
Spectral Clustering Community Detection Algorithm Based on Point-Wise Mutual Information Graph Kernel


Abstract
1. Introduction
2. Related Work
2.1. Traditional Algorithms for Estimating the Number of Communities
2.2. Graph-Kernel-Based Spectral Clustering Algorithm
3. BI-CNE Algorithm
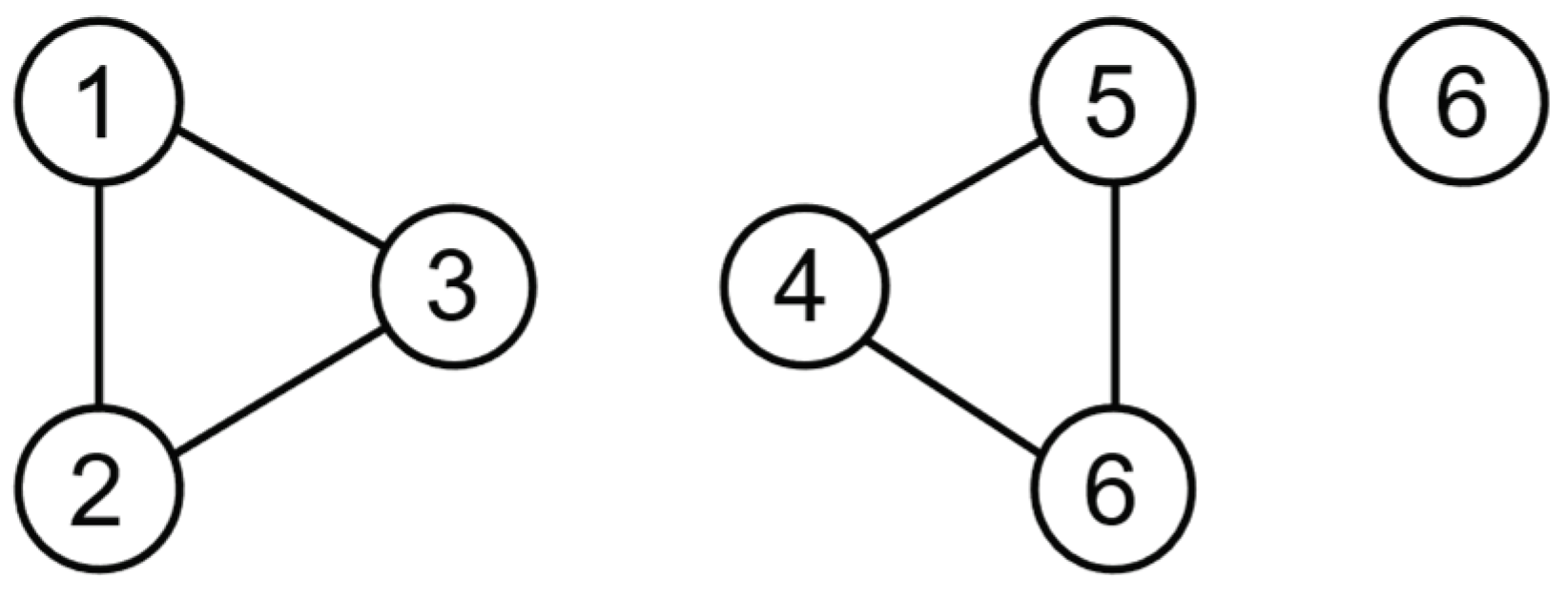
3.1. Network Pruning Reconstruction
3.2. Bayesian Inference
3.3. Monte Carlo Sampling
- Move node from community to an existing community , then
- Move node to a new community, then .
- (1)
- Initialization: Disorder the nodes and assign them to the given maximum communities; note that there is no empty community here.
- (2)
- Sampling: Execute Operation 1 with probability or Operation 2 with probability .
- Operation 1: Randomly select communities ,. Randomly select a node from community and move it to community . If node is the last node of community , then delete community and renumber the communities, and that makes .
- Operation 2: Randomly select a community . Randomly select a node from community and move it to a new empty community . If node is the last node of community , this operation is rejected, and remains unchanged. Otherwise, it makes .
- (3)
- Accept the operation: The operation in Step 2 will be accepted following the acceptance probability:
- (4)
- Repeat steps 2 and 3.
