1. Introduction
With the vigorous development of artificial intelligence, machine learning, the core technology and implementation means of artificial intelligence, has been deployed by many applications since it can extract features and capture relations from data to provide a generalization ability. On the one hand, with the expansion of the research field, machine learning has more application scenarios, such as image classification and recognition [
1], natural language processing [
2], emotion analysis [
3], and disease detection [
4]. On the other hand, the blossoming of cloud computing systems [
5] enables cloud platforms to undertake large-scale computation tasks of machine learning services to provide efficient machine learning tasks for clients. Thus, cloud platforms have launched the functionality of Machine Learning as a Service (MLaaS) [
6]. MLaaS enables service requesters to complete the construction of customized machine learning models through their private data and desired training models, providing a broader and more effective prediction service. Consider a typical application of MLaaS, where a client wishes to evaluate the data under a cloud’s machine learning model. During the prediction phase, the cloud server conducts the prediction service and returns the result to the client.
Meanwhile, due to their high scalability and efficiency, blockchains with hybrid architecture [
7,
8] have increasingly received consideration. These systems combine the characteristics of blockchains and off-chain services. On-chain consensus makes the system more secure [
9], while off-chain computing service increases the efficiency compared to blockchain systems. The blockchain provides an open and transparent platform where transactions and storage are executed in private and immutable manners. Off-chain cloud servers can undertake computing services to solve the problem of the slow computing speed on the blockchain. Due to the immutability and verifiability of blockchain, using a hybrid blockchain system to solve the problems of integrity and verifiability in machine learning services is a promising method.
Despite the enticing benefits of MLaaS, security concerns and privacy issues gradually emerge [
10,
11,
12]. A typical machine learning service for inference on the cloud is as follows. The model owner, e.g., an enterprise with an online cloud server, owns or stores a well-trained machine learning model. The service requester uploads the data sample to the cloud server. In the prediction phase, the cloud server executes the machine learning inference algorithm on the input data to calculate the result. In this scenario, data privacy and model privacy shall be protected since they are the private property of the service requester and the model owner [
13]. Meanwhile, the service requester shall refrain from acquiring any information on the machine learning model during the inference phase. Moreover, the model owner may fail to execute the prediction services correctly due to calculation failures or malicious external attacks.
Therefore, machine learning services’ security and integrity threats are increasingly receiving attention. In a cloud computing system, verifying the correctness of machine learning predictions while maintaining privacy is difficult. Thus, ensuring the correctness of prediction results is vital for machine learning prediction services on cloud platforms, which is called the verifiability of machine learning. In cloud setting environments, selfish cloud servers are incentivized to return incorrect inference results for subjective reasons to reduce computational overhead [
14]. An opportunistic method for machine learning classification services is to return forged or random classification labels without running the classification algorithms. Therefore, the property of result verifiability is vital for cloud service scenarios. However, creating a solution to ensure machine learning models’ integrity and verifiability takes time and effort. In addition, to meet the needs of machine learning services in more scenarios, the cloud server may update the machine learning model [
15]. Thus, it is also essential to efficiently verify whether the cloud server updates the machine learning model while maintaining the verifiability of machine learning prediction. It remains challenging to update the machine learning model on the cloud server.
