

GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation


Abstract
:1. Introduction
- (i)
- The Global Feature Interaction Network (GFI-Net) was designed in which the geometric information of the scene is fully utilized. The use of geometric information helps to construct fine-grained depth maps. In addition, the depth of the plane parallel to the camera is continuous.
- (ii)
- The Global Interactive Attention Mechanism (GIAM) was designed to improve the accuracy of the depth map, guaranteeing the same depth at the same distance from the camera plane. It fully preserves the network’s channel and spatial information, enhances the interaction between the three dimensions of the feature map width, height, and channel, and mitigates information loss.
- (iii)
- Using the Transformer block as an encoder avoids the loss of information from continuous down-sampling and increases the accuracy of depth estimation while improving the perceptual field of the network. The global–local fusion module was designed to efficiently fuse low-level pixel information with high-level semantic information to build a fine-grained depth map and connect a low-complexity decoder.
- (iv)
- The experimental results on the NYU-Depth-v2 and KITTI datasets showed that our network model achieved state-of-the-art performance, achieving depth continuity in planes parallel to the camera and recovering more complete details. Testing in real scenarios demonstrated the network’s good generalization.
2. Related Work
- (i)
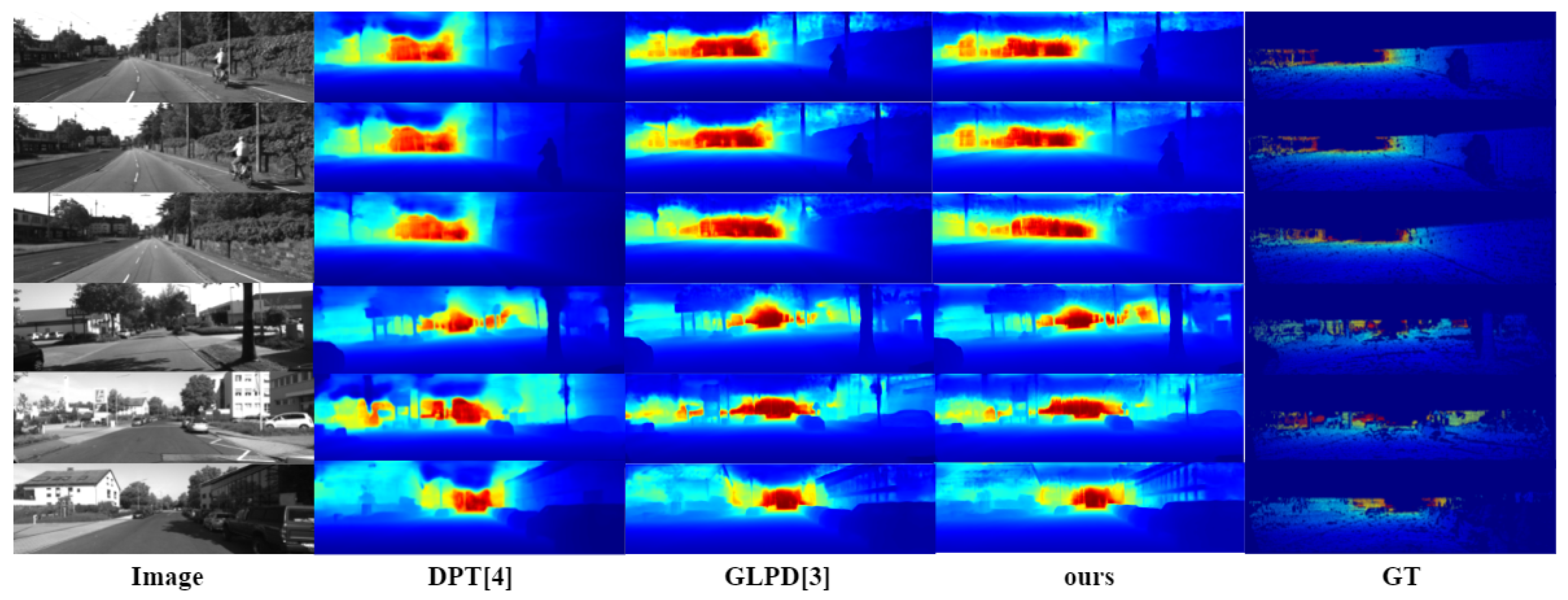
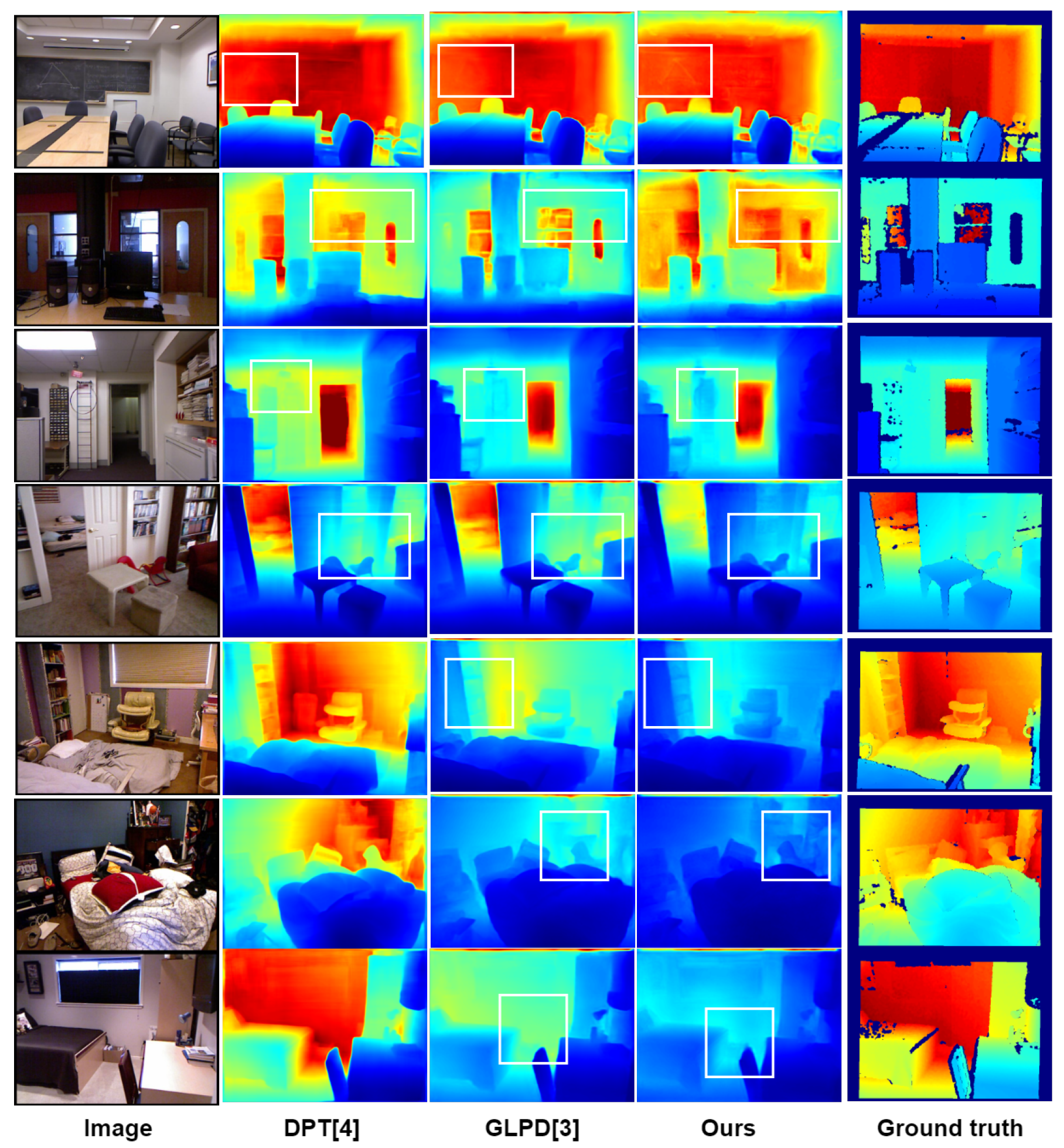
- The encoder in the network greatly compresses the resolution of the image when extracting features from the network input, resulting in inaccurate edge localization by the decoder when recovering the depth map, so many methods are investigating the precise location of depth edges with large variations in the depth map. As in Figure 1 [10], from left to right, the scene images, the true values of the depth values, and the estimation results of the existing network model are shown. In Figure 1 [10], the edges of the sofa in the first row, the edges of the bedside table in the second row, and the items on the dining table in the third row appear to have blurred depth edges, as shown in the white boxes. Therefore, the Transformer block is used as an encoder to reduce information loss and improve the accuracy of the depth map.
