1. Introduction
Deep learning technology has demonstrated excellent performance and has played a key role in many fields, such as finance, medical care, and public safety [
1,
2,
3,
4]. However, deep learning is also a double-edged sword, and its security issues have aroused widespread concern among researchers and engineers. Among them, the research on adversarial examples has gained momentum in recent years [
5]. Combining a clean example with a slight adversarial perturbation yields an adversarial example. An adversarial attack is a term for this process of creating perturbations. Deep neural networks (DNNs) may produce incorrect predictions due to adversarial attacks, which may then cause decision-making or other subsequent sub-tasks to perform incorrectly. This phenomenon puts safety-sensitive tasks in a dangerous situation. As an illustration, attacking autonomous driving may cause misrecognition of traffic signs, failure to detect vehicles in front, and loss of seeing passing pedestrians [
6,
7,
8]. It is easy to foresee that these misidentifications will significantly harm the safety of people and their property in many different industries. Therefore, research on adversarial attacks and defenses is in full swing to examine the causes and decrease the probability of misidentifications.
From an attack perspective, researchers are working on exposing the vulnerabilities of DNNs to explore their mechanisms and interpretability. There are many ways to classify attack methods, which can be divided into white-box, gray-box, and black-box attacks according to the degree of information acquisition of the attacked model or system. In a white-box attack, the adversary has complete knowledge of the DNN, including its design, weights, inputs, and outputs. Specifically, the generation of the adversarial instances involves resolving an optimization issue guided by the gradient of a model. Common white-box attacks include gradient-based attacks [
9,
10] and optimization-based attacks [
11,
12]. In a grey-box attack, the adversary has limited knowledge of the model, and it has access to the model’s training data, but knows nothing about the model architecture. Therefore, its goal is to replace the original model with an approximate model and then use its gradients to generate adversarial examples like in the white-box scenario. Finally, the adversary knows nothing about the model in a black-box attack. As a result, the adversary can produce adversarial examples by leveraging the input sample content and the transferability properties of the adversarial examples. Common black-box attacks include gradient estimation-based attacks [
