

Topological Data Analysis for Multivariate Time Series Data



Abstract
:1. Introduction
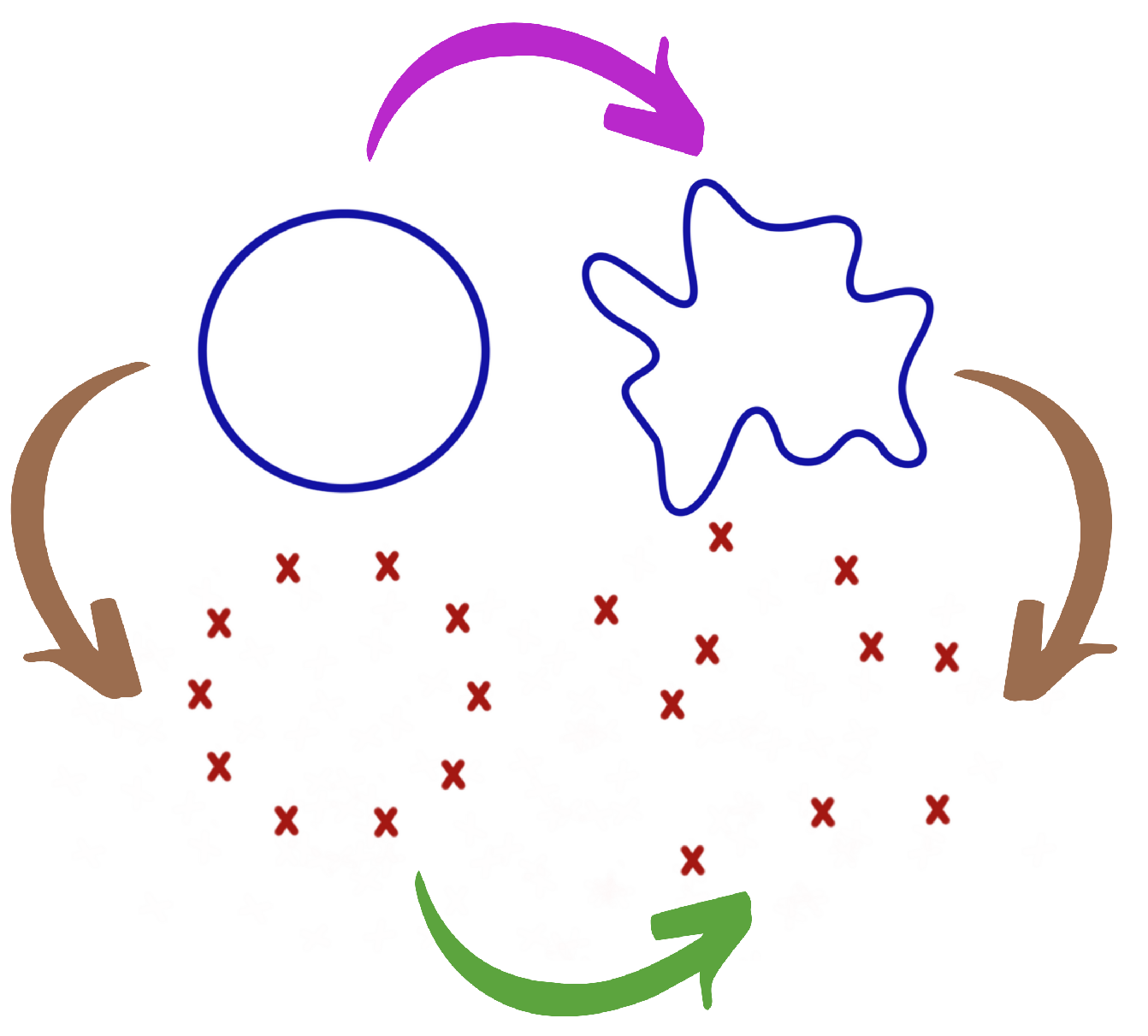
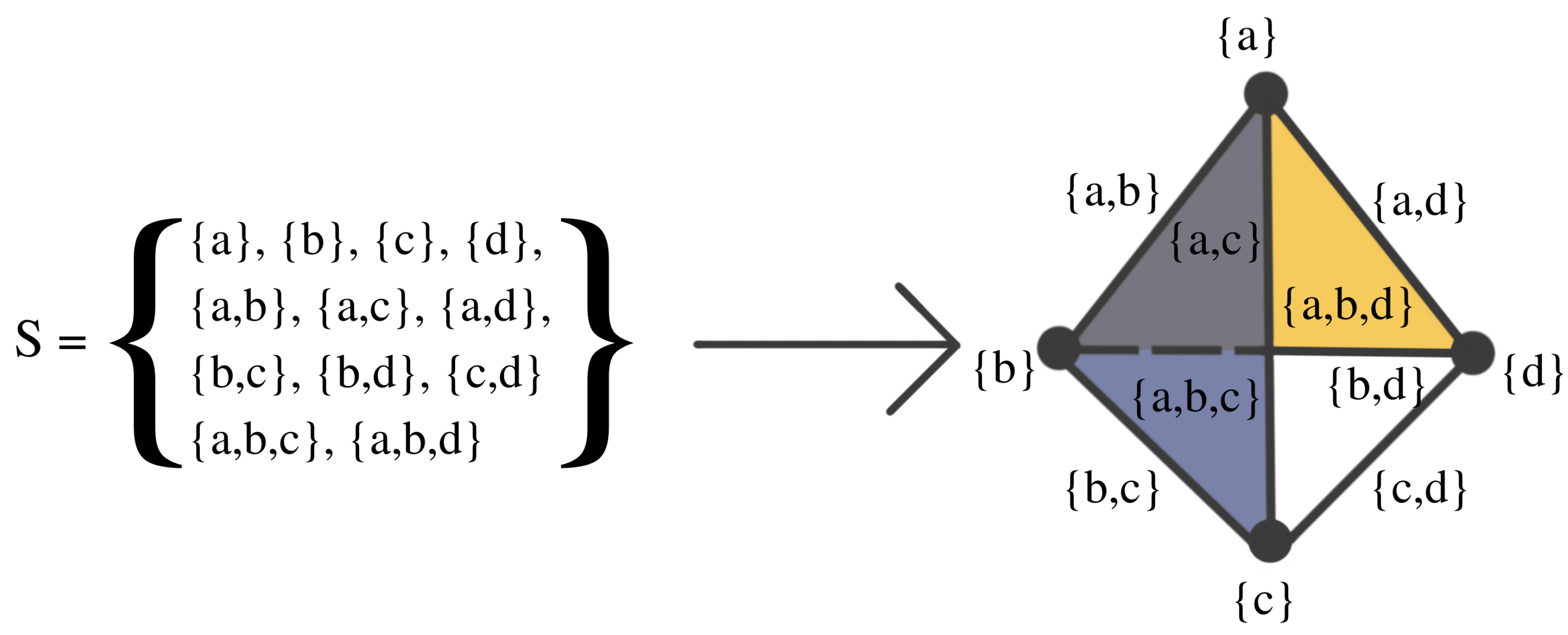
2. Background Material For TDA
- Meaning of data: What constitutes data?
- Meaning of distance: How can we define a meaningful distance (or discrepancy) between data points?
- Notion of stability: Is this given TDA summary stable? This is addressed through stability theorems.
