1. Introduction
When a data set contains an excess of zero counts over the expectation of a standard statistical distribution, a zero-inflated model helps to analyze such data sets. In many scenarios, count data have two sources of zeros. They are the structural zeros and sampling zeros. Structural zeros mean that the response variable cannot take positive values because of inherent constraints or conditions, and sampling zeros mean the zeros result from random chance. The idea behind the zero-inflated model is to account for two sources of zeros using a mixture of two separated distributions. One model characterizes the probability of structural zeros, and the other describes the non-zero counts. This mixture mechanism of the zero-inflated model allows for better representing the complexities when the data set has excess zeros. The zero-inflated Poisson (ZIP) model and zero-inflated negative Binomial (ZINB) model are two major zero-inflated models.
Imbalanced data refers to the distribution of categories in the data set that is highly disproportionate. For example, in a data set with two types, one type has significantly more instances than another. The situation results in an unequal representation of the two categories. Data sets could be inherently imbalanced in real-world scenarios for various reasons. One example of imbalanced data in medical applications can be diagnosing a rare disease with only a tiny percentage of patients with the condition. In this case, the class size of the rare event will be severely smaller than the common event.
Traditional machine learning algorithms and statistical models could be challenged to handle imbalanced data. The prediction results could be biased toward the majority class and lead to poor performance of the minority class. However, the minority class is often more significantly interesting in many applications. The well-known drawbacks of machine learning algorithms caused by imbalanced data sets are model bias, poor generalization, and misleading evaluation metrics. Several techniques can be used to address the issue of imbalanced data, including resampling, synthetic data generation, using ensemble methods, and more.
The artificial neural network (ANN) has been widely used to implement categorical classification. Rosenblatt [
1] proposed a theory of perception about a hypothetical nervous system that can sense, remember, and recognize information from the physical world. Rumelhart et al. [
2] discussed a learning algorithm for backpropagation ANNs. The algorithm adjusts the weights of the connections in the network to minimize the error between the realistic output and the desired output. Hirose et al. [
3] modified the backpropagation algorithm by varying the number of hidden units in the ANN. Their algorithm can reduce the probability of becoming trapped in local minima and speed up the convergence compared to conventional backpropagation ANN. Sietsma and Dow [
4] studied the relationship between the size and structure of an ANN and its ability to generalize from a training set. Using a complex classification task, they investigated the effects of pruning and noise training on network performance.
In the previous decade, Devi et al. [
5] emphasized the classification of cervical cancer using ANN methods to develop a strategy for accurately categorizing cervical cancer cases. Sze et al. [
6] provided a comprehensive tutorial and survey on the efficient processing of deep neural networks. Abiodun et al. [
7] surveyed the ANN applications to provide a taxonomy of ANN models and provided readers with knowledge of current and emerging trends in ANN research. Nasser and Abu-Naser [
8] addressed the detection of lung cancer using an ANN method to explore the feasibility of employing ANN technology for identifying lung cancer, which is a significant advancement in medical diagnostics. Muhammad et al. [
9] delved into predicting pancreatic cancer using an ANN method. Umar [
10] predicted student academic performance using ANN methods to forecast students’ academic achievements. Shen et al. [
11] introduced a novel ensemble classification model for imbalanced credit risk evaluation. The model integrates neural networks with a classifier optimization technique. The study addressed the challenge of imbalanced data sets in credit risk assessment by leveraging the strengths of neural networks and advanced optimization techniques.
Lambert [
12] proposed a ZIP regression model to process count data with excess zeros. The author applied the ZIP regression model to a soldering defects data set on the printed wiring board and compared the performance of the proposed model with other models. Hall [
13] presented a case study of ZIP and zero-inflated binomial (ZIB) regression with random effects. The author showed that zero-inflated models are useful when the data contains an excess of zeros, and random effects can be used to account for the correlation between observations within clusters. Cheung [
14] discussed the theoretical underpinnings of zero-inflated models, provided examples of their application, and discussed the implications of using these models for accurate inference in the context of growth and development studies. Gelfand and Citron-Pousty [
15] presented how to use zero-inflated models for spatial count data within the environmental and ecological statistics field. They explored how zero-inflated models can account for both the spatial correlation and the excess zero counts often found in environmental and ecological applications. Rodrigues [
16] discussed how Bayesian techniques can be applied to estimate the parameters of zero-inflated models and provided practical examples to demonstrate the approach.
