1. Introduction
Analyzing large datasets is crucial for deriving meaningful and actionable insights that go beyond simple correlations. With the advent of big data, datasets can contain millions of examples (rows) and features (columns) [
1,
2]. Data complexity analysis uses a broad category of measures that offer such insights. For example, the complexity of optimization problems can be quantified using landscape analysis which includes fitness landscape analysis (FLA) [
3] and exploratory landscape analysis (ELA) [
4]. Topological data analysis (TDA) measures the topological features in data, and the relationships between them, to assess complexity [
5,
6]. Complexity measures for regression problems include feature correlation measures, linearity measures, smoothness measures, and geometrical, topology, and density measures [
7]. Lastly, complexity measures for classification problems focus on the geometrical complexity of the class boundary [
8]. Complexity measures for classification problems include feature-based measures, linearity measures, neighborhood measures, network measures, dimensionality measures, and class imbalance measures [
9]. Applications of these measures include data analysis, data pre-processing, understanding algorithm performance, meta-learning or automated machine learning, and selecting benchmarks that cover a variety of complexity characteristics [
7,
9,
10,
11,
12,
13,
14].
This paper is concerned with feature-based complexity measures for classification problems. A classification problem is a type of supervised learning where the goal is to take advantage of geometric shapes in the data to separate instances of different classes. Feature-based complexity measures quantify the discriminative power of the descriptive features in a dataset—that is, how useful the features are in separating instances of different classes [
9]. Classification datasets with highly discriminative features are considered simple, while datasets with features that exhibit little to no discriminative power are considered complex.
It is worth noting that various statistical approaches, including chi-squared statistics, ANOVA F-value, mutual information, lasso regression, two-sample t-test, Kruskal–Wallis test, Kolmogorov–Smirnov test, and more, are commonly used to estimate feature informative power and selection. These approaches have a different objective compared to feature-based complexity measures, which is to quantify feature informative power for feature selection, while feature-based complexity measures focus on estimating the complexity of the dataset. Despite this distinction, there is a similarity between these two types of approaches, making it worthwhile to explore the possibility of using these statistical measures as complexity measures, similar to how feature-based complexity measures have been utilized for feature selection.
Unfortunately, existing feature-based complexity measures are not designed to handle multinomial classification problems; they are designed for binary classification problems. These measures typically use the minimum and maximum feature values of each class to determine the overlapping region of the classes. The instances outside of this region are seen as instances that can be easily discriminated by the features. However, the use of the minimum and maximum values of each class for each feature presents two problems. Firstly, there is sensitivity to noise, as a single noisy instance could result in an overestimation of complexity. Secondly, the use of minimum and maximum values cannot estimate the complexity of real-world classification problems, such as cases where the instances of one class lie between those of another class. To handle multinomial classification problems, existing measures require decomposing the classification problem into multiple sub-problems using the one-versus-one (OVO) strategy. The average of these sub-problems is then taken as the complexity value. However, the use of OVO is computationally inefficient, and as shown in this paper, the use OVO does not properly capture the complexity of the classification problem..
This paper proposes the F5 measure, which is a new feature-based complexity measure that is designed to effectively handle multinomial classification problems. The measure determines the most discriminative feature by identifying the longest sequence of uninterrupted instances for each class for each feature. These sequences are considered to be discriminated by their respective features. The feature that discriminates the most instances is selected, and its sequences are removed from the dataset. The measure then proceeds to consider the remaining features. This process continues until either there are no more features to consider, or there are no more instances to be removed. The number of instances remaining in the dataset after this process relative to the original number of instances in the dataset is interpreted as the complexity of the dataset. It is shown that the proposed measure better represents intuitions about feature complexity. This work is useful as it can enhance the application of complexity measures in various domains, including those mentioned earlier.
The rest of the paper is organized as follows: Formal definitions for existing feature-base complexity measures are given in
Section 2.
Section 3 proposes a new feature-based complexity measure.
Section 4 details the experiments used to demonstrate the difference between the proposed measure and existing measures and presents the results.
Section 5 concludes the paper.
2. Feature Complexity
A tabular classification problem is defined by the data in a dataset where the objective is to correctly predict the class of each instance, assuming that each instance has only has a single class. Formally, a dataset,
T, contains
n instances in which each instance
is described by
m descriptive features and a target feature in
that corresponds to its class. Feature-based complexity measures estimate how informative the
m features are in discriminating among instances of different class labels [
13]: that is to say, how useful the features are in separating the
classes. The more instances that can be separated, the simpler the problem.
