1. Introduction
Multiple hypothesis testing (MHT) is a collection of statistical methods that are used to perform more than one statistical test simultaneously. Specifically, if there are m statistical tests to be performed, these methods aim to categorize these m tests into two groups: tests where the null hypothesis is true, indicated as , and tests where the alternative hypothesis is true, indicated as . This categorization is conducted in a way that controls the maximum allowable value of some error. MHT methods are particularly useful in applied statistics because they can handle large datasets, such as Big Data, where the real problem at hand often involves testing multiple scientific hypotheses simultaneously. One of the pioneering applications for MHT methods is in Genome-Wide Association Studies (GWASs) using RNA-seq technology. In this context, m represents the number of gene abundance tests for an Expression Sequence Tag (EST) in a given biological sample. These abundance counts are then compared across two different biological populations to test m hypotheses about comparisons and identify genes associated with a specific characteristic or phenotype related to the two biological populations.
Because it is not feasible to model all tests together using a single comprehensive sampling model, each test (each gene) is modeled independently. These individual models are combined in an MHT procedure. The MHT procedure takes the marginal evidence from each test as input and outputs the joint evidence in all tests for a given threshold
t in all tests which leads to a separation between tests supposed to be under
from those under
. The primary goal of using an MHT procedure is to control certain types of errors. On the one side those related to the number of errors in declaring tests as coming from
when they are actually from
: these are the False Positive Rate (
) the proportion of false rejections among all rejections and the False Discovery Rate (FDR), which is the expectation over the random sample of
, it is the proportion of those rejections that should not have been rejected; while on the other side, we wish to control the proportion of missed rejections (declaring tests as coming from the
when they are from
) overall rejection, the False Nonrejection Proportion (
) and its expectation False Non-rejection Rate (FNR). An MHT procedure aims to generate a Receiver Operating Characteristic (ROC) curve:
versus
so that the Area Under the Curve (AUC) approaches 1. This happens when
for all thresholds
t and considering the expectation referred to above, this is equivalent to having a
. In this sense, we consider equivalent controlling FPR and FDR, although they are not exactly the same. This occurs, for example, for the well-known Benjamini–Hochberg (BH) procedure [
1] for
under assumptions untestable on a given sample [
2]. These assumptions generally relate to the dependencies between the tests and the marginal sampling distributions of the test statistics [
3], which are represented by the
p-values
.
The most common MHT methods usually rely on
p-values generated by statistical tests. Because
p-values can be derived from a wide range of statistical models, from simple to complex models such as Bayesian models with intractable likelihoods [
4], they are often the go-to choice in MHT. In ideal conditions where the null hypothesis is simple or the test statistic is ancillary to the nuisance parameters, the
p-values are uniformly distributed between 0 and 1. Such
p-values are referred to as
calibrated, making constructing reliable MHT procedures straightforward.
However, these ideal conditions are rare. In many practical cases, the
p-values deviate from the uniform distribution, making them unreliable for controlling the FDR [
3].
This problem has led researchers to create adaptive MHT methods that estimate the true distribution of
p-values [
5,
6,
7]. There is also growing interest in using additional samples to recalibrate existing MHT methods [
7,
8]. We propose a contemporary approach that utilizes deep learning techniques for this recalibration. The way we use this technique is also known as
transfer learning in the machine learning language. Transfer learning is meant as a statistical technique in machine learning where a model developed for a particular task (i.e., analyzing an MHT problem where the truth is known) is reused as the starting point for a model on a second task (i.e., analyzing an MHT problem where the true is unknown). It is an optimization that allows for rapid progress or improved performance when modeling the second task. In the context of neural networks, this involves transferring the weights and learned features from a pre-trained neural network to a new neural network being trained for a different, but related, task.
Here, to work around the difficulties of using
p-values that are often uncalibrated, we call for a Bayesian approach using Bayes factors (BF) for testing. BFs are the ratio between the marginal probability of the sample under the alternative hypothesis and the null. Individual test evidence from a BF strongly depends on the prior evidence for the unknown parameters in the composite null hypotheses. These are parameters that are not common to all hypotheses, and the prior distribution affects the marginal of the data and hence the BFs. Then the BFs could be arbitrarily driven by the prior rather than by the data. In contrast, for MHT, it has been shown in [
9] that it is possible to use the so-called uncalibrated BF,
, from
, where cBi is the ith full BF of the alternative hypothesis against the null in test i, and c > 0, is the ratio between the two prior normalization constants for the null and alternative hypotheses.
is not a BF as it misses the prior normalizing constants
c which is why it is referred to as uncalibrated, i.e., its interpretation is not that of the relative evidence between two hypotheses. Suppose that many tests involve models with one or more nuisance parameters (composite null hypotheses). In this case, an expert would need to elicit a prior distribution of unknowns in each test, which is unfeasible given the large value of
m. Therefore, substituting the presence of an expert by employing formal rules in the prior definition leads to two usually vague or improper priors that must be employed for the alternative and null models. Therefore, the BF for the single hypothesis test is not determined due to the ratio between the prior
pseudo-constants
, where
and
are the unbounded prior normalization constants for the parameters of the null hypothesis,
and the alternative
, respectively (see [
9,
10]). Furthermore, in [
9,
10], it is shown that the use of proper well-calibrated priors, leading to fully defined and interpretable BFs
, is not necessary in MHT. Uncalibrated BFs,
in MHT avoids employing nonscalable computational techniques to obtain a properly defined BF
for each test.
Although a comprehensive overview of the literature on Multiple Hypotheses Testing (MHT) is beyond the scope of this article, readers are encouraged to consult seminal review articles such as [
11,
12,
13] for insights specifically relevant to Genome-wide Association Studies (GWAS).
The crucial insight to highlight is that all MHT methodologies essentially rely on an ordered sequence of test statistics, and the order is sample-dependent, and thus per se random. This is typically presented as
in conventional methods or as
in the BF approach [
9,
10], in which it is clear that
does not alter the order. These ordered sequences serve as the output of various statistical tests and the input of MHT and the methodology proposed in this article. The sequences are valuable for segregating the tests that fall under the null hypothesis from those that fall under the alternative hypothesis.
The core concept is that the same sampling models used for obtaining p-values or BFs can also produce a training set of either p-values or BFs. The labels for the null and alternative hypotheses under which p-values or BFs are generated are already known in this training set. This training set can then be used to fit a classification model during a learning phase. In this light, the problem of MHT becomes one of classifying subsequences of p-values or BFs originating from either the null or alternative hypotheses.
