Abstract
The analysis of market correlations is crucial for optimal portfolio selection of correlated assets, but their memory effects have often been neglected. In this work, we analyse the mean market correlation of the S&P500, which corresponds to the main market mode in principle component analysis. We fit a generalised Langevin equation (GLE) to the data whose memory kernel implies that there is a significant memory effect in the market correlation ranging back at least three trading weeks. The memory kernel improves the forecasting accuracy of the GLE compared to models without memory and hence, such a memory effect has to be taken into account for optimal portfolio selection to minimise risk or for predicting future correlations. Moreover, a Bayesian resilience estimation provides further evidence for non-Markovianity in the data and suggests the existence of a hidden slow time scale that operates on much slower times than the observed daily market data. Assuming that such a slow time scale exists, our work supports previous research on the existence of locally stable market states.
1. Introduction
The S&P500 is an aggregated index of the stocks of the 500 largest companies traded at US stock exchanges and therefore serves as an indicator of the overall US economic performance. Estimating and predicting the correlation between different assets is crucial for optimal portfolio selection and risk management and has been the focus of financial research since Markowitz’s portfolio theory [1].
The economy is a system with a large number of nonlinearly interacting parts, such as, e.g., traders, industrial producers, consumers and employees. These interactions can lead to positive and negative feedbacks and emergent effects like self-organisation. Therefore, the economy can be understood as a complex system and is amenable to the analysis tools from complex systems science [2,3].
Due to the increasing availability of data for the economy, highly data-driven methods can be applied in this field of research and many researchers have chosen to focus on the correlations between the relative price changes of different stocks, i.e., the correlations of the stocks’ returns [1,4,5,6,7,8]. In [9,10,11], the authors identified states of the economy by analysing correlation matrices of daily S&P 500 data and found eight clusters. These can be interpreted as economic states reflecting, e.g., times of economic growth or crises [9] and are found to be locally stable [10,11]. Further analyses showed that exogenous events, precursors for crises and collective market behaviour can also be identified via the correlation matrix approach [12,13,14]. Analysis of the eigenvalues of the correlation matrix revealed that the largest eigenvalue, called the “market mode” or “market factor”, is far outside of the expected spectrum of purely random matrices and is furthermore essentially captured by the mean market correlation. The market mode is thus interpreted as a hint at collective behaviour in the economic system [5,8] and used to classify market states by focusing on the market mode [11]. Moreover, a study on how the market mode’s eigenvector entries scale with the length of the time series revealed a strongly coupled market core and weakly linked periphery [3]. Thus, the mean market correlation or market mode captures a lot of information about the financial market in a low-dimensional observable and therefore, we analyse the time series of the mean market correlation to gain new insights into the market dynamics.
Ever since Bachelier’s seminal work introduced the random walk model to describe stock prices [15], the inherent stochasticity of financial data has been taken into account by researchers and practitioners alike. The Langevin equation is a model for stochastic differential equations that includes a deterministic drift and a random diffusion and can be used to describe such stochastic data. Much research has been devoted to estimating Langevin equations from data [16,17,18,19,20,21,22] and Langevin equations have found applications in various fields of research such as fluid dynamics [23], molecular dynamics [24] and meteorology [25] (cf. [26] for a review of applications). The generalised Langevin equation (GLE) expands the Langevin model by introducing a kernel function to include memory effects [27]. Bayesian statistics includes a collection of methods that reverse the classical approach to statistics and focuses on calculating posterior distributions of model parameters as probabilities conditional on the observed data [28,29]. This approach enables an efficient estimation of non-Markovian Langevin equations [30,31]. Also, other time series analysis methods can be implemented in the Bayesian framework to, e.g., detect change points in time series data [32].
We show that an estimated GLE model manages to achieve a high goodness-of-fit for the correlation time series and implies a strong memory effect, which has to be taken into account when predicting future market correlations. Furthermore, we perform a detailed comparison of a Markovian mono-time scale and a non-Markovian two-time scale model with a hidden slow time scale, which confirms the GLE analysis results regarding non-Markovian memory effects. Additionally, the analysis supports the theory of locally stable and quasi-stationary market states discussed in Stepanov et al. [11] and provides evidence that a hidden slow time scale might be involved in the mean market correlation dynamics. It is not far-fetched to assume that a complex system like the human economy involves a multitude of time scales and our findings coincide with such reasoning. The slow time scales might be connected to business and innovation cycles or similar economic mechanisms even though we could not extract a quantitatively reasonable magnitude of the hidden slow time scale.
The remainder of this article is structured as follows: Section 2 explains the data gathering and preprocessing in Section 2.1, the Bayesian methodology in Section 2.2, the GLE estimation procedure in Section 2.3 and the resilience analysis in Section 2.4. Section 3 describes the goodness-of-fit and the estimated memory parameters for the GLE model in Section 3.1 as well as the resilience results for two time scales in Section 3.2. Finally, the results of these analyses are interpreted and compared to the results from [11] in Section 4.
2. Data and Methods
2.1. Data Preparation
The S&P 500 is a stock index containing 500 large US companies traded at American stock exchanges. Daily stock data from these companies were downloaded via the Python package yfinance [33] for the time period between 1992 and 2012, which is the same time period as in [10,11]. Although this limits our analysis to slightly outdated data, it ensures that we can compare our methodology and results to the findings in [11]. Only stock data of companies that were part of the S&P 500 index during at least 99.5% of the time were used for this analysis. Note that while this data selection is in line with [9,10,11,34], it introduces a survivorship bias by disregarding the information about companies that went bankrupt during this time period, as pointed out in [34]. However, it ensures that all considered companies experience the same macroeconomic events, which would not be the case for those companies that vanish during the considered time period due to bankruptcy. If a company’s price time series is not available for the full time period, the remaining 0.5% of the price time series data are interpolated linearly with the .interpolate() method in pandas [35,36]. Overall, there are 249 companies’ time series for 5291 trading days with one observation per date. Each company’s returns are locally normalised to remedy the impact of sudden changes in the drift of the time series with the method introduced in [37], as
Here, denotes a local mean across the n most recent data points, i.e., is subjected to a standard normalisation transformation with respect to the local mean and standard deviation (i.e., volatility ). Following [9], was chosen for the daily data. For each time step t and each pair of sectors the local correlation coefficients
are calculated over a time period of trading days such as in [9] (the 42 working days correspond to 2 trading months) with the local standard deviations . It should be kept in mind that the correlation coefficient only detects linear dependencies. However, it is used ubiquitously in data-driven inference on financial markets [3]. As shown via Principle Component Analysis in [11], the mean correlation
already describes much of the variability in the data as the largest eigenvalue or market mode of the correlation matrix. While the majority of the eigenvalue spectrum follows the Marcenko-Pastur distribution that is expected for purely random matrices, the market mode is far outside of this spectrum. Therefore, it hints at a strongly non-random effect [2,3,5]. Note that [3] also points out that this property is not only found in US stock markets, but is a general observation across markets. Hence, it makes sense to restrict the analysis to this one-dimensional time series (shown in Figure 1). The time t is here selected as the central value of the time window of length in order to have a symmetrical window. The preprocessed time series is available via [38].
