Abstract
The literature on the fall of civilizations spans from the archaeology of early state societies to the history of the 20th century. Explanations for the fall of civilizations abound, from general extrinsic causes (drought, warfare) to general intrinsic causes (intergroup competition, socioeconomic inequality, collapse of trade networks) and combinations of these, to case-specific explanations for the specific demise of early state societies. Here, we focus on ancient civilizations, which archaeologists typically define by a set of characteristics including hierarchical organization, standardization of specialized knowledge, occupation and technologies, and hierarchical exchange networks and settlements. We take a general approach, with a model suggesting that state societies arise and dissolve through the same processes of innovation. Drawing on the field of cumulative cultural evolution, we demonstrate a model that replicates the essence of a civilization’s rise and fall, in which agents at various scales—individuals, households, specialist communities, polities—copy each other in an unbiased manner but with varying degrees of institutional memory, invention rate, and propensity to copy locally versus globally. The results, which produce an increasingly extreme hierarchy of success among agents, suggest that civilizations become increasingly vulnerable to even small increases in propensity to copy locally.
1. Introduction
Over the past 10,000 years, most of the world’s population has transitioned from egalitarian foraging societies, whose small scale and social norms limited individual power, wealth and prestige [1,2,3] to a global economy in which institutionally facilitated, inherited wealth differs by perhaps ten orders of magnitude from the poorest individuals to the wealthiest elites [4].
A facilitator of this inequality was the rise of state civilizations 5000 years ago and their subsequent cycles of integration and dissolution [5,6,7,8,9,10]. In prehistory, the likely prerequisites for the origins of state societies include intensified agriculture, which not only supported larger populations of increasingly diverse specializations, but also the unequal access to resources that gave rise to inherited wealth inequalities and status hierarchies [4]. Thousands of years before state societies, for example, early Neolithic societies show the beginnings of inter-generational wealth transmission [11,12,13,14] that became an inherent feature of social complexity [15,16].
Theories differ over whether the elite increased inequality, through wealth inheritance, or decreased it, through re-distributive institutions. On one hand, the kin-based authority of chieftains may have facilitated the redistribution of resources, reducing wealth inequality [17,18,19]. On the other hand, or just later in this process, the inheritance of wealth institutionalized differential access to resources, leading to enforced hierarchy, division of labor, and—as early states began to form—authority based on territory rather than kin [8,16,20,21].
What has caused the decline of early state societies? Is there a general principle? Numerous models attribute the fall of early states, as a breakdown in complexity, as typically driven by exogenous events, the deaths of rulers, or demographic change [6,22,23,24]. Another category of models is more general, effectively seeing early states having arisen and collapsed as two sides of the same coin, through the dynamics of competition between elites and commoners [25,26,27].
Here, we take a general approach, with a model suggesting that state societies arise and dissolve through the same processes of innovation. We focus on ancient civilizations, which archaeologists typically define by a set of characteristics including hierarchical organization, standardization of specialized knowledge, occupation and technologies, and hierarchical exchange networks and settlements.
The central process underlying this organization is cumulative cultural evolution [28,29,30,31], or the capacity for human knowledge to build on itself through advancing knowledge of previous generations by a combination of innovation (copying) and invention (creating novelty).
Here, we demonstrate a model that replicates the essence of a civilization’s rise and fall, in which agents at various scales—individuals, households, specialist communities, polities—copy each other in an unbiased manner but with varying degrees of institutional memory, invention rate, and propensity to copy locally versus globally. The results, which produce an increasingly extreme hierarchy of success among agents, suggest that civilizations become increasingly vulnerable to even small increases in propensity to copy locally.
We use a simple agent-based model that replicates both the rise and fall of socioeconomic inequality and hierarchy. The process is parsimonious: agents at various scales—individuals, households, specialist communities, polities—copy each other in an unbiased manner but with varying degree of institutional memory, invention rate, and propensity to copy locally versus globally. This simple process produces an increasingly right-skewed distribution of success among agents, but also makes them increasingly vulnerable to small parameter changes, particularly any increase in the propensity to copy locally rather than globally.
The widely used model of preferential attachment [32,33,34] is a special case of this general model of unbiased copying. New entrants into the model are attached to existing locations with a probability equal to the proportion of previous entrants attached to each location. Under strict preferential attachment, however, once a sufficient number of agents have entered the model, the higher-ranked locations (in terms of the numbers of attached agents) become effectively locked in. As ‘super-stable’ nodes [35] establish themselves, the probability of the second most popular location, say, overtaking the first becomes exceptionally small.
More conducive to change, even at the top, than preferential attachment, our model of cultural evolution incorporates the aspect of invention; with small probability, , any agent entering the model can select a location entirely at random. If the agent does not carry this out, then its location is governed by preferential attachment. The variation introduced by invention means that the rankings of locations do not become locked in; the highest-ranked location will, at some point, be overtaken by a location that previously ranked below it [36]. The higher the value of , the less time any location will spend at the top rank [37].