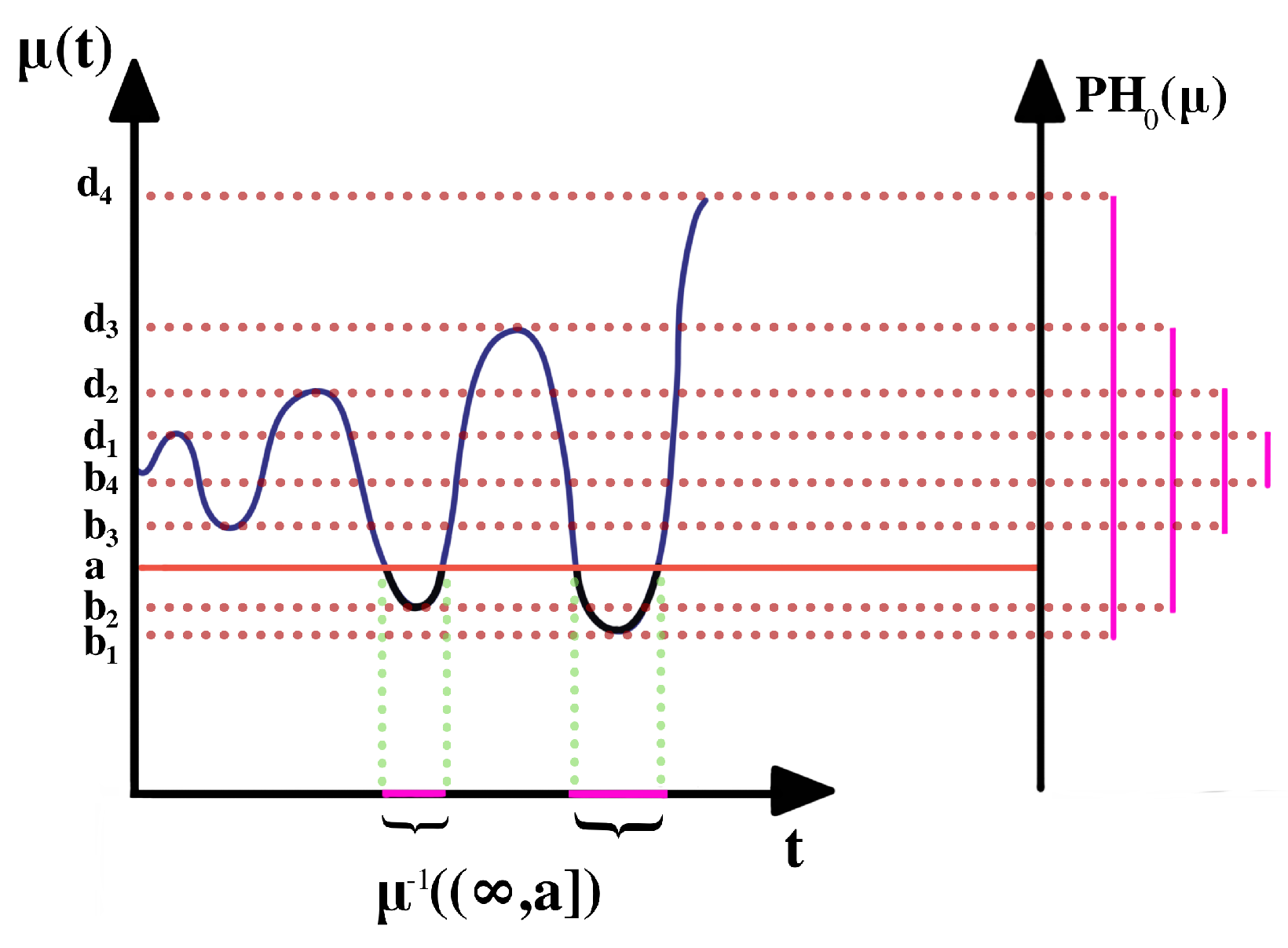
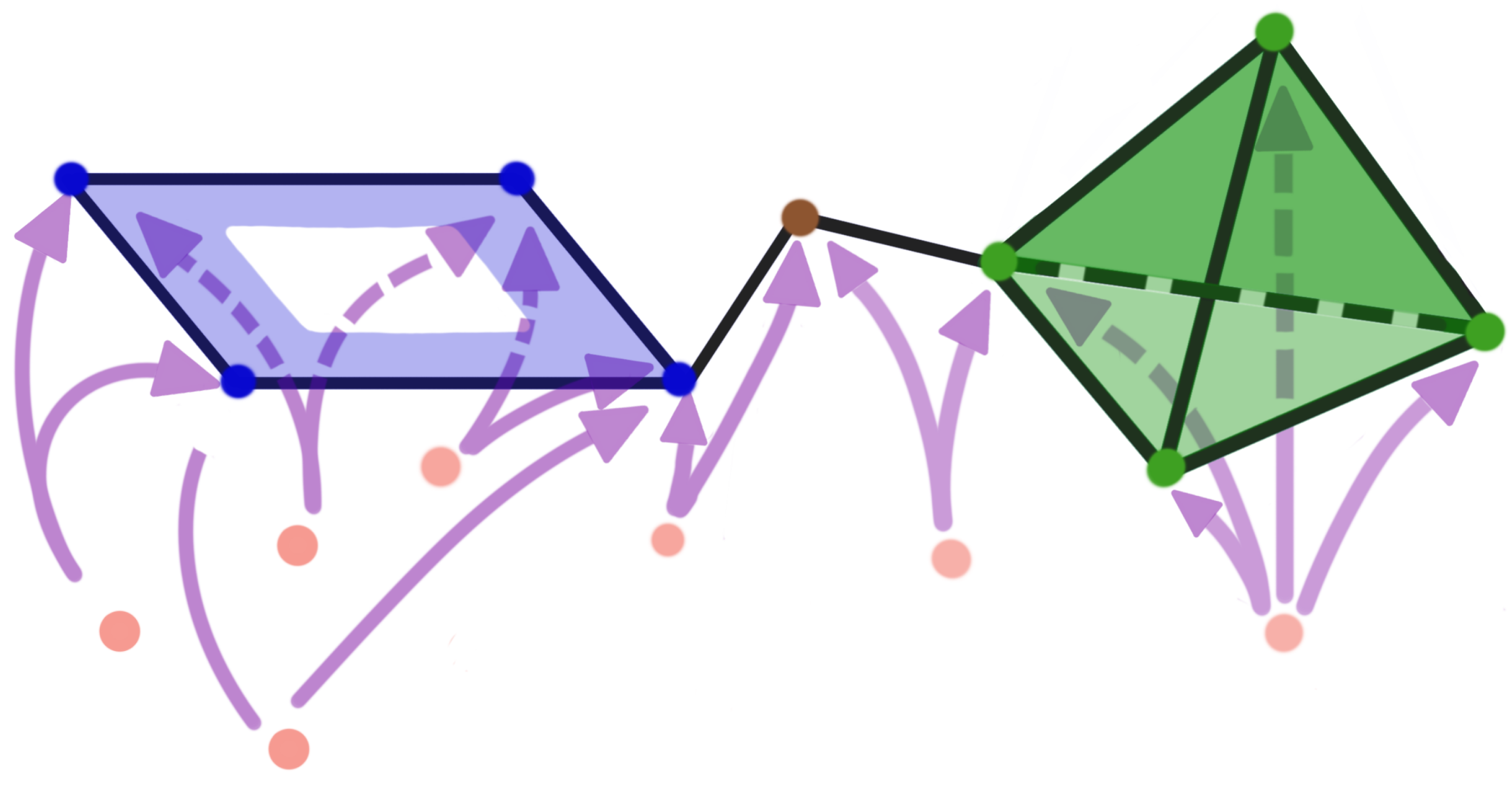
2.1. Persistent Homology of Morse Filtration
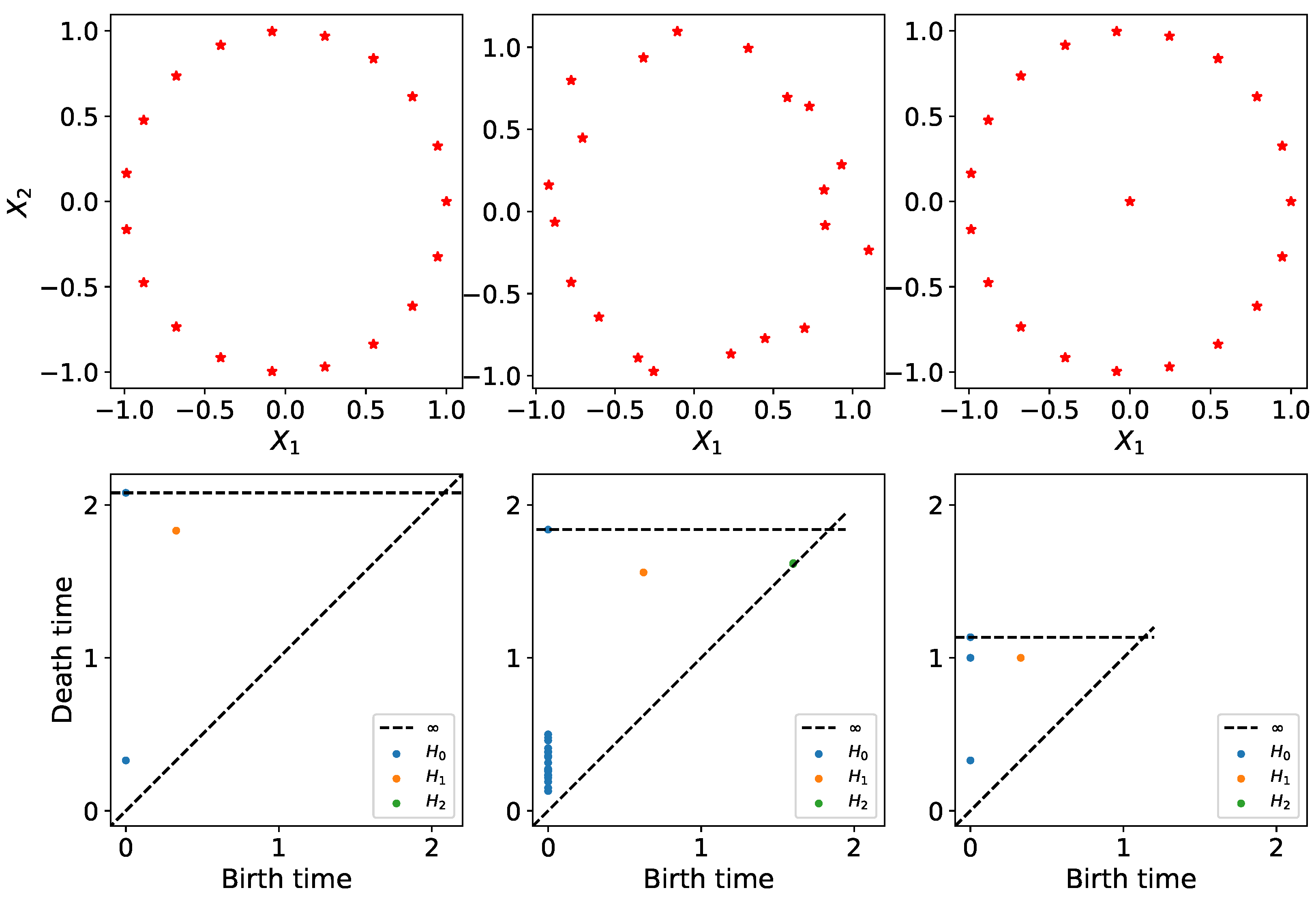
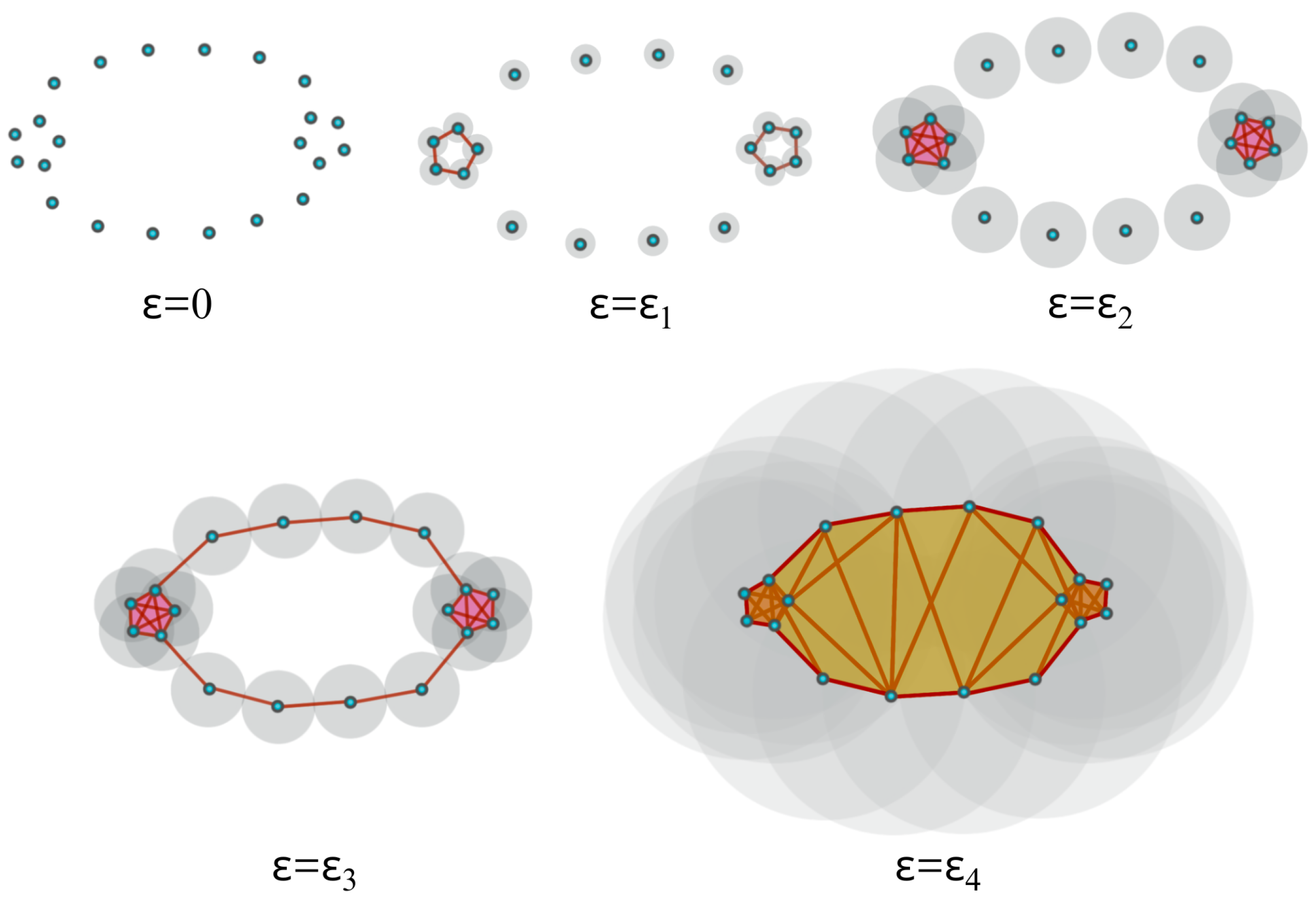