- (ii)
- The existing monocular depth estimation algorithm based on depth learning rarely considers the relative change of pixel information, which will lead to the phenomenon of depth discontinuity in the plane parallel to the camera. As in Figure 2 [10], from left to right, the real picture of the scene, the real value of the depth value, and the depth estimation results of existing methods are shown. In the existing estimation results, the same plane parallel to the camera will have depth discontinuity. As shown in the white box in the Figure 2 [10], the wall in the first row, the blackboard on the back wall in the second row, and the wall in the third row all have depth discontinuities. Therefore, the global attention interaction mechanism was designed in the network to capture the interactive information of the width, height, and channel of the feature map. Interactive information can effectively capture the relative position relationship between pixels and solve the problem of discontinuity at the same depth.
3. Methods
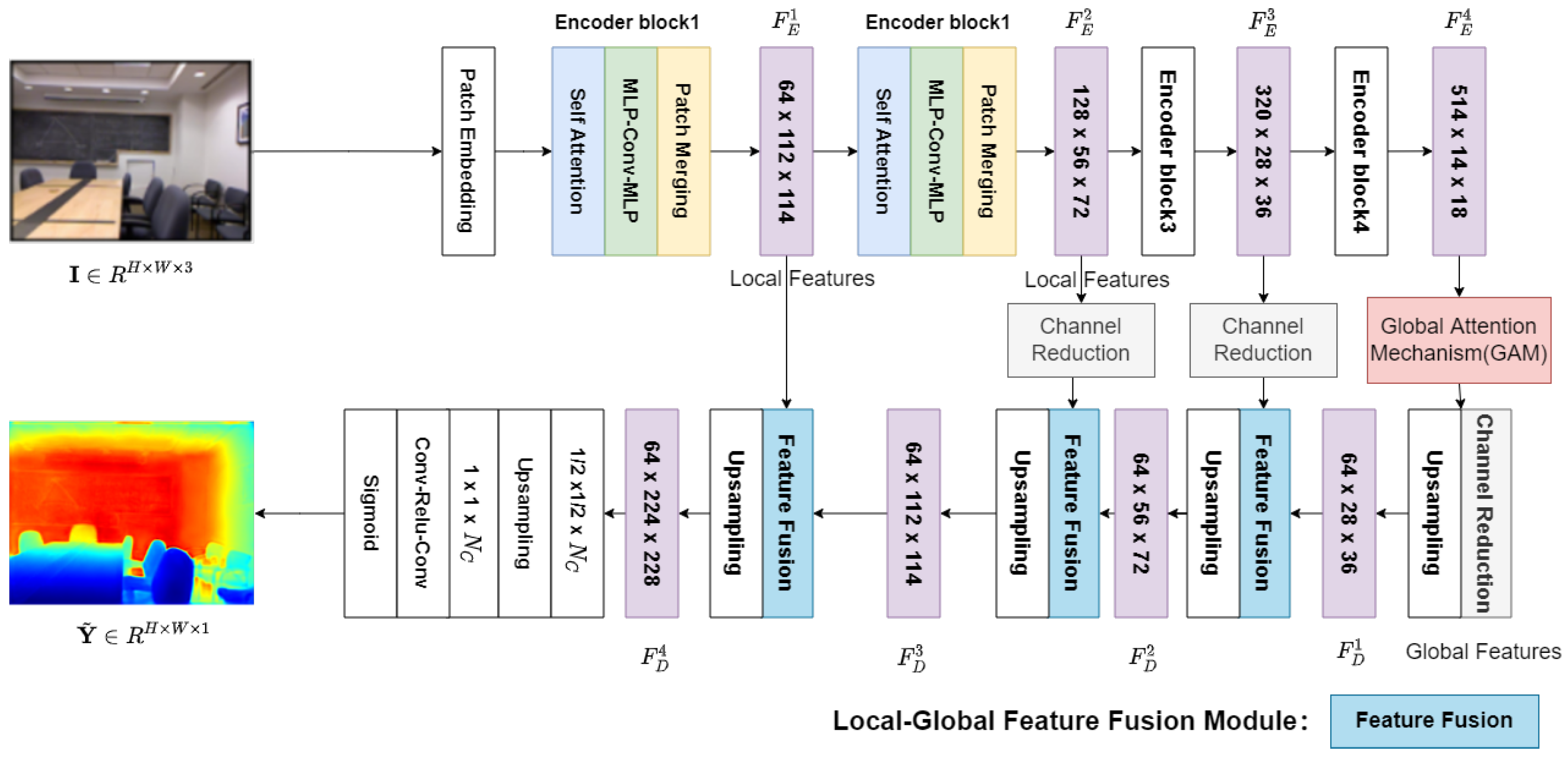