Today, the problem of classifying subsequences is very well handled using complicated functions known as Neural Networks (NN), for instance, the
one-channel convolutional NN (CNN). CNN is a specific class of NN suitable for analyzing structured (e.g., dependent) samples as images [
14] with the general purpose of classifying them to obtain, for example, a medical diagnosis [
15]. Furthermore, for our purposes, it is worth stressing that there is evidence that CNNs are very useful for analyzing Time Series [
16] better than other architectures such as NN recurrent and long-short-term memory [
17]. The architecture of a CNN is based on a connecting set of neurons (mathematical operations on some input) that are supposed to be trained to recognize relevant features in the observed sequence to achieve the minimum classification error, and thus the minimum FPR and FNP.
In the following sections, we limit our discussion to those aspects of CNNs directly relevant to their application in MHT. We refer the reader to existing reviews or books on the subject for a more comprehensive understanding, such as [
14]. The rest of this paper provides the actual code (based on Keras and Tensorflow) used to construct and train CNN. Detailed technical information is available there, and we conclude by emphasizing that all computations were performed on a standard laptop, negating the need for specialized hardware. The accompanying R code is accessible at: 14 December 2023
https://colab.research.google.com/drive/1TdM1FSVKm1GI55riUXoLbzcEcM3FeoNg?usp=sharing.
The remainder of this paper is structured as follows. Initially,
Section 2 outlines the MHT approach that we propose, with particular emphasis on estimating the probability, denoted
, that a hypothesis is part of the alternative set. Subsequently,
Section 2.1 demonstrates this framework through a simulation study based on a parametric example. Subsequently,
Section 4 delves into more intricate models by revisiting two RNA-seq experiments, where we contrast the evidence derived from BF and conventional
p-values. Concluding thoughts with an exposition of the limitations of this approach and additional comments are reserved for
Section 5.
2. Convolutional Neural Network for Multiple Testing Arising from Uncalibrated Bayes Factors
The MHT methodology elaborated in this study is based on a sequence of ordered BFs, , , ranging from the weakest to the strongest evidence of some common alternative hypothesis (to m) against a common null hypothesis. This empirically determined sequence serves as the classification subject for CNN.
To be precise, consider
as an ordered set of
BFs, where
is only introduced for notational convenience. We define the relative weights of the evidence among the
m alternative hypotheses as
with
. This set
represents the differential evidence that favors each alternative hypothesis relative to its predecessor.
The ordered sequence of interest is
, where each
corresponds to a BF
. Tests appearing earlier in this sequence are supposed to originate from the null hypothesis, while those appearing later are more likely from the alternative. In particular, although the individual
may not be interpretable due to the unknown scaling factor
c, the relative evidence
remains meaningful [
9].
Let the original set of hypotheses, denoted as
, be partitioned into two supposed nonempty sets
and
, representing true alternative and true null hypotheses, respectively. To estimate
with an ordered sequence of
W, it would suffice to estimate its size
, subject to
. As discussed in
Section 3, this can often, but not necessarily, be accomplished by estimating the position
of a change point in the sequence
.
To elucidate,
Figure 1 shows a simulated example with tests
and
, detailing how this methodology works in practice.
Figure 1 also reports the already mentioned training set for CNN that will be applied later in real-world scenarios where
and
are unknown.
The efficacy of using this particular CNN formulates the crux of our argument, affirming that the method’s robustness is not heavily dependent on various unknowns such as the number of tests under the null, , data signal strength (i.e., sharp or no sharp evidence from tests), test dependencies, and sampling distributions, among others.
2.1. Sequence of the Relative Weights of Evidence
This section introduces a generalized definition of customized later for specific parametric model environments. Consider a vector of experimental outcomes, , each featuring m distinct attributes such as gene abundance levels measured by RNA-seq counts. The vector includes replications for the ith feature, with .
The MHT issue can be framed as a Bayesian multiple model selection problem, where each test
i compares the evidence supporting the alternative hypothesis
against the null hypothesis
, which have the same prior probabilities (i.e.,
) as follows:
Here, and are typically default and often improper prior distributions on the unknown model parameters. The sets are a of partition , where .
Prior distributions are assumed to be the same across all tests (as the sampling model in each test) and are derived from a standard formal rule applied to each
for
. Such rules include but are not limited to, Jeffreys, Intrinsic, Reference, Matching, Nonlocal priors, or Conventional priors [
18,
19,
20,
21,
22,
23].
Consequently, for all
i:
where
and
are two positive functions (not necessarily measurable) and
and
act as normalizing pseudoconstants.
We assume the existence of prior predictive distributions for both the null and alternative hypotheses.
The BF of
against
can then be formulated as:
This calibrated BF, in the sense that it reports the posterior relative evidence of
against
according to the Jeffreys interpretation, is practically unscaled due to the arbitrarily low ratio
. We then define the uncalibrated or unscaled BF as follows:
Although
lacks standalone interpretability, it serves as a comparative measure [
9,
10]. For example, if
for all
, then the evidence supporting
over
is stronger than that for
over
, regardless of
c.
In summary, even if the priors are specified as vague or improper, their normalizing constants are effectively simplified in the sequence of Ws. This does not imply that priors are irrelevant in MHT, but their impact, specifically that of the constants and , is mitigated in the collective evidence derived from the tests.
2.2. Convolutional Neural Network on the Sequence of Relative Weights of Evidence
A one-dimensional CNN is fitted to the observed sequence
. The loss function used is the binary cross-entropy, which is the logarithmic representation of the Bernoulli density:
, where
(
) if the test
i has been observed under the alternative (null) in the training set. This function minimizes the classification error, and thus the FPR and FNP. For each test
i, the fitted CNN produces a point estimate of the probability,
, that it belongs to
. The decision about the set of observed tests from the alternative is formulated as
where
q is the FDR level (or the averaged FPR) that we want to control when testing the hypotheses. It can be argued that
is the maximum
a posteriori probability that the test
i is observed under the alternative given the set of
m tests and the priors of the underlying Gaussian process prior to the NN weights [
24].
Using CNN, we establish a complicated function
that accounts for the dependencies among the
W’s. This is how the
m tests are jointly considered to control the FDR at level
q, as will be discussed in the next
Section 3.
