
Papaver somniferum and Papaver rhoeas Classification Based on Visible Capsule Images Using a Modified MobileNetV3-Small Network with Transfer Learning

Abstract
1. Introduction
- A database of 1496 Papaver somniferum capsule images and 1325 Papaver rhoeas capsule images is established;
- The structure of the MobileNetV3 network is improved to reduce the number of parameters and amount of computation, achieving fast, convenient, accurate, and non-destructive identification of PSPR;
- The effectiveness of data expansion and transfer learning for model training is experimentally verified, and the influence of different transfer learning methods on the model is compared;
- The improved MobileNetV3 model combined with transfer learning solves the problem of low classification accuracy and slow model convergence due to the small number of PSPR capsule image samples, and it improves the robustness and classification accuracy of the proposed classification model.
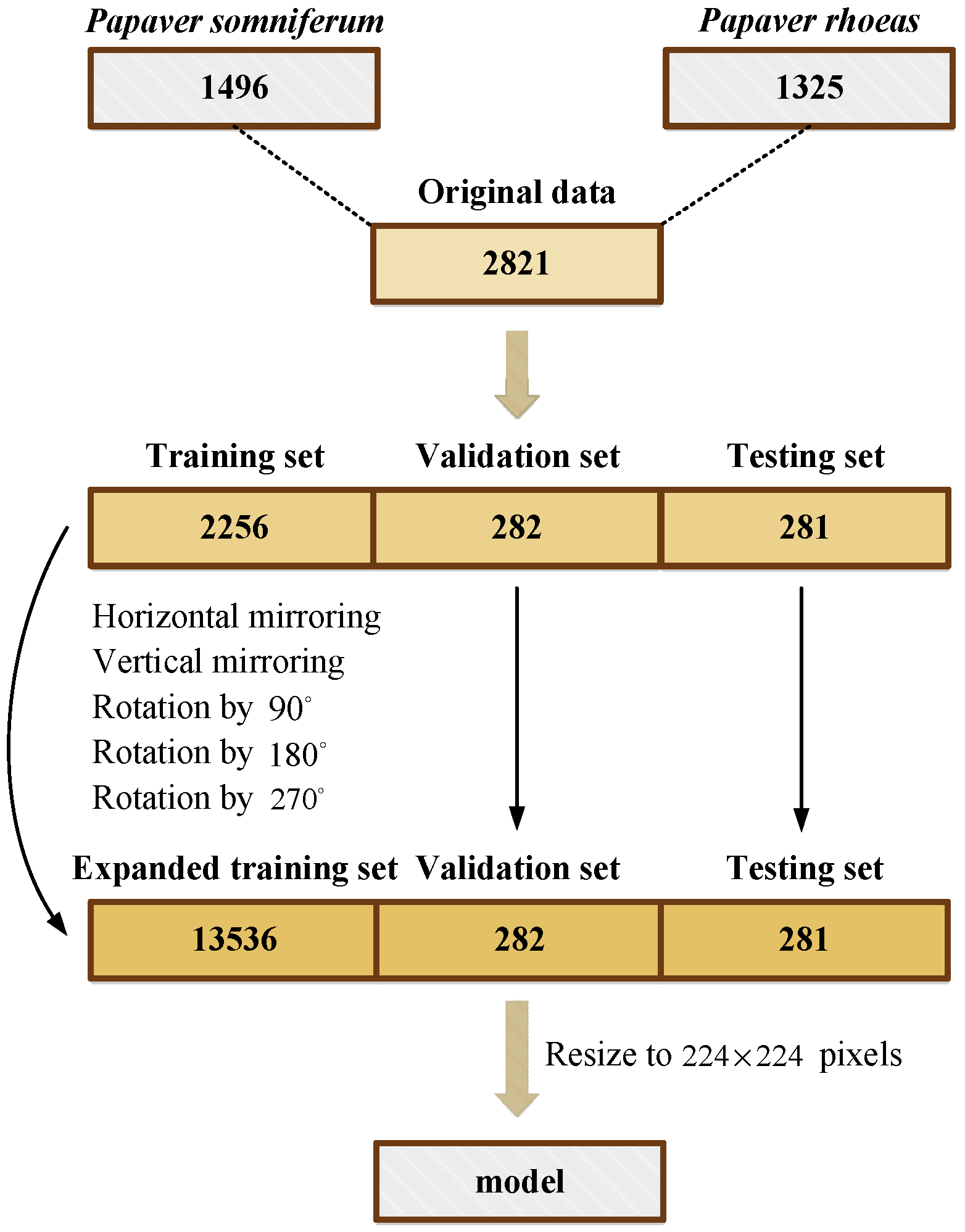
2. Data
- First, the dataset was mixed and scrambled and separated into training, validation, and testing data at a ratio of 8:1:1;
- To improve the model’s feature-extraction and generalization ability and avoid the problems of overfitting and low classification accuracy caused by a small sample dataset, the capsule image training set was expanded using common data expansion methods in deep learning [28], that is, horizontal mirroring, vertical mirroring, and rotation by 90, 180, and 270 degrees, respectively, as shown in Figure 2. As in Figure 1, the capsule images in Figure 2 are resized to a consistent size. The expanded training set includes 7170 Papaver somniferum capsule images and 6366 Papaver rhoeas capsule images;
- Finally, all image sizes were resized to pixels to ensure that the data suited the model’s input size.
