1. Introduction
Rotating machinery plays an important role in the development of modern industry. The faults will cause shutdown. The timely and effective fault diagnosis of rotating machinery is good for reducing maintenance costs and shorting the shutdown time. Thus, it is important to develop effective fault diagnosis systems for rotating machinery, and artificial intelligence (AI) [
1] has been widely utilized for the fault diagnosis of rotating machinery, such as bearings, gears (or gearboxes), engines and turbines. There are two kinds of AI methods for fault diagnosis: machine learning [
2] and deep learning [
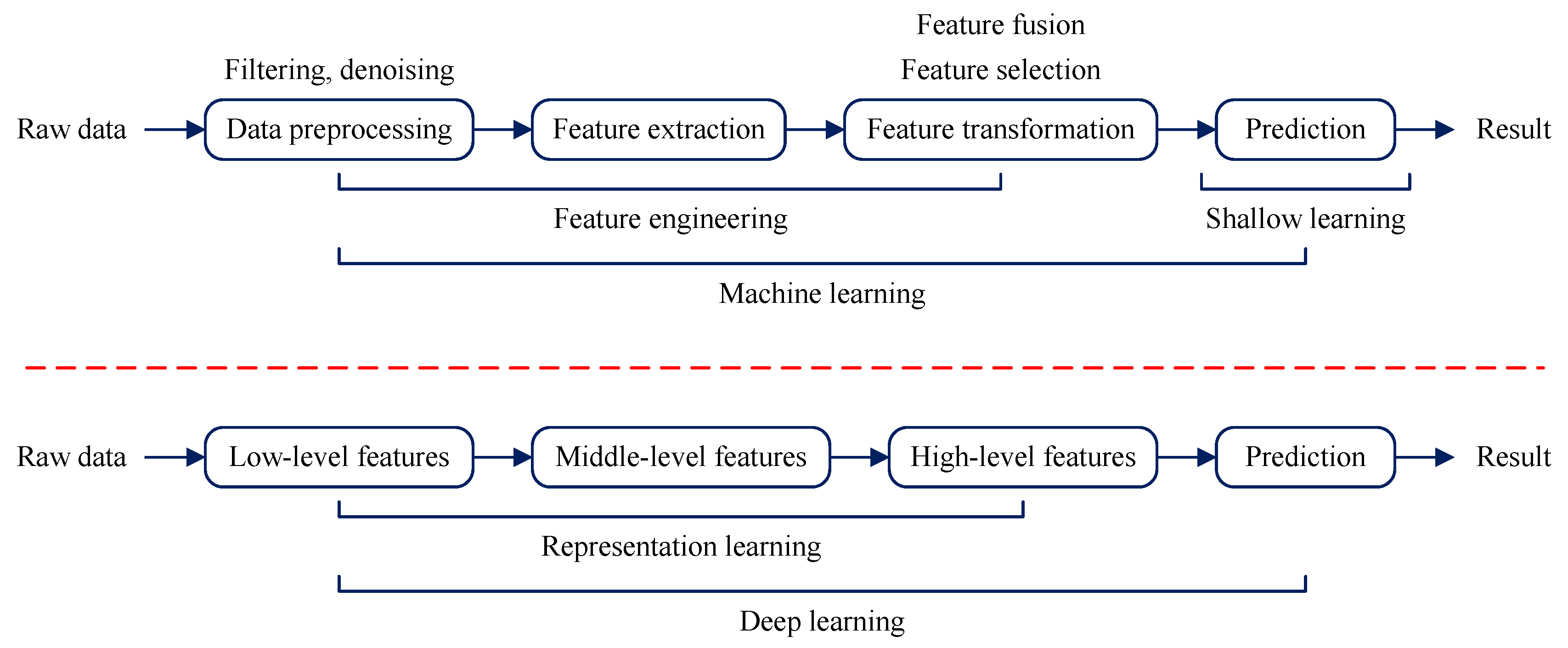
3], as shown in
Figure 1. As for machine learning, it consists of feature engineering and shallow learning. It should be noted that feature engineering generally needs experience to select ‘good’ features, and consider the time-consuming of modeling, thus, the feature engineering of machine learning is the research object in this work.
Feature engineering plays a significant role for the predictive performance of the fault diagnosis system. From the previous studies, it can be found that feature engineering mainly includes three aspects: data preprocessing, feature extraction, and feature transformation. As for feature extraction, the commonly used are the time-domain, the frequency-domain, and the time-frequency domain features [
4]. It should be noted that the commonly used signal decomposition techniques can provide numerous time-frequency domain features for the fault diagnosis of rotating machinery, such as wavelet transform (WT) [
5], wavelet package transform (WPT) [
6,
7,
8], and empirical model decomposition (EMD) [
6,
9,
10,
11,
12,
13]. Normally, the time-frequency domain features are obtained by extracting statistical features, energy, energy ratio, energy entropy or Shannon entropy from sub-signals that are obtained by WT, WPT or EMD. Moreover, excellent feature extraction methods also need to be developed for further improving the diagnostic performance of the decision-making system. Muruganatham et al. [
14] applied a singular spectrum analysis (SSA) to extract fault features of roller element bearing. Singular values (SV) and energy of the corresponding principal components of the selected SV were adopted as fault features, respectively. Experimental results showed that the presented method was simple, noise immune and efficient. Liu et al. [
15] proposed a short-time matching method based on a kind of atomic decomposition (i.e., matching pursuit). Experimental results showed that the proposed method outperformed the traditional time-domain methods in detecting a bearing incipient fault. Cai et al. [
16] proposed a sparsity-enabled signal decomposition method by the combination of a tunable Q-factor WT and morphological component analysis (MCA). Experimental results showed that the proposed method outperformed EMD and spectral kurtosis in identifying a gearbox fault. Li et al. [
17] proposed a novel extraction method of deep representation features by utilizing a Boltzmann machine to fuse statistical parameters of WPT. Experimental results showed that the proposed method outperformed the corresponding shallow representations in gearbox fault diagnosis. Gao et al. [
18] applied an empirical wavelet transformation (EWT) in time series forecasting. Different from discrete WT, EWT analyzes the data in Fourier domain and implements the spectrum separation, which may make it suitable for analyzing complex and non-stationary vibration signals, especially for rotating machinery. From the previous studies [
14,
15,
16,
17,
18], it can be found that how to obtain effective fault features through feature engineering or representation learning is an extremely important and complex task in the fault diagnosis of rotating machinery.
In general, the extracted features contain some invalid and redundant features, which will affect the efficiency and accuracy of modeling. Thus, feature transformation is necessary to remove the noise and redundancy features, to improve the predictive performance of rotating machinery fault diagnosis system. Feature selection can remove invalid features that are not sensitive to fault information of rotating machinery. The commonly used feature selection methods include classification accuracy evaluation [
11], distance evaluation technique [
12] and genetic algorithm (GA) [
19,
20]. Compared with feature selection, feature fusion is a better method, which is conductive to removing noise and redundancy simultaneously. The commonly used feature fusion methods include principal components analysis (PCA) [
7], kernel PCA (KPCA) [
7], and manifold learning [
5,
6,
7,
13]. Yu [
5] utilized the locality preserving projection (LPP) to fuse the original features for the bearing fault diagnosis and found that LPP performed better than PCA. Li et al. [
6] utilized locally linear embedding (LLE) to extract distinct features for gear fault diagnosis and found that LLE performed a little better than PCA (less than 1%). In the identification of different gear crack levels, Wan et al. [
7] utilized five methods (PCA, KPCA, ISOMAP, LLE and Laplacian Eigenmaps) to carry out dimension-reduction and found that PCA performed the best. Moreover, they pointed out that more case studies should be investigated so as to check whether PCA was still effective. Tang et al. [
13] applied orthogonal neighborhood preserving embedding (NPE) for dimension-reduction with regard to turbine fault diagnosis, and found that orthogonal NPE (ONPE) performed better than LPP and LLE. It is worth noting that PCA and KPCA belong to global-preserving techniques while manifold learning (LPP, LLE, NPE, ISOMAP, and Laplacian Eigenmaps) belong to local-preserving techniques [
5,
21]. In addition to [
5,
6], image recognition tasks also proved that local-preserving techniques were more suitable for classification problems [
22,
23]. Thus, manifold learning is recommended for dimension-reduction in the fault diagnosis of rotating machinery. However, how to determine the model parameters and the dimension of the fused features of manifold learning are two thorny problems.
