1. Introduction
Speech enhancement is an important task in improving the speech signal-to-noise ratio and speech quality, and has a wide range of applications in improving the performance of speech processing systems, mobile communication, and human–computer interaction systems [
1]. According to different principles, speech enhancement methods can be divided into traditional methods based on signal processing and deep-learning methods. Traditional methods are generally classified according to the operation domain and can be divided into the time domain, frequency domain, and time-frequency domain. The representative classical algorithms are subspace-based methods [
2], spectral subtraction [
3], wavelet packets [
4], etc.
The development of machine learning has led to the gradual replacement of many traditional speech enhancement methods by neural network-based approaches. Deep learning-based methods can be studied in three ways: input features, model structure, and target optimization. This paper mainly focuses on the study of the model structure.
The continuous development of network structures such as RNNs [
5], CNNs [
6], and transformer [
7] and their successful application in various fields have brought performance improvements to speech enhancement systems. The advantages and disadvantages of RNNs and CNNs as early proposed networks are becoming more and more obvious in practical work, and how to combine the two to achieve excellent performance has become a hot issue. An end-to-end architecture called CRN [
8] incorporates CNN and RNN. The sparsity of the CNN makes the model more efficient in terms of data and computational processing power. The use of bidirectional RNNs helps to model the dynamic association between consecutive frames and improves generalization. In [
9], the effect of the size and type of RNN network on the CRN structure is investigated, as well as the convolutional layers and skip connections, and, finally, an efficient CRN structure is proposed that can significantly reduce the loss due to reverberation. In addition, a new model of DPCRN [
10] that combines Dual-path RNN [
5] and CRN was proposed. This model uses two types of RNNs. One is an intra-chunk RNN for estimating the spectrum for a single period. The other is an inter-chunk RNN used to model the spectrum over time. According to the results of the Deep Noise Suppression Challenge in recent years, some multi-stage methods have also combined multiple structures to improve performance. A neural cascade structure [
11] consisting of CRN and UNet [
12] was proposed by researchers. It is capable of sequentially estimating the amplitude spectrogram, the time-domain signal, and the complex spectrogram of the enhanced speech, and then training the model with a new three-domain loss function. The above work shows that combining CNN and RNN structures in the model can lead to new enhancement effects. This is also demonstrated in our work.
In addition to CRN, studies on the attention mechanism and transformer model also bring new solutions to improve speech enhancement performance. Currently, models with better enhancement performance, such as CRN and UNet, perform poorly in modeling long sequences and are computationally expensive. The attention mechanism can alleviate these problems. In the paper [
13], a complex convolution block attention module, CCBAM, was proposed, which improves the modeling capabilities of complex convolution layers by building more informative features. In addition, a module called Stream Axis Self-Attention (ASA) [
14] is used as a new module for speech-intensive prediction, which has played a good role in eliminating echo and reverberation.
Transformer [
15] is a purely attention-based network that does not use RNNs or CNNs. It is frequently used in NLP and image processing, and some researchers have found its advantages in speech. A Unet-based Conformer network [
16] uses temporal attention and frequency attention to learn dimensional information and achieves good performance in speech enhancement. In addition, a two-stage transformer neural network (TSTNN) [
17] possessing an improved transformer was proposed for time-domain speech denoising.
Although some approaches to speech processing in the time domain have achieved good results, more studies [
18] have shown that the methods based on the frequency domain can often obtain better speech quality, have strong generalization ability and logical interpretation, and are easier to combine with existing speech processing algorithms. Most of the previous frequency-domain-based methods [
19] have only used amplitude as the input feature, ignoring phase. However, various studies have shown that the phase still has a large impact on the improvement of speech quality. For example, the method [
20] proposes a phase compensation function to modify the phase spectrum to achieve enhancement, and the article [
21] decouples amplitude and phase optimization using a two-stage system. All these studies show that improving the estimation of the phase spectrum yields better-enhanced speech quality. To further address this issue, the researchers proposed the ideal complex ratio mask (CRM) [
22] to find the real and imaginary parts of the complex spectrum. Better performance will be obtained if the advantages of the above-mentioned CRN and transformer structure can be fully utilized to estimate the CRM. In addition, considering the fusion of multiple features, multi-modal fusion methods [
23] can benefit the task by efficiently extracting high-level nonlinear feature representations. In [
24], a method for fusing different features is proposed to fully combine the advantages of the features for complex spectral mapping.