To further differentiate from preferential attachment, a memory parameter, m, determines how many previous steps of the model are taken into account when determining the probabilities of copying a given location [38]. Preferential attachment, in which all previous time steps are taken into account, would be a case without invention and where the memory is infinite [37].
Empirically, vertical inequality is well defined using measures like income Gini coefficient, even in archaeological contexts [17], whereas heterarchy (also known as horizontal inequality) is more difficult to measure [39]. In economics, the Herfindahl–Hirschman Index (HHI)—equivalent to the Simpson index in ecology—is used to measure the size of firms in relation to the industry which they are in. It is simply the sum of the market shares, expressed as a proportion, of all the firms in the market. It ranges between 1/N, where N is the number of firms in the market, and 1. When HHI is 1, we have the case of pure monopoly, when there is just a single firm in the market. In archaeology, quantitative data are sparse but can include site hierarchies [40] and measures of individual wealth or status from grave contents [17].
2. Materials and Methods
We extend a theoretical model that is already highly cited in scientific literature and generate results from it by simulating the model in Julia. The model code is set out in the Supplementary Material file.
The model is that of neutral selection described above. We initially examine the properties of the model when the locations are isolated from each other. Units of fitness accumulate at each location, but no location is able to obtain further units as a result of its connection to any other location.
Table 1 lists the model parameters. In addition to the invention parameter, , subsequent introductions to the neutral model have included a memory parameter, m, and an affinity parameter, , which characterizes how the influence of other locations on the choice made by an agent declines with (physical or social) distance [37,38,41]. The memory parameter, m, determines how many previous steps of a model solution are taken into account when new entrants into the model are allocated to the locations using the principle of preferential attachment.

Table 1.
Parameters of the model.
We have a fixed number, k, of locations. Units of fitness enter the model and are attached to the locations. The initial number, , is allocated at random. At each subsequent step, N more fitness units enter. These are attached to the locations by the neutral selection model, with invention parameter and memory parameter m. The number of fitness units attached to each location is modified by a weighted sum of the numbers at other locations, with the weights being defined by .
We also report the turnover of the top y locations, i.e., the y locations that have the most units of fitness. By turnover, we mean the proportion of the total number of steps in any given solution in which at least one of the top y locations is replaced by one not in the top y in the previous step of the solution.
3. Results
We start with the locations placed on a circle and set the distance between each pair equal to 1. We work with 100 locations. At the moment, there is no rule to make a weak location extinct. They all stay in, no matter how few fitness units they attract.
Initially, as noted above, we simulate the special case of the model in which there are no connections between any of the locations. In other words, the parameter does not appear.
The model is programmed in Julia and runs multiple solutions in which 100,000 units eventually enter the model. Test runs indicate that 100,000 is more than enough to establish the properties of the model, as the results for any given set of parameters are the same, even if 1 million or 10 million enter.
We report results for ten integer values of the parameter m from 1 through 10 and for values of twenty values of ranging from 0.001 to 0.1. We therefore consider 200 separate pairs of parameter values. We report results after 1000 simulation steps per solution of each parameter pair, which summarizes 500 separate solutions of the model at each time step. Investigation of the model showed that with this number of steps, the results are the same across a range of model properties as when 100,000 or even 1 million steps are used.
The choice of and N does not substantially affect the results that are obtained. We therefore propose to use , although we note that increasing or decreasing N during the simulation would favour the most recent and oldest agents, respectively [42].
The properties of the basic model of neutral choice are well known. By way of illustration, Figure 1 shows some results for various combinations of the parameters µ and m. We plot the average market share of the locations by rank across 500 simulations, where rank 1 is the highest market share and 100 the lowest in each simulation. We use a log–log scale, which illustrates the differences more clearly.
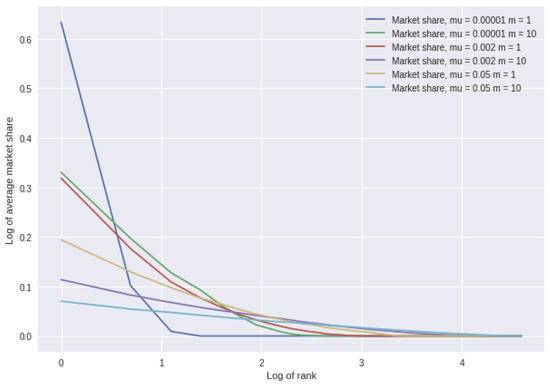
Figure 1.
Average market share over 500 simulations as a function of the rank on a log–log scale (note on a log scale, 0 corresponds to rank 1).
We calculate a range of metrics to describe the output of the model. We measure the degree of concentration of the fitness units by the HH index (HHI), described above. An HHI value of 1 means that one unit has all the fitness. Next, we calculate across all solutions and all steps the time spent at the number 1 position by the location with the most fitness units. We record the top y (usually y is set to 3 out of the total of 100) and measure the turnover at each step. If the top y remains the same as in the previous step, even if they change ranks between each other, no turnover is recorded. We measure the percentage of steps in which turnover is 0, 1, 2, and 3.
