Abstract
The remaining useful life (RUL) prediction of rolling bearings based on vibration signals has attracted widespread attention. It is not satisfactory to adopt information theory (such as information entropy) to realize RUL prediction for complex vibration signals. Recent research has used more deep learning methods based on the automatic extraction of feature information to replace traditional methods (such as information theory or signal processing) to obtain higher prediction accuracy. Convolutional neural networks (CNNs) based on multi-scale information extraction have demonstrated promising effectiveness. However, the existing multi-scale methods significantly increase the number of model parameters and lack efficient learning mechanisms to distinguish the importance of different scale information. To deal with the issue, the authors of this paper developed a novel feature reuse multi-scale attention residual network (FRMARNet) for the RUL prediction of rolling bearings. Firstly, a cross-channel maximum pooling layer was designed to automatically select the more important information. Secondly, a lightweight feature reuse multi-scale attention unit was developed to extract the multi-scale degradation information in the vibration signals and recalibrate the multi-scale information. Then, end-to-end mapping between the vibration signal and the RUL was established. Finally, extensive experiments were used to demonstrate that the proposed FRMARNet model can improve prediction accuracy while reducing the number of model parameters, and it outperformed other state-of-the-art methods.
1. Introduction
New industrial paradigms, including network collaborative manufacturing, industrial big data, and cyber-physical systems, have promoted the transformation of traditional manufacturing to intelligent manufacturing [1]. High accuracy, high reliability, and high efficiency are the main development directions of rotary machinery health monitoring against the background of intelligent manufacturing [2]. Various sensors installed on rotating machinery equipment can collect massive data, which contains a large amount of information related to equipment degradation. Therefore, big data provides new opportunities and challenges for rotating machinery health monitoring. Rotating machinery structures are becoming more complex and operate in harsh environments for long periods of time [3,4]. Rolling bearing is one of the most important components in rotating machinery whose abnormal state and fault may lead to equipment shutdown, resulting in huge economic losses and even safety accidents [5]. Therefore, to achieve predictive maintenance and improve the reliability of rotating machinery, it is necessary to carry out remaining useful life (RUL) prediction for the intelligent health monitoring of rolling bearings. RUL prediction is defined as an estimate of time to failure according to the International Organization for Standardization [6].
The RUL prediction methods of rolling bearings are mainly divided into model-based methods, data-driven methods, and hybrid methods [7]. The model-based method is based on the degradation mechanism of rolling bearings and relies on expert experience and prior knowledge to establish a physical model that can accurately reflect the changing trend of RUL. However, modern mechanical equipment is becoming more and more complex, and it is difficult or even impossible to establish such a physical model [8], the model-based approach is difficult to popularize in industrial applications. With the development of sensor technology and data transmission technology in recent years, data-based methods have developed rapidly [9]. The data-based method collects the monitoring data of rolling bearings, and then the machine learning (ML) model is adopted to establish a nonlinear mapping between easily obtained monitoring signals and difficult-to-obtain RUL values. This approach is mainly based on a large amount of data acquired by sensors and requires less inherent degradation mechanism and prior knowledge of the system. Hybrid methods are still based on rolling bearing degradation mechanisms and have the same disadvantages as physics-based methods. It is still challenging to establish effective hybrid models.
Among the above three approaches, data-driven methods have the advantages of simple implementation, fast response, high prediction accuracy, less prior knowledge, and expert experience, and they are conducive to deployment in real industrial applications. Therefore, data-driven methods have attracted the interest of many researchers in academia and industry [7]. Data-based methods can be further divided into traditional ML-based methods and deep learning-based methods. The traditional ML-based method is mainly divided into four steps: data acquisition, manual feature extraction and selection, model training, and RUL prediction [8,10]. However, there are two main problems with traditional ML methods. Firstly, with traditional ML methods, it is difficult to extract deep features from massive data and they cannot make full use of the advantages of big data [11]. Secondly, manual feature extraction and selection is time-consuming and challenging. The vibration signal of rolling bearings exhibits non-stationary and complex characteristics [12]. The degradation trend of mechanical equipment performance cannot be accurately obtained by artificial feature information extraction methods, such as information entropy [13]. It is not satisfactory to adopt information theory (such as information entropy) to realize RUL prediction for complex vibration signals. Deep learning (DL) can automatically and adaptively extract key feature information from vibration signals, which can well replace artificial feature information extraction based on methods such as information entropy or signal processing. Therefore, the lack of large-scale data processing and automatic feature information extraction capabilities limits the application of traditional ML methods in modern industry.
To deal with the above shortcomings, DL was proposed by Hinton in 2006 [14]. DL can automatically extract discriminative deep features from raw data by superimposing deep hidden layers and nonlinear transformation [15]. Therefore, in terms of processing flow, the most significant difference between DL-based methods and traditional ML-based methods is that automatic feature extraction replaces manual feature extraction. The DL model can automatically learn a set of optimal parameters for feature extraction without manual feature selection. The powerful feature extraction ability promotes DL to achieve promising performance in rotating machinery condition monitoring [16], fault diagnosis [17,18], and RUL prediction [5,19]. Many scholars have adopted DL technologies, such as auto-encoder [20], vanilla convolutional neural networks (CNNs) [21], residual networks (ResNets) [22], recurrent neural networks (RNNs) [23], and transformers [24] for RUL prediction. The methods based on DL have been widely used in the prediction of rolling bearing RUL. Specifically, CNN takes convolution operation as the core, the characteristics of sparse connection, and weight sharing to reduce the parameter number to be trained and the computational burden. The identity mapping of ResNet is beneficial for stacking deeper models for extracting deep features. The powerful feature extraction ability and efficient network training process contribute a CNN-based method to the most widely used model for RUL prediction of rolling bearings. In general, the convolution operation adopts a fixed convolution kernel for feature extraction. For convolution operation, a large convolution kernel is preferred to extract a large range of global information, while a small convolution kernel is preferred to extract a small range of local information. Therefore, the use of a fixed convolution kernel will inevitably lose feature information and lead to a decline in prediction accuracy. Researchers have developed many multi-scale CNN models for RUL prediction. Li et al. [9] adopted three parallel branches with different convolution kernels to extract multi-scale features in the raw data and then aggregated the features with a sum for RUL prediction. In the studies [2,25], multiple convolution kernels of different sizes have extracted features in parallel, and the sum of feature maps has been obtained after weighted processing for fault diagnosis. In addition, some other researchers have aggregated multi-branch feature information by concatenation. In the studies [26,27,28,29,30,31,32], convolution kernels of different sizes have been adopted to extract features in parallel and then concatenated together. However, the above multi-scale CNN methods for the RUL prediction of rolling bearings have two obvious disadvantages.
(1) Existing multi-scale CNN methods adopt different convolutional kernel branches to extract multi-scale features in parallel and then simply aggregate the feature maps by addition or concatenation. This method will significantly increase the parameter number of the model, which results in serious computational burden and parameter optimization difficulties. (2) Since the degradation features of rolling bearings may be distributed at different ranges at different stages of their life cycle, the features extracted by multibranch parallelization are redundant. Different convolutional channels may contain feature information of different scales. The existing methods lack cross-channel feature interaction and an explicit learning mechanism to efficiently distinguish the importance of feature information contained in different channels.
