
A Survey on Deep Learning Based Segmentation, Detection and Classification for 3D Point Clouds


Abstract
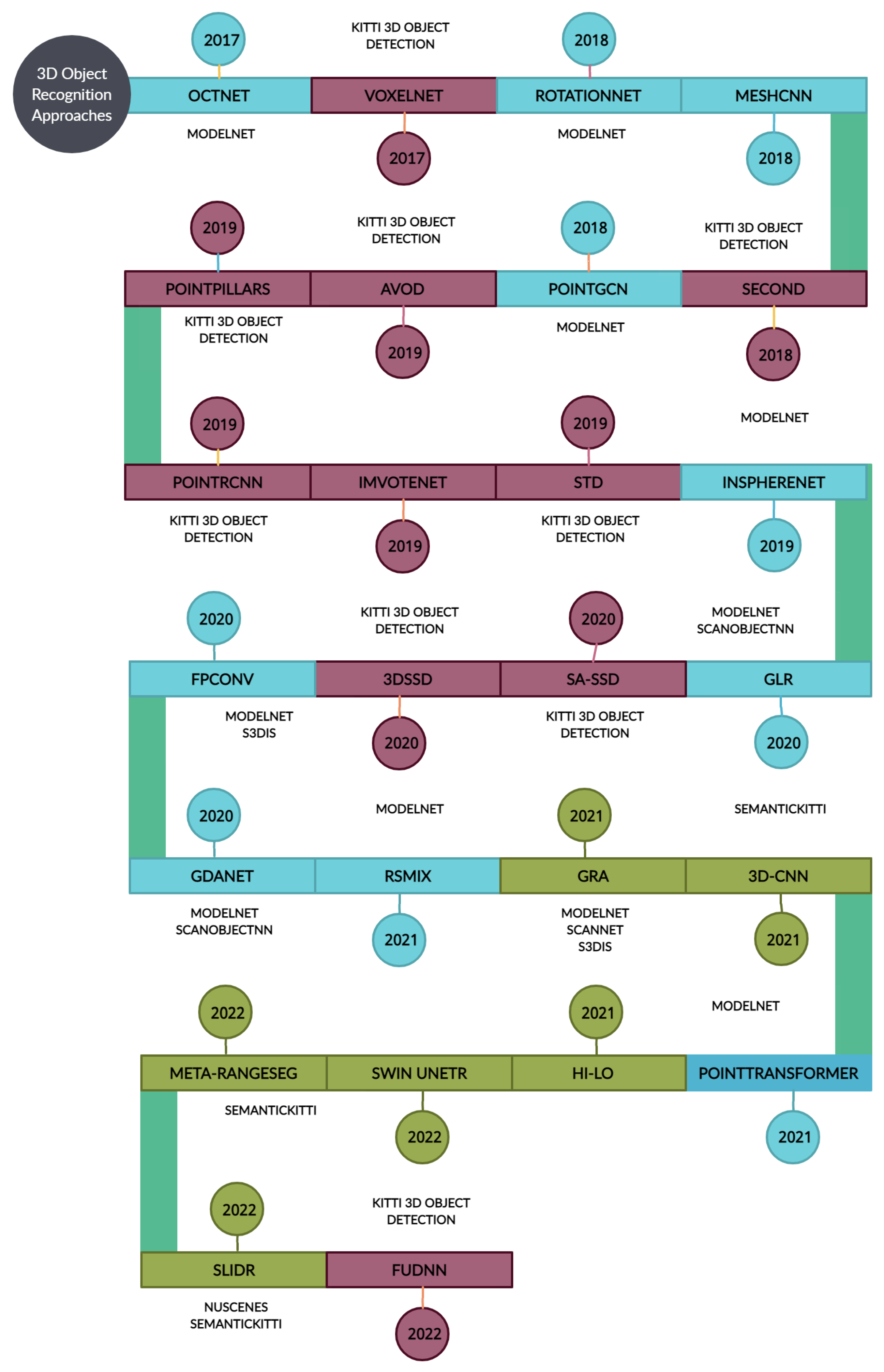
:1. Introduction
- This work thoroughly discusses some of the state-of-the-art and/or benchmarking deep learning techniques for 3D object recognition, which includes segmentation, object detection, and classification, by utilizing a variety of 3D data formats, including RGB-D (IMVoteNet) [13], voxels (VoxelNet) [1], point clouds (PointRCNN) [3], mesh (MeshCNN) [14] and 3D video (Meta-RangeSeg) [15].
- We provide an extensive analysis of the relative advantages and disadvantages of different types of 3D object identification methods.
- Our work places special emphasis on deep learning techniques created expressly for 3D object recognition, including 3D segmentation, detection and classification.
2. Datasets
2.1. KITTI 3D Object Detection
