


A Novel Strategy for Extracting Richer Semantic Information Based on Fault Detection in Power Transmission Lines

Abstract
:1. Introduction
- Aiming at the challenges of limited computational resources of lightweight embedded devices and easy confusion of defect categories in the field transmission power lines defect detection, we propose a strategy with a lightweight network to acquire high-level semantic features, which is capable of extracting rich semantic feature representations without excessively increasing the depth of the network and improves the detection accuracy of the network. Compared to SOTA, our strategy achieves comparable performance with a small number of network layers.
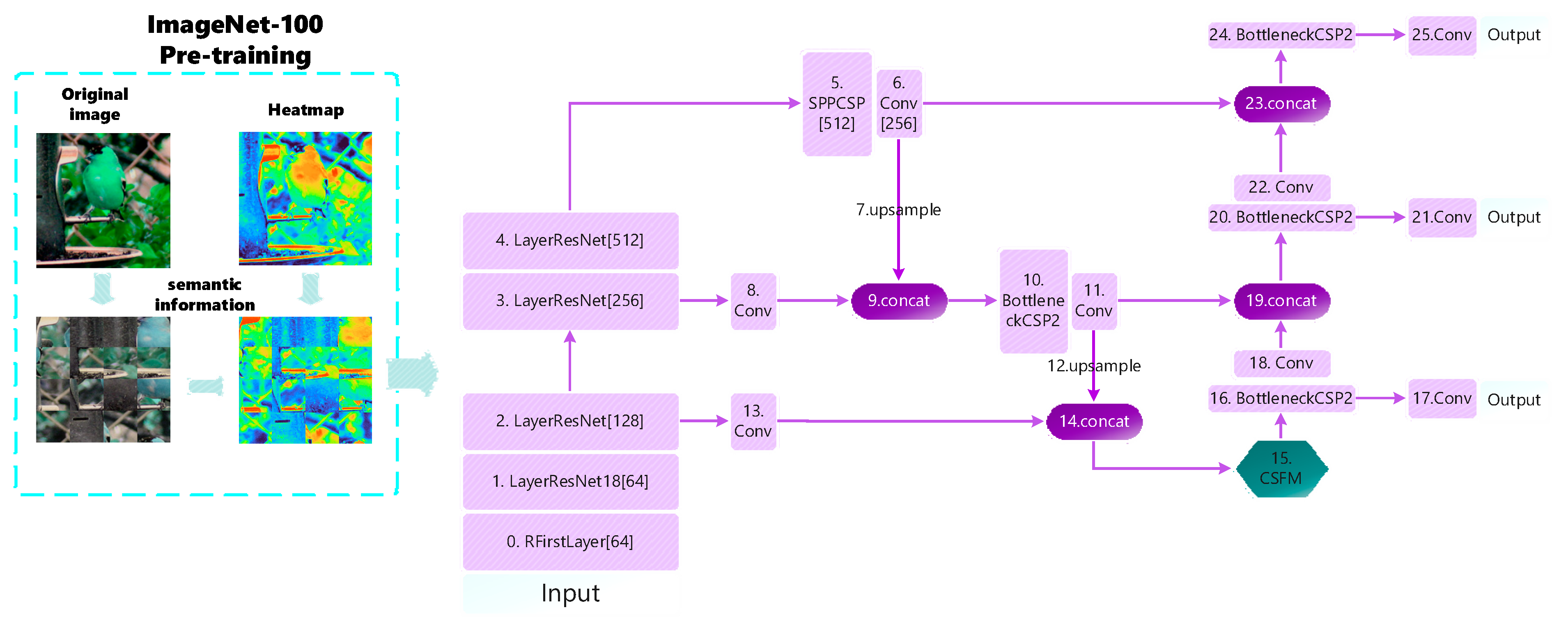
- To address the problem of ignoring shallow semantic information, one scheme is proposed to extract shallow semantic information without increasing the depth of the network. The inherent shallow features such as texture and location are broken in the pre-training stage to reduce the network’s dependence on shallow features. And the contrast learning capability of the Simsiame [24] network is utilized to mine the intrinsic semantic feature representations of images. Then, transfer learning is utilized to fine-tune small datasets in practical defect detection to leverage the powerful semantic representations learned from the pre-trained models and guide the extraction of shallow semantic information in the new task.
