Figure 1.
The previous methods can be distilled into the schema illustrated in the above figures [
18,
19,
20].
Figure 1.
The previous methods can be distilled into the schema illustrated in the above figures [
18,
19,
20].
Figure 2.
For (a), the text only mentions record breakers, not fish. Adding image description information, the text becomes “a big fish, florida man reported as record breaker for …”. This will bridge the gaps between the text and image. For (b), adding image description information will form conflicting statements with the original text, that is, “a fallen leaf on the ground, roast chicken on the ground.” The conflicting statements will help the model judge fake news.
Figure 2.
For (a), the text only mentions record breakers, not fish. Adding image description information, the text becomes “a big fish, florida man reported as record breaker for …”. This will bridge the gaps between the text and image. For (b), adding image description information will form conflicting statements with the original text, that is, “a fallen leaf on the ground, roast chicken on the ground.” The conflicting statements will help the model judge fake news.
Figure 3.
For (a), through caption information, we can conclude that the content of the text and image match. For (b), through caption information, we can conclude that the content of the text and image do not match. For (c), through caption information, we can conclude that the image originated from a screenshot, which is a false image.
Figure 3.
For (a), through caption information, we can conclude that the content of the text and image match. For (b), through caption information, we can conclude that the content of the text and image do not match. For (c), through caption information, we can conclude that the image originated from a screenshot, which is a false image.
Figure 4.