3. Methods
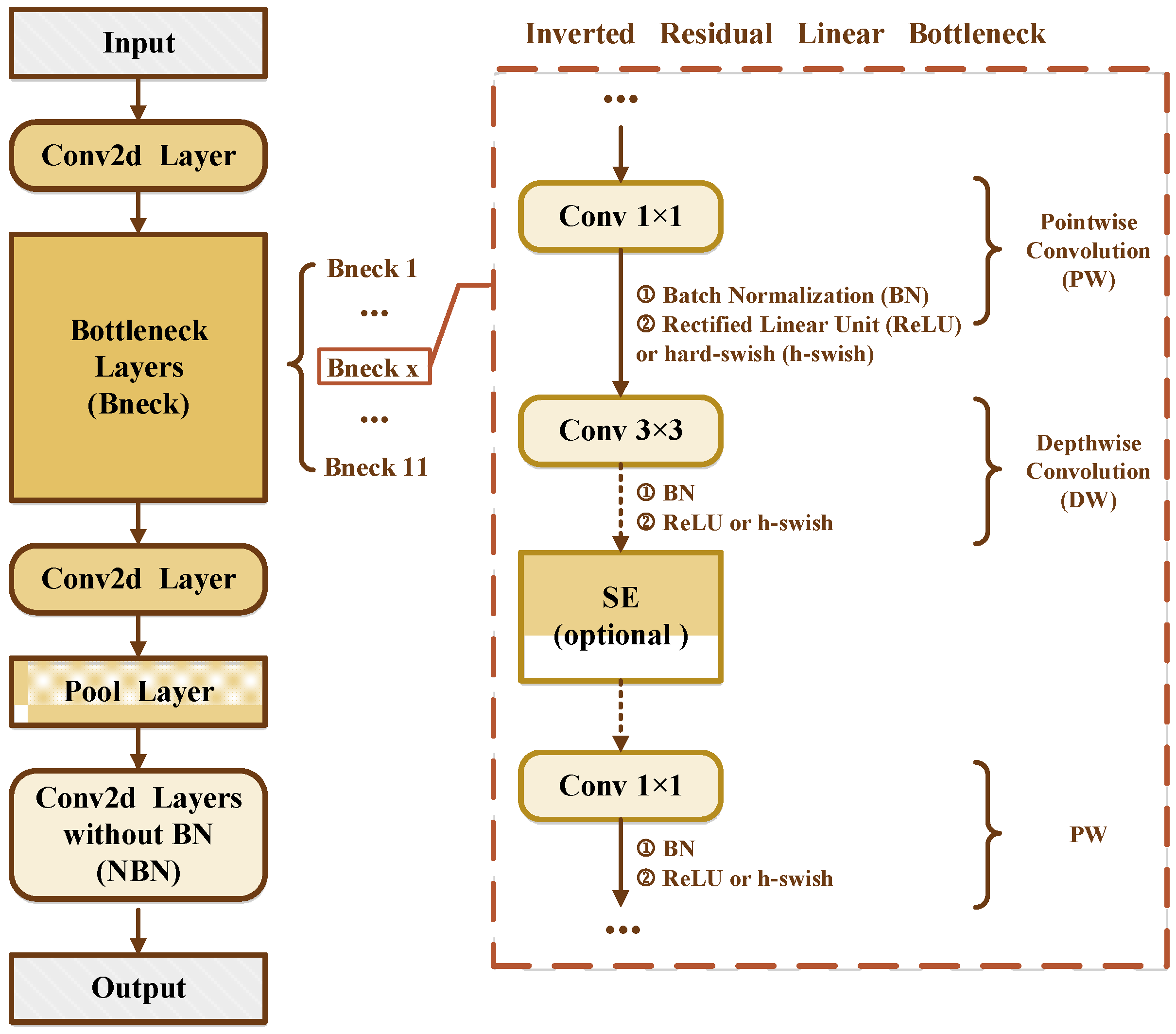
3.1. Basic MobileNetV3-Small
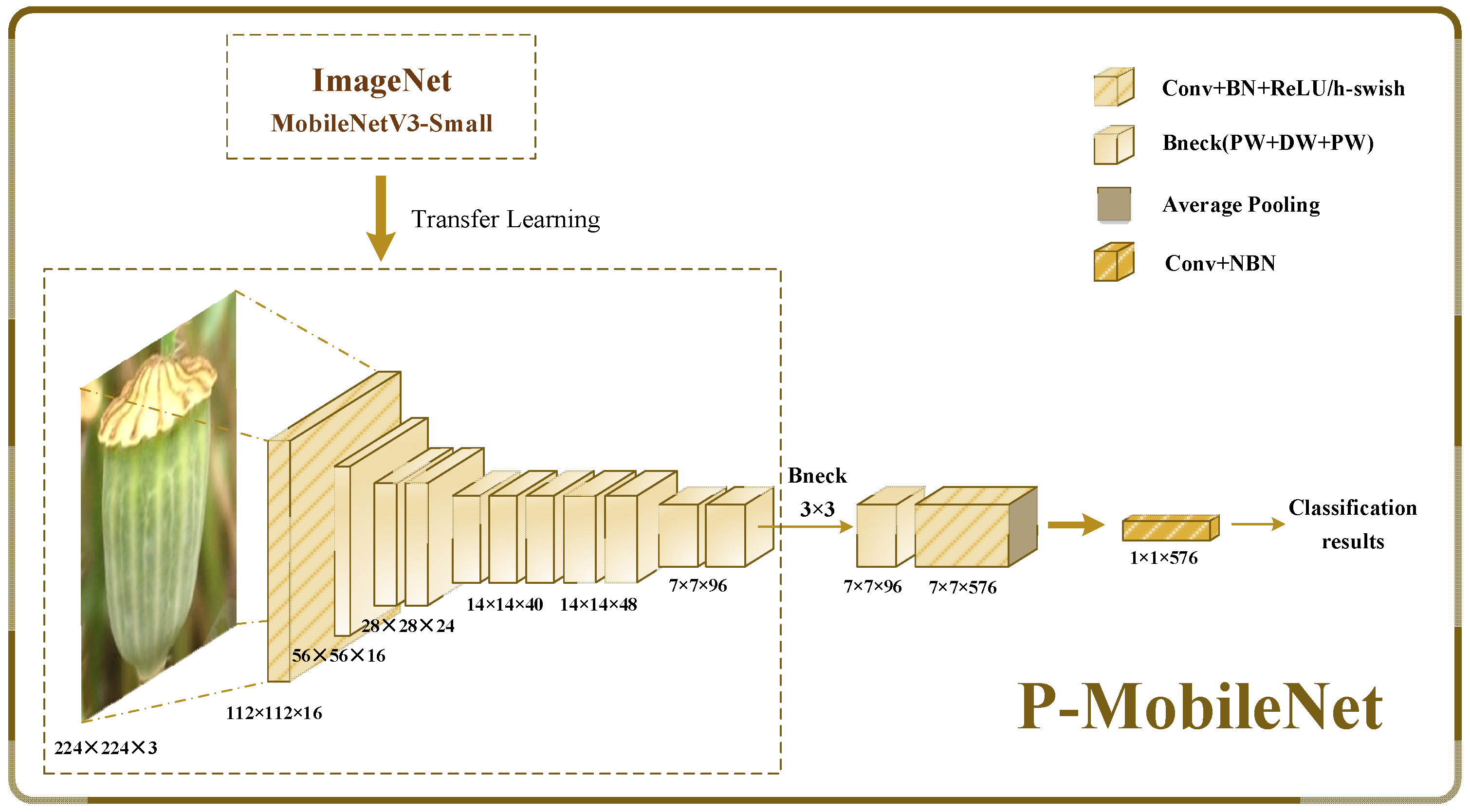
3.2. Construction of Network for Papaver Somniferum Identification
