Abstract
Anomaly detection in multivariate time series is an important problem with applications in several domains. However, the key limitation of the approaches that have been proposed so far lies in the lack of a highly parallel model that can fuse temporal and spatial features. In this paper, we propose TDRT, a three-dimensional ResNet and transformer-based anomaly detection method. TDRT can automatically learn the multi-dimensional features of temporal–spatial data to improve the accuracy of anomaly detection. Using the TDRT method, we were able to obtain temporal–spatial correlations from multi-dimensional industrial control temporal–spatial data and quickly mine long-term dependencies. We compared the performance of five state-of-the-art algorithms on three datasets (SWaT, WADI, and BATADAL). TDRT achieves an average anomaly detection F1 score higher than 0.98 and a recall of 0.98, significantly outperforming five state-of-the-art anomaly detection methods.
1. Introduction
1.1. Motivation
Anomaly detection is the core technology that enables a wide variety of applications, such as video surveillance, industrial anomaly detection, fraud detection, and medical anomaly detection. Traditional approaches use clustering algorithms [1] and probabilistic methods [2]. However, clustering-based approaches have limitations, with the possibility of a dimensional disaster as the number of dimensions increases. Probabilistic-based approaches require a lot of domain knowledge. Recently, deep learning-based approaches, such as DeepLog [3], THOC [4], and USAD [5], have been applied to time series anomaly detection. DeepLog uses long short-term memory (LSTM) to learn the sequential relationships of time series. THOC uses a dilated recurrent neural network (RNN) to learn the temporal information of time series hierarchically. USAD combines generative adversarial networks (GAN) and autoencoders to model multidimensional time series. Their key advantages over traditional approaches are that they can mine the inherent nonlinear correlation hidden in large-scale multivariate time series and do not require artificial design features.
1.2. Limitations of Prior Art
The key limitation of this deep learning-based anomaly detection method is the lack of highly parallel models that can fuse the temporal and spatial features. As such, most of these approaches rely on the time correlation of time series data for detecting anomalies. The lack of such a model limits the further development of deep learning-based anomaly detection technology. Without such a model, it is difficult to achieve an anomaly detection method with high accuracy, a low false alarm rate, and a fast detection speed.
1.3. Proposed Approach
In this paper, we propose TDRT, a three-dimensional ResNet and transformer-based anomaly detection method. TDRT can automatically learn the multi-dimensional features of temporal–spatial data to improve the accuracy of anomaly detection. TDRT is composed of three parts. The first part is three-dimensional mapping of multivariate time series data, the second part is time series embedding, and the third part is attention learning. TDRT combines the representation learning power of a three-dimensional convolution network with the temporal modeling ability of a transformer model. Via the three-dimensional convolution network, our model aims to capture the temporal–spatial regularities of the temporal–spatial data, while the transformer module attempts to model the longer- term trend.
Our TDRT model advances the state of the art in deep learning-based anomaly detection on two fronts. First, it provides a method to capture the temporal–spatial features for industrial control temporal–spatial data. Our model shows that anomaly detection methods that consider temporal–spatial features have higher accuracy than methods that only consider temporal features. Second, our model has a faster detection rate than the approach that uses LSTM and one-dimensional convolution separately and then fuses the features because it has better parallelism.
1.4. Technical Challenges and Our Solutions
The first challenge is to obtain the temporal–spatial correlation from multi-dimensional industrial control temporal–spatial data. This is challenging because the data in an industrial system are affected by multiple factors. The value of a sensor or controller may change over time and with other values. For example, SWAT [6] consists of six stages from P1 to P6; pump P101 acts on the P1 stage, and, during the P3 stage, the liquid level of tank T301 is affected by pump P101. When the value of the pump in the P1 stage is maliciously changed, the liquid level of the tank in the P3 stage will also fluctuate. Hence, it is beneficial to detect abnormal behavior by mining the relationship between multidimensional time series. Therefore, we use a three-dimensional convolutional neural network (3D-CNN) to capture the features in two dimensions. The advantage of a 3D-CNN is that its cube convolution kernel can be convolved in the two dimensions of time and space.
The second challenge is to build a model for mining a long-term dependency relationship quickly. During a period of operation, the industrial control system operates in accordance with certain regular patterns. To address this challenge, we use the transformer to obtain long-term dependencies. The advantage of the transformer lies in two aspects. On the one hand, its self-attention mechanism can produce a more interpretable model, and the attention distribution can be checked from the model. On the other hand, it has less computational complexity and can reduce the running time.
1.5. Key Technical Novelty and Results
The key technical novelty of this paper is two fold. First, we propose a approach that simultaneously focuses on the order information of time series and the relationship between multiple dimensions of time series, which can extract temporal and spatial features at once instead of separately. Second, we propose a approach to apply an attention mechanism to three-dimensional convolutional neural network. We evaluated TDRT on three data sets (SWaT, WADI, BATADAL). Our results show that TDRT achieves an anomaly recognition precision rate of over 98% on the three data sets.
