
Computational-Intelligence-Based Scheduling with Edge Computing in Cyber–Physical Production Systems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- To the best of our understanding, no previous works have studied CI-based prediction for high-reliability real-time scheduling in an industrial system with edge computing capabilities. This paper is the first to propose a job scheduling method that makes limited use of prediction results obtained via CI techniques to solve the JSP in a high real-time and high-reliability cloud–edge collaboration scenario.
- (2)
- To meet the requirements for industrial customized production (especially for unexpected jobs), this paper proposes a DRPS method to establish a trade-off between resource utilization and system performance. That is, DRPS enables the dynamic adjustment of the scheduling policy to meet the industrial requirement based on a given reliability parameter. Furthermore, DRPS permits localized migration of unexpected jobs, thereby mitigating the uncertainty associated with CI techniques and improving the system response speed. The results of both numerical simulations and physical experiments indicate the effectiveness of our method.
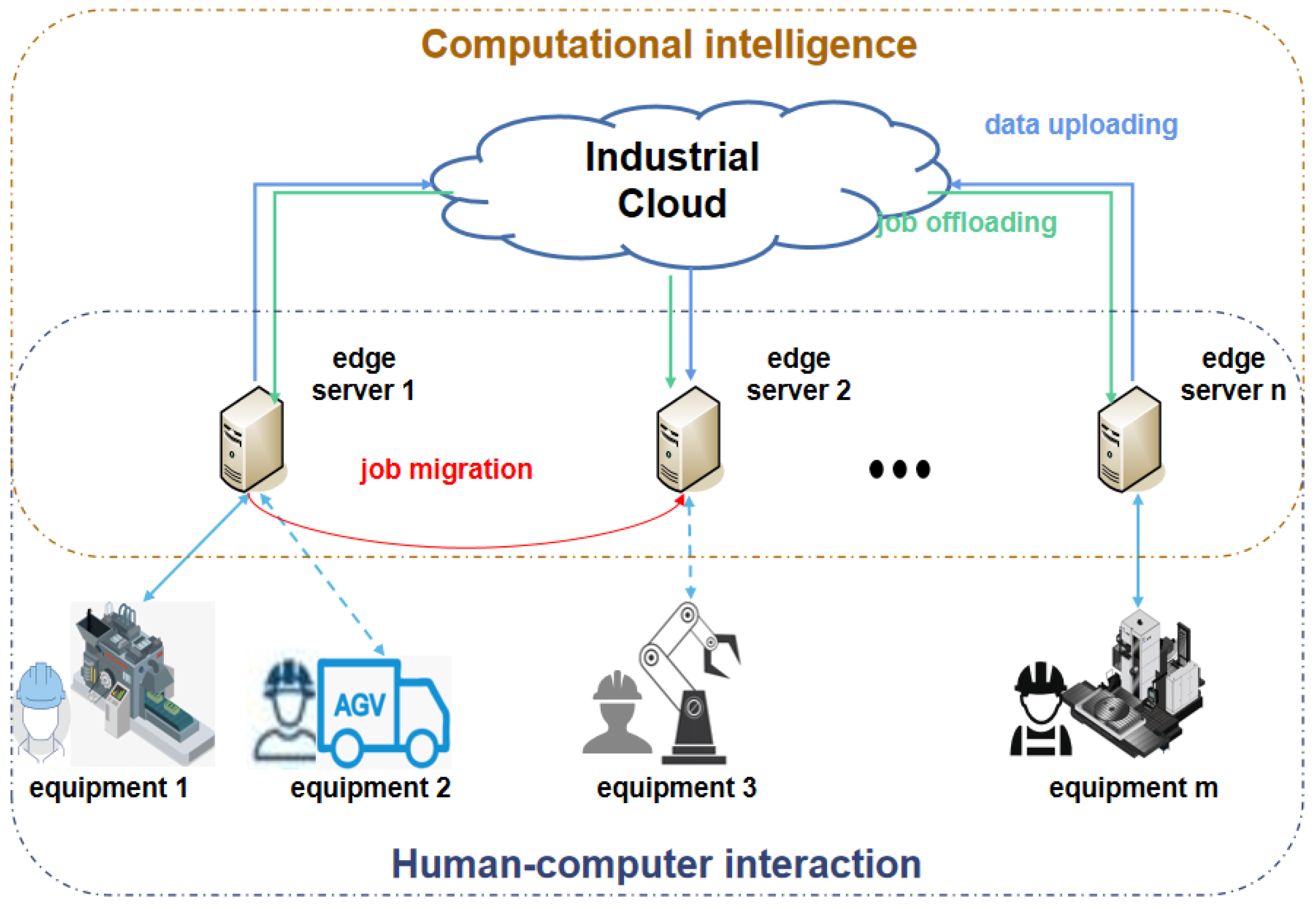
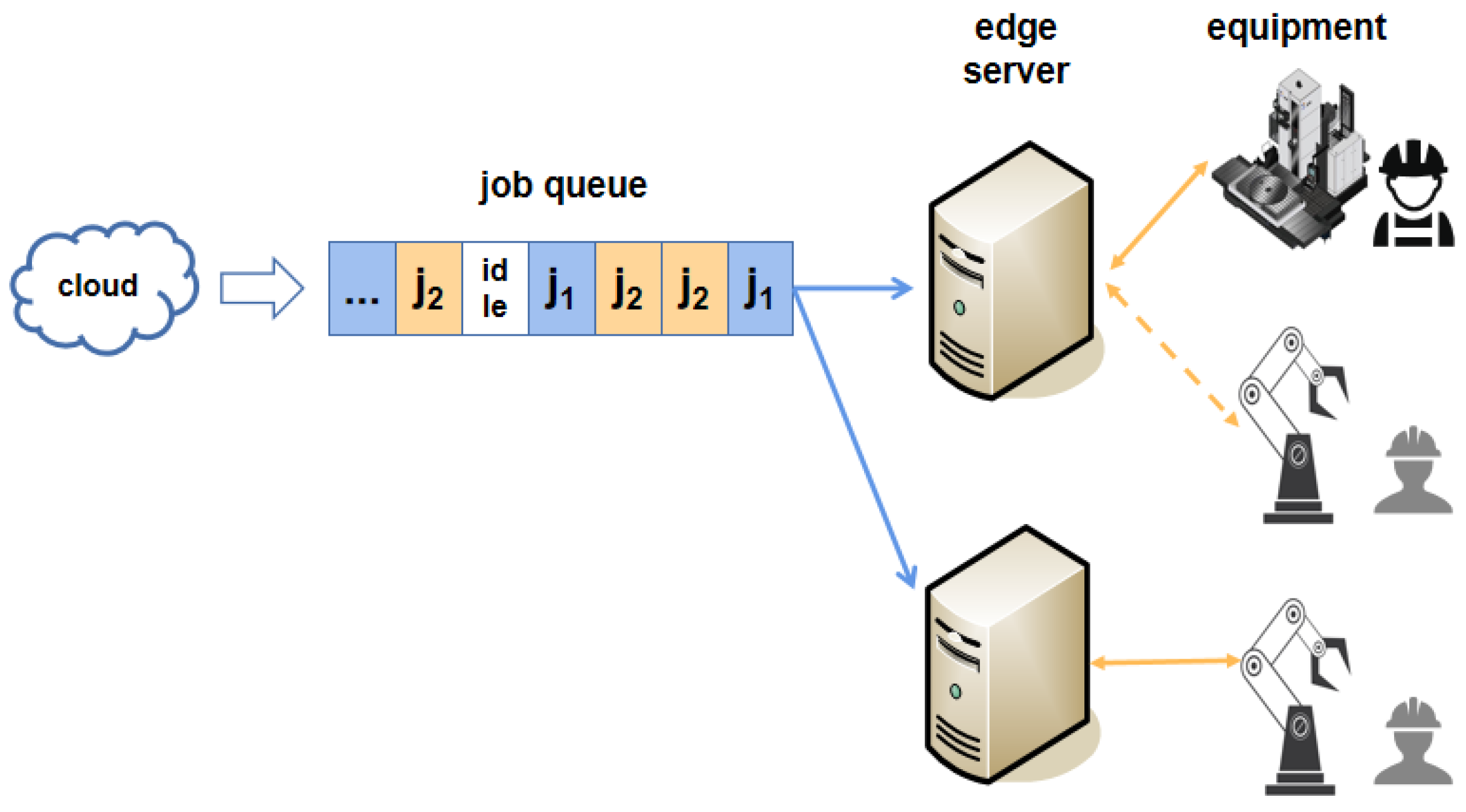
2. Problem Description
- (1)
- Fast response: when unexpected jobs occur, how to achieve real-time selection of an edge server with little or no transmission with the cloud.