To address the issues above, researchers focus on designing verifiable machine learning approaches on training and inference processes over various models, e.g., linear regression [
16], support vector machine [
17], deep neural network [
18], and convolutional neural network [
19,
20,
21]. Several verifiable mechanisms have been proposed by [
17,
22] based on homomorphic encryption methods to verify the correctness of inference results. Niu et al. [
17] designed MVP, a verifiable privacy-preserving machine learning prediction service system. The system guarantees the verifiability and privacy-preserving of the SVM machine learning prediction service. Li et al. [
22] implemented VPMLP based on OU homomorphic encryption, which performed the prediction of linear regression models in a privacy-preserving manner and designed a verifiable inference scheme for verification. Hu et al. [
23] proposed an efficient privacy-preserving outsourced support vector machine scheme (EPoSVM). The authors designed eight secure computation protocols to allow the cloud server to efficiently execute basic integer and floating-point computations in support vector machines. From the above review, however, existing studies only focus on designing the security and privacy of the prediction over a specific machine learning model, which cannot be directly applied to solve the verifiability and privacy-preserving problems of the decision tree model predictions. Additionally, existing studies focus on cloud servers as machine learning service providers and rarely consider cloud servers as proxy machine learning services. However, it is tough to propose a generalized verification scheme for the prediction task of most machine learning models. Researchers need to implement specific verification algorithms for models based on studying the characteristics of different machine learning models.
Because of their great explainability and interpretability, decision tree models stand out among all the machine learning models. Therefore, our study selects the decision tree model as the specific machine learning model. Researchers proposed a few schemes to construct verifiable decision tree prediction to verify the integrity of the decision tree model. Zhang et al. [
24] implemented zero-knowledge proof for the decision tree model and proposed zkDT. zkDT exploits the unique properties of the tree structure and constructs commitments from it. zkDT presents efficient protocols to verify decision tree prediction and prediction accuracy by combining zero-knowledge proofs with cryptographic commitments. Wang et al. [
25] proposed a specific non-interactive zero-knowledge (NIZK) based on verifiable proof for a private decision tree prediction scheme. The NIZK protocol can prove the correctness of the public verifiable private decision tree prediction results without leaking extra information. However, we have noticed that most system applications are computationally expensive zero-knowledge proof, which limits the practical deployment application of verifiable decision trees. Thus, we aim to discover an efficient way to verify the integrity of the decision tree scheme using a lightweight cryptographic method.
In this paper, we propose a general verifiable decision tree scheme for decision tree prediction in cloud service scenarios to tackle the aforementioned security challenges. Specifically, we construct a verifiable decision tree scheme by leveraging the Merkle tree and hash function. Using the blockchain, the client can effectively verify the correctness of the results. Our VDT scheme ensures the integrity of machine learning predictions and detects errors in machine learning predictions with a 100% probability. We also extend our techniques with minimal changes to support minor updates of the decision tree model. The concrete contributions of the article are summarized as follows:
- (1)
We proposed a verifiable decision tree scheme to verify the decision tree prediction results. Merkle tree, hash function, and commitments are used to generate the verification proof efficiently.
- (2)
We further proposed an efficient decision tree update algorithm to support minor model updates. Specifically, the algorithm generates related parameters and proofs of the changes between the prior and current models. It efficiently updates the model without losing the verifiable property of the decision tree.
- (3)
Taking advantage of the immutable and traceable nature of the blockchain, we employ the blockchain combined with a cloud server to verify the calculation results and guarantee correctness. It can not only realize a simpler verification algorithm, but also acknowledge the service functions of off-chain storage and calculation fairness, which is a promising application scenario in cloud services.
- (4)
We theoretically analyze the scheme’s correctness and security. The analysis shows that our scheme can perform correctly. We implement and evaluate the proposed scheme using different real-world datasets and decision tree models. The experimental results show that our scheme is practical.
The rest of the paper is organized as follows.
Section 2 gives the preliminaries of the decision tree and cryptographic primitives.
Section 3 introduces our system model, workflow and security requirements.
Section 4 presents our concrete verifiable decision tree scheme.
Section 5 provide an update method for decision tree changes.
Section 6 analyzes the security of our proposed scheme.
Section 7 shows the experimental results of our scheme.
Section 8 surveys the related work. Finally, in
Section 9, we conclude our work.
4. Detailed Scheme of Verifiable Decision Tree
In this section, our verifiable decision tree scheme is introduced in detail, containing the basic VDT scheme and the update algorithm. For ease of understanding, the notations used in our scheme are summarized in
Table 1.