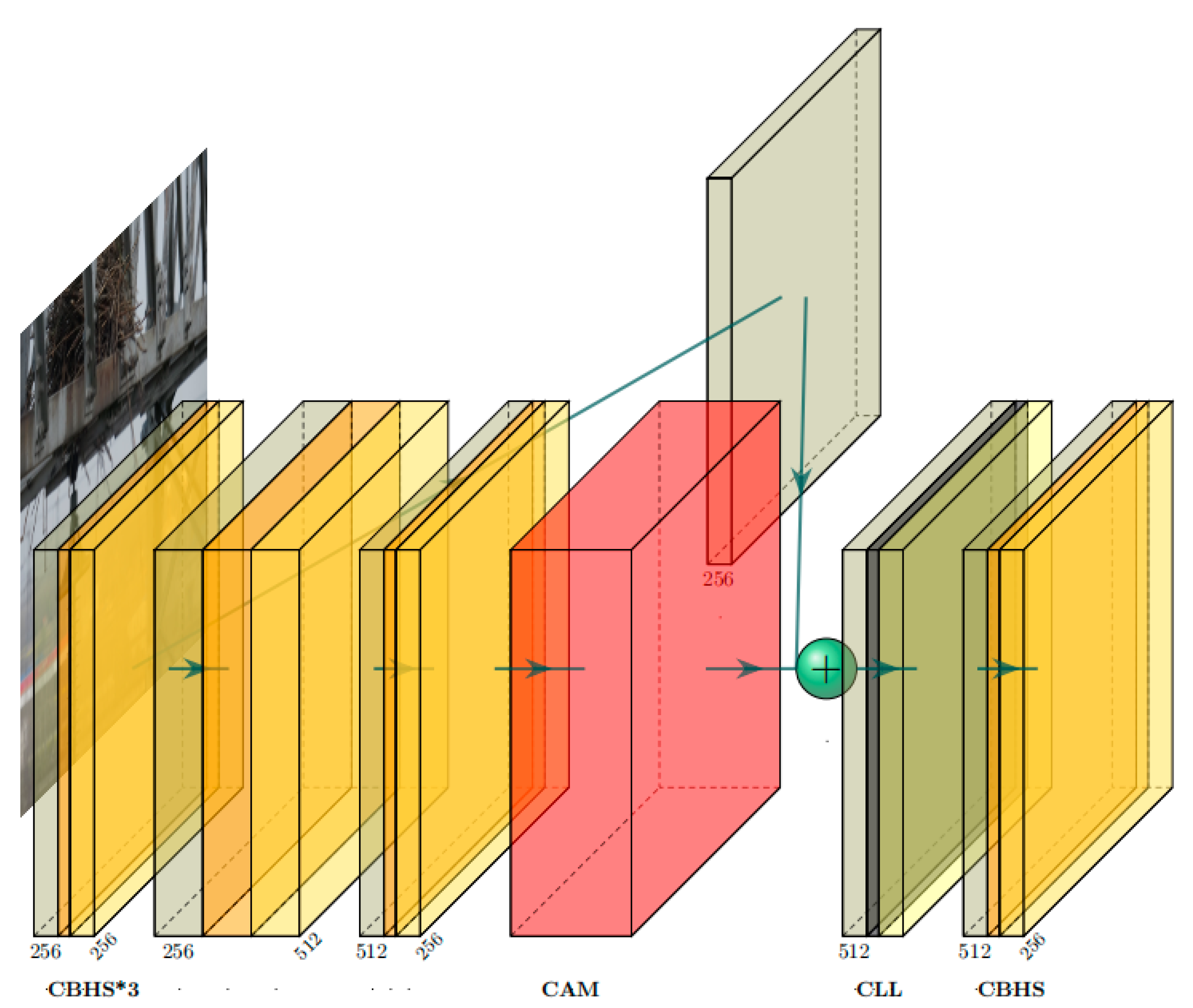
- In the feature fusion stage, to obtain more semantic information, we design the category semantic fusion module (CSFM) to focus more on categories. The channel attention is used to extract important channel features and again retain the initial features by one more branch. Also, the association of local features is modeled. Richer semantic information is fused by synthesizing global information and locally important features. This improves the detection accuracy of the network.