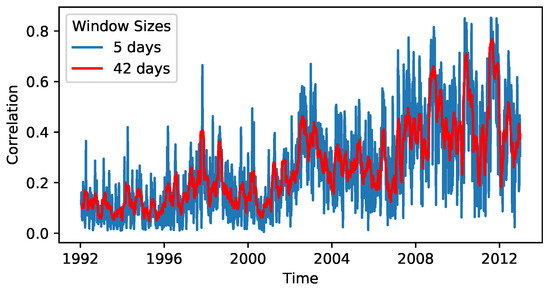
Figure 1.
The mean correlation of the S&P500. The depicted time series are the mean values of correlation matrices, which were calculated based on moving windows of length days plotted against the centre of the -days-interval. This figure depicts and .
2.2. Bayesian Statistics
Bayes’ theorem for the conditional probability distributions of model parameters and observed data
connects the standard statistical likelihood and prior knowledge about the model parameters to a posterior distribution of the unknown model parameters conditional on the observed data [39]. A bundle of methods have been derived from this approach and are collectively referred to as Bayesian Statistics [28,29]. Markov chain Monte Carlo algorithms (MCMC) can be used to infer the posterior distribution by simulating several random walkers that explore the (potentially high-dimensional) posterior distribution [40]. It generates uncorrelated samples of the model parameters by cutting off the first exploration steps as a burn-in period and thinning the remaining samples. The resulting MCMC samples can also be used to integrate the posterior distribution over all but one model parameter to derive the marginal posterior distribution of this single parameter. Parameter estimation can then be conducted via the mean of the posterior distribution or via its maximum (abbreviated as MAP for maximum a posteriori) and credible intervals (CIs) of, e.g., credibility can be directly derived from the quantiles of the samples for .
2.3. Fitting a Generalised Langevin Equation with Memory Kernel
Sections 4 and 5 of [11] analyse the one-dimensional mean correlation time series by fitting a Langevin model
with independent Gaussian noise , a deterministic time-dependent drift function and a time-independent diffusion function . Note that the Langevin equation is a Markovian model, i.e., it has no memory. As an alternative model, a Generalised Langevin Equation (GLE) includes previous values of the time series in a memory kernel , but has only time-independent parameters with a functional equation
A Bayesian estimation of the parameters of Equation (6) is implemented in [30]. It discretises the memory kernel to and discretises the observed data into different bins to significantly speed up the estimation procedure. Because an overlap of the windows used to calculate can lead to artefacts in the memory effects (cf. Appendix A), we choose to calculate with different parameters than and from [11] (the mean correlation of every sth day is retained for the analysis; hence, for , the full time series is used). Instead, we set and , meaning that the mean market correlation is calculated over one trading () week for the end of the trading week in disjoint windows (i.e., we create a time series whose length is of the original time series). Because using disjoint intervals automatically leads to a thinning of the time series, this seemed like a useful trade-off with a real-world interpretation as weekly correlation. It is worth noting that while the calculation of only considers data from five trading days, the correlation matrix encompasses approximately correlation values. Even though each correlation pair is determined over a brief time window, the large ensemble of values, with their average being , underscores our confidence in the accuracy of the mean . The resulting time series is shown in Figure 1 together with the time series used in [11] and although it obviously becomes much noisier due to the shorter window size, it still retains some of the features of the less noisy time series such as, e.g., the position of spikes with high correlation.
As described in [30], the memory effects are aggregated to a quantity (named in [30]) that measures the strength of all memory effects from 1 up to k time steps ago. If saturates towards a plateau at step , then is the maximum length of any reasonable memory kernel. This often also coincides with kernel values of at . The estimated values for the model parameters are chosen by calculating the marginal posterior distribution and choosing the mean or MAP parameter estimation. The goodness-of-fit is also evaluated by using MCMC to simulate an artificial time series with the estimated model and comparing the autocorrelation function and the distributions of and the increments to those of the original data. Finally, the inferred model structure can be trained on only a subset of the data (training data) and be used to predict the remaining test data to evaluate its predictive performance.
2.4. Resilience Estimation
By applying Bayes’ theorem (4), we can deduce a quantitative measure of resilience under given model assumptions. Therefore, we infer the parameters of two models of stochastic differential equations in a rolling window approach that allows us to resolve the time evolution of the resilience and noise level and accounts for the quasi-stationary nature of the time series that is observed in Stepanov et al. [11]. Following the quasi-stationarity argument, we assume to be in a fixed state in each window, i.e., the fixed point , which is approximated by averaging over the mean market correlation data per window. First, we estimate a Markovian Langevin Equation (5) with the Taylor-expanded drift
with the drift parameters per rolling window and the constant diffusion . We choose uninformed priors, which are given by
for the linear part of the drift function and the Jeffreys scale prior [29]
for the noise level with suitable prior ranges. The priors of higher-order parameters are chosen to be
with Gaussian distributions centred around the mean with a standard deviation and .
Since we consider economic systems to operate on multiple time scales whose combination often leads to non-Markovian time series, we additionally introduce a two-dimensional non-Markovian model analogous to Willers and Kamps [22]. This model is given by
with a hidden Ornstein–Uhlenbeck process (OU-process) , drift and diffusion . Drift and diffusion of the observed process remain unchanged. The non-Markovian analogue to the constant noise level of the Langevin equation is given by the composite noise level
with the small discrete sampling time step h.
For the OU-process, an invariant prior of a straight line and a scale prior for the diffusion are multiplied:
Furthermore, via the prior we introduce a pre-defined time scale separation of the time scales and of the observed and unobserved process, respectively; i.e., we require either or with a scale separation coefficient . The characteristic time scales [41] are approximated by
The priors for the model of the observed data also remain unchanged with the exception of the term , which corresponds to a coupling constant in the non-Markovian model. We simply apply a Gaussian prior similar to the one in Equation (10) to in this case.
Inspired by the formalism of linear stability analysis for both models, we calculate the drift slope
per window as a Bayesian parametric resilience measure. For the Markovian model, the calculations are performed with the open-source Python toolkit antiCPy [42,43]. In this modelling framework, a stable state corresponds to a negative drift slope , whereas a changing sign indicates destabilisation via a bifurcation. More details on the procedure can be found in [32].
3. Results
3.1. Estimated GLE Model
The data are split into equally wide bins and an initial modelling attempt with a rather long kernel is tested, i.e., for all . It shows a plateau emerging at around (cf. Appendix B). Hence, a model with is used as a reasonable length for the memory kernel and its goodness-of-fit is evaluated. We then use a very conservative estimation of the memory up to to evaluate the GLE’s predictive power.
3.1.1. Goodness-of-Fit
A time series of length is simulated via Euler–Maruyama integration of the GLE model to compute the autocorrelation function (ACF) and to compare it to the ACF of the original time series. The best model is chosen via MAP estimation in the Bayesian framework of [30], but selecting the mean estimation yields almost identical results. Both ACFs are computed via the function statsmodels.tsa.stattools.acf from the Python package statsmodels [44]. Figure 2 shows that the two ACFs show very good agreement up to lags of 10 trading weeks and decent agreement up to lags of 20 weeks. The distributions of the time series and the first two increments for the original and the simulated data are shown in Figure 3 for the MAP estimation and also for the mean estimation. Figure 3 shows an almost perfect overlap between the two estimation procedures and a good agreement between the estimated time series and the original time series, especially for the increment distributions. Overall, these diagnostics indicate that the estimated model with memory kernel length 6 manages to reproduce these important statistical properties of the original time series.