Ghosh et al. [
17] provided a Bayesian analysis of zero-inflated regression models. Their Bayesian approach suggested a coherent way to handle the challenges of excess zeros in count data, offering insights into parameter estimation and uncertainty quantification. Harri and Zhao [
18] introduced the zero-inflated-ordered probit model to handle ordered response data with excess zeros. The proposed method is applied to analyze tobacco consumption data. Loeys et al. [
19] explored the analysis of zero-inflated count data, going beyond the scope of ZIP regression. Diop et al. [
20] studied the maximum likelihood estimation method in the logistic regression model with a cure fraction. The authors introduced the concept of cure fraction models, which analyze data where many individuals do not experience the event of interest. Staub and Winkelmann [
21] studied the consistent estimation of zero-inflated count models. He et al. [
22] discussed the concept of structural zeros and their relevance to zero-inflated models. Diop et al. [
23] studied simulation-based inference in a zero-inflated Bernoulli regression model. This research is valuable for practitioners working with binary data exhibiting excess zeros.
Alsabti et al. [
24] present a novel decision tree classifier called CLOUDS for classification using big data. The authors showed that techniques such as discretization and data set sampling can be used to scale up decision tree classifiers to large data sets. However, both methods can cause a significant accuracy loss. Friedman [
25] introduced Gradient Boosting Machines (GBMs) with a powerful technique for building predictive models by iteratively combining weak learners. GBMs are known for their effectiveness in handling complex, high-dimensional data with robustness against overfitting. Jin and Agrawal [
26] addressed the challenge of constructing decision trees efficiently in a parallel computing environment. They improved communication and memory efficiency during the parallel construction of decision trees.
Chen and Guestrin [
27] developed the “XGBoost”, a scalable tree-boosting system. XGBoost is a powerful and efficient algorithm for boosting decision trees. Ke et al. [
28] introduced “LightGBM”, a highly efficient gradient boosting decision tree algorithm. This tool dramatically contributes to machine learning, particularly boosting techniques. LightGBM has gained attention for its speed and scalability, making it suitable for handling large data sets and complex problems. Wang et al. [
29] applied “LightGBM” for the miRNA classification in breast cancer patients. Ma et al. [
30] used multi-observation and multi-dimensional data cleaning methods and the algorithms of LightGBM and XGboost for prediction. The authors concluded that the LightGBM algorithm based on multiple observational data set classification prediction results is the best. Machado et al. [
31] introduced LightGBM, showing it is an excellent decision tree gradient boosting method. The authors applied LightGBM to predict customer loyalty within the finance industry. Minstireanu and Mesnita [
32] employed the LightGBM algorithm for online click fraud detection. Daoud [
33] compared three popular gradient boosting algorithms, XGBoost, LightGBM, and CatBoost, to evaluate the strengths and weaknesses of each algorithm in the context of credit risk assessment or related tasks.
Some open challenges for implementing imbalanced data analysis have been comprehensively discussed by Krawczyk [
34] and Nalepa and Kawulok [
35]. The two works provided insights into imbalanced data modeling. Krawczyk [
34] pointed out the open challenges including the binary and multi-class classification problems, how to do multi-label and multi-instance learning, and unsupervised and semi-supervised handling for imbalanced data sets. It is also challenging to perform regression on skewed cases and a well-designed procedure for learning from imbalanced data streams under stationary and drifting environments, then extending the model for large-scale and big-data cases. Nalepa and Kawulok [
35] reviewed the issue of selecting training sets for support vector machines. They did an extensive survey on existing methods for using the support vector machine method to train data in big-data applications. Nalepa and Kawulok [
35] separated these helpful techniques into several categories. This work helps users understand the underlying ideas behind the algorithms used.