2. Industrial Control Network and Threat Model
2.1. Industrial Control Network
With the rapid development of the Industrial Internet, the Industrial Control Network has increasingly integrated network processes with physical components. The physical process is controlled by the computer and interacts with users through the computer. The local fieldbus communication between sensors, actuators, and programmable logic controllers (PLCs) in the Industrial Control Network can be realized through wired and wireless channels. Commands are sent between the PLC, sensors, and actuators through network protocols, such as industrial EtherNet/IP, common industrial protocol (CIP), or Modbus. The process control layer network is the core of the Industrial Control Network, including human–machine interfaces (HMIs), the historian, and a supervisory control and data acquisition (SCADA) workstation. The HMI is used to monitor the control process and can display the historical status information of the control process through the historical data server. The historian is used to collect and store data from the PLC. The role of the supervisory control and data acquisition (SCADA) workstation is to monitor and control the PLC.
2.2. Threat Model
The Industrial Control Network plays a key role in infrastructure (i.e., electricity, energy, petroleum, and chemical engineering), smart manufacturing, smart cities, and military manufacturing, making the Industrial Control Network an important target for attackers [7,8,9,10,11]. Adversaries have a variety of motivations, and the potential impacts include damage to industrial equipment, interruption of the production process, data disclosure, data loss, and financial damage. Factors such as insecure network communication protocols, insecure equipment, and insecure management systems may all become the reasons for an attacker’s successful intrusion. As shown in Figure 1, the adversary can attack the system in the following ways:
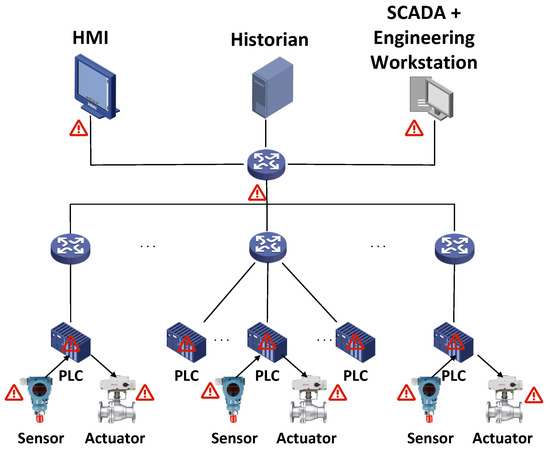
Figure 1.
ICS architecture and possible attacks.
- Intruders can attack sensors, actuators, and controllers. For example, attackers modify the settings or configurations of sensors, actuators, and controllers, causing them to send incorrect information [12].
- Intruders can attack the HMI. For example, attackers exploit vulnerabilities in their software to affect the physical machines with which they interact.
- Intruders can attack the network. For example, attackers can affect the transmitted data by injecting false data, replaying old data, or discarding a portion of the data.
- Intruders can physically attack the Industrial Control Network components. For example, attackers can maliciously modify the location of devices, physically change device settings, install malware, or directly manipulate the sensors.
This paper considers a powerful adversary who can maliciously destroy the system through the above attacks. Their ultimate goal is to manipulate the normal operations of the plant. Attacks can exist anywhere in the system, and the adversary is able to eavesdrop on all exchanged sensor and command data, rewrite sensors or command values, and display false status information to the operators. Attackers attack the system in different ways, and all of them can eventually manifest as physical attacks. Therefore, we can detect anomalies by exploiting the deviation of the system caused by changes in the sensors and instructions.
3. Related Works
Anomaly detection is a challenging task that has been largely studied. Anomalies can be identified as outliers and time series anomalies, of which outlier detection has been largely studied [13,14,15,16]; however, this work focuses on the overall anomaly of multivariate time series. In industrial control systems, such as water treatment plants, a large number of sensors work together and generate a large amount of measurement data that can be used for detection. These measurement data restrict each other, during which a value identified as abnormal and outside the normal value range may cause its related value to change, but the passively changed value may not exceed the normal value range. Therefore, it is necessary to study the overall anomaly of multivariate time series within a period [17]. Among the different time series anomaly detection methods that have been proposed, the methods can be identified as clustering, probability-based, and deep learning-based methods.
3.1. Clustering-Based
Clustering-based anomaly detection methods leverage similarity measures to identify critical and normal states. The key to this approach lies in how to choose the similarity, such as the Euclidean distance and shape distance. Clustering methods initially use the Euclidean distance as a similarity measure to divide data into different clusters. Almalawi [1] proposed a method that applies the DBSCAN algorithm [18] to cluster supervisory control and data acquisition (SCADA) data into finite groups of dense clusters. Then, the critical states are sparsely distributed and have large anomaly scores. Because DBSCAN is not sensitive to the order of the samples, it is difficult to detect order anomalies. In addition, this method is only suitable for data with a uniform density distribution; it does not perform well on data with non-uniform density. Due to the particularity of time series, a k-shape clustering method for time series has been proposed [19], which is a shape distance-based method. Boniol et al. proposed a SAND algorithm by extending the k-shape algorithm, which is designed to adapt and learn changes in data features [20]. This is a technique that has been specifically designed for use in time series; however, it mainly focuses on temporal correlations and rarely on correlations between the dimensions of the time series.