2. Related Work
2.1. Detection of Defects in Power Transmission Lines
2.2. Semantic Information
2.3. Transfer Learning
2.4. Channel Attention
3. Methods
3.1. Shallow Network Semantic Information Extraction Scheme
| Algorithm 1 Pseudo code of shallow network semantic information extraction scheme. |
| Input: sequence of image blocks T Method: crop_trans: segmentation and random spatial transformation, rand_aug: random augmentation, e: feature extractor, m: mlp prediction header, S: negative cosine similarity Variable: ɑ: hyperparameter, n: number of blocks for image segmentation 1 import tensorflow as tf 2 for t in T: # load images 3 t1, t2 = crop_trans(t, n), rand_aug(t) 4 f1, f2 = e(t1), e(t2) 5 p1, p2 = m(f1), m(f2) 6 loss = ɑ*S( p1, f2)+(1-ɑ)*S( p2, f1) 7 8 def crop_trans(t, n) : 9 blocks = Lambda(lambda x: tf.image.extract_patches(x)(t) 10 block_shape = tf.shape(blocks) 11 num_blocks = block_shape[1]*block_shape[2] 12 blocks = tf.reshape(blocks, [block_shape[0], num_blocks, n, n, 3]) 13 # Random space transformation 14 return Tc = tf.random.shuffle(tf.transpose(blocks, perm=[0, 2, 1, 3, 4])) 15 16 def S ( p, f ) : # negative cosine similarity 17 pn = normalize( p, dim=1) # l2 normlization 18 fn = normalize( f, dim=1) # l2 normlization 19 return - p*f / pn*fn |
3.2. Category Semantic Fusion Module
4. Experiment
4.1. Experimental Configuration
4.2. Datasets
4.3. Evaluation of Indicators
4.4. Experimental Results
4.4.1. Comprehensive Experimental Results
4.4.2. Ablation Experiment
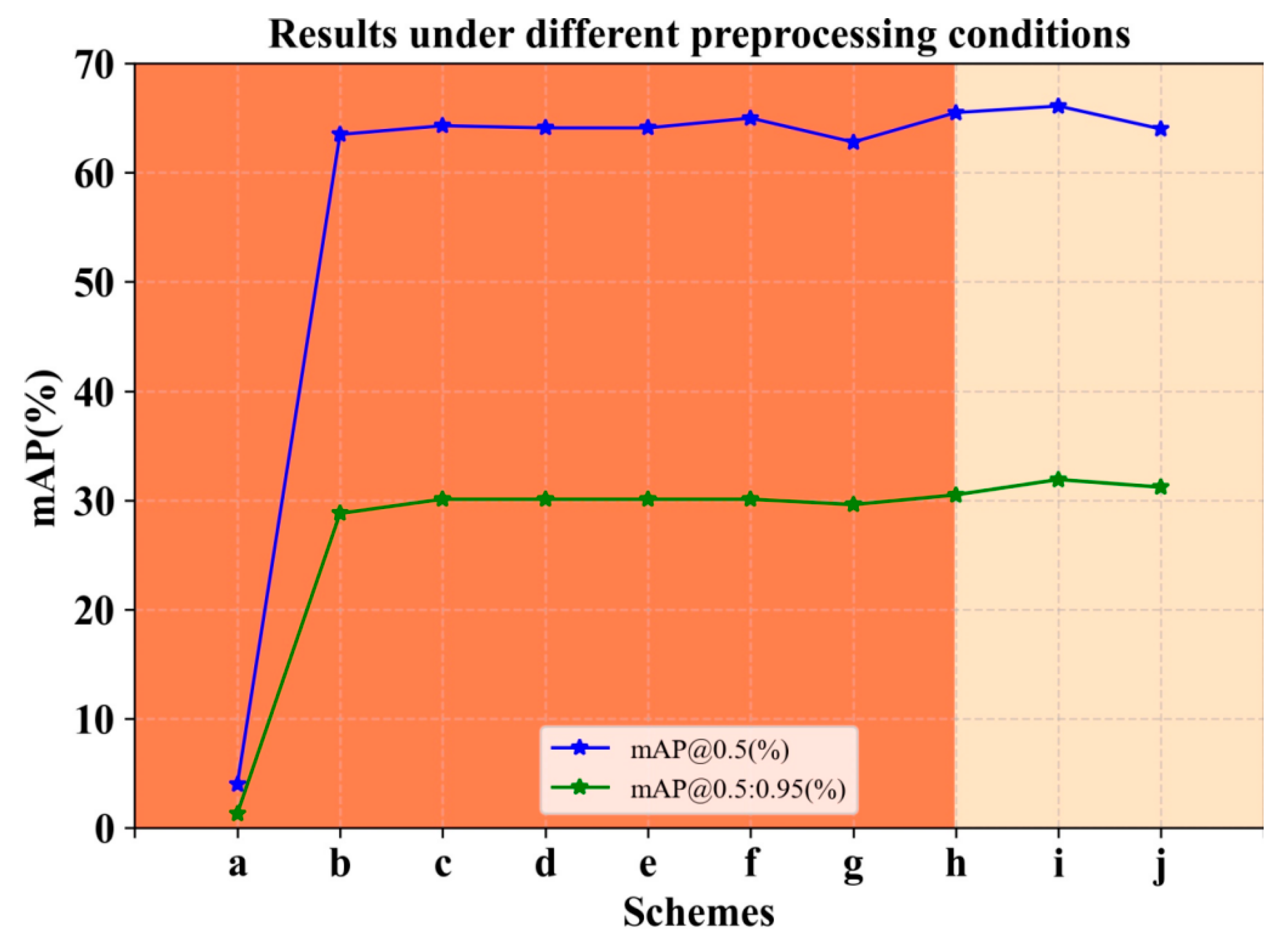
- Different preprocessing
- To explore the two schemes mentioned in Section 3.1, we conducted the following experiments with ResNet18 as the backbone network, respectively:
- Randomly initialize and preprocess the image itself by cutting and changing its position, i.e., Scheme 1.
