
Efficient Integration of Rate-Adaptive Reconciliation with Syndrome-Based Error Estimation and Subblock Confirmation for Quantum Key Distribution

Abstract
:1. Introduction
- (1)
- Distribution of quantum information: In the BB84 protocol [6], Alice encodes random bits into the polarization states of single photons, which are then transmitted to Bob over the quantum channel. Bob subsequently randomly selects measurement bases to measure the polarization of a received photon and obtains classical measurement bits. After this step, both parties have a record of binary information, known as the raw key. Upon accumulating a sufficient amount of raw key, they perform the following post-processing steps [8,9], using the authenticated classical channel to distill secure secret keys.
- (2)
- Sifting: Alice and Bob communicate and compare their encoding and measurement bases. Then, any bits in raw key with non-matching bases are discarded, allowing both parties (Alice and Bob) to obtain correlated classical bits with the same length, called the sifted key.
- (3)
- Channel error estimation: Alice and Bob typically estimate the quantum bit error rate (QBER) by using random key sampling. If the estimated QBER exceeds a predetermined threshold value, both parties must abort the QKD protocol to prevent potential security breaches.
- (4)
- Information reconciliation: Alice and Bob correct the discrepancies between their sifted keys using error-correction algorithms to produce the reconciled key.
- (5)
- Confirmation: Alice and Bob utilize a universal hash function to verify whether their reconciled keys are identical. If the hash values from Alice and Bob do not match, they can return to the information reconciliation step or abort the QKD protocol.
- (6)
- Privacy amplification: To eliminate any partial information eavesdropped by Eve through both the quantum and classical channels, Alice and Bob compress their identical keys using universal hashing. The resulting shortened keys, known as the secret keys, are statistically independent of Eve’s information and are identical between Alice and Bob.
2. Information Reconciliation in QKD Post-Processing
2.1. Information Reconciliation Based on Channel Coding Theorem
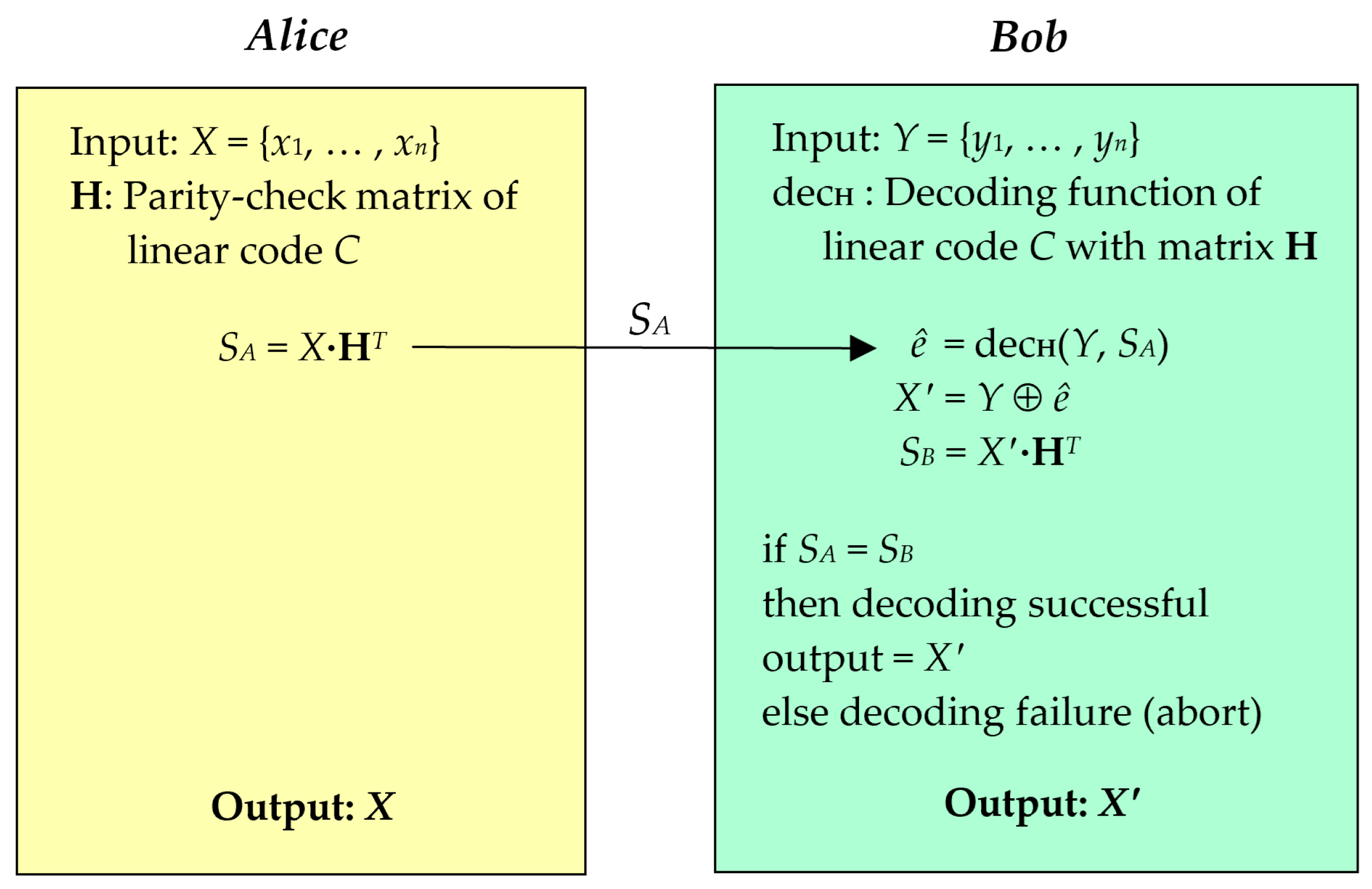
- (1)
- Encoding: Alice performs the encoding function of the linear code C to generate the syndrome SA, where SA = X·HT. The syndrome SA is then transmitted over the classical channel to Bob.
- (2)
- Decoding: Upon receiving the syndrome SA, Bob computes ê using the decoding function of C, denoted by decH, where ê = decH(Y, SA). The value of ê indicates the error position in Y, and Bob calculates the output value X′ by performing X′ = Y ⊕ ê.