2.2. Persistent Homology of Vietoris–Rips Filtration
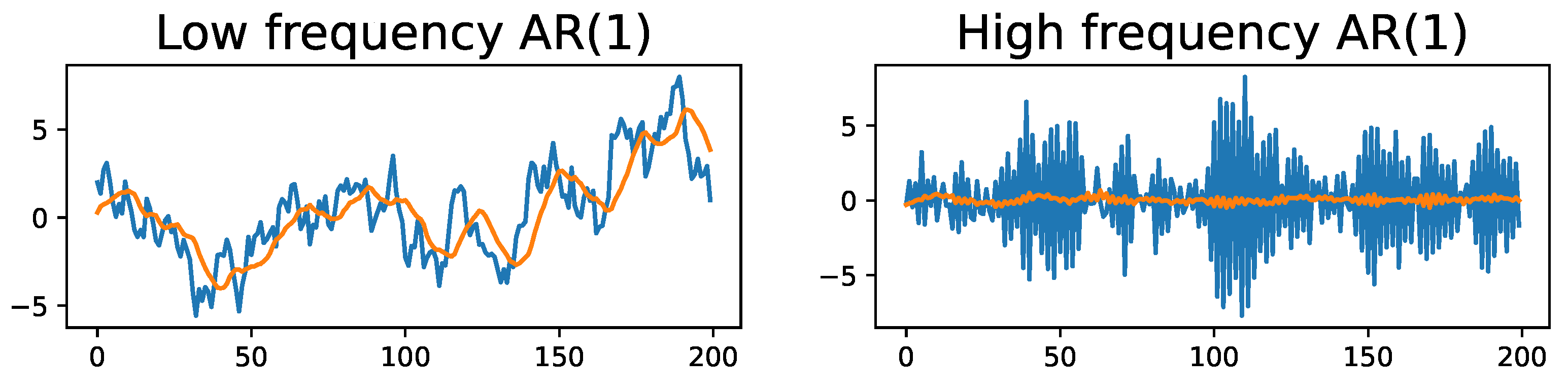
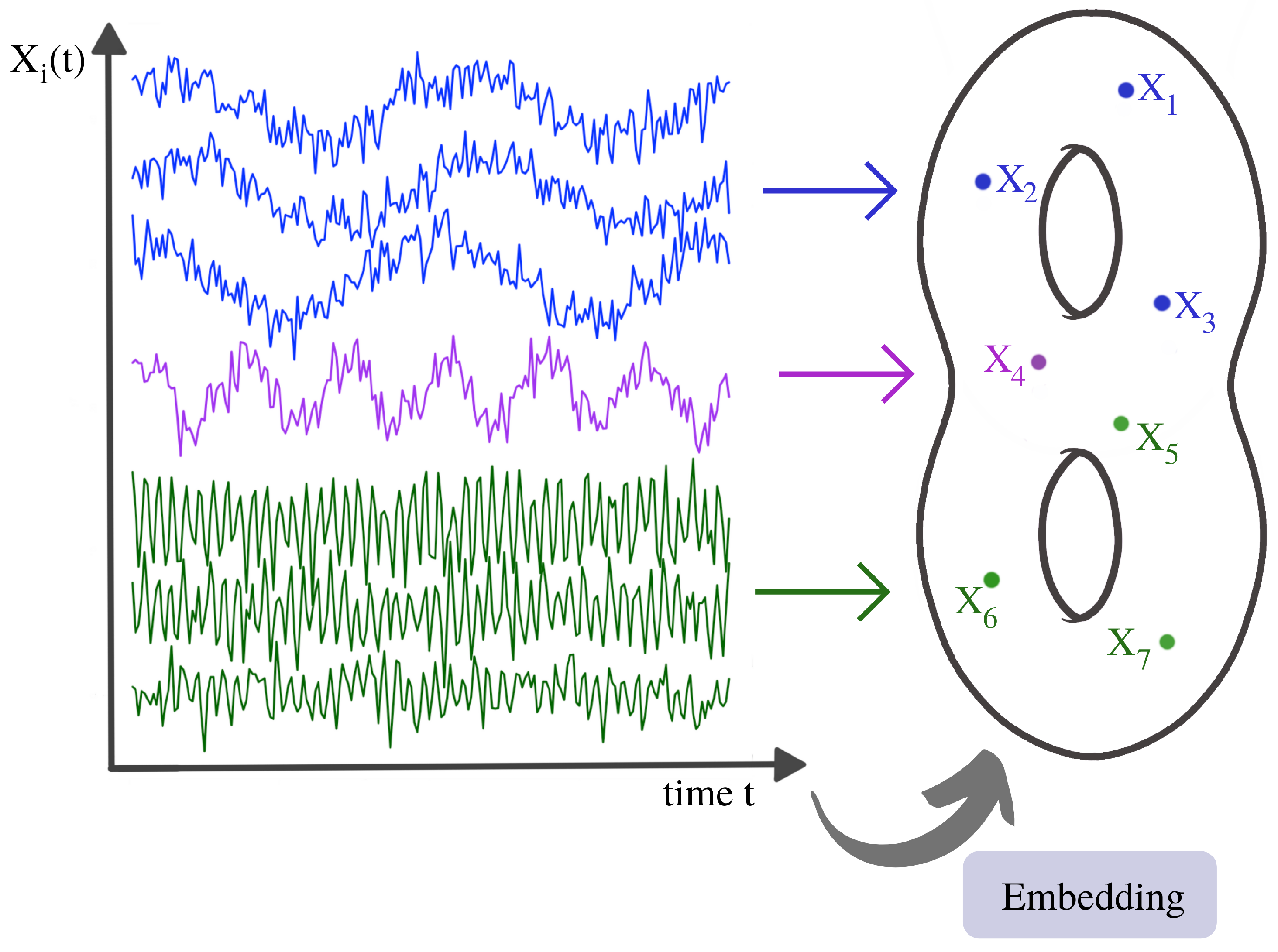
2.3. Time-Delay Embeddings of Univariate Time Series
3. Topological Methods for Analyzing Multivariate Time Series
