1. Introduction
Crude oil, which is the world’s most important chemical raw material and strategic resource, ensures the normal operation of the national economy and people’s livelihoods, and it is a critical support for the development of the entire modern industrial society. Crude oil plays an important role in the global economy, political situation, and military strength of various countries as a basic energy source. As a result, changes in crude oil prices have sparked widespread concern worldwide. Because of the interactive impact of various factors such as the global economy, exchange rate changes, speculative behavior, and geopolitics, the oil price always exhibits non-linearity, non-stationarity, and high complexity, which poses significant challenges to crude oil price forecasting.
In the literature, various linear and nonlinear models have been used separately or in combination to make forecast (see, e.g., Buyuksahin & Ertekin [
1]). Linear methods assume that a given time series is regular with no sudden movements. It becomes challenging because sudden movements with variation and extreme values are normal in many real-world time series such as financial data and renewable energy data (see, e.g., Xu et al. [
2]). Numerous nonlinear time series prediction methods (see, e.g., Kantz & Schreiber [
3]) have been proposed in the literature to capture these nonlinearities. Conventional linear methods can better approximate time series with no high volatility and multicollinearity. Zhang et al. [
4] and Elman [
5] show that nonlinear methods have the advantages when modeling a complex structure in time series with high accuracy. No universal model is suitable for all circumstances because each type of method outperforms others in different domains. Individually capturing general patterns in the time series data using only one linear or nonlinear model appears to be difficult (see, e.g., Khashei & Bijari [
6]). To overcome this limitation, Taskaya & Casey [
7] proposed hybrid techniques with both linear and nonlinear models. The hybrid methodology is a synthesis of various prediction methods. It is usually a combination of traditional econometric models and AI algorithms (see, e.g., Wang et al. [
8]) or a combination of different econometric models or AI algorithms.
In addition to the hybrid methodology, the ensemble learning algorithm is an important paradigm to overcome the limitations of single methods. Both hybrid methodology and the ensemble method consider the shortcomings of single models. With the divide-and-conquer strategy (see, e.g., Yu et al. [
9] and Dong et al. [
10]), the decomposition–ensemble learning methods are an important branch of ensemble learning paradigms. Because it will take a lot of time to make individual prediction from all decomposed components, the number of decomposed components is necessarily reduced. Yu et al. [
11] first proposed a decomposition–ensemble model with a reconstruction step that considered some data characteristics. Recently, Yu & Ma [
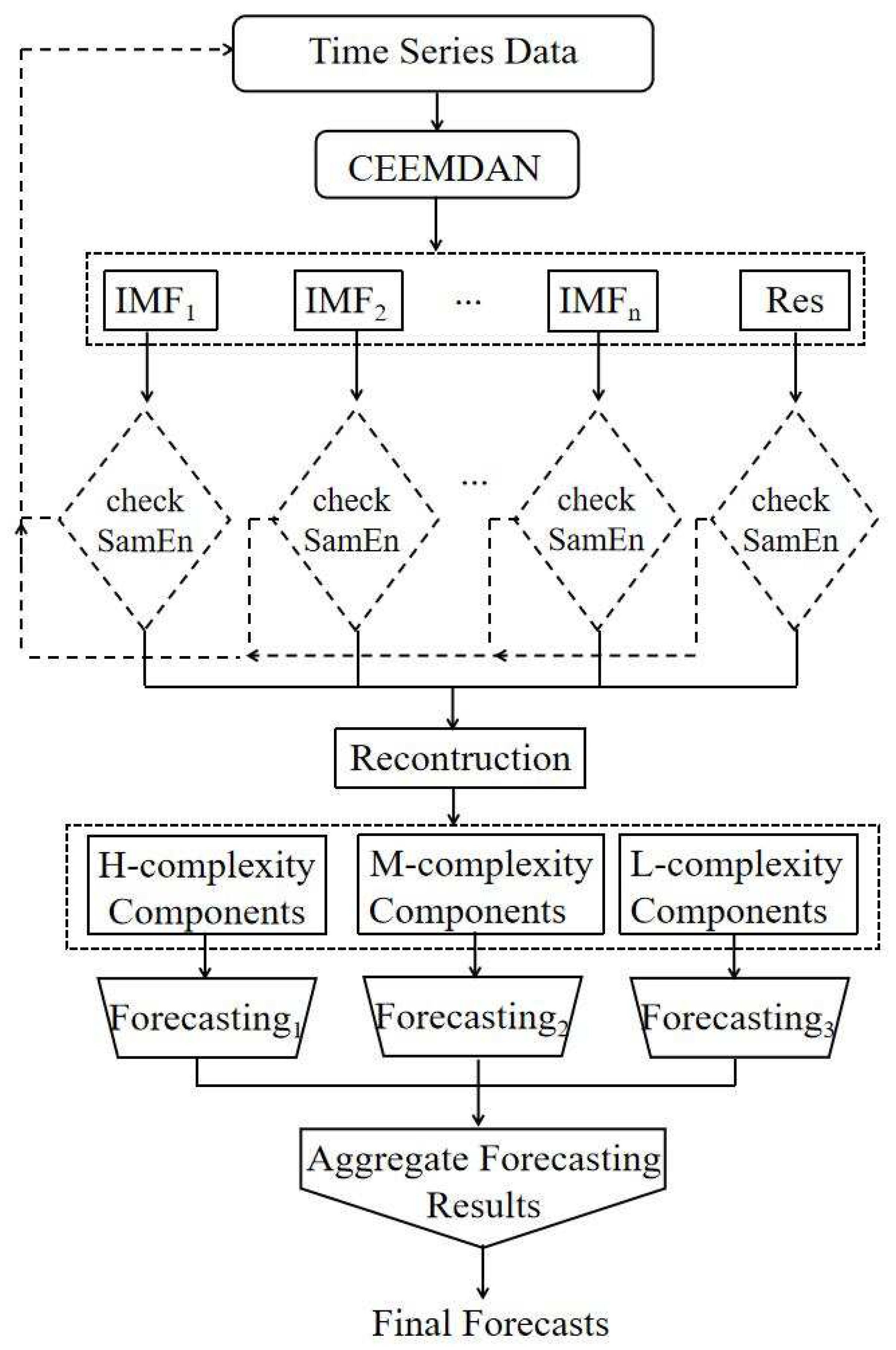
12] introduced a memory-trait-driven reconstruction method into the decomposition and ensemble framework. Inspired by their work, a new model based on decomposition–ensemble learning with a reconstruction step that considers the data complexity traits is used to explore the price predictions of crude oil. In this model, all steps of mode reconstruction, component prediction, and ensemble prediction are driven by complexity traits. First, a decomposition–ensemble approach is used to decompose the oil price time series. Second, the complexity of these decomposed components are separately computed. Then, each component can be identified based on its complexity ranking from high to low. Different components are predicted through appropriated models. Finally, the forecasting for different components can be aggregated to produce the final prediction output. The contributions of the article are as follows:
A novel decomposition–reconstruction–ensemble method is proposed with clustering capability to capture the inner complexity traits. The performance of the proposed recursive CEEMDAN for different complexity traits of data is tested and validated using popular single models and several decomposition–reconstruction–ensemble models.
The proposed recursive CEEMDAN technique is used to improve the performance of the CEEMDAN decomposition method by recursively decomposing the rapidly fluctuating components into less volatile sub-components.