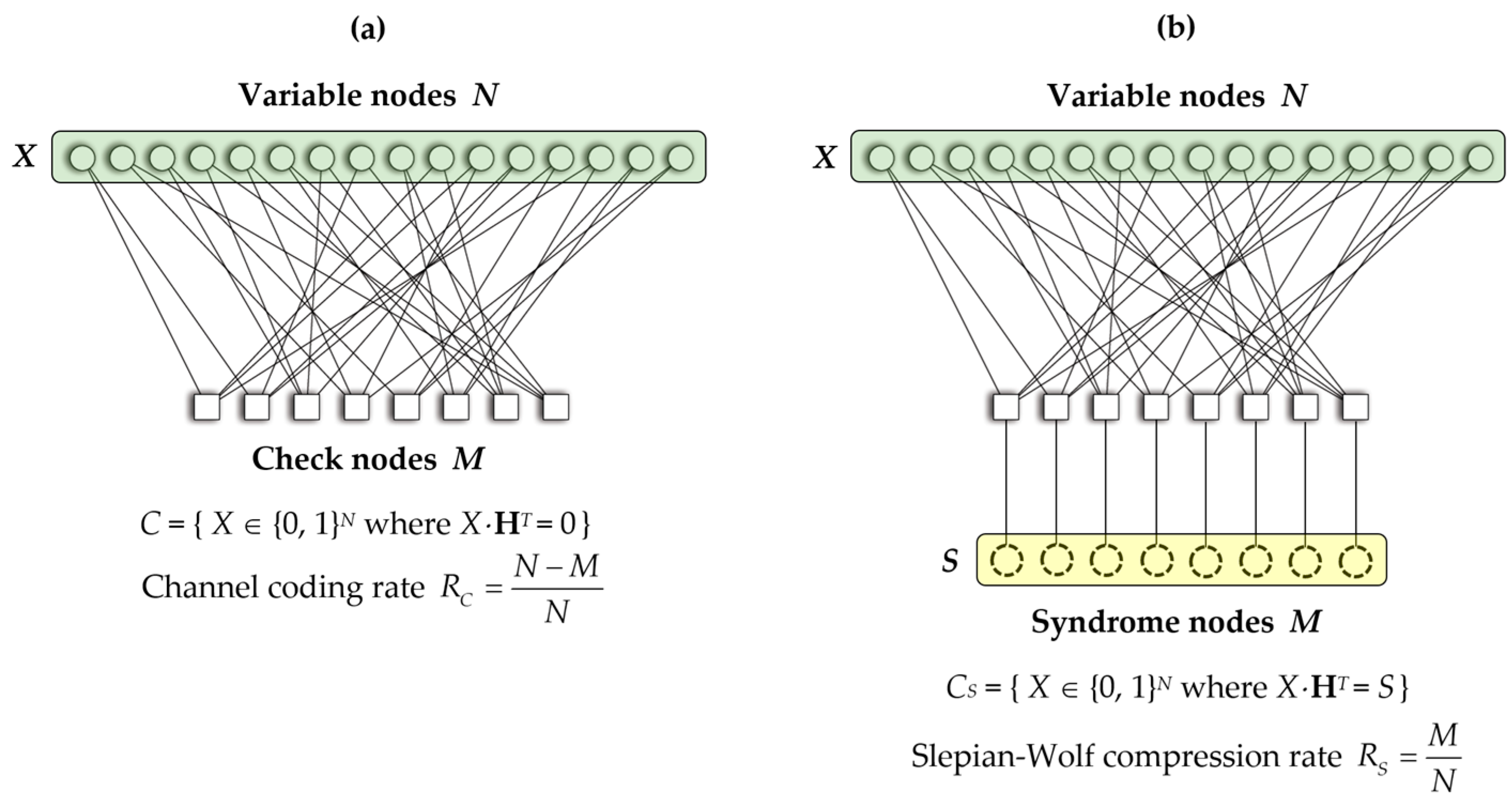
2.2. Application of Slepian–Wolf Coding to Information Reconciliation Based on Channel Coding
2.3. Rate-Adaptive LDPC Codes and Efficiency Metric of Information Reconciliation
- is the total detection rate for events where photons are transmitted from Alice to Bob.
- is the theoretical efficiency of the BB84 protocol.
- is the operational clock rate of QKD devices.
- FER is the frame error rate, indicating the failure probability of decoding, which affects the likelihood of non-identical reconciled keys for Alice and Bob.
- is the actual secret key rate, depending on from Equation (6), which can be defined as .
3. Rate-Adaptive LDPC Codes for Information Reconciliation: Integrating Syndrome-Based Error Estimation and Subblock Confirmation
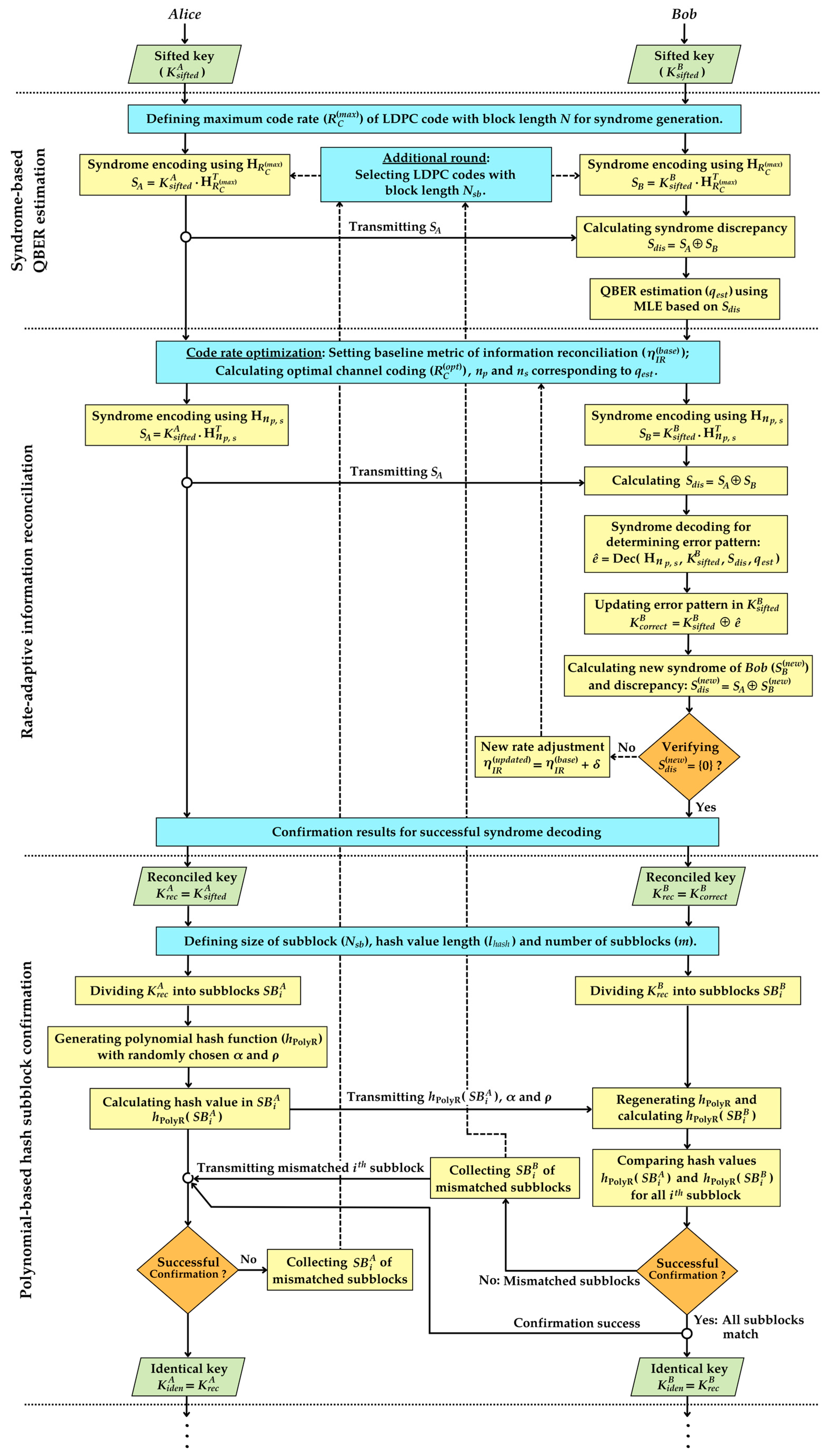
- (1)
- Initialization of LDPC code parameters: Alice and Bob mutually agree on two sets of irregular LDPC codes with block lengths N and . Specifically, N corresponds to the size of the sifted key in the primary round of each post-processing cycle, and pertains to the size of the subblock in the additional round, employed only after a failure of the confirmation step. Each of these two irregular LDPC codes includes a set of mother code rates, as follows:These rates are fine-tuned using puncturing and shortening techniques to select the appropriate code rate for the rate-adaptive information reconciliation step.