For (a), adding caption information will bridge the gaps between the text and image. For (b), The irony can be seen through the caption and the content in the text. For (c), through caption, our model can be inferred that the corresponding news is a story about fools. For (d), through caption, our model can be inferred that the text is generated by bot. For (e), through caption, our model can be inferred that the image in this news do not accurately support their text descriptions. For (f), through caption, our model can be inferred that the content has been purposely manipulated through manual editing or other forms. of alteration.
Figure 4.
For (a), adding caption information will bridge the gaps between the text and image. For (b), The irony can be seen through the caption and the content in the text. For (c), through caption, our model can be inferred that the corresponding news is a story about fools. For (d), through caption, our model can be inferred that the text is generated by bot. For (e), through caption, our model can be inferred that the image in this news do not accurately support their text descriptions. For (f), through caption, our model can be inferred that the content has been purposely manipulated through manual editing or other forms. of alteration.
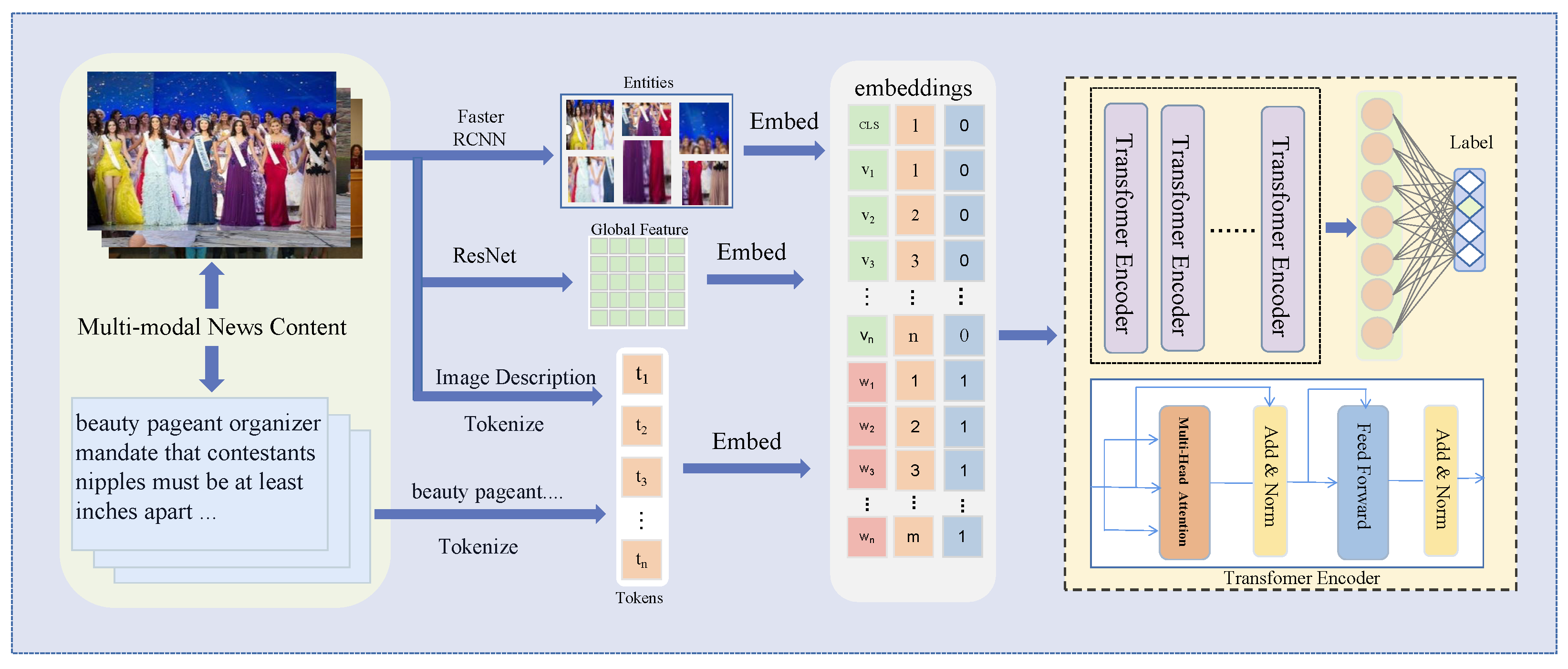
Figure 5.
We utilize the ResNet and Faster R-CNN to extract global and entity features from images and BERT’s tokenizer to encode the text and image caption, which are then concatenated to form the final embedding. This embedding is subsequently fed into a multi-modal transformer for classification.
Figure 5.
We utilize the ResNet and Faster R-CNN to extract global and entity features from images and BERT’s tokenizer to encode the text and image caption, which are then concatenated to form the final embedding. This embedding is subsequently fed into a multi-modal transformer for classification.