3.2.1. Transfer Learning
3.2.2. Modified MobileNetV3-Small Model
4. Experimental Results and Discussion
4.1. Experimental Environment
4.2. Evaluation Indicators
4.3. Experiments on Influencing Factors of Model Performance
4.3.1. Experimental Design
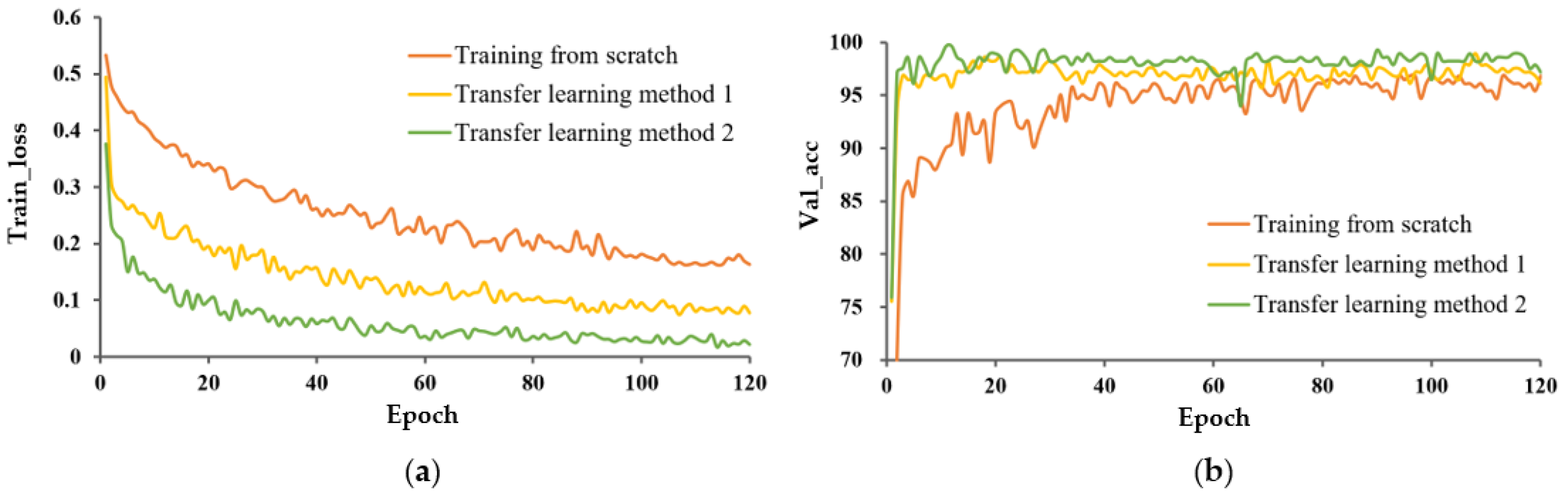
4.3.2. Experimental Results and Analysis
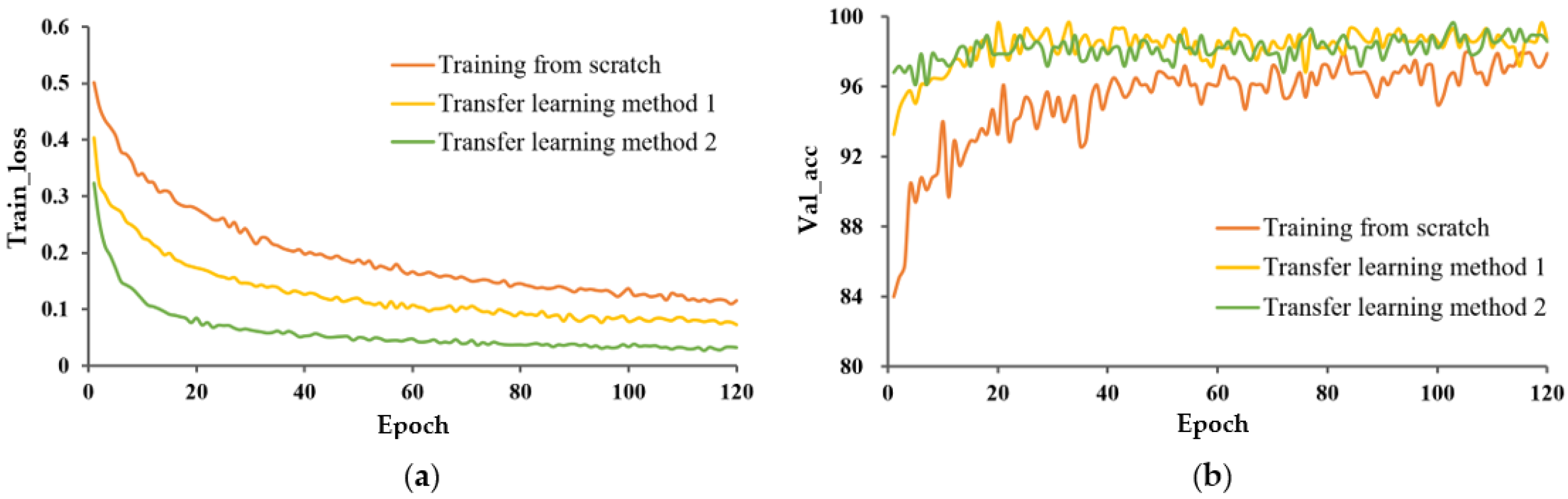
- Influence of different learning methods on model performance.