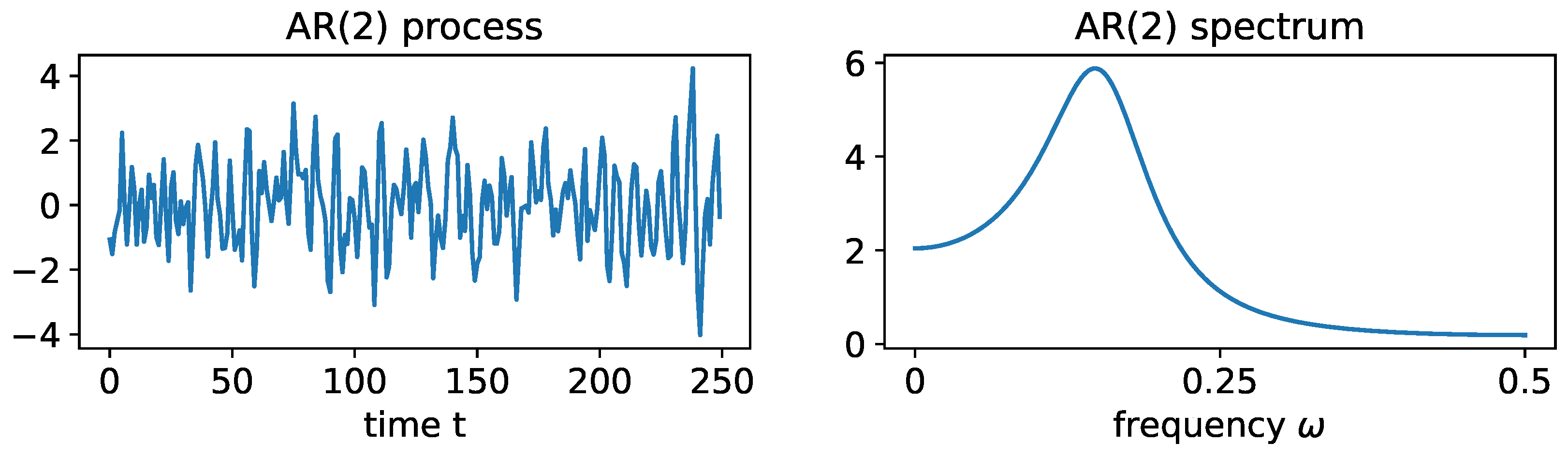
3.1. Examples of Time Series Models
- Groups of neurons firing together (presence of clusters);
- Groups of neurons sharing some latent processes (potential cycles).
