
Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition

Abstract
:1. Introduction
2. Related Work
2.1. Global Features for Micro-Expression Recognition
2.2. Local Features for Micro-Expression Recognition
3. Methodology
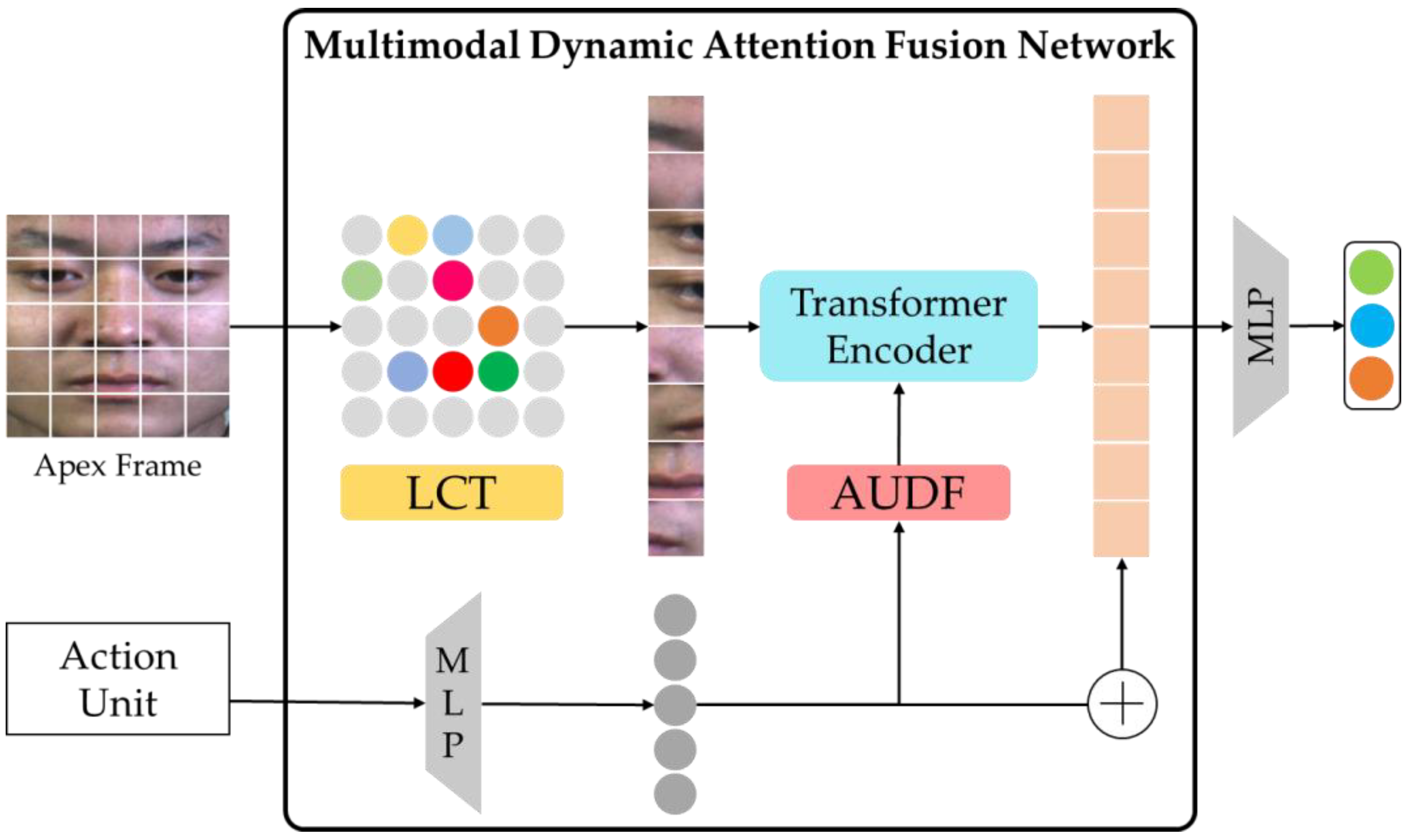
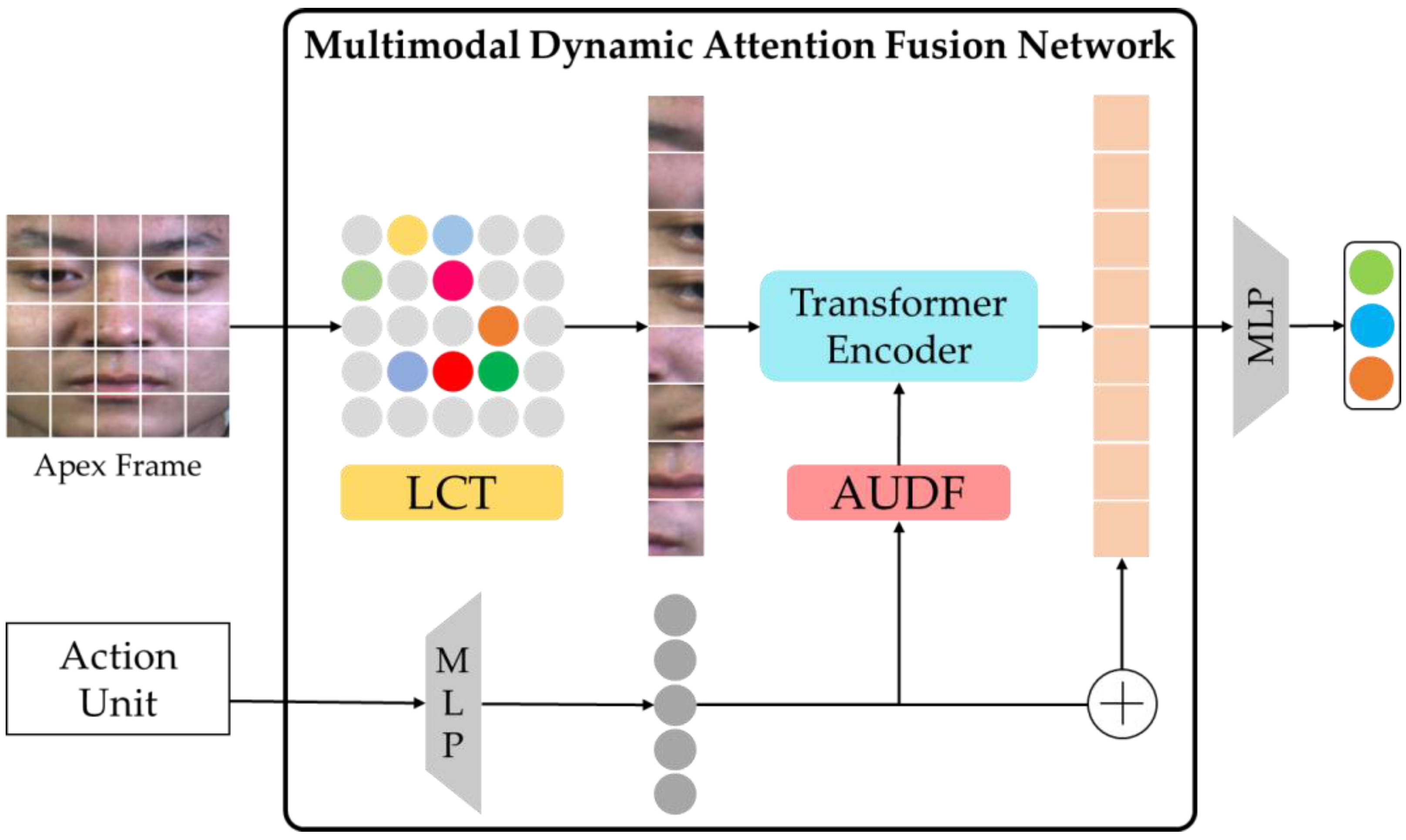
3.1. Multimodal Dynamic Attention Fusion Network
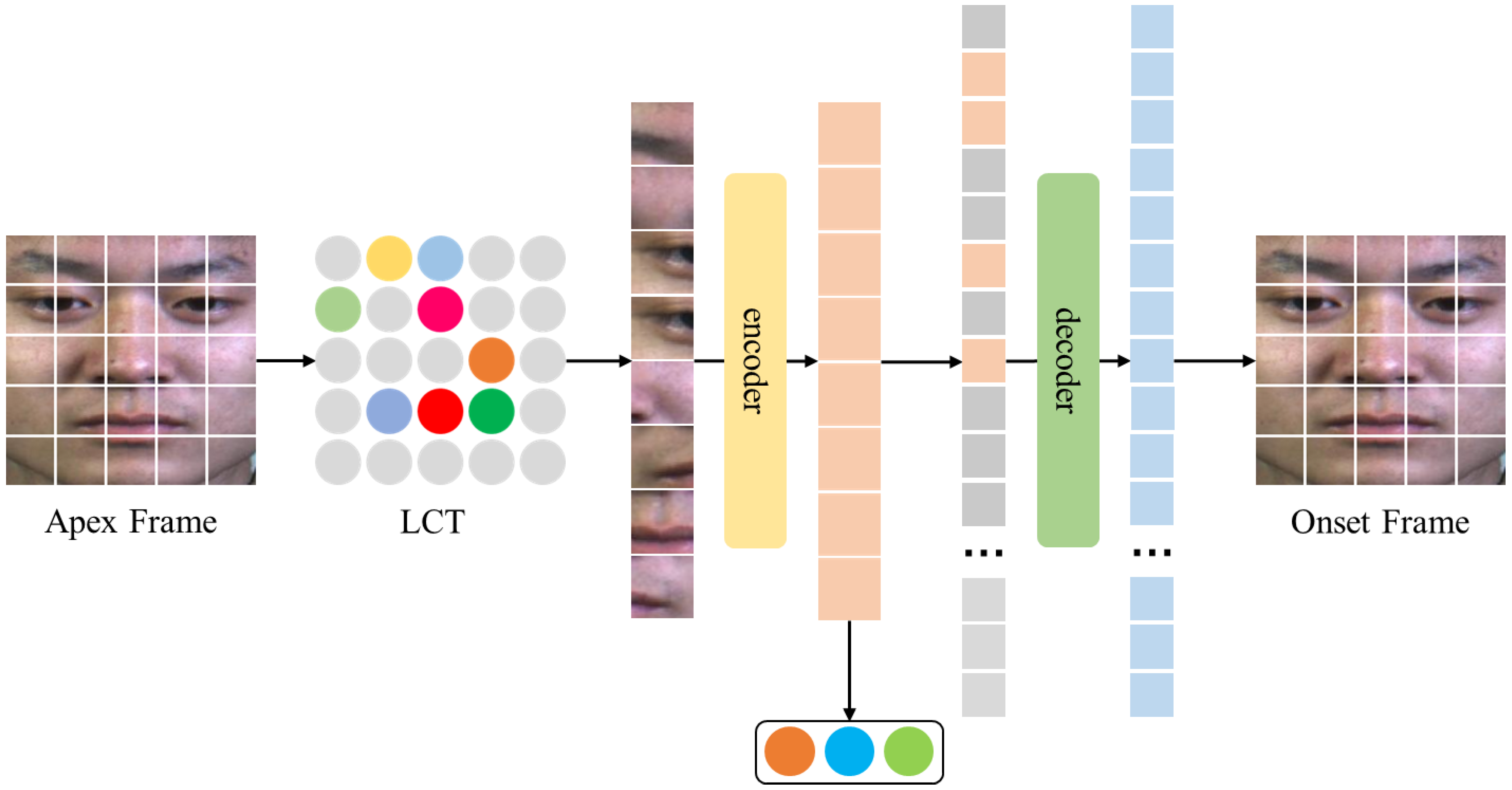
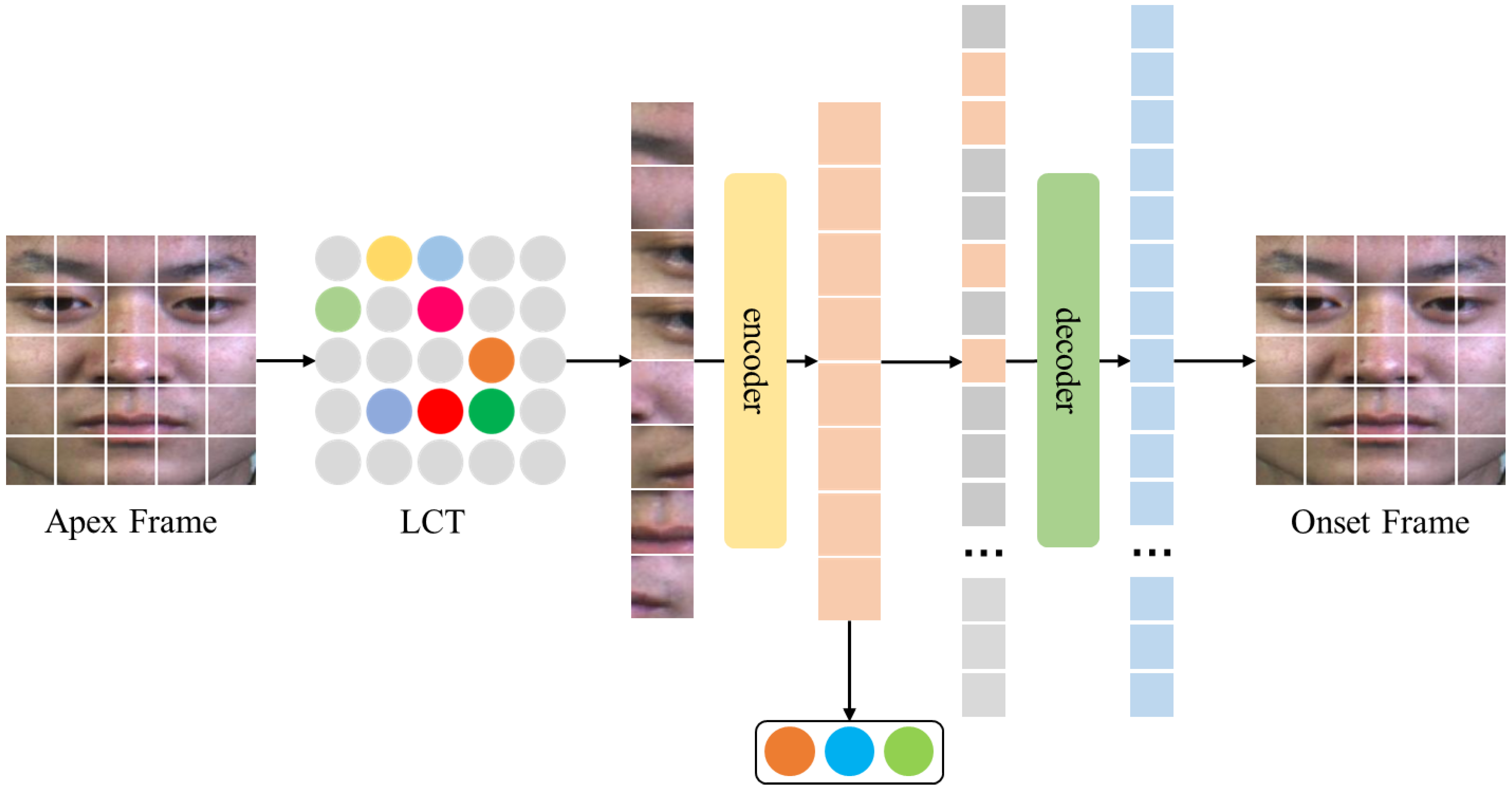
3.2. Image Autoencoders Based on Learnable Class Token
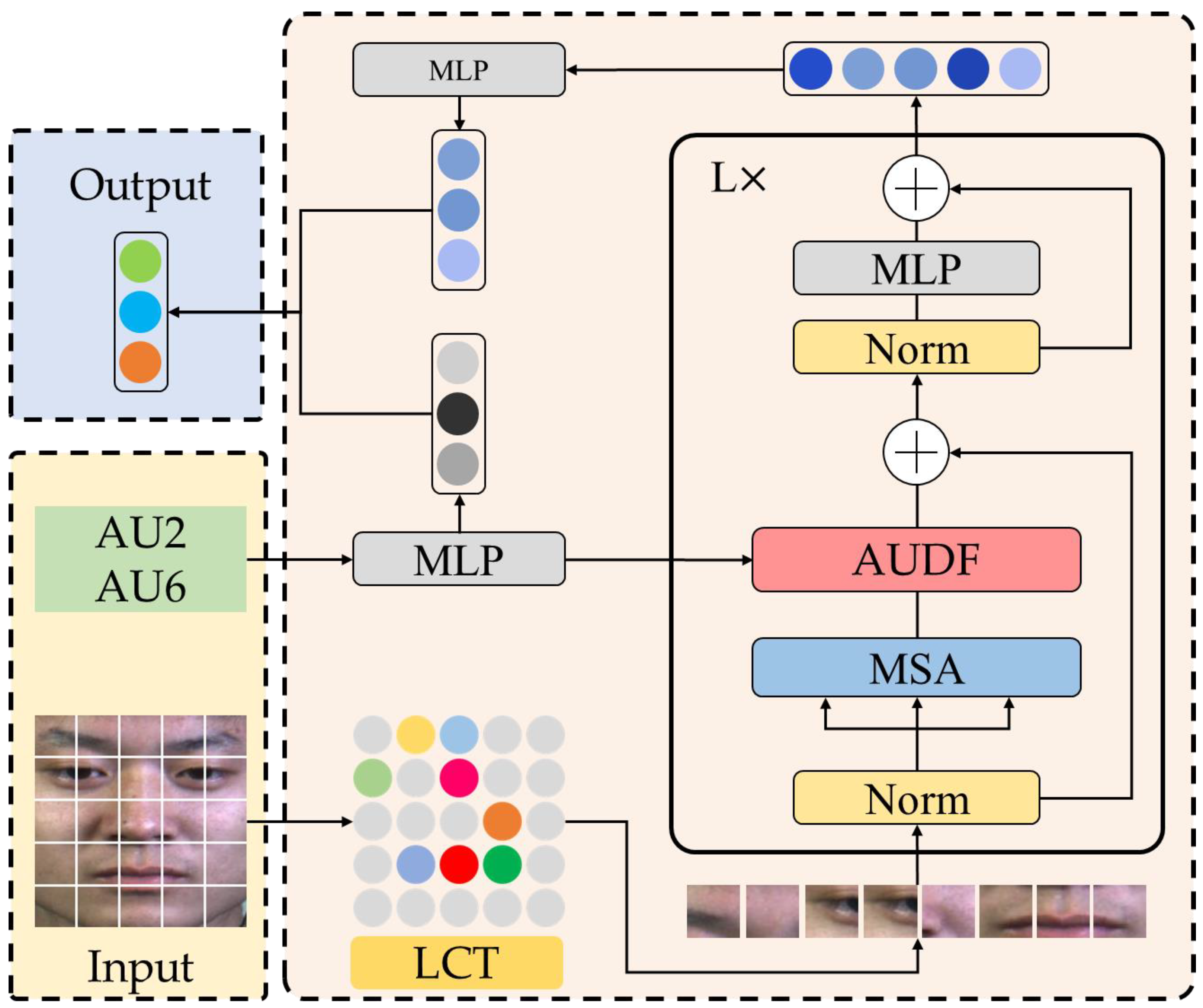
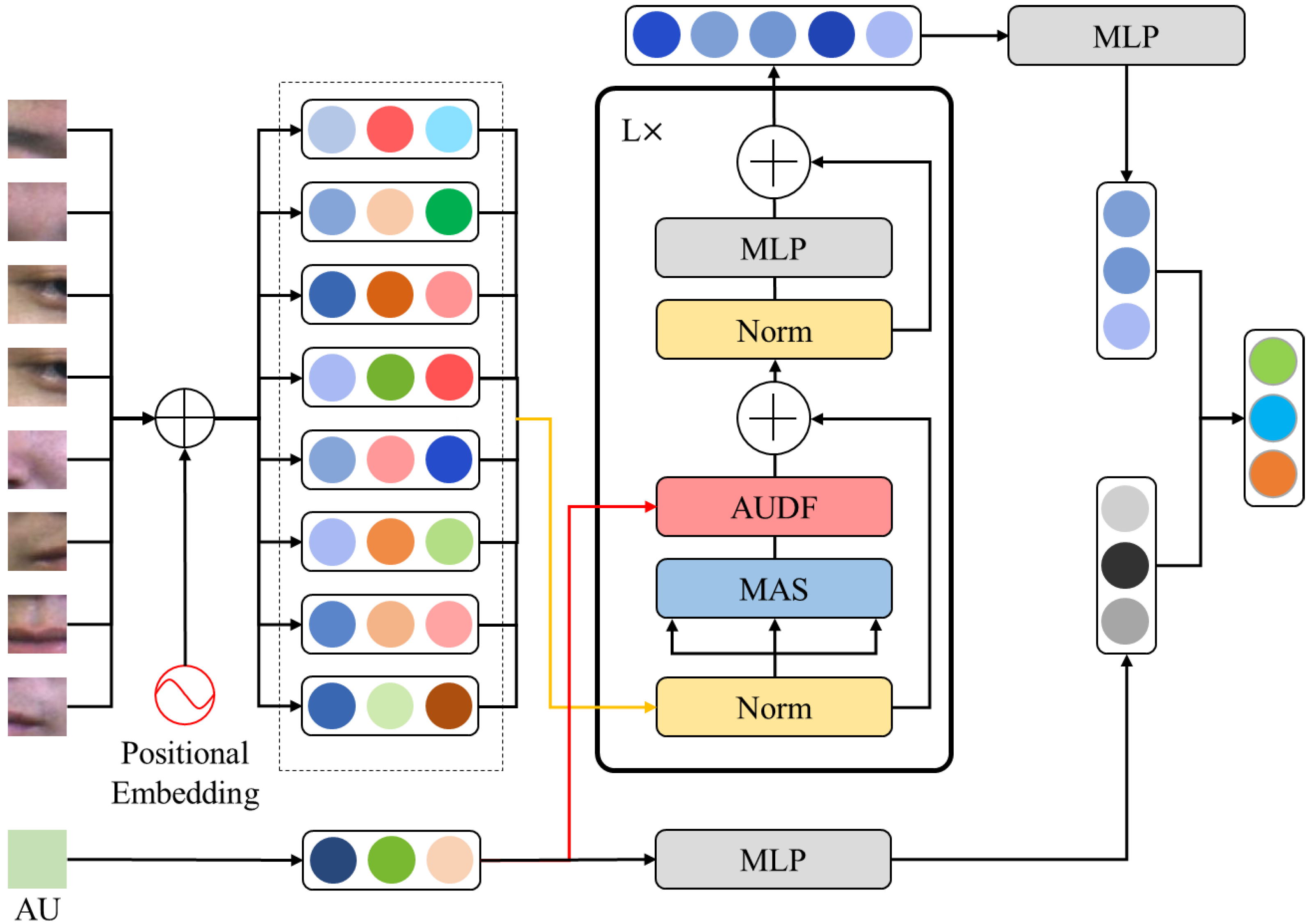
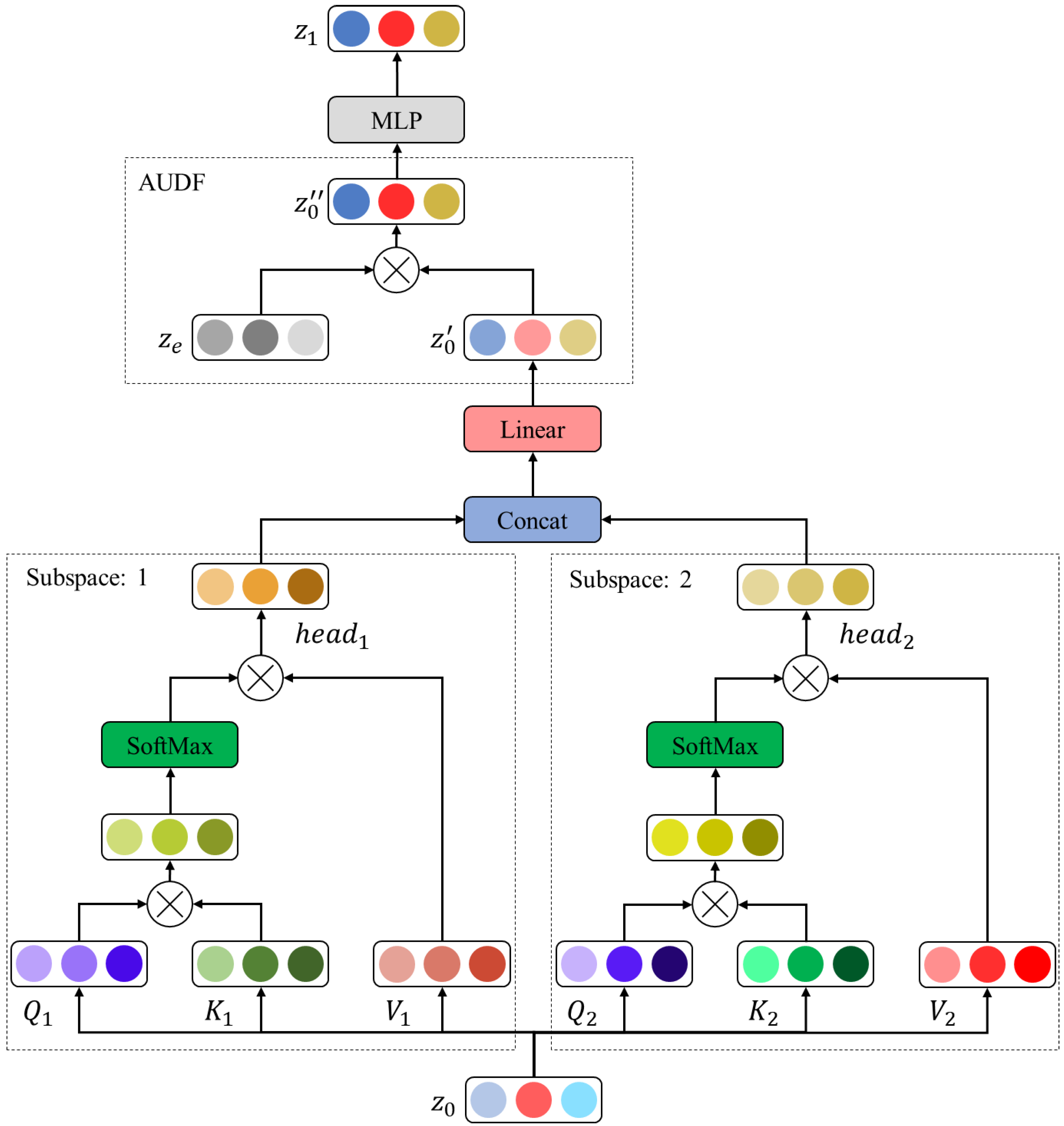
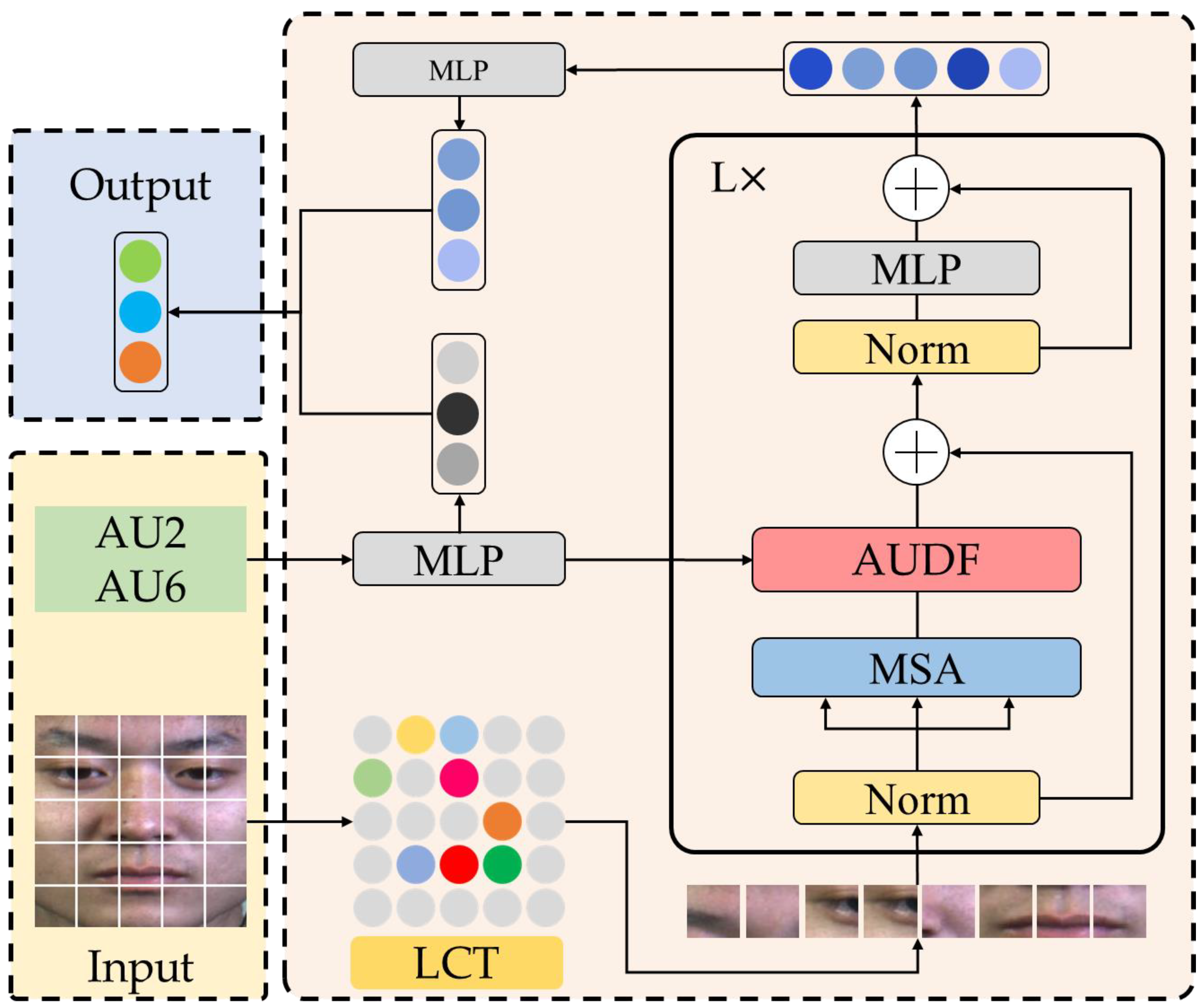
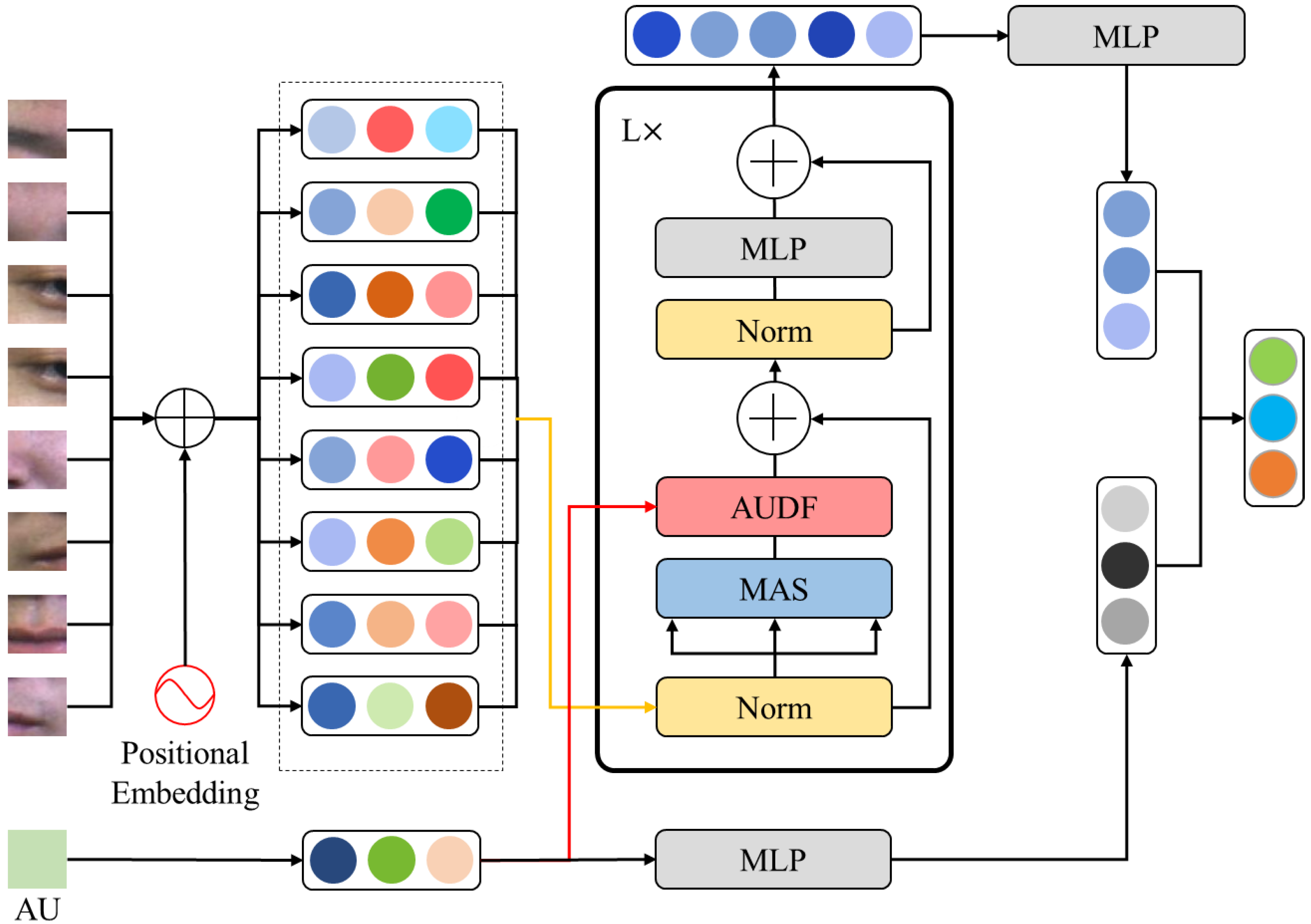
3.3. Vision Transformer Model Based on Action Unit Dynamic Fusion
4. Results and Analysis
4.1. Quantitative Analysis
4.1.1. SMIC
4.1.2. CAMSE II
4.1.3. SAMM
4.1.4. MEGC2019
4.2. Ablation Experiment Analysis
4.2.1. Basic Model
4.2.2. Mask Sampling
4.2.3. Fusion Strategy
4.3. Parameters
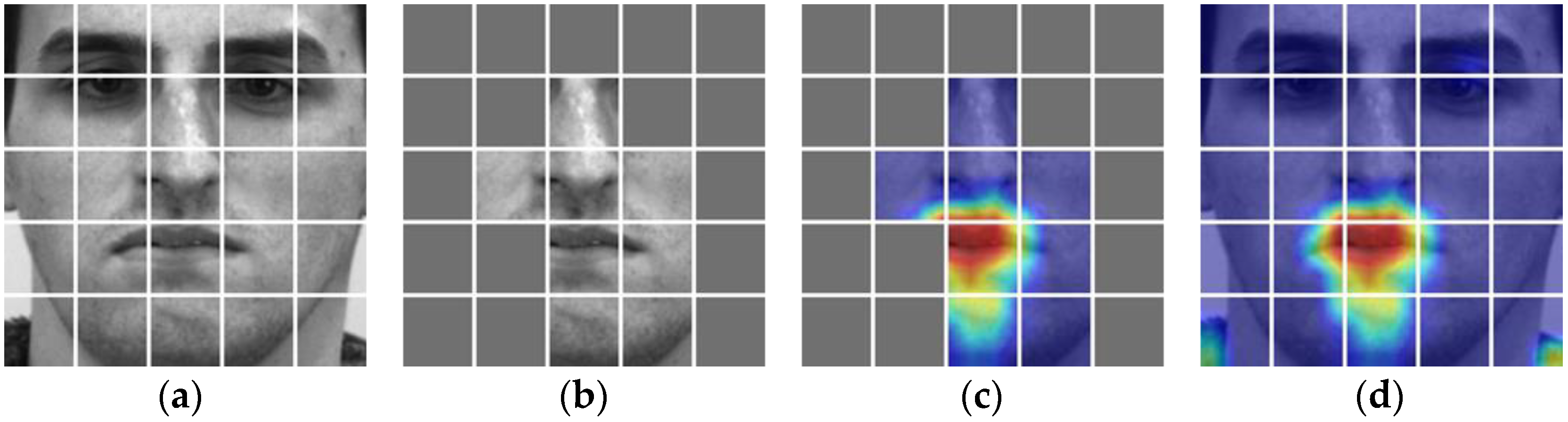
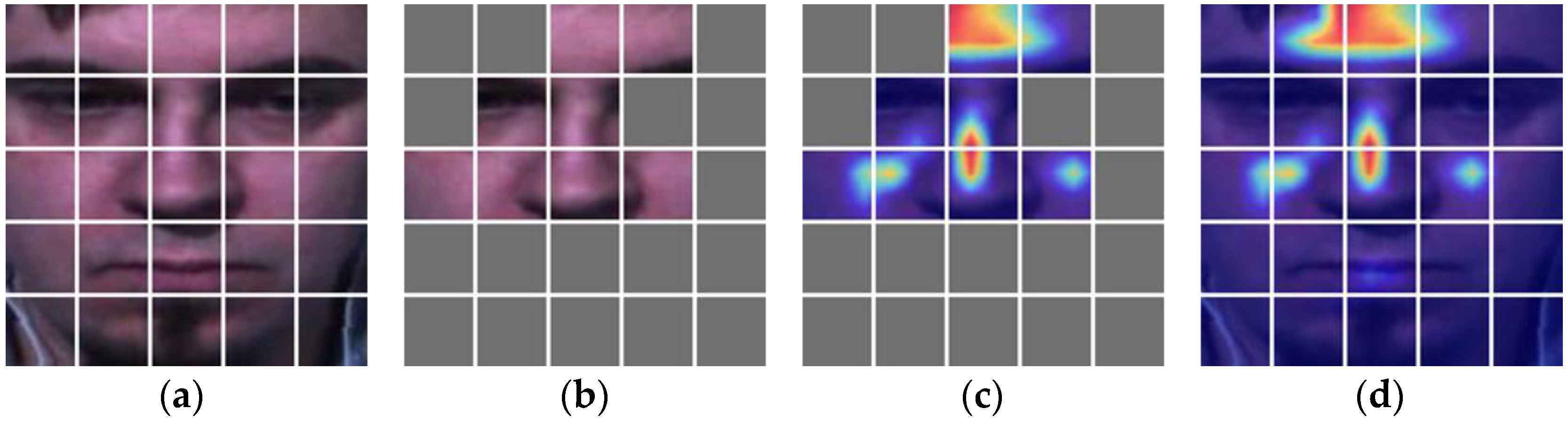
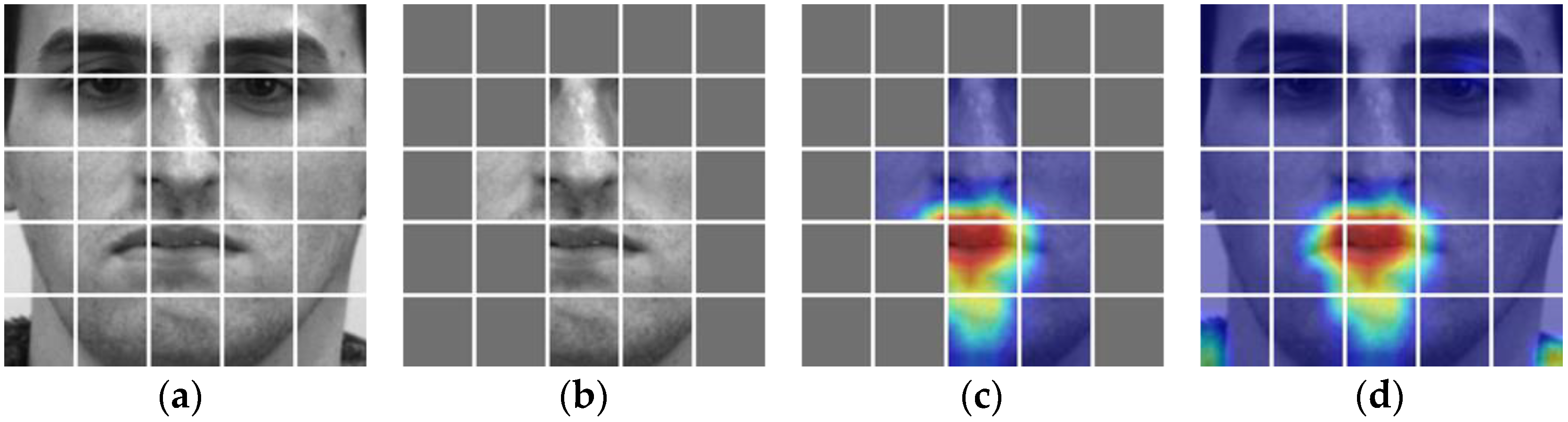
4.4. Visualization Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ekman, P. Lie catching and microexpressions. Philos. Decept. 2009, 1, 5. [Google Scholar]
- Holler, J.; Levinson, S.C. Multimodal language processing in human communication. Trends Cognit. Sci. 2019, 23, 639–652. [Google Scholar] [CrossRef]
- O’Sullivan, M.; Frank, M.G.; Hurley, C.M.; Tiwana, J. Police lie detection accuracy: The effect of lie scenario. Law. Human. Behav. 2009, 33, 530. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Huang, X.; Zhao, G. Micro-expression action unit detection with spatial and channel attention. Neurocomputing 2021, 436, 221–231. [Google Scholar] [CrossRef]
- Xie, H.-X.; Lo, L.; Shuai, H.-H.; Cheng, W.-H. AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition. In Proceedings of the ACM International Conference on Multimedia (ACM MM), Seattle, WA, USA, 12–16 October 2020; pp. 2871–2880. [Google Scholar]