3.2. Probability-Based
Anomaly detection has also been studied using probabilistic techniques [2,21,22,23,24]. The traditional hidden Markov model (HMM) is a common paradigm for probability-based anomaly detection. The idea is to estimate a sequence of hidden variables from a given sequence of observed variables and predict future observed variables. However, the HMM has the problems of a high false-positive rate and high time complexity. Chen and Chen alleviated this problem by integrating an incremental HMM (IHMM) and adaptive boosting (Adaboost) [2]. However, they only test univariate time series. Melnyk proposed a method for multivariate time series anomaly detection for aviation systems [23]. The approach models the data using a dynamic Bayesian network–semi-Markov switching vector autoregressive (SMS-VAR) model. However, it lacks the ability to model long-term sequences. Motivated by the problems in the above method, Xu [25] proposed an anomaly detection method based on a state transition probability graph. However, it has a limitation in that the detection speed becomes slower as the number of states increases.
3.3. Deep Learning-Based
Recently deep networks have been applied to time series anomaly detection because of their powerful representation learning capabilities [3,4,5,26,27,28,29,30,31,32,33,34]. Deep learning-based approaches can handle the huge feature space of multidimensional time series with less domain knowledge. In recent years, many deep-learning approaches have been developed to detect time series anomalies. To capture the underlying temporal dependencies of time series, a common approach is to use recurrent neural networks, and Du [3] adapted long short-term memory (LSTM) to model time series. However, it cannot be effectively parallelized, making training time-consuming. Shen [4] adopted the dilated recurrent neural network (RNN) to effectively alleviate this problem. The dilated RNN can implement hierarchical learning of dependencies and can implement parallel computing. However, the above approaches all model the time sequence information of time series and pay little attention to the relationship between time series dimensions. Zhang [30] considered this problem and proposed the use of LSTM to model the sequential information of time series while using a one-dimensional convolution to model the relationships between time series dimensions. However, they separately model the relationship between the time sequence information and sequence dimensions of the time series, and this method cannot achieve parallel computing. Recently, deep generative models have also been proposed for anomaly detection. Li [31] proposed MAD-GAN, a variant of generative adversarial networks (GAN), in which they modeled time series using a long short-term memory recurrent neural network (LSTM-RNN) as the generator and discriminator of the GAN. In addition, Audibert et al. [5] also adopted the idea of GAN and proposed USAD; they used the autoencoder as the generator and discriminator of the GAN and used adversarial training to learn the sequential information of time series. However, in practice, it is usually difficult to achieve convergence during GAN training, and it has instability.
4. Problem Formulation
An industrial control system measurement device set contains m measuring devices (sensors and actuators), where is the mth device. A multivariate time series is represented as an ordered sequence of m dimensions, where l is the length of the time series, and m is the number of measuring devices. A sequence is an overlapping subsequence of a length l in the sequence X starting at timestamp t. We define the set of all overlapping subsequences in a given time series X: , where is the length of the series X.
Given a set of all subsequences of a data series X, where is the number of all subsequences, and the corresponding label represents each time subsequence. In this work, we focus on the time subsequence anomalies. The task of TDRT is to train a model given an unknown sequence X and return A, a set of abnormal subsequences.
5. Proposed Approach
In this section, we first introduce the overall architecture of our newly proposed TDRT method in Section 5.1. Then, we explain the components of our model in Section 5.2, Section 5.3 and Section 5.4. Finally, we describe the dynamic window selection method in Section 5.5.
5.1. Overview
Figure 2 shows the overall architecture of our proposed model. The input to our model is a set of multivariate time series. To model the relationship between temporal and multivariate dimensions, we propose a method to map multivariate time series into a three-dimensional space. Taking the multivariate time series in the bsize time window in Figure 2 as an example, we move the time series by d steps each time to obtain a subsequence and finally obtain a group of subsequences in the bsize time window. A detailed description of the method for mapping time series to three-dimensional spaces can be found in Section 5.2.
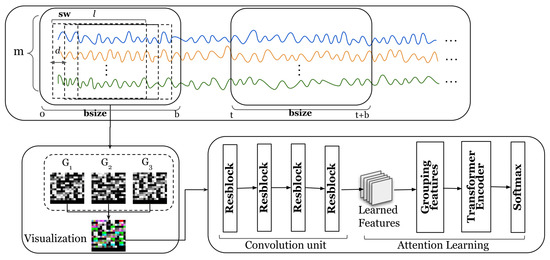
Figure 2.
Overall architecture of the TDRT model. The m lines of different colors represent the time series collected by m sensors.
After completing the three-dimensional mapping, a low-dimensional time series embedding is learned in the convolutional unit. Specifically, we apply four stacked three-dimensional convolutional layers to model the relationships between the sequential information of a time series and the time series dimensions. A detailed description of the low-dimensional embedding learning method can be found in Section 5.3. After learning the low-dimensional embeddings, we use the embeddings of the training samples as the input to the attention learning module. Specifically, we group the low-dimensional embeddings, and each group of low-dimensional embeddings is vectorized as an input to the attention learning module. A detailed description of the attention learning method can be found in Section 5.4.
Furthermore, we propose a method to dynamically choose the temporal window size. Specifically, the dynamic window selection method utilizes similarity to group multivariate time series, and a batch of time series with high similarity is divided into a group. Details of the dynamic window selection method can be found in Section 5.2.