- (2)
- Performance guarantee: how to dynamically migrate these unexpected jobs before the system runs out of computational resources, such as when a regular job with high resource utilization arrives on the selected edge server.
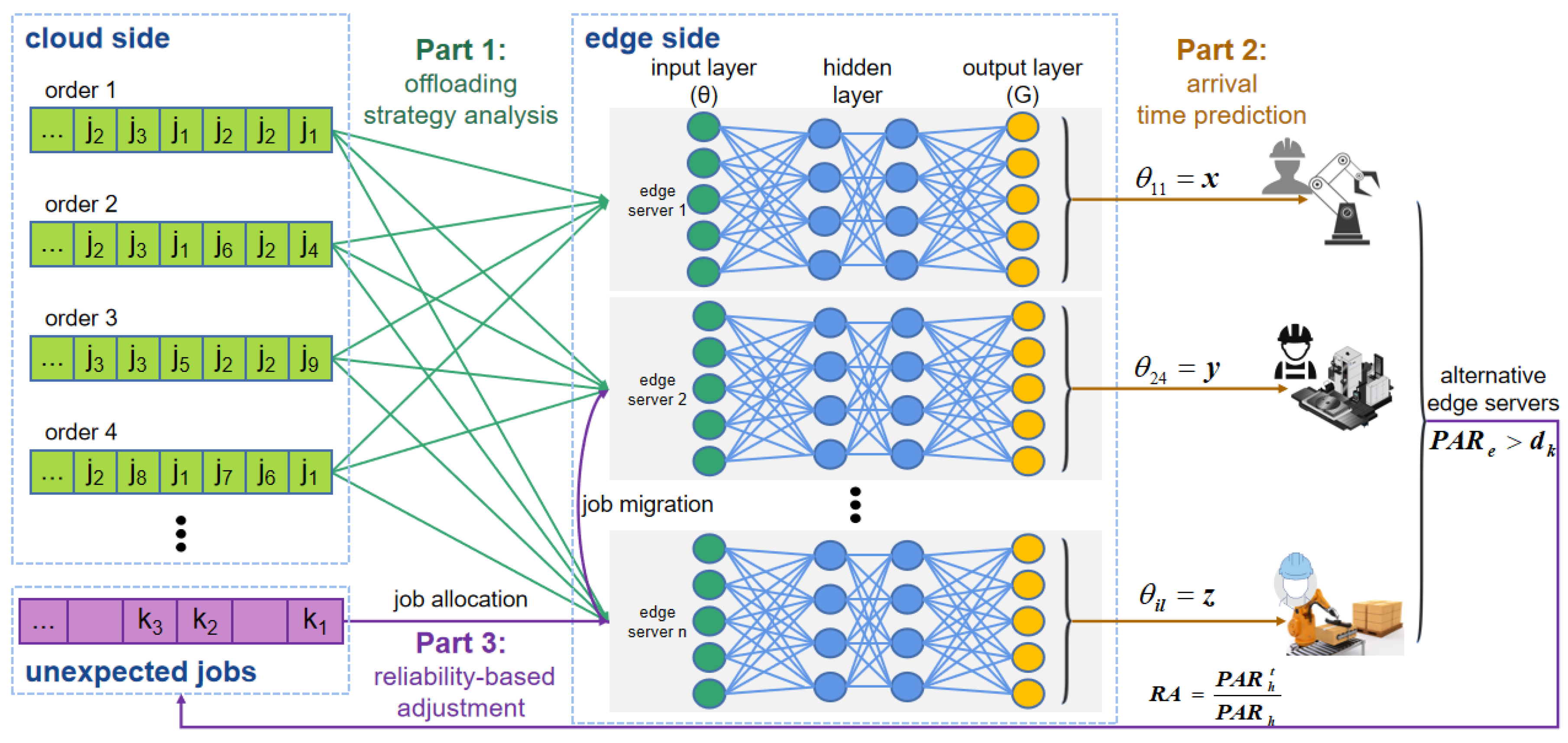
3. Dynamic Resource Prediction Scheduling
3.1. Offloading Strategy Analysis
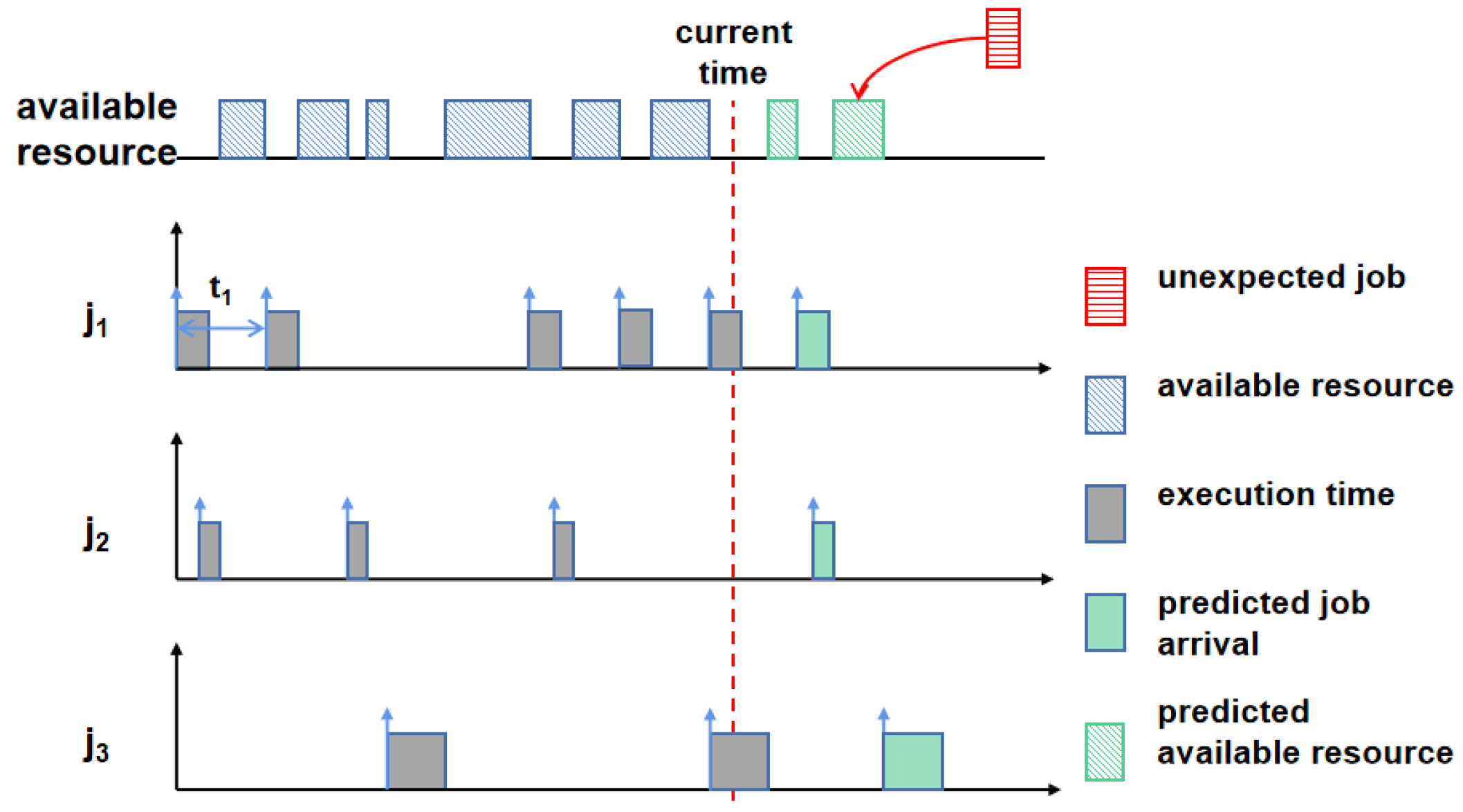
3.2. Arrival Time Prediction
- (1)
- : the maximum arrival interval among all jobs in ; in this work, it is assumed that the maximum arrival interval for a job is twice its period.
- (2)
- : the minimum arrival interval among all jobs in ; in this work, the minimum arrival interval for a job is set as equal to its period.
- (3)
- : number of edge servers.
| Algorithm 1 Arrival time prediction method |
Input: the historical data set of job arrival times A and workload features for the current edge server; the learning rate Output: the schedulability of the emergency flow and the acceptance ratio for regular flows
|
3.3. Reliability-Based Policy Adjustment
- (1)
- CI-based first-fit offloading: When the predictive accuracy of the ATPM is no less than the given reliability index R, unexpected job k first searches for an edge server e with sufficient available resources, ; if none of the edge servers meet this condition, job k is assigned to the first edge server on which resources become available.When the predictive accuracy of the ATPM is less than R, job k is directly assigned to the first edge server on which resources become available.
- (2)