- (2)
- Syndrome-based QBER estimation: This step utilizes the properties of a maximum likelihood estimator based on the syndrome information of LDPC codes to estimate QBER over the possible ranges of errors in a QKD system. The process consists of the following subsequent steps:
- (2.1)
- Syndrome encoding: Alice and Bob generate their syndrome information, denoted as SA and SB, by encoding their sifted keys and , respectively. Both parties employ the syndrome encoding formula , where is the transpose of the parity-check matrix associated with the maximum code rate with block length N. Then, Alice transmits SA to Bob over the authenticated classical channel.
- (2.2)
- Calculation of syndrome discrepancy: On Bob’s side, the syndrome discrepancy, denoted as Sdis, is determined by calculating the difference between the syndrome information SA and SB. Specifically, Sdis = SA ⊕ SB, where ⊕ signifies the bitwise XOR operation.
- (2.3)
- QBER estimation: Bob computes the initial estimate of QBER (qest) using a maximum likelihood estimator (MLE) based on Sdis [21,22,23]. The estimation is determined as follows:where is the likelihood function for estimating the value of QBER q based on Sdis, and qthreshold is the maximum QBER threshold that ensures the security of the QKD system. Within this context, each ith syndrome bit is probabilistically determined by a Bernoulli distribution. The explicit expression for is given as follows:where , , and denotes the number of 1s in the ith row of the parity-check matrix H for irregular LDPC codes. Specifically, when the syndrome bits originate from a mother code with its maximum rate , the likelihood function can be reformulated as follows:where the function , which signifies the probability that Sdis[i] = 1, is defined as:Furthermore, the syndrome bits are generated from the parity-check matrix, which is affected by the puncturing and shortening positions, denoted as p and s, respectively. For accurate QBER estimation, it is essential to use only syndrome bits that reflect QBER influences, excluding those adjusted by p and s at the position Sdis[i]. In this context, ωi denotes the set of positions with entries of 1 in the ith row of the parity-check matrix H, and essentially identifies the position Sdis [ i ]. To mitigate the effects of punctured and shortening, it is necessary to ensure that ωi ∩ p = ∅. The count of bit positions in the ith row of matrix H corresponding to ωi is then defined as = [22]. Consequently, the likelihood function in Equation (11) can be reformulated as follows:In the syndrome-based QBER estimation, the source of the syndrome information determines the selected likelihood function. If the syndrome information is derived from the original matrix H of the mother code , the likelihood function , as given in Equation (11), is employed. Conversely, when the syndrome information is generated based on the matrix H that incorporates both puncturing and shortening, the likelihood function specified in Equation (13) is considered as the appropriate approach for syndrome-based QBER estimation. After this step, Bob obtains the value of the estimated QBER (qest). This value is then communicated to Alice and is subsequently used to determine the optimal coding rate in the information reconciliation step. If qest exceeds the maximum tolerable QBER of 11% [32], the system is required to abort, thereby preventing the use of these sifted keys in subsequent steps to ensure security.
- (3)
- Rate-adaptive information reconciliation: In this step, Alice and Bob employ the value of the estimated QBER (qest) to optimize the initial coding rate (). This optimization requires setting up the baseline efficiency metric for information reconciliation (), which is used to calculate the number of puncturing bits () and shortening bits () based on qest, as defined in Equation (6). This metric ensures that Alice can generate sufficient syndrome information, allowing Bob to decode and correct errors within his sifted key. It is essential to note that is obtained from the performance evaluation when deploying the specific irregular LDPC codes in the experimental settings. This process comprises the following subsequent steps:
- (3.1)
- Code rate optimization: Alice and Bob collaboratively select a set of mother code rates , associated with the block length N. They also agree on the baseline efficiency metric for information reconciliation (), which is employed to calculate the optimal coding rate () based on the entropy function of the estimated QBER (). In this scenario, the mother code rate ( is selected from such that its value is closest to the calculated . According to Equation (6), is derived using:To identify the desired from the set , the selection criteria is determined bywhere . After selection, is then adapted to attain the value of by adjusting the parameters of and , given as Equation (4). Importantly, the relationship between the puncturing and shortening parameters is defined by = + , where is the total number of punctured and shortened bits used to determine the values for and . Consequently, both and can be derived from Equation (6) by considering and aswhere ⌈…⌉ is the ceiling function rounding up to the nearest integer, and both and must be the positive value. If either or is calculated to be negative, the selection of the mother code rate is decreased to the next available in the set . The values of and are then recalculated using this newly selected according to Equation (16), ensuring both and are positive. After successfully determining and , specific positions for puncturing (p) and shortening (s) are identified and used to modify the original parity-check matrix H of the selected . The modified matrix () is then employed in subsequent syndrome encoding and decoding processes.
- (3.2)
- Syndrome encoding: Alice and Bob employ the modified matrix () of to encode their sifted keys and , respectively. Both parties apply the syndrome encoding to produce the appropriate amount of syndrome information based on qest. Subsequently, Alice sends SA to Bob through the authenticated classical channel.
- (3.3)
- Syndrome decoding and verification: In the syndrome decoding step, Bob utilizes the syndrome information SA received from Alice and his syndrome SB to compute the discrepancy syndrome Sdis = SA ⊕ SB. The decoding process is performed by the belief propagation algorithm, which employs the log-likelihood ratios to identify the error pattern within the sifted key . This algorithm operates with the modified parity-check matrix (), which corresponds to the specific positions of puncturing p and shortening s. Within this context, the value of QBER estimation (qest) is utilized to model the transmission errors as the crossover probability in a binary symmetric channel (BSC). The simplified decoding function for determining the error pattern is expressed as:Then, Bob uses to update , resulting in . To verify the success of syndrome decoding, the proposed scheme introduces a step that re-checks the syndrome discrepancy. By employing the same parity-check matrix , Bob computes the new syndrome and then calculates the new syndrome discrepancy with SA, expressed as . If , it confirms successful decoding between Alice and Bob. Otherwise, a decoding failure feedback is announced, and the protocol returns to step 3.1 to adjust the new code rate (). In this case, the initial metric for information reconciliation is incremented by the factor δ, expressed as = + δ. This updated is subsequently employed to determine the new values for and with respect to . The adjusted rate is then applied in the re-processing of syndrome encoding and decoding. After the successful decoding, both Alice and Bob exclude the bit positions that are affected by puncturing and shortening, as represented by p ∪ s.