5.2. Three-Dimensional Mapping
We first describe the method for projecting a data sequence into a three-dimensional space. Our TDRT method aims to learn relationships between sensors from two perspectives, on the one hand learning the sequential information of the time series and, on the other hand, learning the relationships between the time series dimensions. This facilitates the consideration of both temporal and spatial relationships. In the specific case of a data series, the length of the data series changes over time. To facilitate the analysis of a time series, we define a time window . The length of the time window is b. To describe the subsequences, we define a subsequence window . The subsequence window length is a fixed value l. The subsequence window is moved by steps each time. Given a time window , the set of subsequences within the time window can be represented as , where t represents the start time of the time window . We reshape each subsequence within the time window into an matrix, where , represents the smallest integer greater than or equal to the given input. When the value of is less than , add zero padding at the end. Given three adjacent subsequences, we stack the reshaped three matrices together to obtain a three-dimensional matrix. Specifically, the input of the three-dimensional mapping component is a time series X, each time window of the time series is represented as a three-dimensional matrix, and the output is a three-dimensional matrix group .
To better understand the process of three-dimensional mapping, we have visualized the process. Figure 3 shows a visual representation of a multidimensional time series. Given an matrix, the value of each element in the matrix is between , where corresponds to 256 grayscales. Each matrix forms a grayscale image. We stack three adjacent grayscale images together to form a color image. The three-dimensional representation of time series allows us to model both the sequential information of time series and the relationships of the time series dimensions.
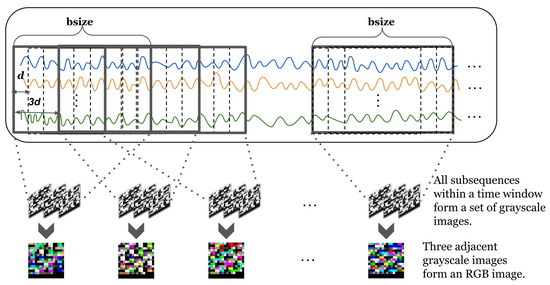
Figure 3.
Visual representation of a multidimensional time series. Lines of different colors represent different time series.
5.3. Time Series Embedding
In this work, we focus on subsequence anomalies of multivariate time series. The key is to extract the sequential information and the information between the time series dimensions. The multivariate time series embedding is for learning the embedding information of multivariate time series through convolutional units. The convolution unit is composed of four cascaded three-dimensional residual blocks. The reason we chose a three-dimensional convolutional neural network is that its convolution kernel is a cube, which can perform convolution operations in three dimensions at the same time. Figure 4 shows the embedding process of time series. The time series embedding component learns low-dimensional embeddings for all subsequences of each time window through a convolutional unit. The residual blocks that make up the convolution unit are composed of three-dimensional convolution layers, batch normalization, and ReLU activation functions. We set the kernel of the convolutional layer to and the size of the filter to 128. The channel size for batch normalization is set to 128. Specifically, the input of the time series embedding component is a three-dimensional matrix group , which is processed by the three-dimensional convolution layer, batch normalization, and ReLU activation function, and the result of the residual module is the output. After the above steps are carried out many times, the output is , where f is the filter size of the last convolutional layer, and c is the output dimension of the convolution operation.
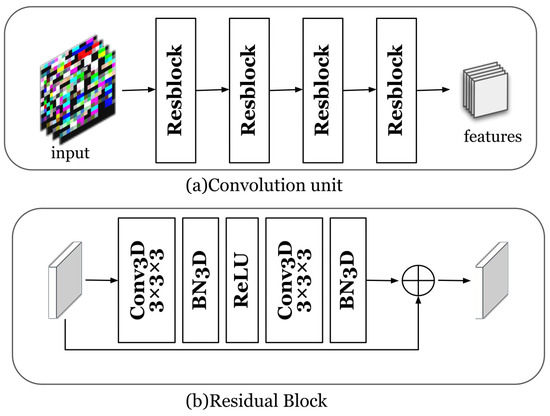
Figure 4.
Time series embedding: (a) the convolution unit; (b) the residual block component.
5.4. Attention Learning
At the core of attention learning is a transformer encoder. The reason for this design choice is to avoid overfitting of datasets with small data sizes. Figure 5 shows the attention learning method. As described in Section 5.3, the time series encoding component obtains the output feature tensor as . The feature tensor is first divided into groups: and then linearly projected to obtain the vector. The linear projection is shown in Formula (1):
where w and b are learnable parameters.
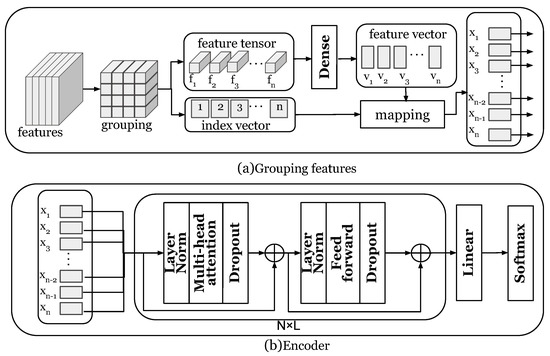
Figure 5.
Attention learning.