As for the construction of a decision-making system, many machine learning methods have been utilized for fault diagnosis of rotating machinery, such as
k-nearest neighbors (
k-NN) [
6,
11], artificial neural network (ANN) [
8,
14,
19,
20], support vector machine (SVM) [
9,
12,
13,
15], least square SVM (LS-SVM) [
10], and the hidden Markov model (HMM) [
24]. In these methods,
k-NN is easy to understand and implement. However,
k-NN requires a large amount of calculation since the distance from test points to all samples must be calculated to obtain the
k nearest neighbors. Moreover,
k-NN is very vulnerable to sample unbalance. Objectively speaking, ANN, SVM and HMM are more pertinent choices. Nevertheless, how to determine the hyper parameters of ANN, SVM and HMM is a thorny problem, especially for novice researchers. Moreover, these methods [
6,
8,
9,
10,
11,
12,
13,
14,
15,
19,
20,
24] do not belong to a true sparse model, since all features of test points need to participate in calculation. Thus, on the premise of guaranteeing the diagnostic performance, how to develop a true sparse model and greatly reduce the test time is a great challenge.
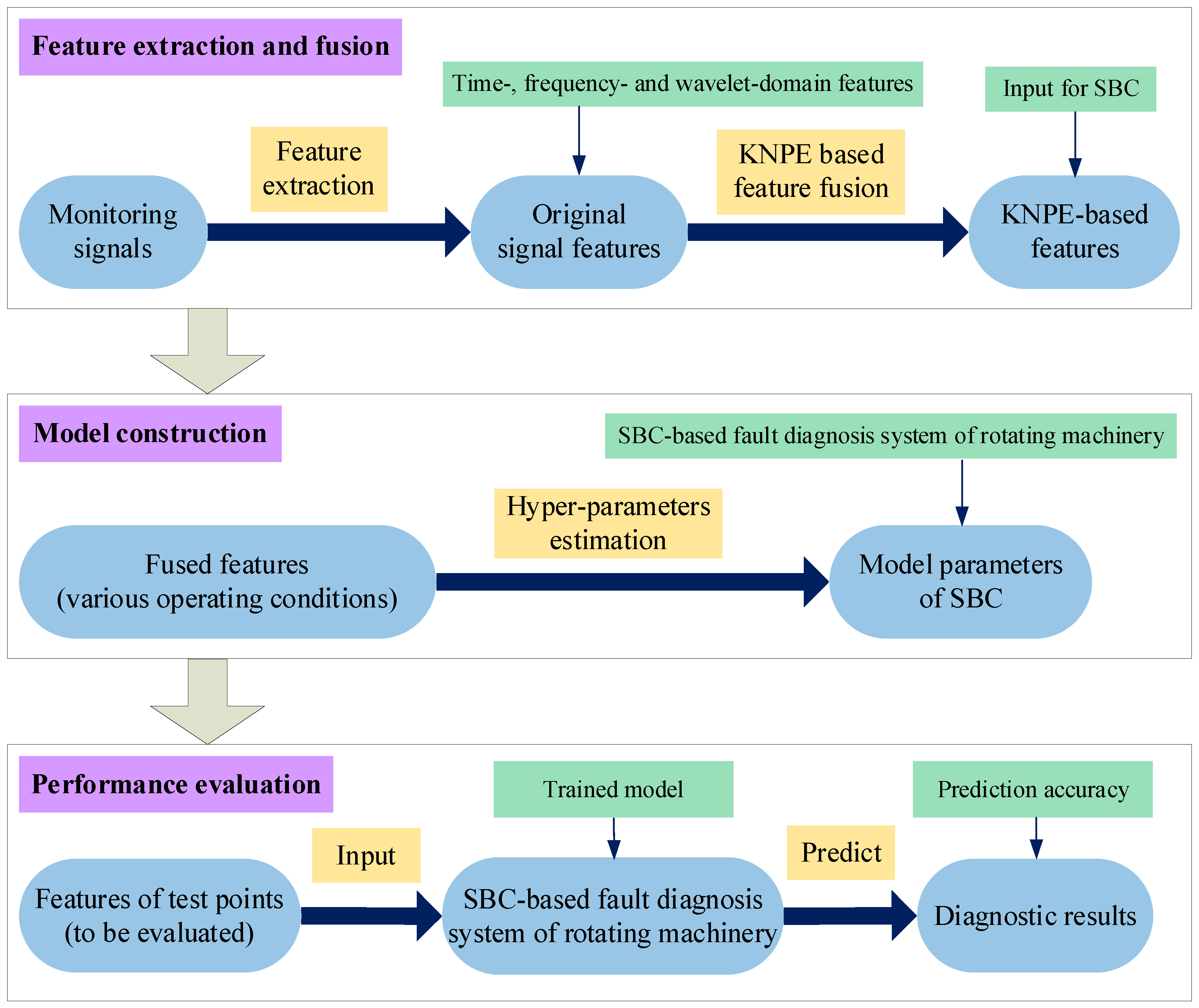