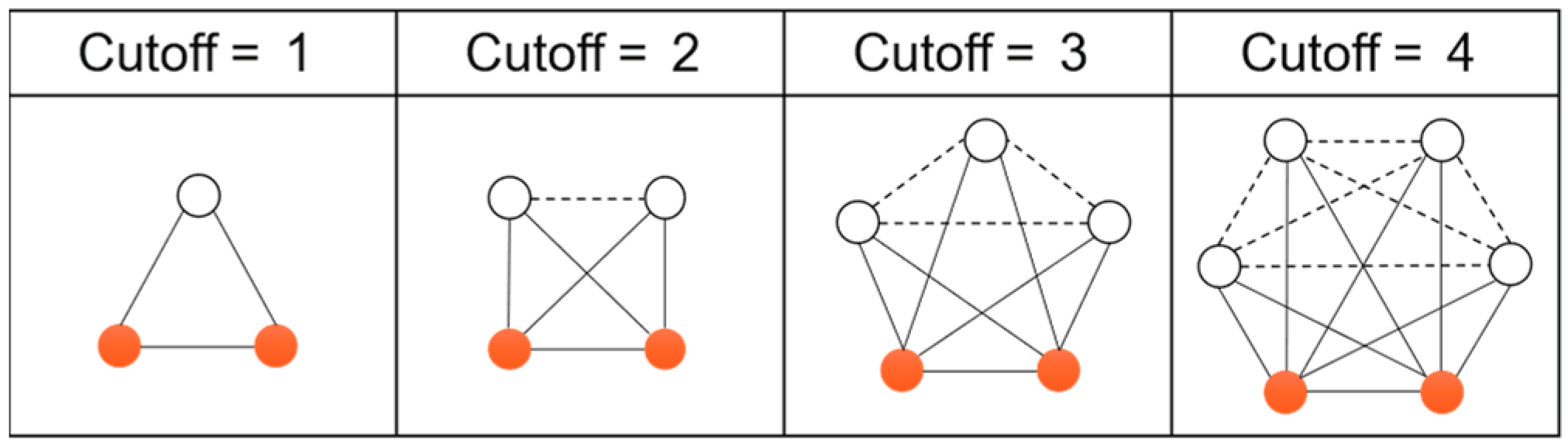
3.4. Sampling Acceleration
- Node is more closely connected to its neighboring communities;
- Community is more closely connected to the neighboring communities of node ;
- The size of the community is smaller.
4. PMIK-SC Algorithm
4.1. PMI-Kernel Derivation
- A large amount of structural information in non-isomorphic subgraphs is ignored.
- The positions of isomorphic sub-structures in the original network cannot be reflected by the kernels.
- The kernels only deal with small-size sub-structures, which cannot fully reflect the structural information of the network.
- The matrix is not symmetric since the transfer probability from node to node is not necessarily equal but determined by the degree of the two nodes and all possible paths starting from node and node .
- From the range of PMI values: , we know that there may be negative elements in the matrix.
4.2. Implementation
4.2.1. Number of Communities
4.2.2. Graph Reconstruction
4.2.3. Graph Cut Criterion
- (1)
- Calculate the first-order transfer probability matrix and the infinite-order transfer probability matrix according to Equation (18).
- (2)
- Calculate the PMI matrix , according to Equation (21).
- (3)
- Symmetrize and normalize to obtain the PMI-Kernel matrix .
- (4)
- Calculate the distance matrix using Equation (24).
- (5)
- Reconstruct the network based on by Equation (25) and obtain the weight adjacency matrix .
- (6)
- Construct the symmetric normalized Laplacian matrix using Equation (26).
- (7)
- Eigendecompose the Laplacian matrix to obtain the first smallest eigenvalues and the corresponding eigenvectors to form the feature matrix.
- (8)
- Perform k-means clustering on the row vectors of the feature matrix to obtain the final community partitioning result .