The assumption of exchangeability between the training (simulated) sample and the observed sample of
W’s is understood within the context of the sampling model induced by the fitted CNN. The existence of untestable assumptions needed when using the usual MHT has to be compared with the possibility of assessing the goodness-of-fit of a trained CNN. This can be conducted using routine analyses typical of the machine learning literature by assessing performance on test sets, which can also be simulated. This is exactly what is conducted in
Section 4.2. In general, the fact that in
Section 4.2 the sampling model for individual tests differs from the one used in the training set lends reliability to the estimates
even if CNN was fitted only to a simulated data set of
,
, as shown at the top of
Figure 1. For this purpose, it is crucial to note that we trained only one CNN in
in
Figure 1 for all subsequent analyses in this paper. In the training sample, we have
values of
simulated from independent tests on the mean of two independent normal populations with equal but unknown unit variances, as detailed in
Section 4.2. In
, we have
tests simulated from
with a mean 3 in one population and the rest from
with both populations with zero mean.
Understanding CNN from the MHT perspective is important for confidence in the proposed method. A CNN is an NN where (deterministic) nodes are functions of inputs and are connected according to a specific structure. Nodes are typically operations with weights that are set to minimize the global error in classifying the results of tests in (or ) when they come from (or ). In a CNN, we have two types of nodes:
- 1.
Feature detection nodes. They have as input the subsequences of
,
where
is known as the
kernel size. These subsequences of a minimum length of
bear local information about the random sequence of
W’s. Such nodes return subsequences of
’s all of the same size
k, in which relevant features are detected through the so-called
filters. Filter functions are defined on sets of weights and are devoted to detecting
locally features on each
. The systematic application of the same filter across the
sequences is useful for our problem. Each filter, that is, each set of weights, detects a specific behavior in the series
, especially near the separation point
, mentioned above. The problem is that we do not know the relevant behavior to be detected and where it should be expected in the
W’ s sequence. Therefore, all filters are applied to all sequences
, along the entire observed sequence of
W’s. This filtering process allows CNN to discover what and where the behavior of
W is expected to estimate
correctly. We know, for example, that it should be important to analyze the behavior around
where
can be anywhere between 1 and
m. This capability is commonly referred to as the
translation invariance of a CNN. Fortunately, and contrary to the usual interpretation of NN as black boxes, it is possible to show the features detected by each filter, as shown in
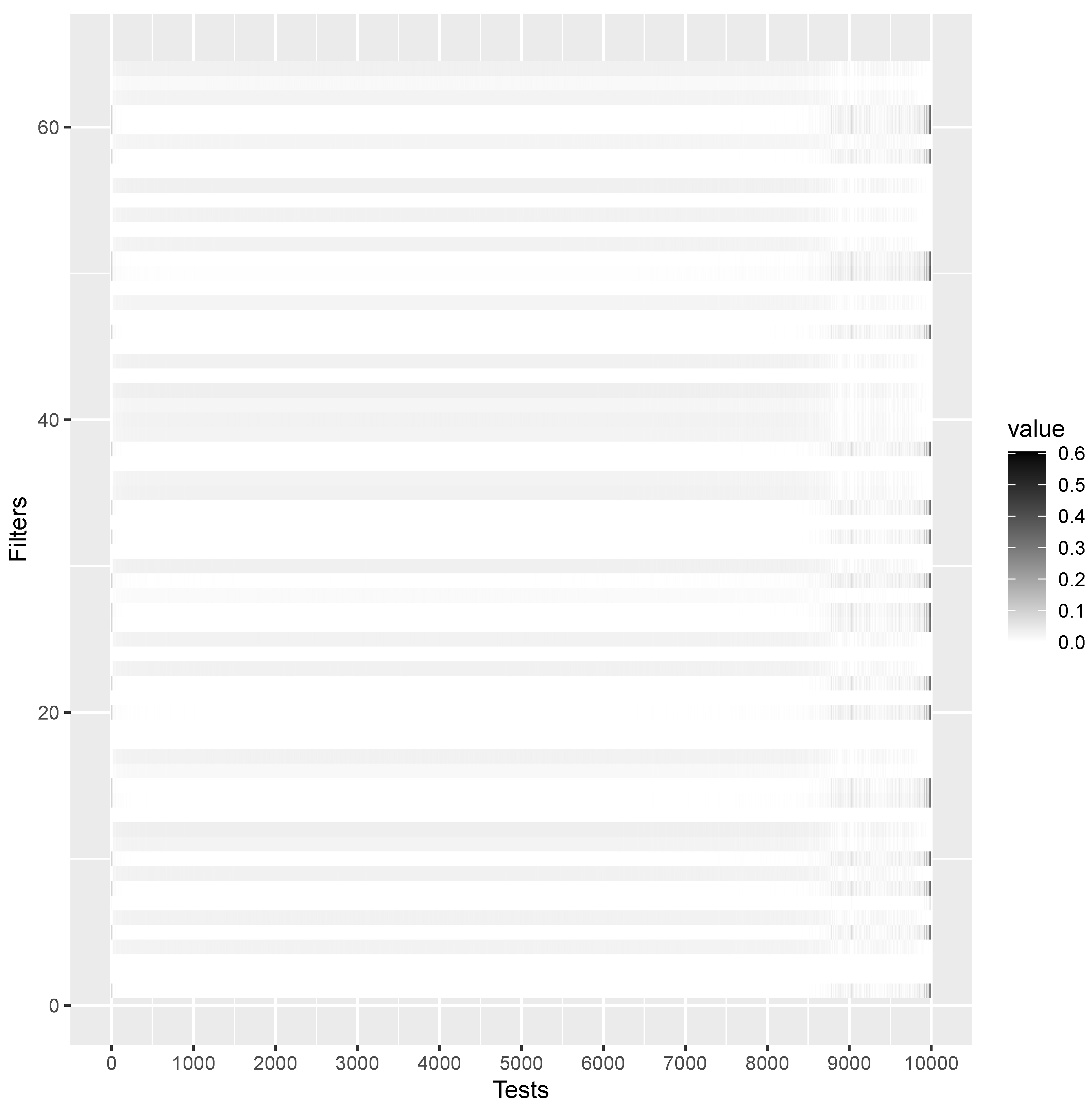
Figure 2, which reports the CNN weight values for the first convolution layer, which has 64 filters and thus weights
. From
Figure 2, it is possible to appreciate a change of activation around position 9001, which is the actual
point mentioned above.
- 2.
Pooling nodes. These nodes connect all filters through the pooling function. The filter is just a dot product of the input, , using a set of weights. The output of such a product is the input of the pooling function that leads to a result of a dimension less than k, for example, considering the maximum output resulting from a filtered . The set of pooling nodes is also called the feature map because it gives a map of the relevant filters along the sequence of W’s for classifying tests.
The architecture of the CNN captures three vital characteristics when modeling :
Localized Feature Detection: Kernels of small sizes are employed to focus on local features in the series of ’s. This contributes to sparse modeling of the sequence and enables the capture of intricate dependencies between tests.
