

CGA-MGAN: Metric GAN Based on Convolution-Augmented Gated Attention for Speech Enhancement


Abstract
:1. Introduction
- We construct an encoder–decoder structure including gating blocks using the decoupling-style phase-aware method that can collaboratively estimate the magnitude and phase information of clean speech in parallel and avoid the compensation effect between magnitude and phase;
- We propose a convolution-augmented gated attention unit that can capture time and frequency dependence with lower computational complexity and achieve better results than the conformer;
- The proposed approach is superior to the previous approaches on the Voice Bank + DEMAND dataset [28], and an ablation experiment has verified our design choice.
2. Related Works
2.1. MetricGAN
- Input noisy speech, , into the generator to generate enhanced speech, ;
- Input a clean–clean speech pair, , into the discriminator to calculate the output, , and calculate through the objective evaluation function;
- Input an enhanced–clean speech pair, , into the discriminator to calculate the output, , and calculate through the objective evaluation function;
- Calculate the loss function of the generator and the discriminator and update the weights of both networks.
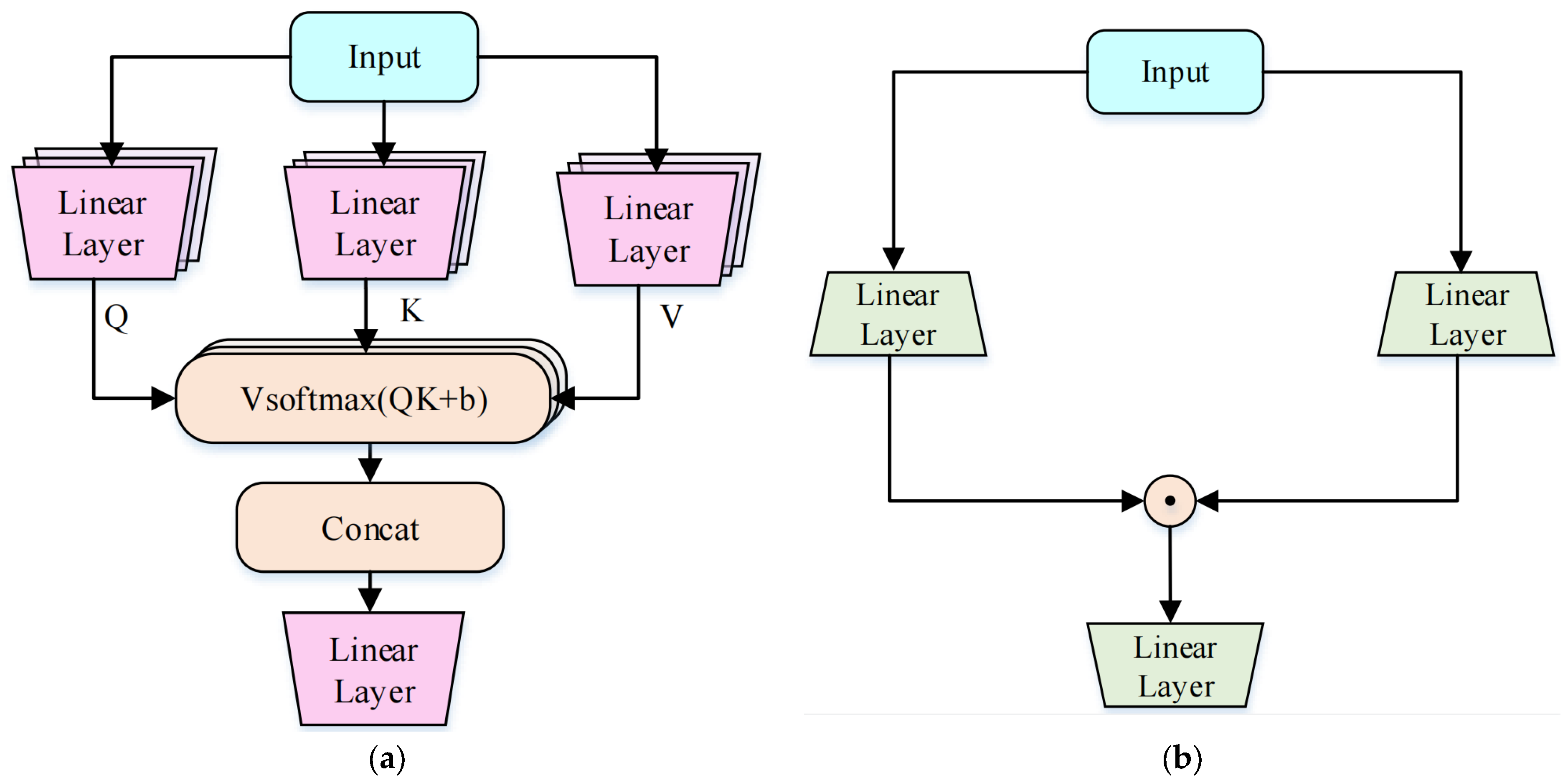
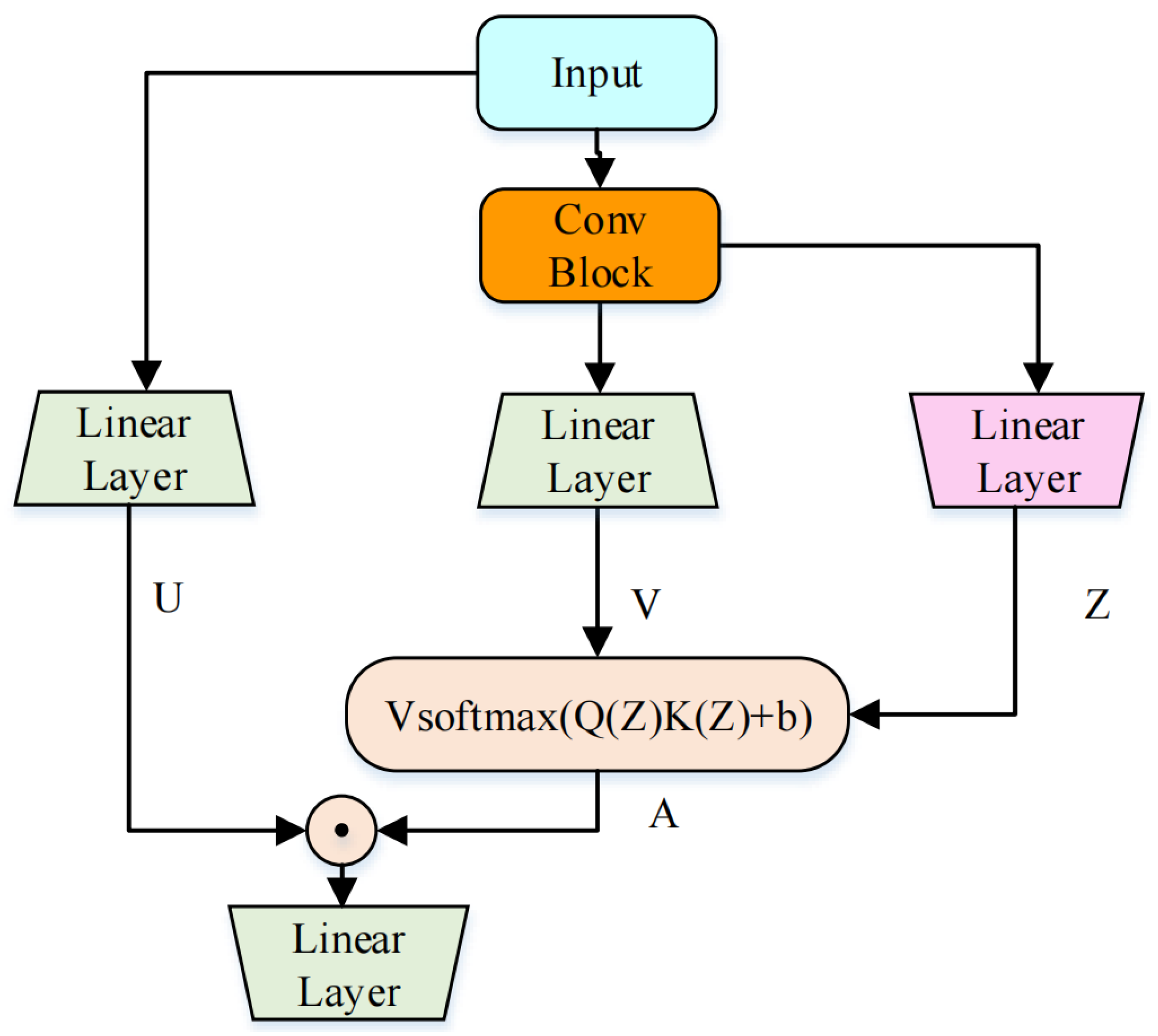
2.2. Gated Attention Unit