13] and decision boundary-based attacks [
14].
The defense works are trying every means to solve exposed or potential loopholes to ensure the reliability and trustworthiness of DNNs in practical applications. There are numerous ways to categorize defense strategies, which can be separated into intrusive and non-intrusive methods depending on whether the protected model is modified. Intrusive methods mainly include modifying model regularization loss [
15,
16] and adversarial training [
17,
18]. The adversarial training or regularization method is computationally expensive, despite effectively solving the defensive problem. On whether to alter the prediction results, non-intrusive approaches could be primarily split into input transformation methods [
19,
20,
21,
22] and detection methods [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33]. These techniques have a low computational cost and the ability to generalize across models, but their defense performance is often much weaker than that of intrusive methods.
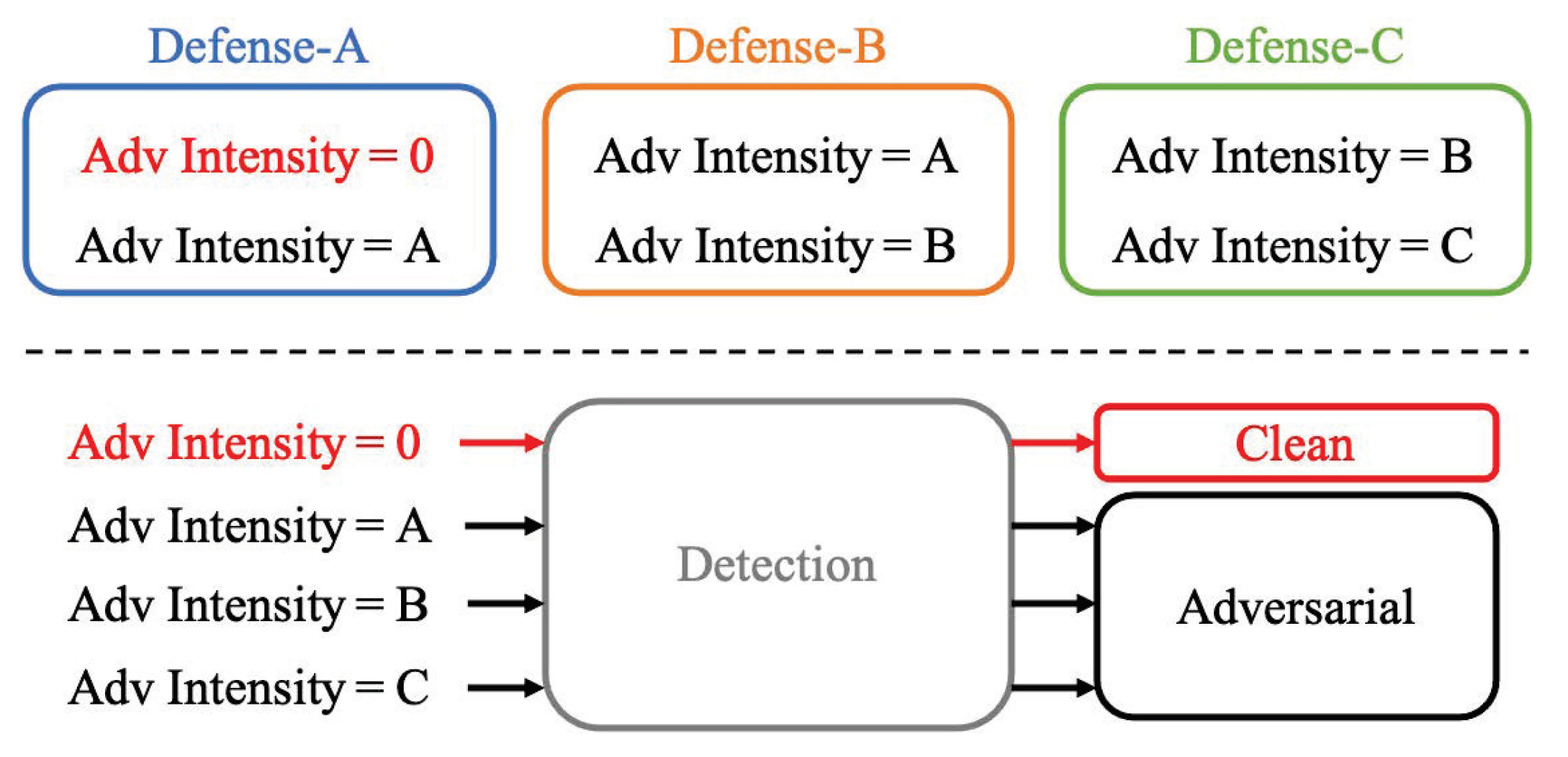
