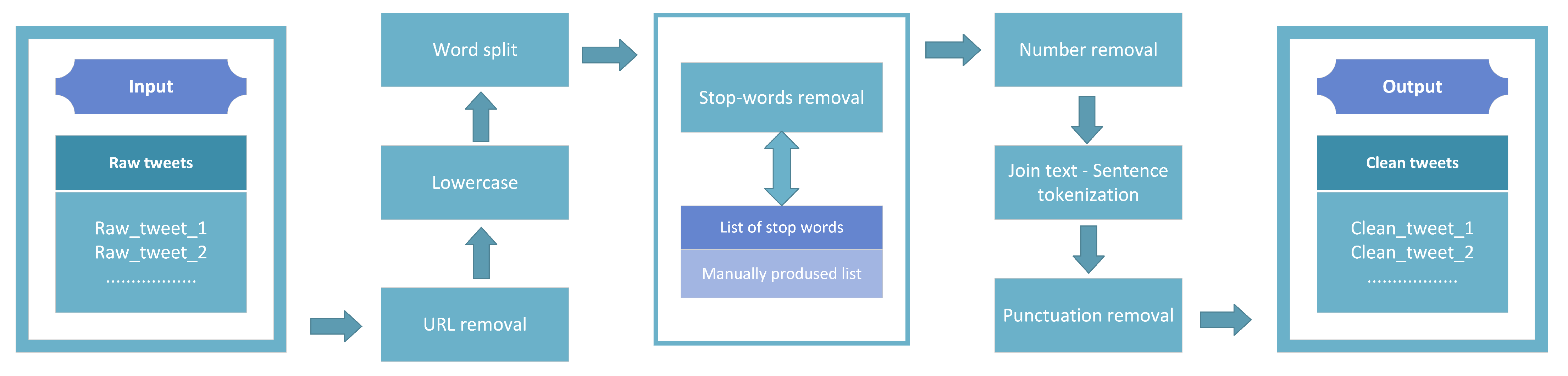
1. Introduction
Somewhere in the course of history, the human species’ need for knowledge of possible future outcomes of various events emerged. Associative norms were thus constructed between decision-making and observed data that were influenced by theoretical biases that had been inductively established on the basis of such observations. Protoscience was formed. Or not?
Even if this hypothetical description of human initiation into scientific capacities is naive or even unfounded, the bottom line is that the human species partly operates on the basis of predictions. Observing time-evolving phenomena and questioning their structure in the direction of an understanding that will derive predictions about their projected future behavior constitutes an inherent part of post-primitive human history. In response to this self-referential demand and assuming that the authors are post-primitive individuals, the core of the present work is about predicting sequential and time-dependent phenomena. This domain is called time series forecasting. Time series forecasting is, in broad terms, the process of using a model to predict future values of variables that characterize a phenomenon based on historical data. A time series is a set of time-dependent observations sampled at specific points in time. The sampling rate depends on the nature of the problem. Moreover, depending on the number of variables describing the sequentially recorded observations, a distinction is made between univariate and multivariate time series. Since there is a wide range of time-evolving problems, the field is quite relevant in modern times, with an increasing demand for model accuracy and robustness.
In addition, there are phenomena, the mathematical formalism of which is represented by time series with values which are also sub-determined by the given composition of a society of individuals. This means that the attitudes of such individuals, as they nonetheless form within the whole, are somewhat informative about aspects of the phenomenon in question. It is natural, given human nature and the consequent conceptual treatment of the world as part of it, that these attitudes are articulated somewhere linguistically. Therefore, a hypothesis on which mathematical quantifications of the attitudes of which such linguistic representations that are signs are possible could, if valid, describe a framework for improving the modeling of the phenomena in question. For example, specific economic figures can be points in a context, the elements of which are partially shaped by what is said about them. Accordingly, it can be argued that a line of research that would investigate whether stock closing prices can be modeled in terms of their future fluctuations using relevant linguistic data collected from social networks is valid.
Thus, in this work, the incorporation of sentiment analysis in stock market forecasting is investigated. In particular, a large number of state-of-the-art methods are put under an experimental framework that includes multiple configurations of input features that incorporate quantified values of sentiment attitudes in the form of time series. These time series consist of sentiment scores extracted from Twitter using three different sentiment analysis methods. Regarding prediction methods, there are schemes that come from both the field of statistics and machine learning. Within the machine learning domain, deep learning and other state-of-the-art methods are currently in use, dominating research. Here, a large number of such widely used state-of-the-art models were benchmarked in terms of performance. Moreover, various sentiment setups of input features were tested. Two distinct case studies were investigated. In the first case study, the evaluations were organized according to methods. The subsequent comparisons followed the grouping. In the second case study, the comparisons concerned the feature setups used as inputs. Sentiment scores were tested in the context of improving the predictive capacities of the various models used. All comparisons yielded results from an extended experimental procedure that incorporated various steps. The whole setting involved a wide range of multivariate setups, which included various sentiment time series. Multiple evaluation metrics and three different time frames were used to derive multiple-view results. Below, first, a brief presentation of related literature is given. Then, the experimental procedure is thoroughly presented, which is followed by the results. Finally,
Section 5 lists the extracted conclusions.
2. Related Work
The continuous and ever-increasing demand for accurate forecasts across a wide range of human activity has been a key causal factor contributing to the unabated research activity occurring within the field of time series forecasting. Thus, the prediction of time series constitutes a strong pole of interest for the scientific community. Consequently, in recent decades, this interest has been reflected in a wealth of published work and important results. In this section, a brief presentation of relevant literature is given. Due to space constraints, this presentation is more indicative than exhaustive, and its purpose is just to provide a starting point for a more thorough and in-depth review.
A trivial way to distinguish the problems associated with time series forecasting would be to divide the task into two categories with respect to the type of final output. The first category includes problems where the goal is to predict whether a future value is expected to increase or decrease over a given time horizon. This task can essentially be treated as a binary classification problem. The second category includes tasks where the goal is to accurately predict the price of a time series in a specific time frame. Here, the output can take any value within a continuous interval, and hence, the prediction process can be treated as a regression problem. One can easily imagine that the difficulty of the problems belonging to the second category is greater than that of the first and that their treatment requires more complex and precise refinements. Apparently, interesting works can be found in both categories, but the context of this paper dictates a focus on the latter.
A subclass of problems regarding focus on the direction in which a time series will move features those involving the increase or decrease of closing price values of various stocks. In particular, in [
1], an ensemble technique based on tree classifiers—specifically on
random forests and
gradient boosted decision trees—which predicts movement in various time frames is proposed. For the same purpose in [
2],
support vector machines (SVMs) are used in combination with sentiment analysis performed on data drawn from two forums considered to be the largest and most active mainstream communities in China. This paper is an attempt to predict stock price direction using SVMs and taking into account the so-called day-of-week effect. Adding sentiment variables results in up to 18% better predictions. Similar results, which indicate the superiority of SVMs compared to other classification algorithms, are also presented in [
3], where well-known methods such as
linear discriminant analysis,
quadratic discriminant analysis, and
Elman backpropagation neural networks are used for comparison. Encouraging results regarding the prediction of time series movement direction have also been achieved using hybrid methods, where modern schemes combining
deep neural network architectures are applied to big data [
4]—again—for the daily-based prediction of stock market prices. Regarding the second category, where the goal is to predict the specific future values of a time series and not merely its direction, the literature appears richer. This seems as if it is a fact rather expected if one takes into account the increased difficulty of the task and the high interest of the research community in pursuing the production of improved results. In the past decades, traditional statistical methods seemed to dominate the field of time series forecasting [
5,
6]. However, as expected, according to their general effectiveness, machine learning methods began to gain ground and dominate the field [
7,
8]. Traditional machine learning methods are incorporated in various time series forecasting tasks, such as using SVMs for economic data predictions [
9] and short-term electric load forecasting [
10], while architectures based on neural networks are also particularly popular. Regarding the latter—as this is probably the largest part of the literature regarding the use of machine learning in prediction problems—the use of such methods has covered a wide range of applications. Some indicative examples are the prediction of oil production [
11] and traffic congestion [
12] using deep
LSTM recurrent networks, while an aggregated version of LSTMs has additionally been used for the short-term prediction of air pollution. Forecasting river water temperature using a hybrid model based on
wavelet-neural network architecture was presented in [
13], while
recurrent neural networks (RNNs) have been deployed to forecast agricultural commodity prices in China [
14]. Since the list of examples where neural network-based techniques show promise is long, the reader is urged to pursue additional personal research.
Furthermore, it is possibly worth mentioning the fact that in addition to increasingly sophisticated methods, techniques based on the theory of
ensembles are also gaining ground. Roughly speaking, these are techniques in which the final result is derived through a process of using different models, with the prediction being formed from the combination of the individual ones. As an example, one can mention the ensemble scheme proposed in [
15] for the prediction of energy consumption: it combines
support vector regression (SVR),
backpropagation neural network (BPNN), and
linear regression (LR) learners. A similar endeavor is presented in [
16], where an ensemble consisting of four learners, that is,
long short-term memory (LSTM),
gate recurrent unit (GRU),
autoencoder LSTM (Auto-LSTM), and
auto-GRU, is used for the prediction of solar energy production. A comparison involving over 300 individual and ensemble predictive layouts over Greek energy load data is presented in [
17]. There, in addition to the large number of ensembles tested, the comparison also concerns both a number of forecast time frames as well as different modifications of the input data in various multivariate arrangements. In [
18], an ensemble scheme based on
linear regression (LR),
support vector regression (SVR), and the
M5P regression tree (M5PRT) is proposed to predict cases and deaths attributed to the COVID-19 pandemic regarding southern and central European countries.