2.3. Conformer
2.4. Limitations and Our Approach
3. Methodology
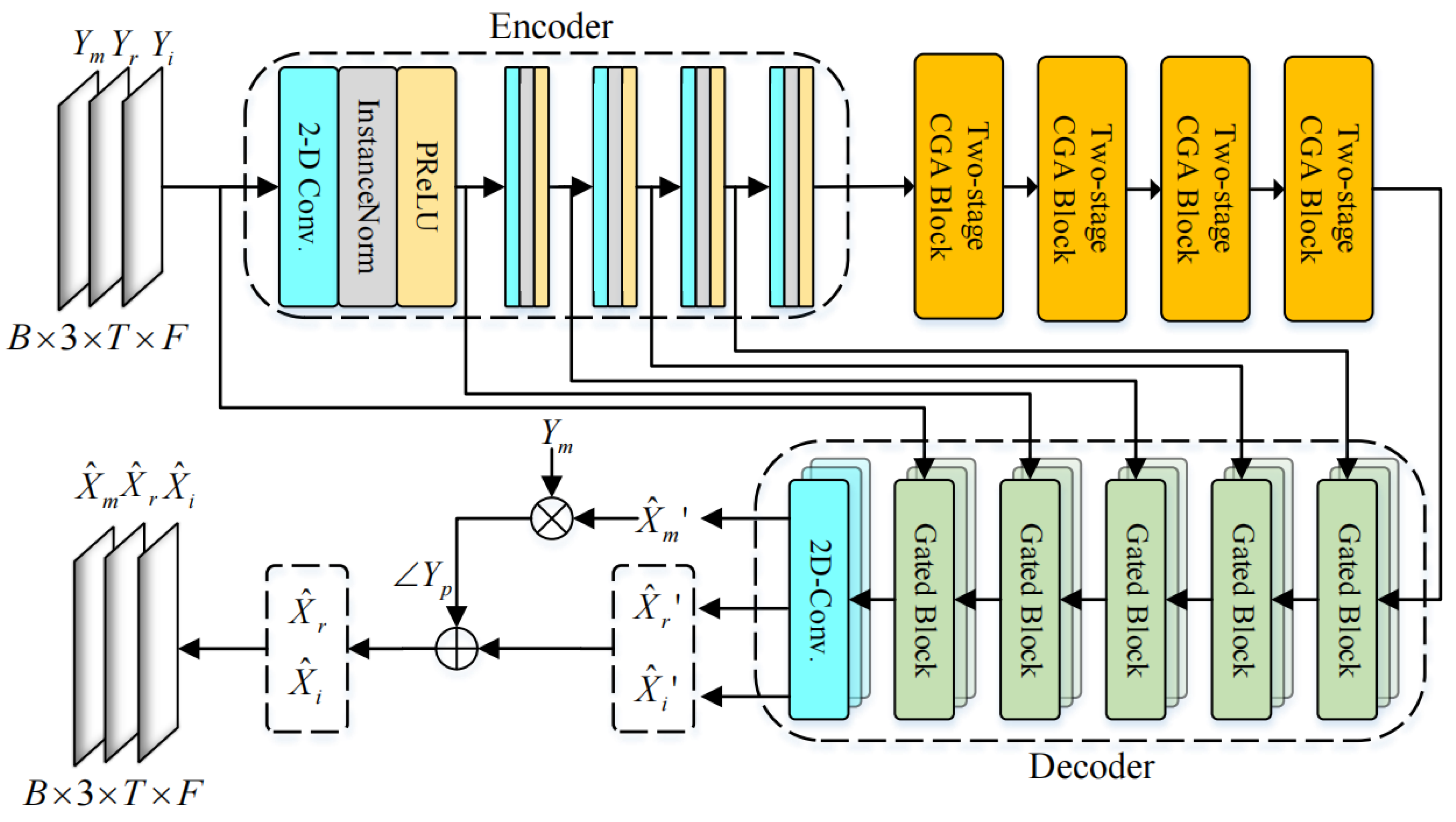
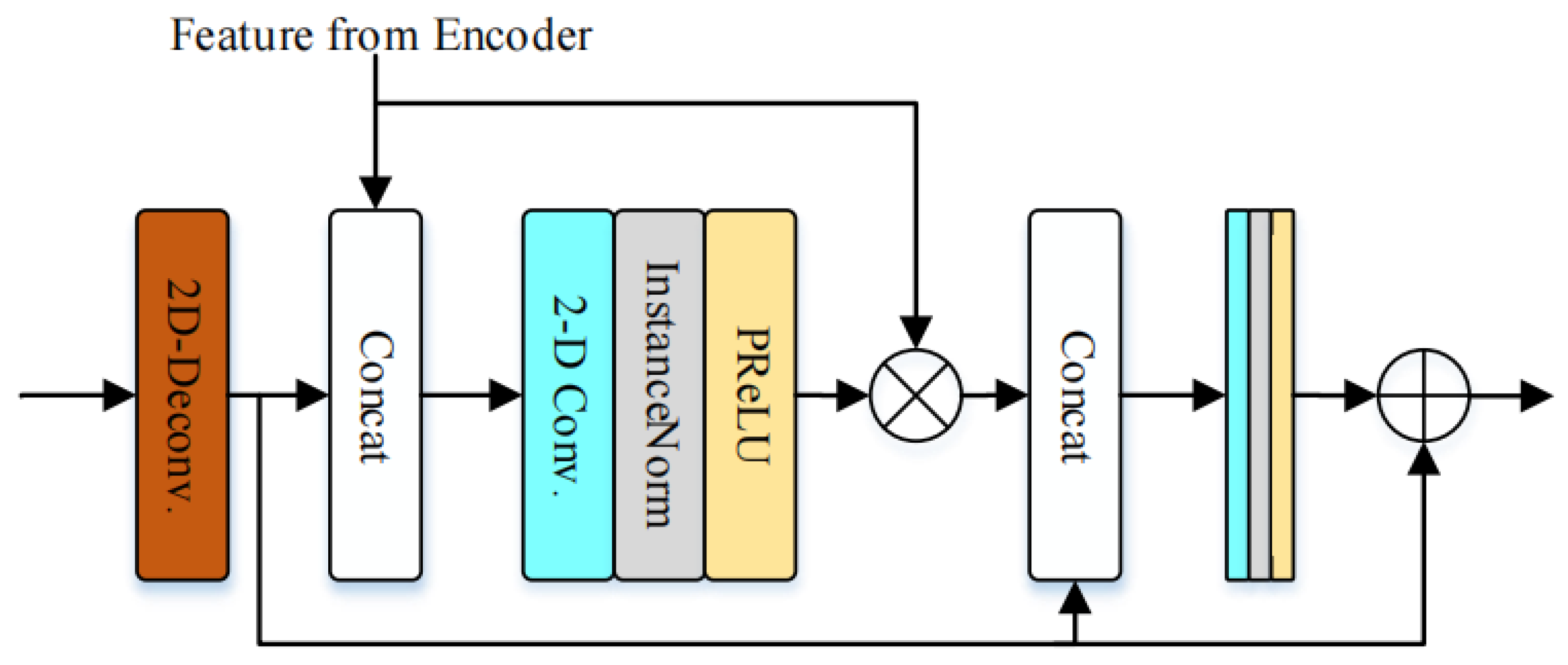
3.1. Encoder and Decoder
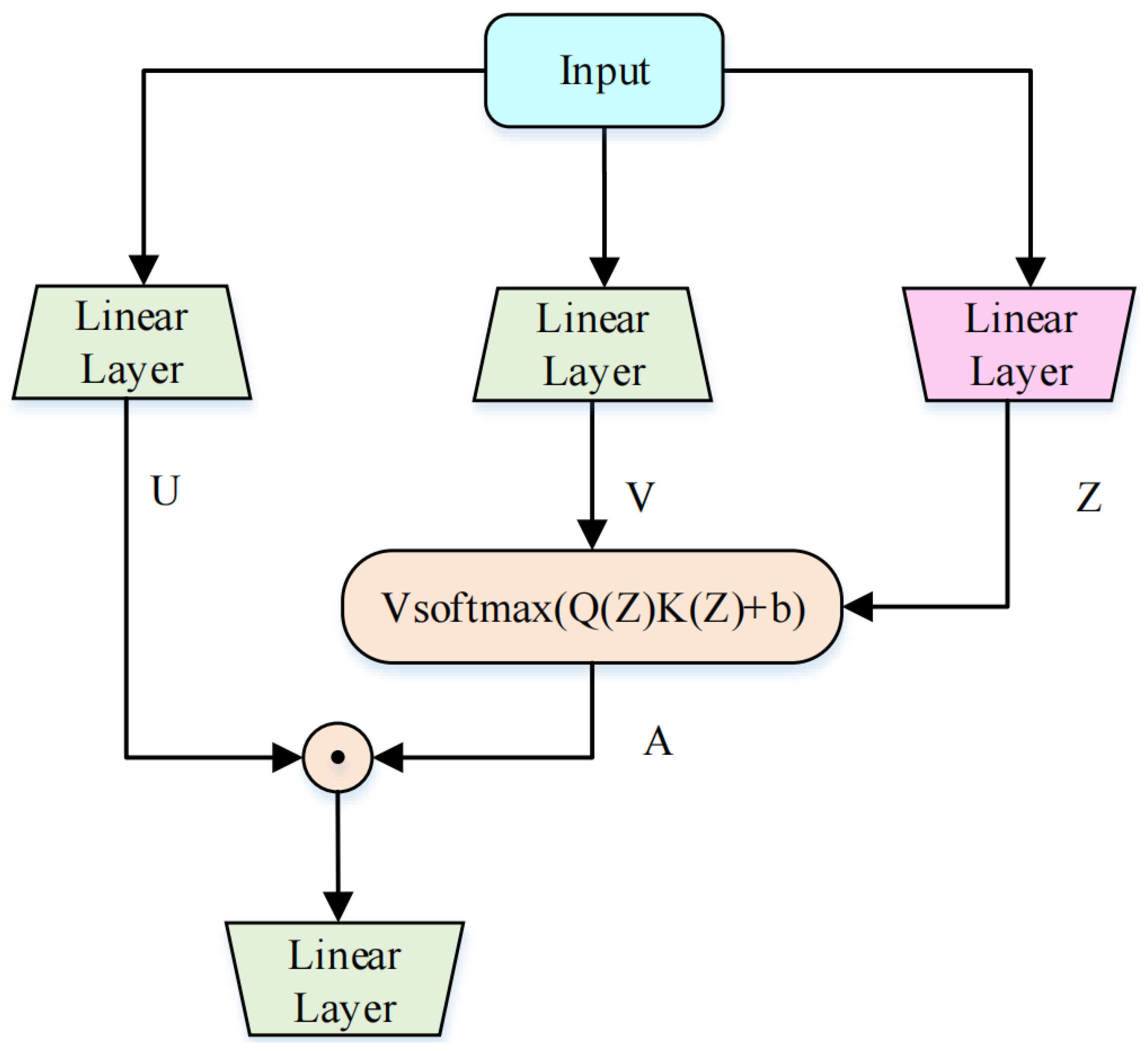
3.2. Two-Stage CGA Block
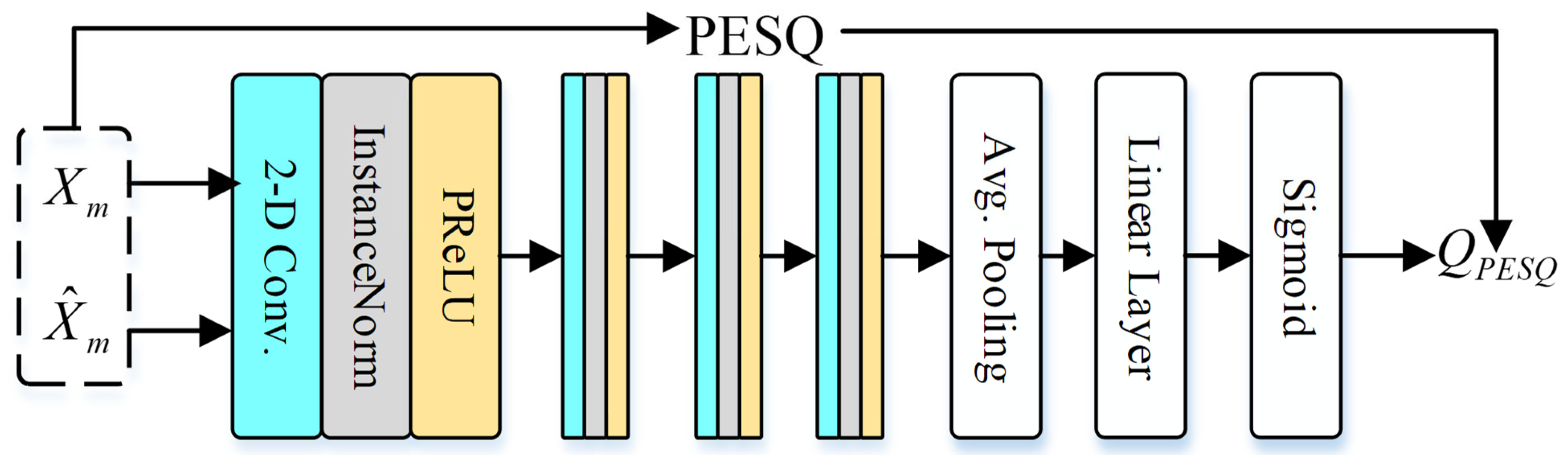
3.3. Metric Discriminator
3.4. Loss Function
4. Experiments
4.1. Datasets and Settings
4.2. Evaluation Indicators
5. Results and Discussion
5.1. Baselines and Results Analysis
5.2. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, D.; Chen, J. Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Farid, M.N.; Arifianto, D. Speech enhancement on smartphone voice recording. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2016; p. 012072. [Google Scholar]
- Tasell, D.J.V. Hearing loss, speech, and hearing aids. J. Speech Lang. Hear. Res. 1993, 36, 228–244. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, H.; Zheng, C.; Li, X. Spectral subtraction based on two-stage spectral estimation and modified cepstrum thresholding. Appl. Acoust. 2013, 74, 450–458. [Google Scholar] [CrossRef]
- Abd El-Fattah, M.A.; Dessouky, M.I.; Abbas, A.M.; Diab, S.M.; El-Rabaie, E.-S.M.; Al-Nuaimy, W.; Alshebeili, S.A.; Abd El-samie, F.E. Speech enhancement with an adaptive Wiener filter. Int. J. Speech Technol. 2014, 17, 53–64. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef] [Green Version]
