.58% | 62.33% | 64.08% | 71.33% | |
| Client 3 | 40.50% | — | 54.41% | 58.41% | 61.33% | 62.25% | 70.16% | |
| Mean | — | — | 59.91% | 58.83% | 62.39% | 63.69% | 71.11% | |
| Experiment 6 | Client 1 | — | 57.17% | 61.92% | 59.16% | 61.33% | 64.58% | 72.25% |
| Client 2 | 37.17% | 51.17% | 62.25% | 58.33% | 61.41% | 63.00% | 68.58% | |
| Client 3 | 38.83% | — | 54.75% | 57.33% | 60.58% | 61.00% | 70.83% | |
| Mean | — | — | 59.64% | 58.27% | 61.11% | 62.86% | 70.55% |
| Fault Type | Fault Simulation Method | Fault Level | Label |
|---|---|---|---|
| Normal | \ | 0 | 0 |
| Bearing inner-ring fault | Fault grooves are machined through the inner raceway of the bearing via laser etching. | 0.5 mm | 1 |
| Bearing outer-ring fault | Fault grooves are machined through the outer raceway of the bearing via laser etching. | 0.5 mm | 2 |
| Shaft bending fault | Pressure is applied to the rotor using a press to obtain different degrees of bending. | 0.3 mm | 3 |
| Broken rotor bar fault | The milling process breaks part of the copper bar in the rotor. | Break two bars | 4 |
| Rotor imbalance fault | The local mass of the rotor is removed. | 4 g | 5 |
| Misalignment fault | The bearing mounting position is widened, and bolts are used to adjust the bearing position. | 0.25 mm | 6 |
| Voltage unbalance | An external control box is used to adjust the resistance value to produce different levels of voltage imbalance. | 50% | 7 |
| Out-of-phase fault | External control box: the phase loss button is turned on and off. | Out of V-phase | 8 |
| Winding short-circuit fault | A short-circuit terminal is preset in the control box; the resistance value is adjusted to introduce different degrees of a winding short-circuit fault. | 10% | 9 |
| Experiment | Quantity of Data for Client 1 | Quantity of Data for Client 2 | Quantity of Data for Client 3 | |||
|---|---|---|---|---|---|---|
| Labeled | Unlabeled | Labeled | Unlabeled | Labeled | Unlabeled | |
| Experiment 1 | 10 × 100 | 0 | 10 × 50 | 10 × 5000 | 0 | 10 × 10,000 |
| Experiment 2 | 10 × 50 | 0 | 10 × 30 | 10 × 5000 | 0 | 10 × 10,000 |
| Experiment 3 | 10 × 20 | 0 | 10 × 10 | 10 × 5000 | 0 | 10 × 10,000 |
| Experiment 4 | 10 × 20 | 0 | 10 × 10 | 10 × 1000 | 0 | 10 × 3000 |
| Experiment 5 | 10 × 20 | 0 | 10 × 10 | 10 × 100 | 0 | 10 × 300 |
| Experiment | Client | Feature Clustering | DNN | FedAvg | FedSem | Sem-Fed | ANN-SSFL | SSFL-ATT |
|---|---|---|---|---|---|---|---|---|
| Experiment 1 | Client 1 | — | 70.45% | 74.05% | 71.97% | 73.58% | 75.32% | 87.30% |
| Client 2 | 41.50% | 66.26% | 74.65% | 70.36% | 73.66% | 75.26% | 87.77% | |
| Client 3 | 48.63% | — | 64.45% | 68.06% | 72.57% | 74.23% | 87.33% | |
| Mean | — | — | 71.05% | 70.13% | 73.27% | 74.94% | 87.47% | |
| Experiment 2 | Client 1 | — | 65.35% | 71.32% | 67.93% | 70.96% | 74.03% | 83.77% |
| Client 2 | 42.12% | 61.47% | 70.65% | 67.04% | 69.06% | 73.73% | 84.22% | |
| Client 3 | 47.55% | — | 60.37% | 64.78% | 68.00% | 73.25% | 83.55% | |
| Mean | — | — | 67.45% | 66.58% | 69.34% | 73.67% | 83.85% | |
| Experiment 3 | Client 1 | — | 59.32% | 65.35% | 62.05% | 64.70% | 66.05% | 72.91% |
| Client 2 | 41.12% | 57.15% | 64.35% | 60.98% | 63.23% | 65.67% | 72.49% | |
| Client 3 | 46.63% | — | 55.35% | 58.45% | 62.98% | 64.03% | 71.34% | |
| Mean | — | — | 61.68% | 60.49% | 63.64% | 65.25% | 72.25% |
| Experiment | Client | Feature Clustering | DNN | FedAvg | FedSem | Sem-Fed | ANN-SSFL | SSFL-ATT |
|---|---|---|---|---|---|---|---|---|
| Experiment 4 | Client 1 | — | 58.82% | 64.35% | 61.21% | 63.31% | 64.80% | 71.79% |
| Client 2 | 32.50% | 56.84% | 63.35% | 60.54% | 62.34% | 63.69% | 70.60% | |
| Client 3 | 37.45% | — | 54.82% | 58.45% | 62.77% | 62.27% | 69.56% | |
| Mean | — | — | 60.84% | 60.07% | 62.81% | 63.59% | 70.65% | |
| Experiment 5 | Client 1 | — | 59.32% | 63.35% | 60.58% | 61.35% | 62.62% | 69.70% |
| Client 2 | 29.35% | 57.15% | 62.35% | 57.56% | 60.20% | 61.44% | 69.52% | |
| Client 3 | 38.63% | — | 54.82% | 57.31% | 58.64% | 60.64% | 68.06% | |
| Mean | — | — | 60.17% | 58.48% | 60.06% | 61.57% | 69.09% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Zhou, F.; Tang, S.; Hu, X.; Wang, C.; Wang, T. Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism. Entropy 2023, 25, 1470. https://doi.org/10.3390/e25101470
Liu S, Zhou F, Tang S, Hu X, Wang C, Wang T. Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism. Entropy. 2023; 25(10):1470. https://doi.org/10.3390/e25101470
Chicago/Turabian StyleLiu, Shun, Funa Zhou, Shanjie Tang, Xiong Hu, Chaoge Wang, and Tianzhen Wang. 2023. "Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism" Entropy 25, no. 10: 1470. https://doi.org/10.3390/e25101470
APA StyleLiu, S., Zhou, F., Tang, S., Hu, X., Wang, C., & Wang, T. (2023). Dynamic Semi-Supervised Federated Learning Fault Diagnosis Method Based on an Attention Mechanism. Entropy, 25(10), 1470. https://doi.org/10.3390/e25101470