1. Introduction
There is a plethora of algorithms used in cryptography, with different purposes; amongst them, Genetic Algorithms (GAs) have received an increased focus of attention, as can be observed from the number of recent publications on the subject. GAs have been applied to different areas of science. For example, in [
1], the authors discussed various methods to find approximate solutions to the TSP problem (Traveling Salesman Problem), and they proposed a modification of GAs to solve the problem of streamlining the shipping route. In [
2], a method based on GAs for processing and classifying electroencephalogram signals was proposed. In [
3], a combination of GAs with neural networks was applied to electronic commerce. Other applications can be found in [
4,
5,
6,
7], amongst many others.
In recent years, the use of GAs in cryptography has increased, particularly within cryptanalysis, intending to find an optimal solution (the so-called key) within the key space and one that is as close as possible to the real key. Some of the works in this direction are the following: In [
8], the authors applied GAs to the cryptanalysis of the RSA (
Rivest, Shamir, and Adleman) cipher. Something similar was done in [
9], where GAs were used to look up factors of the RSA public key. According to the authors, the research results suggest that GAs can break the RSA encryption’s public key. In [
10], the authors proposed an attack method inspired by GAs based on the collateral channel attack. One of the algorithms to which they applied this tool was DES (
Data Encryption Standard).
In [
11], a hybrid tool was developed that creates ciphertexts from the combination of GAs and the Particle Swarm Optimization algorithm. Shannon’s Entropy method was used as a fitness function in both algorithms. The authors claimed that the proposed application offers an alternative data encryption and decryption method that can be used to transmit messages. In [
12], a technique for encrypting texts based on the mutation and crossing operations of GAs was presented. The proposed encryption technique consisted of dividing the plaintext characters into parts and applying the crossover operation between them, followed by the mutation operation to obtain the ciphertext. In [
13], the authors discussed comparing traditional cryptographic algorithms and GA-based cryptosystems.
For more details on the structure and values of the parameters and operators of GAs, which are used in the experiments presented in this article, see [
14]. More details on the use of GAs in cryptography can be seen, for example, in [
15,
16,
17,
18,
19].
Other investigations are directed to the analysis and improvement of the properties and characteristics of the GAs. An example of the above is [
14], where several aptitude functions are proposed, and through some experiments, it was studied which of these functions provide the best results in the application of GAs; thus, it has been possible to appreciate the scarcity of theoretical results that can be used in such analysis. On the other hand, there is also the problem of analyzing whether the closeness to 1 of the fitness functions that use decimal distance implies decimal closeness between the new element found and the real key. In this sense, in the present work, a study was conducted on the fitness functions that intervene in GAs with the aim of improving their properties. So our contributions are: (1) a methodology to verify that the closeness to 1 of the values of some fitness functions that use decimal distance implies decimal closeness to the key; (2) a block cipher attack methodology based on the results of (1); and (3) the foundation of a theory that allows us to characterize fitness functions and determine, a priori and from a theoretical point of view, if one fitness function is more efficient than another in attacking block ciphers.
3. About the Closeness Problem
The analysis will focus on the fitness function
, from Equation (
3), which measures the fitness of each individual
X of the key space, comparing the ciphertext
C, and the text obtained from encrypting
T with
X. In short, it measures the decimal distance between ciphertexts. In this sense, the focus is on the problem of verifying if the approximation to 1 of
in the comparison of the ciphertexts (that is, the approximation of
to
), implies decimal proximity to the real key
K being searched for, with which
T was encrypted to obtain
C. This problem will be referred to as
Closeness Problem (CP).
