In order to explore the space of parameters, we are primarily interested in the difference between statistically homogeneous networks and statistically heterogeneous ones. To this end, we will explore the parameter space of the model by specifying a value for J and sampling certain transformed parameters from a distribution for each class, where . The quantity will be referred to as the ‘fitness’, or ‘hidden variable’, of node i. The broader the distribution of the fitness, the more heterogeneous the resulting network structure.
5.1.1. Homogeneous Fitness: Erdős–Rényi Graphs with Overlap
The simplest distribution from which we can sample
is the delta distribution centered at
x, such that
and, therefore,
, resulting in statistically homogeneous networks. With this choice of parameters, our model is an extension of the Erdős–Rényi model, which is a random graph model that can be derived within the ERGM by solely constraining the total number of links in the network, and where all links occur with the same probability. As we shall see, the extension derives from the fact that the extra constraint on the overlap can lead to a symmetry-breaking phase transition, although the broken symmetry might not manifest at first sight. Indeed, since the parameters are the same for all pairs of nodes, the condition for the existence of multiple solutions is also the same, and, therefore, there is a unique phase transition where, depending on the values of
and
J, pairs of nodes are either all ‘magnetized’ or all ‘non-magnetized’. Similarly, since here
, the spontaneous symmetry-breaking condition discussed in
Section 3.1 for the vanishing of the external field is the same for all pairs of nodes, and given by
. In the symmetry-broken (magnetized) phase, for all pairs of nodes, the expected value of
(or equivalently, of the ‘magnetization’
) is the same, and is always between the two typical (high-density and low-density) realized values. However, since all pairs are independent, the actual realized values of
are also independent across pairs, so on average, over the entire network, the magnetization will realize both the low-density and high-density values, with equal probability. In other words, different pairs of nodes are i.i.d. realizations of the same system. This is a peculiar situation where the realized values of
L and
O (which represent sums of all pairs of nodes) will still coincide with their expected values as if no symmetry breaking was present, even if different pairs of nodes actually realize different symmetry-broken values that are individually different from the expected value. The net result is an expected number of links
) equal to half the maximum one, or equivalently, an average zero magnetization in the associated spin system. Similar considerations apply to the case
, with the difference that, in that case, the symmetry is not broken spontaneously, but by the direction of the external field (value of
), which implies that the two typical realized values of the magnetization for a given pair of nodes are no longer symmetric around the expected value. Still, both typical values will be realized, independently and with their probabilities, across the entire network, because different pairs of nodes are still independent. So, irrespective of the value of
J and
, we expect to observe realized values of
L and
O that correspond again to what one would observe without symmetry breaking, using the ensemble averages for each pair, irrespective of the phase of the system. All these considerations are confirmed below.
By looking at Equation (
38), we can see that a uniform
essentially means that instead of constraining the average layer degrees
, we constrain the total number of links
L in the multiplex network. In this case, the combined maximum entropy and maximum likelihood equations become
where
is the solution to Equation (
69). Note that we now have a single equation for
u, confirming the existence of a single
global phase transition across the multiplex network, rather than separate local phase transitions for every multilink
. Additionally, we note that if
can be considered as the density (and the link probability) of the network, then the value of
is exactly the same as the value of the density
p in the Erdős–Rényi model [
14,
27], which solely constrains the number of links in the network. The difference between our model and the Erdős–Rényi model is that our model contains the possibility of a phase transition. However, since the number of links
also determines the overlap
, the two quantities cannot be tuned independently of each other.
By using the Metropolis–Hastings algorithm, we have sampled our ERGM for multiplexes with
layers and
nodes for various values of
and/or
J. If we repeat the simulations for
and
,
, and
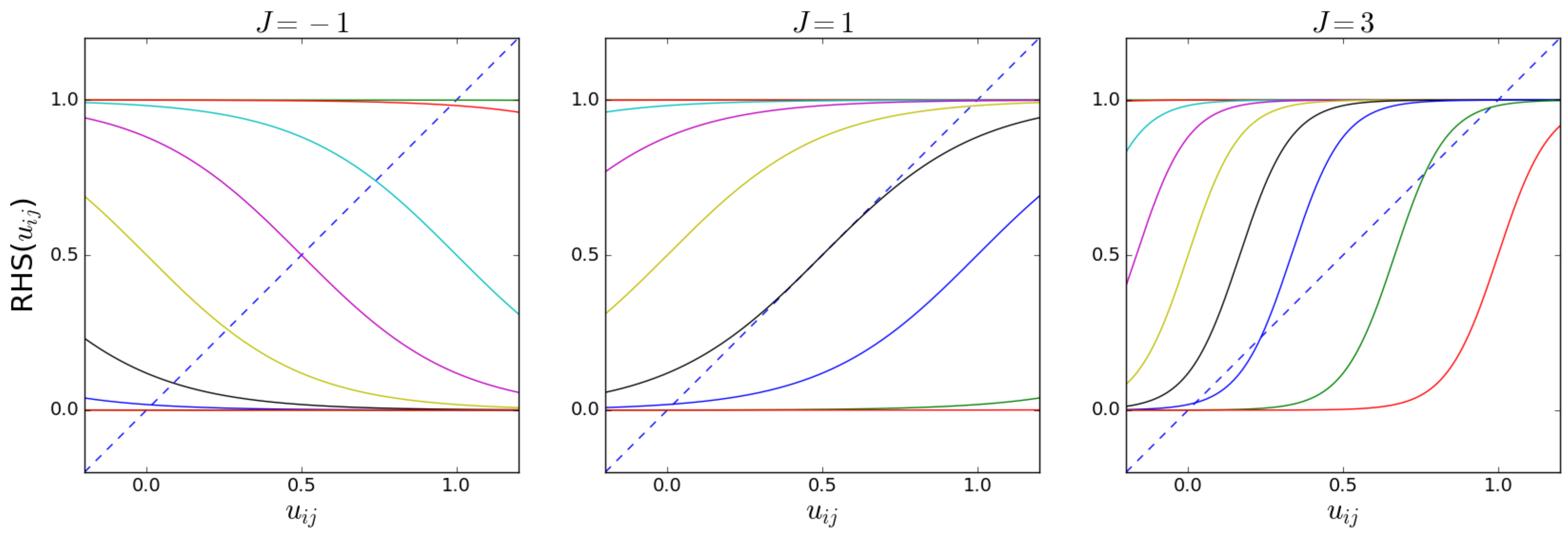
, the system must undergo a phase transition as per
Figure 3. We expect an abrupt change in the value of
, and according to Equations (
70) and (
71), we therefore expect an abrupt change in the equilibrium value of both
L and
O.