| Algorithm 1. PMIK-SC algorithm |
| Require: Adjacency matrix , number of communities |
| Ensure: Community partition |
| 1: |
| 2: |
| 3: |
| 4: |
| 5: |
| 6: for to do |
| 7: |
| 8: end for |
| 9: symmetrize and normalize |
| 10: proximities_to_distances() |
| 11: for to do |
| 12: if in KNN() or in KNN() then |
| 13: |
| 14: else |
| 15: |
| 16: end if |
| 17: end for |
| 18: |
| 19: |
| 20: |
| 21: |
| 22: |
| 23: |
| 24: return community partition result |
5. Experiment
5.1. Preparation of the Experiments
5.1.1. Datasets
5.1.2. Evaluation Indexes
5.1.3. Hardware Information
5.2. BI-CNE Algorithm Experiments
5.2.1. Network Pruning Reconstruction
5.2.2. Comparison Results
5.2.3. Sampling Acceleration
5.2.4. Complexity Analysis
5.3. PMIK-SC Algorithm Experiments
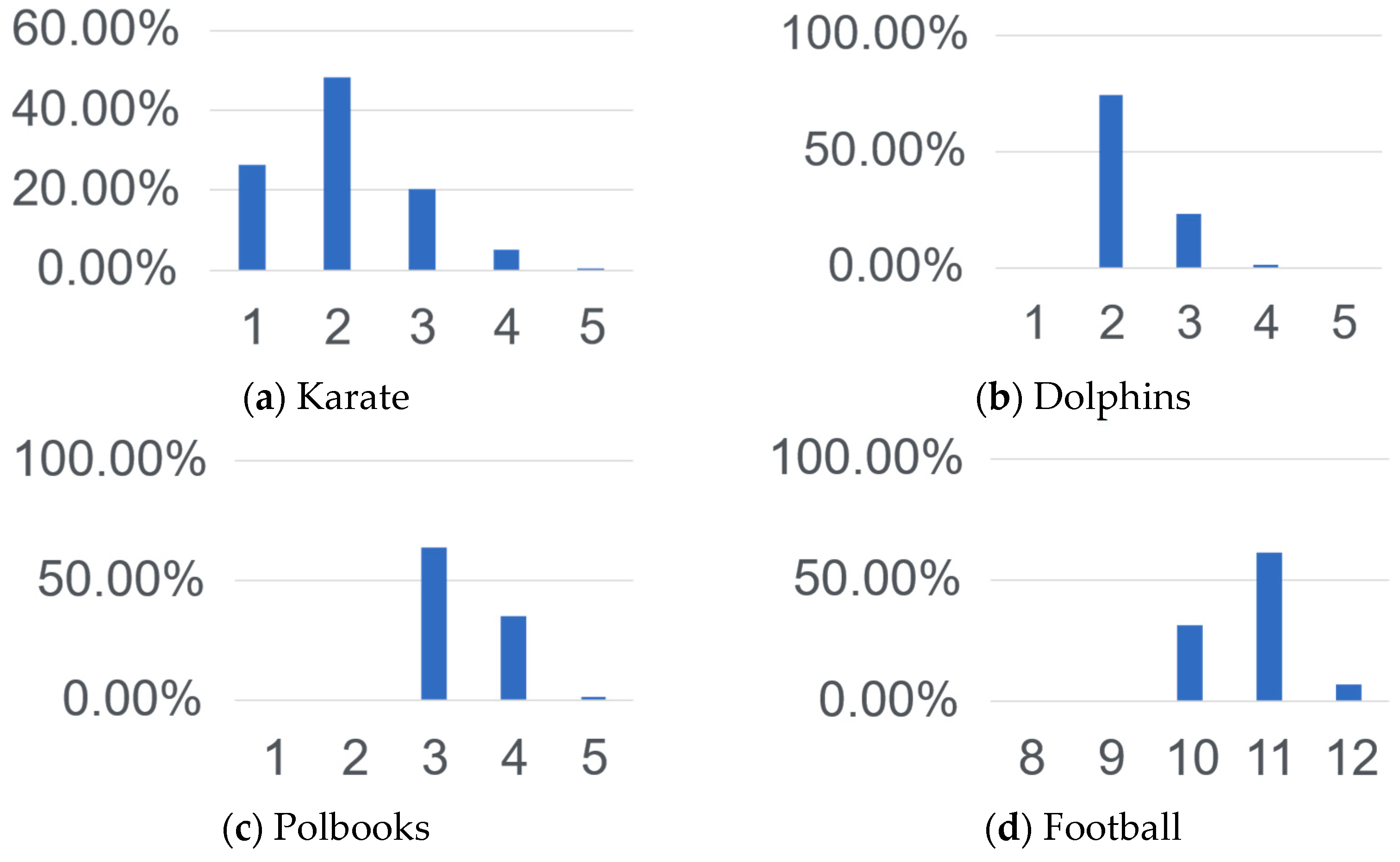
5.3.1. l-Order Transfer Probability Matrix for Approximating the Infinite-Order One
5.3.2. Complexity Analysis
5.3.3. Community Detection Tasks
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hofman, J.M.; Sharma, A.; Watts, D.J. Prediction and explanation in social systems. Science 2017, 355, 486–488. [Google Scholar] [CrossRef] [PubMed]
- Del Sol, A.; O’Meara, P. Small-world network approach to identify key residues in protein-protein interaction. Proteins 2005, 58, 672–682. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of small-world networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Newman, M.E.J.; Girvan, M. Finding and evaluating community structure in networks. Phys. Rev. E 2004, 69, 026113. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wang, C.; Li, D. MINC-NRL: An information-based approach for community detection. Algorithms 2022, 15, 20. [Google Scholar] [CrossRef]
- Chen, Y.; Li, D.; Ye, M. A multi-label propagation algorithm for community detection based on average mutual information. Wirel. Commun. Mob. Comput. 2022, 2022, 2749091. [Google Scholar] [CrossRef]
- Newman, M.E.J.; Reinert, G. Estimating the number of communities in a network. Phys. Rev. Lett. 2016, 117, 078301. [Google Scholar] [CrossRef]
- Newman, M.E.J. Fast algorithm for detecting community structure in networks. Phys. Rev. E 2004, 69, 066133. [Google Scholar] [CrossRef]
- Newman, M.E.J. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Fortunato, S.; Barthelemy, M. Resolution limit in community detection. Proc. Natl. Acad. Sci. USA 2007, 104, 36–41. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Chen, Z.; Zhao, Y.; Chen, S. A community detection algorithm based on topology potential and spectral clustering. Sci. World J. 2014, 2014, 329325. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Côme, E.; Latouche, P. Model selection and clustering in stochastic block models based on the exact integrated complete data likelihood. Stat. Model. 2015, 15, 564–589. [Google Scholar] [CrossRef]