Inspired by the above factors, we propose a dual-path network that incorporates amplitude and complex domain features. The proposed network not only does not discard the phase information, but also facilitates the estimation of complex masks by simultaneously learning the amplitude features. In this work, our contributions are as follows.
First, this paper proposes a dual-path network that can simultaneously extract complex spectral features and amplitude feature masks to obtain better-enhanced speech estimation. Second, in the dual-path structure, an attention-aware feature fusion module is used to help the two branches work together and interact with each other for information, thus making it possible to achieve optimal mask estimation. Third, the improved transformer module processes the data from both directions to learn local and global information.
Section 2 describes each part of the proposed dual-path network in detail.
We not only compare the proposed method with other methods in our experiments, but also verify the effectiveness of the dual-path structure, the attention-aware fusion module, and the improved transformer module. The network proposed in this paper is based on a mask-based approach, so the effect of different positions of the input and mask multiplication on the system performance is also investigated in the experiments. The detailed results and analysis are given in
Section 4.
In addition,
Section 3 gives the dataset, setup, and evaluation metrics of the experiments.
Section 5 is the discussion section, which gives several observations obtained in this paper. Conclusions and future research directions are given in
Section 6.
2. Proposed Dual-Path Speech Enhancement Network
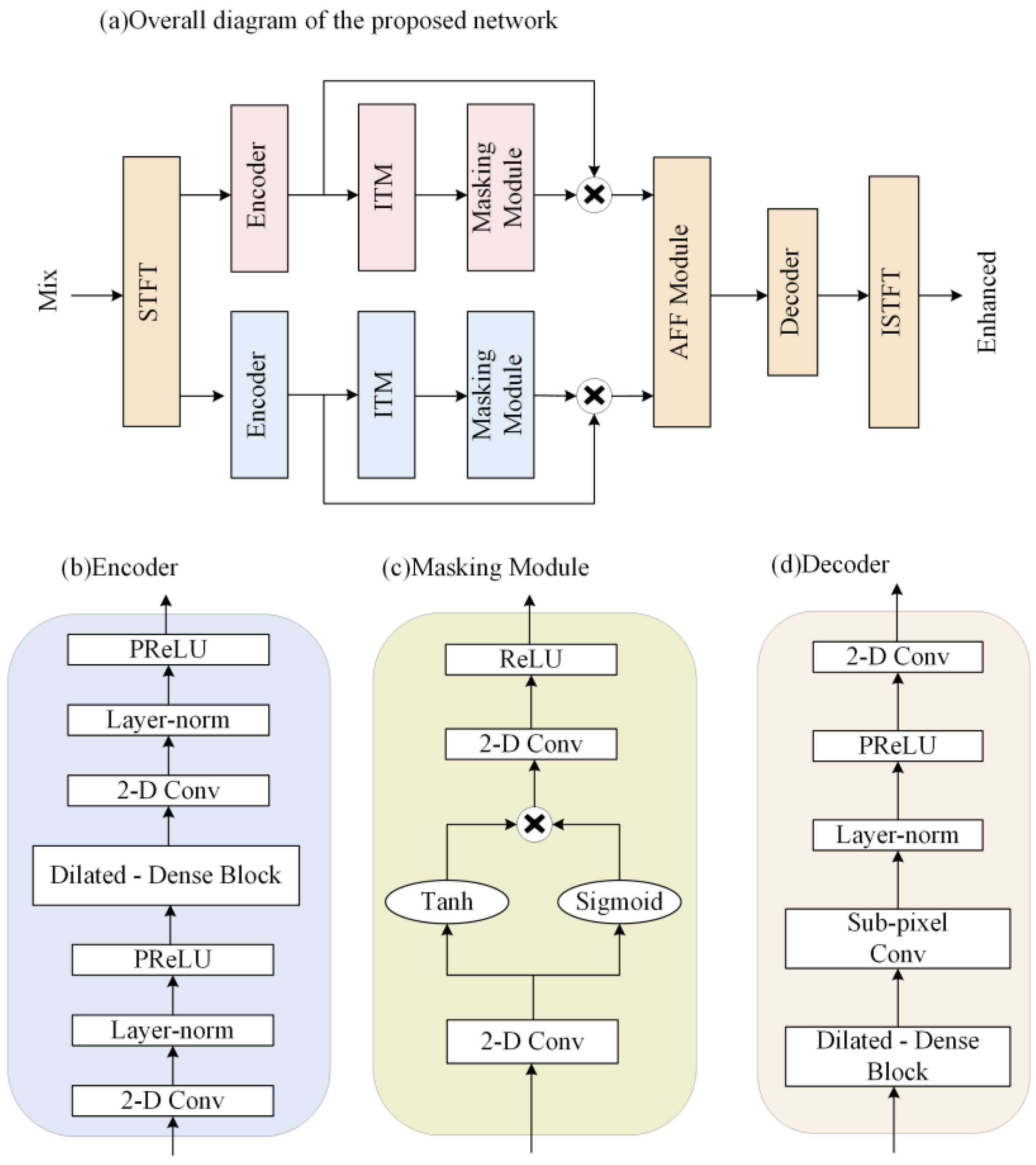
In this section, the proposed two-path network, which jointly learns the characteristics of the complex and amplitude domains, is described in detail. As shown in