- Lei, L.; Chen, T.; Li, S.; Li, J. Micro-expression recognition based on facial graph representation learning and facial action unit fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar]
- Zhao, X.; Ma, H.; Wang, R. STA-GCN: Spatio-Temporal AU Graph Convolution Network for Facial Micro-expression Recognition. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Beijing, China, 29 October–1 November 2021; pp. 80–91. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Wang, Y.; Huang, R.; Song, S.; Huang, Z.; Huang, G. Not All Images are Worth 16 × 16 Words: Dynamic Transformers for Efficient Image Recognition. In Proceedings of the Advances Conference on Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Based YOLO for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. Transgan: Two pure transformers can make one strong gan, and that can scale up. Adv. Neural Inf. Process. Syst. 2021, 34, 14745–14758. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- See, J.; Yap, M.H.; Li, J.; Hong, X.; Wang, S.J. Megc 2019—The second facial micro-expressions grand challenge. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Pfister, T.; Li, X.; Zhao, G.; Pietikäinen, M. Recognising spontaneous facial micro-expressions. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1449–1456. [Google Scholar]
- Huang, X.; Wang, S.J.; Zhao, G.; Piteikainen, M. Facial micro-expression recognition using spatiotemporal local binary pattern with integral projection. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 1–9. [Google Scholar]
- Le Ngo, A.C.; Liong, S.T.; See, J.; Phan, R.C.W. Are subtle expressions too sparse to recognize? In Proceedings of the IEEE International Conference on Digital Signal Processing, Singapore, 21–24 July 2015; pp. 1246–1250. [Google Scholar]
- Huang, X.; Zhao, G.; Hong, X.; Zheng, W.; Pietikäinen, M. Spontaneous facial micro-expression analysis using spatiotemporal completed local quantized patterns. Neurocomputing 2016, 175, 564–578. [Google Scholar] [CrossRef]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. 2017, 9, 563–577. [Google Scholar] [CrossRef]