- (4)
- Polynomial-based hash subblock confirmation: In the confirmation step, a polynomial-based hash function [26], a form of universal hashing, is employed to verify the equality of Alice and Bob’s reconciled keys and . To mitigate the risk of discarding the entire key due to a confirmation failure, both parties adopt a subblock verification approach by partitioning the reconciled keys into subblocks of size . Subsequently, a polynomial hash value is generated for each subblock to verify its integrity. This process is divided into the following steps:
- (4.1)
- Dividing the reconciled keys into subblocks: Alice and Bob update the sizes of their reconciled keys and then divide and into subblocks of size . Each subblock is referred to as the ith subblock, where i ranges from 1 to m, and . The partition of the reconciled keys in each subblock of Alice and Bob () is defined as:Afterward, Alice and Bob have corresponding subblocks of their reconciled keys, denoted as and , respectively.
- (4.2)
- Generation of polynomial hash function and hash values calculation: To generate the polynomial hash function, Alice first defines the hash value length ( and then randomly selects the parameters of the polynomial base α and the prime modulus . Specifically, α is chosen from the set α ∈ {2, 3, …, }, and is a prime number constrained by . Subsequently, the polynomial hash function is applied to calculate the hash values of the reconciled keys in each subblock . This can be mathematically represented asFollowing this calculation, Alice transmits the resulting hash values for each subblock ) to Bob. This transmission corresponds to the parameters of the polynomial hash function α and , which were previously chosen by Alice.
- (4.3)
- Hash verification and result confirmation: On Bob’s side, he uses the received parameters α and to generate the polynomial hash function and computes the corresponding hash values for his reconciled keys in each subblock ), as defined in Equation (19). To verify the identical keys, Bob compares ) with the received ) for each subblock. This step is considered successfully completed if the hash values match for all subblocks from 1 to m, which is expressed as:Otherwise, Bob sends feedback to Alice indicating the confirmation failure and identifying the mismatched ith subblock. Then, only the reconciled keys from the mismatched subblocks are reprocessed, and the procedure returns to the steps of syndrome-based error estimation and rate-adaptive reconciliation in the additional round. During this round, specific irregular LDPC codes with block lengths are employed to estimate QBER, optimize the code rate, and correct errors using the same procedure. The process continues until the subblocks are successfully verified using polynomial-based hashing. Ultimately, Alice and Bob obtain the identical keys, denoted as and , respectively.