To tackle the aforementioned shortcomings, we propose an extremely lightweight DL model for the RUL prediction of rolling bearings, the so-called feature reuse multi-scale attention residual network (FRMARNet). In the proposed FRMARNet, a novel cross-channel feature interaction layer is first constructed to extract the more important feature information. Then, a feature reuse multi-scale attention (FRMA) learning strategy is developed by partitioning channels into groups, and the current group reuses the features of the previous group, which efficiently captures the features of various scales without increasing the model parameters. In the FRMA unit, the attention module is constructed to emphasize more important scale information. Finally, the learned high-level degradation features are fed into the regression layer to predict the RUL. A bearing RUL prediction experiment was conducted to evaluate the effectiveness and superiority of the proposed method. The experimental results indicate that the developed framework can obtain better prediction performance, and the accuracy was superior to other DL models. The main contributions of this paper can be summarized as follows.
(1) A cross-channel feature interaction mechanism is proposed to automatically select important feature information without increasing the model parameters and reducing the impact of low-value redundant information on subsequent network feature extraction.
(2) A new extremely lightweight FRMA unit is proposed for the RUL prediction of rolling bearings, which consists of a feature reuse multi-scale module and a multi-scale feature adaptive calibration module.
(3) FRMARNet was constructed using a feature interaction layer and by stacking multiple FRMA units. Extensive experiments were conducted to evaluate the developed method.
The rest parts of this paper are organized as follows. In the upcoming section, the theoretical background of ResNet and multi-scale CNN is presented. Section 3 details the proposed FRMARNet. In Section 4, bearing run-to-failure datasets are used to evaluate the effectiveness of the proposed method in improving the accuracy of RUL prediction. Finally, the conclusions are given in Section 5.
2. Theoretical Background
In this section, the basic structure of ResNet is presented, and then the basic principle of multi-scale CNN is introduced.
2.1. Basic Structure of ResNet
In recent years, ResNet has become the most popular DL method for the RUL prediction of rolling bearings. The major superiority of ResNet is that it can still optimize parameters well when the model is deeper in layers [33]. Specifically, as described in reference [33], the training error of a 56-layer convolution is higher than that of 20 layers on the CIFAR-10 dataset. With the network depth increasing, the accuracy becomes saturated and then degrades rapidly. The model adds more layers to a suitable depth, which leads to higher training errors. ResNet adds identity mapping between networks to optimize model training. The entire network can be optimized end-to-end by stochastic gradient descent (SGD) with error backpropagation. The typical structure of a residual building unit (RBU) and ResNet is shown in Figure 1. The RBU is the core component of ResNet, which is composed of multiple convolution (Conv) layers, batch normalization (BN) [34] layers, and rectified linear unit (ReLU) activation function layers. ResNet is constructed by stacking Conv + BN + ReLU, a maxpooling layer, multiple RBUs, a global average pooling (GAP) layer, and a fully connected layer.
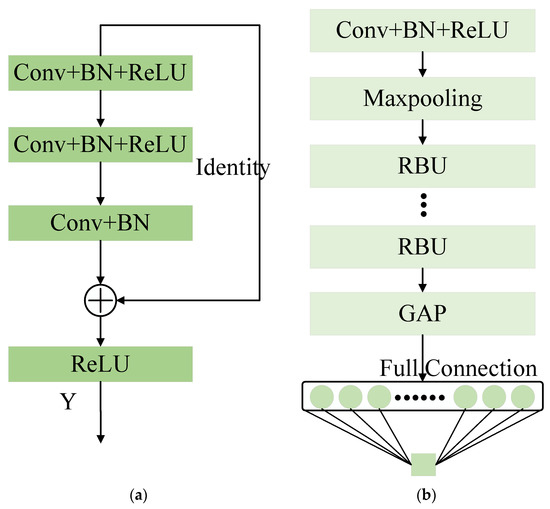
Figure 1.
A brief architecture of RBU and ResNet: (a) RBU; (b) ResNet.
The convolution layer extracts the feature matrix by the convolution operation. The convolution operation is performed by sliding a convolution kernel of a certain size over the data matrix and multiplying the values at the corresponding positions to sum the results to form a new feature matrix. Compared to the traditional full-connection neural network, sparse connection and weight sharing contribute a CNN that is relatively easy to train. The convolution operation can be expressed as [35]:
where is the th channel output feature map of the th convolutional layer, is the bias of the th feature map, denotes the weight matrix of the convolution kernel; denotes the number of input channels; denotes the convolution operation; and is the th channel input feature map of the th convolutional layer.
BN is an adaptive normalization method used to reduce the internal covariance shift problems and accelerate deep network training, making the feature distribution more stable across batches. BN can be formulated as follows [34]:
where denotes the number of samples contained in each batch is the data of the th sample in a batch; and denote the mean and variance of a batch, respectively; denotes a constant very close to zero; is the output after passing through the BN layer; and are two trainable parameters by gradient descent to optimize the adaptive normalization method.
Nonlinear transformation is implemented in ResNet using the ReLU activation function. The derivative of the ReLU activation function can only be 1 or 0, which helps to alleviate the problem of gradient disappearance and gradient explosion. The output of ReLU is .
An RBU consists of three convolutional layers, three ReLU activation function layers, three BN layers alternately combined, and an identity shortcut, as shown in Figure 1a. The output of RBU can be expressed as [33]:
where denotes the input of the RBU; is the output of the third convolutional layer in the RBU. The identity shortcut improves the efficiency of the parameter optimization, allowing ResNet to outperform the vanilla CNN.
GAP is used before the fully connected layer to significantly reduce the feature dimension, thus reducing the number of parameters in the fully connected layer, which is beneficial for improving training efficiency and preventing overfitting. Given the input , , and represent the row, column, and channel spatial dimension of the input matrix . The output of the th channel after the GAP operation can be expressed as:
2.2. Multi-Scale CNN
The size of the convolution kernel is an important parameter of CNNs, and different sizes of the convolution kernel can extract features from different time scales. Specifically, the monitoring signals of rotating machinery may contain less degradation feature information at the early stage of equipment degradation, so these degradation features are distributed over a larger time range. In the late stage of equipment degradation, equipment wear becomes more serious, and the probability of failure greatly increases. The monitoring signal may contain more degradation feature information, so this feature information may be distributed in a small time range [31]. According to the way in which different convolution kernel branch operation results are aggregated, they can be divided into concatenation and sum modes. The concatenation mode aggregates the feature maps of different convolution kernel branches through channel concatenation, as shown in Figure 2a. The sum mode aggregates the feature maps of different convolution kernel branches through element-wise summation, as shown in Figure 2b. Note that the stride of the convolution operation is set to as 2.
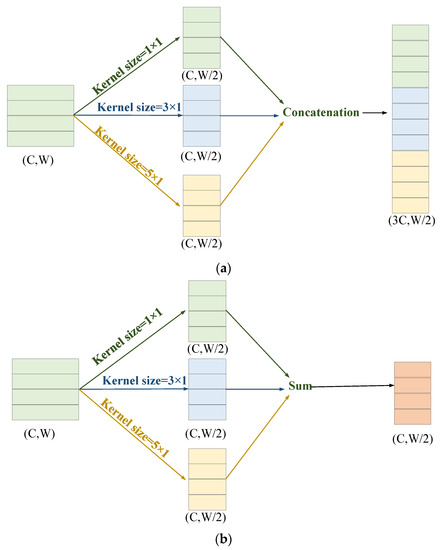
Figure 2.
Diagram of the multi-scale convolutional aggregation features: (a) soncatenation; (b) sum.