Figure 1a, the proposed network consists of two paths. One path models the features in the complex domain, and the other path models the features in the amplitude domain. These two paths have independent parts and intersecting parts. The independent parts are the respective encoders, the improved transformer modules, and the masking modules, and the intersecting parts are the attention-aware feature fusion module, the decoder, the STFT, and the ISTFT. The network encodes the complex and amplitude separately, and the encoded features are fed to the improved transformer modules for feature extraction, and then the masking modules compute the masks of the two features. Next, the attention-aware feature fusion module fuses the amplitude and complex features after multiplying with the mask to obtain the optimal complex estimate. Then, the features of the same size as the original signal are obtained by the decoder. Finally, the complex features are transformed to obtain the enhanced time-domain signal. A detailed description of each module in
Figure 1a will be given in the following subsections.
2.1. Encoder
The encoder and decoder structure can efficiently extract the features of the speech signal. The data passing through the encoder has a reduced amount of data per frame, but the number of channels increases, so that more efficient data can be processed using a smaller computational cost, and the data are restored to the original data size by the decoder.
Compared to the complex LSTM, TCNs perform better in modeling long sequences, and has parallelable convolution operations. Thus, training a TCN takes less time. Considering the success of TCNs in speech separation and speaker target extraction, adding it to the enhancement model gives better results. We decided to use a TCN as the main encoder and decoder structure.
The structure of the proposed encoder is improved from the convolutional block in the Conv-TasNet [
25]. The detailed network structure of the encoder is shown in
Figure 1b. The original convolution block consists of a 2D convolution and a Depthwise convolution (D-conv) [
26]. In the modified encoder, we placed the dilated-dense block in the middle of two 2D convolution blocks, and added the PReLU activation function and the normalization operation. The purpose of this is to use 2D convolution to project the input to a higher channel space and trim the data, then use the dilated-dense block to obtain a larger receptive field. The final module obtains smaller features by convolution to save the computational cost of subsequent modules.