With regard now to the context of this work, and given that its purpose—which is an extension of the work in [
19]—is twofold, aiming, on the one hand, to compare a large number of methods and, on the other hand, to investigate the contribution of incorporating sentiment analysis into the forecasting process, it follows that a simple presentation of similarly targeted tasks seems quite essential. As for the first objective—that of comparing methods—there are several interesting works that have been carried out in recent years. In [
20], the comparison between the traditional
ARIMA method and
LSTMs using economic data is investigated. A similar comparison between the two methods is implemented in [
21], now aiming to predict bitcoin values, while in [
22], the
gated recurrent unit (GRU) scheme is also included in the comparison. Comparative works of the
ARIMA method with various schemes have also been carried out, such as with
neural network auto-regressive (NNAR) techniques [
23], with the
prophet method [
24], with
LSTMs and the
XGBOOST method [
25], as well as with
wavelet neural network (WNN) and
support vector machines (SVM) [
26]. Although, in general, modern schemes tend to perform better than ARIMA, any absolute statement would not be representative of reality. Indeed, research focused on comprehensively reviewing the use of modern methods can provide a detailed overview of the relevant work to date. Indicatively, in [
27], an extensive review of the use of artificial neural networks in time series forecasting is presented, covering studies published from 2006 onwards, over a decade. A similar survey covering the period from 2005 to 2019 and focusing on deep learning techniques with applications to financial data can be found in [
28]. Furthermore, regarding the experimental evaluation of modern machine learning architectures, in [
29], a thorough experimental comparison is presented, concerning seven different deep learning architectures applied to 12 different forecasting problems, using more than 50,000 time series. According to the implementation of more than 38000 models, it is argued that the architectures of
LSTMs and
CNNs outperform all others. In [
30], the comparison of a number of methods—such as
ARIMA,
neural basis expansion analysis (NBEATS), and probabilistic methods based on deep learning models—applied to time series of financial data is presented. Additionally, in [
31], a comparison between
CNNs,
LSTMs, and a hybrid model of them is given, which was deployed on data concerning the forecasting of the energy load coming from photovoltaics. There, the generated results, on the one hand, indicate the dominance of the hybrid model—emphasizing the necessity to create efficient combinatorial schemes—and, on the other, show that the models’ predictions improve by using a larger amount of data in the training set.
In relation to the second objective—which concerns the investigation of whether the use of information based on sentiment analysis regarding public opinion extracted from social networks favors the predictions—the available literature seems comparatively poorer but presents equally interesting results. The relationship between tweet board literature and financial market instruments is examined in [
32], with results revealing a high correlation between stock prices and Twitter sentiments. In [
33], using targeted topics to extract sentiment from social media, a model to predict stock price movement is presented. Moreover, the effectiveness of incorporating sentiment analysis into stock forecasting is demonstrated. In addition, ref. [
34] is an attempt to capture the various relationships between news articles and stock trends using well-known machine learning techniques such as
random forest and
support vector machines. In [
35], after assembling a financial-based sentiment analysis dictionary, a model incorporating the dictionary was developed and tested on data from the pharmaceutical market, exhibiting encouraging results. In [
36], sentiment polarity is extracted by observing the logarithmic return of the ratio between the average stock price one minute before and one minute after the relevant stock’s news is published. Then, using
RNNs and
LSTMs, the direction of the stock is successfully predicted. The exploitation of sentiment analysis techniques has also been used to predict the stock market during health crises [
37] such as H1N1 and, more recently, COVID-19. Possible links between social media posts and closing stock prices at specific time horizons were found. More specifically, for COVID-19, the polarity of the posts seemed to affect the stock prices after a period of about six days.
Regarding the prediction of various stock market closing prices—which is also the thematic center of this paper—in [
38], data collected from Twitter are initially analyzed in terms of their sentiment scores and are then used to predict the movement of stock prices, using
naive Bayes and
multiclass SVM classifiers. A similar procedure was followed in [
39], where
least squares support vector regression (LSSVR) and
backpropagation neural networks were deployed to predict the total monthly sales of vehicles in the USA, using additional sentiment information combined with historical sales data. Data collected from the online editions of international newspapers were used in [
40] to predict the closing stock price values, incorporating both traditional methods, such as
ARIMA, and newer ones, such as the Facebook
prophet algorithm and
RNN architectures that use as input both numerical values of the time series to be predicted as well as combinations of the polarity of extracted sentiments.
In [
41], both traditional and modern machine learning methods such as
support vector machines,
linear regression,
naive Bayes, and
long short-term memory are used in combination with the incorporation of opinion data, current news, and past stock prices. In [
42], sentiment analysis and
empirical model decomposition are used so that complex time series can be broken down into simpler and easier to manage parts, together with an
attention mechanism that attributes weight to the information considered most useful for the task being performed each time. A method based on the architecture of
LSTMs that uses information derived from sentiment analysis together with multiple data sources is presented in [
43]. Initially, textual data related to the stock in question are collected, and using methods based on
convolutional neural network architectures, the polarity of investors’ sentiment is extracted. This information is then combined with that of the stock’s past closing prices and other technical indicators to produce the final forecast. In [
44], a hybrid model that leverages deep learning architectures, such as
convolutional neural networks, to extract and categorize investor sentiment as detected in financial forums is described. The extracted sentiments are then combined with information derived from technical financial indicators to predict future stock prices in real-world problems using
LSTM architectures.
SVM architectures are used on Twitter data to extract polarity in [
45]. The extracted polarities are used in an incremental active learning scheme, where the continuous stream of content-changing tweets is used to predict the closing stock price of the stock market.
Sentiment analysis has also been used to predict the price of bitcoin in real time, using—and at the same time comparing—
LSTM techniques and the classical
ARIMA method [
46], where the exploitation of the information derived from sentiment analysis has been beneficial. Similar research focused on predicting the price direction of the cryptocurrencies Bitcoin and Ethereum using sentiment analysis from data drawn from Twitter and Google Trends and given as input to a linear predictive model is presented in [
47]. Interestingly, the volume of tweets affects the prediction to a greater extent than the polarity of the sentiment extracted from the tweets. Forecasting the price direction of four popular cryptocurrencies—Bitcoin, Ethereum, Ripple, and Litecoin—using machine learning techniques and data drawn from social networks is presented in [
48]. Classical methods such as
neural networks (NN),
support vector machines (SVM), and
random forests (RF) are compared. An interesting fact is that Twitter, roughly speaking, seems to favor the prediction of specific cryptocurrencies rather than all of them. Using sentiment analysis has also been beneficial in the field of cybersecurity. In [
49], a methodology that exploits the knowledge of hacker behavior for predicting malicious events in cyberspace by performing sentiment analysis with different techniques (
VADER,
LIWC15, and
SentiStrength) on data collected from hacking forums, both on the dark web and on the surface web, is presented.
The—rather diverse—list of applications in which the use of sentiment analysis techniques can improve the generated forecasts is proportional to the fields in which time series forecasting is applied since, in general, the utilization of public opinion knowledge appears to have a positive effect on the forecasting process. Some of them that have been implemented in the last five years have already been mentioned in passing, and many others can be added. Such would include predicting the course of epidemics, such as that of the Zika virus in the USA in 2016 [
50] or the COVID-19 pandemic, the outcome of electoral contests [
51], the prediction of the price of e-commerce products [
52], and the list goes on. Given human nature and the consequent conceptual coping of the world by human subjects, sentiment analysis seems justifiably relevant in a multitude of applications. The reader is therefore encouraged to conduct additional bibliographic research.
4. Results
Returning to the dual objective of this work, the two case studies whose results will be presented in this chapter were:
On the one hand, the comparison of a large number of time series forecasting contemporary algorithms;
On the other hand, the investigation of whether knowledge of public opinion, as reflected in social networks and quantified using three different sentiment analysis methods, can improve the derived predictions.