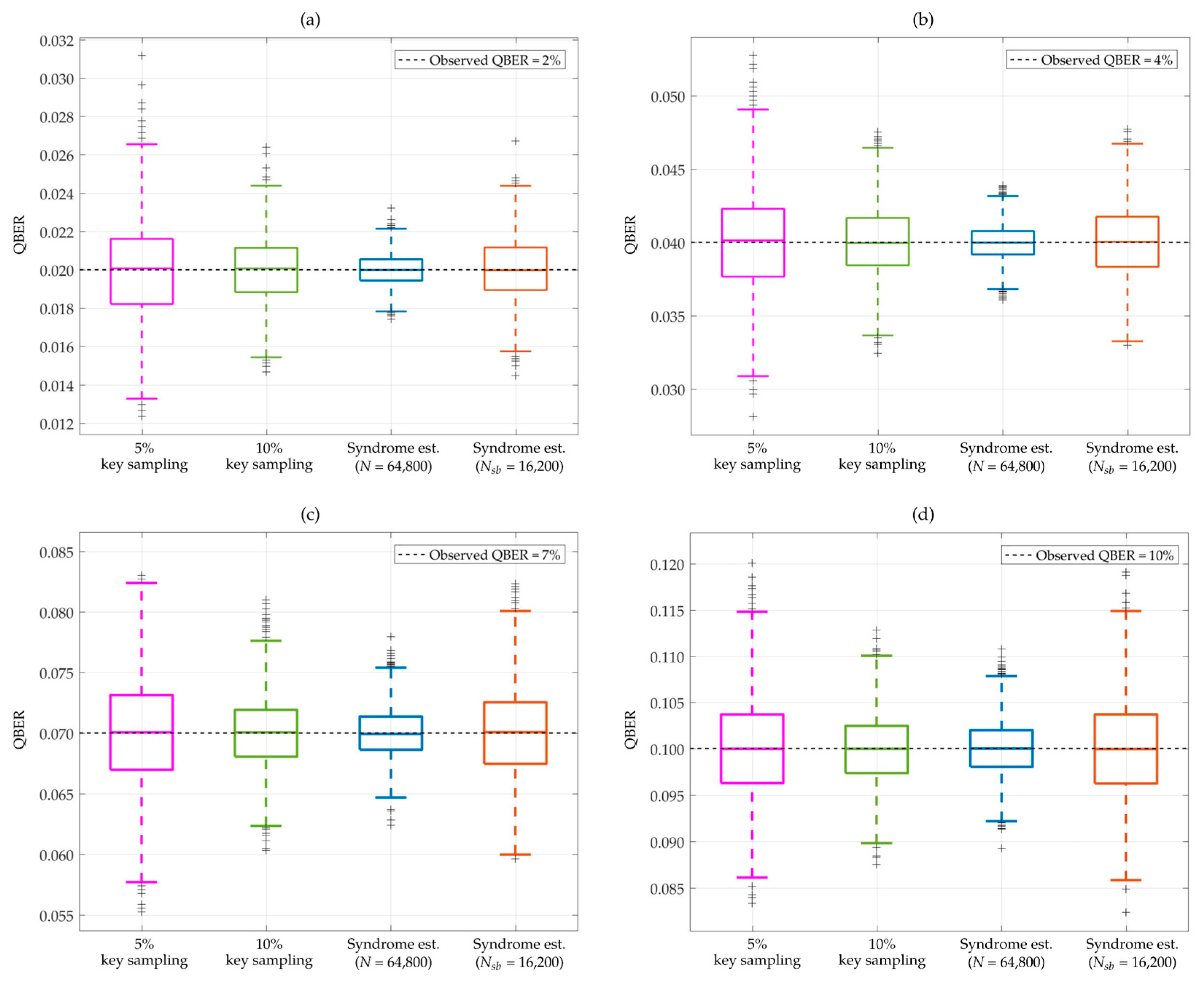
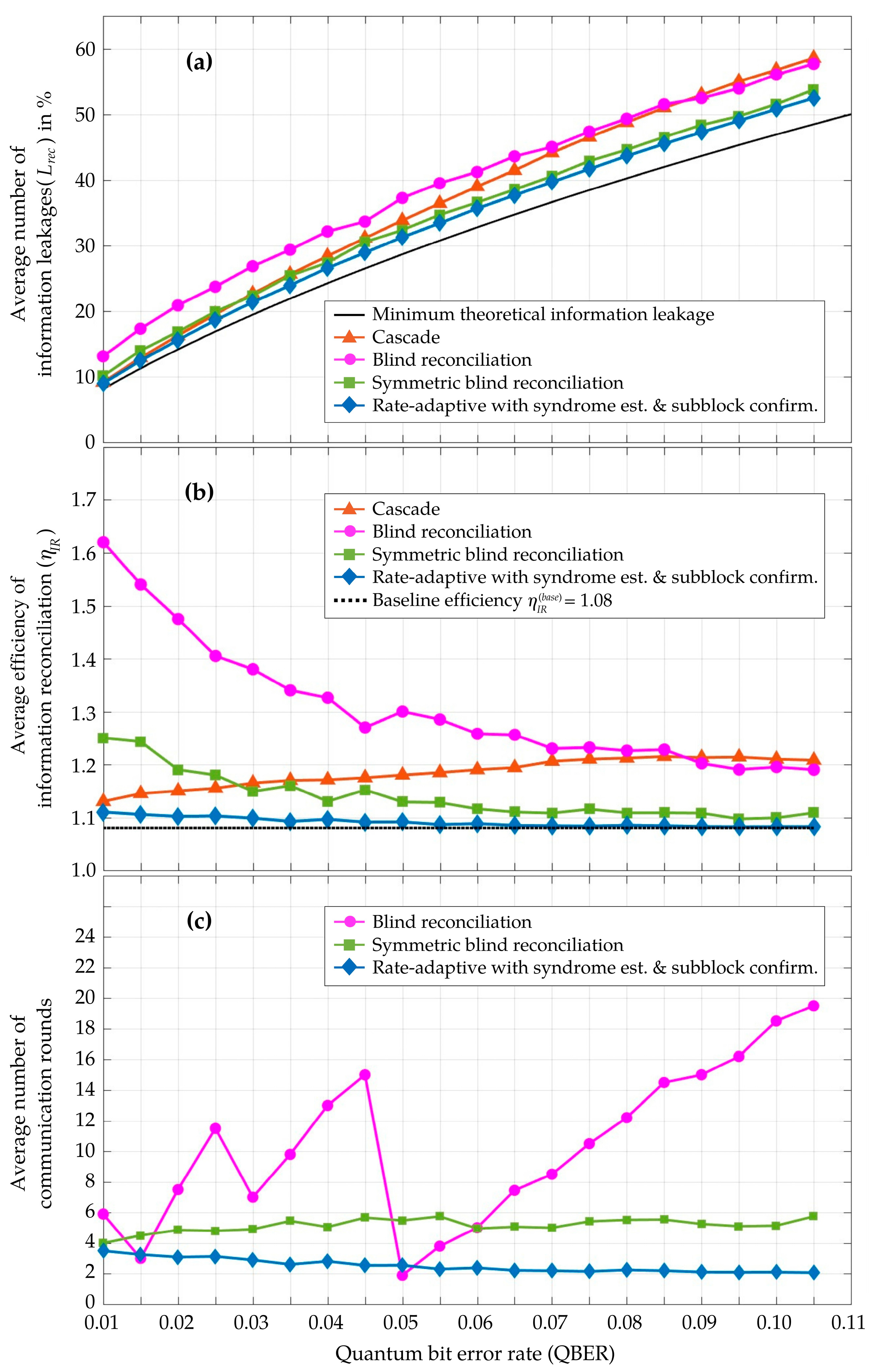
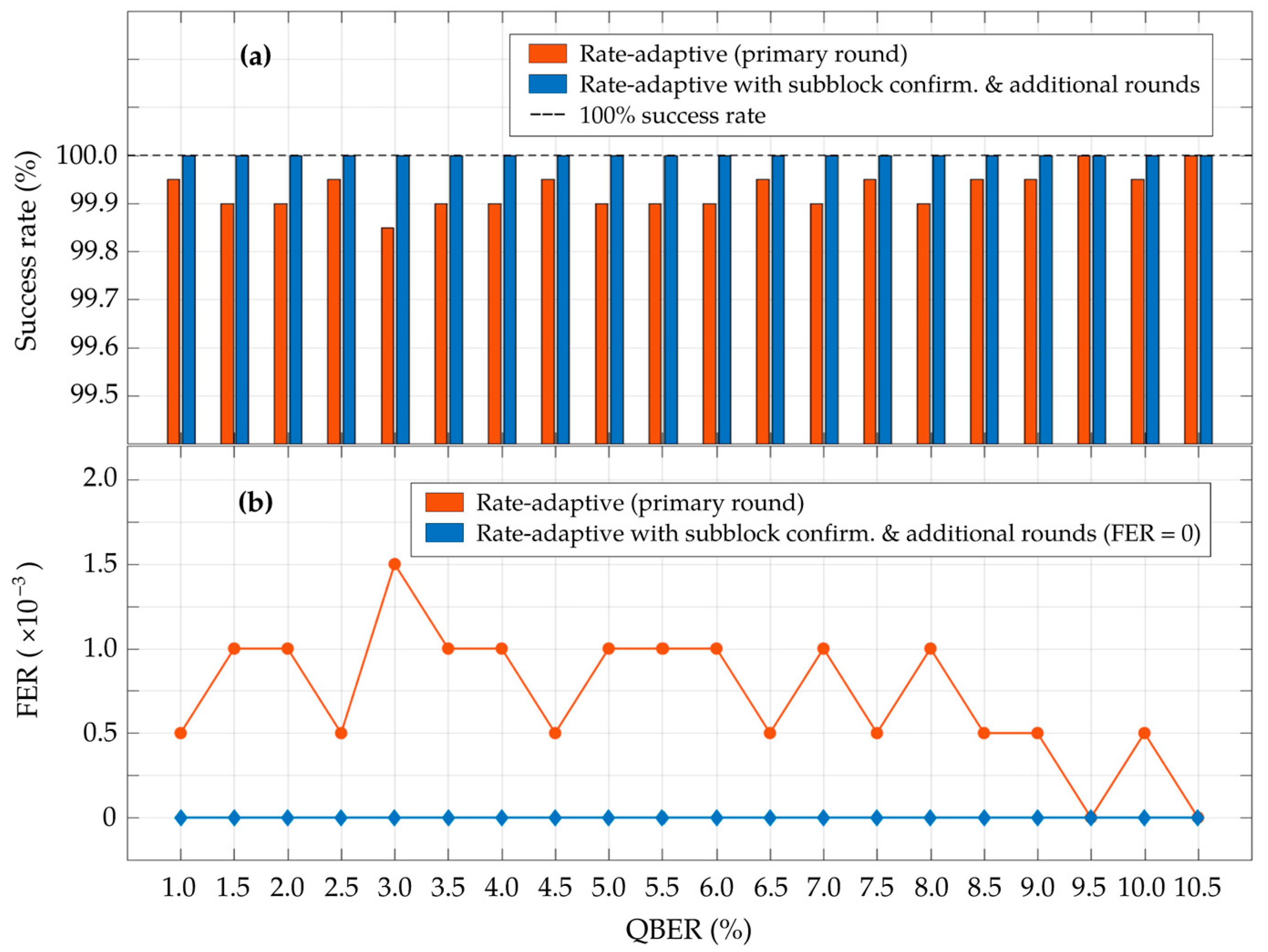
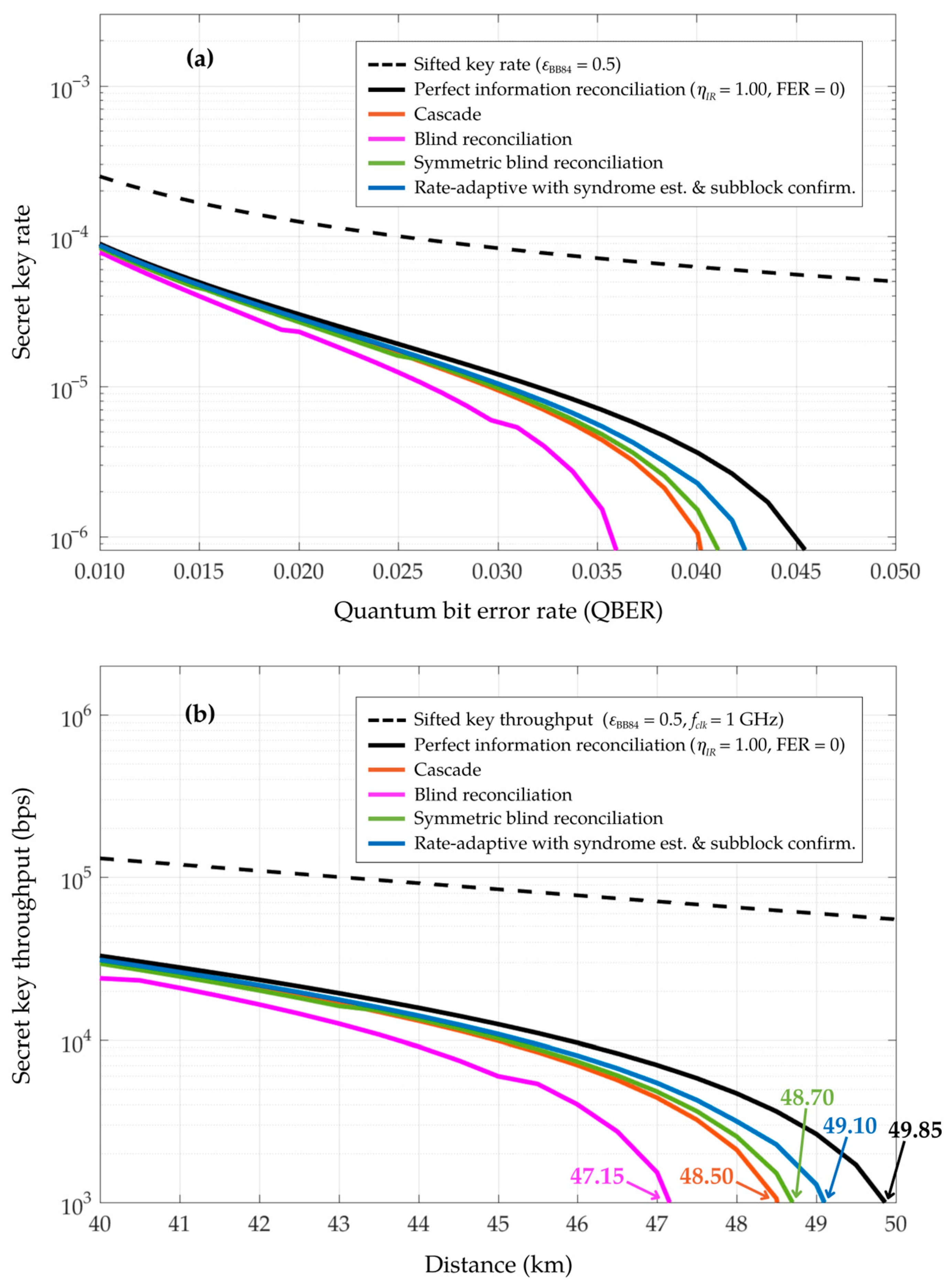
4. Simulation and Results
5. Conclusions and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Diffie, W.; Hellman, M.E. New directions in cryptography. IEEE Trans. Inf. Theory. 1976, 22, 644–654. [Google Scholar] [CrossRef]
- Rivest, R.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Strangio, M.A. Efficient Diffie-Hellmann two-party key agreement protocols based on elliptic curves. In Proceedings of the 20th Annual ACM symposium on Applied computing (SAC 2005), Socorro, NM, USA, 13–17 March 2005; pp. 324–331. [Google Scholar] [CrossRef]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature. 2019, 574, 505–511. [Google Scholar] [CrossRef] [PubMed]
- Yan, B.; Tan, Z.; Wei, S.; Jiang, H.; Wang, W.; Wang, H.; Luo, L.; Duan, Q.; Liu, Y.; Shi, W.; et al. Factoring integers with sublinear resources on a superconducting quantum processor. arXiv 2023, arXiv:2212.12372. [Google Scholar] [CrossRef]
- Bennett, C.H.; Brassard, G. Quantum cryptography: Public key distribution and coin tossing. In Proceedings of the IEEE International Conference on Computers, Systems, and Signal Processing, Bangalore, India, 9–12 December 1984; pp. 175–179. [Google Scholar] [CrossRef]
- Renner, R.; Gisin, N.; Kraus, B. Information-theoretic security proof for quantum-key-distribution protocols. Phys. Rev. A 2005, 72, 012332. [Google Scholar] [CrossRef]
- Fung, C.-H.F.; Ma, X.; Chau, H.F. Practical issues in quantum-key-distribution postprocessing. Phys. Rev. A 2010, 81, 012318. [Google Scholar] [CrossRef]
- Kiktenko, E.O.; Trushechkin, A.S.; Kurochkin, Y.V.; Fedorov, A.K. Post-processing procedure for industrial quantum key distribution systems. J. Phys. Conf. Ser. 2016, 741, 012081. [Google Scholar] [CrossRef]
- Brassard, G.; Salvail, L. Secret-key reconciliation by public discussion. In Proceedings of the Advances in Cryptology–EUROCRYPT ‘93, Workshop on the Theory and Application of Cryptographic Techniques, Lofthus, Norway, 23–27 May 1993; pp. 410–423. [Google Scholar] [CrossRef]
- Pedersen, T.B.; Toyran, M. High performance information reconciliation for QKD with cascade. Quantum Inf. Comput. 2015, 15, 419–434. [Google Scholar] [CrossRef]