Parameter Efficiency: To achieve parsimonious modeling, the same set of weights (i.e., model parameters) are reused throughout the sequence . This design leverages the power of shared evidence for NN parameters, offering a more accurate weight estimation based on multiple samples.
Robust Feature Recognition: The CNN is equipped to identify critical features in the data sequence, invariant to factors such as location, scale, position of the separation point
, and test dependencies. This robustness potentially uncovers features to be described that are instrumental in estimating the sets
and
. For example, the translation invariance property mentioned above is not shared by common change point detection techniques [
25], such as the cumulative sum control chart (CUSUM) [
26].
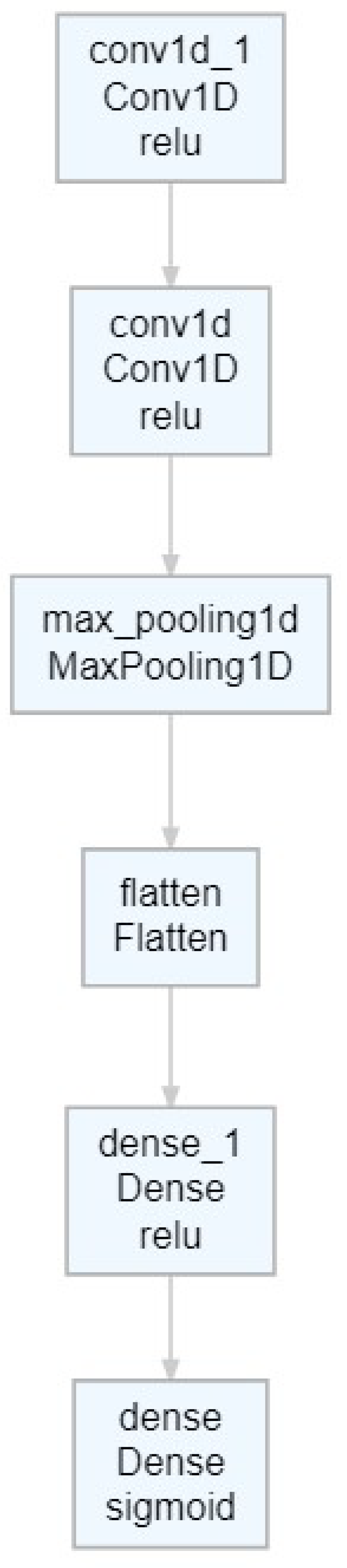
Further details about the specific CNN architecture used in this study are provided in
Appendix B. Although we do not insist that this architecture is universally optimal for MHT, it has been proven effective for the illustrative purposes of this paper.
To reiterate, we trained a single CNN model using the simulated set of
m tests displayed in
Figure 1. Subsequent results validate CNN’s capability for MHT, demonstrating its proficiency in classifying tests. For other practical scenarios, CNN could be trained using the results of a calibration experiment—assuming that such data are available and the ground truth is known—instead of relying on simulated data as in
Figure 1.
3. Sketch of the Theory
The objective of this section is not to provide rigorous proof of the method’s consistency but to offer theoretical insights supporting its asymptotic behavior, as observed in the simulation studies. Specifically, our objective is to theoretically substantiate that the proposed method demonstrates asymptotic consistency with respect to both the sample size n and the number of tests m, as evidenced by negligible FDR and FNR for sufficiently large values of n and m.
First, at a specific separation point
in the sequence of ordered Bayes factors
, the corresponding
is defined as:
where
indicates the marginal probability of observing the evidence of test
in the alternative set, which is the numerator of BF
.
The proposition guarantees the asymptotic existence of this separation point in the sequence of W’s.
Proposition 1. For then .
Proof. The proof relies on the well-known consistency of BF (see, e.g., [
27]) for every
, that is, for
and
, we have
(for
) or
(for
) and thus
for
. At the separation point
we have
as
and
as the test
, therefore,
. □
Second, the objective of the paper is to present evidence supporting the asymptotic consistency of the CNN estimator
as
. Previous work [
28,
29], has established the consistency of feedforward NNs in distance
, which can, in principle, be applied to CNNs, although there is no specific literature on CNN consistency [
30,
31]. Define
as a CNN oracle such that
if you test
and 0 otherwise. The CNN adjusted to the tests of
m is denoted by
. According to the aforementioned literature [
28,
29,
32], the distance
between these CNNs vanishes asymptotically as
:
Furthermore, we argue that
is as
for each
, where
. This is a less restrictive condition than assuming the same stochastic process generating the observable variables, and thus the BFs. It is well known that the asymptotic consistency of the BFs can be achieved in the true model, but as
n increases, the BF favors the model (although not the true one), minimizing the Kullback–Leibler (KL) divergence, making the model closest (to the true one) increasingly probable. CNN learns this characteristic of BF as illustrated in
Figure 2, where CNN successfully identifies the characteristics around the discrimination point
.
In this framework, the CNN can accurately classify the tests as belonging to and the rest to . The method offers bounded FDR and FNR as n and m grow. As mentioned above, the joint control of FDR and FNR suggests that the area under the ROC curve is .
Empirical validation supports , which confirms the robustness and effectiveness of the model.
We also applied the transfer learning approach to the p-values by repeating the same analysis on BFs, but we do not have evidence of high as in the case of BFs.
4. Simulations and Real Examples
4.1. Training Dataset
The data set shown in
Figure 1 is generated to address the classical statistical problem of testing the equivalence of means between two independent normal populations subject to heteroskedasticity. Specifically, we consider two independent populations,
and
, each with sample sizes
and
, respectively. This example has been extensively detailed in [
9,
10], and additional information on computing the unscaled Bayes factor,
, is provided in
Appendix A.