Many adversarial defense strategies have already been developed, but as far as we can tell, they all have flaws. For instance, they may only be effective against adversarial examples with a specific range of perturbation intensities or may result in relatively high accuracy loss for clean inputs. In other words, even when defenses have been deployed, deep learning systems are still susceptible to attacks outside the range of an effective defense. The problem with limited defense range is shown at the top of
Figure 1, where Defense-A is effective for adversarial intensities of 0 or A, and Defense-B and Defense-C can only defend against adversarial examples of some intensities. Meanwhile, existing adversarial detection methods only classify input samples into clean samples and adversarial examples [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33], and there is no technique to classify the intensity of input samples, as shown at the bottom of
Figure 1. To address the problem in
Figure 1, a fine-grained adversarial detection (FAD) method with perturbation intensity classification is proposed in this paper. FAD is used to classify the potential perturbation intensities in the input samples to accurately provide adversarial examples with different perturbation intensities for different defense subtasks.
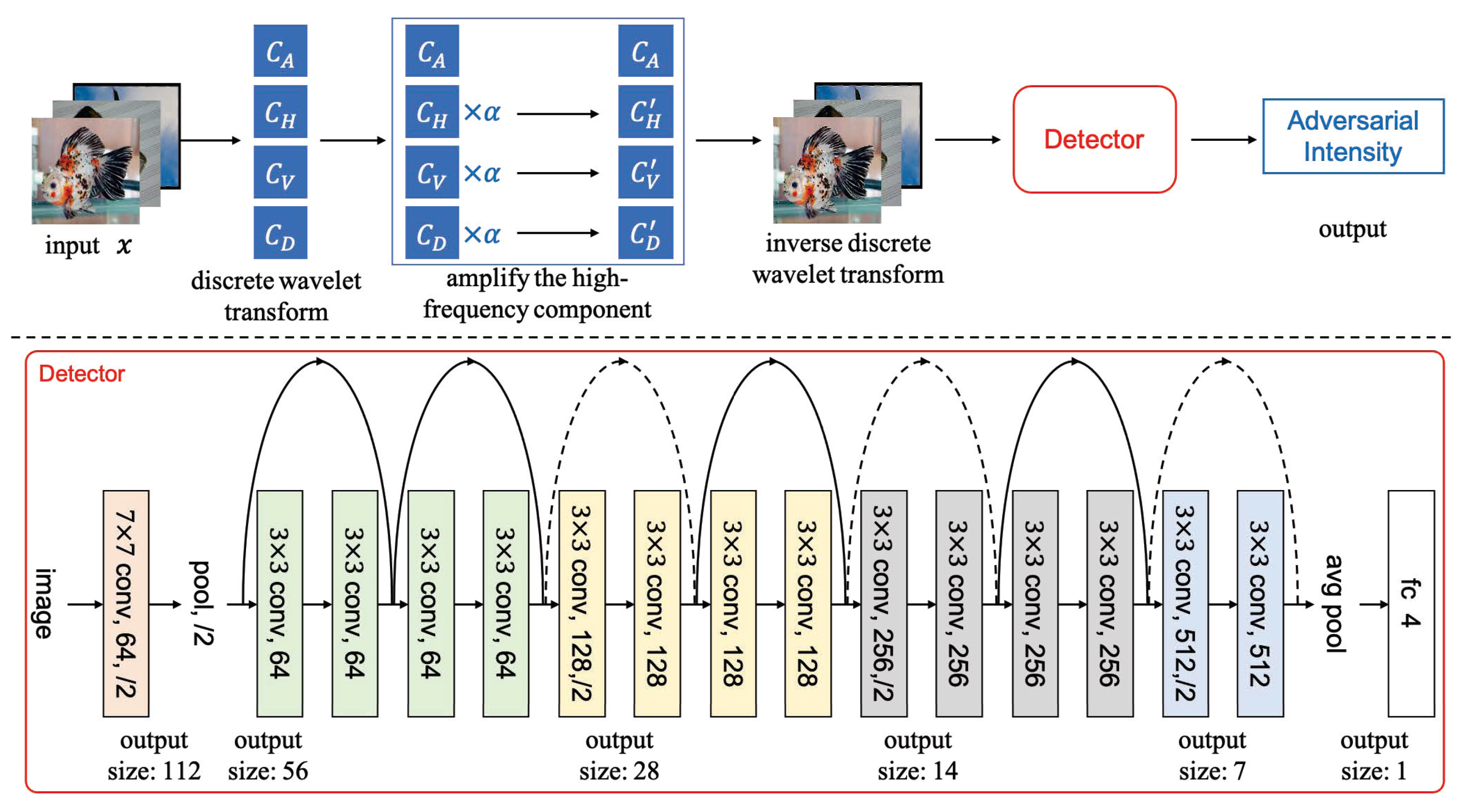
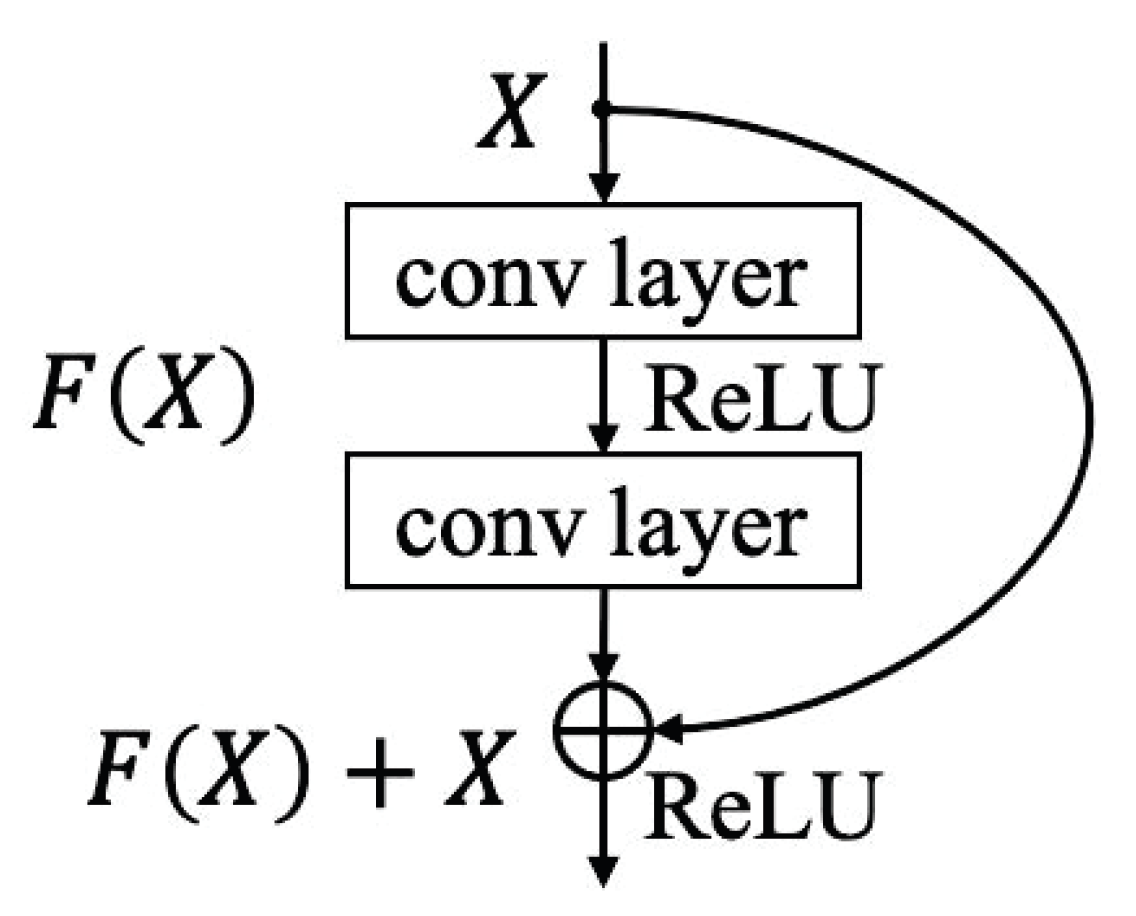
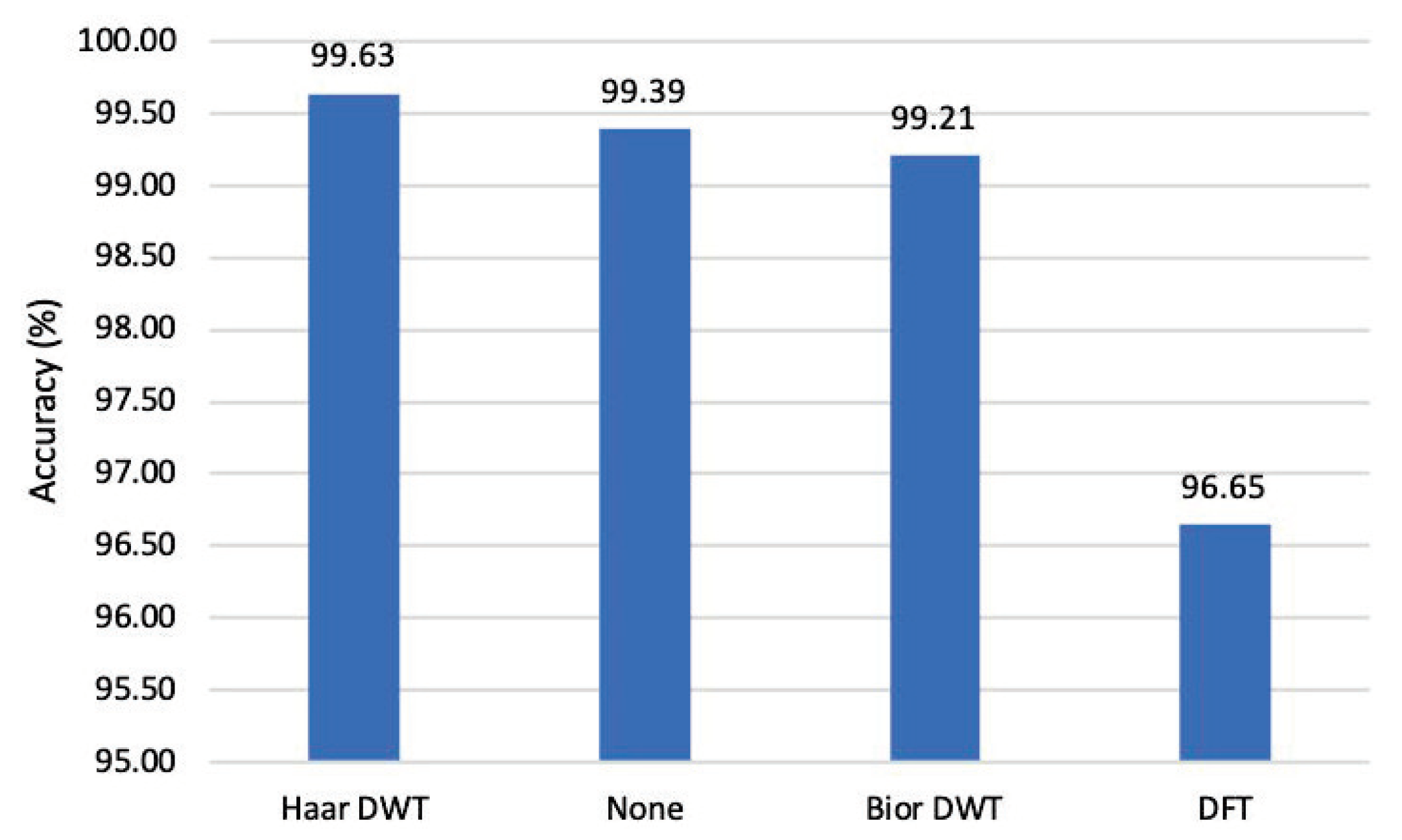