- Karrer, B.; Newman, M.E.J. Stochastic blockmodels and community structure in networks. Phys. Rev. E 2011, 83, 016107. [Google Scholar] [CrossRef]
- Funke, T.; Becker, T. Stochastic block models: A comparison of variants and inference methods. PLoS ONE 2019, 14, e0215296. [Google Scholar] [CrossRef] [PubMed]
- Riolo, M.A.; Cantwell, G.T.; Reinert, G.; Newman, M.E.J. Efficient method for estimating the number of communities in a network. Phys. Rev. E 2017, 96, 032310. [Google Scholar] [CrossRef]
- Yang, X.; Yu, W.; Wang, R.; Zhang, G.; Nie, F. Fast spectral clustering learning with hierarchical bipartite graph for large-scale data. Pattern Recognit. Lett. 2020, 130, 345–352. [Google Scholar] [CrossRef]
- Estrada, E.; Hatano, N. Communicability in complex networks. Phys. Rev. E 2008, 77, 036111. [Google Scholar] [CrossRef]
- Ibrahim, R.; Gleich, D. Nonlinear diffusion for community detection and semi-supervised learning. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 739–750. [Google Scholar]
- Kloster, K.; Gleich, D.F. Heat kernel based community detection. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1386–1395. [Google Scholar]
- Saerens, M.; Fouss, F.; Yen, L.; Dupont, P. The principal components analysis of a graph, and its relationships to spectral clustering. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 371–383. [Google Scholar]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, P10008. [Google Scholar] [CrossRef]
- Avrachenkov, K.; Chebotarev, P.; Rubanov, D. Similarities on graphs: Kernels versus proximity measures. Eur. J. Comb. 2019, 80, 47–56. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef] [PubMed]
- Danon, L.; Diaz-Guilera, A.; Duch, J.; Arenas, A. Comparing community structure identification. J. Stat. Mech. Theory Exp. 2005, 2005, P09008. [Google Scholar] [CrossRef]
- Bollobás, B.; Bollobas, B. Modern Graph Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Gleich, D. Hierarchical directed spectral graph partitioning. Inf. Netw. 2006, 443, 1–24. [Google Scholar]
- Miasnikof, P.; Pitsoulis, L.; Bonner, A.J.; Lawryshyn, Y.; Pardalos, P.M. Graph clustering via intra-cluster density maximization. In Proceedings of the Network Algorithms, Data Mining, and Applications: NET, Moscow, Russia, 8 May 2018; Springer International Publishing: Cham, Switzerland, 2020; pp. 37–48. [Google Scholar]
- Williams, V.V. Multiplying matrices faster than Coppersmith-Winograd. In Proceedings of the Forty-Fourth Annual ACM Symposium on Theory of Computing, New York, NY, USA, 20–22 May 2012; pp. 887–898. [Google Scholar]
- Ivashkin, V.; Chebotarev, P. Do logarithmic proximity measures outperform plain ones in graph clustering? In International Conference on Network Analysis; Springer: Cham, Switzerland, 2016; pp. 87–105. [Google Scholar]
- Kuikka, V.; Aalto, H.; Ijäs, M.; Kaski, K.K. Efficiency of Algorithms for Computing Influence and Information Spreading on Social Networks. Algorithms 2022, 15, 262. [Google Scholar] [CrossRef]