Figure 1 illustrates a sequence of
Ws generated with parameters
,
,
,
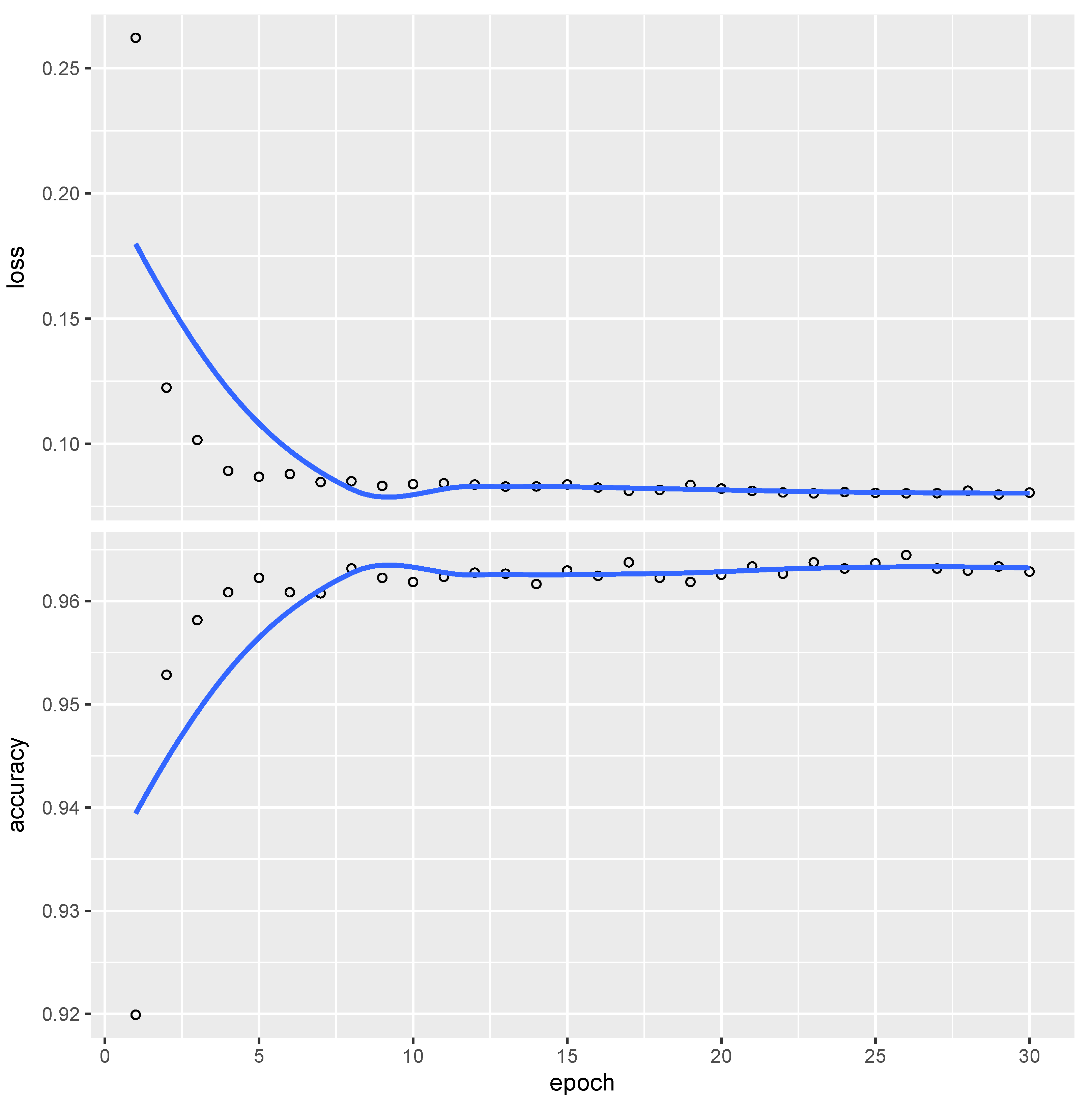
, and distribution parameters set as specified. CNN underwent 30 optimization epochs, with the training result presented in
Figure 3.
The trained CNN achieves an accuracy slightly exceeding 96%, indicating that fewer than 4% of the tests are misclassified relative to and in this large sample.
Furthermore, to assess the advantage of using
Ws over
p-values for better hypothesis testing representation, as discussed in [
9,
10], we also trained the CNN on an ordered sequence of
p-values, achieving comparable accuracy levels as shown in
Figure 3.
In subsequent sections, we juxtapose our CNN-based approach with traditional methods commonly used in medical research. We compare the evidence derived from ordered
p-values, obtained using Student’s
t-test with Welch’s correction, to that obtained through our CNN model. These
p-values are further adjusted using the BH FDR procedure, serving as our benchmark in the actual practice of MHT. Other procedures could have been considered [
13,
33,
34], but keep in mind that, for instance, the BH procedure is also considered the limiting procedure of other approaches to MHT as the
q-values when
[
35]. Therefore, other approaches would not have added much to the exposed results.
We then evaluate these methods using the ROC curve to account for various experimental conditions in which different types of error may be of differing importance. The AUC serves as a summary metric to evaluate the precision in classifying the null and alternative hypothesis sets, and , thus controlling the corresponding FDR and FNR.
4.2. Simulation Study
Employing the pre-trained CNN with varying input features—specifically Ws, p-values, and p-values adjusted according to the Benjamini–Hochberg (BH) scale—we systematically evaluate the average AUC through 1000 replications of the AUC. These replications are obtained under a composite set of scenarios designed to mirror various real-world conditions encountered in GWAS. The scenarios are delineated as follows.
Signal Variation for Alternatives: The means for the alternative hypotheses, , are set to values in the set for .
Sample Size and Asymptotic Behavior: Both and are set to the value n, which ranges from 3 to 10.
Heteroscedasticity: The standard deviations and for and vary in the set .
Proportion of True Alternatives: The ratio is adjusted to one of the following: 0.9, 0.95, or 0.99.
Asymptotic Number of Tests: The total number of tests, m, is set to 1000 or 10,000.
Test Dependence: Two schemes are considered, one with all independent tests and another with block-dependent tests. In block-dependent tests, there are tests belonging to a set that are dependent on them and independent of the others, and there are also different sets. These tests induced a block-diagonal correlation matrix among the test statistics (see [
36]). In the block-dependent case, variable blocks
,
of sizes 2, 5, and 10 are formed, and their correlations are drawn randomly from a uniform distribution between −1 and 1, subject to the constraint of a positive semidefinite correlation matrix.