Existing multi-scale methods have significantly increased the parameter numbers in the model, thus imposing a heavy computational and parameter optimization burden. Taking one-dimensional RBU as an example to compare the number of parameters of the vanilla CNN (VCNN), the sum multi-scale CNN (SMCNN), and the concatenation multi-scale CNN (CMCNN), the parameter quantities for each model are calculated as:
where , , and represent the number of parameters for the three different models, respectively. represents the number of input channels. and represent the number of convolution channels and kernel size in the th layer, respectively. represents the th kernel size in the multi-scale convolution. It is obvious that , and as the number of convolution layers increases, and will be significantly larger than . Therefore, although multi-scale CNNs can improve model prediction accuracy to a certain extent in theory, they also bring many parameters, which leads to increased difficulty in parameter optimization and increased risk of overfitting.
3. The Proposed RUL Prediction Method
This section introduces in detail the proposed FRMARNet model. The proposed FRMARNet utilizes raw monitoring data as the input. Firstly, a cross-channel maximum pooling (CMP) is proposed to automatically select important feature information. Secondly, to extract more important multi-scale features, the FRMA unit is developed to capture multi-scale information in the data and recalibrate the importance of the feature information. Note that the proposed FRMARNet model is a lightweight approach; the CMP layer and FRMA unit hardly increase the number of parameters.
3.1. Feature Reuse Multi-Scale Attention Residual Network
(1) Cross-channel maximum pooling
In the high-dimensional features extracted by deep CNN models, larger values contain more important feature information, and smaller values contain more redundant or even noisy information. The maximum pooling operation is based on this idea used in CNN for feature dimensionality reduction and the removal of redundant information. The maximum pooling is on each channel, and the maximum value in the pooling region is selected as the output, as shown in Figure 3a, where the red area represents the first pooling block, the blue area represents the second pooling block with a sampling interval of 1, represents the number of channels, and represents the data width. The one-dimensional maximum pooling can be expressed as:
where is the value of the pooling layer output at coordinates , represents the sampling interval of pooling; represents the th channel, and represents the th data point. is the value of the input feature map at coordinates , where , represents the size of the pooling region.
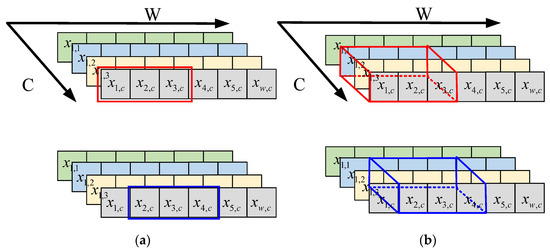
Figure 3.
Diagram of the two pooling methods: (a) one-dimensional maximum pooling; (b) CMP.
For the original one-dimensional signal, the high-dimensional features obtained by a convolution operation are fed into the one-dimensional pooling operation to highlight the important feature information. However, this approach does not consider the effect of features between different channels. Cross-channel interactions are often mapped as new combinations of features that consider the interaction of features between different channels. Cross-channel feature interactions have been used in attention mechanisms [36,37] and have significantly improved the ability of DL models to extract important feature information. Inspired by the idea of cross-channel interaction, without increasing the number of model parameters, this paper proposes a CMP operation based on one-dimensional maximum pooling, as shown in Figure 3b. CMP can be expressed as:
where . Assuming the size of the pooling area is 3 and the number of cross-channels is 3, CMP selects the maximum of nine positions as the output. Compared to the original maximum pooling operation, CMP not only considers the feature information of adjacent positions of the same channel but also considers the feature information of adjacent channels, which is helpful for the network to extract more important feature information.
(2) Feature reuse multi-scale attention unit
To capture the multi-scale degradation information in the signal without increasing the parameters and to recalibrate the importance of multi-scale information, an improved Res2Net [38] block, the so-called FRMA unit, is proposed in this paper. Unlike the original Res2Net, an attention mechanism is added to the FRMA unit to recalibrate the importance of the feature information at different scales, thus highlighting important scale information and suppressing redundant scale information. Specifically, we implement the FRMA unit via three steps, as illustrated in Figure 4. In , different colors represent different groups. The red box shows the attention mechanism. The detailed implementation of FRMA is described as follows.
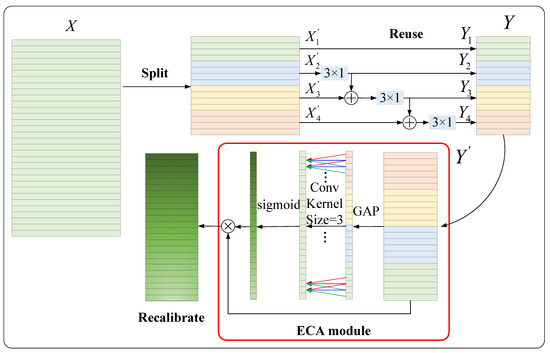
Figure 4.
Diagram of the proposed FRMA unit.
Split: First, to reduce the number of parameters in multi-scale feature extraction, the convolution operation with a kernel size of is adopted for channel dimensionality reduction. An excessive channel dimensionality reduction ratio will result in the loss of important feature information, while a small channel size reduction rate is insufficient to compress feature information and is not conducive to parameter reduction. The channel dimension reduction ratio is an empirical hyperparameter and set as 2, which follows the settings in references [33,38]. The given feature map is transformed to . Then, the input channels are split into groups, , where represents the number of groups, and represents the feature map subsets, . In Figure 4, a four-group case is shown.
Reuse: As mentioned in the previous section, our goal is to achieve multi-scale feature extraction without increasing the number of parameters. In the well-known InceptionV3 network [39], a serial structure with two convolutional kernels of can equivalently obtain scale information of . To achieve this goal, the authors of this paper adopted a hierarchical structure of feature information reuse. The basic idea is to reuse feature map subsets from different groups. Specifically, the former group of features that have been convolved and the next group of features that have not been convolved are fused and then sent into the convolution operation. After multiple processing steps, the model can obtain information at different scales. The output of the feature map subsets can be expressed as:
where denotes the output of the feature map subsets ; represents the tandem connection of the one-dimensional convolutional layer with a kernel size of , a BN layer, and a ReLU activation function layer. It can be seen in Equation (13) that when , the input to is the sum of the sub-feature map and . Taking as an example, obtains the receptive field of , so + also contains the receptive field of , and the next convolution operation with a kernel size of can obtain the receptive field of . Similarly, can obtain a receptive field of . Finally, is concatenated together to form a new feature map . This grouped hierarchical structure of feature information reuse not only extracts multi-scale information and enhances the feature interaction between channels but also further reduces the number of model parameters. The parameter quantities of the FRMA unit are calculated as:
where represents the number of channels in the feature map , . It can be seen in Equation (14) that FRMA significantly reduced the parameters compared to the vanilla CNN and the multi-scale CNN in Section 2.2.