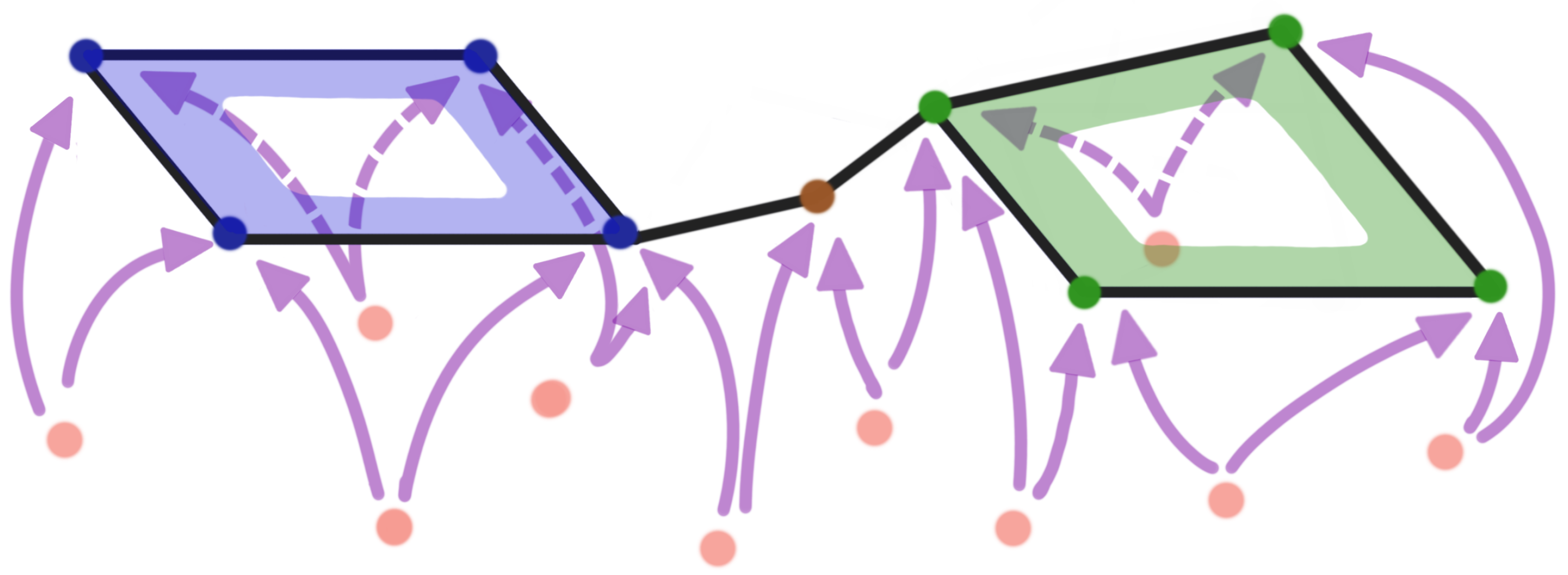
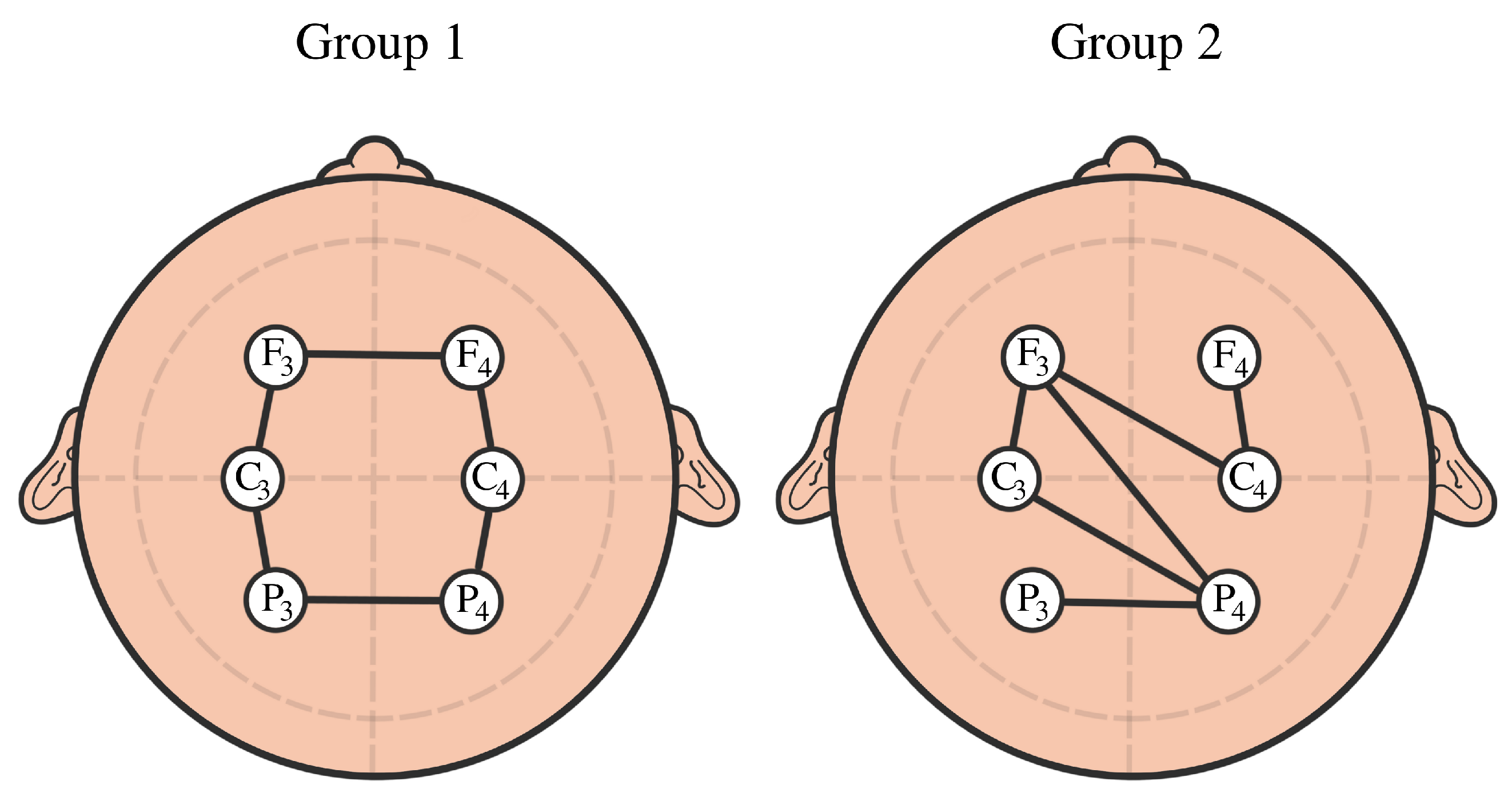
3.2. TDA vs. Graph-Theoretical Modeling of Brain Connectivity
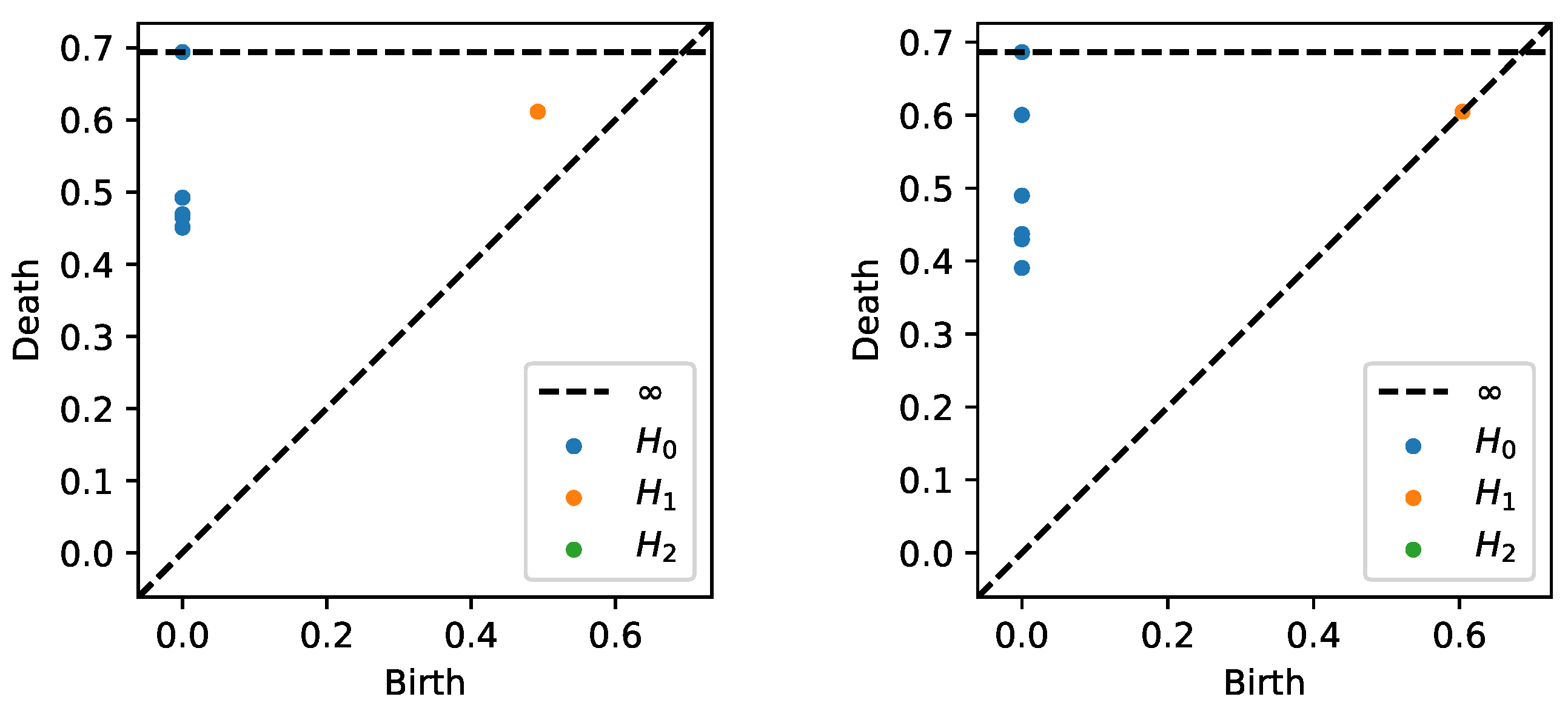