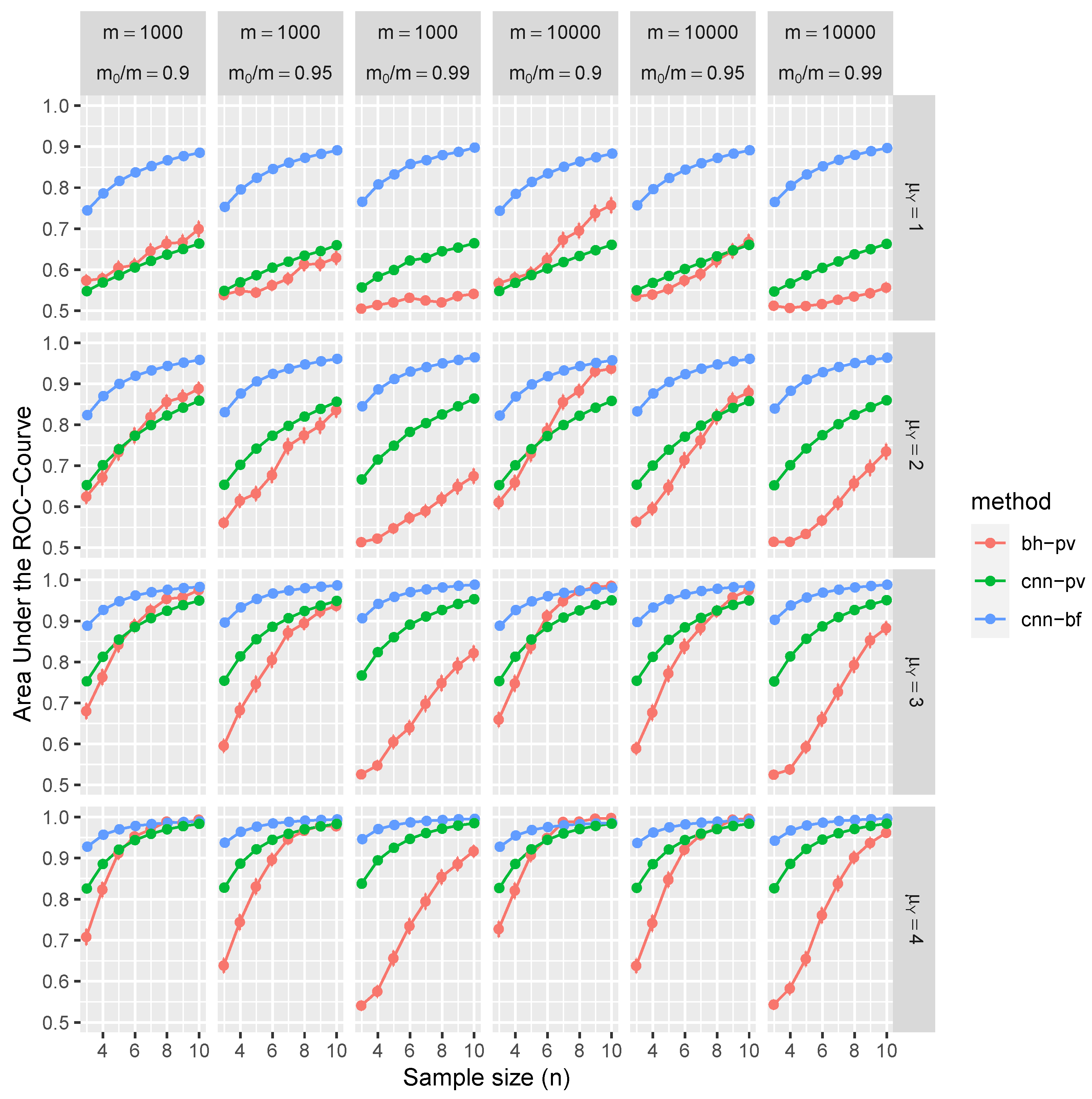
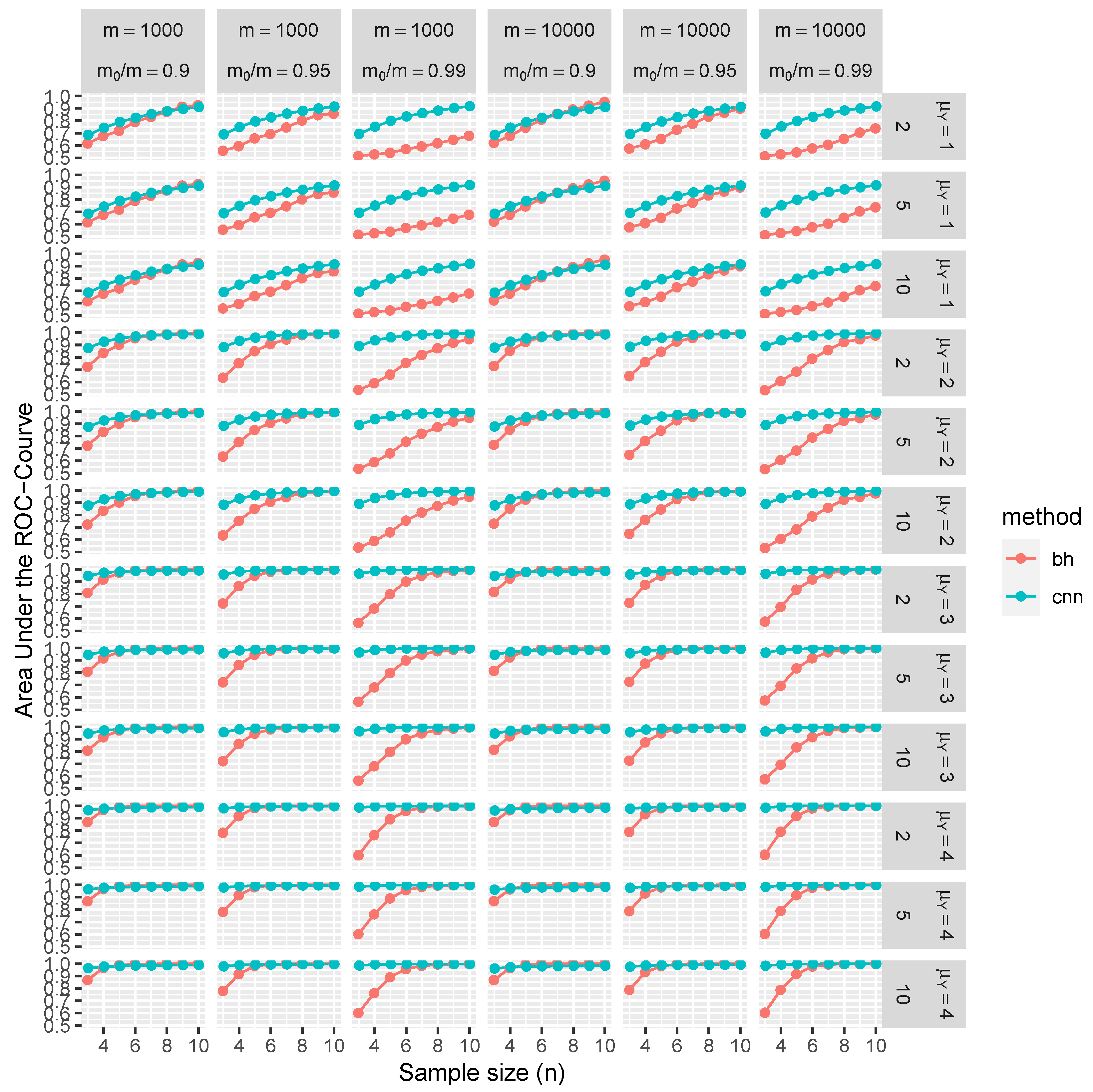
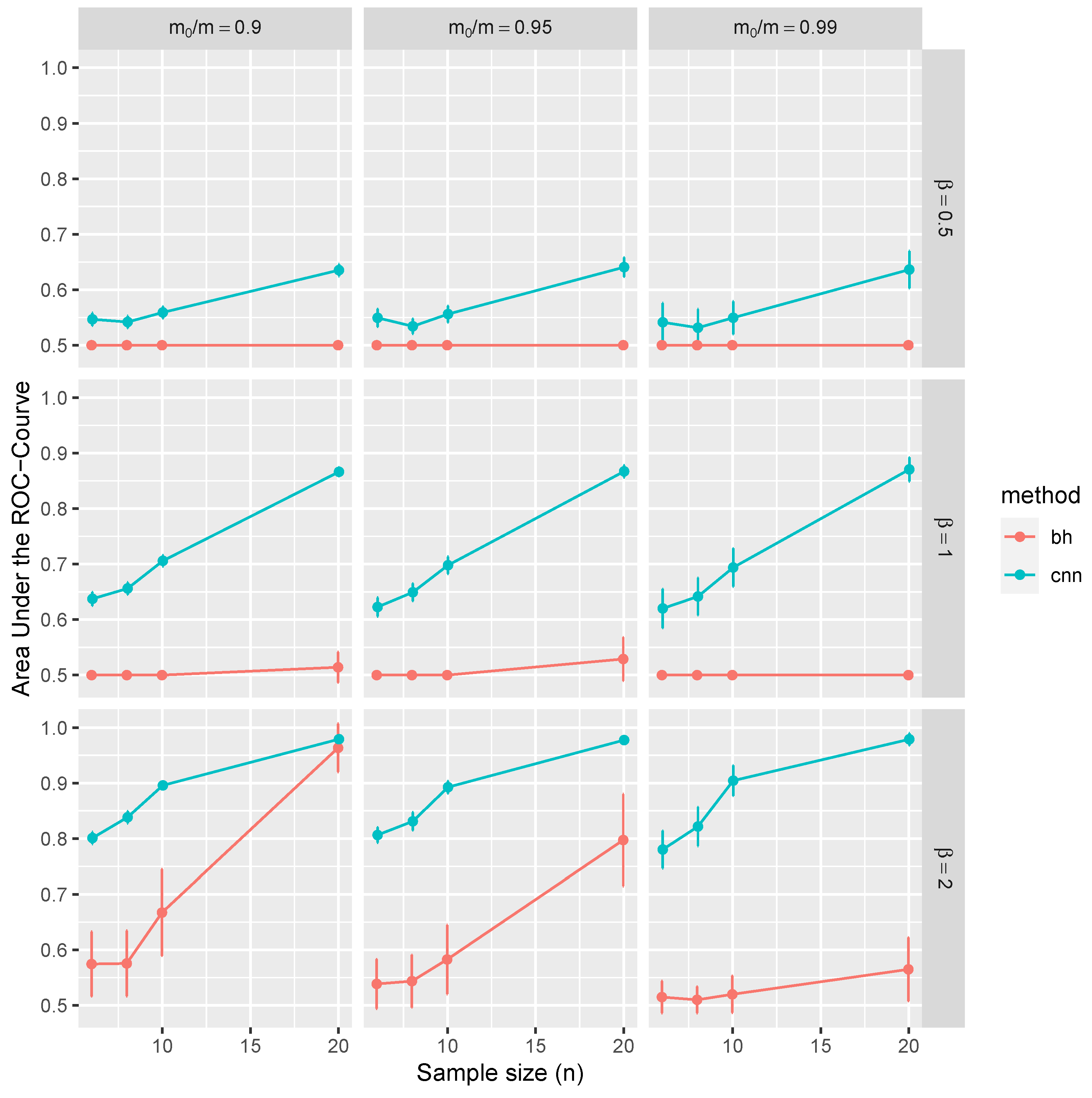
Figure 4 and
Figure 5 present the statistical evaluation of the average AUC along with its 99.9% confidence intervals. These metrics are computed across 1000 replications and under various simulation scenarios explicitly enumerated in each figure’s axis labels and captions.
Consider the top-left panel of
Figure 4 for illustrative purposes. It shows the average AUC and associated confidence intervals, conditioned on independent tests with parameters
,
,
for
and
n ranging from 3 to 10. Color-coded markers represent the BH procedure (in red), CNN applied to
Ws (in blue), and CNN also applied to
p-values (in green). The results in this panel are marginal outcomes aggregated over 1000 replications and for all combinations of
and
.
Figure 5 extends this analysis to include block-dependent tests, which are also conditioned on the sizes of these blocks.
The results of our simulation study provide compelling evidence that the proposed CNN demonstrates robust control over FDR and FNR in a diverse range of conditions. Remarkably, these performance metrics are better than those achieved using BH procedures. Furthermore, CNN’s efficacy is noticeably higher when trained on test statistics W than when trained on classical p-values.
The distinctive advantages of the proposed methodology become more pronounced in scenarios with weaker signals, characterized by lower means (), greater variances, or smaller sample sizes (n). These disparities can be attributed to the fact that the p-values are calibrated asymptotically in n, and the number of samples is often limited, especially given the high costs associated with replications of RNA sequences. Interestingly, the selected range of m has a negligible impact on CNN performance. On the contrary, traditional MHT procedures, such as the BH method, control FDR asymptotically in m, which is evident through slight improvements in the ROC curve at higher values of m. In summary, the increased dependencies among tests further accentuate the benefits of employing the CNN-based approach over traditional methods.
4.3. Example RNA-Seq 1: Squamous Cell Carcinomas versus Matched Normal Tissue
We examine RNA-seq count data from a paired design study focusing on oral squamous cell carcinomas and the corresponding normal tissue samples from six patients [
37].
The primary objective of the analysis is to identify genes that exhibit differential expression between tumor and normal tissue samples. To account for patient-specific variations, we employ a mixed-effects Bayesian Poisson regression model with flat improper priors for the Poisson regression coefficients. Additionally, an exceedingly vague prior is utilized for the logarithm of the random effects variance (refer to the
Appendix C for complete details). It should be noted that the analytical framework employed here is substantially more flexible than the conventional negative binomial regression commonly used in RNA-seq count data analysis [
37]. Furthermore, it diverges from the
t test-based analysis that generated the training sample depicted in
Figure 1.