Our VDT scheme contains four phases, i.e., Model Initialization, Model Prediction, Proof Construction, and Result verification. Without loss of generality, we consider binary decision trees as our specific decision tree model for classification problems. Our scheme can be generalized naturally to multivariate decision trees, random forests, and regression trees with minor modifications.
4.1. Model Initialization
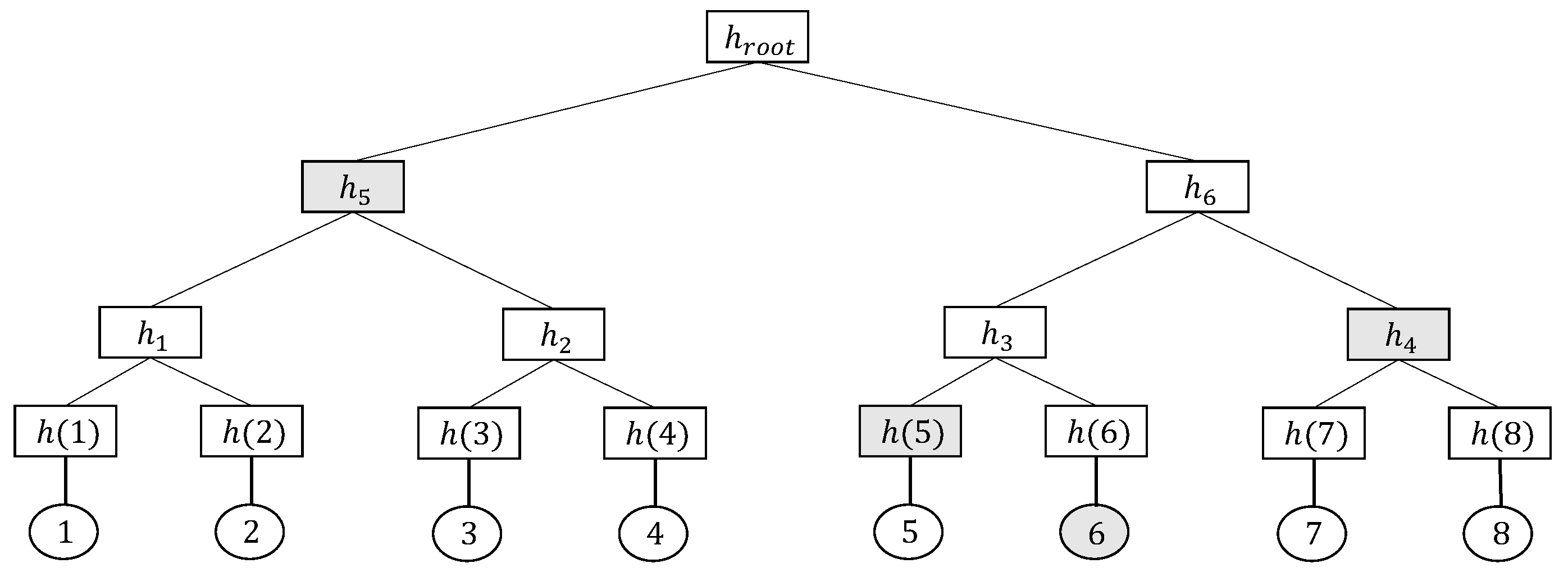
In the model initialization phase, the CS constructs the verifiable decision tree. Inspired by the Merkle tree generate process, CS selects a specific hash function
H to construct an authenticated data structure (ADS) based on the tree structure of the decision tree. For binary decision trees, each non-leaf node has two children. As mentioned in
Section 2.1, we define the decision branch of the node points to its left child node if the data sample’s attribute is smaller than the decision node’s threshold, otherwise to its right child node. In this tree-shaped ADS, each node not only stores all the information of the original decision tree, but also stores the hash value of the node itself. More specifically, each internal node
includes the identification number of the node, the associate attribute index and the threshold of the node, the pointer to its child node to maintain the tree structure, and the node’s hash value calculated from its children, recorded as:
For each leaf node
, it includes the identification number of the node, the final decision classification result, and the node’s hash, recorded as:
where the computation of the leaf node’s hash value includes the identification number and the classification result:
Figure 3 denotes the construction of ADS. The construction of ADS starts from the hash value calculation of the leaf nodes. Each internal node stores a hash value derived from its two child nodes, calculates hash value calculation from the leaf nodes to the tree root, and finally obtains the hash value of the root node. After the construction of the ADS, CS stores the tree-shaped ADS and the root hash of ADS on the blockchain. Specifically, the root hash of the ADS is public. The storage on the blockchain enables clients to confirm that the CS has a decision tree model, thereby continuing the process of decision tree prediction.