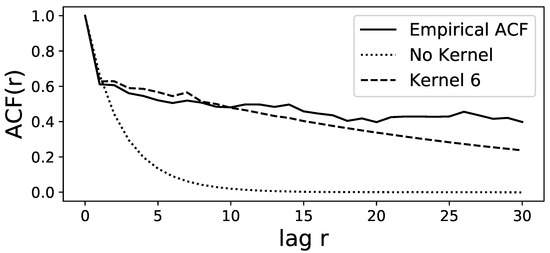
Figure 2.
Comparison between the autocorrelation functions of the original time series (solid line) and the simulated data from the model with kernel length 6 (dashed line) simulated via MAP estimation of the MCMC-integrated marginal densities. Up to lag 30, the ACFs show good agreement. The alternative simulation via mean estimation of the density yields an almost identical ACF. However, the ACF based on the model with no memory kernel (dotted line) fails to capture the empirical ACF.
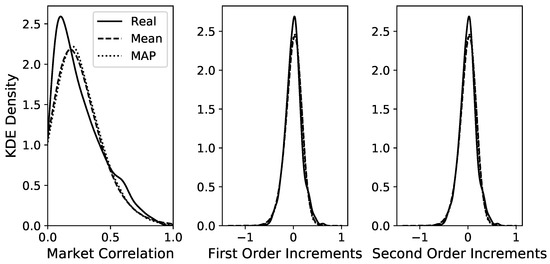
Figure 3.
KDE plots to compare the distributions between the real data and the MCMC samples for the two estimated GLE models with kernel length 6 for the time series data (left), the increments (centre) and (right). Differences between the two simulated models are hardly visible and overall, there is a good overlap with the real data. For the LE without memory, the respective distributions are depicted in Appendix C.
Because the realised values of the time series are not distributed uniformly, we also use a modelling procedure with unequal bin widths so that each of the 10 bins has the same amount of data. However, this barely changes the model diagnostics shown in Figure 2 and Figure 3. The only noticeable change is that for long kernels with length , the ACF seems to be captured a little more poorly in the shown range of Figure 2, but manages to fit more closely to the empirical ACF for large lags at around . While the regular LE without memory has a very similar increment distribution, the ACF is considerably poorer than the GLE.
3.1.2. Estimated Memory Kernel
To make further inference on the memory kernel and to estimate its quantitative effect, the posterior distribution of the model with memory length 6 is sampled via MCMC. 100 walkers are simulated for time steps and after a burn-in period of 450 initial time steps is discarded, the chains are thinned by only keeping every 450th step to obtain uncorrelated samples. Bayesian CIs can now be calculated at the level for each parameter in the kernel function and the results are shown in Figure 4.
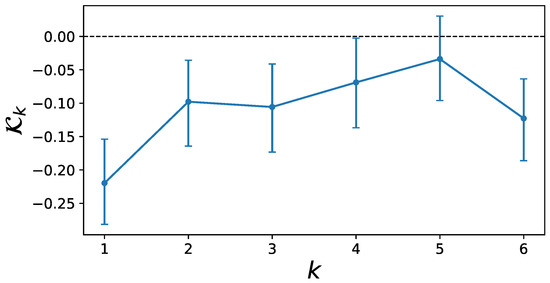
Figure 4.
Values for the memory kernel in the model with memory length 6. Credible intervals were estimated via MCMC at the 95% level. The inclusion of 0 in the credible interval of combined with the uncertainty about the beginning of the plateau in Figure A2 imply that the nonzero memory effect for may be misleading. All previous memory kernels have nonzero values at the 95% credibility level.
The CIs of are already very close to the zero line and those of include zero, meaning that there is no evidence for a memory term at five weeks distance. Interestingly, the CIs for clearly exclude the value zero. Because it is difficult to exactly identify the beginning of the plateau in the memory aggregation in Figure A2, it may be possible that the plateau already emerges at and that the nonzero memory kernel is therefore unreliable. However, the results in Figure 4 clearly imply a nonzero memory effect for four time steps with a clearly nonzero effect strength for memories up to trading weeks.
3.1.3. Prediction via the GLE with Kernel Length 3
With a conservative interpretation of the results in Section 3.1.2, a model with memory length is used to evaluate the GLE’s power to predict a future value by forecasting an accurate prediction . It is tested against a regular Langevin equation (LE) model without any memory effects (corresponding to and also estimated with the code in [30]) and against the naive benchmark of predicting the next time step by simply setting it to the last previously known value: . To test these three methods, the Langevin models are trained on the first of the time series (the training data) and the predictions of the GLE, the LE and the naive forecast are evaluated on both the training data (as in-sample predictions) and on the remaining test data (as out-of-sample predictions). The coefficient of prediction is used to evaluate their predictive accuracy. If n observations are forecasted as , then the coefficient of prediction is given by
with the denoting the mean value. It takes the value of , if the prediction is always exactly true, and , if the prediction is only as accurate as always using the mean , and , if it is less accurate than using the mean and is computed via the function sklearn.metrics.r2_score from [45]. The results in Table 1 show that the GLE model consistently achieves the highest accuracy on in-sample and out-of-sample predictions for the three chosen test data sizes. Notably, the negative of the naive method for the test data indicates that the out-of-sample prediction is by no means trivial, meaning that the low, but positive of the GLE on the test data nevertheless constitutes a good performance. The GLE achieves slightly better results than the LE, indicating that the memory effect should be taken into account for prediction tasks. Figure 5 shows the predictions of the LE and GLE for the in-sample and out-of-sample predictions with . The same visual comparison between naive forecast and the GLE can be found in the Appendix D.

Table 1.
Comparing the predictions of the naive forecast , the Langevin equation (LE) and the GLE with memory kernel length via their score on in-sample training data and out-of-sample test data ( training data and the last of the time series as test data). Note that the partially negative for the test data indicates that the test data is quite difficult to predict, which corresponds to the high fluctuations in the final part of the time series in Figure 1.
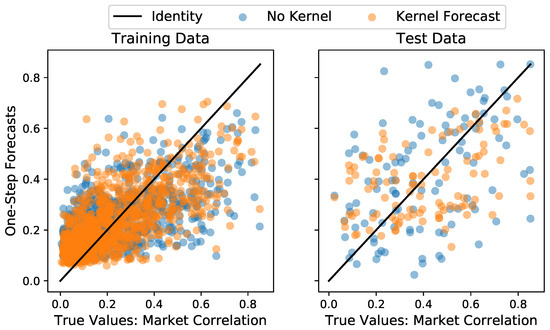
Figure 5.
Comparison between one-step-ahead forecasts of the GLE model with Kernel against a regular Langevin estimation without memory effects on the training data (left) and the test data (right). The identity is given as a benchmark for perfect predictive accuracy. Here, of the time series were used as training data.