3.1. Global Feature Interaction Network
3.2. Transformer Encoder
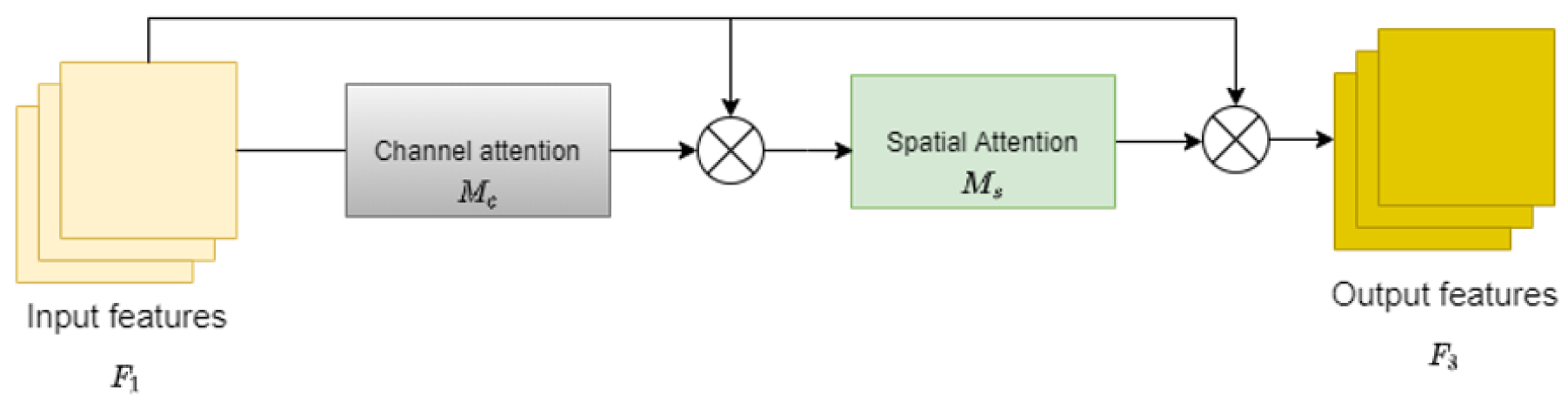
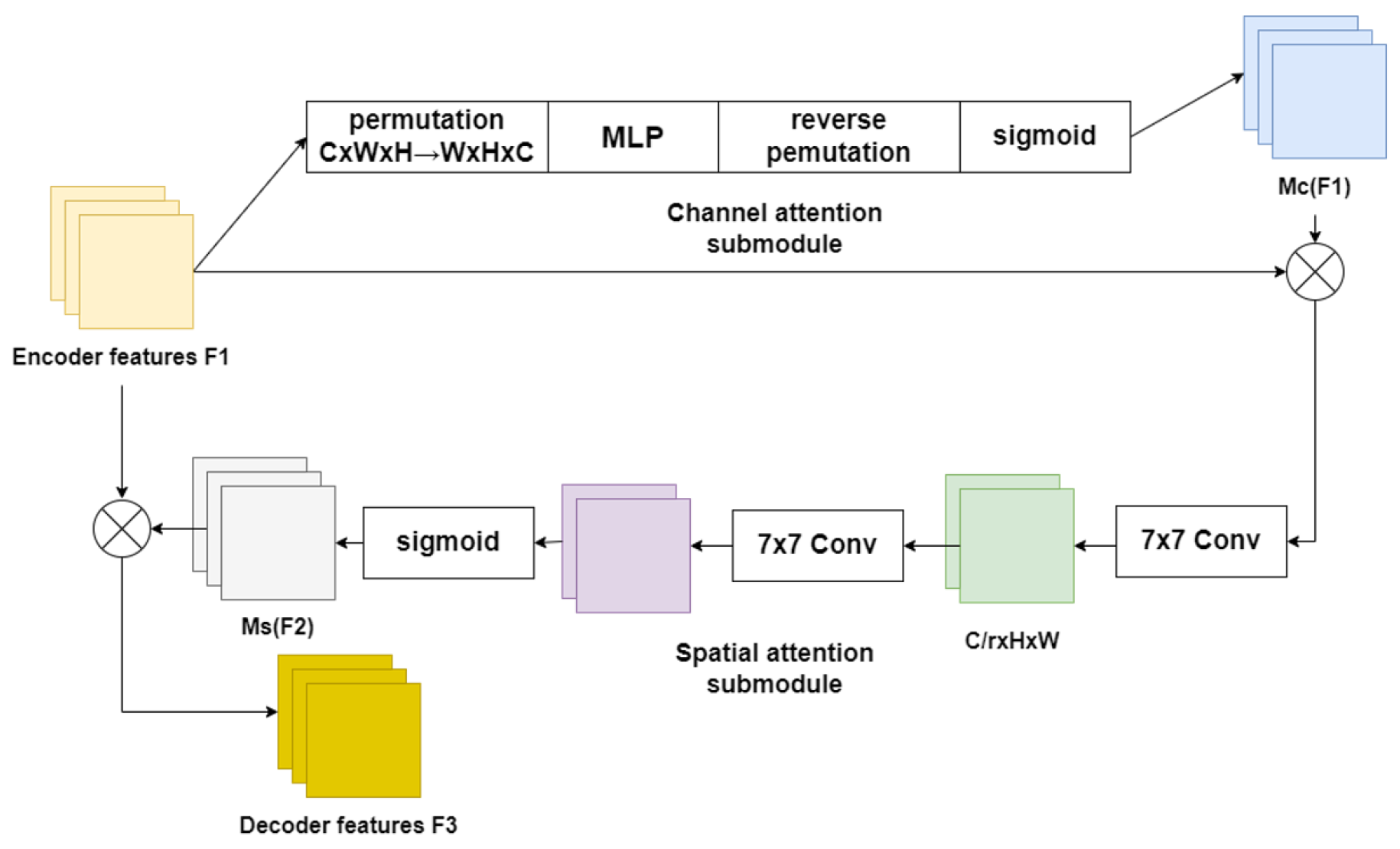
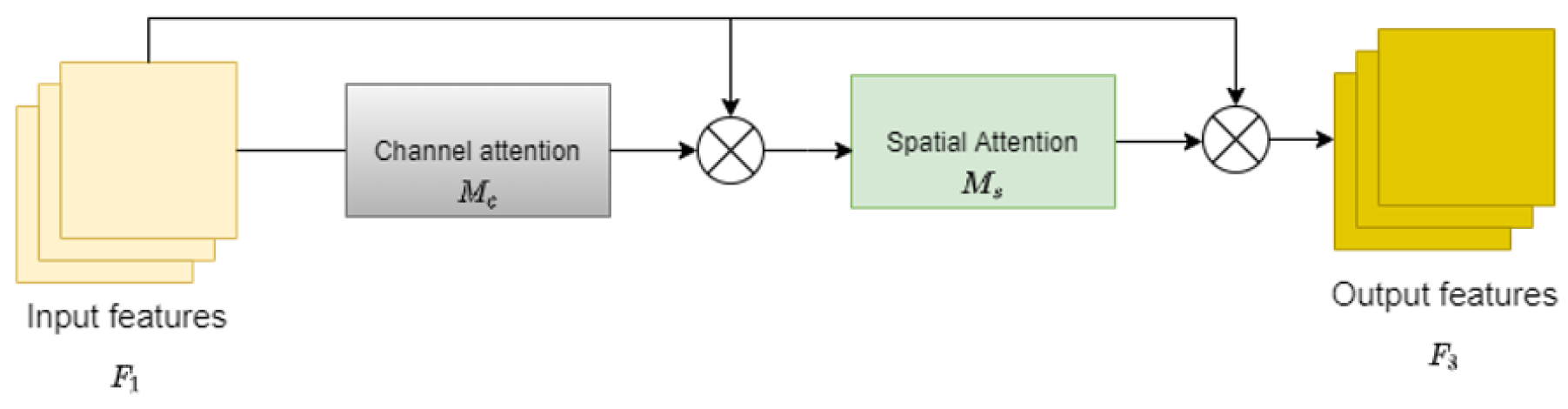
3.3. Global Interaction Attention Mechanism
3.4. Lightweight Decoder
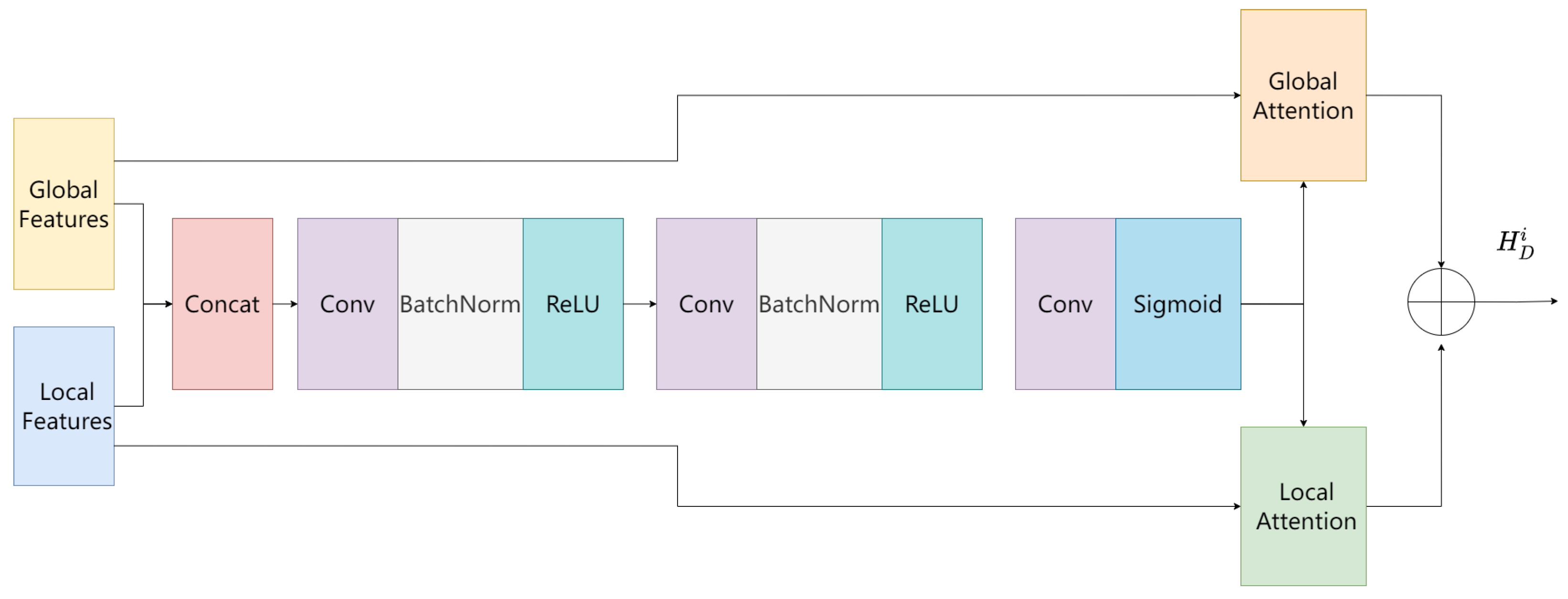
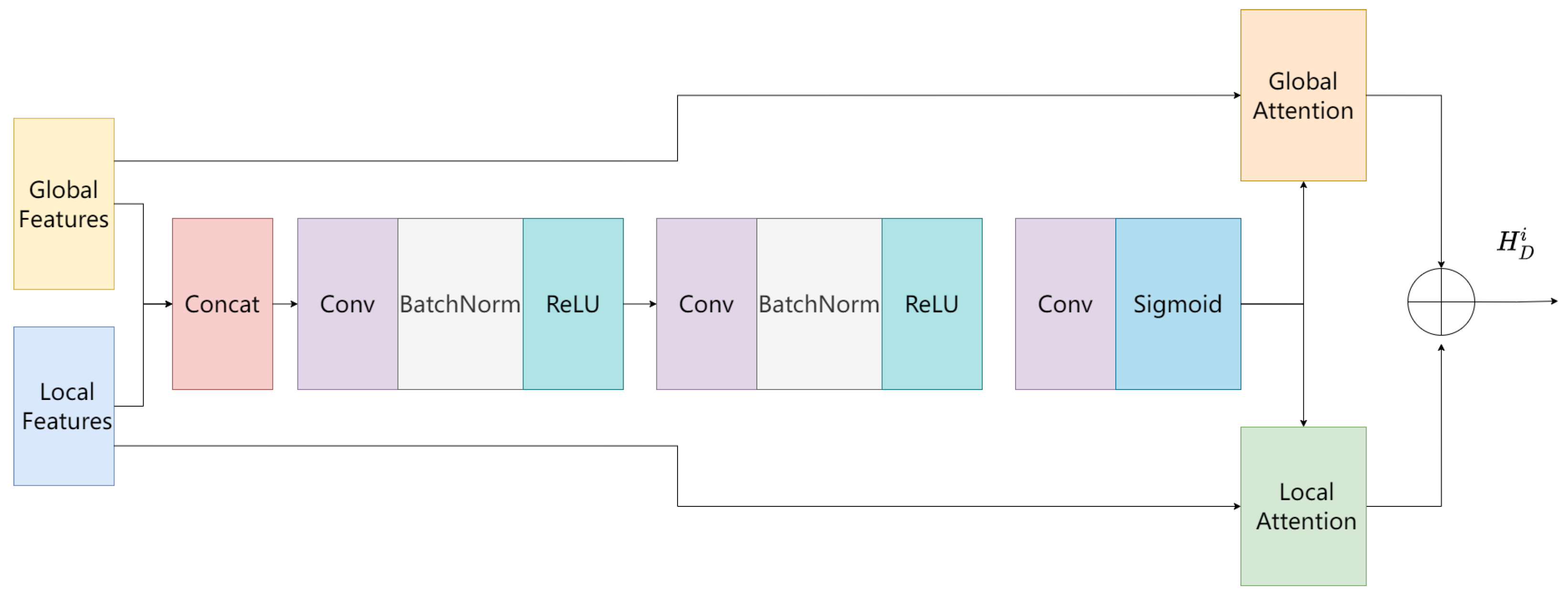
3.5. Local–Global Feature Fusion Module
3.6. Loss Function
4. Experiments
4.1. Dataset
4.2. Implementation Detail
4.3. Comparison with the Latest Methods
4.4. Real Scene Test Results and Analysis
5. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, J.H.; Han, M.K.; Ko, D.W.; Suh, I.H. From big to small: Multi-scale local planar guidance for monocular depth estimation. arXiv 2019, arXiv:1907.10326. [Google Scholar]
- Kim, D.; Lee, S.; Lee, J.; Kim, J. Leveraging contextual information for monocular depth estimation. IEEE Access 2020, 8, 147808–147817. [Google Scholar]
- Kim, D.; Ga, W.; Ahn, P.; Joo, D.; Chun, S.; Kim, J. Global-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth. arXiv 2022, arXiv:2201.07436. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12179–12188. [Google Scholar]