When a location stops being number 1, we record the distance from it of the location that replaces it, and the frequency of this distribution (we have to adjust the numbers for location at distance 10, because for any location, there are two at distance 1 through 9, but only one at 10). We also record how many times a location returns to number 1 once it has stopped being number 1. Finally, we measure the length of time it takes for a number 1, once it stops being 1, to drop to rank y, where integer y ranges from 2 to 20.
We initially examine the properties of the model when the locations are isolated from each other. Units of fitness accumulate at each location, but no location is able to obtain further units as a result of its connection to any other location.
Figure 2, left, plots the median value of the HH Index against the parameter µ. There is obviously a highly non-linear relationship. The lower the ability of locations to innovate of their own accord, the more concentrated fitness becomes, approaching the theoretical limit of all fitness units being concentrated at a single location as approaches zero.
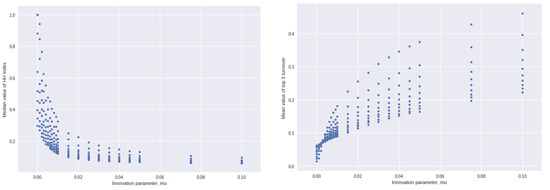
Figure 2.
Left: Median value of HH index over 500 separate solutions of each step after 1000 steps and the parameter , no influence between locations. Right: Effect of the parameter on the proportion of steps in which just one of the top 3 location drops is replaced by one outside the top 3 in the previous step. Average proportion of steps, across 500 solutions, each of 1000 steps.
Figure 2, right, shows the effect of on the proportion of steps in which just one of the top three locations (in terms of fitness units they have) is replaced by one outside the top three in the previous step. Again, we see a non-linear relationship. As the capacity of locations to innovate of their own accord increases, turnover in the top three rises.
There is more variation across the individual solutions when we consider the relationship between the two outcomes of interest and the parameter m. Accordingly, we plot in Figure 3 the average values of HHI and turnover, respectively, for each integer value of the memory parameter, m.
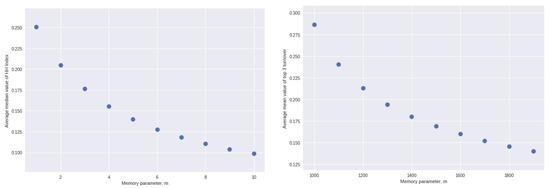
Figure 3.
Left: Average value of the HH index for each value of the parameter m across 500 separate solutions). Right: Average proportion of times 1 of the top 3 drops out for each value of the parameter m across 500 separate solutions).
Table 2 shows estimates, by simple regression, of the logs of both the median HH index and the turnover variable against the logs of the two parameters, and m (we use logarithms due to the non-linear relationship).
Table 2.
Regressions of HHI and turnover (of 1 of the top 3) against the parameters and m (all variables in natural logs).
Before carrying out a full analysis of the properties of the model when the affinity parameter, , is introduced, we examine the impact of when and . As noted above, without , the solution converges on a ‘winner takes all’ scenario, in which the the HH index is 1 and the turnover in the top three becomes zero.
The values of in themselves have no intrinsic meaning. We define the impact of through the following formula:
where the distance is the distance between locations i and j along the arc of a unit circle. Locations are placed equidistantly on the circle.
What is of interest is the weights assigned to each location in terms of its distance from any other. For the values of that we use, effectively only the nearest neighbours (i.e., those immediately either side of any particular location) of any given location carry any weight. We examine 28 separate values of the parameter, with the weights on the immediate neighbours varying between 0.0002 and 0.082. We find that for values of that assign greater weights, the influence of the parameter becomes very strong, and the distribution of the units of fitness at each location converges on the random uniform.
With no similarity influence or invention, one location obtains all the units of fitness, and the maximum length of time at which any particular location occupies this number 1 slot approaches the number of solution steps of the model (i.e., the winner gets locked in quickly). The effect of affinity on the HHI (median after 1000 steps of the model, solved 500 times each step) appears to reach a tipping point, beyond which exercises an increasing influence (low lambda means high “influence”). For high vales of (lower influence), median HH is always 1.
In terms of turnover in the top three, plays a big role, but note that it starts to take effect only when there is more influence than when HH begins to change. This indicates a range in which there is stability in rankings but with a more egalitarian outcome overall. Not surprisingly, the weaker the influence of the number 1 unit, the more likely number 1 is to be replaced by its immediate neighbours. These results are illustrated in Table 3 and Table 4, which show the regressions of HHI and turnover on and m for selected values of .
Table 3.
Regressions of HHI and turnover of 1 of the top 3 on and m, selected values of , all variables in natural logs. The dependent variable is HHI (median value, in logs).
Table 4.