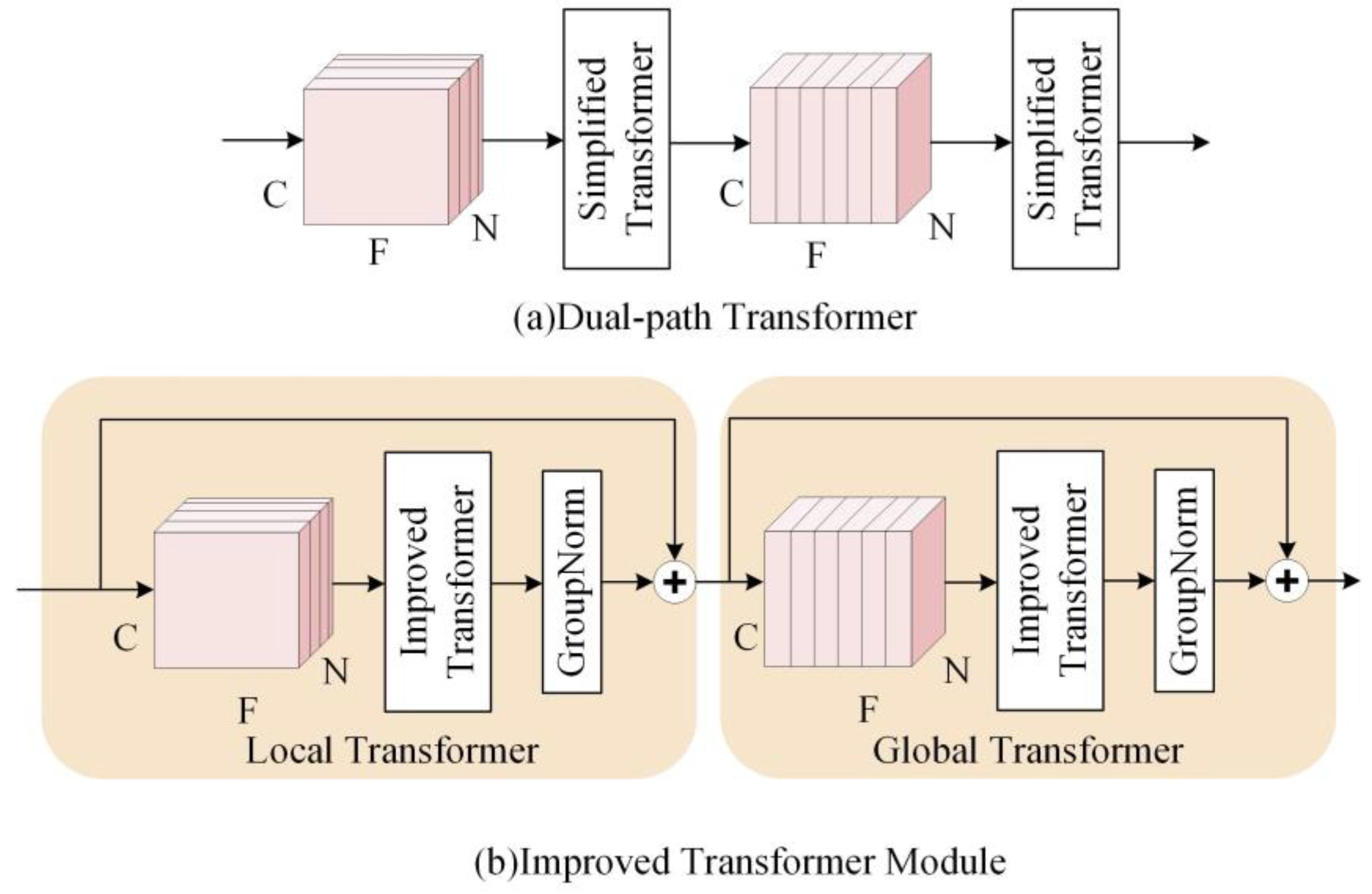
2.2. Improved Transformer Module
Dual-path RNN [
5] and dual-path transformer [
27] have successively obtained excellent performance in speech separation tasks. In speech enhancement, feature extraction is very important for the improvement of speech quality. Although the dual-path transformer enables context-aware modeling of speech sequences, its ability to integrate local information is limited. We improve the dual-path transformer and use it as the main feature extraction module of the proposed network. The improved transformer module is able to learn local and global contextual features and does not change the size of the data. It is described in detail in this section.