Since there is a positional dependency between the groups of the feature tensor, in order to make the position information of the feature tensor clearer, we add an index vector to the vector V: . Let be the input for the transformer encoder. We denote the number of encoder layers by L. During implementation, the number of encoder layers L is set to 6. The transformer encoder is composed of two sub-layers, a multi-head attention layer, and a feed-forward neural network layer. The multi-layer attention mechanism does not encode local information but calculates different weights on the input data to grasp the global information. Given n input information , the query vector sequence Q, the key vector sequence K, and the value vector sequence V are obtained through the linear projection of . The output of each self-attention layer is . The output of the multi-head attention layer is concatenated by the output of each layer of self-attention, and each layer has independent parameters. The second sub-layer of the encoder is a feed-forward neural network layer, which performs two linear projections and a ReLU activation operation on each input vector. Residual networks are used for each sub-layer: . The output of the L-layer encoder is fed to the linear layer, and the output layer is a softmax. The loss function adopts the cross entropy loss function, and the training of our model can be optimized by gradient descent methods. The values of the parameters in the network are represented in Table 1.

Table 1.
Parameter settings.
5.5. Dynamic Window Selection
The previous industrial control time series processing approaches operate on a fixed-size sliding window. We now describe how to design dynamic time windows. To describe the correlation calculation method, we redefine a time series , where is an m-dimension vector. For instance, when six sensors collect six pieces of data at time i, can be represented as a vector with the dimension . First, we normalize the time series T. The normalization method is shown in Equation (2).
where is the mean of , and is the standard deviation of . Given a time series T, represents the normalized time series, where represents a normalized m-dimension vector.
For the time series , we define a time window , the size of is not fixed, and there is a set of non-overlapping subsequences in each time window . The length of each subsequence is determined by the correlation. Figure 6 shows the calculation process of the dynamic window. Given a sequence , we calculate the similarity between and . If the similarity exceeds the threshold , it means that and are strongly correlated. In this paper, we set . We group a set of consecutive sequences with a strong correlation into a subsequence. Specifically, when k sequences from to have strong correlations, then the length of a subsequence of the time window is k, that is, . The time window is shifted by the length of one subsequence at a time. In this example, is moved by steps. The correlation calculation is shown in Equation (3).
where is the mean of , and is the mean of .
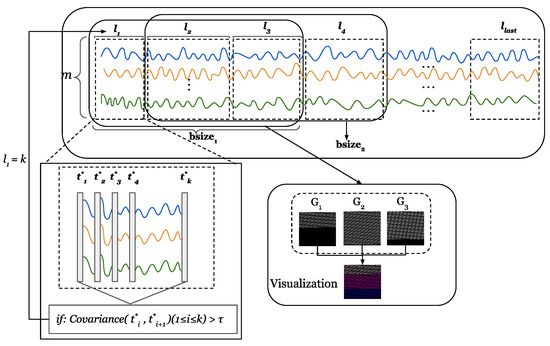
Figure 6.
The process of dynamic window calculation.The m lines of different colors represent the time series collected by m sensors.
A given time series is grouped according to the correlation to obtain a sub-sequence set . The length of all subsequences can be denoted as . In three-dimensional mapping, since the length of each subsequence is different, we choose the maximum length of L to calculate the value of M in order to provide a unified standard. It is worth mentioning that the value of is obtained from training and applied to anomaly detection. We reshape each subsequence within the time window into an matrix, , represents the smallest integer greater than or equal to the given input. When the value of is less than , add zero padding at the end. The rest of the steps are the same as the fixed window method.
6. Experimental Setup
This section describes the three publicly available datasets and metrics for evaluation. We evaluate the performance of TDRT and compare it with other state-of-the-art methods.
6.1. Public Datasets
Three publicly available datasets are used in our experiments: two real-world datasets, SWaT (Secure Water Treatment) and WADI (Water Distribution), and a simulated dataset, BATADAL (Battle of Attack Detection Algorithms). The characteristics of the three datasets are summarized in Table 2, and more details are described below. When dividing the dataset, the WADI dataset has fewer instances of the test set compared to the SWaT and BATADAL datasets. The reason for this is that the number of instances in the WADI data set has reached the million level, and it is enough to use hundreds of thousands of data instances for testing; more data can be used for training.
Table 2.
Details of the three datasets.
SWaT Dataset: SWaT is a testbed for the production of filtered water, which is a scaled-down version of a real water treatment plant. The SWaT testbed is under normal operation for 7 days and under the attack scenario for 4 days. The SWaT dataset is collected for 11 days of data.
WADI Dataset: WADI is an extension of SWaT, and it forms a complete and realistic water treatment, storage, and distribution network. The WADI testbed is under normal operation for 14 days and under the attack scenario for 2 days. The WADI dataset is collected for 16 days of data.
BATADAL Dataset: BATADAL is a competition to detect cyber attacks on water distribution systems. The BATADAL dataset collects one year of normal data and six months of attack data, and the BATADAL dataset is generated by simulation.
6.2. Evaluation Metrics
We consider that once there is an abnormal point in the time window , the time window is marked as an anomalous sequence. We adopt Precision (), Recall (), and F1 score () to evaluate the performance of our approach:
where represents the true positives, represents the false positives, and represents the false negatives.
In addition, we use the score to evaluate the average performance of all baseline methods:
where and , respectively, represent the average precision and the average recall.
7. Experiments and Results
We study the performance of TDRT by comparing it to other state-of-the-art methods (Section 7.1), analyzing the influence of different parameters on the method (Section 7.2), and assessing the performance of the TDRT variant (Section 7.3) through an ablation study (Section 7.4).
7.1. Overall Performance
For a comparison of the anomaly detection performance of TDRT, we select several state-of-the-art methods for multivariate time series anomaly detection as baselines.
