Abstract
We develop a method for estimating a simple matrix for a multidimensional item response theory model. Our proposed method allows each test item to correspond to a single latent trait, making the results easier to interpret. It also enables clustering of test items based on their corresponding latent traits. The basic idea of our approach is to use the prenet (product-based elastic net) penalty, as proposed in factor analysis. For optimization, we show that combining stochastic EM algorithms, proximal gradient methods, and coordinate descent methods efficiently yields solutions. Furthermore, our numerical experiments demonstrate its effectiveness, especially in cases where the number of test subjects is small, compared to methods using the existing penalty.
1. Introduction
Item Response Theory (IRT) is a mathematical model used for applying and evaluating tests, and is employed in the creation and operation of various large-scale ability tests such as language proficiency exams. Although IRT models are practical, they assume a unidimensional latent trait, which is not suitable when the test measures multiple abilities. Therefore, to measure multiple latent traits, Multidimensional IRT (MIRT) models [1] are utilized, extending the IRT model to multiple dimensions. However, MIRT models can be challenging to interpret from the estimation results, such as understanding what each latent trait represents and the relationships among test items. Therefore, to facilitate interpretation, such as “what latent traits are the test items measuring,” it is desirable to have a simple structure in the estimated matrix, like having many zeros. In this paper, we propose a method for estimating a matrix with a simple structure where one item corresponds to one latent trait, using binary (correct/incorrect) response data.
In MIRT, the simplicity of the estimation results plays an important role in interpretability. Existing research has proposed penalization methods using -regularization, as employed in lasso [2,3], for MIRT [4]. Using -regularization shrinks the estimates towards zero, allowing some variables to be precisely zero. Thus, the method simplifies the estimated matrix by excluding unnecessary variables and performing variable selection. The properties of -regularization in linear regression have been widely studied and are known to provide high-accuracy estimates with consistency in model selection [5,6,7].
However, -regularization does not necessarily produce interpretable and simple matrices as estimation results. For example, if the regularization parameter is too large, all variables are estimated as zero, making the analysis meaningless. Indeed, numerical experiments (Section 4) have shown that when the number of subjects (examinees) is small, selecting the regularization parameter using the Bayesian Information Criterion (BIC) [8] leads to selecting a matrix where all components are zero. Also, -regularization uniformly shrinks all variables to zero, leading to more frequent zero estimates for variables close to zero.
In this study, we employ the product-based elastic net penalty (prenet penalty) [9], proposed in the field of factor analysis, for structure regularization. The prenet penalty is a penalty for the product of pairs in the same row of a matrix, and using this penalty ensures that the estimates have at most one nonzero component per row. Therefore, it allows clustering of test items by latent traits, with one item corresponding to one latent trait. If responses are multi-valued, the obtained responses can be treated as continuous values and solved within the framework of factor analysis. However, in cases like this study where responses are binary, solving within the conventional factor analysis framework is unnatural. Thus, this study can be seen as an extension of the prenet penalty to discrete factor analysis. The optimization of the proposed method efficiently combines the stochastic EM algorithm [10], the proximal gradient method [11], and the coordinate descent method [12].
The regularization parameter of the prenet penalty controls the simplicity of the estimated matrix. In this study, the regularization parameter is determined using BIC. Furthermore, a Monte Carlo simulation using synthetic data is conducted to compare -regularization with the proposed method using prenet. The proposed method with prenet demonstrates its ability to estimate the true structure of the matrix even with a small number of subjects.
The remainder of this paper is organized as follows: Section 2 describes the MIRT model and the prenet penalty dealt with in this study. Section 3 presents the optimization methods to obtain solutions to the proposed method. Section 4 demonstrates the performance comparison between -regularization and prenet penalty using Monte Carlo simulations with synthetic data. Finally, Section 5 concludes the paper and discusses future extensions.
2. MIRT Model and Prenet Penalty
2.1. 2-Parameter Multidimensional IRT Model
Consider a situation with responses from N subjects to J items. The response of subject i to item j is binary, denoted by . Each subject has K-dimensional latent traits, represented by . Assuming that comes from a 2-parameter multidimensional IRT (2-PL MIRT) model with , the model is
Furthermore, we assume local independence among responses, that is, let , , and . Then, it is assumed that
holds.
Assuming the prior distribution of as , the likelihood function for the complete data, given the latent traits and responses of each subject , is
In this paper, is modeled as the density function of independent normal distributions , where is the K-dimensional identity matrix. While it is possible to estimate the covariance matrix by considering a prior distribution of , in this context, we choose to fix as . The log-likelihood of , marginalized over , is
In marginal maximum likelihood estimation of conventional MIRT, one seeks to maximize (3) to find . However, this study considers adding regularization P to impose a simple structure on , with as the regularization parameter:
Setting results in -regularization, as proposed in [4].
2.2. Item Clustering Using structure Regularization
With -regularization like in lasso [3], when , the estimate , making clustering infeasible. In addition, the estimates are reduced by . This study uses for the product-based elastic net penalty (prenet penalty) [9]:
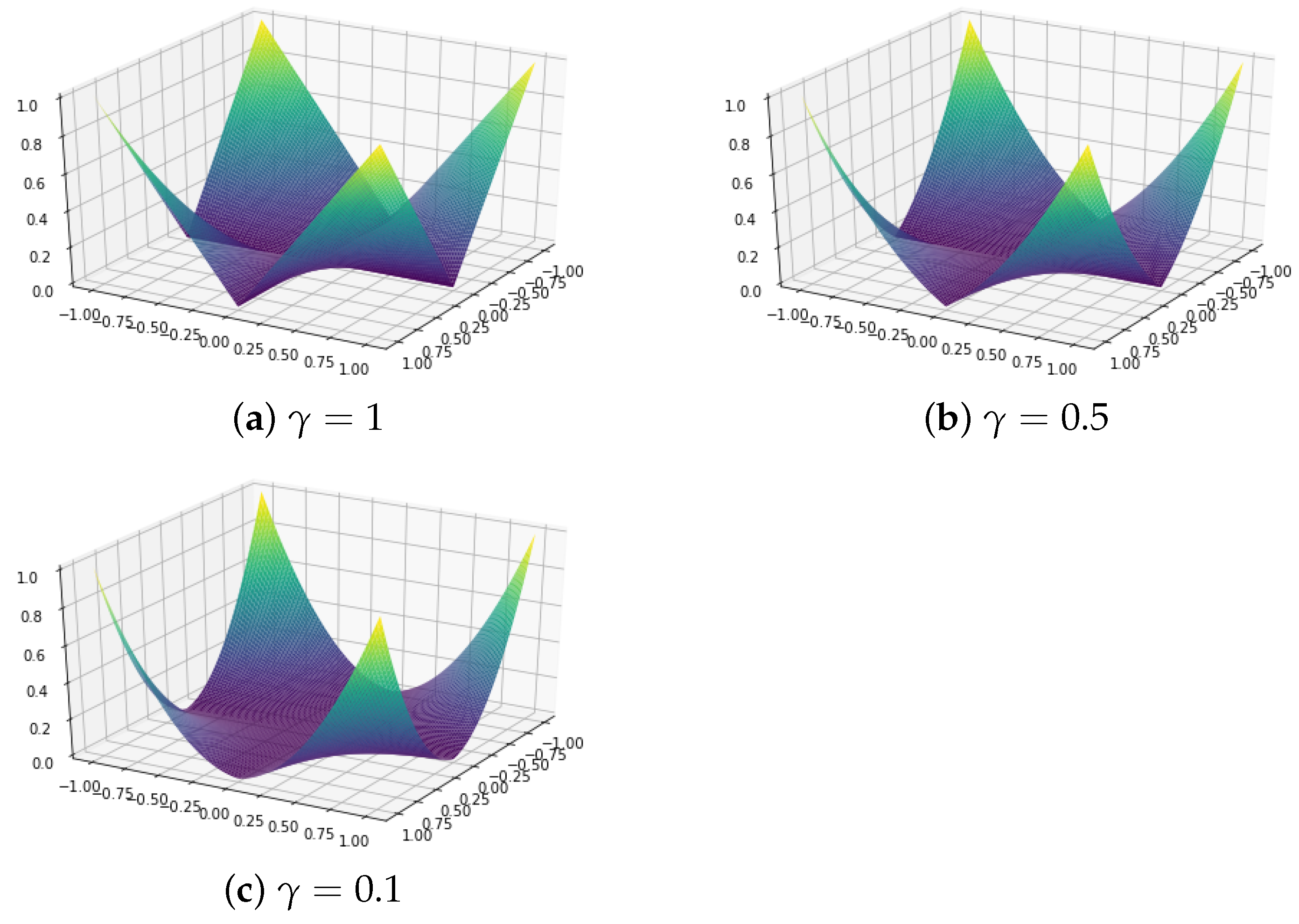
The prenet penalty () for is shown in Figure 1. Prenet has a pointed shape when or , and although it is not a convex function overall, it has the property of being multi-convex, becoming convex when other variables are fixed. Due to this property, an efficient solution can be obtained using the coordinate descent method.