3.2. Hidden Slow Time Scale and Non-Markovianity
Applying the resilience analysis method from Section 2.4, we can deduce some interesting evidence for multiple time scales and further confirm that non-Markovianity is present in the considered economic time series. The results for both the simple Markovian and multi-scale non-Markovian model (cf. (5) and (12), respectively) are compared in Figure 6a–c. The parameters of the calculations are listed in Table A1 of Appendix E.
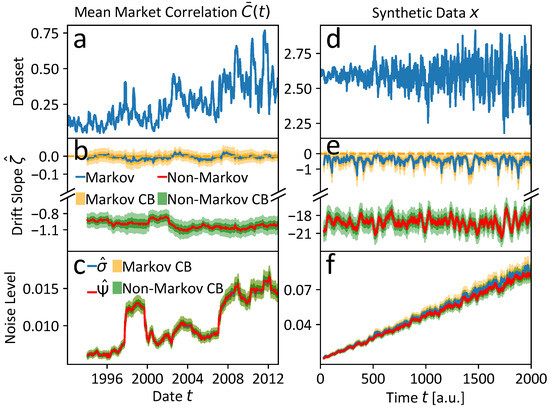
Figure 6.
Results of the resilience analyses based on the Markovian Langevin Equation (5) and the non-Markovian model (12) with an unobserved slow time scale , i.e., under the prior assumption : (a) for the mean market correlation and (d) for a synthetic dataset x that shares the multi-scaling features and non-Markovianity with the economic time series . (b) The Markovian model suggests persistent latent instability, i.e., , whereas the non-Markovian slopes agree with locally quasi-stationary economic states as observed in Stepanov et al. [11]. (c) The noise level estimates are almost identical and tend to increase over time, which might reflect more turbulent economic times towards the the financial crisis 2008. The plateau of ca. one rolling window length around 1998 might be due to the incorporation of some outliers in the time of the ending Asian crisis and the beginning of the Russian financial crisis. (e) Drift slope results of the synthetic dataset x analogous to (b). The qualitative results are in good agreement with (b), which might be a hint that the mean market correlation exhibits non-Markovian features and is additionally governed by processes on a slower time scale . (f) The estimated noise levels of the synthetic dataset x are almost identical, which is also observed for the noise levels of the mean market correlation in (c). For more details see the running text.
Stepanov et al. [11] argue for quasi-stationary economic states, which are occupied over finite time periods before they transition into another quasi-stationary economic state. The estimated potential landscape for the mean market correlation in the article [11] suggests that there might be shifts in the fixed point positions over time, but no bifurcation-induced tipping (B-tipping) is involved, i.e., no qualitative change of stable and unstable fixed points or attractors is observed. Instead of B-tipping mechanisms, the intrinsic economic stochasticity drives the jumps between alternative quasi-stationary states, which is a mechanism basically related to noise-induced tipping (N-tipping).
If we choose a model that captures the key features of the data generating process, we should thus be able to uncover generally negative drift slope estimates , corresponding to data of a locally quasi-stationary state in each rolling window of the mean market correlation , the data of which is shown again in Figure 6a.
In this spirit, we find the non-Markovian model with an unobserved slow time scale, i.e., with , to yield the expected result of negative drift slope estimates as presented in Figure 6b and indicated by the red solid line with green credibility bands (CBs).
This result is supported by rather intuitive qualitative considerations: Economic processes are known to operate on various fast and slow time scales. On the one hand, these dynamics contain, e.g., high-frequency trading, trading psychology and sudden external events, whether that might be political, sociological, severe weather or other impacts. These fast-scale processes could be called “economic weather” in a climatologist’s metaphor. On the other hand, long-term “economic climate evolution” takes place on much slower time-scales. Examples could be innovation processes and technical revolutions such as the invention of the steam engine or the internet, economic cycle theories such as that of Marx ( 2 to 10 years) [46,47], Keynes, Schumpeter or Kondratjew [48,49,50,51], cycles of fiscal and demographic developments [52], cultural evolution [53] and generational changes influencing economic reasoning, adaptions to climate change and the scarcity of resources and much more. Keeping that in mind, the trading day resolution of the data is rather fine-grained and it might be reasonable to assume that a hidden slow time scale is present in the data. The slow time scale of the presented non-Markovian model is determined by the upper boundary of the prior range, which is chosen to correspond roughly to 6 years, which is the time of an average business cycle and coincides with the first zero-crossing of the autocorrelation function of the mean market correlation . If the prior is chosen more broadly, the model converges to roughly 700 to 4000 years, which is not a plausible magnitude of the time scale of economic evolution (cf. Appendix E). However, the main results of local quasi-stationary economic states is not affected by the prior choice. The estimation of a more reasonable magnitude of the slow time scale without prior restriction might be prohibited by the very limited amount of data per window, since the window range does not even include one complete business cycle, which would be the smallest proposed slow time scale candidate. Further note that the two-time scale non-Markovian model in Equation (12) incorporates noise in the slow non-observed variable . In that way, it could formally reflect intermediate dynamics on a time scale with . However, since it is coupled to the mean market correlation on trading day resolution, we consider the noise operating on a time scale .
In contrast to the multi-scale non-Markovian model, the mono-scale Markovian model cannot reflect the local quasi-stationarity of the economic states, postulated in Stepanov et al. [11], but the drift slope estimates , indicated by the blue solid line with orange CBs in Figure 6b, suggest persistently latent instability with . The noise analogues and of the Markovian and non-Markovian model are almost identical, as depicted in Figure 6c, following the same color-coding. The noise level seems to increase over the years with a clear increase in the periods of the global financial crisis and the Euro crisis, which accounts for a higher N-tipping probability in this highly turbulent economic period. The noise plateau of roughly one window length around the end of the Asian and the beginning of the Russian financial crises around 1998 is probably the result of the outliers that are incorporated into the windows.
Since the discussed observations alone only allow for relatively weak qualitative deduction of the discussed features of multi-scaling and non-Markovianity, we additionally perform an analogous analysis on a synthetic time series x that shares the key features of a hidden slow time scale and non-Markovianity with the original one. In Figure 7, we provide a comparison of the per definition stationary first differences, (a) of the original mean market correlation and (b), of the synthetic time series x. The noise level in x is assumed to increase over time to mirror the noise level evolution of the mean market correlation , suggested by the estimates in Figure 6c, and is adjusted to cover almost the range of the first differences in . Only the positive trend of the mean market correlation visible in Figure 6a is not included in the simulations of x. In that way, the PDFs of the two time series’ first differences are shaped similarly, apart from the fact that the highly centered probability mass of the mean market correlation with steep tails due to rare outliers is a bit more smeared out into flatter tails of the synthetic time series x. More simulation details can be found in the Appendix E.
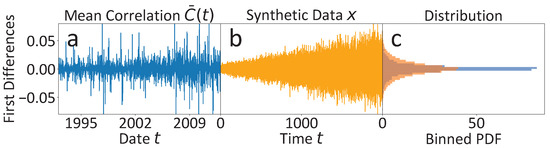
Figure 7.