4.2. Model Prediction
In this phase, the client sends the input data of the prediction service to the CS. The CS executes the decision tree prediction service and returns the prediction results and related proofs. Due to the classification method of the decision tree, CS obtains not only the inference result, but also a prediction path from the root node to the leaf node. Algorithm 2 describes the detailed procedure of the decision tree prediction service executed by the CS. The algorithm takes the verifiable decision tree
T and the data sample
as input and outputs the prediction result
and the prediction path
. CS first initializes the prediction path and current node (line 1). Then, to prove that CS has not changed the decision tree model, the running model is consistent with the model stored on the blockchain. CS commits the ADS with a random number
r (line 2). More specifically, CS computes hashes from the leaf node to the ADS root with a random number
r, which is added to protect the privacy of the decision tree model. Then, CS starts the prediction from the decision tree’s root node and determines the decision branches and the prediction path by comparing attributes and thresholds (lines 3–10). When the current decision node
v is a non-leaf node, CS finds the associate attribute index
and the decision threshold
of the current node and compares the threshold
with the value of the associate attribute of the data sample
. The current node moves to its left children if
and otherwise moves to its right children. Meanwhile, the decision branches of all nodes are recorded as the prediction path
. When reaching the leaf node of the decision tree, CS obtains the classification result
and the prediction path
(lines 11–13), which are sent to the client and construct the verification proof, respectively. Our validation scheme is built on a decision tree and does not affect the process of comparing and making decisions among nodes in the decision tree prediction. Thus, our VDT scheme provides a reliable guarantee for decision tree prediction without affecting prediction accuracy. However, to validate the prediction path’s correctness, the client must check the comparison between the thresholds and the attributes. We have found that this problem can be effectively and quickly solved through auxiliary proofs. Thus, in our VDT scheme, CS leverages techniques in [
31] to generate an auxiliary proof for prediction path
for comparison operations in the verification process and sends
to the client.
| Algorithm 2: Model Prediction |
Input: Verifiable Decision Tree T, data sample Output: Prediction Result , Prediction Path 1: Initialize path as a list Initialize current node 2: Commit(): the CS commits the verifiable decision tree by computing hashes of the root node from the leaf nodes with a random number r 3: for v is not a leaf node of decision tree T do 4: if 5: v points to the left children 6: else 7: v points to the right children 8: end if 9: 10: end for 11: if v is a leaf node of decision tree T then 12: return , , 13: end If
|
4.3. Proof Construction
Following the algorithm to obtain the classification result, we further present our scheme to prove the correctness of the prediction. A naive approach is to directly send the prediction path with the whole construction of ADS to the client. However, recent research shows that the client can infer sensitive information or reconstruct the decision tree models with several prediction paths obtained. Thus, this approach is impractical since it would cause model privacy leakage. To protect the privacy of the decision tree model, we propose the verification proof in a way that does not return plaintext information of the prediction path. We divide the whole verification process into three parts: (1) Determine whether the decision tree has changed; (2) check the validity of the prediction path
; (3) verify that the classification result
is calculated from the data sample
a. The commitment
constructed in Algorithm 2 ensures the correctness of the first part. Then, we construct the relative proofs for verifying the prediction path and data sample using the Merkle-tree-based ADS. We will analyze the correctness of the proofs in
Section 6.