- Randomly initialize, without any processing of images and networks, as a reference group.
- In Scheme 2, set the value of to 5; that is, divide the image into 32 blocks for pre-training.
- In Scheme 2, set the value of to 4; that is, divide the image into 16 blocks for pre-training.
- In Scheme 2, set the value of to 3; that is, divide the image into 8 blocks for pre-training.
- In Scheme 2, set the value of to 2; that is, divide the image into 4 blocks for pre-training.
- In Scheme 2, set the value of to 1; that is, divide the image into 2 blocks for pre-training.
- Based on the c-experiment, the part of the network fusion is inserted into the CSFM.
- Based on the d-experiment, the part of the network fusion is inserted into the CSFM.
- Based on the j-experiment, the part of the network fusion is inserted into the CSFM.
- 2.
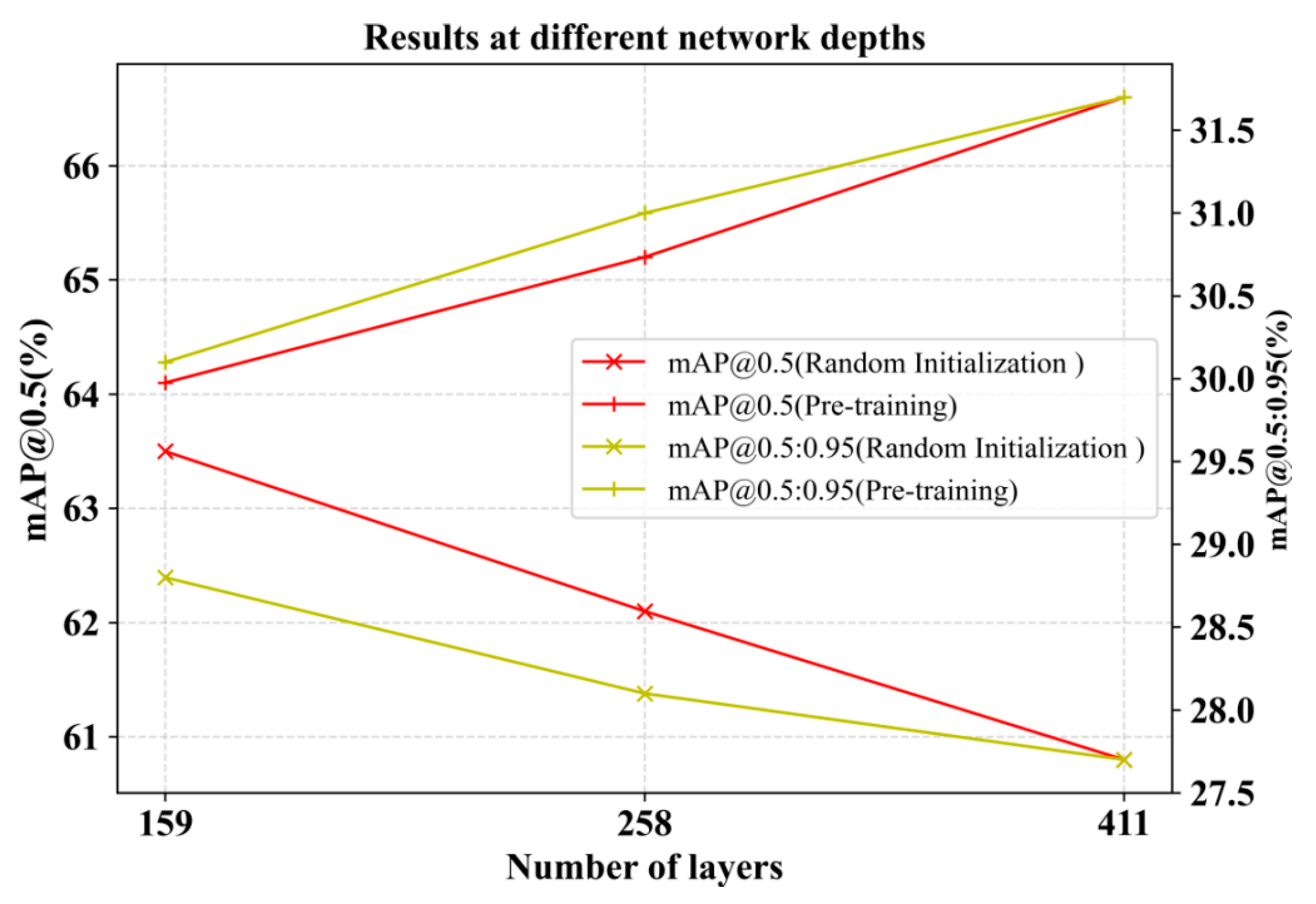
- An Exploration of Network Depth and Detection Effectiveness
- 3.