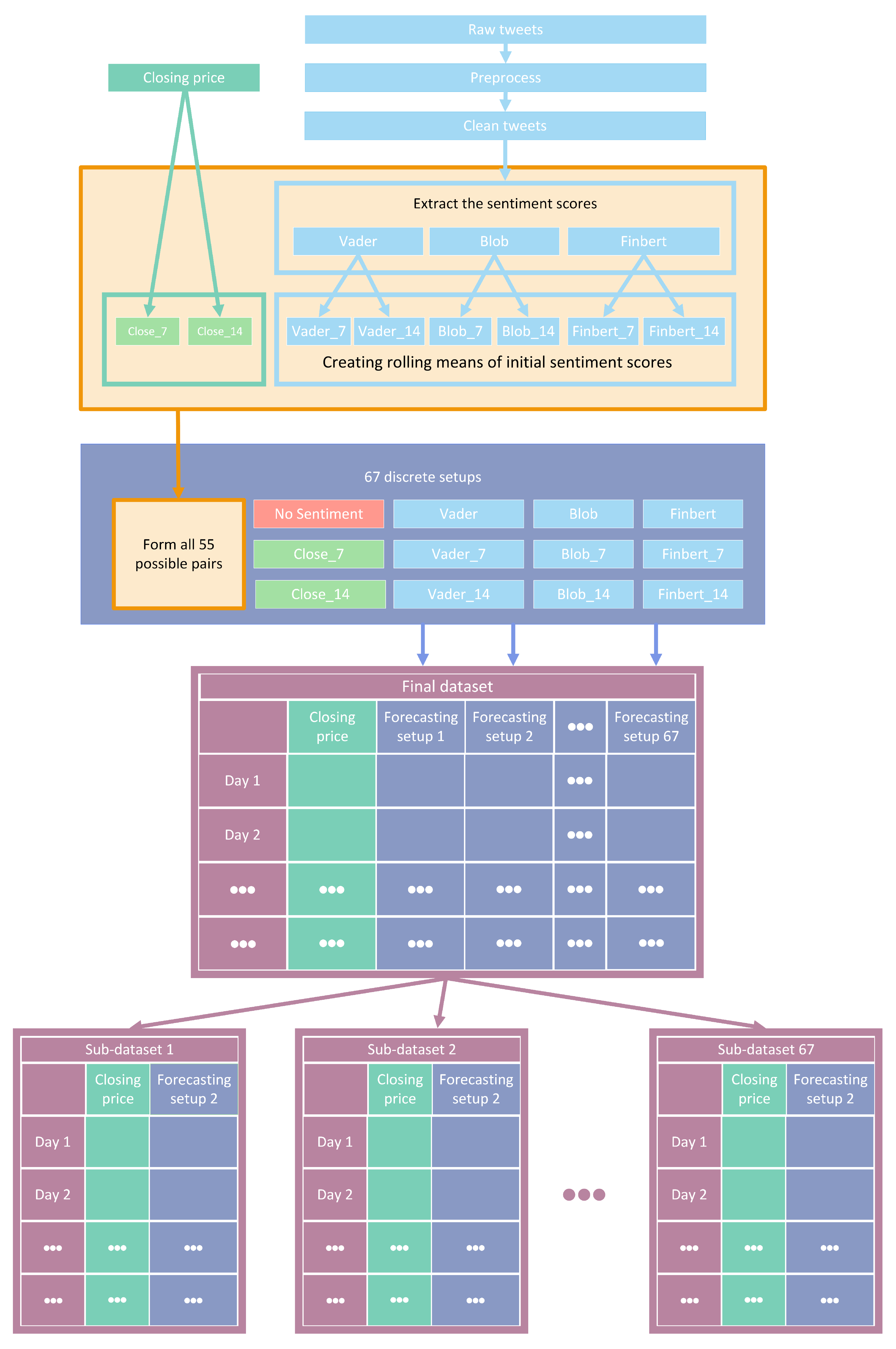
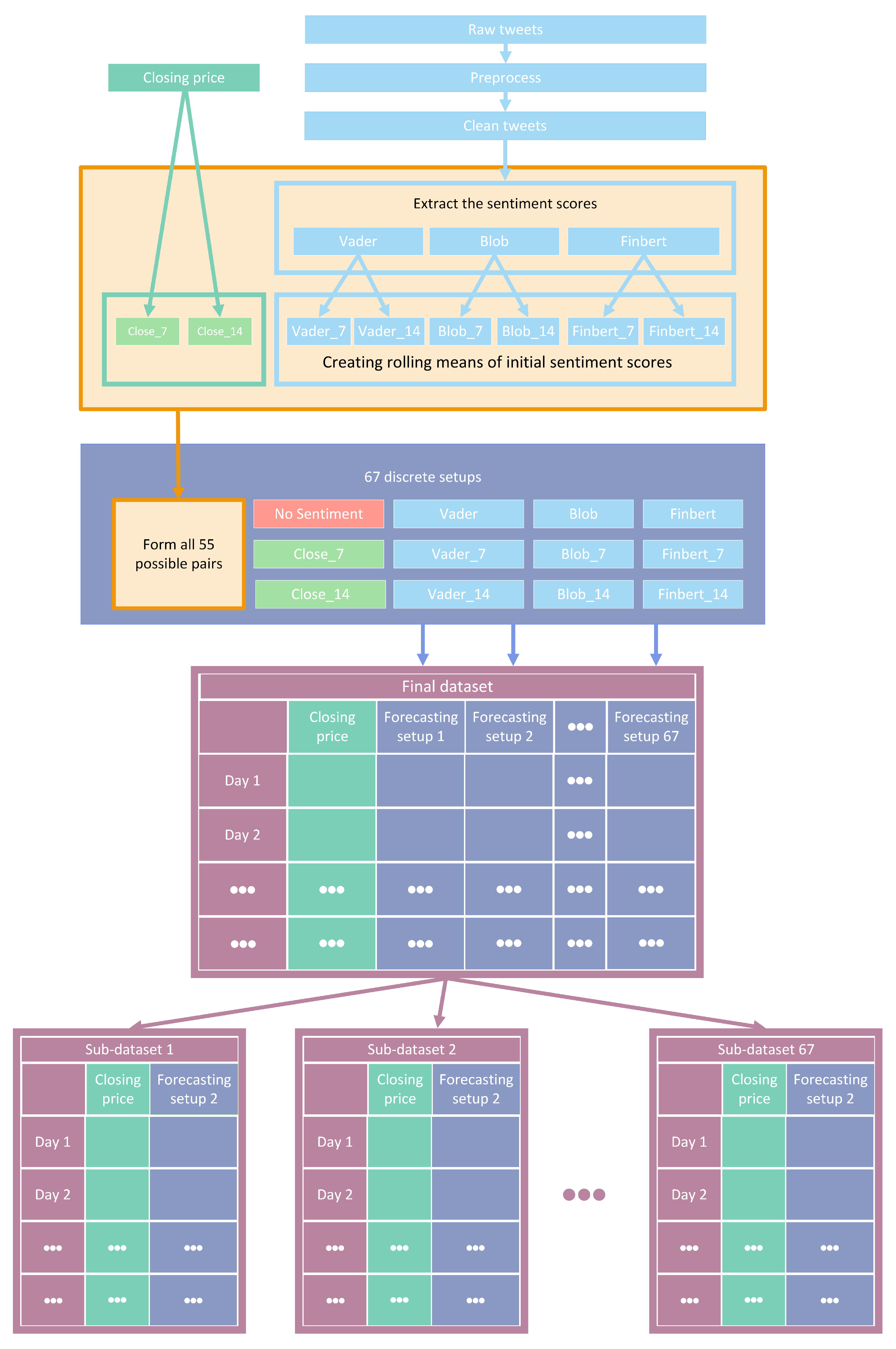
Accordingly, the presentation of the results of the experimental process is split into two distinct parts. In what follows, both various statistical analysis and visualization methods are incorporated. However, it should be noted that the number of comparisons performed yielded a quite large volume of results. Specifically, as already pointed out, in each case, the performance of the 30 predictive schemes and the 67 different feature setups was investigated over three different time frames (1, 7, and 14 day shifts). Note that these three time-shifting options have no—or at least no intended—financial consequences. Here, the primary goal in designing the framework was to forecast the stock market over short time frames, such as a few days. Then, an expansion was made to investigate the performance of both methods and feature setups over longer periods of time. Each of these schemas was evaluated with six different metrics, while the process was repeated for each of the datasets. Consequently, it becomes clear that the complete tables with the numerical results cannot contribute satisfactorily to the understanding of the conclusions drawn. Below, following a necessary brief reminder of the process, results are presented.
As has already been mentioned, during the procedure, for each of the stocks, the following strategy was followed: each of the thirty algorithms to be compared was “ran” 67 times, each time accepting as input one of the different feature setups. This was repeated three times, once for each of the three forecast time frames. In each of the above runs, the six metrics used in the evaluation of the results were calculated. The comparison of the algorithms was performed by using Friedman’s statistical tests in terms of feature setups for each of the time shifts. Thus, given setups and stocks, the ranking of the methods per evaluation metric was extracted according to the use of the Friedman test [
88]. Therefore, regarding this case study, a total of 67 × 6 × 3 = 1206
statistical tests were executed. In a similar way, the Friedman rankings of input feature setups were estimated in terms of metrics and time shifts, given the various algorithms and stocks. Here, a total of 30 × 6 × 3 = 540
statistical tests were performed. An additional abstraction of the results was derived as follows: For each of the 30 methods, the average rank achieved by each method in terms of feature setups and shares was calculated. So, for each metric and each of the three time frames, a more comprehensive display of the information was obtained based on the average value of the different setups. In an identical way, in the case of checking the effectiveness of features, the average value of the 30 algorithms for each of the 67 different input setups was calculated in each case. In both cases, the ranking was calculated based on the positions produced by the Friedman test, while at the same time, with the Nemenyi post hoc test [
89] that followed, every schema was checked pair-wise for significant differences. The results of the Nemenyi post hoc tests are shown in the corresponding Critical Difference diagrams (CD-diagrams), in which methods that are not significantly different are joined by black horizontal lines. Two methods are considered not significantly different when the difference between their mean ranks is less than the CD value.