2.2.1. Improved Transformer
In previous neural networks, all features received the same attention. However, in the attention mechanism, important features receive more attention, which saves a lot of computational and storage resources. We want the improved transformer to act as an attention module that learns features better rather than doing the whole enhancement work, and therefore use a simplified structure consisting of a Multi-head Attention layer and a feed-forward layer. The specific structure is shown in
Figure 2. In deep networks, residual connections can solve the problem of gradient exploding and gradient vanishing in training. In order to reduce the information loss and obtain more local and global information, referring to the results of the paper [
9], we add residual connections with 1*1 convolution to the Multi-head Attention layer and feed-forward layer, as shown in
Figure 2a.
The mathematical model of the improved transformer is as follows.
is the input data and
is the output. Letting
be the Multi-head Attention function and
be the feed-forward layer function, then
Multi-head Attention connects features extracted by different Single-head Attention layers to obtain the final output. This allows Multi-headed Attention to focus on information from different locations that represent features in different subspaces. In the proposed model, we set the number of times to find Single-head Attention, which is also the number of parallel attention layers, to four.
The feed-forward layer of the original transformer is a two-layer, fully connected layer. Such a feed-forward layer is not suitable for learning the location information of speech sequences. Considering the learning ability of RNN in time series, GRU is used as the first layer in the feed-forward layer. The second layer uses the ReLU function, which can significantly alleviate the gradient vanishing problem of the deep network and accelerate the convergence speed of gradient descent. Finally, the linear layer is used as the third layer of the feed-forward network.
2.2.2. The Architecture of Improved Transformer Module
Figure 3a shows the two-path transformer proposed in the paper [
27], which has an insufficient ability to integrate local information. Therefore, based on the improved transformer, an improved transformer module (ITM) is used in this paper. As shown in
Figure 3b, it consists of two identical modules, including the improvement transformer and the group normalization layer. The input data are first sliced to obtain 3D data (C, N, F). N denotes the number of frames, F is the amount of data per frame, and C is the number of channels. Then, the first transformer, called the local transformer, processes the data in the last dimension of the tensor and learns the local information in parallel. Then, the second transformer, called the global transformer, processes the data in the second dimension of the tensor, fusing the local information and learning the connections between the data blocks.
2.3. Attention-Aware Feature Fusion Module
The attention-aware feature fusion (AFF) module is proposed in this paper to fuse the amplitude and complex features learned from the dual-path structure to obtain the best spectral estimate. From Equations (4) and (6), we obtain the complex and amplitude features corrected by the mask. The amplitude and phase information found by the complex number branch can be obtained according to Equation (5). Equation (7) shows how to fuse the amplitude features of the complex branch with the features of the amplitude branch. The parameter W is obtained from the attention-aware network, the detailed structure of which is shown in
Figure 4. Finally, the final complex spectrum is calculated using the fused amplitude combination according to Equation (8).
where
,
, and
denote the amplitude, complex real, and imaginary parts after encoding.
,
, and
denote their masks.
,
, and
are after mask correction;
is the amplitude feature after fusion obtained by attention weights, and
and
are the complex feature after fusion.
The attention network used by the AFF module is similar to the multi-modal fusion module proposed in the paper [
28]. Ours is characterized by the use of a two-branch network with global extractors and local extractors. The local extractor consists of two layers of point-wise convolution and a ReLU activation function. The global extractor adds a global average pooling layer to the local extractor. This attention network can combine local and global information to give optimal weights.
2.4. Masking Module
First, the contextual relevance of the speech signal is considered to have an important impact on speech quality. It can effectively improve speech quality if longer speech sequences can be modeled. Secondly, the temporal convolution (TCN) module has been shown to outperform RNNs in modeling long sequences.
Considering the above two factors, we improved the TCN-based S-TCM [
29] as a masking module. The masking module generates masks after learning the features extracted by the ITM. The structure is shown in
Figure 1c. Convolution and activation functions are used before and after the double branch to obtain an accurate estimation of the mask. The module uses different activation functions in the double branch. The Tanh function is the activation function of the main branch to speed up the convergence and avoid the gradient exploding problem. Sigmoid is used as the activation function for the gated branch, adjusting the output value to (0, 1), which allows a better flow of information in the gradient propagation.