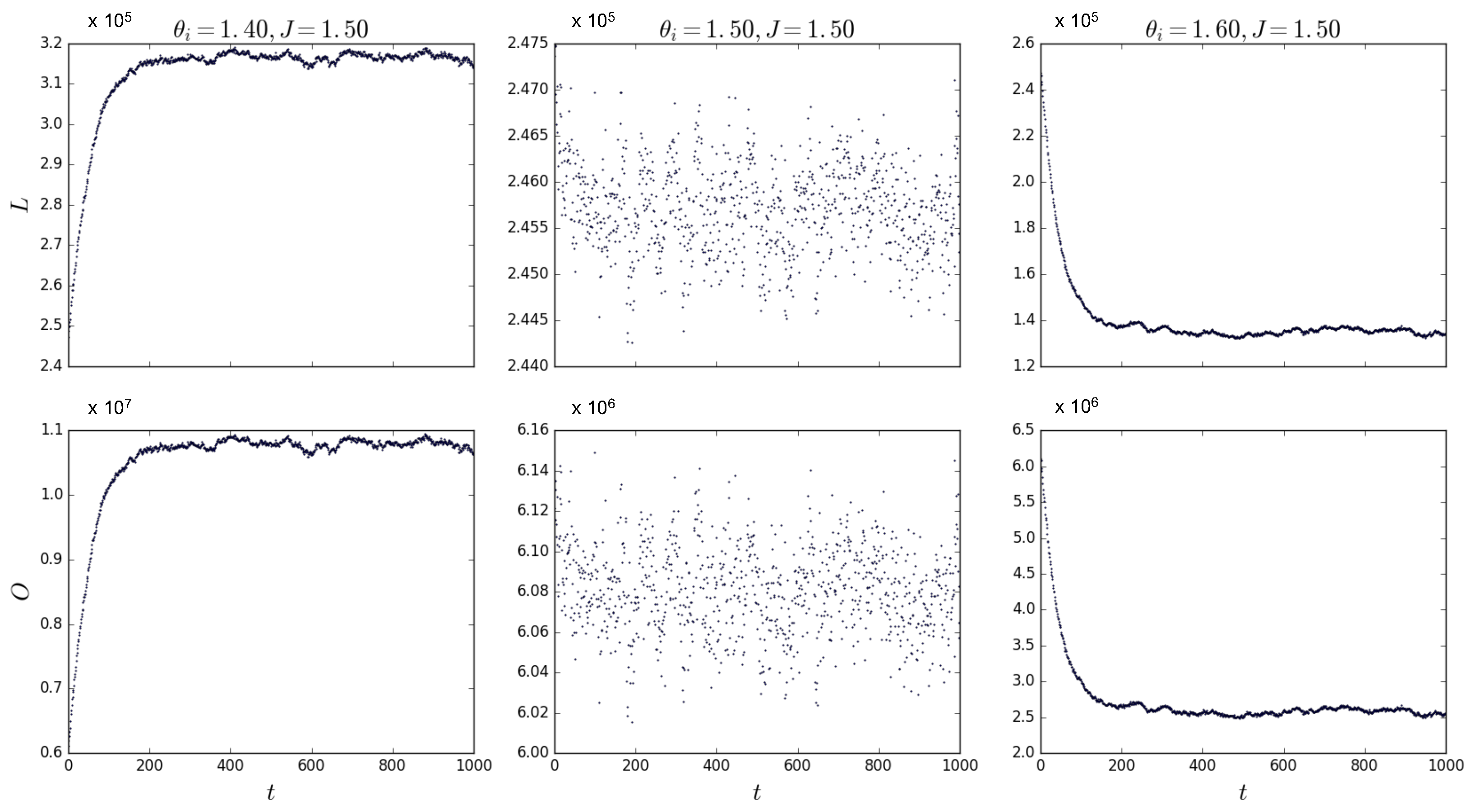
Figure 4 shows simulations for
confirming the transition from a relatively high to a low density as the value of the field
changes sign. These simulations have been repeated for different combinations of values for
J and
around the point where
B changes sign, confirming the results shown here. Note that the middle plot in
Figure 4 shows that the algorithm converges to multiplexes with a density of
, confirming that, when
,
L is approximately half of the total amount of possible links in the multiplex, as we expected above.