- UAE Frequency: UAE Frequency [35] is a lightweight anomaly detection algorithm that uses undercomplete autoencoders and a frequency domain analysis to detect anomalies in multivariate time series data.
- MAD-GAN: MAD-GAN [31] is a GAN-based anomaly detection algorithm that uses LSTM-RNN as the generator and discriminator of GAN to focus on temporal–spatial dependencies.
- OmniAnomaly: OmniAnomaly [17] is a stochastic recurrent neural network for multivariate time series anomaly detection that learns the distribution of the latent space using techniques such as stochastic variable connection and planar normalizing flow.
- USAD: USAD [5] is an anomaly detection algorithm for multivariate time series that is adversarially trained using two autoencoders to amplify anomalous reconstruction errors.
- NSIBF: NSIBF [36] is a time series anomaly detection algorithm called neural system identification and Bayesian filtering. It combines neural networks with traditional CPS state estimation methods for anomaly detection by estimating the likelihood of observed sensor measurements over time.
On average, TDRT is the best performing method on all datasets, with an score of over 98%. Table 3 shows the results of all methods in SWaT, WADI, and BATADAL. Table 4 shows the average performance over all datasets. Overall, MAD-GAN presents the lowest performance. This is a GAN-based anomaly detection method that exhibits instability during training and cannot be improved even with a longer training time. The other baseline methods compared in this paper all use the observed temporal information for modeling and rarely consider the information between the time series dimensions. For multivariate time series, temporal information and information between the sequence dimensions are equally important because the observations are related in both the time and space dimensions. In TDRT, the input is a series of observations containing information that preserves temporal and spatial relationships. The performance of TDRT in BATADAL is relatively low, which can be explained by the size of the training set. SWaT and WADI have larger datasets; their training datasets are 56 and 119 times larger than BATADAL, respectively, so the performance on these two datasets is higher than that on the BATADAL dataset.
Table 3.
Precision (Pre), recall (Rec), and F1 score results (as %) on various datasets.
Table 4.
Average performance (±standard deviation) over all datasets.
7.2. Effect of Parameters
Different time windows have different effects on the performance of TDRT. In this section, we study the effect of the parameter on the performance of TDRT. Considering that may have different effects on different datasets, we set different time windows on the three datasets to explore the impact of time windows on performance. The size of the time window can have an impact on the accuracy and speed of detection. Since different time series have different characteristics, an inappropriate time window may reduce the accuracy of the model. In addition, it is empirically known that larger time windows require waiting for more observations, so longer detection times are required. Essentially, the size of the time window is reflected in the subsequence window . Therefore, we take as the research objective to explore the effect of time windows on model performance. Figure 7 shows the results on three datasets for five different window sizes. When the subsequence window is set to 10, TDRT shows the best performance on the SWaT dataset. The performance of TDRT on the WADI dataset is relatively insensitive to the subsequence window, and the performance on different windows is relatively stable. Considering that a larger subsequence window requires a longer detection time, we set the subsequence window of the WADI dataset to five. The performance of TDRT on the BATADAL dataset is relatively sensitive to the subsequence window. When the subsequence window , TDRT shows the best performance on the BATADAL dataset.
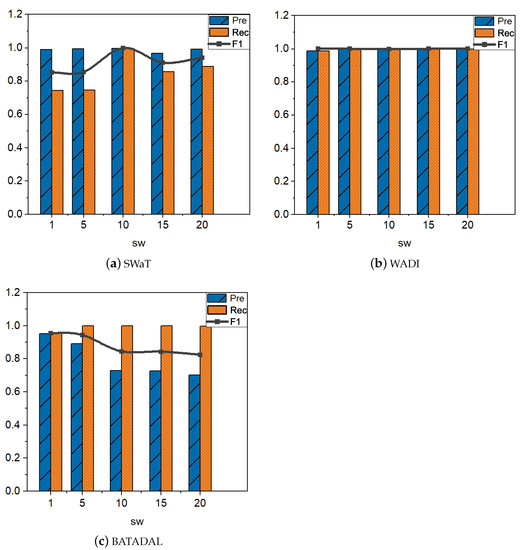
Figure 7.
The effect of the subsequence window on Precision, Recall, and F1 score.
7.3. Performance of TDRT-Variant
The average F1 score for the TDRT variant is over 95%. Recall that we studied the effect of different time windows on the performance of TDRT. Choosing an appropriate time window is computationally intensive, so we propose a variant of TDRT that provides a unified approach that does not require much computation. In this experiment, we investigate the effectiveness of the TDRT variant. The results are shown in Figure 8. As can be seen, the proposed TDRT variant, although relatively less effective than the method with carefully chosen time windows, outperforms other state-of-the-art methods in the average F1 score.
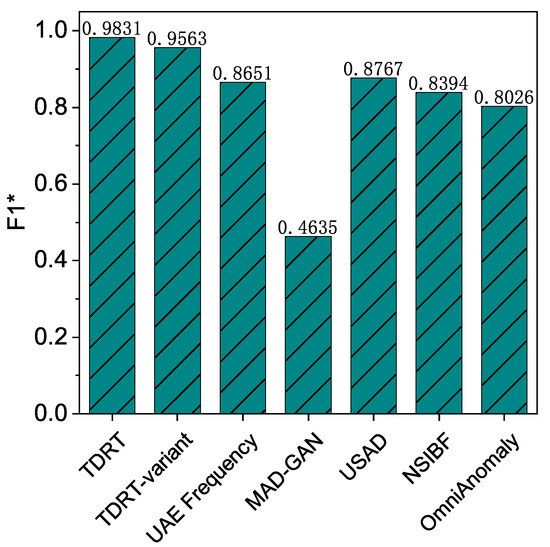
Figure 8.