First differences (FD) and corresponding PDFs of the raw mean market correlation data and the synthetic dataset x, which shares the key features of non-Markovianity and an unobserved slow time scale with the mean market correlation data . (a) The FDs of the mean market correlation are highly centered around zero with some outliers. (b) The FD capture essentially the same range as the FDs of , but are less centered around zero. The time series is modelled with increasing coupling strength to imitate the increase of the noise level found for the mean market correlation in Figure 6c. (c) The FD PDFs of both time series are comparable. The PDFs only deviate to some extent in the flatter tails of the synthetic orange histogram with less dense probability density around zero. The positive trend of is not modelled in the simulated time series x.
The resilience analyses of the synthetic time series x are shown in Figure 6d–f and are in very good agreement with the results of the original analysis in Figure 6a–c. That serves as an independent qualitative confirmation of our findings’ interpretation. Moreover, this interpretation is supported by two additional facts: First, the estimation of a Markovian model on the Gaussian kernel detrended version of the mean market correlation results in similar results to the multi-scale non-Markovian model. This strengthens our previous findings, because the detrending subtracts a non-stationary slow process suspected to be present in the data. We notice that weaker detrending leads to positive trends in the drift slope estimates , which could be due to increasing distortions due to incomplete detrending of the non-stationarity. Second, we fit a multi-scale non-Markovian model with inverse time scale separation with (i.e., the observed trading day time scale of the mean market correlation is considered to be at least two times slower than the hidden time scale). This leads to results similar to the Markovian model with and without detrending. This is an expected result, since the prior restriction of the time scale separation basically restricts the model to the Markovian case in which only the trading day time scale can be resolved apart from an even faster stochastic contribution. In other words, the prior assumption with prohibits the incorporation of an unobserved slower time scale, even if it is present in the data. The discussed results are presented in more detail in Appendix E.
4. Discussion and Conclusions
The estimated GLE model manages to reproduce the statistical properties of the original data for the end-of-week correlations, as shown in Figure 2 and Figure 3. The estimated memory kernel parameters show that even with a highly conservative interpretation of the 95% credible level, there are clearly nonzero memory effects for memory terms for all lags as far back as a lag of three weeks. Therefore, it is advised to use a model with memory to describe the correlation of the S&P500 market, which is an improvement to the Markovian Langevin model estimated in [11]. Moreover, the GLE estimation presented in this article achieves a high goodness-of-fit for the entire time series, whereas Stepanov et al. used a time-dependent Langevin model by splitting the time series into different intervals and estimating Markovian Langevin equations for each of them. Our work shows that this procedure can be circumvented by using a model with memory of at least three trading weeks. The major advantage of our method is its possible application in predicting future market correlation: The time-dependent drift estimation in [11] has no clear or smooth functional dependence on time and therefore, little information can be inferred about future values of the correlation time series. Our method needs no time dependency, generalises over the entire time series and can be used to predict future correlation values, which can be used for portfolio risk assessment. As shown in Section 3.1.3, the memory kernel helps the GLE to achieve better prediction accuracy than the regular Langevin equation and much better results than the naive forecasting method of using the last observation as the predicted value.
Notably, the existence of memory effects in the market’s correlation structure can be interpreted in the context of volatility clustering. It is a well-known stylised fact from empirical research on financial markets that the volatility of a stock’s returns tends to cluster: periods of high volatility are often followed by periods of high volatility and vice versa for low volatility [3,54,55]. The correlation between two asset returns and with expectation values and volatilities is defined as
and therefore directly includes the volatility values and . Because the time series of volatility estimators shows a well-known memory effect, it is not far-fetched to assume a similar memory effect in the correlations between two assets or, as we have discussed in this article, in the mean correlation of the market as a whole. Note that other memory effects have already been described and discussed in the literature, e.g., originating from large-scale traders splitting their strategy into many small orders over a longer period of time [56], via a cascading process along multiple time scales [3] or in the transition between market states [57].
These considerations are complemented by a resilience analysis that involves the estimation of a mono-time scale Markovian model and a two-time scale non-Markovian model. In contrast to the memoryless Markovian model, only the non-Markovian model exhibits the negative drift slopes, which are in line with the hypothesis of locally quasi-stationary economic states postulated and observed in Stepanov et al. [11]. An independent change point analysis approach also supports this view [58]. Overall, these findings provide new evidence for the existence of such locally quasi-stationary economic states and for the presence of a significant non-Markovian memory effect. The investigated stocks and time period were chosen to enable a comparison between our results and the findings in [11]. However, our methods can be used on data from different time periods and analysing data from other stock markets could lead to fruitful future work to cross-check the robustness and universality of our results. A possible candidate is the German DAX, for which the market mode has also been analysed [3].
Extending the analysis to more recent data opens up several new research questions: Is there a difference in memory effects before and after the 2020 Covid-crisis? Does globalisation lead to memory effects across the various national markets? Does the increasing ubiquity of algorithmic trading decrease the memory length by moving the market closer to its equilibrium? However, future research on large-scale data is necessary to adequately address those questions.
Interestingly, the resilience analysis yields some evidence that a second time scale, which is slower than the trading day time scale of the mean market correlation data, is involved in the underlying economic dynamics. Economic processes operate on various fast and slow time scales, e.g., intra-day trading, trading psychology and sudden external events—whether that might be political, sociologic, severe weather or other impacts—may be incorporated in the fast trading day resolution of the mean market correlation data. We refer to these fast-scale processes in terms of “economic weather” to employ a metaphor from climatology (cf. also the distinction in climate-like and weather-like tasks in [59] and the discussion of multiple time scales in [60,61]).
In contrast to the fast time scales, the long-term evolution of the “economic climate” might involve innovation processes and technical revolutions such as the invention of the steam engine or the internet, economic cycle theories like that of Marx ( 2 to 10 years), Keynes, Schumpeter or Kondratjew [46,47,48,49,50,51,52], cultural evolution [53] and generational changes influencing economic reasoning, adaptions to climate change and the scarcity of resources and much more. However, we were not able to derive an economically reasonable magnitude of the slow time scale, which we would expect to lie in the range of decades up to hundreds of years, corresponding to well-known economic cycle theories or cultural evolution processes. Instead, our applied MCMC model estimation without prior range restriction converges to a hidden slow time scale of roughly 700 to 4000 years. Nevertheless, our results suggest that there should be at least two time scales involved in the data-generating process, which is an interesting starting point for future research. Notably, it is not particularly surprising that we could not quantify the hidden time scale, since we employ a very simple model parametrisation, have only access to one variable of the high-dimensional economic state space and perform our estimation on small windows that do not even include the smallest economic cycle time scale of roughly two to ten years that typically correspond to business cycles. Note that the largest eigenvalues of the correlation matrix have already been interpreted in the context of different time scales with respect to Haken’s slaving principle: In [3], their time scale is found to be slower than that of the sub-dominant eigenvalue processes. Interestingly, our study hints at the existence of a hidden process operating on an even slower time scale. Against this background, it might be an interesting challenge for future research to develop more realistic models and estimation procedures that perform reliably under the circumstances of limited data per window and incomplete variable sets to uncover the manifold of hidden time scales in the complex system of the human economy.