- Wang, D. On ideal binary mask as the computational goal of auditory scene analysis. In Speech Separation by Humans and Machines; Springer: Berlin/Heidelberg, Germany, 2005; pp. 181–197. [Google Scholar]
- Narayanan, A.; Wang, D. Ideal Ratio Mask Estimation using Deep Neural Networks for Robust Speech Recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7092–7096. [Google Scholar]
- Wang, Y.; Narayanan, A.; Wang, D. On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1849–1858. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Du, J.; Dai, L.-R.; Lee, C.-H. A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 23, 7–19. [Google Scholar] [CrossRef]
- Paliwal, K.; Wójcicki, K.; Shannon, B. The importance of phase in speech enhancement. Speech Commun. 2011, 53, 465–494. [Google Scholar] [CrossRef]
- Yin, D.; Luo, C.; Xiong, Z.; Zeng, W. Phasen: A Phase-And-Harmonics-Aware Speech Enhancement Network. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9458–9465. [Google Scholar]
- Hu, Y.; Liu, Y.; Lv, S.; Xing, M.; Zhang, S.; Fu, Y.; Wu, J.; Zhang, B.; Xie, L. DCCRN: Deep complex convolution recurrent network for phase-aware speech enhancement. arXiv 2020, arXiv:2008.00264. [Google Scholar]
- Williamson, D.S.; Wang, Y.; Wang, D. Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 24, 483–492. [Google Scholar] [CrossRef] [Green Version]