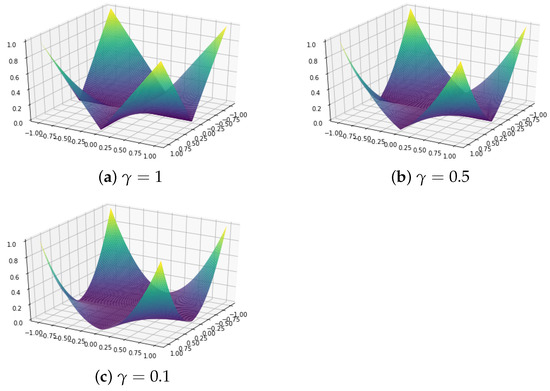
Figure 1.
The prenet penalty for .
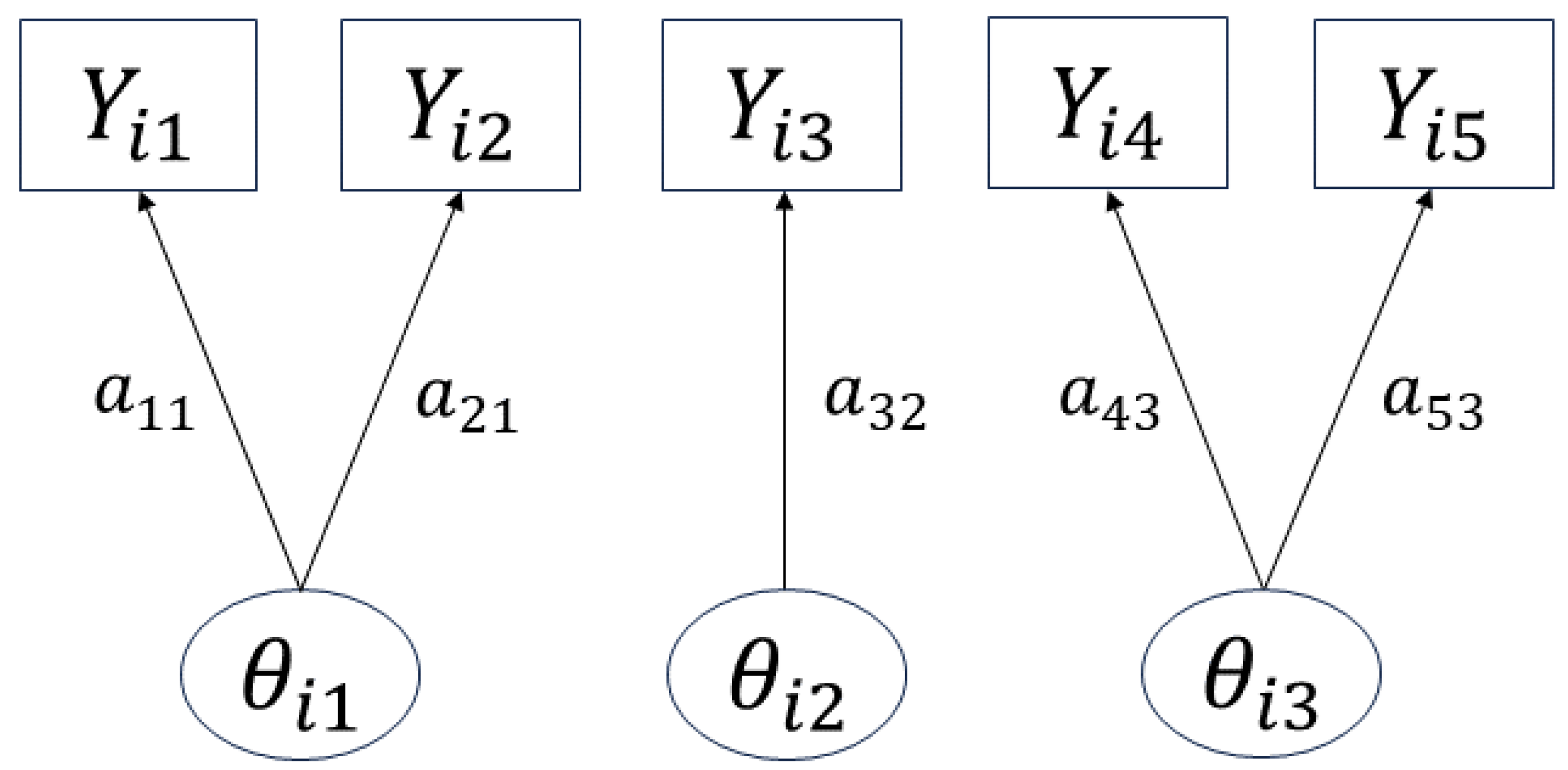
Using the prenet penalty, when , a simple structure is imposed on . In fact, when , as , has at most one nonzero component per row (Proposition 1 in [9]), thus leading to a situation like in Figure 2, where each item corresponds to at most one latent trait. Therefore, it becomes possible to categorize each item by the necessary latent traits, enabling item clustering. The prenet penalty is also discussed in relation to k-means in [9], and can be seen as a generalization of the k-means.