2.2. SemanticKITTI
2.3. ModelNet
2.4. S3DIS
2.5. nuScene
2.6. ScanNet
2.7. ScanObjectNN
3. Segmentation
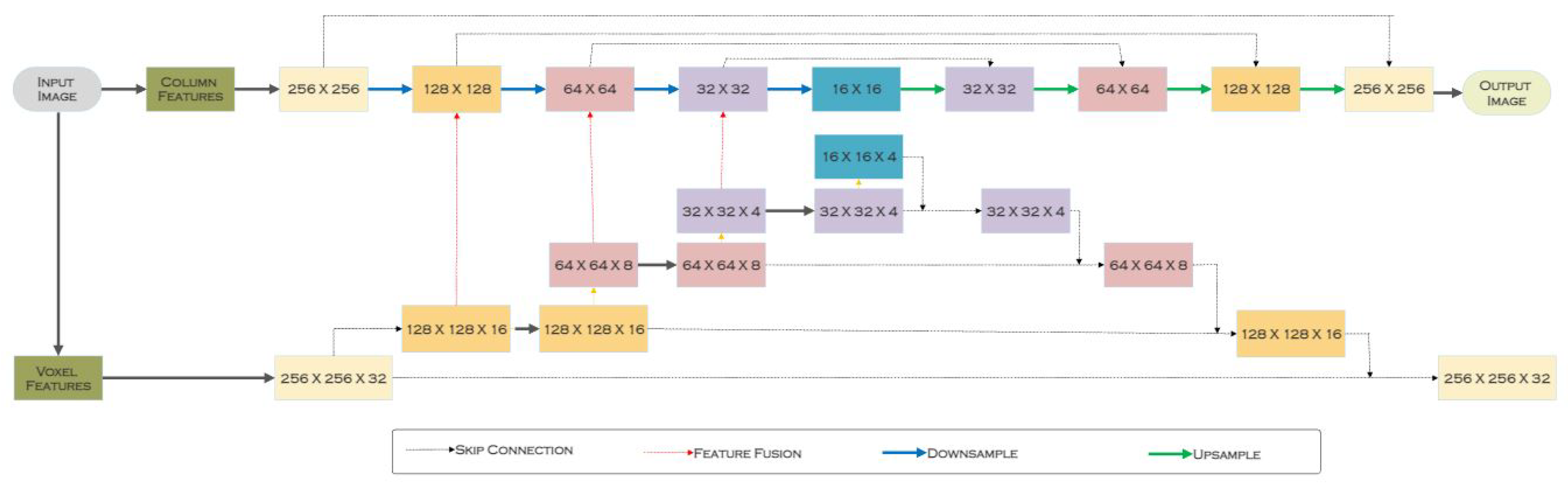
3.1. Bird’s Eye View (BEV) Projection Segmentation
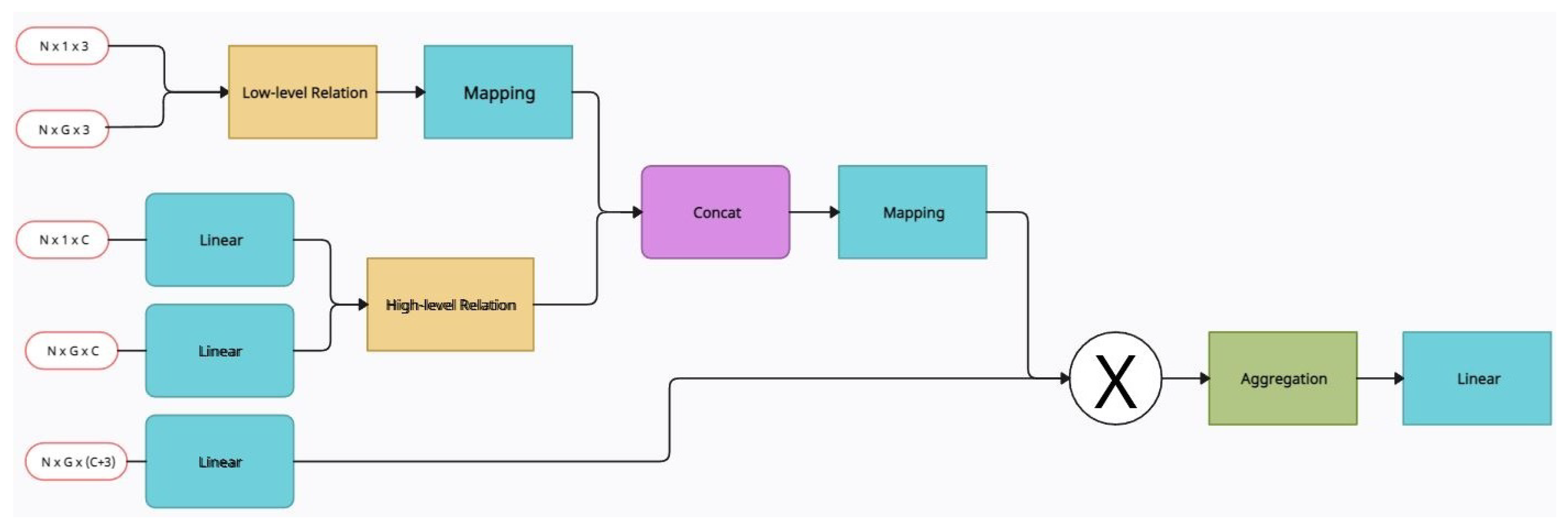
3.2. Group Relation Aggregator (GRA)
3.3. HiLo-Network
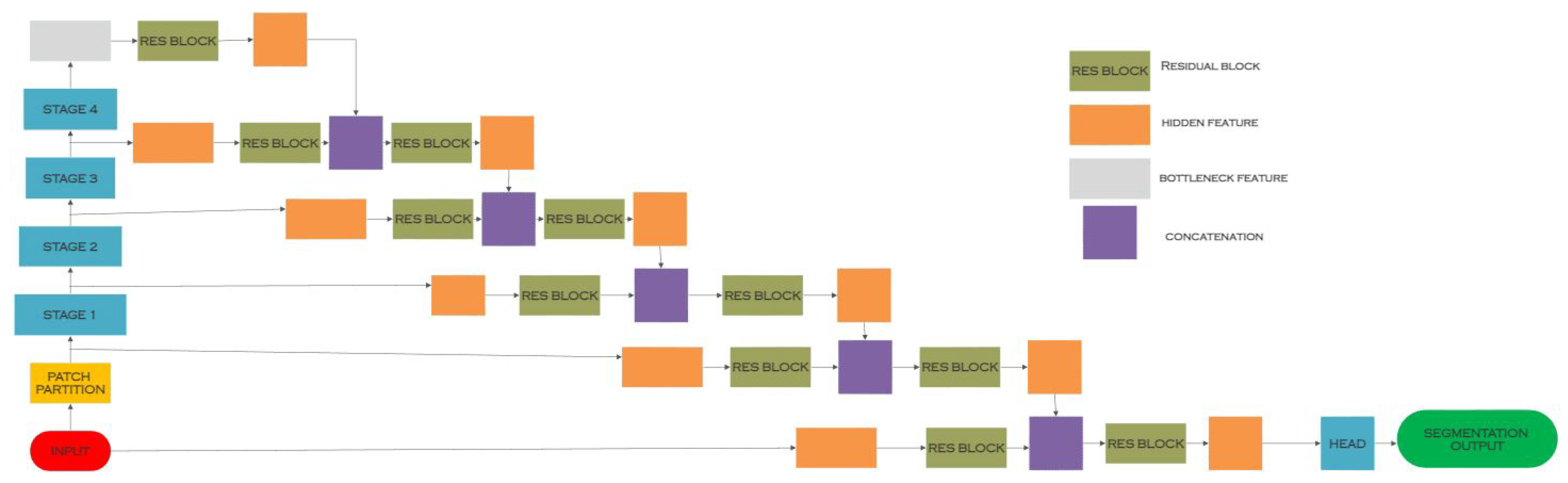
3.4. Swin UNETR
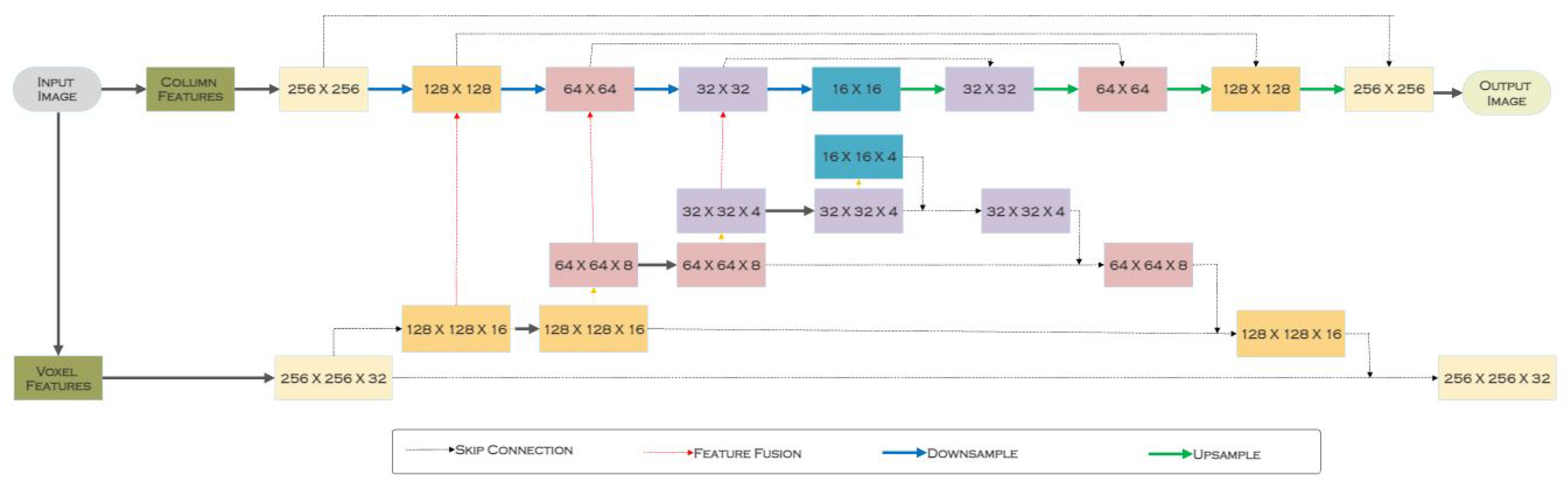
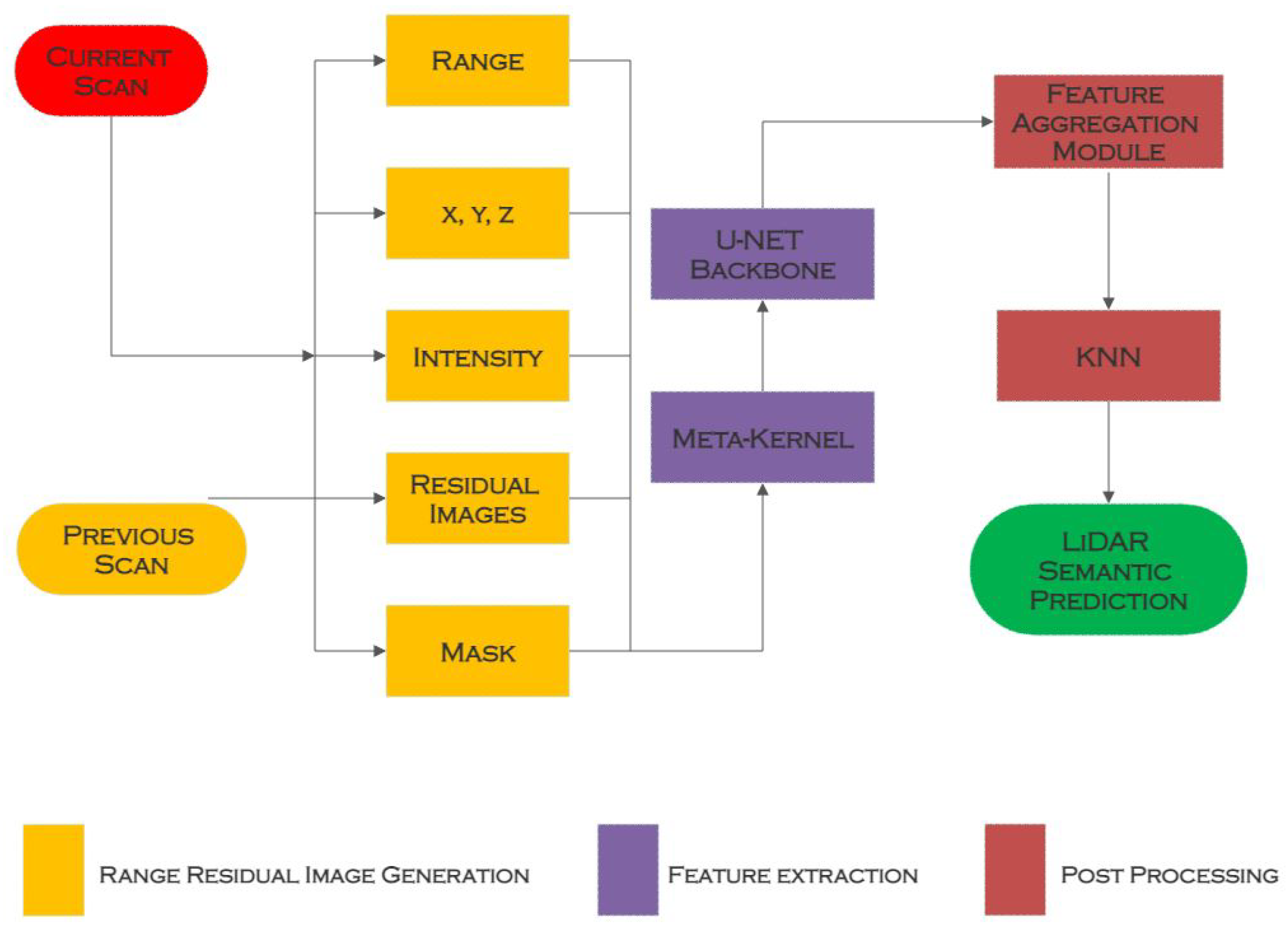
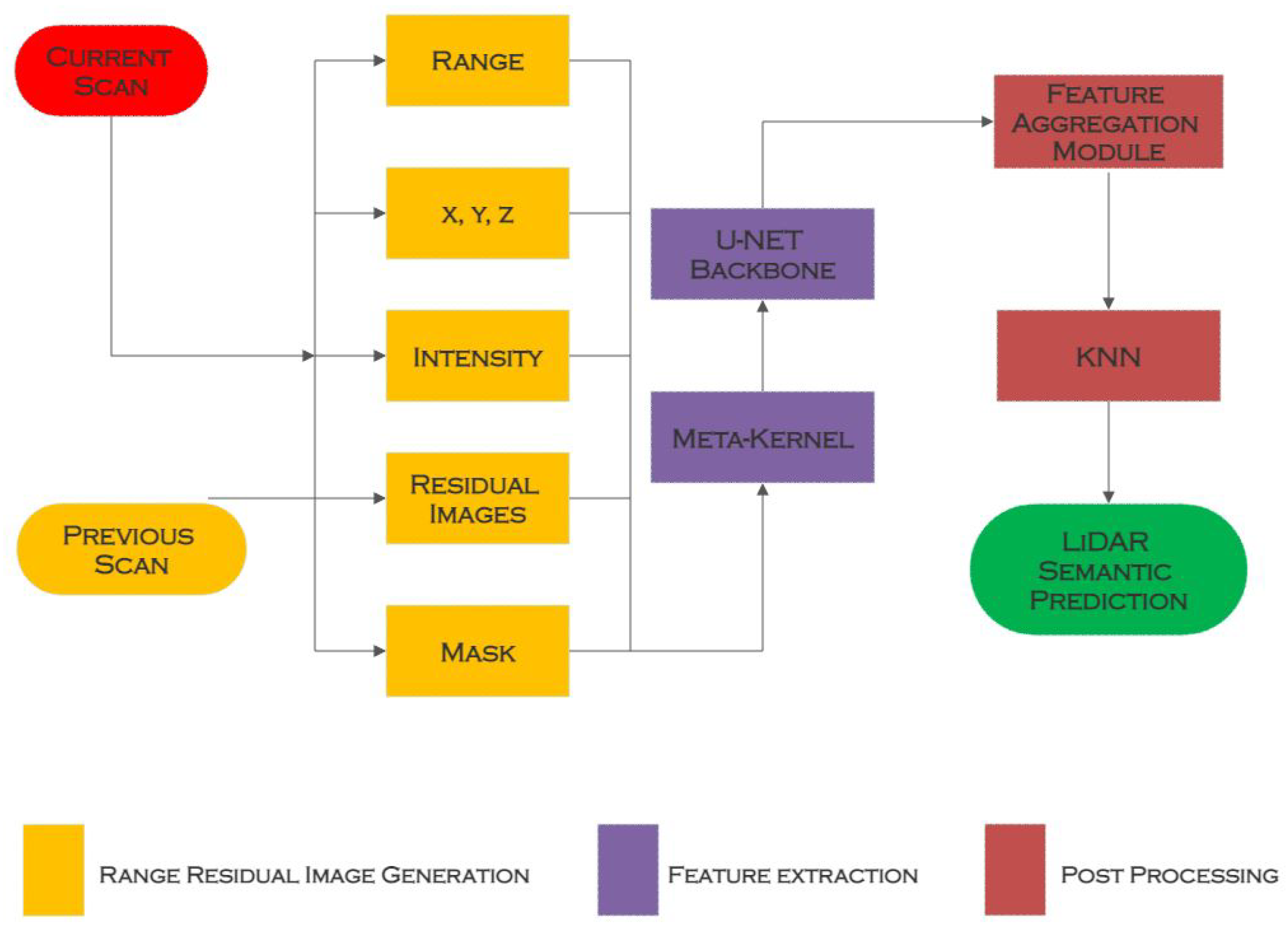
3.5. Meta-RangeSeg
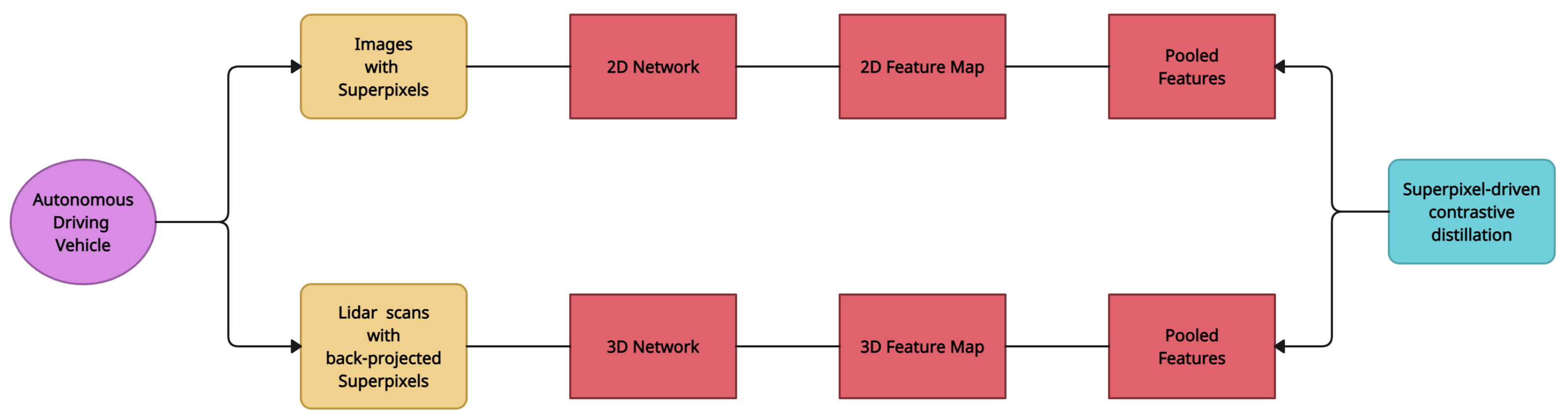
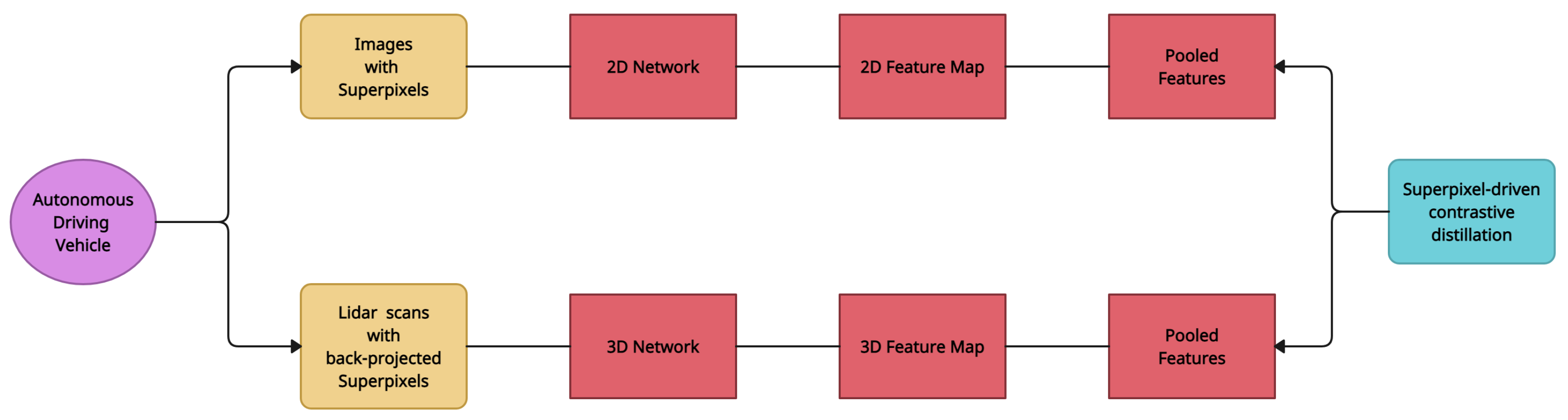
3.6. SLidR
4. Object Detection
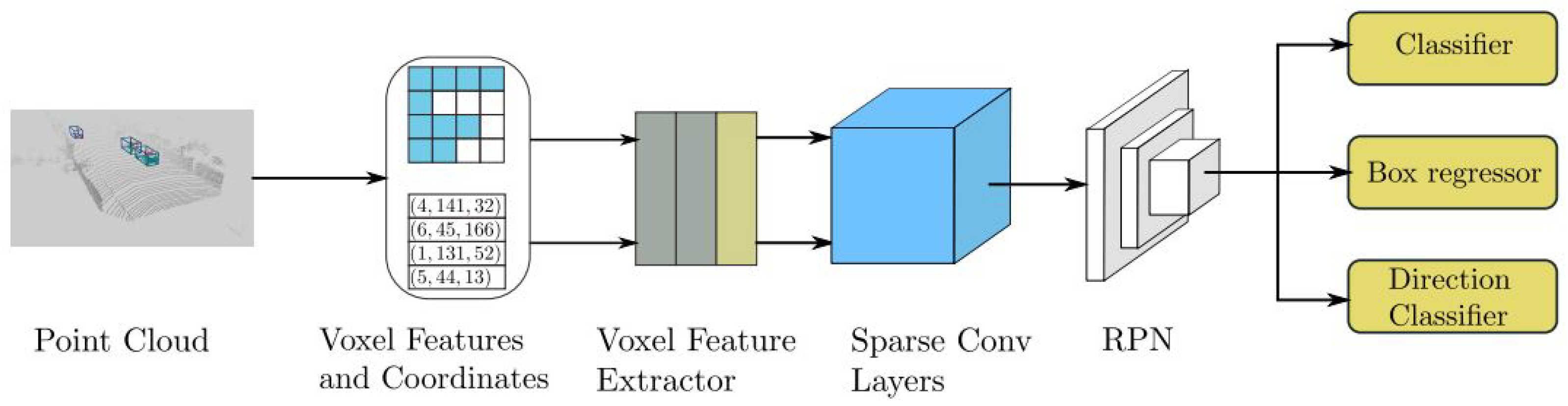
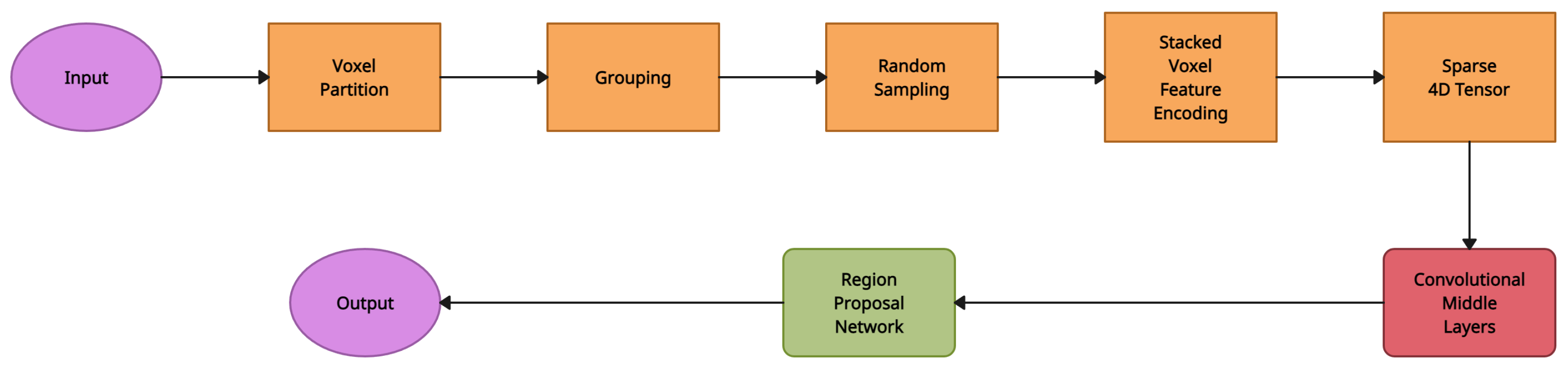
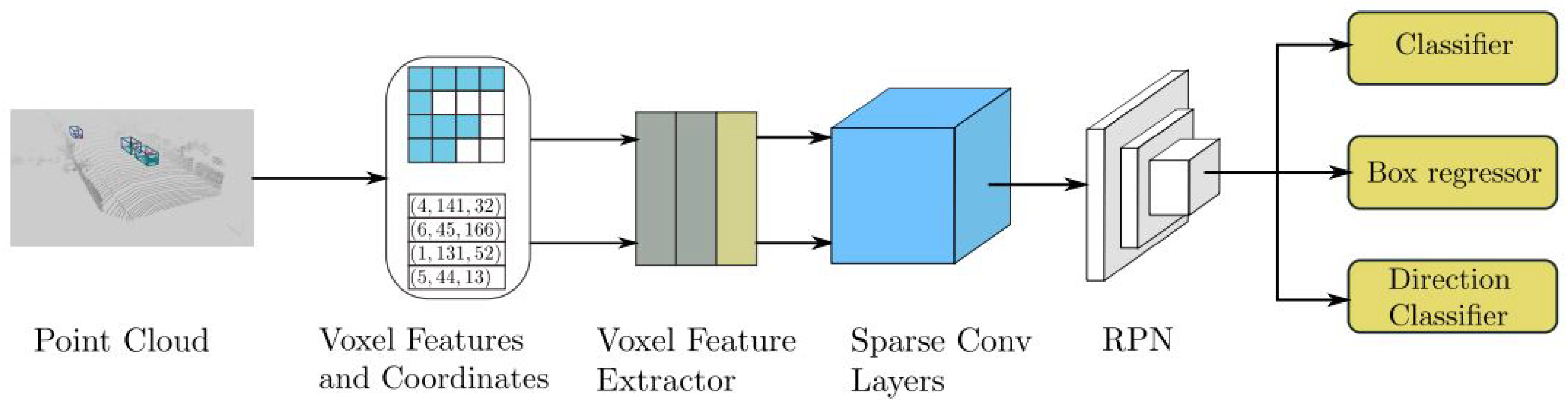
4.1. VoxelNet
4.2. Sparsely Embedded CONvolutional Detection (SECOND)
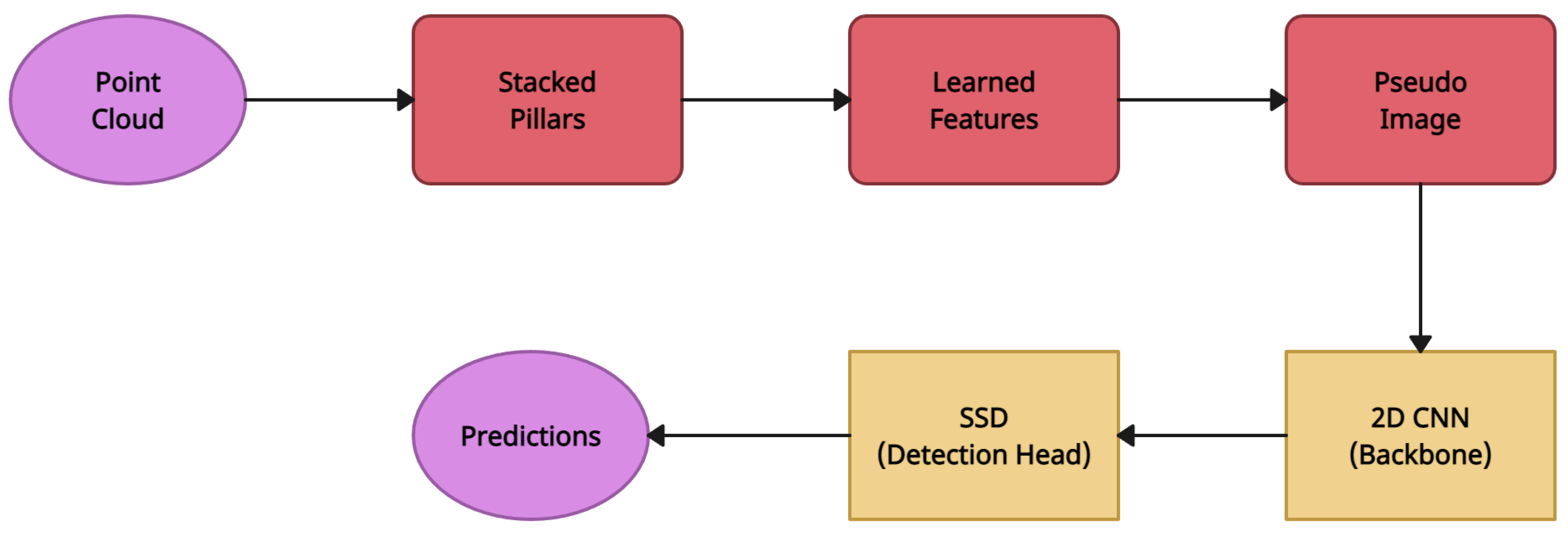
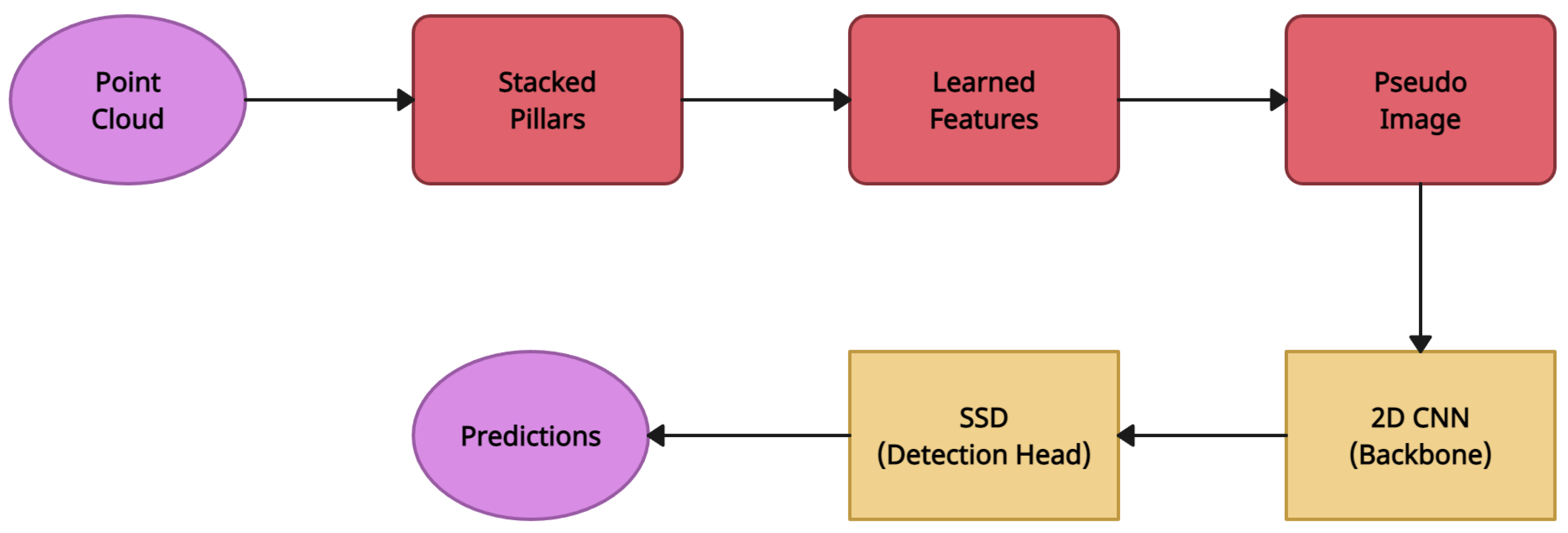
4.3. PointPillars