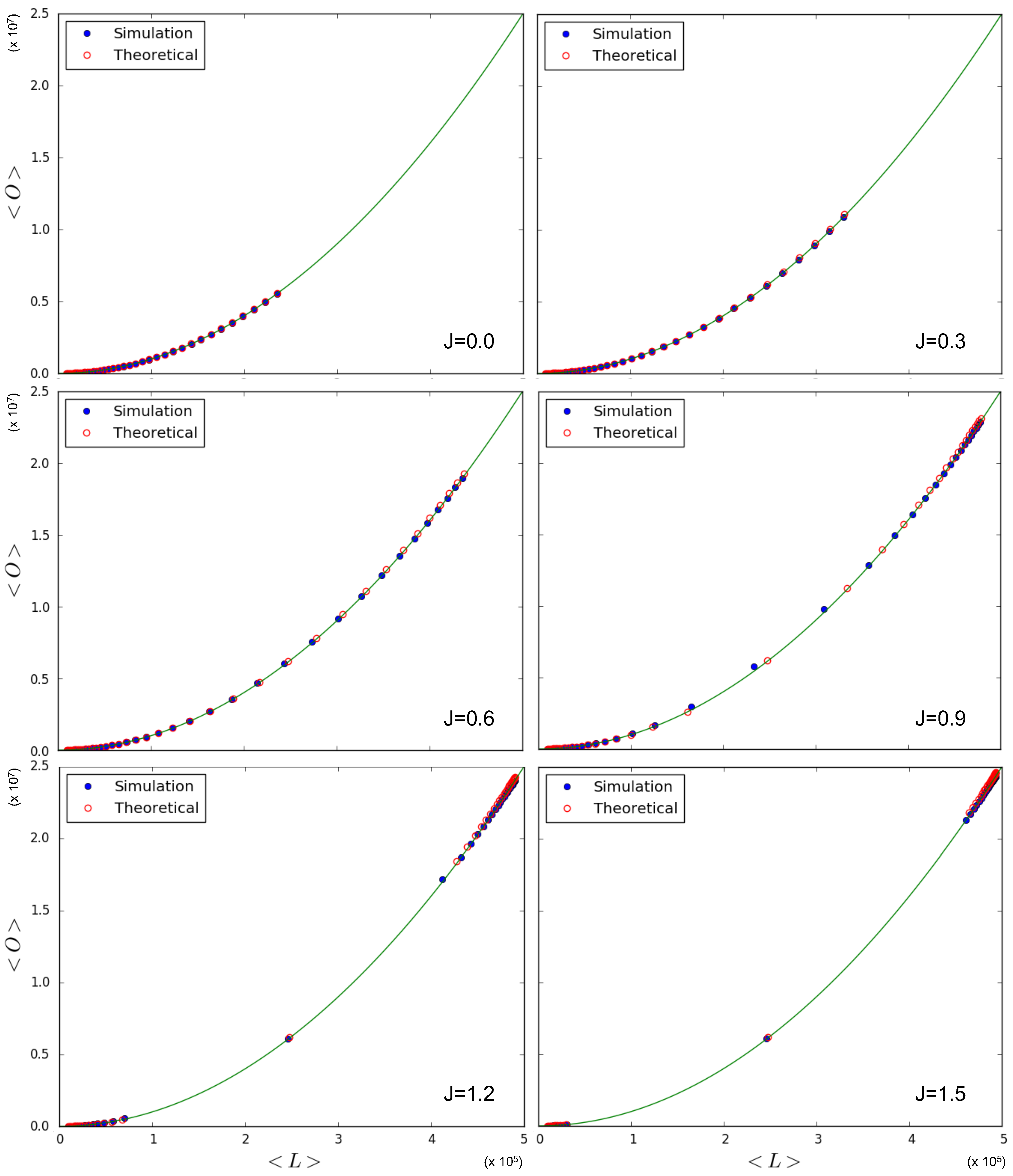
In
Figure 5 we test the prediction, given by Equations (
70) and (
71), of the quadratic relationship
. Note that this quadratic trend is predicted irrespective of the value of
, and even coincides with what Equation (
68) predicts in the case
for a homogeneous multiplex with constant
, as considered here. So, in this case, the expected relationship between
and
is not informative regarding the phase transition, although the specific values picked up by the system along the curve are. Indeed, we again simulate multiplexes with
layers,
nodes, and a variety of values for
and
J. Each simulation results in a value for
and a value for
, which we plot against each other. These points are then compared to the theoretical points predicted by Equations (
69)–(
71) for the chosen parameter values, and added to
Figure 5. We see that the relationship between simulated quantities is in agreement with the one predicted by the model. As we had anticipated, this is the result of the fact that different pairs of nodes are i.i.d. realizations of the same system, so that the ensemble average is realized as a sample average of the pairs of nodes across the network, even if in the symmetry-broken phase, the ensemble average of
is not representative of any of the values realized locally for individual pairs of nodes. Therefore, the only scaling we observe coincides with the one given in Equation (
68) for the ‘non-magnetized’ regime in the case where
is the same for all nodes. The only, although very important, signature of the phase transition we see in
Figure 5 is the fact that, for
and
, both the simulated data and the corresponding theoretical predictions ‘drift away’ from the intermediate values of
(which are still obtained for
) towards either low (
) or high (
) values of
. This is because the realized multiplex networks are either low-density or high-density, which is an indication of a phase transition occurring when increasing the value of
J, exactly as predicted by
Figure 3.