Regressions of turnover of 1 of the top 3 on and m, selected values of , all variables in natural logs. The dependent variable is the proportion of times that one of the top three turns over (in logs).
In all the regressions of Table 3 and Table 4, the estimated coefficients are highly significantly different from zero. Figure 4 plots the median value of the HH index, again after 1000 steps of the model and 500 separate solutions, and , with and in all solutions. For values of , in other words, when influence is weak, after 1000 steps in all solutions, the value of HHI has converged on its theoretical value of 1. Figure 4 therefore shows the effect of values of in the range 1000 to 3500.
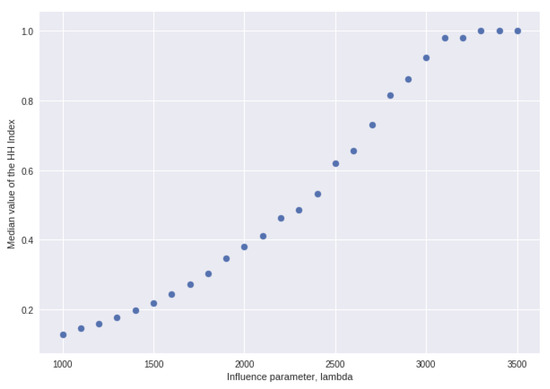
Figure 4.
Median HH index after 1000 steps and 500 separate solutions and the influence parameter , with and .
A simple linear regression of the HHI on lambda gives . Similarly, a linear regression of the proportion of steps in which one of the top three locations is replaced on yields .
When is introduced to the model, there is a third statistic in the output that is of interest. When top location is replaced as the top by another, we measure the proportion of these events in which it is replaced by either of its immediate neighbours, by those next to them and so on to the location furthest away. As the influence of declines, the replacement becomes more and more random with respect to distance (Table 5).
Table 5.
Regression of the proportion of times that number 1 is replaced with an immediate neighbour, versus selected values of , m, and . All variables are listed as natural logs (n.s. means not significantly different from zero).
Finally, we simulate the model with the previous 200 combinations of m and () with 28 finely graded values of , making 5600 combinations in total.
A linear regression of the median value of HHI after 1000 steps with 500 separate solutions at each step on the three parameters (all variables in natural logs) gives and . Carrying out the linear regression for each of the 28 values of increases this to . Similarly for turnover, we obtain and , respectively.
Using machine learning algorithms, we can obtain an almost perfect fit to the values in the model solutions. We carry out 5-fold cross-validation and report the fits for the out of sample “predictions”. Using the random forest algorithm in Python and the default values of the required inputs yields for HHI and for turnover.
The machine learning output gives an estimate of feature importance. This is not, to put it into the more familiar context of linear regression, whether a particular variable has a coefficient that is significantly greater than zero, but how much it contributes to the overall fit. For the HHI, for example, the most important is invention rate, , with m and being very similar. This finding is reflected in linear regression, in which each of the three factors is left out in turn.
From the above analysis, it will be apparent that the model, with its three parameters, can readily be calibrated to a wide range of empirical non-Gaussian outcomes. By way of illustration, we can usefully consider the degree of inequality that existed in early societies, for which a large number of estimates have been made.
In archaeology and anthropology, the distributions of site sizes, house sizes, burial wealth, or individual wealth, for example, are often estimated from sparse data. For this reason, a useful metric is the Gini coefficient [17]. Table 6 shows how the median value of the Gini relates to the three model parameters by simple linear regression. All parameters have a significant effect. As expected [37], invention reduces the Gini coefficient because the introduction of variation increases turnover among the top ranks. Increasing the memory parameter readily reduces the Gini coefficient, because memory acts to retain variation, as less copied locations are not as quickly ‘forgotten’.
Table 6.
Regressions between median Gini index and three model parameters. Adjusted = 0.871.
The effect of the affinity parameter is to increase Gini coefficient. It is important to note that a higher means a steeper decline in interaction with distance. So, the less the interaction between locations is, the greater the degree of inequality between them (other things being equal). Of course, the lower the level of interaction, the lower the level of competition that the leading sites face, so the impact of the parameter is in line with theoretical expectations.
With the parameter triples that we described above, the median value of the Gini coefficient across all the solutions for each of the individual triples ranges from 0.36 to as high as 0.99. It is straightforward, however, to obtain lower values by widening the range of parameters. For example, increasing memory reduces the Gini coefficient.
4. Discussion and Conclusions
Overall, the results demonstrate the capacity of the model to be calibrated against a wide range of different outcomes. It offers a theoretical framework for the understanding of the rise and fall of civilisations. The parsimonious model containing only the invention rate and memory tends to produce not only low turnover amongst the top-ranked locations in terms of fitness units but, especially for low values of invention, to exhibit “winner-take-all” properties. These properties, as noted in the Introduction, are typical features of early states, in which secrecy and hierarchy were important.