- Yen, L.; Fouss, F.; Decaestecker, C.; Francq, P.; Saerens, M. Graph nodes clustering with the sigmoid commute-time kernel: A comparative study. Data Knowl. Eng. 2009, 68, 338–361. [Google Scholar] [CrossRef]
- Avrachenkov, K.; Gonçalves, P.; Sokol, M. On the choice of kernel and labelled data in semi-supervised learning methods. In International Workshop on Algorithms and Models for the Web-Graph; Springer: Cham, Switzerland, 2013; pp. 56–67. [Google Scholar]
- Rozemberczki, B.; Davies, R.; Sarkar, R.; Sutton, C. Gemsec: Graph embedding with self clustering. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 65–72. [Google Scholar]
- Coscia, M.; Rossetti, G.; Giannotti, F.; Pedreschi, D. Demon: A local-first discovery method for overlapping communities. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 615–623. [Google Scholar]
- Epasto, A.; Lattanzi, S.; Paes Leme, R. Ego-splitting framework: From non-overlapping to overlapping clusters. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 145–154. [Google Scholar]
- Li, P.Z.; Huang, L.; Wang, C.D.; Lai, J.H. Edmot: An edge enhancement approach for motif-aware community detection. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 479–487. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | n | m | K |
|---|---|---|---|
| Karate | 34 | 78 | 2 |
| Dolphins | 62 | 162 | 2 |
| Polbooks | 105 | 441 | 3 |
| Football | 115 | 613 | 12 |
| Dataset | n | m | K | d | µ |
|---|---|---|---|---|---|
| L1 | 1000 | 7395 | 51 | 15 | 0.1 |
| L2 | 1000 | 7646 | 47 | 15 | 0.2 |
| L3 | 1000 | 7692 | 54 | 15 | 0.3 |
| L4 | 1000 | 7549 | 44 | 15 | 0.4 |
| L5 | 500 | 14,086 | 3 | 30 | 0.3 |
| L6 | 1000 | 30,288 | 7 | 30 | 0.3 |
| L7 | 2000 | 60,306 | 4 | 30 | 0.3 |
| L8 | 5000 | 143,972 | 17 | 30 | 0.3 |
| L9 | 10,000 | 302,282 | 87 | 30 | 0.3 |
| CPU | Intel(R) Core(TM) i7-9700 |
|---|---|
| Cores | 8 |
| Frequency | 3.0 GHz |
| Memory | 8 GB |
| Karate | Dolphins | Polbooks | Football | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cutoff | Node | Edge | Part | Node | Edge | Part | Node | Edge | Part | Node | Edge | Part |
| 0 | 34 | 78 | 1 | 62 | 159 | 1 | 105 | 441 | 1 | 115 | 613 | 1 |
| 1 | 32 | 67 | 1 | 46 | 121 | 1 | 104 | 423 | 1 | 115 | 517 | 1 |
| 2 | 17 | 32 | 1 | 40 | 84 | 2 | 98 | 364 | 1 | 115 | 449 | 2 |
| 3 | 11 | 18 | 2 | 25 | 45 | 4 | 84 | 289 | 4 | 113 | 411 | 8 |
| 4 | 6 | 7 | 2 | 16 | 21 | 3 | 65 | 221 | 4 | 108 | 393 | 10 |
| 5 | 6 | 4 | 2 | 9 | 8 | 3 | 48 | 128 | 4 | 105 | 327 | 13 |
| 6 | 4 | 2 | 2 | 8 | 5 | 3 | 33 | 81 | 2 | 95 | 219 | 18 |
| L1 | L2 | L3 | L4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cutoff | Node | Edge | Part | Node | Edge | Part | Node | Edge | Part | Node | Edge | Part |
| 0 | 1000 | 7652 | 1 | 1000 | 15,354 | 1 | 1000 | 7603 | 1 | 1000 | 15,078 | 1 |
| 1 | 1000 | 5899 | 9 | 1000 | 12,688 | 1 | 994 | 4835 | 1 | 1000 | 11,559 | 1 |