- 2.
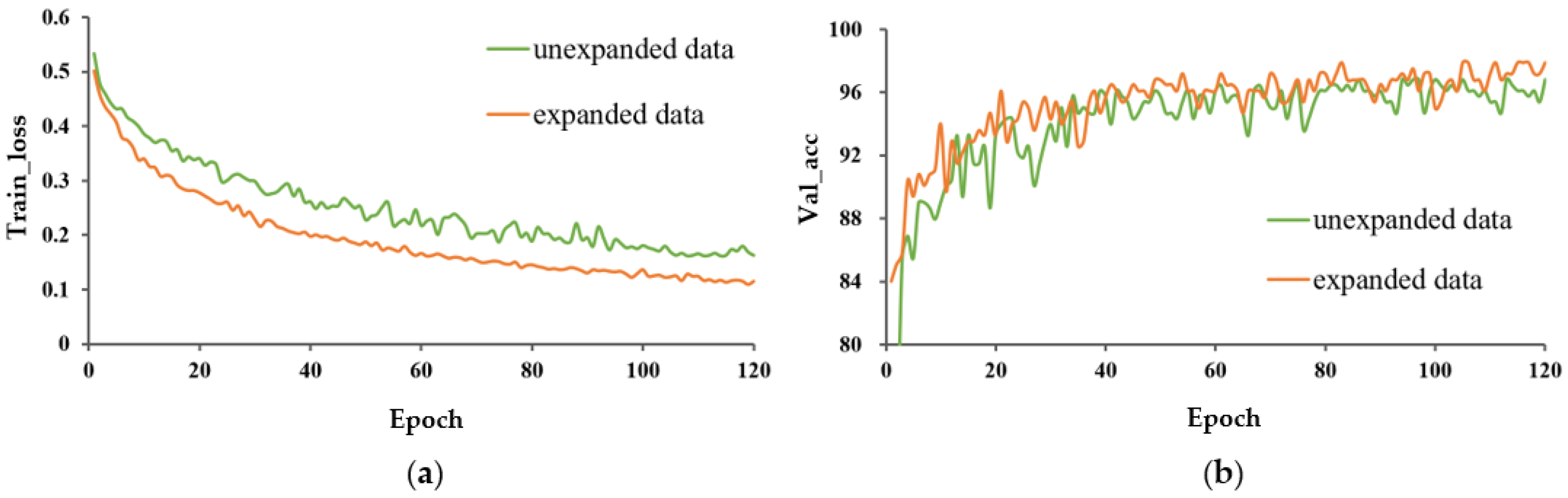
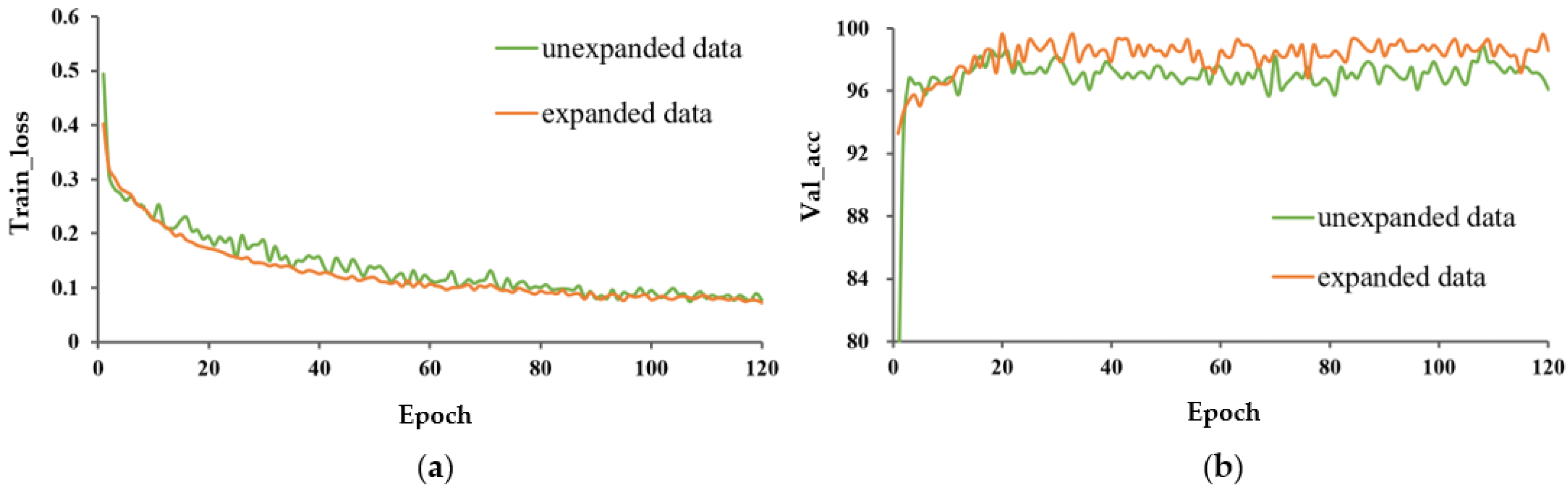
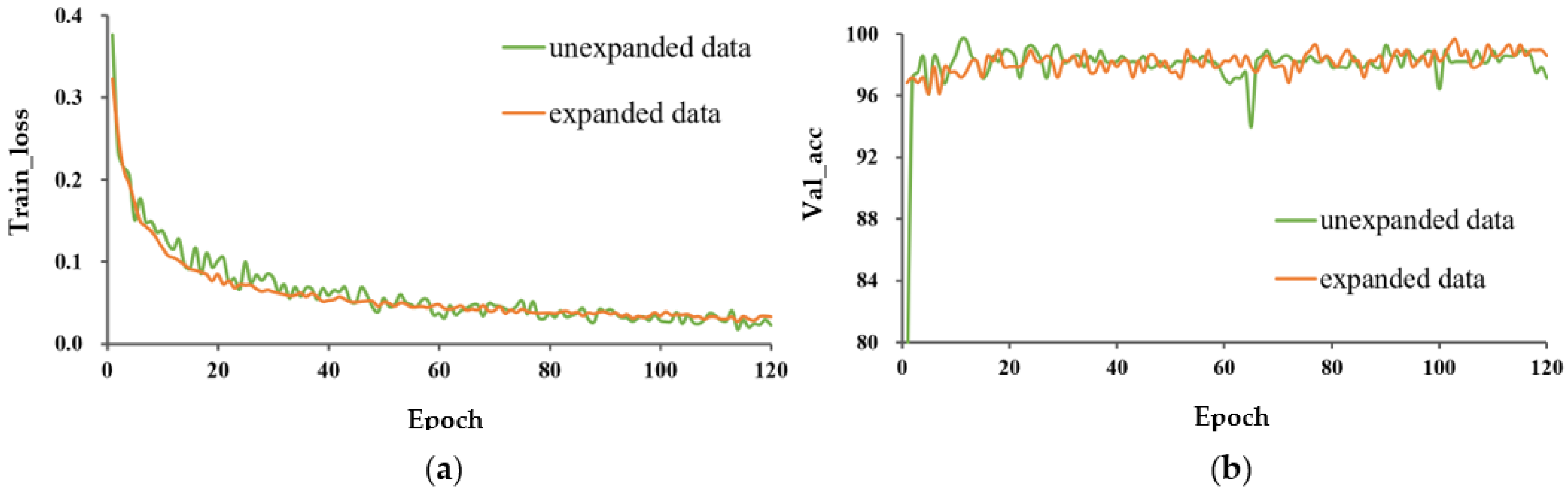
- Effect of data expansion on model performance.