- Faisal, M.M.; Mohammed, M.S.; Abduljabar, A.M.; Abdulhussain, S.H.; Mahmmod, B.M.; Khan, W.; Hussain, A. Object Detection and Distance Measurement Using AI. In Proceedings of the 2021 14th International Conference on Developments in eSystems Engineering (DeSE), Sharjah, United Arab Emirates, 7–10 December 2021; pp. 559–565. [Google Scholar]
- Mohammed, M.S.; Abduljabar, A.M.; Faisal, M.M.; Mahmmod, B.M.; Abdulhussain, S.H.; Khan, W.; Liatsis, P.; Hussain, A. Low-cost autonomous car level 2: Design and implementation for conventional vehicles. Results Eng. 2023, 17, 100969. [Google Scholar] [CrossRef]
- Wang, S.J.; Yan, W.J.; Li, X.; Zhao, G.; Fu, X. Micro-expression recognition using dynamic textures on tensor independent color space. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4678–4683. [Google Scholar]
- Tang, J.; Li, L.; Tang, M.; Xie, J. A novel micro-expression recognition algorithm using dual-stream combining optical flow and dynamic image convolutional neural networks. Signal Image Video Process. 2023, 17, 769–776. [Google Scholar] [CrossRef]
- Thuseethan, S.; Rajasegarar, S.; Yearwood, J. Deep3DCANN: A Deep 3DCNN-ANN framework for spontaneous micro-expression recognition. Inf. Sci. 2023, 630, 341–355. [Google Scholar] [CrossRef]
- Wang, T.; Shang, L. Temporal augmented contrastive learning for micro-expression recognition. Pattern Recognit. Lett. 2023, 167, 122–131. [Google Scholar] [CrossRef]
- Kim, D.H.; Baddar, W.J.; Ro, Y.M. Micro-expression recognition with expression-state constrained spatio-temporal feature representations. In Proceedings of the ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 382–386. [Google Scholar]
- Gan, Y.S.; Liong, S.T.; Yau, W.C.; Huang, Y.C.; Tan, L.K. Off-apexnet on micro-expression recognition system. Signal Process. Image Commun. 2019, 74, 129–139. [Google Scholar] [CrossRef]
- Van Quang, N.; Chun, J.; Tokuyama, T. Capsulenet for micro-expression recognition. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–7. [Google Scholar]