The parameter has a significant effect on the model, and relates to the many approaches in archaeology to how network interactions facilitated the rise of early states and the specialization, hierarchy/heterarchy, and inequality.
Our model can readily generate a very broad range of Gini coefficients that represent a range of sociopolitical economies from broadly egalitarian to highly unequal. The degree of inequality within a given society at a point in time can readily be calibrated using the model. The different stages of its evolution will be characterised by different values of the three parameters of innovation, memory, and affinity.
Substantial literature exists that provides estimates on the degree of inequality within early societies [17,43]. Among modern hunter-gatherers, for instance, the Gini coefficient is around 0.17 [4]. Gini coefficients are estimated between 0.35 and 0.46 in early farming societies [4] as resource access began to be inherited over generations [12]. In early complex state societies, estimated Gini coefficients include 0.57 at Cahokia (Mississippian N. America), 0.53 at Dadiwan in Late Yangshao China, 0.52–0.54 at Herculaneum and Pompeii in the Roman Empire, 0.62 at Mayan Tikal, and 0.68 at Kahun in Middle Kingdom Egypt [4].
From the perspective of offering initial evidence for the ability of the model to be calibrated to data, a key point to note is that inequality within any given society was in general not time-invariant. In prehistory, inequality generally increased over time. In prehistoric western North America, for example, analysis of the grave goods in hundreds of burials spanning several millennia indicate that Gini index increased from about 0.3 to about 0.6 [17,44]. More broadly, Figure 5 shows how Gini indices in ancient societies of the Old World and New World changed over thousands of years, using house-size distributions [4], which can be a good proxy for wealth [17]. In the New World, a decline in Gini index occurred upon the collapse of Mayan states around AD 900, even as it increased in North America into the Mississippian, at Cahokia (Figure 5).
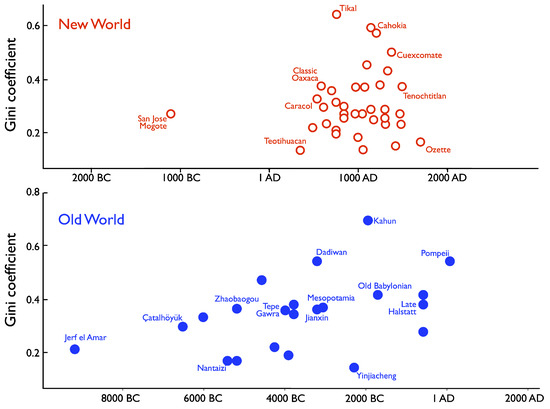
Figure 5.
Gini indices through time in ancient societies. After [4].
The difference between Teotihuacan, where the estimated Gini index is quite low at 0.12, versus the Mayan polity of Tikal with its high Gini index of 0.62 [4], suggests the importance of the affinity parameter, , as a measure of social distance. An established archaeological model of how elites maintain power [45,46] describes network strategies, as in Maya societies, which emphasize long-distance exchange with other elites to maintain their elite social ties and obtain exotic goods used to reward their followers. Although items are exchanged over geographic distances, the elite social network was exclusive, and hence, would be high. In contrast, leaders in corporate strategies, as at Teotihuacan, derived power from locals living and working in the city or region [17,45,47]. Although these people were close by, their ranks were more diverse, and hence, would be smaller.
In other words, the elite social network strategy is analogous to high , whereas the local kin-based corporate strategy resembles a low . The way that predicts HHI in the simulations seems to reflect this ‘corporate-network’ distinction. In the corporate strategy, elites facilitate the redistribution of wealth [18,19]. Through kin-based authority, early elites were facilitators of economic cooperation and levellers of inequality—‘bankers’ who managed the local economy to everyone’s benefit [48]. Early states varied in their degree of redistribution, from temple-based redistributive states (e.g., Mesopotamia) to subsequent expansive and tributary states where wealth and land, as war spoils, were accumulated by state elites, not for redistribution [20,21,49]. This accumulation required a hierarchy of people in a bureaucracy as well as settlements, from producers to assembly points to central points for redistribution [22]. As societies became more complex, the network strategy likely predominated, as elites competed to hold power, increasingly through exclusive, long-distance exchange between elites of other societies rather than merely support of local populations. Examples include the Classic Maya society, or even the 9th-10th century trade of prestigious gifts at the highest levels of social and political power across the Islamic Mediterranean world, from Western Europe to China [50]. State institutions and systematized differential access to resources, enforced hierarchy, division of labour, and authority were based on territory rather than kin [8,17,21].
In a more general way, archaeologists often emphasize the interdependence of specialization and intergroup cooperation, often called “heterarchy” [8,17,21,47,51] or ‘horizontal inequality’ [9,52]. In small-scale societies, intergroup competition often yields asymmetric payoffs that differentiate groups in terms of status, wealth, ethnic group [53], which can motivate those profiting from such inequality to initiate between-group aggression, even at the expense of the welfare of their group [54].