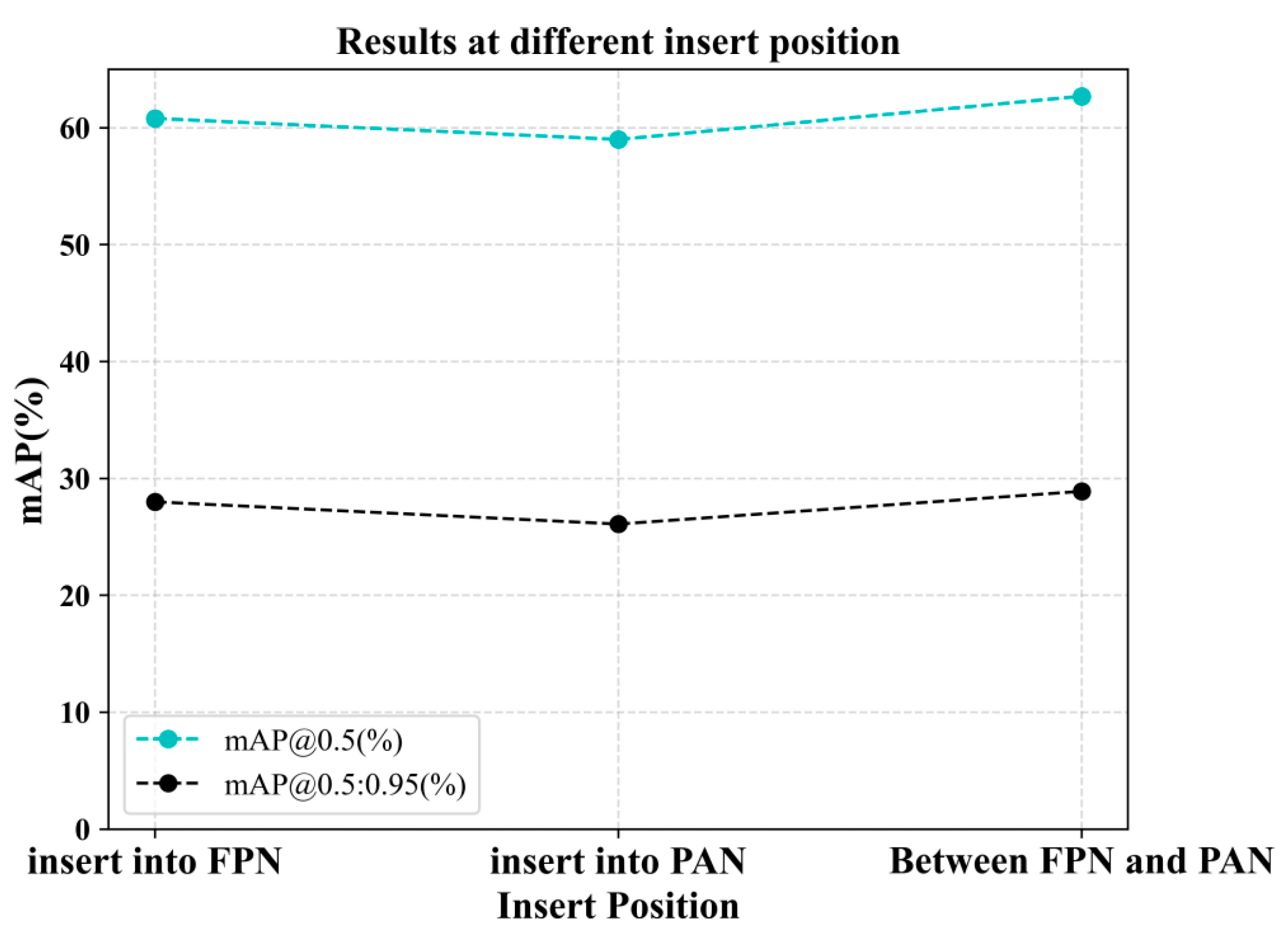
- Exploration of CSFM insertion locations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Li, Z.; Liu, X.; Li, Z. Masking transmission line outages via false data injection attacks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1592–1602. [Google Scholar] [CrossRef]
- Ritzmann, D.; Wright, P.S.; Holderbaum, W.; Potter, B. A method for accurate transmission line impedance parameter estimation. IEEE Trans. Instrum. Meas. 2016, 65, 2204–2213. [Google Scholar] [CrossRef]
- Yu, H.; Schaekers, M.; Schram, T.; Rosseel, E.; Martens, K.; Demuynck, S.; Horiguchi, N.; Barla, K.; Collaert, N.; Meyer, K.D.; et al. Multiring circular transmission line model for ultralow contact resistivity extraction. IEEE Electron Device Lett. 2015, 36, 600–602. [Google Scholar] [CrossRef]
- Ding, T.; Bo, R.; Li, F.; Sun, H. Optimal power flow with the consideration of flexible transmission line impedance. IEEE Trans. Power Syst. 2015, 31, 1655–1656. [Google Scholar] [CrossRef]
- Luo, P.; Wang, B.; Wang, H.; Ma, F.; Ma, H.; Wang, L. An ultrasmall bolt defect detection method for transmission line inspection. IEEE Trans. Instrum. Meas. 2023, 72, 1–12. [Google Scholar] [CrossRef]
- Su, T.; Liu, D. Transmission line defect detection based on feature enhancement. Multimed. Tools Appl. 2023, 1–13. [Google Scholar] [CrossRef]
- Liang, H.; Zuo, C.; Wei, W. Detection and evaluation method of transmission line defects based on deep learning. IEEE Access 2020, 8, 38448–38458. [Google Scholar] [CrossRef]
- Zheng, X.; Jia, R.; Aisikaer; Gong, L.; Zhang, G.; Dang, J. Component identification and defect detection in transmission lines based on deep learning. J. Intell. Fuzzy Syst. 2021, 40, 3147–3158. [Google Scholar] [CrossRef]
- Wang, K.; Wang, Y.; Zhang, S.; Tian, Y.; Li, D. SLMS-SSD: Improving the balance of semantic and spatial information in object detection. Expert Syst. Appl. 2022, 206, 117682. [Google Scholar] [CrossRef]
- Lee, N.; Ajanthan, T.; Torr, P.H.S. Snip: Single-shot network pruning based on connection sensitivity. arXiv 2018, arXiv:1810.02340. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Li, G.; Wang, F.; Zhou, L.; Jin, S.; Xie, X.; Ding, C.; Pan, X.; Zhang, W. MCANet: Multi-channel attention network with multi-color space encoder for underwater image classification. Comput. Electr. Eng. 2023, 108, 108724. [Google Scholar] [CrossRef]
- Zhang, A.; Jia, L.; Wang, J.; Wang, C. SAR Image Classification Using Gated Channel Attention Based Convolutional Neural Network. Remote Sens. 2023, 15, 362. [Google Scholar] [CrossRef]
- Wu, H.; Shi, C.; Wang, L.; Jin, Z. A Cross-Channel Dense Connection and Multi-Scale Dual Aggregated Attention Network for Hyperspectral Image Classification. Remote Sens. 2023, 15, 2367. [Google Scholar] [CrossRef]
- Yang, Y.; Jiao, L.; Liu, X.; Liu, F.; Yang, S.; Li, L.; Chen, P.; Li, X.; Huang, Z. Dual Wavelet Attention Networks for Image Classification. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1899–1910. [Google Scholar] [CrossRef]