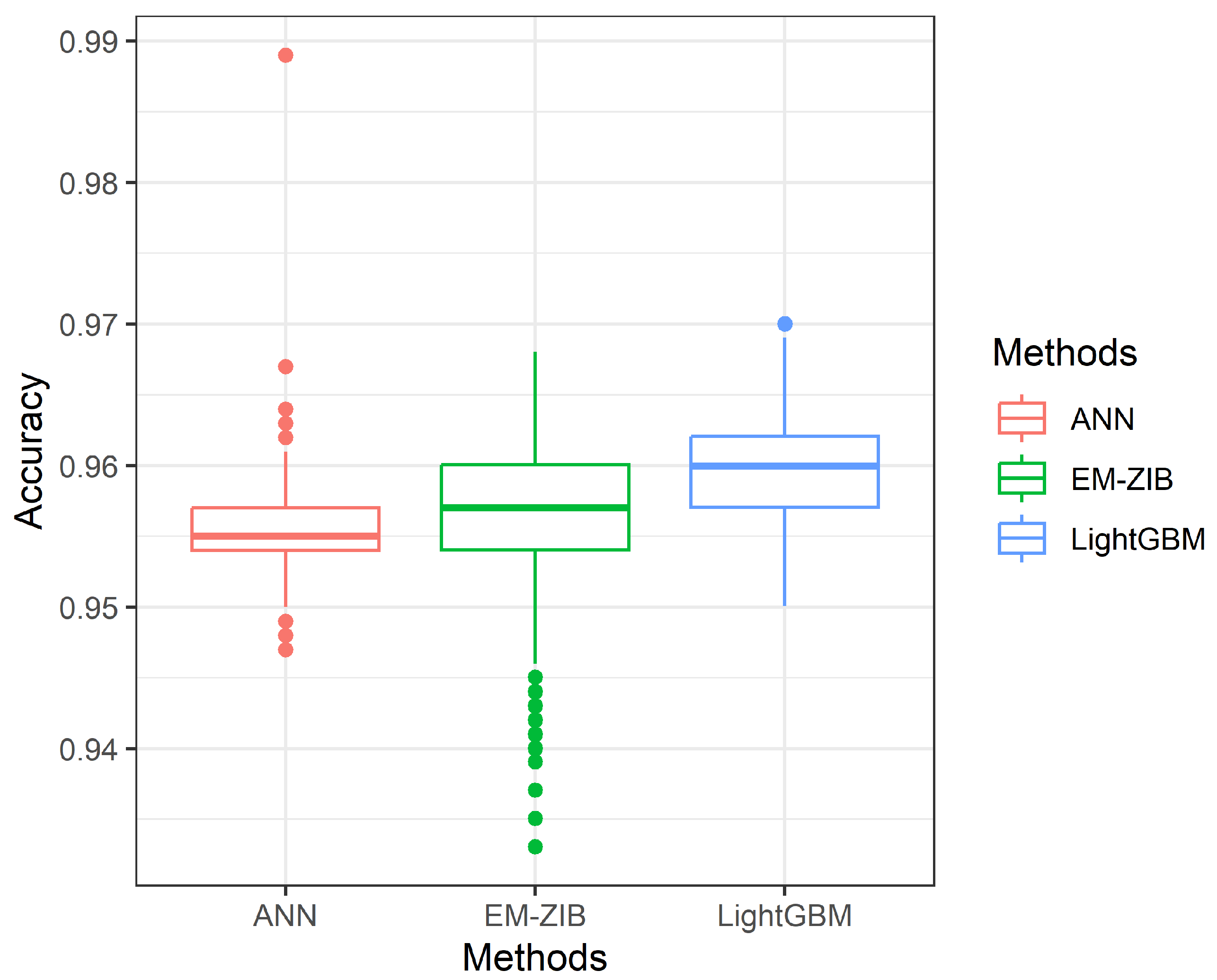
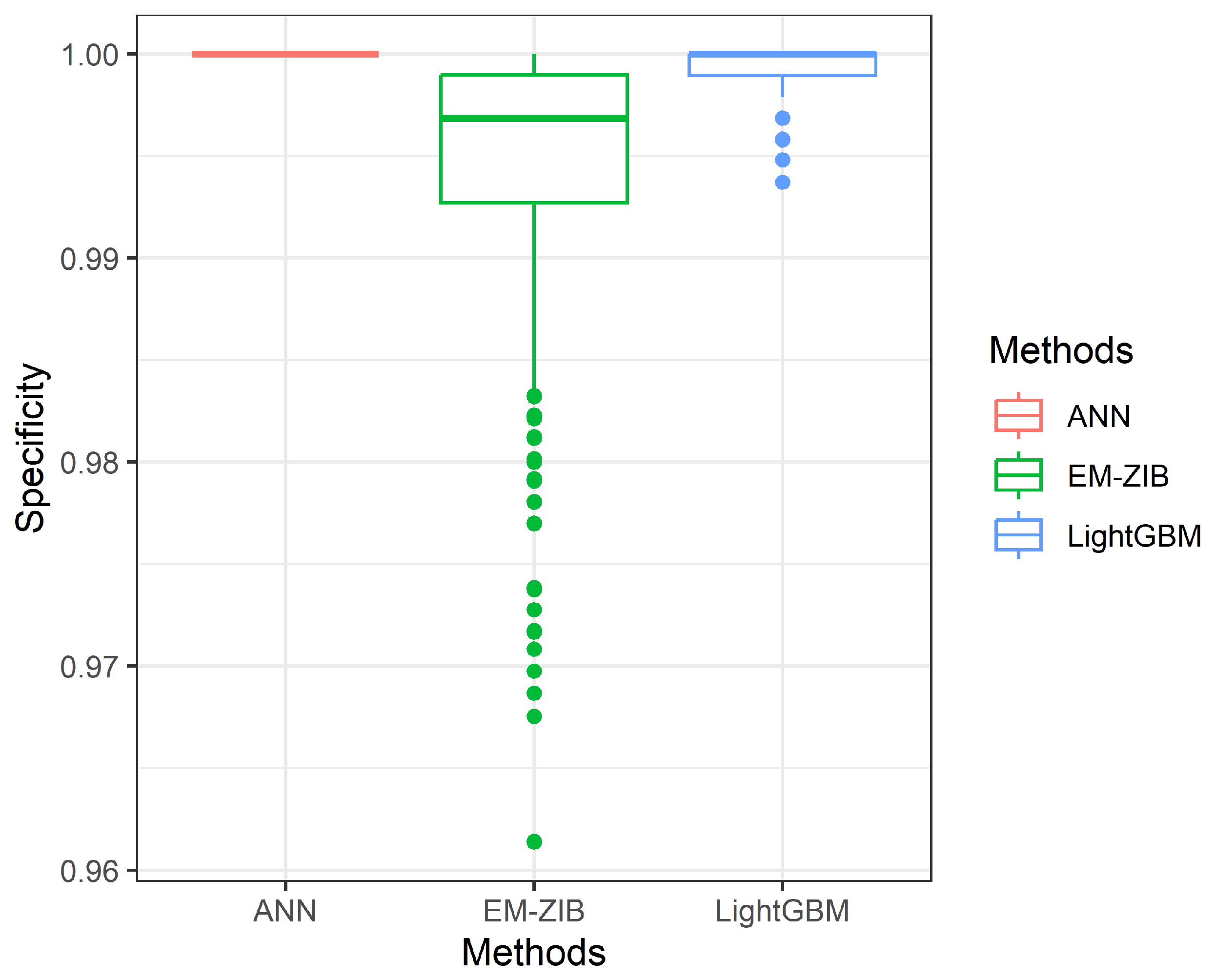
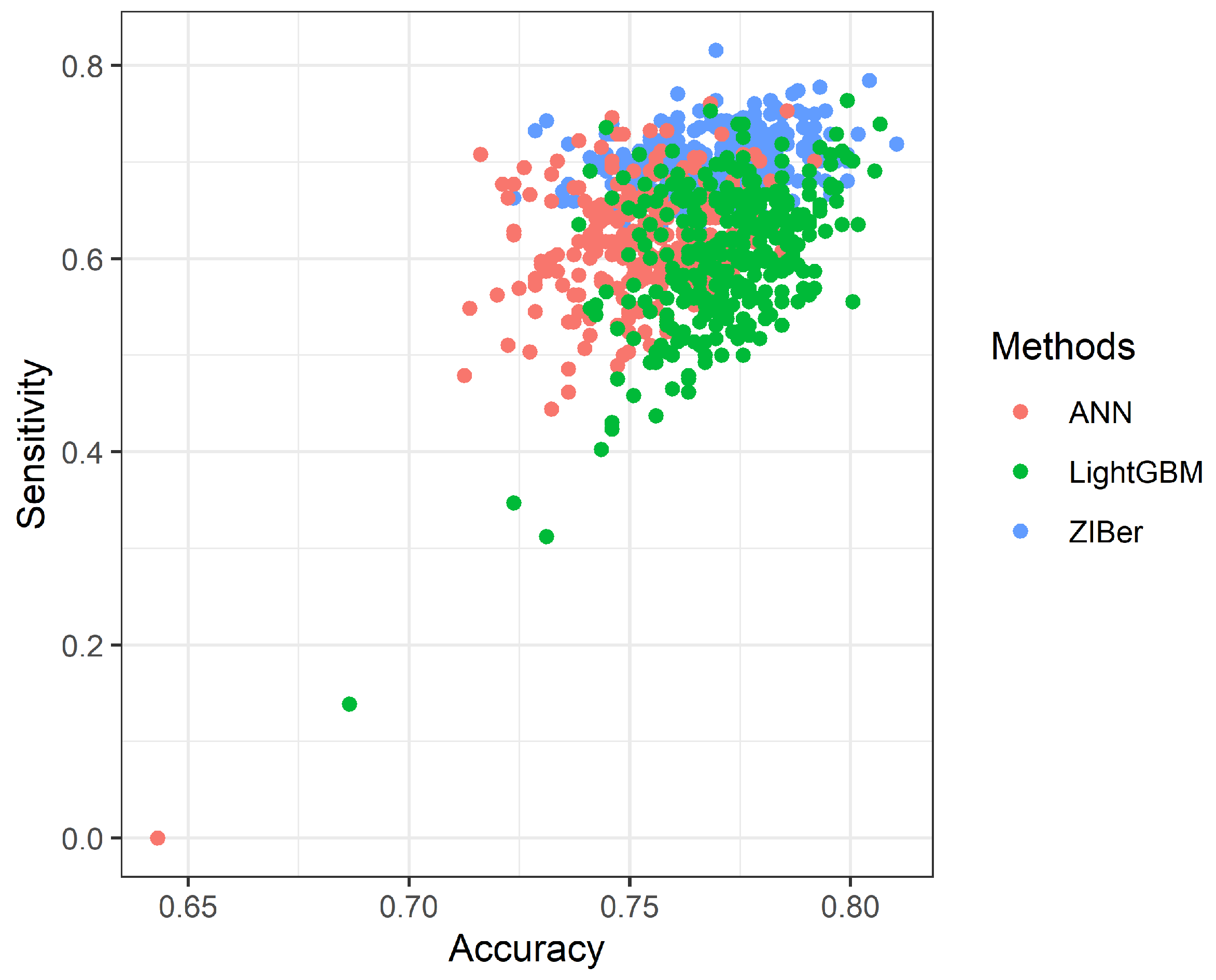
Even a ZIBer regression model has been proposed in the literature. How to obtain the maximum likelihood estimates (MLEs) of the ZIBer regression model parameters can be a gap in this topic. We are also interested in studying the performance of the ZIBer regression model compared with machine learning classifiers, for example, the LighGBM and ANN methods. In this study, we propose an EM algorithm to obtain reliable MLEs of the ZIBer regression model parameters based on zero-inflated-imbalanced binary data. The logistic model links the event or non-event probability with explanatory variables. The innovation is to propose the theoretical process of the EM algorithm to obtain reliable MLEs for the ZIBer regression model using imbalanced data sets. Monte Carlo simulations were conducted to show the predictive performance of the ZIBer, LightGBM, and ANN methods for binary classification under imbalanced data.