Section 2.1,
Section 2.2,
Section 2.3,
Section 2.4 and
Section 2.5 describe existing feature-based complexity measures, namely F1, F1v, F2, F3 and F4, respectively. Note that lower values returned by the measures indicate the presence of one or more features that exhibit a large amount of discriminative power. Larger values, on the other hand, indicate that the descriptive features are discriminatively weak and, thus, are more complex.
2.1. Maximum Fisher’s Discriminant Ratio
Ho and Basu proposed the maximum Fisher’s discriminant ratio measure (F1) to capture the complexity of a dataset [
8]. They argued that multi-dimensional classification problems are easy so long as there exists one discriminating feature. The F1 measure returns the Fisher statistics of the feature with the largest contribution to class discrimination [
14]. In other words, the F1 measure identifies the feature with the largest discriminative power [
8]. This paper takes the inverse of the original F1 formulation, so that the measure returns low values for simple classification problems and larger values for more complex classification problems [
9]. The inverse of the F1 measure is
where
is a discriminant ratio for each feature
. The discriminant ratio is calculated as
where
is the number of instances in class
,
is the mean of feature
across examples of class
,
is the mean of the
values across all the classes, and
denotes the individual value of the feature
for an example from class
[
8,
11]. The computational cost of the F1 measure is
, and it returns values in
[
9]. A hyperplane can be drawn perpendicular to this feature’s axis to separate the classes. Lorena et al. noted that if the required hyperplane is oblique to the feature axes, F1 may not be able to capture the simplicity of the classification problem [
9].
2.2. Directional-Vector Maximum Fisher’s Discriminant Ratio
Orriols-Puig et al. proposed the directional-vector maximum Fisher’s discriminant ratio (F1v) as a complement to the F1 measure [
15]. This measure searches for a vector which can separate instances after the instances have been projected into the vector [
9,
15].
The directional Fisher criterion [
16] is defined as
where
and
Vector
d is the directional vector onto which data is projected in order to maximize class separation,
B is the between class scatter matrix,
W is the within-class scatter matrix,
is the centroid (mean vector) of class
,
is the pseudo-inverse of W,
is the proportion of examples in class
, and
is the scatter matrix of class
.
Formally, the F1v measure is
F1v was implemented for two-class classification problems and has a computational cost of
. The measure can be extended to classification problems with more than two classes (referred to as multinomial classification problems) by decomposing the problem into sub-problems using a ovo strategy [
9]. However, F1v for multinomial classification problems is computationally expensive with a cost of
—assuming that each class has the same number of instances [
9]. As for the F1 measure, F1v values are bounded in (0,1].
2.3. Volume of Overlapping Region
F2 measures the volume of the overlapping region for two-class classification problems. An overlapping region is a region in the dataset that contains instances of different classes. The F2 measure computes, for each feature, the ratio of the width of the overlapping region of the classes to the width of the feature [
15]. The width of the feature is the difference between the maximum and minimum values of that feature. The measure then computes the product of these ratios. Formally, the F2 measure is
where
and
and
) are the maximum and minimum values of each feature in a class
, respectively.
F2 returns values in [0,1] and has a computational cost of . For multinomial classification problems, the measure can also be extended using ovo, in which case the computational cost is .
F2 can identify only one overlapping region per feature. Alternatively, F2 can be thought of as only being able to identify two hyperplanes that separate classes per feature, since it computes one overlapping region and considers the instances on either side of that region. Hu et al. noted that the F2 measure does not capture the simplicity of a linear oblique border since the measure assumes that the class boundaries are perpendicular to the features axes [
17]. Lorena et al. noted that F2 values can become very small when the product is calculated over a large number of features [
9]. Thus, a complex classification problem with many descriptive features may produce a low F2 value, giving the impression that the problem is simple. Lastly, a single noisy class instance could result in an overlapping region that is wider than necessary [
9].
2.4. Maximum Individual Feature Efficiency
The maximum individual feature efficiency (F3) measure returns the ratio of the feature that can discriminate the largest number of instances relative to the total number of instances in the dataset [
15]. This ratio,
, is calculated using
where
I is an indicator function that returns 1 if its argument is true, otherwise 0,
and
are as defined in Equation (
9), and ∧ is the logical and operator. The F3 measure is then defined as
As for the F2 measure, F3 has a computational cost of , and it returns values in [0,1]. F3 also uses the minimum and maximum values of a feature for different classes in its calculation of complexity and therefore suffers from the same problems, namely only being able to identify one overlapping region per feature, unable to identify orthogonal hyperplanes that separate classes, and sensitivity to noise.