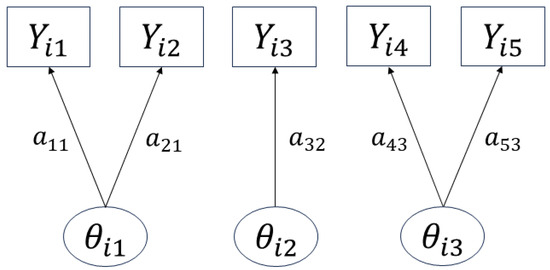
Figure 2.
Image of the obtained estimation results.
2.3. Determining the Regularization Parameter
In this study, the regularization parameter is determined using the Bayesian Information Criterion (BIC) [8]. The BIC is defined as follows:
Here, represents the number of nonzero components in A. The BIC applies a penalty based on the number of nonzero components in , thus penalizing the model’s complexity. We calculate the BIC (6) for several values of and select the parameter that minimizes the BIC. The parameter for the prenet penalty should also be determined using the BIC, but in the experiments of this paper, only is used. Furthermore, when clustering is the goal, a sufficiently large can yield item clusters, but if is too large, the non-convexity of the prenet penalty becomes strong, leading to convergence to a local minimum and instability in the solution. Therefore, it is advisable not to make excessively large.
Just as in factor analysis, when the identifiability conditions of the orthogonal model (e.g., Theorem 5.1 in [13]) are satisfied, the solution becomes unique apart from the indeterminacy of orthogonal rotation. To fix this rotation, some constraints must be imposed on A. For instance, for , . Under these identifiability conditions and the constraint that has at most one nonzero component per row, implying the perfect simple structure, becomes unique except for the sign and permutation of columns. Using the prenet penalty, with the perfect simple structure can be estimated when . Therefore, in this study, we conducted estimation without adding any special constraints other than the prenet penalty.
3. Optimization Method
This section discusses methods to solve the optimization problem (4). In this paper, we employ the stochastic expectation-maximization (stEM) algorithm, as proposed in standard marginal likelihood estimation [10,14]. The EM algorithm is a method that seeks a solution by repeating the E-step, which calculates the expected log-likelihood of the posterior distribution, and the M-step, which maximizes the expected log-likelihood obtained in the E-step. In the stEM algorithm, the E-step is efficiently performed using random numbers from the posterior distribution, consequently making the calculations in the M-step more efficient.
3.1. Stochastic E-step (stE-step)
Let be the parameters at the t-th iteration. In the standard E-step, for iteration , the expected log-likelihood of the posterior distribution is computed as follows:
In the case of MIRT model, it is difficult to compute this as usual, so existing research [4] has used a lattice point approximation. In this study, we approximate by generating random numbers from the posterior distribution using the Markov chain Monte Carlo (MCMC) method, namely Gibbs sampling. The details of the random number generation method using Gibbs sampling are described in Section 3.3.
In the StE-step, random numbers from the posterior distribution are generated only once per iteration. That is,
is sampled, and
is approximated in this way.
3.2. M-Step
In the M-step, we maximize the regularized expected log-likelihood obtained in the stE-step (9). Specifically, using as the random numbers generated in the stE-step, we solve for
The part to be maximized, the expected log-likelihood, is composed of J logistic regressions, allowing easy calculation of gradients and Hessians. Therefore, it can be calculated using methods such as the proximal Newton method [15]. In this paper, we solve it using the proximal gradient method [11] and the coordinate descent method for -regularization [12]. Details of the optimization calculations are presented in Appendix A.
3.3. Gibbs Sampling
We consider the method of sampling from the posterior distribution in the StE-step. In this study, following [16], we generate random numbers from the posterior distribution using Gibbs sampling with the Pólya-Gamma distribution. This approach is an extension of the method proposed for logistic regression [17].
Definition 1.
When a random variable X follows the distribution
we say that X follows the Pólya-Gamma distribution with parameters , denoted as . Here, is the gamma distribution with parameters .
Using the Pólya-Gamma distribution, the logistic function for can be expressed as an integral in the following form:
where is the probability density function of and . From (12), the model (1) with can be written as
Thus, the conditional distribution of given is
where . In this study, since the prior distribution for is , the conditional distribution (13) becomes a normal distribution, and
where .
Furthermore, considering the conditional distribution of , we have
Therefore, in the th step of the stE-step, we use Gibbs sampling to generate random numbers conforming to the posterior distribution as follows:
Random numbers from the Pólya-Gamma distribution can be obtained using R packages such as “pg”.
3.4. Calculation of Final Estimation Results
In the StEM algorithm, since the stE-step computes stochastically using random numbers as in (9), it does not converge to a certain value like the conventional EM algorithm. Therefore, the final estimation result is obtained by operations such as averaging. In [10], the last m steps are used with as
However, since stochastic operations are performed in the stE-step, even if regularization terms such as -regularization or prenet penalty are added, is not always zero in steps . Therefore, if the estimation result is obtained using (18), the advantages of regularization cannot be fully utilized. In this study, for the estimation of , the median of the last m steps is used as
By using the median, if is mostly zero, is estimated as zero. Note that for the estimation of , the average of the last m steps is used, similar to (18).
4. Numerical Experiments
In this section, we evaluate the performance of the proposed method using synthetic data with a prenet penalty.
Comparison with Lasso
The synthetic data used in this study, with , is generated as follows:
with . The parameter for the prenet penalty is set to 0.1. For lasso, estimation is performed with values of , and the BIC is calculated for each. The result with the smallest BIC is chosen as the lasso estimation result. Similarly, for our method with the prenet penalty, estimation is carried out with values of , and the result with the smallest BIC is chosen. For both methods, a warm start is performed. The estimation begins by determining the maximum , and subsequently, is decreased. The estimation at each step uses the preceding as the initial value.