- Zhou, L.; Mao, Q.; Xue, L. Dual-inception network for cross-database micro-expression recognition. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Liong, S.T.; Gan, Y.S.; See, J.; Khor, H.Q.; Huang, Y.C. Shallow triple stream three-dimensional cnn (ststnet) for micro-expression recognition. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Liu, Y.; Du, H.; Zheng, L.; Gedeon, T. A neural micro-expression recognizer. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–4. [Google Scholar]
- Wang, S.J.; Yan, W.J.; Li, X.; Zhao, G.; Zhou, C.G. Micro-Expression Recognition Using Color Spaces. IEEE Trans. Image Process. 2015, 24, 6034–6047. [Google Scholar] [CrossRef]
- Davison, A.; Merghani, W.; Lansley, C.; Ng, C.C.; Yap, M.H. Objective micro-facial movement detection using facs-based regions and baseline evaluation. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 642–649. [Google Scholar]
- Wang, S.J.; Yan, W.J.; Zhao, G.; Fu, X.; Zhou, C.G. Micro-expression recognition using robust principal component analysis and local spatiotemporal directional features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 325–338. [Google Scholar]
- Liu, Y.J.; Zhang, J.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Xu, F.; Zhang, J.P.; Wang, J.Z. Microexpression identification and categorization using a facial dynamics map. IEEE Trans. Affect. Comput. 2017, 8, 254–267. [Google Scholar] [CrossRef]
- Happy, S.; Routray, A. Fuzzy histogram of optical flow orientations for micro-expression recognition. IEEE Trans. Affect. Comput. 2017, 10, 394–406. [Google Scholar] [CrossRef]
- Liong, S.T.; See, J.; Wong, K.; Phan, R.C.W. Less is more: Micro-expression recognition from video using apex frame. Signal Process. Image Commun. 2018, 62, 82–92. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, Z.; Liu, N.; Tan, Y.; Liu, X.; Chen, T. Spatiotemporal Convolutional Neural Network with Convolutional Block Attention Module for Micro-Expression Recognition. Information 2020, 11, 380. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Zhao, G. Joint Local and Global Information Learning With Single Apex Frame Detection for Micro-Expression Recognition. IEEE Trans. Image Process. 2020, 30, 249–263. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Peng, M.; Bi, T.; Chen, T. Micro-attention for micro-expression recognition. Neurocomputing 2020, 410, 354–362. [Google Scholar] [CrossRef]
- Xia, Z.; Peng, W.; Khor, H.Q.; Feng, X.; Zhao, G. Revealing the invisible with model and data shrinking for composite-database micro-expression recognition. IEEE Trans. Image Process. 2020, 29, 8590–8605. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Jia, X.; De Brabandere, B.; Tuytelaars, T.; Gool, L.V. Dynamic filter networks. Adv. Neural Inf. Process. Syst. 2016, 29, 667–675. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32, 1307–1318. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]
- Terry, J.C.D.; Roy, H.E.; August, T.A. Thinking like a naturalist: Enhancing computer vision of citizen science images by harnessing contextual data. Methods Ecol. Evol. 2020, 11, 303–315. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy (%) | F1-Score |
|---|---|---|
| LBP-TOP (ICCV 2011) | 48.78 | 0.4600 |
| DiSTLBP-RIP (FADS 2019) | 63.41 | N/A |
| LBP-SDG (NC 2021) | 69.68 | 0.6200 |
| LBP-FIP (MTAP 2022) | 67.86 | N/A |
| KTGSL (NC 2022) | 75.64 | 0.6900 |
| OFF-Apex (SPIC 2019) | 67.68 | 0.6709 |
| DSSN (ICIP 2019) | 63.41 | 0.6462 |
| TSCNN (IEEE Access 2019) | 72.74 | 0.7236 |
| GEME (NC 2021) | 64.63 | 0.6158 |
| MoCo (PRL 2023) | 75.61 | 0.7492 |
| RPCA (ECCV 2014) | 58.00 | 0.6000 |
| MDMO (TAC 2015) | 58.97 | 0.5845 |
| FDM (TAC 2017) | 54.88 | 0.5380 |
| Bi-WOOF (SPIC 2018) | 61.59 | 0.6110 |
| FHOFO (TAC 2019) | 51.83 | 0.5243 |
| SMDMO (TAC 2021) | 70.51 | 0.7041 |
| CBAM (Information 2020) | 54.84 | N/A |
| RNMA (NC 2020) | 49.40 | 0.4960 |
| LGCconD (TIP 2020) | 63.41 | 0.6200 |
| MADFN | 81.71 | 0.8202 |
| Methods | Accuracy (%) | F1-Score |
|---|---|---|
| LBP-TOP (ICCV 2011) | 39.68 | 0.3589 |
| LTOGP (ICASSP 2019) | 66.00 | N/A |