Next, organized in both cases based on time frames, the results concerning the comparison of the forecast algorithms are presented, which are followed by those regarding the feature setups.
4.1. Method Comparison
The presentation begins with results concerning the investigation of methods. The results are presented per forecast time shift. In each case, the Friedman Ranking results for all six metrics are listed. To save space, only methods that occupy the top ten positions of the ranking are listed. Full tables are available at:
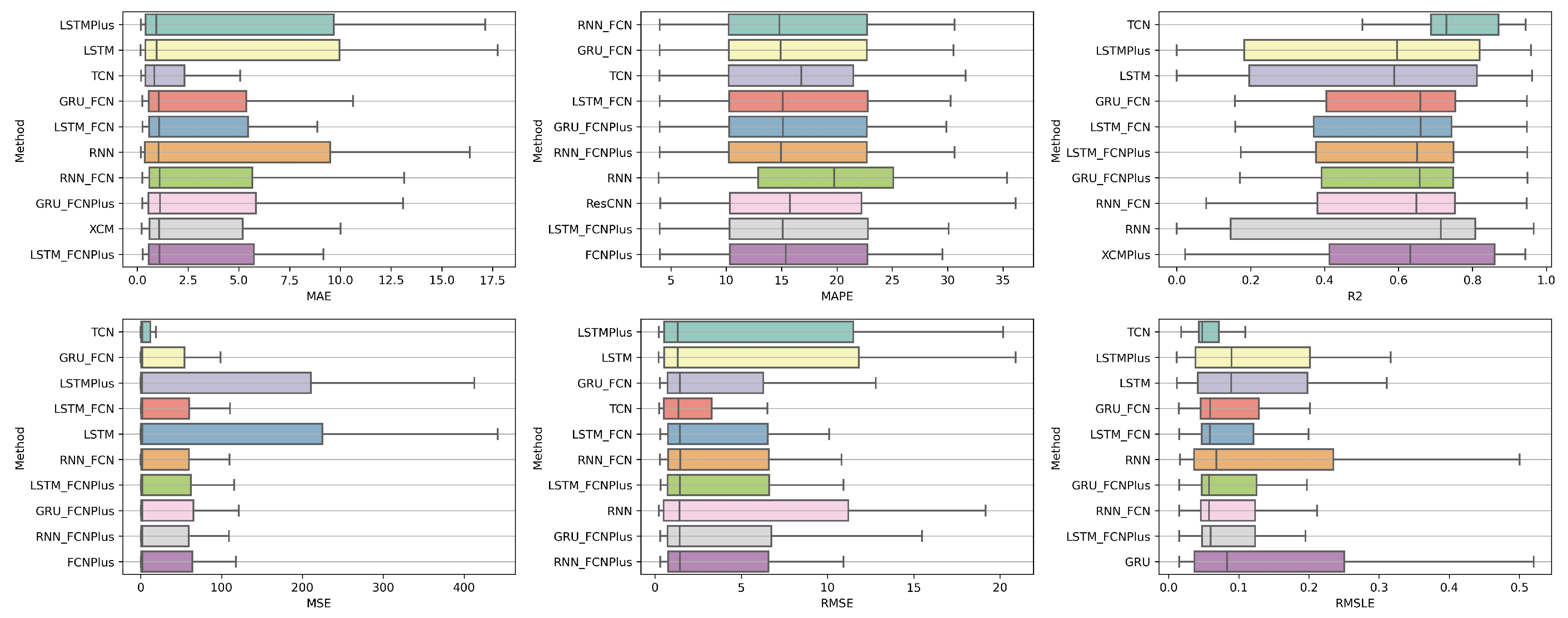
shorturl.at/FTU06 (accessed on 15 January 2023). The CD diagrams follow. There, we can visually observe which of the methods exhibit similar behavior and which differ significantly. Finally, box plots of results per metric are presented, again for the best 10 methods. The box plots present in a graphical and concise manner information concerning the distribution of the aforementioned data, that is, in our case, the average values of the sentiment setups per algorithm for all stocks. In particular, one can derive information about the maximum and minimum value of the data, the median, as well as the 1st and 3rd quartile values isolated by 25% and 75% of the observations, respectively.
4.1.1. Time Shift 1
With respect to the one-day forecasts,
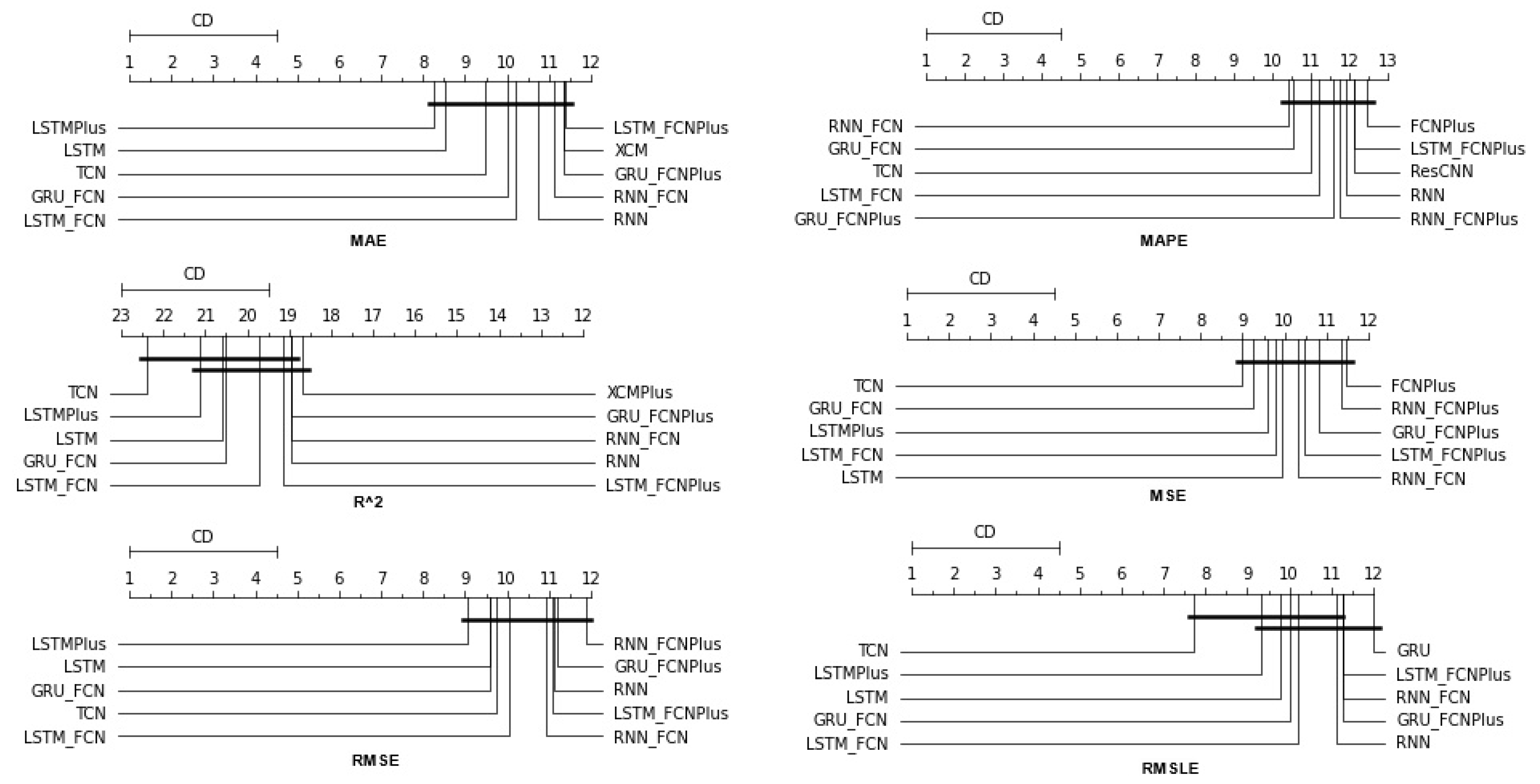