In this work, we intend to study from two aspects: feature fusion and model construction, about fault diagnosis of rotating machinery. As for the traditional manifold learning methods [
5,
6,
7,
13], the model parameters and the dimension of the fused features are hard to determine. To solve these problems, a novel dimension-increment technique is proposed for feature fusion. Kernel neighborhood preserving embedding (KNPE) is realized by the combination of KPCA [
25] and NPE [
26]. KNPE is conductive to enriching the valid information related to a rotating machinery fault by utilizing the dimension-increment method. Moreover, a novel sparse Bayesian classification (Standard_SBC) method is proposed for model construction, which aims to optimize hyper parameters, overcome non-sparsity and reduce time consumption. Standard_SBC is a variant version of the relevance vector machine (RVM) [
27], by removing the kernelization operation. This gives Standard_SBC two advantages: (1) no kernel parameter needs to be optimized in model construction; (2) it automatically selects out more important features in model construction, i.e., integrating feature selection into model construction. This avoids the process of optimization of kernel parameter and feature selection, which greatly reduces the time-consumption of system modeling and helps to realize rapid modeling. In the previous studies [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
19,
20,
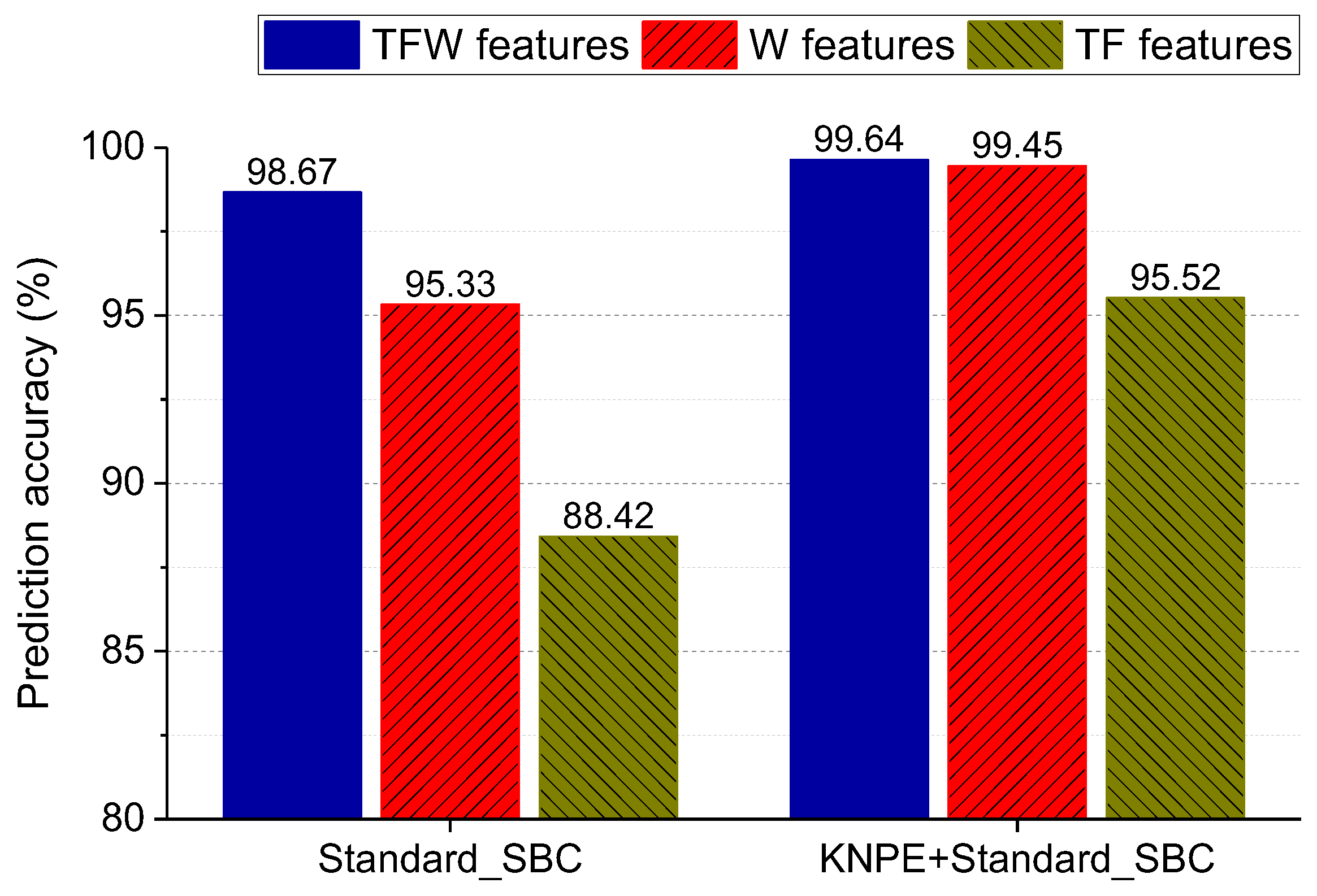
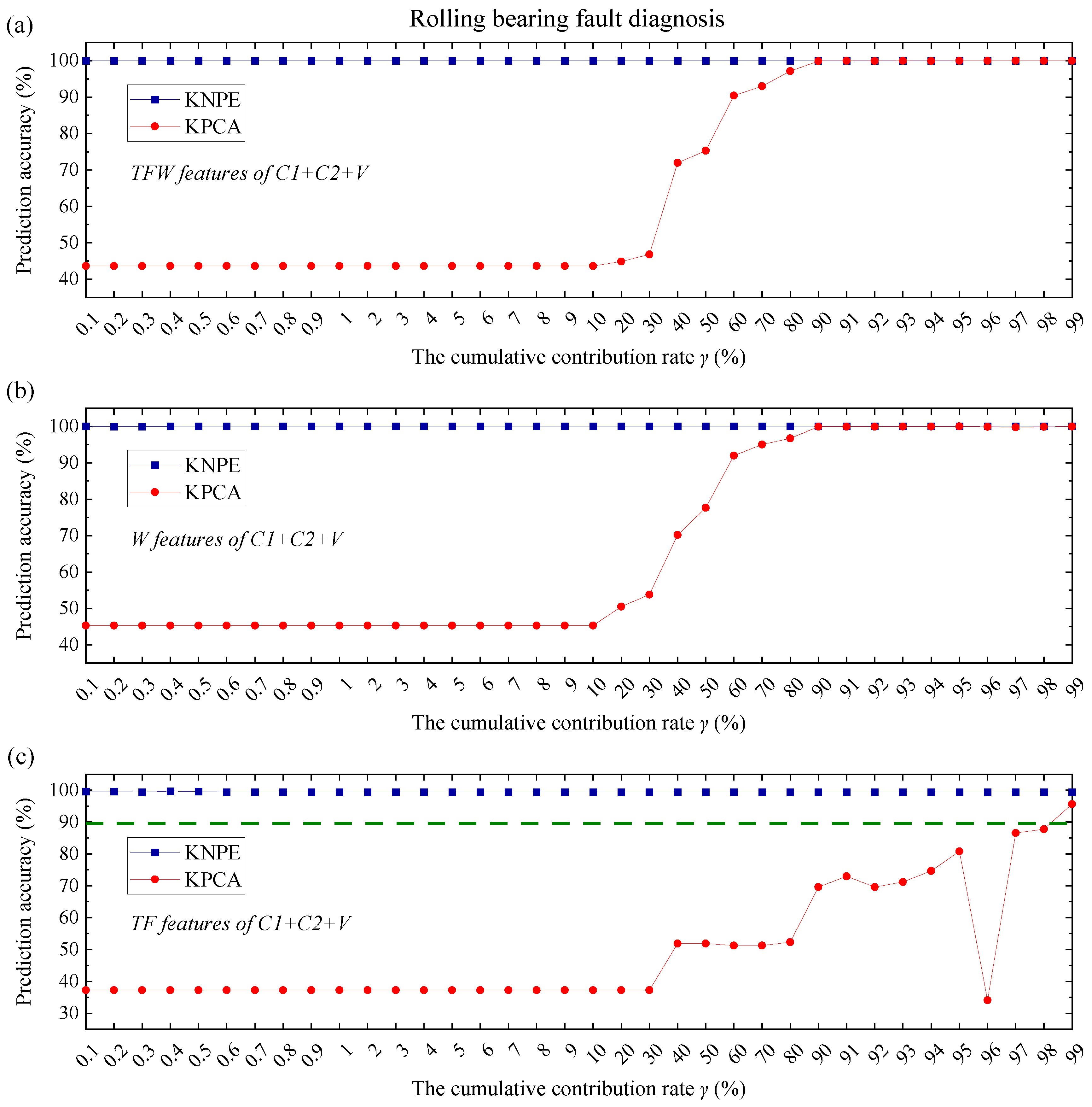
24], determination of the features is independent of the model construction for the fault diagnosis of rotating machinery. It is worth noting that the combination of KNPE and Standard_SBC avoids the determination of feature dimension (a problem that must be solved in traditional dimension-reduction methods), which greatly reduces the workload of feature engineering. In short, the fused features of KNPE are adopted as the input of Standard_SBC, with the aim to construct a more effective SBC-based fault diagnosis system. To show the superiority of KNPE and Standard_SBC, KPCA and RVM are utilized for feature fusion and model construction, respectively.
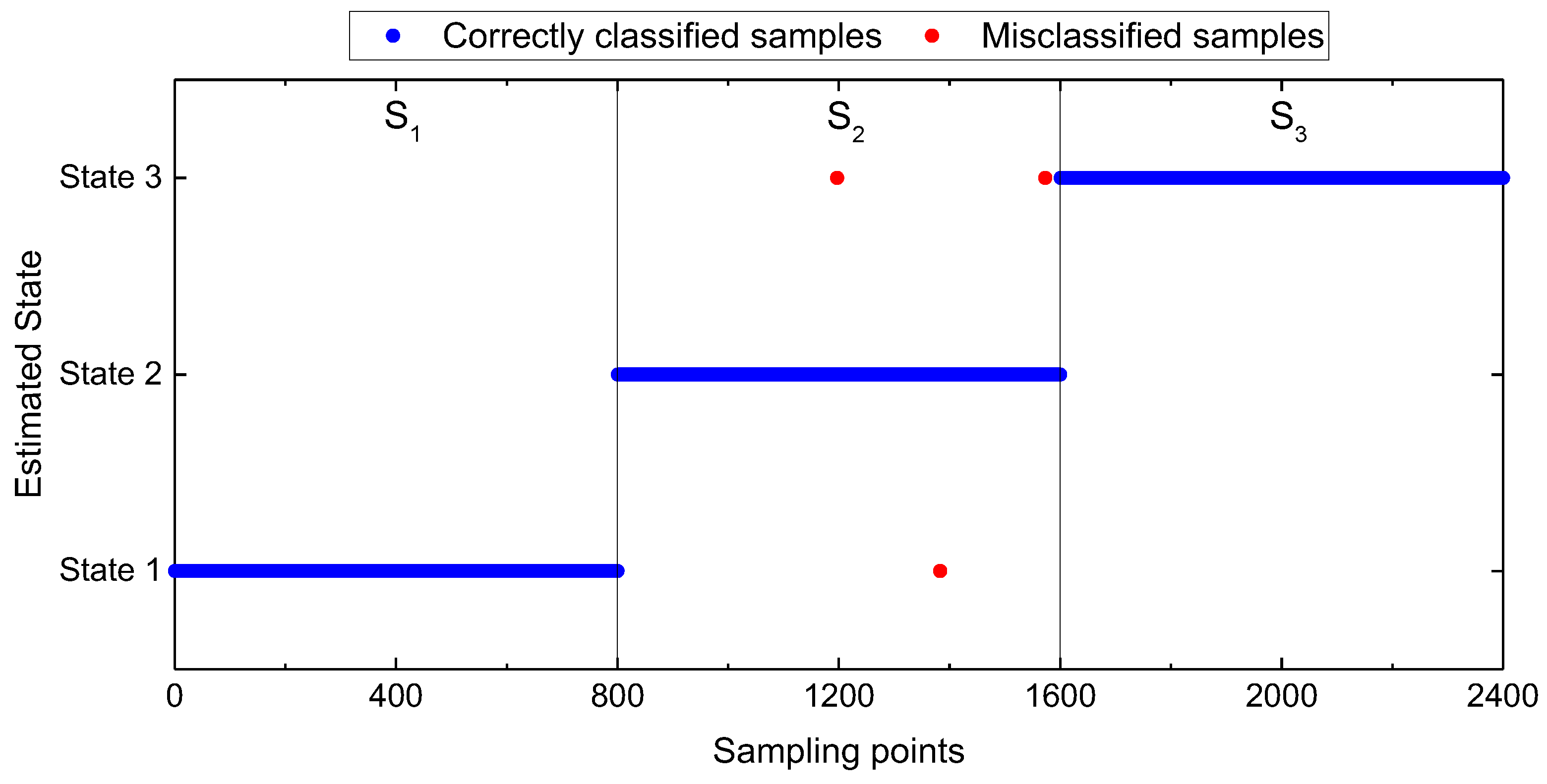
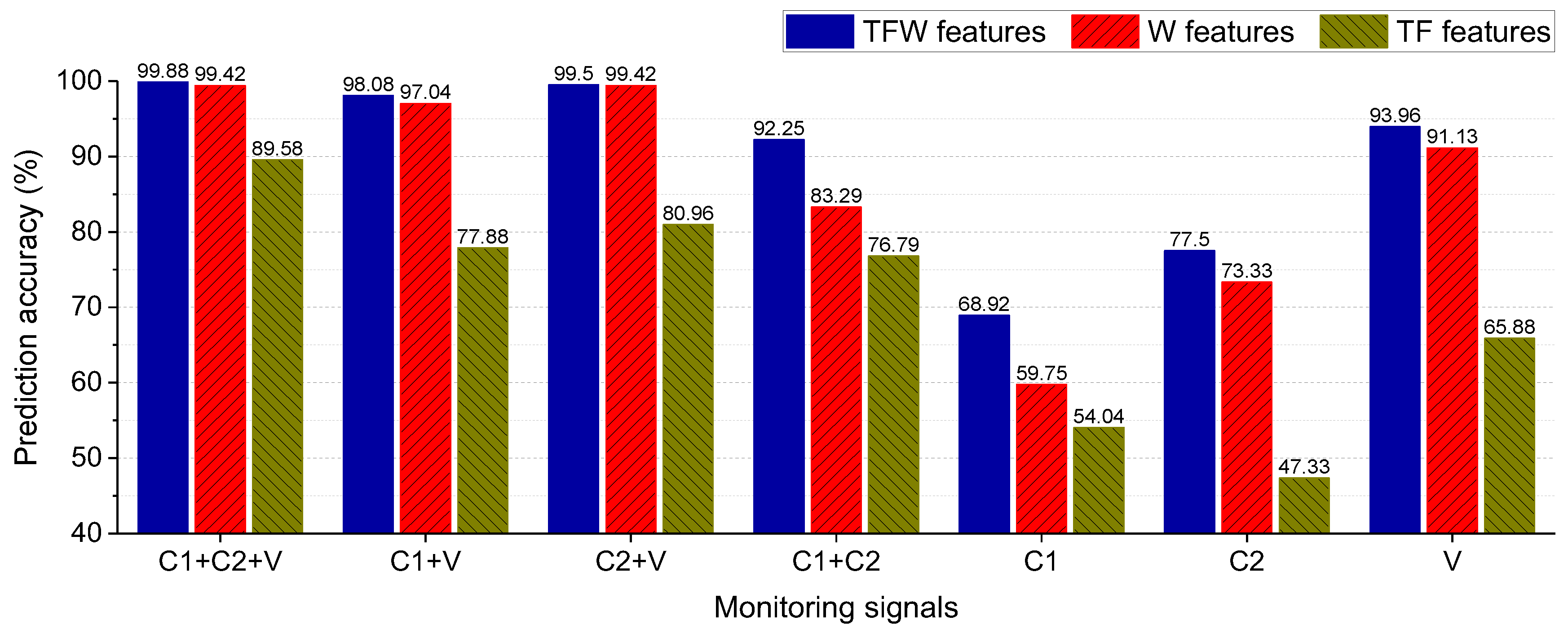
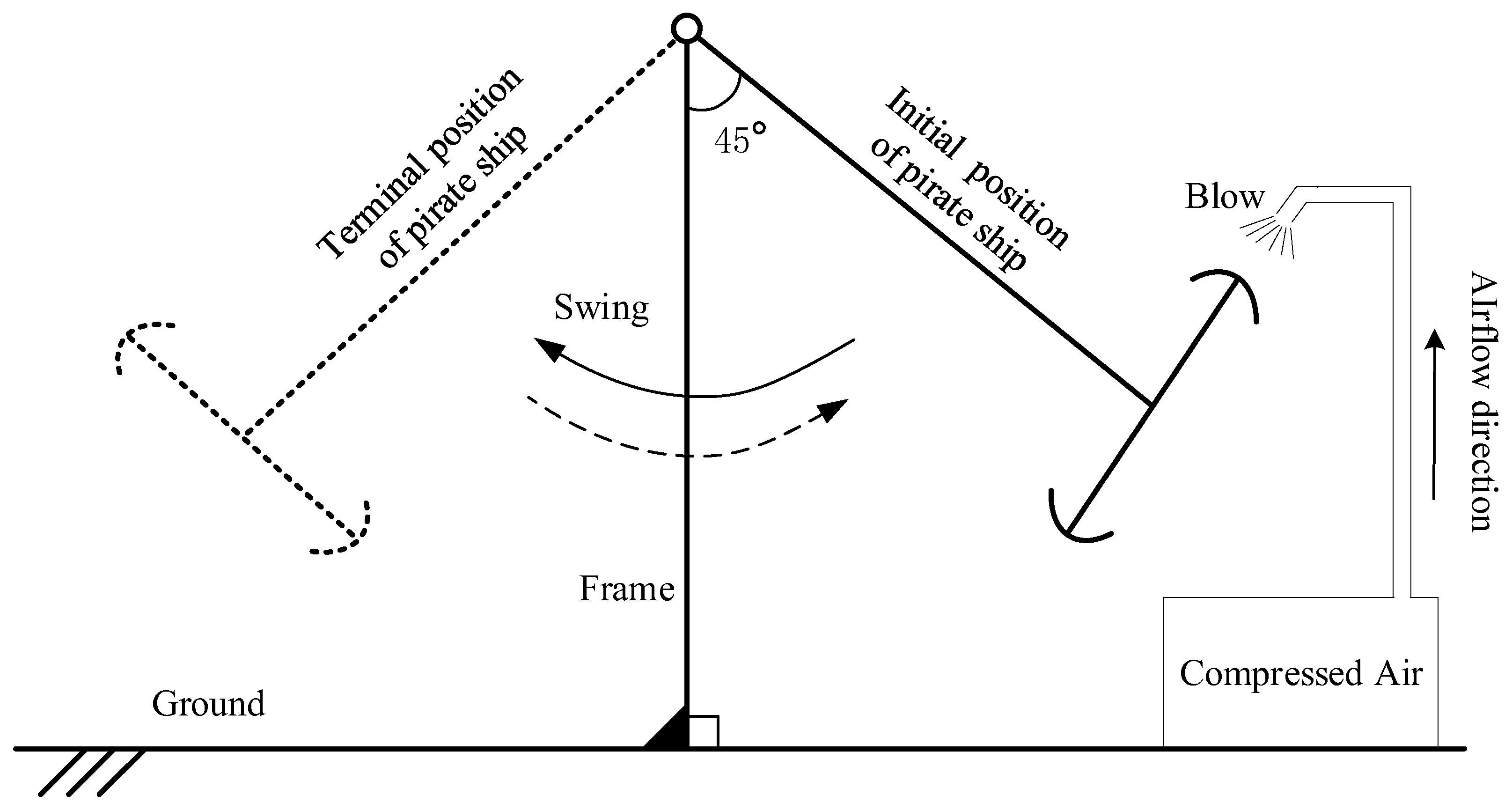
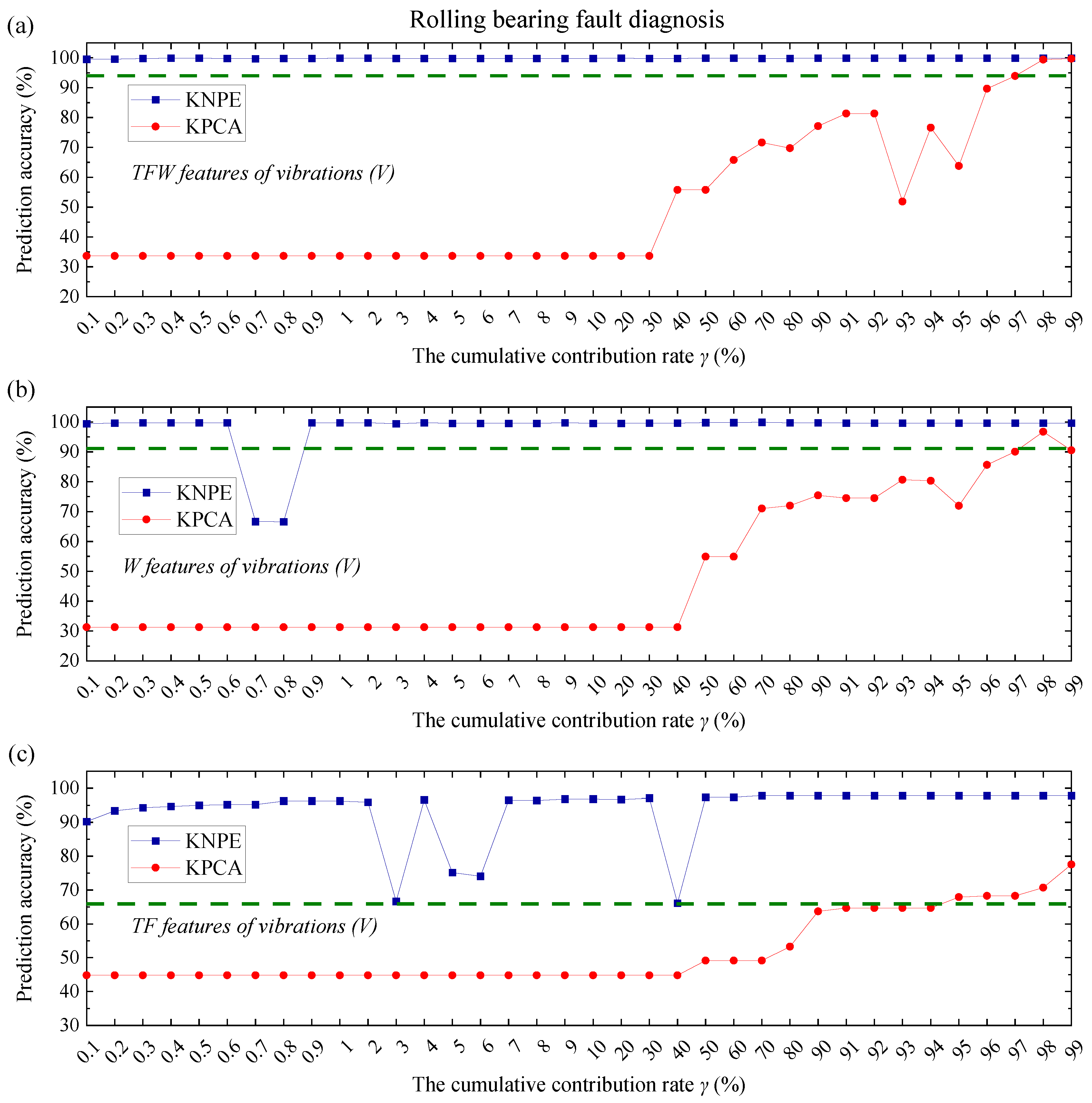