We conclude our discussion of the homogeneous case by noting that, given an empirical multiplex
of interest, the entropy of the data given, in general, by Equation (
58) reduces, in this case, to
where we have used Equation (
9) (denoting, via
, the total number of links in the multiplex, which also equals the expected value
) and the fact that the pair partition function
, given by Equation (
52), has the same value
for all the
pairs of nodes. From Equation (
72), we see that the entropy is determined, as expected, by both
and
. At the same time, we know that
depends uniquely and quadratically on
in this homogeneous model. The values achieved by the entropy are, therefore, bound by the relationship between
and
, which here is the same irrespective of the value of
, including when
. In any case, the entropy also depends on the specific values of
, and Equation (
63) guarantees that an upper bound for
is given by the entropy
of the ACM model with
and
(clearly, the homogeneity implies that
for all
in the ACM model as well).
5.1.2. Power-Law-Distributed Fitness: Scale-Free Networks with Overlap
We now move away from the homogeneous case and consider a situation where the fitness values
are drawn from a heavy-tailed distribution, in particular, a power law. This choice will produce a high degree of heterogeneity. In the ACM (see
Section 2.5), the expected degree distribution is determined by the Lagrange multipliers
, or equivalently, the transformed hidden variables
. If
x is distributed according to a power law, the expected degree distribution shall be distributed according to a power law as well, with the modulo as an upper cut-off. Since our OACM is an extension of the ACM, we will still sample
from a power law distribution
for various values of
, even though the expected degree distribution is not solely determined by the hidden variables
, but depends on
J as well. In any case, a higher level of heterogeneity in the hidden variables
will lead to a higher level of heterogeneity in the degrees. Since the parameter space is rather large (
-dimensional), we define
where
z is a scaling factor. We sample
only
once from every chosen distribution. The value of
is varied by varying the scaling factor
z. The parameter space to be explored will then be
, which is 2-dimensional. We deduce that
which shows that an increasing
z leads to a decreasing
. In the ACM, we have shown that the link probability is equal to
, which means that larger values of
lead to a larger expected degree, so that increasing all the fitness values will increase the density in the network. This qualitative relationship still holds with the addition of the constraint on the expected overlap (for fixed
J).
The complexity of Equations (
53), (
55), and (
56) does not allow us to easily derive the expected relationship between the overlap and the number of links in the network, as was the case when
was constant. It is, however, possible to visualize the relationship between the overlap and the number of links by using the Metropolis–Hastings algorithm.