2.5. Decoder
The structure of the decoder is shown in
Figure 1d. It consists of a dilated-dense block, subpixel convolution [
30], normalization layer, PReLU activation function, and 2D convolution layer. The decoder uses the dilated-dense block and subpixel convolution to obtain the up-sampled data. Normalization and activation functions make the data more normalized. Then, 2D convolution is used to change the multichannel data into a single-channel speech frame. The function of the decoder is to reconstruct the processed features to obtain the same size data as the input. After these data are summed by inverse STFT and overlap-add, we can obtain enhanced speech.
2.6. Loss Function
The loss function of the proposed dual-path network combines the loss functions in the time domain and time-frequency domain. The loss function ensures that the error between the estimated results and the clean complex domain features is minimized, obtaining better speech intelligibility and perceptual quality, as defined below:
where
,
,
,
denote the real and imaginary parts of the spectrum of the clean waveform, and the real and imaginary parts of the spectrum of the enhanced waveform, at the time frame
t and frequency index
f, respectively.
T and
F are the number of time frames and frequency bins. The enhanced speech frames are converted to waveforms using overlap-add, and the loss is calculated in the time domain using the mean square error between the enhanced and clean speech. The time-domain loss function [
31] is defined as follows:
where
and
denote clean and noise signals of the time index
. The
is the number of samples. The loss function used in this paper is obtained according to the following equation:
where
is an adjustable parameter and is set to 0.2 in this experiment.
5. Discussion
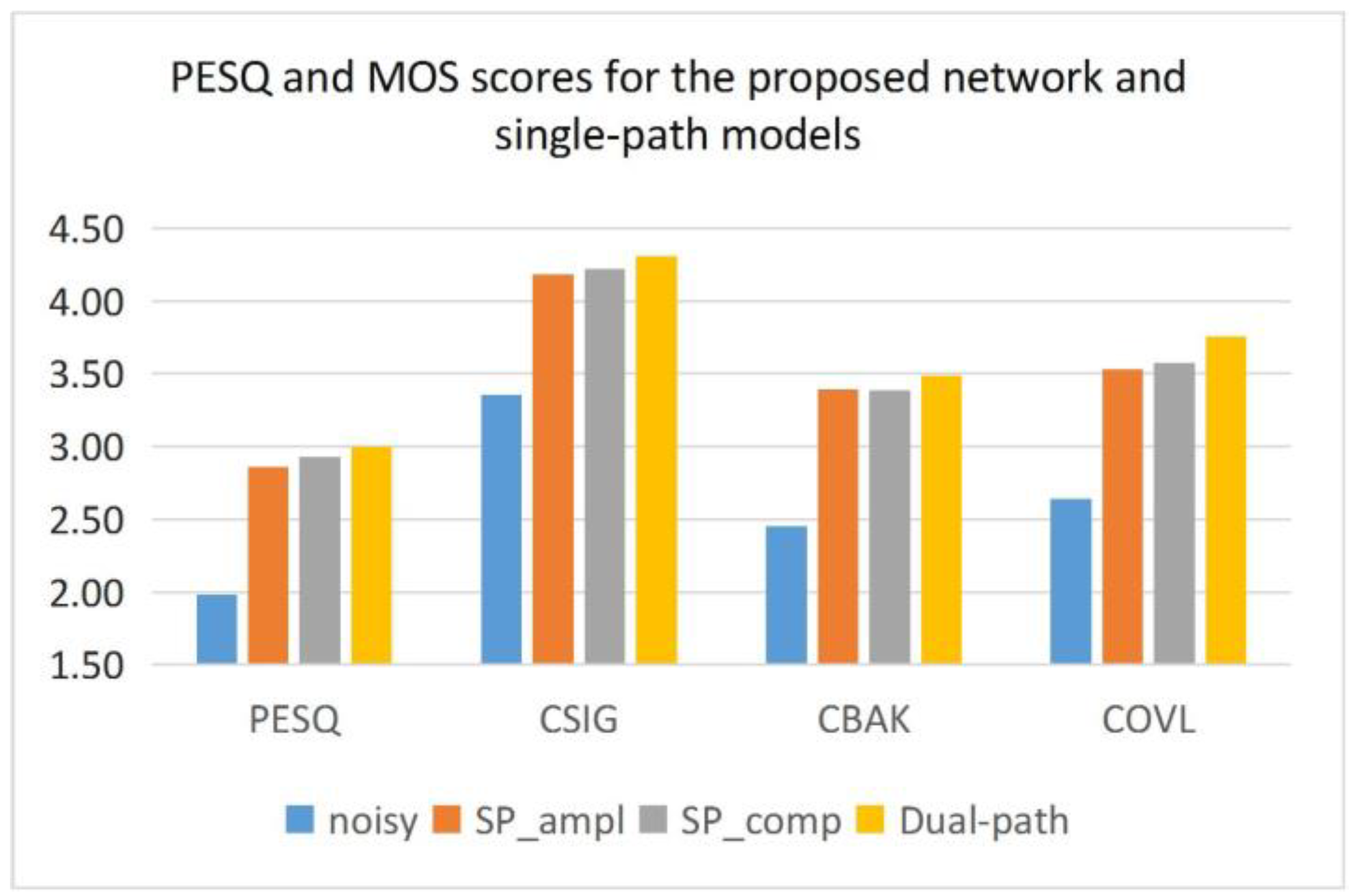
In this paper, an improved transformer network is proposed, and the superiority of the proposed dual-path model in terms of denoising effect and speech quality is verified through a series of experiments on the Voice Bank + DEMAND dataset. After analyzing the experimental results, some observations are given in the following.
Compared to the single-path model, our approach offers consistent advantages over the single-path model for most of the metrics tested. The reasons considered are as follows. Compared to the single-path model that learns only the amplitude and the single-path model that learns only the complex spectral features, the proposed dual-path model not only learns both features, but also enables effective information interaction between the two, which gives the model a better learning capability.