- Martinez-Mateo, J.; Pacher, C.; Peev, M.; Ciurana, A.; Martin, V. Demystifying the information reconciliation protocol cascade. Quantum Inf. Comput. 2015, 15, 453–477. [Google Scholar] [CrossRef]
- Buttler, W.T.; Lamoreaux, S.K.; Torgerson, J.R.; Nickel, G.H.; Donahue, C.H.; Peterson, C.G. Fast, efficient error reconciliation for quantum cryptography. Phys. Rev. A 2003, 67, 052303. [Google Scholar] [CrossRef]
- Makkaveev, A.P.; Molotkov, S.N.; Pomozov, D.I.; Timofeev, A.V. Practical error-correction procedures in quantum cryptography. J. Exp. Theor. Phys. 2005, 101, 230–252. [Google Scholar] [CrossRef]
- Treeviriyanupab, P.; Sangwongngam, P.; Sripimanwat, K.; Sangaroon, O. BCH-based Slepian-Wolf coding with feedback syndrome decoding for quantum key reconciliation. In Proceedings of the 9th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON 2012), Phetchaburi, Thailand, 16–18 May 2012. [Google Scholar] [CrossRef]
- Pearson, D. High-speed QKD reconciliation using forward error correction. In Proceedings of the 7th International Conference on Quantum Communication, Measurement and Computing (QCMC 2004), Glasgow, Scotland, 25–29 July 2004; pp. 299–302. [Google Scholar] [CrossRef]
- Elkouss, D.; Leverrier, A.; Alléaume, R.; Boutros, J.J. Efficient reconciliation protocol for discrete-variable quantum key distribution. In Proceedings of the IEEE International Symposium on Information Theory (ISIT 2009), Seoul, Republic of Korea, 28 June–3 July 2009; pp. 1879–1883. [Google Scholar] [CrossRef]
- Martinez-Mateo, J.; Elkouss, D.; Martin, V. Blind reconciliation. Quantum Inf. Comput. 2012, 12, 791–812. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Z.; Huang, A. Blind information reconciliation with variable step sizes for quantum key distribution. Sci. Rep. 2020, 10, 171. [Google Scholar] [CrossRef] [PubMed]
- Kiktenko, E.O.; Trushechkin, A.S.; Lim, C.C.W.; Kurochkin, Y.V.; Fedorov, A.K. Symmetric blind information reconciliation for quantum key distribution. Phys. Rev. Appl. 2017, 8, 044017. [Google Scholar] [CrossRef]
- Treeviriyanupab, P.; Phromsa-ard, T.; Zhang, C.-M.; Li, M.; Sangwongngam, P.; Sanevong Na Ayutaya, T.; Songneam, N.; Rattanatamma, R.; Ingkavet, C.; Sanor, W.; et al. Rate-adaptive reconciliation and its estimator for quantum bit error rate. In Proceedings of the 14th International Symposium on Communications and Information Technologies (ISCIT 2014), Incheon, Republic of Korea, 24–26 September 2014; pp. 351–355. [Google Scholar] [CrossRef]
- Kiktenko, E.O.; Malyshev, A.O.; Bozhedarov, A.A.; Pozhar, N.O.; Anufriev, M.N.; Fedorov, A.K. Error estimation at the information reconciliation stage of quantum key distribution. J. Russ. Laser. Res. 2018, 39, 558–567. [Google Scholar] [CrossRef]
