


Unsupervised Embedding Learning for Large-Scale Heterogeneous Networks Based on Metapath Graph Sampling


Abstract
:1. Introduction
- (1)
- LHGI is an embedding learning model designed for large-scale heterogeneous networks. LHGI adopts the graph sampling strategy under the guidance of metapaths, so that the model can compress the network while preserving the low-order and high-order neighbor relationships between nodes as much as possible. This provides a guarantee for the model to generate high-quality node embedding vectors.
- (2)
- LHGI is an unsupervised embedding learning model. LHGI introduces the idea of contrastive learning, which enables LHGI to optimize parameters in the model, so that the embedding vectors of nodes can be learned without any supervision information.
2. Related Work
3. Overall Architecture of the LHGI Model
3.1. Definitions
- Definition 1: Heterogeneous network
- Definition 2: Metapath
3.2. Framework of LHGI Model
3.2.1. Meta Path Generation Module
- Principle 1: In one metapath, up to two nodes in a certain type can exist.
- Principle 2: In one metapath, up to three different types of nodes can exist.
- Principle 3: Metapaths containing a subpath with 1:1 relationship between its head and tail node will be excluded.
- Principle 4: Only metapaths with the same type of head and tail nodes are retained.
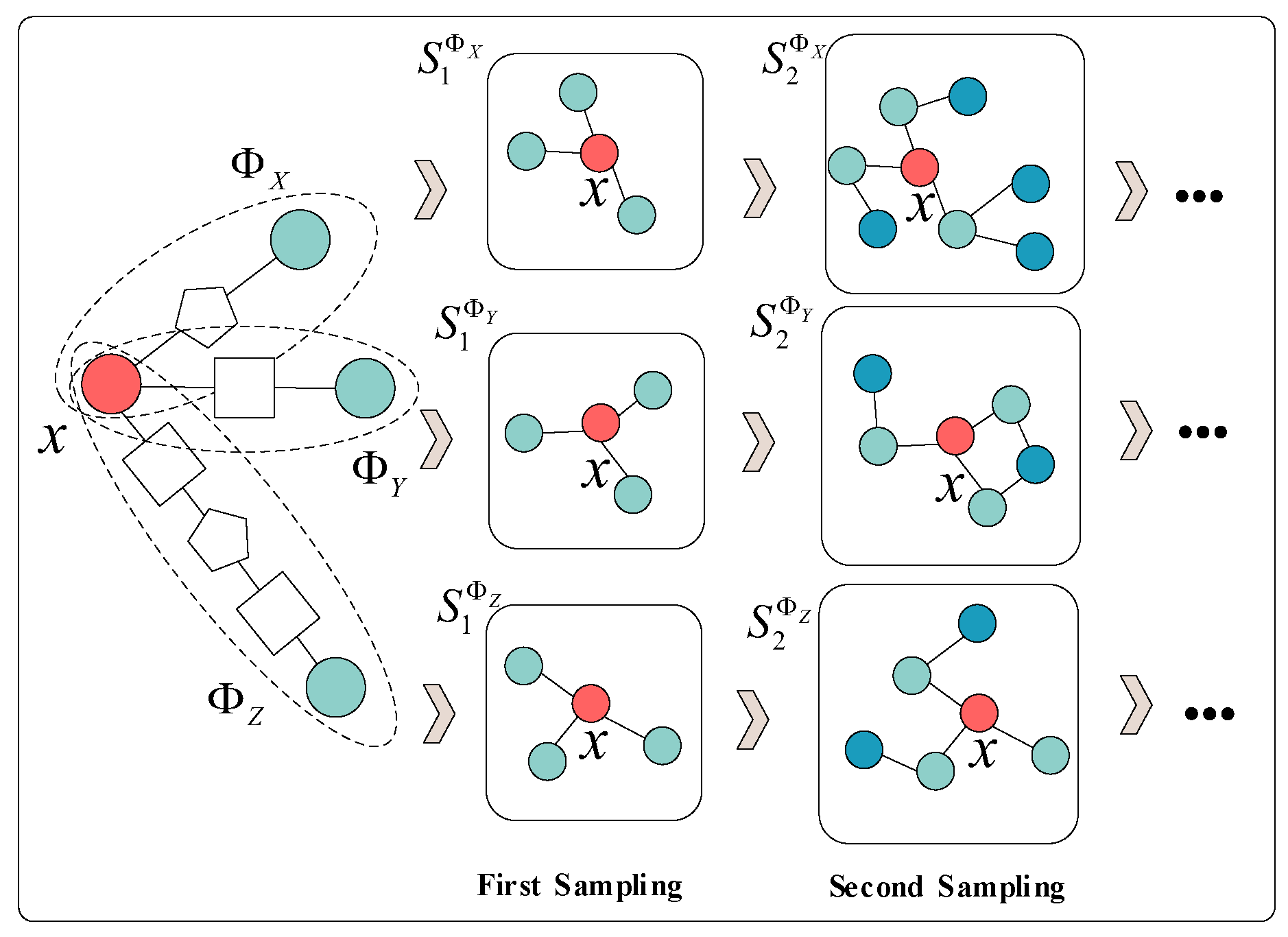
3.2.2. Meta Path Guided Graph Sampling Module
3.2.3. Sampling Graph Aggregation Encoding Module
3.2.4. Discriminator Module
3.2.5. Complexity Analysis
4. Experimental Results & Discussions
4.1. Baseline Models
- Metapath2vec(M2V) [22]: M2V is a model based on random walk, which takes Word2vec model as its backbone architecture.