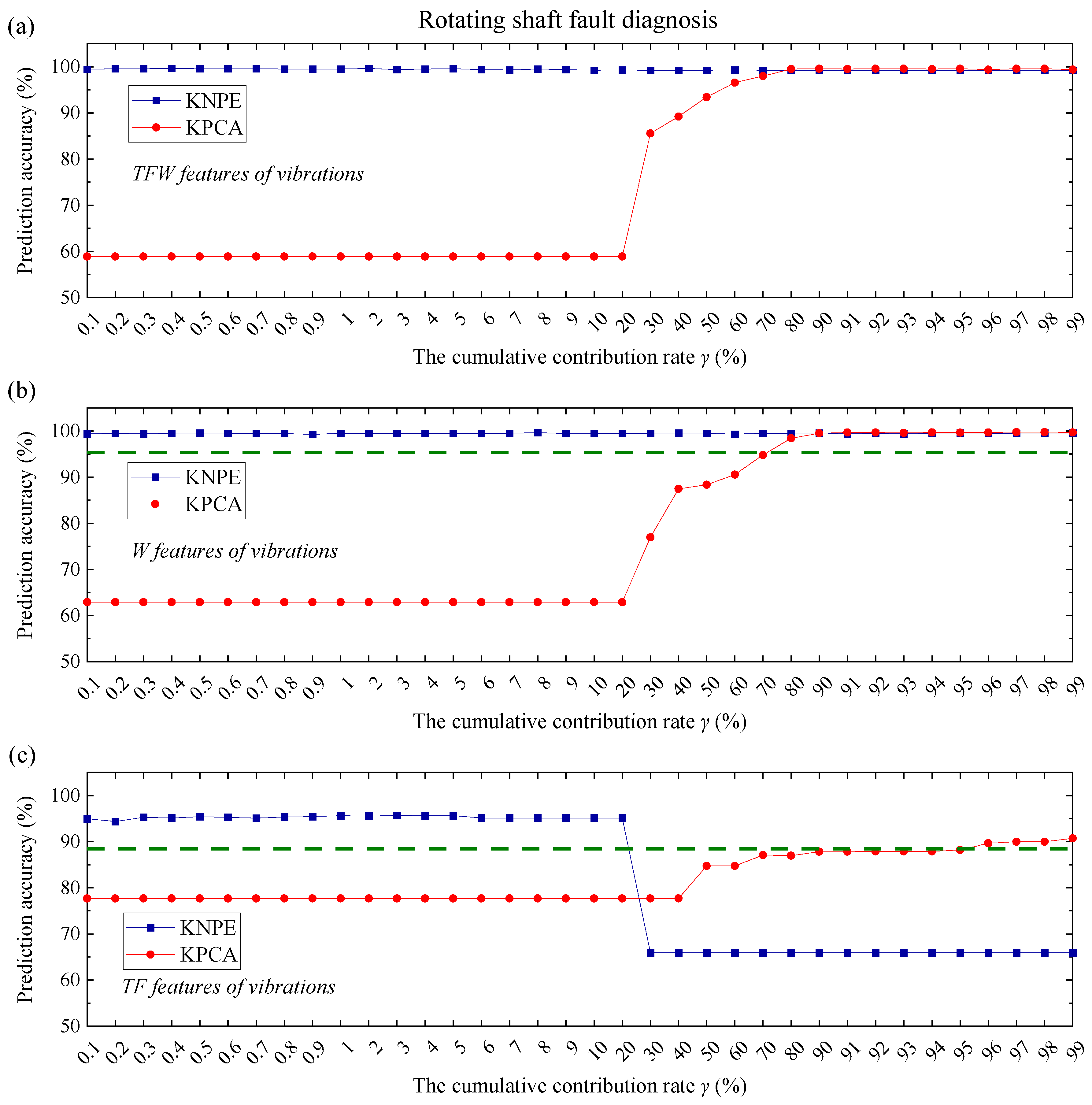
In this work, two application cases are analyzed to show the effectiveness of the presented method (KNPE + Standard_SBC). The first one is rolling bearing fault diagnosis. The experimental data are obtained from the Bearing Data Center of Paderborn University [
28,
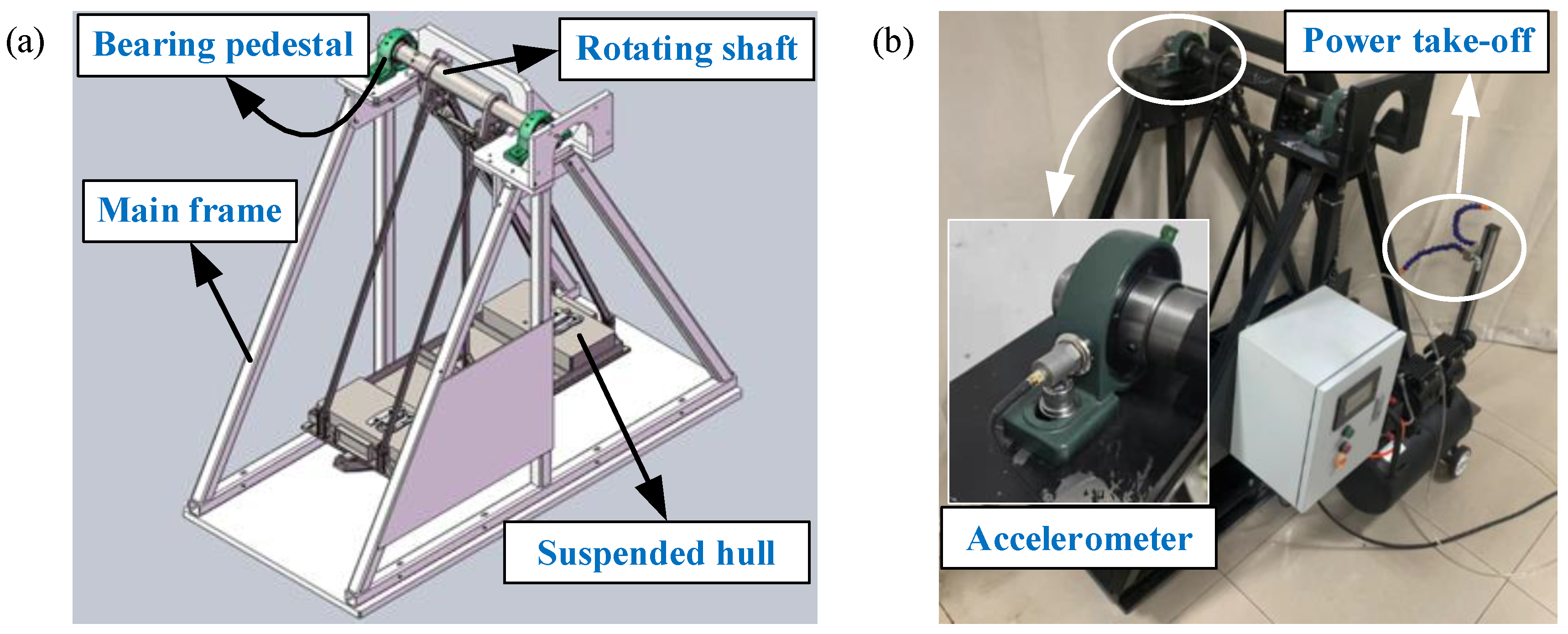
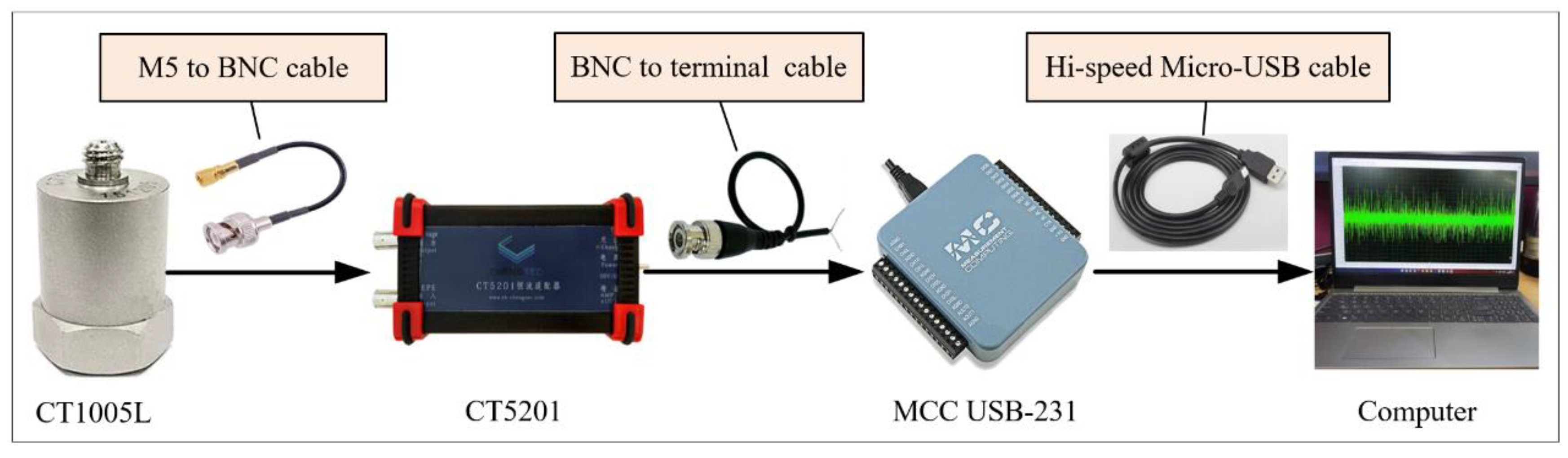
29]. Another one is the rotating shaft fault diagnosis. The manned recreational facility “Pirate Ship” is popular because of its extreme overweight and weightlessness experience. How to ensure the safe operation of the pirate ship is the top priority. The pirate ship is a kind of large semi-rotating machinery, and the rotating shaft of the suspended hull is subjected to tension and friction for a long time. Once the rotating shaft of the suspended hull fails, it will cause equipment damage and even casualties. Thus, the rotating shaft fault diagnosis is necessary to ensure the safe operation of the pirate ship.
The following are the main contributions of our paper:
- (1)
A new classification method abbreviated as Standard_SBC is firstly proposed, which aims at rapidly constructing the sparse diagnostic model.