- Zhou, W.; Xia, Z.; Dou, P.; Su, T.; Hu, H. Double attention based on graph attention network for image multi-label classification. ACM Trans. Multimed. Comput. Commun. Appl. 2023, 19, 1–23. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intel. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, C.; Zhuo, L.; Li, J. Arbitrary-Oriented Object Detection in Aerial Images with Dynamic Deformable Convolution and Self-Normalizing Channel Attention. Electronics 2023, 12, 2132. [Google Scholar] [CrossRef]
- Xie, X.K.; Li, C.; Liu, Y.; Song, J.; Ahn, J.; Zhang, Z. An Efficient Channel Attention-Enhanced Lightweight Neural Network Model for Metal Surface Defect Detection. J. Circuit Syst. Comp. 2022, 32, 2350178. [Google Scholar] [CrossRef]
- Su, S.; Chen, R.; Fang, X.; Zhang, T. A Novel Transformer-Based Adaptive Object Detection Method. Electronics 2023, 12, 478. [Google Scholar] [CrossRef]
- Xiang, J.; Pan, Q.; Zhang, Z.; Fu, S.; Qin, Y. Double-branch fusion network with a parallel attention selection mechanism for camouflaged object detection. Sci. China Inf. Sci. 2023, 66, 162403. [Google Scholar] [CrossRef]
- Ortiz, A.; Robinson, C.; Morris, D.; Fuentes, O.; Kiekintveld, C.; Hassan, M.M.; Jojic, N. Local context normalization: Revisiting local normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11276–11285. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Ha, H.; Han, S.; Lee, J. Fault detection on transmission lines using a microphone array and an infrared thermal imaging camera. IEEE Trans. Instrum. Meas. 2011, 61, 267–275. [Google Scholar] [CrossRef]
- Kim, M.-G.; Jeong, S.; Kim, S.-T.; Oh, K.-Y. Anomaly Detection of Underground Transmission-Line through Multiscale Mask DCNN and Image Strengthening. Mathematics 2023, 11, 3143. [Google Scholar] [CrossRef]
- Sun, J.; Fan, Y.; Qiu, W.; Song, S.; Tan, X.; Tian, Y.; Jiao, X.; Wang, H.; Wu, N. Applicability of the acoustic–electrical joint detection method to identify defects in gas insulated system. IET Sci. Meas. Technol. 2023, 17, 147–157. [Google Scholar] [CrossRef]
- Llano, L.E.; Moreno, J. On-line analysis of fault events in power transmission systems using SOE, fuzzy logic and expert systems. Rev. Técnica De La Fac. De Ing. Univ. Del Zulia 2013, 36, 174–182. [Google Scholar]
- Lv, A.; Li, J. On-line monitoring system of 35 kV 3-core submarine power cable based on φ-OTDR. Sens. Actuators A Phys. 2018, 273, 134–139. [Google Scholar] [CrossRef]
- Zhao, Z.; Qi, H.; Qi, Y.; Zhang, K.; Zhai, Y.; Zhao, W. Detection method based on automatic visual shape clustering for pin-missing defect in transmission lines. IEEE Trans. Instrum. Measurement. 2020, 69, 6080–6091. [Google Scholar] [CrossRef]
- Manninen, H.; Ramlal, C.J.; Singh, A.; Rocke, S.; Kilter, J.; Landsberg, M. Toward automatic condition assessment of high-voltage transmission infrastructure using deep learning techniques. Int. J. Electr. Power Energy Syst. 2021, 128, 106726. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, G.; He, W.; Fan, F.; Ye, X. Key target and defect detection of high-voltage power transmission lines with deep learning. Int. J. Electr. Power Energy Syst. 2022, 142, 108277. [Google Scholar] [CrossRef]
- Yan, X.; Cheng, S.; Guo, L. Bug localization based on syntactical and semantic information of source code. J. Syst. Eng. Electron. 2023, 34, 236–246. [Google Scholar] [CrossRef]