First, we evaluate the estimation results of lasso and prenet regularization when data is generated 50 times with . The evaluation metrics used are the mean squared error (MSE) and the correct estimate rate (CER). MSE and CER for the sth data’s estimation result can be calculated as follows:
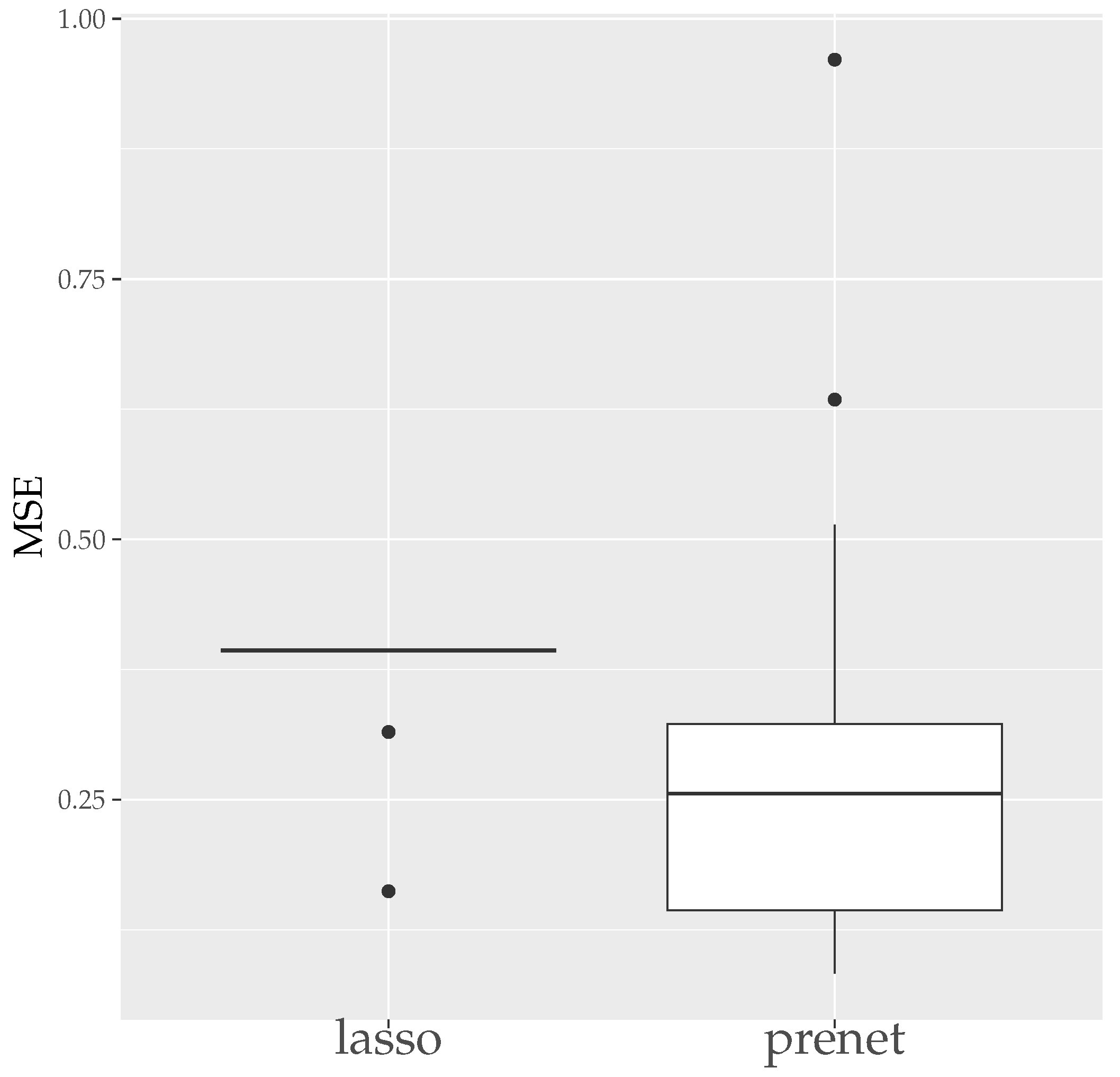
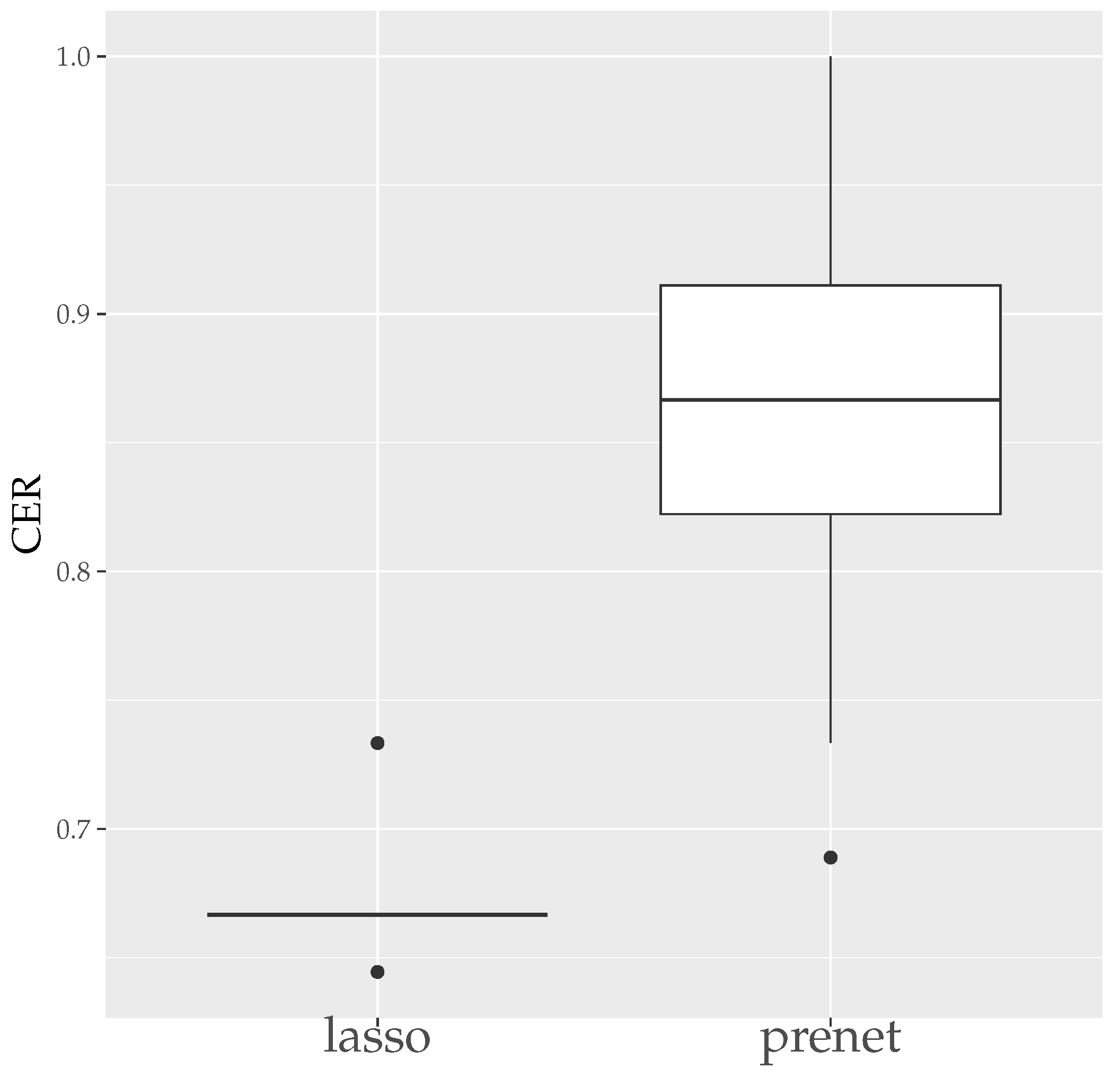
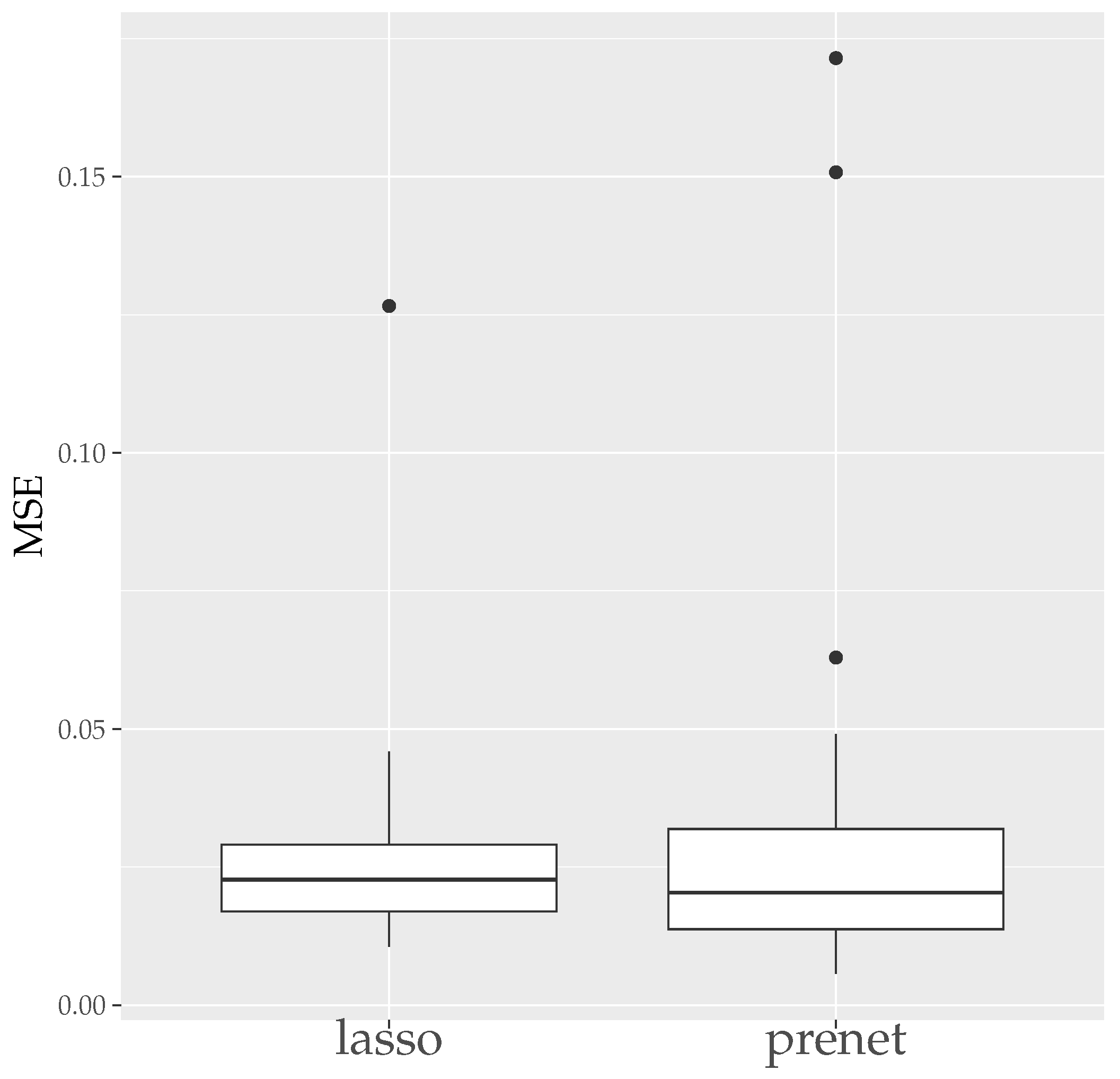
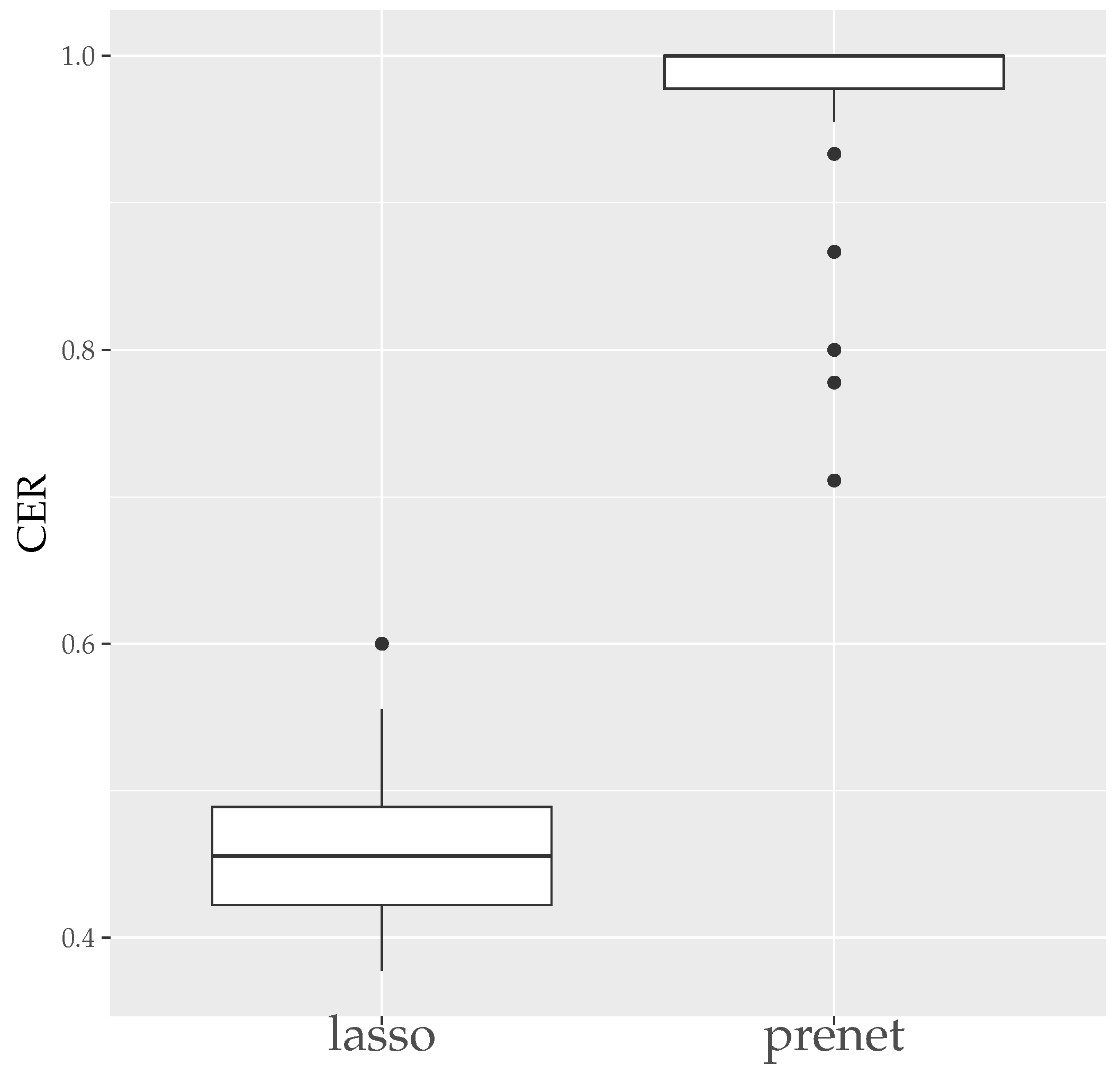
MSE measures how well is estimated, and CER measures how well the structure of is estimated. Since the estimation results of lasso and prenet are indeterminate with respect to the sign and permutation of the columns of , MSE and CER are calculated for all sign and permutation combinations, choosing the smallest one. Figure 3 shows the boxplot of MSE when is selected by BIC. In the case of lasso, choosing by BIC often results in , with estimated only twice. On the other hand, for prenet, one component in each row does not become zero, resulting in and generally smaller MSE compared to lasso. Next, Figure 4 shows the boxplot of CER. For lasso, as mentioned earlier, all components become zero, failing to estimate the structure of well. For prenet, the average CER is around 85%, indicating a good estimation of the structure. As a result, with a small sample size of , lasso fails to estimate the structure of , reducing all components of to zero. In contrast, prenet successfully estimates the structure of , performing better than lasso.