| 2 | 999 | 5410 | 28 | 1000 | 11,281 | 1 | 951 | 3576 | 10 | 1000 | 8918 | 1 |
| 3 | 995 | 5131 | 36 | 1000 | 10,840 | 5 | 814 | 2667 | 25 | 1000 | 7650 | 1 |
| 4 | 964 | 4656 | 46 | 1000 | 10,759 | 22 | 606 | 1845 | 38 | 998 | 6919 | 2 |
| 5 | 791 | 3749 | 48 | 1000 | 10,720 | 27 | 472 | 1309 | 41 | 996 | 6290 | 15 |
| 6 | 658 | 3057 | 42 | 1000 | 10,654 | 29 | 367 | 962 | 37 | 977 | 5564 | 29 |
| Dataset | K | A1 | A2 | A3 | BI-CNE |
|---|---|---|---|---|---|
| Karate | 2 | 2 | 2 | 2 | 2 |
| Dolphins | 2 | 2 | 2 | 3 | 2 |
| Polbooks | 3 | 4 | 5 | 5 | 3 |
| Football | 12 | 10 | 11 | 11 | 11 |
| Dataset | K | A1 | A2 | A3 | BI-CNE |
|---|---|---|---|---|---|
| L1 | 49 | 11 | - | 47 | 49 |
| L2 | 29 | 6 | - | 54 | 29 |
| L3 | 49 | 11 | - | 72 | 63 |
| L4 | 31 | 8 | - | 80 | 51 |
| Orders (l) | L5 | L6 | L7 | L8 | L9 |
|---|---|---|---|---|---|
| 1 | 0.038 | 0.035 | 0.035 | 0.010 | 0.031 |
| 2 | 0.012 | 0.024 | 0.011 | 0.004 | 0.022 |
| 3 | 0.004 | 0.014 | 0.001 | 0.008 | 0.007 |
| 4 | 0.001 | 0.008 | 0.000 | 0.009 | 0.002 |
| 5 | 0.000 | 0.002 | 0.000 | 0.003 | 0.000 |
| 6 | 0.000 | 0.000 | 0.000 | 0.001 | 0.000 |
| 7 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 8 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| 9 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| Orders (l) | L5 | L6 | L7 | L8 | L9 |
|---|---|---|---|---|---|
| infinite | 0.606 | 2.389 | 9.843 | 61.675 | 272.757 |
| 1 | 2.750 | 2.722 | 3.109 | 8.035 | 36.333 |
| 2 | 2.758 | 2.765 | 3.201 | 9.465 | 49.704 |
| 3 | 2.773 | 2.758 | 3.332 | 9.992 | 51.951 |
| 4 | 2.779 | 2.789 | 3.371 | 10.816 | 56.247 |
| 5 | 2.777 | 2.844 | 3.424 | 12.063 | 63.485 |
| 6 | 2.792 | 2.883 | 3.538 | 13.263 | 75.159 |
| 7 | 2.729 | 2.765 | 3.662 | 14.160 | 82.486 |
| 8 | 2.815 | 2.851 | 3.724 | 15.348 | 86.140 |
| 9 | 2.830 | 2.875 | 3.725 | 16.142 | 92.631 |
| Algorithm | Time Complexity | Space Complexity | |
|---|---|---|---|
| PMIK-SC | is the number of nodes of the network. | ||
| Comm | |||
| Heat | |||
| Katz | |||
| SCCT | |||
| PPR | |||
| MINC-NRL | is the max number of communities. is the max number of levels in overlapping hierarchical clustering. | ||
| AMI-MLPA | is the max number of the labels for each node. | ||
| GEMSEC | is the dimension of the embeddings for each node. | ||
| EdMot | is the number of edges of the network. | ||
| DEMON | is the average degree of the nodes | ||
| Ego-splitting |
| Karate | Dolphins | Football | Polbooks | L1 | L2 | L3 | L4 | Avg. | |
|---|---|---|---|---|---|---|---|---|---|
| PMIK-SC | 1.000 | 0.889 | 0.924 | 0.589 | 0.999 | 0.997 | 0.994 | 0.990 | 0.923 |
| Comm | 0.836 | 0.655 | 0.728 | 0.360 | 0.873 | 0.816 | 0.755 | 0.662 | 0.711 |
| Heat | 0.836 | 0.889 | 0.924 | 0.601 | 1.000 | 0.913 | 0.869 | 0.630 | 0.833 |
| Katz | 1.000 | 0.704 | 0.718 | 0.319 | 0.835 | 0.786 | 0.716 | 0.616 | 0.712 |
| SCCT | 1.000 | 0.889 | 0.927 | 0.563 | 1.000 | 0.982 | 0.963 | 0.961 | 0.911 |