- Li, A.; Zheng, C.; Yu, G.; Cai, J.; Li, X. Filtering and Refining: A Collaborative-Style Framework for Single-Channel Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2156–2172. [Google Scholar] [CrossRef]
- Wang, Z.-Q.; Wichern, G.; Le Roux, J. On the compensation between magnitude and phase in speech separation. IEEE Signal Process. Lett. 2021, 28, 2018–2022. [Google Scholar] [CrossRef]
- Yu, G.; Li, A.; Zheng, C.; Guo, Y.; Wang, Y.; Wang, H. Dual-Branch Attention-In-Attention Transformer for Single-Channel Speech Enhancement. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7847–7851. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Subakan, C.; Ravanelli, M.; Cornell, S.; Bronzi, M.; Zhong, J. Attention is All You Need in Speech Separation. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 21–25. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [Green Version]
- Pandey, A.; Wang, D. TCNN: Temporal Convolutional Neural Network for Real-Time Speech Enhancement in the Time Domain. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6875–6879. [Google Scholar]
- Jia, X.; Li, D. TFCN: Temporal-Frequential Convolutional Network for Single-Channel Speech Enhancement. arXiv 2022, arXiv:2201.00480. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Chen, S.; Wu, Y.; Chen, Z.; Wu, J.; Li, J.; Yoshioka, T.; Wang, C.; Liu, S.; Zhou, M. Continuous Speech Separation with Conformer. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 5749–5753. [Google Scholar]