The rest of this article is organized as follows.
Section 2 presents the ZIBer regression model and the proposed EM procedure that produces reliable MLEs of the model parameters. In
Section 3, two examples are used to illustrate the applications of using the proposed EM algorithm to the ZIBer regression model. In
Section 4, Monte Carlo simulations were conducted to compare the classification rate of the ZIBer model, LighGBM, and ANN methods in three measures. The design of Monte Carlo simulations and their implementation are studied in this section. Some concluding remarks are given in
Section 5.
2. Zero-Inflated Bernoulli Regression Model and EM Algorithm
Consider a special case about the infection status of a specific disease.
denotes the infection status for the specific disease of the
i-th individual in a sample of size
n;
if the individual is infected and
otherwise. The conditional distribution of
can be a Bernoulli distribution, denoted by
, where
is the conditional probability of
, given a
vector of explanatory variables,
. The logistic function to link
and
can be expressed by
where
is the coefficient vector. Failure to account for the extra zeros in a zero-inflated model can result in biased estimates and inferences.
Let
control the probability of
being a structural zero.
can be an unconditional probability of
being a structural zero controlled by an unobserved factor, say
. When
,
, otherwise,
,
can be 0 or 1, determined by the model
, where
. It can be shown that the unobserved factor
for
. Two situations result in
; the first situation is that
is a structural zero with probability
, and the other is the situation that
is not a structural zero but has the probability
to be zero. The unconditional probability of
can be presented by
where
. The unconditional probability of
can be presented by
We can obtain the unconditional distribution of
by
.
Using the second logistic function to link
and the
covariate vector of
, we obtain
where
is the vector of model parameters. After algebraic formulation, we can show that
Assume that sample
is available. The likelihood function can be constructed as follows:
After algebraic formulation, we can obtain the log-likelihood equation,
To obtain reliable maximum likelihood estimators, it could be challenging to directly maximize the log-likelihood function in Equation (
7). So, we suggest an EM algorithm to maximize the log-likelihood function.
Assume that an unobserved probability
can determine whether
is a structural zero or not; when
implies that
is a structural zero, and
implies that the Bernoulli distribution determines the response
is 1 or 0. The likelihood function based on complete data
can be represented by
The log-likelihood function can be represented by
and the log-likelihood function can be obtained by
where
and
Using Equations (
11) and (
12) to implement the following E-step and M-step until convergences of the estimates of parameters,
and
, are obtained.
- E-step:
Iteration
: Estimate
by its posterior mean
given the estimates
and
. If
, then
; otherwise,
where
A and
denote that
has a structure zero and is from a Bernoulli distribution.
- M-step:
Maximizing
to obtain
, and maximizing
to obtain
.
3. Examples
3.1. Example 1
A diabetes data set is used for illustration. The data set can be obtained from the R package version 2.1–3.1 “mlbench”. There are 768 records with eight independent variables including
The number of pregnancies.
The glucose concentration in the 2-h oral glucose tolerance test.
The diastolic blood pressure in mm Hg.
The triceps skin-fold thickness in millimeters.
Two-hour serum insulin in mu U/mL.
Body mass.
Diabetes pedigree function.
Age in years.
The response variable is Diabetes, which can be negative or positive. After removing incomplete records, we have 392 records for the final sample for illustration. We labeled all the independent variables by , . Moreover, the variables of “The diastolic blood pressure in mm Hg”, “Body mass”, and “Age” are selected as the independent variables, labeled by , to develop the second logistic regression model. The diabetes rate is 0.332 in this example.