- Okpala, I.; Rodriguez, G.R.; Tapia, A.; Halse, S.; Kropczynski, J. A Semantic Approach to Negation Detection and Word Disambiguation with Natural Language Processing. arXiv 2023, arXiv:2302.02291. [Google Scholar]
- Hu, L.; Zhang, Y.; Wang, Y.; Yang, H.; Tan, S. Salient Semantic Segmentation Based on RGB-D Camera for Robot Semantic Mapping. Appl. Sci. 2023, 13, 3576. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Y.; Guo, X. Boosting semantic segmentation via feature enhancement. J. Vis. Commun. Image Represent. 2023, 92, 103796. [Google Scholar] [CrossRef]
- Jing, Z.; Qizhao, J.; Hongzhen, W.; Cheng, D.; Shiming, X.; Chunhong, P. Semantic segmentation on remote sensing images with multi-scale feature fusion. J. Comput.-Aided Des. Comput. Graph. 2019, 31, 1509–1517. [Google Scholar]
- Li, K.; Yang, J.; Huang, Z. Improved YOLOv3 target detection based on boundary limit point features. J. Comput. Appl. 2023, 43, 81. [Google Scholar]
- Chen, Y.; Zhu, X.; Li, Y.; Wei, Y.; Ye, L. Enhanced semantic feature pyramid network for small object detection. Signal Process. Image Commun. 2023, 113, 116919. [Google Scholar] [CrossRef]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung pattern classification for interstitial lung diseases using a deep convolutional neural network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characterristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1297. [Google Scholar] [CrossRef]
- İrsoy, O.; Alpaydın, E. Continuously constructive deep neural networks. arXiv 2018, arXiv:1804.02491. [Google Scholar] [CrossRef]
- Boyd, A.; Czajka, A.; Bowyer, K. Deep learning-based feature extraction in iris recognition: Use existing models, fine-tune or train from scratch? In Proceedings of the 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS), Tampa, FL, USA, 23–26 September 2019; pp. 1–9. [Google Scholar]
- Zhang, T.; Gao, P.; Dong, H.; Zhuang, Y.; Wang, G.; Zhang, W.; Chen, H. Consecutive Pre-Training: A Knowledge Transfer Learning Strategy with Relevant Unlabeled Data for Remote Sensing Domain. Remote Sens. 2022, 14, 5675. [Google Scholar] [CrossRef]
- Baykal, E.; Dogan, H.; Ercin, M.E.; Ersoz, S.; Ekinci, M. Transfer learning with pre-trained deep convolutional neural networks for serous cell classification. Multimed. Tools Appl. 2020, 79, 15593–15611. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global second-order pooling convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3024–3033. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. A2-nets: Double attention networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, Z.-D.; Zhang, B.; Lan, Z.-C.; Liu, H.-C.; Li, D.-Y.; Pei, L.; Yu, W.-X. FINet: An insulator dataset and detection benchmark based on synthetic fog and improved YOLOv5. IEEE Trans. Instrum. Mea. 2022, 71, 1–8. [Google Scholar] [CrossRef]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An insulator in transmission lines recognition and fault detection model based on improved faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 1–8. [Google Scholar] [CrossRef]