| DiSTLBP-RIP (FADS 2019) | 64.78 | N/A |
| LBP-SDG (NC 2021) | 71.32 | 0.6700 |
| LBP-FIP (MTAP 2022) | 70.00 | N/A |
| KTGSL (NC 2022) | 72.58 | 0.6800 |
| OFF-Apex (SPIC 2019) | 68.94 | 0.6967 |
| DSSN (ICIP 2019) | 70.78 | 0.7297 |
| TSCNN (IEEE Access 2019) | 80.97 | 0.8070 |
| Graph-TCN (MM 2020) | 73.98 | 0.7246 |
| GEME (NC 2021) | 64.63 | 0.6158 |
| MoCo (PRL 2023) | 76.30 | 0.7366 |
| FDCN (SIVP 2023) | 73.09 | 0.7200 |
| MERSiamC3D (NC 2021) | 81.89 | 0.8300 |
| RPCA (ECCV 2014) | 49.00 | 0.5100 |
| MDMO (TAC 2015) | 51.69 | 0.4966 |
| FDM (TAC 2017) | 45.93 | 0.4053 |
| Bi-WOOF (SPIC 2018) | 57.89 | 0.6125 |
| FHOFO (TAC 2019) | 56.64 | 0.5248 |
| RAM (FG 2020) | 68.20 | 0.5700 |
| SMDMO (TAC 2021) | 66.95 | 0.6911 |
| CBAM (Information 2020) | 69.92 | N/A |
| RNMA (NC 2020) | 65.90 | 0.5390 |
| LGCconD (TIP 2020) | 65.02 | 0.6400 |
| AU-GCN (CVPR 2021) | 74.27 | 0.7047 |
| TSGACN (CVPR 2021) | 81.30 | 0.7090 |
| MADFN | 82.11 | 0.8095 |
| Methods | Accuracy (%) | F1-Score |
|---|---|---|
| LBP-TOP (ICCV 2011) | 35.56 | 0.3589 |
| KTGSL (NC 2022) | 56.11 | 0.4900 |
| DSSN (ICIP 2019) | 57.35 | 0.4644 |
| TSCNN (IEEE Access 2019) | 71.76 | 0.6942 |
| Graph-TCN (MM 2020) | 75.00 | 0.6985 |
| GEME (NC 2021) | 64.63 | 0.6158 |
| MoCo (PRL 2023) | 68.38 | 0.7366 |
| FDCN (SIVP 2023) | 58.07 | 0.5700 |
| MERSiamC3D (NC 2021) | 68.75 | 0.5436 |
| RNMA (NC 2020) | 48.50 | 0.4020 |
| LGCconD (TIP 2020) | 40.90 | 0.3400 |
| AU-GCN (CVPR 2021) | 74.26 | 0.7045 |
| TSGACN (CVPR 2021) | 88.24 | 0.8279 |
| MADFN | 77.21 | 0.7489 |
| Methods | SMIC | CASME II | SAMM | 3DB-Combined | ||||
|---|---|---|---|---|---|---|---|---|
| UF1 | UAR | UF1 | UAR | UF1 | UAR | UF1 | UAR | |
| LBP-TOP (ICCV 2011) | 0.2000 | 0.5280 | 0.7026 | 0.7429 | 0.3954 | 0.4102 | 0.5882 | 0.5785 |
| Bi-WOOF (SPIC 2018) | 0.5727 | 0.5829 | 0.7805 | 0.8026 | 0.5211 | 0.5139 | 0.6296 | 0.6227 |
| OFF-Apex (SPIC 2019) | 0.6817 | 0.6695 | 0.8764 | 0.8681 | 0.5409 | 0.5409 | 0.7196 | 0.7096 |
| CapsuleNet (FG 2019) | 0.5820 | 0.5877 | 0.7068 | 0.7018 | 0.6209 | 0.5989 | 0.6520 | 0.6506 |