- Bhat, S.F.; Alhashim, I.; Wonka, P. Adabins: Depth estimation using adaptive bins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4009–4018. [Google Scholar]
- Collins, T.; Bartoli, A. Planar structure-from-motion with affine camera models: Closed-form solutions, ambiguities and degeneracy analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1237–1255. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1623–1637. [Google Scholar]
- Ning, J.; Li, C.; Zhang, Z.; Geng, Z.; Dai, Q.; He, K.; Hu, H. All in Tokens: Unifying Output Space of Visual Tasks via Soft Token. arXiv 2023, arXiv:2301.02229. [Google Scholar]
- Fu, H.; Gong, M.; Wang, C.; Batmanghelich, K.; Tao, D. Deep ordinal regression network for monocular depth estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2002–2011. [Google Scholar]
- Agarwal, A.; Arora, C. Attention Attention Everywhere: Monocular Depth Prediction with Skip Attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 5861–5870. [Google Scholar]
- Yin, W.; Liu, Y.; Shen, C.; Yan, Y. Enforcing geometric constraints of virtual normal for depth prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5684–5693. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 783–792. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin, Germany, 2012; pp. 746–760. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Huynh, L.; Nguyen-Ha, P.; Matas, J.; Rahtu, E.; Heikkilä, J. Guiding monocular depth estimation using depth-attention volume. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin, Germany, 2020; pp. 581–597. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params (M) | ||||||
|---|---|---|---|---|---|---|---|
| Eigen [7] | 141 | 0.769 | 0.950 | 0.988 | 0.158 | 0.641 | - |
| Fu [10] | 110 | 0.828 | 0.965 | 0.992 | 0.115 | 0.509 | 0.051 |
| Yin [12] | 114 | 0.875 | 0.976 | 0.994 | 0.108 | 0.416 | 0.048 |
| DAV [24] | 25 | 0.882 | 0.980 | 0.996 | 0.108 | 0.412 | - |
| BTS [1] | 113 | 0.885 | 0.978 | 0.994 | 0.110 | 0.392 | 0.047 |