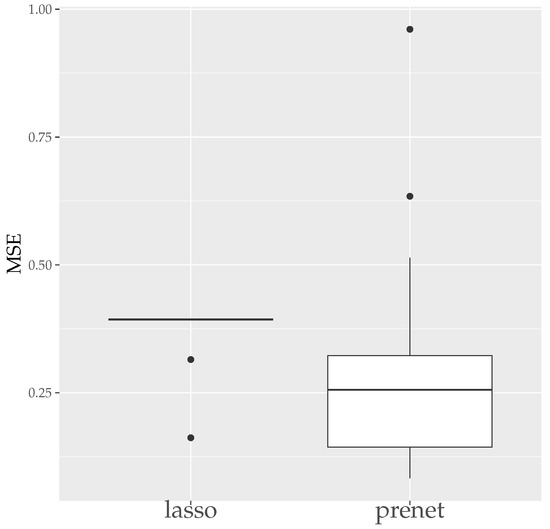
Figure 3.
MSE of (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
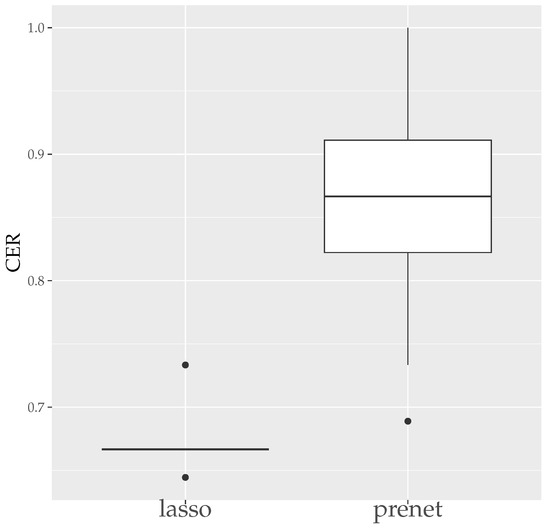
Figure 4.
CER of (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
Next, we present the boxplots of MER and CER for the estimation results when generating data 50 times with in Figure 5 and Figure 6. As seen in Figure 5, unlike the case of , the estimation results by lasso are not zero when , and the MSE is smaller compared to prenet. However, the CER of the results of the lasso estimation is low, indicating that it does not accurately estimate the structure of . On the other hand, prenet has a slightly higher MSE but a higher CER, successfully estimating the structure of . In fact, in more than half of the cases, the CER reaches 1, perfectly estimating the structure of .
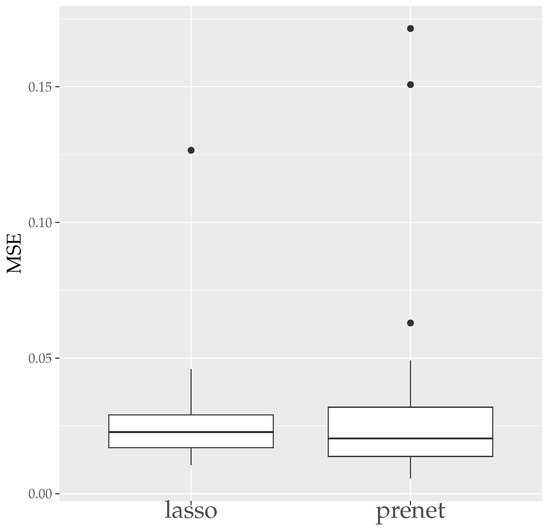
Figure 5.
MSE of (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
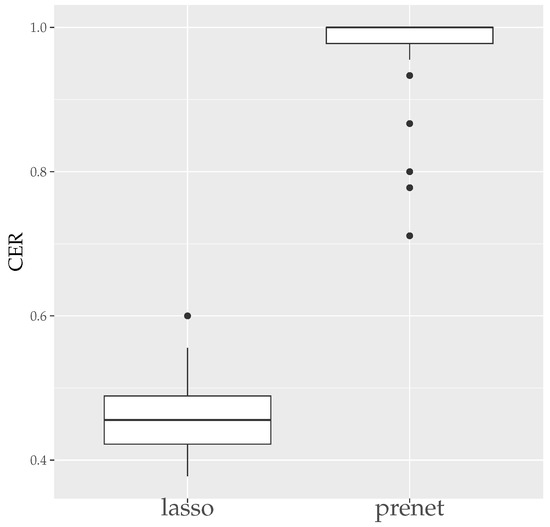
Figure 6.