Recalibrate: First, to better fuse information at different scales and enrich the feature information, the convolutional operation with a kernel size of is adopted to achieve channel dimensionality increase. An excessive channel dimension increase ratio will bring too many parameters to subsequent convolution operations. The channel dimension increase ratio is an empirical hyperparameter and set as 4, which follows the settings in references [33,38]. The feature map is transformed to . The feature information extracted by the feature reuse multi-scale module contains multi-scale information and a large amount of redundant information. The authors of this paper adopted the efficient channel attention (ECA) mechanism [37] for adaptive prompting of the modules to focus on the scale information related to device degradation and to weaken redundant information. As shown in Figure 4, the components in the red box form the ECA mechanism module. The input passes through the GAP layer, 1D convolution layer, and sigmoid activation function layer in turn to obtain the weights of different channels. Specifically, the global information of each layer is first obtained through GAP. Then, the channel-wise dependencies are captured by 1D convolutional operations with a fixed kernel size of 3 × 1. The ECA module captures local cross-channel interaction by considering every channel and its 3 neighbors. Note that the 1D convolution with a kernel size of 3 × 1 and channel 1 brings a negligible amount of 3 parameters. Therefore, unlike the squeeze-and-excitation (SE) attention module [36], the ECA module is a lightweight plug-and-play unit. Thirdly, the simple gating mechanism with a sigmoid activation is employed to generate the corresponding channel weights . Finally, the output refers to channel-wise multiplication between the input and the channel weights . The th channel of is calculated by:
where represents GAP, represents a convolutional operation with a fixed kernel size of , and represents the sigmoid activation function.
3.2. RUL Prediction Based on FRMARNet
The core building block of FRMARNet can be established using the FRMA unit and an RBU. As shown in Figure 5a, the new multi-scale attention residual module FRMA-RBU can be constructed by replacing the second Conv+BN+ReLU layer in the original RBU with an FRMA unit. As shown in Figure 5b, the FRMARNet model is constructed by stacking the Conv+BN+ReLU layer, CMP layer, and multiple FRMA-RBU modules in sequence, which is beneficial to learn valuable high-level multi-scale features from the raw vibration data. RUL prediction can be achieved by feeding the learned features into the GAP and FC layers. In terms of implementation details, compared to Figure 1, the CMP layer replaces the maximum pooling layer, and the FRMA-RBU module replaces the RBU module in the original ResNet model.
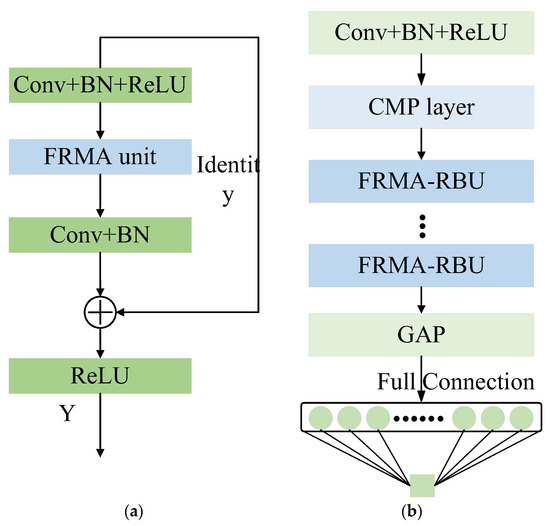
Figure 5.
Architecture of the developed FRMARNet: (a) FRMA-RBU module; (b) FRMARNet.
The regression layer consisting of a full connection is used to predict the RUL. Gradient descent and error backpropagation are employed to train the FRMARNet model. Given a training dataset with samples, the developed FRMARNet utilizes the root mean square error (RMSE) loss function to optimize the parameters, which is suitable for the regression problem. RMSE can be expressed as:
where and denote the true and predicted values, respectively. represents loss function. represents the trainable parameters in the FRMARNet, which can be updated and optimized by Adam with error backpropagation:
where is the learning rate. On the basis of SGD, many parameter optimizations have been developed. RMSprop can be considered an enhancement of SGD. Combining momentum and RMSprop, Adam was identified as a desirable method for dynamically adjusting the learning rate [40]. In order to obtain the optimized model, Adam was selected as the optimizer in this paper. The momentum was set as 0.9. The training steps and parameter optimization of FRMARNet are presented in Algorithm 1.
| Algorithm 1: training of FRMARNet |
| Input: Training dataset: ; Learning rate: ; Batch size: ; Max-epoch:; Momentum = 0.9. 1: Initialize trainable parameters of FRMARNet 2: for epoch = 1, 2, 3,……, Max-epoch do 3: for step = 1, 2, 3,……, Max-step do 4: //Feature extract 5: Conv+BN+ReLU module; 6: CMP module; 7: FRMA-RBU module; 8: GAP module; 9: //regressor 10: Feed into full connection and obtain ; 11: //Calculate loss and gradient descent 12: Calculate RMSE loss ; 13: Calculate gradient and update parameters, 14: , . 15: end for 16: end for Output: Optimized weights and biases |
Based on the proposed FRMARNet, we present a new RUL estimation framework as follows. The framework includes four steps: signal collection, signal preprocessing, multi-scale degradation information extraction, and RUL prediction, as shown in Figure 6. The signal collection part comes from the PRONOSTIA platform [41].
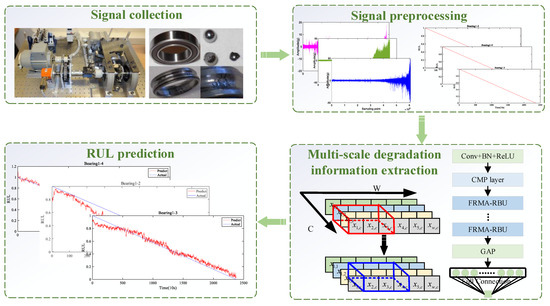
Figure 6.
The RUL prediction procedure of the proposed FRMARNet method.
Step 1: Collecting rolling bearing run-to-failure vibration dataset by conducting accelerated degradation experiments.
Step 2: Multiple rolling bearings are divided into training and testing sets. Some of the bearings are used for training, while the others are used for testing. The vibration signal of each rolling bearing is divided into multiple samples, tagging samples with RUL values to construct run-to-failure datasets. The principle of tagging samples with RUL values is explained in Section 4.2.
Step 3: After determining the relevant hyperparameters and initializing the network weights, the training data are fed into the constructed FRMARNet for multi-scale degradation information. This step enables offline training of the DL model.
Step 4: The trained model is deployed online and used on test data for RUL prediction. The prediction results can be used for the predictive maintenance of rotating machinery.
4. Experimental Verifications
To validate the proposed method in dealing with the RUL prediction of rolling bearings, a case study was conducted to evaluate the prediction performance of FRMARNet in this section.
4.1. Experimental Platform
Bearing real run-to-failure degradation data from the PRONOSTIA platform [41] were employed for experimental verification. The main objective of the experimental platform is to provide realistic experimental data to characterize the degradation of ball bearings throughout their whole operational life. As shown in Figure 7, the experimental platform consisted of three parts: the rotating part, the degradation generation part, and the measurement part. The rotating part mainly included an asynchronous motor and gearboxes. The motor generated 250 W of power and transmit the rotating motion to drive the bearing through the gearboxes. The degradation generation part was the core of the whole experimental platform. The radial force generated by the jack acted on the tested bearing. Radial forces reduced the bearing life by setting the value to the maximum dynamic load of the bearing (4000 N). The measurement part mainly included an NI data acquisition device and accelerometers. The accelerometers were placed on the outer ring of the bearing to measure degradation data in both the horizontal and vertical directions. The degradation data sampling frequency was 25.6 kHz, the sampling time was 0.1 s, and the sampling interval was 10 s. In other words, 2560 numbers in 0.1 s were collected every 10 s. Therefore, each sample contained 2560 numbers and an RUL label.