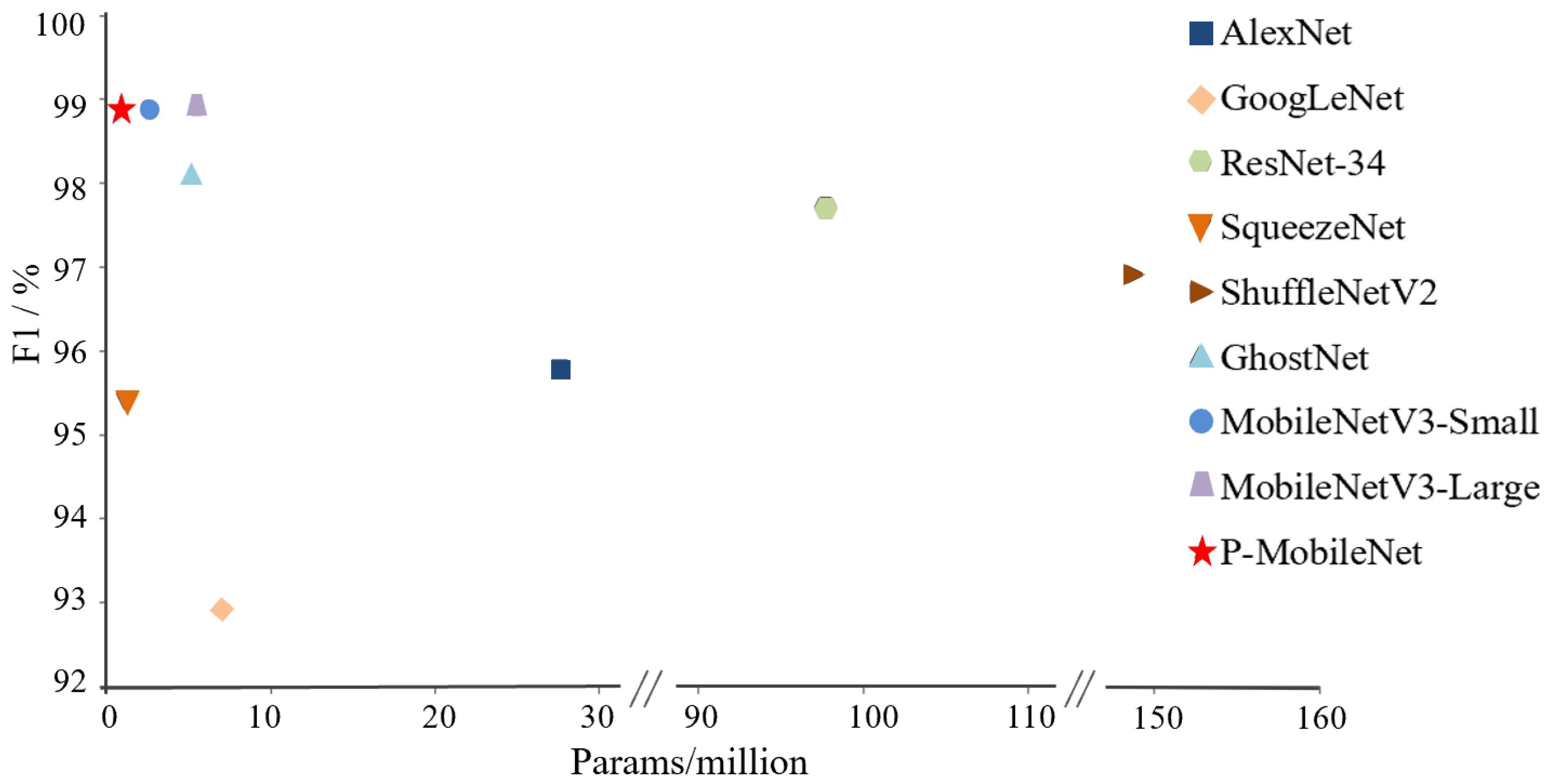
4.4. Comparison of Classification Networks
5. Conclusions
- Compared with training from scratch, transfer learning could fully utilize the knowledge learned on large datasets, significantly accelerated the convergence speed of the model, and improved the classification performance. Regardless of the type of transfer learning method adopted, pre-training and fine-tuning P-MobileNet had a superior impact than that obtained by training P-MobileNet from scratch. The feature extraction ability of the random initialization model was not good enough under a small sample dataset;
- The impact of data expansion on the model trained from scratch was greater than that of the model with transfer learning. Data expansion enriched the diversity of data, which was helpful to mitigate overfitting and improved the classification performance of the model. Although transfer learning weakened the effect of data expansion, a certain amount of training set expansion was necessary to improve the robustness of the model;
- Analysis of the classification performance of different models showed that the proposed P-MobileNet model has the advantages of high classification accuracy, a few parameters, and a fast detection speed. Compared with MobileNetV3-Small, P-MobileNet maintains a high classification accuracy of 98.9%, with only 36% of the parameters of the MobileNetV3-Small model; the FLOPs are reduced by 2 M; and the detection speed is improved to 45.7 ms/image. This study provides a means to achieve the rapid, accurate, and non-destructive identification of PSPR on mobile terminals.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, C.-J.; Cheng, C.-G. Identification of Papaver Somniferum L. and Papaver Rhoeas Using DSWT-FTIR-RBFNN. Spectrosc. Spect. Anal. 2009, 29, 1255–1259. [Google Scholar]
- Choe, S.; Kim, S.; Lee, C.; Yang, W.; Park, Y.; Choi, H.; Chung, H.; Lee, D.; Hwang, B.Y. Species identification of Papaver by metabolite profiling. Forensic Sci. Int. 2011, 211, 51–60. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Qin, L.-A.; Jing, X.; He, F.; Tan, F.-F.; Hou, Z.-H. Research of identification of papaver based on spectral analysis. Chin. J. Quantum Electron 2019, 36, 151–155. (In Chinese) [Google Scholar]
- Li, Y.-Y. Construction and Application of a Fluorescent Complex Amplification System for Three Poppy SSR Motifs. Master’s Thesis, Hebei Medical University, Shijiazhuang, Hebei, 2016. (In Chinese). [Google Scholar]
- Liu, X.; Tian, Y.; Yuan, C.; Zhang, F.; Yang, G. Opium poppy detection using deep learning. Remote Sens. 2018, 10, 1886. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Q.; Wu, H.; Zhao, C.; Teng, G.; Li, J. Low-altitude remote sensing opium poppy image detection based on modified yolov3. Remote Sens. 2021, 13, 2130. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Wei, J.; Liu, A.-J.; Tang, J.-W. Research on alarm model of digital TV monitoring platform based on deep learning neural network technology. Cable Telev. Technol. 2017, 24, 78–82. (In Chinese) [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM. 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yang, Z.-Z.; Kuang, N.; Fan, L.; Kang, B. A Review of Image Classification Algorithms Based on Convolutional Neural Networks. J. Signal Process. 2018, 34, 1474–1489. (In Chinese) [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hao, L.; Weigen, Q.; Lichen, Z. Improved ShuffleNet V2 for Lightweight Crop Disease Identification. Comput. Eng. Appl. 2022, 58, 260–268. [Google Scholar]