- (2)
A new dimension-increment technique abbreviated as KNPE is firstly proposed, which aims at enriching the valid information related to the rotating machinery fault.
- (3)
Standard_SBC can automatically select out more important features from the fused features of KNPE, which greatly simplifies the SBC-based model. The combination of KNPE and Standard_SBC is conductive to rapidly constructing an effective and feasible fault diagnosis system for rotating machinery.
- (4)
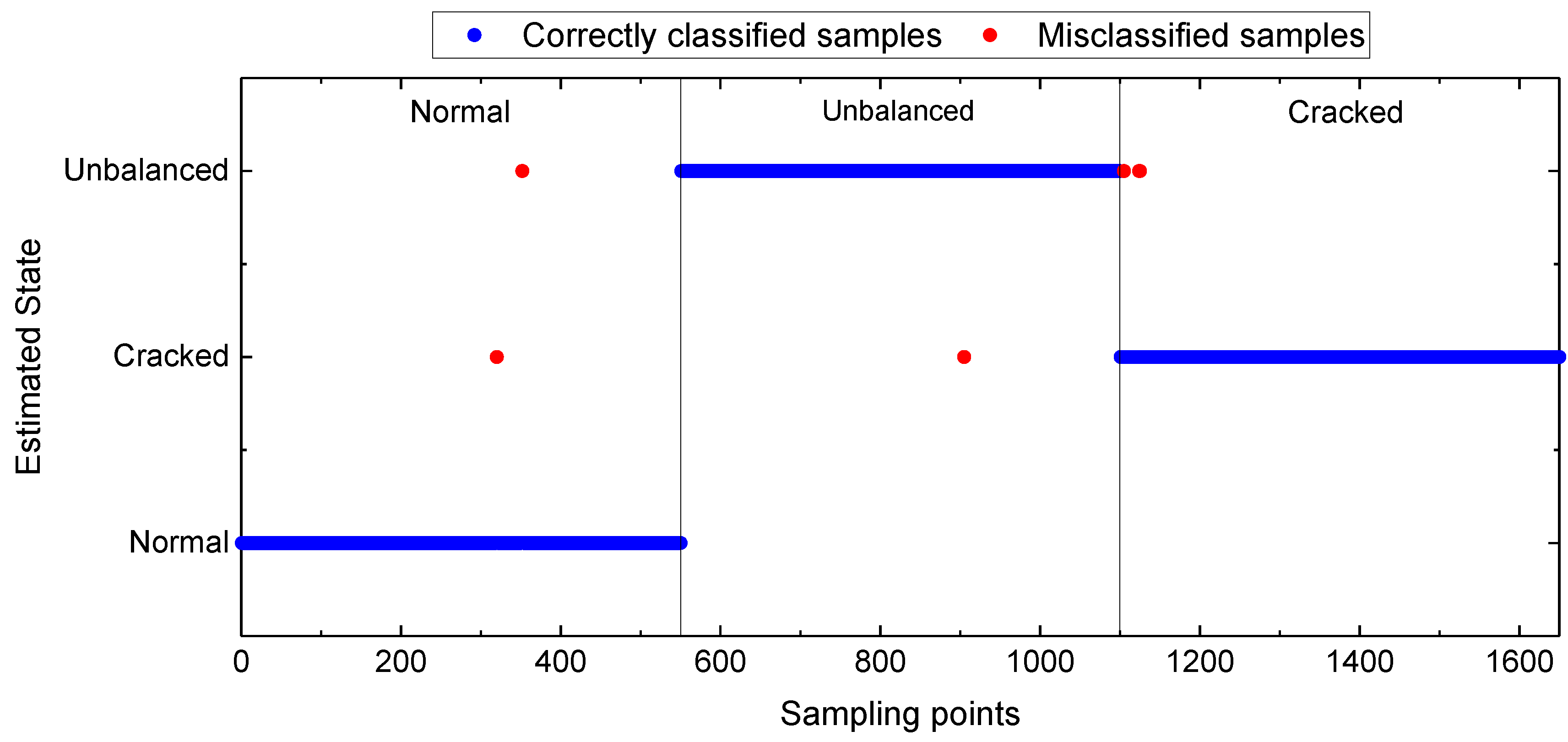
A superior diagnostic performance is demonstrated by Standard_SBC when supported by KNPE. Two case studies (on the rolling bearing fault diagnosis and rotating shaft fault diagnosis) validate the effectiveness of KNPE and Standard_SBLR fault diagnosis systems.
The following is the organization of this paper. The background of KNPE and SBC is presented in
Section 2.
Section 3 presents the fault diagnosis system based on KNPE and Standard_SBC.
Section 4 analyzes the presented model and presents the experimental results. Other details about KNPE, Standard_SBC, and future research are provided in
Section 5. The paper is concluded in
Section 6.