2.5. Collective Feature Efficiency
The F4 measure is similar to F3 but considers the collective discriminative power of all the features [
15]. F4 selects the most discriminative feature according to the F3 ratio of each feature. Then, all the instances that are discriminated by this feature are removed from the dataset. The next most discriminative feature, with respect to the remaining instances, is then selected, and the instances that are discriminated are removed. This function, defined below, is repeated until all of the instances are discriminated or all the features have been analyzed:
where
is computed according to Equation (
10);
is the dataset at round
r, and it is defined as
where
is the initial dataset,
and
are as defined in Equation (
9), and ∨ is the logical OR operator.
Formally, F4 is defined as
where
measures the number of instances in the overlapping region of feature
.
The F4 measure returns values in [0,1], which can be interpreted as the proportion of instances that could be discriminated by drawing hyperplanes perpendicular to the feature axes. The computational cost of F4 is . However, since F4 uses the F3 measure, F4 suffers from the same problems.
3. Collective Feature Efficiency for Multinomial Classification Problems
This section proposes a new feature-based complexity measure referred to as the F5 measure. The F5 measure is an extension of the F4 measure, which, like its predecessor, builds upon the F3 measure. However, while the F4 measure relies on the minimum and maximum values of class instances per feature, the F5 measure identifies the longest uninterrupted sequence of instances instead. Additionally, the F5 measure takes into account the discriminative power of each feature separately for each class. These modifications are made to handle multinomial classification problems without the need for ovo decomposition.
Section 3.1 introduces the idea of walking along a feature axis used to identify sequences of instances of the same class. The process of selecting the most discriminative feature is explained in
Section 3.2. Finally, the F5 measure is proposed in
Section 3.3.
3.1. Identifying Sequences of Instances of the Same Class
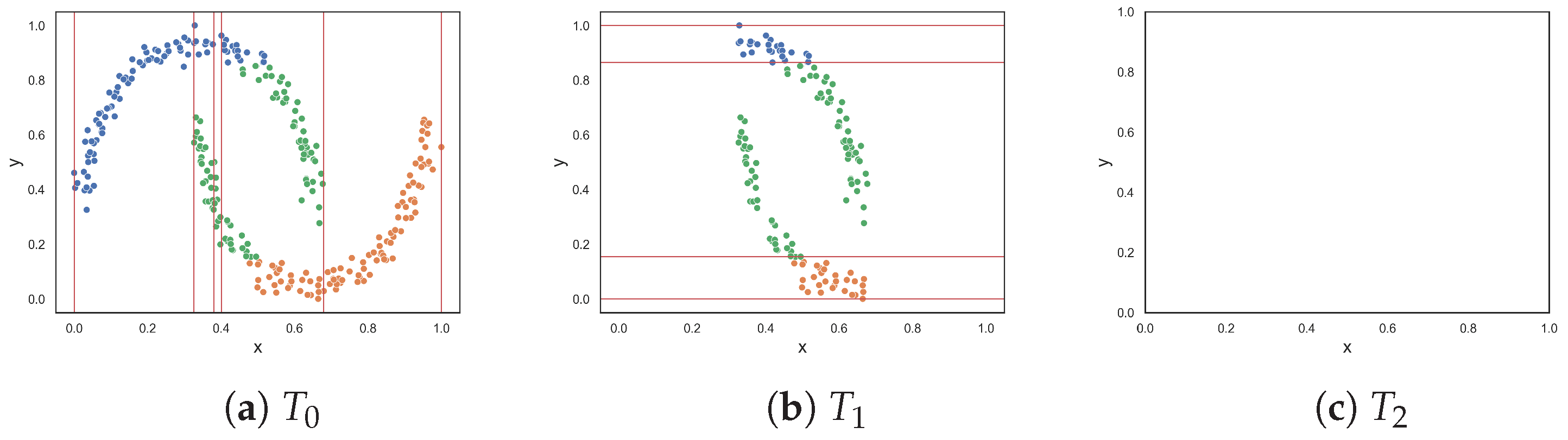
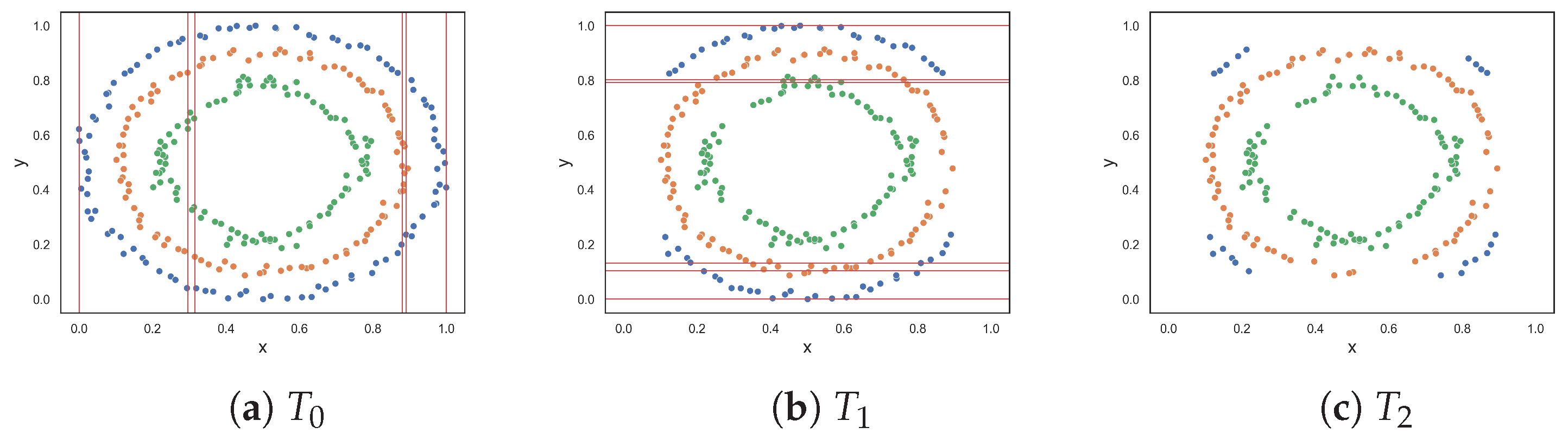
To better understand the ability of a dataset to discriminate between instances of different classes, imagine performing a random walk through the data and recording the class changes from one instance to the next. Similarly, the F5 measure employs a walking strategy along each feature axis, identifying the longest uninterrupted sequences of instances of the same class. Multiple sequences of each class may exist for each feature, and such sequences can be represented by the corresponding row IDs of the instances or the feature values at the start and end of the sequence. While traversing along a feature axis, if an instance shares a value with another instance but belongs to a different class, that sequence ends, and a new sequence starts. Longer sequences represent non-overlapping areas of the feature axis where lines may be drawn perpendicular to the feature axis to separate the classes. Conversely, shorter sequences may represent noise or reflect more challenging characteristics of the feature axis that are difficult to classify. The lengths of sequences are weighted by the total number of instances of the same class. It is important to note that having a longer sequence of instances from one class does not necessarily imply greater discriminative power, especially when other classes have significantly fewer samples. To address this issue, the lengths of the sequences are weighted according to their class distribution.