- Kim, E.; Seo, H. SE-Conformer: Time-Domain Speech Enhancement Using Conformer. In Proceedings of the Interspeech, Brno, Czech Republic, 30 August–3 September 2021; pp. 2736–2740. [Google Scholar]
- Cao, R.; Abdulatif, S.; Yang, B. CMGAN: Conformer-based Metric GAN for Speech Enhancement. arXiv 2022, arXiv:2203.15149. [Google Scholar]
- Fu, S.-W.; Liao, C.-F.; Tsao, Y.; Lin, S.-D. Metricgan: Generative Adversarial Networks Based Black-Box Metric Scores Optimization for Speech Enhancement. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 2031–2041. [Google Scholar]
- Valentini-Botinhao, C.; Wang, X.; Takaki, S.; Yamagishi, J. Investigating RNN-Based Speech Enhancement Methods for Noise-Robust Text-to-Speech. In Proceedings of the SSW, Sunnyvale, CA, USA, 13–15 September 2016; pp. 146–152. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Hua, W.; Dai, Z.; Liu, H.; Le, Q. Transformer Quality in Linear Time. In Proceedings of the International Conference on Machine Learning, Guangzhou, China, 18–21 February 2022; pp. 9099–9117. [Google Scholar]
- Lu, Y.; Li, Z.; He, D.; Sun, Z.; Dong, B.; Qin, T.; Wang, L.; Liu, T.-Y. Understanding and improving transformer from a multi-particle dynamic system point of view. arXiv 2019, arXiv:1906.02762. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Wen, B.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. arXiv 2021, arXiv:2104.09864. [Google Scholar]
- Braun, S.; Tashev, I. A Consolidated View of Loss Functions for Supervised Deep Learning-Based Speech Enhancement. In Proceedings of the 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 26–28 July 2021; pp. 72–76. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual Evaluation of Speech Quality (PESQ)—A New Method for Speech Quality Assessment of Telephone Networks and Codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2007, 16, 229–238. [Google Scholar] [CrossRef]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A Short-Time Objective Intelligibility Measure for Time-Frequency Weighted Noisy Speech. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serra, J. SEGAN: Speech enhancement generative adversarial network. arXiv 2017, arXiv:1703.09452. [Google Scholar]
- Ye, S.; Hu, X.; Xu, X. Tdcgan: Temporal dilated convolutional generative adversarial network for end-to-end speech enhancement. arXiv 2020, arXiv:2008.07787. [Google Scholar]
- Fu, S.-W.; Yu, C.; Hsieh, T.-A.; Plantinga, P.; Ravanelli, M.; Lu, X.; Tsao, Y. Metricgan+: An improved version of metricgan for speech enhancement. arXiv 2021, arXiv:2104.03538. [Google Scholar]