- HCI-based high-accessibility migration: When insufficient resources are available to complete job k, job k is immediately migrated when its execution on the current edge server is suspended. The migration target is chosen as the edge server h with the highest resource accessibility RA, which can be calculated aswhere represents the ascertainable resources calculated based on the characteristics of the sporadic jobs.
4. Experimental Results
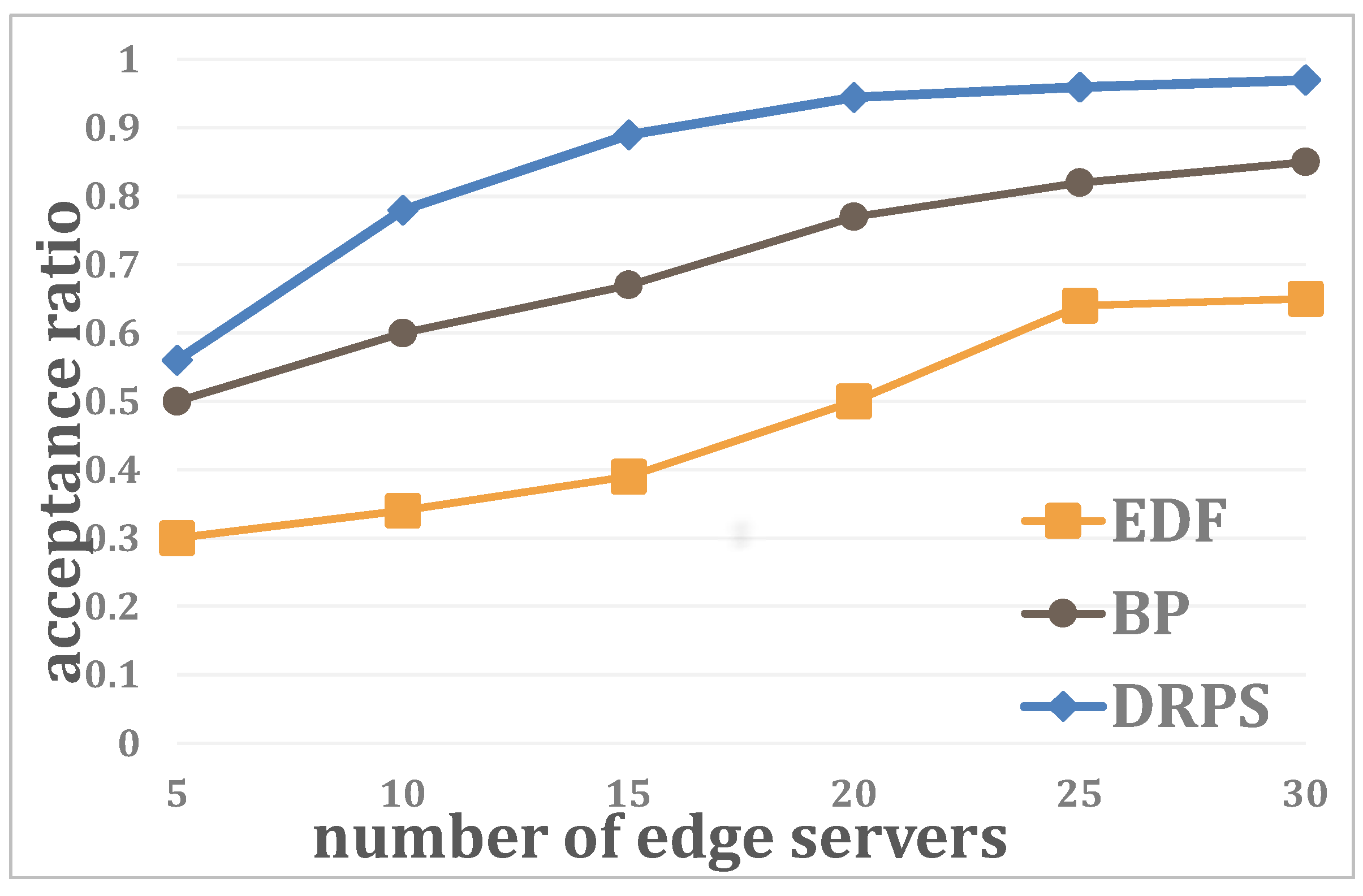
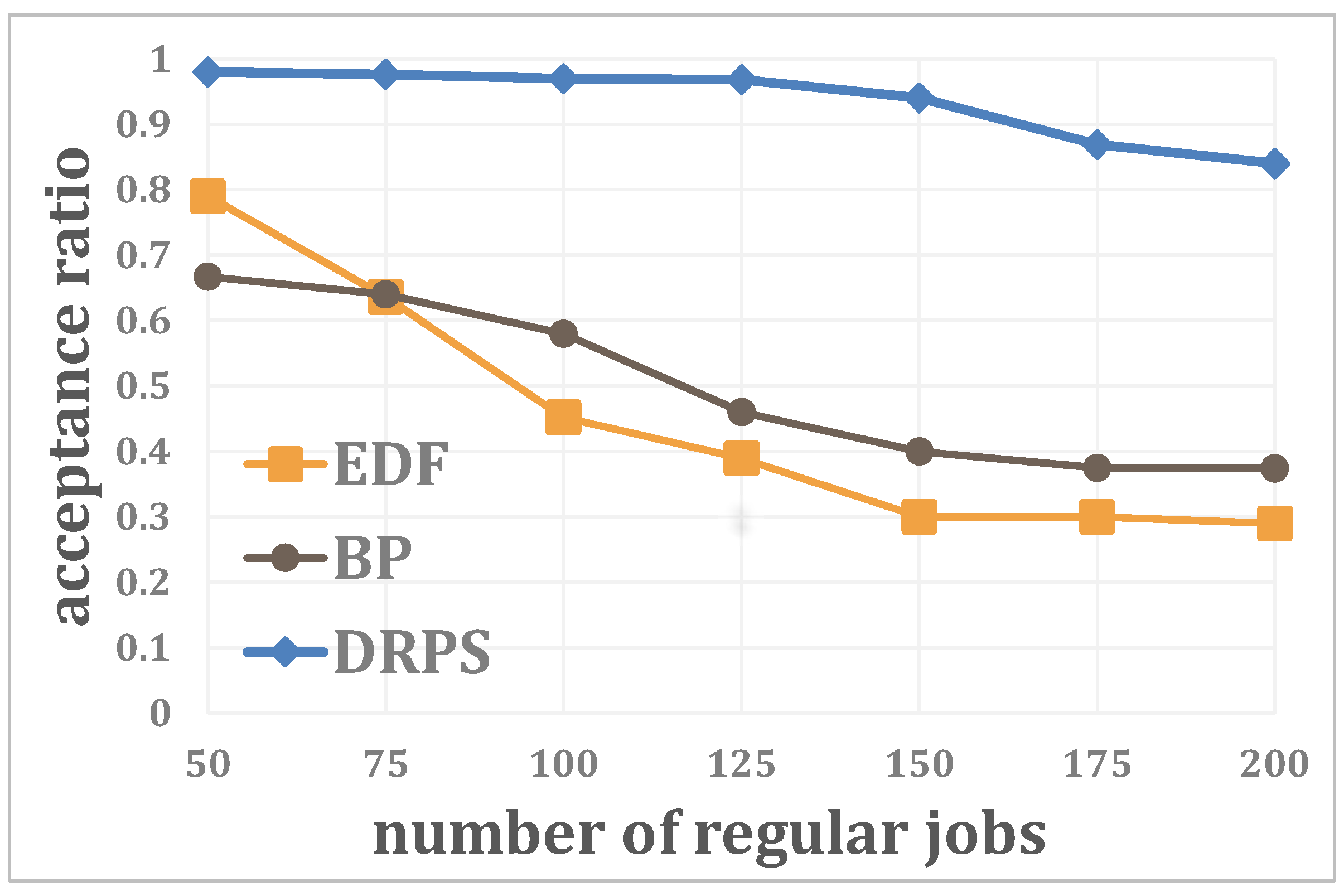
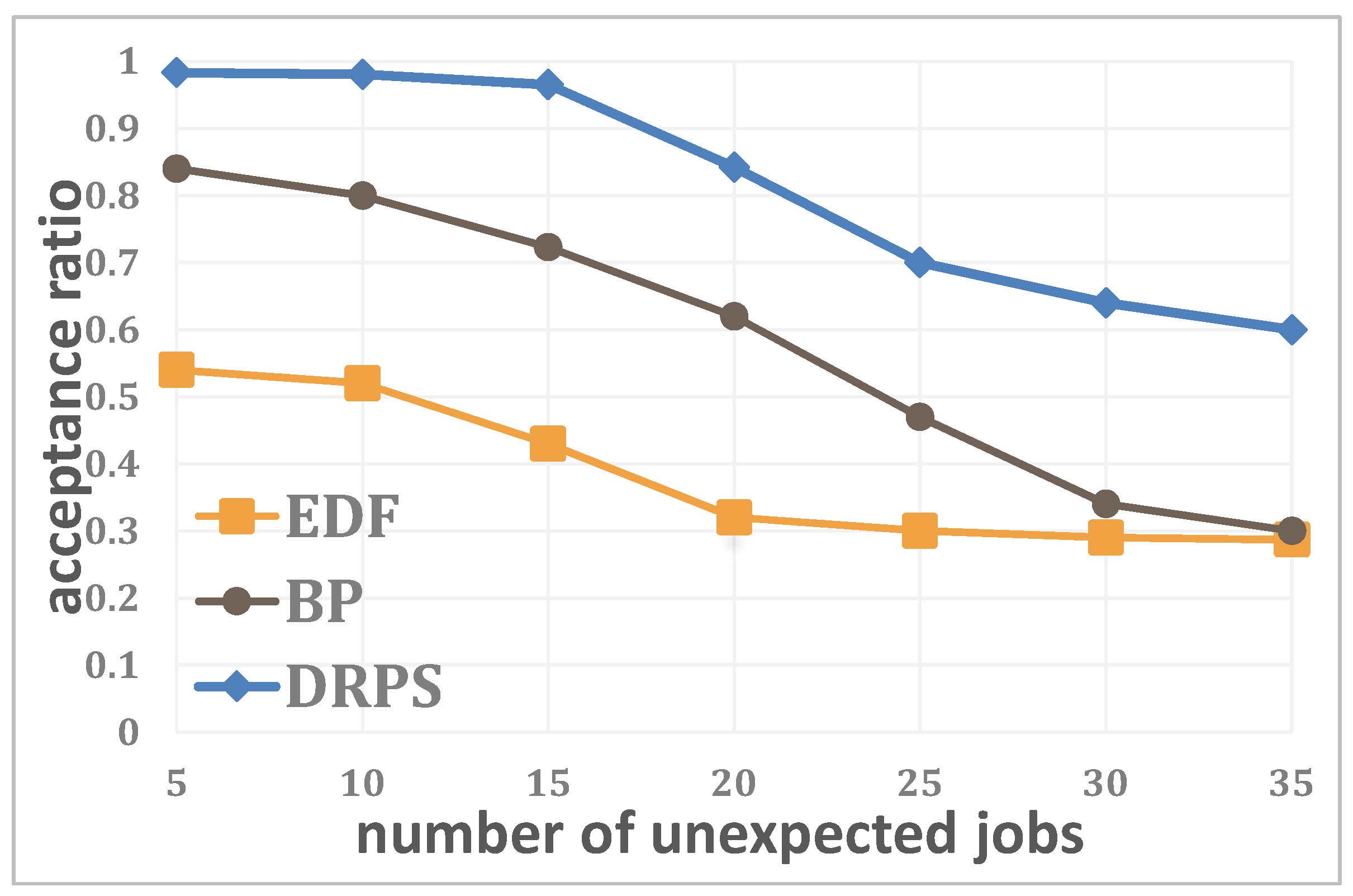
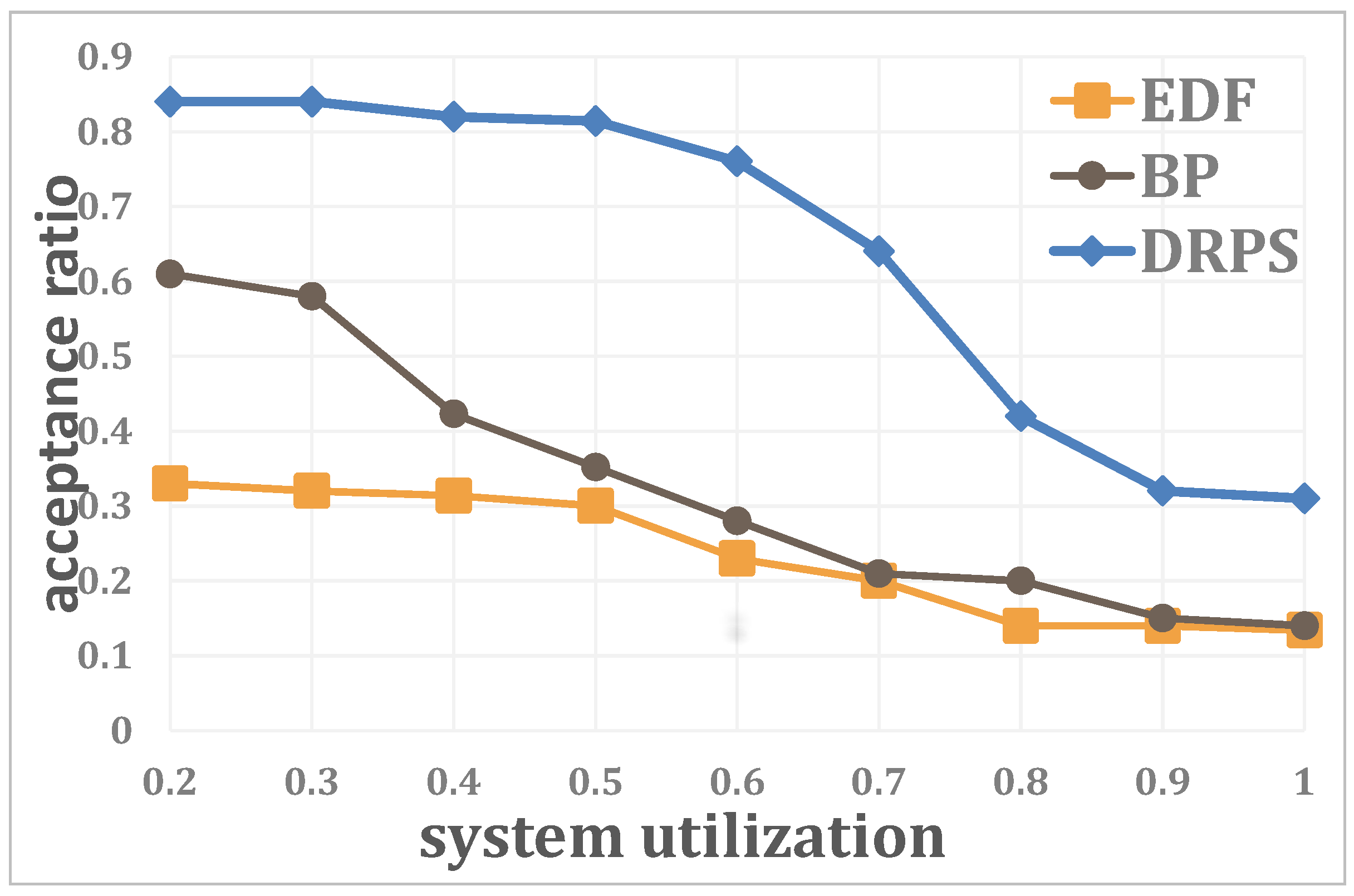
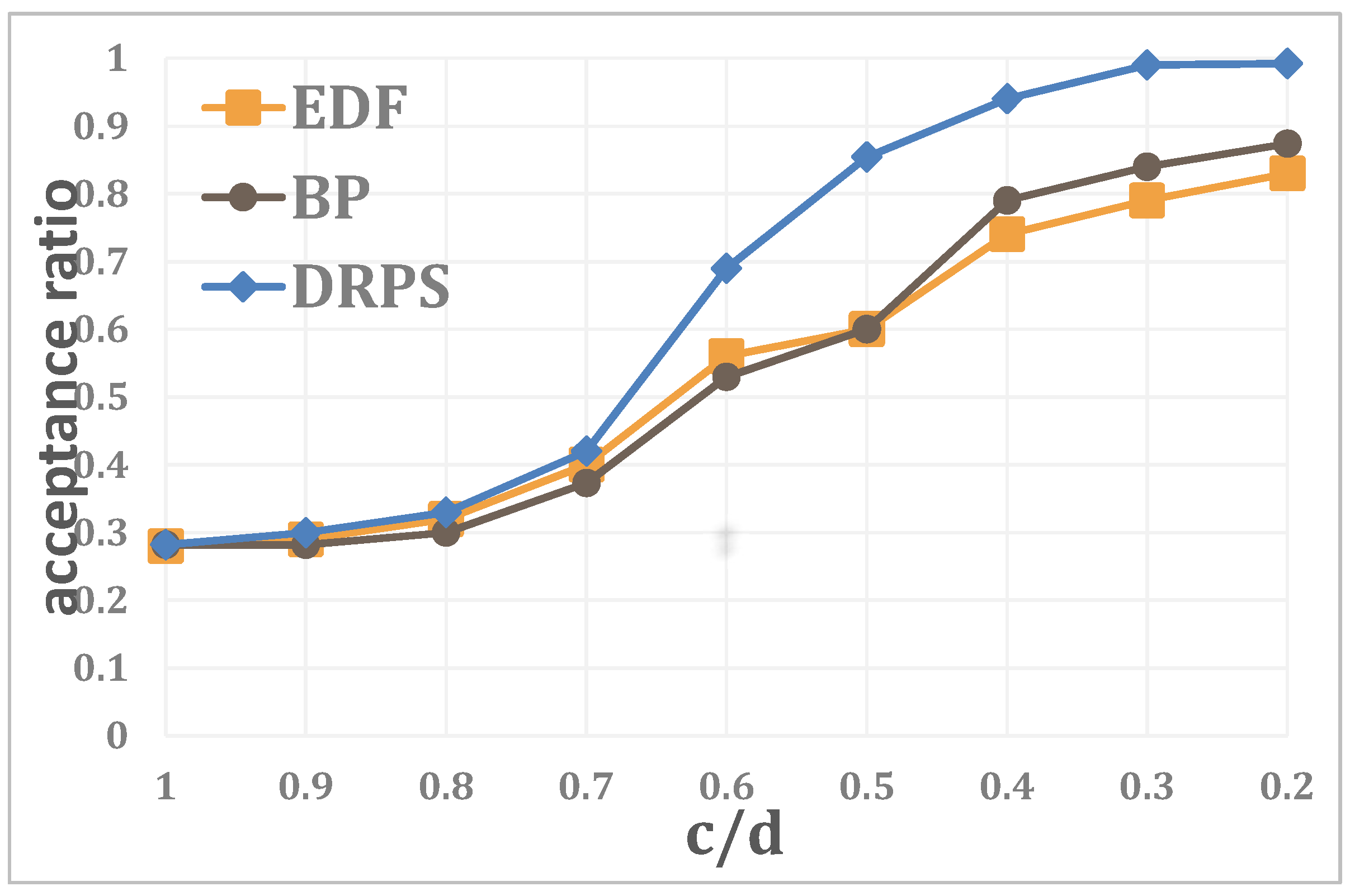
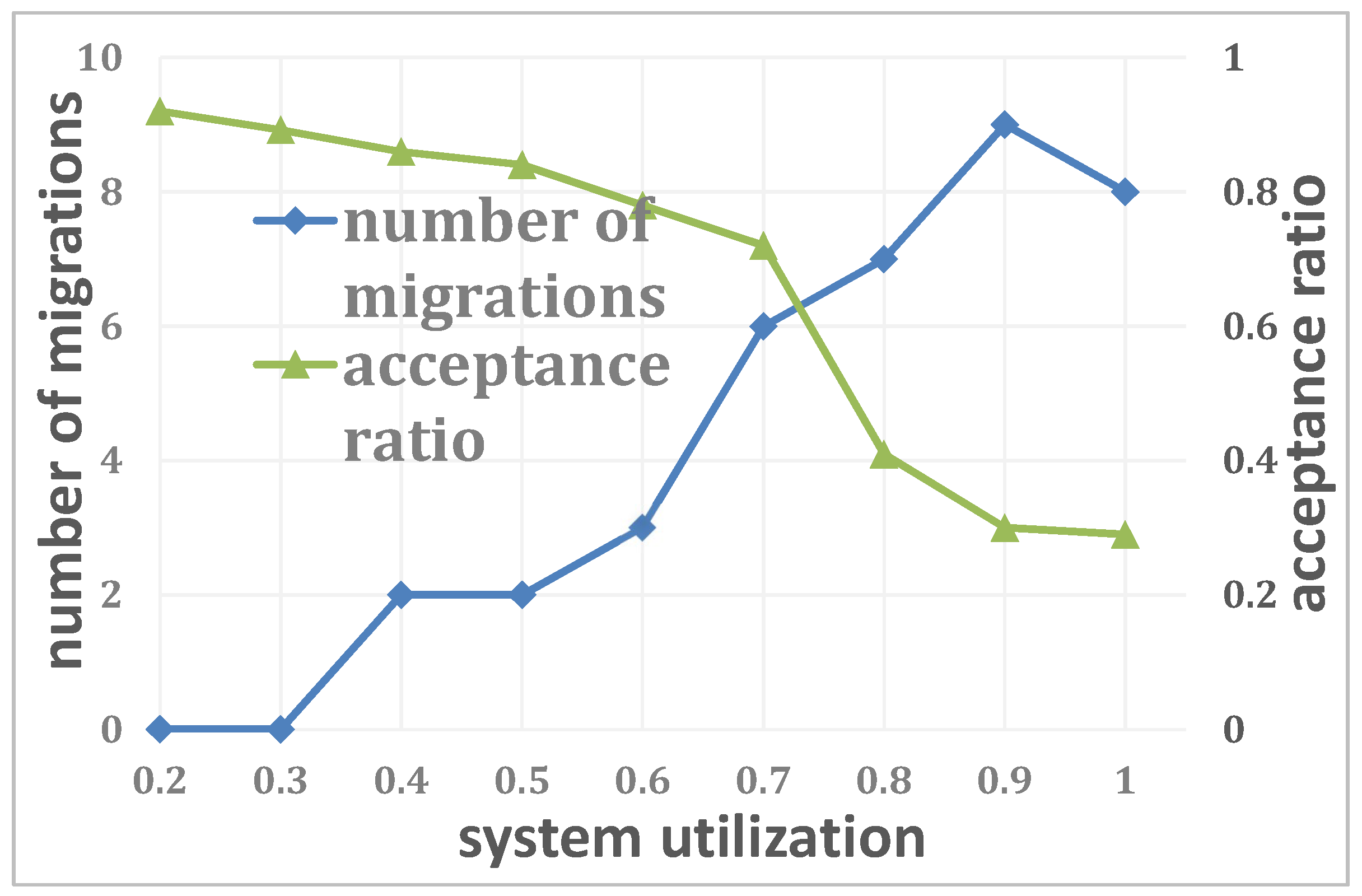
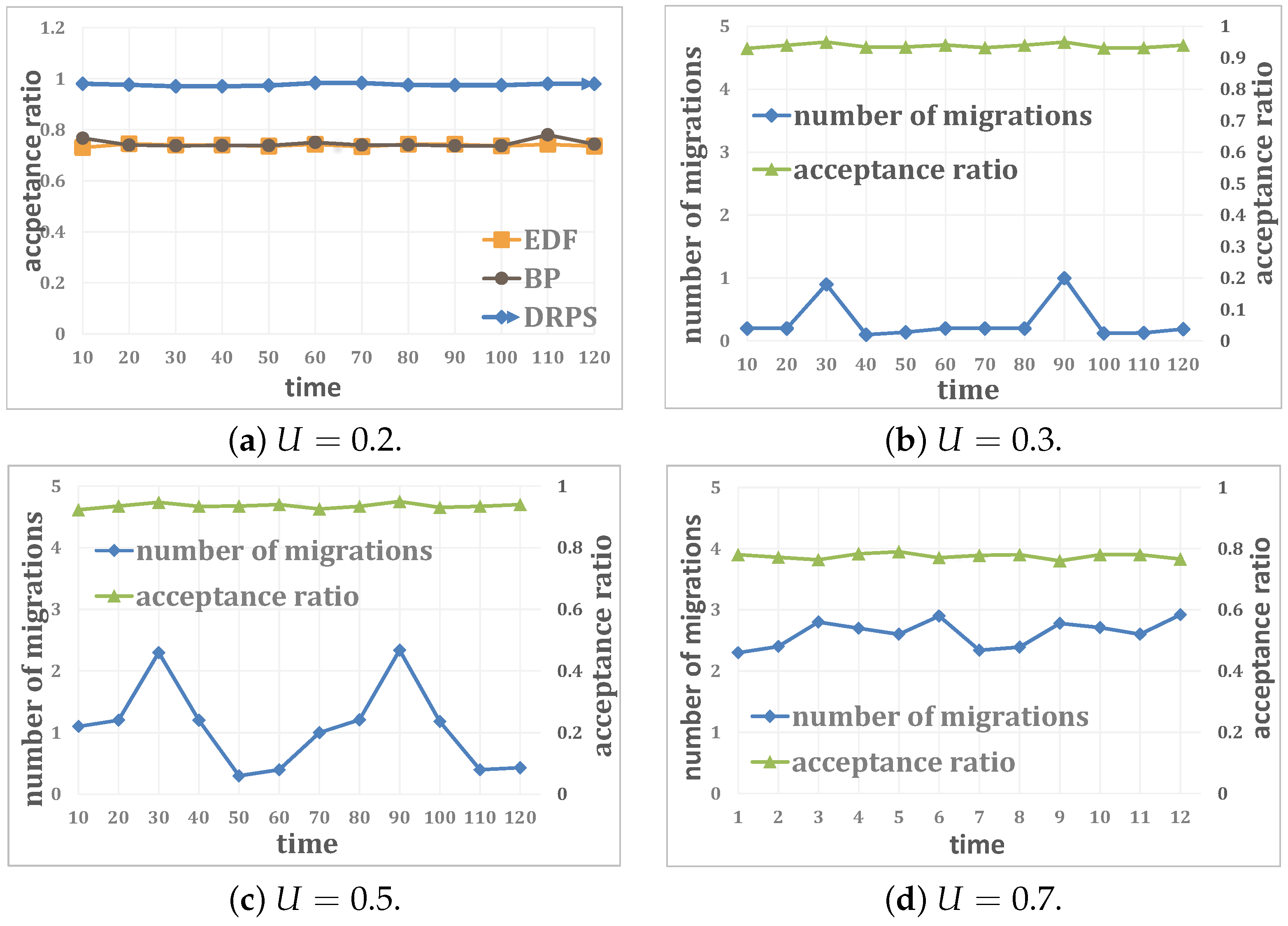
4.1. Simulations
4.2. Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dix, A.; Dix, A.J.; Finlay, J.; Abowd, G.D.; Beale, R. Human-Computer Interaction; Pearson Education: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Engelbrecht, A.P. Computational Intelligence: An Introduction; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Lin, C.C.; Deng, D.J.; Chih, Y.L.; Chiu, H.T. Smart manufacturing scheduling with edge computing using multiclass deep q network. IEEE Trans. Ind. Inform. 2019, 15, 4276–4284. [Google Scholar] [CrossRef]
- Applegate, D.; Cook, W. A computational study of the job-shop scheduling problem. ORSA J. Comput. 1991, 3, 149–156. [Google Scholar] [CrossRef]