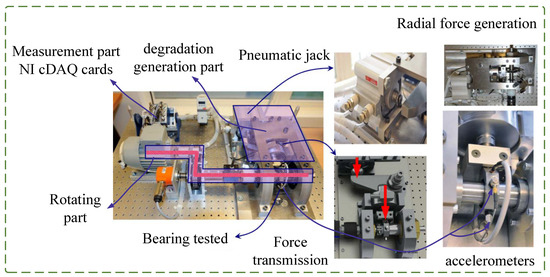
Figure 7.
Experimental platform for collecting bearing degradation data.
4.2. Dataset Description
Under the working conditions of a motor speed of 1800 r/min and a load of 4000 N, the real run-to-failure degradation data of seven bearings were collected. These bearings are of the same type and dimensions. The characteristics of the tested bearings are shown in Table 1. Horizontal vibration signals from the accelerometer were used in the RUL prediction studies. The details of the used dataset are shown in Table 2; different bearings had different accelerated degradation lifetimes and sample lengths. The longest experiment duration was bearing1_1, with 28,030 s, and the shortest experiment duration was bearing1_2, with 8710s. There were 14,647 sample instances in total, and each sample instance contained 2560 data points. To comprehensively evaluate the performance of the model, the leave-one-out cross-validation strategy [24,42] was utilized for each test. That is, during the cross-validation process, while one bearing was used for testing, the other six bearings were used for training. For example, the dataset of bearing1_2–bearing1_7 was used as the training data and that of bearing1_1 as the testing data in the first cross-validation.

Table 1.
The characteristics of the tested bearings.
Table 2.
Description of the degradation experiment dataset.
The health indicator is a custom indicator that helps researchers to evaluate the health status of machinery in real time [10]. The health indicator is also the label corresponding to each sample in RUL prediction. In physical model-based RUL prediction, it is critical to construct an appropriate health indicator through expert experience and prior knowledge. In the data-based approach, to reduce the manual and empirical process, a linear health indicator representation was utilized [24,42]. Specifically, the RUL percentages were calculated as the health indicator to evaluate the health status of the bearings. The RUL label corresponding to the sample was converted into the RUL percentage for training. Assuming that the sample serial numbers collected during the whole life of the bearing are in sequence, the health indicator of the th sample in any stage can be calculated by:
where represents the health indicator of the th sample, and represents the total number of samples. Note that the health indicator was confined in the range of [0, 1], where the larger the indicator value, the healthier the bearing state. The smaller the indicator value, the closer the bearing is to failure. Specifically, taking bearing1_1 as an example, a health indicator equal to 1 means that the bearing is in a brand-new state, and the real RUL is 28,030 s. A health indicator equal to 0.5 means that the real RUL is 14,015 s, and a health indicator equal to 0 means the bearing has failed, and the real RUL is 0.
4.3. Evaluation Metrics
To quantitatively evaluate the predictive performance of the proposed FRMARNet model, the RMSE and mean absolute error (MAE) were utilized as the evaluation metrics, which can be calculated by:
where and denote the true and predicted health indicators, respectively, and represents the total number of samples. Smaller RMSE and MAE values represent better prediction performance. To further reduce the deviation between the predicted and real values, and to make the prediction results better reflect the equipment degradation trend, a weighted average method was employed to smooth the prediction result, as described in the literature [42].
4.4. Model Structure and Hyperparameter Configurations
In this section, the FRMARNet is established for RUL prediction, and we will determine the proposed DL model structure and hyperparameters. The architecture of the developed model is listed in Table 3, where represents that the convolutional kernel size is and stride is 2 with 16 output channels. represents that the size of the CMP layer pooling region is 3, cross-channel number is 3, and the sampling interval is 2. For , 64 represents the first convolutional kernel size is , stride is 1, and output channel is 64 in the FRMA-RBU module. represents the number of convolutional channels in the feature map is , stride is 2, and groups is in the FRMA-RBU module. The number 128 represents the third convolutional kernel size is , stride is 1, and output channel is 128 in the FRMA-RBU module. The values of and will be determined by experimental studies in Section 4.5. represents the GAP pooling region is . denotes that the final output is 1, which is a fixed value in a regression problem. The input feature size represents the input data width, which is 1252, and the input data channel, which is 16 of the layer. Output feature size means the output data width is 626 and the output data channel is 8 of the layer.
Table 3.
The model structure of FRMARNet.
In addition, the other hyperparameters in DL that are relevant for model training are obtained empirically. The batch size was set to 256, indicating that 256 samples were randomly selected for model training in each iteration. The learning rate was set to 0.00003 for bearing1_1 and bearing1_3–bearing1_7 and 0.000005 for bearing1_2. The Adam optimization algorithm was selected as the optimizer of the FRMARNet model. Finally, the experiment was iterated for a total of 120 epochs.
4.5. RUL Estimation
(1) RUL prediction results
The RUL prediction experiment was carried out in Windows, i7 CPU, and RTX 2060 SUPER GPU. The program was developed in a Python environment based on the PyTorch framework. Each experiment was repeated five times to reduce the influence of the randomization of the initial parameters. The average values of the evaluation metrics were used as the final evaluation. Bearings1_1–bearing1_7 were all used for testing. The number of channels and the number of groups are two important hyperparameters of the feature reuse multi-scale module. When is fixed, a larger contains richer scale information, but it may bring too much redundant information. A smaller contains less scale information, the degradation information in the data may not be completely extracted. When is fixed, the larger is, the larger the number of parameters will be, which may reduce the precision. This may be due to overfitting caused by many parameters. An value that is too little will not extract enough representative features.
The authors of this paper compared five different combinations, and the experimental results are shown in Table 4 and Table 5 and Figure 8. When fixing , the lowest RMSE and MAE were achieved when in all bearings except bearing1_6. The lowest RMSE and MAE were achieved when in bearing1_6. When fixing , the lowest RMSE and MAE were achieved when in all bearings. This phenomenon indicates that and values that are too large bring too much redundant information and parametric quantities, which is not conducive to extracting important feature information and parameter optimization. and values that are too small do not fully extract important feature information. The experimental results show that and are the optimal hyperparameter combination.
Table 4.
RMSE results of different hyperparameters.
Table 5.
MAE results of different hyperparameters.
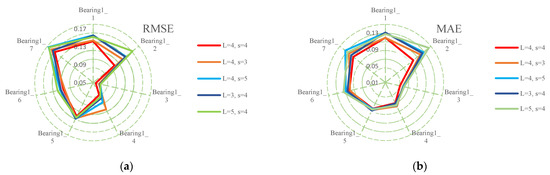
Figure 8.
The accuracy comparison of different hyperparameters: (a) RMSE; (b) MAE.
Figure 9 shows the visualization of the RUL prediction results for the seven bearings by the developed FRMARNet. The figure clearly shows that the proposed model accurately captured the degradation trend of the bearings. Note that the different types of bearing failures and degradation rates resulted in very different experimental durations. The FRMARNet model can capture not only long and slow degradation processes of bearings (for instance, bearing1_1 and bearing 1_6), but also rapid degradation processes (for instance, bearing1_2). Some bearings are difficult to predict when they are close to failure, which may be caused by the inconsistent pattern of bearing failure causing large differences in vibration signal fluctuations. This is followed by a quantitative comparison with other multi-scale structures, attention mechanisms, and several state-of-the-art (SOTA) RUL prediction methods.