Author Contributions
Conceptualization, T.W., M.H. and O.K.; methodology, T.W., M.H. and O.K.; formal analysis, T.W. and M.H.; data curation, T.W.; writing—original draft preparation, T.W. and M.H.; writing—review and editing, T.W., M.H. and O.K.; supervision, O.K. All authors have read and agreed to the published version of the manuscript.
Funding
T.W. and M.H. were funded by the Studienstiftung des deutschen Volkes.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
All data are publicly available and the raw data can be accessed via the package [33]. The preprocessed time series is available via [38].
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACF | Autocorrelation function |
| B-tipping | bifurcation-induced tipping |
| CI | Credible Intervals |
| GLE | Generalised Langevin Equation |
| LE | Langevin Equation |
| MAP | Maximum a posteriori (estimation) |
| MCMC | Markov chain Monte Carlo |
| N-tipping | noise-induced tipping |
Appendix A. GLE: Overlapping Windows for the Mean Correlation
If the mean correlation is calculated via a window size of and a shift of , as in [11], then the GLE fit indicates some problems: The estimated memory kernel shows very strong negative values at and the doubled temporal distance . Although the memory kernel suggests that there is a strong memory effect, this is most probably only attributable to the overlap of the window ranges used to calculate .

Figure A1.
Example for a model with a long kernel memory for correlation matrix window size and shift with the lag k in days on the x-axis. The kernel has noticeably negative values for and . This probably indicates that the overlap of the artificially created windows ends at a distance of instead of reflecting a real-world relationship.
Figure A1.
Example for a model with a long kernel memory for correlation matrix window size and shift with the lag k in days on the x-axis. The kernel has noticeably negative values for and . This probably indicates that the overlap of the artificially created windows ends at a distance of instead of reflecting a real-world relationship.

Appendix B. GLE: Selection of Reasonable Kernel Length
To select a model with a reasonable kernel length, we first fit a model with a rather large kernel length and evaluate its combined memory aggregation . The for which reaches a plateau is then chosen as a memory kernel length for the subsequent model fitting.

Figure A2.
For a model with a long kernel , the combined memory effect reaches a plateau at around and oscillates around it.
Figure A2.
For a model with a long kernel , the combined memory effect reaches a plateau at around and oscillates around it.

Appendix C. LE: Increment Distribution


Appendix D. GLE: Prediction
The results of the naive forecasting method are compared to the GLE in this figure, showcasing the superior accuracy of the GLE, which can also be seen by comparing the values in Table 1.

Figure A4.
The same comparison between the prediction results as in Figure 5, but now for the naive forecasting method vs. the GLE. Again, .
Figure A4.
The same comparison between the prediction results as in Figure 5, but now for the naive forecasting method vs. the GLE. Again, .

Appendix E. Resilience Analyses
This section complements the interpretation of the resilience analysis, which hints to a hidden slow time scale and non-Markovianity, discussed in Section 3.2 of the main article. In Appendix E.1, we describe the simulation of the synthetic time series x of the main article in detail, before we provide additional calculations in Appendix E.2, which fit in with our previous results. At last, we provide the analyses’ parameters in Appendix E.3.
Appendix E.1. Synthetic Time Series
The synthetic model
is simulated via the Euler–Maruyama scheme for 30,000 steps in the time interval . The x-coupling parameter q is linearly increased from to 4 over the whole time interval to create a first differences PDF with a width comparable to the PDF of the original mean market correlation data (cf. Figure 7 in the main article).
Appendix E.2. Additional Results
The evaluation of the resilience analysis of the mean market correlation without and with Gaussian kernel detrending is performed for the Markovian model and the multi-scale non-Markovian model with the inverse prior time scale separation , whereby . the results are shown in Figure A5. Since the chosen time scale separation of the non-Markovian model determines the slowest time scale to be the observed trading day scale, which is identical to the Markovian one, the calculations of both models are almost the same. The suggested local stability in the detrended cases confirms the interpretation that a second slow time scale might be hidden in the mean market correlation data. Detrendings with broader kernel widths tend to exhibit more pronounced positive trends, which could on the one hand indicate a destabilisation of the local potential landscape due to uprising bifurcations. On the other hand, this behaviour might be triggered by remaining non-stationarity of the data due to more and more incomplete detrending of the slow trend if the kernel width is increased.
In order to guarantee that the overall qualitative behaviour of the non-Markovian model in the main article with an unobserved slow time scale, i.e., with , remains unchanged if the Ornstein-Uhlenbeck (OU) parameter is not restricted by the upper bound of its prior range, we present the converging results of significantly broader prior ranges in Figure A6. The exact parameters are listed in Table A1. The drift slope estimates indicate locally stable economic states with in agreement with the results of the main article. The range of the OU parameter is roughly between 420 and 1000, which does not correspond to any reasonable slow economic time scale. However, this might be due to the limited quantity of data available per window, which fails to encompass even the shortest inferred time scale of business cycles that typically span from approximately two to ten years. Furthermore, the assumed polynomial model might be too simple to estimate quantitatively reasonable time scales.

Figure A5.
Additional resilience analyses of the mean market correlation data without and with subtracting the slow trend fitted by a Gaussian kernel of width 10 using the Python function scipy.ndimage.filters.gaussian_filter for the mono-scale Markovian model and the non-Markovian model with inverse time scale separation of the observed time scale and the unobserved one , i.e., . (a–c) Results of both models evaluated on the original raw data. (d–f) Results of both models evaluated on the detrended data. The results of both models are almost the same. See the running text for a more detailed discussion.
Figure A5.
Additional resilience analyses of the mean market correlation data without and with subtracting the slow trend fitted by a Gaussian kernel of width 10 using the Python function scipy.ndimage.filters.gaussian_filter for the mono-scale Markovian model and the non-Markovian model with inverse time scale separation of the observed time scale and the unobserved one , i.e., . (a–c) Results of both models evaluated on the original raw data. (d–f) Results of both models evaluated on the detrended data. The results of both models are almost the same. See the running text for a more detailed discussion.


Figure A6.
Results of the multi-scale non-Markovian model Equation (12) of the main article, i.e., the slow time scale is unobserved with time scales , but with significantly broader prior ranges (cf. Table A2) that allow for an OU parameter convergence independent from the upper prior bound. The orange CBs are defined by the 16% to 84% and 1% to 99%, respectively. (a,b) The qualitative results compared to the results of the main article remain unchanged indicating locally stable economic states by negative drift slope estimates . The noise level estimates increase over time. (c) The coupling strength of Equation (12) including the CBs are not determined by the prior range for and are almost estimated as . (d) Similar to the noise level estimates the OU parameter including the CBs is not determined by the prior range of of Equation (12). However, the determined slow time scale does not correspond to any reasonable economic scale. See the running text for a more detailed discussion.
Figure A6.