| PPR | 0.580 | 0.407 | 0.731 | 0.424 | 0.808 | 0.737 | 0.700 | 0.575 | 0.620 |
| MINC-NRL | 1.000 | 0.889 | 0.927 | 0.523 | 0.926 | 0.886 | 0.804 | 0.122 | 0.760 |
| AMI-MLPA | 1.000 | 0.889 | 0.924 | 0.545 | 1.000 | 0.999 | 0.984 | 0.815 | 0.895 |
| GEMSEC | 0.442 | 0.337 | 0.822 | 0.408 | 0.473 | 0.35 | 0.315 | 0.305 | 0.432 |
| Edmot | 0.579 | 0.493 | 0.904 | 0.472 | 0.995 | 0.981 | 0.965 | 0.974 | 0.795 |
| DEMON | 0.244 | 0.362 | 0.632 | 0.466 | 0.989 | 0.905 | 0.860 | 0.792 | 0.656 |
| Ego-splitting | 0.545 | 0.496 | 0.911 | 0.500 | 0.995 | 0.981 | 0.963 | 0.974 | 0.796 |
| Karate | Dolphins | Football | Polbooks | L1 | L2 | L3 | L4 | Avg. | |
|---|---|---|---|---|---|---|---|---|---|
| PMIK-SC | 0.371 | 0.379 | 0.601 | 0.496 | 0.874 | 0.759 | 0.655 | 0.563 | 0.587 |
| Comm | 0.345 | 0.377 | 0.456 | 0.432 | 0.7 | 0.554 | 0.431 | 0.321 | 0.452 |
| Heat | 0.360 | 0.379 | 0.601 | 0.485 | 0.875 | 0.67 | 0.519 | 0.279 | 0.521 |
| Katz | 0.371 | 0.364 | 0.438 | 0.382 | 0.652 | 0.529 | 0.373 | 0.278 | 0.423 |
| SCCT | 0.371 | 0.379 | 0.601 | 0.502 | 0.875 | 0.751 | 0.619 | 0.541 | 0.580 |
| PPR | 0.334 | 0.289 | 0.426 | 0.402 | 0.609 | 0.405 | 0.339 | 0.234 | 0.380 |
| MINC-NRL | 0.371 | 0.379 | 0.601 | 0.46 | 0.872 | 0.759 | 0.654 | 0.069 | 0.521 |
| AMI-MLPA | 0.371 | 0.379 | 0.601 | 0.493 | 0.875 | 0.762 | 0.633 | 0.436 | 0.569 |
| GEMSEC | 0.436 | 0.495 | 0.583 | 0.543 | 0.458 | 0.349 | 0.305 | 0.211 | 0.423 |
| Edmot | 0.514 | 0.602 | 0.650 | 0.579 | 0.887 | 0.787 | 0.702 | 0.615 | 0.667 |
| DEMON | 0.130 | 0.311 | 0.450 | 0.390 | 0.852 | 0.578 | 0.44 | 0.301 | 0.432 |
| Ego-splitting | 0.502 | 0.598 | 0.651 | 0.565 | 0.887 | 0.787 | 0.702 | 0.615 | 0.663 |
| Karate | Dolphins | Football | Polbooks | L1 | L2 | L3 | L4 | Avg. | |
|---|---|---|---|---|---|---|---|---|---|
| PMIK-SC | 0.132 | 0.064 | 0.337 | 0.122 | 0.104 | 0.213 | 0.312 | 0.404 | 0.211 |
| Comm | 0.162 | 0.103 | 0.518 | 0.240 | 0.396 | 0.493 | 0.589 | 0.667 | 0.396 |
| Heat | 0.152 | 0.064 | 0.337 | 0.151 | 0.102 | 0.319 | 0.426 | 0.643 | 0.274 |
| Katz | 0.132 | 0.102 | 0.519 | 0.280 | 0.428 | 0.534 | 0.631 | 0.702 | 0.416 |
| SCCT | 0.132 | 0.064 | 0.340 | 0.143 | 0.102 | 0.280 | 0.383 | 0.447 | 0.236 |
| PPR | 0.182 | 0.175 | 0.543 | 0.285 | 0.438 | 0.578 | 0.642 | 0.754 | 0.450 |
| MINC-NRL | 0.132 | 0.064 | 0.340 | 0.246 | 0.088 | 0.176 | 0.254 | 0.445 | 0.218 |
| AMI-MLPA | 0.132 | 0.064 | 0.337 | 0.163 | 0.102 | 0.203 | 0.433 | 0.643 | 0.260 |
| GEMSEC | 0.428 | 0.354 | 0.283 | 0.332 | 0.090 | 0.299 | 0.386 | 0.463 | 0.329 |
| Edmot | 0.270 | 0.230 | 0.263 | 0.254 | 0.088 | 0.172 | 0.257 | 0.344 | 0.235 |
| DEMON | 0.802 | 0.840 | 0.316 | 0.584 | 0.112 | 0.287 | 0.415 | 0.566 | 0.490 |
| Ego-splitting | 0.296 | 0.233 | 0.263 | 0.255 | 0.088 | 0.172 | 0.257 | 0.344 | 0.239 |
| Karate | Dolphins | Football | Polbooks | L1 | L2 | L3 | L4 | Avg. | |