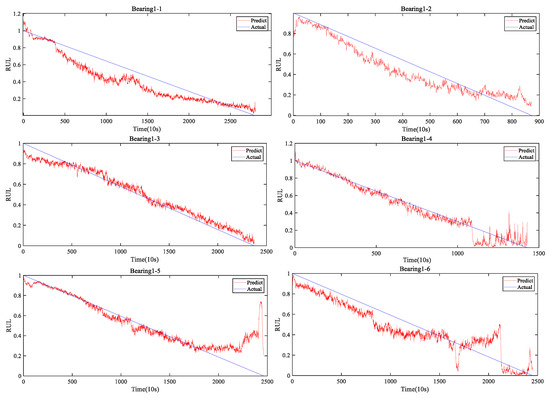
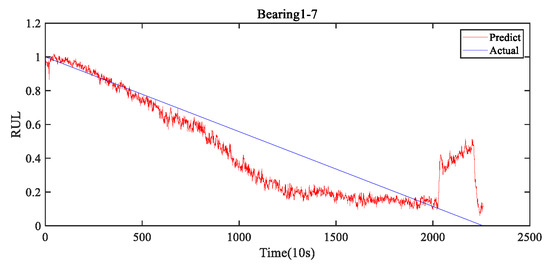
Figure 9.
The visualization of the RUL prediction results on FRMARNet for Bearing1_1-Bearing1_7.
(2) Comparison with multi-scale structures
To verify that the FRMARNet model can improve the prediction accuracy while reducing the number of parameters, the feature reuse multi-scale attention structure in the FRMA-RBU unit is replaced by the concatenation and sum modes mentioned in Section 2.2. The rest of the network structure and hyperparameters are the same for all three methods. The average and standard deviation of the prediction results for each of the seven bearings are shown in Table 6 and Table 7 and Figure 10. Note that in FRMARNet, to enrich the feature information, the channel dimension increase ratio was 4. Due to the limitation of the computer memory capacity, the dimension increase ratio in the concatenation mode was 3, and the scale information with convolution kernels of 3, 5, and 7 was used. More scale information and a larger dimension increase ratio will significantly increase the number of parameters. As can be seen in Table 6 and Table 7, on each bearing, the RMSE and MAE of the prediction values of the proposed FRMARNet method were smaller than the other two multi-scale structures. The average RMSE decreased by 0.012 and 0.013, respectively, and the average MAE values both decreased by 0.01. In addition, the proposed method had smaller standard deviations in two evaluation metrics, which indicates that the developed model had better robustness. At the same time, the statistics of the parameter numbers show that the FRMARNet had a smaller number of parameters. The number of parameters decreased by 63.9% and 53.2% in the concatenation and sum modes, respectively, which is conducive to model optimization and reduces the computational burden. In addition, Figure 11 visualizes the RUL prediction results of different multi-scale structures for bearing1_3. Compared to the other two multi-scale structures, the FRMARNet model better captured the degradation trend of the bearings.
Table 6.
RMSE results of different multi-scale structures.
Table 7.
MAE results of different multi-scale structures.
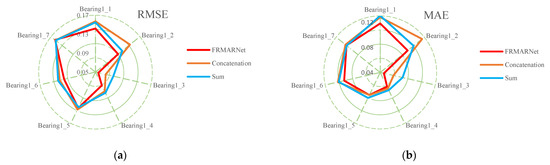
Figure 10.
Comparison results with other multi-scale structures: (a) RMSE; (b) MAE.
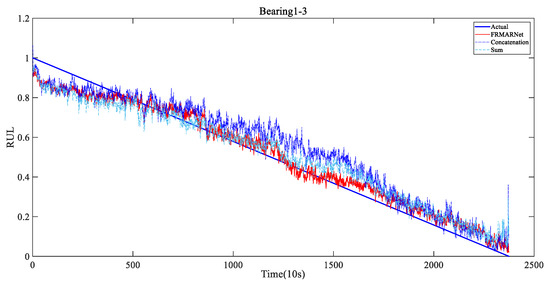
Figure 11.
RUL prediction results of different multi-scale structures for Bearing1_3.
(3) Ablation experiments
The feature extraction capability of the model is enhanced by embedding a CMP layer and FRMA units in ResNet. Compared to the vanilla ResNet model, the developed FRMARNet model has several improvements, including the CMP layer, a feature reuse multi-scale convolution structure, and an ECA mechanism. Ablation experiments were conducted to demonstrate the effectiveness of these components in improving model prediction accuracy. We studied the impact of these differences on the prediction results by removing or changing these new improvements and keeping other parameter settings unchanged. The ablation experiments are detailed as follows:
Network-1 replaced the feature reuse multi-scale convolution structure with standard convolution and removed the ECA module. Network-2 only removed the ECA module. Network-3 only replaced the CMP layer with one-dimensional maximum pooling. Network-4 replaced the ECA module with SE attention. The detailed results of the ablation experiments are presented in Table 8 and Table 9 and Figure 12. The prediction error increased significantly when these components were removed or replaced. Specifically, comparing Network-1 with Network-2, when the feature reuse multi-scale structure was removed, the average RMSE and MAE increased by 0.02 and 0.013, respectively. The feature reuse multi-scale structure can extract different scale information from the original signal. Comparing Network-2 with the FRMARNet models, when the ECA module was removed, the average RMSE and MAE increased by 0.01 and 0.01, respectively. Comparing Network-4 with the FRMARNet models, when replacing the ECA module with SE attention, the average RMSE and MAE increased by 0.019 and 0.012, respectively. The ECA module hardly increased the parameters and was able to recalibrate scale information so that the model focused on more important scale information. Comparing Network-3 with the FRMARNet models, when the CMP layer was removed, the average RMSE and MAE increased by 0.012 and 0.009, respectively. The CMP layer was beneficial for the model to concentrate on more important feature information. The prediction results fully confirm the theoretical analysis in Section 3. In addition, Figure 13 visualizes the RUL prediction results of the ablation experiments for bearing1_4. The comparison results indicate that the FRMARNet model better captured the degradation trend of the bearings. The effectiveness of these improvements in improving the prediction accuracy of the proposed FRMARNet model can thus be demonstrated.
Table 8.
RMSE results of ablation experiments.
Table 9.
MAE results of ablation experiments.
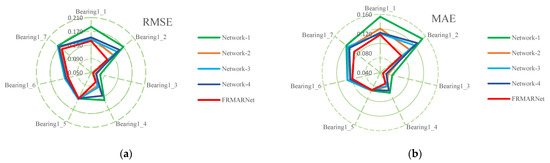
Figure 12.
Comparison results of ablation experiments: (a) RMSE; (b) MAE.
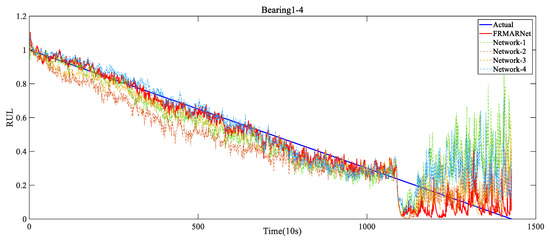
Figure 13.
RUL prediction results of the ablation experiments for Bearing1_4.