- Zhang, X.; Zou, J.; He, K.; Sun, J. Accelerating very deep convolutional networks for classification and detection. ITPAM 2015, 38, 1943–1955. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 116–131. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018, arXiv:1801.04381. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar]
- Han, K.; Wang, Y.H.; Tian, Q.; Guo, J.Y.; Xu, C.J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Cui, Y.; Xia, J.; Wang, Z.; Gao, S.; Wang, L. Lightweight Spectral–Spatial Attention Network for Hyperspectral Image Classification. ITGRS 2022, 60, 1. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, J.; Chen, L.; Jiao, H. Garbage classification system based on improved shufflenet v2. Resour. Conserv. Recycl. 2022, 178, 106090. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, Z.; Zhu, J.; Shen, Z.; Sun, L. A Classification Algorithm of Grain Crop Image Based on Improved SqueezeNet Model. In Proceedings of the 2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), Greenville, SC, USA, 12–14 November 2021; pp. 246–252. [Google Scholar]
- Wei, B.; Shen, X.; Yuan, Y. Remote sensing scene classification based on improved Ghostnet. In Proceedings of the International Conference on Computer Science and Communication. The Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; p. 01209. [Google Scholar]
- Yang, H.-Y.; Xiao, X.-M.; Huang, Q.; Zheng, G.-L.; Yi, W.-L. Rice Pest Identification Based on Convolutional Neural Network and Transfer Learning. Laser Optoelectron. Prog. 2022, 59, 1615004. (In Chinese) [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Bataa, E.; Wu, J. An investigation of transfer learning-based sentiment analysis in Japanese. arXiv 2019, arXiv:1905.09642. [Google Scholar]
- Kumar, S.; Janet, B. DTMIC: Deep transfer learning for malware image classification. J. Inf. Secur. Appl. 2022, 64, 103063. [Google Scholar] [CrossRef]
- Lu, X.; Sun, X.; Diao, W.; Feng, Y.; Wang, P.; Fu, K. LIL: Lightweight incremental learning approach through feature transfer for remote sensing image scene classification. ITGRS 2021, 60, 1–20. [Google Scholar] [CrossRef]
- Peng, L.; Liang, H.; Li, T.; Sun, J. Rethink Transfer Learning in Medical Image Classification. arXiv 2021, arXiv:2106.05152. [Google Scholar]
- Pan, W.; Liu, M.; Ming, Z. Transfer learning for heterogeneous one-class collaborative filtering. IEEE Intell. Syst. 2016, 31, 43–49. [Google Scholar] [CrossRef]
- Cai, W.; Zheng, J.; Pan, W.; Lin, J.; Li, L.; Chen, L.; Peng, X.; Ming, Z. Neighborhood-enhanced transfer learning for one-class collaborative filtering. Neurocomputing 2019, 341, 80–87. [Google Scholar] [CrossRef]
- Chen, X.; Pan, W.; Ming, Z. Adaptive Transfer Learning for Heterogeneous One-Class Collaborative Filtering. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Zhuo, H.H.; Yang, Q. Action-model acquisition for planning via transfer learning. Artif. Intell. 2014, 212, 80–103. [Google Scholar] [CrossRef]
- Yu, L.; Shao, X.; Wei, Y.; Zhou, K. Intelligent land-vehicle model transfer trajectory planning method based on deep reinforcement learning. Sensors 2018, 18, 2905. [Google Scholar] [CrossRef]
- Zoph, B.A.L.; Quoc, V. Neural Architecture Search with Reinforcement Learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. NetAdapt: Platform-Aware Neural Network Adaptation for Mobile Applications. arXiv 2018, arXiv:1804.03230. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Gan, J.; Qi, L.; Qin, C.; He, G. Lightweight fingerprint classification model combined with transfer learning. J. Image Graph. 2019, 24, 1086–1095. [Google Scholar]