|---|---|---|---|---|---|---|---|---|---|
| PMIK-SC | 0.252 | 0.171 | 0.848 | 0.270 | 0.707 | 0.568 | 0.584 | 0.451 | 0.481 |
| Comm | 0.250 | 0.155 | 0.624 | 0.209 | 0.628 | 0.490 | 0.443 | 0.336 | 0.392 |
| Heat | 0.250 | 0.171 | 0.848 | 0.259 | 0.710 | 0.581 | 0.567 | 0.479 | 0.483 |
| Katz | 0.252 | 0.169 | 0.621 | 0.239 | 0.542 | 0.416 | 0.382 | 0.267 | 0.361 |
| SCCT | 0.252 | 0.171 | 0.860 | 0.240 | 0.710 | 0.486 | 0.496 | 0.398 | 0.452 |
| PPR | 0.251 | 0.192 | 0.594 | 0.211 | 0.585 | 0.428 | 0.396 | 0.238 | 0.362 |
| MINC-NRL | 0.252 | 0.171 | 0.860 | 0.176 | 0.558 | 0.463 | 0.412 | 0.290 | 0.398 |
| AMI-MLPA | 0.252 | 0.171 | 0.848 | 0.226 | 0.710 | 0.582 | 0.491 | 0.175 | 0.432 |
| GEMSEC | 0.626 | 0.609 | 0.841 | 0.616 | 0.459 | 0.626 | 0.620 | 0.556 | 0.619 |
| Edmot | 0.526 | 0.393 | 0.828 | 0.450 | 0.665 | 0.467 | 0.438 | 0.347 | 0.514 |
| DEMON | 0.144 | 0.052 | 0.316 | 0.083 | 0.699 | 0.516 | 0.465 | 0.267 | 0.318 |
| Ego-splitting | 0.464 | 0.387 | 0.817 | 0.546 | 0.667 | 0.467 | 0.426 | 0.347 | 0.515 |
| Karate | Dolphins | Football | Polbooks | L1 | L2 | L3 | L4 | |
|---|---|---|---|---|---|---|---|---|
| PMIK-SC | 9.337 | 5.641 | 6.077 | 6.219 | 12.660 | 13.203 | 12.649 | 13.417 |
| Comm | 0.439 | 0.058 | 1.737 | 0.699 | 19.188 | 20.465 | 21.590 | 18.870 |
| Heat | 0.487 | 0.075 | 0.904 | 0.637 | 17.420 | 18.511 | 22.907 | 22.231 |
| Katz | 0.554 | 0.069 | 0.405 | 0.090 | 15.766 | 14.057 | 17.949 | 13.426 |
| SCCT | 0.647 | 0.083 | 0.298 | 0.203 | 16.246 | 32.359 | 31.506 | 37.175 |
| PPR | 0.461 | 0.647 | 2.268 | 2.033 | 19.787 | 19.341 | 21.555 | 19.339 |
| MINC-NRL | 0.138 | 0.245 | 0.687 | 0.482 | 11.137 | 11.474 | 10.910 | 12.077 |
| AMI-MLPA | 0.172 | 0.618 | 14.705 | 0.069 | 4.506 | 8.490 | 52.197 | 148.010 |
| GEMSEC | 13.564 | 26.322 | 48.974 | 42.578 | 349.881 | 298.914 | 297.126 | 297.421 |
| Edmot | 0.022 | 0.005 | 0.010 | 0.010 | 0.126 | 0.150 | 0.180 | 0.149 |
| DEMON | 0.018 | 0.019 | 0.076 | 0.049 | 1.649 | 1.166 | 1.000 | 0.871 |
| Ego-splitting | 0.030 | 0.006 | 0.018 | 0.014 | 0.153 | 0.193 | 0.187 | 0.161 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Ye, W.; Li, D. Spectral Clustering Community Detection Algorithm Based on Point-Wise Mutual Information Graph Kernel. Entropy 2023, 25, 1617. https://doi.org/10.3390/e25121617
Chen Y, Ye W, Li D. Spectral Clustering Community Detection Algorithm Based on Point-Wise Mutual Information Graph Kernel. Entropy. 2023; 25(12):1617. https://doi.org/10.3390/e25121617
Chicago/Turabian StyleChen, Yinan, Wenbin Ye, and Dong Li. 2023. "Spectral Clustering Community Detection Algorithm Based on Point-Wise Mutual Information Graph Kernel" Entropy 25, no. 12: 1617. https://doi.org/10.3390/e25121617
APA StyleChen, Y., Ye, W., & Li, D. (2023). Spectral Clustering Community Detection Algorithm Based on Point-Wise Mutual Information Graph Kernel. Entropy, 25(12), 1617. https://doi.org/10.3390/e25121617