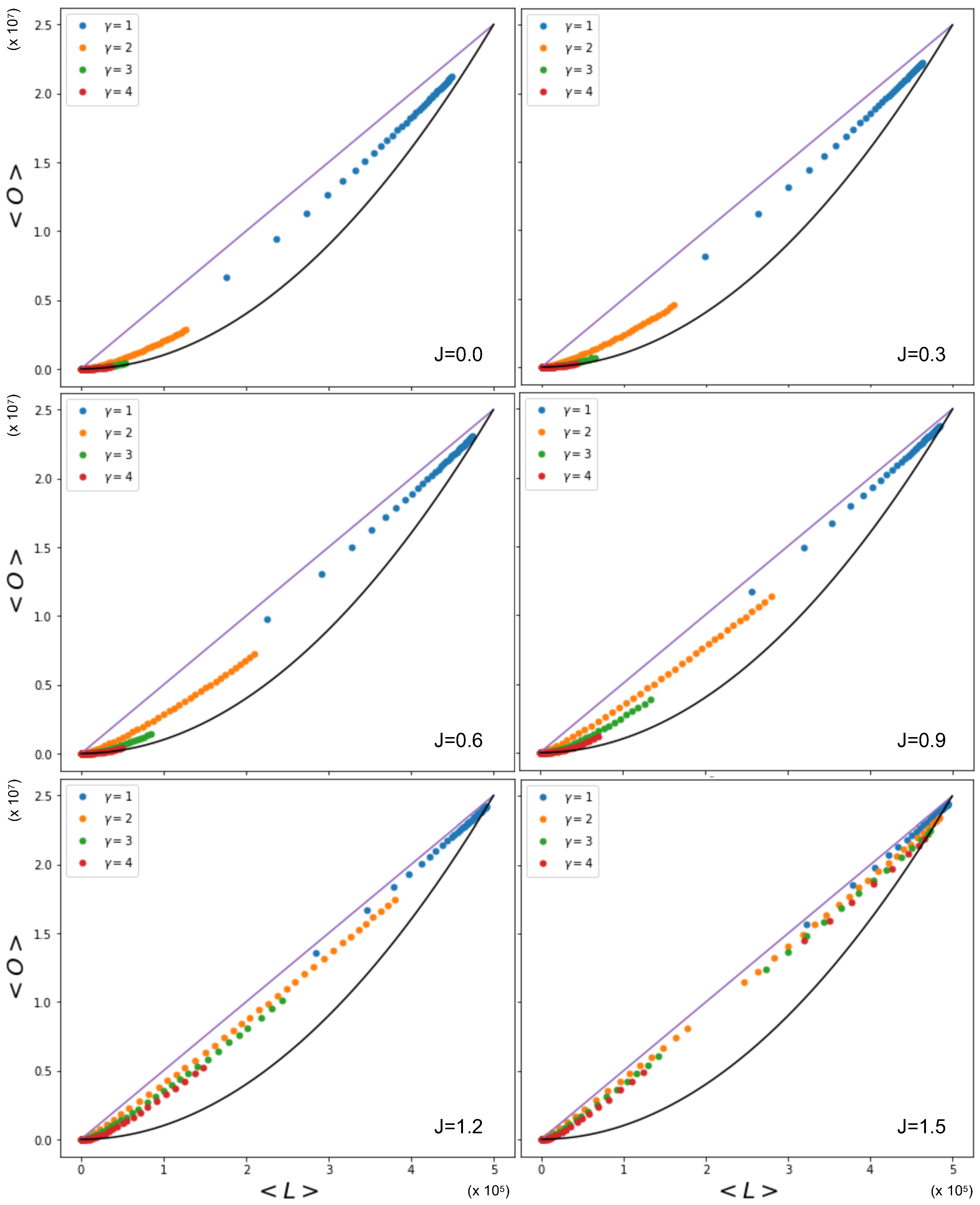
Figure 6 shows this relationship, where
is sampled from power law distributions with various values of
, alongside the expected quadratic term previously observed to occur for homogeneous values of the fitness
(delta distribution). We see that the overlap for a given number of links is higher in the cases where
x is drawn from a power law distribution than when
x is drawn from a delta distribution, even though the coupling parameter
J is kept constant. The cause of this difference lies in the level of heterogeneity of the fitness distribution: unlike the homogeneous case, now different pairs of nodes have very different values of
, and, therefore, the condition
for the vanishing of the ‘external field’
(spontaneous symmetry-breaking condition) cannot be realized simultaneously by all pairs. The figure also shows the effect of different exponents of the power law distributions of the fitness. A smaller value of
leads to a higher overlap for a given number of links. By increasing the value of
, the power law distribution becomes more sharply peaked, and will therefore lead to more homogeneous networks. Note, however, that increasing the value of the coupling parameter
J itself also leads to an increase in the overlap for a given number of links for the same distribution.
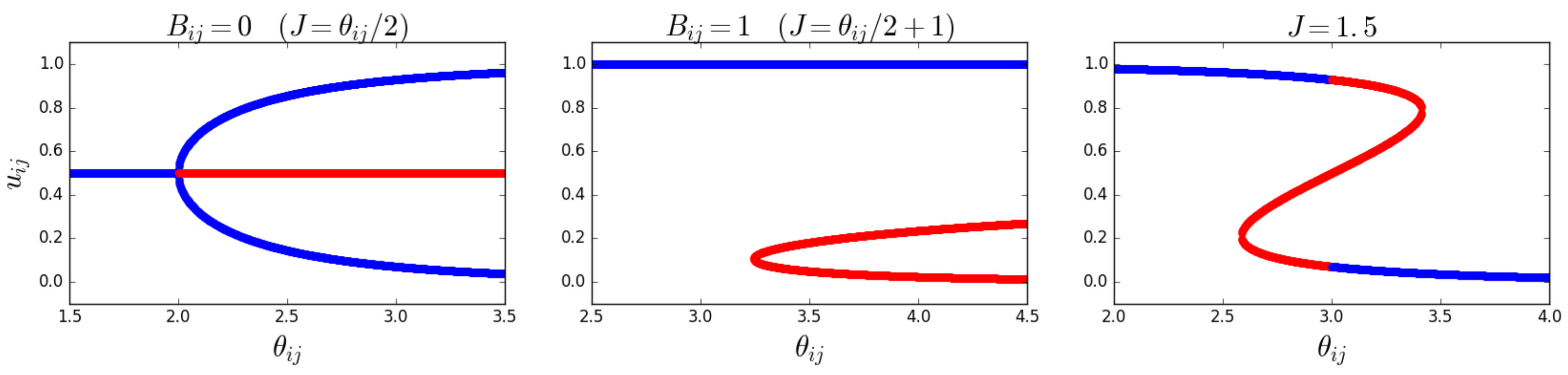
Importantly, the phase transition now occurs for different pairs of nodes as
J is varied. Some pairs of nodes will be in the non-magnetized phase, while others will be in the magnetized phase. The effective number
of independent layers will, in general, depend on the choice of parameters. Among the magnetized pairs, the realized values of the overlap are no longer those corresponding to the ensemble average (as in the homogeneous case), but typically to the symmetry-broken solution with lower energy (hence dictated by the value of
), because no other pair of nodes will, in general, exist with the same parameters and such that the two symmetry-broken values are averaged by the resulting value of the realized overlap. In particular, while for
all node pairs are in the non-magnetized phase, as
J increases from 1 towards larger values, the pairs of nodes that first undergo the phase transition are the ones with values
that fall between the limits set by Equations (
65) and (
66). As those equations and
Figure 2 show, there are more and more combinations
entering the magnetized phase as
J increases. When
J is sufficiently large, all pairs will be magnetized. Clearly, for any two pairs of nodes,
and
, that share the same node,
i, the values of
and
will be correlated, as they share the same term
. This means that the pairs of nodes entering the magnetized phase typically have nodes in common, even if it would be incorrect to say that individual nodes enter the magnetized phase ‘one by one’, while this is certainly correct for individual node pairs, if the sum
is different across all of them.