Figure 6.
For the examples of multi-modal news entities, we randomly sampled 4 real news and 4 fake news from the Fakedit dataset, respectively. For each instance, the top of the image is its label information, and the bottom is the text information. (b,c,e,h) represent real news. (a,d,f,g) represent fake news.
Figure 6.
For the examples of multi-modal news entities, we randomly sampled 4 real news and 4 fake news from the Fakedit dataset, respectively. For each instance, the top of the image is its label information, and the bottom is the text information. (b,c,e,h) represent real news. (a,d,f,g) represent fake news.
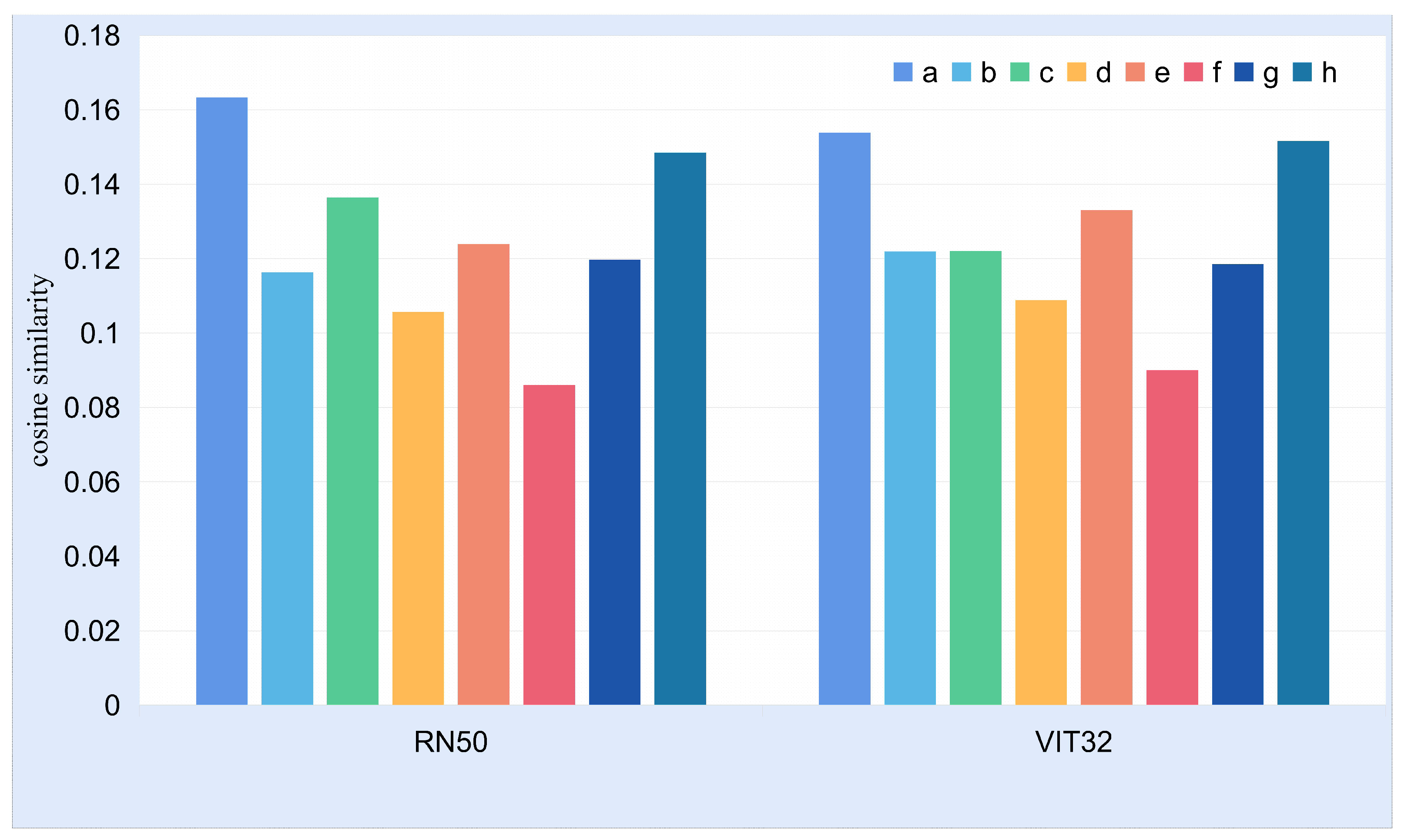
Figure 7.
This figure shows the cross-modal similarity between the text and the image in
Figure 6. RN50 means that the image encoding used in CLIP is RN50, and VIT32 means that ViT-B/32 is used as the encoder.
Figure 7.
This figure shows the cross-modal similarity between the text and the image in
Figure 6. RN50 means that the image encoding used in CLIP is RN50, and VIT32 means that ViT-B/32 is used as the encoder.
Figure 8.
The impact of introducing the image caption on the prediction results of the model. The blue results indicate the prediction results after the introduction of the image caption. Introducing image caption information can enhance the confidence of the results for subgraphs (a,b), whereas for subgraph (c), the predicted result is rectified upon the inclusion of image caption information.
Figure 8.
The impact of introducing the image caption on the prediction results of the model. The blue results indicate the prediction results after the introduction of the image caption. Introducing image caption information can enhance the confidence of the results for subgraphs (a,b), whereas for subgraph (c), the predicted result is rectified upon the inclusion of image caption information.