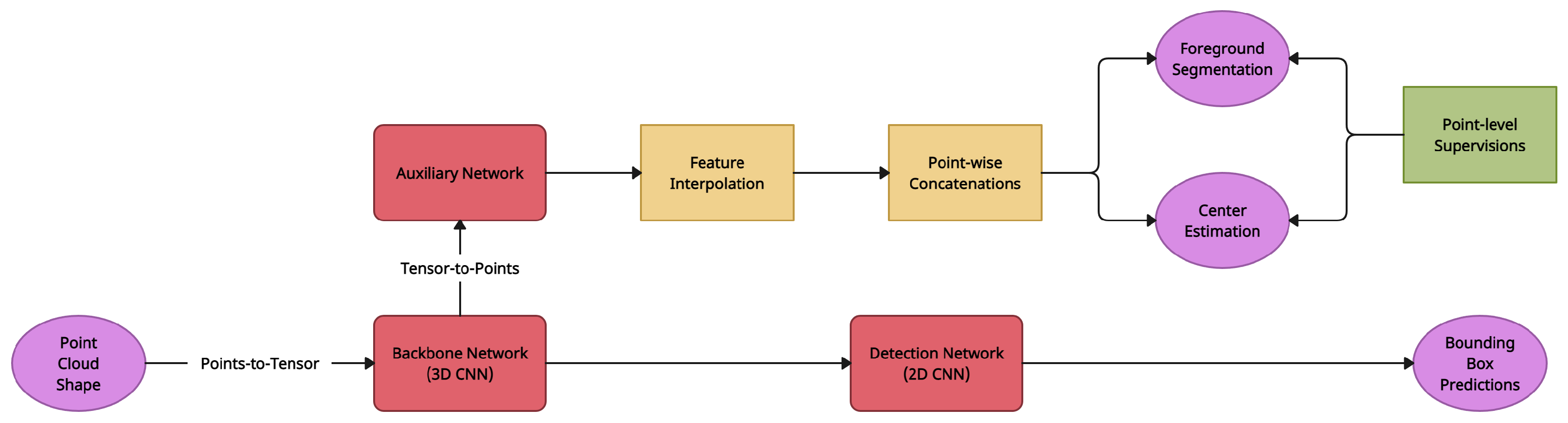
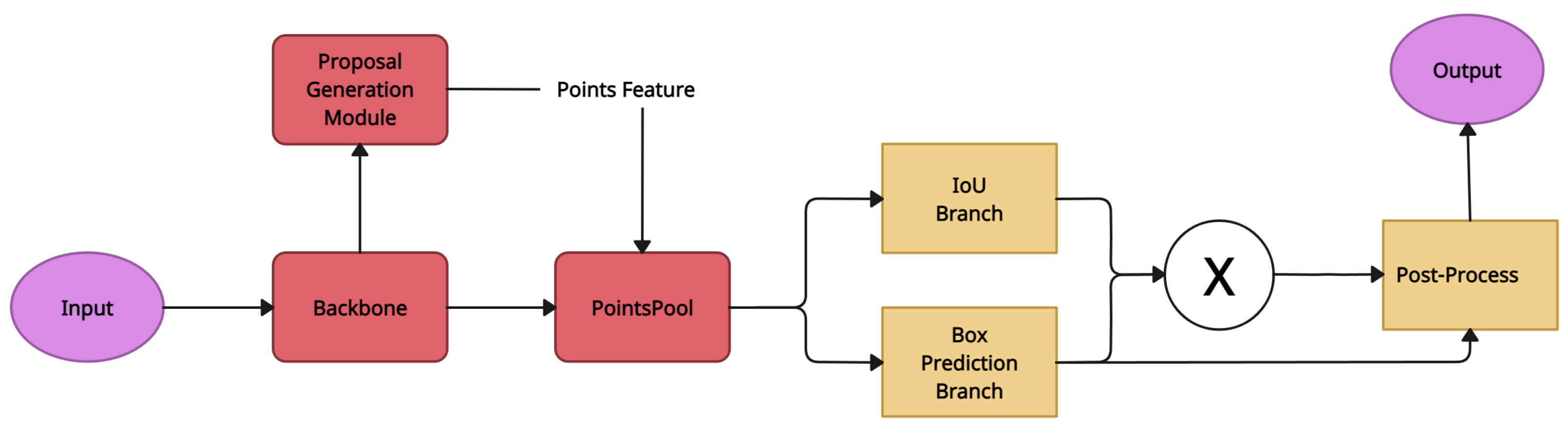
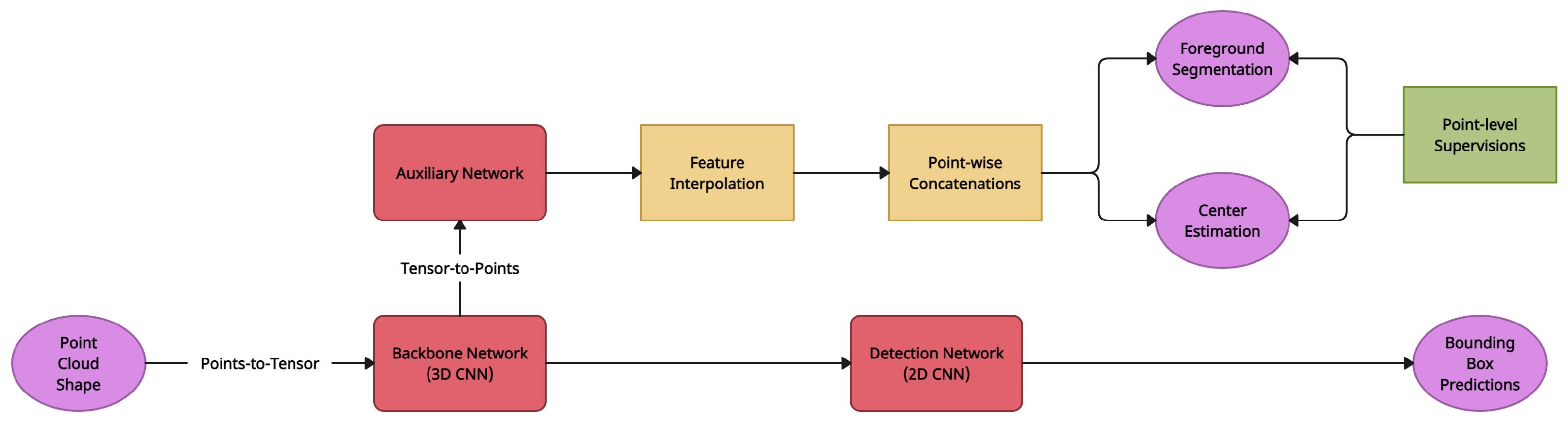
4.4. Structure-Aware Single Stage 3D Object Detector (SA-SSD)
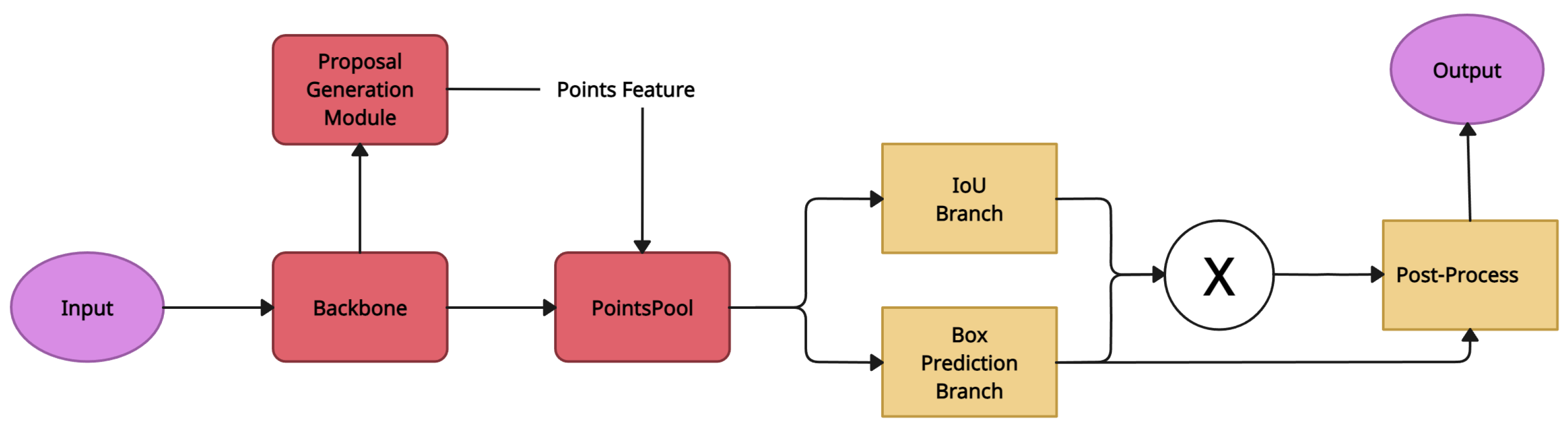
4.5. Sparse-to-Dense 3D Object Detector (STD)
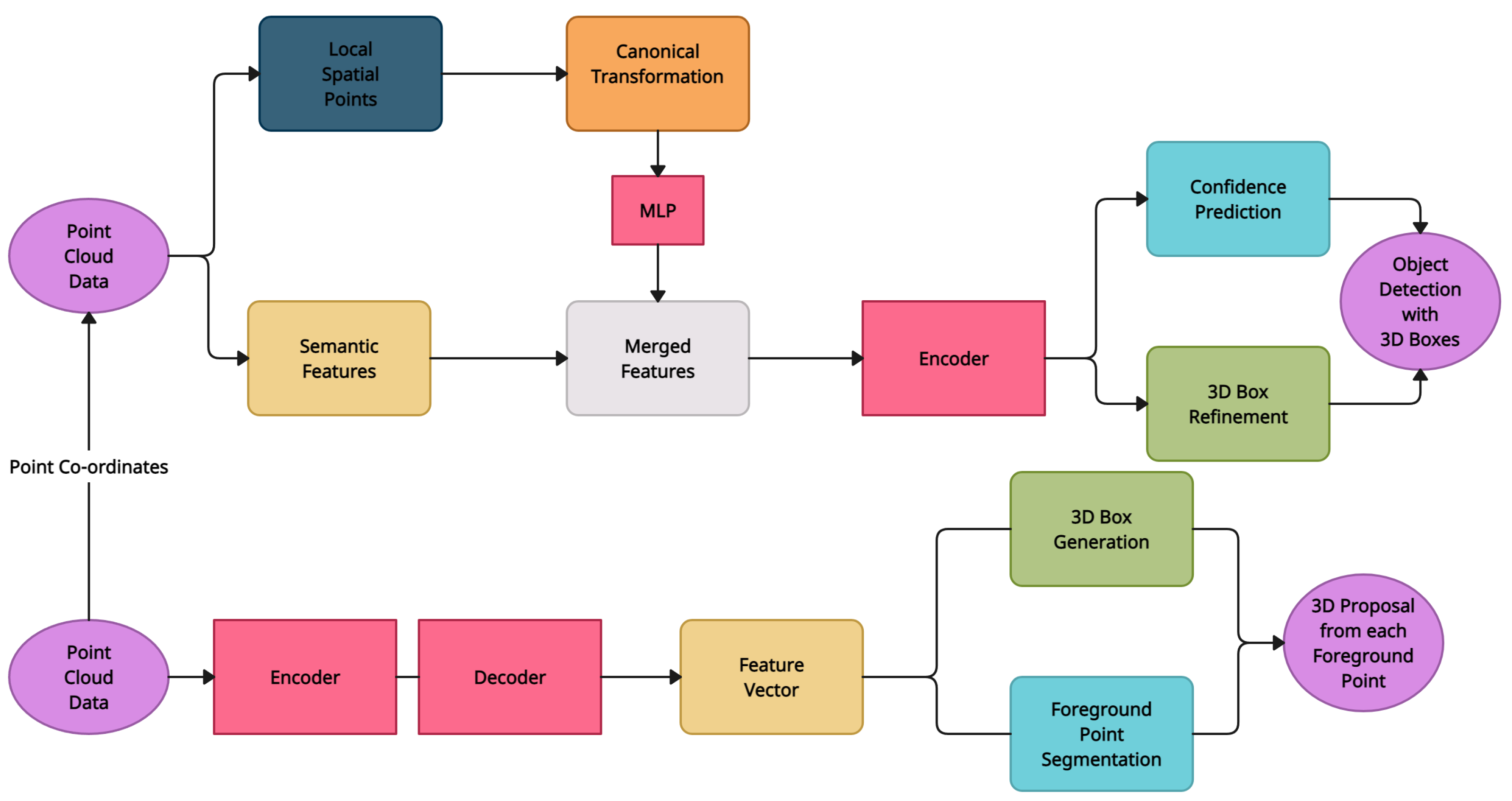
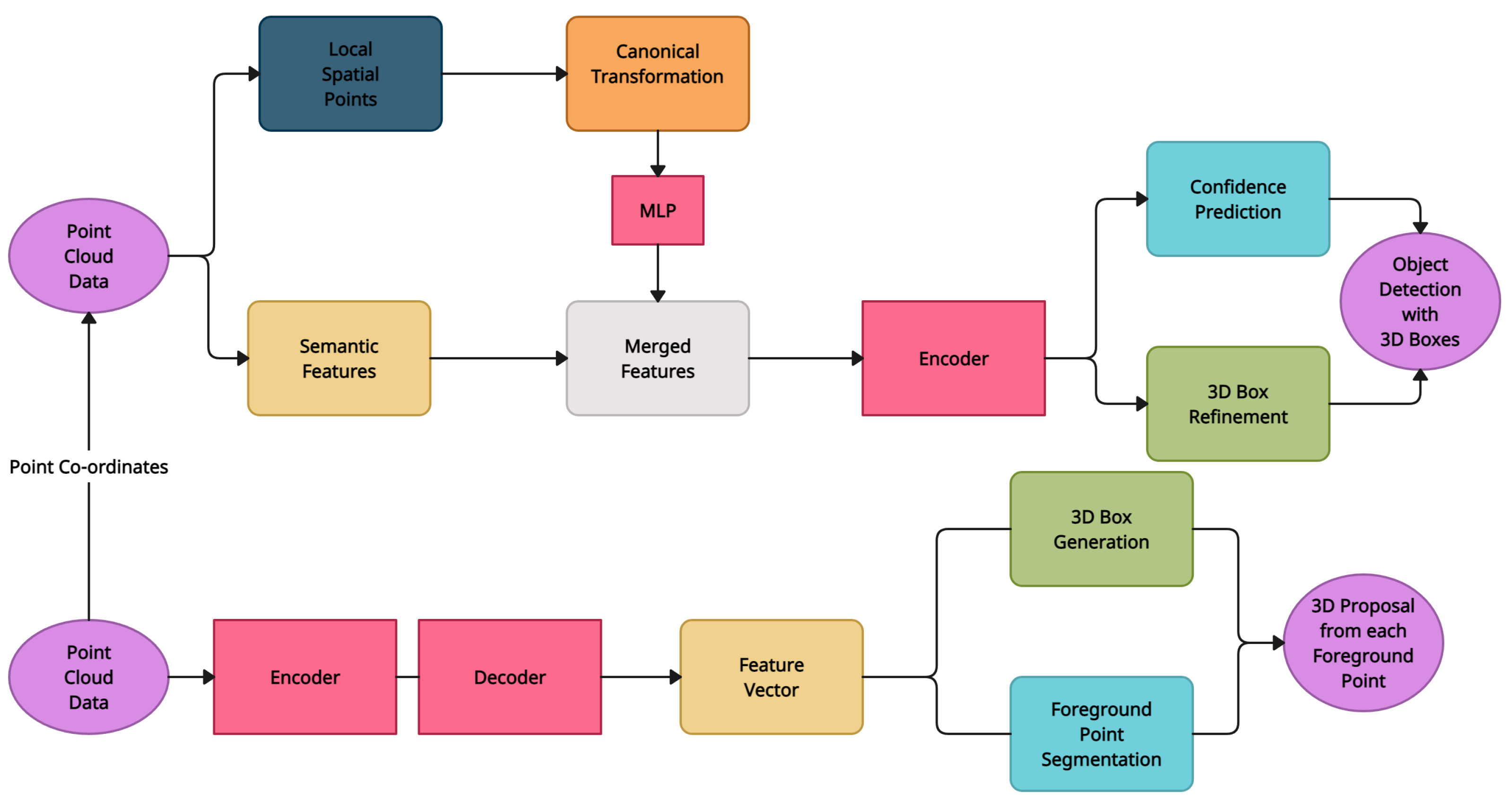
4.6. PointRCNN
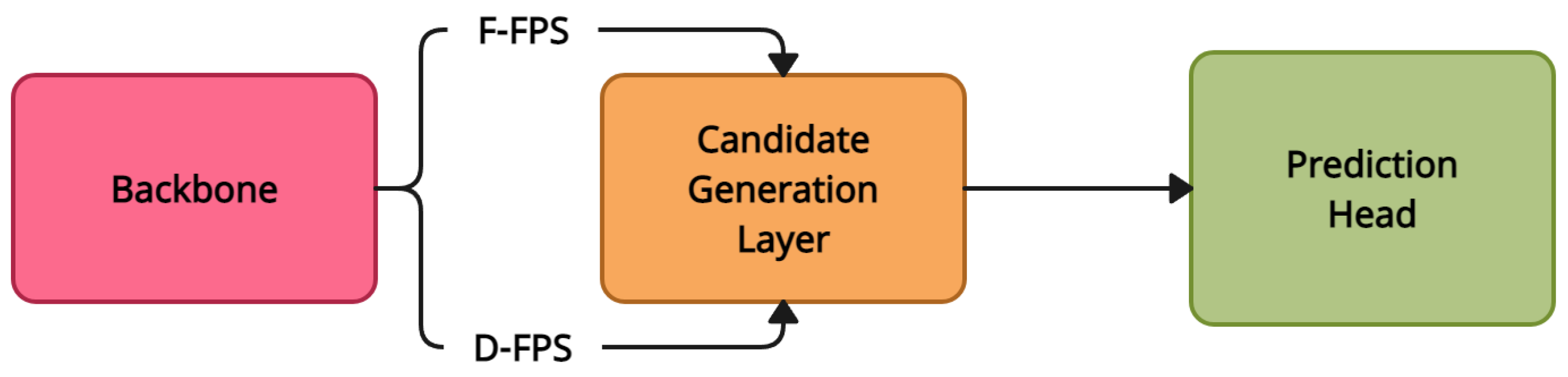
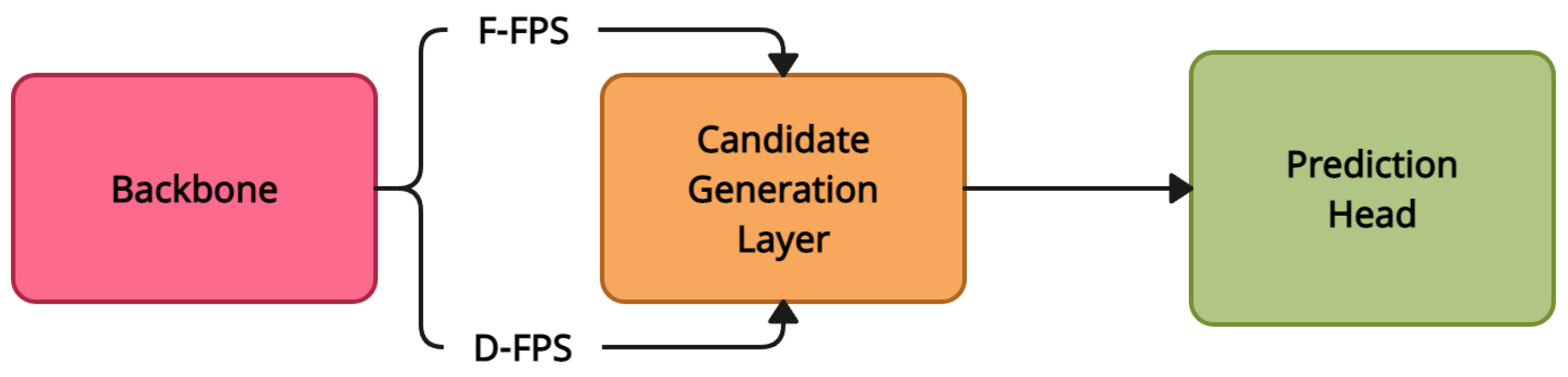
4.7. 3DSSD
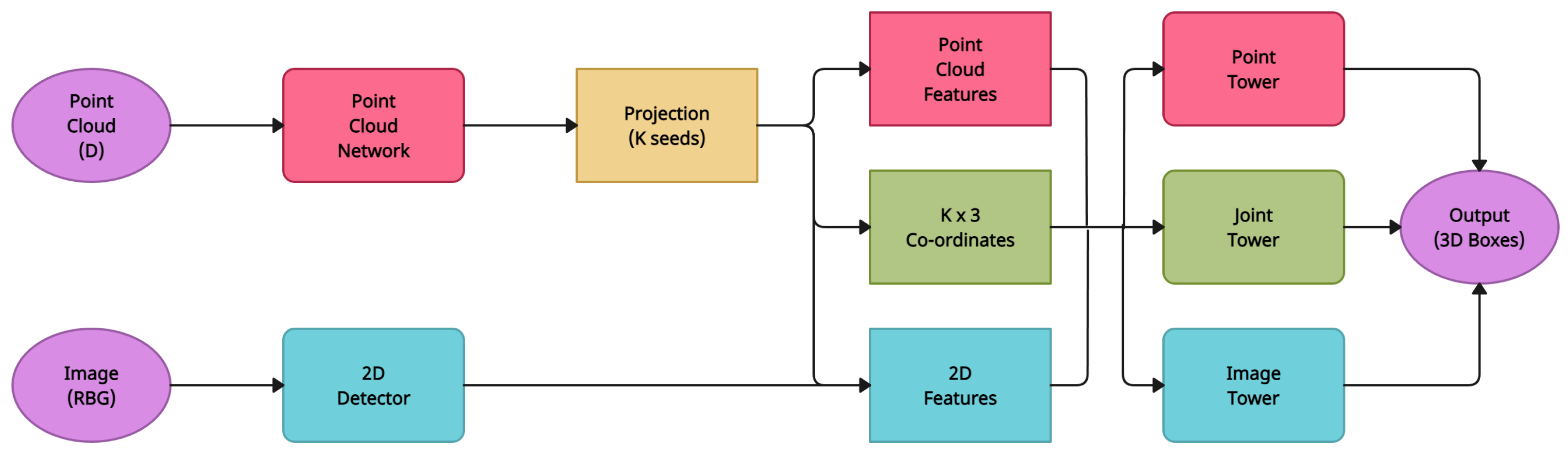
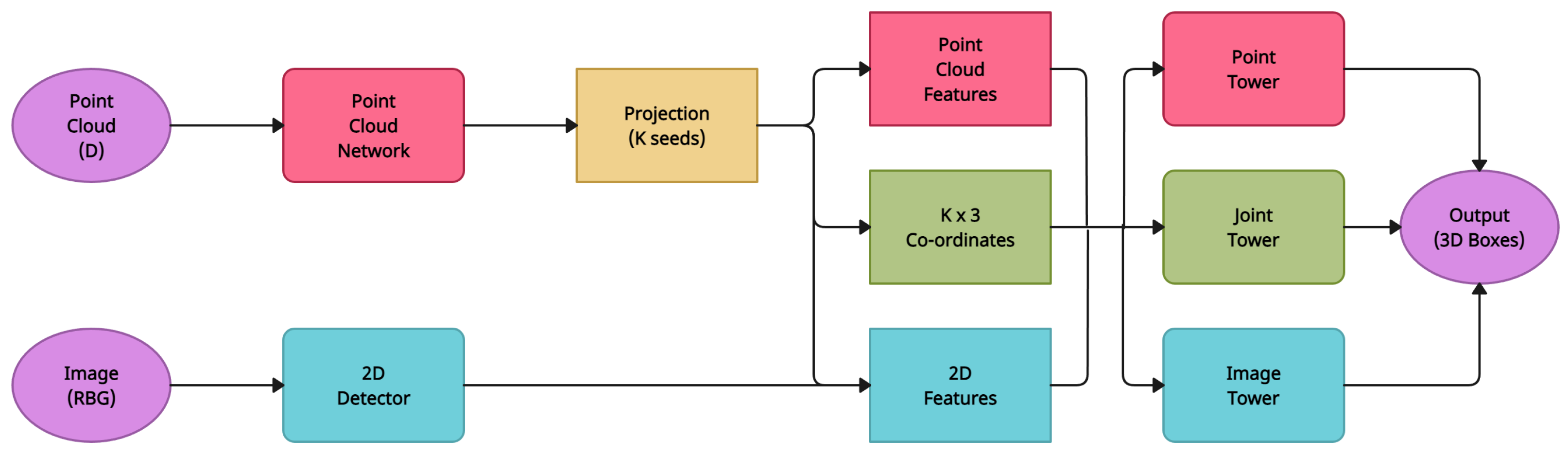
4.8. IMVoteNet
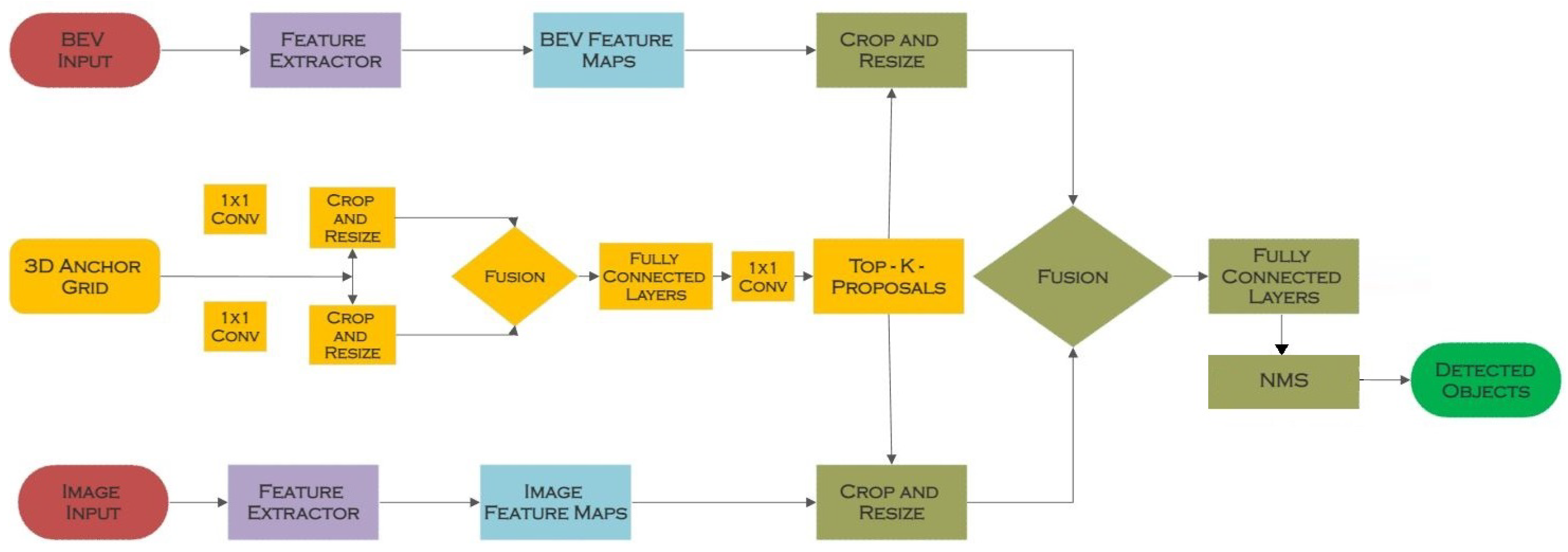
4.9. Aggregate View Object Detection (AVOD)
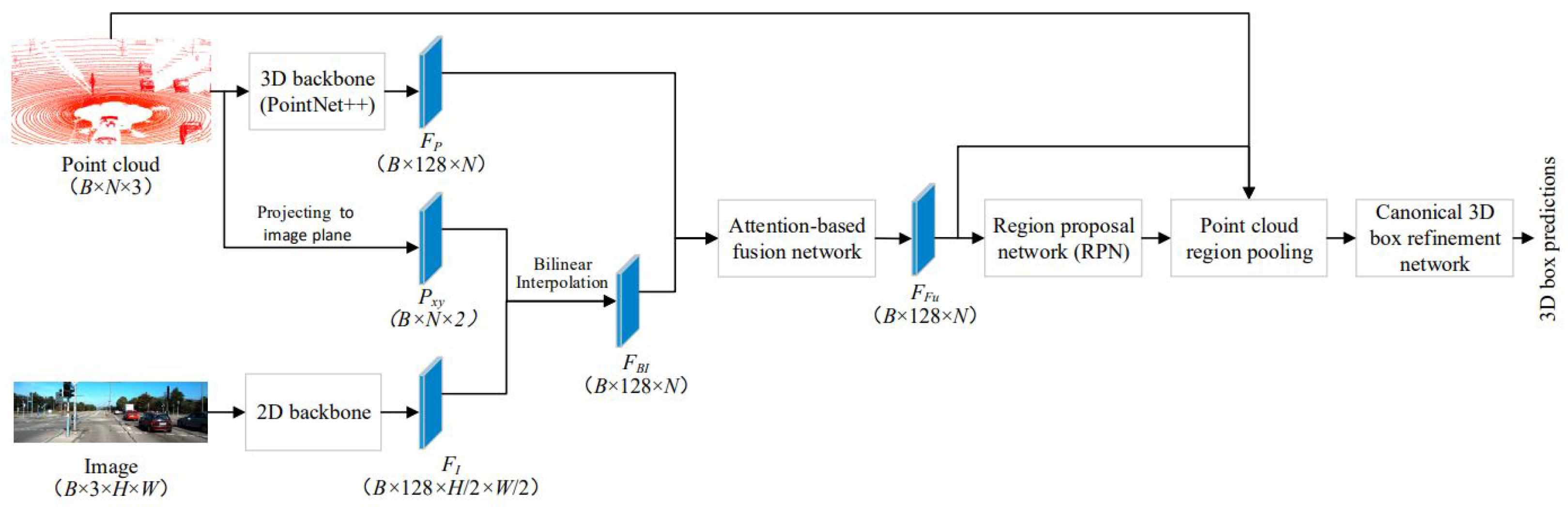
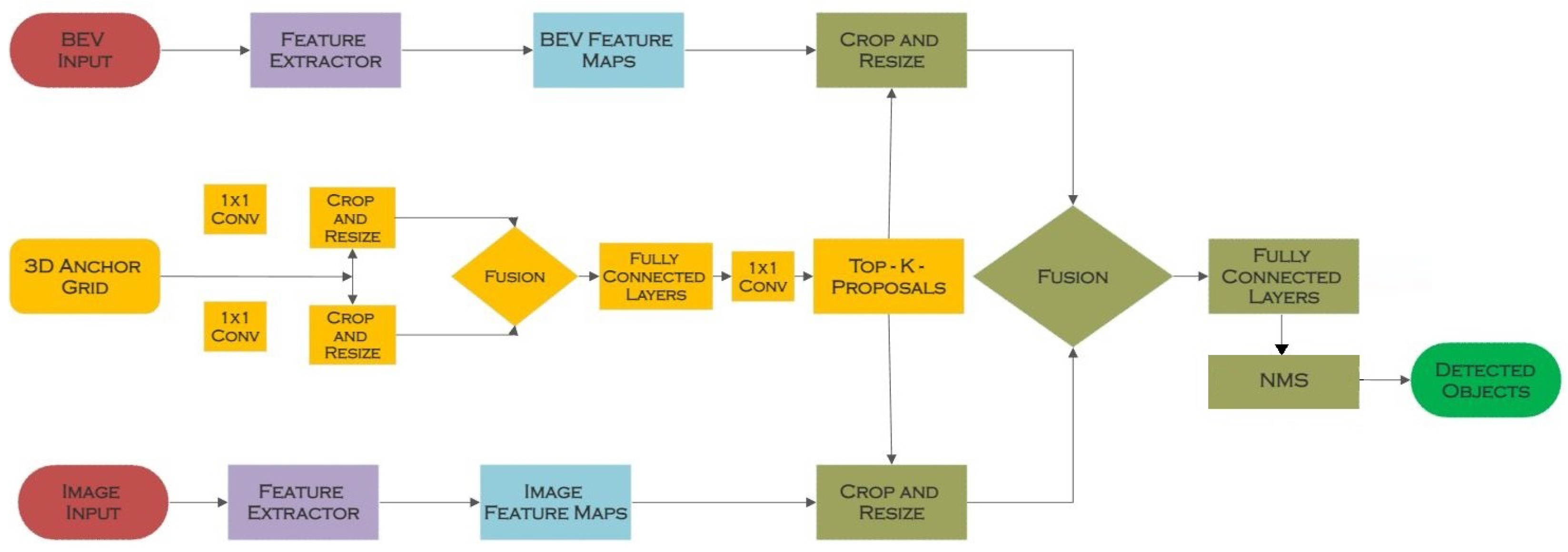
4.10. FuDNN
5. Deep Learning Based 3D Object Classification
5.1. OctNet
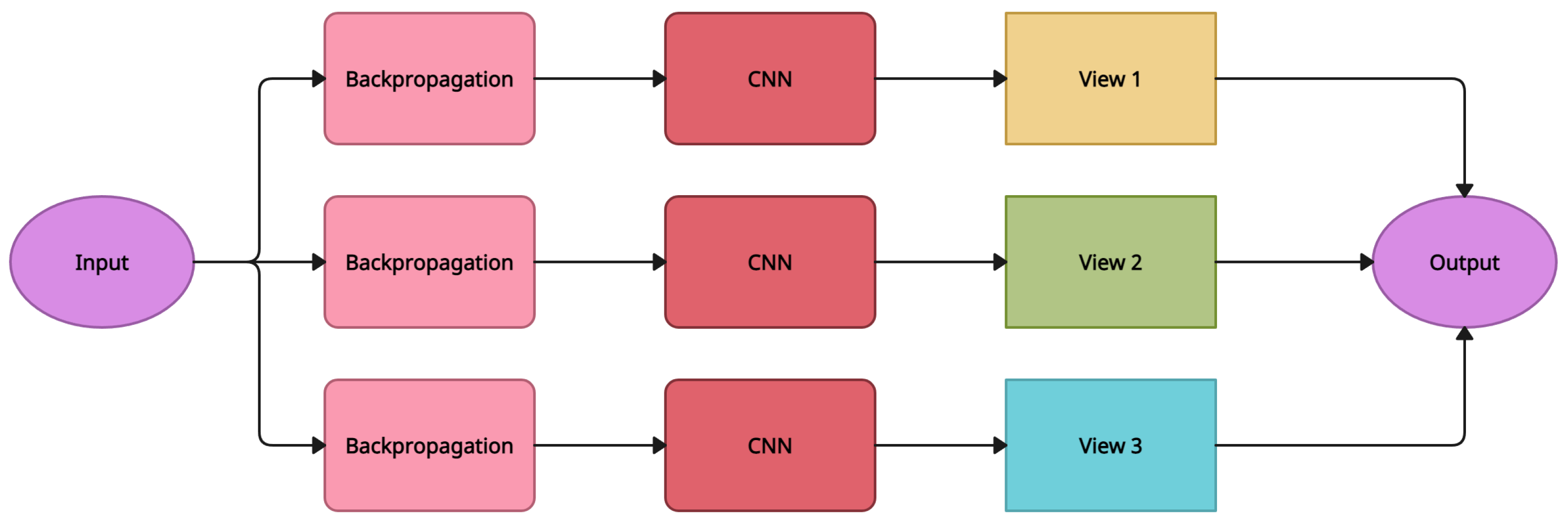
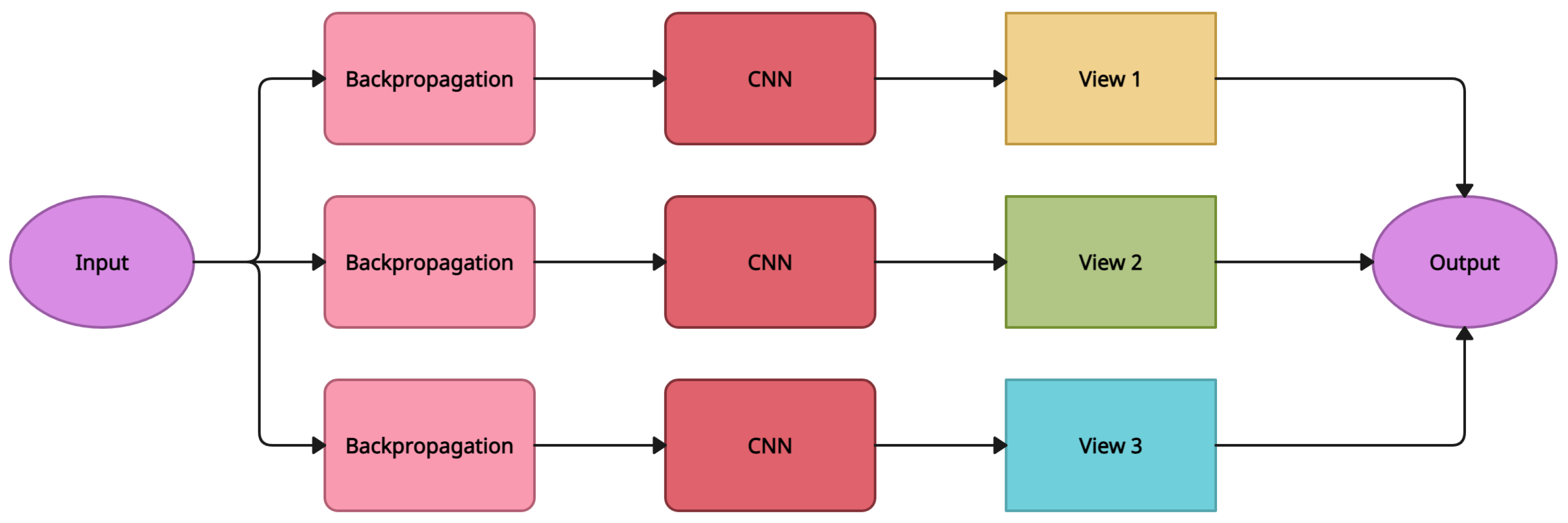
5.2. RotationNet