There is a special case where a feature exhibits discriminatory behavior primarily toward the ends of its feature axis. For example, a long sequence of instances exists at the beginning of the feature axis, and a similarly long sequence of the same class appears at the end of the axis. Between these two sequences are shorter sequences. It is reasonable to interpret these intermediate sequences as representing overlapping regions of multiple classes, while the sequences at the beginning and end of the feature axis are discriminated by the feature. In such a case, these sequences are concatenated and treated as a single sequence. The pseudocode for identifying these sequences is provided in Algorithm 1.
| Algorithm 1: Identifying sequences |
![Entropy 25 01000 i001]() |
3.2. Selecting the Most Discriminative Feature
Algorithm 1 is used to identify sequences for each feature. Only the longest sequence of each class is considered to be discriminated by its respective feature. This approach avoids the need for a control parameter to determine the number of sequences to consider, and thus, it also avoids the need for multiple reruns of the F5 measure with differing control parameter values. The feature that discriminates the most instances is selected, and the instances that it discriminates are removed from the dataset. For example, consider a dataset with features ‘x’ and ‘y’ and classes 0 and 1. The F5 measure calculates the longest sequence of instances for class 0 and class 1 separately for features ‘x’ and ‘y’. Suppose that feature ‘x’ discriminates the greatest number of instances. These instances are removed from the dataset and the remaining feature, ‘y’, is then taken into consideration for further analysis.
3.3. F5 Measure
The F5 measure works as follows: The most discriminative feature is selected using the process defined in
Section 3.2. The remaining features and instances are then considered, and the next most discriminative feature is selected. This process is repeated until there are no more features to consider or until all instances have been discriminated. Formally, this function is calculated as
where
returns the number of the instances in
that can be discriminated by feature
. Dataset
is the dataset of the
r-th round after the instances from
previous rounds have been removed;
. Note that when the relative entropy is calculated, the number of instances of each class is taken from
and not subsequent rounds.
The F5 measure is then defined as
where
n is the total number of instances in
T. The computational cost of the F5 measure is
, which is less than the computational cost of the F4 measure without the use of OVO. The F5 measure returns values in [0,1). A large F5 value indicates that a classification problem is complex, since it has descriptive features that discriminate few instances. Conversely, a small F5 value indicates that a classification problem has descriptive features that discriminate many instances and is therefore simple.