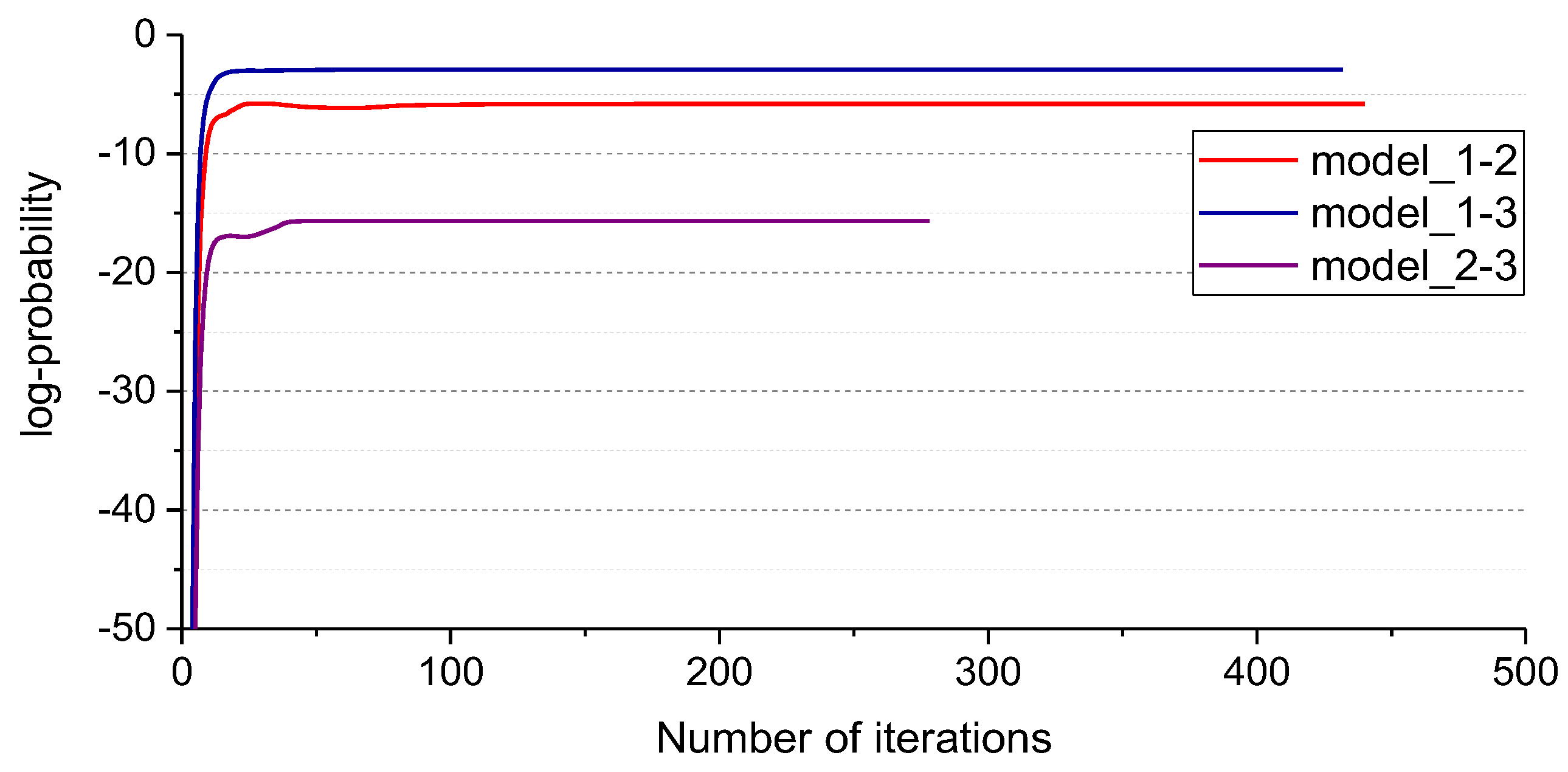
5. Discussion
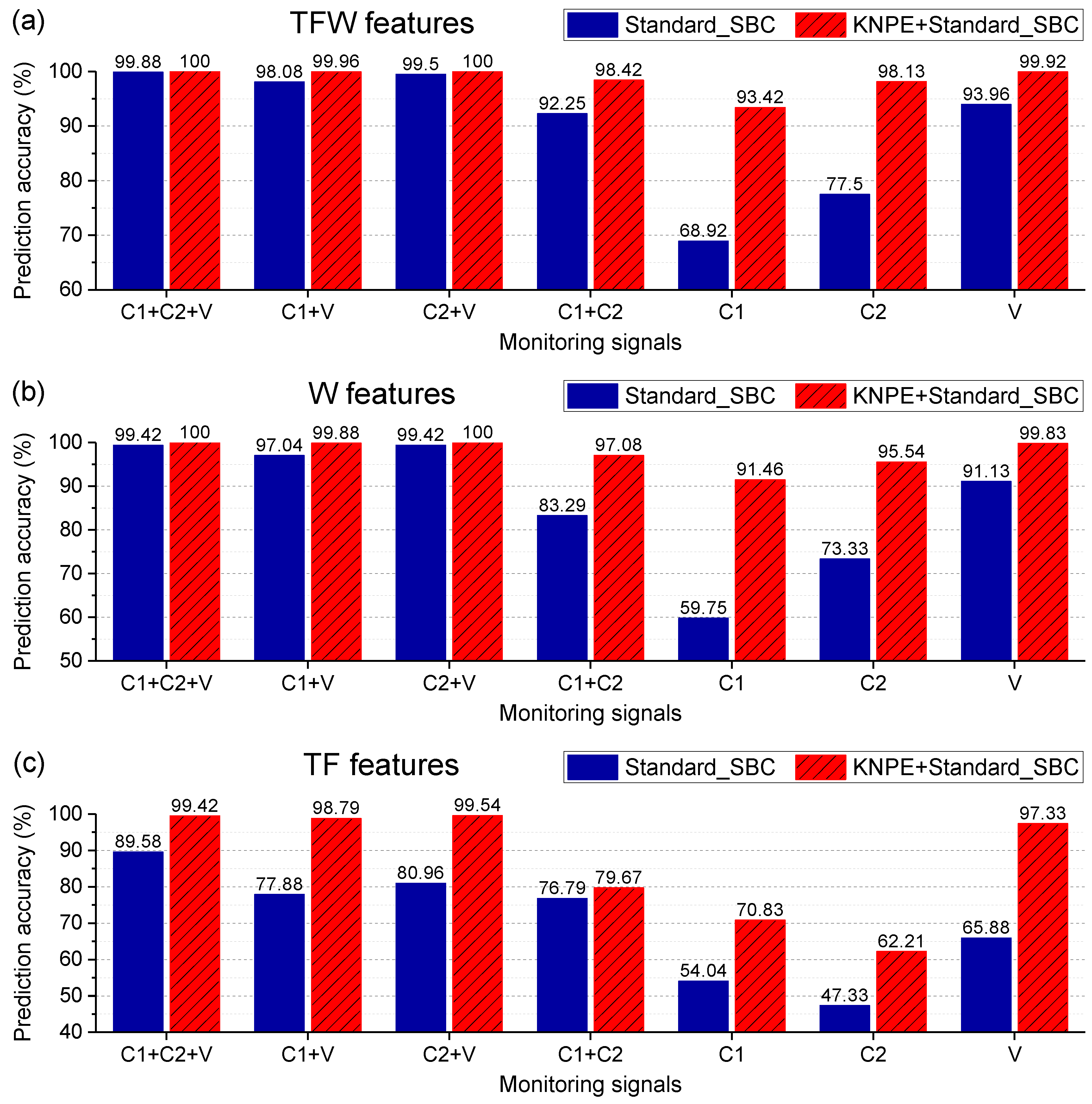
In this work, Standard_SBC is proposed on the basis of sparse Bayesian classification (SBC). Sparseness is an attribute of SBC. As for Kernelized_SBC (i.e., RVM), sparseness is directed against the training samples. However, as for Standard_SBC, sparseness is directed against the dimensions of training samples. In comparison with Kernelized_SBC, the superiority of Standard_SBC is that no kernel parameter needs to be optimized in model construction, which is conductive to rapid modeling.