- Hin2vec [24]: Hin2Vec is a model based on metapath random walk, which uses a logical binary classifier to predict whether there is a specific relationship between two given nodes to guide the learning process.
- HeGAN [25]: HeGAN is a model based on contrastive learning, which uses a generator to generate pseudo nodes, and uses a discriminator to identify the authenticity of nodes.
- HDGI [27]: HDGI uses a metapath to capture the semantic structure in a heterogeneous network, and uses graph convolution modules and semantic level attention mechanisms to learn the embedding of nodes.
- HGT [29]: The HGT model is a learning model proposed for supervised large-scale heterogeneous networks. It uses HG sampling algorithm to compress the size of network. The sampling algorithm can reserve the same number of heterogeneous neighbors and edges for the target node. In order to compare with other unsupervised embedding models, the original supervised loss function in the HGT model is replaced with the loss function consistent with LHGI model. That is, a loss function of maximizing mutual information is used to optimize the parameters in HGT model.
4.2. Data Sets
- (1)
- IMDB: IMDB is a movie dataset, which contains three types of nodes, including 4278 movies, 2081 directors and 5257 actors. Among them, movie nodes are divided into three categories: action movies, comedy movies and drama movies.
- (2)
- DBLP: DBLP is a citation network dataset, which contains 4 types of nodes, including 4057 authors, 14,376 papers, 20 conferences, and 8920 terms. Among them, author nodes are divided into four categories: database, data mining, information retrieval and machine learning.
- (3)
- Yelp: Yelp is a commercial data set, which contains 5 types of nodes, including 2614 business, 1286 users, 2 service types, 2 reservation, and 7 stars levels. Among them, business nodes are divided into three types: Mexican flavor, hamburger type, and food bar.
- (4)
- AMiner: AMiner is a large-scale heterogeneous citation network, which contains 4,888,069 nodes in total. These nodes are specifically divided into 134 venues, 1,693,531 authors and 3,194,405 papers. The author nodes are divided into eight types in AMiner.
- (5)
- ogbn-mag: ogbn-mag (Open Graph Benchmark Node Property Prediction-Microsoft Academic Graph) is a heterogeneous graph composed of a subset of the Microsoft Academic Graph. It contains four types of entities, including 736,389 papers, 1,134,649 authors, 8740 institutions, and 59,965 fields of study. The paper nodes are divided into 349 types according to the venue (conference or journal) of each paper.