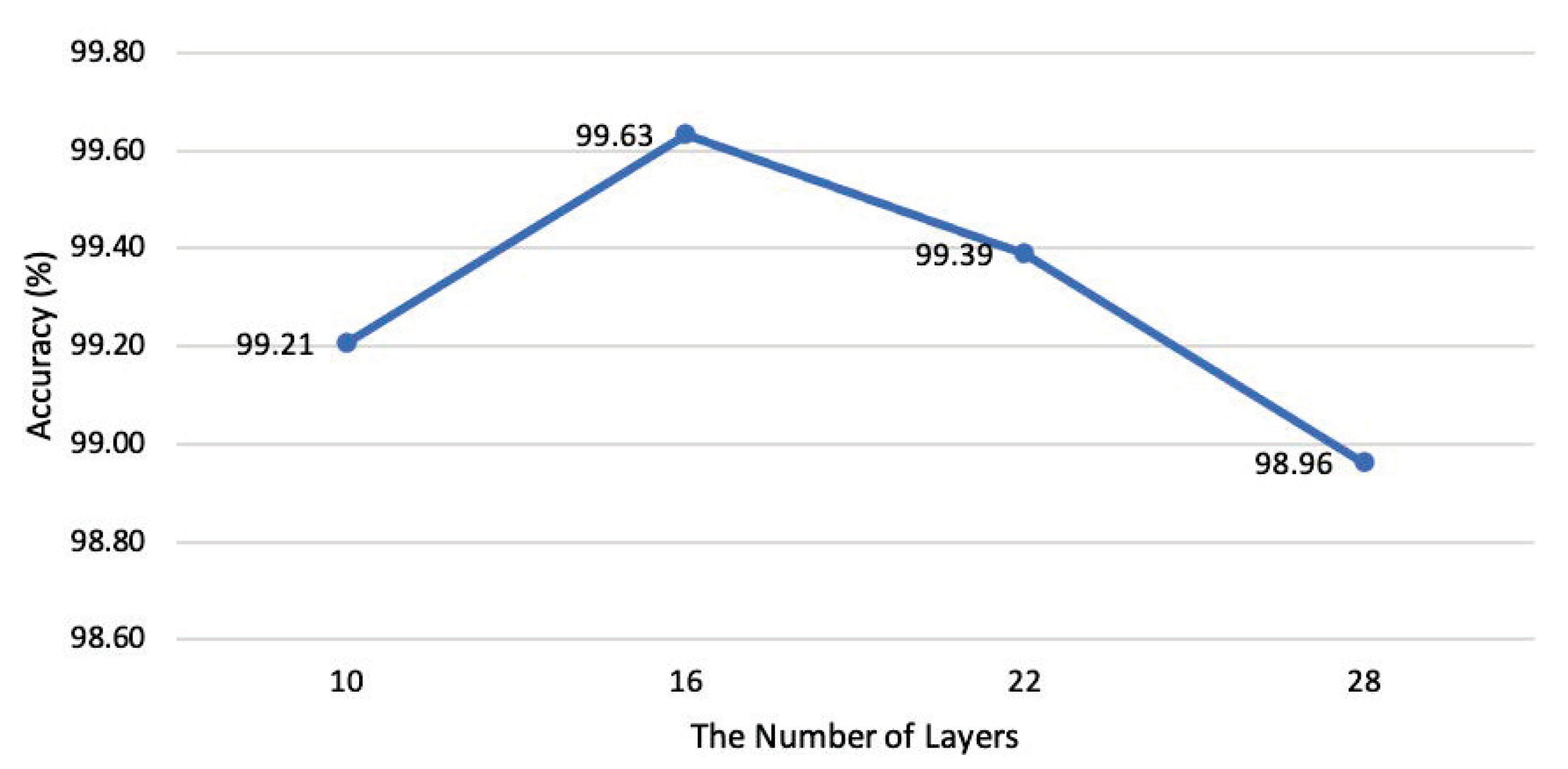
The main steps of the proposed FAD method are as follows: first of all, through the statistical observation of the spectrum of clean samples and adversarial examples with different intensities, this paper proposes an approach based on amplifying high-frequency components to improve the distinguishability of adversarial examples. The procedure is to use the Haar discrete wavelet transform (DWT) to decompose the high-frequency and low-frequency components, amplify the high-frequency components, and then use the inverse discrete wavelet transform (IDWT) to create the reconstructed image. Then, through the experimental observation of DNN to distinguish adversarial examples and refer to the existing methods of using DNN to detect adversarial examples, this paper proposes to use DNN to classify the perturbation intensity of the reconstructed image. This paper designs a 16-layer network based on the residual block structure [
34] to achieve a fine-grained classification of adversarial intensity. This is done in light of the residual block structure’s excellent performance. Finally, the training sample adopts a representative AutoAttack method (AA) [
35] to produce the training sample of the adversarial intensity classifier to obtain strong performance.