Figure 6 indeed shows the effect of the changing number of magnetized node pairs as
J increases above 1. We note that, for larger and larger
J, the relationship between
and
tends towards the ‘maximally multiplexed’ linear extreme (shown as a straight line) given in Equation (
67). At the same time, we see that the ‘non-multiplexed’ case (
) described by Equation (
68) now realizes values of the overlap that are very different from the quadratic trend achieved by the homogeneous model (also shown as a solid curve in
Figure 6), which now turns out to represent a lower bound. We can ‘zoom in’ to better see this difference by looking at
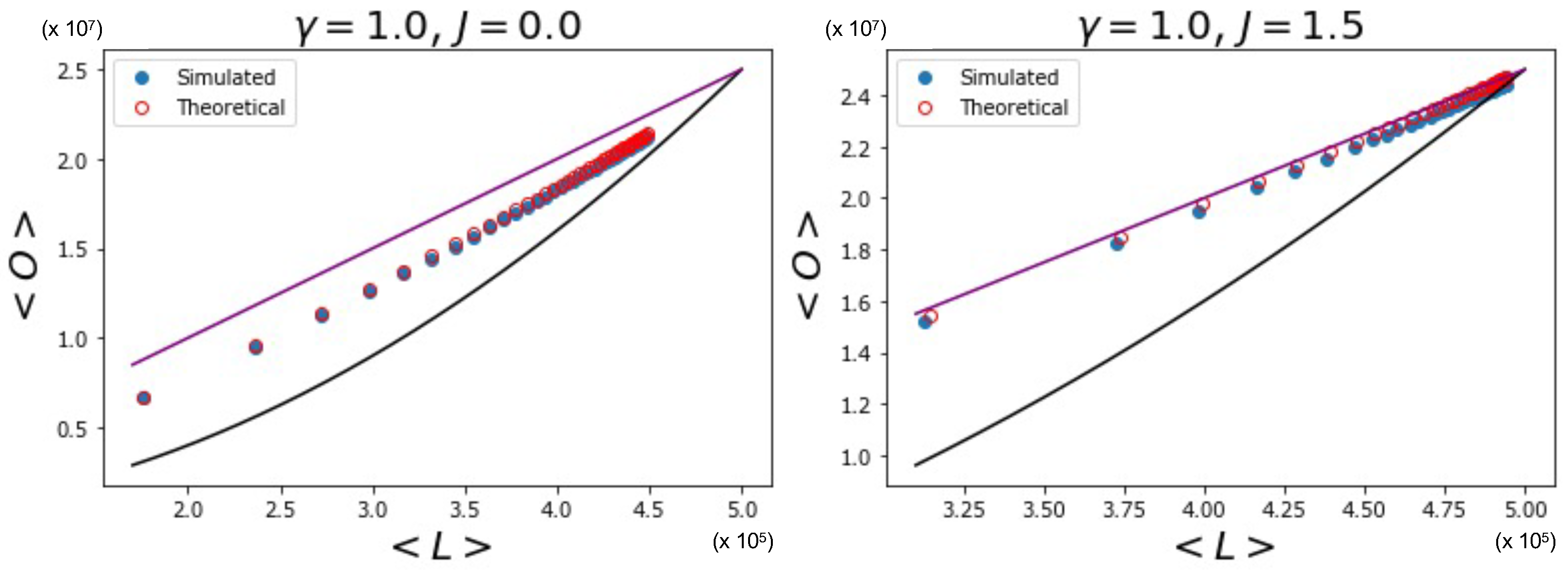
Figure 7, where, by using Equations (
53), (
55), and (
56), we additionally calculate the theoretically predicted values of
and
and compare them to the simulation data, where
is sampled from a power law distribution with
(the results for
are qualitatively similar and are therefore not shown here). The figure confirms a strong deviation from the curve for the homogeneous model, even when
(signaling a much higher but spurious overlap, arising only from the rising correlation among node degrees across different layers), and a close agreement with the maximally overlapping value in Equation (
67) already for
(corresponding to a further increase in overlap, arising from an additional, genuine coupling between layers).
5.1.3. Log-Normally Distributed Fitness
The delta and power law distributions we have considered so far represent examples of completely homogeneous and extremely heterogeneous (especially for
) distributions, respectively. We now consider the log-normal distribution as a third example between these two extremes. This analysis will indeed lead to results that are in some sense intermediate between what we have observed so far, and useful for interpreting the real-world case that we will present later on. A log-normal distribution is the distribution of a random variable whose logarithm is normally distributed (i.e., if the random variable
x is log-normally distributed, then
follows a normal distribution). The probability density for a log-normal distribution is
where
and
correspond to the mean and the standard deviation of the normal distribution of
. We will vary the value of
by again introducing a scaling factor that can be changed such that
and
, where we sample
once from the log-normal distribution for a variety of values for
and
.
The log-normal distribution allows us to inspect the transition in the relationship between the overlap and the number of links from the quadratic lower limit to the linear upper limit by varying the value of . Indeed, when , the normal distribution of is sharply peaked. By decreasing the value of towards 0, (and, therefore, as well) shall approach a delta distribution. This is the distribution that led us to the quadratic lower limit for the relationship between the overlap and the number of links in the network. Conversely, when , the log-normal distribution approaches a distribution with a power law tail with . This distribution led us to the linear upper limit between the overlap and the number of links in the network (when J was sufficiently large). By increasing the value of from 0 to a sufficiently large value (e.g., ), we can therefore increase the heterogeneity of the network from a completely homogeneous network achieving the quadratic lower limit to an extremely heterogeneous network close to the linear upper limit relationship in the simulation data.