| Dual-Inception (FG 2019) | 0.6645 | 0.6726 | 0.8621 | 0.8560 | 0.5868 | 0.5663 | 0.7322 | 0.7278 |
| STSTNet (FG 2019) | 0.6801 | 0.7013 | 0.8382 | 0.8686 | 0.6588 | 0.6810 | 0.7353 | 0.7605 |
| EMR (FG 2019) | 0.7461 | 0.7530 | 0.8293 | 0.8209 | 0.7754 | 0.7152 | 0.7885 | 0.7824 |
| SHCFNet (2020) | 0.6100 | 0.6311 | 0.6540 | 0.6536 | 0.6089 | 0.5926 | 0.6242 | 0.6222 |
| MERSiamC3D (NE 2021) | 0.7356 | 0.7598 | 0.8818 | 0.8763 | 0.7475 | 0.7280 | 0.8068 | 0.7986 |
| FeatRef (PR 2022) | 0.7011 | 0.7083 | 0.8915 | 0.8873 | 0.7372 | 0.7155 | 0.7838 | 0.7832 |
| GEME (NC 2021) | 0.6288 | 0.6570 | 0.8401 | 0.8508 | 0.6868 | 0.6541 | 0.7395 | 0.7500 |
| Bi-WOOF (SPIC 2018) | 0.5727 | 0.5829 | 0.7805 | 0.8026 | 0.5211 | 0.5139 | 0.6296 | 0.6227 |
| RCN-A (TIP 2020) | 0.6441 | 0.6326 | 0.8123 | 0.8512 | 0.6715 | 0.7601 | 0.7190 | 0.7432 |
| RCN-S (TIP 2020) | 0.6572 | 0.6519 | 0.7914 | 0.8360 | 0.6565 | 0.7647 | 0.7106 | 0.7466 |
| RCN-W (TIP 2020) | 0.6600 | 0.6584 | 0.8131 | 0.8522 | 0.6164 | 0.7164 | 0.7100 | 0.7422 |
| RCN-F (TIP 2020) | 0.5980 | 0.5991 | 0.8087 | 0.8563 | 0.6771 | 0.6976 | 0.7052 | 0.7164 |
| LGCcon (TIP 2021) | N/A | N/A | 0.7929 | 0.7639 | 0.5248 | 0.4955 | 0.7914 | 0.7933 |
| LGCconD (TIP 2020) | 0.6195 | 0.6066 | 0.7762 | 0.7499 | 0.4924 | 0.4711 | 0.7715 | 0.7864 |
| AU-GCN (CVPR 2020) | 0.7192 | 0.7215 | 0.8798 | 0.8710 | 0.7751 | 0.7890 | 0.7979 | 0.8041 |
| PLAN_S (NN 2022) | 0.7127 | 0.7256 | 0.8632 | 0.8778 | 0.7164 | 0.7418 | 0.7826 | 0.7891 |
| PLAN (NN 2022) | N/A | N/A | 0.8941 | 0.8962 | 0.7358 | 0.7687 | 0.8075 | 0.8013 |
| MADFN | 0.8179 | 0.8102 | 0.9061 | 0.8986 | 0.8322 | 0.8289 | 0.8100 | 0.8044 |
| Model | Patch Size | Layers | Hidden Size | MLP Size | Heads |
|---|---|---|---|---|---|
| ViT-Base | 16 × 16 | 12 | 768 | 3072 | 12 |
| ViT-Large | 16 × 16 | 24 | 1024 | 4086 | 16 |
| ViT-Huge | 14 × 14 | 32 | 1280 | 5120 | 16 |
| Model | SMIC | CASME II | SAMM | |||
|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| ViT-B/16 | 64.63 | 0.6602 | 53.79 | 0.4780 | 58.19 | 0.3598 |