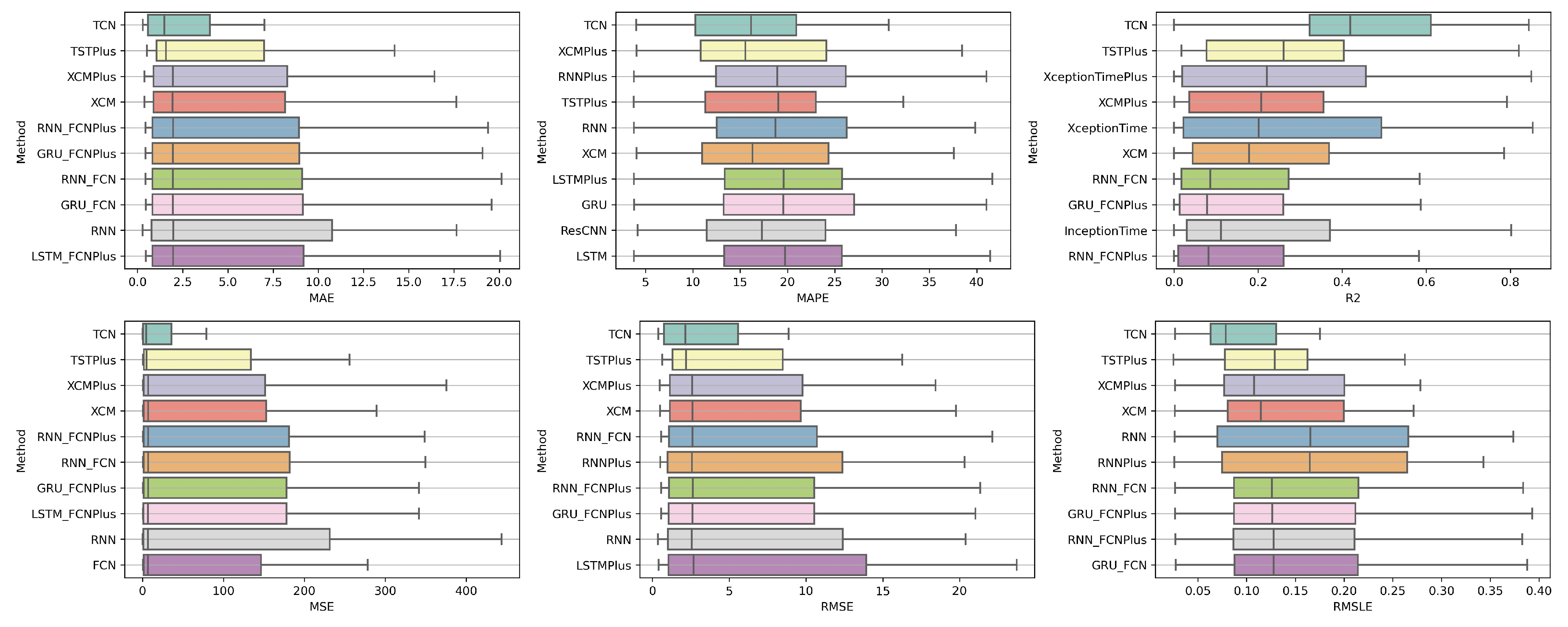
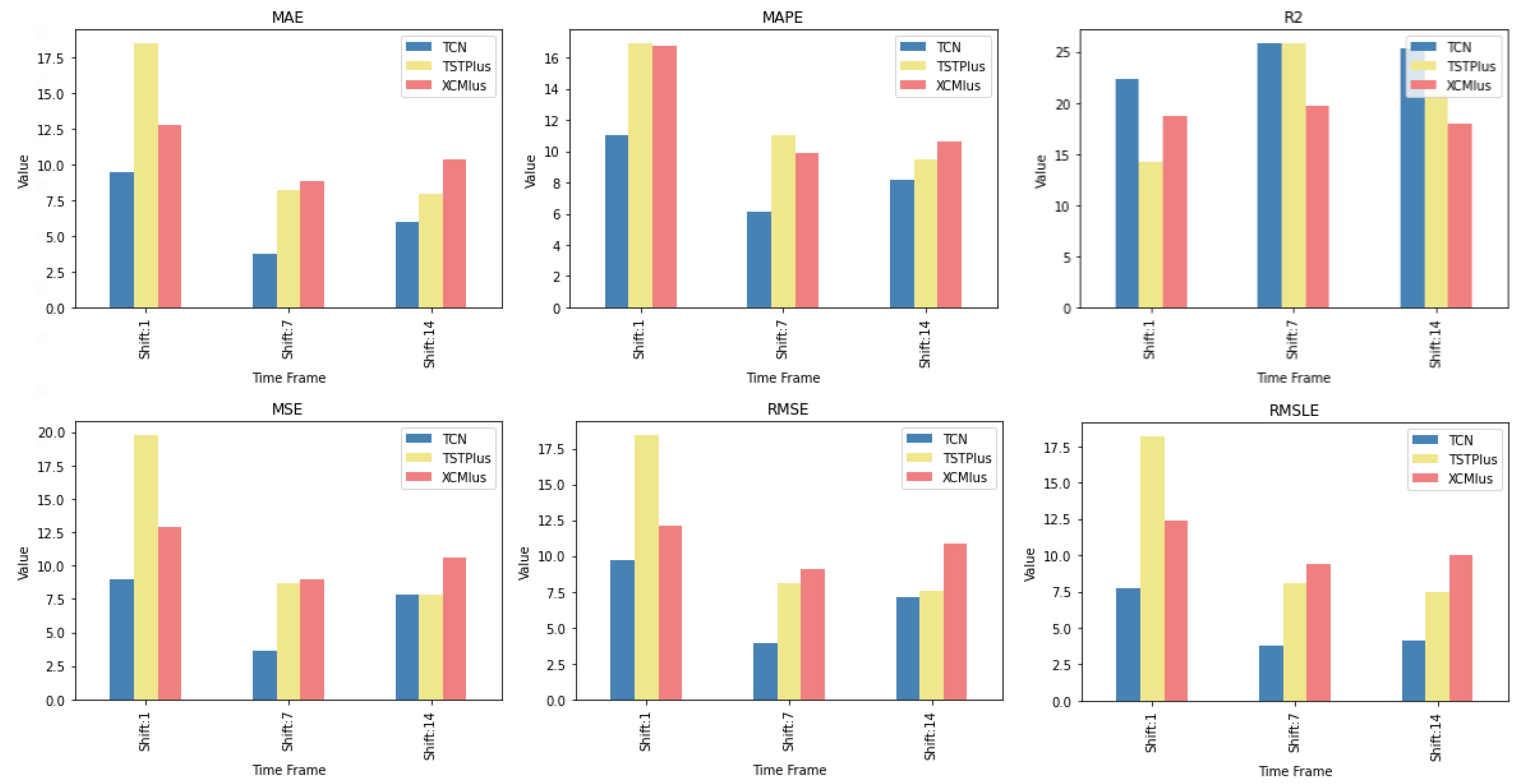
Table A1 lists the Friedman Ranking results for the top 10 scoring methods per metric. Although there is no single method that dominates all metrics and significant reorderings are also observed in the table positions, the TCN method achieves the best ranking in three out of six metrics (MAPE, R2, and RMSLE) and is always in the top four. Furthermore, from the box plots, it is evident that TCN has by far the smallest range of values.
Apart from this, in all metrics, GRU_FCN is always in the top five. It is also observed that LSTM_FCN and LSTMPlus behave equally well. The latter shows a drop in the MAPE metric, but in all other cases, it is in the top three, while in two metricsm it ranks first. It should also be noted that the LSTMPlus method ranks first in two metrics, namely MAE and RMSE. In terms of R and RMSLE, it occupies the second position of the ranking, while regarding MSE, LSTMPlus ranks third. However, at the same time, according to MAPE, the method is not even in the top ten. Thus, as will be seen in the following, TCN is the consistent choice.
The results produced by Friedman’s statistical test, in terms of the six metrics, are presented in
Table A1, while the corresponding CD diagrams and box plots are depicted in
Figure 3 and
Figure 4.