CER of (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
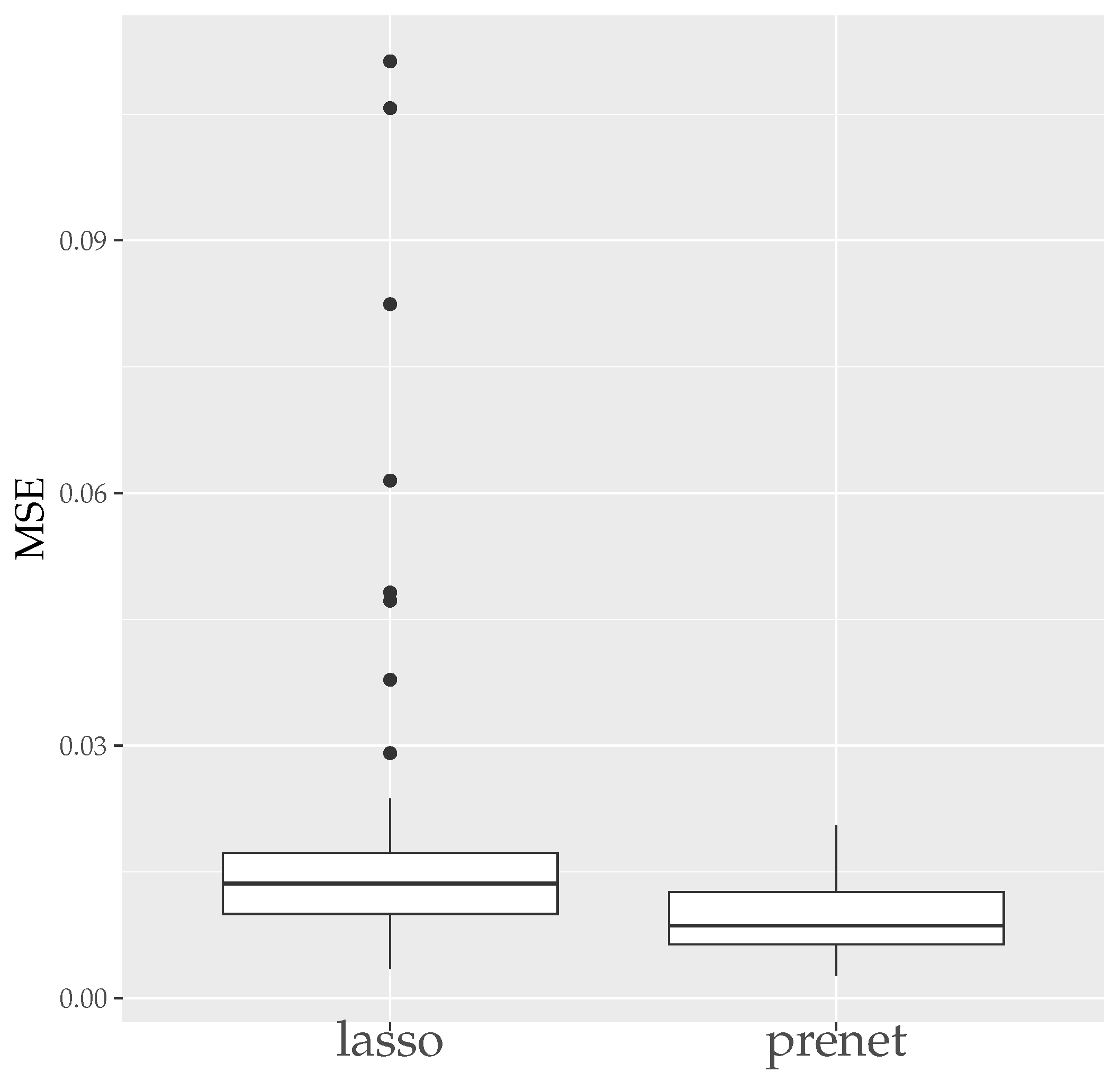
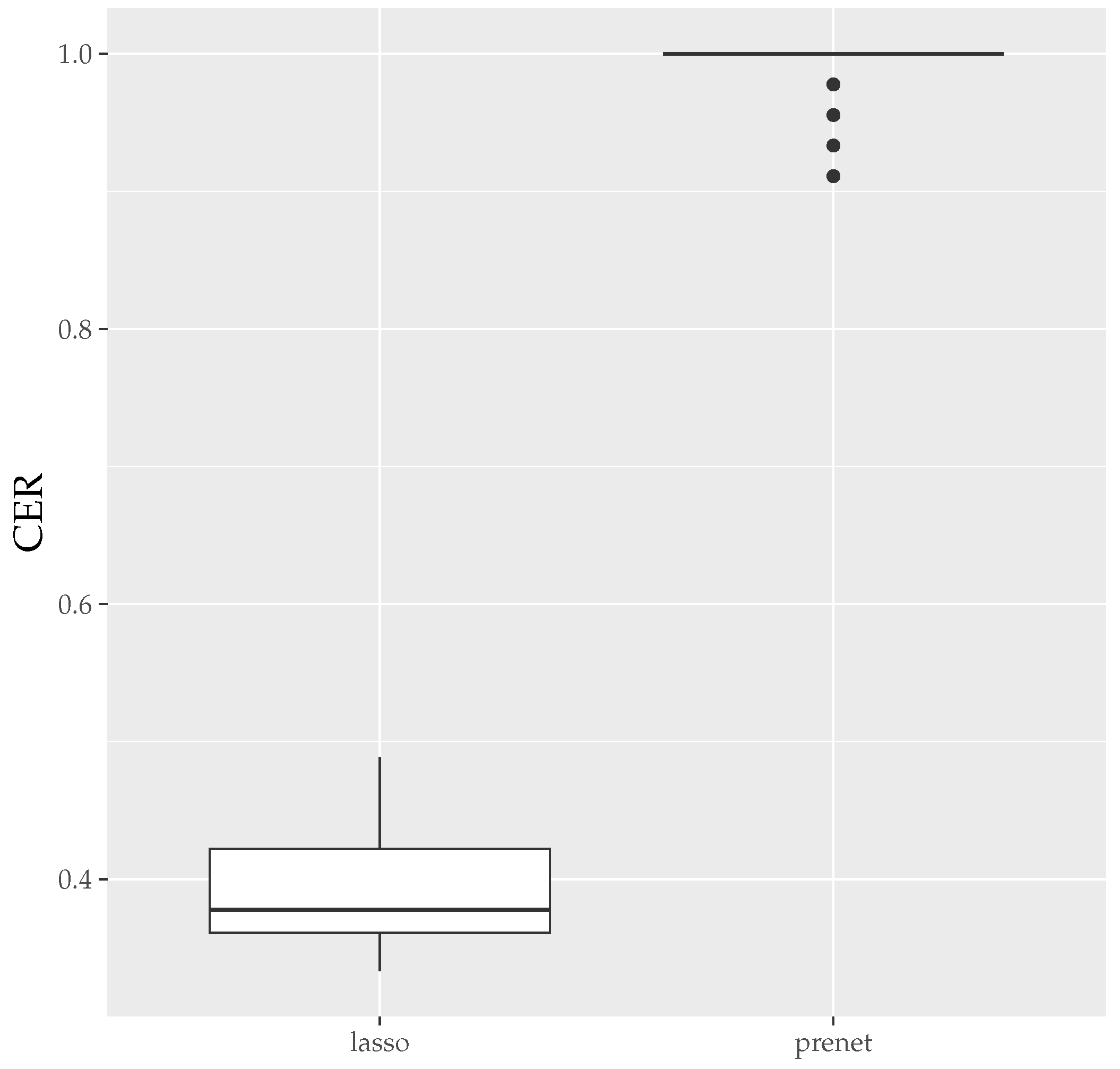
Finally, the boxplots of the Mean Error Rate (MER) and the Correct Estimation Rate (CER) for the estimation results generated 50 times with are shown in Figure 7 and Figure 8. As seen in Figure 7, unlike the case of , the estimation results by prenet are smaller and more stable compared to lasso when . Regarding the CER, while lasso is mostly unable to estimate the structure of , prenet can perfectly estimate the structure of in most cases, resulting in a CER of 1.