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, C.; Wang, R.N.; Wang, X. Survey on Analysis and Application of Heterogeneous Information Networks. J. Softw. 2022, 33, 598–621. [Google Scholar] [CrossRef]
- Gao, M.; Wu, P.; Pan, L. Malware Detection with Limited Supervised Information via Contrastive Learning on API Call Sequences. In Proceedings of the International Conference on Information and Communications Security, Chongqing, China, 24–26 August 2020; Springer: Berlin/Heidelberg, Germany; University of Kent: Canterbury, UK, 2022; pp. 492–507. [Google Scholar]
- Chen, K.J.; Lu, H.; Liu, Z.; Zhang, J. Heterogeneous graph convolutional network with local influence. Knowl. Based Syst. 2022, 236, 107699. [Google Scholar] [CrossRef]
- Li, J.; Zhu, J.; Zhang, B. Discriminative deep random walk for network classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1004–1013. [Google Scholar]
- Nasiri, E.; Berahmand, K.; Li, Y. A new link prediction in multiplex networks using topologically biased random walks. Chaos Solitons Fractals 2021, 151, 111230. [Google Scholar] [CrossRef]
- Hu, Q.; Lin, F.; Wang, B.Z.; Li, C.Y. MBRep: Motif-based representation learning in heterogeneous networks. Expert Syst. Appl. 2022, 190, 116031. [Google Scholar] [CrossRef]
- Lei, F.; Cheng, J.; Yang, Y.; Tang, X.; Sheng, V.; Huang, C. Improving Heterogeneous Network Knowledge Transfer Based on the Principle of Generative Adversarial. Electronics 2021, 10, 1525. [Google Scholar] [CrossRef]
- Ruan, C.Y.; Wang, Y.; Ma, J.; Zhang, Y.; Chen, X.-T. Adversarial heterogeneous network embedding with metapath attention mechanism. J. Comput. Sci. Technol. 2019, 34, 1217–1229. [Google Scholar] [CrossRef]
- Yuan, M.; Liu, Q.; Wang, G.; Guo, Y. HNECV: Heterogeneous Network Embedding via Cloud Model and Variational Inference. In Proceedings of the CAAI International Conference on Artificial Intelligence, Hangzhou, China, 29–30 May–5–6 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 747–758. [Google Scholar]
- Ma, M.; Na, S.; Wang, H. AEGCN: An autoencoder-constrained graph convolutional network. Neurocomputing 2021, 432, 21–31. [Google Scholar] [CrossRef]
- Dong, Y.X.; Hu, Z.N.; Wang, K.S.; Sun, Y.Z.; Tang, J. Heterogeneous Network Representation Learning. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, Yokohama, Japan, 11–17 July 2020; Volume 20, pp. 4861–4867. [Google Scholar]
- Zeng, H.; Zhou, H.; Srivastava, A.; Kannan, R.; Prasanna, V. Graphsaint: Graph sampling based inductive learning method. arXiv 2019, arXiv:1907.04931, 2019. [Google Scholar]
- Zeng, H.; Zhang, M.; Xia, Y. Decoupling the depth and scope of graph neural networks. Adv. Neural Inf. Process. Syst. 2021, 34, 19665–19679. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Ribeiro LF, R.; Saverese PH, P.; Figueiredo, D.R. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 385–394. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. Int. Conf. Learn. Represent. Poster 2019, 2, 4. [Google Scholar]
- Yang, C.; Xiao, Y.X.; Zhang, Y.; Sun, Y.Z.; Han, J.W. Heterogeneous network representation learning: A unified framework with survey and benchmark. IEEE Trans. Knowl. Data Eng. 2020, arXiv:2004.0021634, 4854–4873. [Google Scholar] [CrossRef]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Shi, C.; Hu, B.; Zhao, W.X.; Yu, P.S. Heterogeneous information network embedding for recommendation. IEEE Trans. Knowl. Data Eng. 2018, 31, 357–370. [Google Scholar] [CrossRef]
- Fu, T.; Lee, W.C.; Lei, Z. Hin2vec: Explore meta-paths in heterogeneous information networks for representation learning. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1797–1806. [Google Scholar]
- Hu, B.; Fang, Y.; Shi, C. Contrastive learning on heterogeneous information networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 4–8 August 2019; pp. 120–129. [Google Scholar]
- Ali, Z.; Qi, G.; Muhammad, K.; Kefalas, P.; Khusro, S. Global citation recommendation employing generative adversarial network. Expert Syst. Appl. 2021, 180, 114888. [Google Scholar] [CrossRef]