3.1. Closeness Strategy
In this section, the first approximation of the CP is proposed. To test it, an attack strategy is proposed that links the two key space partitioning methodologies, BBM and TBB, and will be referred to as the Closeness Strategy. We will divide the strategy into three stages, which are detailed below:
First, the idea is that, given
T,
K and
C, such that
, choose
and
in the TBB methodology and then search for the key
K in any class of the quotient group of keys
(see [
19]). For uniformity, the key will be searched for in the class to which the ciphertext belongs. The purpose at this first moment is not for the GA to find the key directly (that is why the choice of the class could even be random or chosen according to another criterion) but, in the end, to choose the individual of the population with the greatest adaptation, the fittest, returned as a solution by the GA, say
. At this point, the fitness of
, and its decimal distance to
K, must be calculated:
, and,
;
Then, partition the space using the BBM methodology (in this case, exchanging the values of and , to perform the search under the same conditions as with the TBB methodology). Select the class in which the fittest individual is found that was obtained as a solution with the TBB methodology in Stage 1 (). At the end of the GA, the best-fit individual returned is taken as the solution, say, . As in the previous case, the fitness of is taken, and its decimal distance to K: , and, ;
For the purposes of testing the Closeness Problem, we will say that a better solution was obtained at Stage 2 if the following condition holds,
That is, if is closer to K than , at the same time, it is more suitable.
Note that, when performing the partition with the TBB methodology, each class has individuals from the population distributed throughout the space. In this sense, all the intervals of the BBM methodology have at least one individual of each class taken from TBB. For this reason, the TBB methodology is used first, where the individual with the highest fitness is expected to be closest to the key K, according to the decimal distance. Stage 1 is based on this fact.
Then, the idea of Stage 2 is to search for the key in an integer interval around
, with the goal of finding an individual
that is closest to the key in its decimal place, and at the same time, has a higher fitness value than
. For this purpose, the search is carried out in this stage with the BBM methodology, which partitions into integer intervals (see
Section 2.3). The interval to choose is the class to which the individual
belongs when performing the partition with BBM. Suppose that
q is the class to which
belongs in BBM and in which to start searching. So, if one wants to widen the search range, one should take the classes immediately before and after
q, starting with this one. In other words, it searches successively in the classes,
which would be equivalent to progressively increasing the radius of the interval to the desired depth level. As explained above, reversing the order of the methodologies in the Stages 1 and 2 would not make the same sense concerning testing the Closeness Problem and the decimal distance.
Stage 3 is essential for answering the Closeness Problem. Remember that the main objective is to verify if the closeness of the ciphertexts, and, therefore, the tendency to 1 of the fitness function, implies positional decimal closeness of the individual to the real key. Therefore, to say that the result obtained in the second stage is good is not enough to find an individual with greater fitness. Worse still is finding an individual closer to
K; on the contrary, its adaptation is less than the solution found in the first stage. In the first case in which an individual is found that only complies with having greater fitness, no data are obtained to verify the proximity to
K since it could be further from it than the individual in the first stage. For this reason, both conditions must be fulfilled simultaneously and, therefore, the relationship in Equation (
5).
The importance of the Closeness Problem lies in the fact that we are getting closer to the key, even if it is not known. When performing the attack to search for the key, if it is not found, then the idea is to have a certain degree of certainty that the individual who found the solution is positionally closest to the key.
3.2. Applications to Cryptanalysis
For future research, and with processors with higher computing capacity, it would be interesting to test the following attack methodology based on the Closeness Problem and which will be referred to as the Decimal Closeness Attack (DCA). The DCA constitutes an application of the results concerning the CP to the attack on block ciphers.
Given
T and
C as defined above, the attack’s goal is to find
K such that
. The main idea of the DCA is to increase the radius of the search interval around
q and search for the key with the GAs in those classes. That is, each time Step 1 is applied, Step 2 should be applied several times. The rationale is precise that each time a solution with higher fitness is found, it will also be assumed that it is closer to the key and, therefore, that it satisfies the relationship shown in Equation (
5).
Once the experiments were performed, an average reference distance
was calculated, obtained as the average of the distances,
in the attacks made to each trio
:
In other words,
is the average distance of the solution obtained in the second stage,
, from the key
K. Assuming this distance in the DCA, the search will also be performed on the two classes,
, corresponding to the individuals
:
That is, it will not only search for an interval around , but also around and . The last two cases would be the result of experimentation; the more experiments that are carried out, the more precise the estimate of will be. In this case, the advantage of the BBM and TBB key space partitioning methodologies is that they allow the search to be performed simultaneously in different classes, saving time in the attack.