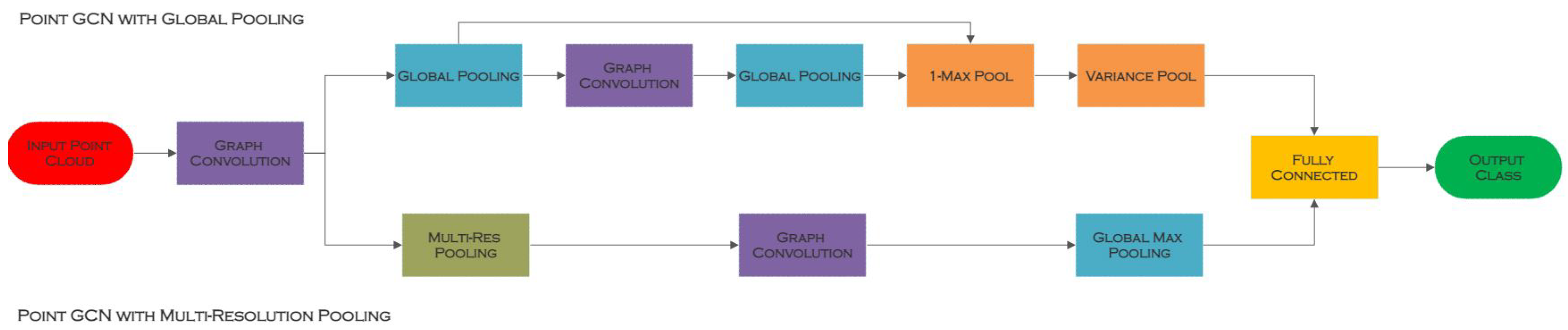
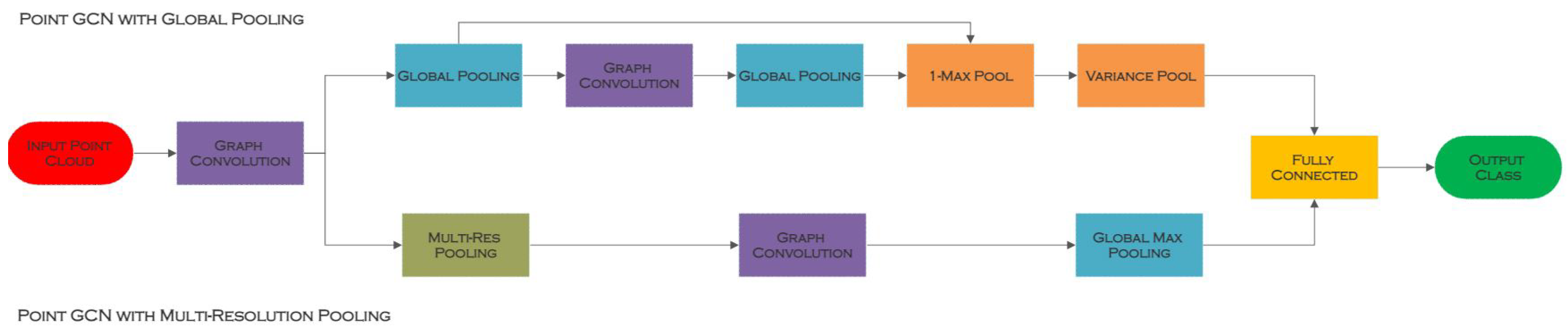
5.3. PointGCN
5.4. MeshCNN
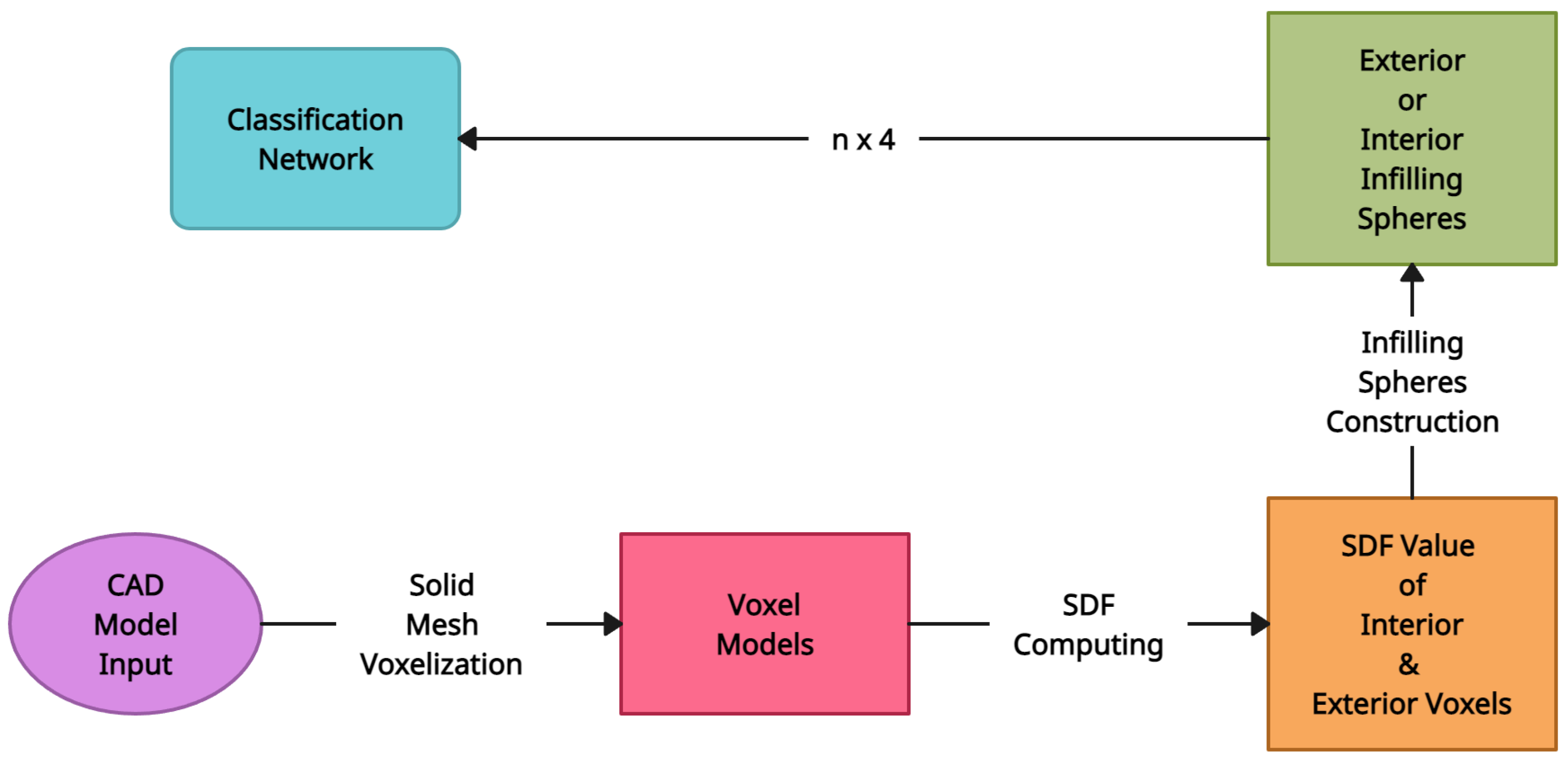
5.5. InSphereNet
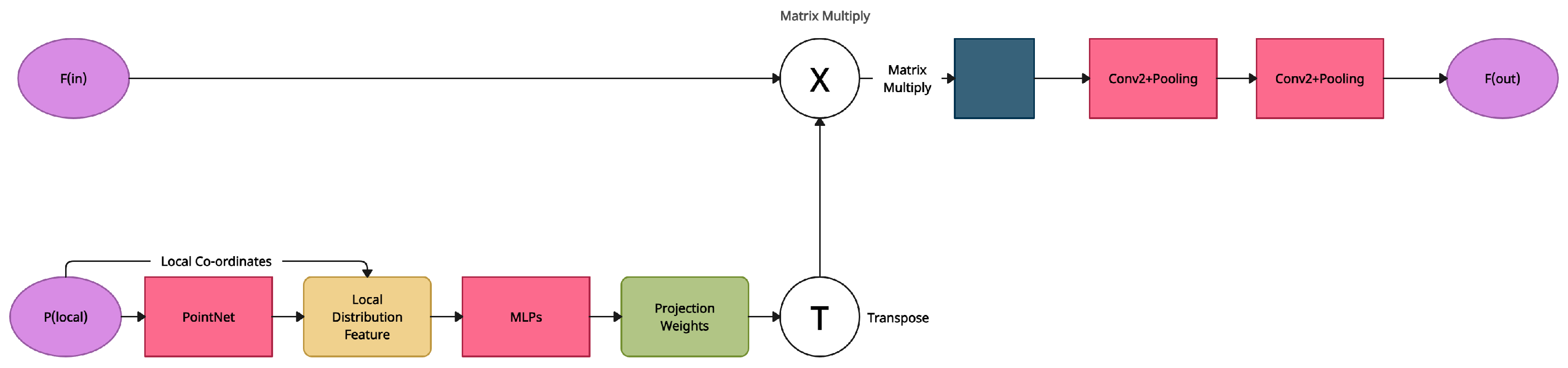
5.6. FPConv
5.7. Global-Local Bidirectional Reasoning (GLR)
5.8. Rigid Subset Mix (RSMix)
5.9. GDANet
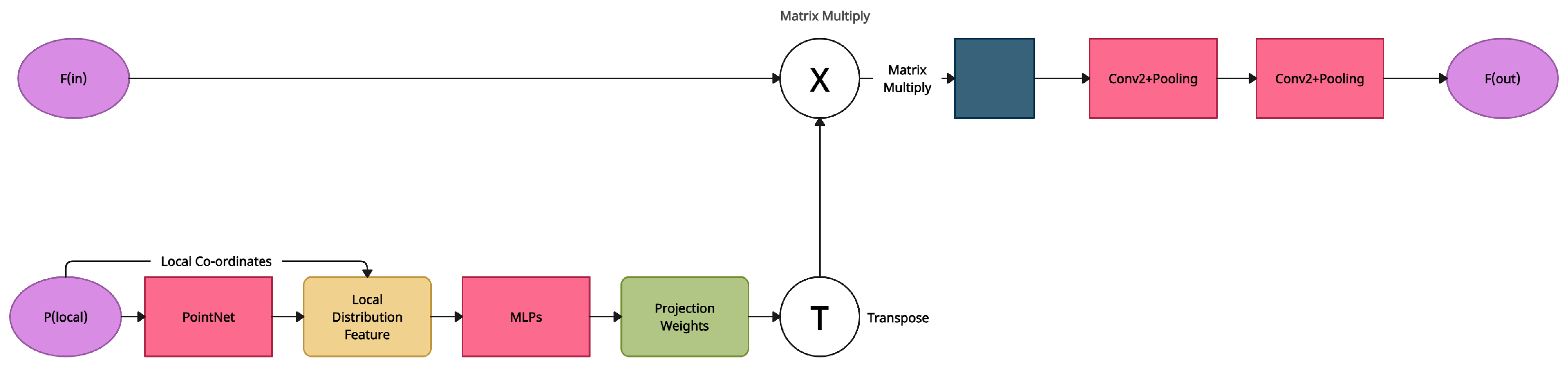
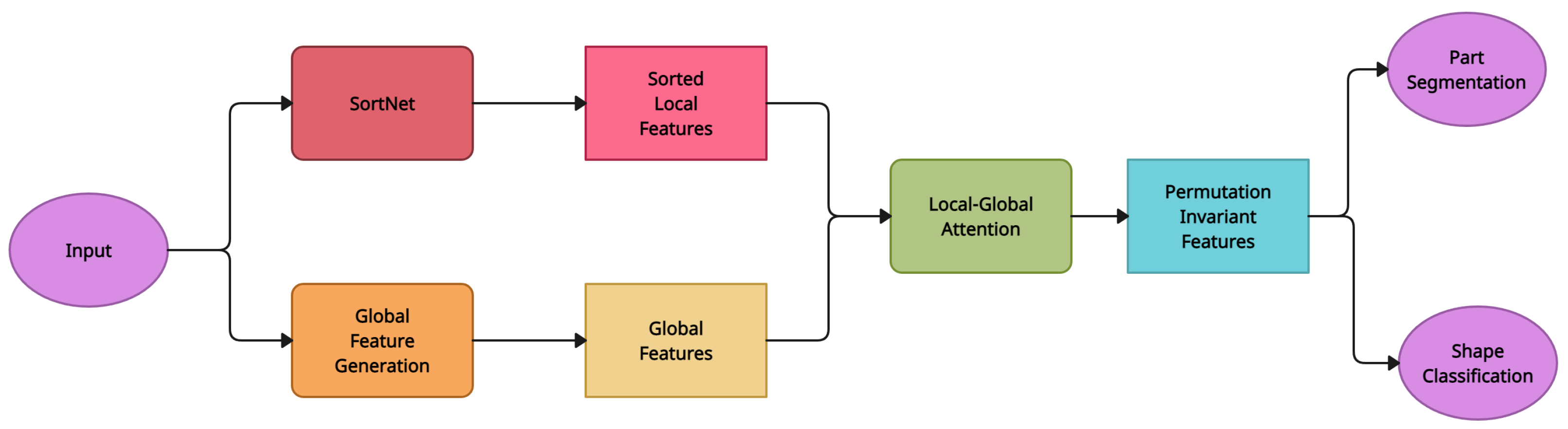
5.10. Point Transformer
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | three-dimensional |
| 2D | two-dimensional |
| LiDAR | Light Detection And Ranging |
| RGB-D | Red, Green, Blue plus Depth |
| CAD | Computer-Aided Design |
| MLP | Multiple Layer Perceptron |
| BEV | Bird’s Eye View |
| CNN | Convolutional Neural Network |
| GRA | Group Relation Aggregator |
| GPU | Graphics Processing Unit |
| RAM | Random Access Memory |
| MRI | Magnetic Resonance Imaging |