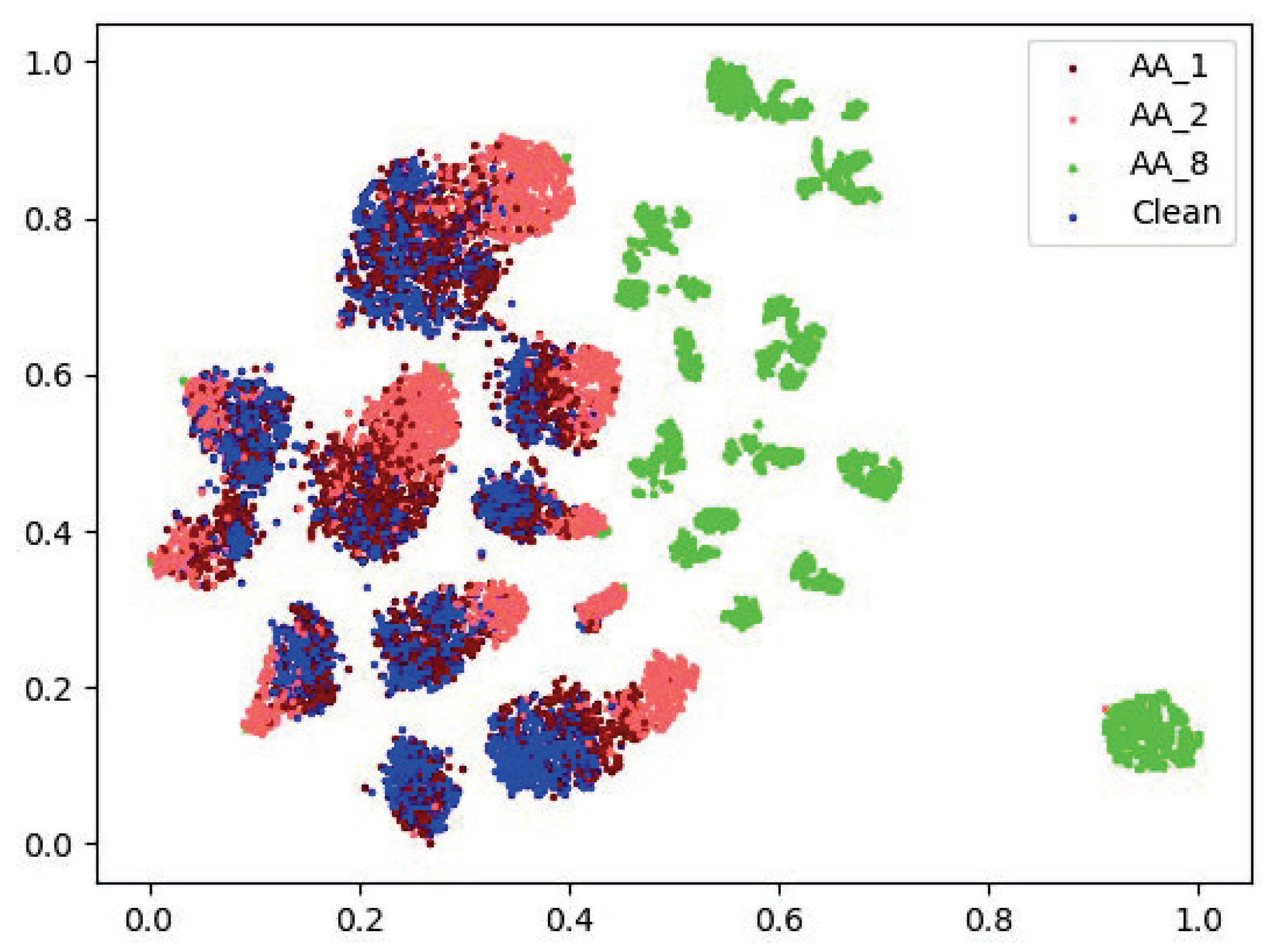
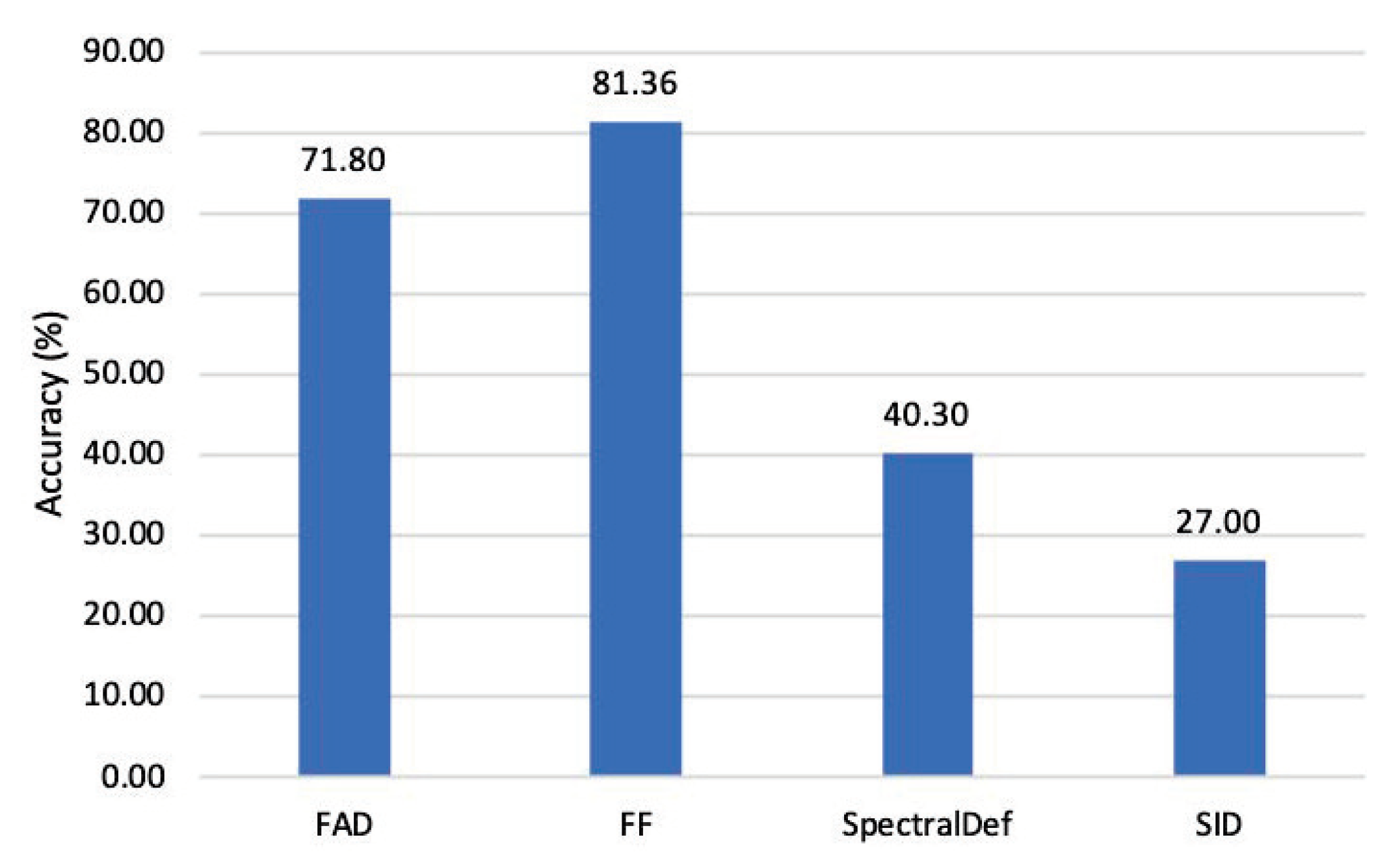
By studying the pattern of various intensity perturbations of AA in the feature space, the proposed FAD could extend to the fine-grained categorization of perturbation intensity of additional attack methods (especially high-frequency features). Our proposed method has a strong detection capability and can correctly classify the intensity of adversarial examples generated by different attack methods. The average classification accuracy of the proposed FAD technique, which detects different intensities of different adversarial attacks under the norm, is 98.95%.
The main contributions of this paper are as follows:
To the best of our knowledge, FAD is the first fine-grained adversarial perturbation intensity classification method, and is a non-intrusive adversarial detection method.