In the proposed recursive CEEMDAN decomposition–reconstruction–ensemble forecasting methodology, the reconstruction method, prediction method, and ensemble method are determined by the complexity traits of the crude oil data themselves.
The remainder of this paper is organized as follows.
Section 2 considers a comparison to the related works. Research data and the decomposition–reconstruction–ensemble method are discussed in
Section 3.
Section 4 presents the error measures to validate the prediction models. Some main findings are illustrated by comparing the results of the proposed model to the benchmark models. The prediction performance of the proposed model is further discussed in
Section 5.
Section 6 summarizes this paper and provides the improvement direction of future research.
6. Conclusions and Future Directions
This paper proposes a new complexity-traits-driven recursively CEEMDAN decomposition–reconstruction–ensemble method for WTI and Brent crude oil price forecasting. All steps of component reconstruction for decomposed components, component prediction, and ensemble prediction are driven by the complexity traits, and the proposed method proves to be more effective than the benchmark models.
In the empirical analysis, the proposed recursive CEEMDAN decomposition– reconstruction–ensemble learning paradigm is significantly better than the most popular single models, different decomposition–reconstruction–ensemble models, and ensemble models based on the EEMD decomposition methods or different reconstruction rules. Based on the empirical experiments, four insightful conclusions can be summarized.
First, the prediction accuracy of WTI and Brent crude oil price data demonstrates that the proposed model outperforms all benchmark models. Specifically, compared with different benchmark models, the proposed model for WTI crude oil price forecasting improves the prediction accuracy by 56.16%, 59.19%, and 57.46% on average, and the proposed model for Brent crude oil price forecasting improves the prediction accuracy by 57.48%, 58.53%, and 58.56% on average. Therefore, the proposed model can be a useful tool to forecast WTI and Brent crude oil prices in the near future.
Second, CEEMDAN can achieve better prediction performance than the EEMD decom-position-based method. For example, compared with the EEMD decomposition-based models, on average, the proposed model improves the prediction accuracy by 10.10%, 13.28%, and 11.35% for WTI crude oil price forecasting and by 17.27%, 21.0%, and 16.50% for Brent crude oil price forecasting.
Third, the prediction performance of crude oil price data can be further improved by selecting appropriate prediction models for the reconstructed components with different degrees of complexity. For example, compared with the benchmark decomposition–reconstruction–ensemble models (i.e., D-R-KRR, D-R-ELM, D-R-SVR, and D-R-ANN), on average, the proposed model improves the prediction accuracy by 52.42%, 55.06%, and 53.10% for WTI crude oil price forecasting and by 52.96%, 51.17%, and 51.47% for Brent crude oil price forecasting. Therefore, it is essential to choose the appropriate prediction models according to the complexity traits.
Finally, compared with the existing reconstruction rules, the recursively decomposition-reconstruction method based on the complexity traits can reduce the modeling complexity well, which shows its usefulness and efficacy in WTI and Brent crude oil price forecasting. For example, on average, the proposed model improves the prediction accuracy by 10.89%, 16.03%, and 12.75% for WTI crude oil price forecasting and by 20.04%, 24.32%, and 18.84% for Brent crude oil price forecasting. Thus, mode reconstruction driven by complexity traits is effective.
In addition to the sample entropy used by our recursive CEEMDAN method, other time series features such as the frequency change rate and autocorrelation can be used. Future research extensions will focus on the following: (1) verifying more advanced decomposition methods under the proposed framework in this paper and (2) exploring more results in other research areas such as the stock market, power market, and other emerging markets using the proposed complexity-trait-driven reconstruction-ensemble learning paradigm.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}