To summarize, given the pair
, the DCA consists of the following. Apply Stage 1 and get
. Apply the Stage 2 with the BBM methodology and search the class to which
belongs to obtain
. Finally, search with the GA around
,
, and,
, that is, in the classes,
Only five classes were searched, and
is large. However, as the search radius increases around
q in experiments,
will become smaller. See
Section 5 for the experiments with the closeness strategy.
4. On the Fitness Functions and the Change Detection
From now on,
,
, and
will be the space for the plaintexts, keys, and ciphertexts, respectively. The purpose is to characterize fitness functions and determine, in advance, whether one fitness function is better than another. Informally, we will say that the fitness function
(
) is better than
, if
detects more changes in
x than
. Each change in
x is detected in different function values each time. For example, given
if
remains constant in
,
so it is not detecting changes from
to
. Therefore, it does not reflect the approach of
to
. In the extreme case, neither is the closeness to
, despite the fact that
is closer to
than
. However, if
were different in all cases, then it would detect the changes and the closeness of
to
. This fact causes better behavior of
concerning
. It is clear that the probabilistic and pseudo-random complexity that both encryption algorithms and GAs have are being overlooked in the above (and later). The focus is only on the structure of the fitness functions since the characteristics of the cryptosystems and the GAs do not depend on them.
The functions
and
(see
Section 2.2) use two different distances, Hamming’s distance and the decimal distance. There are changes that
does not detect, unlike
. For example, suppose the key is
, and
is the possible key, both in binary. It is clear that Hamming’s distance is 5, and the decimal distance is 62 since
, and
; and the fitness functions take the values
for
and
for
. Now, if
, the function
would still be 0.17 since there are still five different bits; on the other hand,
, so
takes the value
. Finally, if we take
, then Hamming’s distance remains constant but the decimal keeps changing, so the fitness function does too and takes the value 0.49. Therefore, this shows that the change of
b is detected by the decimal distance most of the time, contrary to the binary distance, which stays the same over many more changes.
Considering the above, the objective of what is proposed in this section is to start the basis of a theory that allows an explanation of the aforementioned. Let f be a fitness function that depends on a distance function d; the analysis will focus separately on the characteristics of f and d, understanding that the results on the distance influence f also.
Definition 1. Given , we will call the Completeness Kernel
of f in δ, , to the set: The completeness kernel is a way to obtain a range of elements in which
f is remained constant and therefore does not reflect changes occurring in the keys. In the example with
,
That is, at least it is known that the elements are in the completeness kernel .
Definition 2. The Center of Completeness
of f, , is the set,The Degree of Completeness, , of f, is the maximum of its center of completeness, . Then, f is said to be -complete. The degree of completeness globally measures the worst result of f in terms of the number of elements in its completeness kernels. The larger is, the less effective f is, in the sense that the larger the range in which it detects no change. What is desired is to have fitness functions that are 1-complete.
Lemma 1. If there is a kernel of completeness of f with cardinality θ, then the degree of completeness of f is greater than or equal to θ. More formally, Proof. Given a fitness function f, suppose there exists with cardinality , for some value . It is clear that , and there are only two possibilities—that it is less than or equal to the maximum of , which is equivalent to —therefore, it must be . □
It is a hard problem to determine the degree of completeness of a fitness function. This is due, first of all, to the size of the key space. Another point is the very structural complexity of the E cipher, which depends on the key, and at the same time, most fitness functions also use E in their construction.
The cipher
E often takes the same value for different keys
x because the combination of keys and plaintexts is much larger than the cardinality of the ciphertext space. Then, by Dirichlet’s Principle, at least one pair of keys
, returns the same ciphertext:
In this sense, it is complicated to ensure higher bounds for (other than ). This fact influences some fitness functions not detecting the change between and . However, that would not depend on them but on the cipher E. In practice, it is a hard problem to determine the pairs in which equal ciphertext is obtained. The same would happen in the opposite case, where the fitness functions compare the plaintexts from the cryptosystem’s decryption algorithm.