- Wang, Q.; Jiang, J. Comparative examination on architecture and protocol of industrial wireless sensor network standards. IEEE Commun. Surv. Tutor. 2016, 18, 2197–2219. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, E.C.-H.; Zhou, L.; Wei, J.; Cheng, J.; Hu, B. Energy-latency tradeoff for energy-aware offloading in mobile edge computing networks. IEEE Internet Things J. 2017, 5, 2633–2645. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Fisher, N.; Yin, G. Probabilistic per-packet real-time guarantees for wireless networked sensing and control. IEEE Trans. Ind. Inform. 2018, 14, 2133–2145. [Google Scholar] [CrossRef]
- Alameddine, H.A.; Sharafeddine, S.; Sebbah, S.; Ayoubi, S.; Assi, C. Dynamic task offloading and scheduling for low-latency iot services in multi-access edge computing. IEEE J. Sel. Areas Commun. 2019, 37, 668–682. [Google Scholar] [CrossRef]
- Wang, X.; Ning, Z.; Wang, L. Offloading in internet of vehicles: A fog-enabled real-time traffic management system. IEEE Trans. Ind. Inform. 2018, 14, 4568–4578. [Google Scholar] [CrossRef]
- Ning, Z.; Huang, J.; Wang, X.; Rodrigues, J.J.P.C.; Guo, L. Mobile edge computing-enabled internet of vehicles: Toward energy-efficient scheduling. IEEE Netw. 2019, 33, 198–205. [Google Scholar] [CrossRef]
- McEnroe, P.; Wang, S.; Liyanage, M. A survey on the convergence of edge computing and ai for uavs: Opportunities and challenges. IEEE Internet Things J. 2022, 9, 15435–15459. [Google Scholar] [CrossRef]
- Zhong, R.Y.; Xu, X.; Klotz, E.; Newman, S.T. Intelligent manufacturing in the context of industry 4.0: A review. Engineering 2017, 3, 616–630. [Google Scholar] [CrossRef]