| AdaBins [5] | 78 | 0.903 | 0.984 | 0.997 | 0.103 | 0.364 | 0.044 |
| DPT [4] | 123 | 0.904 | 0.988 | 0.998 | 0.110 | 0.357 | 0.045 |
| GLPD [3] | 62 | 0.907 | 0.986 | 0.997 | 0.098 | 0.350 | 0.042 |
| Ours | 67 | 0.908 | 0.986 | 0.997 | 0.100 | 0.347 | 0.042 |
| Method | Params (M) | ||||||
|---|---|---|---|---|---|---|---|
| Eigen [7] | 141 | 0.702 | 0.898 | 0.967 | 0.203 | 0.6.307 | 0.282 |
| Fu [10] | 110 | 0.932 | 0.984 | 0.994 | 0.072 | 2.727 | 0.120 |
| Yin [12] | 114 | 0.938 | 0.984 | 0.998 | 0.072 | 3.258 | 0.117 |
| BTS [1] | 113 | 0.956 | 0.993 | 0.998 | 0.059 | 2.756 | 0.088 |
| DPT [4] | 123 | 0.959 | 0.995 | 0.999 | 0.062 | 2.573 | 0.092 |
| AdaBins [5] | 78 | 0.964 | 0.995 | 0.999 | 0.058 | 2.360 | 0.088 |
| GLPD [3] | 62 | 0.963 | 0.995 | 0.999 | 0.059 | 2.322 | 0.089 |
| Ours | 67 | 0.996 | 0.966 | 0.999 | 0.057 | 2.303 | 0.087 |
| Method | ||||||
|---|---|---|---|---|---|---|
| GAM(ch) | 0.904 | 0.985 | 0.996 | 0.103 | 0.352 | 0.043 |
| GAM(sp) | 0.911 | 0.986 | 0.997 | 0.098 | 0.351 | 0.042 |
| GAM | 0.907 | 0.986 | 0.997 | 0.098 | 0.350 | 0.042 |