An example is the Indus civilization, a homogeneous 500,000 square miles of standardized crafts, which measures cities and urban planning, with a four-tier settlement hierarchy. Lacking rich tombs or elite residences, there is little evidence that the Indus civilization was highly socially stratified; instead, the Indus Valley civilization reflects heterarchy through a sorting of the population by craft and settlement specialization, facilitated by the administrative and economic functions of writings and seals. Cities like Mohenjo–Daro and Harappa grew because they lay at the crossroads within trade networks that connected different agriculture and resource zones [7]. Certain merchants may have profited as ‘hubs’ in this network, by controlling the knowledge and multi-step specialized production of complex technology like faience, stoneware, and red carnelian and other long-distance exchange goods [7,55]. Around 1900 BCE, the core cities of the Indus collapsed and were abandoned, with the disappearance of urban forms, public buildings, and the written script. This has been interpreted through both exogenous and endogenous causes, such as a well-documented regional drought [56] that disrupted the trade networks, which then destabilized the traditional structures of authority within the Indus civilization.
In principle, our model is applicable to contemporary societies. Models of modern economic inequality invoke bad governance, political instability, and conflict from outside groups [5,9], whereas other models emphasise intrinsic causes such as the increase in political and economic inequality to the point of driving grievances between competing groups within the larger society [57,58,59,60,61].
Supplementary Materials
The Julia code for this study can be downloaded at: https://www.mdpi.com/article/10.3390/e25091298/s1.
Author Contributions
Conceptualization, P.O.; methodology, R.A.B. and P.O.; software, R.N.; formal analysis, P.O. and R.N.; writing—original draft preparation, R.A.B. and P.O.; writing—review and editing, P.O. and R.A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The Julia code for this study is provided in the Supplementary Materials.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fukuyama, F. The Origins of Political Order: From Prehuman Times to the French Revolution; Farrar, Straus and Giroux: New York, NY, USA, 2009. [Google Scholar]
- Morris, I. Foragers, Farmers, and Fossil Fuels: How Human Values Evolve; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Henrich, J.; Broesch, J. On the nature of cultural transmission networks. Phil. Trans. R. Soc. B 2011, 366, 1139–1148. [Google Scholar] [CrossRef] [PubMed]
- Kohler, T.A.; Smith, M.E.; Bogaard, A.; Feinman, G.M.; Peterson, C.E.; Betzenhauser, A.; Pailes, M.; Stone, E.C.; Prentiss, A.M.; Dennehy, T.J.; et al. Greater post-Neolithic wealth disparities in Eurasia than in North America and Mesoamerica. Nature 2017, 551, 619–622. [Google Scholar] [CrossRef] [PubMed]
- Schneidel, W. The Great Leveler: Violence and the History of Inequality from the Stone Age to the Twenty-First Century; Princeton University Press: Princeton, NJ, USA, 2018. [Google Scholar]
- Turchin, P. Historical Dynamics: Why States Rise and Fall; Princeton University Press: Princeton, NJ, USA, 2003. [Google Scholar]
- Kenoyer, J.M. Ancient Cities of the Indus Valley Civilization; Oxford University Press: New York, NY, USA, 1998. [Google Scholar]
- Yoffee, N. Myths of the Archaic State: Evolution of the Earliest Cities, States, and Civilizations; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Houle, C.; Ruck, D.J.; Bentley, R.A.; Gavrilets, S. Inequality between identity groups and social unrest. J. Roy. Soc. Interface 2022, 19, 20210725. [Google Scholar] [CrossRef] [PubMed]
- Shennan, S.; Downey, S.S.; Timpson, A.; Edinborough, K.; Colledge, S.; Kerig, T.; Manning, K.; Thomas, M.G. Regional population collapse followed initial agriculture booms in mid-Holocene Europe. Nat. Commun. 2013, 4, 2486. [Google Scholar] [CrossRef]
- Bentley, R.A.; Bickle, P.; Fibiger, L.; Nowell, G.M.; Dale, C.W.; Hedges, R.E.M.; Hamilton, J.; Wahl, J.; Francken, M.; Grupe, G.; et al. Community differentiation and kinship among Europe’s first farmers. Proc. Natl Acad. Sci. USA 2012, 109, 9326–9330. [Google Scholar] [CrossRef]