- Velosa, J.D.; Cobo, L.; Castillo, F.; Castillo, C. Methodological proposal for use of virtual reality vr and augmented reality ar in the formation of professional skills in industrial maintenance and industrial safety. In Online Engineering & Internet of Things; Springer: Berlin/Heidelberg, Germany, 2018; pp. 987–1000. [Google Scholar]
- Beruvides, G.; Quiza, R.; del Toro, R.; Castaño, F.; Haber, R.E. Correlation of the holes quality with the force signals in a microdrilling process of a sintered tungsten-copper alloy. Int. J. Precis. Eng. Manuf. 2014, 15, 1801–1808. [Google Scholar] [CrossRef]
- Bastug, E.; Bennis, M.; Médard, M.; Debbah, M. Toward interconnected virtual reality: Opportunities, challenges, and enablers. IEEE Commun. Mag. 2017, 55, 110–117. [Google Scholar] [CrossRef]
- Zhou, R.; Zhang, X.; Qin, S.; Lui, J.C.S.; Zhou, Z.; Huang, H.; Li, Z. Online task offloading for 5g small cell networks. IEEE Trans. Mob. Comput. 2020, 21, 2103–2115. [Google Scholar] [CrossRef]
- Sun, Z.; Nakhai, M.R. Edge intelligence: Distributed task offloading and service management under uncertainty. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Zhang, X.; Zhang, J.; Liu, Z.; Cui, Q.; Tao, X.; Wang, S. Mdp-based task offloading for vehicular edge computing under certain and uncertain transition probabilities. IEEE Trans. Veh. Technol. 2020, 69, 3296–3309. [Google Scholar] [CrossRef]
- Villalonga, A.; Negri, E.; Fumagalli, L.; Macchi, M.; Casta no, F.; Haber, R. Local decision making based on distributed digital twin framework. IFAC-PapersOnLine 2020, 53, 10568–10573. [Google Scholar] [CrossRef]
- Zhou, Z.; Liao, H.; Zhao, X.; Ai, B.; Guizani, M. Reliable task offloading for vehicular fog computing under information asymmetry and information uncertainty. IEEE Trans. Veh. Technol. 2019, 68, 8322–8335. [Google Scholar] [CrossRef]