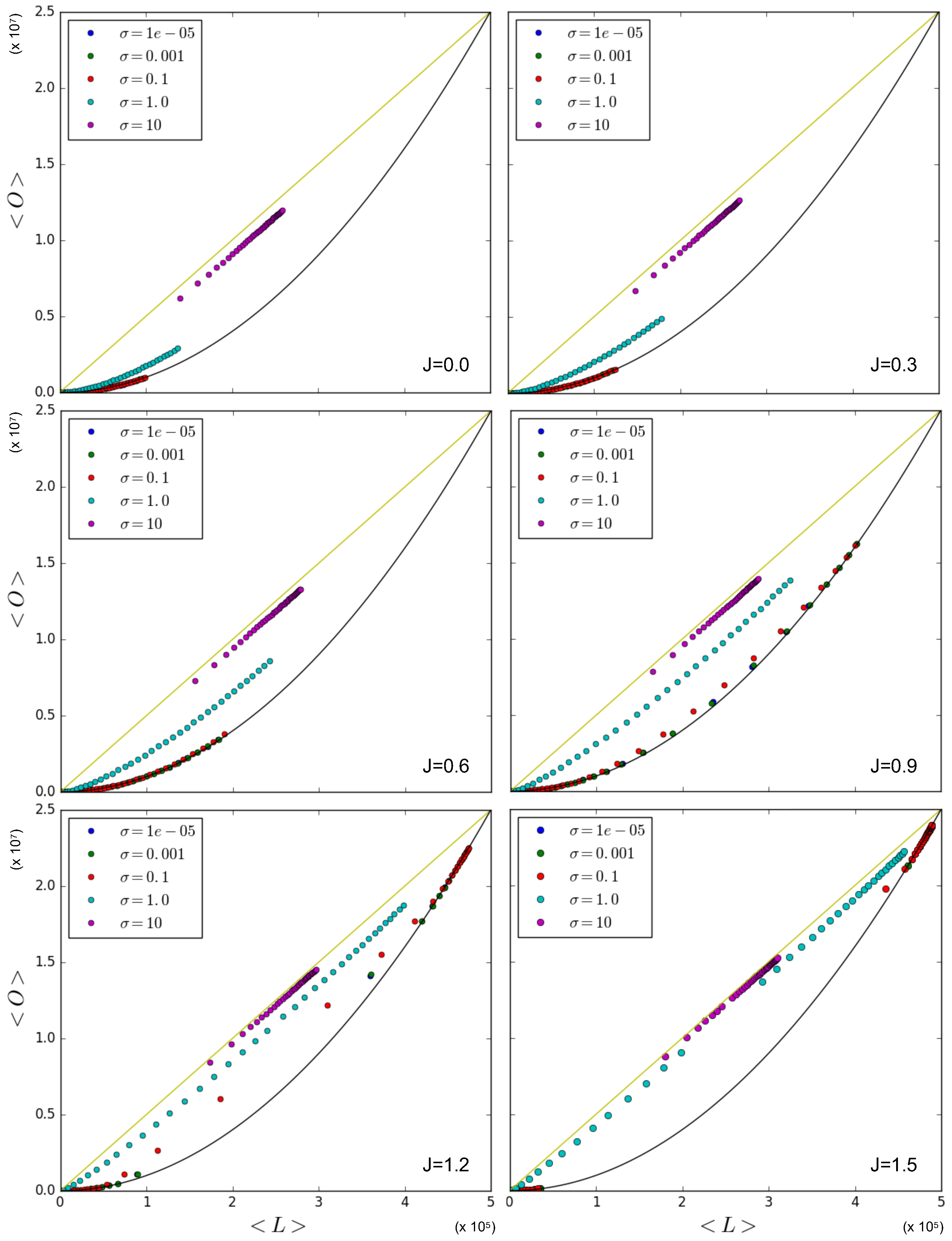
Figure 8 shows the relationship between the average overlap and the number of links in the network with simulation data that were obtained by using the Metropolis–Hastings algorithm for a variety of values for
J and
. Again, the linear upper limit is illustrated as a straight line and the quadratic lower limit as a solid curve. The figure confirms that in the case where
, the data points that correspond to
being sampled from a log-normal distribution with a relatively low value for
are either on or close to the quadratic lower limit curve. On the other hand, the case where
results in data points where the overlap in the network for a given number of links is almost maximal, and therefore approaches the linear upper limit. This first set of results confirms the strong role of node heterogeneity in determining increased correlations between the degrees of the same node across different layers, which, in turn, increase the inter-layer overlap even without any explicit coupling (
), and hence, in a ‘spurious’ manner. On the other hand, when we increase the value of
J, the data points corresponding to relatively low values of
(e.g.,
and
) stay on or close to the quadratic lower limit, a finding similar to the results in
Section 5.1.1, showing that the symmetry-broken values realized by different pairs of nodes, when averaged across the network, restore the ensemble average because the node pairs are all independent and (almost) identically distributed. Remarkably this means that, in a certain sense, node homogeneity ‘suppresses’ the effects of the true inter-layer coupling (
) on the realized overlap. For the intermediate value
, the data are distributed close to the quadratic lower limit curve only for low values of
J, while increasing the value of
J leads to a more linear trend, eventually approaching the linear upper limit. In this case, the coupling is effective in producing a higher realized overlap. In the case where
, the linear trend is instead achieved already for
(although the points are aligned below it); hence, increasing the value of
J barely influences the value of the overlap for a given number of links.