Results of the multi-scale non-Markovian model Equation (12) of the main article, i.e., the slow time scale is unobserved with time scales , but with significantly broader prior ranges (cf. Table A2) that allow for an OU parameter convergence independent from the upper prior bound. The orange CBs are defined by the 16% to 84% and 1% to 99%, respectively. (a,b) The qualitative results compared to the results of the main article remain unchanged indicating locally stable economic states by negative drift slope estimates . The noise level estimates increase over time. (c) The coupling strength of Equation (12) including the CBs are not determined by the prior range for and are almost estimated as . (d) Similar to the noise level estimates the OU parameter including the CBs is not determined by the prior range of of Equation (12). However, the determined slow time scale does not correspond to any reasonable economic scale. See the running text for a more detailed discussion.

Appendix E.3. Parameter Documentation
In this subsection, we summarise the parameter sets involved in the resilience calculations of the main article and the appendices in order to guarantee reproducibility without affecting the readability of the main article. The parameters are listed in Table A1 and prior configurations are given in Table A2.
Table A1.
Rolling window and MCMC parameters of the resilience calculations.
Table A1.
Rolling window and MCMC parameters of the resilience calculations.
| Figure | Model | Rolling Window | MCMC Parameters | |||
|---|---|---|---|---|---|---|
| Size | Shift | Walkers | Steps | Burn In | ||
| Figure 6a–c | Markov | 500 | 15 | 50 | 15,000 | 200 |
| Figure 6a–c | Non-Markov | 500 | 15 | 50 | 20,000 | 200 |
| Figure 6d–f | Markov | 500 | 15 | 50 | 20,000 | 200 |
| Figure 6d–f | Non-Markov | 500 | 15 | 50 | 30,000 | 200 |
| Figure A5a–c | Non-Markov | 500 | 15 | 50 | 20,000 | 200 |
| Figure A5d–f | Markov | 500 | 15 | 50 | 15,000 | 200 |
| Figure A5d–f | Non-Markov | 500 | 15 | 50 | 20,000 | 200 |
| Figure A6a–d | Non-Markov | 500 | 15 | 50 | 30,000 | 200 |
Table A2.
Prior configurations of the resilience calculations. TSS is an abbreviation for time scale separation.
Table A2.
Prior configurations of the resilience calculations. TSS is an abbreviation for time scale separation.
| Figure | Model | Prior (Range) | ||||||
|---|---|---|---|---|---|---|---|---|
| TSS | ||||||||
| Figure 6a–c | Markov | — | — | |||||
| Figure 6a–c | Non-Markov | |||||||
| Figure 6d–f | Markov | — | — | |||||
| Figure 6d–f | Non-Markov | |||||||
| Figure A5a–c | Non-Markov | |||||||
| Figure A5d–f | Markov | — | — | |||||
| Figure A5d–f | Non-Markov | |||||||
| Figure A6a–d | Non-Markov | |||||||
References
- Markowitz, H. Portfolio Selection. J. Financ. 1952, 7, 77. [Google Scholar]
- Mantegna, R.; Stanley, H. An Introduction to Econophysics; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Kwapień, J.; Drożdż, S. Physical approach to complex systems. Phys. Rep. 2012, 515, 115–226. [Google Scholar] [CrossRef]
- Brown, S.J. The Number of Factors in Security Returns. J. Financ. 1989, 44, 1247–1262. [Google Scholar] [CrossRef]
- Laloux, L.; Cizeau, P.; Bouchaud, J.P.; Potters, M. Noise Dressing of Financial Correlation Matrices. Phys. Rev. Lett. 1999, 83, 1467–1470. [Google Scholar] [CrossRef]
- Mantegna, R.N. Degree of correlation inside a financial market. AIP Conf. Proc. 1997, 411, 197–202. [Google Scholar]
- Marti, G.; Nielsen, F.; Bińkowski, M.; Donnat, P. A Review of Two Decades of Correlations, Hierarchies, Networks and Clustering in Financial Markets. In Progress in Information Geometry: Theory and Applications; Nielsen, F., Ed.; Springer International Publishing: Cham, Switzerland, 2021; pp. 245–274. [Google Scholar]
- Plerou, V.; Gopikrishnan, P.; Rosenow, B.; Nunes Amaral, L.A.; Stanley, H.E. Universal and Nonuniversal Properties of Cross Correlations in Financial Time Series. Phys. Rev. Lett. 1999, 83, 1471–1474. [Google Scholar] [CrossRef]
- Münnix, M.C.; Shimada, T.; Schäfer, R.; Leyvraz, F.; Seligman, T.H.; Guhr, T.; Stanley, H.E. Identifying States of a Financial Market. Sci. Rep. 2012, 2, 644. [Google Scholar] [CrossRef] [PubMed]
- Rinn, P.; Stepanov, Y.; Peinke, J.; Guhr, T.; Schäfer, R. Dynamics of quasi-stationary systems: Finance as an example. EPL Europhys. Lett. 2015, 110, 68003. [Google Scholar] [CrossRef]
- Stepanov, Y.; Rinn, P.; Guhr, T.; Peinke, J.; Schäfer, R. Stability and hierarchy of quasi-stationary states: Financial markets as an example. J. Stat. Mech. Theory Exp. 2015, 2015, P08011. [Google Scholar] [CrossRef]
- Heckens, A.J.; Krause, S.M.; Guhr, T. Uncovering the dynamics of correlation structures relative to the collective market motion. J. Stat. Mech. Theory Exp. 2020, 2020, 103402. [Google Scholar] [CrossRef]
- Heckens, A.J.; Guhr, T. A new attempt to identify long-term precursors for endogenous financial crises in the market correlation structures. J. Stat. Mech. Theory Exp. 2022, 2022, 043401. [Google Scholar] [CrossRef]
- Heckens, A.J.; Guhr, T. New collectivity measures for financial covariances and correlations. Phys. A Stat. Mech. Appl. 2022, 604, 127704. [Google Scholar] [CrossRef]
- Bachelier, L. Théorie de la spéculation. Ann. Sci. L’école Norm. Supér. 1900, 17, 21–86. [Google Scholar] [CrossRef]
- Friedrich, R.; Siegert, S.; Peinke, J.; Lück, S.; Siefert, M.; Lindemann, M.; Raethjen, J.; Deuschl, G.; Pfister, G. Extracting model equations from experimental data. Phys. Lett. A 2000, 271, 217–222. [Google Scholar] [CrossRef]
- Siegert, S.; Friedrich, R.; Peinke, J. Analysis of data sets of stochastic systems. Phys. Lett. A 1998, 243, 275–280. [Google Scholar] [CrossRef]
- Ragwitz, M.; Kantz, H. Indispensable Finite Time Corrections for Fokker-Planck Equations from Time Series Data. Phys. Rev. Lett. 2001, 87, 254501. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, R.; Renner, C.; Siefert, M.; Peinke, J. Comment on “Indispensable Finite Time Corrections for Fokker-Planck Equations from Time Series Data”. Phys. Rev. Lett. 2002, 89, 149401. [Google Scholar] [CrossRef]
- Ragwitz, M.; Kantz, H. Ragwitz and Kantz Reply. Phys. Rev. Lett. 2002, 89, 149402. [Google Scholar] [CrossRef]