- Serrà, J.; Pascual, S.; Pons, J.; Araz, R.O.; Scaini, D. Universal Speech Enhancement with Score-based Diffusion. arXiv 2022, arXiv:2206.03065. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Dang, F.; Chen, H.; Zhang, P. DPT-FSNet: Dual-Path Transformer Based Full-Band and Sub-Band Fusion Network for Speech Enhancement. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6857–6861. [Google Scholar]
- Yu, G.; Li, A.; Wang, H.; Wang, Y.; Ke, Y.; Zheng, C. DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement. arXiv 2022, arXiv:2202.07931. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Size(M) | PESQ | CSIG | CBAK | COVL | SSNR | STOI |
|---|---|---|---|---|---|---|---|
| Noisy | - * | 1.97 | 3.35 | 2.44 | 2.63 | 1.68 | 0.91 |
| SEGAN | 97.47 | 2.16 | 3.48 | 2.94 | 2.80 | 7.73 | 0.92 |
| DCCRN | 3.70 | 2.68 | 3.88 | 3.18 | 3.27 | - | 0.94 |
| Conv-TasNet | 5.1 | 2.84 | 2.33 | 2.62 | 2.51 | - | - |
| TDCGAN | 5.12 | 2.87 | 4.17 | 3.46 | 3.53 | 9.82 | 0.95 |
| MetricGAN+ | - | 3.15 | 4.14 | 3.16 | 3.64 | - | - |
| UNIVERSE | - | 3.33 | - | - | 3.82 | - | 0.95 |
| CDiffuSE | - | 2.52 | 3.72 | 2.91 | 3.10 | - | - |
| SE-Conformer | - | 3.13 | 4.45 | 3.55 | 3.82 | - | 0.95 |
| DB-AIAT | 2.81 | 3.31 | 4.61 | 3.75 | 3.96 | 10.79 | 0.96 |
| DPT-FSNet | 0.91 | 3.33 | 4.58 | 3.72 | 4.00 | - | 0.96 |