Proof for the prediction path. After the CS obtains the predicted path, it uses Algorithm 3 to generate a verifiable proof for the prediction. The Proof Generation algorithm takes the Merkle-tree-based ADS
T and prediction path
as input and outputs the verification proof
. The algorithm is similar to the verification method in a Merkle tree. The verification proof for prediction includes information on the prediction path
, which denotes the whole procedure in the inference process. In addition, due to the tree structure of our ADS, the hash values of all the siblings of the node contained in
should be included (lines 3–5). By executing Algorithms 2 and 3, the CS obtains the classification result
of the input data, the predicted path
, and the related proof
based on the ADS structure. The classification result
, the commitment
, and the related proof
are sent to the client.
| Algorithm 3: Proof Generation |
Input: Verifiable Decision Tree T, Prediction Path Onput: Verification Proof 1: Initialize list Initialize node v, , 2: while the length of prediction path do 3: 4: 5: find the other child node of the parent node of 6: 7: .pop(0) 8: end while 9: reverse( ) 10: return
|
Proof for the data sample. The Proof Generation algorithm only proves that the classification result
is obtained from the decision tree prediction. However, the verification is not fully guaranteed since the client does not know whether the returned result is the classification of the data sample
or not. Thus, CS should provide an extra proof to convince the client that the results are indeed calculated from the input data. We aim to collect all the attributes used in the prediction and check whether the data sample
contains those attributes. CS generates a vector
ordered by the decision sequences of the attributes, i.e.,
of all nodes on the prediction path. However, the arrangement of attributes used and collected in our VDT scheme differs from the attribute arrangement of input data
. Therefore, we use a permutation test to verify that
is indeed a rearrangement of the input data
. For a prediction path with
d categorical attributes, CS generates the permutation index pair according to the order:
CS then sends
to the client for verification.
4.4. Result Verification
After receiving the inference result and related proofs from CS, the client checks the decision tree’s consistency. The user first invokes the smart contract to obtain the hash value of the decision tree root node stored on the blockchain. Given the random number r, the client opens the commitment and compares it to the ADS root hash stored on the blockchain. If they match, the client believes the decision tree has not changed.
Verification for prediction path. Then, the client checks the verification of the prediction path. Algorithm 4 implements the specific Prediction Path Verification algorithm to verify the correctness of the prediction path. Since our decision tree model is a binary decision tree, all hash calculations involve two elements. The first and second items in
are the hash values of the leaf nodes, and the last item is the hash value of the root node of the decision tree. To be concrete, the algorithm starts from the first two elements in the prediction path
and iteratively calculates the hash value of the concatenation of the two elements until all the elements in
are involved in the calculation (lines 2–4). After that, the calculation result is compared to the root hash value sent from the blockchain (lines 5–8). If they are equal, the verification passes; otherwise, it fails. The algorithm verifies that the prediction path exists in the ADS structure.
| Algorithm 4: Prediction Path Verification |
Input: Verification Proof , Hash value stored on the blockchain Onput: 0,1 1: Initialize 2: for to do 3: 4: end for 5: if then 6: return 1 for verification passed 7: else 8: return 0 for verification failed 9: end if
|
Another security concern for validating the prediction path is that the client needs to learn whether each decision step works appropriately. Thus, the client needs to check that for each node
in the prediction path whose order in
is
j, it holds that (1)
; and (2)
if
, otherwise
. With the help of the construction of
and the existing method for equality tests and comparisons in [
31], this concern can be efficiently solved by using an arithmetic circuit.