| SECOND | Sparsely Embedded CONvolutional Detection |
| IoU | Intersection over Union |
| RPN | Region Proposal Network |
| GLR | Global-Local Bidirectional Reasoning |
References
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; Available online: http://xxx.lanl.gov/abs/1812.04244 (accessed on 1 February 2023).
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. STD: Sparse-to-Dense 3D Object Detector for Point Cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–27 November 2019; Available online: http://xxx.lanl.gov/abs/1907.10471 (accessed on 1 February 2023).
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Available online: http://xxx.lanl.gov/abs/1812.05784 (accessed on 1 February 2023).
- He, C.; Zeng, H.; Huang, J.; Hua, X.S.; Zhang, L. Structure Aware Single-Stage 3D Object Detection From Point Cloud. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11870–11879. [Google Scholar] [CrossRef]
- Sautier, C.; Puy, G.; Gidaris, S.; Boulch, A.; Bursuc, A.; Marlet, R. Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data. arXiv 2022, arXiv:2203.16258. [Google Scholar]
- Zhang, Y.; Rabbat, M. A graph-cnn for 3d point cloud classification. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6279–6283. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; Available online: http://xxx.lanl.gov/abs/1712.02294 (accessed on 1 February 2023).
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Honolulu, HI, USA, 21–26 July 2019; pp. 9297–9307. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3d semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1534–1543. [Google Scholar]
- Qi, C.R.; Chen, X.; Litany, O.; Guibas, L.J. ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; Available online: http://xxx.lanl.gov/abs/2001.10692 (accessed on 1 February 2023).