Performance of all solutions.
7.4. Ablation Study
The average F1 score improved by 5.6% relative to methods that did not use attentional learning. Using the SWaT, WADI, and BATADAL datasets, we investigate the effect of attentional learning. Figure 9 shows a performance comparison in terms of the F1 score for TDRT with and without attention learning. The ablated version of TDRT has a lower F1 score than that of TDRT without ablation. In conclusion, ablation leads to performance degradation.
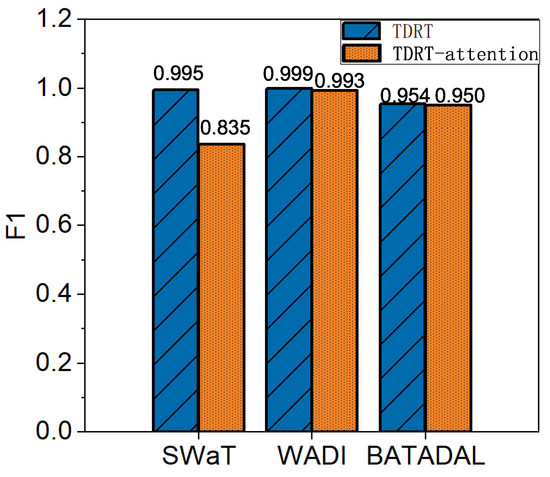
Figure 9.
Impact with and without attention learning on TDRT.
8. Conclusions
In this paper, we make the following two key contributions: First, we propose TDRT, an anomaly detection method for multivariate time series, which simultaneously models the order information of multivariate time series and the relationships between the time series dimensions. By extracting spatiotemporal dependencies in multivariate time series of Industrial Control Networks, TDRT can accurately detect anomalies from multivariate time series. In comprehensive experiments on three high-dimensional datasets, TDRT outperforms state-of-the-art multivariate time series anomaly detection methods. Our results show that the average F1 score of TDRT is over 98%. Second, we propose a method to automatically select the temporal window size called the TDRT variant. In comprehensive experiments on three high-dimensional datasets, the TDRT variant provides significant performance advantages over state-of-the-art multivariate time series anomaly detection methods. Our results show that the average F1 score of the TDRT variant is over 95%.
A limitation of this study is that the application scenarios of the multivariate time series used in the experiments are relatively homogeneous. In the future, we will conduct further research using datasets from various domains, such as natural gas transportation and the smart grid.
Author Contributions
Conceptualization, D.Z.; Methodology, L.X.; Validation, Z.Z.; Writing—original draft, X.D.; Project administration, A.X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Natural Science Foundation of Shandong Province under Grants ZR2021MF132 and ZR2020YQ06; in part by the Young innovation team of colleges and universities in Shandong province (2021KJ001); in part by the Pilot Project for Integrated Innovation of Science, Education, and Industry of Qilu University of Technology (Shandong Academy of Sciences) (2022JBZ01-01); in part by the Key R & D Plan of Shandong Province (Soft Science Project) (2021RZB01002); and in part by the Innovation Ability Promotion Project for Small- and Medium-Sized Technology-Based Enterprise of Shandong Province (2022TSGC2098).
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Almalawi, A.; Fahad, A.; Tari, Z.; Alamri, A.; AlGhamdi, R.; Zomaya, A.Y. An efficient data-driven clustering technique to detect attacks in SCADA systems. IEEE Trans. Inf. Forensics Secur. 2015, 11, 893–906. [Google Scholar] [CrossRef]
- Chen, Y.S.; Chen, Y.M. Combining incremental hidden Markov model and Adaboost algorithm for anomaly intrusion detection. In Proceedings of the ACM SIGKDD Workshop on Cybersecurity and Intelligence Informatics, Paris, France, 28 June 2009; pp. 3–9. [Google Scholar]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar]
- Shen, L.; Li, Z.; Kwok, J. Timeseries anomaly detection using temporal hierarchical one-class network. Adv. Neural Inf. Process. Syst. 2020, 33, 13016–13026. [Google Scholar]
- Audibert, J.; Michiardi, P.; Guyard, F.; Marti, S.; Zuluaga, M.A. Usad: Unsupervised anomaly detection on multivariate time series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 23–27 August 2020; pp. 3395–3404. [Google Scholar]
- Mathur, A.P.; Tippenhauer, N.O. SWaT: A water treatment testbed for research and training on ICS security. In Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks (CySWater), Vienna, Austria, 11 April 2016; pp. 31–36. [Google Scholar]
- Xu, L.; Wang, B.; Wang, L.; Zhao, D.; Han, X.; Yang, S. PLC-SEIFF: A programmable logic controller security incident forensics framework based on automatic construction of security constraints. Comput. Secur. 2020, 92, 101749. [Google Scholar] [CrossRef]
- Xu, L.; Wang, B.; Wu, X.; Zhao, D.; Zhang, L.; Wang, Z. Detecting Semantic Attack in SCADA System: A Behavioral Model Based on Secondary Labeling of States-Duration Evolution Graph. IEEE Trans. Netw. Sci. Eng. 2021, 9, 703–715. [Google Scholar] [CrossRef]
- Kravchik, M.; Shabtai, A. Detecting cyber attacks in industrial control systems using convolutional neural networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and Privacy, Toronto, ON, Canada, 19 October 2018; pp. 72–83. [Google Scholar]
- Zhao, D.; Wang, L.; Wang, Z.; Xiao, G. Virus propagation and patch distribution in multiplex networks: Modeling, analysis, and optimal allocation. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1755–1767. [Google Scholar] [CrossRef]