- Liao, H.; Zhou, Z.; Zhao, X.; Zhang, L.; Mumtaz, S.; Jolfaei, A.; Ahmed, S.H.; Bashir, A.K. Learning-based context-aware resource allocation for edge-computing-empowered industrial iot. IEEE Internet Things J. 2019, 7, 4260–4277. [Google Scholar] [CrossRef]
- Gui, G.; Zhou, Z.; Wang, J.; Liu, F.; Sun, J. Machine learning aided air traffic flow analysis based on aviation big data. IEEE Trans. Veh. Technol. 2020, 69, 4817–4826. [Google Scholar] [CrossRef]
- Shah, S.D.A.; Gregory, M.A.; Li, S.; Fontes, R.D.R. Sdn enhanced multi-access edge computing (mec) for e2e mobility and qos management. IEEE Access 2020, 8, 77459–77469. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Zhang, Y.; Mumtaz, S. Blockchain-empowered secure spectrum sharing for 5g heterogeneous networks. IEEE Netw. 2020, 34, 24–31. [Google Scholar] [CrossRef]
- Liao, H.; Mu, Y.; Zhou, Z.; Sun, M.; Wang, Z.; Pan, C. Blockchain and learning-based secure and intelligent task offloading for vehicular fog computing. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4051–4063. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, Z.; Yu, H.; Liao, H.; Mumtaz, S.; Oliveira, L.; Frascolla, V. Learning-based urllc-aware task offloading for internet of health things. IEEE J. Sel. Areas Commun. 2020, 39, 396–410. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Sharma, S.K.; Wang, X. Live data analytics with collaborative edge and cloud processing in wireless iot networks. IEEE Access 2017, 5, 4621–4635. [Google Scholar] [CrossRef]