- Hanocka, R.; Hertz, A.; Fish, N.; Giryes, R.; Fleishman, S.; Cohen-Or, D. Meshcnn: A network with an edge. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Zhu, J.; Zhang, R. Meta-RangeSeg: LiDAR Sequence Semantic Segmentation Using Multiple Feature Aggregation. arXiv 2022, arXiv:2202.13377. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 17–19 June 2015; pp. 1912–1920. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Uy, M.A.; Pham, Q.H.; Hua, B.S.; Nguyen, T.; Yeung, S.K. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF International conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 1588–1597. [Google Scholar]
- Memmel, M.; Reich, C.; Wagner, N.; Saeedan, F. Scalable 3D Semantic Segmentation for Gun Detection in CT Scans. arXiv 2021, arXiv:2112.03917. [Google Scholar]
- Kanezaki, A.; Matsushita, Y.; Nishida, Y. Rotationnet: Joint object categorization and pose estimation using multiviews from unsupervised viewpoints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5010–5019. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3DSSD: Point-Based 3D Single Stage Object Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
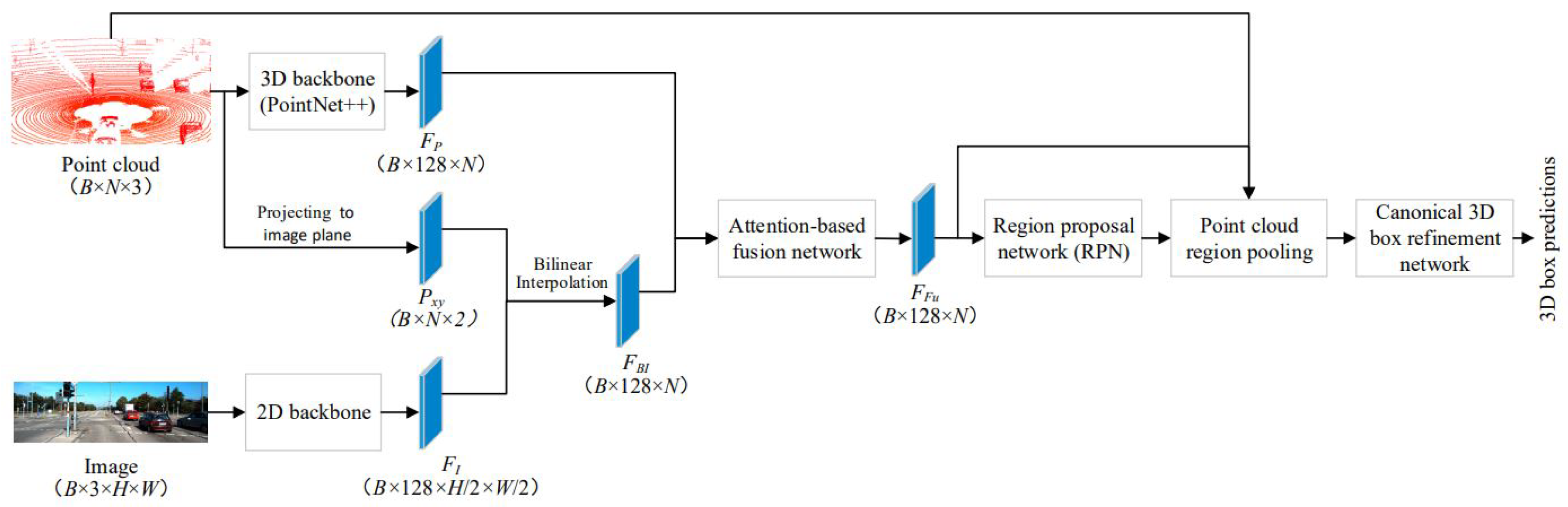
- Liu, L.; He, J.; Ren, K.; Xiao, Z.; Hou, Y. A LiDAR–Camera Fusion 3D Object Detection Algorithm. Information 2022, 13, 169. [Google Scholar] [CrossRef]
- Yang, X.; Zou, H.; Kong, X.; Huang, T.; Liu, Y.; Li, W.; Wen, F.; Zhang, H. Semantic Segmentation-assisted Scene Completion for LiDAR Point Clouds. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3555–3562. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Shilane, P.; Min, P.; Kazhdan, M.; Funkhouser, T. The princeton shape benchmark. In Proceedings of the Shape Modeling Applications, Genova, Italy, 7–9 June 2004; pp. 167–178. [Google Scholar]
- Ran, H.; Zhuo, W.; Liu, J.; Lu, L. Learning inner-group relations on point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15477–15487. [Google Scholar]
- Cao, H.; Du, H.; Zhang, S.; Cai, S. Inspherenet: A concise representation and classification method for 3d object. In Proceedings of the International Conference on Multimedia Modeling, Daejeon, Republic of Korea, 5–8 January 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–339. [Google Scholar]
- Lin, Y.; Yan, Z.; Huang, H.; Du, D.; Liu, L.; Cui, S.; Han, X. Fpconv: Learning local flattening for point convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4293–4302. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Global-local bidirectional reasoning for unsupervised representation learning of 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5376–5385. [Google Scholar]
- Lee, D.; Lee, J.; Lee, J.; Lee, H.; Lee, M.; Woo, S.; Lee, S. Regularization strategy for point cloud via rigidly mixed sample. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2021; pp. 15900–15909. [Google Scholar]
- Xu, M.; Zhang, J.; Zhou, Z.; Xu, M.; Qi, X.; Qiao, Y. Learning geometry-disentangled representation for complementary understanding of 3d object point cloud. arXiv 2021, arXiv:2012.10921. [Google Scholar] [CrossRef]
- Engel, N.; Belagiannis, V.; Dietmayer, K. Point transformer. IEEE Access 2021, 9, 134826–134840. [Google Scholar] [CrossRef]
- Hua, B.S.; Pham, Q.H.; Nguyen, D.T.; Tran, M.K.; Yu, L.F.; Yeung, S.K. SceneNN: A Scene Meshes Dataset with aNNotations. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 92–101. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Hatamizadeh, A.; Nath, V.; Tang, Y.; Yang, D.; Roth, H.; Xu, D. Swin UNETR: Swin Transformers for Semantic Segmentation of Brain Tumors in MRI Images. arXiv 2022, arXiv:2201.01266. [Google Scholar]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S.; et al. The RSNA-ASNR-MICCAI BraTS 2021 benchmark on brain tumor segmentation and radiogenomic classification. arXiv 2021, arXiv:2107.02314. [Google Scholar]
- Zou, Z.; Li, Y. Efficient Urban-scale Point Clouds Segmentation with BEV Projection. arXiv 2021, arXiv:2109.09074. [Google Scholar]
- Huang, S.Y.; Hsu, H.Y.; Wang, Y.C.F. SPoVT: Semantic-Prototype Variational Transformer for Dense Point Cloud Semantic Completion. In Proceedings of the Advances in Neural Information Processing Systems, San Francisco, CA, USA, 30 November–3 December 1992. [Google Scholar]
- Xie, S.; Song, R.; Zhao, Y.; Huang, X.; Li, Y.; Zhang, W. Circular Accessible Depth: A Robust Traversability Representation for UGV Navigation. arXiv 2022, arXiv:2212.13676. [Google Scholar]
- Kharroubi, A.; Poux, F.; Ballouch, Z.; Hajji, R.; Billen, R. Three Dimensional Change Detection Using Point Clouds: A Review. Geomatics 2022, 2, 457–485. [Google Scholar] [CrossRef]
- Xia, Z.; Liu, Y.; Li, X.; Zhu, X.; Ma, Y.; Li, Y.; Hou, Y.; Qiao, Y. SCPNet: Semantic Scene Completion on Point Cloud. arXiv 2023, arXiv:2303.06884. [Google Scholar]
- Ma, X.; Qin, C.; You, H.; Ran, H.; Fu, Y. Rethinking network design and local geometry in point cloud: A simple residual MLP framework. arXiv 2022, arXiv:2202.07123. [Google Scholar]
- Ran, H.; Liu, J.; Wang, C. Surface representation for point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18942–18952. [Google Scholar]
- Floris, A.; Frittoli, L.; Carrera, D.; Boracchi, G. Composite Layers for Deep Anomaly Detection on 3D Point Clouds. arXiv 2022, arXiv:2209.11796. [Google Scholar]
- Zhan, L.; Li, W.; Min, W. FA-ResNet: Feature affine residual network for large-scale point cloud segmentation. Int. J. Appl. Earth Obs. Geoinf. 2023, 118, 103259. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. arXiv 2022, arXiv:2201.09873. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Tang, Y.; Wang, C.; Landman, B.A.; Zhou, S.K. Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives. Med. Image Anal. 2023, 85, 102762. [Google Scholar] [CrossRef]
- Amin, J.; Anjum, M.A.; Gul, N.; Sharif, M. A secure two-qubit quantum model for segmentation and classification of brain tumor using MRI images based on blockchain. Neural Comput. Appl. 2022, 34, 17315–17328. [Google Scholar] [CrossRef]
- Yang, H.; Yang, D. CSwin-PNet: A CNN-Swin Transformer combined pyramid network for breast lesion segmentation in ultrasound images. Expert Syst. Appl. 2023, 213, 119024. [Google Scholar] [CrossRef]
- Cui, C.; Ren, Y.; Liu, J.; Huang, R.; Zhao, Z. VarietySound: Timbre-Controllable Video to Sound Generation via Unsupervised Information Disentanglement. arXiv 2022, arXiv:2211.10666. [Google Scholar]
- Ding, B. LENet: Lightweight And Efficient LiDAR Semantic Segmentation Using Multi-Scale Convolution Attention. arXiv 2023, arXiv:2301.04275. [Google Scholar]
- Zhang, R.; Wang, L.; Qiao, Y.; Gao, P.; Li, H. Learning 3D Representations from 2D Pre-trained Models via Image-to-Point Masked Autoencoders. arXiv 2022, arXiv:2212.06785. [Google Scholar]
- Zhang, L.; Dong, R.; Tai, H.S.; Ma, K. Pointdistiller: Structured knowledge distillation towards efficient and compact 3d detection. arXiv 2022, arXiv:2205.11098. [Google Scholar]
- Chen, R.; Liu, Y.; Kong, L.; Zhu, X.; Ma, Y.; Li, Y.; Hou, Y.; Qiao, Y.; Wang, W. CLIP2Scene: Towards Label-efficient 3D Scene Understanding by CLIP. arXiv 2023, arXiv:2301.04926. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Yin, T.; Zhou, X.; Krahenbuhl, P. Center-based 3d object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-ensembling single-stage object detector from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14494–14503. [Google Scholar]
- Fernandes, D.; Silva, A.; Névoa, R.; Simões, C.; Gonzalez, D.; Guevara, M.; Novais, P.; Monteiro, J.; Melo-Pinto, P. Point-cloud based 3D object detection and classification methods for self-driving applications: A survey and taxonomy. Inf. Fusion 2021, 68, 161–191. [Google Scholar] [CrossRef]
- Weng, X.; Wang, J.; Held, D.; Kitani, K. 3D Multi-Object Tracking: A Baseline and New Evaluation Metrics. 2020. Available online: http://xxx.lanl.gov/abs/1907.03961 (accessed on 1 February 2023).
- Zhou, X.; Koltun, V.; Krähenbühl, P. Tracking objects as points. In Computer Vision–ECCV 2020: Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–490. [Google Scholar]
- Du, G.; Wang, K.; Lian, S.; Zhao, K. Vision-based robotic grasping from object localization, object pose estimation to grasp estimation for parallel grippers: A review. Artif. Intell. Rev. 2021, 54, 1677–1734. [Google Scholar] [CrossRef]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Qi, C.R.; Litany, O.; He, K.; Guibas, L.J. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; Available online: http://xxx.lanl.gov/abs/1904.09664 (accessed on 1 February 2023).
- Leibe, B.; Leonardis, A.; Schiele, B. Combined object categorization and segmentation with an implicit shape model. In Proceedings of the Workshop on Statistical Learning in Computer Vision, ECCV, Prague, Czech Republic, 15 May 2004; Volume 2, p. 7. [Google Scholar]
- Song, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 567–576. [Google Scholar]
- Misra, I.; Girdhar, R.; Joulin, A. An end-to-end transformer model for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2906–2917. [Google Scholar]
- Zhang, Y.; Liu, K.; Bao, H.; Zheng, Y.; Yang, Y. PMPF: Point-Cloud Multiple-Pixel Fusion-Based 3D Object Detection for Autonomous Driving. Remote Sens. 2023, 15, 1580. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, Z.; Zhao, X.; Ji, R.; Gao, Y. Gvcnn: Group-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 264–272. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. Deepsdf: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 165–174. [Google Scholar]
- Qi, S.; Ning, X.; Yang, G.; Zhang, L.; Long, P.; Cai, W.; Li, W. Review of multi-view 3D object recognition methods based on deep learning. Displays 2021, 69, 102053. [Google Scholar] [CrossRef]
- Chen, C.; Fragonara, L.Z.; Tsourdos, A. GAPNet: Graph attention based point neural network for exploiting local feature of point cloud. arXiv 2019, arXiv:1905.08705. [Google Scholar]
- Kim, S.; Park, J.; Han, B. Rotation-invariant local-to-global representation learning for 3d point cloud. Adv. Neural Inf. Process. Syst. 2020, 33, 8174–8185. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Zeng, Z.; Yuan, D.; Qiu, Q. DGANet: A dilated graph attention-based network for local feature extraction on 3D point clouds. Remote Sens. 2021, 13, 3484. [Google Scholar] [CrossRef]
- Pfaff, T.; Fortunato, M.; Sanchez-Gonzalez, A.; Battaglia, P.W. Learning mesh-based simulation with graph networks. arXiv 2020, arXiv:2010.03409. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Sharp, N.; Attaiki, S.; Crane, K.; Ovsjanikov, M. Diffusionnet: Discretization agnostic learning on surfaces. ACM Trans. Graph. (TOG) 2022, 41, 1–16. [Google Scholar] [CrossRef]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. Paconv: Position adaptive convolution with dynamic kernel assembling on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3173–3182. [Google Scholar]
- Afham, M.; Dissanayake, I.; Dissanayake, D.; Dharmasiri, A.; Thilakarathna, K.; Rodrigo, R. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9902–9912. [Google Scholar]
- Xiao, A.; Huang, J.; Guan, D.; Lu, S. Unsupervised representation learning for point clouds: A survey. arXiv 2022, arXiv:2202.13589. [Google Scholar]
- Chen, Y.; Liu, J.; Ni, B.; Wang, H.; Yang, J.; Liu, N.; Li, T.; Tian, Q. Shape self-correction for unsupervised point cloud understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 8382–8391. [Google Scholar]
- Sun, C.Y.; Yang, Y.Q.; Guo, H.X.; Wang, P.S.; Tong, X.; Liu, Y.; Shum, H.Y. Semi-supervised 3D shape segmentation with multilevel consistency and part substitution. Comput. Vis. Media 2023, 9, 229–247. [Google Scholar] [CrossRef]
- Ren, J.; Pan, L.; Liu, Z. Benchmarking and analyzing point cloud classification under corruptions. In Proceedings of the International Conference on Machine Learning (PMLR 2022), Baltimore, MD, USA, 17–23 July 2022; pp. 18559–18575. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modality | Method Category | Methods |
|---|---|---|
| LiDAR-based | Voxel-based | VoxelNet [1], SECOND [2] |
| LiDAR-based | Point-based | PointRCNN [3], STD [4], PointPillars [5], SA-SSD [6], SLidR [7] |
| LiDAR-based | Graph-based | PointGCN [8] |
| LiDAR-Camera Fusion | Multi-view | AVOD [9] |
| Datasets | Number of Frames | Number of Labels | Object Type | 5 Common Classes | URL |
|---|---|---|---|---|---|
| KITTI 3D Object Detection [16] | 12,000 | 40,000 | Scans of autonomous driving platform | Car, Cylclist, Pedestrian, Tram, Van | https://www.cvlibs.net/datasets/kitti/ (accessed on: 1 February 2023) |
| SemanticKITTI [11] | 43,000 | 25 | Scans from KITTI Vision odometry | Bicycle, Bicyclist, Building, Car, Fence | http://www.semantic-kitti.org/dataset.html (accessed on: 1 February 2023) |
| ModelNet [17] | 151,128 | 660 | 3D CAD scans | Bed, Chair, Desk, Sofa, Table | https://modelnet.cs.princeton.edu/ (accessed on: 1 February 2023) |
| S3DIS [12] | 271 | 12 | Scans of restrooms, lobbies, stairways, hallways | Beam, Board, Chair, Door, Sofa | http://buildingparser.stanford.edu/ (accessed on: 1 February 2023) |
| nuScene [18] | 1000 | 23 | Scans of autonomous driving platform | Bicycle, Car, Lane, Stop Line, Walkaway | https://nuscenes.org/ (accessed on: 1 February 2023) |