Verification for data sample. The verification of the data sample ensures that the result
is the accurate classification of data sample
. For a decision tree with
d categorical attributes, the input data
can be expressed as
. This verification is converted into a permutation test between
and
. We adopt the characteristic polynomial technique proposed in [
32]. For example, given a vector
, the characteristic polynomial of the vector
is
=
. Thus, the permutation test transforms into the proof that the characteristic polynomial of
and
have the same value at a random point r selected in the field
F, that is:
For the proof of permutation test of index pairs, each index pair is first packed into a single value using random linear combinations. For each index pair (i,) and (i,), by selecting random number z, the packed value is and , respectively. Then, the client selects a random number r to complete the permutation test. If the permutation test passes, the verification of the data sample is completed. Otherwise, the verification failed.
Together with the commitment and the prediction path verification, the result verification process ensures that is the correct classification result of . The client accepts the result only if all the above verification passes.
5. Verifiable Decision Tree Update
The above section solves the verifiable problem of decision tree prediction, and this section focuses on a practical approach.In the real world, decision tree classifiers may retrain and update the model based on the situations and classification tasks. To maintain the verifiability of our VDT scheme and adapt to scenarios where the decision tree model changes, a naive approach is to construct the ADS structure for the new decision tree model. However, we have observed that when the classification task has few changes, the decision tree changes little. Inspired by this phenomenon and the node insertion and update technique in the Merkle tree, we design verifiable decision tree update algorithms for decision tree classifiers with minor dynamic updates. After the decision tree update process, our VDT scheme can be directly used to provide the verifiability for the new decision tree prediction process without additional modification. Our update algorithms consist of three steps:
- (1)
CS trains a new decision tree classifier; here, we assume that there are few differences between the prior and new models.
- (2)
CS reconstructs the ADS of the prior model and generate proofs for the differences between the two model.
- (3)
The blockchain receives the proof for update and verifies the completeness of the updated proof by a smart contract. After the verification is passed, a new hash value of the root node is calculated and stored on the blockchain.
Since there are few changes in the decision tree, the updated proof provided by CS to the blockchain only needs to include the difference between the prior and new decision trees, i.e., the information of the modified nodes. Considering that most nodes make up changed subtrees, we decompose the update operation of the decision tree to the deletion and insertion of subtrees on the decision tree model. The apparent problem with updating decision trees on the blockchain is that the blockchain needs the structure of a complete decision tree model. The blockchain requires the CS to send the proof information to update the hash value of the root node securely. Thus, CS needs to provide an updated proof for all the changed subtrees. CS first finds all m changed subtrees (,…,) by traversing the difference between the two trees and the path from the root node of the decision tree to each subtree’s root node . Secondly, CS locates the root nodes of all the subtrees and records a piece of location information for each node. In our binary decision tree setting, each internal node has at most two children, and the threshold of the left child node is smaller than the threshold of the right child node. For each decision branch of a node, we define the pointer to the left children as 0 and the pointer to the right children as 1. Thus, the location information of the root nodes of all the subtrees can be represented as a binary bit string up to h bits, where h is the tree’s height.
Figure 4 denotes the query of location information. For example, the location information of node
,
, and
(shaded in
Figure 4) is the bit string 00, 10, and 111, respectively. After that, CS constructs the ADS structure for all the subtrees and updates the hash value using the hash function
H. Meanwhile, CS records the update operation of each subtree insertion or deletion using the bit string
b, with insertion being 1 and deletion being 0. Algorithm 5 generates the updated proof. The algorithm takes the updated decision tree model and the subtree information as input and constructs updated proofs for each subtree. Since there are
m subtrees, the final updated proof is
. The updated proof consists of the location information
, the updated proof for subtrees, the hash value of the root of the decision tree, and the bit string
b.