In this experiment, we consider
genes and only
patients under each condition, making a total of six patients. For every gene
i, the unscaled Bayes factor,
, is computed separately to evaluate the model incorporating tissue effects against the null model devoid of such effects. Both models incorporate patient-specific random effects. Using the trained Convolutional Neural Network (CNN) based on the data shown in
Figure 1, we report in
Table 1 the probabilities and genes that could be linked to carcinoma tissue. These results are presented in conjunction with the results obtained by the BH procedure, which tests the significance of the tissue effect coefficient.
Most of the remaining genes exhibit a probability of less than 50% of relevance to the condition under study. In particular, 658 genes produced adjusted p-values less than 0.001 according to the BH procedure, which is a very noisy result.
Interestingly, according to the proposed procedure, only the TTN and KRT genes had previously been identified in the study by [
37]. Other genes such as SPRR [
38], NEB [
39], ITGB [
40], and PLEC [
41] have been subsequently associated with tumor conditions in the cited literature. This observation underscores the valuable insights that could be gleaned from the data if analyzed using our proposed approach. In contrast, genes highlighted by the BH method, such as PTHLH, COL4A6, and PTGFR, have only tangential associations with tumors. For example, PTHLH has been discussed in the context of cow tumors [
42], again suggesting that the BH method may produce noisy results compared to the proposed one.
Unlike the situation described in
Section 4.2, the ground truth in this case is unknown. However, our objective is to demonstrate that the proposed CNN methodology outperforms the BH approach. This is particularly noteworthy given that the Bayesian Poisson sampling model (see
Appendix C) diverges substantially from the model used to generate
Figure 1. This argument is further substantiated by an additional simulation study detailed in
Appendix D. The suboptimal performance of the BH method is attributable to the misspecification of the negative binomial model [
37] due to the inclusion of patient-specific random effects. Furthermore, the presence of a nuisance dispersion parameter adversely affects the reliability of
p-values, since these are no longer calibrated with respect to the
distribution, thus compromising the efficacy of multiple hypothesis testing procedures such as BH [
3].
4.4. Example RNA-Seq 2: Normal vs. Tumor Tissue
We reviewed the RNA-Seq data of Arabidopsis thaliana as discussed in [
43]. The data set focuses on the plant’s response to the bacterium Pseudomonas syringae, a model organism for studying plant-pathogen interactions. The purpose of the analysis is to identify differentially expressed genes that illuminate how plants defend themselves against such pathogens.
Three Arabidopsis plants, each six weeks old, were treated with Pseudomonas syringae, while control plants were given a mock pathogen. Subsequently, total RNA was extracted from the leaves, resulting in three independent biological replicates. Each set, comprising RNA samples, was sequenced and RNA-Seq counts were collected for genes. Samples are not independent, and this requires an adjustment for time-dependent effects.
The Bayesian regression model used is analogous to the one described in
Section 4.3. However, an additional layer of complexity is introduced by incorporating a first-order autoregressive process to account for temporal random effects (see
Appendix E). As before, the BFs are unscaled due to improper priors on the model coefficients.
Our results, detailed in
Table A1 of the
Appendix F, highlight only 31 genes with a probability greater than 0.5 of having an interaction effect with Pseudomonas syringae. This contrasts starkly with the 387 genes identified in the original study by [
43], which employed the
q-values [
33] to control FDR at 5%. The BH method identified as many as 1805 genes, reinforcing the notion of an inflated Type I error because of maybe-dependent tests. In particular, the FDR control using
q-values has been shown to converge to the BH control [
33] asymptotically, validating our use of the BH method as a benchmark. Interestingly, all but two of the 31 genes were previously reported in [
43]. The two exceptions,
AT4G12800 and
AT1G54410, have been implicated in the response of the pathogen in subsequent studies [
44,
45].
5. Remarks
We alert the reader to three critical limitations associated with the use of CNNs, which also constitute the main theoretical drawbacks of this study: (i) The output of the neural network does not come with associated uncertainty measures; () Due to its complex architecture and predictive focus, an exact interpretation of the trained CNN is elusive, although some insights can still be gleaned; () Like any statistical model, the efficacy of an NN rests on the (untestable) assumption on the sampling model for tests that makes the training and testing samples exchangeable.
Looking at the usage of BFs in this work, we may think that there always exist proper priors that make , a proper BF for test i interpretable in the sense of providing the evidence for test i as suggested by Jeffreys, which is true but at the cost of introducing arbitrary c in the term. Then is interpretable, but it is also arbitrarily interpretable as a measure of evidence due to the presence of c. In contrast, in the definition of W, based on the proper BFs , c simplifies and the same occurs when ordering tests according to the BFs . The problem of finding a cutoff on is exactly that of fitting a CNN that allows one to fix a cutoff on the scale of that considers the multiplicity of tests, as do some MHT procedures with adjusted p-values. We claim that the proposed scale on which lies is much more interpretable as the direct probability that the test is observed under the null or alternative given the evidence from all tests.
The current methodology can also be implemented without explicit Bayesian computations. In particular, BFs, denoted
, can be substitute calibrated
p values according to the lower bound of the BF as elaborated in [
46,
47]. Specifically, for all
, the infimum of the BF for the
ith test can be expressed as
where
c symbolizes the calibration constant for the unknown true BF
. This uncalibrated BF can then be utilized in our method after scaling the computed
p-values by Equation (
5). In the end, this allows us to generally extend the use of the proposed method to statistical analyses that are not per se Bayesian.
Our strategy relies on a singularly trained CNN. Future work could explore alternative architectures, such as bidirectional CNNs [
48]. However, our existing CNN demonstrates remarkable performance in various settings, almost achieving an AUC close to 1, irrespective of the underlying sampling model specifically considered.
This innovative application of transfer learning [
49] to MHT serves as the cornerstone of this study. The approach draws parallels with classical statistical techniques like the use of the Central Limit Theorem but within a computational context. The primary advantage lies in reusing CNN weights trained on one dataset (simulated and observed from calibration studies), as seen in
Figure 1, to analyze different MHT problems. This approach essentially mirrors the untestable assumptions used in the BH procedure, such as positive regression dependence [
1,
50].
In summary, our results are promising for broader adoption of CNN-based strategies in MHT, especially given that the network performs consistently across divergent testing frameworks (e.g., t-tests, mixed-effect models, dependent/independent tests).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