- Wang, M.; Zhuang, Z.; Wang, K.; Zhou, S.; Liu, Z. Intelligent classification of ground-based visible cloud images using a transfer convolutional neural network and fine-tuning. OExpr 2021, 29, 41176–41190. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Penatti, O.A.B.; Nogueira, K.; Santos, J.A.D. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition, Eric, P.X., Tony, J., Eds. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Azizpour, H.; Sharif Razavian, A.; Sullivan, J.; Maki, A.; Carlsson, S. From generic to specific deep representations for visual recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 36–45. [Google Scholar]
- Yu, X.; Kang, C.; Guttery, D.S.; Kadry, S.; Chen, Y.; Zhang, Y.D. ResNet-SCDA-50 for Breast Abnormality Classification. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 94–102. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | Exp Size | Out | SE | NL | S |
|---|---|---|---|---|---|---|
| Conv2d, | - | 16 | - | HS | 2 | |
| Bneck, | 16 | 16 | √ | RE | 2 | |
| Bneck, | 72 | 24 | - | RE | 2 | |
| Bneck, | 88 | 24 | - | RE | 1 | |
| Bneck, | 96 | 40 | √ | HS | 2 | |
| Bneck, | 240 | 40 | √ | HS | 1 | |
| Bneck, | 240 | 40 | √ | HS | 1 | |
| Bneck, | 120 | 48 | √ | HS | 1 | |
| Bneck, | 144 | 48 | √ | HS | 1 | |
| Bneck, | 288 | 96 | √ | HS | 2 | |
| Bneck, | 576 | 96 | √ | HS | 1 | |
| Bneck, | 576 | 96 | √ | HS | 1 | |
| Conv2d, | - | 576 | √ | HS | 1 | |
| Pool, | - | - | - | - | 1 | |
| Conv2d , NBN | - | 2 | - | - | 1 |
| Learning Method | Data Expansion | Accuracy/% | Precision/% | Recall/% | F1/% | SD of Train_Loss | SD of Val_Acc |
|---|---|---|---|---|---|---|---|
| Training from scratch | × | 95.0 | 94.7 | 94.7 | 94.7 | 0.083 | 5.430 |
| √ | 96.4 | 97.7 | 94.7 | 96.2 | 0.081 | 2.506 | |
| TL_M1 | × | 97.2 | 97.7 | 96.2 | 96.9 | 0.063 | 2.150 |
| √ | 97.9 | 98.5 | 97.0 | 97.7 | 0.059 | 1.035 | |
| TL_M2 | × | 98.6 | 99.2 | 97.7 | 98.5 | 0.050 | 2.076 |
| √ | 98.9 | 99.2 | 98.5 | 98.9 | 0.045 | 0.647 |
| Model | Accuracy/% | Precision/% | Recall/% | F1/% | Params/Million (M) | FLOPs/Million (M) | Model Size /MB | Test Time /ms |
|---|---|---|---|---|---|---|---|---|
| AlexNet | 96.1 | 95.5 | 96.2 | 95.8 | 27.6 | 681.2 | 97.4 | 38.6 |
| GoogLeNet | 93.2 | 91.9 | 93.9 | 92.9 | 7.0 | 1624.1 | 39.3 | 54.6 |
| ResNet-34 | 97.9 | 100 | 95.5 | 97.7 | 97.7 | 3759.1 | 81.3 | 88.6 |
| SqueezeNet | 95.7 | 96.2 | 94.7 | 95.4 | 1.2 | 351.9 | 2.8 | 48.6 |
| ShuffleNetV2 | 97.2 | 97.7 | 96.2 | 96.9 | 148.8 | 2.3 | 5.0 | 50.3 |
| GhostNet | 98.2 | 99.2 | 97.0 | 98.1 | 5.2 | 148.8 | 15.1 | 48.6 |
| MobileNetV3-Small | 98.9 | 100 | 97.7 | 98.9 | 2.5 | 59.4 | 5.9 | 47.5 |
| MobileNetV3-Large | 98.9 | 100 | 97.7 | 98.9 | 5.5 | 225.4 | 16.2 | 48.2 |
| P-MobileNet | 98.9 | 99.2 | 98.5 | 98.9 | 0.9 | 57.3 | 3.6 | 45.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Zhang, C.; Zhang, C. Papaver somniferum and Papaver rhoeas Classification Based on Visible Capsule Images Using a Modified MobileNetV3-Small Network with Transfer Learning. Entropy 2023, 25, 447. https://doi.org/10.3390/e25030447
Zhu J, Zhang C, Zhang C. Papaver somniferum and Papaver rhoeas Classification Based on Visible Capsule Images Using a Modified MobileNetV3-Small Network with Transfer Learning. Entropy. 2023; 25(3):447. https://doi.org/10.3390/e25030447
Chicago/Turabian StyleZhu, Jin, Chuanhui Zhang, and Changjiang Zhang. 2023. "Papaver somniferum and Papaver rhoeas Classification Based on Visible Capsule Images Using a Modified MobileNetV3-Small Network with Transfer Learning" Entropy 25, no. 3: 447. https://doi.org/10.3390/e25030447
APA StyleZhu, J., Zhang, C., & Zhang, C. (2023). Papaver somniferum and Papaver rhoeas Classification Based on Visible Capsule Images Using a Modified MobileNetV3-Small Network with Transfer Learning. Entropy, 25(3), 447. https://doi.org/10.3390/e25030447