(4) Visualization of attention weights
The attention mechanism attempted to establish the relationship between different channels, and the attention weights reflect the focus degree on different channels. To reveal the internal operation mechanism of the attention module and prove that the model indeed learned different weights for different channels, the attention weights in the FRMA-RBU4 module are displayed visually in Figure 14, and the weights were extracted and visualized by averaging all test samples along the channel direction. Figure 14a and Figure 14b show the attention weights of bearing1_3 and bearing1_4, respectively. There was a significant difference in the weights along the channel, which indicates that the contributions of the different channels were inconsistent. The maximum value of the weight of bearing1_3 was 0.6348 for channel 19, and the minimum value was 0.3235 for channel 109. The maximum value of the weight of bearing1_4 was 0.6021 for channel 18, and the minimum value was 0.3965 for channel 447. It can be demonstrated that the ECA module has learned a group of weights with different sizes to recalibrate different channels, and adaptively endowed channels containing more degradation information with greater weights.
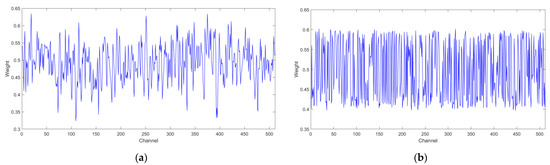
Figure 14.
Visualization of attentional mechanisms: (a) bearing1_3; (b) bearing1_4.
(5) Comparison with SOTA methods
To further demonstrate the superiority of the FRMARNet-based RUL prediction method proposed in this paper, several SOTA methods were employed for comparison, including Wu et al.’s vanilla long short-term memory (LSTM) neural networks [23], Chen et al.’s gate recurrent unit (GRU) [43], Zhu et al.’s multi-scale CNN (MSCNN) [32], Wang et al.’s deep separable ResNet (DSRN) [8], Shang et al.’s bidirectional GRU and CNN (CNN-BGRU) [42], Chen et al.’s RNN based on an encoder–decoder framework with an attention mechanism (REA) [44], Wang et al.’s feature fusion based ensemble method (FFEM) [45], and Ding et al.’s convolutional transformer (CoT) [24].
The results of the RUL prediction performance comparison are presented in Table 10. The comparison results show that the proposed FRMARNet model had lower average RMSE and MAE values than the other eight existing SOTA approaches, which means that the developed FRMARNet method outperformed the other bearing RUL prediction methods. Specifically, the prediction performance of the FRMARNet-based model was significantly better than that of the vanilla LSTM and GRU models, which is because the vanilla LSTM and GRU models are only able to extract long-distance time-series relationships in the data, resulting in low modeling efficiency and accuracy. For MSCNN and the multi-scale structure mentioned in Section 2.2, the prediction error was larger than that of the FRMARNet-based approach due to the complex network results, resulting in many parameters and optimization difficulties, as well as a lack of an effective mechanism to highlight important feature information. For some other compared methods, multi-scale local and global information is not extracted simultaneously, or recalibration of multi-scale information is lacking, and none of them utilize CMP or have cross-channel information interactions. This performance improvement again validates the benefits of the CMP layer, the feature reuse multi-scale structure, and the ECA module. It should be noted that, unlike some comparison methods that use signal processing to obtain artificial features, the FRMARNet model proposed in this paper uses the original signal as the input and is an end-to-end prediction framework. The methods without targeted signal processing, information entropy, and artificial feature selection lose some seemingly unimportant feature information. The raw vibration signal contains the richest information on degraded features.
Table 10.
Comparison results with SOTA methods.
5. Conclusions
Accurate rolling bearing RUL prediction is highly dependent on significant multi-scale feature information extracted from the original signal. The authors of this paper developed a novel lightweight FRMARNet architecture for rolling bearing RUL prediction that combines the advantages of cross-channel interaction, multi-scale features, and attention mechanisms. The CMP based on cross-channel interaction can automatically select important feature information, and the FRMA unit based on multi-scale and attention mechanisms can extract multi-scale information and recalibrate multi-scale information to emphasize important feature information and suppress redundant information. In addition, extensive experiments were carried out on the bearing dataset to validate the developed method. Comparative tests with the existing concatenation and sum multi-scale structure indicate that the average RMSE decreased by 9.5% and 10.2%, respectively, and the average MAE both decreased by 10.2%. The number of parameters decreased by 63.9% and 53.2%, respectively. The experimental results demonstrate that the proposed FRMA unit significantly improved the prediction accuracy while reducing the number of model parameters. The ablation experiments indicate that the average RMSE increased by 13.9%, 8%, and 9.5% (the MAE increased by 11.7%, 10.2%, and 9.3%) when the feature reuse multi-scale structure, ECA module, and CMP layer were removed, respectively. The effectiveness of the CMP layer, the feature reuse multi-scale structure, and the ECA module are demonstrated. The attention weight visualization shows that the model learned a set of weights of different sizes to recalibrate the scale information. Compared to the SOTA method, the average RMSE was reduced by at least 8% and the MAE was reduced by at least 5%. These results prove the superiority of the method. In summary, extensive experiments were conducted to verify the advancement and effectiveness of the developed method, as well as the necessity and reasonableness of the improvements. In future work, we need to investigate not only the effects of multi-scale information on prediction performance but also the effects of the temporal characteristics of raw data on prediction performance. The self-attention mechanism can establish long-distance dependence on the data and capture the temporal characteristics in the data. The combination of the developed method in this paper and self-attention mechanism is a promising research direction.
Author Contributions
Conceptualization, L.S. and J.W.; methodology, L.S.; software, L.S. and G.C.; validation, J.W., L.W. and Z.L.; formal analysis, L.S.; investigation, L.S., G.C. and Y.S.; resources, L.S.; data curation, G.C.; writing—original draft preparation, L.S.; writing—review and editing, J.W. and Z.L.; visualization, Y.S.; supervision, L.W.; project administration, L.S.; funding acquisition, J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China under grant 2019YFB1706703, and by the Panzhihua University Cultivation Program under grant 2020ZD009.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding authors.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this paper.