The proposed network has a better performance compared to the model using convolutional layers instead of an ITM. This well illustrates that using a transformer between the encoder and decoder to model the features is a better choice than adding more convolutional layers. One reason for our consideration is that CNNs focus only on the interconnections between two-dimensional local data. Our improved transformer module can take advantage of the correlation between the whole and the local, which is beneficial for speech spectrum feature extraction. In addition, the use of AFF for feature fusion improves the system performance more than using fixed weights, which may be due to the fact that AFF has an attention-aware network that learns the potential relationship between two features and gives weights adaptively.
For the mask-based DNN speech enhancement method, experiments are conducted in this paper to discuss the effect of the position of the input multiplied with the mask on the model performance. With the results in
Section 4.3, we find that decoding before multiplying does not lead to better performance of the proposed model and imposes a greater computational burden.
In summary, our proposed dual-path network chooses the optimal strategy of multiplying masks with inputs. It outperforms the single-path baseline models with a transformer in most metrics and has fewer parameters.
6. Conclusions
This paper proposes an improved transformer-based dual-path speech enhancement network with amplitude and complex feature fusion. The network has two paths, modeling both complex spectrum and amplitude, and uses a fusion module for information interaction and improved transformer modules to fully extract features. We used the Voice Bank + DEMAND dataset to train and test the proposed network. The results show that the proposed network has better speech quality performance and fewer trainable parameters compared to the baseline models. In addition, ablation experiments validate the necessity of two-path networks, improved transformers, and attention-aware feature fusion, and some observations about mask-based enhancement methods are given.
In the future, we will modify the modeling module to accommodate the characteristics of different features, instead of using the same structure. In this way, we expect to obtain more accurate spectral information and improve speech quality. In addition, we will also study the performance of our method in complex environments where noise, reverberation, and speaker interference are all present.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}