- Bentley, R.A. Prehistoric kinship. Ann. Rev. Anthropol. 2022, 51, 137–154. [Google Scholar] [CrossRef]
- Watkins, T. Southwest Asia: From mobile foraging to settled farming. In Human Past Essentials; Scarre, C., Stone, T., Eds.; Thames and Hudson: New York, NY, USA, 2021; pp. 110–137. [Google Scholar]
- Borgerhoff Mulder, M.; Bowles, S.; Hertz, T.; Bell, A.; Beise, J.; Clark, G.; Fazzio, I.; Gurven, M.; Hill, K.; Hooper, P.L.; et al. Intergenerational wealth transmission and the dynamics of inequality in small-scale societies. Science 2009, 326, 682–688. [Google Scholar] [CrossRef]
- Bowles, S.; Choi, J.-K. The Neolithic agricultural revolution and the origins of private property. J. Polit. Econ. 2019, 127, 2186–2228. [Google Scholar] [CrossRef]
- Leppard, T.P. Social complexity and social inequality in the prehistoric Mediterranean. Curr. Anthropol. 2019, 60, 283–308. [Google Scholar] [CrossRef]
- Ames, K. The archaeology of rank. In Handbook of Archaeological Theories; Bentley, R.A., Maschner, H.D.G., Chippendale, C., Eds.; AltaMira Press: Lanham, MD, USA, 2008; pp. 487–513. [Google Scholar]
- Brumfiel, E.M.; Earle, T.K. Specialization, Exchange, and Complex Societies; Cambridge University Press: Cambridge, UK, 1987. [Google Scholar]
- Stark, M.T. Comment on Thomas P. Leppard’s Social Complexity and Social Inequality in the Prehistoric Mediterranean. Curr. Anthropol. 2019, 60, 301–302. [Google Scholar]
- Manzanilla, E. Early urban societies: Challenges and perspectives. In Emergence and Change in Early Urban Societies; Manzanilla, E., Ed.; Springer: New York, NY, USA, 1997; pp. 3–39. [Google Scholar]
- Stein, G.J. Heterogeneity, power, and political economy. J. Archaeol. Res. 1998, 6, 1–44. [Google Scholar] [CrossRef]
- Wright, H.T. Recent research on the origin of the state. Ann. Rev. Anthropol. 1977, 6, 379–397. [Google Scholar] [CrossRef]
- Anderson, D.G. The Savannah River Chiefdoms; University of Alabama Press: Tuscaloosa, AL, USA, 1994. [Google Scholar]
- Gavrilets, S.; Anderson, D.G.; Turchin, P. Cycling in the complexity of early societies. Cliodynamics 2010, 1, 55–80. [Google Scholar]
- Bentley, R.A.; Maschner, H.D.G.; Chippendale, C. (Eds.) Marxism. In Handbook of Archaeological Theories; AltaMira Press: Lanham, MD, USA, 2008; pp. 73–93. [Google Scholar]
- Renfrew, C. Trajectory discontinuity and morphogenesis: The implications of catastrophe theory for archaeology. Am. Antiq. 1978, 43, 203–222. [Google Scholar] [CrossRef]
- Lawson, D.J.; Oak, N. Apparent strength conceals instability in a model for the collapse of historical states. PLoS ONE 2014, 9, e96523. [Google Scholar] [CrossRef] [PubMed]
- Kolodny, O.; Creanza, N.; Feldman, M.W. Evolution in leaps: The punctuated accumulation and loss of cultural innovations. Proc. Natl. Acad. Sci. USA 2015, 112, E6762–E6769. [Google Scholar] [CrossRef]
- Derex, M.; Mesoudi, A. Cumulative cultural evolution within evolving population structures. Trends Cog. Sci. 2020, 24, 654–667. [Google Scholar] [CrossRef]
- Dean, L.G.; Vale, G.L.; Laland, K.N.; Flynn, E.; Kendal, R.L. Human cumulative culture: A comparative perspective. Biol. Rev. Camb. Phil. Soc. 2014, 89, 284–301. [Google Scholar] [CrossRef]
- Henrich, J.; Boyd, R.; Derex, M.; Kline, M.A.; Mesoudi, A.; Muthukrishna, M.; Powell, A.T.; Shennan, S.J.; Thomas, M.G. Understanding cumulative cultural evolution. Proc. Natl. Acad. Sci. USA 2016, 113, E6724–E6725. [Google Scholar] [CrossRef]
- Yule, G.U. A mathematical theory of evolution, based on the conclusions of Dr. J. C. Willis, F.R.S. Phil. Trans. R. Soc. B 1924, 213, 21–87. [Google Scholar]
- Simon, H.A. On a class of skew distribution functions. Biometrika 1955, 42, 425–440. [Google Scholar] [CrossRef]
- Barabási, A.-L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Ghoshal, G.; Barabási, A.L. Ranking stability and super-stable nodes in complex networks. Nat. Commun. 2011, 2, 394. [Google Scholar] [CrossRef] [PubMed]
- Bentley, R.A.; Lipo, C.P.; Hahn, M.W.; Herzog, H.A. Regular rates of popular culture change reflect random copying. Evol. Hum. Behav. 2007, 28, 151–158. [Google Scholar] [CrossRef]