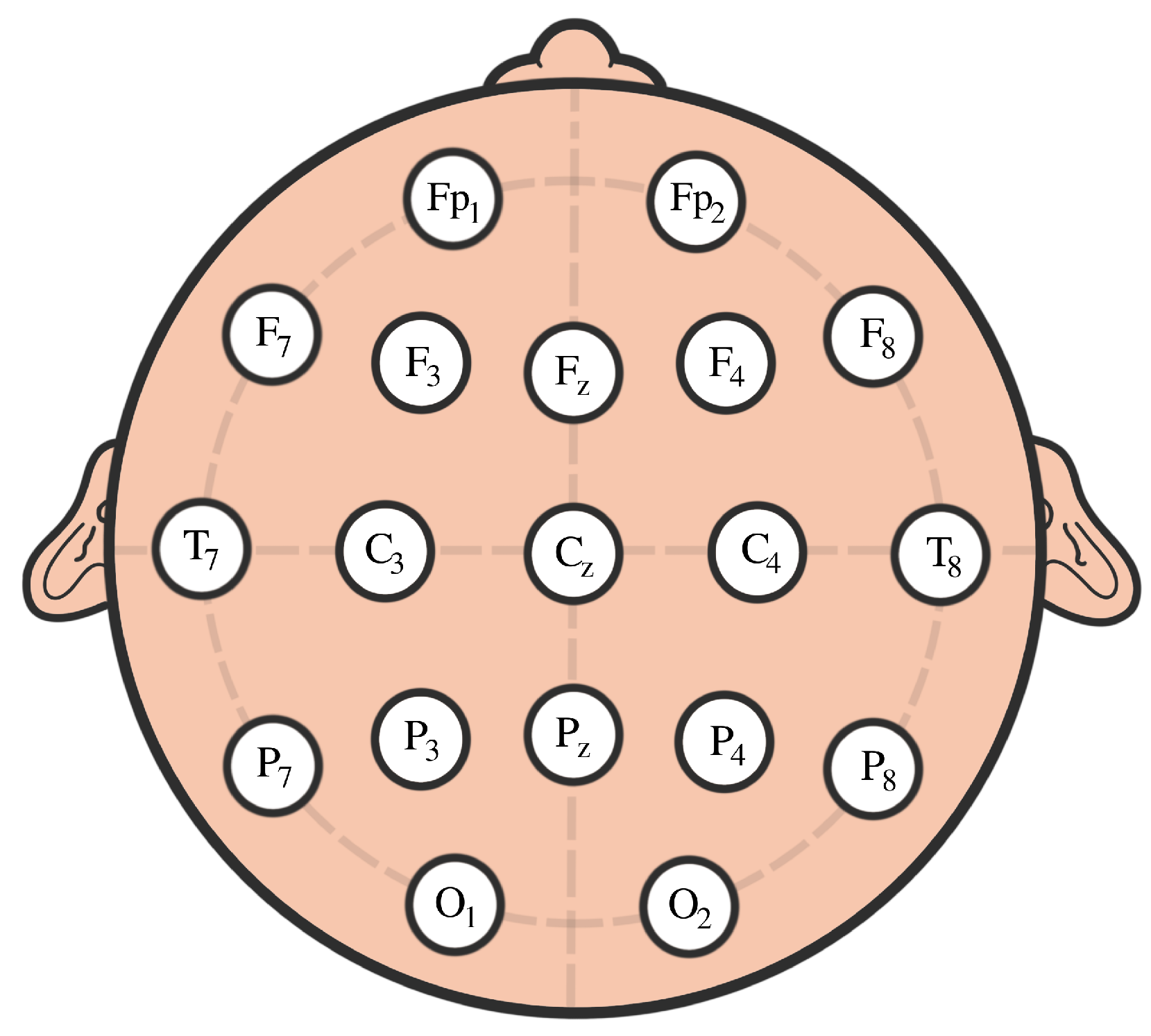
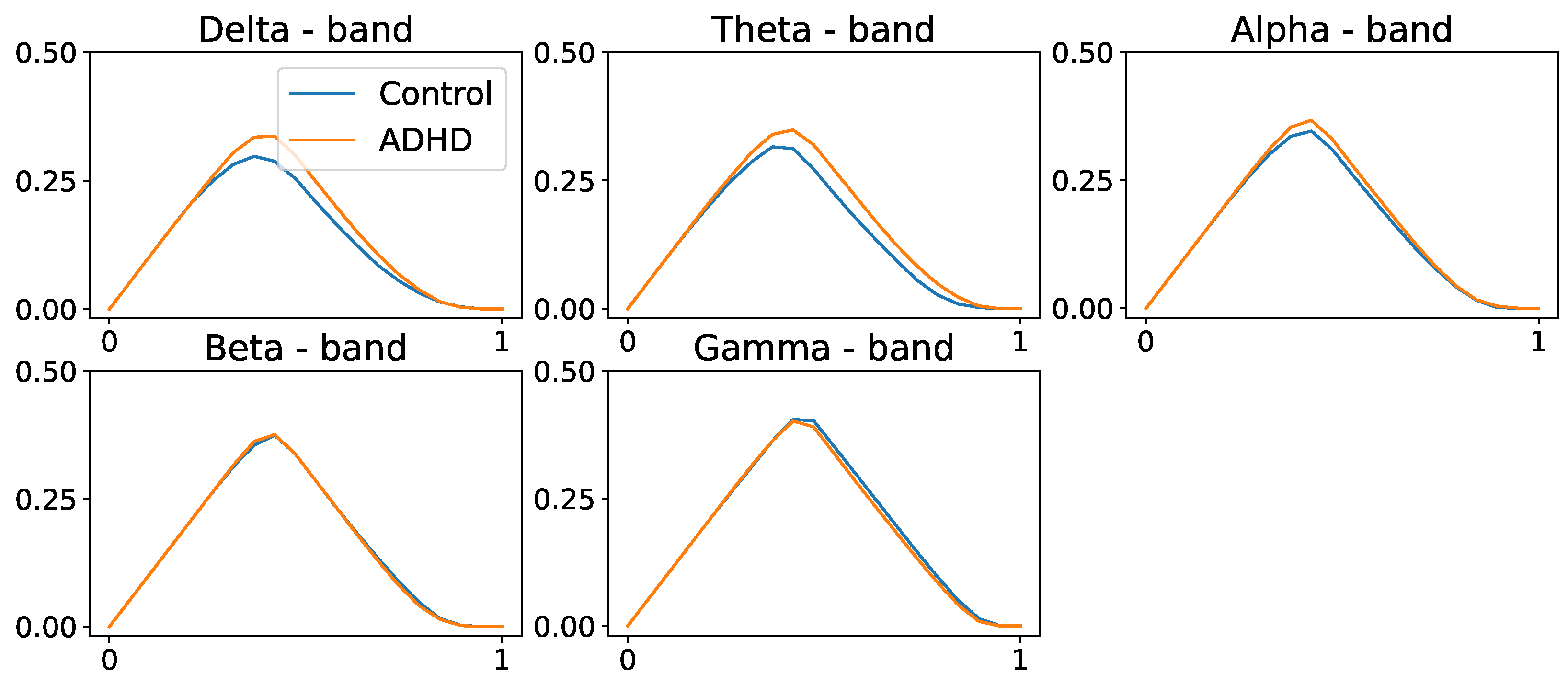
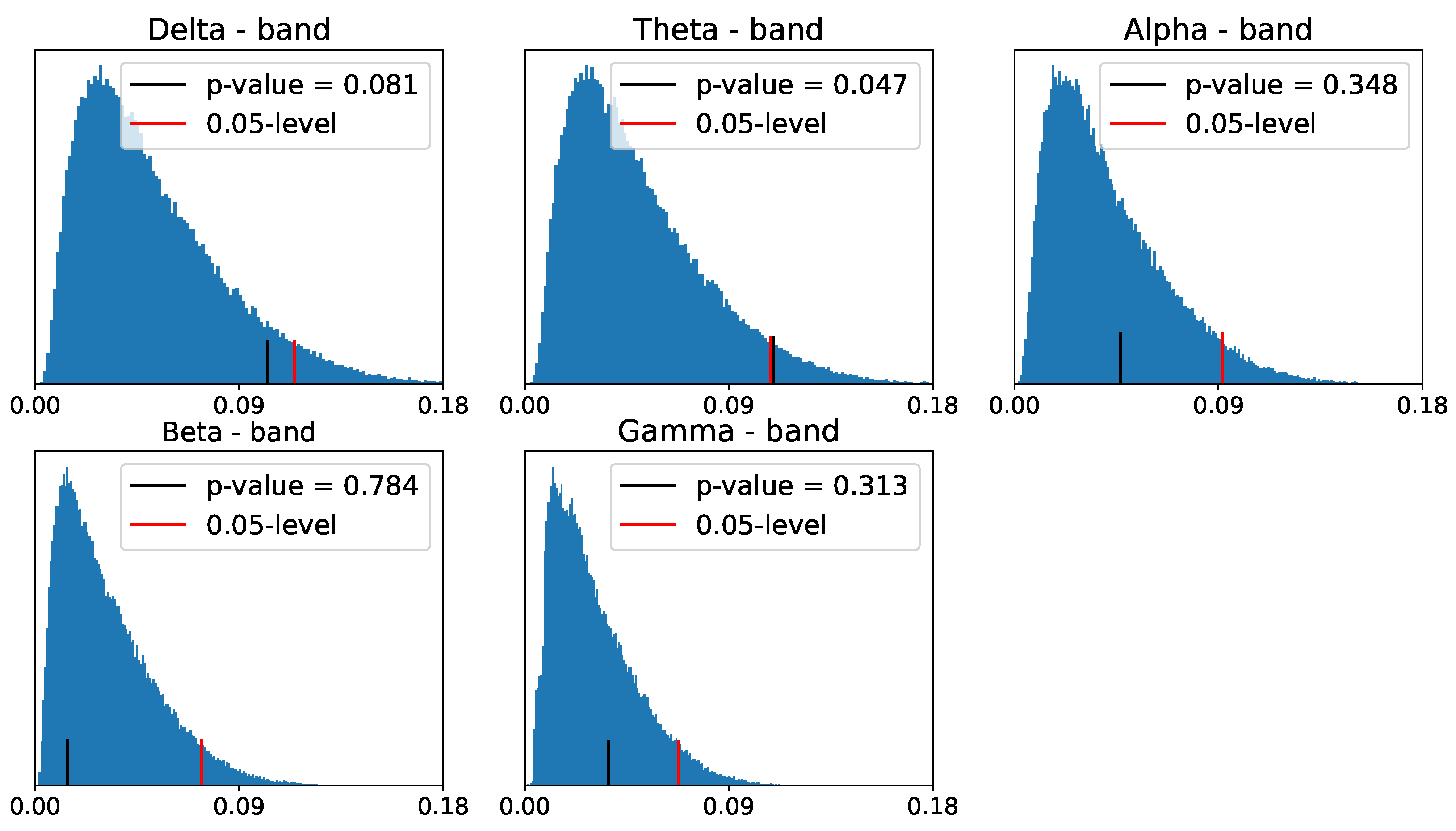
4. EEG Analysis and Permutation Testing
- Compute the sample test statistic from the original PLs: and .