4.1.2. Time Shift 7
At the one-week forecast time frame, the algorithms that occupy the top positions in the ranking produced by the statistical control appear to have stabilized. The corresponding ranking produced by the Friedman statistical test regarding the ten best methods with respect to the six metrics is presented in
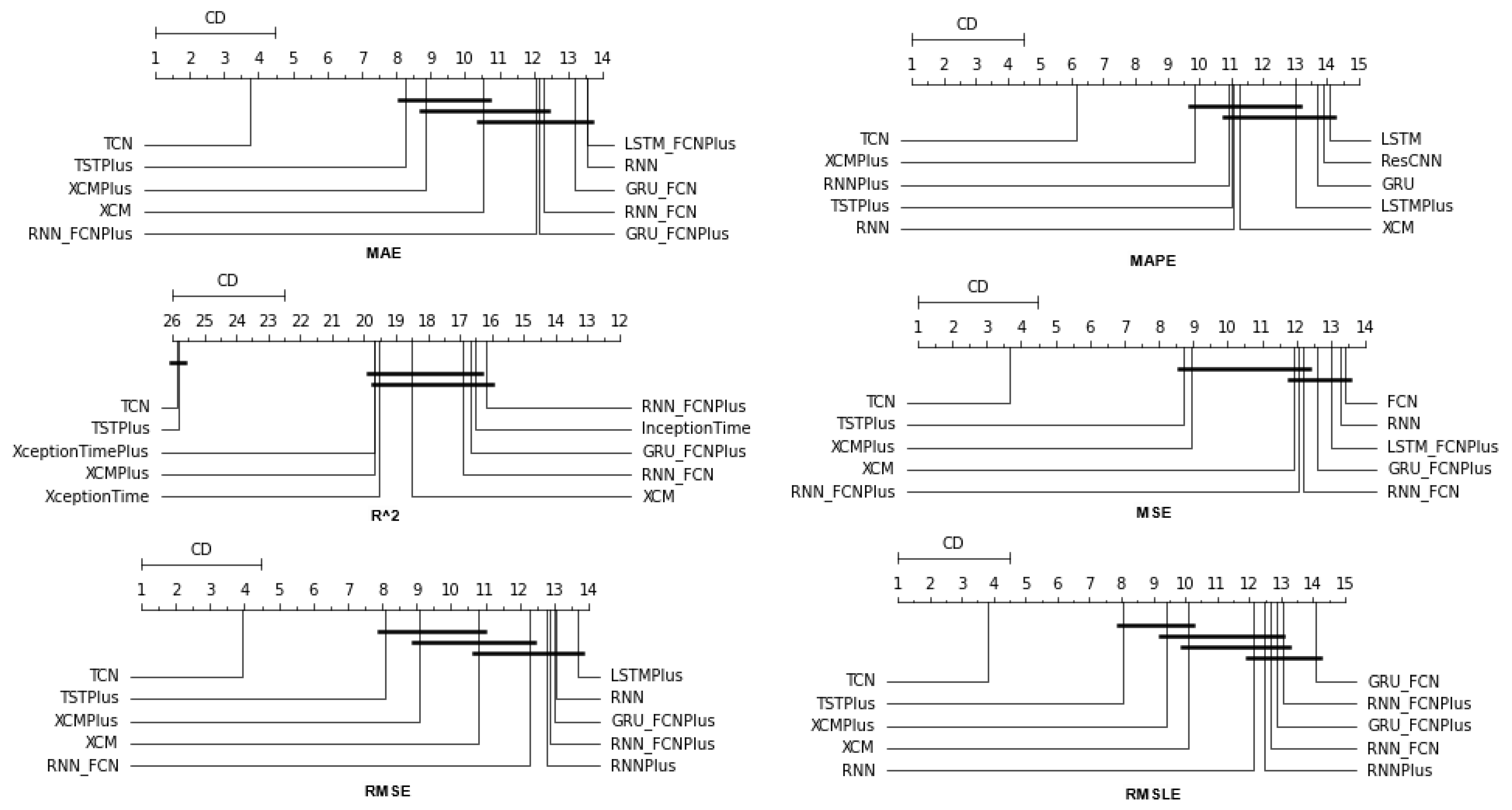
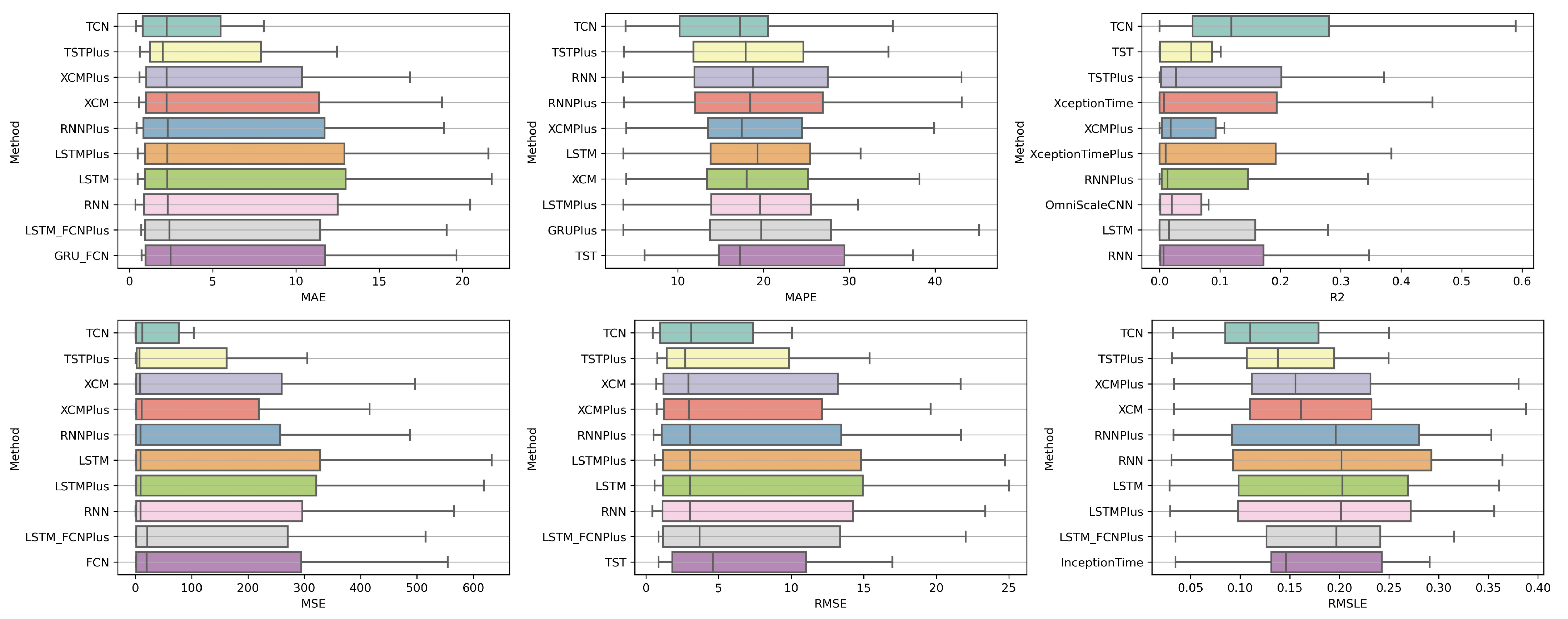
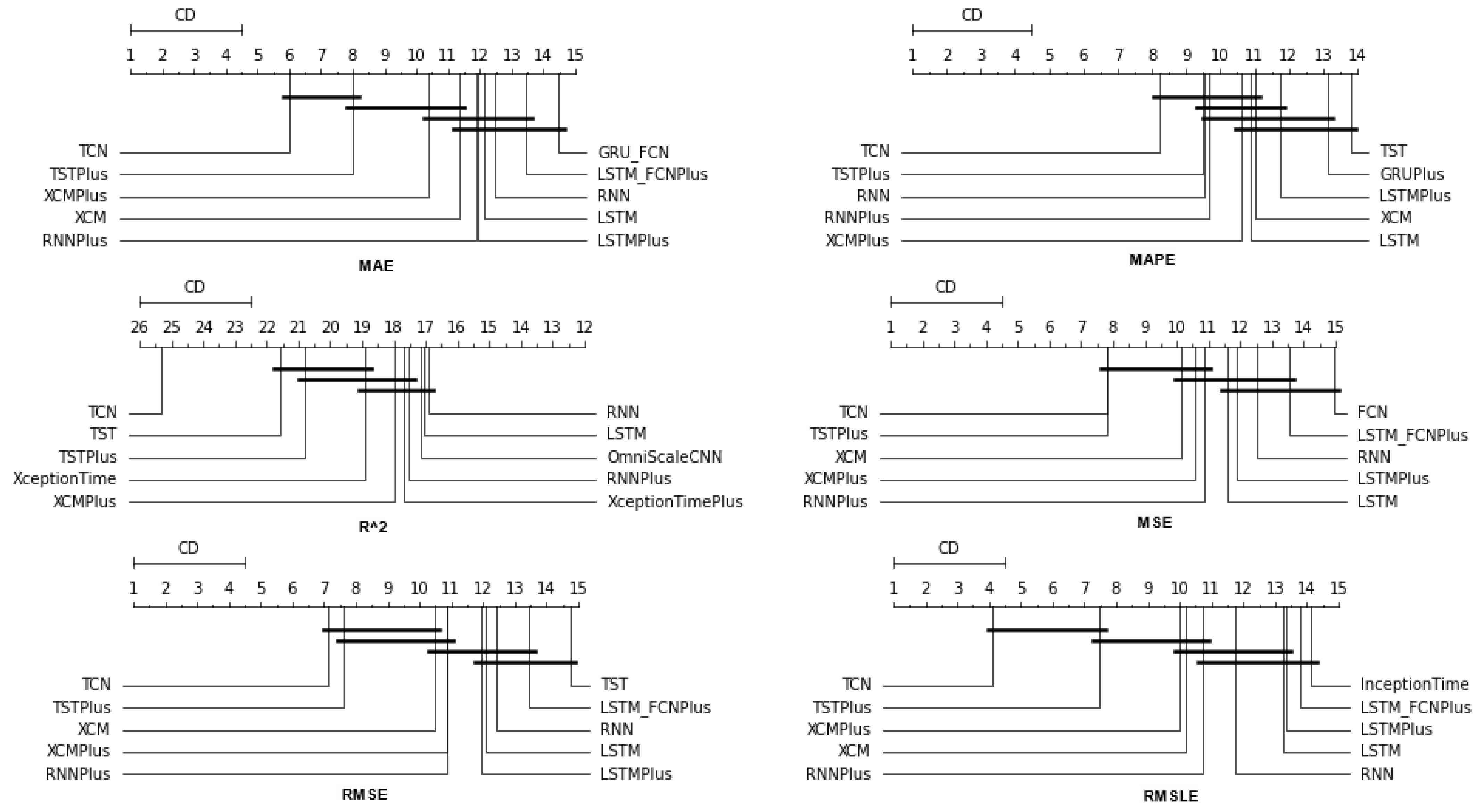
Table A2. In all metrics, the TCN method ranks first. From the CD diagrams, it can be seen that in all metrics—except for R2—this superiority is also validated by the fact that this method differs significantly from the others. Box plots show the method also having the smallest range around the median.