- Kleinhans, D.; Friedrich, R. Maximum likelihood estimation of drift and diffusion functions. Phys. Lett. A 2007, 368, 194–198. [Google Scholar] [CrossRef][Green Version]
- Willers, C.; Kamps, O. Non-parametric estimation of a Langevin model driven by correlated noise. Eur. Phys. J. B 2021, 94, 149. [Google Scholar] [CrossRef]
- Sieber, M.; Paschereit, C.O.; Oberleithner, K. Stochastic modelling of a noise-driven global instability in a turbulent swirling jet. J. Fluid Mech. 2021, 916, A7. [Google Scholar] [CrossRef]
- Klippenstein, V.; Tripathy, M.; Jung, G.; Schmid, F.; van der Vegt, N.F.A. Introducing Memory in Coarse-Grained Molecular Simulations. J. Phys. Chem. B 2021, 125, 4931–4954. [Google Scholar] [CrossRef] [PubMed]
- Czechowski, Z. Reconstruction of the modified discrete Langevin equation from persistent time series. Chaos Interdiscip. J. Nonlinear Sci. 2016, 26, 053109. [Google Scholar] [CrossRef] [PubMed]
- Friedrich, R.; Peinke, J.; Sahimi, M.; Reza Rahimi Tabar, M. Approaching complexity by stochastic methods: From biological systems to turbulence. Phys. Rep. 2011, 506, 87–162. [Google Scholar] [CrossRef]
- Mori, H. Transport, Collective Motion, and Brownian Motion. Prog. Theor. Phys. 1965, 33, 423–455. [Google Scholar] [CrossRef]
- Sivia, D.; Skilling, J. Data Analysis, 2nd ed.; Oxford University Press: London, UK, 2006. [Google Scholar]
- Von der Linden, W.; Dose, V.; Von Toussaint, U. Bayesian Probability Theory: Applications in the Physical Sciences; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Willers, C.; Kamps, O. Efficient Bayesian estimation of the generalized Langevin equation from data. arXiv 2021, arXiv:2107.04560. [Google Scholar] [CrossRef]
- Willers, C.; Kamps, O. Efficient Bayesian estimation of a non-Markovian Langevin model driven by correlated noise. arXiv 2022, arXiv:2207.10637. [Google Scholar] [CrossRef]
- Heßler, M.; Kamps, O. Bayesian on-line anticipation of critical transitions. New J. Phys. 2021, 24, 063021. [Google Scholar] [CrossRef]
- Aroussi, R. yfinance 0.1.70, 2022. Available online: https://pypi.org/project/yfinance/ (accessed on 21 August 2023).
- Wand, T.; Heßler, M.; Kamps, O. Identifying dominant industrial sectors in market states of the S&P 500 financial data. J. Stat. Mech. Theory Exp. 2023, 2023, 043402. [Google Scholar] [CrossRef]
- Reback, J.; jbrockmendel; McKinney, W.; Van Den Bossche, J.; Roeschke, M.; Augspurger, T.; Hawkins, S.; Cloud, P.; gfyoung; Sinhrks; et al. pandas-dev/pandas: Pandas 1.4.3. 2022. Available online: https://zenodo.org/record/6702671 (accessed on 21 August 2023).
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef]
- Schäfer, R.; Guhr, T. Local normalization. Uncovering correlations in non-stationary financial time series. Phys. A 2010, 389, 3856–3865. [Google Scholar] [CrossRef]
- Wand, T. S&P500 Mean Correlation Time Series (1992–2012). Available online: https://zenodo.org/record/8167592 (accessed on 21 August 2023).
- Bayes, T. LII. An essay towards solving a problem in the doctrine of chances. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Strogatz, S.H. Nonlinear Dynamics and Chaos. With Applications to Physics, Biology, Chemistry and Engineering, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Heßler, M. AntiCPy. 2021. Available online: https://github.com/MartinHessler/antiCPy (accessed on 21 August 2023).
- Heßler, M. AntiCPy’s Documentation. Available online: https://anticpy.readthedocs.io (accessed on 31 December 2021).
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 92–96. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Marx, K. Das Kapital—Kritik der Politischen Ökonomie; Nikol Verlagsges mbH: Hamburg, Germany, 2014; ISBN 9780140445688. [Google Scholar]
- Harvey, A.C.; Trimbur, T.M.; Van Dijk, H.K. Trends and cycles in economic time series: A Bayesian approach. J. Econom. 2007, 140, 618–649. [Google Scholar] [CrossRef]
- Bernard, L.; Gevorkyan, A.V.; Palley, T.; Semmler, W. Time Scales and Mechanisms of Economic Cycles: A Review of Theories of Long Waves 1; PERI Working Paper Series WP337; University of Massachusetts: Amherst, MA, USA, 2013. [Google Scholar] [CrossRef]
- Kondratieff, N.D.; Stolper, W.F. The Long Waves in Economic Life. Rev. Econ. Stat. 1935, 17, 105–115. [Google Scholar] [CrossRef]
- Schumpeter, J. Konjunkturzyklen; Vandenhoeck & Ruprecht: Göttingen, Germany, 1961. [Google Scholar]
- Zhang, W.-B. Synergetic Economics–Time and Change in Nonlinear Economics; Springer: Berlin/Heidelberg, Germany, 1991. [Google Scholar]
- Turchin, P. Historical Dynamics: Why States Rise and Fall; Princeton University Press: Princeton, NJ, USA, 2003. [Google Scholar]
- Wand, T.; Hoyer, D. The Characteristic Time Scale of Cultural Evolution. arXiv 2023, arXiv:2212.00563. [Google Scholar] [CrossRef]
- Gaunersdorfer, A.; Hommes, C.H.; Wagener, F.O. Bifurcation Routes to Volatility Clustering under Evolutionary Learning. J. Econ. Behav. Organ. 2008, 67, 27–47. [Google Scholar] [CrossRef]
- He, X.Z.; Li, K.; Wang, C. Volatility clustering: A nonlinear theoretical approach. J. Econ. Behav. Organ. 2016, 130, 274–297. [Google Scholar] [CrossRef]
- Sato, Y.; Kanazawa, K. Can we infer microscopic financial information from the long memory in market-order flow?: A quantitative test of the Lillo-Mike-Farmer model. arXiv 2023, arXiv:2301.13505. [Google Scholar] [CrossRef]
- Marsili, M. Dissecting financial markets: Sectors and states. Quant. Financ. 2002, 2, 297–302. [Google Scholar] [CrossRef]
- Heßler, M.; Wand, T.; Kamps, O. Efficient Multi-Change Point Analysis to decode Economic Crisis Information from the S&P500 Mean Market Correlation. arXiv 2023, arXiv:2308.00087. [Google Scholar] [CrossRef]
- Thompson, E.; Smith, L. Escape from model-land. Economics 2019, 13, 20190040. [Google Scholar] [CrossRef]
- Ghashghaie, S.; Breymann, W.; Peinke, J.; Talkner, P.; Dodge, Y. Turbulent cascades in foreign exchange markets. Nature 1996, 381, 767–770. [Google Scholar] [CrossRef]
- Müller, U.A.; Dacorogna, M.M.; Davé, R.D.; Olsen, R.B.; Pictet, O.V.; von Weizsäcker, J.E. Volatilities of different time resolutions—Analyzing the dynamics of market components. J. Empir. Financ. 1997, 4, 213–239. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).