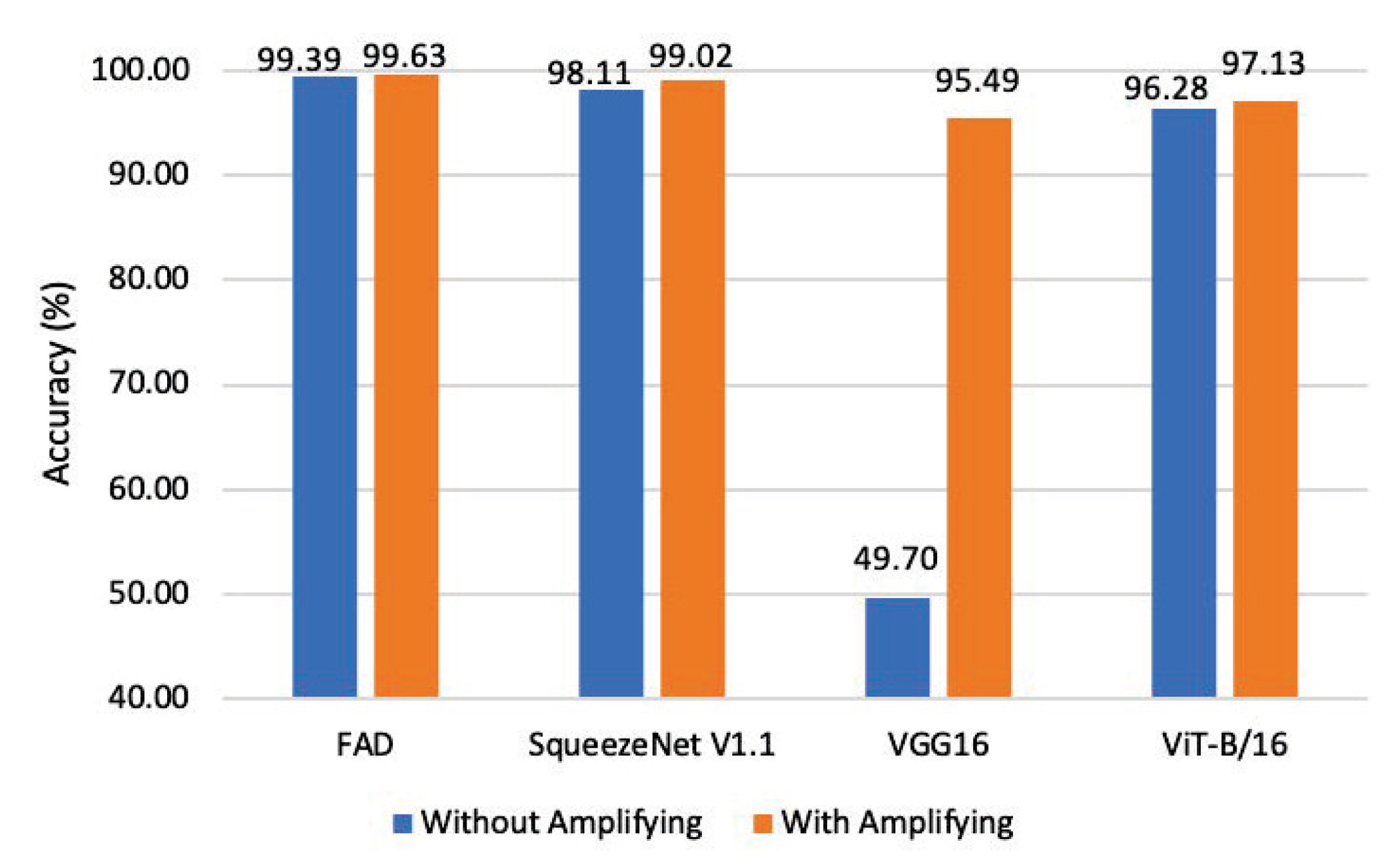
The FAD approach, which amplifies the high-frequency portion of the image, provides cross-model generalization capabilities as well as the ability to detect unseen and various mechanism adversarial attacks.
We empirically demonstrate the feasibility of fine-grained perturbation intensity classification for adversarial examples, providing a detection component for general AI firewalls.
The rest of this paper is organized as follows.
Section 2 presents the existing adversarial attack and defense methods. We describe our proposed method’s workflow and network architecture in
Section 3.
Section 4 describes the experimental details and compares the corresponding experimental results with other state-of-the-art (SOTA) detection methods. Furthermore, ablation studies are performed evaluating each component of the proposed defense. Finally,
Section 5 concludes this work and provides an outlook on future fine-grained adversarial detection research.
5. Conclusions and Discussion
In this work, we efficiently classify adversarial examples of various intensities by augmenting the high-frequency components of the image and feeding the augmented image into our constructed DNN based on the residual block structure. Moreover, the proposed FAD performs well for classifying norm attack examples with varying intensities in a fine-grained manner and can be applied as a detection component of a general AI firewall. Compared to the SOTA adversarial detection method, FAD has superior detection performance and could even be used to detect norm adversarial examples. Furthermore, FAD is extensible, as it can be applied to image classification tasks as well as to other image analysis tasks (e.g., image segmentation) for adversarial sample detection.
At the same time, the FAD method can detect the adversarial examples generated by the unseen attack method and can be generalized to the adversarial examples generated by attacking the unseen model. Existing attack methods for identifying traffic sign classifiers can cause the classifier to incorrectly predict a “Speed Limit 30” sign as a “Speed Limit 80” sign by adding shadows. In this classification task case, the use of our method can potentially reduce the number of rejections of adversarial samples (compared to the current detection methods). In addition, combining our method with defense methods applicable to different intensities has the potential to increase the proportion of correctly identified frames among several consecutive frames, improving the stability and reliability of DNN continuous decision-making. For future studies, we intend to investigate a more accurate distinguishing of different intensities of adversarial examples in the transform domain to obtain a more general fine-grained categorization of adversarial example intensities.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}