- James CR Whittington and Bogacz, R. Theories of error back-propagation in the brain. Trends Cogn. Sci. 2019, 23, 235–250. [Google Scholar]
- Tang, F.; Niu, B.; Zong, G.; Zhao, X.; Xu, N. Periodic event-triggered adaptive tracking control design for nonlinear discrete-time systems via reinforcement learning. Neural Netw. 2022, 154, 43–55. [Google Scholar] [CrossRef]
- Sun, X.; Gu, Z.; Mu, X. Observer-based memory-event-triggered controller design for quarter-vehicle suspension systems subject to deception attacks. Int. J. Robust Nonlinear Control 2023, 33, 7004–7019. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile edge computing: A survey on architecture and computation offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Hammadeh, Z.A.H.; Quinton, S.; Ernst, R. Weakly-hard real-time guarantees for earliest deadline first scheduling of independent tasks. ACM Trans. Embed. Comput. Syst. (TECS) 2019, 18, 1–25. [Google Scholar] [CrossRef]
- Rox, J.; Ernst, R. Compositional performance analysis with improved analysis techniques for obtaining viable end-to-end latencies in distributed embedded systems. Int. J. Softw. Tools Technol. 2013, 15, 171–187. [Google Scholar] [CrossRef]
- Baruah, S.K.; Mok, A.K.; Rosier, L.E. Preemptively scheduling hard-real-time sporadic tasks on one processor. In Proceedings of the 11th Real-Symposium, Lake Buena Vista, FL, USA, 5–7 December 1990; pp. 182–190. [Google Scholar]
- Xia, C.; Jin, X.; Kong, L.; Zeng, P. Bounding the demand of mixed-criticality industrial wireless sensor networks. IEEE Access 2017, 5, 7505–7516. [Google Scholar] [CrossRef]