All independent variables are scaling with
and
for
. Using the proposed EM algorithm, we can obtain the following ZIBer models,
and
When the estimated probability
,
, the corresponding person is identified for diabetes. Based on the obtained model, the accuracy is 0.806. We want to study how much efficiency is lost using the typical logistic regression model. Based on the typical logistic regression model, we obtain the following estimation function form,
When the estimated probability
,
, the corresponding person is identified for diabetes. Based on the obtained model, the accuracy is 0.798. The efficiency of the typical logistic regression model can be improved, but the improvement is not significant based on only 0.008 increment on the Accuracy. The diabetes rate is 0.332. If the success rate is high, the improvement of replacing the typical logistic regression model with the ZIBer regression model could not be significant. The finding makes sense because the imbalance in this example is insignificant. The R codes using the proposed EM algorithm to obtain the MLEs of the ZIBer regression model parameters are given in
Appendix A. We use the best cut-rate of 0.53 to predict the value of Diabetes and identify it as positive if
and 0 otherwise. We can obtain the Accuracy, Sensitivity, and Specificity as 0.806, 0.608, and 0.905, respectively.
3.2. Example 2
A Taiwan credit data set is used for illustration. This data set can be obtained from the UC Irvine Machine Learning Repository by the hyperlink
https://archive.ics.uci.edu/dataset/350/default+of+credit+card+clients; this data set was donated to UC Irvine Machine Learning Reponsitory on 25 January 2016. The response variable is the default payment, Yes = 1 for default and Yes = 0 for non-default. There are 30,000 records with the following 23 explanatory variables:
The Given Credit Amount of NT dollars, including the individual consumer and his (or her) family (supplementary) credits.
Gender, 1 for male and 2 for female.
Education, 1 for graduate school, 2 for university, 3 for high school, and 4 for other.
Marital Status, 1 for married, 2 for single, and 3 for other.
Age in years.
The history of past payments in 2005 from September to April in decent order of the columns. The measurement scale is −1 for pay duly, 1 for a one-month payment delay, 2 for a two-month payment delay, …, 8 for an eight-month payment delay, and 9 for a nine-month payment delay and above.
The number of bill statements in 2005 with NT dollars from September to April in decent order of the columns.
The amount of previous payments in 2005 with NT dollars from September to April in decent order of the columns.
The response variable of Default Payment is labeled by Y. We use the columns of The Given Credit Amount of NT dollars, Gender, Education, Marital Status, Age, and the payment statuses of April, May, June, July, and August as the independent variables, labeled by , , …, and , respectively, to develop the ZIBer regression model. In many instances, we need to subjectively determine the independent variables of for establishing the second logistic regression model. In this example, we select the columns of Gender, Education, Marital Status, and Age as the independent variables of for the second logistic regression model.
No missing records were found in this data set. First, we searched the rows with labels that were not well-defined in the independent variables and removed all records that were not well-defined from the data set. Finally, 4030 records are used in the illustrative data set for constructing the ZIBer regression model.
The summary of the credit card users in the categories of Default Payment, Gender, Education, and Marriage is given below.
1436 default and 2594 non-default credit card users are included in the illustrative data set. The proportion is 35.63%.
2385 female and 1645 male credit card users are in the illustrative data set. The proportions are 59.18% and 40.82%, respectively.
The number of credit card users in the education categories of Senior High School, College, Graduate, and Others are 624, 1713, 1683, and 10, respectively. The proportions are 15.48%, 42.51%, 41.76%, and 0.25%.
2076 credit card users are married, 1920 credit card users are single, and 34 credit card users are other. The proportions are 51.51%, 47.64%, and 0.85%.
Before model construction, we transform the categorical variable with three or larger categories into dummy variables. Hence, the Marital Status needs to be transformed into two dummy variables. If
, and 3, the new dummy variables of M1 and M2 can be obtained by
and (1,1), respectively. Let
,
,
,
, and
. All independent variables are scaling with
and
for
. Using the proposed EM algorithm, we can obtain the following ZIBer models,
and
When the estimated probability , , the corresponding customer is identified as a default. Based on the obtained model, the Accuracy is 0.911.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}