| GAM(sp+ch) | 0.908 | 0.986 | 0.997 | 0.100 | 0.347 | 0.042 |
| Method | ||||||
|---|---|---|---|---|---|---|
| GAM(ch) | 0.964 | 0.995 | 0.998 | 0.060 | 2.327 | 0.085 |
| GAM(sp) | 0.965 | 0.995 | 0.998 | 0.058 | 2.344 | 0.089 |
| GAM | 0.964 | 0.995 | 0.999 | 0.059 | 2.322 | 0.089 |
| GAM(sp+ch) | 0.966 | 0.996 | 0.999 | 0.057 | 2.303 | 0.087 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Xu, K.; Ma, Y.; Wan, J. GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation. Entropy 2023, 25, 421. https://doi.org/10.3390/e25030421
Zhang C, Xu K, Ma Y, Wan J. GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation. Entropy. 2023; 25(3):421. https://doi.org/10.3390/e25030421
Chicago/Turabian StyleZhang, Cong, Ke Xu, Yanxin Ma, and Jianwei Wan. 2023. "GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation" Entropy 25, no. 3: 421. https://doi.org/10.3390/e25030421
APA StyleZhang, C., Xu, K., Ma, Y., & Wan, J. (2023). GFI-Net: Global Feature Interaction Network for Monocular Depth Estimation. Entropy, 25(3), 421. https://doi.org/10.3390/e25030421