- Sipple, J. Interpretable, multidimensional, multimodal anomaly detection with negative sampling for detection of device failure. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual Event, 13–18 July 2020; pp. 9016–9025. [Google Scholar]
- Formby, D.; Beyah, R. Temporal execution behavior for host anomaly detection in programmable logic controllers. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1455–1469. [Google Scholar] [CrossRef]
- Marteau, P.F. Random partitioning forest for point-wise and collective anomaly detection—application to network intrusion detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2157–2172. [Google Scholar] [CrossRef]
- Siffer, A.; Fouque, P.A.; Termier, A.; Largouet, C. Anomaly detection in streams with extreme value theory. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1067–1075. [Google Scholar]
- Yoon, S.; Lee, J.G.; Lee, B.S. Ultrafast local outlier detection from a data stream with stationary region skipping. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 1181–1191. [Google Scholar]
- Song, H.; Li, P.; Liu, H. Deep Clustering based Fair Outlier Detection. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1481–1489. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD, Portland, Oregon, 2 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Paparrizos, J.; Gravano, L. k-shape: Efficient and accurate clustering of time series. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Victoria, Australia, 31 May–4 June 2015; pp. 1855–1870. [Google Scholar]
- Boniol, P.; Paparrizos, J.; Palpanas, T.; Franklin, M.J. SAND: Streaming subsequence anomaly detection. Proc. VLDB Endow. 2021, 14, 1717–1729. [Google Scholar] [CrossRef]
- Shawly, T.; Elghariani, A.; Kobes, J.; Ghafoor, A. Architectures for detecting interleaved multi-stage network attacks using hidden Markov models. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2316–2330. [Google Scholar] [CrossRef]
- Iwata, T.; Yamada, M. Multi-view anomaly detection via robust probabilistic latent variable models. Adv. Neural Inf. Process. Syst. 2016, 29, 1136–1144. [Google Scholar]
- Melnyk, I.; Banerjee, A.; Matthews, B.; Oza, N. Semi-Markov switching vector autoregressive model-based anomaly detection in aviation systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1065–1074. [Google Scholar]
- Yang, J.; Chen, X.; Chen, S.; Jiang, X.; Tan, X. Conditional variational auto-encoder and extreme value theory aided two-stage learning approach for intelligent fine-grained known/unknown intrusion detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3538–3553. [Google Scholar] [CrossRef]
- Xu, L.; Wang, B.; Yang, M.; Zhao, D.; Han, J. Multi-Mode Attack Detection and Evaluation of Abnormal States for Industrial Control Network. Comput. Res. Dev. 2021, 11, 2333–2349. [Google Scholar]
- Xu, C.; Shen, J.; Du, X. A method of few-shot network intrusion detection based on meta-learning framework. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3540–3552. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Han, J.; Su, Y.; Jiao, R.; Wen, X.; Pei, D. Multivariate time series anomaly detection and interpretation using hierarchical inter-metric and temporal embedding. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 3220–3230. [Google Scholar]
- Du, M.; Chen, Z.; Liu, C.; Oak, R.; Song, D. Lifelong anomaly detection through unlearning. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 1283–1297. [Google Scholar]
- Zerveas, G.; Jayaraman, S.; Patel, D.; Bhamidipaty, A.; Eickhoff, C. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 2114–2124. [Google Scholar]
- Zhang, X.; Gao, Y.; Lin, J.; Lu, C.T. Tapnet: Multivariate time series classification with attentional prototypical network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6845–6852. [Google Scholar]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; pp. 703–716. [Google Scholar]
- Chen, W.; Tian, L.; Chen, B.; Dai, L.; Duan, Z.; Zhou, M. Deep Variational Graph Convolutional Recurrent Network for Multivariate Time Series Anomaly Detection. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MA, USA, 17–23 July 2022; pp. 3621–3633. [Google Scholar]
- Tuli, S.; Casale, G.; Jennings, N.R. TranAD: Deep transformer networks for anomaly detection in multivariate time series data. arXiv 2022, arXiv:2201.07284. [Google Scholar] [CrossRef]
- Han, S.; Woo, S.S. Learning Sparse Latent Graph Representations for Anomaly Detection in Multivariate Time Series. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2977–2986. [Google Scholar]
- Kravchik, M.; Shabtai, A. Efficient cyber attack detection in industrial control systems using lightweight neural networks and pca. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2179–2197. [Google Scholar] [CrossRef]
- Feng, C.; Tian, P. Time series anomaly detection for cyber-physical systems via neural system identification and bayesian filtering. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 2858–2867. [Google Scholar]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).