- Gao, C.; Jiang, D.; Guo, Y.; Chen, L. Multi-matrix error estimation and reconciliation for quantum key distribution. Opt. Express 2019, 27, 14545–14566. [Google Scholar] [CrossRef]
- Borisov, N.; Petrov, I.; Tayduganov, A. Asymmetric adaptive LDPC-based information reconciliation for industrial quantum key distribution. Entropy 2023, 25, 31. [Google Scholar] [CrossRef]
- Fedorov, A.K.; Kiktenko, E.O.; Trushechkin, A.S. Symmetric blind information reconciliation and hash-function-based verification for quantum key distribution. Lobachevskii J. Math. 2018, 39, 992–996. [Google Scholar] [CrossRef]
- Krovetz, T.; Rogaway, P. Fast universal hashing with small keys and no preprocessing: The PolyR construction. In Proceedings of the 3rd International Conference on Information Security and Cryptology (ICISC 2000), Seoul, Republic of Korea, 8–9 December 2000; pp. 73–89. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Slepian, D.; Wolf, J.K. Noiseless coding of correlated information sources. IEEE Trans. Inform. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Gallager, R. Low-Density Parity-Check Codes. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1963. [Google Scholar] [CrossRef]
- Tian, T.; Jones, C.R. Construction of rate-compatible LDPC codes utilizing information shortening and parity puncturing. EURASIP J. Wirel. Comm. 2005, 5, 789–795. [Google Scholar] [CrossRef]
- Elkouss, D.; Martinez-Mateo, J.; Martin, V. Information reconciliation for quantum key distribution. Quantum Inf. Comput. 2011, 11, 226–238. [Google Scholar]
- Lo, H.-K.; Chau, H.F.; Ardehali, M. Efficient quantum key distribution scheme and a proof of its unconditional security. J. Cryptol. 2004, 18, 133–165. [Google Scholar] [CrossRef]
- Gottesman, D.; Lo, H.-K.; Lütkenhaus, N.; Preskill, J. Security of quantum key distribution with imperfect devices. Quantum Inf. Comput. 2004, 4, 325–360. [Google Scholar]
- Ma, X.; Lütkenhaus, N. Improved data post-processing in quantum key distribution and application to loss thresholds in device independent QKD. Quantum Inf. Comput. 2012, 12, 203–214. [Google Scholar] [CrossRef]
- Martinez-Mateo, J.; Elkouss, D.; Martin, V. Key reconciliation for high performance quantum key distribution. Sci. Rep. 2013, 3, 1576. [Google Scholar] [CrossRef]
- ETSI Standard: ETSI EN 302307-1; Digital Video Broadcasting (DVB); Second Generation Framing Structure, Channel Coding and Modulation Systems for Broadcasting, Interactive Services, News Gathering and Other Broadband Satellite Applications. Part 1: DVB-S2; (V1.4.1), 12 November 2014. European Telecommunications Standards Institute: Sophia Antipolis, France, 2014.