- Permute the ADHD and healthy control group labels to obtain and .
- Compute the sample discrepancy from the permuted PLs:.
- Repeat steps 2 to 3, B times.
- Compute the threshold as the ()-quantile of the empirical distribution of test statistic .
5. Open Problems
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TDA | topological data analysis |
| PL | persistence diagram |
| PD | persistence landscape |
| EEG | electroencephalogram |
| LFP | local field potential |
| ERP | event-related potential |
| fMRI | functional magnetic resonance imaging |
| ADHD | attention deficit hyperactivity disorder |
References
- Richeson, D.S. Euler’s Gem: The Polyhedron Formula and the Birth of Topology; Princeton University Press: Princeton, NJ, USA, 2008. [Google Scholar]
- James, I.M. Reflections on the history of topology. Semin. Mat. Fis. Milano 1996, 66, 87–96. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Letscher, D.; Zomorodian, A. Topological Persistence and Simplification. Discret. Comput. Geom. 2002, 28, 511–533. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Harer, J. Persistent homology—A survey. Discret. Comput. Geom. 2008, 453, 257–282. [Google Scholar] [CrossRef]
- Ghrist, R. Barcodes: The persistent topology of data. Bull. Am. Math. Soc. 2008, 45, 61–75. [Google Scholar] [CrossRef]
- Carlsson, G. Topology and Data. Bull. Am. Math. Soc. 2009, 46, 255–308. [Google Scholar] [CrossRef]
- Topaz, C.M.; Ziegelmeier, L.; Halverson, T. Topological Data Analysis of Biological Aggregation Models. PLoS ONE 2015, 10, e0126383. [Google Scholar] [CrossRef]
- Gidea, M.; Katz, Y.A. Topological Data Analysis of Financial Time Series: Landscapes of Crashes. Phys. A Stat. Mech. Its Appl. 2018, 491, 820–834. [Google Scholar] [CrossRef]
- Lee, H.; Kang, H.; Chung, M.K.; Kim, B.N.; Lee, D.S. Persistent Brain Network Homology From the Perspective of Dendrogram. IEEE Trans. Med. Imaging 2012, 31, 2267–2277. [Google Scholar] [CrossRef]
- Bendich, P.; Marron, J.S.; Miller, E.; Pieloch, A.; Skwerer, S. Persistent homology analysis of brain artery trees. Ann. Appl. Stat. 2016, 10, 198–218. [Google Scholar] [CrossRef]
- Rim, B.; Sung, N.J.; Min, S.; Hong, M. Deep Learning in Physiological Signal Data: A Survey. Sensors 2020, 20, 969. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time-Series. In The Handbook of Brain Theory and Neural Networks; The MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Sarvamangala, D.; Kulkarni, R. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2022, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Luo, S.; Li, X.; Li, J. Automatic Alzheimer’s Disease Recognition from MRI Data Using Deep Learning Method. J. Appl. Math. Phys. 2017, 5, 1892–1898. [Google Scholar] [CrossRef]
- Dolz, J.; Desrosiers, C.; Ben Ayed, I. 3D fully convolutional networks for subcortical segmentation in MRI: A large-scale study. NeuroImage 2018, 170, 456–470. [Google Scholar] [CrossRef]
- Gao, Y.; Phillips, J.M.; Zheng, Y.; Min, R.; Fletcher, P.T.; Gerig, G. Fully convolutional structured LSTM networks for joint 4D medical image segmentation. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1104–1108. [Google Scholar] [CrossRef]
- Azevedo, T.; Campbell, A.; Romero-Garcia, R.; Passamonti, L.; Bethlehem, R.A.; Liò, P.; Toschi, N. A deep graph neural network architecture for modelling spatio-temporal dynamics in resting-state functional MRI data. Med. Image Anal. 2022, 79, 102471. [Google Scholar] [CrossRef] [PubMed]
- Alves, C.L.; Pineda, A.M.; Roster, K.; Thielemann, C.; Rodrigues, F.A. EEG functional connectivity and deep learning for automatic diagnosis of brain disorders: Alzheimer’s disease and schizophrenia. J. Phys. Complex. 2022, 3, 025001. [Google Scholar] [CrossRef]
- Heinsfeld, A.S.; Franco, A.R.; Craddock, R.C.; Buchweitz, A.; Meneguzzi, F. Identification of autism spectrum disorder using deep learning and the ABIDE dataset. NeuroImage Clin. 2018, 17, 16–23. [Google Scholar] [CrossRef] [PubMed]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Micheli, A. Neural Network for Graphs: A Contextual Constructive Approach. IEEE Trans. Neural Netw. 2009, 20, 498–511. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, M.; Liu, M.; Zhang, D. A Survey on Deep Learning for Neuroimaging-Based Brain Disorder Analysis. Front. Neurosci. 2020, 14, 779. [Google Scholar] [CrossRef]
- Xu, X.; Zhao, X.; Wei, M.; Li, Z. A comprehensive review of graph convolutional networks: Approaches and applications. Electron. Res. Arch. 2023, 31, 4185–4215. [Google Scholar] [CrossRef]
- Li, X.; Zhou, Y.; Dvornek, N.; Zhang, M.; Gao, S.; Zhuang, J.; Scheinost, D.; Staib, L.H.; Ventola, P.; Duncan, J.S. BrainGNN: Interpretable Brain Graph Neural Network for fMRI Analysis. Med. Image Anal. 2021, 74, 102233. [Google Scholar] [CrossRef]
- Lei, D.; Qin, K.; Pinaya, W.H.L.; Young, J.; Van Amelsvoort, T.; Marcelis, M.; Donohoe, G.; Mothersill, D.O.; Corvin, A.; Vieira, S.; et al. Graph Convolutional Networks Reveal Network-Level Functional Dysconnectivity in Schizophrenia. Schizophr. Bull. 2022, 48, 881–892. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Dong, Z.; Lin, H. Learning persistent homology of 3D point clouds. Comput. Graph. 2022, 102, 269–279. [Google Scholar] [CrossRef]
- Chung, M.K.; Bubenik, P.; Kim, P.T. Persistence diagrams of cortical surface data. Inf. Process. Med. Imaging 2009, 21, 403–414. [Google Scholar] [CrossRef]
- Wang, Y.; Ombao, H.; Chung, M.K. Topological Data Analysis of Single-Trial Electroencephalographic Signals. Ann. Appl. Stat. 2018, 12, 1506–1534. [Google Scholar] [CrossRef]
- Adler, R.; Bobrowski, O.; Borman, M.; Subag, E.; Weinberger, S. Persistent Homology for Random Fields and Complexes. Borrow. Strength Theory Powering Appl. 2010, 6, 124–143. [Google Scholar] [CrossRef]
- Ombao, H.; Pinto, M. Spectral Dependence. arXiv 2021, arXiv:stat.ME/2103.17240. [Google Scholar] [CrossRef]
- Cohen-Steiner, D.; Edelsbrunner, H.; Harer, J. Stability of persistence diagrams. Discret. Comput. Geom. 2007, 37, 103–120. [Google Scholar] [CrossRef]
- Banyaga, A.; Hurtubise, D. Lectures on Morse Homology; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2004; Volume 29. [Google Scholar] [CrossRef]
- Hausmann, J.C. On the Vietoris-Rips Complexes and a Cohomology Theory for Metric Spaces; Princeton University Press: Princeton, NJ, USA, 2016; pp. 175–188. [Google Scholar] [CrossRef]