| ViT-L/16 | 68.29 | 0.6858 | 57.24 | 0.5136 | 62.70 | 0.5280 |
| ViT-H/14 | 65.24 | 0.6412 | 58.62 | 0.5386 | 59.69 | 0.4704 |
| Model | SMIC | CASME II | SAMM | |||
|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |
| BS | 65.85 | 0.6658 | 48.17 | 0.5069 | 68.38 | 0.6643 |
| GS | 65.24 | 0.6696 | 48.17 | 0.5008 | 67.64 | 0.6481 |
| RS | 68.29 | 0.6822 | 59.79 | 0.6033 | 69.11 | 0.6819 |
| LS | 69.51 | 0.7008 | 72.63 | 0.7327 | 72.46 | 0.7082 |
| Methods | Image | AU | SMIC | CASME II | SAMM | |||
|---|---|---|---|---|---|---|---|---|
| Accuracy | F1-Score | Accuracy | F1-Score | Accuracy | F1-Score | |||
| ViT | √ | 69.51 | 0.7008 | 72.63 | 0.7327 | 72.46 | 0.7082 | |
| ViT-C-AU | √ | √ | 71.85 | 0.7026 | 73.17 | 0.7327 | 73.44 | 0.7181 |
| ViT-S-AU | √ | √ | 71.68 | 0.7030 | 73.62 | 0.7386 | 73.70 | 0.7180 |
| ViT-M-AU | √ | √ | 73.51 | 0.7208 | 74.63 | 0.7427 | 74.11 | 0.7219 |
| AUDF | √ | √ | 78.04 | 0.7784 | 77.64 | 0.7520 | 75.73 | 0.7316 |
| AUDF-E | √ | √ | 81.71 | 0.8202 | 82.11 | 0.8095 | 77.21 | 0.7489 |
| Model | Params | Training Times | Test Times |
|---|---|---|---|
| ViT-Base | 86M | 7.3H | 13MS |
| ViT-Large | 307M | 10.6H | 18MS |
| ViT-Huge | 632M | 24.2H | 24MS |
| MADFN | 224M | 9.2H | 25MS |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Xie, L.; Pan, H.; Li, C.; Wang, Z.; Zhong, J. Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition. Entropy 2023, 25, 1246. https://doi.org/10.3390/e25091246
Yang H, Xie L, Pan H, Li C, Wang Z, Zhong J. Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition. Entropy. 2023; 25(9):1246. https://doi.org/10.3390/e25091246
Chicago/Turabian StyleYang, Hongling, Lun Xie, Hang Pan, Chiqin Li, Zhiliang Wang, and Jialiang Zhong. 2023. "Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition" Entropy 25, no. 9: 1246. https://doi.org/10.3390/e25091246
APA StyleYang, H., Xie, L., Pan, H., Li, C., Wang, Z., & Zhong, J. (2023). Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition. Entropy, 25(9), 1246. https://doi.org/10.3390/e25091246