- Song, J.; Qian, J.; Liu, Z.; Jiao, Y.; Zhou, J.; Li, Y.; Chen, Y.; Guo, J.; Wang, Z. Research on Arc Sag Measurement Methods for Transmission Lines Based on Deep Learning and Photogrammetry Technology. Remote Sens. 2023, 15, 2533. [Google Scholar] [CrossRef]
- Tang, C.; Dong, H.; Huang, Y.; Han, T.; Fang, M.; Fu, J. Foreign object detection for transmission lines based on Swin Transformer V2 and YOLOX. Vis. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Zhao, L.; Liu, C.; Qu, H. Transmission line object detection method based on contextual information enhancement and joint heterogeneous representation. Sensors 2022, 22, 6855. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, X. Recognition of bird nests on transmission lines based on YOLOv5 and DETR using small samples. Energy Rep. 2023, 9, 6219–6226. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameters | Values |
|---|---|
| Batch size | 64 |
| Image size | 448 |
| Optimizer | SGD |
| Initial learning rate | 0.01 |
| Momentum | 0.937 |
| Weight decay | 0.005 |
| Focal loss gamma | 0 |
| Anchor-multiple threshold | 4.0 |
| Ground Truth | Prediction | |
|---|---|---|
| TP (True Positive) | positive | positive |
| TN (True Negative) | negative | negative |
| FP (False Positive) | positive | negative |
| FN (False Negative) | negative | positive |
| Pre-Training | Backbone | Neck | mAP@0.5 |
|---|---|---|---|
| Random Initialization | ResNet18 | FPN + PAN | 63.5 |
| Random Initialization | ResNet18 | FPN + CSFM + PAN | 64.1 |
| Pre-training _crop16d | ResNet18 | FPN + CSFM + PAN | 66.1 |
| Pre-Training | Backbone | Neck | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| Random Initialization | ResNet18 | FPN + PAN | 83.6 | 60.9 |
| Random Initialization | ResNet18 | FPN + CSFM + PAN | 83.8 | 61.6 |
| crop16d | ResNet18 | FPN + CSFM + PAN | 84.5 | 62.5 |
| Detection Mechanism | Detection Model | P | R | mAP@0.5 | Number of Layers |
|---|---|---|---|---|---|
| FINet (SOTA) | FINet | 93.1 | 99.5 | 99.5 | 311 |
| Mainstream fault Detection mechanisms | Faster RCNN | - | - | 98.4 | - |
| Mask RCNN | - | - | 98.3 | - | |
| YOLOX | - | - | 99.4 | - | |
| Swin-Transformer | - | - | 99.0 | - | |
| YOLOv5 | - | - | 99.3 | 266 | |
| Ours | TL + CSFM | 95 | 99.5 | 99.4 | 177 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, S.; Li, J.; Wang, J.; Liu, G.; Ai, A.; Liu, R. A Novel Strategy for Extracting Richer Semantic Information Based on Fault Detection in Power Transmission Lines. Entropy 2023, 25, 1333. https://doi.org/10.3390/e25091333
Yan S, Li J, Wang J, Liu G, Ai A, Liu R. A Novel Strategy for Extracting Richer Semantic Information Based on Fault Detection in Power Transmission Lines. Entropy. 2023; 25(9):1333. https://doi.org/10.3390/e25091333
Chicago/Turabian StyleYan, Shuxia, Junhuan Li, Jiachen Wang, Gaohua Liu, Anhai Ai, and Rui Liu. 2023. "A Novel Strategy for Extracting Richer Semantic Information Based on Fault Detection in Power Transmission Lines" Entropy 25, no. 9: 1333. https://doi.org/10.3390/e25091333
APA StyleYan, S., Li, J., Wang, J., Liu, G., Ai, A., & Liu, R. (2023). A Novel Strategy for Extracting Richer Semantic Information Based on Fault Detection in Power Transmission Lines. Entropy, 25(9), 1333. https://doi.org/10.3390/e25091333