Definition 3. Let d be a distance function, and, be the distance between two arbitrary elements of . We will call the Plateau
of d at with respect to s, the set (or simply ): We will say that is the Axis of the Plateau.
Definition 4 (Reduced Plateau).
Let , d be a distance function, be the distance between two arbitrary elements of , and, a plateau of d. Two arbitrary elements , of are equivalent in , if they can be obtained with the same keys, i.e.,The reduced plateau is the one obtained by eliminating equivalent elements in , leaving only one representative in each case for each key.
Definition 5 (Maximum plateau). Let d be a distance function. The maximum plateau of d, , is the largest cardinal reduced plateau for all possible axes and values of .
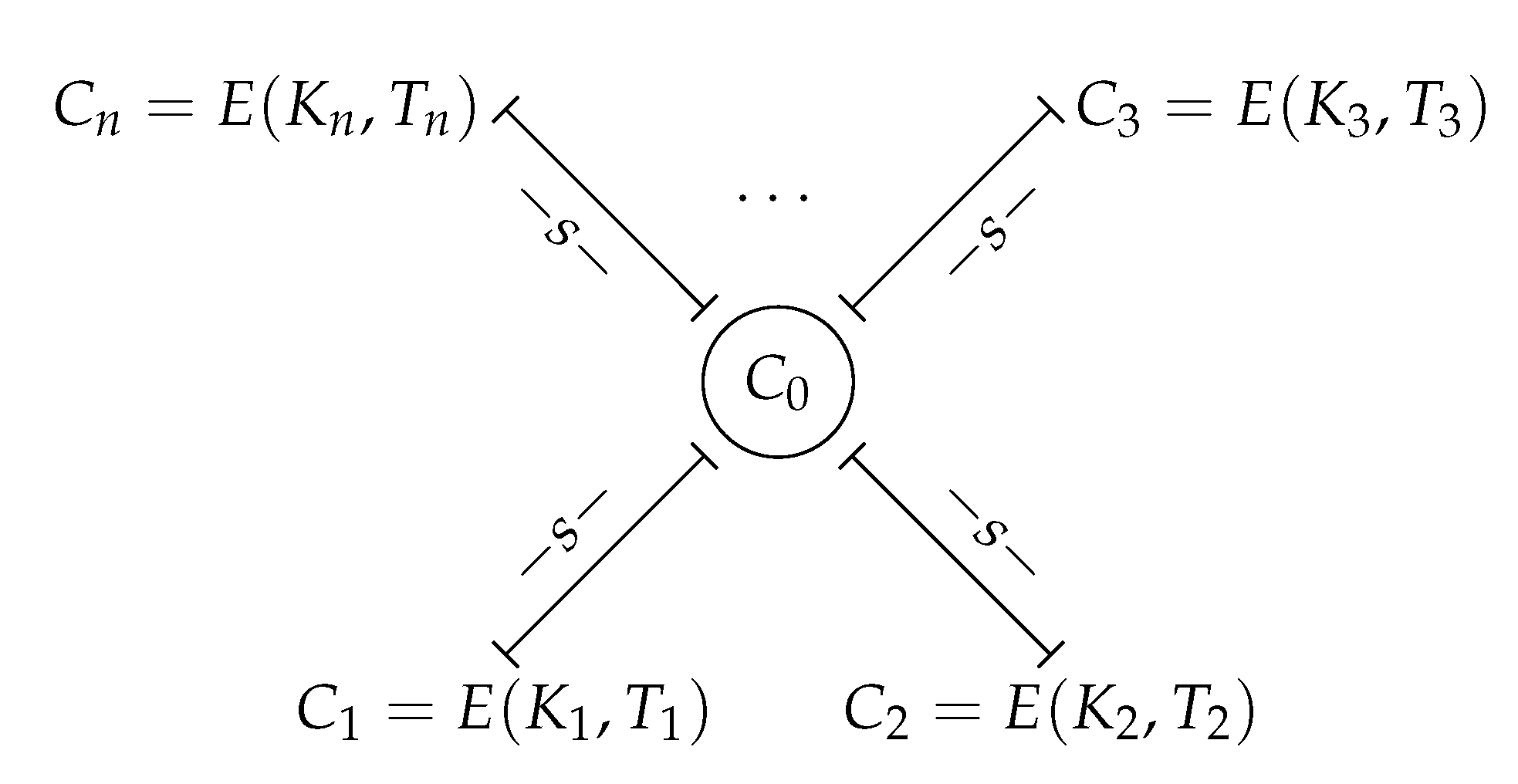
Figure 3 shows a schematic example of a plateau of cardinality
n. In general, the
can be the same all at once. However, if the plateau were reduced, the keys
, must be different two by two. The reason is that the analysis of the fitness functions focuses on the changes of the individuals in the GA population, which coincide with the elements of the key space.