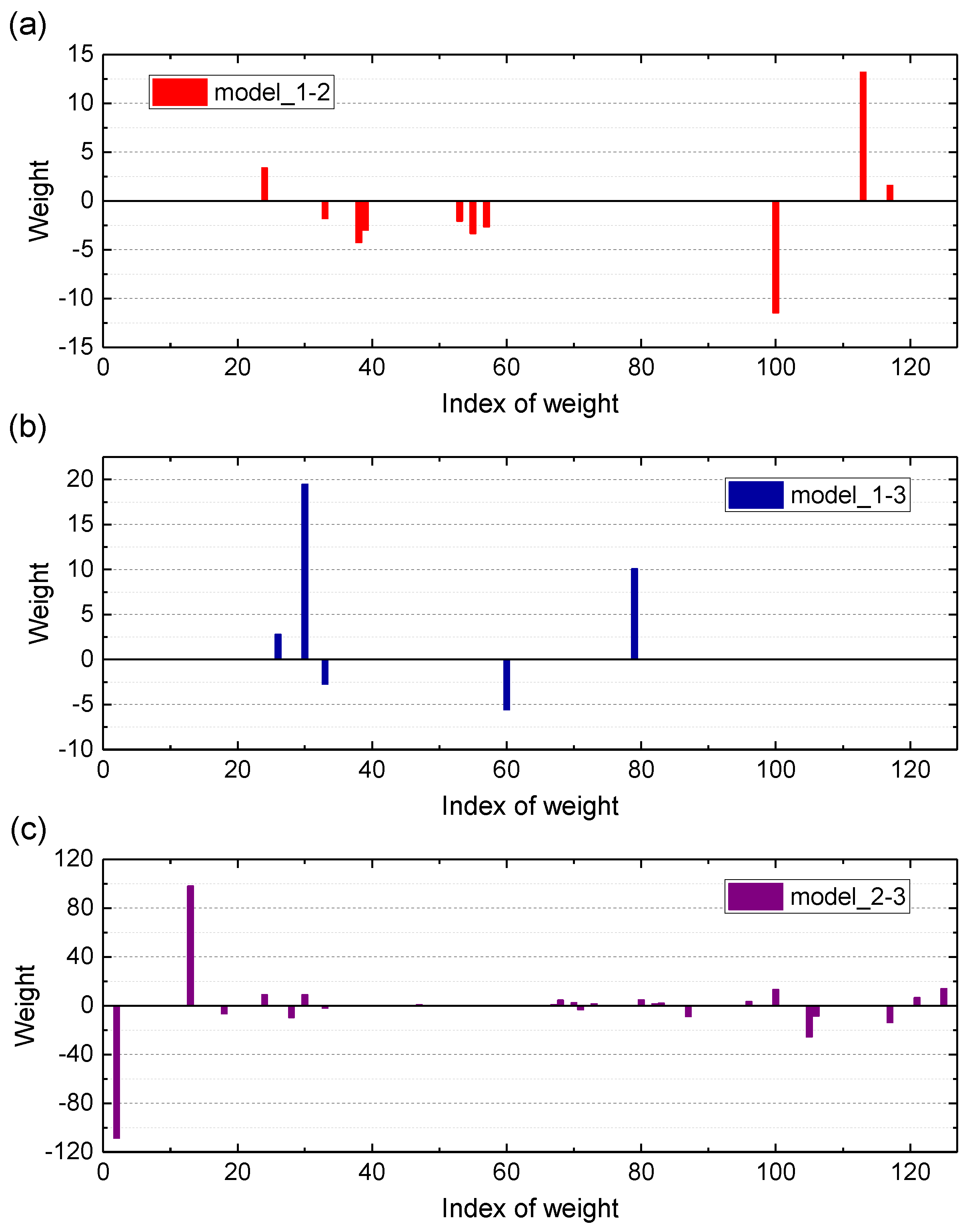
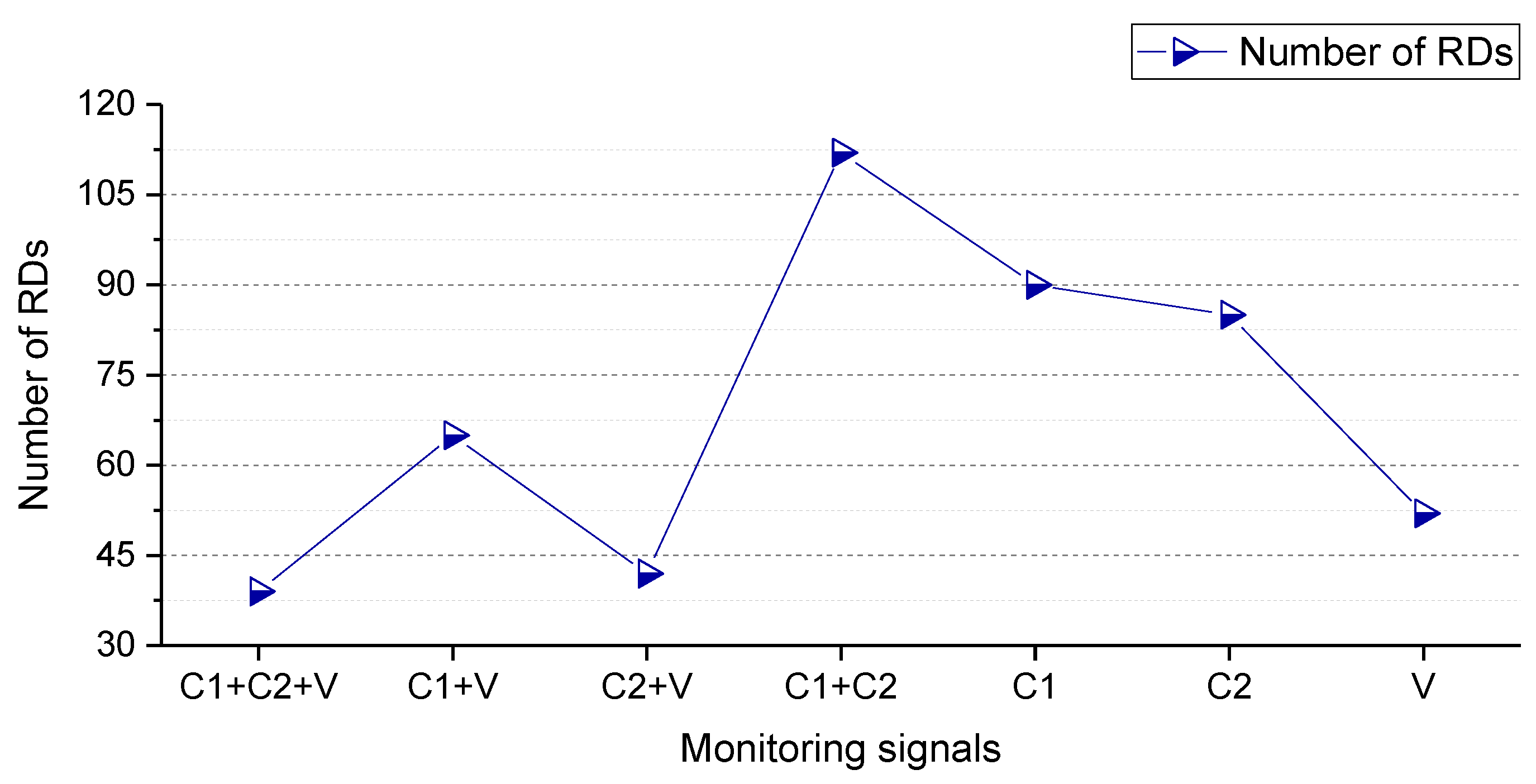
It is worth noting that the sparsity connotation of Kernelized_SBC and Standard_SBC is different. As for Kernelized_SBC (i.e., RVM), its sparsity refers to only the ‘relevance vectors’ (RVs) are involved in decision making, as given by Equation (35). However, all the dimensions of the test points need to be involved in the calculation for decision making. As for Standard_SBC, its sparsity refers to only the ‘relevance dimensions’ (RDs) being involved in decision-making, as given by Equation (34), i.e., only a small percentage of the dimensions of the test points need to be involved in the calculation for decision making. From the perspective of the number of the dimensions of the test points involved in decision making, the proposed Standard_SBC belongs to a true sparse predictive model.
Moreover, KNPE is proposed by the combination of KPCA and NPE. In this work, the parameters ( and ) of KNPE are determined by training. There is no doubt that a selection of the model parameters ( and ) will affect the effectiveness of the KNPE-based fusion features. In the following research, the selection and optimization of the parameters ( and ) of KNPE will be carried out.
As mentioned in the previous sections, KNPE is a novel feature dimension-increment method. It means that the dimension of the KNPE-based fusion features may be much larger than that of the original features, which greatly enriches the valid information related to the rotating machinery fault. However, a large number of features will greatly increase the complexity of the diagnostic model. Fortunately, Standard_SBC can automatically select more important features from the fused features of KNPE, which avoids the generation of more complex diagnostic models that may be caused by a dimension-increment operation. This greatly simplifies the SBC-based fault diagnosis system of rotating machinery.
In future research, the fault diagnosis system of rotating machinery based on KNPE and Standard_SBC will be validated through more case studies, such as rotor fault diagnosis and gear fault diagnosis. In addition, KNPE and Standard_SBC will be applied to other fields as well.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}