| RUL | Remaining useful life |
| ML | Machine learning |
| DL | Deep learning |
| ResNets | Residual networks |
| CNNs | Convolutional neural networks |
| RNNs | Recurrent neural networks |
| FRMARNet | Feature reuse multi-scale attention residual network |
| FRMA | Feature reuse multi-scale attention |
| SGD | Stochastic gradient descent |
| RBU | Residual building unit |
| Conv | Convolution |
| BN | Batch normalization |
| ReLU | Rectified linear unit |
| GAP | Global average pooling |
| VCNN | Vanilla CNN |
| SMCNN | Sum multi-scale CNN |
| CMCNN | Concatenation multi-scale CNN |
| CMP | Cross-channel maximum pooling |
| ECA | Efficient channel attention |
| SE | Squeeze-and-excitation |
| RMSE | Root mean square error |
| MAE | Mean absolute error |
| SOTA | State-of-the-art |
| LSTM | Long short-term memory |
| GRU | Gate recurrent unit |
| MSCNN | Multi-scale CNN |
| DSRN | Deep separable ResNet |
| CNN-BGRU | Bidirectional GRU and CNN |
| REA | RNN based on an encoder–decoder framework with an attention mechanism |
| FFEM | Feature fusion-based ensemble method |
| CoT | Convolutional transformer |
References
- Song, L.; Wang, L.; Wu, J.; Liang, J.; Liu, Z. Integrating physics and data driven cyber-physical system for condition monitoring of critical transmission components in smart production line. Appl. Sci. 2021, 11, 8967. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Z.; Chen, Y.; Jin, Y.; Bai, G. Selective kernel convolution deep residual network based on channel-spatial attention mechanism and feature fusion for mechanical fault diagnosis. ISA Trans. 2022, 133, 369–383. [Google Scholar] [CrossRef]
- Cui, H.; Wu, J.; Zhang, B.; Wang, L.; Huang, T. Energy consumption comparison of a novel parallel tracker and its corresponding serial tracker. Math. Probl. Eng. 2021, 2021, 6634989. [Google Scholar] [CrossRef]
- Cui, H.; Wu, J.; Li, Q. A distribution method of driving torque for a novel 3UPS-RR redundant solar tracker. J. Mech. Robot. 2021, 13, 040909. [Google Scholar] [CrossRef]
- Zhou, J.; Qin, Y.; Chen, D.; Liu, F.; Qian, Q. Remaining useful life prediction of bearings by a new reinforced memory GRU network. Adv. Eng. Inform. 2022, 53, 101682. [Google Scholar] [CrossRef]
- Zhao, Z.; Wu, J.; Li, T.; Sun, C.; Yan, R.; Chen, X. Challenges and opportunities of AI-enabled monitoring, diagnosis & prognosis: A review. Chin. J. Mech. Eng. 2021, 34, 56. [Google Scholar]
- Li, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Degradation alignment in remaining useful life prediction using deep cycle-consistent learning. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5480–5491. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Yan, T. Deep separable convolutional network for remaining useful life prediction of machinery. Mech. Syst. Signal Process. 2019, 134, 106330. [Google Scholar] [CrossRef]
- Li, H.; Zhao, W.; Zhang, Y.; Zio, E. Remaining useful life prediction using multi-scale deep convolutional neural network. Appl. Soft Comput. 2020, 89, 106113. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Zhao, B.; Zhang, X.; Li, H.; Yang, Z. Intelligent fault diagnosis of rolling bearings based on normalized CNN considering data imbalance and variable working conditions. Knowl. Based Syst. 2020, 199, 105971. [Google Scholar] [CrossRef]
- Huang, J.; Cui, X.; Li, C.; Xiao, Z.; Chen, Q. Multivariate time-varying complex signal processing framework and its application in rotating machinery rotor-bearing system. Meas. Sci. Technol. 2022, 33, 125114. [Google Scholar] [CrossRef]
- Ren, J.; Jin, W.; Wu, Y.; Sun, Z.; Li, L. Research on performance degradation estimation of key components of high-speed train bogie based on multi-task learning. Entropy 2023, 25, 696. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Miao, M.; Yu, J.; Zhao, Z. A sparse domain adaption network for remaining useful life prediction of rolling bearings under different working conditions. Reliab. Eng. Syst. Saf. 2022, 219, 108259. [Google Scholar] [CrossRef]
- Liang, J.; Wang, L.; Wu, J.; Liu, Z.; Yu, G. Prediction of spindle rotation error through vibration signal based on Bi-LSTM classification network. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1043, 042033. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, Q.; Yu, X.; Sun, C.; Wang, S.; Yan, R.; Chen, X. Applications of unsupervised deep transfer learning to intelligent fault diagnosis: A survey and comparative study. IEEE Trans. Instrum. Meas. 2021, 70, 1–28. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, T.; Wu, J.; Sun, C.; Wang, S.; Yan, R.; Chen, X. Deep learning algorithms for rotating machinery intelligent diagnosis: An open source benchmark study. ISA Trans. 2020, 107, 224–255. [Google Scholar] [CrossRef]
- Xu, X.; Li, X.; Ming, W.; Chen, M. A novel multi-scale CNN and attention mechanism method with multi-sensor signal for remaining useful life prediction. Comput. Ind. Eng. 2022, 169, 108204. [Google Scholar] [CrossRef]
- Ma, J.; Su, H.; Zhao, W.L.; Liu, B. Predicting the remaining useful life of an aircraft engine using a stacked sparse autoencoder with multilayer self-learning. Complexity 2018, 2018, 3813029. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Wen, L.; Dong, Y.; Gao, L. A new ensemble residual convolutional neural network for remaining useful life estimation. Math. Biosci. Eng. 2019, 16, 862–880. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M. Convolutional Transformer: An enhanced attention mechanism architecture for remaining useful life estimation of bearings. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Liang, H.; Cao, J.; Zhao, X. Multi-scale dynamic adaptive residual network for fault diagnosis. Measurement 2022, 188, 110397. [Google Scholar] [CrossRef]
- Li, X.; Zhang, W.; Ding, Q. Deep learning-based remaining useful life estimation of bearings using multi-scale feature extraction. Reliab. Eng. Syst. Saf. 2019, 182, 208–218. [Google Scholar] [CrossRef]
- Du, X.; Jia, W.; Yu, P.; Shi, Y.; Cheng, S. A remaining useful life prediction method based on time–frequency images of the mechanical vibration signals. Measurement 2022, 202, 111782. [Google Scholar] [CrossRef]
- Ge, Y.; Liu, J.J.; Ma, J.X. Remaining useful life prediction using deep multi-scale convolution neural networks. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1043, 032011. [Google Scholar] [CrossRef]
- Wang, R.; Shi, R.; Hu, X.; Shen, C. Remaining useful life prediction of rolling bearings based on multiscale convolutional neural network with integrated dilated convolution blocks. Shock Vib. 2021, 2021, 6616861. [Google Scholar] [CrossRef]
- Deng, F.; Bi, Y.; Liu, Y.; Yang, S. Deep-learning-based remaining useful life prediction based on a multi-scale dilated convolution network. Mathematics 2021, 9, 3035. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Wang, W. Multiscale convolutional attention network for predicting remaining useful life of machinery. IEEE Trans. Ind. Electron. 2020, 68, 7496–7504. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, N.; Peng, W. Estimation of bearing remaining useful life based on multiscale convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 3208–3216. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning PMLR 2015, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Han, Y.; Tang, B.; Deng, L. An enhanced convolutional neural network with enlarged receptive fields for fault diagnosis of planetary gearboxes. Comput. Ind. 2019, 107, 50–58. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Volume 2018, pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; Volume 2020, pp. 11534–11542. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 2818–2826. [Google Scholar]
- Tang, S.; Zhu, Y.; Yuan, S. An improved convolutional neural network with an adaptable learning rate towards multi-signal fault diagnosis of hydraulic piston pump. Adv. Eng. Inform. 2021, 50, 101406. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12 2012, Beijing, China, 23–25 May 2012; pp. 1–8. [Google Scholar]
- Shang, Y.; Tang, X.; Zhao, G.; Jiang, P.; Lin, T.R. A remaining life prediction of rolling element bearings based on a bidirectional gate recurrent unit and convolution neural network. Measurement 2022, 202, 111893. [Google Scholar] [CrossRef]
- Chen, J.; Jing, H.; Chang, Y.; Liu, Q. Gated recurrent unit based recurrent neural network for remaining useful life prediction of nonlinear deterioration process. Reliab. Eng. Syst. Saf. 2019, 185, 372–382. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Zhu, Z.; Li, S. A novel deep learning method based on attention mechanism for bearing remaining useful life prediction. Appl. Soft Comput. 2020, 86, 105919. [Google Scholar] [CrossRef]
- Wang, G.; Li, H.; Zhang, F.; Wu, Z. Feature fusion based ensemble method for remaining useful life prediction of machinery. Appl. Soft Comput. 2022, 129, 109604. [Google Scholar] [CrossRef]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).