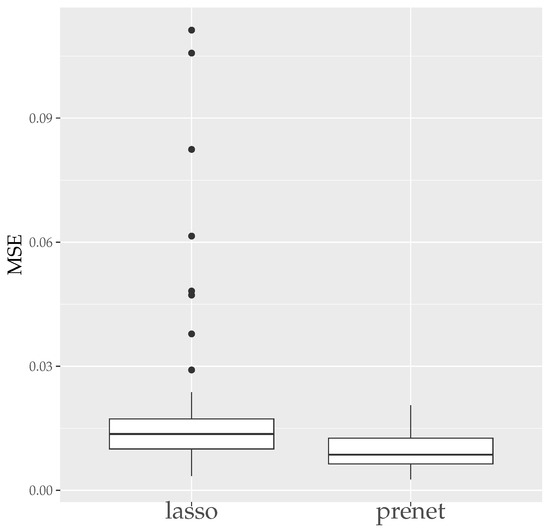
Figure 7.
MSE of A (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
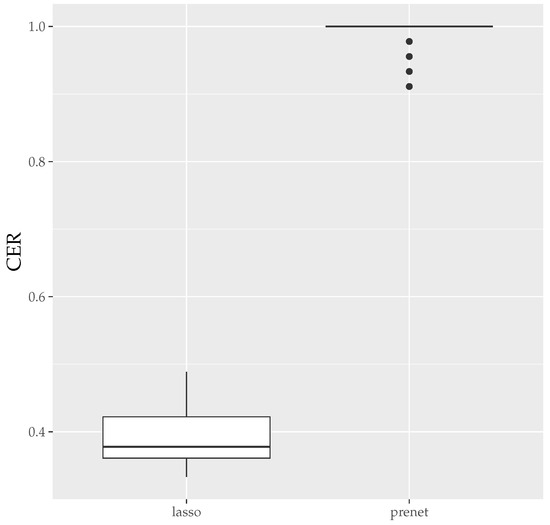
Figure 8.
CER of A (). The median (central line in the box), the interquartile range (width of the box) and the outliers (points outside the lines) are illustrated.
5. Conclusions
In this study, we proposed a method for clustering test items in the 2-PL MIRT model using the prenet penalty for structure regularization. The prenet penalty allows each item to be affected by only one latent trait, resulting in a simple structure, making the estimation results easier to interpret. Although the prenet penalty is generally non-convex and thus difficult to optimize directly, it has a multi-convex property where it becomes convex when focusing on one variable and fixing the others, allowing efficient solution via the coordinate descent method. In this study, we efficiently estimated using the stochastic-EM algorithm with the proximal gradient method and the coordinate descent method, also used in lasso. However, the estimation results may stop at a local minimum, so it is necessary to compute several times with different initial values. In numerical experiments, we applied the method to synthetic data and demonstrated that it can estimate the structure of the item matrix better than lasso. With lasso, when the number of subjects is small, using BIC to determine parameters results in all estimates becoming zero, while prenet does not have this issue and can estimate well even with a small number of subjects. Also, with lasso, all estimates shrink, and with large , is estimated, but with prenet, if only one component per row is nonzero, the prenet penalty becomes zero, avoiding such shrinkage. Therefore, the estimates becoming entirely zero is almost non-existent.
In this study, we dealt with the 2-PL MIRT model where responses are binary, but future research should extend to models with guessing and to cases where responses are multi-valued. Also, while this study only dealt with synthetic data, applications to real data and a further detailed evaluation of the performance of the proposed method are necessary. Furthermore, it is necessary to examine how estimates would be affected when imposing additional constraints such as for , .
Author Contributions
Methodology, R.S. and J.S.; validation and writing, R.S.; supervision, J.S. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by JSPS KAKENHI Grant Number JP23KJ1458 and the Grant-in-Aid for Scientific Research (C) 22K11931.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not aplicable.
Data Availability Statement
The evaluation in the paper is based on synthetic data described above.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Details of the M-Step
Appendix A.1. Proximal Gradient Method
Here, we consider the update method in the M-step when the regularization parameters are fixed. The proximal gradient method [11] minimizes a function expressible as with respect to . Starting with an initial value and a step size ,
is updated in this manner. Here, is called the proximal operator. In the case of this study, to optimize (10) at the step of the EM algorithm, we set and
Defining , the gradient of f is
Here, , , , and is a vector with all components as 1. Therefore, applying the proximal gradient method, at each step u using the gradients of ,
are solved to update . Here, is the Frobenius norm, which is the sum of squares of all elements in a matrix.
Since there is no regularization applied to b,
can be updated simply. The update method for is explained in the following section.
Appendix A.2. Computation of the Proximal Operator
Here, we consider the update of as in (A5). The prenet penalty is non-convex, making a direct update of challenging. However, as the prenet penalty is multi-convex, optimizing one variable while fixing the others is straightforward. Therefore, we can solve (A5) using the coordinate descent method.
The calculation formula is as follows:
Here, . Note that are values from the previous step in the proximal gradient method. Therefore, using (A7), we update for each , and repeat until convergence to find the proximal operator for .
References
- Reckase, M.D. Multidimensional Item Response Theory, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Sun, J.; Chen, Y.; Liu, J.; Ying, Z.; Xin, T. Latent variable selection for multidimensional item response theory models via L 1 regularization. Psychometrika 2016, 81, 921–939. [Google Scholar] [CrossRef] [PubMed]
- Fu, W.; Knight, K. Asymptotics for lasso-type estimators. Ann. Stat. 2000, 28, 1356–1378. [Google Scholar] [CrossRef]
- Wainwright, M.J. Sharp thresholds for High-Dimensional and noisy sparsity recovery using-Constrained Quadratic Programming (Lasso). IEEE Trans. Inf. Theory 2009, 55, 2183–2202. [Google Scholar] [CrossRef]
- Zhao, P.; Yu, B. On model selection consistency of Lasso. J. Mach. Learn. Res. 2006, 7, 2541–2563. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Hirose, K.; Terada, Y. Sparse and simple structure estimation via prenet penalization. Psychometrika 2022, 88, 1381–1406. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Chen, Y.; Liu, Y. An improved stochastic EM algorithm for large-scale full-information item factor analysis. Br. J. Math. Stat. Psychol. 2020, 73, 44–71. [Google Scholar] [CrossRef] [PubMed]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization paths for generalized linear models via coordinate descent. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Anderson, T.W.; Rubin, H. Statistical Inference in Factor Analysis. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 26–31 December 1954; University of California Press: Berkeley, CA, USA, 1956. [Google Scholar]
- Celeux, G.; Diebolt, J. A stochastic approximation type EM algorithm for the mixture problem. Stochastics 1992, 41, 119–134. [Google Scholar] [CrossRef]
- Lee, J.D.; Sun, Y.; Saunders, M. Proximal Newton-type methods for convex optimization. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar]
- Jiang, Z.; Templin, J. Gibbs samplers for logistic item response models via the Pólya–Gamma distribution: A computationally efficient data-augmentation strategy. Psychometrika 2019, 84, 358–374. [Google Scholar] [CrossRef] [PubMed]
- Polson, N.G.; Scott, J.G.; Windle, J. Bayesian inference for logistic models using Pólya–Gamma latent variables. J. Am. Stat. Assoc. 2013, 108, 1339–1349. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).