| Algorithm 5: Updated Proof (CS) |
Input: Update decision tree model , the root nodes of the subtrees , the path of the subtree Onput: Updated Proof 1: Initialize 2: for to m 3: Find the path from root of the entire tree to 4: while is not do 5: .append(the other child node of the not on ) 6: ← the child node of on 7: end while 8: if is then 9: .append() 10: end if 11: end for 12: return
|
After receiving the updated proof from CS, the blockchain first confirms the location of each subtree by . Then, by invoking a smart contract, the blockchain calculates the hash value of the root node of each subtree from the leaf node to the root node. Specifically, keeping the hash values of other nodes unchanged, the smart contract recalculates the hash value of the ADS root node. When the reconstructed root hash value is the same as the hash value of the root of the ADS, the correctness of the update is verified. It means that the hash value of other nodes has not changed, and the subtrees are the part newly added to the decision tree model. Finally, the smart contract stores the updated version of the decision tree and updates the root hash on-chain.
6. Security Analysis
In this section, we analyze the security of the proposed VDT algorithms. As mentioned in
Section 3.2 and
Section 3.3, we mainly analyze the soundness and completeness of the overall scheme.
Theorem 1. Our VDT scheme satisfies soundness and completeness if the hash function has the properties of irreversible and collision-resistance, and the executions on the blockchain are secure.
Proof. This theorem is true when all three processes of the entire verification process (see
Section 4.3) satisfy soundness and completeness. The commitment
guarantees the completeness of the scheme straightforwardly. Since the hash function establishes the commitment, the soundness holds due to the collision-resistance property of the hash function.
Next, we prove the correctness of prediction path verification. Recall that the client verifies the prediction path verification by comparing the calculated hash value based on the proof provided by the CS and the root hash value stored by the blockchain. The prove contains the hash value of the leaf node representing the prediction result and the hash value of all root nodes of the prediction path. Therefore, based on the binary verifiable decision tree construction, can be obtained by calculating every two elements starting from the first item. Therefore, if the prediction result has not been tampered with, we have , which stands for the completeness of the algorithm. Since our scheme is constructed based on hash values and Merkle tree structure, the soundness of the algorithm is based on the collision-resistance property of the hash function. As long as the collision-resistance property of the hash function remains unchanged, our VDT scheme is correct. Since only the nodes’ hash values are used in the proof process, clients cannot obtain the plaintext of the decision tree model during the verification process.
Finally, we prove the soundness and completeness of the permutation test performed in
Section 4.4. The completeness of the permutation test can be derived from the characteristic polynomial. If
is the permutation of
, then Formula (1) always holds regardless of the random point
r. The client can conclude that the result is calculated from data
.
As for the soundness of the permutation, suppose that
is not a permutation of
, then there must be an index pair
that is not included in
. According to the random linear combination, we have:
The probability that there exists an index pair (
i,
) with the same result as the random linear combination of
in
is less than
. Therefore, the probability that the characteristic polynomial
c and
have the same root is less than or equal to
, and the soundness error is less than
. Since
, the soundness of the permutation test is guaranteed. □
Theorem 2. Our Verifiable Decision Tree Update algorithm is secure if the underlying cryptographic primitives and the executions on the blockchain are secure.
Proof. Recall that the update algorithm consists of inserting and deleting nodes, and the related proofs are provided by . A successful attack would mean either the executions on the blockchain are not secure or the input information is tampered with. The first case is a contradiction to the assumption. For the second case, a tampered proof that passes the verification means that there exist two decision trees with different nodes but the same root hash. However, this implies a collision of the hash function, which contradicts the security assumption of underlying cryptographic primitives. Thus, our update algorithm is secure. □
Formal verification of the smart contract. Since our scheme applies the smart contract to achieve interaction between blockchain and other entities, we use a formal verification method [
33] to verify the correctness of the smart contract to prevent errors and security breaches. Following the idea proposed in [
34], we use the BIP (Behavior Interaction Priorities) framework for smart contract verification [
35]. Atomic components are used to describe the system behavior, and the obtained smart contract behavior model is essentially a finite-state machine. Then, we use SMC (Statistical Model Checking) tool to check whether the behavior model satisfies the safeness of the system. The formal verification of the smart contract guarantees the integrity of the smart contract executed on the blockchain.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}