Therefore the effect of increasing
J in networks with a moderate heterogeneity is a transition from multiplex configurations with densities of all levels towards multiplex configurations with either low or high density, which is a result of the phase transition. It also shows that a very high level of heterogeneity leads to an overlap in the network that is already close to maximal for a given number of links, irrespective of the phase transition and the value of
J. However, in the case where we have an intermediate level of heterogeneity (
), we observe that the effect of the coupling can be relatively strong, and we can therefore construct networks with a combination of the overlap and number of links falling between the extreme linear upper limit and the quadratic lower limit in a controlled, systematic manner. Note that
Figure 8 also shows that, as
J increases above 1, the (symmetry-broken) realized data start to ‘drift away’ from the intermediate densities, in a way similar to what we observed in
Figure 5, but in a more pronounced manner. This is due to the fact that, as
J increases, a larger number of multilinks shall be either in the low-density or high-density phase.
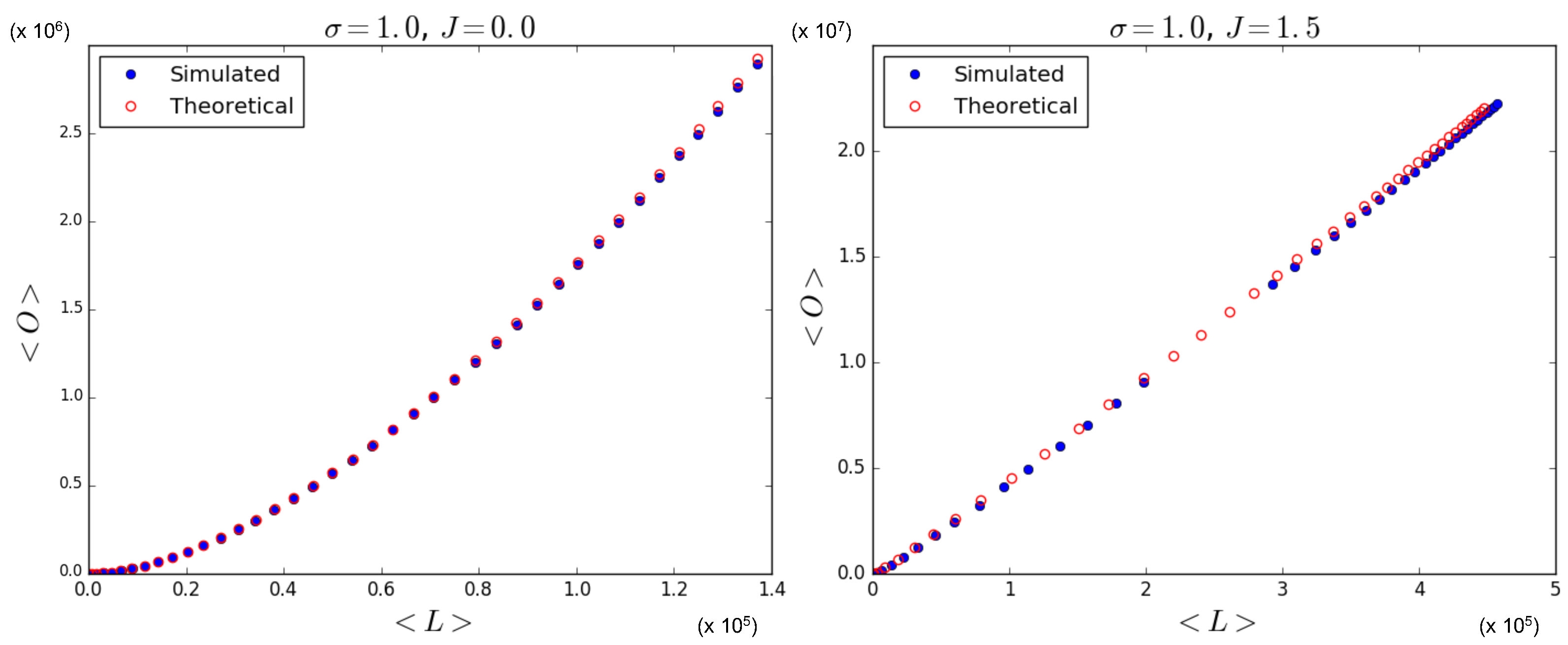
Again, in
Figure 9 (which is the counterpart of
Figure 7), we ‘zoom in’, and, using Equations (
53), (
55), and (
56), we show the theoretically predicted values of
and
and compare them to the simulation data, where
is sampled from a log-normal distribution with
, for
and
. The results for
are not shown here since relatively low and high values for
lead to results similar to those we have shown in
Section 5.1.1 and
Section 5.1.2, respectively.
Figure 9 confirms that the theoretical predictions are in good agreement with the simulation data, apart from the expected ‘drifting away’ of symmetry-broken values from the corresponding ensemble average.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