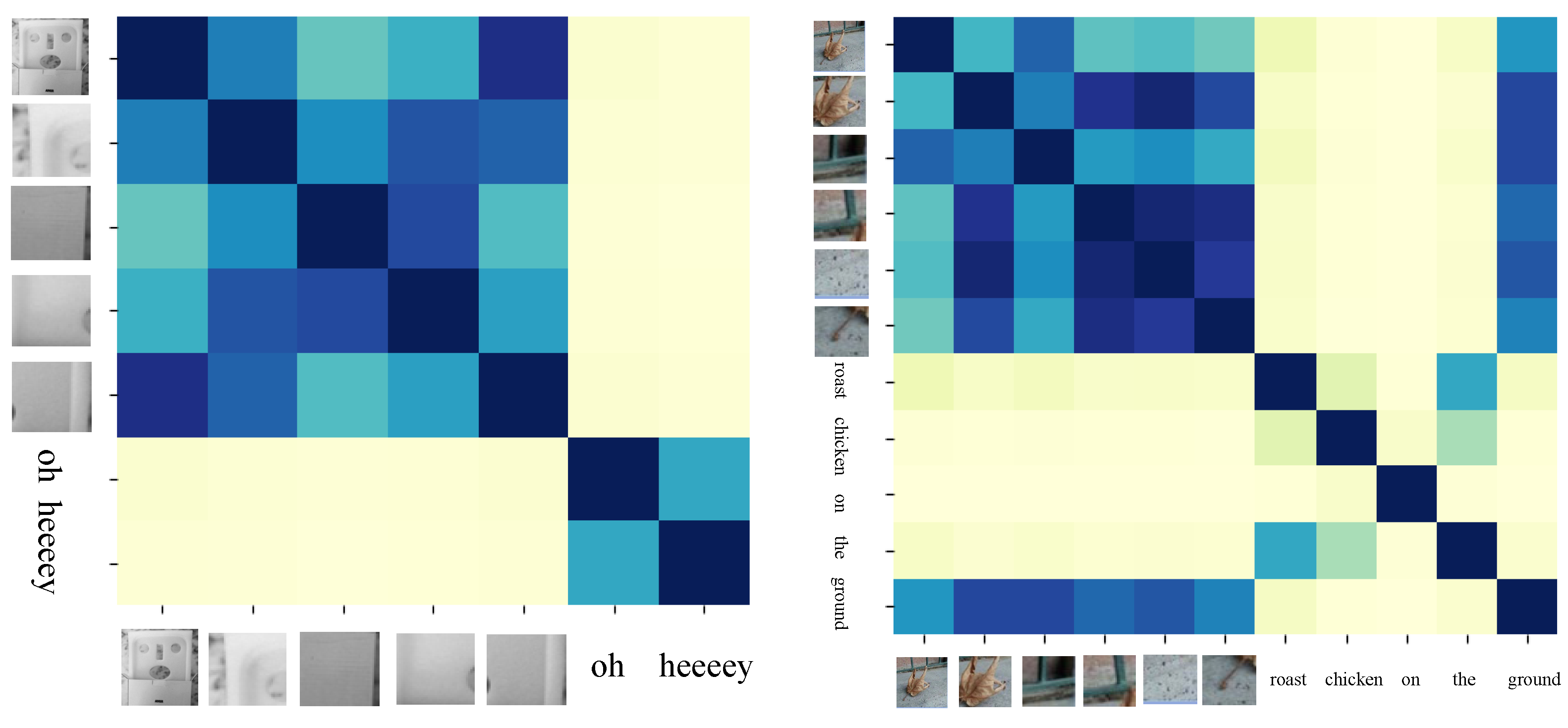
Figure 9.
The text and image information in the left image are almost unrelated. However, in the image on the right, the word “ground” has a strong correlation with the small local regions corresponding to the image containing ground.
Figure 9.
The text and image information in the left image are almost unrelated. However, in the image on the right, the word “ground” has a strong correlation with the small local regions corresponding to the image containing ground.
Table 1.
Details of Fakeddit and Weibo datasets. R and F mean real and fake, respectively.
Table 1.
Details of Fakeddit and Weibo datasets. R and F mean real and fake, respectively.
| Dataset | Train (No.) | Validate (No.) | Test (No.) | Label | R:F |
|---|
| Fakeddit | 563,523 | 59,283 | 59,257 | 2/3/6 | 2:3 |
| Weibo | 7183 | - | 1840 | 2 | 1:1 |
Table 2.
Comparative results on the Fakeddit. Bold text in the table indicates the best results.
Table 2.
Comparative results on the Fakeddit. Bold text in the table indicates the best results.
| Method | 2-Class | 3-Class | 6-Class |
|---|
| Acc | P | R | F1 | Acc | Acc |
|---|
| Single-modal | Naive Bayes | 0.7933 | 0.8139 | 0.8522 | 0.8326 | 0.7750 | 0.6469 |
| BERT | 0.8788 | 0.9147 | 0.8814 | 0.8977 | 0.8731 | 0.8070 |
| ResNet | 0.7534 | 0.8032 | 0.7832 | 0.7911 | 0.7442 | 0.6936 |
| Multi-modal | EANN | 0.8750 | 0.9043 | 0.8811 | 0.8926 | 0.8702 | 0.8319 |
| MVAE | 0.8875 | 0.9011 | 0.9139 | 0.9074 | 0.8838 | 0.8413 |
| BERT and ResNet | 0.8942 | 0.9124 | 0.9122 | 0.9123 | 0.8926 | 0.8502 |
| MMBT | 0.9111 | 0.9274 | 0.9251 | 0.9263 | 0.9058 | 0.8830 |
| MTTV | 0.9188 | 0.9348 | 0.9303 | 0.9325 | 0.9162 | 0.8982 |
| Our | 0.9251 | 0.9383 | 0.9374 | 0.9379 | 0.9221 | 0.9057 |
Table 3.