- ETSI Standard: ETSI EN 302307-2; Digital Video Broadcasting (DVB); Second Generation Framing Structure, Channel Coding and Modulation Systems for Broadcasting, Interactive Services, News Gathering and Other Broadband Satellite Applications. Part 2: DVB-S2 Extensions (DVB-S2X); (V1.3.1), 8 February 2021. European Telecommunications Standards Institute: Sophia Antipolis, France, 2021.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Procedure Step | Parameter | Value |
|---|---|---|
| Syndrome-based error estimation | Sifted key size (primary/additional round) [bit] | 64,800/16,200 |
| Maximum code rate () | 9/10 for block length N 8/9 for block length | |
| Maximum QBER threshold (qthreshold) | 0.25 | |
| Rate-adaptive information reconciliation | Block length of LDPC codes: N for primary round/ for additional round [bit] | N = 64,800/ = 16,200 |
| Set of mother code rates () | For block length N: {9/10, 8/9, 154/180, 5/6, 4/5, 7/9, 3/4, 22/30, 128/180, 25/36, 2/3, 116/180, 28/45, 3/5, 26/45, 11/20, 96/180, 1/2} [36,37] For block length : {8/9, 5/6, 4/5, 3/4, 32/45, 2/3, 3/5, 26/45, 8/15, 1/2} [36,37] | |
| Baseline metric () | 1.08 | |
| Total number of punctured and shortened bits (nd) [bit] | 3200 for block length N 1200 for block length | |
| Maximum number of decoding iterations [iteration] | 100 | |
| Increment factor for updating the efficiency metric (δ) | 0.2 | |
| Subblock confirmation | Subblock size ) [bit] | 16,200 |
| Number of subblocks (m) | 4 | |
| Hash value length ( [bit /byte] | 64/8 |
| QBER Estimation Methods | 5% Random Key Sampling | 10% Random Key Sampling | Syndrome est. (N = 64,800 bits/ = 9/10) | Syndrome est. = 16,200 Bits/ = 8/9) |
|---|---|---|---|---|
| (a) Observed QBER: 2% | ||||
| Mean accuracy (%) | 99.8092 | 99.8685 | 99.9545 | 99.9035 |
| Mean estimated QBER (qest) | 0.019962 | 0.020019 | 0.019994 | 0.020039 |
| Mean squared error (MSE) | 5.7996 × 10−6 | 2.7454 × 10−6 | 3.2805 × 10−7 | 1.4677 × 10−6 |
| Median | 0.020062 | 0.020062 | 0.019988 | 0.019978 |
| Interquartile range (IQR) | 0.003395 | 0.002315 | 0.001104 | 0.002225 |
| Mean number of outliers | 0.0090 | 0.0070 | 0.0065 | 0.0085 |
| (b) Observed QBER: 4% | ||||
| Mean accuracy (%) | 99.7352 | 99.8195 | 99.9220 | 99.8443 |
| Mean estimated QBER (qest) | 0.040069 | 0.040069 | 0.039987 | 0.040081 |
| Mean squared error (MSE) | 1.1270 × 10−5 | 5.1504 × 10−6 | 9.6916 × 10−7 | 3.8172 × 10−6 |
| Median | 0.040123 | 0.039969 | 0.039984 | 0.040027 |
| Interquartile range (IQR) | 0.004630 | 0.003241 | 0.001599 | 0.003413 |
| Mean number of outliers | 0.0115 | 0.0085 | 0.0120 | 0.0050 |
| (c) Observed QBER: 7% | ||||
| Mean accuracy (%) | 99.6501 | 99.7682 | 99.8574 | 99.7451 |
| Mean estimated QBER (qest) | 0.070037 | 0.070037 | 0.070031 | 0.070105 |
| Mean squared error (MSE) | 1.9198 × 10−5 | 8.4687 × 10−6 | 3.1647 × 10−6 | 1.0266 × 10−5 |
| Median | 0.070062 | 0.070062 | 0.069934 | 0.070078 |
| Interquartile range (IQR) | 0.006173 | 0.003858 | 0.002734 | 0.005078 |
| Mean number of outliers | 0.0060 | 0.0125 | 0.0080 | 0.0060 |
| (d) Observed QBER: 10% | ||||
| Mean accuracy (%) | 99.5781 | 99.7186 | 99.7808 | 99.6005 |
| Mean estimated QBER (qest) | 0.100013 | 0.099960 | 0.100085 | 0.100068 |
| Mean squared error (MSE) | 2.7643 × 10−5 | 1.2399 × 10−5 | 7.6506 × 10−6 | 2.4914 × 10−5 |
| Median | 0.100000 | 0.100000 | 0.100027 | 0.099976 |
| Interquartile range (IQR) | 0.007407 | 0.005093 | 0.003965 | 0.007457 |
| Mean number of outliers | 0.0070 | 0.0070 | 0.0120 | 0.0050 |
| QBER Estimation Methods | 5% Random Key Sampling | 10% Random Key Sampling | Syndrome est. (N = 64,800/ = 9/10) | Syndrome est. =16,200/ = 8/9) |
|---|---|---|---|---|
| (a) Low error range: observed QBER 1.00–3.50% | ||||
| Mean accuracy (%) | 99.7985 | 99.8618 | 99.9498 | 99.9006 |
| Standard deviation (SD) | 0.1589 | 0.1050 | 0.0417 | 0.0803 |
| Lower error bar (mean—SD) (%) | 99.6396 | 99.7568 | 99.9081 | 99.8203 |
| Upper error bar (mean + SD) (%) | 99.9574 | 99.9668 | 99.9915 | 99.9809 |
| Mean squared error (MSE) | 6.5846 × 10−6 | 3.0130 × 10−6 | 4.2539 × 10−7 | 1.6325 × 10−6 |
| (b) Middle error range: observed QBER 3.51–7.00% | ||||
| Mean accuracy (%) | 99.6941 | 99.7939 | 99.8984 | 99.8025 |
| Standard deviation (SD) | 0.2342 | 0.1609 | 0.0807 | 0.1545 |
| Lower error bar (mean—SD) (%) | 99.4599 | 99.6330 | 99.8177 | 99.6480 |
| Upper error bar (mean + SD) (%) | 99.9283 | 99.9548 | 99.9791 | 99.9570 |
| Mean squared error (MSE) | 1.4840 × 10−5 | 6.8321 × 10−6 | 1.6833 × 10−6 | 6.2887 × 10−6 |
| (c) High error range: observed QBER 7.01–11.00% | ||||
| Mean accuracy (%) | 99.6168 | 99.7283 | 99.8092 | 99.6556 |
| Standard deviation (SD) | 0.2935 | 0.2003 | 0.1490 | 0.2698 |
| Lower error bar (mean—SD) (%) | 99.3233 | 99.5280 | 99.6602 | 99.3858 |
| Upper error bar (mean + SD) (%) | 99.9103 | 99.9286 | 99.9582 | 99.9254 |
| Mean squared error (MSE) | 2.3293 × 10−5 | 1.1395 × 10−5 | 5.8601 × 10−6 | 1.9135 × 10−5 |
| Sifted key size after channel error estimation (bits) | ||||
| N = 64,800/ = 16,200 bits (100% sifted key) | 61,560/15,390 (95%) | 58,320/14,580 (90%) | 64,800 (100%) | 16,200 (100%) |
| Parameter | Efficiency of BB84 Protocol () | Efficiency of Single-Photon Detector () | Dark Count Probability of Single-Photon Detector (pdark) | Optical Fiber Losses (dB/km) |
|---|---|---|---|---|
| Value | 0.5 | 0.1 | 10−5 | 0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Treeviriyanupab, P.; Zhang, C.-M. Efficient Integration of Rate-Adaptive Reconciliation with Syndrome-Based Error Estimation and Subblock Confirmation for Quantum Key Distribution. Entropy 2024, 26, 53. https://doi.org/10.3390/e26010053
Treeviriyanupab P, Zhang C-M. Efficient Integration of Rate-Adaptive Reconciliation with Syndrome-Based Error Estimation and Subblock Confirmation for Quantum Key Distribution. Entropy. 2024; 26(1):53. https://doi.org/10.3390/e26010053
Chicago/Turabian StyleTreeviriyanupab, Patcharapong, and Chun-Mei Zhang. 2024. "Efficient Integration of Rate-Adaptive Reconciliation with Syndrome-Based Error Estimation and Subblock Confirmation for Quantum Key Distribution" Entropy 26, no. 1: 53. https://doi.org/10.3390/e26010053