- Bentley, R.A.; Ormerod, P.; Batty, M. Evolving social influence in large populations. Behav. Ecol. Sociobiol. 2011, 65, 537–546. [Google Scholar] [CrossRef]
- Gleeson, J.P.; Cellai, D.; Onnela, J.-P.; Porter, M.A.; Reed-Tsochas, F. A simple generative model of collective online behavior. Proc. Natl. Acad. Sci. USA 2014, 111, 10411–10415. [Google Scholar] [CrossRef] [PubMed]
- Canelas, C.; Gisselquist, R.M. Horizontal inequality and data challenges. Soc. Indic. Res. 2019, 143, 157–172. [Google Scholar] [CrossRef]
- Duffy, P.R. Site size hierarchy in middle-range societies. J. Anthropol. Arch. 2015, 37, 85–99. [Google Scholar] [CrossRef]
- Bentley, R.A.; Caiado, C.C.S.; Ormerod, P. Effects of memory on spatial heterogeneity in neutrally transmitted culture. Evol. Hum. Behav. 2014, 35, 257–263. [Google Scholar] [CrossRef][Green Version]
- Crema, E.; Kandler, A.; Shennan, S.J. Revealing patterns of cultural transmission from frequency data: Equilibrium and non-equilibrium assumptions. Sci. Rep. 2016, 6, 39122. [Google Scholar] [CrossRef]
- Salzman, P.C. Is inequality universal? Curr. Anthropol. 1999, 40, 31–61. [Google Scholar] [CrossRef]
- Schulting, R.J. Mortuary Variability and Status Differentiation on the Columbia-Fraser Plateau; SFU Archaeology Press: Burnaby, BC, Canada, 1995. [Google Scholar]
- Blanton, R.E.; Feinman, G.M.; Kowalewski, S.A.; Peregrine, P.N. A dual-processual theory for the evolution of Mesoamerican civilization. Curr. Anthropol. 1996, 37, 1–14. [Google Scholar] [CrossRef]
- Renfrew, C. Beyond a subsistence economy: The evolution of social organization in prehistoric Europe. In Reconstructing Complex Societies; Moore, C., Ed.; School of Oriental Research: Ann Arbor, MI, USA, 1974; pp. 69–95. [Google Scholar]
- Earle, T. Cultural anthropology and archaeology. In Handbook of Archaeological Theories; Bentley, R.A., Maschner, H.D.G., Chippendale, C., Eds.; AltaMira Press: Lanham, MD, USA, 2008; pp. 187–202. [Google Scholar]
- Brahm, F.; Poblete, J. The evolution of productive organizations. Nat. Hum. Behav. 2021, 5, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Turchin, P.; Currie, T.E.; Turner, E.A.L.; Gavrilets, S. War, space, and the evolution of Old World complex societies. Proc. Natl. Acad. Sci. USA 2013, 110, 16384–16389. [Google Scholar] [CrossRef]
- Gutiérrez, A.; Gerrard, C.; Zhang, R.; Guangyao, W. The earliest Chinese ceramics in Europe? Antiquity 2021, 95, 1213–1230. [Google Scholar] [CrossRef]
- Ehrenreich, R.M.; Crumley, C.L.; Levy, J.E. (Eds.) Heterarchy and the Analysis of Complex Societies; American Anthropological Association: Arlington, VA, USA, 1995. [Google Scholar]
- Canelas, C.; Gisselquist, R.M. Horizontal inequality as an outcome. Oxford Dev. Stud. 2018, 46, 305–324. [Google Scholar] [CrossRef]
- Alesina, A.; Michalopoulos, S.; Papaioannou, E. Ethnic Inequality. J. Polit. Econ. 2016, 124, 428–488. [Google Scholar] [CrossRef]
- Doğan, G.; Glowacki, L.; Rusch, H. Spoils division rules shape aggression between natural groups. Nat. Hum. Behav. 2018, 2, 322–326. [Google Scholar] [CrossRef]
- Conningham, R. South Asia. In Human Past Essentials; Scarre, C., Stone, T., Eds.; Thames and Hudson: New York, NY, USA, 2021; pp. 164–181. [Google Scholar]
- deMenocal, P. Cultural responses to climate change during the Late Holocene. Science 2001, 292, 667–673. [Google Scholar] [CrossRef]
- Østby, G. Inequality and political violence: A review of the literature. Int. Area Stud. Rev. 2013, 16, 206–231. [Google Scholar]
- Cederman, L.-E.; Weidmann, N.B.; Gleditsch, K.S. Horizontal inequalities and ethnonationalist civil war: A global comparison. Am. Polit. Sci. Rev. 2011, 105, 478–495. [Google Scholar] [CrossRef]
- Acemoglu, D.; Robinson, J.A. Persistence of power, elites, and institutions. Am. Econ. Rev. 2008, 98, 267–293. [Google Scholar] [CrossRef]
- Acemoglu, D.; Egorov, G.; Sonin, K. Dynamics and stability of constitutions, coalitions, and clubs. Am. Econ. Rev. 2012, 102, 1446–1476. [Google Scholar] [CrossRef]
- Henrich, J.; Boyd, R. The evolution of conformist transmission and the emergence of between-group differences. Evol. Hum. Behav. 1998, 19, 215–241. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).