- Ren, Y.; Liu, B.; Huang, C.; Dai, P.; Bo, L.; Zhang, J. Heterogeneous deep graph infomax. arXiv 2019, arXiv:1911.08538. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1–19. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Sun, Y. Heterogeneous graph transformer. In Proceedings of the Web Conference 2020, Taipei, China, 20–24 April 2020; pp. 2704–2710. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 3844–3852. [Google Scholar]
- Gao, Y.; Zhang, Z.Z.; Lin, H.J.; Zhao, X.B.; Du, S.Y. Hypergraph Learning: Methods and Practices. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2548–2566. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, Y.Y. A Survey on Hyperlink Prediction. arXiv 2022, arXiv:2207.02911v1. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Node Type | Nodes | Edge Type | Edges | Labeled Nodes |
|---|---|---|---|---|---|
| IMDB | Movie(M) Director(D) Actor (A) | 4278 2081 5257 | M-D M-A D-M A-M | 4278 12,828 4278 12,828 | Movie (3) |
| DBLP | Author (A) Conference (C) Paper (P) Term (T) | 4057 20 14,376 8920 | P-A P-C P-T | 19,645 14,376 114,625 | Author (4) |
| Yelp | Business (B) Reservation (R) Service (S) Stars Level (SL) User (U) | 2614 2 2 9 1286 | B-SL B-R B-S B-U | 2614 2614 2614 30,839 | Business (3) |
| AMiner | Author (A) Paper (P) Venue (V) | 1,693,531 3,194,405 134 | A-P P-V | 9,323,605 3,194,405 | Author (8) |
| ogbn-mag | Author (A) Paper (P) Institutions (I) fields of study (F) | 1,134,649 736,389 8740 59,965 | P-P P-F A-P A-I | 5,416,271 7,505,078 7,145,660 1,043,998 | Paper (349) |
| HLGI | DBLP | Yelp | IMDB | ||||||
|---|---|---|---|---|---|---|---|---|---|
| F1_mic | NMI | Time | F1_mic | NMI | Time | F1_mic | NMI | Time | |
| GCNConv | 0.8915 | 0.6188 | 5.740 | 0.6984 | 0.3510 | 6.722 | 0.4711 | 0.0427 | 5.401 |
| ChebConv | 0.8766 | 0.5644 | 6.768 | 0.6761 | 0.3431 | 7.876 | 0.4928 | 0.0755 | 6.207 |
| SAGEConv | 0.6307 | 0.5918 | 4.457 | 0.6689 | 0.3480 | 5.229 | 0.4979 | 0.0299 | 4.188 |
| MODEL | DBLP | Yelp | IMDB | ALL_DATA | ||||
|---|---|---|---|---|---|---|---|---|
| F1_mac | F1_mic | F1_mac | F1_mic | F1_mac | F1_mic | mac_avg | mic_avg | |
| M2V | 0.6985 | 0.6874 | 0.4534 | 0.5171 | 0.3933 | 0.4051 | 0.515 | 0.5365 |
| Hin2vec | 0.605 | 0.594 | 0.4011 | 0.3541 | 0.325 | 0.3261 | 0.4437 | 0.4247 |
| HeGAN | 0.7544 | 0.7702 | 0.4578 | 0.5264 | 0.4057 | 0.4177 | 0.5393 | 0.5714 |
| HDGI | 0.7153 | 0.7259 | 0.4096 | 0.4429 | 0.4445 | 0.4466 | 0.5231 | 0.5384 |
| HGT | 0.6403 | 0.6885 | 0.5917 | 0.6775 | 0.386 | 0.3882 | 0.5393 | 0.5847 |
| LHGI | 0.884 | 0.8915 | 0.625 | 0.6984 | 0.4650 | 0.4711 | 0.6600 | 0.6850 |
| MODEL | DBLP | YELP | IMDB | ALL_DATA | ||||
|---|---|---|---|---|---|---|---|---|
| NMI | ARI | NMI | ARI | NMI | ARI | NMI _avg | ARI _avg | |
| M2V | 0.4577 | 0.4806 | 0.1102 | 0.1443 | 0.0115 | 0.0151 | 0.1931 | 0.2133 |
| Hin2vec | 0.442 | 0.4699 | 0.2324 | 0.24 | 0.0102 | 0.0105 | 0.2282 | 0.2401 |
| HeGAN | 0.5546 | 0.572 | 0.2544 | 0.2608 | 0.0366 | 0.0376 | 0.2818 | 0.2901 |
| HDGI | 0.6076 | 0.6076 | 0.2334 | 0.2011 | 0.0187 | 0.037 | 0.2865 | 0.2882 |
| HGT | 0.4603 | 0.4712 | 0.2018 | 0.2146 | 0.0124 | 0.0165 | 0.2248 | 0.2341 |
| HLGI | 0.6188 | 0.6203 | 0.3510 | 0.4018 | 0.0427 | 0.0241 | 0.3375 | 0.3487 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, H.; Wang, M.; Zhang, X. Unsupervised Embedding Learning for Large-Scale Heterogeneous Networks Based on Metapath Graph Sampling. Entropy 2023, 25, 297. https://doi.org/10.3390/e25020297
Zhong H, Wang M, Zhang X. Unsupervised Embedding Learning for Large-Scale Heterogeneous Networks Based on Metapath Graph Sampling. Entropy. 2023; 25(2):297. https://doi.org/10.3390/e25020297
Chicago/Turabian StyleZhong, Hongwei, Mingyang Wang, and Xinyue Zhang. 2023. "Unsupervised Embedding Learning for Large-Scale Heterogeneous Networks Based on Metapath Graph Sampling" Entropy 25, no. 2: 297. https://doi.org/10.3390/e25020297
APA StyleZhong, H., Wang, M., & Zhang, X. (2023). Unsupervised Embedding Learning for Large-Scale Heterogeneous Networks Based on Metapath Graph Sampling. Entropy, 25(2), 297. https://doi.org/10.3390/e25020297