- Jobshop-Instance. 2015. Available online: http://jobshop.jjvh.nl/index.php (accessed on 1 January 2018).
- Lawrence, S. An Experimental Investigation of Heuristic Scheduling Techniques. Supplement to Resource Constrained Project Scheduling. Ph.D. Dissertation, Graduate School of Industrial Administration, Carnegie-Mellon University, Pittsburgh, PA, USA, 1984. [Google Scholar]
- Davis, R.I.; Burns, A. A survey of hard real-time scheduling for multiprocessor systems. ACM Comput. Surv. (CSUR) 2011, 43, 1–44. [Google Scholar] [CrossRef]
- Bini, E.; Buttazzo, G.C. Measuring the performance of schedulability tests. Real-Time Syst. 2005, 30, 129–154. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, C.; Jin, X.; Xu, C.; Zeng, P. Computational-Intelligence-Based Scheduling with Edge Computing in Cyber–Physical Production Systems. Entropy 2023, 25, 1640. https://doi.org/10.3390/e25121640
Xia C, Jin X, Xu C, Zeng P. Computational-Intelligence-Based Scheduling with Edge Computing in Cyber–Physical Production Systems. Entropy. 2023; 25(12):1640. https://doi.org/10.3390/e25121640
Chicago/Turabian StyleXia, Changqing, Xi Jin, Chi Xu, and Peng Zeng. 2023. "Computational-Intelligence-Based Scheduling with Edge Computing in Cyber–Physical Production Systems" Entropy 25, no. 12: 1640. https://doi.org/10.3390/e25121640
APA StyleXia, C., Jin, X., Xu, C., & Zeng, P. (2023). Computational-Intelligence-Based Scheduling with Edge Computing in Cyber–Physical Production Systems. Entropy, 25(12), 1640. https://doi.org/10.3390/e25121640