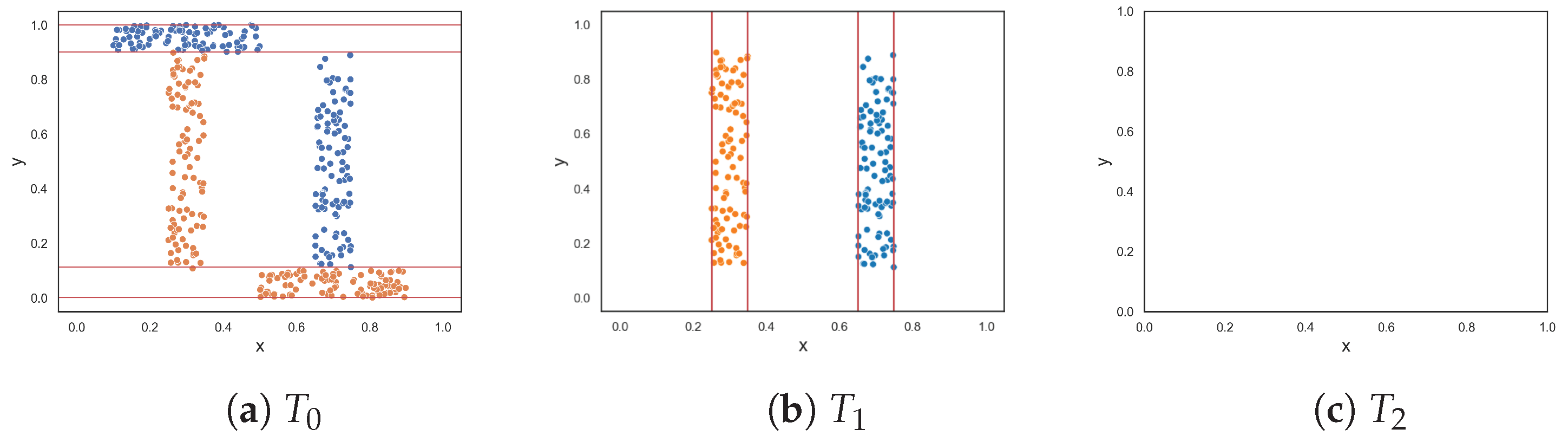
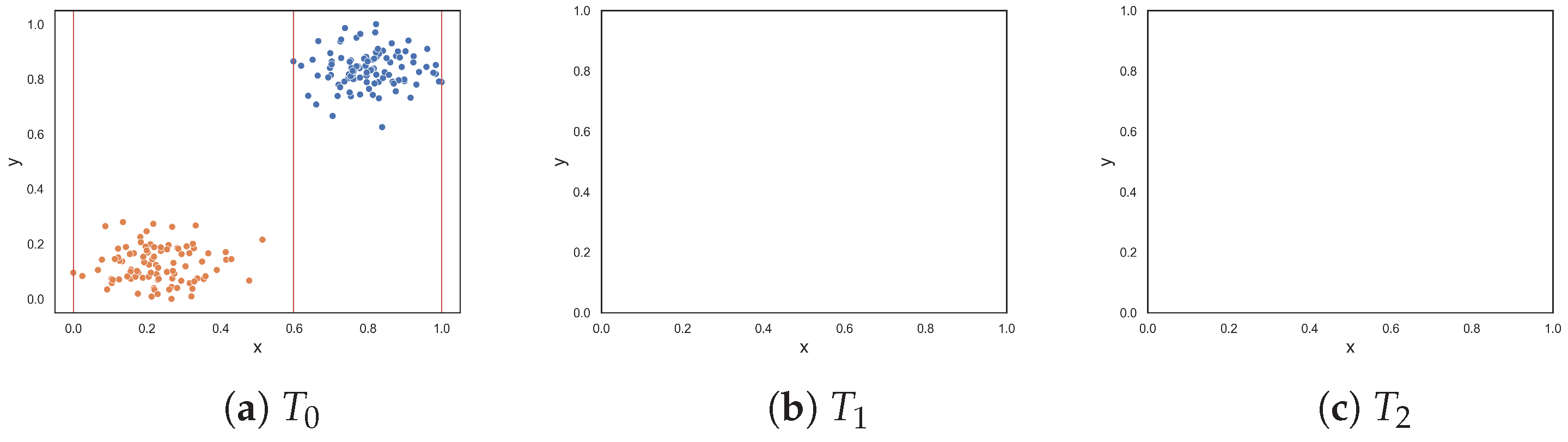
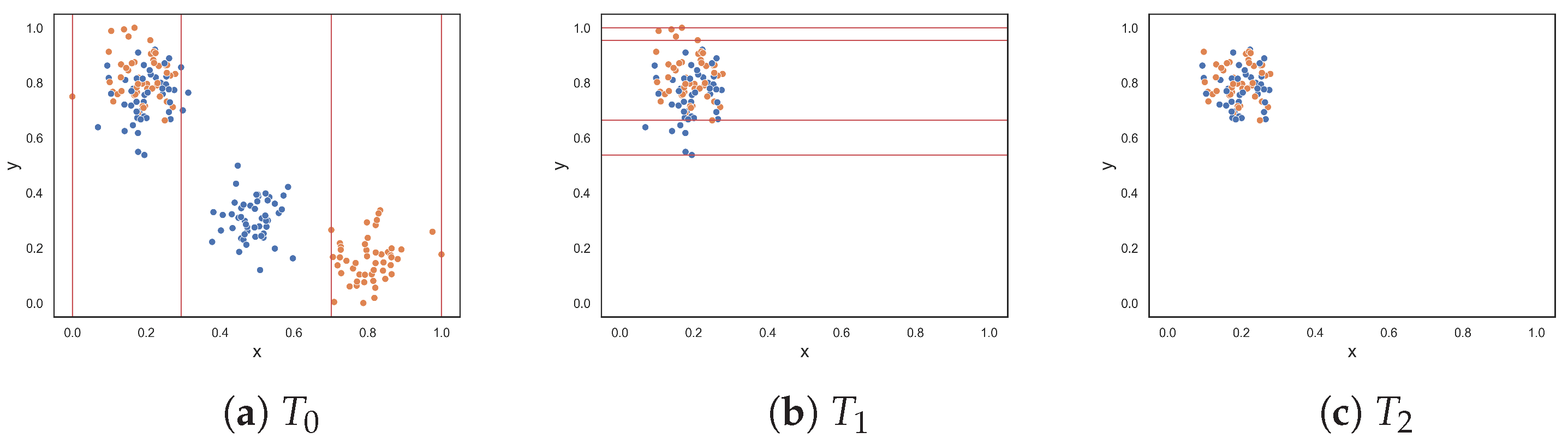
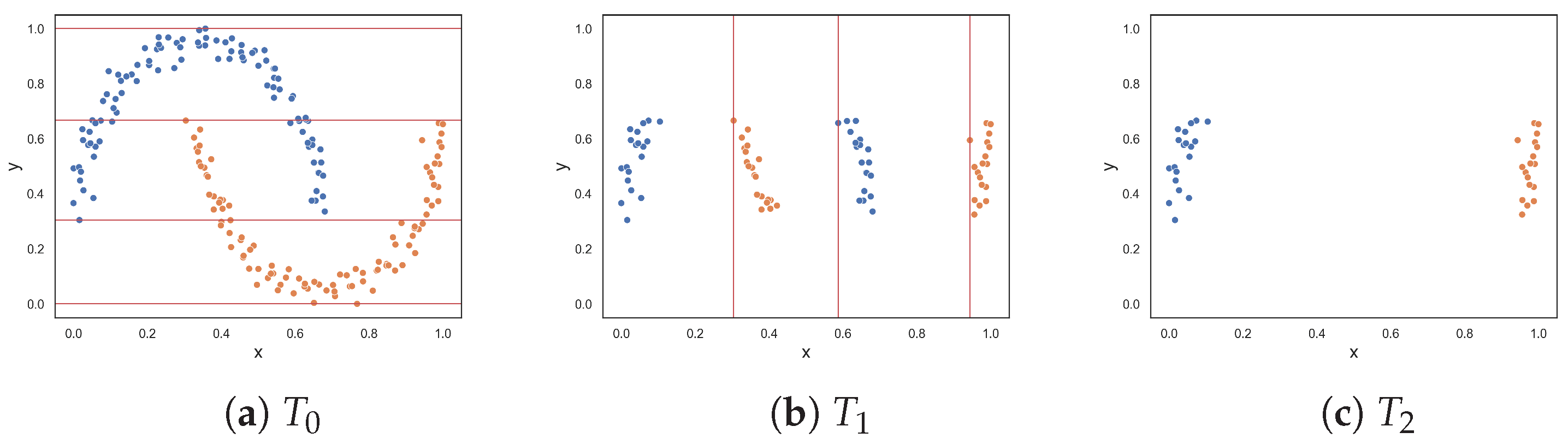
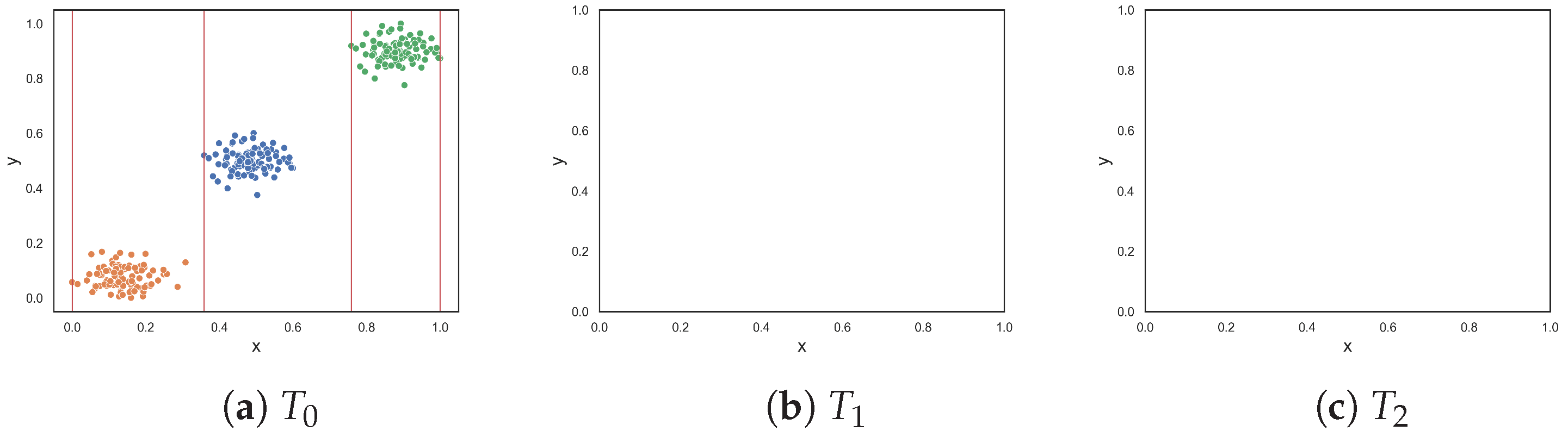
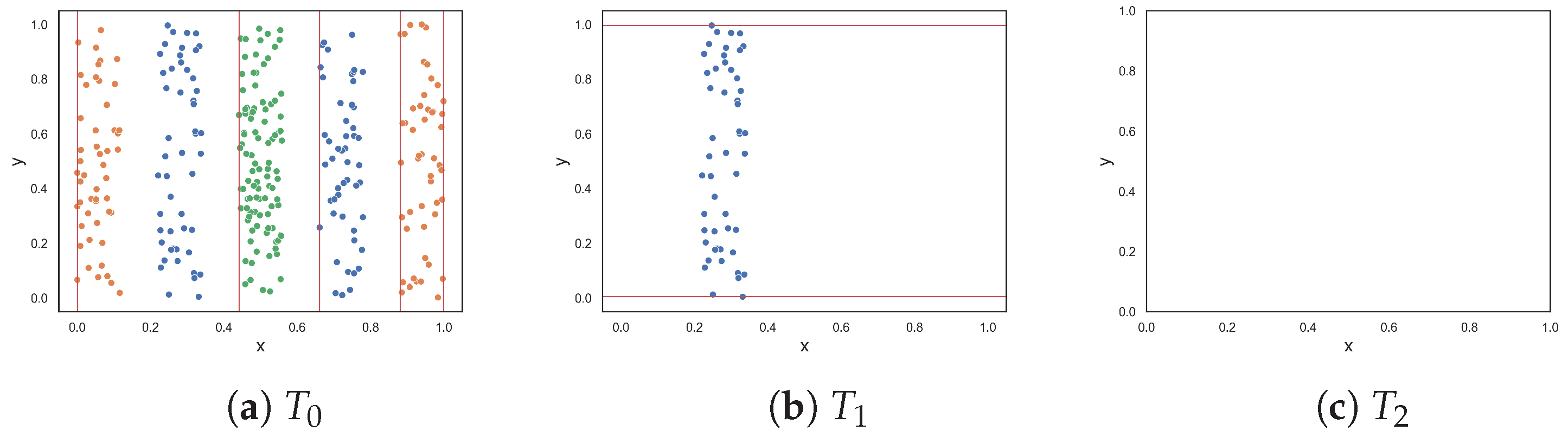
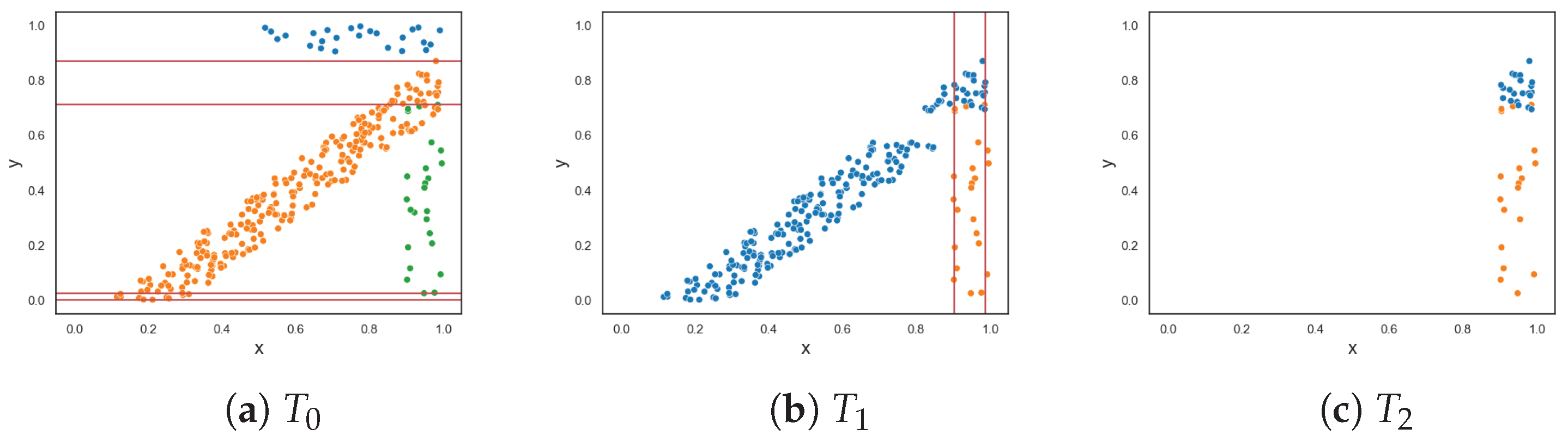
To demonstrate the F5 measure, consider the synthetic dataset in
Figure 1a at
that contains two T-shaped data. The F5 measure examines the features and determines that the y-axis can discriminate the highest number of instances, since it has the longest uninterrupted sequences. Using these sequence, lines could be drawn perpendicular to the y-axis (i.e., near the bottom and top of the axis) to separate the instances. The resulting dataset is illustrated in
Figure 1b. The F5 measure looks at the remaining feature, i.e., the x-axis. The measure finds the longest sequence of each class and removes these instances. The final dataset is shown in
Figure 1c. Thus, the complexity of this dataset is 0, which makes sense.
5. Conclusions