The interesting property of the maximum plateau is its cardinal. In this sense, there is no difficulty if several maximum plateaus have the same number of elements.
Definition 6. Let d be a distance function, and and two reduced plateaus of d. We will say that and are equivalent if they have the same cardinality: It is clear that if is a maximum plateau, then so is .
Definition 7 (Degree of detection). The Degree of Detection of a fitness function f is the pair , and will be written simply, . The function f is of perfect degree if it is 1-complete and .
The ideal would be to look for fitness functions for GAs applications whose degree of detection is getting closer and closer to the perfect degree.
Proposition 1. Given , a distance and a fitness function with . If f is of the form and d has a reduced plateau of cardinal ρ, then, .
This statement says nothing about the internal structure of d.
Proof. Let
,
be a distance and
be a fitness function with
. Suppose
f has the form,
and that
is a reduced plateau of
d, such that,
, for some
and
. By the Definitions 3 and 4, there exist
keys
,
, such that,
. From the form of
f in (
22), it is clear that
f is also remained constant and equal to
for each of these keys. Therefore, the set,
is a completeness kernel of
f of cardinal
. Then, applying the Lemma 1 with
, we obtain,
. □



 ,
, 

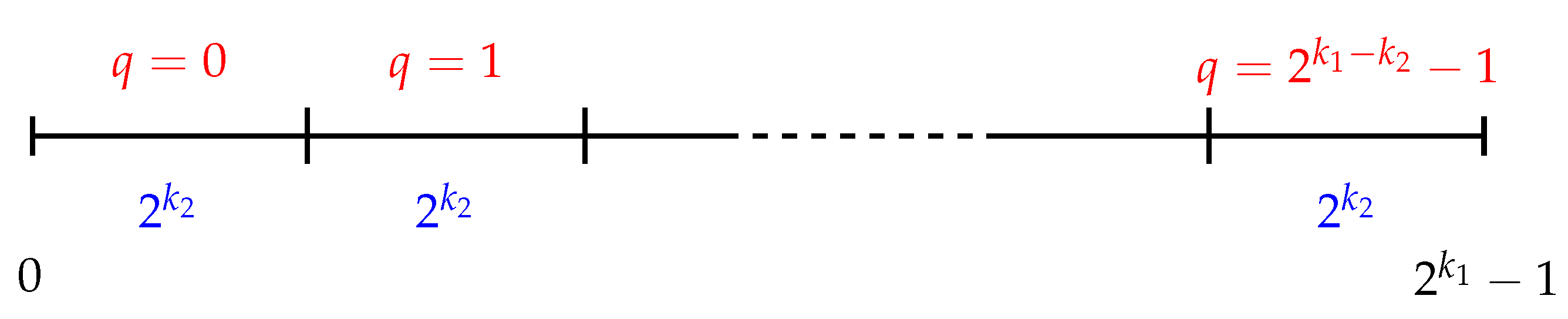{kind=link}
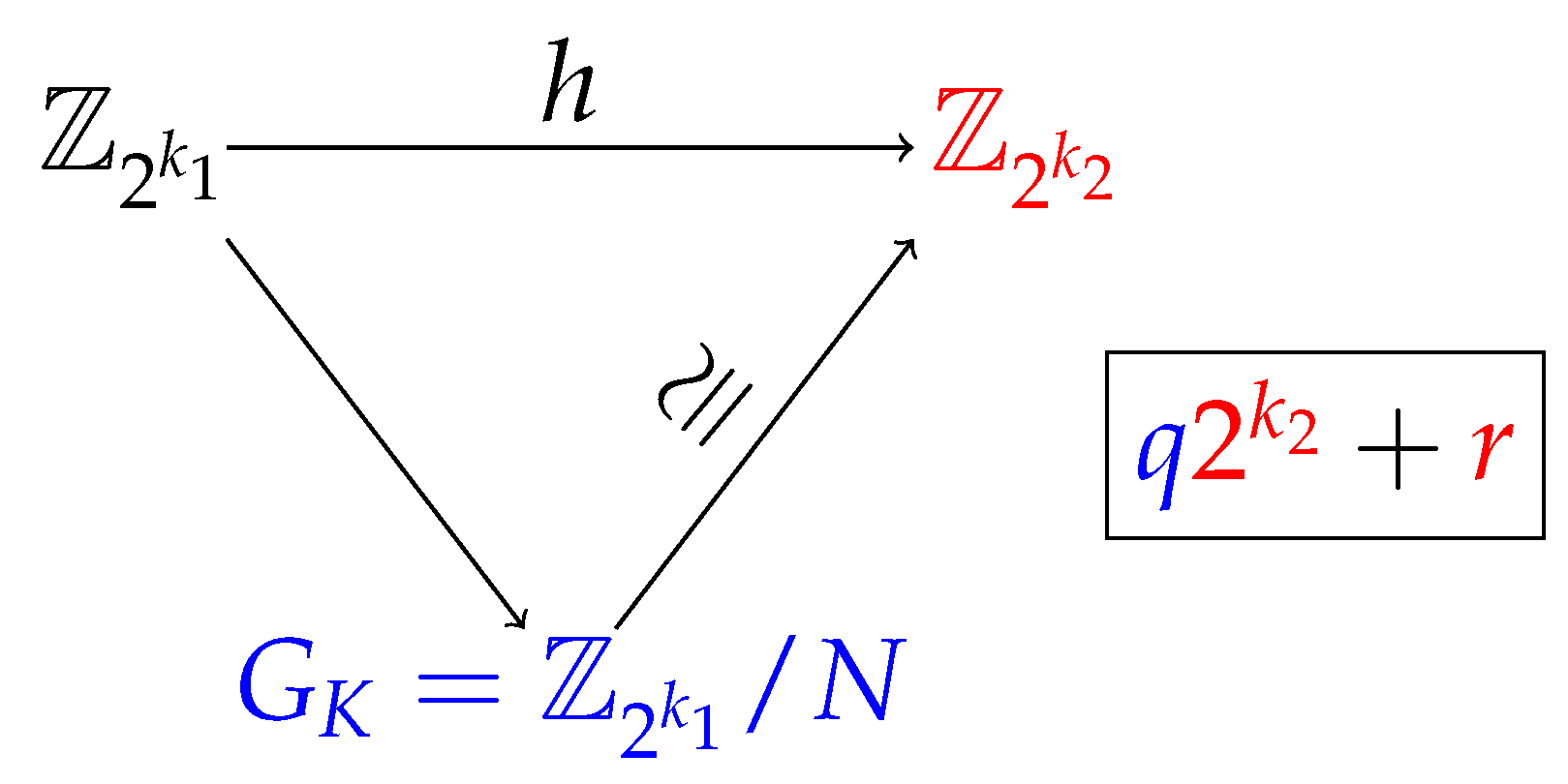{kind=link}
{kind=link}
{kind=link}