Figure 5 and
Figure 6 contain the relevant results in the form of box plots and CD-diagrams.
Other methods that clearly show some dominance over the rest in terms of given performance ratings are, on the one hand, TSTPlus, which ranks second in all metrics except MAPE, and, on the other hand, XCMPlus and XCM, which are mostly found in the top five. In general, the same methods can be found in similar positions in all metrics, with minor rank variations. In addition, the statistical correlations between the methods are shown in the CD diagram plots.
4.1.3. Time Shift 14
In the forecast results with a two-week shift, a relative agreement can be seen in the top-ranking algorithms with those of the one-week frames. The ranking produced by the Friedman statistical test for the ten best methods with respect to the six metrics is presented in
Table A3.
Once more, TCN ranks first in all metrics. TSTPlus again ranks second in all metrics except for R2, where it ranks third. In almost all cases, XCMPlus and RNNPlus appear in the top five. Likewise, as in the previous time shift, there is a relative agreement in the methods appearing in the corresponding positions regarding all metrics. Moreover, according to the above, an argument regarding the general superiority of the TCN method in this particular scenario is easily obtained. An obvious predominance of the TCN method is established. The corresponding CD diagrams and box plots for the 10 best performing algorithms are seen in
Figure 7 and
Figure 8.
4.2. Feature Setup Comparison
Now, we are moving on to the findings of the second case study, which concern, on the one hand, the investigation of whether the use of sentiment analysis contributes to the improvement of the extracted predictions and, on the other hand, the identification of specific feature setups whose use improves the model’s predictive ability.
Again, the results of the experimental procedure will be presented separately for the three forecast time frames. Likewise, due to the volume of results, only the 10 most promising feature setups will be listed. These were again derived based on the Friedman classification of the averages calculated for each of them, taking into account the predictions in the use of the 30 forecast methods used. The full rankings of all 67 setups can be found at
shorturl.at/alqwx (accessed on 13 December 2022). For the presentation below, again, the corresponding CD diagrams and box plots were used.
4.2.1. Time Shift 1
Starting with the results concerning one-day depth forecasting, one notices that the univariate version, in which the forecasts are based only on the stock price of the previous days, ranks first only in the case of the R
metric. In fact, in three metrics, the univariate version is not even in the top twenty of the ranking (See
Figure 9 and
Figure 10).
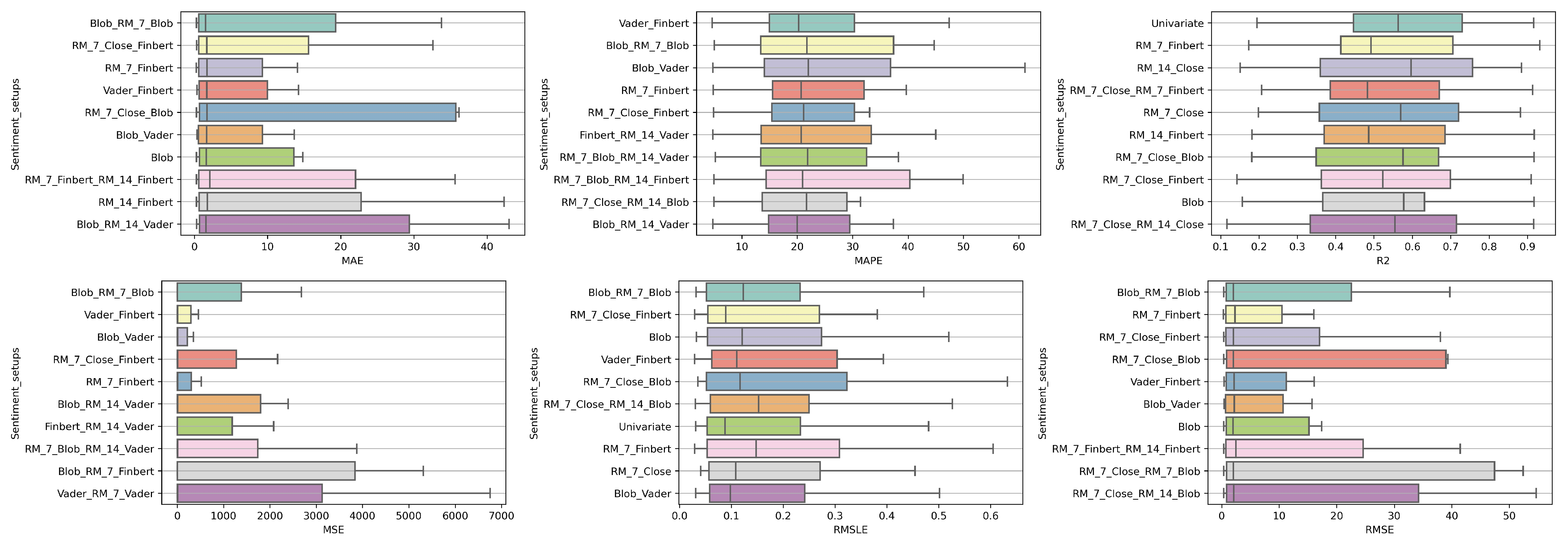
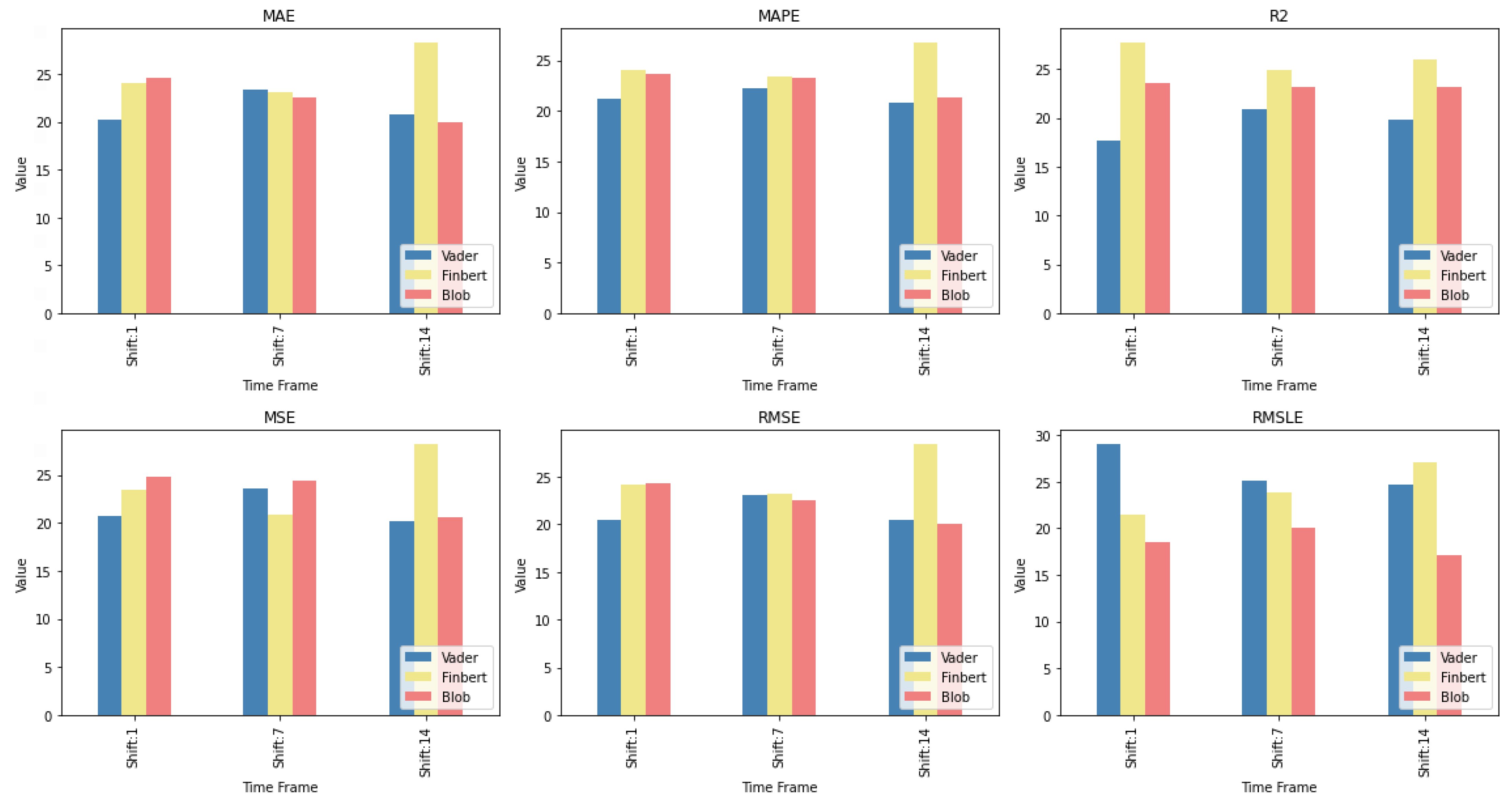
Another interesting observation would be that even though there are rerankings of the sentiment setups in terms of their performance on the six metrics, the Blob_RM_7_Blob setup—that is, the setup incorporating Blob and Rolling Mean 7 Blob along with the closing values time series—although it does not score well in the ranking regarding R, it is, on the one hand, at the top ranking in four metrics, that is, MAE, MSE, RMSE, RMSLE, and, on the other hand, second in MAPE. Moreover, from the results, it becomes evident that an argument in favor of using sentiment analysis in multivariate time series layouts, even in the case where the forecasts concern one-day depth, is, at least, relevant. At the same time, using smoothed versions of both the sentiment time series and those containing the closing stock price values appears to be beneficial in general.