Meaningful insights into data help researchers to understand the problem being solved. Without such insights, time and effort are wasted. Complexity measures are tools designed for deriving such insights into data. This paper focused on feature-based complexity measures, which assess the discriminative power of descriptive features to separate instances of different classes within a dataset. The findings of this research indicate that current feature-based complexity measures generally do not perform well when applied to multinomial classification problems.
This paper proposed a new feature-based complexity measure, the F5 measure. This measure identifies uninterrupted sequences of instances belonging to the same class for each feature. The sequences correspond to instances that are discriminated by the features. The feature that discriminates the highest number of instances is identified as the most discriminant feature. Instances discriminated by this feature are removed and the feature is no longer considered. This process repeats until all instances have been removed or there are no more features to consider. The complexity score is the proportion of instances remaining in the dataset relative to the total number of instances in the dataset. The proposed measure is shown to accurately capture the feature complexity on a variety of synthetic datasets better than existing measures—especially multinomial datasets.
The work in this paper can be continued in the following ways (but it is not limited to them): Feature-based complexity measures have previously been used as feature selection tools, since the measures identify the most discriminative features in a dataset. Thus, an idea for future work is to investigate the performance of the F5 measure as a means of feature selection and to compare it with other feature-based complexity measures and existing feature-selection strategies. Similarly, exploring the use of commonly employed statistics used for feature selection (such as chi-squared statistics, ANOVA F-value, mutual information, lasso regression, two-sample t-test, Kruskal–Wallis test, Kolmogorov–Smirnov test and more) as complexity measures would provide valuable insights and an alternative perspective on feature-based complexity. Another idea for future work is to use the F5 measure as a meta-characteristic in automated machine learning and to investigate whether it leads to better performance. Additionally, the introduction of a hyperparameter to set a minimum sequence length would allow researchers to systematically explore the impact of different minimum lengths on the complexity measure, providing lower and upper bounds for dataset complexity. The number of removals required in the F5 measure grows as the number of classes increases, which may become costly or lead to an inaccurate assessment of complexity. To address the issue, the same feature could be selected multiple times in proportion to the number of classes. Future work should also include comparisons with performance measures obtained from machine learning algorithms on synthetic and real-world datasets to gain a better understanding of the relationship between complexity and predictive performance.





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}