Comparative results on the Weibo. Bold text in the table indicates the best results.
Table 3.
Comparative results on the Weibo. Bold text in the table indicates the best results.
| Method | Acc | P | R | F1 |
|---|
| Single-modal | Naive Bayes | 0.7130 | 0.6685 | 0.8213 | 0.7371 |
| BERT | 0.8538 | 0.8427 | 0.8624 | 0.8524 |
| ResNet | 0.6451 | 0.6483 | 0.6016 | 0.6241 |
| Multi-modal | EANN | 0.7950 | 0.8060 | 0.7950 | 0.8000 |
| MVAE | 0.8240 | 0.8540 | 0.7690 | 0.8090 |
| BERT and ResNet | 0.8603 | 0.9055 | 0.7980 | 0.8484 |
| MMBT | 0.8658 | 0.8733 | 0.8491 | 0.8610 |
| MTTV | 0.8766 | 0.8616 | 0.8912 | 0.8762 |
| Our | 0.8886 | 0.8692 | 0.9201 | 0.8939 |
Table 4.
The effectiveness of image caption on a single-modal on Fakeddit datasets. IC means image caption information. Bold text in the table indicates the best results.
Table 4.
The effectiveness of image caption on a single-modal on Fakeddit datasets. IC means image caption information. Bold text in the table indicates the best results.
| Modal | 2-Class | 3-Class | 6-Class |
|---|
| Acc | P | R | F1 | Acc | Acc |
|---|
| Text | 0.8788 | 0.9147 | 0.8814 | 0.8977 | 0.8731 | 0.8070 |
| Text w/ IC | 0.8940 | 0.9141 | 0.9099 | 0.9120 | 0.8881 | 0.8134 |
| Image | 0.7534 | 0.8032 | 0.7832 | 0.7911 | 0.7442 | 0.6936 |
| Image w/ IC | 0.8103 | 0.8626 | 0.8154 | 0.8384 | 0.8016 | 0.7600 |
Table 5.
The effectiveness of image caption on a single-modal on Weibo datasets. IC means image caption information. Bold text in the table indicates the best results.
Table 5.
The effectiveness of image caption on a single-modal on Weibo datasets. IC means image caption information. Bold text in the table indicates the best results.
| Modal | Acc | P | R | F1 |
|---|
| Text | 0.8538 | 0.8427 | 0.8624 | 0.8524 |
| Text w/ IC | 0.8571 | 0.8603 | 0.8594 | 0.8598 |
| Image | 0.6451 | 0.6483 | 0.6016 | 0.6241 |
| Image w/ IC | 0.6565 | 0.6574 | 0.6826 | 0.6698 |
Table 6.
Ablation results on Weibo. GF, EF and IC represent global features, entity features, and image caption information, respectively. Bold text in the table indicates the best results.
Table 6.
Ablation results on Weibo. GF, EF and IC represent global features, entity features, and image caption information, respectively. Bold text in the table indicates the best results.
| Configuration | Acc | P | R | F1 |
|---|
| Remove GF | 0.8815 | 0.8523 | 0.9286 | 0.8896 |
| Remove EF | 0.8820 | 0.8525 | 0.9297 | 0.8894 |
| Remove IC | 0.8766 | 0.8429 | 0.9318 | 0.8889 |
| Our | 0.8886 | 0.8692 | 0.9201 | 0.8939 |
Table 7.
Ablation results on Fakeddit. GF, EF and IC represent global features, entity features, and image caption information, respectively. Bold text in the table indicates the best results.
Table 7.
Ablation results on Fakeddit. GF, EF and IC represent global features, entity features, and image caption information, respectively. Bold text in the table indicates the best results.
| Configuration | 2-Class | 3-Class | 6-Class |
|---|
| Acc | P | R | F1 | Acc | Acc |
|---|
| Remove GF | 0.9205 | 0.9221 | 0.9482 | 0.9350 | 0.9202 | 0.9018 |
| Remove EF | 0.9211 | 0.9305 | 0.9394 | 0.9349 | 0.9206 | 0.9031 |
| Remove IC | 0.9139 | 0.9212 | 0.9374 | 0.9293 | 0.9169 | 0.8913 |
| Our | 0.9251 | 0.9383 | 0.9374 | 0.9379 | 0.9221 | 0.9057 |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}