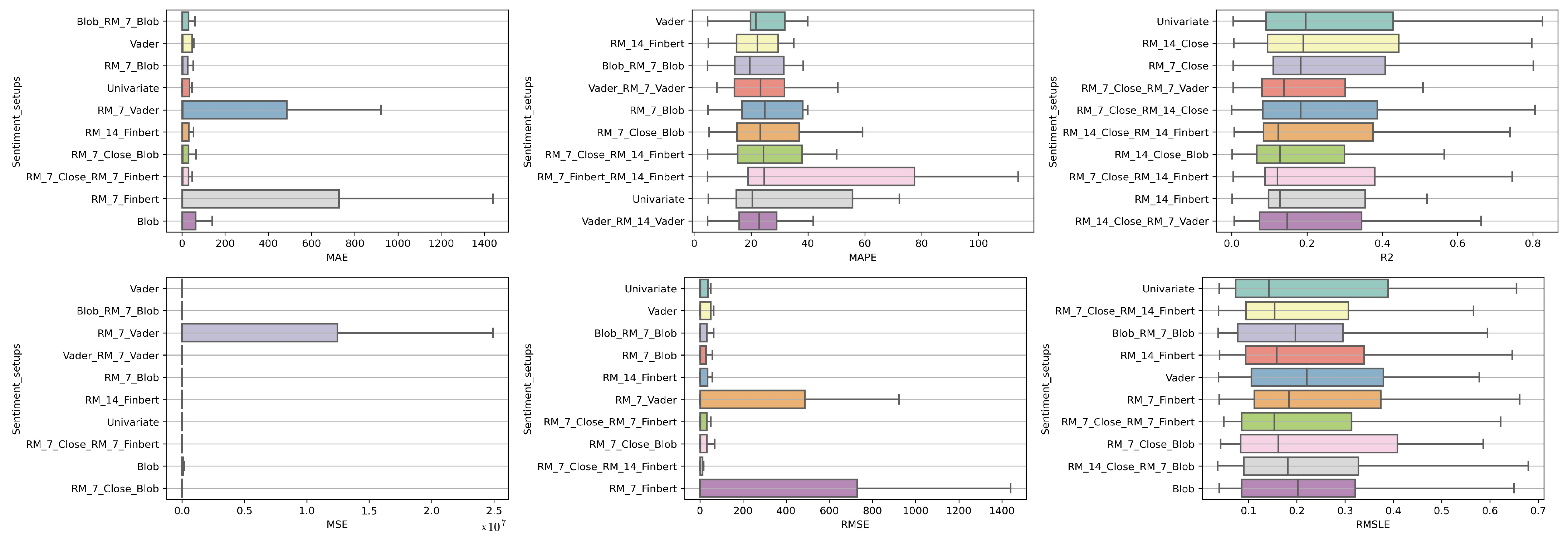
4.2.2. Time Shift 7
Regarding the time frame of one week, one can notice that the use of the univariate version is marginally ranked first in three metrics, namely, the R
, RMSE and RMSLE, while in two metrics, the Vader sentiment setup appears to be superior, actually being, at the same time, in second place regarding the MAPE and RMSE metrics and fifth regarding the RMSLE (
Figure 11 and
Figure 12).
It is also notable that Blob_RM_7_Blob, which appeared to perform particularly well during the one-day shift, remains in the top three rankings in five of the six metrics. More generally, once again, one notices that there are rearrangements, especially in the central positions of the table. However, given the small differences in performance between the different setups, this should not be considered unreasonable. Overall, the picture still points in favor of using multivariate inputs containing sentiment data.
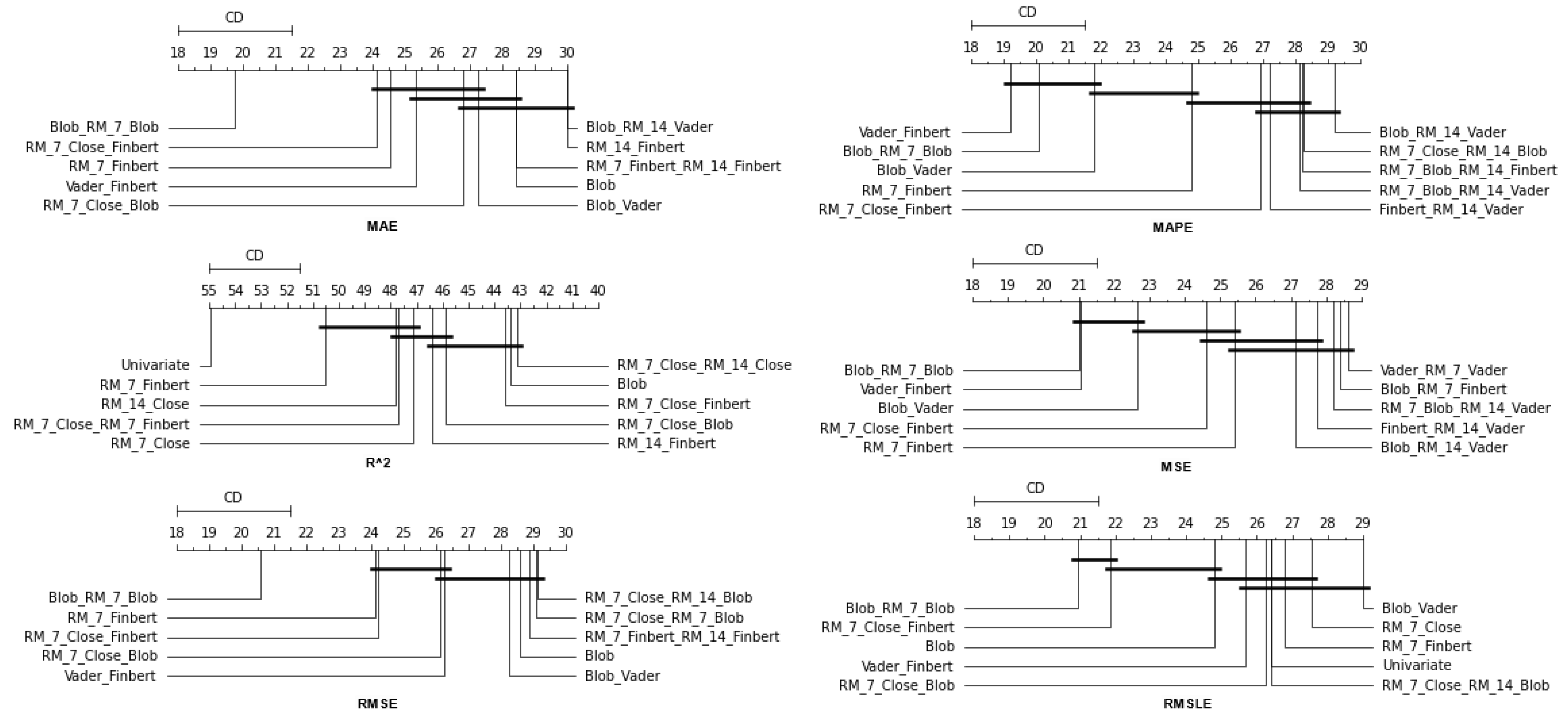
4.2.3. Time Shift 14
Finally, regarding the two-week time frame, a first observation is that in relation to the R
, a feature setup that does not contain sentiment data dominates. This pattern is also present in the previous time shifts (See
Figure 13 and
Figure 14).
In addition, although there are metrics in which the univariate version is in the top ten, in these cases, the difference in its performance with those in the first positions is quite significant. This is easily seen from the CD diagrams: there are no connections with setups that appear in the top positions. At the seven-day time lag, it was observed that the univariate version prevailed in three cases. However, as one examines the 14-day time shift, one notices that the superiority of methods that use sentiment data is reinforced.
At the same time, combinations containing the closing price appear in the first positions of the table more often than in the previous two setups. Furthermore, it is observed that the setup that dominates four of the six metrics is RM_7_Close_Blob. These metrics are MAE, MAPE, MSE, and RMSE. The RM_7_Close_Blob feature setup is the one that incorporates both a smoothed version of the closing values as well as sentiment scores. Thus, the use of weighted averages in the original time series along with the incorporation of sentiment scores is mostly shown to be optimal regardless of the individual choice of a specific layout. Methodologically, the utilization of both has an improving effect.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}