| DBT-Net | 2.91 | 3.30 | 4.59 | 3.75 | 3.92 | - | 0.96 |
| CGA-MGAN | 1.14 | 3.47 | 4.56 | 3.86 | 4.06 | 11.09 | 0.96 |
| Method | PESQ | CSIG | CBAK | COVL | SSNR | STOI |
|---|---|---|---|---|---|---|
| CGA-MGAN | 3.47 | 4.56 | 3.86 | 4.06 | 11.09 | 0.96 |
| w/o Conv. Block | 3.37 | 4.50 | 3.80 | 3.97 | 10.97 | 0.96 |
| Using Conformer | 3.33 | 4.43 | 3.72 | 3.91 | 10.18 | 0.96 |
| w/o Gating Decoders | 3.43 | 4.52 | 3.83 | 4.02 | 10.99 | 0.96 |
| Mag-only | 3.42 | 4.54 | 3.80 | 4.03 | 10.73 | 0.96 |
| w/o Discriminator | 3.37 | 4.54 | 3.79 | 4.00 | 10.83 | 0.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, X. CGA-MGAN: Metric GAN Based on Convolution-Augmented Gated Attention for Speech Enhancement. Entropy 2023, 25, 628. https://doi.org/10.3390/e25040628
Chen H, Zhang X. CGA-MGAN: Metric GAN Based on Convolution-Augmented Gated Attention for Speech Enhancement. Entropy. 2023; 25(4):628. https://doi.org/10.3390/e25040628
Chicago/Turabian StyleChen, Haozhe, and Xiaojuan Zhang. 2023. "CGA-MGAN: Metric GAN Based on Convolution-Augmented Gated Attention for Speech Enhancement" Entropy 25, no. 4: 628. https://doi.org/10.3390/e25040628
APA StyleChen, H., & Zhang, X. (2023). CGA-MGAN: Metric GAN Based on Convolution-Augmented Gated Attention for Speech Enhancement. Entropy, 25(4), 628. https://doi.org/10.3390/e25040628