| ScanNet [19] | 2,492,518 | 1513 | Scans of bedrooms, kitchen, offices | Bed, Chair, Desk, Door, Floor | http://www.scan-net.org/ (accessed on: 1 February 2023) |
| ScanObjectNN [20] | 15,000 | 2902 | Scans of bedrooms, kitchen, offices | Bag, Bed, Bin, Box, Desk | https://hkust-vgd.github.io/scanobjectnn/ (accessed on: 1 February 2023) |
| Models | Dataset | Average Precision (AP) | IoU Threshold |
|---|---|---|---|
| VoxelNet [1] | KITTI 3D Object Detection [16] | 81.97 | 0.7 |
| AVOD [9] | KITTI 3D Object Detection [16] | 84.41 | 0.7 |
| SECOND [2] | KITTI 3D Object Detection [16] | 87.43 | 0.7 |
| PointRCNN [3] | KITTI 3D Object Detection [16] | 88.88 | 0.7 |
| STD [4] | KITTI 3D Object Detection [16] | 89.7 | 0.7 |
| 3DSSD [23] | KITTI 3D Object Detection [16] | 89.71 | 0.7 |
| SA-SSD [6] | KITTI 3D Object Detection [16] | 90.15 | 0.7 |
| PointPillars [5] | KITTI 3D Object Detection [16] | 90.19 | 0.7 |
| FuDNN [24] | KITTI 3D Object Detection [16] | 92.48 | 0.7 |
| Models | Dataset | Accuracy |
|---|---|---|
| PointGCN [8] | ModelNet10 [17] | 91.91 |
| GLR [31] | ModelNet10 [17] | 95.53 |
| RSMix [32] | ModelNet10 [17] | 95.9 |
| RotationNet [22] | ModelNet10 [17] | 98.46 |
| Models | Dataset | AP |
|---|---|---|
| PointGCN [8] | ModelNet40 [17] | 89.51 |
| InSphereNet [29] | ModelNet40 [17] | 92.1 |
| FPConv [30] | ModelNet40 [17] | 92.5 |
| Point Transformer | ModelNet40 [17] | 92.8 |
| GLR [31] | ModelNet40 [17] | 93.02 |
| RSMix [32] | ModelNet40 [17] | 93.5 |
| GDANet [33] | ModelNet40 [17] | 93.8 |
| RPNet [28] | ModelNet40 [17] | 94.1 |
| RotationNet [22] | ModelNet40 [17] | 97.37 |
| Models | Dataset | Mean Per-Class IoU (%) |
|---|---|---|
| FPConv [30] | S3DIS [12] | 66.7 |
| GRA [28] | S3DIS [12] | 70.8 |
| Models | Dataset | Accuracy |
|---|---|---|
| GLR [31] | ScanObjectNN [20] | 87.2 |
| GDANet [33] | ScanObjectNN [20] | 88.5 |
| Models | Technology | Datasets Used | BackBone |
|---|---|---|---|
| 3D-CNN [25] | Bird’s Eye View (BEV) projection | SemanticKITTI [11] | 2DCNN |
| RPNet [28] | Group Relation Aggregator (GRA) | ModelNet40 [17], ScanNet [19], S3DIS [12] | PointNet++ [36] |
| HiLo [21] | Semantic Segmentation | 3D-CT | CNN, O-Net |
| Swin UNETR [37] | Semantic Segmentation | Multi-modal Brain Tumor Segmentation Challenge (BraTS) [38] | Swin Transformer |
| Meta-RangeSeg [15] | Range Residual Image | SemanticKITTI [11] | U-Net |
| SLiDR [7] | Image-to-LiDAR Self-supervised Distillation | nuScenes [18], SemanticKITTI [11] | U-Net |
| Models | Technology | Advantages | Limitations |
|---|---|---|---|
| 3D-CNN [25] | Bird’s Eye View (BEV) projection | Addressed the issue of Occlusion by using deep learning to fill in the occluded parts | This approach depends heavily on voxel-wise completion labels and perform poorly on little, distant objects and cluttered scenes |
| RPNet [28] | Group Relation Aggregator (GRA) | Uses relations to learn from local structural information essential for learning point cloud information | Non-convolutional as the input of it’s MLPs contains the absolute location of the points |
| HiLo [21] | Semantic Segmentation | Can successfully separate firearms within baggage | None of the evaluated super-resolution O-Net topologies can attain the necessary results |
| Swin UNETR [37] | Semantic Segmentation | Computes self-attention via an efficient shifting window partitioning algorithm and ranks first on the BraTs 2021 validation set [38] | Requires a swin transformer to extract and down-sample feature maps before feeding them into a transformer |
| Meta-RangeSeg [15] | Range Residual Image | This technique can handle the problem of hazy segmentation borders | Requires boundary loss function to handle the problem of hazy segmentation borders |
| SLiDR [7] | Image-to-LiDAR Self-supervised Distillation | Pre-training process does not require any annotation of the images nor of the point clouds | Heavily reliant on a huge collection of annotated point clouds |
| Models | Technology | Datasets Used | BackBone |
|---|---|---|---|
| VoxelNet [1] | Voxel Feature Encoding | KITTI 3D Object Detection [16] | PointNet [57], Regional Proposal Network (RPN) |
| SECOND [2] | Sparse Convolution | KITTI 3D Object Detection [16] | Sparse Convolution, Regional Proposal Network (RPN) |
| PointPillars [5] | Pointcloud to Pseudo-Image Conversion | KITTI 3D Object Detection [16] | 2DCNN |
| SA-SSD [6] | Feature Map Warping | KITTI 3D Object Detection [16] | Auxiliary Network (CNN) |
| STD [4] | Proposal Feature Generation | KITTI 3D Object Detection [16] | PointNet++ [36] |
| PointRCNN [3] | Bottom-Up 3D Proposal Generation | KITTI 3D Object Detection [16] | PointNet++ [36] |
| 3DSSD [23] | Fusion of D-FPS and F-FPS | KITTI 3D Object Detection [16], nuScenes [18] | Multi-Layer Perceptron (MLP) |
| IMVoteNet [13] | Reformulated Hough Voting | SUN RBG-D | PointNet++ [36] |
| AVOD [9] | Multimodal Feature Fusion | KITTI 3D Object Detection [16] | Feature Fusion Regional Proposal Network (RPN) |
| FuDNN [24] | Attention-based Fusion | KITTI 3D Object Detection [16] | 2DCNN, Region Proposal Network (RPN) |
| Models | Technology | Advantages | Limitations |
|---|---|---|---|
| VoxelNet [1] | Voxel Feature Encoding | Demonstrates that switching from a box representation to a center-based representation results in a 3-4 mAP boost | Requires a 3D encoder to quantize the point-cloud into regular bins |
| SECOND [2] | Sparse Convolution | Streamlines the VoxelNet and accelerates sparse 3D convolutions | Similar to VoxelNet [1], a 3D encoder is used that adds needless costs when selecting thresholds for different classes or datasets |
| PointPillars [5] | Pointcloud to Pseudo-Image Conversion | Demonstrated a lidar-only solution that outperformed many previous fusion-based algorithms. Quickest recorded method in terms of inference time | More effort is required to integrate multimodal measures in a principled way |
| SA-SSD [6] | Feature Map Warping | This work enhances feature representation by utilising auxiliary tasks without incurring additional computing burden during inference | Similar to VoxelNet [1] and SECOND [2], a 3D encoder is required to quantize the point-cloud into regular bins |
| STD [4] | Proposal Feature Generation | Uses a refinement network that is completely independent of the previous pipeline step, which provides more alternatives in terms of training and testing methodologies, resulting in better results | Increases inference time |
| PointRCNN [3] | Bottom-Up 3D Proposal Generation | Extracts discriminative features directly from raw point clouds for 3D detection | Suffers from the sparse and non-uniform point distribution, as well as the time-consuming process of sampling and searching for nearby points |
| 3DSSD [23] | Fusion of D-FPS and F-FPS | Achieves a good combination of accuracy and efficiency | Suffers from the sparse and non-uniform point distribution, as well as the time-consuming process of sampling and searching for nearby points |
| IMVoteNet [13] | Reformulated Hough Voting | Primarily based on the set abstraction operation, which permits adjustable receptive fields for learning point cloud features | Depends on Non-Maximal Suppression (NMS) as a post-processing step to eliminate the loss |
| AVOD [9] | Multimodal Feature Fusion | Converts irregular point clouds to 2D bird-view maps, which may then be effectively processed by 3D or 2D CNN to train point features for 3D detection | Hard-coded feature extraction method may not extend to new setups without substantial engineering work |
| FuDNN [24] | Attention-based Fusion | Creates 3D region proposals based on a bird’s-eye view and conducts 3D bounding box regression | Texture information in the picture data may not be properly exploited. |
| Models | Technology | Datasets Used | BackBone |
|---|---|---|---|
| OctNet [10] | Hybrid Grid-OctTree Data Structure | ModelNet10 [17] | U-shaped Network |
| RotationNet [22] | Pose Estimation from Multi-View Images of an Object | ModelNet10 [17], ModelNet40 [17], MIRO | CNN |
| PointGCN [8] | Graph Convolutions and Graph Downsampling Operations | ModelNet10 [17], ModelNet40 [17] | GCN |
| MeshCNN [14] | Convolution, Poling and Unpooling of Mesh | SHREC, COSEG | CNN |
| InSphereNet [29] | Signed Distance Field (SDF) Computation | ModelNet40 [17] | MLP |
| FPConv [30] | Flattening Projection Convolution | ModelNet40 [17], S3DIS [12] | 2DCNN |
| GLR [31] | Unsupervised Feature Learning | ModelNet10 [17], ModelNet40 [17], ScanObjectNN [20] | PointNet++ [36], Relation-Shape CNN (RSCNN) |
| RSMix [32] | Shape-preserving Data Augmentation | ModelNet10 [17], ModelNet40 [17] | Pointnet++ [36], DGCNN |
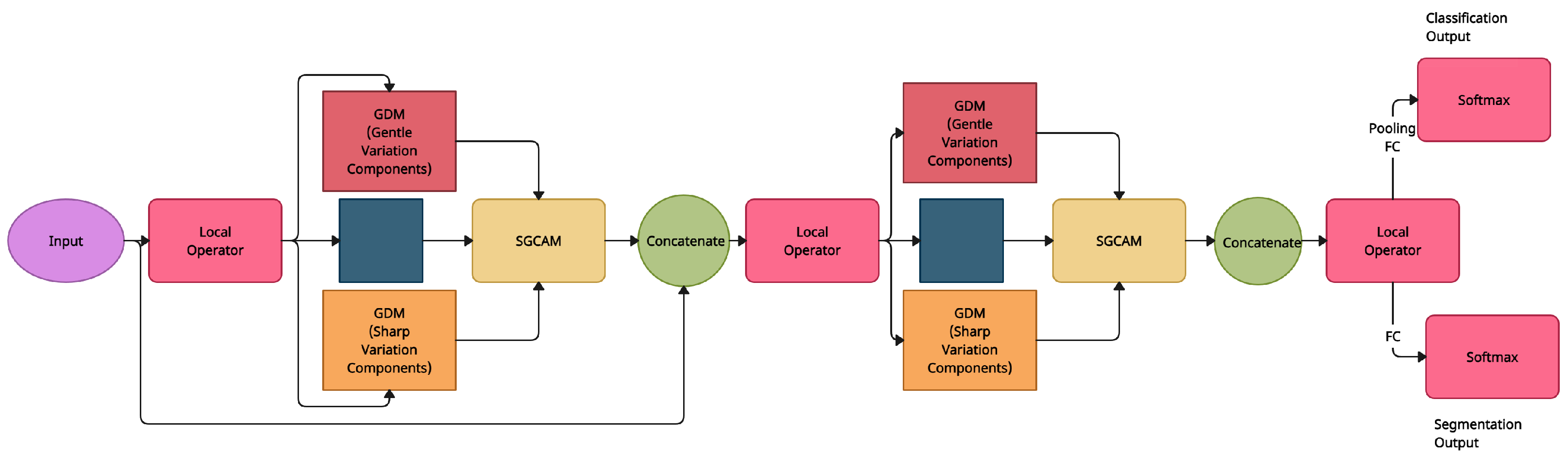
| GDANet [33] | Geometry Disentanglement | ModelNet40 [17], ScanObjectNN [20] | GDM, SGCAM |
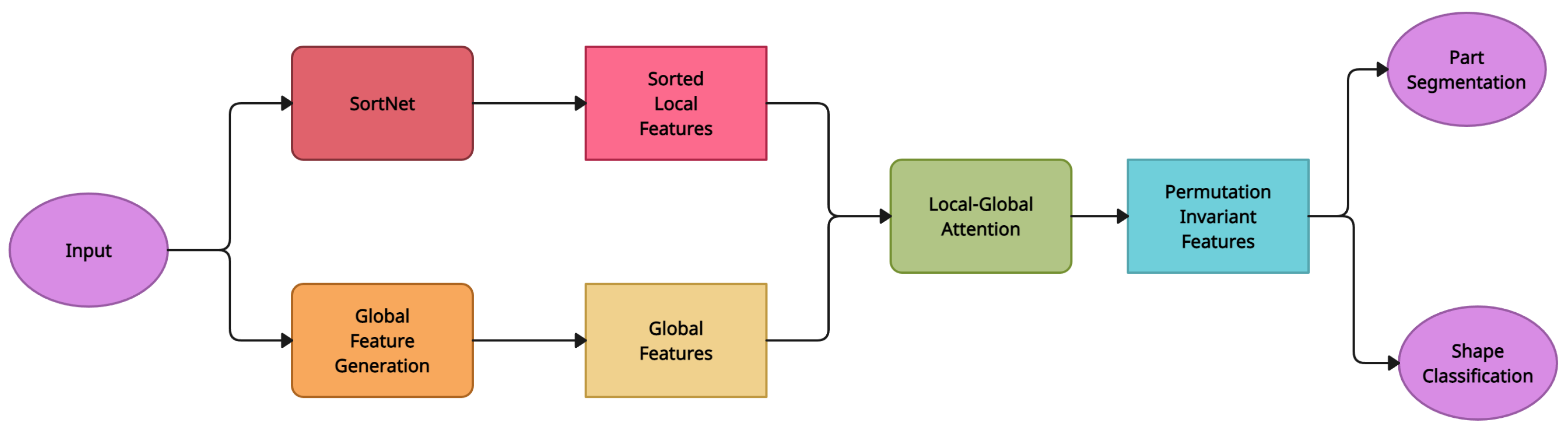
| Point Transformer [34] | Local-Global Attention Mechanism | ModelNet40 [17] | SortNet |
| Models | Technology | Advantages | Limitations |
|---|---|---|---|
| OctNet [10] | Hybrid Grid-OctTree Data Structure | Employs octrees that allows for wider grids and improved speed | Octrees are imbalanced and have hierarchical divisions. This network lacks flexibility because its kernels are limited to 27 or 125 voxels |
| RotationNet [22] | Pose Estimation from Multi-View Images of an Object | Employs AlexNet [74] as the backbone network, which is smaller than the VGG-M [75] network design and can achieve competitive performance for 3D object retrieval and categorization | Needs each image to be viewed from one of the predetermined views, which is quite limiting when there are fewer predefined viewpoints. Evaluating all perspectives necessitates a significant amount of computing, and not every view is useful for recognition. |
| PointGCN [8] | Graph Convolutions and Graph Downsampling | Creates a graph CNN architecture to capture local structure and categorise point clouds, demonstrating the enormous potential of geometric deep learning for unordered point cloud research | K-NN is utilised which is incapable of integrating long-distance geometric correlations in a constrained environment, restricting the geometric representation of local points and assisting the point network in capturing more local information |
| MeshCNN [14] | Convolution, Pooling and Unpooling of Mesh | Works on meshes that are increasingly being used for learnt geometry and form processing | Mesh-based simulations have not found considerable usage in machine learning for physics prediction. Too expensive to run. |
| InSphereNet [29] | Signed Distance Field (SDF) Computation | Outperforms PointNet [57] especially when the number of DNN layers and parameters are reduced significantly, the results are still good | Infilling spheres remain unstructured |
| FPConv [30] | Flattening Projection Convolution | Uses soft weights to flatten local patches onto conventional 2D grids | Strongly relies on tangent plane estimate, and the projection procedure will unavoidably compromise 3D geometry information |
| GLR [31] | Unsupervised Feature Learning | Effectively captures the underlying high-level semantic information and achieves improved performance on classification tests | Based on hierarchical local features and is not ideal for networks such as PointNet |
| RSMix [32] | Shape-preserving Data Augmentation | Point cloud augmentation techniques can improve point cloud classification and can be extended to shape segmentation | Uses rigid transformation to combine two point clouds making classifiers become more susceptible to scaling effects |
| GDANet [33] | Geometry Disentanglement | Creates sophisticated grouping strategies like Frequency Grouping to include structural prior into architecture design | Frequency grouping takes more time during both training and assessment |
| Point Transformer [34] | Local-Global Attention Mechanism | SortNet is used to generate point cloud local features making the output of local-global attention ordered and permutation invariant. This makes it useful for visual tasks such as form classification and part-segmentation. | Inclusion of delicate extractors significantly increases computing complexity, resulting in prohibitive inference delay. With the introduction of local feature extractors, the performance increase on prominent benchmarks has begun to saturate. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vinodkumar, P.K.; Karabulut, D.; Avots, E.; Ozcinar, C.; Anbarjafari, G. A Survey on Deep Learning Based Segmentation, Detection and Classification for 3D Point Clouds. Entropy 2023, 25, 635. https://doi.org/10.3390/e25040635
Vinodkumar PK, Karabulut D, Avots E, Ozcinar C, Anbarjafari G. A Survey on Deep Learning Based Segmentation, Detection and Classification for 3D Point Clouds. Entropy. 2023; 25(4):635. https://doi.org/10.3390/e25040635
Chicago/Turabian StyleVinodkumar, Prasoon Kumar, Dogus Karabulut, Egils Avots, Cagri Ozcinar, and Gholamreza Anbarjafari. 2023. "A Survey on Deep Learning Based Segmentation, Detection and Classification for 3D Point Clouds" Entropy 25, no. 4: 635. https://doi.org/10.3390/e25040635
APA StyleVinodkumar, P. K., Karabulut, D., Avots, E., Ozcinar, C., & Anbarjafari, G. (2023). A Survey on Deep Learning Based Segmentation, Detection and Classification for 3D Point Clouds. Entropy, 25(4), 635. https://doi.org/10.3390/e25040635