- Björner, A. Topological methods. Handb. Comb. 1995, 2, 1819–1872. [Google Scholar]
- Agami, S. Comparison of persistence diagrams. Commun. Stat.–Simul. Comput. 2023, 52, 1948–1961. [Google Scholar] [CrossRef]
- Bubenik, P. Statistical Topological Data Analysis Using Persistence Landscapes. J. Mach. Learn. Res. 2015, 16, 77–102. [Google Scholar]
- Takens, F. Detecting strange attractors in turbulence. Dyn. Syst. Turbul. Lect. Notes Math. 1981, 898, 366–381. [Google Scholar]
- Seversky, L.; Davis, S.; Berger, M. On Time-Series Topological Data Analysis: New Data and Opportunities. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 1014–1022. [Google Scholar] [CrossRef]
- Lazar, N. The Statistical Analysis of Functional MRI Data; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef]
- Lindquist, M.A. The Statistical Analysis of fMRI Data. Stat. Sci. 2008, 23, 439–464. [Google Scholar] [CrossRef]
- Wager, T.D.; Atlas, L.Y.; Lindquist, M.A.; Roy, M.; Woo, C.W.; Kross, E. An fMRI-Based Neurologic Signature of Physical Pain. N. Engl. J. Med. 2013, 368, 1388–1397. [Google Scholar] [CrossRef] [PubMed]
- Van Straaten, E.C.; Stam, C.J. Structure out of chaos: Functional brain network analysis with EEG, MEG, and functional MRI. Eur. Neuropsychopharmacol. 2013, 23, 7–18. [Google Scholar] [CrossRef]
- Hasenstab, K.; Sugar, C.; Telesca, D.; Mcevoy, K.; Jeste, S.; Şentürk, D. Identifying longitudinal trends within EEG experiments. Biometrics 2015, 71, 1090–1100. [Google Scholar] [CrossRef]
- Wang, Y.; Kang, J.; Kemmer, P.B.; Guo, Y. An Efficient and Reliable Statistical Method for Estimating Functional Connectivity in Large Scale Brain Networks Using Partial Correlation. Front. Neurosci. 2016, 10, 123. [Google Scholar] [CrossRef]
- Ting, C.M.; Samdin, S.B.; Tang, M.; Ombao, H. Detecting Dynamic Community Structure in Functional Brain Networks Across Individuals: A Multilayer Approach. IEEE Trans. Med. Imaging 2021, 40, 468–480. [Google Scholar] [CrossRef]
- Guerrero, M.; Huser, R.; Ombao, H. Conex-Connect: Learning Patterns in Extremal Brain Connectivity From Multi-Channel EEG Data. Ann. Appl. Stat. 2021, 17, 178–198. [Google Scholar]
- Cabral, J.; Kringelbach, M.L.; Deco, G. Exploring the network dynamics underlying brain activity during rest. Prog. Neurobiol. 2014, 114, 102–131. [Google Scholar] [CrossRef]
- Hu, L.; Fortin, N.; Ombao, H. Modeling High-Dimensional Multichannel Brain Signals. Stat. Biosci. 2017, 11, 91–126. [Google Scholar] [CrossRef]
- Langer, N.; Pedroni, A.; Jäncke, L. The Problem of Thresholding in Small-World Network Analysis. PLoS ONE 2013, 8, e53199. [Google Scholar] [CrossRef] [PubMed]
- Bordier, C.; Nicolini, C.; Bifone, A. Graph Analysis and Modularity of Brain Functional Connectivity Networks: Searching for the Optimal Threshold. Front. Neurosci. 2017, 11, 441. [Google Scholar] [CrossRef] [PubMed]
- Caputi, L.; Pidnebesna, A.; Hlinka, J. Promises and pitfalls of topological data analysis for brain connectivity analysis. NeuroImage 2021, 238, 118–245. [Google Scholar] [CrossRef]
- Munkres, J.R. Elements of Algebraic Topology; Addison Wesley Publishing Company: Boston, MA, USA, 1984. [Google Scholar]
- Merkulov, S. Algebraic topology. Proc. Edinb. Math. Soc. 2003, 46. [Google Scholar] [CrossRef]
- Granados-Garcia, G.; Fiecas, M.; Shahbaba, B.; Fortin, N.; Ombao, H. Modeling Brain Waves as a Mixture of Latent Processes. arXiv 2021, arXiv:2102.11971. [Google Scholar]
- Shumway, R.H.; Stoffer, D.S. Time Series Analysis and Its Applications; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Ombao, H.; van Bellegem, S. Evolutionary Coherence of Nonstationary Signals. IEEE Trans. Signal Process. 2008, 56, 2259–2266. [Google Scholar] [CrossRef]
- He, Y.; Evans, A. Graph theoretical modeling of brain connectivity. Curr. Opin. Neurol. 2010, 23, 341–350. [Google Scholar] [CrossRef]
- Stam, C.; Reijneveld, J. Graph theoretical analysis of complex networks in the brain. Nonlinear Biomed. Phys. 2007, 1, 3. [Google Scholar] [CrossRef]
- Bullmore, E.; Sporns, O. Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 2009, 10, 186–198. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Barabasi, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Chen, Z.; Gong, G.; Evans, A. Neuronal Networks in Alzheimer’s Disease. Neurosci. 2009, 15, 333–350. [Google Scholar] [CrossRef]
- Bassett, D.S.; Bullmore, E.T. Human brain networks in health and disease. Curr. Opin. Neurol. 2009, 22, 340–347. [Google Scholar] [CrossRef]
- Motie Nasrabadi, A.; Allahverdy, A.; Samavati, M.; Mohammadi, M.R. EEG data for ADHD/Control Children. IEEE Dataport. Available online: https://ieee-dataport.org/open-access/eeg-data-adhd-control-children (accessed on 10 June 2020).
- Raz, J.; Zheng, H.; Ombao, H.; Turetsky, B. Statistical tests for fMRI based on experimental randomization. NeuroImage 2003, 19, 226–232. [Google Scholar] [CrossRef] [PubMed]
- Robinson, A.; Turner, K. Hypothesis Testing for Topological Data Analysis. J. Appl. Comput. Topol. 2017, 1, 241–261. [Google Scholar] [CrossRef]
- Cericola, C.; Johnson, I.J.; Kiers, J.; Krock, M.; Purdy, J.; Torrence, J. Extending hypothesis testing with persistent homology to three or more groups. Involv. A J. Math. 2018, 11, 27–51. [Google Scholar] [CrossRef]
- Nichols, T.; Holmes, A. Nonparametric permutation tests for functional neuroimaging: A primer with examples. Hum. Brain Mapp. 2002, 15, 1–25. [Google Scholar] [CrossRef]































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| CNN at the voxel level |
|
|
| GNN Based on FC |
|
|
| Morse Filtration |
|
|
| Time-Delay Embedding |
|
|
| Vietoris–Rips Filtration |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Yaagoubi, A.B.; Chung, M.K.; Ombao, H. Topological Data Analysis for Multivariate Time Series Data. Entropy 2023, 25, 1509. https://doi.org/10.3390/e25111509
El-Yaagoubi AB, Chung MK, Ombao H. Topological Data Analysis for Multivariate Time Series Data. Entropy. 2023; 25(11):1509. https://doi.org/10.3390/e25111509
Chicago/Turabian StyleEl-Yaagoubi, Anass B., Moo K. Chung, and Hernando Ombao. 2023. "Topological Data Analysis for Multivariate Time Series Data" Entropy 25, no. 11: 1509. https://doi.org/10.3390/e25111509
APA StyleEl-Yaagoubi, A. B., Chung, M. K., & Ombao, H. (2023). Topological Data Analysis for Multivariate Time Series Data. Entropy, 25(11), 1509. https://doi.org/10.3390/e25111509